ordonnancement hierarchique multi objectifs d …
TRANSCRIPT

République Algérienne Démocratique et Populaire Ministère de l’enseignement supérieur et de la recherche Scientifique
Université d’Oran Es-sénia
Faculté des Sciences
Département d’informatique
THESE
Présenté par : BENYAMINA Abou El Hassan
Pour obtenir
LE DIPLOME DE DOCTORAT D’ETAT
Spécialité : Informatique Option : « CAO/IAO &Simulation »
Intitulé :
ORDONNANCEMENT HIERARCHIQUE MULTI-OBJECTIFS D'APPLICATIONS
EMBARQUEES INTENSIVES Soutenu le : Devant les membres du jury:
Mr K.RAHMOUNI Président Prof Université d’Oran Es-Senia.
Mr B.BELJILALI Encadreur Prof Université d’Oran Es-Senia.
Mr P.BOULET Encadreur Prof Université de Lille France
Mr M.BENYETTOU Examinateur Prof USTO. Oran Mr B.YAGOUBI Examinateur Prof Université d’Oran Es-Senia
1

INTRODUCTION GENERALE
2

Contexte
Au début des années 70, l’humanité a pris connaissance de la conception par Marcian Hoff du premier microprocesseur commercial Intel 4004. Même si depuis de nombreuses technologies ont été proposées, les microprocesseurs reposent presque tous sur le même principe d’exécution dit Von Neumann. La complexité de ces dispositifs est passée de 2250 transistors, pour l’Intel 4004, à des centaines de milliers pour les microprocesseurs actuels. La puissance de traitement elle, a augmenté pendant la même période de 6000 instructions exécutées par seconde à plusieurs milliards pour les processeurs les plus performants. Cette évolution rapide de la technologie informatique représente l’un des plus importants phénomènes techniques depuis plusieurs décennies. C’est elle qui a déclenché cette course, que nous vivons maintenant, à la miniaturisation de tout appareil électronique.
L’exemple le plus illustrant de ce phénomène est la téléphonie mobile. Les premiers systèmes offrant le service de téléphonie mobile ont été introduits au début des années cinquante. A cette époque ils étaient souvent assez gros et avaient une antenne assez importante. Ils étaient limités par une mobilité assez restreinte, une capacité basse, un service réduit et une mauvaise qualité du son en plus de leur prix qui était souvent très élevé. Actuellement, le monde, avec la révolution numérique, est transformé par la création des téléphones mobiles numériques plus petits, plus légers et plus performants. Ces téléphones sont également, de plus en plus multimédia et fournissent une meilleure qualité et un grand nombre de service. Ce qui a permis leur utilisation dans des domaines très variés : pour passer des appels bien sûr, pour prendre des photos, pour écouter la musique, et même pour visualiser des vidéos. De plus, de nos jours, ils offrent des fonctions de traitement d’images impressionnantes qui demandent des puissances de calcul similaire à celle des ordinateurs.
Ce rythme d’évolution effréné provient des avances technologiques des circuits intégrés et de leurs architectures qui ont permis de développer des systèmes informatiques plus petits, plus compacts et plus rapides, grâce en grande partie à la capacité d’intégration de plus en plus élevée. Un type de ces systèmes qui a profité largement de cette évolution est le système embarqué. Les techniques de conception de ces systèmes permettent maintenant de regrouper des systèmes hétérogènes sur la même puce électronique, donnant ainsi naissance à un nouveau paradigme dans les systèmes embarqués : les systèmes sur puce (SoC : System on Chip).
De part leur forte capacité d’intégration, les SoCs offrent des grandes économies en consommation d’énergie et en espace ainsi qu’un gain important en performance. Du fait de ces avantages, les SoCs sont donc souvent intégrés dans des systèmes embarqués afin de remplacer certaines ressources informatiques. Mais on ne peut pas parler uniquement d’avantage sans citer des inconvénients, dont le plus important est la complexité de leur conception. Le risque que le produit final ne corresponde pas à la spécification et les délais de production qui les rend obsolètes avant même leur mise sur le marché, sans oublier la demande toujours croissante en puissance de calcul complique énormément leur conception.
Cet inconvénient, qui est de taille, ne devait pas freiner les industriels et les chercheurs. Ils doivent suivre cette révolution technologique au prix d’énormes efforts en recherche et
3

développement. C’est dans cette optique que plusieurs équipes de chercheur se sont constituées afin de proposer une méthodologie de conception et de développement facile de ces systèmes. Le projet INRIA DaRT1 en fait partie. C’est dans ce projet que notre travail, qu’on présentera par la suite, s’inscrit. L’un des principaux objectifs de cette équipe est la mise en œuvre d’une méthodologie et d’un environnement de développement pour les systèmes sur puce à hautes performances. C'est-à-dire, un cadre unifié pour le développement de ces systèmes en partant de leur modélisation au plus haut niveau d’abstraction jusqu’à la généralisation du code.
DaRT vise comme domaine d’application le traitement systématique à parallélisme massif dont la caractéristique principale est qu’il effectue une grande quantité de calculs réguliers sur des données multidimensionnelles. Les applications de ce domaine opèrent dans des conditions temps réel, elles sont généralement critiques et présentent un degré élevé de parallélisme de données de calcul. Le projet DaRT a donc pour objectif de fournir un environnement de développement pour ces applications de traitement parallèles en se basant sur le modèle de spécification ARRAY-OL.
Problématique
Comme on l’a présenté auparavant, notre travail s’inscrit dans le cadre d’un projet global supporté par toute l’équipe DaRT de l’INRIA. Ce projet consiste à réaliser un flot de conception et de développement de SoC. Ce flot de conception est connu sous le nom GASPARD2 et qui fit partie des méthodes classiques en « Y » pour les SoC. Dans ce flot de conception la phase de placement (mapping) ou association application/matérielle constitue une étape très importante, car elle participe d’une façon critique dans l’atteinte des objectifs arrêtés lors de la spécification du SoC.
Ce mapping a une particularité, dans ce contexte, car il ne s’agit pas uniquement d’un placement classique qu’on a l’habitude de rencontrer dans les systèmes parallèles mais il englobe trois phases : Assignation, Affectation et Scheduling (AAS). De plus, du fait que Gaspard2 vise à traiter aussi des applications de traitement intensif, on est amené à prendre en considérations dans le mapping la nature répétitive de certaines tâches qui traitent des données multidimensionnelles.
Ce dernier problème nous permet de caractériser le placement par deux catégories : le placement des calculs (tâches) et le placement de données. Le premier type de placement nous permet de trouver sur quel processeur doit s’exécuter quelle tâche et à quel moment. Le deuxième type de placement doit déterminer un accès efficace et rapide aux données avec si c’est possible des chemins d’accès le plus court possible en prenant en considération les caractéristiques de la topologie cible telle la bande passante.
Donc on ne peut faire un bon placement si on ne prend pas en considération tous les aspects où on a des tâches qui ne sont pas répétitives et d’autres qui le sont. Ce type de placement ou mapping est connu comme étant un placement GILR (Globally Irregular Locally Regular), il consiste à exploiter le parallélisme de tâches et de données dans une architecture 1 http://www.inria.fr/rapportsactivite.RA2005/dart/dart_tf.html
4

multiprocesseurs. Les bénéfices et utilités des GILR ont été prouvé dans et bien entendu dans [17] pour les deux types d’architectures hétérogènes et homogène.
Adopter directement des solutions proposées dans les systèmes distribués classiques n’est pas conseillé pour les architectures MPSoC. Ces dernières sont globalement hétérogènes et ont quelques éléments réguliers homogènes (Tableau de PE. Ce qui doit nous amener à extraire les parties régulières et irrégulières de ‘architecture pour exploiter au maximum la correspondance dans l’application. Le graphe suivant illustre un GILR où les couleurs représentent les étapes suivies.
Figure I : Illustration du GILR
En généralisant cet exemple par une modélisation graphique on obtiendra des graphes hiérarchiques. Et là on parlera d’un placement hiérarchique multi-niveaux, où les nœuds peuvent être de trois types : élémentaire, composé ou répétitif.
Donc un placement GILR nous amène à trouver le meilleur mapping d’un graphe hiérarchique de l’application (HTG) sur le graphe hiérarchique de l’architecture.
Contribution
Afin de traiter le problème dans sa globalité (GILR) on l’a décomposé en sous problèmes complémentaires :
1- Pour le mapping des tâches irrégulières sur l’architecture correspondante on a proposé un algorithme hybride. Ce dernier cherche l’optimisation multi-objectif du placement d’un DAG application sur un DAG architecture. En effet, pour prendre en considération les spécificités et les exigences des SoCs(NoC), on ne cherche pas la meilleure solutions selon un seul objectif (temps, consommation d’énergie, taille mémoire,..) mais plusieurs. Dans notre cas on a fait du bi-objectif (temps et énergie), car ils sont les plus importants. Cependant, le coût global du placement ne dépend pas uniquement des coûts des unités de traitements, il dépend aussi des coûts des communications. D’où une autre méthode permettant de chercher le meilleur
5
mapping des communications sur la topologie cible, ce qui fat de l’algorithme, proposé pour ce sous problème, un algorithme hybride d’optimisation multi-objectif.
2- Pour le mapping des tâches répétitives et des données régulières, exprimées par le langage Array-Ol, une autre approche est utilisée. Si pour le premier cas on a utilisé une méta-heuristique qui se justifie par la taille des DAG en entrée, dans ce cas c’est plutôt une méthode exacte qui est utilisée. On justifie ce choix par le fait que les données, sur lesquelles le traitement répétitif se fait, sont infinies. Le mapping de ces données ne les prends pas toutes en même temps mais par des paquets ayant le même profil et la même taille, appelés Motifs. La taille de ces Motifs est petite, fixe et connue, et de même pour l’architecture régulière cible. Donc pour ce problème un algorithme hybride exact est proposé pour trouver le meilleur placement d’une application DSP (chapitre 3) sur une architecture régulière.
3- En fin le troisième sous problème consiste à prendre le GILR en entier avec son aspect hiérarchique. Ainsi pour placer une application hiérarchique présentée par le graphe suivant (Figure II) on doit balayer les deux graphes (HTG et HAG) de bas vers le haut en cherchant à chaque niveau l’optimalité en y faisant appel aux algorithmes proposés pour les phases 1 et 2. L’explication de la démarche se fera dans le chapitre 6.
Enfin, pour valider les résultats (ce qui n’est pas très évident du fait de l’originalité de la démarche), on a essayé de comparer les résultats obtenus selon les deux critères temporel et qualitatif. Pour le premier critère on a fait la comparaison des temps de convergence de la méthode par rapport à ceux obtenus par des méthodes exactes d’énumération en ayant en entrée des benchmarks de graphes. Pour le deuxième critère on a comparé les résultats obtenus par rapport à ceux d’un exemple réel (le HS69) modélisant une application DSP.
Figure II : Exemple de graphe hiérarchique
Plan du document
Le reste du document est structuré en 7 parties selon un ordre qu’on a pensé qu’il permettra au lecteur de suivre et comprendre la démarche. Evidemment, les premiers chapitres sont
6

relatifs au contexte et l’état de l’art. Toute fois un lecteur initié aux concepts présentés peut les éviter et passer directement aux parties qui l’intéressent.
Chapitre 1 : Dans cette partie on commence par introduire le concept des systèmes embarqués et les domaines de leurs utilisations. On y abordera aussi avec plus de détails les SoC et leurs sous familles NoC et MPSoC.
Chapitre 2 : Les méthodologies de conception et développement des SoCs sont très complexes et d’elles dépendra leur réussite. C’est ce qu’on essayera de présenter dans cette partie par l’énumération de certains flots de conception, en insistant sur le flot GASPARD2 développé par l’équipe DaRT INRIA. Ce flot avec tous les packages constituant son profil sont bien présentés dans cette partie afin de permettre au lecteur de s’y familiariser ou au moins de pouvoir y situer notre contribution.
Chapitre 3 : Dans la partie précédente en parlant des différents flots de modélisation on a abordé la modélisation des applications DSP. Afin de ne pas encombrer le chapitre précédent on a préféré les présenter et les détailler dans ce chapitre.
Chapitre 4 : On ne peut parler de notre apport et du travail d’optimisation dans les SoCs, qu’on doit faire dans l’équipe DaRT, sans aborder la problématique de l’AAS en général. Dans ce chapitre on étudiera les différentes méthodes et approches les plus connues l’ayant abordé.
Chapitre 5 : Ce chapitre sera consacré complètement à l’optimisation combinatoire multi-objectif. Les concepts qui y sont introduits sont nécessaire au non initié à l’optimisation pour comprendre le chapitre 6 en faisant le lien avec lui qui la précédé.
Chapitre 6 : Dans cet avant dernier chapitre on présentera notre démarche pour l’AAS du GILR. Les différentes démarches ainsi que les formalismes qui les entourent seront présentés avec détails afin de clarifier au maximum notre contribution et mettre en évidence l’originalité de la proposition.
Chapitre 7 : Les démarches et contributions, présentées dans le chapitre 6, doivent être validées par des implémentations et expérimentations. C’est l’objet de ce dernier chapitre qu’on consacrera à la présentation de l’environnement d’expérimentation et discussion des résultats.
7

CHAPITRE 1
Introduction aux systèmes embarqués
8

Les Systèmes On Chip (SOC) sont le résultat de l’évolution technologique qui a permet l’intégration de plateforme complexe sur une seule puce. Les derniers permettent l’intégration de plusieurs CPU avec des sous systèmes pour exécuter le Soft et connecter entre eux selon les meilleures topologies connues dans les réseaux. Ces systèmes sont appelés « Multiprocessors System on Chip » (MPSOC). Pour gérer et exploiter ce haut degré de parallélisme obtenu au
niveau hardware et software nous devons utiliser des constructeurs réguliers pour l’architecture et le software à la fois. A travers ce chapitre, nous ferons un bref survol sur la
problématique de l’embarqué, en parlant brièvement des différentes architectures et topologies.
1.1 Motivation et objectifs des systèmes embarqués
On peu affirmer que les systèmes embarqués nous entourent et nous sommes littéralement envahis par eux, fidèles au poste et prêts à nous rendre service. Pour cela, il suffit de regarder autour de soi au quotidien pour voir et avoir la réponse sous ses yeux. Vous êtes réveillé le matin par votre radio-réveil ; c’est un système embarqué…vous programmez votre machine à café pour avoir un bon petit serré ; c’est un système embarqué…vous allumez la télévision et utilisez votre télécommande ; ce sont des systèmes embarqués … vous allumez la télévision et utilisez votre télécommande ; ce sont des systèmes embarqués…vous prenez votre voiture et la voix suave du calculateur vous dit que vous n’avez pas mis votre ceinture ; c’est un système embarqué…vous appelez votre patron avec votre téléphone portable pour signaler que vous serez en retard ; c’est un système embarqué. La liste est encore longue des domaines de notre vie quotidienne où on fait appel à ce type de système.
1.1.1 Définition
Un système embarqué peut être défini comme un système électronique et informatique autonome, qui est dédié à une tâche bien précise. Il ne possède généralement pas des entrées/sorties standards et classiques comme un clavier ou un écran d’ordinateur. Le système matériel et l’application sont intimement liés, le logiciel embarqué étant enfoui, noyé dans le matériel. Ce dernier et le logiciel ne sont pas aussi facilement discernables comme dans un environnement de travail classique de type ordinateur P.C [1].
1.1.2 Les types de systèmes embarqués
Calcul général (Général computing)
• Application similaire à une application de bureau mais empaquetée dans un système embarqué.
• Jeu - video, Set-top box.
Contrôle de système
• Contrôle de système en temps réel : Moteur d’automobile, processus chimique, processus nucléaire, système de navigation aérien.
Traitement de signal : Signal processing .
9
1.1.3 Caractéristiques principales d’un système embarqué
Pour les systèmes embarqués on énumère les caractéristiques principales suivantes :
• C’est un système principalement numérique
• Il met en œuvre généralement un ou plusieurs processeurs.
• Il exécute une application logicielle dédiée pour réaliser une fonctionnalité précise et n’exécute donc pas une application scientifique ou grand public traditionnelle.
• Il n’a pas réellement de clavier standard (bouton poussoir, clavier matriciel…). L’affichage est limité (Ecran LCD) ou n’existe pas du tout.
• Ce n’est pas un PC en général mais des architectures similaires basse consommation sont de plus en plus utilisées pour certaines applications embarquées.
De ce fait on constate que :
Les ressources (énergie, surface) sont limitées.
L’interface IHM peut être aussi simple qu’une LED qui clignote ou aussi complexe qu’un cockpit d’avion en ligne.
Des circuits numériques ou des circuits analogiques sont utilisés en plus pour augmenter les performances du système embarqués ou sa fiabilité.
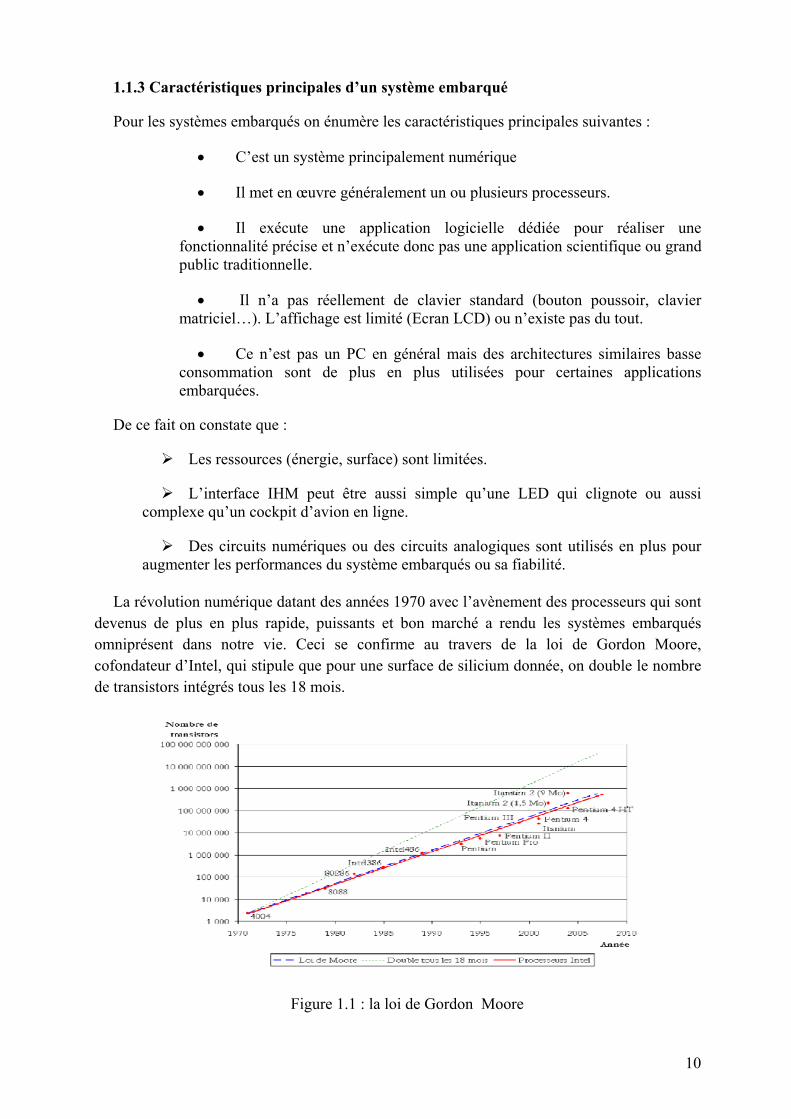
La révolution numérique datant des années 1970 avec l’avènement des processeurs qui sont devenus de plus en plus rapide, puissants et bon marché a rendu les systèmes embarqués omniprésent dans notre vie. Ceci se confirme au travers de la loi de Gordon Moore, cofondateur d’Intel, qui stipule que pour une surface de silicium donnée, on double le nombre de transistors intégrés tous les 18 mois.
Figure 1.1 : la loi de Gordon Moore
10

La figure suivante illustre un système embarqué typique.
Figure 1.2 : Système embarqué typique
On retrouve en entrée des capteurs généralement analogiques couplés à des convertisseurs A/N.
On retrouve en sortie des actionneurs généralement analogiques couplés à des convertisseurs N/A.
Au milieu, on trouve le calculateur mettant en œuvre un processeur embarqué et ses périphériques d’E/S. Il est à noter qu’il est complété généralement d’un circuit FPGA jouant le rôle de coprocesseur afin de proposer des accélérations matérielles au processeur.
Sur ce schéma théorique se greffe un paramètre important : le rôle de l’environnement extérieur. Contrairement au PC, un système embarqué doit faire face à des environnements plus hostiles en faisant face à un ensemble de paramètres agressifs :
Variations de la température.
Vibrations, choc.
Variations des alimentations.
Interférences RF.
Corrosion.
Eau, feu, radiations.
(Etc)
11

L’environnement dans lequel opère le système embarqué n’est pas contrôlé ou contrôlable. Il doit être pris en considération lors de la conception du système. On doit par exemple prendre en compte les évolutions des caractéristiques électriques des composants en fonction de la température, des radiations.
Les systèmes embarqués, actuellement, sont fortement communicants. Cela est possible grâce aux puissances de calcul offertes par les processeurs pour l’embarqué (32 bits en particulier) et grâce aussi à l’explosion de l’usage de la connectivité Internet ou connectivité IP (Intellectual Property). La connectivité IP permet fondamentalement de contrôler à distance un système embarqué par internet. Cde n’est en fait que l’aboutissement du contrôle à distance d’un système électronique par des liaisons de tous types : liaison RS232, RS485, bus de terrain. Cela permet l’emploi des technologies modernes du web pour ce contrôle à distance par l’utilisateur : Il suffit d’embarquer un serveur web dans son équipement électronique pour pouvoir le contrôler ensuite à distance, de n’importe où, à l’aide d’un simple navigateur ; il n’y a plus d’IHM (Interface Homme Machine) spécifique à concevoir pour cela, ce rôle étant rempli par le navigateur Web. Cela est une réalité : Les chauffagistes proposent maintenant des chaudières pouvant être pilotées par le Web. On note aussi que les communications sans fil sont plus utilisées dans l’embarqué que les communications filaires pour limiter le câblage et faciliter la mise en place du système embarqué. Le WIFI et toutes les normes de réseaux sans fil IEEE 802.15 comme Zig bée ont le vent en poupe dans l’embarqué et surtout en domotique (réseau de capteurs sans fil par exemple). Mais, cela a bien sûr un revers : la sécurité du système embarqué puisque connecté à Internet.
1.1.3.1 Les systèmes embarqués et les contraintes de temps
On lie souvent les systèmes embarqués au temps réel : Un système embarqué doit généralement respecter des contraintes temporelles fortes (Hard real time) et l’on y trouve enfoui un système d’exploitation ou un noyau temps Réel (Real Time Operating System, RTOS). Le concept du temps réel est un peu vague et chacun a sa propre idée sur la question, mais on pourrait le définir comme : « un système est dit temps réel lorsque l’information après acquisition et traitement reste encore pertinente ».
Cela veut dire que dans le cas d’une information arrivant de façon périodique (sous forme d’une interruption périodique du système), les temps d’acquisition et de traitement doivent rester inférieurs à la période de rafraîchissement de cette information. Un temps maximum d’exécution est garanti (pire cas) et non un temps moyen ; [2]
Pour cela, il faut que le noyau ou le système temps réel :
• Soit déterministe : les mêmes effets sont produits suite aux mêmes causes et avec les mêmes temps d’exécution.
• Soit préemptif : la tâche de plus forte priorité prête à être exécutée doit toujours avoir accès au processeur.
Donc pour un système embarqué ces conditions sont nécessaires mais pas suffisantes pour dire qu’il est temps réel par définition, sans qu’on ait à mélanger temps réel et puissance de
12

calcul. On entend souvent : Etre temps réel, c’est avoir beaucoup de puissance : des MIPS et MFLOPS. Ceci n’est pas toujours vérifié. D’une façon plus précise, être temps réel dans l’exemple donné précédemment, c’est être capable d’acquitter l’interruption périodique (moyennant un temps de latence de traitement d’interruption imposée par le matériel), traiter l’information et le signaler au niveau utilisateur (réveil d’une tâche, libération d’un sémaphore…) dans un temps inférieur au temps entre deux interruptions périodiques consécutives. Puisqu’on est lié à la contrainte durée entre deux interruptions. C’est donc le processus extérieur à contrôler qui impose ses contraintes temporelles au système embarqué et non le contraire. Si cette durée est de l’ordre de la seconde (pour le contrôle d’une réaction chimique par exemple), il ne sert à rien d’avoir un système à base de processeur 32 bits performant. Un simple processeur 8 bits voire même un processeur 4 bits fera amplement l’affaire, ce qui permettra de minimiser les coût sur des quantités à produire. Dans le cas d’un temps de quelques dizaines de microsecondes il est alors nécessaire de choisir un processeur nettement plus performant. Dans le pire cas, le traitement en temps réel sera réalisé en logique câblée tout simplement. Il convient donc avant de concevoir le système embarqué de connaître la durée minimale entre deux interruption ; ce qui est assez difficile à estimer voire même impossible. C’est pour cela que l’on a tendance à concevoir dans ce cas des systèmes performants et souvent surdimensionnés pour respecter des contraintes temps réel mal cernées à priori. Ceci induit en cas de surdimensionnement un surcoût non négligeable.
1.2 Informatique embarquée
Par le terme informatique embarqué on désigne les aspects logiciels se trouvant à l’intérieur des équipements n’ayant pas une vocation purement informatique. L’ensemble logiciel, matériel intégré dans un équipement constitue un système embarqué [3]. Comme toute informatique, celle-ci a ses propres impératifs qui la distingue, on peut la caractérisée principalement par :
La criticité : Les systèmes embarqués sont souvent critiques, et les systèmes critiques sont presque toujours embarqués. En effet, comme un tel système agit sur un environnement physique, les actions qu’il effectue sont irrémédiables. Le degré de criticité est fonction des conséquences des déviations par rapport à un comportement normal, conséquences qui peuvent concerner la sûreté des personnes et des biens, la sécurité, l’accomplissement des missions, la rentabilité économique.
La réactivité : Ces systèmes doivent interagir avec leur environnement à une vitesse qui est imposée par ce dernier. Ceci induit donc des impératifs de temps de réponses. C’est pour cette raison que l’informatique embarquée est souvent basée sur un système réel.
L’autonomie : Les systèmes embarqués doivent en général être autonomes, c'est-à-dire remplir leur mission pendant de longues périodes sans intervention humaine. Cette autonomie est nécessaire lorsque l’intervention humaine est impossible, mais aussi lorsque la réaction humaine est trop lente ou insuffisamment fiable.
La robustesse, sécurité et fiabilité : L’environnement est souvent hostile, pour des raisons physiques (chocs, variation de température, impact d’ions lourds dans les systèmes
13

spatiaux,…) ou humaines (malveillance). C’est pour cela que la sécurité au sens de la résistance aux malveillances, et la fiabilité, au sens continuité de service, sont souvent rattachées à la problématique des systèmes embarqués.
Et enfin des contraintes non fonctionnelles, comme par exemple l’occupation mémoire, la consommation d’énergie,….
1.3 Les différentes architectures des différents systèmes embarqués
La technologie de fabrication de circuits intégrés, qui a permis l’intégration de plusieurs composants sur une seule puce, a permis l’apparition des systèmes sur puce qui ont rapidement pris une place importante dans le domaine de la microélectronique en intégrant dans le même circuit plusieurs processeurs, de nombreux composants numériques spécialisés et hétérogènes (mémoire, périphériques et unité de calcul spécifiques), du logiciel et souvent des circuits mixtes pour fournir un système intégré complet.
Les systèmes mono puce multiprocesseurs sont généralement dédiés aux applications spécifiques dans des domaines différents comme par exemple dans le domaine de l’automobile, des télécommunications, du multimédia et leurs diversités ne cesse pas d’accroître [1].
1.3.1 Mono-puce ( SOC)
Un système mono-puce appelé encore SOC (Système On Chip) ou système sur puce, désigne l’intégration d’un système complet sur une seule pièce de silicium. Ce terme est devenu très populaire dans le milieu industriel malgré l’absence d’une définition standard [4]. Certains considèrent qu’un circuit complexe en fait automatiquement un SOC, ce qui est faux. Une définition plus appropriée de système mono-puce serait : un système complet sur une seule pièce de silicium, résultant de la cohabitation sur silicium de nombreuses fonctions déjà complexes en elles même, processeurs, convertisseurs, mémoire, bus..Etc. Il doit comporter au minimum une unité de traitement de logiciel (un CPU) et ne doit dépendre d’aucun (ou de très peu) de composants externes pour exécuter sa tâche. En conséquence, il nécessite à la fois du matériel et du logiciel.
Dans la figure 1.3 est présenté un exemple de système mono-puce typique. Il se compose d’un cœur de processeur (CPU), d’un processeur de signal numérique (DSP), de la mémoire embarquée, et de quelques périphériques tels qu’un DMA (Direct Memory Access) et un contrôleur d’E/S. Le CPU peut exécuter plusieurs tâches via l’intégration d’un OS, le DSP est habituellement responsable de décharger le CPU en faisant le calcul numérique sur les signaux de provenance du onvertisseur A/N.
c
Figure 1.3 – Un exemple de système mono-puce (SOC)
14

Le système pourrait être construit exclusivement de composants existants et de solutions faites sur mesure. Plus récemment, il y a eu beaucoup d’efforts pour implémenter des systèmes multiprocesseurs sur puce [5].
La solution mono puce, pour diverses raisons, représente une manière attrayante pour implémenter un système. Les processus de fabrication (de plus en plus fins) d’aujourd’hui permettent de combiner la logique et la mémoire sur une seule puce, réduisant le temps global des accès mémoires, étant donné que le besoin en mémoire de l’application ne dépasse pas la taille de la mémoire embarquée sur puce, la latence de la mémoire sera réduite grâce à l’élimination de trafic de données entre des puces séparées. Le nombre de broches peut être réduit puisqu’il n’a y plus besoin d’accéder à la mémoire sur des puces externes et l’utilisation de bus sur carte devient inutile. Le coût total de fabrication est réduit à cause de la réduction du coût de l’encapsulation qui représente en moyenne 50% du coût global du processus de fabrication de puce. Ces caractéristiques aussi bien que la faible consommation et la courte durée de conception permettent une mise sur le marché rapide de produits plus économiques et plus performants.
1.3.2 Les multiprocesseurs on SOC (MPSOC)
Les progrès technologiques et la capacité d’intégration de centaines de millions de transistors sur une seule puce ont fait émerger deux tendances pour relever ce défi. La première tendance consiste à utiliser une architecture monoprocesseur tout en améliorant considérablement les performances du CPU utilisé et l’utilisation de coprocesseurs.
Un tel CPU utilisé se distingue par une fréquence de fonctionnement très élevée, des structures matérielles spécialisées, un ensemble d’instructions sophistiquées, plusieurs niveaux de hiérarchie mémoire (plusieurs niveaux de cache), et des techniques spécialisées d’optimisation logicielle (nombre d’accès mémoire, taille, etc.). La figure 1.4 prés ente un exemple d’architecture µp/co-processeurs. Dans de telles architectures la communication est basée sur le principe maître/esclave. Le CPU est le maître et les périphériques sont des esclaves.
Figure 1.4 : Un exemple d’architecture monoprocesseur (µp/co-processeurs)
La deuxième tendance consiste à utiliser des architectures multiprocesseurs (multi-maîtres) qui étaient réservées jusqu’à maintenant aux machines de calculs scientifiques. L’idée derrière cette tendance se base sur les avancements en technologie et architectures sous jacentes, car il s’avère qu’il est peut être de plus en plus difficile d’avoir des architectures monoprocesseurs assez rapide alors que les multiprocesseurs sur puce sont déjà réalisables. D’autres raisons peuvent conforter ceux qui sont derrière cette tendance et qui sont [6]:
15

Le parallélisme : Les transistors supplémentaires disponibles sur la puce sont utilisés par les concepteurs principalement pour extraire le parallélisme à partir des programmes afin d’effectuer plus de travail par cycle d’horloge, la majorité des transistors sont employés pour construire les processeurs super scalaires. Ces processeurs visent à exploiter une quantité plus élevée de parallélisme au niveau instruction, malheureusement, comme les instructions sont, en général, fortement interdépendantes, les processeurs qui exploitent cette technique voient leur rendement diminuer malgré l’augmentation quadratique de la logique nécessaire au traitement de multiple instructions par cycle d’horloge, une architecture multiprocesseurs évite cette limitation en employant un type complètement différent de parallélisme : le parallélisme au niveau tâche. Ce type de parallélisme est obtenu en exécutant simultanément des séquences d’instructions complètement séparées sur chacun des processeurs.
Les retards causés par les interconnections : Ils sont devenus plus significatifs à cause de la rapidité croissante des portes Cmos et des tailles devenues physiquement plus grande des puces. Ainsi, les fils, dans les années prochaines, pourront seulement acheminer les signaux sur une petite partie de la puce durant chaque cycle d’horloge ce qui diminue drastiquement la performance dans le cas de large puce monoprocesseur. Cependant, une puce multiprocesseur peut être conçue de telle façon que chacun de ses petits processeurs occupe un secteur relativement petit réduisant, ainsi, au minimum la largeur de ses fils et simplifiant la conception de chemins critiques. Seulement les fils, connectant les processeurs, les plus rarement employés et donc les moins critiques peuvent être longs.
Le temps de conception : Il est déjà difficile de concevoir des processeurs. Le nombre croissant de transistors, les méthodes de plus en plus complexes d’extraction de parallélisme au niveau instruction et le problème des retards causés par les interconnections rendront ceci encore plus difficile. Une architecture multiprocesseurs mono-puce, cependant, permet de réduite ce temps de conception car il permet l’instanciation de plusieurs composants pré-validés qui peuvent être réutilisés dans plusieurs applications de différentes tailles (en changeant le nombre de composants). Seulement la logique d’interconnexion entre composants n’est pas entièrement reproduite.
Puisqu’une architecture multiprocesseurs mono-puce traite tous ces problèmes potentiels d’une façon directe et extensible, pourquoi ne sont ils pas déjà répondu ? Une raison est que les densités d’intégration viennent juste d’atteindre les niveaux ou ces problèmes deviennent assez significatifs pour considérer un changement de paradigme dans la conception des systèmes. Une autre raison, cependant, est que le problème de synchronisation et de communication entre les différents processeurs survient. Ceci rappelle encore une fois l’importance de l’architecture de communication dans les systèmes multiprocesseurs.
1.3.3 Les NOC (Network On Chip)
Les premiers travaux universitaires conséquents sur le thème des réseaux intégrés furent publiés dès la fin du précédent millénaire. Ils portaient tous sur la réalisation de réseaux de communication complets. Citons entre autre le routeur à commutation de paquets R_SPIN développé à l’université PARIS VI [7], le bus centralisé asynchrone à mailles du processeur ultra faible consommation Maia développé par l’université de Berkeley [8].
16

A travers ces travaux on cherchait à déterminer une architecture performante de réseau sur silicium la plus générique possible, ce qui leur a permet tous, à l’époque, de parvenir à cette conclusion: l’utilisation traditionnelle d’un bus centralisé est obsolète et doit être remplacée par des topologies de réseaux distribués sur le modèle des réseaux utilisés en télécommunications et pour les calculateurs parallèles hautes performances [9]. En outre, la topologie efficace de ces réseaux est fortement dépendante de l’application et des contraintes de performances.
Ces travaux et d’autres plus récents [10] mirent également en évidence l’émergence des problèmes nouveaux liés à la réalisation de larges systèmes complexes hétérogènes multi-horloges et aux contraintes de performance élevées : très faible consommation ou très haut débit ou très haute hétérogénéité des modules intégrés au sein d’un même système, impliquant une très grande flexibilité. Ces nouveaux défis ne dispensant évidemment pas le système de communication de respecter les contraintes d’implémentation physique que l’on exige de lui.
Après la loi de Moore qui a soutenu dans l’industrie de semi conducteur pendant plus de 35 années, une puce simple est prévue pour pouvoir intégrer quatre milliards de transistors 50nm fonctionnant en dessous d’un volt et fonctionnant à 10 gigahertz vers la fin de la décennie. Dû à sa capacité énorme, la puce de milliard de transistors peut prendre sur des fonctionnalités très complexes avec des centaines de microprocesseurs reliées à un ensemble de ressources informatiques. De telles ressources peuvent être programmables comme CPU’s, dédiées comme ASIC’s, configurable comme FPGA’s, ou passif comme les mémoires …etc, les ressources hétérogènes impliquent de divers interfaces ou protocoles, logiciels d’exploitation, etc.…, qui est difficile de les intégrer sur une puce simple.
Une plateforme de NOC est une structure de maille composée de passages avec chaque commutateur connecté à une ressource, comme il est montré sur la figure 1.5. Les ressources sont placées sur les fentes constituées par les commutateurs. Le commutateur de réseau offre une communication pour des ressources. Les ressources exécutent leurs propres fonctionnalités informatiques et fournissent le Ressource-Réseau-Interface (RNI).
1.3.4 Architecture régulière à base de tableau de processeurs identiques
M.C Herbord[11] dans sa thèse intitulé « The evaluation of Massively parallel Array Architecture” a surtout insisté sur l’évaluation du gain, du modèle et des paramètres techniques d’un tel système et leur application. D’après notre point de vue les architectures régulières pour les systèmes embarqués seront très utilisées dans le future, spécialement pour les MPSOC.
1.4 L’interconnexion dans les SOC
Dans le future des SOC multiéléments, la technologie d’interconnexion va jouer un rôle important dans les performances par l’intégration de centaines peut être plus d’éléments composants (PE, FPGE, ASIC, DSP, Mémoire, contrôleurs…etc). Dans ce qui suit on présentera et discutera quelques topologies d’interconnexion, leur extensibilité à travers les paramètres de communication (latence et bande passante), les exigences des applications DSP et leurs perspectives [12].
17

S
RNI Ressource
RNI Ressource
RNI Ressource
RNI Ressource
RNI Ressource
RNI Ressource
RNI Ressource
RNI Ressource
RNI Ressource
S S S
SS S
S S
Figure 1.5 : Un NOC de structure de maille avec 9 nœuds où chaque noeud dans la maille contient un commutateur et une ressource.
1.4.1 Du SOC au NOC
L’avancée technologique des semi conducteurs va accroître l’existence des SOC dans les futurs systèmes. Ils seront capables dans la prochaine décade d’intégrer des centaines si c’est des milliers de composants PE et/ou d’éléments de stockage dans une même puce. La conception des SOC à ce stade ne va pas démarrer de zéro mais ils seront conçus en réutilisant des composants existants tels les processeurs, les contrôleurs et les tableaux de mémoires.
Donc les méthodologies de conception des futures SOC se baseront sur la réutilisation de composants dans « plug and play » dans l’objectif est de diminuer les temps de conception et répondre aux exigences de fabrication. Ainsi dans ces futurs systèmes le facteur le plus critique sera la communication entre les composants. La fiabilité, consommation de peu d’énergie et l’augmentation de puissance de communication d’architecture sur puce vont devenir la nouvelle contrainte pour atteindre les objectifs opérationnels. Néanmoins, les concepteurs prévoient une vue centrée sur les communications dans les nouvelles méthodologies de conception dans les années à venir [13], du fait de la prédominance des technologies 50-100nm dans la deuxième partie de cette décade. Les structures de communication sur puce traditionnel ou contourner plusieurs limitations dans la conception des VLSI d’aujourd’hui. Mais plusieurs de ces limitations vont devenir problématiques quand les semi-conducteurs progresseront dans les nouvelles générations. Ces limitations ont un lien direct avec la taille (nombre de composants) des SoC[14]. Si la taille augmente on risque de se retrouver avec un goulot d’étranglement des communications dans les SoC.
Contrainte de Bande passante (Throughput limitation) : Les structures de communication (bus) des SOC traditionnels ne peuvent pas augmenter quand le nombre de composants augmente. Quand plusieurs flots de données sont transmis en même temps ils vont se partager la même ressource, ce qui pose d’autres problèmes de congestion et de conflits d’accès.
Consommation d’énergie : du fait de la diminution de l’apport des composants VLSI, les liens de connexion sont devenus l’une des majeures contributions pour la consommation d’énergie du système. L’utilisation des Bus dans les SOC actuels n’est pas très intéressante sur
18

le plan consommation d’énergie car l’envoie d’un bit est propagé à travers le bus à chaque terminal.
Dans la perspective de contourner ses limitations et dans l’ordre d’intégrer plus de composants, l’avenir des intercommunication des systèmes sur puce va devenir plus complexe et va hériter de plusieurs théories et techniques des topologies d’interconnexion des multicomputers traditionnels pour répondre aux exigences de fiabilité, énergie et performance.
Comparaison entre l’utilisation des NOC et Bus par Les MPSOC [12]
Depuis l’introduction du concept des SOC dans les années 90, la solution pour les communications était basée généralement sur les bus ou les liens point à point [15] figure 1.6. L’utilisation des bus est maîtrisée et facile mais il peut facilement créer des goulots d’étranglement quand le nombre de composants accroît. Le problème se pose aussi pour la consommation d’énergie et sans oublier l’autre problème important qui est le problème d’arbitrage et des conflits d’accès du fait de la ressource partagée qui est le Bus.
Figure 1.6 : trois types d’interconnexions utilisées dans les MPSOC
D’un certain point de vue, le bus l’emporte dans les systèmes à moins de 20 composants. Mais quand la taille du système augmente il pose plus de problèmes et devient une contrainte insurmontable dans l’attente d’objectifs tels le temps d’exécution total. Pour plus de flexibilité et d’extensibilité une solution plus générale s’impose en utilisant une structure de communication globale segmentée et partagée. Ceci nous amène à penser à un réseau constitué de liens et des nœuds routeurs implémentés sur puce. A la différence des structures de communication traditionnelles vue auparavant, ces nouvelles structures de communication distribuée se comporte mieux avec l’extension, la taille de la puce et la complexité. Un concept commun de ces structures de communication dans les SOC est basé sur les réseaux, il est connu sous le nom « Network on Chip » (NOC) [17,7,16,18,19]. Dans la communauté des chercheurs, certains voient les NOC comme un sous ensemble des SOC et pour d’autres les NOC sont une extension de SoC. Mais généralement pour simplifier la hiérarchie des concepts on adopte la vue suivante :
Système embarqué d’aujourd’hui
SOC MPSOC Bus (NOC)
19

1.4.2 Topologies
L’augmentation constante du nombre de fonctions intégrées dans une seule puce a fortement augmenté les contraintes et les exigences sur les réseaux de communication. Les concepteurs de ces réseaux et les intégrateurs systèmes se sont tournés vers les techniques éprouvées des réseaux à grande échelle utilisés dans le monde des télécommunications et des calculateurs parallèles haute performance.
Les réseaux de communication présentent donc aujourd'hui une grande variété d’implémentations physiques. Ce paragraphe présente donc les principes des familles de topologies les plus utilisées, sachant que de nombreuses solutions spécifiques sont développées à partir de ces familles pour adapter le réseau de communication à l'application cible. Les Figures suivantes présentent ainsi le schéma de principe de quelques unes des topologies les plus couramment employées [9].
Ces réseaux intégrés sont composés de ressources de routage et de transport de l’information, Ces ressources doivent permettre l’échange de données entre périphériques.
1.4.2.1. Chemins de communication point à point :
Il s’agit de l’utilisation de ressources de transmission spécifiques et dédiées à l’implémentation d’un lien entre deux éléments.
Figure 1.7 : Liaison point à point.
Figure 1.8 : Anneau simple
La ressource de transmission étant dédiée à une unique communication, elle est toujours disponible pour cette dernière et peut ainsi lui offrir sa pleine bande passante. De plus, du fait de la simplicité du contrôle de telles connexions, les débits y sont élevés et les latences dépendent principalement de la longueur du chemin. Par contre la surface de ces connexions sera proportionnelle au nombre de liens.
1.4.2.2. Les topologies multipoints :
Dans l'ensemble des topologies présentées, les besoins gourmands en performance ont conduit de manière universelle au développement de réseaux d’interconnexion.
Le bus centralisé est en abandon progressif en tant que médium principal de communication par l'ensemble des acteurs qui se veulent à la pointe des solutions "système sur silicium". Le marché se déplace, de plus en plus rapidement, vers des solutions globales de
20

transport et de management du trafic au sein des systèmes sur silicium, s'inspirant fortement des réseaux de calculateurs parallèles [20].
Les systèmes sur silicium présentant une forte hétérogénéité de composants et possèdent rarement un seul type de réseau embarqué. Ils privilégient d'avantage l'utilisation conjuguée :
• D'un réseau d’interconnexions point à point, de type maille ou crossbar (figures 1.9 et 1.10) pour les besoins de parallélisme élevés entre sous-ensembles de composants du système.
Commutateur (Switch)
Figure 1.9 : maille complètement connecté Figure 1.10 : Crossbar complet
• Avec un ou plusieurs bus partagés pour les communications entre les composants de chaque sous-ensemble du système, ces communications nécessitant beaucoup de contrôle et une économie de surface.
1.4.2.2.1. Le Bus centralisé ou partagé :
Il s’agit d’implémenter plusieurs liens logiques de communication par un unique médium de communication à accès partagé : le bus. Ce médium permet la mise en place de liens uni ou multidirectionnels entre un maître et un ou plusieurs esclaves.
Les bus Ethernet et USB sont deux exemples célèbres de bus partagés. Tous les éléments sont susceptibles de piloter les lignes du bus de données, mais seuls un ou certains d’entre eux peuvent piloter le bus d’Adresse.
Figure 1.11 : Bus centralisé.
Ces éléments sont appelés maîtres du bus, les autres esclaves. Les maîtres initient des transactions sur le bus avec des esclaves. Les maîtres peuvent aussi se comporter en esclaves.
Le bus est alloué dynamiquement à une communication, plus précisément à un maître. Les échanges peuvent être cadencés par :
21

• Une horloge globale (système) : bus globalement synchrone ;
• Une horloge spécifique au bus : bus de séquencement local synchrone. Le système devient Globalement Asynchrone et Localement Synchrone (GALS) ;
• L’état du maître et des esclaves : bus asynchrone. Le système est toujours de type
GALS, sauf si l'ensemble des périphériques est également asynchrone. On obtient alors un système Globalement Asynchrone et Localement Asynchrone (GALA).
Les deux dernières catégories permettent de faire communiquer des éléments de l’architecture ayant des horloges indépendantes, alors que la première nécessite l’utilisation de la même horloge pour tous les composants connectés au bus. Ces bus sont généralement utilisés pour des systèmes ne nécessitant pas de larges bandes passantes.
Le bus Advanced Multi-masters Bus Architecture (AMBA) et le bus CoreConnect sont des exemples de bus partagés.
1.4.2.2.2. Les réseaux en étoile et en anneau :
Une première alternative intéressante au bus partagé est les réseaux en étoile, de type Ethernet avec un serveur central, et en anneau. L'Octagon a récemment su tirer parti des avantages conjugués de ces deux architectures.
Ces systèmes contiennent des commutateurs de paquets, au centre de l'étoile ou sur chaque nœud de l'anneau .Elles peuvent offrir une grande bande passante dans le réseau et une bande passante réduite moins coûteuse avec le composant périphérique.
Figure 1.12 : Anneau découplé. Figure 1.13 : Étoile.
1.4.2.2.3. Les réseaux Crossbar :
Il s’agit de la mise en parallèle de n lignes de transmission concurrentes [9].Le réseau de périphériques s’articule autour d’une matrice (appelée FPIC ou Switch Fabric) permettant la mise en oeuvre concurrente de plusieurs canaux de communication. La configuration de cette matrice peut être:
• Statique par programmation de la matrice lors de la fabrication, compliquant ainsi la réutilisation de la plateforme.
22

• Dynamique par reconfiguration des interconnexions à chaque démarrage de l’application.
1.4.2.2.4. Les réseaux commutés ou à maille :
Ce type de réseau comporte plusieurs étages, dont le franchissement s’opère au travers d’un commutateur qui se charge de router le message.
L’implémentation de chaque commutateur peut être à base de multiplexeurs voire à base de petits bus crossbar. La propagation de l’information peut suivre l’un des deux schémas suivants :
• Une connexion source-destination (aussi appelée session) permettant le transport continue et transparent de l’information au travers des étages;
• Une propagation de l’information d’étage en étage où elle est temporairement bufférisée dans une unité de routage. Ce mode de transmission est appelé wormhole.
Figure 1.14 : Interconnexions totales. Figure 1.15 : Topologie hybride bus + étoile.
Figure 1.16 : Liaison des nœuds à des commutateurs.
Si deux paquets entrants doivent être routés vers la même sortie, on parle alors de collision, et un paquet doit être élu et transmis tandis que l’autre est bufférisé pour ne pas être perdu.
1.4.3. Les exigences de conception d'un réseau sur silicium :
Ces nouvelles contraintes très fortes qui pèsent sur les réseaux de communication intégrés déterminent un ensemble d'exigences de conception que les concepteurs de ces réseaux et les
23

intégrateurs de système vont devoir spécifier, implémenter et évaluer pour concevoir des réseaux sur silicium performants. Ces exigences, ou critères, sont les suivants :
• La performance en termes de latence et débit que peut garantir le système de communication : les systèmes sur silicium actuels intègrent plusieurs périphériques capables chacun de réaliser des traitements à plusieurs gigabits par seconde. Tous ces périphériques opérant simultanément, le réseau d'interconnexion doit leur offrir une bande passante suffisante pour établir entre eux des communications.
• Le placement et le routage des réseaux sur silicium qui présentent le risque d'occuper une surface de silicium plus grande que les périphériques intégrés.
• Les temps de communication qui deviennent plus coûteux que les temps de calcul.
• Les contraintes d’ordre système deviennent prépondérantes, en particulier la vérification et l’interfaçage du système de communication avec les couches logicielles basses de l'application.
• La testabilité. Les plus complexes des réseaux de communication peuvent embarquer de la logique de tests permettant d’espionner leurs états internes.
• L'aptitude du système de communication à synchroniser des blocs cadencés par des horloges différentes (asynchronisme).
• La flexibilité dans la définition des protocoles de communication. C'est une nécessité pour permettre la connexion au bus de blocs fonctionnels de nature et d'origine très diverses.
• La flexibilité dans la définition des services offerts par le système de communication. On peut citer : la gestion de priorités, l'accès parallèle aux ressources, la mémorisation de message…
• La fiabilité des mécanismes de communication est une propriété très importante. Il faut prendre en compte la fiabilité des protocoles de synchronisations au niveau le plus bas.
L'ensemble de ces exigences ou critères détermine le choix d'une topologie du réseau sur silicium synchrone ou asynchrone.
Ainsi les performances du réseau de communication vont dépendre de la topologie de ses composants et de leur bande passante, du nombre de liens logiques se partageant les mêmes ressources et nécessitant donc une latence d’accès à une ressource partagée, mais aussi du protocole d’échange. La consommation du réseau de communication doit être soigneusement réduite car le réseau représente une part très importante de la charge de fonctionnement d'un système sur silicium. En outre, le réseau d'interconnexion est à la fois un émetteur puissant et un récepteur sensible d'ondes électromagnétiques, pouvant parasiter l’ensemble du système.
24

Enfin, la surface occupée sur le circuit par le réseau doit rester la plus faible possible par rapport à la surface attribuable sur ce même circuit aux unités de calcul.
Tous ces critères ne se retrouvent pas de manière critique dans toutes les applications.
Cependant une infrastructure de communication se doit aujourd'hui d'être conçue performante bien sûr, mais également flexible afin d’être réutilisable pour le plus grand nombre possible d’applications.
1.5 Conclusion
Cette brève introduction aux concepts qui composent les systèmes embarqués nous permet de constater que pour concevoir des applications pour ce type de plateformes on doit prendre en considération leurs spécificités. L’architecture doit répondre aux besoins de l’application et cette dernière prends en considération leurs caractéristiques. C'est-à-dire qu’à un moment de la conception du système on ne peut concevoir l’application sans le matérielle sur lequel elle va être exécutée et on ne peut arrêté le matériel sans connaître le type d’application qu’il va supporter. D’où la méthodologie ou flot de co-conception qu’on va introduire dans le chapitre suivant.
25

CHAPITRE 2
Flots de conception dans les SOC
26

Dans ce chapitre, nous présentons la deuxième partie du contexte de notre étude concernant la modélisation à haut niveau et la conception des systèmes sur puce. Cette approche est basée sur la méthode d’Ingénierie Dirigée par les Modèles (IDM ou MDE en anglais) qui permet de faciliter l’étude et le développement de ces systèmes. L’IDM, apparue vers la fin des années 1990, s’est particulièrement développée lors de la parution de l’initiative Model Architecture [21] de l’Objet management Groupe. Comme son nom l’indique, l’IDM est une approche dont l’élément clé est la notion de modèle. Après avoir introduit les principes de base de cette démarche, nous allons présenter l’environnement de développement GASPARD2, principalement conçu pour la conception des systèmes sur puce défini autour des applications et d’architectures basées sur Array-OL.
2.1 La notion de modèle
Le but d’un modèle est de proposer une abstraction simplifier d’une certaine réalité ou de l’élément modélisé en omettant certains détails et en ne laissant apparaître que les informations qui seront utiles à l’utilisateur du modèle. Dans [22], BEZIVIN fournit une présentation très détaillée des principaux concepts de l’IDM. Il se sert de la carte géographique pour expliquer le rôle de modèle. En effet, la carte est un modèle de la réalité, une simplification du monde réel dans lequel on ne va laisser apparaître de manière compréhensible qu’un nombre limité d’informations. On peut aussi représenter une réalité par plusieurs modèles. Chacun modélisant un domaine précis. Ainsi une personne désirant obtenir des informations sur un terrain va alors utiliser différents types de cartes suivant qu’elle s’intéresse à la géopolitique, l’économie, la géologie ou encore la circulation routière.
Dans le cas des systèmes sur puce, les détails d’implémentation seraient par exemple abstraits. Merise [23], SSADM [24] et UML [25] sont des exemples de méthodes de modélisation. Ces méthodes permettent de manipuler le concept de modèle appliqué à l’information en proposant des concepts et une notation permettant de décrire le système à concevoir. Chaque étape du cycle de développement du système produit un ensemble de documents le plus souvent constitués de diagrammes permettant aux différents acteurs du projet de partager leurs points de vue sur le système.
Leur lourdeur et leur déficit de souplesse en réaction à l’évolution rapide des logiciels ont parfois été à l’origine de critiques qui ont conduit à la notion de modèles contemplatifs essentiellement destinés à la communication et à la compréhension. Ces modèles restent toutefois passifs à la production, contribuant à laisser, comme c’est le cas depuis plus de cinquante ans, le code au cœur du processus de production logicielle. L’IDM tente de combler ce manque au niveau des méthodes traditionnelles de modélisation en fournissant un cadre de développement logiciel au sein duquel les modèles passent de l’état contemplatif (passif) à l’état productif (actif), c'est-à-dire compréhensibles et interprétables par les machines.
2.2 L’Ingénierie Dirigée par les Modèles (IDM)
Les systèmes étudiés peuvent être modélisés selon différentes approches adaptées à la nature de ces systèmes et au contexte d’application dans lequel ils sont définis. Parmi ces approches, l’Ingénierie Dirigée par Les Modèles présente une contribution importante dans le
27

domaine de la conception de systèmes logiciels [26]. Elle représente une forme d’ingénierie générative, par laquelle tout ou partie d’une application est générée à partir des modèles.
On peut voir l’IDM comme une famille d’approches qui se développent à la fois dans les laboratoires de recherche et chez les industriels impliqués dans les projets de développement logiciels. Cette approche offre un cadre méthodologique et technologique qui permet d’unifier différentes façons de faire dans un processus homogène. Il est aussi possible d’utiliser la technologie la mieux adaptée pour chacune des étapes du développement, tout en ayant un processus de développement global unifié. Le code source, dans l’IDM, n’est plus considéré comme l’élément central d’un système, mais comme un élément dérivé de la fusion d’éléments de modélisation. L’étude est basée sur la construction de modèles qui occupent la place principale dans le cycle de développement du système, et doivent en contrepartie être suffisamment précis afin de pouvoir être interprétés ou transformés par des machines vues comme un ensemble de transformation de modèles. Généralement, l’IDM peut être défini autour de trois concepts de base : les modèles, les méta- modèles et les transformations (figure 2.1).
Figure 2.1 : Architecture en 4 couches employée par IDM
Pour borner le nombre de couches superposables, on détermine un type de méta-modèle particulier appelé méta-méta-modèle. La particularité de celui-ci est qu’il est capable de s’auto décrire : Il est donc conforme à lui-même. En effet, un méta-méta-modèle est un méta-modèle introduisant des notions permettant de définir des méta-modèles : On va donc pouvoir utiliser ces notions pour définir le méta-méta-modèle.
Un des apports essentiels de l’approche IDM, consiste à automatiser la transformation de modèles. Il s’agit de transformer le code d’un langage en un autre, ou une modélisation abstraite en une structure de classe, ou même un modèle de données en un autre modèle tout en assurant que les propriétés des données sont conservées lors de la transformation. Dans ce contexte, la vérification de modèles basée sur des approches formelles donnant de spécifications rigoureuses a pour objectif de garantir que les modèles possèdent toutes les qualités attendues, en particulier lorsqu’ils ont en charge de modéliser la fabrication de systèmes critiques développés dans des secteurs comme les transports ferroviaires, l’avionique, le spatial, les télécommunications ou l’énergie. L’approche IDM ouvre ainsi de nouvelles perspectives dans le cadre de la conception des systèmes embarqués critiques. De
28

plus, une caractéristique principale de l’approche IDM consiste à favoriser l’étude séparée des différents aspects du système. Cette séparation augmente la réutilisation et aide les membres de l’équipe de conception à partager et s’échanger leurs travaux indépendamment de leur domaine d’expertise. Ce concept est particulièrement intéressant dans le domaine de conception des systèmes sur puce où les deux technologies logicielle et matérielle vont interagir pour la définition du comportement global du système.
2.3 Model Driven Architecture MDA
Le MDA est une variante2 de l’IDM définie par l’OMG3 (Object Management Groupe). Cette approche fournit un ensemble de directives permettant de séparer les contraintes fonctionnelles des contraintes techniques, elle est basée sur l’utilisation de modèles pour la description des systèmes logiciels à développer.
Le MDA est basé sur la description du système à plusieurs niveaux d’abstractions en séparant sa spécification fonctionnelle des détails de sa plateforme d’exécution et des contraintes techniques.
Ainsi ce concept fournit une approche et des outils pour :
- Spécifier les fonctionnalités du système indépendamment de sa plateforme d’exécution (niveau PIM : Platform Independent Model),
- Spécifier les plateformes d’exécution,
- Choisir une plateforme particulière pour le système, et
- Transformer la spécification du système vers une spécification plus adaptée à la plateforme choisie (niveau PSM : Platform Specific Model).
Dans la première étape du MDA (PIM) on réalise un modèle indépendamment de toutes plateformes d’exécution. Le PIM représente uniquement les caractéristiques fonctionnelles et le comportement du système sous forme d’un modèle simple et claire. La clarté de ce modèle permet aux concepteurs de mieux comprendre les fonctionnalités du système, et donc de pouvoir vérifier ses caractéristiques et sa cohérence. La deuxième phase dans le processus MDA consiste à transformer le PIM vers un PSM. Le PSM permet d’obtenir un modèle spécifique à la plateforme d’exécution utilisée pour la mise en œuvre du système. A ce niveau, les caractéristiques d’exécution et les informations technologiques sont prises en compte dans la description du modèle [27].
Les transformations entre les niveaux PIM e PSM sont généralement effectuées via des outils automatisés tel que QUT (Queries/Views/Transformations) [28], le langage de transformation de modèles standardisé par l’OMG. L’approche MDA se présente sous la forme d’un ensemble de standards utilisés pour créer un modèle et l’affiner jusqu’à obtenir,
2 Historiquement, l’approche MDA a été proposée avant l’approche IDM 3 http://www.omg.org
29

idéalement, un produit fini, comme du code source. Cette approche fait généralement appel à l’utilisation de langages de modélisation et d’outils de développement commun standardisés.
2.4 Modélisation UML
L’UML (Unified Modeling Langage) [29] est des plus répandu Méta-modèle. Il a été standardisé par l’OMG et vise la modélisation de système informatique de tout type. Son principal atout en plus d’être répandu et connu de beaucoup d’utilisateurs est son caractère généraliste. Cependant, dans sa forme livrée, il ne permet pas une utilisation directe dans un processus d’ingénierie dirigée par les modèles du fait de sa sémantique généraliste qui manque de précision et ne permet pas de produire directement un système. Plus précisément, de nombreux points laissent apparaître une sémantique ambiguë, laissant l’utilisateur comme seul décideur de la signification à leur apporter (Figure 2.2).
Depar l’iprofil descripermeattribu
L’upouvo
2.4
TelgénéraCepen
Figure 2.2 : Classification des 13 diagrammes du langage UML
nos jours, l’utilisation d’UML dans un cadre d’ingénierie dirigée par les modèles se fait ntermédiaire de son mécanisme interne de méta-modélisation que l’on appelle profil. Un est un ensemble d’extensions et de restrictions permettant la spécialisation et la
ption d’un domaine particulier. Les extensions sont appelées stéréotypes, elles ttent de spécialiser une ou plusieurs classes UML et peuvent contenir de nouveaux ts appelés tagged values.
tilisation des profils permet d’obtenir un pouvoir d’expression quasiment identique au ir d’expression du modèle tout en ayant accès aux concepts existants proposés par UML.
.1 Extensibilité d’UML : la notion de profil
qu’on l’a avancé dans le paragraphe précédent, l’UML est un langage de modélisation liste. Son méta-modèle vise à couvrir tous les aspects de la modélisation logicielle. dant, il arrive qu’en pratique son utilisation, telle quelle, ne soit pas adaptée pour
30

modéliser les concepts d’un domaine bien particulier. Conscients de ce problème, les auteurs de ce langage y ont introduit la possibilité de le spécialiser par le mécanisme Profil lui permettant de pas er d’un la langage généraliste à un DSL (Domaine Specifi Language).
Pour spécialise
Extension du d’UML par l’utillangage UML (sméta-classe héritad’ajouter des nouà noter qu’il est pque l’utilisateur n
Fermeture ddifférents domainL’extension d’unpoints de variatiofait.
Ajout de conts’utilise à priori eil est possible d’astéréotype. Un édde signaler une er
Spécialisation particulière au sgraphique en sdynamiquement c
Définition d’ude bien le documprofil est fait poudiagramme il do 4 En empêchant la spspécialisation, ce quide limiter les possibi
s
Figure 2.3 : Spécialisation d’UML par le mécanisme de profil
r UML un profil joue sur différents points :
méta-modèle : Le mécanisme offre un moyen d’étendre le méta-modèle isation de stéréotypes. Un stéréotype permet d’étendre toute méta-classe du auf la Méta-classe stéréotypée elle-même4) et de créer ainsi une nouvelle nt de toutes les propriétés de la méta-classe étendue. Il devient aussi possible velles propriétés à cette nouvelle méta-classe à l’aide de Tagged values. Il est ossible d’obliger l’utilisation de stéréotypes sur la méta-classe, de telle sorte e soit plus autorisé à employer le méta classe original dans un modèle.
e points de variation sémantique : En vue de pouvoir s’adapter dans es, la norme UML laisse délibérément certains points de sémantique ouverts. e méta-classe cause l’héritage de sa sémantique, ce qui oblige à fixer les n sémantique pour le langage crée en fonction de la spécialisation que l’on en
raintes OCL : La nouvelle méta-classe que l’on crée à l’aide d’un stéréotype n respectant les contraintes appliquées à la méta-classe étendue. Cependant, jouter des contraintes supplémentaires en associant des contraintes OCL au iteur UML suffisamment évolué sera capable d’interpréter ces contraintes et reur de modélisation.
de la syntaxe graphique : Le profil permet d’associer une forme visuelle téréotype que l’on définit. Ce qui nous permet de spécialiser la syntaxe pécialisant les diagrammes. Un éditeur évolué permet de charger es images et d’éditer directement ce nouveau type de diagramme.
ne méthodologie de modélisation : Le profil une fois défini, il est nécessaire enter, notamment en identifiant clairement les diagrammes avec lesquels ce r être utilisé. En effet, un stéréotype ne précise pas par lui-même dans quel it être utilisé. Lorsqu’un élément d’un méta-modèle peut apparaître dans écialisation de la notion de stéréotype, UML s’empêche de modifier son mécanisme de permet de pouvoir interpréter un profil de manière systématique, mais qui a aussi pour effet lités de spécialisation ?
31

différents diagrammes, le stéréotype qui l’étend le peut aussi. Or la transformation d’UML en un DSL cherche à choisir les représentations les plus expressives pour le domaine que l’on vise. Pour illustrer le mécanisme de profil, imaginons que l’on veuille exprimer avec UML les concepts du méta-modèle de la figure II.4 dont la définition du profil correspondant est donnée par la figure 2.5.
Figure 2.
On voreprésentcomposaOn voit dnotre "<stéréotyp
En effdit que cnotre casdes "<dslexprimée
Figure 2.4 : Exemple de méta-modèle
5 : Exemple de profile pour le méta-modèle de l’exemple de la figure II.4.
it que le stéréotype "<dsl-Systeme"> spécialise la notion de classe servira à er la notion de système introduite dans notre méta-modèle. Le stéréotype "<dsl-nt"> étend la notion de property d’UML et stéréotype "<dsl-port"> la notion de port. e plus qu’une tagged value est ajoutée à ce dernier afin de spécifier la direction de
dsl-Systeme">, notion qui n’existe pas dans le meta-modèle original d’UML. Enfin le e "<dsl-connection"> étend la notion de connector d’UML.
et, la norme UML laisse un point de sémantique ouvert pour les connecteurs : il est e qui rend des éléments connectables compatibles est un point de variation. Dans , nous pouvons le préciser en disant que les éléments connectables doivent être -Systeme"> [revol], et qu’ils ne peuvent être connectés que si leurs directions s par les tagged values sont complémentaires. Ceci pourrait de plus se décrire à l’aide
32

d’une contrainte OCL afin qu’elle soit évaluée et que l’outil UML puisse vérifier qu’elle est respectée.
2.5 GASPARD : Flot de conception pour les SOC
Gaspard [30] est un environnement de développement permettant la co-conception de système sur puce dans un cadre d’ingénierie dirigée par les modèles (IDM). Il est développé au sein de l’équipe DaRT et est orienté vers les applications de traitement de signal intensif. Ces applications sont rencontrées souvent dans les SOC et sont caractérisées par leur gourmandise en termes de puissance de calcul ce qui nécessite la parallélisation des traitements. Gaspard permet donc d’exploiter les principes de l’ingénierie dirigée par les modèles pour Co-modéliser des MPSOC ou massivement parallèle qui sera utilisé dans une application de traitement de signal intensif.
Il adopte un flot de conception en "Y", ce qui permet aux concepteurs du système de modéliser de manière indépendante l’application et l’architecture matérielle du système, ensuite l’étape d’association permet de les réunir en plaçant l’application sur l’architecture. Ces trois modèles permettent, par l’intermédiaire de transformations, de générer des simulations à des niveaux de précision de plus en plus importants. La vérification formelle de la modélisation de l’application est rendue possible par la génération de langages synchrones déclaratifs [31] comme lustre [32] ou Signal [33].
L’exécution concurrente de différents processus sur une architecture multiprocesseurs est rendue possible par la génération de langages procéduraux comme Fortran/Open MP. La finalité étant de générer un code de simulation, avec System C par exemple, prenant en considération à la fois les parties matérielles et logicielles du système sur puce complet. La figure 2.6 illustre le flot de conception en "Y".
Figure 2.6 : Flot de conception en Y de GASPARD 2
Ce méta-modèle s’inspire de standard de l’OMG comme SPT [34] pour la représentation de l’architecture matérielle, SysML pour les mécanismes d’association et UML pour l’approche
33

de modélisation par composants. Gaspard offre également la possibilité de modéliser sous une forme factorisée des applications et des architectures régulières ayant un caractère répétitif ; cette expression est basée sur le langage Array-Ol (que nous présenterons par la suite). Un mécanisme de factorisation permettant de représenter de manière compacte les systèmes répétitifs réguliers basé sur le langage Array-Ol est présent. Précisons aussi que ce méta-modèle est en partie à la base du récent standard MARTE.
Il faut noter aussi que le contexte de développement, ce n’est pas le méta-modèle Gaspard qui est directement manipulé mais le profil UML associé, ceci afin de permettre l’utilisation des outils standards de modélisation graphiques basés sur UML. Une fois modélisé, le modèle conforme au profil UML Gaspard est transformé vers un modèle conforme au méta-modèle gaspard à l’aide d’une transformation de modèles [35].
2.5.1 Modélisation des applications DSP
Quel est le bénéfice que l’on peut tirer par l’utilisation des approches IDM (MDE) pour faire des applications DSP (Digital Signal Processing). Il n’y a pas un seul avantage mais plusieurs, des avantages techniques à la convivialité. Ceux cités ci-après constituent les plus en vue.
Interopérabilité : IDM est devenu de plus en plus utilisé comme approche pour développer le software. Ainsi plusieurs outils sont devenus disponibles pour manipuler des modèles, méta-modèles et les transformations de modèles. Ces outils souvent attachés à des standards permettent une certaine interopérabilité entre eux. En utilisant les outils de transformation de modèle, il est facile d’extraire à partir d’un modèle connu les formats de fichiers d’entrée pour l’allocation, l’assignation et le Scheduling
Abstraction : L’autre point fort des MDE est l’abstraction. Généralement les modèles sont construits pour être facilement lus et compris par les humains. L’utilisateur peut modéliser son application, le hardware et leur association comme une seule pièce en utilisant une approche descendante, ascendante ou hybride comme il le souhaite, et réutiliser des parties de ce modèle facilement. L’abstraction devrait aussi permettre l’intégration des heuristiques différentes de placement et d’ordonnancement, partager des modèles communs de l’application, du matériel et leurs associations. Ces modèles devraient être extensibles pour permettre l’adaptation de futures techniques. L’IDM aide dans cet aspect en permettant une facile extension de modèle.
Caractérisation : Dans le but de définir complètement l’application et les paramètres de l’architecture matérielle, le graphe modèle doit être caractérisé. Ces caractéristiques sont les attributs des nœuds et arcs. Certaines de ces caractéristiques sont spécifiques à l’application telles les contraintes de temps réel et la consommation d’énergie. D’autres sont relatives à l’architecture tel l’ensemble d’instructions du processeur, fréquence d’horloge, consommation d’énergie, taille mémoire, largeur de bande…etc. Sans oublier ceux qui caractérisent l’association des composants d’application aux composants de l’architecture telles les temps estimés ou les contraintes de placement. Ces derniers sont représentés par des liens entre le graphe d’application et le graphe d’architecture.
34

2.5.2 Principe de modélisation dans Gaspard2
2.5.2.1 Graphe de tâche hiérarchique (à reformuler)
Un programme peut être décomposé en structure de boucle et un graphe de tâches de dépendance acyclique (ADTG) représentant le corps de chaque boucle ou sub-routine. Le parallélisme inhérent dans ces graphes acycliques augmente le parallélisme au niveau boucle disponible dans le programme. Ainsi Un graphe représentant un tel programme, avec ces boucles localement encapsulées comme un seul nœud de tâche et globalement vu comme un ADTG, est appelé graphe de tâche hiérarchique (HATG Hierarchical Application Task Graph). Pour plus de simplification dans la lecture on l’appellera par la suite HTG (Hierarchical Task Graph). Le problème d’ordonnancement d’un tel graphe avec des critères d’optimisation est très complexe, car la construction d’un tel graphe nécessite la modélisation des communications inter-tâches et inter-processeurs. Traiter ce graphe comme un ADTG pendant l’ordonnancement nous fait perdre le parallélisme présent dans les nœuds locaux encapsulés ce qui a des conséquences sur le potentiel d’optimisation.
La plupart des heuristiques de placement utilisent des graphes basés sur la description de l’application et de l’architecture. Dans le but de traiter des systèmes plus complexes on doit avoir une description hiérarchique d’au moins l’application. Il est aussi important d’avoir une description hiérarchique de l’architecture afin d’accommoder les granularités. Avec ça on peut commencer par une optimisation grossière qu’on essaye de raffiner par la suite. Une autre exigence dans ces représentations est la modélisation des répétitions telles les boucles dans les applications ou les unités SIMD dans le Hardware. Car de cette représentation dépend le gain de la parallélisation des traitements et des données. Puisque nous dépendons de l’algorithme d’optimisation utilisé pour placer et ordonnancer ces structures répétitives on doit les voir comme des entités indivisibles ou comme une répétition de structure (régulières) ou même comme de non structure (irrégulière) d’ensemble de tâches. On a proposé des modèles de graphe hiérarchique pour décrire le calcul intensif des applications embarquées et les plateformes de SOC [36,37]. Ces modèles sont basés sur le profil UML2 et sont incorporés dans l’outil de co-modeling Gaspard2 [30].
Une application Gaspard2 est un ensemble de composants connectés entre eux par des dépendances de données. Ces composants doivent être construits à partir d’un bas niveau (visuel ou textuel) composant. Les données échangées entre ces composants sont des données parallèles (tableaux multidimensionnelles d’objets élémentaires). Le composant graphe introduit le parallélisme de tâche et les composants peuvent être utilisés dans des itérateurs parallèles de données. S’il y a utilisation de ces itérateurs parallèles de données, le composant donné est exécuté en parallèle sur des éléments d’un tableau d’objets.
L’idée fondamentale, ici, est que les composants de base doivent être parallèles, le programmeur n’a pas à apprendre une librairie de programmation parallèle ou un langage lui permettant intuitivement de les composer en parallèle, tout est donné au niveau visuel, ce qui permet un développement rapide.
35

Pour construire une application régulière distribuée, Gaspard 2 implémente le modèle Array-Ol [38,39]. Il propose une approche à deux niveaux. Le premier est le niveau graphe de tâche qui permet l’ordonnancement de tâches comme une fonction de dépendances entre tâches et tableaux. Le deuxième niveau permet de définir les répétitions parallèles de composants.
Le modèle mathématique implémenté dans Gaspard 2 est un HTG avec deux types de nœuds.
• Nœud Acyclique Direct (DAN Directed Acylique Node) qui est défini comme un de DAG.
• Nœud Répétitif (RN) qui représente la répétition parallèle de données d’un nœud.
La seule structure de donnée qui est autorisée dans GASPARD 2 (et Array-ol) concerne les tableaux multidimensionnels. Cette structure de données est adaptée au traitement de signal dont l’importance dans les SOC a été soulignée précédemment. Les applications de traitement de signal sont habituellement organisées autour d’un flot infini de données régulières. Ce flot est capturé dans des tableaux avec si c’est possible une dimension infinie. Certaines dimensions spatiales de tableaux utilisés dans le traitement de signal correspondent à des capteurs.
2.5.2.2 Nœud Direct Acyclique
Ces nœuds sont des DAG de nœud connectés entre eux par des arcs représentant la dépendance de données entre ces nœuds. Les données représentées par ces arcs sont des tableaux. Ainsi ce graphe est un graphe de dépendance et non un flot de données.
2.5.2.3 Nœud répétitif
Ces nœuds permettent de représenter les répétitions de données parallèles des sous nœuds. Ces répétitions prennent comme entrées/sorties des parties de tableaux en entrée et en sortie du nœud répétitif. Ces parties de tableaux ont toutes la même forme et sont appelés Motifs (patterns). Les Motifs en sortie sont produits en appliquant le sous-nœud sur le Motif du tableau en entrée.
Toutes les répétitions des sous-nœuds sont indépendantes et définies dans un espace de répétition Q. Pour chaque entrée/sortie du nœud répété, on a les informations nécessaires. Dans le Chapitre 3, on décrira comment on obtient ces informations grâce à Array-Ol.
2.6 L’environnement GASPARD 2
Comme on l’a avancé précédemment, dans le contexte de développement, ce n’est pas le méta-modèle Gaspard qui est directement manipulé mais le profil UML associé, ceci afin de permettre l’utilisation des outils standards de modélisation graphiques basés sur UML. Une fois modélisé, le modèle conforme au profil UML gaspard est transformé vers un modèle conforme au méta-modèle gaspard à l’aide d’une transformation de modèle. Les principaux paquetages composants le méta-modèle permettent de modéliser les notions de composants, de
36

factorisation, d’application, d’architecture et d’association. La figure 2.7 illustre l’organisation des différents éléments constitutifs du profil, agencés de manière à bien illustrer le "Y" formé par les paquetages application, hardware architecture et association.
Figure 2.7 : Vue d’ensemble des différents paquetages constituants le profil Gaspard
2.6.1 Le paquetage Component
L’un des concepts de base du méta-modèle Gaspard est le paquetage Component qui permet de définir l’approche orientée composant qui sera utilisée pour la modélisation. Ce paquetage à travers les outils qu’il apporte permet de construire d’une façon structurée des applications et des architectures matérielles. En adoptant les concepts apportés par UML, il permet de mettre en œuvre différents mécanismes. Le mécanisme d’encapsulation permet de rendre la définition d’un composant indépendante de l’environnement dans lequel il est utilisé. Cette séparation est tracée entre l’intérieur du composant (son implémentation) et la façon dont il perçoit son environnement, ou la façon dont il est perçu par son environnement. La couche hiérarchique est apportée par un mécanisme de composition et d’assemblage pour organiser l’intérieur du composant. Cette couche permet d’exprimer la structure d’un composant car il peut être composé de plusieurs composants. Afin, par exemple, de simplifier les fonctionnalités, l’assemblage de ces composants permet alors d’implémenter des comportements plus complexes. Le component est l’élément réutilisable manipulé au sein d’un modèle GASPARD. IL est défini par un ensemble d’interfaces proposées par l’intermédiaire de Ports et par sa structure composée par un assemblage d’instances reliées par des connecteurs. Si un composant A contient une instance d’un composant B, cela signifie que le composant A utilise B dans son implémentation. Elementery component est un composant ne contenant aucune instance ce qui nous permet de le rapprocher d’une « boite noire », désignant un niveau de précision à partir duquel le modèle n’apporte plus d’informations.
37

La figure II.8 illustre ces différents concepts avec un exemple d’unité de calcul « Processing Unit » définie à l’aide de trois composants élémentaires : un processeur MIPS, une mémoire Memory et un crossbar Crossbar4.
Figcompo
Selonqualifiésrecevoirconnectports ayinstance
2.6.2
Ce prend le permettecomposconceptmodélis
2.6.2
Ce coà une incompostableau nombresà-dire le
ure 2.8 : Un exemple de composant gaspard, processing Unit composé de trois sous sants instanciés sous les noms cb, mem et mips. Les ports et les connecteurs indiquent
les relations entre les instances
le cas où l’interface, reçoit ou émet des données, les ports utilisés peuvent être de In ou out. En l’absence de qualificatif, l’interface est capable d’émettre et de . Ces qualificatifs sont très importants vis-à-vis des connexions, en effet les eurs de délégation, reliant un composant à une instance, ne peuvent connecter que des ant la même orientation tandis que les connecteurs d’assemblage, reliant deux s, ne peuvent connecter que des ports ayant des orientations opposées.
Le paquetage factorisation
aquetage est très important dans GASPARD, car c’est à travers ces concepts qu’on méta-modèle très adapté aux systèmes massivement parallèles réguliers. Des concepts nt de représenter sous une forme très compacte la répétition d’un ensemble de
ants identiques. Il propose au développeur de systèmes sur puce multiprocesseurs les s apportés par Array-Ol, mais généralisés afin d’en permettre l’utilisation pour er les applications mais également les architectures matérielles et les associations.
.1 La notion de Shape
ncept permet d’indiquer qu’un élément possède une multiplicité, il peut être appliqué stance ou à un port. Shape est appliqué sur un élément vu comme une collection
ée d’un nombre d’éléments qu’il détermine. Cette collection est structurée avec un multidimensionnel et son expression se fait par l’intermédiaire d’un vecteur de entiers strictement positifs, chaque composante du vecteur déterminant la taille, c'est- nombre d’éléments, de la dimension du tableau associé. La figure 2.9 illustre ce
38

concept avec un exemple représentant 4 instances d’un composant organisées sous la forme d’un tableau bidimensionnel de 2x2 instances.
A noter qu’une dimension peut être déclarée comme infinie en spécifiant le symbole ~ à la place d’un entier, cette spécificité ne s’applique évidemment qu’à l’application pour représenter un traitement répété de manière infinie dans le temps, définir un composant matériel aux ressources physiques illimitées n’ayant bien sûr pas de sens [35].
Figure 2.9 : Représentation d’un composant Gaspard2 avec une multiplicité bidimensionnelle (sur la gauche) et son équivalent en UML2 (sur la droite)
2.6.2.2 Notion de Tiler
Le concept de Tiler a été crée pour accéder aux éléments des tableaux multidimensionnels caractérisés par un Shape d’une façon simple et compact. On commence par identifier au sein de ces tableaux des ensembles de points qu’on appelle « Motifs », appelés aussi tuile (Tile en anglais), ils sont caractérisés par un espacement régulier des différents points c’est ce qu’on appelle l’ajustage (fitting en anglais). Avec un ensemble de Motifs il est donc possible de parcourir tout le tableau afin d’en récupérer tous les éléments. Comme les éléments des motifs, les différentes tuiles sont caractérisées par un espacement entre elles, c’est le pavage (paving en anglais). La couverture complète d’un tableau nécessite trois informations supplémentaires : Une origine, point faisant office de référence, un espace de répétition délivrant une information concernant le nombre de tuiles à utiliser afin de parcourir tout le tableau et la taille du motif (le nombre de points à considérer pour chaque dimension du tableau). Ce sont là les notions de base du modèle de calcul Array-ol qu’on introduira dans le chapitre suivant. Pour un motif donné, la tuile correspondante est identifiée à partir d’un élément de référence dans le tableau, nous l’appellerons ref. L’espacement des différents éléments au sein de la tuile est déterminé par l’intermédiaire de la matrice d’ajustage et en rapport avec le point de référence. Le nombre de lignes de la matrice correspond au nombre de dimensions du tableau et le nombre de colonnes correspond au nombre de dimensions du motif que l’on veut récupérer. Chaque élément ei de la tuile est déterminé par la somme des
39

coordonnées du point de référence et de la multiplication de la matrice d’ajustage par les coordonnées i de l’élément du motif, comme exprimé dans la formule suivante :
∀i 0≤i< Spattern, ei=ref+F.i modSarray
Spattern représentant la forme du motif, Sarray représentant la forme du tableau et F étant la matrice d’ajustage.
Dans la figure 2.10 on présente un exemple de Tiler dans une application. Le connecteur situé entre les ports m1 et A, par exemple, le port m1 a une dimension 128x128 et le port A a une dimension de 8x8, le Tiler permet de décomposer le tableau situé sur m1 par bloc de 8x8 éléments contigus.
Figure 2.10 : Illustration de la notion de Tiler
2.6.2.3 La notion de Reshape
Le concept de Reshape a été introduit afin de permettre la liaison élément par élément de deux tableaux ayant des formes différentes [35]. Au niveau conceptuel, un reshape se contente simplement d’associer deux Tilers l’un après l’autre, le premier Tiler ayant pour tâche de rassembler par motif les éléments du premier tableau vers un motif intermédiaire et le second Tiler ayant pour fonction de répartir les éléments du motif intermédiaire sous une nouvelle forme dans le tableau de sortie. En plus des deux Tilers, , le Reshape apporte les notions de Pattern Shape et de Repetition Space, le PatternShap permettant de représenter la forme du motif intermédiaire et le Repetition-Space permettant d’exprimer l’espace de répétition parcouru afin de complètement remplir le tableau de sortie. La figure 2.11 illustre un exemple de Reshape. Dans cet exemple, il y a deux tâches t1 et t2, chaque ligne du tableau de sortie t1 est rangée dans une colonne du tableau d’entrée t2. On passe donc d’un tableau de dimension 3x2 à un tableau d dimension 2x3.
e
Figure 2.11: Un exemple de Reshape
40
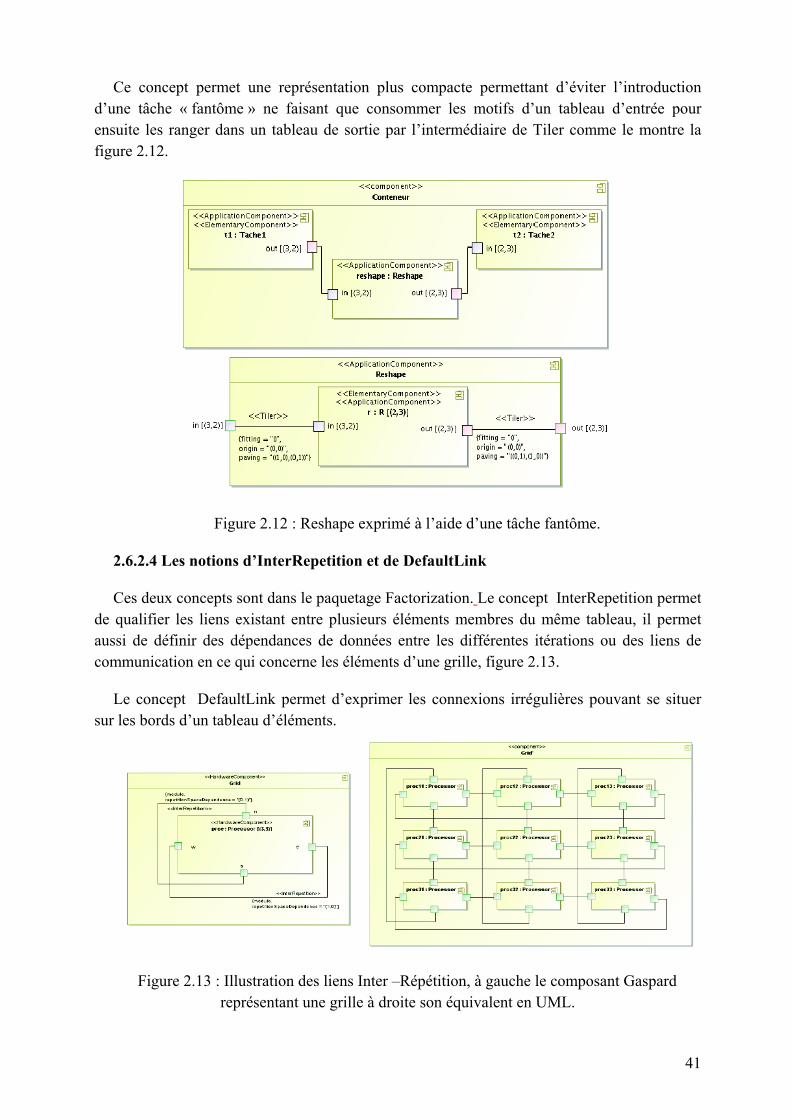
Ce concept permet une représentation plus compacte permettant d’éviter l’introduction d’une tâche « fantôme » ne faisant que consommer les motifs d’un tableau d’entrée pour ensuite les ranger dans un tableau de sortie par l’intermédiaire de Tiler comme le montre la figure 2.12.
2.6.2.4 L
Ces deuxde qualifieraussi de décommunica
Le concesu les bord
Figur
Figure 2.12 : Reshape exprimé à l’aide d’une tâche fantôme.
es notions d’InterRepetition et de DefaultLink
concepts sont dans le paquetage Factorization. Le concept InterRepetition permet les liens existant entre plusieurs éléments membres du même tableau, il permet finir des dépendances de données entre les différentes itérations ou des liens de tion en ce qui concerne les éléments d’une grille, figure 2.13.
pt DefaultLink permet d’exprimer les connexions irrégulières pouvant se situer s d’un tableau d’éléments.
re 2.13 : Illustration des liens Inter –Répétition, à gauche le composant Gaspard représentant une grille à droite son équivalent en UML.
41

2.6.3 Paquetage Application
Ce paquetage à travers les notions qu’il apporte permet d’associer une sémantique propre à tout composant représentant une partie de l’application. Avec cette sémantique, les applications peuvent être représentées par langage de flot de données s’appuyant sur les concepts définis dans les paquetages Component et Factorization. Ce langage est très fortement inspiré de Array-Ol que nous allons voir par la suite. Par application on définit le comportement du système en fonction des entrées qu’on lui fournit, tout ou partie de l’application peut donc être sous forme logicielle ou matérielle.
L’objectif est de permettre l’expression d’applications de traitement de signal intensif travaillant avec des tableaux multidimensionnels. La mise au point de telles applications n’est pas complexe à cause des fonctions élémentaires les constituant mais de leur association ainsi que de la manière d’accéder aux tableaux utilisés. La finalité de tels systèmes étant d’en ressortir des performances, il est indispensable d’utiliser le parallélisme potentiel offert par l’application de manière à l’associer au parallélisme disponible offert par l’architecture matérielle.
Pour constituer ce langage un certain nombre de principes de base ont été choisis :
• Expression de tout le parallélisme potentiel ;
• Expliciter toutes les dépendances de données ;
• Les tableaux sont à assignation unique, chaque élément peut être lu plusieurs fois mais ne peut être écrit qu’une seule fois ;
• Il n’y a pas de différentiation dans le traitement des dimensions spatiale et temporelle dans les tableaux
Ainsi l’application est vue comme un graphe de dépendance où les nœuds représentent des tâches et les arêtes les dépendances entre elles. En plus le graphe possède un caractère hiérarchique, de telle façon que chaque nœud peut contenir lui-même un graphe de dépendance. Ce qui rend l’application vue comme un ensemble de tâches connectées par l’intermédiaire de ports. Au niveau de Gaspard les tâches sont représentées par des instances de ApplicationComponents et les ports par des Ports.
Trois types de tâches ont recensées
- Les tâches élémentaires, représentées par des instances d’ElementComponent et qui correspondent à des fonctions cachées à l’intérieur de boites noires ;
- Les tâches composées, représentées par l’instance d’un Component contenant plusieurs instances, de telles tâches correspondent à des graphes de dépendances ;
- Les tâches répétées, représentées par des instances de Component sur lesquelles des Shape ont été spécifiées.
42

Des tableaux multidimensionnels pouvant avoir une dimension infinie assurent la communication entre es tâches. Chaque tableau étant spécifié par une Shape pour préciser sa taille. Les ports sont également spécifiés avec une Shape et avec le type des éléments du tableau auquel il accède.
2.6.3.1 Parallélisme de tâches
La notion de parallélisme de tâches n’a de sens que dans le contexte de tâches composées. Dans ce cas, la composition interne d’un composant correspond à un graphe acyclique orienté, chaque nœud du graphe correspond à une tâche et chaque arrête correspond à une dépendance reliant deux ports de même taille et de même type, un nœud représentant une instance et une arrête connecteur reliant port de sortie et port d’entrée [35]. On n’a pas de contrainte sur le type et la taille des ports d’entrée et de sortie d’une tâche. Cette dernière peut lire deux tableaux à une dimension pour ne produire qu’un tableau à deux dimensions. La figure 2.14 présente un parallélisme de tâches avec un exemple contenant 4 tâches : un producteur, deux consommateurs et un agrégateur. Celui ci possède une dépendance sur les consommateurs C1 et C2. Les ports de chaque composant sont orientés, imposant l’exécution du producteur p avant les autres tâches. Les deux consommateurs C1 et C2 peuvent être exécutés en parallèle.
tâch
dedoqucom
du
Figure 2.14 : Exemple d’une tâche composée dans Gaspard, elle est constituée de 4 sous ches, p, c1, c2 et a. La tâche a possède deux dépendances sur c1 et c2, possédant elle-même acune une dépendance sur p. Les tâches c1 et c2 peuvent être exécutée en parallèle.
2.6.3.2 Parallélisme de données
Il est toujours lié à l’expression des répétitions de tâches, l’idée étant que chaque répétition la tâche est indépendante : il n’y a pas d’ordre imposé pour l’exécution, les tâches peuvent nc être exécutées en parallèle. Les connectors qui interviennent ne peuvent être spécifiés ’avec des Tilers. Ils vont permettre de découper les tableaux présents sur les ports du mposant père, pour en faire des motifs qui seront présents sur les ports du composant lui-ême [35].
Ainsi chaque répétition de tâche n’a le droit d’accéder qu’aux sous ensembles des tableaux composant. La figure 2.15 présente un exemple d’application mettant en œuvre le
43

parallélisme de données. E composant A plus B contient une tâche Sum répétées 16x16 fois et prenant en entrée les données de deux matrices pour en sortir un résultat. Chaque répétition de la tâche a s’occuper de traiter deux motifs des tableaux d’entrée.
Le padépendadétermind’entréetâches.
2.6.4
La dl’aide dpermettedirectesétant éqfils. Lecatégoridécomppour reapplicatreprés
Figcomp
v
Figure 2.15 : Parallélisme de données
quetage Application apporte des notions de sémantique permettant de représenter les nces entre les tâches et les répétitions de tâches. Il est également possible de er les dépendances entre un élément du tableau de sortie et les éléments du tableau
. Toutes ces informations permettent à la fin, de déduire un ordre d’exécution des
Le paquetage HardwareArchitecture
éfinition de la composition de l’architecture matérielle du système sur puce se fait à es éléments apportés par ce paquetage. Les notions du paquetage Component nt de représenter la structure et la hiérarchie du matériel à un haut niveau. Les liaisons
entre composants sont représentées par les ports et les connecteurs, un connecteur uivalent à une connexion de transaction c'est-à-dire qu’il représente un ensemble de s différents éléments de l’architecture matérielle ont été classifiés dans quatre es : Processor, Memory, Communication et I/O. Chaque catégorie étant elle-même osée en un ensemble de sous types plus précis assurant un niveau de détails suffisant présenter de manière globale l’architecture du système afin d’y associer une ion. Le comportement de l’architecture se situe au niveau des « boites noires » tant des composants matériels élémentaires. La figure 2.16 en illustre un exemple.
enure 2.16 Un exemple de composant gaspard, processing Unit composé de trois sous osants instanciés sous les noms cb, mem et mips correspondant respectivement à un
crossbar, une mémoire et un processeur.
44

Il faut noter aussi que les concepts introduits par le paquetage Factorization concernant les multiplicités peuvent être appliqués aux composants matériels, la figure 2.17 illustre la spécification d’une grille de processeurs et ce d’une manière très compacte.
Figure 2.17 : Composant matériel Gaspard représentant une grille de 16 unités de calcul réparties sur deux dimensions
2.6.5 Le paquetage association
Ce paquetage est le dernier du méta-modèle MARTE, il a permis de compléter le modèle ''Y'' grâce aux notions qu’il a apporté. Grâce à lui on peut faire un lien entre une application et une architecture matérielle servant de support d’exécution. L’association consiste donc à placer les éléments de l’application sur des éléments de l’architecture matérielle. Les allocations peuvent être de plusieurs types :
- TaskAllocation permet de décrire l’association d’une tâche sur une ressource de calcul (processeur, accélérateur matériel),
- DataAllocation permet d’indiquer comment synchroniser deux mémoires, son utilisation est indiquée lorsque plusieurs tâches partagent des données allouées sur différentes mémoires de la plateforme d’exécution et dans ce cas,
Les données sont copiées en suivant l’information concernant la route donnée pour l’allocation. Ces différentes notions d’allocation ne permettent néanmoins de ne spécifier que des placements spaciaux d’application. La gestion du caractère temporel du placement est confiée au compilateur qui la charge de prendre ces décisions. La figure 2.18 donne un exemple d’allocation simple d’une tâche sur un processeur [35].
Il faut noter que ces notions d’allocations ne concernent que des éléments simples. Pour prendre en compte les aspects introduits par le paquetage Factorization et leur utilisation pour les éléments d’une application et d’une architecture matérielles, la notion de Distribution a été introduite. Elle permet de distribuer une tâche répétée sur un ensemble de processeur mais également de spécifier le placement d’un tableau de données sur un ensemble de mémoires. La figure 2.19 suivante illustre cette notion à l’aide d’un exemple de distribution de tâches sur un élément d’une architecture matérielle.
45
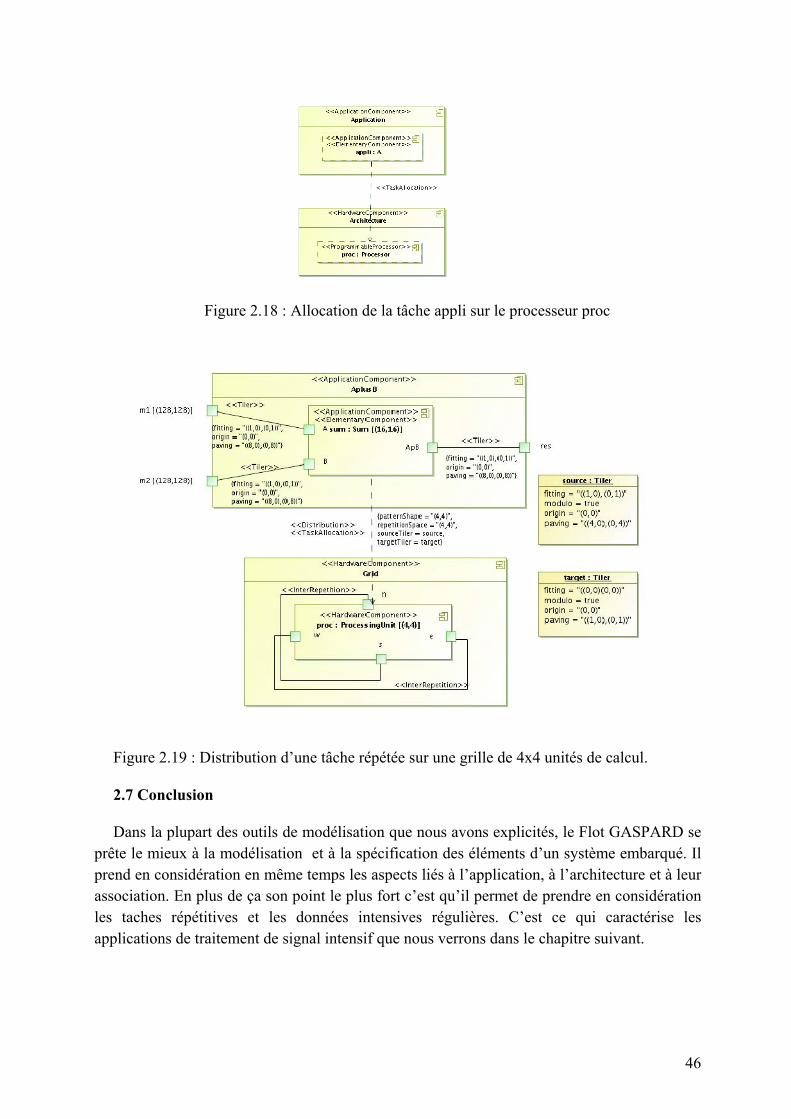
Figure 2.18
Figure 2.19 : Distribution d
2.7 Conclusion
Dans la plupart des outils prête le mieux à la modélisatprend en considération en mêassociation. En plus de ça sonles taches répétitives et lesapplications de traitement de
: Allocation de la tâche appli sur le processeur proc
’une tâche répétée sur une grille de 4x4 unités de calcul.
de modélisation que nous avons explicités, le Flot GASPARD se ion et à la spécification des éléments d’un système embarqué. Il me temps les aspects liés à l’application, à l’architecture et à leur point le plus fort c’est qu’il permet de prendre en considération données intensives régulières. C’est ce qui caractérise les signal intensif que nous verrons dans le chapitre suivant.
46

Chapitre 3 Calcul intensif et applications DSP
47

Afin de pouvoir présenter le placement dans sa globalité (le graphe HTG), nous devons commencer par présenter une de ses parties importantes qui est le traitement intensif. Dans ce chapitre on introduira le principe général des applications de traitement de signal intensif, les domaines faisant appel à ce type de traitement et les principaux modèles de calcul existants pour leur spécification. Par la suite, nous étudierons le principe du modèle Array-Ol, principalement conçu pour l’expression du parallélisme de données et des dépendances de tâches pour ce type d’applications.
3.1 Introduction
Les applications de traitement systématique et intensif sont de plus en plus présentes dans plusieurs domaines. Elles se trouvent aussi bien dans le domaine de calcul scientifique que dans le domaine de traitement de signal intensif (télécommunications, traitement multimédia, traitement d’images et de la vidéo, etc.…). Le développement des systèmes logiciels se base énormément sur ces applications qui occupent une place importante dans le milieu de la recherche scientifique. Les caractéristiques principales de ces applications sont qu’elles effectuent une grande quantité de calculs réguliers, elles opèrent dans des conditions temps réel, et sont généralement complexes et critiques.
Un signal est assimilé à un support véhiculant de l’information. Le traitement du signal (TS) est l’art de manipuler un signal afin d’en extraire cette information. Le traitement du signal intensif (TSI) est le sous-ensemble du traitement du signal le plus gourmand en calcul, dont la partie la plus régulière est le traitement du signal systématique (TSS). Il consiste à réaliser des calculs sur les signaux indépendamment de leur valeur dans le but d’en extraire des propriétés intéressantes (par exemple pour détecter la présence d’un obstacle dans le contexte d’un radar anti-collision ou de chercher une forme bien précisée dans une image). La deuxième étape dans le traitement du signal est le TDI (traitement de données intensif), c’est une étape plus irrégulière et dépendante de la valeur des données. Cette étape suit celle de TSS dans le temps. Elle analyse le signal issu du traitement systématique et prend éventuellement des décisions (freinage d’urgence lors de la détection d’un obstacle ou analyse de façon plus détaillée une forme détectée dans une image).
Dans ces travaux, nous nous intéressons au traitement de données intensif dont le positio nement dans le traitement du signal est représenté par la figure 3.1.
Unréguliedes ré
n
La figure 3.1 : Positionnement du TSS dans le domaine TS.
e application est systématique si son traitement consiste principalement en des calculs rs et indépendants, appliqués systématiquement sur des données en entrée pour fournir
sultats.
48

Une application est dite intensive si elle opère sur une grande masse de données, et s’il faut fortement l’optimiser pour obtenir la puissance de calcul requise et répondre aux contraintes d’exécution du système [40].
Généralement, les applications de traitement systématique et intensif nécessitent de grandes capacités de traitement de données faisant souvent appel à des techniques de calcul parallèle et distribué. Les difficultés de développement de ces applications sont donc principalement l’exploitation du parallélisme de données et de calcul, et le respect des contraintes de temps et de ressources du parallélisme [41].
Le caractère critique de ces applications exige des environnements de programmation spécialisés pour leur spécification, simulation, vérification et exécution, fin de réduire les temps de développement et donc de mise sur le marché. Leur principal objectif est d’assurer le traitement de grandes quantités d’informations tout en exploitant au mieux le parallélisme présent dans l’application. Nous rencontrons les applications complexes de traitement systématique et intensif dans plusieurs domaines d’application tels que les réseaux de communication, le trafic aérien, l’automobile et les systèmes multimédias.
3.2 Exemples d’applications (hautement régulières)
De nombreuses applications permettent la décomposition du TSI en TSS et TDI :
Radar anti-collisions : la prévention des collisions dans un système nécessite l’utilisation d’une antenne qui renvoie le signal sous la forme d’un flux de données contenant des informations relatives à la présence d’obstacles, un écho. Ces informations sont masquées pare du bruit (des parasites) et sont étalées sur le flux de données temporel. Une phase de prétraitement qui relève du traitement du signal systématique, filtre ce signal de manière à en faire ressortir les caractéristiques intéressantes (la présence d’obstacles). La régularité se trouve dans l’étape suivante qui consiste à analyser ce nouveau flux de données de manière à valider la présence d’un obstacle, à déclencher un freinage d’urgence où à le poursuivre si né ssaire [42]. Cette application est illustrée par la figure 3.2.
sig
encema
ce
Figure 3.2 : Représentation de l’application Radar anti-collision. La phase du traitement du nal systématique précède celle du traitement de données intensif.
Traitement sonar : une vision plus large de la scène est nécessaire dans l’analyse d’un vironnement maritime (qui est similaire à celui d’un routier). Dans le cas d’un sous-marin, n’est pas une antenne qui est utilisée mais plusieurs hydrophones répartis autour de ce sous-rin. La première phase de traitement est systématique et est composée d’une FFT
49

(Transformations de fourrier). Le traitement est dédié à la détection d’objets et à leur poursuite au cours du temps.
Convertisseur 16/9-4/3 : Souvent devant notre télévision et en utilisant une télécommande on peut passer d’un format à un autre avec une certaine facilité. En pratique ce processus se décompose en deux phases. La première consiste à créer des pixels à partir du signal vidéo au format 16/9 via une interpolation, il en résulte un nouveau signal vidéo. La seconde phase supprime certains pixels de ce signal de manière à ne conserver qu’une partie de l’information, cela permet le passage au format 4/3. Cette application ne considère à aucun moment la valeur des pixels, il s’agit de traitement de signal. D’autres exemples encore illustrent l’utilisation du TSI : encodeur/décodeur.
JPEG 2000, récepteur de radio numérique, etc. Chacune de ces applications réalise des traitements réguliers sur les données, certaines exploitent le résultat de ces traitements pour prendre des décisions. Nous pouvons par ailleurs remarquer la diversité de la sémantique portée par les dimensions des tableaux de données manipulées par ces applications (temporel, spatial et fréquentiel) et leur nombre. Il s’agit là d’une caractéristique très spécifique aux applications de traitement du signal intensif qu’est la manipulation de tableaux multidimensionnels.
3.3 Exemples d’application DSP à tâches irrégulières
Si on considère des domaines d’application courants tels l’intelligence artificielle, surveillance, maintenance, médecine à distance, gestion des catastrophes, etc. avec des plateformes de calcul à files ou sans où il y a différents types de nœud (laptops, palmtop, mobile, PDA, etc.) on a ici un scénario commun typique de la transmission vidéo et audio (one to one, one to many, many to many). Le problème ici, en plus des vitesses de calcul différentes des différentes unités de traitement, se situe aussi au niveau des communications. Cette particularité est due aux bandes passantes différentes, aux périphériques hétérogènes, à la latence etc. Dans ce type d’application le transcoder, qu’on présentera juste après, joue tout son rôle.
Transcoder : Il peut être mobile ou relié à un réseau fixe. Le transcoder convertit un format vidéo en d’autres en considérant la compatibilité avec des passantes du réseau, puissance de calcul et l’utilisation des périphériques utilisateurs [43]. Transcoder un flot vidéo se fait en deux phases :
a- Décoder X-Format
b- Encoder dans Y-Format, figure 3.3.
Figure 3.3 : Phases d’un Transcoder
50

La phase encoder nécessite plus de puissance de calcul que l’autre phase (en général 3 à 4 fois plus de temps pour le même encodage) et elle est très dépendante des paramètres (tels la taille des frames).
La fonction de base pour les deux étapes est :
1- Décoder, le flot MPEG dans un format ligne (YUV, YU12, PPM, etc.).
2- Encoder, transforme la ligne dans la vidéo MPEG avec les nouveaux paramètres.
Eliminateur de parasites (CSLC Coherent Side Love Cancellation) : est un autre exemple de traitement technique. Cette application a pour but de réduire les parasites avec cohérence sur les antennes. Dans la figure 3.4, nous donnons le graphe global de l’application CSLC où on voit que la FFT est appelée deux fois et l’IFFT une seule. Ceux-ci constituent les blocs majeurs d’une application CSLC. Les autres blocs constituent des nœuds réguliers mais sont moins gourmand en termes de calcul par rapport au FFT et l’IFFT. Un tel domaine d’application est hautement à données intensives et donne plus de chance de faire du parallélisme de données que celui de tâches.
Figure 3.4 : Application CSLC (Coherent Side Love Cancellation)
3.4 Spécification multidimensionnelle et modèles de calcul pour le TSI
Beaucoup de modèles de calcul ont été proposés pour la modélisation et la mise en œuvre des applications de traitement du signal intensif. On peut citer MATLAB/SIMULINK, ALPHA [44], MDSDF (MultiDimensional Synchronous Data Flow) [45], GMDSDF ( Generalized MultiDimensional Synchronous Data Flow) [46] et le langage Array-Ol (Array Oriented Langage). Malgré la diversité, de ces modèles, leu occupation principale consistant à mieux modéliser les grandes quantités de données multidimensionnelles dont le but de faciliter la description et l’étude des applications de traitement intensif à parallélisme de données massif.
3.4.1 MATLAB/SIMULINK
Le logiciel de calcul MATLAB peut être vu comme un système interactif et convivial de calcul numérique et de visualisation graphique où beaucoup des ces interactions (fonctions) sont basées sur un calcul matriciel simplifié. Il permet de distinguer plusieurs types de matrices : monodimensionnelles (vecteurs), bidimensionnelles (matrices), tridimensionnelles…etc. Grâce à ses fonction spécialisées (analyse numérique, calcul matriciel, traitement du signal, etc.), MATLAB est considéré comme un langage de
51

programmation adapté pour les divers problèmes d’ingénierie. La méthodologie de conception basée sur MATLAB permet de réduire le temps de mise sur le marché en offrant le moyen pour la spécification des systèmes au plus haut niveau d’abstraction.
L’extension graphique de MATLAB est SIMULINK qui permet de représenter les fonctions mathématiques et les systèmes sous forme de diagramme de blocs (ou diagrammes structurels) facilitant par là la modélisation, l’analyse et la simulation d’une large variété de systèmes physiques et mathématiques, y compris ceux avec des éléments non linéaires et ceux qui se servent du temps continu discret. Le diagramme structurel dans SIMULINK met en évidence la structure du système et permet de visualiser les interactions entre les différentes grandeurs internes et externes. Le diagramme structurel est composé des éléments représentants des opérations mathématiques (addition, soustraction, multiplication, intégration et différenciation). Cet environnement fournit aussi des outils pour la modélisation hiérarchique et la gestion des données qui permettent une représentation précise et concise de l’application indépendamment de la complexité du système étudié.
Pour beaucoup des logiciels, MATLAB/SIMULINK sont devenus des standards pour la conception de systèmes. Cependant, ils sont une pure création de numériciens et d’automaticiens, et n’a aucune des qualités informatiques requises pour la génération du code pour des systèmes embarqués critiques. Ce sont des logiciels principalement conçus pour la simulation des applications de traitement numérique et ne prennent pas en considération l’expression et l’exploitation du parallélisme de données présent dans ces applications.
3.4.2 ALPHA
C’est un langage à parallélisme de données [47,48] et fonctionnel crée par l’équipe API à l’IRISA de Rennes. La première définition de ce langage a été proposé par Mauras en 1989 [44] et est fondée sur le formalisme des systèmes d’équations récurrentes [49], mais depuis il a évolué. C’est un langage à parallélisme de données permettant la description de haut niveau d’algorithmes de calcul réguliers. Le formalisme qui est derrière le langage est appelé le modèle polyédrique, et se trouve aujourd’hui, à la base de plusieurs méthodes de parallélisation automatique des boucles et de la synthèse de réseaux systoliques. Un algorithme, dans ce langage, est décrit par des équations sur des variables définies dans des domaines multidimensionnels. Par des transformations successives, telle que la parallélisation des instances, ces descriptions peuvent être raffinées jusqu’à leur interprétation par des outils de synthèse logique dans le but de générer des architectures VLSI. Ce langage est donc proposé pour faciliter la synthèse d’architecture parallèles intégrées pour ces algorithmes afin de les exécuter en temps raisonnable (temps réel pour les applications de traitement de signal). Les transformations du langage ALPHA sont implémentées dans l’environnement MMALPHA qui est une interface, principalement basée sur MATHEMATICA, pour la manipulation de ce langage.
La notion de temps, ou même d’exécution, n’existe pas en ALPHA : un programme décrit un ensemble de calculs dont les dépendances de données expriment l’ordre dans lequel ces calculs peuvent être réalisés. Cela implique qu’ALPHA soit un langage à assignation unique et qu’il existe potentiellement plusieurs ordonnancements pour l’exécution d’un programme.
52

Un programme ALPHA est un système dont les variables sont définies à l’aide des fonctions de l’ensemble de points entiers d’un espace vectoriel vers un ensemble de valeurs5. Les données manipulées par ALPHA sont multidimensionnelles : Elles correspondent à des unions de polyèdres convexes. Leurs formes ne sont donc pas restreintes à de simples tableaux rectangulaires. Par exemple le code suivant :
V : i, j 1 ≤ i ≤ j ; j ≤ 3 of real ;
Déclare une variable V de type réel. Le domaine de cette variable est l’ensemble de points (i,j) dans le triangle 1 ≤ i ≤ j , j ≤ 3, et qui représente la collection de valeurs suivantes :
V1,1 V1,2 V1,3
V2,2 V2,3
V3,3
ALPHA est en mesure d’exprimer de façon compacte des formes de données complexes (un triangle par exemple). Cependant, en traitement du signal, les données sont souvent manipulées sous la forme de tableaux « simples », la puissance de l’expression des formes de données dans ALPHA est donc rarement nécessaire. En plus, ce langage ne gère pas les accès cycliques dans les tableaux de données, accès pourtant indispensables, par exemple, pour l’application du traitement Sonar vu précédemment. En outre, les programmes ALPHA manipulent des indices pour les accès aux données, ce qui implique que le programmeur calcule ces indices. Cela augmente considérablement le risque d’erreurs quand à l’expression des dépendances de données sur des tableaux multidimensionnels.
3.4.3 MDSDF : Multidimensional Synchronous Dataflox
IL a été proposé par Edward Lee en 2002 [45]. Il étend le concept du modèle SDF (Synchronous DataFlow) [50,51] pour l’appliquer dans un contexte multidimensionnel. L’objectif est de permettre la spécification des applications de traitement du signal manipulant des données multidimensionnelles tels que le traitement d’image et de la vidéo.
Le modèle SDF représente un cas spécial des modèles flot de données qui sont généralement utilisés pour décrire des applications de traitement du signal par des graphes, en représentant les fonctions par des nœuds et les données par les arrêtes du graphe. L’ajout du terme « synchrone » implique que le nombre de données consommées et produites soit connu dès la conception de l’application, c'est-à-dire qui permet de réaliser des ordonnancements statiques. Ce modèle est intégré à PTOLEMY6, l’environnement de modélisation et de simulation d’applications pour les systèmes embarqués.
Une application, dans SDF, est décrite par un graphe orienté acyclique où chaque nœud consomme des données en entrée et produit des résultats en sortie. Donc les calculs sont représentés par des nœuds [Actor] et les données [Tokens] par des arcs (figure 3.5). Les
5 Le type des valeurs peut être entier, réel ou booléen 6 http://ptolemy.eecs.berkeley.edu
53

symboles associés aux entrées et aux sorties de chaque acteur dans un graphe SDF spécifient le nombre de jetons consommés ou produits par l’acteur en question. Ainsi, la relation entre les acteurs dans un graphe SDF doit satisfaire la relation suivante :
riOi = ri+1 Ii+1 où ri représente le nombre de répétition d’un acteur i et Oi (res Ii) est le nombre de jetons produits (resp consommés) par l’acteur i. Le vecteur r =[r1 r2…rn] peut regrouper les répétitions des acteurs. Dans l’exemple de la figure 40, r= [1 10 100 10] qui signifie que pour chaque exécution de l’acteur A, il y aura 10 exécutions de l’acteur B, 100 de l’acteur C et 10 de l’acteur D.
Les applicmodélisées paest réservé à systèmes étudjustifié l’introcompte des ap
L’objectif données paraltâches.
Le fonctiopour chaque aflot, sachant qde deux acteuest calculé co
La figure image de 40xde forme bidila première dB consommerA,1=rA,2=1, rB
Figure 3.5 : Exemple d’un graphe d’une application en SDF
ations basées sur des flots de données synchrones peuvent être facilement r ce modèle en spécifiant les dépendances entre tâches. Cependant, ce modèle
l’expression des applications monodimensionnelle limitant ainsi le domaine des iés à celui manipulant des flots de données monodimensionnelles. Ce qui a duction du modèle MDSDF pour résoudre ce problème et permettre la prise en plications à flot de données multidimensionnelles.
de ce modèle est de donner un moyen pour la modélisation des traitements de lèles, et d’avoir une meilleure expression des dépendances de données entre les
nnement de MDSDF est similaire à celui de SDF. Ainsi, il suffit juste de préciser cteur le nombre de jetons consommés et produits sur chacune des dimensions du ue ce nombre est représenté par un n-uplet. Dans ce cas, le nombre de répétitions rs A et B d’un graphe MDSDF manipulant un flot de données de n dimensions mme suit : rA,i OA,i = rB,i OB,i , i=[1,n].
3.6 donne un exemple d’une application en MDSDF qui prend en entrée une 48 pixels et la divise en des blocs de 8x8. Dans cet exemple, le flot représenté est mensionnelle, le premier acteur A produit un rectangle de jetons de taille 40 sur imension, et de taille 48 sur la deuxième pour chaque itération. Ensuite l’acteur sur les deux dimensions un rectangle de jetons de taille 8. Pour cet exemple, ,1=5, rB,2=6 [41].
Figure 3.6
: Exemple d’un graphe d’une application en MDSDF
54

Avec MDSDF on rend plus exacte l’expression d’une application multidimensionnelle et possible la modélisation d’application qui ne pouvait être décrite en SDF. La figure 3.7 illustre un exemple d’une application non représentable en SDF. On a un acteur A qui produit une colonne de deux jetons et un acteur B qui consomme une ligne de trois jetons. Les deux jetons de la colonne ne seront donc pas consommés par la même itération du deuxième acteur comme le montre le graphe de dépendances. La modélisation de cette application en SDF n’est pas possible puisque ce dernier ne permet pas de spécifier le mode de construction du graphe de dépendance [52].
Figure 3.7 : Une
En fin, on peut dire que mêmemultidimensionnelles, il est contran’évolue jamais et il n’est pas potraitement de signal, telle la FFT7,le modèle MDSDF est que la cparallèles aux axes. Ce que Murphce modèle appelé GMDSF (Gener
3.4.4 ARRAY-OL (Array Orient
C’est un langage spécialisé dans lComme on l’a présenté précémanipulation de grande quantité façon régulière. Le langage Arrayapplications vient des accès auxcalcul. C’est un langage à assigexprimées et où les dimensions spmodèle Array-Ol est multidimecomplet sur des applications, quetâches.
Avant de comprendre l’apport deutilisé le Array-Ol, en commença[53].
• Peu de modèles de calcul s
7 Fast Fourier Transformation
application MDSDF non représentable en SDF
si ce modèle rend possible l’utilisation de flot de données ignant sur le nombre de dimensions du flot de données qui
ssible d’en créer ou supprimer. Or pour cette application de la création de dimension est utile. Une autre limitation dans onsommation et la production des données doivent être y et Lée ont essayé de combler en proposant une extension à alized MultiDimensional Synchronous DataFlow).
ed Language)
a description d’applications de traitement du signal intensif. demment, ce type d’application est caractérisé par une de données qui sont traitées par un ensemble de tâches de -Ol est basé sur la constatation que la complexité de telles données (toujours des tableaux) et non des fonctions de nation unique où seules les dépendances de données sont atiales et temporelles des tableaux sont banalisées. Donc le
nsionnel et permet d’exprimer un parallélisme potentiel ce soit un parallélisme de données ou un parallélisme de
ce langage, on doit comprendre le contexte dans lequel est nt par ces applications qui présentent plusieurs difficultés
ont multidimensionnels,
55

• Les profils d’accès aux tableaux de données sont diverses et complexes,
• Ordonnancer ces applications avec un temps et des ressources limités est un chalenge spécialement dans les contextes distribués.
A ce jour uniquement deux modèles de calcul ont tenté de proposer un formalisme pour modéliser et ordonnancer de telles applications de traitement de signal multidimensionnel : MDSDF (vu précédemment), son suivant GMDSDF et Array-Ol [54,55]. Ce dernier est introduit par Thomas Marconi Sonar et dont la compilation a été étudiée par Demeure, Soula, Dumont et al [54,55, 56,57].
Ces deux langages proposés ont les mêmes objectifs et même s’ils sont différents dans la forme, ils partagent un certain nombre de principes tels que :
La structure de données doit avoir des dimensions multiples visibles.
Placement statique doit être possible avec des ressources limitées.
Domaine d’application est le même : application de traitement de signal intensif multidimensionnel.
Comme une première remarque on doit attirer l’attention sur le faut que Array-Ol est uniquement un langage de spécification. Il n’y a pas de règles spécifiées pour l’exécution d’application décrite avec ce langage. Toute fois un ordonnancement peut être facilement obtenu en utilisant la description.
3.4.4.1 Principes
L’objectif initial de Array-ol est de fournir un langage textuel et graphique permettant l’expression d’application de traitement de signal intensif et multidimensionnel. La difficulté de ce type d’applications ne vient pas des fonctions élémentaires qu’elle combine (somme, produit, FFT) mais de la manière dont ces fonctions accèdent à leurs données en entrée et sortie comme tableau multidimensionnel. L’accès complexe aux parties du tableau augmente encore plus les difficultés de placement de ces applications sur des plateformes d’exécution parallèles et distribuées. Et puisque ces application traitent une quantité importante De données en temps réduit (contrainte temporelle), l’utilisation efficace du potentiel parallèle de l’application sur une architecture parallèle est nécessaire.
A partir de ces exigences, on peut expliciter les principes de base qui supportent ce langage [53].
o Array-Ol est un langage d’expression de dépendance de données. Uniquement les vraies dépendances de données sont exprimées dans le but d’exprimer le parallélisme total de l’application en définissant un ordre minimal de tâches.
o L’accès aux données se fait à travers de sous tableaux appelés Motifs (pattern en anglais).
56

o Le langage est hiérarchique permettant la description des différents niveaux de granularité et de traiter la complexité de l’application. Les dépendances de données exprimées à un niveau (entre tableau) sont des approximations de dépendances précises des niveaux intermédiaires (entre Motifs).
o Tout le potentiel de parallélisme dans l’application doit être explicité dans la spécification selon les deux axes parallélisme de tâches et parallélisme de données.
o C’est un formalisme à assignation unique. Une donnée élémentaire même si elle peut être lue plusieurs fois elle n’est jamais écrite deux fois.
o Les dimensions spatiales et temporelles sont traitées équitablement dans le tableau. En particulier le temps est considéré comme une des dimensions des tableaux.
o Les tableaux sont toriques. Ce qui veut dire que certaines dimensions spatiales représentent des concepts toriques physiques (tels les hydrophones autour d’un sous marin) et certains domaines de fréquences obtenues par les FFT qui sont aussi toriques.
Le modèle usuel de description de dépendance est un graphe de dépendance où les nœuds représentent les tâches et les arcs les dépendances. Plusieurs types de ces graphes sont proposés mais les plus utilisés, qu’on va adopter comme modèles, sont les graphes de tâches. Dans l’ordre de représenter des applications complexes, une extension commune à ces graphes est la hiérarchie.
Ainsi un nœud peut lui-même être un graphe. Array-Ol permet la construction de tels graphes hiérarchiques de dépendance en ajoutant un nouveau type de nœud qui représente le parallélisme de données de l’application : nœuds répétitifs.
D’une façon formelle, une application Array-Ol est un ensemble de composants connectés à travers des ports. Les composants sont équivalents aux fonctions mathématiques lisant les données à travers les ports d’entrée et écrivant les autres à travers leurs ports de sortie. On a trois types de composants :
Elémentaire : se sont des composants atomiques (boite noire).
Composé : c’est un graphe de dépendance où les nœuds sont des composants connectés à travers leurs ports.
Répétitif : c’est un composant exprimant comment un sous composé est répété.
Toutes les données échangées entre les composants sont des tableaux qui sont multidimensionnels caractérisés par leurs profils Shape et le nombre d’éléments sur chacune des dimensions. Chaque port est caractérisé par le profil et le type des éléments des tableaux à partir du quel il lit ou dans lequel il écrit.
Tel qu’on l’a avancé précédemment, Array-Ol est à assignation unique. Le temps est donc représenté par une (ou plusieurs) dimensions des tableaux de données. Par exemple un tableau
57

représentant une vidéo a des motifs à trois dimensions (largeur de frame, hauteur de frame, nombre de frame).
Toute description d’une application en Array-ol fait successivement appel à deux niveaux. Le premier niveau, appelé modèle global, définit l’enchaînement des différentes parties de l’application dans son ensemble alors que le deuxième niveau appelé modèle local précise les actions élémentaires à effectuer sur les éléments de tableaux et le parallélisme de données sur les différentes tâches.
3.4.4.2 Modèle global (parallélisme de tâches)
Ce modèle permet de nommer et de définir les tableaux et les tâches de calcul d’une application (figure 3.8).
Figure définition
Ce motâche, et c
Le nomentre les nconsomm
La crédimensionqu’il doittemps. Ensens où la
3.8 : Exemple de composant : réduction à partir d’une haute définition vers une TV standard
dèle est représenté par un graphe dirigé acyclique où chaque nœud représente une haque arc représente un tableau multidimensionnel (figure 3.9).
Figure 3.9 : Modèle global
bre de tableaux en entrée et en sortie est illimité. Il n’y a pas non plus de corrélation ombres de dimensions de ces tableaux. Dans ce cas il est possible pour une tâche de
er deux tableaux bidimensionnels et de produire un tableau tridimensionnel.
ation de dimension est très utile, par exemple dans le cas d’une FFT qui crée une fréquentielle. Cependant, la seule limitation sur les dimensions des tableaux est y avoir une seule dimension infinie par tableau qui représente généralement le plus, les tableaux utilisés dans Array-Ol sont considérés comme toriques dans le consommation ou la production de leurs éléments peut se faire modulo à leur taille.
58

Chaque tâche, au moment de l’exécution, consomme un ou plusieurs tableaux, effectue un traitement quelconque sur leurs éléments et produit un ou plusieurs tableaux résultats. Le nombre d’arcs en entrée ou en sortie de la tâche correspond au nombre de tableaux consommés ou produits. Ainsi le graphe obtenu est un graphe de dépendance et non un graphe de flots de données.
Il est aussi possible d’ordonnancer l’exécution des différentes tâches d’une application à partir du modèle global. Cependant, il est impossible d’exprimer le parallélisme de données présentes dans cette application puisque aucun détail sur les calculs réalisés n’est donné à ce niveau de spécification. C’est ce qui justifie l’introduction du modèle local (ou parallélisme de données)
3.4.4.3 Modèle Local (parallélisme de données)
La répétition de données parallèles d’une tâche est spécifiée dans le composant répétitif. L’hypothèse de base est que toutes les répétitions de cette tâche sont indépendantes. Elles peuvent être ordonnancées dans n’importe quel ordre même en parallèle. La seconde hypothèse est que chaque sous tâche opère avec les sous tableaux des entrées/sorties de la répétition.
Donc le modèle local permet d’exprimer tout le parallélisme potentiel dans une tâche, et de définir l’interaction entre une tâche et ses tableaux opérandes et résultats. C’est un graphe dans lequel chaque tableau opérande et résultat est relié à la tâche de ce modèle en spécifiant comment les données sont consommées et produites par cette tâche. Une tâche, dans ce modèle, est toujours composée d’un constructeur de répétition, où chaque répétition est indépendante et appliquée sur un sous ensemble fini de points des différents tableaux en entrée et en sortie (figure 3.10). Pour chaque répétition le rôle d’une tâche consiste à extraire des motifs (morceaux de tableaux ayant la même forme) à partir de chaque tableau en entrée, à appliquer une fonction de calcul qui produit des valeurs associées aux motifs en sortie, et à ranger ces dernières dans les tableaux résultats.
La taille et la forme des motifs pour les différents tableaux en entrée ou en sortie peuvent être différentes. Cependant, pour les différentes répétitions sur un même tableau, les motifs doivent être réguliers (ajustage de tableau) et répartis régulièrement sur les tableaux (pavage du tableau). Cette hypothèse permet une représentation compacte de la répétition et sa cohérence avec le domaine d’application d’Array-Ol qui permet de décrire des algorithmes très réguliers.
Afin de donner toutes les informations nécessaires à la construction des motifs, un Tiler est associé à chaque tableau (c'est-à-dire arc). Un Tiler est capable de construire un motif à partir d’un tableau ou le stocker. Il contient les informations suivantes :
59

Figure 3.10 : Un exemple du modèle local en Array-ol
F : Une matrice appelée matrice d’ajustage (fitting matrix) qui décrit comment remplir le motif par les éléments du tableau.
O : l’origine du motif référence (pour la référence répétition).
P : Une matrice appelée matrice de pavage (paving matrix) qui permet de décrire comment les motifs couvrent le tableau.
Les profils des tableaux et des motifs sont notés sur les ports (comme dans le composant de description). L’espace de répétition indique le nombre de répétitions il est défini lui-même comme un tableau multidimensionnel avec un profil. Chaque dimension de cet espace de répétition peut être vue comme une boucle parallèle et le profil de l’espace de répétition donne les limites des indices (figure 3.11).
A partir d’un élément référence (ref) dans le tableau on peut extraire un motif par l’énumération de ses éléments par rapport à l’élément référence. En utilisant la matrice d’ajustage, les coordonnées des éléments d’un motif (ei) sont obtenues en faisant la somme des coordonnées de l’élément référence avec une combinaison linéaire du vecteur d’ajustage comme suit : ∀i , 0 ≤ i <Spattern, ei=(ref+F x i)modSarray
Où Spattern est le profil d’un motif, modSarray est le profil du tableau et F la matrice d’ajustage.
Figure 3.11 : Exemple de répétition dans un filtre horizontal
60

La figure 3.12 [53] en donne plusieurs exemples de matrices d’ajustage et Motifs. Dans ces exemples, les motifs sont dessinés à partir d’un élément référence dans un tableau 2D.
Figure 3.13 : Un exemple simple d’ajustage des éléments d’un tableau par leurs indexes dans le motif (i), illustrant la formule ∀i , 0 ≤ i <Spattern, ei=ref+F x i
Du fait que dans Array-Ol toutes les dimensions de tableaux sont toroïdales, il faut que toutes les coordonnées des éléments du motif soient calculées modulo la taille des dimensions du tableau. La figure 3.14 fournit plus d’exemples complexes de motifs obtenus à partir d’éléments référence fixe (O comme origine dans la figure) dans des tableaux à taille fixe.
61

Fi
Pour élémentTiler. Lvu précpavage :
Où Sdu table
Ainsi
Où Sde répét
gure 3.14 : Un exemple complexe d’ajustage illustrant la relation ∀i , 0 ≤ i <Spattern, ei=(ref+F x i)modSarray
chaque répétition on doit spécifier les éléments référence des entrées et sortie. Les s référence de la répétition référence sont donné par le vecteur origine O de chaque es éléments référence des autres répétitions sont obtenus à partir du vecteur o. comme édemment, les coordonnées sont obtenues par combinaison linéaire de la matrice de
∀r , 0 ≤ r <Srepetition, refr=(0+P x r)modSarray
repetition est le profil de l’espace répétition, P étant la matrice de pavage et Sarray le profil au (figure 3.15).
on peut résumer toutes ces explications par les deux formules suivantes :
∀r , 0 ≤ r <Srepetition, refr=(0+P x r)modSarray , donne les éléments de référence des motifs.
∀i , 0 ≤ i <Spattern, ei=(ref+F x i)modSarray , Enumère tous les éléments d’un motif d’une répétition r.
array est le profil du tableau, Spattern le profil du motif, Srepetition est le profil de l’espace ition, o est les coordonnées de l’élément référence du motif référence appelé aussi
62

Figure 3.15 : Exemple de pavage illustrant la formule ; ∀r , 0 ≤ r <Srepetition, refr=(0+P x r)modSarray
l’origine, P est la matrice de pavage dont les vecteurs colonnes sont appelés vecteurs de pavage, et qui représentent l’espacement régulier entre les motifs, F est la matrice d’ajustage dont les vecteurs colonnes appelés vecteurs d’ajustage, représentent l’espacement régulier entre les éléments d’un motif du tableau.
Les formules précédentes explicitent quel élément en entrée ou sortie d’un tableau va être consommé ou produit par une répétition. Le lien entre les entrées et sorties est donné par l’index de répétition r.
63

Pour une répétition donnée, les motifs de sortie (pour un index r) sont produits par la tâche répétitive à partir des motifs en entrée (pour l’index r). Ainsi l’ensemble des Tilers, des profils des motifs et l’espace de répétition détermine les dépendances entre les éléments des tableaux en sorties et les éléments des tableaux en entrées d’une répétition.
Pour illustrer l’utilisation de ce langage, nous allons étudier la spécification d’un exemple classique et académique d’un produit de matrices. Cet exemple permet de montrer la puissance du modèle local pour l’expression du parallélisme de données dans un algorithme. A1 étant une matrice de taille 3x2 et A2 une matrice de taille 5x2, nous calculons le produit A1xA2=A3 avec A3 de taille 3x2. Le calcul d’un produit de matrice revient au calcul du produit scalaire de chaque ligne A1 par chaque colonne de A2. Les différents produits scalaires sont indépendants et peuvent être alors effectués en parallèle.
Le langage Array-Ol permet d’exprimer tout ce parallélisme en identifiant les motifs nécessaires en entrée pour produire les motifs résultats. Soit la tâche élémentaire ProduitScalaire qui prend en entrée deux vecteurs de taille 5, et produit en sortie un scalaire correspondant au Produitscalaire de ces deux vecteurs. Dans le modèle local, illustré par la figure 3.16, l’espace de répétition de la tâche ProduitScalaire est défini par le vecteur [41,42] (Une tâche pour la production de chaque point du tableau de sortie). A travers cet exemple on montre la possibilité d’exprimer tout le parallélisme potentiel dans une application, ce qui facilite son interprétation par des outils d’optimisation et de compilation.
Fig. 3.16 : Exemple d’un produit de matrices
Un autre exemple pour illustrer les liens entre les entrées/sorties est la figure 3.17 qui montre plusieurs répétitions de la répétition du filtre horizontal de la figure 3.11.
Dans l’ordre de simplifier la figure, et puisque le traitement est fait frame par frame, uniquement les deux premières dimensions sont représentées. La troisième dimension de l’espace de répétition est aussi infinie. La troisième dimension de l’espace de répétition est aussi infinie. Les motifs ne rencontrent pas cette dimension et uniquement le vecteur de pavage a un élément non nul comme troisième élément (0 0 1)t comme dimension infinie de l’espace de répétition. Les tailles des tableaux ont aussi été réduites par un facteur de 60 dans chaque dimension pour des raisons de lecture.
64
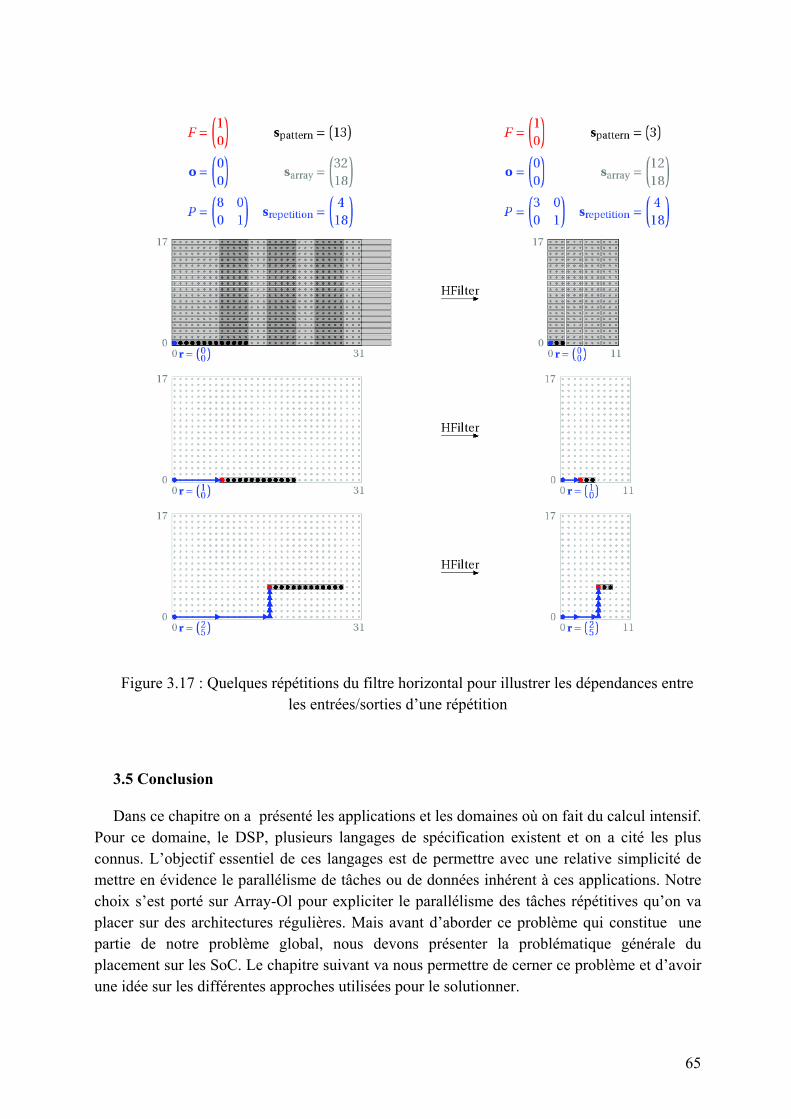
Figure 3.17 : Quelques répétitions du filtre horizontal pour illustrer les dépendances entre les entrées/sorties d’une répétition
3.5 Conclusion
Dans ce chapitre on a présenté les applications et les domaines où on fait du calcul intensif. Pour ce domaine, le DSP, plusieurs langages de spécification existent et on a cité les plus connus. L’objectif essentiel de ces langages est de permettre avec une relative simplicité de mettre en évidence le parallélisme de tâches ou de données inhérent à ces applications. Notre choix s’est porté sur Array-Ol pour expliciter le parallélisme des tâches répétitives qu’on va placer sur des architectures régulières. Mais avant d’aborder ce problème qui constitue une partie de notre problème global, nous devons présenter la problématique générale du placement sur les SoC. Le chapitre suivant va nous permettre de cerner ce problème et d’avoir une idée sur les différentes approches utilisées pour le solutionner.
65

CHAPITRE 4
Placement et Ordonnancement (ou AAS)
66

Le placement et ordonnancement (Mapping and Scheduling) appelé aussi AAS (Assignation Affectation and Scheduling) sont des étapes qui suivent l’étape de spécialisation du NoC. Leur rôle est d’implémenter l’application sur l’architecture sélectionnée. Ceci consiste principalement à assigner et ordonnancer les tâches et communications de l’application sur les ressources d’architecture cible de telle façon que les objectifs spécifiés soient atteints. Le placement des communications (CM : Mapping Communication) et ordonnancement des communication (CS : Scheduling Communication) posent plus de problèmes dans les NoC que dans les SoC, car dans les premiers c’est le problème du plus court chemin qui se pose lors du routage des communications. Dans ce cas, l’usage exclusif des ressources doit être réglé sans arbitre tout en évitant les problèmes de deadlock et de congestion. De plus dans la plupart des NoC la distance des communications a un impact direct sur les délais des communications. Dans ce chapitre on va étudier et comparer diverses techniques de mapping et scheduling d’applications sur des architectures NoC. Mais du fait de la nouveauté, de ces systèmes, uniquement quelques approches seront présentées basées sur une étude comparative avec les systèmes à bus partagé.
4.1. Objectifs de conception des NoC
Les méthodologies de conception des NoC partagent les mêmes objectifs avec les méthodologies de conception des SoC, tels la réduction de la consommation d’énergie, la minimisation de la surface de la puce et la maximisation des temps de performance. La préservation de l’énergie est très importante spécialement dans la conception des systèmes embarqués portables où le fonctionnement du système dépend de la durée de vie de la batterie et de la chaleur des circuits. Dans les NoC, les switchs et les mémoires occupent jusqu’à 80% de la surface de la puce, en réduisant la complexité fonctionnelle des switchs (algorithmes de routage) et en maximisant l’utilisation des mémoires on peut réduire la surface de la puce. Les contraintes de temps réfèrent aux hard et soft deadlines dont le non respect peut causer la panne (ou l’arrêt) du système. Dans la réalité ces objectifs sont contradictoires, car en minimisant la consommation d’énergie on ralentit la vitesse des calculs ce qui affecte les performances du système.
Ainsi lors de la conception des SoC on doit trouver un compromis entre ces différents objectifs, ce qui va nous amener à faire du multi-objectifs qui constitue la partie centrale de notre travail. Durant le placement (mapping) des tâches, celles qui consomment le plus d’énergie sont affectées aux processeurs consommant le moins d’énergie pour équilibrer la consommation totale d’énergie. En fin, on peut dire que le placement est responsable de l’exploitations de la concurrence dans l’application, dépendant du parallélisme de l’architecture cible en prenant en considération les objectifs de temps, surface et énergie. L’ordonnancement a pour but de vérifier les contraintes de temps, mais un ordonnancement de voltage peut aussi être utilisé pour minimiser la consommation d’énergie du système. Ceci s’obtient en faisant exécuter certaines tâches sur certains processeurs à niveau de voltage bas.
Le placement et ordonnancement sont parmi les tâches les plus difficiles lors de la conception, de bons algorithmes de placement et ordonnancement sont cruciaux pour avoir un maximum de performance pour une application sur une plateforme donnée. Les systèmes
67

NOC sont à la base des systèmes multiprocesseurs hétérogènes faiblement couplés utilisant un routage par paquets pour les communications inter-processeurs. Une des plus importante particularité des NoC par rapport aux multiprocesseurs, c’est que les NoC contiennent certains éléments spécialisés qu’on ne peut pas utiliser pour des calculs généraux mais pour uniquement certaines fonctions spécialisées. Cette différence doit être pris en considération lors de la conception et surtout dans la phase de placement.
4.2 Problématique du placement et ordonnancement Dans le flot de conception, l’étape de placement et ordonnancement est directement liée à
l’implémentation de l’application sur une architecture spécialisée. Les entrées de cette phase sont [58]:
• Un modèle d’application, • Un modèle d’architecture cible, • Des contraintes de performance et d’énergie, • Des fonctions objectifs à optimiser.
La sortie de cette phase est une affectation des différentes tâches et communications aux ressources physiques, plus un ordonnancement d’exécution des différentes tâches sur ces ressources.
4.2.1 Le modèle d’architecture et le modèle d’application
Le modèle d’architecture est généralement un graphe orienté avec deux types de nœuds représentant les processeurs (PE) et les switchs qui sont interconnectés par des arcs représentant les liens de communication (CL) dans la plateforme. Puisque le NoC peut être un système multiprocesseur alors les PE peuvent être des processeurs généraux ou spécialisés tels les ASIC, FPGA, etc. CL peut être une connexion point à point ou bus. PE et CL peuvent avoir plusieurs types de voltage permettant leur utilisation dynamique. Les techniques de gestion d’énergie peuvent être utilisées pour carrément arrêter les éléments non utilisés et diminuer par là la consommation d’énergie. D’autres paramètres sont nécessaires pour spécifier la plateforme matérielle, on peut citer : le nombre, type et position des PE. Vitesse (fréquence) et niveau de voltage des PE et CL. Contraintes taille mémoire et surface des PE sans oublier la topologie d’interconnexion des PE.
L’application est, généralement, donnée par un graphe de tâche (TG) dont les nœuds représentent les tâches et les arcs les communications. Plusieurs applications concurrentes peuvent être représentées comme un ensemble de TG qui peuvent être exécutés en parallèle sur la plateforme de calcul. On a quelques paramètres pour caractériser ce graphe, on cite : le temps d’exécution de tâche (ET) sur chaque PE, les deadlines hard et soft des tâches, volume de communication sur chaque arc, consommation d’énergie par cycle à chaque voltage, énergie consommée pour le transfert d’une unité de donnée (bit/byte) en ignorant les distances des communications. La figure 4.1 illustre un exemple d’un problème de placement et ordonnancement sur un NoC 2D où la topologie est à maillage complet avec 3x3 ressources. Dans cet exemple, il y a deux applications concurrentes représentées par deux TG.
68

Lde com(comest com
Lressol’exél’exeplac
Lles dLes l’ordde lacas
Figure 4.1 Illustration d’un problème de placement et ordonnancement
e placement est défini comme l’assignation des tâches (communications) sur les éléments calcul (routage). Le placement pour les NoC peut aussi inclure l’assignation des posants IP aux tuiles du NoC et en même temps l’assignation des chemins de routage munication mapping référée dans la littérature par « l’assignation réseau »). Ce dernier
souvent traité après le placement des tâches et tends à réduire les distances des munications sur la puce.
e scheduling est l’ordonnancement des temps des tâches et communications sur leurs urces auxquelles elles sont assignées. Il doit assurer l’exclusion mutuelle entre cution de tâches sur la même ressource. Dans la figure 4.2 on illustre le scheduling de mple 1. Le graphe de Gantt est utilisé pour une représentation graphique des résultats du
ement et ordonnance ent
Fig
a sortie de cette phasurées d’exécution decontraintes de temonnancement avec l même manière le p
les arcs des NoC vo
m
ure 4.2 : Scheduling de TGs sur une platefome NoC
e est le modèle placé et ordonnancé qui montre les temps de début et s tâches sur les différentes ressources auxquelles elles sont assignées. ps peuvent facilement être vérifiées en comparant la durée de es deadlines données. Le diagramme de Gantt permet aussi d’inclure lacement des communications. La seule différence c’est que dans ce nt apparaître sur certains liens de communication correspondant aux
69

chemins de routage. Ce placement peut être suivi par l’ordonnancement du voltage et les techniques de gestion d’énergie pour minimiser la consommation d’énergie.
L’ordonnancement voltage, implique la sélection voltage (VS), il tend à minimiser la consommation d’énergie dynamique des tâches et communications placées sur des ressources à voltage graduel. Adaptive Body Biasin (ABB) est un cas spécial d’ordonnancement voltage qui minimise la consommation d’énergie statique en ralentissant certaines tâches et les exécutant à des seuils élevé du niveau voltage.
Les techniques de gestion d’énergie (PM) tendent à réduire la consommation d’énergie statique en arrêtant totalement, partiellement ou mettre au repos (idle) certaines ressources. La gestion de l’énergie peut être appliquée en même temps aux éléments de calcul et aux liens de communication.
4.2.2 Problèmes et objectifs
4.2.2.1 Contraintes et fonctions objectifs
Un placement et ordonnancement réalisable est celui qui satisfait les contraintes spécifiées telles que les contraintes de temps, contraintes de précédence de données, contraintes taille mémoire etc. Un placement et ordonnancement de qualité est celui qui, en plus de satisfaire les contraintes, il doit optimiser les fonctions objectifs spécifiées telles que la minimisation de la consommation d’énergie, maximiser les temps de performance ou équilibrage de charges des mémoires. Le Placement et ordonnancement doit, parfois, trouver un compromis entre plusieurs objectifs contradictoires tels la minimisation de la consommation d’énergie et satisfaire les contraintes temps réel, etc.
4.2.2.2 Séparés ou intégrés
Les problèmes de placement et ordonnancement peuvent être traités séparément, ou ensemble intégrés dans un même problème. Dans ce dernier cas la solution optimale correspondra à la meilleure solution. Mais les deux problèmes sont NP.hard, les solutionner séparément est moins coûteux que de les traiter ensemble comme un seul problème c'est-à-dire simultanément.
4.2.2.3 Placement et ordonnancement statique et dynamique
Le placement et ordonnancement peuvent être traités en on-line ou en off-line. En Off-line (ou statique) le placement et ordonnancement sont exécutés avant l’exécution de l’application. Un tableau enregistrant, les temps de début d’exécution des tâches sur les ressources d’assignation avec les niveaux de voltage correspondants et les temps de leurs switching est donné avant le début de l’exécution. Donc, dès que le placement et ordonnancement est exécuté, au moment de la compilation, il n’aura aucune influence sur l’application pendant l’exécution.
Le On-line ou « dynamique mapping et scheduling » donne les affectations et les ordonnancements pendant l’exécution de l’application. Ceci permet une meilleure solution,
70

mais les temps de traitements, pendant l’exécution de l’application, vont augmenter la durée d’exécution et la consommation totale d’énergie de l’application. En plus ce type d’ordonnancement est très difficile à tester.
Comme conséquence le placement et ordonnancement statique est conseillé pour les systèmes embarqués et spécialement pour les NoC où le placement dynamique des communications est très contraignant. C’est ce qui justifie notre choix, dans cette étude, de ne traiter que le placement statique.
Pour le voltage, la notion de statique et dynamique n’a pas la même signification que off-line et on-line. Statique Voltage Sélection (SVS) est d’affecter plusieurs niveaux de voltage à l’échelle des voltages d’une ressource selon l’utilisation de la ressource durant l’exécution d’une application. SVS est souvent appliqué en off-line ou quand le temps d’ordonnancement de tâches sur l’échelle des voltages des ressources est négligeable. Donc dans le SVS les temps de basculement (switching) sont ignorés.
Dynamique Voltage Scheduling (DVS) correspond à l’allocation d’un ou plusieurs niveaux de voltage pour l’exécution des tâches sur des ressources à échelle de voltage. Les niveaux multi-voltages ont des valeurs discrètes où le temps et l’énergie relatifs au switching entre les voltages ne sont pas toujours négligés. DVS peut être appliqué en off-line ou on-line et ils est toujours appliqué après l’ordonnancement des tâches selon l’échelle des voltages des ressources.
La même observation peut aussi être faite pour la gestion d’énergie. La décision d’arrêter les ressources inutilisables peut être prise en off-line ou On-line, mais la manière d’appliquer le PM aux ressources de l’architecture ou aux tâches de l’application donne la signification statique ou dynamique au PM.
4.2.2.4 Algorithmes de placement et d’ordonnancement
Placement et ordonnancement sont des problèmes NP-hard, donc la solution des problèmes à tailles réelles ne peut être envisagée qu’avec des heuristiques de construction ou transformation. Néanmoins les problèmes à petites tailles peuvent être solutionnés avec des méthodes qui déterminent l’optimum d’une façon déterministe. Ces méthodes (déterministes) explorent d’une façon exhaustive tout le domaine des solutions et retournent l’optimum théorique c'est-à-dire exact; Le Branch-and-Bound (BB) en est une.
Les heuristiques sont des méthodes de recherches pseudo aléatoires et des techniques d’optimisation qui explorent et exploitent l’espace des solutions en se basant sur l’expérience apprise. Elles sont utilisées quand une recherche déterministe ou exhaustive est très hard ou impossible et quand le temps de recherche augmente d’une façon exponentielle avec la taille du problème. Les heuristiques permettent d’obtenir des solutions de qualité raisonnable en un temps très court. Les heuristiques constructives permettent de construire graduellement des solutions partielles valides jusqu’à atteindre l’optimum. Les heuristiques de transformation alternent des solutions existantes en cherchant à élargir l’espace d’exploration de l’espace des solutions. LS (List Scheduling) et GA (Genetic Algorithms) sont des exemples, respectivement, d’heuristiques constructives et transformatives.
71

Ce qu’on vient de dire ne doit pas nous fait oublier d’autres approches utilisées même si elles le sont rarement dans notre domaine. La programmation mathématique [62] en est la première avec ces différentes variantes : programmation linéaire en nombre entier (ILP), Programmation non linéaire (NLP) et programmation en nombre entier mixé (MILP). On cite aussi la programmation par contrainte dont la classe englobe celles de ILP et MILP.
4.3 Etat de l’art des approches existantes
Dans cette section on va décrire les méthodes de placement et ordonnancement les plus représentatives pour les NoC et MPSOC à base de bus.
4.3.1 Approches pour les NoC
Les NOC constituent un domaine de recherche nouveau où seulement quelques méthodologies de placement ont été développées. La plupart ne prennent pas en considération le placement des communications alors que pour l’ordonnancement encore moins. Le plus court chemin dans le NoC est souvent déterminé au moment du placement des communications.
On va présenter quatre approches pour les NoC, groupées selon le critère d’assignation réseau. Deux parmi elles, G.Varatkar et al [59] et T.lei et al [61], traite d’une façon très restreinte le problème des communications en laissant de coté le placement et ordonnancement. J.Hu et al [63] proposent une approche qui est la seule qui traite du placement et de l’ordonnancement des communications en fournissant des mesures exactes des échanges. D.Shin et al. [64] se sont concentrés sur les communications dans les NoC en traitant assignation réseau et les vitesses des liens mais en laissant de coté l’ordonnancement.
4.3.1.1 Approches sans assignation réseau
G.Varatkar et al.[59] ont développé une méthodologie en deux étapes pour minimiser la consommation d’énergie totale dans le NoC (figure 4.3). L’étape communication traite simultanément le maping et le scheduling des taches en cherchant à réduire la consommation d’énergie par minimisation du volume des communications inter processeurs. Ça facilite aussi la minimisation d’énergie des tâches dans l’étape de sélection de voltage en maximisant les repos (slack). Les deux objectifs sont alternés par un critère de communication qui a le rôle de fixer le volume local des communication inter-processeurs sous un seuil fixé globalement dépendant des communications de l’application et d’un facteur K (0 ≤ K ≤ 10). Ce facteur permet d’arrêter la boucle externe de la méthodologie jusqu’à ce qu’un optimum est atteint. La deuxième étape de la méthode traite le DVS pour les tâches et exploite la distribution non uniforme des repos (slack) en considérant une valeur maximale pour le temps et l’énergie pendant le basculement des voltages [60]. La méthode ne prend pas en considération le placement et l’ordonnancement des communications ; les distances des communications sont grossièrement estimées. Ainsi les deadlines hard ne sont pas garanties car les délais des communications sont ignorés.
72

Figure 4.3 –Méthogologie de G.Varatkar et al.
T.Lei et al. [4,5] utilisent une méthode à deux étapes basée sur les G.A pour le placement et ensuite appliquent les techniques ASAP/ALAP (ASAP : As Soon As Possible ; ALAP : As Late As Possible) pour l’ordonnancement des tâches (figure 4.4). L’objectif du placement est de maximiser les temps de performance, pendant que l’ordonnancement est utilisé pour respecter les hard deadlines. Les communications ne sont pas placées et schedulées et leurs délais sont estimés en utilisant une distance moyenne dans le NoC ou La distance Manhattan entre processeurs. Cette méthode ne garantie pas les hard deadline cars elle utilise la moyenne dans des pires cas des temps d’exécution (WCET Worst Case Execution Times) pour les tâches et le chemin de communication critique.
La méthodologie a trois étapes. Dans la phase de partitionnement les tâches sont assignées aux classes de composants IP. Dans la phase embarquement (embedding phase) les tâches sont assignées à leurs composants IP à haute performance dans la classe. ASAP/ALAP est appliquée pour la faisabilité de la solution.
J.H et al [63] ont développé une méthode d’optimisation d’énergie qui cherche le plus court chemin des communications dans le NoC (figure 4.5) et calcule la consommation d’énergie pour décider entre des placements possibles pour construire la solution initiale. Cette méthode ne traite pas le voltage sélection et l’assignation réseau mais exploite les repos (relâchement) non uniforme en les distribuant d’une façon proportionnelle selon le timing et les profils d’énergie des tâches.
Cette méthode fournit des mesures des délais de communication, de la consommation d’énergie et tend à satisfaire les hard deadlines. Elle a deux phases, énergie d’ordonnancement (EAS) et recherche-réparation (SaR). Durant la phase EAS la solution est construite en se basant sur LS pour le mapping et scheduling des tâches parallèles et une autre méthode déterministe pour le mapping et scheduling des communications parallèles. La méthode déterministe traite l’ordonnancement des communications pour toutes les tâches prêtes et les processeurs disponibles dans le but de trouver le temps de terminaison le plus court (EFT) de toutes les tâches prêtes.
73

Figure 4.4 : La méthodologie de Lei et al.
La méthode d’Armin et aque celles qui ont précédd’application un GT et comml’ont nommé Core Mappingreprésentant l’application et sur des plateformes à topoloqu’ils retiennent est celle d’est une série de tâches. Enl’exécution d’une tâche préplacé d’une façon optimalsatisfaites. Dans ce travail globale sur tous les liens du
Le graphe TG qui est un chaque sommet Ci représententre Ci et Cj. Chaque prop
Figure 4.5 : Méthodologie de J.Hu et al.
l [66] va être présentée avec plus détail car elle est la plus récente é. Dans leur approche les auteurs utilisent comme modèle e plateforme cible un NOC de dimension deux. Ce processus ils
Technique (CMT) qui commence par définir un graphe de tâche ces tâches. Il se termine par un placement optimal des composants gies différentes (voire chapitre I), mais la plus réaliste et faisable un réseau en 2D-mesh. Le graphe TG modélisant une application plus, chaque composant IP dans le NOC est responsable de
-assignée. L’objectif est de décider quel composant IP doit être e sur quelle tuile tel que les contraintes de performance soient les auteurs cherchent à minimiser la consommation d’énergie
réseau.
graphe caractérisant l’application (APCG) est un graphe direct où e un IP sélectionné. Et chaque arc aij représente la communication riété d(aij) de l’arc aij représente le volume de données en bits
74

transférées de Ci à Cj sur l’arc. D’une façon générale TG peut expliciter les dépendances de données, les dépendances logiques et temporelles entre les tâches.
Pour l’architecture, un graphe direct ACG permet de la modéliser. Chaque sommet ti représente une tuile dans l’architecture et chaque arc rij représente le chemin de ti à tj. Chaque rij a comme propriété Etitj
bit qui représente la consommation d’énergie moyenne par l’envoie d’un bit de ti à tij. Le calcul de Eti,tj
bit a été proposé dans les travaux de [76] selon la formule suivante : Eti,tj
bit = nhops x ESbit + (nhops-1) x Elbit
Où Eti,tjbit est l’énergie consommée par bit entre les noeuds. ESbit est l’énergie consommée
par les switchs entre les nœuds et nhops est le nombre de bit transférés de la tuile source à la tuile destination. Ceci permet de voir que pour un 2D-Mesh avec un routage minimal la consommation moyenne d’énergie par l’envoi d’un bit entre deux nœuds ti, tj est déterminée par la distance de Manhattan entre eux. Ceci est basé sur le fait que tous les liens ont les mêmes caractéristiques. Dans ce travail les auteurs pour généraliser ont supposé que chaque lien a un Elbit différent et chaque switch a un ESbit différent. Ce qui donne l’expression suivante pour le calcul de la consommation d’énergie totale des liens.
∑∑−
==
+=1
11bit
titjE nhops
klbit
nhops
ksbit EE
D’où la consommation d’énergie totale pour transférer les données peut être calculée en multipliant l’énergie obtenue lors de l’équation précédente par le volume des données :
bittitj
total EDatasize×=titjE
Ensuite pour le placement des tâches, ces auteurs, détermine une liste TPL (Task Priority List) qui donne la liste des tâches selon les priorités de leur placement. Pour la plateforme ils utilisent la liste PPL (Platforme Priority List) qui ordonnance les tuiles selon l’ordre descendant des degrés de connectivités (voisinage), ainsi dans cette liste les tuiles du centre sont les premières et celles des frontières sont à la fin de la liste. Les priorités des placements sont exprimées par les règles suivantes :
1- Les tâches qui communiquent le plus sont placées le plus proche possible.
2- Les tâches fonctionnellement très liées doivent avoir la distance Manhattan la plus petite.
3- Les tâches à degré de connectivité le plus élevé ne doivent pas être placées sur des tuiles du bord du NOC mais de préférence sur celles du centre.
Enfin pour déterminer le placement, une fonction coût est définie basée sur la distance minimale et les exigences de la bande passante entre les nœuds source et destination. Comme exemple de la fonction coût relative à la règle 2 on a :
C(i) = max [deg(Ti)] ; où Ti est une tâche dans TG
75

4.3.1.2 Approches avec assignation réseau
D.shin et Al. [64] ont proposé une méthodologie (figure 4.6) basée sur l’assignation réseau et l’allocation des vitesses des liens pour réduire la consommation d’énergie dans les NoC avec une échelle de voltage des liens. Le placement des tâches et l’assignation réseau cible à minimiser le volume des communications inter-processeurs, cependant la sélection statique du voltage et la gestion statique de l’énergie tendent à réduire la consommation d’énergie des liens. Le placement de tâches permet la vérification des contraintes de dimensionnement. Les hard deadlines sont aussi garanties, car quand l’ordonnancement des communications n’est pas performant, les pires délais des communications (Worst Case Communication Delay) des liens sont appliqués. Les liens peuvent être partagés par plusieurs arcs sans contraintes sur les volumes des communications. Comme conséquence d’avoir ignoré l’ordonnancement des communications, la sélection du voltage des liens et la gestion d’énergie sont traitées d’une façon statique.
Cette méthode utilise le GA pour le placement des tâches et l’assignation réseau. Pour l’ordonnancement des tâches et l’assignation des vitesses de liens c’est LS qui est utilisée. Le GA dans cette méthode est basé sur un chromosome de placement, un croisement à deux points et une mutation aléatoire. Le GA pour l’allocation utilise les permutations des tuiles (Tile : éléments de l’architecture) comme chromosome, les cycles de croisement pour générer les solutions acceptables et des changements aléatoire comme mutation. Le GA pour le placement du routage des communications utilise des chromosomes binaires pour coder les mouvements selon les directions X et Y, ce qui a un impact sur les volumes des communications de chaque lien et par là sur les délais de communications.
LS utilise la mobilité des tâches (|ASAPstart -ALAPend|) comme priorité statique qui est basée sur l’estimation pessimiste des délais des communications.
Figure 4.6 : Méthodologie de D.Shin et al.
Hsin-chou et al [67] propose un algorithme qui fait le placement et l’ordonnancement simultanément pour ce cas, en utilisant la technique TDM (Time Division Multiplexing) pour
76

le partage des liens du réseau. Ainsi plusieurs arcs de communication peuvent se partager un même lien entre deux nœuds en se partageant sa bande passante. Ici aussi les auteurs utilisent comme modèles deux graphes : CTG (U,E) (Communication Task Graph) où chaque sommet ui∈U représente un IP, et chaque arc eij ∈ E représente la communication de l’IP ui vers l’IP uj. La propriété de l’arc eij notée par wij représente la bande passante nécessaire pour communiquer entre ui et uj. Le deuxième graphe est nomé NAG(V,P) (NOC Architecture Graph). Chaque sommet vi∈V représente une tuile dans l’architecture et chaque arc pij∈P représente le chemin de vi à vj. La valeur rij associée au lien représente la bande passante.
Pour ces auteurs le mapping est défini par la fonction MAP(U):
MAP : U → V ⇒ vj=map(ui), ui∈U, vj∈V
L(pm,n) est l’ensemble des chemins pm,n.
Un lien est noté par li,j.
rij peut être obtenu par la relation :
Où
En supposant que la bande passante dCTG (U,E) à NAG(V,P) doit au moins sat
La latence est définie comme étantrécepteur. Elle dépend de la latence du slatence du chemin de communication Cn ppeut être calculée par :
LCN = ∑ LSi i≤nh
Où nhops est le nombre de switchs rencLSi dénote la latence du switch Si dans le relation : LSi = TTransfert + TWaiting
TTransfert est le temps de transfert du swpour faire passer le paquet sans le stocketemps de stockage du paquet dans le buffest égal à zéro s’il n’y a pas de stockage d
Donc pour ces auteurs l’objectif est denombre des chemins de communication dl’objectif de l’ordonnancement pour ces a
Où Mest le nombre de switch et Kle switch.
e chaque lien est la même, l’algorithme qui mappe isfaire l’équation maxrij ≤ bande passante du lien.
la durée d’envoie d’un paquet de l’émetteur au witch et de la latence du lien notées par ls et ll. La our l’envoie d’un bit de donnée de la tuilei à la tuilej
+ (nhops-1) x Ll ops
ontrés par le bit pendant son transfert. La latence chemin de communication, elle est obtenue par la
itch. Ce temps est égal à la durée que prend un wicth r dans son buffer. Le temps d’attente TWaiting est le er, il dépend de l’algorithme d’ordonnancement et il e paquet.
minimiser ∑ LCN pour n ≤ N. Où Nest le ans le NOC. Du fait que LCN dépend de LSi alors
uteurs devient min ∑∑ TWaiting ; i ≤ MK.
est le nombre de chemin de communications dans
77

Figure 4.6-Bis : Exemple de placement du CTG sur le NOC. Les lignes fléchées dans le NOC représentent les chemins de communications réservées par l’algorithme de placement
Hin-chou et al font le placement et l’ordonnancement en deux étapes. Dans la première il détermine le placement à l’aide d’une heuristique, le résultat est utilisé pour ordonnancer les chemins de communication dans la deuxième étape (figure 4.6-bis). Si les résultats de l’ordonnancement ne vérifient pas les contraintes de la latence de communication alors le placement est refait en ré-exécutant la première étape. Le processus est répété jusqu’à ce que toutes les latences de communication soient vérifiées.
4.3.1.3 Résumé
Les tables 4.1 et 4.2 [58] synthétisent les étapes et les objectifs des méthodologies vues précédemment.
Mapping
Network assignment
Scheduling
Voltage Selection
Power Management
Réf
Task Tile Comm task Comm Task Comm Task Comm
G.Varatkar et al. [59,60]
LS - - LS - ILP - - -
T.Lei et al. [61] 2-GA - - ASAP/ALAP
- - - - -
J.Hu et al. [63] LS - Determ LS Determ - - - -
D.Shin et al. [64] GA GA GA LS - - LS - LS
Table 4.1 : Méthodologies pour les NoC Energy Consumption Dynamique Static
Timing constraints
Memory Réf
Task comm Task Comm Hard Soft Code Data
Area
G.Varatkar et al. [59,60] DVS Y - - Y - - - -
T.Lei et al. [61] - - - - Y - - - -
J.Hu et al. [63] Y Y - - Y - - - -
D.Shin et al. [64] - SVS - ABB SPM
Y - - - Y
Table 4.2 : Objectifs spécifiés pour les NoC
Comme on le voit dans ces tableaux les méthodologies des N0C ne couvre pas complètement l’espace d’exploration surtout si on prend en considération les communications.
78

Une approche traite de l’assignation réseau [64] et une autre l’ordonnancement des communications [63]. Bien que deux approches [59,64] minimise le volume des communications inter-processeur durant le placement des tâches.
La consommation d’énergie est l’objectif préféré dans les approches d’optimisation. Quatre de ces approches [59, 63, 64, 67] sont basées sur le problème, notamment la consommation d’énergie des tâches et des communications. Ainsi, G. Varatkar et al. [59] utilisent la sélection dynamique des voltages pour les tâches, D. Shin et al. [64] utilisent assignation statique des vitesses de liens et la gestion statique de l’énergie pendant que J.Hu et al [63] la distribution non uniforme des relâchements durant le placement et l’ordonnancement.
Toutes ces approches tendent à vérifier les hard deadlines mais seulement deux [63,64] les garantissent. T.Lei et al. [61], leur méthode maximise les performances d’un ensemble d’applications, mais aucune de ces approches ne traite les soft deadlines.
4.3.2 Approches pour les systèmes embarqués multiprocesseur (MPES ou MPSoC)
Les systèmes embarqués multiprocesseurs dont la communication est à base de bus amplifient la complexité du problème de placement et ordonnancement. Car dans ce type de systèmes les bus sont assimilés à des processeurs, ce qui entraîne le même traitement pour les tâches et les communications. Des approches diverses sont développées pour les MPSOC à base de bus, elles ciblent toutes différents objectifs d’optimisation et focalisent sur certaines étapes de conception. Ainsi, la consommation d’énergie avec DVS est ciblée par M.T.Schmitz et al. [65,68], de même pour A.Andrei et al. [70], F.Gruian et al. [71] et L.Benini et al.[65]. Le traitement de l’ordonnancement avec des deadlines soft est fait par L.A. Cortes et al. [72,73] pendant que le placement et l’ordonnancement pour l’équilibrage de charge de la mémoire est l’intérêt de R.Szymanek et al. [75].
4.3.2.1 Approches basées sur l’énergie
M.T. Schmitz et al. [65,69] ont développé une méthodologie, pour les systèmes embarqués hétérogènes distribués, appelée LOPOCOS (Low Power CO-Synthesis) qui tend à minimiser la consommation d’énergie en off-line des applications multimédia ou télécommunications en garantissant les contraintes temps réel Hard et les contraintes de taille de la puce. Cette méthode est constituée de deux boucles imbriquées : la boucle externe traite l’allocation des composants et le placement des tâches. La boucle interne pour l’ordonnancement de temps, placement des communications et la sélection de voltage (Figure 4.7).
Le placement de tâches est traité séparément du placement des communications et il est implémenté à l’aide du GA. L’algorithme nommé EE-GMA (Energy Efficient Genetic Mapping Algorithm) est basé sur l’optimisation de l’énergie dans le sens où uniquement les solutions de placement et d’ordonnancement correspondantes à la faible consommation d’énergie survivent et s’accouplent, mais sa principale contribution est le faite de garantir les contraintes de la taille de la puce. Ces contraintes sont introduites avec des pénalités dans l’algorithme.
79
Figure 4.7 : Méthodologie de M.T.Schmitz et al.
Le placement des communications est suivi en même temps de l’ordonnancement afin de mieux optimiser les objectifs communs. L’ordonnancement est implémenté à l’aide de la combinaison de la méthode LS avec le G.A où les priorités dynamiques des tâches dans la liste des processus prêts (Ready) est obtenue à l’aide du GA. L’algorithme EE-GLSA (Energy Efficient Genetic List Scheduling Algorithm) cible à garantir les deadlines hard et traite le problème d’énergie dans le sens où les solutions d’ordonnancement à faible consommation d’énergie survivent et s’accouplent, là aussi les contraintes de temps sont introduites sous formes de pénalités.
La sélection voltage est appliquée pour les tâches placées et ordonnancées en utilisant l’algorithme PV-DVS généralisé (Power Variation Dynamique Voltage Scaling). Les relâchements sont exploités en considérant les profiles énergétiques des tâches. Cet algorithme ordonnance les tâches à un voltage dans les domaines continus ou deux voltages dans les domaines discrets en ignorant le total des basculements (switching overhead). Donc PV-DVS est un LS avec des priorités dynamiques qui distribue par incrémentation les relâchements disponibles aux tâches à consommation d’énergie la plus importante.
A.Andrei et al.[70] combine ABB (section 4.2.1) avec DVS pour réduire la perte d’énergie des tâches à cause de l’énergie dynamique des systèmes multiprocesseurs. Cette approche prend le temps et l’énergie comme principaux critères pour switcher entre les niveaux de voltage. La programmation mathématique est appliquée pour des versions de problèmes continus ou discrets avec ou sans le basculement. NLP retourne une seule paire de voltage (Vdd, Vbs) pour chaque tâche dans les domaines continus. MILP retourne le temps utilisé par chaque tâche dans chaque paire multi-voltage (Vdd, Vbs) d’un domaine discret.
F.Gruian et al. [71] a développé une méthode d’ordonnancement et sélection de voltage pour les tâches simultanément pour les MPSoC avec un placement déjà fait (figure 4.8). La méthode tend à minimiser l’énergie consommée par les traitements en vérifiant les contraintes
80

temps hard. DVS avec distribution uniforme des relâchements est appliquée dans les domaines continus et discrets pour des niveaux à simple et double voltage en ignorant la consommation due au switching.
La méthode est implémentée avec LS basé sur des niveaux avec des priorités dynamiques. LS basée niveau donne la priorité à la tâche prête qui donne la plus large minimisation d’énergie si elle est retardée d’une seule unité de temps ou celle qui va atteindre rapidement son temps de début le plus tard (LST : Latest Start Time). Le coefficient α est donné aux tâches urgentes, il permet aussi à la boucle externe de trouver l’optimum entre les délais et la minimisation d’énergie.
Figure 4.8 : Méthodologie de F.Gruain et al.
4.3.2.2 Approche pour les contraintes temps réel soft
L.A Cortes et al. [72,73] a proposé un ordonnancement quasi statique pour les MPSoC avec des contraintes temps réel hard et soft (figure 4.9). L’ordonnancement construit, en off line, un arbre des ordonnancements où il explicite les points de switching dépendants des temps exigés, des temps maximums d’exécution des tâches et sur les fonctions utilitaires associées aux tâches soft. En se basant sur cet aspect, l’algorithme choisi en on-line le chemin d’utilité maximum dans l’arbre d’ordonnancement en fonction des temps d’exécution actuel des tâches et les points activés de switching. L’ordonnancement statique de l’arbre garanti la vérification des deadlines et maximise la fonction d’utilité totale des taches soft. Ceci s’obtient en premier par l’ordonnancement des tâches soft critiques. Il assure aussi le placement des tâches sur les processeurs, les communications et les calculs sont traités de la même manière car les bus sont assimilés à des processeurs.
Pour cette approche les deux méthodes BB et LS sont utilisées pour l’ordonnancement des deadlines soft et pour dét miner les intervalles de temps des points de switching dans l’arbre d’ordonnancement.
er
Figure 4.9 : Méthodologie de L.A.Cortes et al.
81

La fonction totale d’utilité est la somme des fonctions individuelles d’utilité des tâches soft et explicite la qualité de dégradation des performances du système quand les deadlines soft sont ignorés. Les fonctions d’utilité associées aux tâches soft ne subissent pas d’augmentation, elles dépendent des temps nécessaires de traitement des tâches soft et permettent de capter l’importance et la criticité des tâches. Les temps d’exécution des tâches sont variables et non uniformément distribué dans un intervalle.
4.3.2.3 Approche pour les contraintes temps réel hard
Dans leur approche L.Benini et al.[65] introduisent une méthode complexe pour le placement et l’ordonnancement de voltage variable. Ils proposent un formalisme et une solution pour le problème d’optimalité de l’allocation, l’ordonnancement et la sélection du voltage discret en minimisant la perte d’énergie du système et du switching. Cette approche est basée sur la technique de décomposition utilisant les Benders logiques où le problème de placement est résolu à l’aide de la programmation linéaire en nombre entier et l’ordonnancement à l’aide de la programmation par contrainte.
Benini prend aussi comme modèle un graphe de tâches acyclique direct où les nœuds représentent les tâches ayant comme propriétés des deadlines dlt et WCNt comme nombre de cycles d’horloge nécessaire pour son exécution dans le pire cas. Les arcs représentent les communications inter-tâches et ont comme valeur le volume de données échangées entre les tâches représentées par les nœuds reliés par cet arc. Ils introduisent aussi le nombre de cycles d’horloge nécessaires au basculement entre les modes lecture/écriture des données notés par WCNR et WCNW. Les tâches sont exécutées sur un ensemble de processeurs P. Chaque processeur peut fonctionner avec plusieurs modes de vitesse et d’énergie. Chaque tâche nécessite de l’énergie pour son exécution et les communications qu’elle fait. En plus quand un processeur bascule entre les modes il dépense du temps et de l’énergie. Les auteurs notent par Eij l’énergie dépensée par le processeur quand il bascule de la fréquence i à la fréquence j. Et par Tij le temps perdu pour passer de la fréquence i à j. Donc le problème est un DVS, pour le traiter les auteurs l’ont décomposé en deux sous problèmes. Le premier appelé « problème global » consiste à affecter les processeurs et les fréquences aux tâches, le second appelé sous problème fait l’ordonnancement des tâches en utilisant les résultats du problème global.
Pour le problème global ils font le placement avec minimisation de l’énergie selon certaines fréquences tout en respectant les deadlines de chaque tâche.
∑∑∑== =
∀≤++T
tt
m
wttlpttlm
m
rttlpptlm
P
p
M
m m
tptm tdl
fWCN
Wf
WCNR
fWCN
X111 1
]([
Xptm Où est égale à 1 si la tâche t est affectée au processeur p fonctionnant au mode m, 0
sinon. WCNt le nombre de cycles d’horloge nécessaires à l’exécution de t au pire cas. fm est la fréquence de cycle d’horloge quand la tâche est exécutée au mode m. Rppt1m est égale à 1 si la tâche t est affectée au processeur p, lit les données au mode à partir
de t1 quand celle-ci n’est pas affectée à p ; sinon 0. Wptt1m même définition que Rppt1m mais en écriture.
82

WCNrtt1 c’est le nombre de cycles nécessaires pour que t affectée à R lit à partir de t1. WCNwtt1 même définition que WCNrtt1 mais en écriture. dlt c’est le deadline de la tâche t. Dans le sous problème, Benini essaye de faire l’ordonnancement tout en respectant les
temps de début et de fin de chaque tâche. OF, donnée ci-après, est la fonction objectif minimisée dans ce sous problème :
P OF = ∑ ∑ TransCostij P=1 (i,j)∈Sp next(i)=j
Où TransCostij est une valeur obtenue par la méthode introduite par Benini en utilisant la décomposition à l’aide des Benders. Cette fonction objectif doit être minimisée tout en respectant les contraintes de précédence. Si l1 et l2 sont deux activités qui se suivent alors il faut que :
Startl1 + durationl1 + TransTimel1l2 ≤ Startl2
Où Startl1 , Startl2 sont les temps de début des activités l1 et l2 ;
Durationl1 = WCNi/fi
TransTimel1l2 est le temps d’initialisation spécifié dans la matrice des transitions obtenue avec les Benders.
4.3.2.4 Approches basées sur la mémoire
R.Szymanek et al. [74,75] ont développé une méthode qui fait le placement et l’ordonnancement simultanément avec un équilibrage de l’utilisation de la mémoire et en vérifiant les deadlines hard (figure 4.10). La méthodologie fait le placement en mémoire du code et des données et s’assure aussi que les données échangées soient présentes dans les mémoires du producteur et du consommateur pendant la communication.
La méthodologie est basée sur LS avec un objectif adapté et des priorités dynamiques qui aident l’outil CLP à explorer efficacement l’espace des solutions. La tâche la plus importante en consommation de données ou urgente (selon l’objectif) est toujours assignée au processeur le plus pauvre en terme d’utilisation de la mémoire en code ou en données. Les objectifs sont inter-changés quand les co raintes de données ne sont pas vérifiées.
F
nt
igure 4.10 : R.Szymanek et al.Methodology
83

4.3.2.5 Résumé
Les deux tables suivantes synthétisent les méthodologies et les objectifs pour le problème de placement et d’ordonnancement dans les MPSOC à Bus.
Mapping Scheduling Voltage selection Power Management Réf
Task Comm task Comm Task Comm Task Comm
M.T.Schmitz et al. [65,68]
GA GA GA+LS GA+LS LS - LS -
A.Andrei et al.[70] - - - - NLP/MILP
- - -
F.Gruian et al. [71] - - LS - - -
R.Szymanek et al. [75] LS+CLP - - -
L.A.Cortes et al. [72,73] - - BB LS - - -
Tableau 4.3 Méthodologies pour MPSOC à base de Bus
Energy Consumption Dynamique Static
Timing constraints
Memory Réf
Task comm Task Comm Hard Soft Code Data
Area
M.T.Schmitz et al. [65,68]
DVS - - - Y - Y - Y
A.Andrei et al.[70] DVS - ABB - Y - - - -
F.Gruian et al. [71] DVS - - - Y - - - -
R.Szymanek et al. [75] - - - - Y - Y Y -
L.A.Cortes et al. [72,73] - - - Y Y - - -
Table 4.4 Les objectifs des MPSOC à bus
Comme on le voit dans ces tableaux les méthodologies sont développées pour certains domaines et objectifs. Ainsi M.T.Schmitz et al. [65,68] ont développé une méthodologie pour la minimisation d’énergie quand A.Andrei et al.[70] et F.Gruian et al. [71] ont focalisé sur le DVS. L.A.Cortes et al. [72,73] ont développé le placement pour les soft deadlines pendant que R.Szymanek et al. [75] ont travaillé sur un placement et ordonnancement basé sur la mémoire. Dans toutes ces méthodes les deadlines hard sont vérifiées. Les heuristiques constructive (LS) et transformatives (GA) comme la programmation mathématique (NLP, MILP, CLP) et les méthodes déterministes ont été utilisées pour traiter soit séparément ou simultanément les objectifs désignés.
4.4 Comparaison entre les techniques de placement et d’ordonnancement
Les méthodes vues auparavant concernant ce problème vont être comparées par la suite selon les critères : Contraintes de temps, consommation d’énergie et les contraintes de taille ou de surface.
84

4.4.1 Vérification des contraintes de temps réel
Par contraintes de temps réel, on sous entend les deadlines soft et Hard. L’ordonnancement tend souvent à vérifier les contraintes de temps, mais le placement aussi, cible la minimisation du délai total d’exécution. Même si dans les présentations précédentes on a parlé des MPSOC et NOC, dans la suite de cette comparaison c’est uniquement ces derniers qui seront discutés car c’est uniquement eux qui feront l’objet de notre étude.
4.4.1.1 Les contraintes temps réel hard dans les NoC
Les approches pour les NoC ciblent souvent la vérification des contraintes temps réel hard à cause du problème des communications qu’y plus pertinent et complexe. C’est pour cette raison que dans ces systèmes on donne plus d’attention aux délais des communications et l’interdépendance (topologie) des éléments du NOC.
G.Varaktar et al.[59] ne garantissent pas les hard deadlines, les communications ne sont ni placées et ni ordonnancées dans le NOC et les délais sont ignorés pendant la vérification des deadlines. De plus des valeurs moyennes pour le ET (temps d’exécution) des tâches dans le WCET sont utilisées. Durant le placement et l’ordonnancement simultanés, la tâche la plus critique est affectée au processeur dans la disponibilité est la plus proche ou à celui auquel la tâche la plus communicative avec elle est affectée tout en veillant à ce que les deadlines restent vérifiés. La tâche la plus critique est celle qui a le temps de début le plus proche (EST : eraliest start time) plus le temps de fin le plus lointain (LFT : Latest Finish Time) (EST+LFT). EST explicite le moment où une tâche est prête et le processeur disponible pour elle. LFT est le minimum entre le deadline et le temps le plus lointain de début de ses successeurs.
T. Lei et al. [61] ne garantissent pas, eux aussi, les hard deadlines car WCET pour les tâches et des délais moyen pour les communications sont utilisés pendant la vérification des deadlines dans chaque TG de l’ensemble des TG. Le placement et l’ordonnancement des communications ne sont pas traités car le chemin minimal des communications qu’il utilise est estimé d’une façon grossière. C’est du chemin minimal que dépend l’affectation exclusive des liens et l’évitement des deadlock. Le délai final des communications dépend du volume des communications, de la distance minimal de communication et du délai de l’interface réseau pour la « paquetisation et dépaquetisation » des messages. Durant l’allocation des groupes IP et le placement des tâches, le délai global du chemin critique est minimisé pour chaque TG dans l’ensemble T. La fonction objectif est le maximum entre le délais sur le chemin critique et le deadline pour chaque TG. Les deadlines Hard sont vérifiés sur le chemin critique quand la fonction objectif a une valeur inférieure ou égale au deadline maximal de l’ensemble TG.
D. Shin et al. Garantissent le deadline hard. Ils utilisent le WCET des tâches et des valeurs pessimistes pour les délais de communication sont utilisées pendant la vérification des deadlines hard. La communication est placée sur le chemin le plus court du NOC qui est minimisé durant l’allocation des tuiles. Ceci implique que plusieurs arcs du GT peuvent utilisés le même lien ce qui rend plus compliqué les problèmes de routage et de l’ordonnancement des communications. Ce ci rend aussi le délai de communication étroitement lié à la bande passante et la vitesse (fréquence) de transmission des données. Le
85

délai de l’arc (Edge delay) est la somme des délais des liens constituant le chemin de routage tout en ignorant les temps de basculement (dus à l’ordonnancement). Durant l’ordonnancement des tâches, la tâche la moins mobile est la plus prioritaire. La mobilité d’une tâche est données par ASAPstart – ALAPendet elle est basée sur une évaluation pessimiste des délais de communication.
J.Hu et al [63] garantissent aussi les hard deadlines. WCET des tâches et communications sont utilisées pendant la vérification des hard deadlines. Communication est placée et ordonnancée sur le chemin disponible minimal du NOC ayant un deadlock libre (bande passante non saturée). Durant le placement et l’ordonnancement simultanés la tâche la plus critique en temps (EFT ≥ BD : BD = Budgeted deadline) à partir de la liste des tâches prêtes (ready list) est affectée au processeur le plus rapide. La tâche la plus critique en temps est celle qui dépasse son BD avec une différence maximale EFT-BD. Quand aucune tâche critique (EDF < BD) n’est dans la liste, BD reste vérifié quand on affecte la tâche à forte consommation d’énergie au processeur ayant la consommation la plus faible. EFT contient les délais des communications entrantes et WCET ceux des tâches pendant que BD contient la moyenne ET des tâches et leurs relâchement (slack) en ignorant les communications. Les slack sont distribués d’une façon non uniforme sur les tâches, ils sont basés sur leur énergie et les profils de délais (variances).
4.4.1.1.1 Comparaison
Les tables 4.5 et 4.6 résument les approches pour les NOC pour vérifier les contraintes temps réel hard selon les principaux critères. La table 4.5 montre comment le temps de communication est minimisé dans chaque approche et comment les contraintes deadlines hard sont garanties. La table 4.6 représente les modalités de maximisation des performances de temps durant le placement et l’ordonnancement des tâches.
Communication delay Overall delay Ref Min. Comm.Volume
Min. Comm. Distance Link Speed
Task ET Comm. Delay
Guarantee hard Deadlines
G.Varatkar et al. [59]+[60]
TM - - WCET - N
T.Lei et al. [61]
- - Manhattan Const. WCET AVG N
D.Shin et al. [64]
TM NA Manhattan SVS WCET WCRT Y
J.Hu et al. [63]
- CM+CS Min available Const. WCET WCRT Y
Table 4.5 Les délais de communication dans les NOC Task Mapping Task scheduling Ref Goal PE Assignment Priority
G.Varatkar et al. [59,60] - Closest available Time critical min(EST+LFT)
T.Lei et al. [61] Min.Delay Critical Path - ASAP, ALAP D.Shin et al. [64] - - Time critical
minASAPstart–ALAPend J.Hu et al. [63] Repair BD violations
EFT<BD Fastest Greedy reassignments
Time critical max(EFT-BD), EFT≥BD
Table 4.6 Délais de traitement dans les NOC
86

4.4.1.1.1.1 Délai de communication
Le délai de communication dans les NOC a un grand impact sur le coût total. Le délai d’arc (Edge delay) dépend de la taille message, la bande passante et le délai de transmission unitaire. La taille de message par la bande passante nous donne le nombre d’unités à transmettre. Ils représentent souvent le volume de communication de l’arc et de la bande passante du lien respectivement. Le délai de transmission par unité de communication est influencé par l’algorithme de routage et dépend de la distance de la communication et du délai de communication des composants dans le NOC tels que le lien, switch et interface réseau. Le délai du lien dépend de la vitesse du lien, volume de communication du lien et la bande passante du lien. Quand les liens sont utilisés d’une façon exclusive le volume de communication du lien est égal à la bande passante, et la vitesse du lien devient le délai du lien.
A l’exception du volume de communication et distance de communication tous les autres constituants du délai de l’arc sont donnés comme constantes et qui sont uniques pour chaque type de composant de communication dans le NOC. Ainsi minimiser le volume et la distance de la communication a un impact direct sur le délai de communication. Le volume de communication inter processeur peut être minimisé au moment du placement des tâches pendant que le volume de communication du lien est optimisé durant le placement des communications. La minimisation de la distance (longueur du chemin) de communication se fait pendant l’allocation des tuiles et la minimisation du chemin de routage pour chaque arc se fait durant le placement de tâches. Les deadlock (blocage) et congestion peuvent être évités en traitant l’ordonnancement des communications.
4.4.1.1.1.2 Vérification des deadlines hard
Hard deadlines sont garanties si et seulement si les pires ET des délais de tâches et communications sont fournies. ET de tâche sont souvent donnée comme WCET. L’estimation pessimiste des délais de communication nécessite la connaissance des pires conditions dans lesquelles la communication est faite, comme exemple, le volume totale des communications des arcs se partageant un lien [64] ou le chemin minimal disponible quand l’usage des liens est exclusif [63].
4.4.1.1.1.3 Maximiser les performances de temps
Les priorités des tâches pendant l’ordonnancement ou la sélection des processeurs plus un objectif durant le placement de tâches peut accroître les chances de vérifier les deadlines hard tout en minimisant le coût ou le temps global. Ainsi, un meilleur ordonnancement peut être trouvé si la priorité des tâches englobe des informations sur les communications entrantes et relâchements disponibles. On peut faciliter la vérification des deadlines hard par l’affectation des tâches les plus critiques aux processeurs les plus rapides [63].
4.4.2 La minimisation de la consommation d’énergie
Par minimisation d’énergie on veut dire réduction dynamique et statique de la consommation d’énergie par les tâches et les communications durant le placement de tâches et
87

la sélection de voltage. La majorité des approches introduites dans la section 4.3 ciblent la minimisation dynamique d’énergie de tâches. Certaines d’entre elles traitent même les deux problèmes de placement de tâche selon l’énergie et le DVS des tâches. Une seule approche traite SVS pour les liens quand les approches pour les NOC tendent à minimiser l’énergie de communication en minimisant les communications du NOC sur le plan volume et distance. Les autres méthodes traitent la réduction statique de l’énergie.
4.4.2.1 Placement de tâche avec optimisation de l’énergie
Plusieurs approches on été proposées, nous citerons ci-après quelques unes et insistant sur l’impact de la priorité des tâches, assignation des PE et les objectifs spécifiés pour la minimisation d’énergie.
G.Varatkar et al.[59] tendent de minimiser l’énergie des communications en minimisant le volume des communications interprocesseur. Ils se basent aussi sur le fait que les communications ne dépassent pas un certain seuil (critère de communication). Durant le placement et ordonnancement simultanés des tâches, la tâche la plus urgente est assignée au processeur auquel est affectée la tâche avec laquelle elle communique le plus tout en vérifiant les deadlines hard. L’énergie de communication dépend du volume de la communication inter processeur et de la distance moyenne de communication dans le NOC. Le placement et ordonnancement des communications ne sont pas traités, ce qui ne permet pas de connaître le volume de communication par lien. Le critère de communication est utilisé par ces auteurs pour veiller à ce que le volume local moyen de communication par arc (à partir des arc entrant dans le TG) ne dépasse pas le volume moyen global de communication (à partir de tous les arcs dans TG) multiplié par un paramètre K (0≤k≤10), arrêté par l’utilisateur.
D.Shin et al.[64] tendent de minimiser l’énergie de communication en minimisant le volume de communication inter processeur et les distances de communication dans le NOC durant le placement et l’assignation réseau. L’énergie de communication est la somme des énergies statique et dynamique de tous les liens. L’énergie dynamique des liens dépend du volume total des communications des arcs partageant le même lien, la vitesse (fréquence) du lien et la capacité de switching du lien. Le volume de communication de chaque lien est connu après le placement.
J..Hu et al. [63] tendent de minimiser la consommation d’énergie totale. Durant le placement et ordonnancement simultanés les tâches non critiques avec le plus grand intervalle de consommation d’énergie sont affectées aux processeurs ayant les consommations les plus faibles mais qui soient assez rapide pour vérifier les deadlines hard. L’intervalle de consommation d’énergie d’une tâche est la différence entre les deux premières valeurs minimales de la consommation globale d’énergie obtenu à partir des ordonnancements partiaux. Les taches non critiques sont celles ayant EFT<BD. La communication est placée et ordonnancée sur le chemin le plus court disponible et non saturé dans le NOC. La consommation d’énergie globale est la somme des énergies de calcul de toutes les tâches plus l’énergie de communication de tous les arcs. L’énergie de communication d’un arc dépend du volume des communications de cet arc (en bits) et l’énergie de transfert d’un bit. L’énergie de
88

communication par bit s’obtient par une formule fonction de la longueur du chemin de routage, l’énergie du lien et l’énergie de switching.
Ref Task mapping Priority PE Assignment Goal G.Varatkar et al. [59] - Most Comm. Vol. Limit Comm. Vol. D.Shin et al. [64] - - Min. Comm. Vol J.Hu et al. [63] Energy Diff Least Energy -
Table 4.7 : Placement de tâches avec optimisation de l’énergie
La priorité de la tâche au moment de l’ordonnancement aussi bien que l’assignation des PE et l’objectif d’optimisation du placement peuvent augmenter la préservation de la consommation d’énergie dynamique. A cet effet il est conseillé d’affecter la tâche avec le plus grand intervalle de consommation d’énergie à son processeur de consommation minimale durant le traitement du placement et ordonnancement (J.Hu et al. [63]). Le modèle d’énergie de communication dépend du volume de communication et l’énergie de transmission. J.Hu et al.[63] introduisent les informations de routage dans l’énergie de transmission par bit quand D.Shin et al. [64] introduisent des informations pour l’assignation de la vitesse de lien.
En se basant sur ces critères on peut dire que l’approche [63] est la meilleure méthodologie d’optimisation d’énergie pour les NOC car elle minimise la consommation totale d’énergie et ordonnance les communications sur le plus court chemin disponible en vérifiant le deadlock. La deuxième meilleure méthode est celle de D.Shin et al.[64] qui minimise l’énergie de communication et la distance de communication. G.Varatkar et al [59] minimise uniquement le volume de communication inter processeur sans traiter le placement de communication.
4.4.3 Contraintes matérielles et mémoire
Les contraintes matérielles sont relatives à la capacité de la mémoire ou au nombre de tâches pouvant être exécutées par un élément de calcul. Parmi les approches introduites dans la section 4.3 seulement trois traitent ce problème.
D.Shin et al. [64] traitent ces contraintes durant le placement de tâches en imposant que chaque élément de calcul s’accommode avec la tuile du NOC. Ce qui revient à vérifier que pour chaque nombre de tâches affectées à un processeur, la taille mémoire et seuil maximal ne dépassent pas les caractéristiques de la tuile du N0C.
M.T.Schmitz et al. [65,68] traitent eux aussi ces contraintes lors du placement de tâches. Pour eux les contraintes matérielles sont relatives à la taille de la mémoire et la surface de la puce dépendant du type de matérielle (DSP, ASIC, FPGA). Dans la fonction objectif ils introduisent des coefficients permettant de pénaliser la non vérification de ces contraintes.
Pour R.Szymanek et al.[75] les contraintes sont vérifiées après le placement en vérifiant pour chaque mémoire si le code et la quantité des données affectées ne dépassent pas la taille disponible.
89

4.5 Conclusion
L’étude de l’état de l’art dans le domaine du placement sur les NOC nous a permis de tirer quelques constations. La première est que dans ce domaine, par placement on désigne Assignation, affectation et ordonnancement (AAS). Effectivement dans les travaux vus, et surtout ceux fait récemment, on ne traite jamais le placement sans ordonnancement ou l’inverse. Tous les travaux les abordent ensemble. Seulement la manière change, pour certains ils sont traités séquentiellement, c'est-à-dire placement ensuite ordonnancement, pour d’autres ils sont traités ensemble c'est-à-dire simultanément. Pour chacune de ces approches on a vu qu’il y a des avantages et des inconvénients, même si la deuxième approche l’emporte.
Le deuxième constat est que ce problème est traité pour atteindre certains objectifs, comme le temps réel, consommation d’énergie, mémoire, etc. Souvent ces objectifs sont cherchés ensembles. Car, on ne peut minimiser le temps de calcul global sans minimiser le coût de communication global, ou augmenter les performances du NOC sans penser à minimiser la perte de l’énergie, etc. D’où notre conviction que ce problème ne peut être solutionner en cherchant des objectifs séparément mais d’essayer d’au moins d’atteindre quelques objectifs pertinents ensemble. C’est ce qu’on appelle l’optimisation multi-objectifs qui sera présentée dans le chapitre suivant. En plus de ce qui a été avancé, du fait des domaines qu’on aborde où les applications peuvent être hiérarchiques où on rencontre des tâches répétitives et d’autres non, forcément les techniques qu’on va utiliser seront de familles différentes. Si les méta-heuristiques (transformatives) s’imposent pour l’irrégulier dans les problèmes de grande taille, il faut plutôt penser à des méthodes déterministes pour les applications à tâches répétitives.
90

CHAPITRE 5
Optimisation multi-objectif
91

5.1 Introduction
L’optimisation combinatoire consiste à trouver une solution optimisant une fonction coût, généralement pour des problèmes complexes de grandes tailles. Dans le monde industriel, généralement, les problèmes d’optimisation sont de nature multi-objectif puisque plusieurs critères permettent de caractériser une solution. Pour les SoC, objet de notre étude, les critères les plus connus sont le temps de calcul, la consommation d’énergie, les dimensions de la puce, taille mémoire, etc.
5.2 L’optimisation combinatoire
Un problème d’optimisation combinatoire est défini par un ensemble fini de solutions dites réalisables (formant l’espace de décision Ω) et une fonction objectif (f) associant à chaque solution de l’espace de recherche un coût. Cet ensemble de valeurs constitue l’espace objectif (Y, nous avons donc f : Ω→Y). Ainsi une solution réalisable x peut être décrite par un vecteur de décision (x1, x2, …..,xn) à laquelle une valeur objectif est associée à f(x). La résolution d’un problème d’optimisation combinatoire revient donc à trouver la ou les solutions(s) réalisable(s) de coût minimal (ou maximal8) de Ω9.
Définition 1 : x*(x*∈ Ω) est une solution optimale si et seulement si : ∀x ∈ Ω f(x) ≥ f(x*).
Dans l’optimisation combinatoire, la difficulté majeure réside dans le phénomène d’explosion combinatoire (l’augmentation de la taille des données engendre l’augmentation exponentielle de la taille de l’espace de recherche). Ce qui nous emmène à parler de la classe des problèmes NP-difficiles qui correspendent aux problèmes pour lesquels aucun algorithme de résolution polynomial en temps n’est connu. C’est cette explosion de la taille de l’espace de recherche qui empêche l’exploration en un temps raisonnable.
Les méthodes utilisées en optimisation combinatoire peuvent être classées en deux grandes catégories :
- d’un coté nous avons les méthodes exactes permettant de trouver la (ou les) solution(s) optimale(s).
- d’un autre coté, nous avons les méthodes approchées permettant de trouver une solution de bonne qualité mais non optimale.
Du fait que les méthodes exactes sont gourmandes en temps de recherche qui augmente d’une façon exponentielle avec la taille du problème, elles coupent des parties non intéressantes de l’espace de recherche. Elles permettent de trouver la solution optimale mais sont limitées dans la taille des problèmes qu’elles résolvent. Les méthodes approchées effectuent des recherches guidées à l’intérieur de l’espace de recherche afin de caractériser rapidement une solution de bonne qualité. Avec ces méthodes, la solution trouvée n’est pas
8 Notons que min(f(x)) = -max(-f(x)) 9 Dans la suite de ce document, nous considérons un problème de minimisation.
92

optimale (ou si elle l’est, la preuve n’est pas faite). Par contre, ces méthodes ne sont pas limitées par la taille des problèmes.
Actuellement, surtout dans l’industrie, les problèmes d’optimisation rencontrés sont de nature multi-objectif du fait de l’existence de plusieurs objectifs pour la solution finale. C’est pour cette raison que la suite de ce chapitre sera consacrée uniquement à l’optimisation combinatoire multi-objectif.
5.3 L’optimisation combinatoire multi-objectif
On commence dans ce paragraphe par quelques particularités de l’optimisation combinatoire multi-objectif, suivies ensuite, par une présentation rapide des principales méthodes de résolution approchées.
5.3.1 Définition
Un vecteur de fonction coût, est un vecteur dont chacune de ses composantes est un objectif. Donc un problème d’optimisation combinatoire multi-objectif consiste à optimiser plusieurs de ces composantes. Si nous notons Ω l’espace décisionnel, alors un problème d’optimisation multi-objectif peut se définir par :
Min f(x)= (f1(x),f2(x),….,fk(x)) avec x∈ Ω
Avec f la fonction qui associe à chaque variable x de Ω un vecteur coût et K le nombre d’objectifs considérés. La figure 5.1 montre un exemple avec deux variables de décision et trois fonctions objectifs.
Figure 5.1 : Exemple de problème d’optimisation combinatoire multi-objectif
5.3.2 Les solutions d’un problème multi-objectif
5.3.2.1 Solutions optimales et notion de Pareto Optimalité
Un problème d’optimisation multi-objectif n’admet pas une solution optimale unique mais un ensemble de solutions optimales dites de meilleurs compromis. En effet, les solutions n’admettent pas une relation d’ordre total car une solution peut être meilleure qu’une autre sur certains objectifs mais moins bonne sur d’autres. Donc une solution d’optimalité doit être
93

définie pour permettre de cerner un ensemble de solutions optimales. Edge-worth [77] introduit la notion la plus utilisée qui est généralisée par la suite par Pareto [78]. C’est ce qui a permis de parler maintenant dans ce domaine de Pareto et de solution Pareto optimale (c'est-à-dire au sens Pareto). Nous parlerons aussi de l’ensemble des solutions Pareto optimales. La définition suivante permet de caractériser la notion de dominance entre deux solutions.
Définition 2 : Dans un problème de minimisation avec K objectifs, une solution x domine une solution x’ si et seulement si :
∀ k ∈[1..k], fk(x) ≤ fk(x’) ∃ k ∈[1..k], fk(x) < fk(x’) Nous noterons x≼x’
La figure 5.2 illustre une solution x donnée, l’espace qui domine cette solution, l’espace dominé par cette solution et les deux espaces qui n’admettent pas de relation d’ordre avec x au sens de Pareto, pour un problème bi-objectif. Si pour deux solutions x et x’, x⋠x’ et x’⋠x alors nous noterons x∼ x’.
Définition 3 : Une solution x est dite Pareto optimale si et seulement si elle n’est dominée par aucune autre solution réalisable.
Fi
Figure 5
gure 5.2 : Notion de dominance
.3 Exemple de front Pareto optimale
94

Définition 4 : Pour un problème d’optimisation donnée, l’ensemble des solutions Pareto noté (P*) est défini par : P*= x∈ Ω ∄ x’ ∈ Ω ; x’≼x.
La figure 5.3 donne un ensemble représentant l’image dans Y des solutions de l’ensemble Pareto (ensemble des solutions non-dominées) pour un problème bi-objectif, ceci est appelé front Pareto.
5.3.2.2 Points particuliers
Les points particuliers qui existent dans l’espace des objectifs permettent de borner l’ensemble Pareto ou encore de discuter de l’intérêt des solutions trouvées. Ces points peuvent être réalisables ou non (figure 5.4).
1- Le point Ideal, ZI, est défini par : ZI=(f1(ZI),…,fk(ZI)) avec fq(ZI)=minx∈Ωfq(x) ∀q∈[1..K]. Ce point a pour chaque objectif la valeur optimale de cet objectif. Il nous donne donc une borne inf rieure du front Pareto.
Figure 5
2- Le point utopique, ZU, es(U= (1,1,…,1) ∈ℝK). bien entendu non réalisab
3- Le point Nadir, ZN, est
∀q∈[1..K]. Cette solutiol’ensemble Pareto ayant donc une borne supérieur
Dans le cas Bi-objectif cette fi(ZN)=fj(ZI), où j≠i. Il apparaît demande aucun calcul supplément
Comme on le voit l’espace depoint Nadir. Pour les méthodes exparties pertinentes. Le point Idnombreuses méthodes exactes.
10 P* représente l’ensemble des solutions
é
.4 Points particuliers du front Pareto
t défini par : ZU=ZI-∈U avec ∈>0 et U le vecteur unitaire Ce point sera donc un point dominant le point Ideal, il sera le.
défini par ZN=(f1(ZN),…,fk(ZN)) avec fq(ZN)=maxx∈P*fq(x)10 n représente pour chaque objectif la solution appartenant à la valeur la plus mauvaise sur cet objectif. Elle nous donne e du front Pareto.
solution est définie par ZN=(f1(ZN),f2(ZN)), avec ∀i∈[1..2] donc que la recherche du point Nadir en Bi-Objectif ne aire si le point Idéal est connu.
recherche pertinent peut être borné par le point Idéal et le actes le but est de limiter l’espace de recherche à ces seules éal et le point Nadir seront donc primordiaux dans de
95
Pareto optimales

5.3.3 Caractéristique du front Pareto
5.3.3.1 Solution supportées/non supportées
Le front Pareto comporte plusieurs solutions, de meilleur compromis, appelées solutions Pareto Optimales. Nous allons caractériser les différents types de solutions composants ce front. Deux types de solutions le composent.
- Les solutions supportées : leurs images dans Y se trouvent sur l’enveloppe convexe de Y. Chacune de ces solutions peut être trouvée en optimisant une agrégation linéaire des objectifs (voir la théorie de Geoffrion [79]).
- Les solutions non supportées : elles sont Pareto optimales mais leurs images dans Y ne sont pas situées sur l’enveloppe convexe de Y. Aucune de ces solutions ne peut être trouvée en optimisant une agrégation linéaire des objectifs (corollaire du théorème de Goffrion).
Nous pouvons donc avoir des cas extrêmes dans lesquels la frontière Pareto est totalement convexe ou concave (figure 5.5). Souvent le front Pareto sera composé de solutions supportées et non supportées (comme illustré dans la figure 5.6). Les solutions non supportées ne se trouvent pas sur l’enveloppe convexe et ne sont la solution optimale d’aucune agrégation d’objectif. Il peut donc paraître légitime de se demander si elles doivent être recherchées ou non. Pour avoir un compromis entre les objectifs il nous faudra donc choisir une solution non-supportée.
Figure 5.5 : Front Pareto concave/convexe
96

5.3.3.2 Ensemble Pa
Si toutes les valeurs l’ensemble alors il est ade trouver l’ensemble Paussi que le nombredécisionnel/espace objeavoir le même vecteur L’ensemble Pareto de ll’espace objectif est al’ensemble recherché ca
5.3.4 Choix de la mé
D’après nos insertionoptimale unique mais l’intervention humaine à
Donc, avant de lancedu moment où le décirésolution d’un problèm
1- A priori : Le d(exemple : agrunique est obteexemple, les sorevanche l’obte
2- Interactive : Dadernier proposerecherche en fole fait que le dmain, ce qui est
Figure 5.7 : Approch
3- A posteriori : choisisse la sollongue et le noproblème de dé
Figure 5.6 : Exemple de front Pareto Bi-objectif
reto minimal complet/Ensemble Pareto maximal complet
Pareto pouvant être obtenues sont représentées parmi les solutions de ppelé ensemble Pareto complet. Certaines méthodes, ne permettent pas areto complet (exemple : la méthode par agrégation). Il faut remarquer de solutions Pareto dépend de l’espace considéré (espace ctif). Car deux solutions différentes de l’espace décisionnel peuvent coût et donc représenter le même point de l’espace des objectifs. ’espace décisionnel est appelé ensemble Pareto maximal et celui de ppelé ensemble Pareto minimal. Il est donc nécessaire de définir r cela fera varier le nombre de solutions Pareto.
thode d’aide à la décision
s précédentes un problème multi-objectif n’admet pas une solution un ensemble de solutions Pareto optimales, d’où la nécessité de travers un décideur pour le choix de la solution finale à implémenter.
r la résolution d’un problème multi-objectif, il faut se poser la question deur intervient. Il existe trois types d’approches distinctes pour la e multi-objectif [mesmer] :
écideur oriente la recherche dès le début en donnant des préférences égations) à chacun des objectifs. Avec cette méthode une solution nue. Celle-ci ne convient pas forcément à ce qui était souhaité ; par lutions non supportées ne peuvent être atteintes par agrégation. En ntion du résultat est assez rapide.
ns cette méthode il y a interaction de décideurs avec le programme. Ce régulièrement une solution au décideur qui devra alors réorienter la nction de ses objectifs. L’inconvénient de cette approche réside dans
écideur doit attendre entre chaque étape avant d’obtenir à nouveau la parfois long.
e interactive : coopération progressive entre le solveur et le décideur
L’ensemble du front Pareto est obtenu par le décideur afin qu’il ution la plus adaptée. L’obtention du front complet peut s’avérer très mbre des solutions peut être très grand en entraînant de ce fait un
cision de la solution à choisir.
97

Chacune de ces approches présente des inconvénients et des avantages. Dans ce document, nous nous plaçons dans une approche à posteriori qui permet au décideur de faire le choix le plus approprié. Ce type d’approche peut se décomposer en deux étapes : une phase de recherche de l’intégralité du front Pareto (phase d’optimisation) et une phase de décision.
Définition 5 : Un voisinage N est une fonction N : Ω → P(Ω) ; qui associe pour chaque x ∈ Ω un sous ensemble N(x) de Ω des voisinages de x.
Cette définition est importante car la notion de voisinage est très utilisée dans les métaheuristiques de recherche locale comme la recherche tabou ou le recuit simulé. Ce voisinage est défini par un opérateur de recherche locale.
Dans la fugure 5.8, 10 solutions sont représentées dans un espace objectif bi-dimensionnel. Les segments connectant les solutions représentent la structure du voisinage.
Figure 5.8 : Optimum Pareto local
Définition 6 : Une solution x est localement Pareto optimale si et seulement si ∀w∈N(x), w ne domine pas x. dans la figure 5.8, les solutions Pareto optimales sont associées aux points 1,8,9 et les solutions 4 et 10 sont localement Pareto optimales.
5.4 Problèmes d’optimisation multi-objectif
Dans les 30 dernières années, la plupart des travaux ont porté sur la programmation multi-objectif linéaire en variables continues. Les raisons principales de cet intérêt sont d’une part le développement de la programmation linéaire uni-objectif en recherche opérationnelle, et la facilité relative de traiter de tels problèmes, et d’autre part l’abondance des cas pratiques qui peuvent être formulés sous forme linéaire. Ainsi, un certains nombre de logiciels ont vu le jour depuis le développement de la méthode du simplexe multi-objectif [80,81]. Mais ce qui nous intéresse ici ce sont plutôt les problèmes d’optimisation combinatoire multi-objectif pour lesquels il y a beaucoup d’intérêt actuellement. Ci-après quelques exemples aussi bien académiques qu’industriels.
A- Applications académiques
La plupart des benchmarks utilisés dans la comparaison d’algorithme d’optimisation multi-objectif ont été réalisés sur des problèmes académiques. Les problèmes les plus étudiés sont :
98

• Optimisation de fonctions continues : dans la communauté « Algorithmes Génétiques », les fonctions de Schaffer sont souvent utilisées pour évaluer et comparer les performances des algorithmes. La fonction bi-critère f2 est la plus utilisée.
f21(x)=x2 f22(x)=(x-1)2 S.C x∈[-10,10]
Pour ce problème, la frontière Pareto est continue et se trouve dans l’intervalle [0..2].
• Optimisation combinatoire : plusieurs problèmes classiques d’optimisation combinatoire ont été étudiés dans une version multi-objectif [82] : Sac à dos [83], ordonnancement [8,9], plus court chemin dans un graphe [86], arbre recouvrant (minimum spanning tree) [87], affectation [88], voyageur de commerce [89], routage de véhicule [90], etc.
Prenons comme exemple illustratif le problème du sac à dos multi-objectif qui peut être modélisé de la manière suivante [83] :
Max(fi(x))= ∑ Cijxj (i=1,…,n) ; x ∈ Ω
m
Ω =x/ ujxj< u j=1..m Xj ∈ 0,1 ; ∀ j=1,..,m
J=1
Où xj= 1 si l’élement j est dans le sac 0 sinon
Uj le poids (volume) de l’élément j, et Cij l’utilité de l’élément j par rapport au critère i.
B- Applications industrielles
La plupart des travaux portant sur l’optimisation combinatoire multi-objectif concernent des applications industrielles. Plusieurs problèmes ont été traités dans différents domaines d’application :
• Design de systèmes dans les sciences pour l’ingénierie (mécaniques, aéronautique, chimie, etc.) : ailes d’avion, moteurs d’automobiles.
• Ordonnancement et affectation : ordonnancement en productique, localisation d’usines, planification de trajectoires de robots mobiles, etc.
• Transport : gestion de containers, design de réseau de transport, tracé d’autoroutier, etc.
• Environnement : gestion de la qualité de l’air, distribution de l’eau, etc. • Télécommunications : design d’antennes, design de réseaux cellulaires, design
de constellation de satellites, affectation de fréquences, etc. Une liste plus complète d’exemples d’application peut être trouvée dans [91].
5.5 Classification des méthodes
Dans la littérature, une attention particulière a porté sur les problèmes à demi critères en utilisant les méthodes exactes tels que le « branch and bound » [85,92], l’algorithme A* et la programmation dynamique [94]. Ces problèmes sont efficaces pour des problèmes de petites
99

tailles. Pour des problèmes à plus de deux critères ou de grandes tailles, il n’existe pas de procédures exactes efficaces, étant donné les difficultés simultanées de la complexité NP-difficile, et le cadre multicritère des problèmes.
Ainsi, des méthodes heuristiques sont nécessaires pour résoudre les problèmes de grandes tailles et/ou les problèmes avec un nombre de critères supérieurs à deux. Elle ne garantissent pas de trouver de manière exacte l’ensemble PO (Pareto optimale), mais une approximation de cet ensemble noté PO*. Les méthodes heuristiques peuvent être divisées en deux classes : d’une part les algorithmes spécifiques à un problème donné qui utilisent des connaissances du domaine, et d’autre part les algorithmes généraux applicables à une grande variété de PMO, c'est-à-dire les métaheuristiques qui feront l’objet de notre intérêt dans la suite de ce chapitre. Plusieurs adaptations de métaheuristiques ont été proposées dans la littérature pour la résolution de PMO et la détermination des solutions Pareto : le recuit simulé, la recherche tabou et les algorithmes évolutionnaires (algorithmes génétiques, stratégies évolutionnaire). Les approches utilisées pour la résolution de PMO peuvent être classées en trois catégories [talbi] (figure 5.9).
Figure 5.9 : Classification des méthodes d’optimisation multi-objectif
• Approches basées sur la transformation du problème en un problème uni-objectif : Cette classe d’approches comprend par exemple les méthodes basées sur l’agrégation qui combinent les différentes fonctions : coût f(x) du problème en une
100

seule fonction objectif F. Ces approches nécessitent pour le décideur d’avoir une bonne connaissance de son problème.
• Approche non-Pareto : les approches non-Pareto ne transforment pas le PMO en un problème uni-objectif. Elles utilisent des opérateurs de recherche qui traitent séparément les différents objectifs.
• Approche Pareto : Les approches Pareto utilisent directement la notion d’optimalité Pareto dans leur processus de recherche. Le processus de sélection des solutions générées est basé sur la notion de non-dominance.
Parmi ces trois approches c’est cette dernière qui sera retenue lors de la résolution de notre problème. Les détails de son utilisation seront vus dans le chapitre 4.
5.6 Approches de résolution
5.6.1 Les méthodes bi-objectif
5.6.1.1 Utilisation de la recherche lexicographique
Fourman [95] propose une classification des objectifs en fonction d’un ordre d’importance. Ensuite les fonctions objectifs sont traitées dans cet ordre, c'est-à-dire que le premier objectif dans l’ordre d’importance est d’abord optimisé. Ensuite la valeur de cet objectif est conservée et le deuxième objectif est optimisé. Ceci est réalisé itérativement jusqu’à l’optimisation de tous les objectifs tout en ayant conservé les valeurs trouvées pour les précédents.
Comme exemple on peut prendre deux objectifs selon l’ordre f1 puis f2. Tout d’abord l’objectif f1 est optimisé ensuite, la solution x1(x1=(f1(x1),f2(x1)), avec f1(x1)=f1*) est alors trouvée. Ensuite la valeur f1(x1) est conservée pour le premier objectif et le second est optimisé, la solution x2(x2=(f1(x2),f2(x1)), avec f1(x2)=f1(x1)=f1*) est trouvée. De plus, nous savons que x2 est telle que : ∀ x’∈ Ω si f1(x’)=f1* alors f2(x’)≥f2(x). Le principe de cette méthode est illustré sur la f ure 5.10 pour le cas Bi-objectif.
Figu
Cette méthode ne troupossible de faire des varia
ig
re 5.10 : Exemple de recherche lixicographique
ve qu’une seule solution Pareto (un extrême). Il est cependant ntes (avec des contraintes,..) permettant de trouver l’ensemble du
101

front Pareto. Il faut noter que cette méthode reste assez inappropriée pour obtenir l’ensemble du front Pareto d’un problème Multi-objectif, par contre elle est très bien adaptée pour trouver les extrêmes.
5.6.1.2 La méthode des sommes pondérées et la méthode dichotomique
La méthode des sommes pondérées, la plus connue et utilisée, transforme le problème multi-objectif en un problème Mono-objectif en effectuant une combinaison linéaire des objectifs [Mes]. Les problèmes résolus sont de la forme : λ1f1+ λ2f2 (cas Bi-objectif). Selon le théorème de Géoffrion [79], toutes les solutions supportées peuvent être trouvées en choisissant correctement les agrégations, cependant aucune solution non-supportée ne peut être trouvée de cette manière.
La méthode dichotomique trouve l’intégralité du front Pareto grâce à un découpage dichotomique de l’espace de recherche. Dans un premier temps les deux solutions extrêmes du front Pareto sont trouvées (grâce à la résolution de deux optimisations lexicographiques). Puis, pour chaque paire de solutions dans l’espace objectif (f(s) et f(r)), une solution est recherchée en optimisant le problème suivant :
min x∈ Ω f∼(x)= λ1f1(x)+ λ2f2(x) avec f1(x) < f1(s) (C1) f2(x) < f2(r) (C2)
et λ1= f2(r)- f2(s) λ2= f1(s)- f1(r)
La figure 5.11 est une illustration de cette recherche. A chaque étape cette méthode trouve une solution Pareto entre f(r) et f(s), si il en existe une. Dans ce cas, elle sera à l’intérieur du rectangle f(r)Yf(s)Z, où Y est le point (f1(s),f2(r)) et Z est le point (f1(s),f2(s)). Si une nouvelle solution, t , est trouvée alors deux nouvelles recherches seront lancées, une entre f(r) et f(t) et une entre f(t) et f(s) (figure 5.12). On remarque aussi que les solutions non-supportées seront trouvées car les contraintes (C1) et (C2) empêchent la recherche de trouver les solutions f(r) et f(s) déjà obtenues.
On constate ainsi que toutes les solutions Pareto seront trouvées grâce à cette méthode. Elle nécessite par contre de l’ordre 2n recherches, où n est le nombre de solutions de l’ensemble Pareto. Si chacune des recherches est NP-difficile alors cette méthode demandera un temps de calcul important.
Figure 5.11 : Direction de recherche Figure 5.12 : Nouvelles recherches
102

5.6.1.3 Utilisation de la métrique de Tchebycheff
Pour trouver une solution Pareto optimale, il est possible de trouver une solution minimisant sa distance au point Ideal ZI ou au point Utopique ZU. Il nous faut donc définir une notion de distance entre deux points. La distance la plus souvent utilisée est la métrique pondérée de Tchebycheff, définie comme ceci :
Min (max (λi |fi(x) – fi(ZI))) x∈ Ω i=1..k Si les poids (λ) sont choisis d’une façon appropriée, toutes les solutions Pareto peuvent être
trouvées. Pour le cas Bi-objectif, il est, par exemple, possible d’utiliser la méthode Tchebycheff de manière dichotomique sur des rectangles de recherche. Premièrement les extrêmes sont calculés (r et s). Puis une recherche est effectuée dans le rectangle formé par le point Idéal et le point Nadir (figure 5.13). Une fois une nouvelle solution trouvée, deux nouvelles recherches sont lancées dans les rectangles crées de manières dichotomiques (figure 5.14).
Figure V.14 : Division en deux sous recherches
5.6.1
Haimquelconà optimcontrai
Cettappropcontraipar exeborne s(figure dans l’e
Figure V.13 : Recherche entre le point Ideal et le point Nadir
.4 L’approche des e-contraintes
es et al. [96] ont proposé cette approche pour être appliquée pour un nombre que d’objectifs. Elle consiste à borner K-1 objectifs (où K est le nombre d’objectifs) et iser le dernier. Les problèmes résolus sont de la forme (en posant M l’ensemble des
ntes et Mj la contrainte sur l’objectif j) : min x∈ Ωfi(x), i∈1,…,K avec ∀j j ≠ i, fj(x)<Mj
e approche peut trouver toutes les solutions Pareto en choisissant des contraintes riées. La méthode e-contraintes, qu’on va voir, est une application de l’approche e-nte pour les problèmes Bi-objectif. D’abord un des deux extrêmes est calculé, prenons mple l’extrême ayant la plus petite valeur sur f1. Puis, cette solution nous donne une ur l’objectif f2. La meilleure solution sur l’objectif f1 respectant cette borne est calculée 5.15). Généralement, l’objectif le plus facile à optimiser peut être celui à optimiser (f1 xemple) et l’autre sera donc utilisé comme borne.
103

En réalisant cette méthode itérativement, en utilisant à chaque étape la solution précédente afin de définir la nouvelle borne (figure 5.16), il est possible grâce à une méthode mono-objectif de trouver l’ensemble du front Pareto. Cette méthode s’arrête lorsqu’à une étape donnée aucune solution Pareto n’est générée. Dans l’exemple complet illustré par la figure 5.17, les bornes sont numérotées (BorneB1, BorneB2,..) et les solutions sont aussi numérotées en fonction de l’ordre dans lequel elles sont trouvées.
Cette méthode requiert une recherche par solution de l’ensemble Pareto. Chacune de ces recherches est bornée, ce qui signifie souvent l’énumération de nombreuses solutions afin de trouver la solution recherchée. De plus, si il existe une méthode de résolution mono-objectif efficace l’ajout de cette borne empêchera généralement son utilisation. Les recherches peuvent donc prendre un temps de calcul important et être nombreuses.
Figure 5.15: Exemple de recherche pour la figure 5.16: Nouvelle rechrche Méthode des e-contraintes
Figure 5.17 : Méthode des e-contraintes
5.6.1.5 La méthode Deux phases
Cette méthode appelée aussi TPM (Two Phase Method) a été, initialement, proposée par Ulungu et Teghem pour la résolution du problème d’affectation Bi-Objectfi[92]. Cette
104

méthode est composée de deux phases, une première phase où sont recherchées les solutions supportées et une seconde où sont recherchées les solutions non-supportées.
1 La première phase
La première phase consiste à trouver l’intégralité des solutions supportées. Pour ceci des agrégations du type λ1f1+ λ2f2 sont utilisées pour vérifier l’existence d’une solution supportée entre (dans l’espace objectif) deux autres solutions supportées. Pour commencer, les deux extrêmes (qui sont des solutions supportées) sont calculés afin de borner l’espace de recherche (figure 5.18.a).
Pour rechercher entre deux solutions supportées xr et xs, où f(xr) et f(xs) sont leurs images dans l’espace des objectifs (supposons que f1(xr)<f1(xs) et f2(xr)>f2(xs)), la direction de recherche sera perpendiculaire à la ligne (f(xr),f(xs)) en fixant λ1=f2(xr)- f2(xs) et λ2=f1(xs)- f1(xr) (figure 5.18.b). Avec cette recherche s’il existe au moins une solution supportée xt avec f(xt) « entre » f(xr) et f(xs) dans l’espace objectif alors elle sera trouvée. Si une nouvelle solution est trouvée alors deux nouvelles recherches seront lancées, une entre f(xr) et f(xt) l’autre entre f(xt) et f(xs) (figure 5.18.c) [Mesmer]. On constate qu’il y a une forte ressemblance entre cette méthode et la méthode dichotomique. Mais ici seules les solutions supportées sont trouvées car aucune contrainte n’est ajoutée, lors d’une recherche entre deux solutions (xr et xs), l’une de ces deux solutions peut être trouvée (f(xr) ou f(xs)), contrairement à la méthode dichotomique. A la fin de cette phase, toutes les solutions supportées sont connues (figure 5.18.d).
Figure 5.18 : La méthode deux phases
105

2 La deuxième phase
Dans cette phase on cherche toutes les solutions non-supportées de l’ensemble Pareto. Elles ne peuvent être trouvées grâce à une agrégation des objectifs. Par contre nous savons que toutes solutions non supportées xu avec f(xu) placée entre f(xr) et f(xs) (où f(xr) et f(xs) sont des solutions supportées) alors f1(xr)<f1(xu)<f1(xs) et f2(xr)>f2(xu)>f2(xs).
Graphiquement, les solutions supportées entre f(xu) et f(xs) se situent forcément dans les triangles basés sur les solutions f(xr) et f(xs) (figure 5.18.e). Entre chaque paire de solutions supportées un triangle de recherche est construit. Tous les triangles sont alors explorés afin de trouver toutes les solutions non-supportées (figure 5.19.f). La méthode de recherche à l’intérieur de chacun des triangles dépend du problème étudié. A la fin de cette phase, toutes les solutions Pareto sont trouvées (figure 5.19.g).
5.7 Conclusion
Ce chapitre nous a permis de faire le tour des problèmes d’optimisation multi-objectifs (MOP). Une présentation actualisée des différentes méthodes a aussi été réalisée. Bien sûr faire une étude plus approfondie de ces concepts nécessite plus qu’un chapitre, dans la mesure où des thèses ont été consacrés entièrement aux MOP. Ce chapitre, même s’il est très synthétisé, nous a paru important à ce stade de la lecture de ce document pour pouvoir comprendre la démarche qu’on a apporté pour résoudre le problème de mapping dans les SoC dans sa globalité c'est-à-dire le GILR. Cette démarche et cette contribution pour solutionner ce problème feront l’objet du chapitre suivant.
106

CHAPITRE 6
CONTRIBUTION
107

Le problème qu’on a à résoudre dans sa globalité est un problème d’assignation, d’affectation et d’ordonnancement « AAS ». Les travaux présentés par Lahua [97], Prestana [98] et Benini [66] présentent des insuffisances car ces travaux considèrent la topologie des communication en Bus. Les autres tels Hu [63], Mural[19] et Lei [61] présentent des méthodes d’optimisation mono-objectif. C'est-à-dire que ces méthodes ne permettent l’obtention que d’un seul objectif : temps d’exécution, consommation d’énergie, surface, etc. jamais dans ces travaux on a essayé de trouver ou de se rapprocher d’une solution satisfaisant au moins deux objectifs. En plus tous les travaux présentés et cités précédemment, notamment dans le chapitre 4 n’ont pas pris en considération des applications de grandes tailles structurées d’une façon hiérarchique où le modèle est un graphe hiérarchique dont les nœuds peuvent être simples, répétitifs ou composés. Par conséquent notre travail sera basé sur ce dernier problème en proposant une approche de résolution multi-objectif permettant de trouver le meilleur mapping d’une application de ce type sur une architecture NoC.
6.1 Modèle
Les communications entre les composantes d’une application sont représentées par un graphe d’application orienté (figure 6.1)
Définition 1 : Le graphchaque sommet vi∈V repreij∈E représente les commreprésente le volume des c
La connectivité et la bd’architecture.
Figure 6.1
e d’application (TG : Task Graph) est un graphe orienté G(V,E) où ésente un module (tâche) de l’application et l’arc orienté (vi,vj) noté unications entre les modules vi et vj. Le poids de l’arc eij noté par Qij ommunications de vi à vj.
ande passante des liens physiques sont représentées par le graphe
108

Définition 2 : le graphe d’architecture NT (NoC Topology graph) est un graphe orienté P(U,F) où chaque sommet ui∈U représente un nœud de la topologie et l’arc (ui, uj) noté par fij∈F représente un lien physique direct entre les éléments de ui et uj de l’architecture. Le poids de l’arc fij noté par bwij représente la bande passante disponible à travers le lien physique fij.(figure6.2)
La figure 6.3 repr
Le mapping du grapla function mappingmap : V ( U, telque Le mapping est défin
Figure 6.2
ésente une application réelle d’un décodeur vidéo avec communication.
Figure 6.3
he d’application G(V,E) sur le graphe d’architecture P(U,F) est défini par map: map(vi)=uj vi ( V , uj ( U. i quand V≥U (figure 6.4).
109

Définition 3 : Un grd’architecture hiérarchiqud’architecture) où certaind’application ou des tâcherégulière) (figure 6.5).
Le mapping du HTG sniveau. Si HTG et HNT oHTG sur les HNT dans le n
Figure 6.4
aphe d’application hiérarchique HTG (respectivement graphe e HNT) est un graphe d’application (respectivement graphe s sommets (nommés nœuds composés) représentent des graphes s répétitives (respectivement graphe d’architecture ou architecture
Figure 6.5
ur HNT consiste à chercher le mapping des graphes d’un même nt trois niveaux, on commence par chercher le mapping de tous les iveau 3. Ensuite on fait de même au niveau 2 et après le niveau 1.
110

Définition 4 : le mapping ou l’affectation des communications au réseau consiste à placer une communication entre deux tâches ti et tj représentée par l’arc eij∈E sur le réseau de communication. Ce placement consiste à trouver le chemin qui souvent est constitué de plusieurs liens physiques contigus utilisés pour envoyer les données de ti à tj.
Mais avant de considérer le mapping dans sa globalité on doit tout d’abord proposer une solution pour un mapping multi-objectif d’un seul graphe TG sur un seul graphe NT dans un même niveau.
6.2 Formulation mathématique
Pour un TG chaque nœud ou sommet représente une tâche avec ses caractéristiques ou propriétés. Soit T=t1,t2,..........tn l’ensemble des tâches représentées par l’ensemble des sommets V dans TG. P= p1,p2,..........ps l’ensemble des processeurs représentés par l’ensemble des nœuds U dans NT. On considère que chaque processeur p peut s’exécuter à des modes différents m1, m2 or m3.
Comme variable de décision on prend des variables binaires Xmij tels que [ben07].
Xmij= 1 si la tâche i est placée sur le processeur j et s’exécute au mode m, o sinon.
d’mij = la durée d’exécution de la tâche i placée sur pj s’exécutant au mode m (sans prendre
en compte les communications) .
d’mij=WCNm
ij/fmj où WCNm
ij est le nombre de cycles nécessaires à la tâche i pour s’exécuter sur le processeur j au mode m.
fmj est la fréquence d’horloge du processeur j au mode m.
dli est le deadline de la tâche i. C’est le temps auquel la tâche i doit être terminée.
Ainsi dlfinal=dln est le deadline de la dernière tâche n et aussi celui de l’application.
Qij est le volume de données échangées entre les tâches i et j.
d’Qmijpq est la durée des communications entre les tâches i et j si elles sont placées
respectivement sur les processeurs p et q au mode m. On va voir après comment ce paramètre est calculé.
qmpq est la durée de communication unitaire (bit, octet ou paquet) entre p et q au mode m.
empq est l’énergie consommée par une unité de donnée (bit, octet ou paquet ) durant son
transfert de p à q au mode m.
S’il n’existe pas un lien direct entre p et q soit µ(p,q)= (pi,pj) le chemin (succession de liens) reliant p à q.
111

Alors la durée d’utilisation des liens est d’Qmijpq = ∑Qij*qm
plpk où (pl,pk)∈µ(p,q)
La consommation d’énergie due à la communication des tâches i et j si elles sont placées sur les processeurs p et q au mode m en utilisant le même chemin est :
E’mijpq=∑Qij*em
plpk où (pi,pj)∈µ(p,q)
Dans ce modèle on considère que la consommation d’énergie due aux communications intra-processeurs est négligeable, et de même pour la durée des communications. On peut aussi considérer que ces paramètres sont inclus dans les temps d’exécution et l’énergie consommée. Chaque chemin contient un certains nombres de switch et de routeurs qui consomment de l’énergie et causent des durées supplémentaires de communication.
Dans les travaux de Ascia et al le problème est posé mais ils n’expliquent pas comment ils le traitent. Dans ce travail on propose une valeur moyenne de consommation (CSW) et de durée (dSW) due à l’utilisation des switch et routeurs. On peut les estimer en considérant les communications en entrée et sortie des routeurs comme stochastique.
Ainsi si µ(p,q) est la longueur du chemin µ(p,q), la consommation totale des switch et routeurs de ce chemin est égale à :
δ=( µ(p,q) +1)∗ Csw .
Et la durée totale est :
δ’=( µ(p,q) +1)∗ dsw .
On peut donner maintenant l’équation de la consommation totale due aux communications des tâches i et j affectées aux processeurs p et q au mode m.
Em
ijpq= E’mijpq + δ ............1
Et la durée totale des communications :
dQmijpq = d’Qm
ijpq + δ’ ............2
Donc le temps total d’exécution d’une tâche i en prenant en considération les communications
est :
mn N S S mn
Di = ∑ d’mip + ∑ ∑ ∑ ∑ Xm
ip ∗Xmjq∗dQm
ijpq j≠i …..3 m=m1 j=1 p=1 q=p+1 m=m1
Cette équation peut être simplifiée car p est fixe et on considère par hypothèse que les communications intra-processeur sont négligeables. Pour un i fixé, ∑ Xm
ip = 1.
Pour une tâche i, si Distart est son temps de début, alors son temps de terminaison est Di
fin , il est donné par la formule suivante :
112

Difin = Di
start + Di
L’ordonnancement est obtenu par LS où le début de l’application correspond avec le début de sa première tâche t1 et sa fin correspond à la fin de la dernière tâche tn. Ainsi, pour la tâche ti son temps de début Di
start correspond au temps de fin de la dernière des tâches qui la précèdent. Donc la liste LS est obtenue en utilisant la stratégie ASAP (As Soon As Possible).
Dnfin = Dn
start + Dn est le temps de fin de la dernière tâche tn.
Ce temps est donc le temps de fin de l’application Dfin qui est donné par la formule suivante :
Dfin = Dnstart + Dn
Donc si Dstart est le temps de début de l’application, qui correspond au temps de début de la première tâche D1
start, et Dfin le temps de fin de l’application qui aussi celui de la dernière tâche Dn
fin , alors la durée d’exécution totale de l’application est :
D= Dfin – Dstart ……………………..4
C’est ce temps qu’on doit minimiser et s’assurer qu’il vérifie la contrainte temps réel hard, c'est-à-dire :
D ≤ dlfinal.
La consommation d’énergie totale est donnée par la formule suivante en prenant en considération la consommation des processeurs, des liens, des switch et des routeurs.
N S mn N N S S mn
E= ∑ ∑ ∑ Xmip * ETm
ip + ∑ ∑ ∑ ∑ ∑ Xmip ∗Xm
jq∗Emijpq j≠i ….5
i=1 p=i+1 m=m1 i=1 j=i+1 p=1 q=p+1 m=m1
ETmip est la consommation de la tâche i affectée au processeur p au mode m. La méthode
proposée pour qu’elle soit utilisée après dans le mapping global, c'est-à-dire le GILR doit pouvoir traiter des problèmes de grandes tailles. Donc pour converger rapidement lors de la recherche d’une solution optimale pour un problème de grande taille on doit utiliser un algorithme évolutionnaire. Dans cette contribution, on verra par la suite que pour les applications répétitives un algorithme exact est choisi. Il sera présenté par la suite et commenté. Mais pour le moment on doit traiter le cas d’application quelconque et de grande taille tout en essayant d’atteindre plusieurs objectifs en même temps. D’où cette approche hybride basée sur l’algorithme évolutionnaire et une méthode de recherche des communications optimale.
On a à chercher un ensemble de solutions sous plusieurs objectifs. On considère ici spécialement deux objectifs; le temps d’exécution totale et la consommation d’énergie globale. Notre approche est constituée de deux phases. Dans la première on cherche tous les
113

placements qui satisfont le deadline final dl . D’où lors de cette phase on doit fixer le mode d’exécution (au mode mod ) et chercher tous les placements dont le temps total d’exécution ≤ dl .
final
max
final
Ensuite, dans la deuxième phase on essaye d’optimiser la consommation d’énergie en variant les modes c'est-à-dire en ralentissant les processeurs et les communications.
Les deux phases ont à atteindre aussi un autre objectif qui consiste à l’optimisation des communications. C'est-à-dire que pour toute solution s’assurer qu’on a choisi les communications les moins coûteuses en temps et énergie.
6.3 Première phase
Dans cette phase on fixe le mode d’exécution à sa valeur maximale. C'est-à-dire les processeurs sont utilisés lors de cette recherche à leur vitesse d’exécution la plus élevée (m= modmax), alors l’équation 3 devient :
N S S
Di = d’mip + ∑ ∑ ∑ Xm
ip ∗Xmjq∗dQm
ijpq j≠i …..…..6 j=1 p=1 q=p+1
Pour cette phase on propose une technique basée sur les AG hybridée avec une heuristique de recherche du chemin optimal dans l’architecture matérielle. Le choix de cette méthode est justifié, après, par rapport à d’autres méthodes, en plus, du fait qu’elle permet de prendre en considération le multi-objectif. Avec plus de précision, un algorithme évolutionnaire front Pareto (SPEA Strength Pareto Evolutionary Algorithm) qui maintient un ensemble externe pour préserver les solutions non dominées rencontrées avant. Le chromosome est une représentation de la solution du problème qui dans ce cas décrit le mapping. Chaque élément d’exécution dans le mesh lui est associé un gène qui encode la tâche qui lui est affectée. Si on a un NoC en Mesh de S processeurs et une application avec N tâches alors le chromosome est formé de S gènes. Chaque gène contient N bits.
Comme exemple prenant 2 processeurs et 3 tâches, alors le chromosome 101010 représente le mapping de 3 tâches : les tâches 1 et 3 sont affectées au processeur 1, la tâche 2 affectée au processeur 2 (le premier gène est 101 et le second est 010). On doit insérer une contrainte qui spécifie l’assignation unique de chaque tâche, c'est-à-dire une tâche ne peut être mappée (ou affectée) qu’à un seul processeur à la fois et elle ne peut être exécutée qu’à un seul mode.
S Modmax
∑ ∑ Xmip= 1 ∀ ti ∈T
p=1 m=1
On itère cette phase k fois, où k=n/10 si n>100 sinon k=3 (après expérimentation), avec une population =n/5. Les résultat de cette étape sont tous les placements ayant des coût d’exécution total ≤ dl . final
Ayant un chromosome chri, on note par D’(chri) la durée de calcul selon l’équation 6. Ainsi :
114

S'=chri / D'(chri)≤ dlfinal est l’ensemble de tous les placements ayant D'≤dlfinal.
Ce résultat sera l’entrée de la phase 2. Avant de la présenter on doit aussi savoir comment on peut augmenter la vitesse de recherche de cette étape ou autrement dit, comment diminuer le temps de convergence durant cette phase. Comme en le sait toute heuristique ou méthode itérative dépend du choix de ses paramètres et de la solution initiale. Pour notre algorithme on a essayé de placer les tâches qui communiquent le plus sur des processeurs voisins ou carrément sur le même processeurs Afin de s’assurer que dans la population initiale on a quelques bons individus.
Soit σ(ti)=tj ∈ T or V / (ti,tj) ∈ E
Et σ(pi)=pj ∈ Uor P / (pi,pj) ∈ F
Alors σ(ti) nous donne le nombre de voisins de ti.
et σ(pi) nous donne le nombre de voisins de pi.
Pour le premier placement (initial) on affecte la tâche ayant le plus de voisins au processeur ayant le plus de liens physiques directs.
Soit t1i cette tâche et p1
j ce processeur. Alors, T1=T- t1i et P1=P- p1
j .
Ensuite on refait le processus pour les tâches de T1 avec les processeurs de P1. Seulement ici on choisit en premier la tâche qui a un lien avec la tâche t1
i. Sinon, on prend celle qui a le plus grand nombre de voisins en absolu. On arrête ce placement initial quand à l’itération n on obtient Tn-1=Tn-2- tn-1
i .
Souvent le nombre de processeurs est inférieur au nombre de tâches (S<N). Dans ce cas dès que à une phase quelconque de cet algorithme Pk=1, alors réinitialiser Pk+1 à P-Pk.
6.4 Seconde phase
Dans cette étape on cherche à optimiser l’énergie consommée pour les placements trouvés lors de l’étape 1. Etant donné S’, l’ensemble des solutions de l’étape précédente, comme entrée de cette phase. Comme sortie de celle-ci on obtient l’ensemble S. Ce dernier étant l’ensemble des solutions non dominées qui minimisent la consommation et vérifient le deadline final dlfinal comme contrainte. Pour cette phase on définit un autre codage dérivé à partir des chromosomes de S’. Ainsi si on a M modes de fonctionnement des processeurs, le chromosome maintenant va être constitué de S gènes tel que chacun est constitué de n*M bits. Si le bit k+i du gène j a comme valeur 1 alors Xk
ij=1 ; c’est à dire que la tâche i est mappée sur le processeur j et s’exécutant au mode k.
On définit une application φ qui transforme un chromosome de S’ vers la phase 2.
S''=φ (S')= Chri /chri=φ (chrj) et chrj ∈ S'
115

Cette application va nous permettre de préserver le mapping trouvé lors de l’étape1. Car dans la phase deux on cherche à minimiser la consommation d’énergie sans faire déplacer les tâches ou réaffecter les communications. On ne cherche ici qu’à faire diminuer la consommation d’énergie en jouant sur la vitesse des processeurs.
Exemple : pour 2 processeurs et 3 tâches on peut avoir à l’étape 1 le chromosome 101010. Dans l’étape 2 on peut avoir p1 et p2 s’exécutant à deux modes différents. Ainsi si 101010 ∈ S' alors φ(101010)= 001100000010, 101000001000,..... ⊂ S'' Et 100010100000 ∉ S''
Donc, dans cette étape on essaye de minimiser la consommation d’énergie formulée dans l’équation 5 et en même temps on doit respecter le temps d’exécution trouvé dans la phase 2 comme contrainte. Comme résultat on obtient un autre front Pareto S⊂S'.
6.5 Algorithmes
Pour l’étape 1, on utilise un algorithme basé sur le GA qui a les mêmes étapes que n’importe quel algorithme évolutionnaire (figure 6.6). Avant d’expliciter l’algorithme, on essaye de présenter et de décrire les phases les plus importantes le constituant. On commence par la méthode principale (so corps) qui est inspiré du GA (figure 6.7).
n
Figure 6.6
Figure 6.7
116

Dans la première étape on cherche à trouver toutes les solutions dont le temps total d’exécution (équation 4) est ≤ dlfinal. Les résultats de cette étape sont toutes les solutions (mapping) qui vérifient dlfinal. Ces résultats sont considérés comme entrée de l’étape 2, et on essaye ensuite de minimiser la consommation d’énergie tel que dlfinal reste vérifié (équation 5). Pour cette étape un autre algorithme hybride est proposé basé sur une méthode exacte et une heuristique inspirée de l’algorithme de Dijkstra. Dans l’étape précédente la taille d’un chromosome est NxS où N est le nombre de tâches et S le nombre de processeurs.
Avec plus de détails, un chromosome ici est composé de S gènes et chaque gène contient NxM bits. On remarque ici que la taille du chromosome a augmenté mais la taille du domaine de décision a diminué, c’est ce qui a justifié notre choix pour une méthode exacte lors de cette phase.
Algorithme de l’étape 1
0- Début
1- lire le graphe de tâches et le graphe d’architecture,
2- Lire leurs propriétés, contraintes et les paramètres du GA,
3- Générer une solution initiale en se basant sur la technique de la phase 1,
4- répéter
5- Pour chaque population faire,
6- Pour chaque chromosome faire,
7- Vérifier que chaque tâche est affectée à un seul processeur,
8- Traiter les contraintes,
9- Calculer le chemin le plus court,
10- Calculer le temps global d’exécution,
11- Si le chromosome ne vérifie pas les contraintes tel l’équilibrage, taille mémoire, largeur de bande et file d’attente ajouter des pénalités à sa fitness,
12- Créer une nouvelle population en utilisant « croisement » et « mutation »,
13- Utiliser la fitness pour sélectionner le meilleur,
14- Jusqu’à critère d’arrêt vérifié,
15- STOP
117

Algorithme de l’étape 2 1- Début,
2- Initialisation,
3- Soit SS l’ensemble des solutions trouvées lors de la phase 1 et dérivées selon la description donnée en 6.4,
4- Soit BestCost E : consomation d’énergie la plus petite obtenue dans la phase 1 (dans cette phase tous les processeurs s’exécutent à vitesse max) et OPT la solution correspondante à BestCostE alors SS=SS-OPT,
5- tant que SS ≠ ∅ faire,
6- Sélectionner Si ; SS=SS-Si,
7- Calculer le temps d’exécution D(Si) correspondant,
8- Si (D(Si) < dlfinal) alors
9- Calculer la consommation E(Si),
10- Fin si
11- Si (E(Si) < BestCostE ) alors
BestCostE= E(Si) et OPT=Si
Fsi
12- Fin tant que
13- Retourner (Bestsol (OPT, BestCostE).
Algorithme du premier bon choix de l’étape 1
1. Soit TT=T l’ensemble des tâches et PP=P l’ensemble des processeurs.
2. Calculer σ(ti)=tj ∈ T or V / (ti,tj) ∈ E pour toutes les tâches de TT. C’est l’ensemble des voisins de chacune d’elle.
3. Calculer σ(pi)=pj ∈ P or U / (ti,tj) ∈ F pour toutes les tâches de PP. C’est l’ensemble des voisins directs de chaque processeur.
4. Trier TT et PP selon l’ordre décroissant des σ(ti) et σ(pj) .
5. Affecter le premier élément de TT (t1i) au premier élément de PP (p1
j).
6. TT=TT- t1i et PP=PP- p1
j .
7. choisir un t2i de TT de telle façon que t2
i soit parmi les premiers éléments de TT et t2
i ∈σ(t1i). Sinon prendre t2
i tête de liste de TT.
8. choisir p2j de PP de telle façon que p2
i soit parmi les premiers éléments de PP et P2i
∈ σ(P1i). Sinon prendre p2
j comme tête de liste PP.
9. affecter t2i à p2
j. TT=TT- t2i et PP=PP- p2
j .
10. A une itération k < n (n étant le nombre de tâche) faire
11. choisir un tki de TT de telle façon que tk
i soit parmi les premiers éléments de TT et tk
i ∈σ(tk-1i). Sinon prendre tk
i tête de liste de TT.
12. choisir pkj de PP de telle façon que pk
i soit parmi les premiers éléments de PP et Pki
∈ σ(Pk-1i). Sinon prendre pk
j comme tête de liste PP.
118

13. affecter tki à pk
j. TT=TT- tki et si k<S alors PP=PP- pk
j sinon PP=P.
14. si k<n alors allez à 11 sinon affectez tkn à au premier PK
j de PP.
15. Stop
16.
6.6 Mapping des tâches répétitives. Les tâches répétitives ont la particularité de présenter les mêmes caractéristiques : nombre
de cycles d’exécution et la taille des données traitées. En plus ces tâches s’appliquent sur des données de même dimension et structures, qu’on appelle motifs. La figure suivante illustre l’application de détection de contour. Une image est un tableau de valeurs élémentaire appelées pixel. La détection de contour d’une image est réalisée par une « convolution ». Une convolution est une opération simple qui produit chaque pixel de l’image de sortie à partir d’une combinaison linéaire de certains pixels de l’image d’entrée. Les cœfficients de la combinaison linéaire sont donnés dans une matrice de coefficient. (figure 6.8)
Ces tâches pacertaine particulad’exécution et ded’architecture par
Figure 6.8 : Illustre l’application détection de contour
r leurs caractéristiques sont affectées à une architecture présentant une rité. En effet la plateforme d’exécution est constituée elle aussi d’élément communications identiques. C’est pour cette raison qu’on désigne ce type l’appellation « régulière », (figure 6.9).
Figure 6.9 : modèle d’architecture régulière
119

Ce type d’application régulière est très bien décrit et spécifiée par le langage array-ol
présenté auparavant (figure 6.10).
Figure 6.10 : pavage complet d’un tableau par une tuile 3,4
Donc avec Array-ol on est en mesure de spécifier des sous tableaux « motifs » qui ont le même profil. Cette spécification est très importante car elle constitue un formalisme de données dans le traitement vectoriel. Ainsi les traitements effectués sur les motifs sont les mêmes. D’où la notion de tâches répétitives. Ces dernières à partir d’un tableau de données en entrée et des paramètres permettant de localiser le sous tableau qu’elles doivent avoir en entrée elles produisent d’autres tableaux en sortie avec des profils différents (figure 6.8). Ces tableaux de données sont indépendants (indépendance de données) et de même pour les tableaux de sortie. Ceci rend les tâches indépendantes et par conséquent facilement parallélisables. Cet aspect est bien explicité par Array-Ol et qu’on essaye de traiter à part. Ce traitement on l’a nommé « traitement de tâches répétitives sur des architectures régulières ». Dans le graphe hiérarchique d’application HTG (définition 3) ces tâches sont désignées par des nœuds répétitifs qu’on essaye de placer et ordonnancer sur des architectures régulières c’est dire des processeurs identiques.
Ces traitements qui caractérisent les applications DSP ou vectoriel sont gourmands en temps de calcul. Ils manipulent des tableaux de grande taille en entrée. Par conséquent l’approche pour faire le scheduling de ce type d’application diffère de la démarche adoptée précédemment pour les tâches quelconques ou non répétitives. Ce type de traitements est dit souvent régulier pour le distinguer du précédent qui est irrégulier, Ainsi en associant ces deux types de traitements on obtient le GILR (Globalement Irrégulier Localement Régulier). Donc pour le mapping du régulier on n’essaye pas de placer toutes les tâches répétitives en même temps mais de le faire par partie en déterminant un paquet de tâches qu’on place en minimisant le temps d’exécution et la consommation d’énergie. Ensuite c’est même nombre de tâche qui est répété sur d’autres données selon la spécification d’Array-Ol. La figure 6.11 illustre un exemple de répétition d’un paquet de tâches.
Figure 6.11 : Répétition de motifs pour générer l’ordonnancement de N tâches.
120

On voit, dans la figure précédente, que c’est le même placement des communications et des tâches qui est répété selon l’axe de temps. Pour expliquer l’approche adoptée pour résoudre ce problème d’Allocation, Assignation et Scheduling (AAS) on doit définir certains concepts et termes qui facilitent la présentation de l’algorithme.
Du fait du nombre limité de ces tâches la méthode utilisée pour ce placement est à base de méthode exact (branch and bound).
Paquet de tâches : est un ensemble de N tâches indépendantes avec un temps d’exécution unitaire et qui peut s’exécuter en parallèle selon n’importe quel ordre.
Plateforme : C’est un ensemble de S processeurs identiques connectés avec une topologie d’interconnexion arbitraire (Mesh, Cube, Arbre, etc.)
Définition : Un Motif est un ensemble de traitements (tâches) et communications placés (AAS) sur un ensemble d’éléments d’exécution (PE) connectés à travers un réseau de l’architecture.
Objectifs : L’idée derrière le motif est basée sur deux objectifs de base, premièrement, faire de la technique d’AAS indépendamment du nombre total des tâches. Deuxièmement, minimiser la complexité du placement.
Dans les applications DSP on a généralement un flot de données infini qui sont traitées par des tâches répétitives. Considérer cette infinité de tâches répétitives lors de la recherche du placement optimal va accroître la complexité de traitement du processus AAS. C’est pour cette raison qu’on génère des motifs et pour générer le placement total (AAS) de toutes les tâches (Totaltaches) on a qu’à répéter le placement du motif X fois (figure 6.11). Ainsi un placement de motif est généré sans prendre en considération le nombre total de tâches, en fait comme résultat de son placement on obtient le nombre de tâches qui le constituent (Motiftaches). Et X peut être calculé selon la formule suivante : X = Totaltaches / Motiftaches .
Définition : La répétition dans un motif est le nombre de placements (AAS) de communications et tâches répétés dans un même motif avec une même quantité de données en entrée avant de commencer les sorties du motif. On l’appelle aussi motif inter-répétition.
L’exemple de la figure 6.12 donne des motifs illustrés avec le diagramme de Gantt, où la partie supérieur du diagramme représente l’AAS des communications et la partie inférieure l’AAS des tâches ou calculs.
F
répcode
ide
igure 6.12 : l’AAS des communications et tâches avec 5 processeurs. A : une seule inter-
répétition, B : Deux inter-répétitions, et C : trois inter-répétitions.
Objectif : l’objectif derrière l’inter-répétition est de trouver le bon nombre de tâches qu’on ète au sein d’un même motif. Les critères qu’on a retenus sont la diminution de la
nsommation d’énergie et l’utilisation maximale des ressources tout en respectant les adlines.
Soit dli = dlt le deadline d’une tâche. Il est aussi celui de toutes les tâches car elles sont ntiques.
121

Xmij= 1 si la tâche i est placée sur le processeur j et s’exécute au mode m, o sinon.
d’mij = la durée d’exécution de la tâche i placée sur pj s’exécutant au mode m (sans prendre
en compte les communications) . On remarque que par rapport au premier formalisme globalement irrégulier ici d’m
ij n’est pas fonction des processeurs car dans une architecture régulière tous les processeurs sont identiques. Ainsi d’ml
ij= d’mlik pour k≠i s’ils
fonctionnement au même mode m=ml.
d’mij=WCNm
ij/fmj où WCNm
ij est le nombre de cycles nécessaires à la tâche i pour s’exécuter sur le processeur j au mode m. là aussi WCNm
ij varie uniquement selon le mode d’exécution des processeurs.
fmj est la fréquence d’horloge du processeur j au mode m. Elle est aussi la même pour tous
les processeurs à un même mode.
Ainsi si dans un motif, après ordonnancement, la tâche k est la dernière dans l’exécution et dlk est son deadline alors dlfinalmotif = dlk. Il est le temps avant lequel se termine le motif et qui correspond au temps de fin de la dernière tâche du motif.
Qij est le volume de données échangées entre les tâches i et j. Il est le même pour toute les tâches.
d’Qmijpq est la durée des communications entre les tâches i et j si elles sont placées
respectivement sur les processeurs p et q au mode m. ce temps ne dépend pas de la nature des liens car ils sont identiques mais uniquement de la distance ou la longueur du chemin reliant les processeurs sur lesquels s’exécutent ces tâches. On va voir après comment ce paramètre est calculé.
qm est la durée de communication unitaire (bit ou octet).
em est l’énergie consommée par une unité de donnée (bit ou octet) durant son transfert de p
à q voisin (existence de lien physique direct) au mode m.
S’il n’existe pas un lien direct entre p et q soit µ(p,q)= (pi,pj) le chemin (succession de liens) reliant p à q.
Alors la durée d’utilisation des liens est d’Qmijpq = µ(p,q) ∗qm
µ(p,q) est la longueur du chemin µ(p,q).
La consommation d’énergie due à la communication des tâches i et j si elles sont placées sur les processeurs p et q au mode m en utilisant le même chemin est :
E’mijpq= µ(p,q) ∗em
Dans ce modèle on considère que la consommation d’énergie due aux communications intra-processeurs est négligeable. De même pour la durée des communications. On peut aussi considérer que ces paramètres sont inclus dans les temps d’exécution et l’énergie consommée.
122

Chaque chemin contient un certains nombres de switch et de routeurs qui consomment de l’énergie et causent des durées supplémentaires de communication.
Dans les travaux de Ascia et al le problème est posé mais ils n’expliquent pas comment ils le traitent. Dans ce travail on propose une valeur moyenne de consommation (CSW) et de durée (dSW) due à l’utilisation des switch et routeurs. On peut les estimer en considérant les communications en entrée et sortie des routeurs comme stochastique.
Ainsi, la consommation totale des switch et routeurs de ce chemin est égale à :
δ=( µ(p,q) +1)∗ Csw .
Et la durée totale est :
δ’=( µ(p,q) +1)∗ dsw .
(CSW) et (dSW) sont respectivement la consommation moyenne et la durée due à l’utilisation des switch et routeurs. On peut donner maintenant l’équation de la consommation totale due aux communications des tâches i et j affectées aux processeurs p et q au mode m.
Em
ijpq= E’mijpq + δ ............8
Et la durée totale des communications :
dQmijpq = d’Qm
ijpq + δ’ ............9
Donc le temps total d’exécution d’une tâche i en prenant en considération les
communications est :
mn N S S mn
Di = ∑ d’mip + ∑ ∑ ∑ ∑ Xm
ip ∗Xmjq∗dQm
ijpq j≠i …..10 m=m1 j=1 p=1 q=p+1 m=m1
Cette équation peut être simplifiée car p est fixe et on considère par hypothèse que les communications intra-processeur sont négligeables. Pour un i fixé, ∑ Xm
ip = 1.
Pour une tâche i, si Distart est son temps de début, alors son temps de terminaison est Di
fin , il est donné par la formule suivante :
Difin = Di
start + Di
L’ordonnancement est obtenu par LS où le début de l’application correspond avec le début de sa première tâche t1 et sa fin correspond à la fin de la dernière tâche tn. Ainsi, pour la tâche ti son temps de début Di
start correspond au temps de la dernière des tâches qui la précèdent. Donc la liste LS est obtenue en utilisant la stratégie ASAP (As Soon As Possible).
Dnfin = Dn
start + Dn est le temps de fin de la dernière tâche tn du motif.
Ce temps est donc le temps de fin du motif Dfin qui est donné par la formule suivante :
123

Dfin = Dnstart + Dn 11
Donc si Dstart est le temps de début du motif, qui correspond au temps de début de la première tâche D1
start, et Dfin le temps de fin du motif qui aussi celui de la dernière tâche Dnfin
alors la durée d’exécution totale du motif est :
D= Dfin – Dstart ……………………..12
C’est ce temps qu’on doit minimiser et s’assurer qu’il vérifie la contrainte temps réel hard, c'est-à-dire :
D ≤ dlfinal.
La consommation d’énergie totale est donnée par la formule suivante en prenant en considération la consommation des processeurs, des liens, des switchs et des routeurs.
N S mn N N S S mn
E= ∑ ∑ ∑ Xmip * ETm
ip + ∑ ∑ ∑ ∑ ∑ Xmip ∗Xm
jq∗Emijpq j≠i ….13
i=1 p=i+1 m=m1 i=1 j=i+1 p=1 q=p+1 m=m1
Objectifs : essayer de minimiser la consommation d’énergie tout en exploitant au maximum les ressources. Le critère qu’on a adopté ici, en premier, pour l’exploitation maximal des ressources est totalslack. Où totalslack correspond au temps de repos ou relâchement des ressources. C’est ce temps qu’on doit minimiser pour augmenter l’exploitation des ressources. On voit bien que ce critère est conflictuel avec le deuxième objectif qui correspond à la minimisation de la consommation d’énergie. En effet exploiter plus les ressources nous amène à consommer plus d’énergie. La minimisation de la consommation d’énergie revient à optimiser l’objectif donné par la formule 13 par contre le deuxième objectif doit être expliciter ci après.
Donc si on a S ressources d’exécution et N tâches constituant le motif. Notant par DSn la
durée d’exécution d’un motif (formule 12) constitué de N tâches et s’exécutant sur S processeurs.
Alors Tdis= DSn * S donne le temps de disponibilité des ressources.
Le temps d’occupation Toc des S processeurs par les N tâches du motif peut être obtenu à partir de l’équation 10.
i=N Ainsi Toc= ∑ Di i=1
Alors le temps total de relâchement (ou des slack) des S processeurs utilisés pour l’exécution d’un motif de N tâches est obtenu par :
totalslack = Tdis – Toc …………………14
C’est ce temps qu’on doit minimiser en jouant sur le nombre de tâches constituant le motif.
Pour généraliser l’expression notant par totaln,sslack le temps total de relâchement dû au
placement de n tâche sur S processeurs du NoC.
Donc l’objectif est de trouver le N=NN tels que :
124

totalnn,sslack = min totaln,s
slack n=S,..,2S …………15
Etant donnée que le nombre de processeurs est donnée dans une architecture régulière et qui est souvent raisonnable, alors le nombre de tâches constituant le motif est lui aussi raisonnable par rapport au nombre total des tâches répétitives. Pour ce placement on a proposé une approche basée une méthode exacte pour atteindre les objectifs. Pour optimiser les chemins de communication on a, comme pour le GI, utilisé une approche basée sur dijkstra.
La méthode proposée pour solutionner ce problème est une méthode hybride constituée d’une part d’une méthode exacte permettant de trouver le meilleur placement selon plusieurs objectifs. Et d’autre part d’une méthode basée sur Dijkstra pour trouver le mapping des communications. Une fois l’optimisation AAS, d’un motif, obtenue on peut aborder le placement de toutes les taches répétitives.
Définition : Le processus de répétition d’un motif X fois est appelé répétition de motif, où X = Totaltaches / Motiftaches .
Objectif : générer le placement de toutes les tâches répétitives.
Donc la répétition d’un motif est un moyen pour générer l’AAS complet d’un nombre donnée de tâches égale à Totaltaches X fois sans augmenter la complexité des traitements. Ceci est bien illustré par la figure 6.11.
Algorithme de placement des tâches répétitives 1. Début ;
2. Introduire le nombre de PE, S et la matrice de topologie ;
3. Introduire les caractéristiques de l’architecture et des tâches répétitives ;
4. Motiftaches = 0 ; totalslack = ∞ ;
5. Pour N=S à N=S*S faire
6. utiliser la méthode exacte pour trouver le placement au mode max des processeurs
7. Utiliser l’algorithme d’optimisation des communications
8. calculer totalNslack selon la formule 14
9. Si totalNslack < totalslack alors totalslack = totalN
slack et Motiftaches = N sinon rien fsi
10. fin pour
11. faire changer le mode des processeurs
12. Calculer pour chaque placement la durée d’exécution et l’énergie selon les équations 12 et 13
13. Retenir le front Pareto ou les solutions non dominées
14. Fin
6.7 Routage et optimisation des communications Cette phase est très importante dans tout processus d’optimisation AAS. Dans un graphe
d’interconnexion (directionnel ou bidirectionnel) d’une plateforme multi-core, le routage désigne la sélection d’un chemin en utilisant certains algorithmes de routage (Bellman-Ford, Dijkstra, etc.) et des techniques de transmission de données (boite au lettres, direct, etc.) entre des éléments source et destinateur. En plus souvent à travers ce routage en essaye d’atteindre certains objectifs et vérifier certaines contraintes. La sélection du chemin et l’envoie des
125

données peuvent être implémentés d’une façon statique ou dynamique en utilisant quelques concepts de transfert de message car dans n’importe quel environnement multiprocesseurs le mapping des communications constitue une partie intégrante de tout l’AAS.
Le routage peut être classé en deux catégories : routage déterministe et routage adaptatif. Dans le premier, le chemin qu’un paquet doit suivre est entièrement et complètement déterminé par les adresses sources et cibles du paquet. Le deuxième ne dépend seulement que des adresses sources et cibles du paquet à transférer mais aussi des conditions dynamiques du réseau, telles la congestion des liens due à la variabilité du trafic. Le terme routage adaptif est surtout utilisé dans le contexte d’un routage dynamique, où les décisions de sélection d’un chemin sont données au niveau des routeurs.
Le routage dynamique présente certains avantages car il permet d’éviter les congestions en utilisant dynamiquement d’autres chemins de routage, mais le routage déterministe est beaucoup plus utilisés pour les applications sur NoC à cause de :
• La limitation des ressources et les exigences strictes de la latence : un des avantages principaux du routage déterministe c’est sa simplicité en en terme de spécification des routeurs. A cause de la logique simple des routeurs ce type de routage fournit une latence faible quand le réseau n’est pas congestionné. Et d’un coté implémenter des routeurs adaptatifs nécessite plus de ressources. En plus dans un routage adaptatif les paquets doivent respecter l’ordre d’utilisation ce qui nécessite l’implémentation d’autres protocoles qui ne peuvent qu’alourdir la deuxième solution et la rendre coûteuse.
• Estimation du trafic : La plupart des NoC sont développés pour une seule application ou au plus pour une petite classe d’applications. Par conséquent le concepteur a une idée sur les communications et les caractéristiques de la plateforme cible, ce qui lui permet d’utiliser ses informations pour bien placer les IP et trouver un routage évitant les congestions. C’est ce qu’on a fait dans ce travail en vérifiant pour chaque plus court chemin trouvé, en terme de coût, la non saturation de la bande passante. Ce qui rend dans ce type de système l’avantage du routage adaptatif insignifiant.
Donc le concepteur quand il a à choisir entre les deux concepts il doit analyser les spécificités du domaine d’application. Dans notre cas, pour les raisons qu’on a avancé auparavant, on a opté pour le routage déterministe ou off-line car le deuxième n’apporte pas d’avantages. Au contraire il complique la conception du système et alourdis son soft ce qui est très déconseillé dans les SoC. D’un autre coté avec le premier type de routage on a une estimation à l’avance des coûts de communication du moment où ce coût est calculé comme étant la somme des coût des liens qui constitue le chemin de routage.
6.7.1 Génération de chemin Le problème de génération de chemin on l’a formulé comme le plus court chemin à origine
unique. Ce problème consiste à trouver un chemin entre deux sommets tels que la somme des valeurs des arcs le constituant soit minimale. D’une façon plus formelle, ayant un graphe valué où V est l’ensemble des sommets, E l’ensemble des arc et une fonction d’évaluation qui associé à chaque arc une valeur réelle : w : E → R. La valeur du chemin µ=(v1,v2,…,vk) est la somme des valeurs des arcs le constituant.
k W(µ)= ∑ w(vi-1,vi).
i=1
et le chemin de valeur minimale reliant u à v est donné par
µ126

δ(u,v) = min W(µ) : u v si il existe un chemin entre u et v, ∞ sinon
Le plus court chemin entre les sommets u et v est défini par n’importe quel chemin avec un coût W(µ)=δ(u,v). Si δ(u,v)= ∞ alors il n’existe pas de chemin entre ces deux sommets.
6.7.1.1 les différentes variantes des problèmes du plus court chemin Les variantes suivantes des problèmes du plus court chemin peuvent être résolues par l’algorithme du problème de l’origine unique.
Origine unique : consiste à chercher tous les chemin à partir d’un sommet origine unique à tous les sommets v de V ( c’est à dire one to n).
Problème du plus court chemin pour cible unique : C’est trouver le chemin le plus court vers un sommet cible et à partir de tous les sommets de V. ( n to one ).
Problème du plus court chemin entre une paire de sommets : c’est le plus court chemin entre les sommets u et v. Ce problème a une solution si le problème d’origine unique donne des solutions. (c-à-d one to one).
Problème du plus court chemin entre toutes paires de sommets : trouve le plus court chemin entre de u vers v pour les couples de sommets (u,v) de V*V. (c-à-d n to n ).
Le tableau suivant donne les algorithmes plus connus pour ce type de problème.
Algorithme du plus court chemin
Problèmes résolus Complexité (pour un graphe de E arcs et V sommets)
Dijkstra Résout le problème d’origine unique si tous les arcs ont des valeurs ≥ 0. Il permet de trouver tous les chemins les plus courts d’un sommet origines uniques vers tous les autres sommets
A) Une implémentation simple donne une complexité de O(V2).
B) Pour un graphe non dense (sparse) et données binaires l’algorithme nécessite 0((E+V)logV), en utilisant les nombres Fibonacci la complxité augmente à 0(E+VlogV)
Bellman-Ford Trouve la solution du problème d’origine unique avec des arcs pouvant avoir des valeurs négatives
O(VE)
A* search Trouve les solutions du chemin le plus court à origine unique
La complexité en temps de A* dépend de l’heuristique. Il peut avoir une complexité exponentielle dans certains cas mais elle peut être aussi polynomiale sous certaines conditions.
Floyd-Warshall Solutionne le problème du plus court chemin entre paire de sommets
Θ(|V|3).
Johnson Trouve les chemins les plus court O(V2logV+VE).
127

entre des couples de sommets si le graphe est direct, valué et non dense. Dans ce cas cette méthode est très rapide
Tableau 1 : Quelques algorithmes importants utilisés pour résoudre le problème du plus court chemin à origine unique.
On peut citer aussi une méthode très utilisée dans les réseaux et surtout dans les réseaux à Mesh, c’est la méthode X-Y ou Nord-Est. Elle est facile à implémenter et converge rapidement. Seulement cette méthode donne le plus court chemin en terme de nombre d’arcs et non pas la somme des valeurs.
Algorithme de Dijkstra Entrée : G,W,s
Sortie : retourner un ensemble de liens (chemin)
Début
Initialise-origine-unique(G,s) ;
S←∅ ;
Q ← V[G] /* Q est une liste de piorité contanant V-S */ ;
Tantque Q≠∅ faire
U ← EXTRACT-MIN(Q) ;
S-S∪u ;
Pour chaque sommet v∈Adj[u] faire
/*relax(u,v,w)
Si d[v] > d[u] + w(u,v) alors
d[u] ← d[u] + w(u,v)
fsi ;
fpr ;
ftq
Retourner le chemin ;
fin.
Etant donnée que l’algorithme de placement des communications est basé directement sur l’algorithme de recherche du plus court chemin, il est important de connaître sa complexité car à chaque placement on fait appel à l’algorithme de placement des communications. La complexité de notre algorithme AAS dépend étroitement de la complexité en temps de l’algorithme de placement des communications. Le tableau suivant donne les différentes complexités de l’algorithme selon la structure de données choisie.
Temps= Θ(V).TEXTRAIT-MIN + Θ(E).TDECREASE-KEY
128

Q TEXTRAIT-MIN TDECREASE-KEY TOTAL (Worst case)
Array O(V) O(1) O(V2)
Binaire O(lgV) O(lgV) O(ElgV)
Fibonacci O(lgV) O(1) O(E+VlgV)
Tableau 2 : Implémentation de l’algorithme de Dijkstra avec des structures de données différentes
Donc l’algorithme à base de Dijkstra a été utilisé pour solutionner les trois problèmes de base suivants :
Premièrement : A partir d’une topologie d’interconnexion quelconque (Mesh, arbre, cube, etc.) Construire un ensemble de PE selon leur distance à partir du PE racine.
Deuxièmement : A partir d’un ensemble de chemins courts, trouver celui qui a le coût minimal.
Troisièmement : s’assurer de l’équilibrage de charge entre les différents liens de communications du réseau.
L’équilibrage de charge du réseau ou équilibrage des communications consiste à s’assurer que les communications utilisent tous les liens du réseau et non pas uniquement certains. Ceci a l’avantage d’exploiter toutes les ressources du NoC et par là de minimiser le risque de la congestion.
6.7.2 Problème de génération du chemin Après avoir expliqué le fonctionnement des différentes parties constituant notre solution du
problème du plus court chemin, on peut présenter maintenant notre algorithme. La stratégie qu’on a arrêtée et qui correspond à la réalité du problème c'est-à-dire de générer les plus courts chemins à partir d’une origine unique et une cible unique.
Formulation : A partir d’un graphe direct G=(V,E), où les valeurs des arcs sont toutes supérieures ou égales à zéro, on essaye d’atteindre l’objectif consistant à trouver le chemin le plus court entre deux sommets où le coût est égale à la somme des coûts de tous les arcs le constituant. Ainsi, ayant un graphe valué constitué d’un ensemble V de sommets, d’un ensemble E d’arcs et d’une fonction d’évaluation w : E→ R. La valeur du chemin µ=v0,v1,..,vn est la somme des valeurs des arcs le constituant. L’algorithme suivant résume les différentes étapes de l’algorithme de génération d’un chemin.
Algorithme de génération
Début
Pour p=1 à S faire
Si PE=RootPE alors return aucun chemin n’est exigé
Sinon appeler Dijkstra (rootPE,PE, Gparta) ;
Retourne le chemin (Ptsi) c-a-d l’ensemble des liens.
Faire l’ordonancement des paquets
Vérifier la contrainte de charge et de bande passante ;
Si les contraintes sont vérifiées faire le mapping des communications sur les
liens sinon rien ;
Fin ; Fin.
129

6.7.3 Routage statique des paquets Le routage statique (ou routage off-line) est réalisé au moment de la compilation, ce qui
veut dire que tous les chemins de routage doivent être trouvés avant les traitements.
6.7.3.1 Routage direct ou routage statique des paquets Le routage direct est un cas spécial du routage où le chemin est généré uniquement entre
l’origine et la cible. Il faut éviter la collision des paquets et une fois injectés ils doivent atteindre leur cible. Chaque paquet, dans ce cas, a un seul paramètre qui consiste en son temps d’injection. Ce type de routage est important quand les buffers sont chers ou non disponibles tel que dans les réseaux à fibre optique. En considérant les NoC ou MPSoC ce type de routage est bénéfique car il permet de réduit la surface SoC. C’est ce qui a motivé son utilisation lors du routage et placement des communications dans notre algorithme.
6.7.4 Problème du routage des paquets Ce problème joue un rôle central dans l’ordonnancement des tâches et surtout les
ordinateurs parallèles de grande taille dans le sens du nombre de processeurs et de la longueur de son réseau d’interconnexion. Le routage des paquets consiste à déplacer les données d’un endroit à un autre dans le réseau. Le but est de transférer tous les paquets à leur destination aussi rapidement que possible et avec un minimum d’attente si c’est possible. Ce problème on l’a formulé de la façon suivante.
Ayant des paquets Pksi avec des chemins spécifiés Ptsi (path) dans le réseau, où chaque paquet a une source Si et une destination di, l’objectif est d’obtenir un ordonnancement du routage direct tel que à un instant ti pour chaque paquet Pksi ce dernier est injecté pour son transfert direct à sa destination sans collision et avec un minimum de temps.
Le temps de routage : soit ti l’instant d’injection du paquet Pksi dans le réseau. Et Pila longueur du chemin de routage associé à ce paquet. Alors le paquet PKsi atteint sa destination à l’instant ti+Pi(le temps total du routage d’un paquet) et le dernier paquet arrive à l’instant maxi ti+Pi.
Algorithme : L’ordonnancement des paquets dans notre approche AAS.
Debut
Pour PE=1 à S faire
Si PE=ROOTPE alors return aucun chemin n’est exigé
Sinon appel Dijkstra(RootPE, PE, Gparta)
Return l’ensemble des liens constituant le chemin Ptsi ;
Associer l’ensemble paquet Pksi au chemin Ptsi ;
Définir les temps de début d’envoie et fin du paquet à travers chaque lien du
chemin.
Envoie des données.
Fin ;
Fin.
a partie du réseau correspondant au nœud dans le graphe hiérarchique
130

6.7.5 Temps d’exécution
Topologie problème Complexité
Arbre Problème de routage arbitraire sur une topologie en arbre arbitraire
O(C+D)
Mesh Avec n nœuds : permutations O(n1/2)
Mesh Avec chemin arbitraire O(C+D)
A buffer Avec n entrée : destinations et permutations aléatoires
O(lgn)
Hypercube Avec n nœuds : destinations et permutations aléatoires
O(lgn)
Autre topologie de réseau direct
Avec packets de données infnies et source et destination fixés
O((E+M)MlogM)2 ou ≤ O(C+D)
Tableau 4 : Complexité des algorithmes de routage direct 6.8 mapping Global
Dans la démarche qu’on propose pour résoudre le problème du mapping dans sa globalité (c’est à dire le GILR), on essaye de faire l’affectation d’un HTG (Hierarchical Task Graph) à un HNT (Hierarchical Network Graph) avec des niveaux identiques. Dans notre approche on s’impose certaines hypothèses qu’on cite ci-après et peuvent être enlevées dans de futurs travaux :
1- le nombre de niveaux est connu et donné comme entrée.
2- Les deux graphes ont les mêmes niveaux.
3- On considère aussi qu’à n’importe quel niveau on a le même nombre de noeuds composés.
4- On extrait de l’ensemble un optimum (D*,E) or (D,E*)
5- Le dernier niveau contient uniquement des noeuds élémentaires représentants des tâches dans le HTG ou processeurs dans le HNT.
6.8.1 Démarche
Pour trouver le mapping optimal du HTG sur le NHT on commence par chercher le mapping de tous les noeuds composés et répétitifs dans le HTG sur les noeuds composés et réguliers du HNT à l’avant dernier niveau. Si on a N niveaux, on commence par le niveau N-1. Quand tous les mapping des nœuds composés de ce niveau sont trouvés on procède de même pour le niveau N-2 en considérant les mapping trouvés au niveau N-1 comme contraintes. Après on fait de même pour le niveau N-2 et ainsi de suite jusqu’à atteindre le
131

niveau 1 ou la racine. Les grandes lignes de cette démarche sont dans l’algorithme qu’on propose ci-après :
Algorithme de parcours des arbres HTG et HNT.
1- soit l=1,
2- Au niveau N-l on construit deux ensembles,
SN-lTC= Ensemble des noeuds composés dans le niveau N-1 in HTG
SN-lPC= Ensemble des noeuds composés dans le niveau N-1 in HNT.
3- Pour chaque tci ∈ SN-l
TC on calcule σ(tci) et de même pour pc
j ∈ SN-lpC
4- On trie SN-lTC selon σ(tc
i) telque pour deux noeuds successifs tci and tc
i+1 ∈ SN-lTC on a
σ(tci) > σ(tc
i+1) et aub début de l’ensemble SN-lTC on a le noeud tc
i avec le plus grand nombre de voisins. Et on fait de même avec SN-l
pC.
5- heardt ← top of list SN-lTC
heardp ← top of list SN-lpC
map(heardt,heardp) or map(graph(heardt), graph(heardp) )
où graph(heardt) est le graphe représenté par le noeud compose heardt.
6- SN-lTC = SN-l
TC - heardt ; SN-lPC = SN-l
PC - heardp
if SN-lTC or SN-l
PC ≠ ∅ go 5.
7- Pour chaque couple (tci ,pc
j ) on a le coût de placement optimal C*(tci ,pc
j ) obtenu par l’utilisation des algorithmes des étapes 1 et 2 dans le cas d’un nœud composé. (Pour les nœuds répétitifs on fait appel à la méthode placement de tâches répétitives).
8- if level-l-1 ≠ 1 alors on peut considérer les placements (tci ,pc
j ) trouvés dans le niveau level-l comme contrainte et allez à l’étape 2 sinon STOP.
9-END.
6.9 Le choix d’une méthode à base de GA pour le placement irrégulier
Notre choix d’une approche basée sur le génétique pour l’étape 1 et consolidé par une étude comparative avec d’autres approches (voir chapitre suivant). Des jeux d’essai nous ont permis de conclure que la proposition d’un algorithme à base du génétique peut être très efficace à condition que les paramètres soient bien arrêtés. En effet les résultats obtenus nous permis aussi de dire que l’efficacité de cet algorithme dépend étroitement des ses paramètres, notamment de la taille de la population et le nombre d’itérations.
132

6.9.1 paramètres de l’algorithme génétique
6.9.1.1 Nombre de gènes
On a une configuration de S SOC’s (processeurs) et de N tâches. On prend la taille d’un chromosome en gènes : Ch. = S*N ;
6.9.1.2. Le codage :
Dans les sections 6.3 et 6.4 on décrit comment se fait le codage. On a surtout insisté sur le fait qu’on a opté pour de type de codage : le premier codage utilisé dans la première phase de l’algorithme est un codage binaire où chaque chromosome est constitué de N*S bits ou de S gènes chacun composé de N bits. N étant le nombre de tâches et S le nombre de processeurs. Pour un gène k correspondant au processeur k la valeur de son i bit indique l’affectation ou non de la tâche i au kème processeur (1 ou 0).
Dans la deuxième phase les chromosomes sont constitués de S gènes, chacun est constitué N*M bit. Si on veut dans chaque gène on a M paquets de N bits. Pour un gène k correspondant au processeur k, le paquet m dans le gène correspond au mode m de fonctionnement du processeur. Donc si le ième gène de ce paquet est égale à 1 cela veut dire que la tâche i est affectée au processeur k fonctionnant au mode m.
Puisque, ce mapping se fait en off-line tel qu’on l’a justifié dans les sections précédentes alors une tâche est affecté à un seul processeur et s’exécute entièrement en un seul mode. Ce qui nous a poussé à introduire dans notre démarche des contraintes d’intégrité des chromosomes. Ces contraintes sont de la forme suivante :
S Modmax
∑ ∑ Xmip= 1 ∀ ti ∈T ……………………16
p=1 m=1
Pour simplifier cette contrainte on essaye lors de l’implémentation et après chaque croisement ou mutation ne vérifier que les bits concernés. C'est-à-dire supposant qu’on a un chromosome chrx obtenu à une certaine itération. Supposant que ce chromosome correspond à un placement où la tâche i est affectée au processeur j. Dans ce cas le bit i du gène j de ce même chromosome est égal à 1. Alors il faut que tous les autres iéme bit des autres gènes soient égaux à 0. Souvent dans une itération on ne modifie que quelques bits dont le nombre ne dépasse pas 10% des bits. Alors au lieu d’appliquer la formule 15 d’une façon systématique on essaye de vérifier l’intégrité du chromosome uniquement pour les bits concernés. Ainsi pour notre exemple on réaffecte la tâche i après mutation ou croisement on s’assure que :
S-1
∑ Chr(i+N*L) pour L ∈ indices des bits concernés ……………..17 L=0 Chr(i) est la valeur du bit i du chromosome et N le nombre de tâches.
On pense que le remplacement de la formule 16 par cette dernière va nous permettre lors de l’implémentation d’économiser 80 à 90% des calculs dus à la vérification des intégrités des chromosomes.
133

6.9.1.3. Détermination de la population initiale
Pour la première population ou population initiale on a opté pour l’aléatoire total. Quelques chromosome sont choisis aléatoirement mais pour compléter le nombre de chromosome constituant la population initiale on choisit quelques chromosomes selon la stratégie vue dans la section 6.3. En effet, il ne faut pas oublier que le génétique ou tout autre algorithme évolutionnaire est basé sur des phénomènes naturels ou d’évolution tel que c’est le cas pour le génétique. Donc si on prend un cheptel de mouton et que l’on essaye d’améliorer la race selon certains critères, alors si dans le cheptel initial aucun de ces critères n’est vérifié au départ par aucun de ces moutons on pourra difficilement obtenir un cheptel dont les moutons vérifient ces critères. Par contre si au départ on s’assure que dans le cheptel il existe certains moutons qui vérifient certains critères alors on peut rapidement obtenir par croisement et mutation un autre cheptel constitué de moutons dont certains vérifient les critères. C’est ce principe qui a justifié notre choix pour des chromosomes correspondant à de bons placements.
6.9.2. Choix des opérateurs génétiques
6.9.2.1. Sélection
Pendant la création des générations, les premiers chromosomes à être choisis pour la procréation sont les deux meilleurs de la génération parent. Il s’agit d’une adaptation de la stratégie élitiste. Les autres chromosomes seront choisis selon le principe de la roulette.
6.9.2.2. Croisement
Le croisement est le processus selon lequel les gènes de deux chaînes élues sont interchangés afin de générer une nouvelle population.
Il existe plusieurs type de croisement : croisement en un seul lieu, croisement en deux lieus, croisement uniforme.
On a opté pour le croisement uniforme, parce que si on croise deux bons chromosomes, alors on garde les points communs entre ces deux derniers et on a une probabilité de 50% que les gènes différents soient retenus ou changés.
Le croisement des deux éléments issus de la sélection élitiste donnera deux enfants et celui des quatre choisis par la roulette donne douze enfants. Si le nombre des individus choisis est supérieur au nombre d’enfants générés alors on complète les chromosomes manquants aléatoirement.
6.9.2.3. Mutation
Pendant le processus de mutation, un seul bit est choisi aléatoirement parmi l’intervalle
[1, S*N] avec une probabilité de Pm. La valeur du gène qu’on va muter est choisie au hasard. Selon ce principe, il est possible qu’un gène ne subisse aucune mutation puisque sa valeur initiale peut être choisie de nouveau par le processus de randomisation.
134

6.9.3. Transformation de la fonction objectif en fonction Fitness :
Il est nécessaire de préciser que les valeurs de la fonction fitness doivent être non négatives pour que le meilleur individu reçoive la valeur fitness maximum, pour cela des transformations s’imposent :
MAXF(x)= C – Z lorsque Z < Cmax. F(x)= 0 Autrement.
Z : correspond à la fonction objective.
6.9.4. Fonction d’évaluation :
Un des éléments clés de l’algorithme génétique est la fonction d’évaluation (Fitness ou Fonction objective).
Le problème de placement des tâches d’une application sur un NOC revient à minimiser la fonction objective.
Il peut être formulé de la manière suivante :
Etant donné :
- Le graphe d’application (taille de la tache, mémoire d’exécution requise, bande passante requise pour un message et taille du message).
- Le graphe d’architecture (équilibrage de charge (charge minimum et maximum), mémoire disponible dans un SOC, taille de la file d’attente, bande passante et vitesse de transmission des bus).
Minimiser :
- Le coût total Z.
Par choix :
- Du placement des taches sur les différents SOC’s.
Ce qui est équivalent à :
Minimiser Z= i =1,..., m (1) ∑=
n
jjc
1jx
x 0,1 j =1,...,n (2) La détermination de la fonction Fitness (Fonction d’adaptation ou évaluation)
j ∈
135

passe par plusieurs étapes. Chaque fois qu’une population est générée la fonction fitness de chaque un de ses chromosomes doit être évaluée .Les étapes d’évaluation sont les suivantes :
On a en entrée :
- Un chromosome qui représente un placement des taches de l’application dans l’architecture NOC cible.
Evaluation :
- Pour un chromosome, faire la somme des coûts de communication de tous ses messages en éliminant pour chaque message les chemins dont la bande passante est inférieure à celle requise par le message (en utilisant l’algorithme du plus court chemin), donc :
Fitness = C - C MAX
C : est le coût maximal possible d’un placement. MAX
C : correspond au coût total des communications.
On considère quatre pénalités :
Équilibrage de charge : Fitness = C -C * Pequi. MAX
Memoire: Fitness = C -C * Pmem. MAX
File d’attente: Fitness = C -C * Pfil. MAX
Remarque 1 :
Il ne faut pas oublier que les valeurs de la fonction fitness doivent toutes être positives. Dans le premier cas (respect des contraintes), les valeurs seront sûrement positives puisque le coût total d’un placement ne dépassera jamais le coût maximal observé jusqu’ici (tout les points de l’espace de recherche ont un coût compris entre 0 et C ). Par contre, en pénalisant les coûts dans le deuxième cas, on risque d’avoir des valeurs négatives. Le mieux serait de remplacer les valeurs négatives de la fonction fitness correspondant à des configurations infaisables par des 0.
MAX
Remarque 2 :
Les coefficients de pénalités sont choisis de telle façon qu’un placement ayant un coût faible mais ne respectant pas les contraintes ait une valeur fitness inférieure à celle d’un placement ayant un coût plus élevé et qui respecte les contraintes qui sont multipliées par le coût total des messages d’un chromosome si ces contraintes ne sont pas respectées de telle façon qu’un chromosome qui respecte ces contraintes soit meilleur que celui qui ne les respecte pas même si ce dernier a un coût de communication supérieur au premier.
Et on a en sortie la fonction d’évaluation qui est définit de la manière suivante :
136

MAX
MAX
MAX
MAX
MAX
Fitness =
0 si C < C * Pénalité.
C – C * Pfil si la file d’attente n’est pas respectée.
C – C * Pmem si la mémoire n’est pas respectée.
C - C* Pequi. si l’équilibrage de charge n’est pas respecté .
C – C si contrainte respectée.
Comme nous pouvons le constater, la phase d’évaluation comporte plusieurs étapes et de longs calculs. Remarquer que l’évaluation doit être faite pour chaque chromosome ; si une population comporte 100 chromosomes, nous devrons réaliser 100 évaluations pour une génération. Si nous décidons de produire 40 générations, alors notre système aura calculé 4000 différents coûts, rang de matrice et fitness.
6.9.5 Formalisation du problème de placement:
Pour exécuter une application répartie, il est nécessaire de déterminer le meilleur placement des taches qui la composent sur l’architecture NOC cible tout en essayant d’atteindre les objectifs (temps d’exécution, consommation d’énergie) sous contraintes d’équilibrage de charge, mémoire disponible, de taille de la file d’attente et bande passante ce qui va conduire automatiquement a la réduction de la consommation d’énergie.
6.9.5.1. Définition des contraintes :
6.9.5.1.1. Equilibrage de charge :
).*()( ,1
equiiqiq
n
qiq PCCScharXtaSsTt =⇒>×∈∀∈∀ ∑
=
taq est la taille de la tâche tq. Char(S i) est la charge tolérée du processeur Si, elle peut être donnée ou estimée selon le contexte.
Principe constituant à répartir aussi équitablement que possible la charge de travail entre plusieurs éléments d’exécution du SoC. Son but est de garantir qu’aucun processeur ne reste inactif quand il y a d’autres processeurs qui sont lourdement chargés dans le système
137

hétérogène. La pénalité de l’équilibrage de charge est calculée par l’opération suivante :
Pequi = C MAX / C.
6.9.5.1.2. Bande passante :
).(b b' )m( b rj ≥
C’est la quantité d’informations qui peut passer dans un lien par unité de temps, et dans notre problème la bande passante requise pour envoyer un message doit être inférieure ou égale à celle du lien.
6.9.5.1.3. Mémoire :
).*()()(')( , memiqqiiq PCCsMemtMemtFsSsTt =⇒>∧=∈∀∈∀
La mémoire d’exécution requise par une tâche doit être inférieure ou égale à celle disponible dans le processeur auquel elle a été affectée par le placement. La pénalité de la mémoire d’exécution est calculée par l’opération suivante : Pmem = C / C. MAX
6.9.5.1.4. File d’attente :
).*()( )( )( ,1
filiq
n
qqiiq PCCsFilttatFsSsTt =⇒>∧=∈∀∈∀ ∑
=
La file d’attente permet de stocker les tâches si le processeur est occupé par le traitement d’autres taches. Il faut éviter d’affecter une tâche à un SOC qui a une file d’attente saturée. La pénalité de la file d’attente est calculée par l’opération suivante : Pfil. = C / C. MAX
6.10 Conclusion :
Dans ce chapitre on a essayé de proposer une démarche de résolution du problème du mapping dans sa globalité (le GILR). On a vu que cette démarche nécessite l’hybridation de plusieurs techniques pour répondre aux besoins spécifiques de cette problématique. En effet, la résolution de ce problème nécessite à la fois des méthodes de résolution de problèmes de petites tailles et d’autres de grandes tailles. En plus de la spécificité des applications embarquées, il faut aussi résoudre ce problème en essayant d’atteindre plusieurs objectifs à la fois. Toute démarche ne peut être jugée positivement qu’après sa réalisation. Par le passé on vu plusieurs méthodes et algorithmes basés sur des théories solides ou des formalismes mathématiques rigoureux mais au moment de leurs implémentations ils s’avèrent être en décalage sur le plan des résultats par rapport aux attentes des concernés auxquels sont
138

destinées ces solutions. C’est à ces questions qu’on va essayer de répondre dans le chapitre suivant consacré entièrement à l’implémentation et aux résultats.
139

CHAPITRE 7
Mise en œuvre et validation
140

Quelque soit la conception d’un problème, son implémentation pose souvent des contraintes et le programmeur se trouve confronté à des difficultés. De ce fait, l’informaticien se doit de faire une étude supplémentaire réservée au coté implémentation de son travail afin de rendre le logiciel interactif et conforme aux normes des logiciels professionnels. Par ce chapitre aussi, on a essayé d’obtenir et présenter quelques résultats nous permettant de valider la démarche présentée précédemment. Comme ils peuvent aussi nous permettre de faire des critiques qui vont nous ouvrir d’autres perspectives qui feront l’objet de futurs travaux. La plupart des travaux accomplis dans ce projet ont été développés en langage Java sous l’environnement Eclipse qui constitue un outil IDE. Ce choix est très judicieux car le langage Java sur le plan technique est devenu un langage très puissant surtout pour les applications distribuées. D’un autre coté sur le plan conceptuel cet outil permet une translation relativement facile à partir du modèle UML.
7. 1. Spécification des besoins :
Compte tenu de la nature de l’étude menée sur les réseaux sur puce, des exigences du problème de placement et des différentes notions relatives aux algorithmes de mapping, le logiciel doit être capable de répondre aux besoins suivants :
- La possibilité de choisir le type de saisie (matricielle ou graphique).
- La saisie graphique nous permet de représenter :
. L’architecture du NOC sous forme de SOC’s (carré) reliés par des bus (arc), elle permet aussi de paramétrer chaque SOC (charge minimum, charge maximum, mémoire d’exécution disponibles et taille de la file d’attente) et chaque bus (vitesse de transmission et bande passante).
. L’application qu’on veut placer sur l’architecture sous forme de taches (cercle) communicants via des messages (arc), et permet aussi de paramétrer chaque tache (mémoire d’exécution requise et taille de la tache) et chaque message (Taille du message et bande passante requise).
- La saisie matricielle nous permet de représenter :
. L’architecture du NOC en saisissant une matrice d’incidence (processeur-processeur) et de vérifier sa cohérence en la validant, elle permet aussi de paramétrer ses différentes propriétés avec des matrices (charge minimum, charge maximum, mémoire d’exécution disponibles et taille de la file d’attente, vitesse de transmission et bande passante).
. L’application en saisissant une matrice d’incidence (tâche-tâche) et de vérifier sa cohérence en la validant, elle permet aussi de paramétrer ses
141

différentes propriétés avec des matrices (mémoire d’exécution requise et taille de la tâche, taille du message et bande passante requise).
- La possibilité de sauvegarder et charger un modèle.
- La possibilité de sauvegarder et charger une architecture.
- La possibilité de sauvegarder et charger une application.
- La possibilité de lancer une recherche permettant de trouver le placement optimal d’une application sur une architecture à moindre coût de communication (en utilisant l’algorithme du plus court chemin) sous les contraintes suivantes : équilibrage de charge, mémoire d’exécution disponible, taille de la file d’attente et bande passante des bus, et cela par l’implémentation d’un algorithme génétique.
- La possibilité de varier les paramètres de l’algorithme génétique (probabilité de croisement, de mutation, taille de la population, nombre de générations, pénalité d’équilibrage de charge, pénalité de mémoire et pénalité de file d’attente) .
- La possibilité d’affecter à priori une tâche à un SOC (contrainte d’affectation).
- La génération d’un rapport comportant les principales informations concernant les résultats de l’algorithme génétique.
7. 2. Choix du langage de programmation :
Pour atteindre ces objectifs, nous avons opté pour le langage de programmation JAVA, un choix qui se justifie par les nombreux avantages qu’il offre du point de vue interface et traitement.
Eclipse est un environnement de programmation visuelle orienté objet permettant le développement d’applications en vue de leur déploiement sous Windows ou sous Linux. En utilisant JAVA sous Eclipse, vous pouvez créer de puissantes applications inter opérable.
JAVA sous Eclipse propose un ensemble d’outils de conception pour le développement rapide d’applications selon le concept IP, dont des experts programmateurs et des modèles d’applications ou de fiches, et gère la programmation orientée objet avec deux bibliothèques étendues de classes. Cet environnement constitue un bon outil pour l’IDM (ou MDE).
Le projet réalisé est constitué de plusieurs modules développés pendant une durée relativement longue. La première partie du projet est constituée d’un logiciel qui cherche le mapping à l’aide d’un algorithme évolutionnaire pour le Globalement Irrégulier (GI), la deuxième partie est l’implémentation de la démarche pour le placement des tâches répétitives sur des architectures régulières (ou Localement Régulier LR). En fin, la troisième consiste en l’implémentation de la démarche pour le mapping de problèmes hiérarchiques (GILR) en intégrant les deux outils précédents.
142
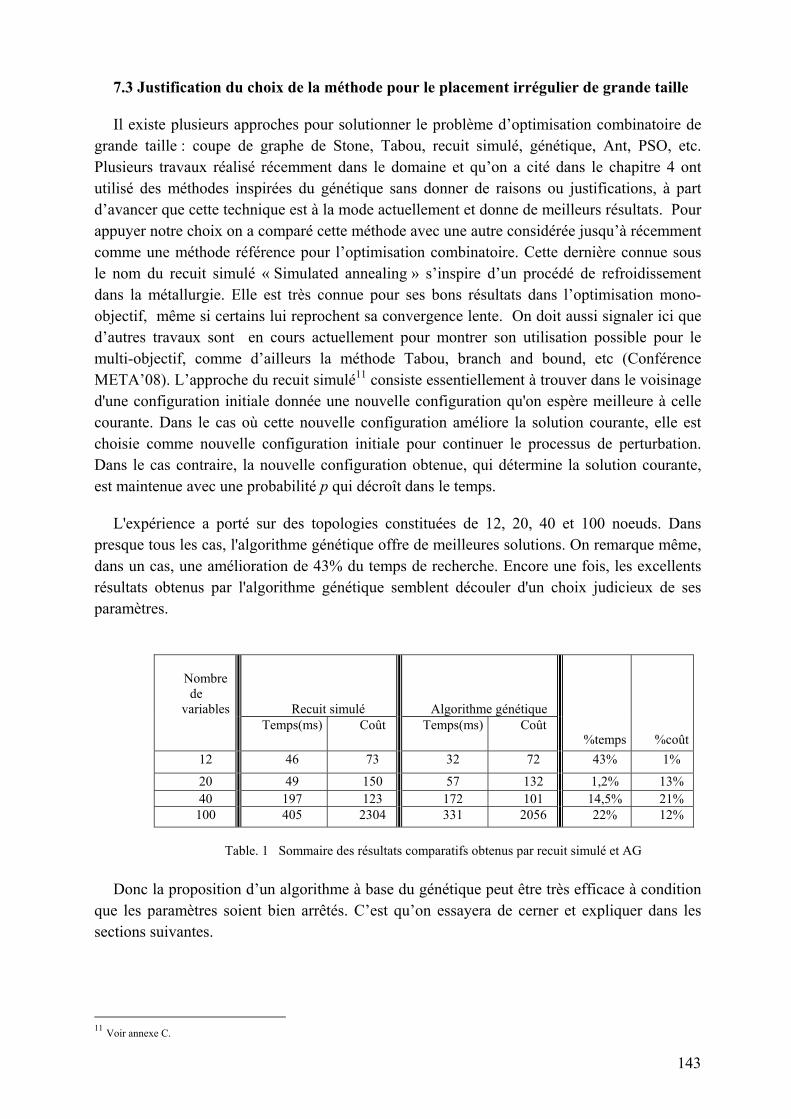
7.3 Justification du choix de la méthode pour le placement irrégulier de grande taille
Il existe plusieurs approches pour solutionner le problème d’optimisation combinatoire de grande taille : coupe de graphe de Stone, Tabou, recuit simulé, génétique, Ant, PSO, etc. Plusieurs travaux réalisé récemment dans le domaine et qu’on a cité dans le chapitre 4 ont utilisé des méthodes inspirées du génétique sans donner de raisons ou justifications, à part d’avancer que cette technique est à la mode actuellement et donne de meilleurs résultats. Pour appuyer notre choix on a comparé cette méthode avec une autre considérée jusqu’à récemment comme une méthode référence pour l’optimisation combinatoire. Cette dernière connue sous le nom du recuit simulé « Simulated annealing » s’inspire d’un procédé de refroidissement dans la métallurgie. Elle est très connue pour ses bons résultats dans l’optimisation mono-objectif, même si certains lui reprochent sa convergence lente. On doit aussi signaler ici que d’autres travaux sont en cours actuellement pour montrer son utilisation possible pour le multi-objectif, comme d’ailleurs la méthode Tabou, branch and bound, etc (Conférence META’08). L’approche du recuit simulé11 consiste essentiellement à trouver dans le voisinage d'une configuration initiale donnée une nouvelle configuration qu'on espère meilleure à celle courante. Dans le cas où cette nouvelle configuration améliore la solution courante, elle est choisie comme nouvelle configuration initiale pour continuer le processus de perturbation. Dans le cas contraire, la nouvelle configuration obtenue, qui détermine la solution courante, est maintenue avec une probabilité p qui décroît dans le temps.
L'expérience a porté sur des topologies constituées de 12, 20, 40 et 100 noeuds. Dans presque tous les cas, l'algorithme génétique offre de meilleures solutions. On remarque même, dans un cas, une amélioration de 43% du temps de recherche. Encore une fois, les excellents résultats obtenus par l'algorithme génétique semblent découler d'un choix judicieux de ses paramètres.
Recuit simulé
Algorithme génétique
Nombre de
variables Temps(ms) Coût Temps(ms) Coût
%temps
%coût12 46 73 32 72 43% 1%
20 49 150 57 132 1,2% 13% 40 197 123 172 101 14,5% 21%
100 405 2304 331 2056 22% 12%
Table. 1 Sommaire des résultats comparatifs obtenus par recuit simulé et AG
Donc la proposition d’un algorithme à base du génétique peut être très efficace à condition que les paramètres soient bien arrêtés. C’est qu’on essayera de cerner et expliquer dans les sections suivantes.
11 Voir annexe C.
143

7. 4. Description du logiciel (Aspect général) :
Le logiciel d’optimisation du placement d’application dans un NOC utilisant un algorithme génétique est constitué de plusieurs composants dont l’interface structurée en plusieurs fenêtres :
1. Form1 (Saisie) : C’est la fenêtre principale du logiciel, elle offre le choix de la saisie de l’application et de l’architecture (graphique ou matricielle).
2. Form2 (Graphe d’application) : Elle permet la saisie graphique d’une application sous forme de tâches reliées par des messages, d’afficher et de modifier les propriétés des taches et des messages.
3. Form3 (Graphe d’architecture) : Elle permet la saisie graphique d’une architecture sous forme de SOC’s reliés par des bus, d’afficher et de modifier les propriétés des SOC’s et des bus.
4. Form4 (SOC) : Elle permet de saisir et de modifier les propriétés des SOC’s.
5. Form5 (Bus) : Elle permet de saisir et de modifier les propriétés des Bus.
6. Form6 (Tache) : Elle permet de saisir et de modifier les propriétés des taches.
7. Form7 (Message) : Elle permet de saisir et de modifier les propriétés des messages.
8. Form8 (Placement génétique) : Elle permet de saisir les paramètres génétiques et de lancer l’algorithme de placement et affiche en résultat un rapport comprenant : la meilleure population, le meilleur placement, les plus courts chemins et la courbe d’évolution de la fitness.
9. Form9 (Contraintes et réglages) : Elle permet de saisir ou de modifier les probabilités de croisement et de mutation ainsi que les pénalités d’équilibrage de charge, mémoire d’exécution et de file d’attente. elle permet aussi d’affecter une tâche directement à un SOC (contrainte d’affectation).
10. Form10 (Propriétés de l’Architecture) : Elle permet de saisir d’une façon matricielle les propriétés de l’architecture (charge minimum, charge maximum, mémoire d’exécution disponible et taille de la file d’attente, vitesse de transmission et bande passante). elle permet aussi de modifier les valeurs par défaut de ces dernières.
11. Form11 (Propriétés de l’Application) : Elle permet de saisir d’une façon matricielle les propriétés de l’Application (mémoire d’exécution requise et taille de la tache, taille du message et bande passante requise). elle permet aussi de modifier les valeurs par défaut de ces dernières.
7. 5. Présentation des organigrammes du logiciel :
144

Nous présentons maintenant les organigrammes qui décrivent, de manière générale, notre logiciel.
7. 5.1. Organigramme représentant les principales étapes du logiciel :
L’organigramme ci-dessous (figure 7.1.) décrit d’une manière générale les enchaînements des modules qui régissent le logiciel. D’abord, l’utilisateur doit choisir le type de la saisie, ensuite, soit on est en mode graphique et il introduit le graphe de l’application et d’architecture avec leurs caractéristiques graphiquement. Soit en mode matricielle et là il introduit les matrices d’incidences d’architecture et d’application avec leurs caractéristiques sous forme matricielle.
Ensuite, l’utilisateur peut lancer l’algorithme génétique en ayant la possibilité de modifier ses paramètres et les contraintes, puis il consulte le rapport contenant les résultats finaux de la recherche.
7.5.2. Organigramme représentant le fonctionnement de l’algorithme génétique (A.G) :
Les algorithmes génétiques suivent tous un principe commun et l’implémentation présentée n’y fais pas défaut : une phase de constitution de population initiale, suivie de phases de régénération de populations grâce aux opérateurs génétiques de sélection, mutation et croisement, comme l’indique la figure 7.2.
Chaque génération produira, en principe, des placements plus performants que les précédents. Plus le nombre de générations est grand, plus la solution se raffinera et la dernière génération devrait contenir une bonne solution. Pendant le processus de création, deux populations existent en parallèle : la population courante, d’où sont puiser les chromosomes parents, et la nouvelle génération en voix de réalisation, où se retrouverons les chromosomes enfants.
7.5.3. Organigramme représentant le processus d’évaluation des individus d’une population :
L’organigramme de la figure 7.3 représente le processus d’évaluation d’un seul individu de la population. Qui se déroule en deux phases :
1. Plus courts chemins : elle passe par 4 étapes :
. Génération de la matrice d’incidence du coût en temps et cela en éliminant les chemins dont la bande passante est insuffisante et en divisant la taille du message sur les vitesses des bus, on aura en sortie une matrice qui contient les coûts en temps de tous les chemins possibles.
. Trouver les processeurs source et les processeurs destination des messages suivant un placement donné.
145

. La génération des plus courts chemins proprement dits et leurs coûts.
. Affectation des résultats à la matrice des plus courts chemins.
2. Pénalité : on a trois contraintes : équilibrage de charge, mémoire d’exécution disponible et taille de la file d’attente.
Si le placement ne respecte pas les contraintes il sera multiplié par des pénalités qui augmenterons sa fitness et diminuera par conséquent ces chances d’être choisit pour le croisement.
Figure 7. 1. Les principales étapes de l’étude.
Fin
Génération d’un rapport récapitulatif des résultats de l’A.G
Exécution de l’A.G avec des paramètres spécifiques
Valider
Introduire les caractéristiques
Modifier les caractéristiques
Charger à partir du disque
Introduire les graphes d’application et d’architecture
Introduire les matrices d’incidences d’application et d’architecture
Matricielle Graphique Saisie
Début
146

Plus_court_chemin ()
Penalite ()
()
,roulette) i
Non
OuiNouvel pop :=Pop courante
Non
Nouvel_ pop Meilleure Pop_courante
Fin
Affichage ()
Oui
Generer_nouvel_population () Selection(élitiste
Nombre de génération atteint
Oui NonNombre de
chromosomes Atteint
Contrainte_affectation
Evaluation
Corriger_chromosome ()
Population_initial ()
Mutation ()
Initialisation ()
Début
Figure 7. 2. Fonctionnement de l’algorithme génétique.
147

Figure 7. 3. Evaluation d’un individu appartenant à une population.
Equilibrage de charge
Evaluer le coût total des messages (C)
C=C*pénalité équilibrage
Taille mémoire Suffisante
C=C*pénalité mémoire
Taille fille D’attente Suffisante
C=C*pénalité mémoire
plus_court_chemin()
message_source_destination()
matric_temp()
Fin
Début
Non
Non
Non
Oui
FITNESS
Oui
Oui
148
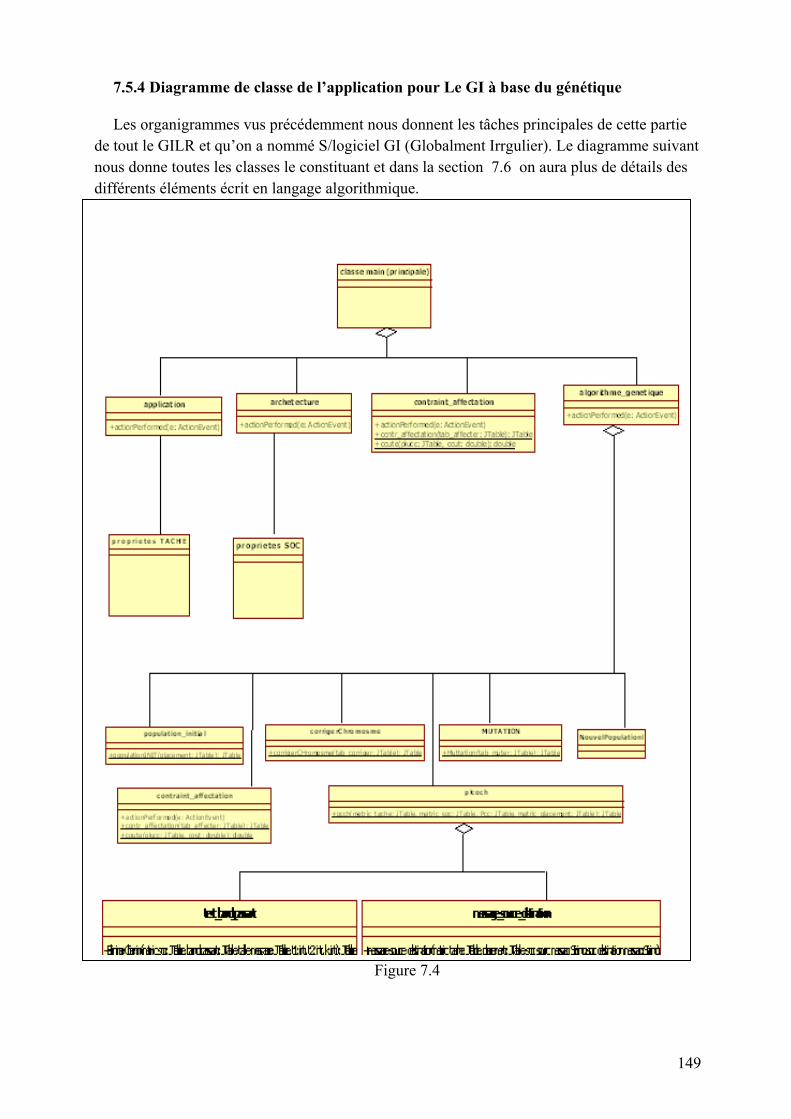
7.5.4 Diagramme de classe de l’application pour Le GI à base du génétique
Les organigrammes vus précédemment nous donnent les tâches principales de cette partie de tout le GILR et qu’on a nommé S/logiciel GI (Globalment Irrgulier). Le diagramme suivant nous donne toutes les classes le constituant et dans la section 7.6 on aura plus de détails des différents éléments écrit en langage algorithmique.
Figure 7.4
149

7. 6. Développement des différents modules :
7. 6.1 Corps du programme principal :
La figure 7.5 montre le programme principal de l’algorithme utilisé.
Une initialisation des paramètres de l’algorithme génétique par l’appel de la procédure initialisation ( ).
Ensuite on génère une population initiale par l’appel de la procédure population_initial( ) pour chaque chromosome en utilisant la procédure mutation ( ).
Figure 7. 5 : Corps du programme principal.
void __fastcall TForm8::Button1Click(TObject *Sender) initialisation(); //Initialisation des paramètres de l'algorithme génétique .
population_initial(); //Génération de la population initiale aléatoirement.
do
for(int i=1;i<=nbr_chromosom;i++)
nb_messag_chrom=0; // le nombre de messages.
cout[i]=0; // Le coût du chromosome i.
entrer(i); // convertie un chromosome i en matrice de placement.
corriger_chromosome(); // corrige les chromosomes afin qu'une tache ne soit
pas Affectée à plusieurs SOC’s en même temps. mutation(); // mutation d'un gène du chromosome i.
contrainte_affectation(); //affecter à l’avance une tache à un SOC .
sortie(i); // convertie la matrice de placement modifiée en
chromosome.
plus_court_chemin(i); // calcule les plus courts chemins du chromosome i.
penalite(i); // multiplie le coût du chromosome i par des penalités s’ il ne respecte pas les contraintes.
150

7 6.1.2. Procédure population_initial ( ) :
Le programme doit commencer par générer aléatoirement une population composée d’individus dont les gènes sont pris au hasard enrichi par quelques chromosomes obtenus selon la méthode du bon choix vue dans le chapitre précédent. C’est cette première génération qui va servir de point de départ à l’algorithme génétique contrairement aux autres algorithmes. Il démarre avec plusieurs individus tirés aléatoirement, ce qui lui permet de choisir les deux meilleures solutions pour démarrer.
void __fastcall TForm8::population_initial() for(int i=1;i<=nbr_chromosom;i++)
for(int a=1;a<=nbr_soc;a++)// initialisation de la matrice de placement à 0.
for(int b=1;b<=nbr_tache;b++) placemen[a][b]=0;
for(int b=1;b<=nbr_tache;b++) placemen[random(nbr_soc-1)+1][b]=1;// génération aléatoire de
la valeur d'un chromosome. sortie(i);
7.6.1.3. Procédure corriger_chromosome ( ) :
La procédure corriger_chromosome( ) sert à corriger les chromosomes afin qu'une tache ne soit pas affectée à plusieurs SOC’s en même temps (voir la figure VI.6).
void __fastcall TForm8::corriger_chromosome() for(int b=1;b<=nbr_tache;b++) // détecte affectations multiples. for(int a=1;a<=nbr_soc;a++) erreur=erreur+placemen[a][b]; if(erreur!=1) // corrige le chromosome . for(int e=1;e<=nbr_soc;e++)placemen[e][b]=0; placemen[random(nbr_soc-1)+1][b]=1;
Figure 7. 6 : Correction des chromosomes.
151

7. 6.1.4. Procédure mutation ( ) :
La procédure mutation ( ) sert à muter un gène de chaque chromosome d’une population
void __fastcall TForm8::mutation() for(int b=1;b<=nbr_tache;b++) if(proba_mutation<=(random(10000)*0.0001)) for(int e=1;e<=nbr_soc;e++) placemen[e][b]=0; placemen[random(nbr_soc-1)+1][b]=1;
Figure 7.7 : Mutation.
l
7. 6.1.5. Procédure contrainte_affectation( ):
void __fastcall TForm8::contrainte_affectation() for(int x=1;x<=nbr_tache;x++) for(int y=1;y<=nbr_soc;y++) if(contraint_affectation[y][x]==1) // affectation de la tache au SOC spécifié
dans la contrainte d'affectation for(int e=1;e<=nbr_soc;e++) placemen[e][x]=contraint_affectation[e][x];
Figure7. 8 : Les contraintes d’affectation.
7. 6.1.6. Procédure plus_court_chemin ( ) :
La procédure plus_court_chemin ( ) sert à calculer les plus courts chemins des messages et eurs coûts en temps d’un chromosome (voir la figure VII.9.).
152

VI. 6.1.6. Procédure penalite ( ) :
void __fastcall TForm8::plus_court_chemin(int i) message_source_destination(); // retourne pour chaque message,son SOC source et
destination. for(int i=1;i<=nbr_messag;i++) // initialisation de la matrice plus court chemin for(int j=1;j<=nbr_soc;j++) plu_court_chemin[j][i]=0; for(int j=1;j<=nb_messag_chrom;j++) sourc_messag=soc_sourc_messag[j]; destination_messag=soc_destination_messag[j]; matric_temp (j); // élimine les chemins dont la bande passante est inférieure à celle requise par le message . for(int f=1;f<=nbr_soc;f++) // retourne le plus court chemin et son coût. mark[f]=0; parcour[f]=0; distanc[f]=999; mark[sourc_messag]=1; parcour[sourc_messag]=0; nbok=1; for(int f=1;f<=nbr_soc;f++) if((matric_archi[f][sourc_messag]!=0)) if(sourc_messag!=0) distanc[f]=StrToFloat(matric_archi[f][sourc_messag]); parcour[f]=sourc_messag; do valmin=998; for(int f=1;f<=nbr_soc;f++) if(mark[f]==0)if(distanc[f]<valmin)valmin=distanc[f];somin=f; mark[somin]=1; nbok=nbok+1; for(int f=1;f<=nbr_soc;f++) if((mark[f]==0)&&(matric_archi[f][somin]!=0)) if(distanc[f]>(distanc[somin]+StrToFloat(matric_archi[f][somin]))) distanc[f]=(distanc[somin]+StrToFloat(matric_archi[f][somin])); parcour[f]=somin; while(nbok<nbr_soc); c=0; //affichage des plus courts chemins et leurs coûts. k=destination_messag; do c=c+1; plu_court_chemin[destination_messag][j]=c; destination_messag=parcour[destination_messag]; while(parcour[destination_messag]!=0);
Figure 7.9
153

La procédure penalite( ) sert à multiplier le coût d’un chromosome par des pénalités s’il ne respecte pas les contraintes d’équilibrage de charge, mémoire disponible et taille de la file d’attente (voir la figure VI.10.).
void __fastcall TForm8::penalite(int i) for(int a=1;a<=nbr_soc;a++) //multiplie les coûts des communications par des
pénalités s’il ne respectent pas les contraintes. fil=0; for(int b=1;b<=nbr_tache;b++) if(placemen[a][b]==1) mem=mem+Form6-> memoir_tach [b]; inst=inst+Form6-> taille_tach [b]; if(inst > Form4->fil[a])cout[i]=cout[i]*penalit_file; if(mem > Form4->mem[a])cout[i]=cout[i]*penalit_memoir; if((inst<(Form4->min[a]))||(inst>Form4>max[a])) cout[i]=cout[i]*penalit_equi_charge;
Figure 7.10 :Evolution de la fitnesse
154

7. 7. Expérimentations pour déterminer les valeurs des paramètres de l’algorithme
Nous avons soumis l’implémentation de l’algorithme génétique détaillée précédemment à une série de tests. Ces tests visent principalement à la mesure de l’efficacité de l’algorithme et de la qualité des solutions qu’il fournit. Nous avons effectué des analyses de sensibilité relatives aux paramètres intrinsèques de l’algorithme génétique, puis mesuré l’évolution de la performance en fonction des variations de ces paramètres.
Les valeurs obtenues pour la configuration de référence sont :
.Taille de la population : 20 chromosomes
.Nombre de générations : 40
.Probabilité de croisement : 0,8
.Probabilité de mutation : 0,25
Etant donné le grand nombre d’expériences possibles, nous avons décidé de ne faire varier qu’un seul paramètre à la fois, les autres conservent les valeurs de la configuration de référence.
7. 7.1. Evolution du temps d’exécution en fonction de la taille du problème :
La figure 7.11 présente l’effet de la taille du problème. Nous avons effectué six expériences de tailles différentes : 15, 25,45, 65, 80, 95. On constate qu’avec une population de 20 chromosomes la convergence devient lente. On a déduit à partir de ce tableau qu’il y a corrélation entre la taille de la population (nombre de chromosomes) et la taille du problème. Ceci nous a amené à dédier une partie de ce travail pour déterminer les intervalles dans les quels on choisi les tailles des populations selon la taille du problème.
influence de la taille du problème sur le temps d'exécutuion
0
500010000
15000
15 25 45 65 80 95
Nombre de taches
Tem
ps
d'ex
écut
ion
Série 1
Figure VII.11 : Influence de la taille du problème sur le temps d’exécution.
155

7. 7.2. Effet du nombre de générations
Nous avons voulu savoir comment se comparent les solutions obtenues à la vingtième, et quarantième génération. Etudions l’évolution des solutions selon les générations. La figure7.12 trace l’évolution des solutions de la configuration de référence de chaque génération. Ce test a été répété plusieurs fois et on trace trois séries correspondant à ces derniers.
Nous pouvons constater que plus le nombre de génération est grand plus la solution s’améliore.
Evolution des solutions en fonction du nombre de générations
0100002000030000
0 5 10 15 20 25 30 40
Nombre de generation
Fitn
ess Série 2
Série 1
Figure 7.12 : Evolution des solutions en fonctions du nombre de générations.
D’après la figure 7.12, on serait porté à croire qu’il n’est pas nécessaire d’étendre la recherche au delà de 20 générations. En effet les expériences tendent plutôt à confirmer qu’un nombre élevé de générations pourrait produire de meilleures solutions en termes de fitness, mais ne détériorera pas la meilleure solution, une fois trouvée.
7. 7.3. Effet de la population :
La prochaine série d’expériences étudie l’influence du nombre de chromosomes de la population sur la qualité de la solution. Nous avons obtenu des résultats pour des populations de 10 et 60 chromosomes. La figure 7.13 Illustre le comportement des solutions de deux séries typiques, avec une population de 10 chromosomes sur une période de 40 générations.
Suivie d'une population de 10 chromosomes
020004000
0 4 10 16 22 28 37
Nombre de generations
fitne
ss
Série 2Série 1
Figure 7.13 : Suivi d’une population de 10 chromosomes.
156

Les résultats confirment l’hypothèse de l’effet qu’une population de petite taille va inévitablement apporter peu de variété aux chromosomes de la population. La figure7.14 indique que la solution optimale a été trouvée après 19 à 22 générations.
Suivie d'une population de 60 chromosomes
05000
1000015000
0 4 10 16 22 28 37
Nombre de generations
fitne
ss Série 2Série 1
Figure 7.14 : Suivi d’une population de 60 chromosomes.
En comparaison, la figure 7.14 Montre le suivie des résultats d’une population de 60 chromosomes sur une période de 40 générations. Nous remarquons qu’il y a une bonne diversité de la population de génération en génération ce qui influe positivement sur la qualité de la solution et la rapidité de la trouver. La figure 7.14. Indique que la solution optimale a été trouvée après la première génération.
Les populations de grande taille sont gage de diversité de chromosomes, et de ce fait de diversité de solutions dans une même population, ceci dit, dans certains cas, la meilleure solution pourrait apparaître même dans la population initiale. Une population de petite taille pourrait tout aussi produire rapidement la meilleure solution, il suffit que des croisements adéquats se produisent.
Donc pour un utilisateur potentiel de ce logiciel on le conseille d’opter pour une population de 100 chromosomes et 20 générations. Ces paramètres sont les plus utilisés par la communauté des chercheurs dans le domaine [98]. En effet pour les problèmes de grandes tailles en général c’est des populations de 100 chromosomes qui sont choisis et c’est ce qu’on a constaté avec nos résultats où souvent avec des populations de 60 chromosomes et plus on a des solutions de bonnes qualités. Ceci dit, pour des problèmes de petites tailles ces paramètres restent valides et ne diminuent pas la qualité de la solution, néanmoins le temps de convergence (ou de recherche) augmente inutilement. C’est pour cette raison que nous conseillons l’utilisateur d’adapter ces paramètres selon ses problèmes.
7. 7.4. Influence de la probabilité de croisement :
Une série d’expériences a été réalisée pour étudier l’influence des variances de la probabilité de croisement. Nous donnerons les valeurs de probabilité suivantes : 0,3 ; 0,6 ; 0,85.
157

Effet des probabilités de croisement
02000400060008000
10000
0,3 0,6 0,85
taux de croisementfit
ness
Série 1
Figure 7.15 : Influence des probabilités de croisement.
Nous remarquons qu’une probabilité de croisement autour de 0,85 donne une grande valeur de fitness donc une solution optimale, cela veut dire que nous retrouvons beaucoup plus de copies intactes de parents jugés performants.
7. 7.5. Influence de la probabilité de mutation :
L’opérateur de mutation a comme seul but d’amener une certaine diversité, les tests de variation de ce paramètre visaient à trouver la meilleure valeur de mutation.
Effet des probabilités de mutation
050000
100000150000
0,05 0,2 0,8
taux de mutation
fitne
ss
Série 1
Figure 7.16 : Influence des probabilités de mutation.
D’après la figure 7.16 nous constatons que les tests ont affirmés que la probabilité de 0.05 donne une grande valeur pour la fonction fitness, c’est-à-dire une solution meilleure.
7.7.6. Influence de l’architecture sur le coût :
Pour faire le mapping on doit avoir en entrée une application et une architecture. Cette dernière est constituée d’un nombre d’éléments d’exécution et des liens physiques qui les lient. La manière de faire ces liens constitue la topologie du NoC. Les caractéristiques des éléments d’exécution sont pris en considération dans le modèle mathématique (chapitre 6) et utilisées comme entrée lors de la saisie du graphe d’architecture. Par contre la manière avec laquelle ce fait les communications n’a pas été introduite dans le modèle. A travers l’expérience suivante on essaye de montrer l’influence de la topologie sur la convergence de l’algorithme de placement et notamment la qualité de la solution. Pour y arriver on a fait
158

exécuter la même application sur différentes architectures ayant des topologies différentes vues dans le chapitre 1. [tableau 7.17].
Effet de l'architecture sur le temps de recherche
0
500
1000
1500
maille anneau bus étoile conexiontotal
Architecture
tem
ps re
cher
che
Série 1
Figure 7.17. Influence de l’architecture sur le temps de recherche
Nous remarquons que toutes les architectures donnent à peu près le même temps de recherche qui varie entre 481 ms et 590 ms, sauf pour celle de l’interconnexion totale qui a donné un temps de 1 s et 111 ms. Nous remarquons aussi que l’architecture en interconnexion totale a donné le temps le plus important. La topologie en maille correspond aux topologies des Mesh-2D. Elle très utilisée dans les systèmes embarqués. Dans tous nos modèles on s’est basé sur elle même si l’application réalisée à travers son paramétrage permet la prise en considération d’architectures avec des topologies différentes.
7.7.7 Mapping multiobjectif d’une application réel
Nous avons repris l’exemple d’une application réelle d’un décodeur vidéo avec communication (figure 7.18).
Figure 7.18 : diagramme de bloc de l’application Figure 7.19 : le graphe de tâche de
l’application figure 7.18
Les communications ainsi que les volumes d’échanges sont donnés par la matrice suivante :
159

t1 t2 t3 t4 t5 t6 t7 t8 t9 t10 t11 t12 t13 t14 t15 t16 t1 70 t2 27 t3 362 t4 362 49 t5 357 t6 353 t7 300 t8 313 t9 313 t10 500 94 t11 16 t12 16 t13 157 t14 16 t15 16 16 t16 362
L’architecture cible est un Mesh-2D constitué de 9 processeurs de deux types différents. Le premier type un GP, le deuxième est un FPGA. La topologie est illustré par le graphe 7.20 où les valeurs sur les arcs indiquent la vitesse de transmission d’une unité de temps et la bande passante du lien correspondant. Les caractéristiques des processeurs sont données par le tableau 3.
Tableau 2 : matrice des communications inter-tâches
P4
P5
P7 P8 P9
P6
4,50 4,50 6,30 6,40 2,40
2,50 6,30 2,50 4,40 4,50
Type du pro
V1 V2 e1 en 10-3
e2 en 10-3
P1 1 200 400 5 7,5 P2 1 100 200 3 4,5 P3 2 650 850 8 12 P4 1 200 450 5 7,5 P5 1 150 250 4 6,5 P6 2 650 950 8 13 P7 2 350 650 6 9 P8 2 400 800 8 12 P9 1 200 300 5 7,5 Tableau 3 : matrcice des caratéristiques de la machine
Figure 7.20
P1 P2 P3 4,50 6,40
V1 la vitesse des processeurs au mode minimum c'est-à-dire lent elle correspond au nombre de cycle exécutés par unité de temps, e1 étant l’énergie consommée en unité voltage pour l’exécution d’un cycle à cette vitesse. V2 et e2 ont les mêmes définitions mais au mode max des processeurs, c'est-à-dire le mode rapide. Les tailles des tâches sont données dans le tableau 4 suivant. Ces tailles sont mesurées en nombre de cycles selon le type de processeur.
160

Tâche Nombre de cycles selon processeurs type 1
Nombre de cycles selon processeurs type 2
t1 14000 19000 t2 30000 36000 t3 24000 16000 t4 30000 36000 t5 14000 19000 t6 25000 15000 t7 32000 18000 t8 45000 32000 t9 17000 19000 t10 17000 19000 t11 25000 15000 t12 14000 19000 t13 32000 18000 t14 24000 16000 t15 17000 19000 t16 30000 36000
Tableau 4 : Les tailles des tâches selon le type du processeur
En utilisant le GI on obtient toutes les bonnes solutions vérifiant les deadlines obtenues au mode max. Ces placements sont donnés dans le tableau 3 suivant où la première colonne désigne les tâches, les autres colonnes les différents placements c'est-à-dire les processeurs auxquels ces tâches sont affectées. L’avant dernière ligne nous donne les coûts d’exécution en unité de temps (ut) correspondants aux différents placements.
Tâche Pla1 Pla2 Pla3 Pla4 Pla5 Pla6 Pla7 Pla8 Pla9 Pla10 Pla11 Pla12t1 P9 P6 P8 P8 P4 P1 P6 P3 P3 P8 P1 P1 t2 P2 P2 P4 P1 P2 P2 P4 P4 P6 P7 P7 P2 t3 P9 P3 P3 P2 P2 P3 P3 P3 P9 P9 P9 P9 t4 P5 P1 P1 P1 P1 P1 P9 P6 P6 P6 P6 P6 t5 P3 P3 P3 P3 P6 P6 P6 P9 P5 P5 P5 P5 t6 P8 P8 P8 P8 P5 P5 P5 P1 P1 P1 P4 P4 t7 P6 P6 P4 P4 P4 P8 P1 P1 P4 P4 P4 P2 t8 P4 P5 P6 P7 P7 P7 P7 P2 P2 P3 P3 P3 t9 P4 P4 P2 P1 P3 P3 P2 P5 P5 P4 P4 P4 t10 P2 P2 P2 P2 P2 P3 P3 P8 P8 P8 P8 P8 t11 P1 P1 P5 P5 P5 P5 P5 P4 P7 P7 P7 P7 t12 P1 P7 P7 P6 P6 P6 P6 P3 P3 P6 P4 P4 t13 P2 P2 P9 P3 P9 P2 P2 P1 P4 P4 P4 P3 t14 P1 P1 P9 P9 P9 P9 P7 P7 P7 P7 P7 P7 t15 P4 P4 P4 P4 P4 P4 P4 P9 P9 P9 P9 P9 t16 P8 P8 P8 P2 P2 P1 P2 P2 P82 P4 P1 P1 Coût d’exéc -ution
1913
,9
1775
,4
1693
,29
1689
1843
,70
1759
,64
1764
,06
1876
,68
1763
,15
1583
,99
1715
1751
Tableau 5 : Les meilleurs placements
161

Les coûts correspondants aux consommations d’énergie de ces placements sont donnés par le tableau suivant : Placement Pla1 Pla2 Pla3 Pla4 Pla5 Pla6 Pla7 Pla8 Pla9 Pla10 Pla11 Pla12 Consommation d’énergie en 10-3 mv
2926 3164 3190 2937 2793 2998 2920 3106 3198 3465 3238 2953
Tableau 6 : Les consommations d’énergie des placements trouvés
Le deadline de cette application est de 18000 ut, donc des meilleures solutions données dans le tableau 5 on dégage l’ensemble S’ des solutions vérifiant le deadline.
S’= Pla2, Pla3, Pla4, Pla6, Pla7, Pla9, Pla10, Pla11, Pla12
On constate que pour le moment le meilleur en temps d’exécution c’est le placement 10, il est aussi le plus coûteux en terme de consommation d’énergie. Le tableau suivant illustre le placement et l’ordonnancement obtenu pour le Placement 10. Le scheduling des autres placements s’obtient de la même manière.
Placement ordonnacement
tâche processeurCoût execution
Coût comm
Coût total Tdebut Tfin
t1 P8 23,75 17,50 41,25 0,00 41,25 t2 P7 55,38 0,00 55,38 41,25 96,63 t3 P9 80,00 181,00 261,00 96,63 357,63 t4 P6 37,89 120,67 158,56 357,63 516,20 t5 P5 56,00 119,00 175,00 516,20 691,20 t6 P1 62,50 117,67 180,17 691,20 871,36 t7 P4 71,11 117,67 188,78 871,36 1060,14 t8 P3 37,65 100,00 137,65 1060,14 1197,79 t9 P4 37,78 52,17 89,94 1197,79 1287,73 t10 P8 23,75 99,00 122,75 1287,73 1410,48 t11 P7 23,08 88,25 111,33 1472,66 1583,99 t12 P6 20,00 3,20 23,20 1287,73 1310,93 t13 P4 71,11 0,00 71,11 1310,93 1382,04 t14 P7 24,62 4,00 28,62 1382,04 1410,66 t15 P9 56,67 5,33 62,00 1410,66 1472,66 t16 P4 66,67 120,67 187,33 516,20 703,53
Tableau 7 : Placement et ordonnancement
L’ordonnancement est obtenu par liste LS. Le temps de fin de l’application selon ce placement est égal au temps de fin de la dernière tâche, Tfin=Tfin(T11)= 1583,99 ut. Le temps d’exécution de l’application est égal au temps de fin de la dernière tâche moins le temps de début de la première tâche dans l’exécution. Pour simplifier les calculs on a pris comme temps de début l’instant Tdeb(T1)=t0=0 alors D=Tdeb(T1)-Tfin(T11)= 1583,99
Processeurs
162

P9 t3 t15 P8 t1 t16 t10 P7 t1 t14 t11 P6 t4 t12 P5 t5 P4 t7 t9 t13 P3 t8 P2 P1 t6
Temps d’exécution
Tableau 5 : explicitant le placement et l’ordonnancement des différentes tâches
Dans la deuxième phase de ce mapping objectif on essaye, pour les placements de l’ensemble S, de ralentir les processeurs afin de minimiser l’énergie de tout en respectant les deadlines. Ceci va nous permettre de ne garder que les solutions non dominées finales qui vont nous donner le front Pareto optimal. Le tableau suivant récapitule les solutions non dominées constituant le front Pareto.
(exécution, énergie) =(1913,2926), (1775.14,3164), (1689,2937), (1843.70,2793), (1759.64,2998), (1764.04,2920), (1876.68,3106), (1763.15,3198), (1583.99,3465), (1715,3238), (1751, 2953), (1696.62, 2876), (1714.11, 2804), (1723.34, 2811), (1775, 2590), (1838.31, 2527), (1706.85, 2811), (1842.96, 2688).
L’interprétation graphique de ces solutions est illustrée par le graphe 7.21 suivant.
1913,00Deadline
2000,002100,002200,002300,002400,002500,002600,002700,002800,002900,003000,003100,003200,003300,003400,003500,003600,00
1500,00 1600,00 1700,00 1800,00 1900,00 2000,00
temps d'exécution
éner
gie
1775,001693,001689,001843,001759,001764,001876,001763,001584,001715,001751,001697,001714,001723 00
Front Pareto
Point idéal
Graphe 7.21 : Front Pareto des solutions de ce problème
163
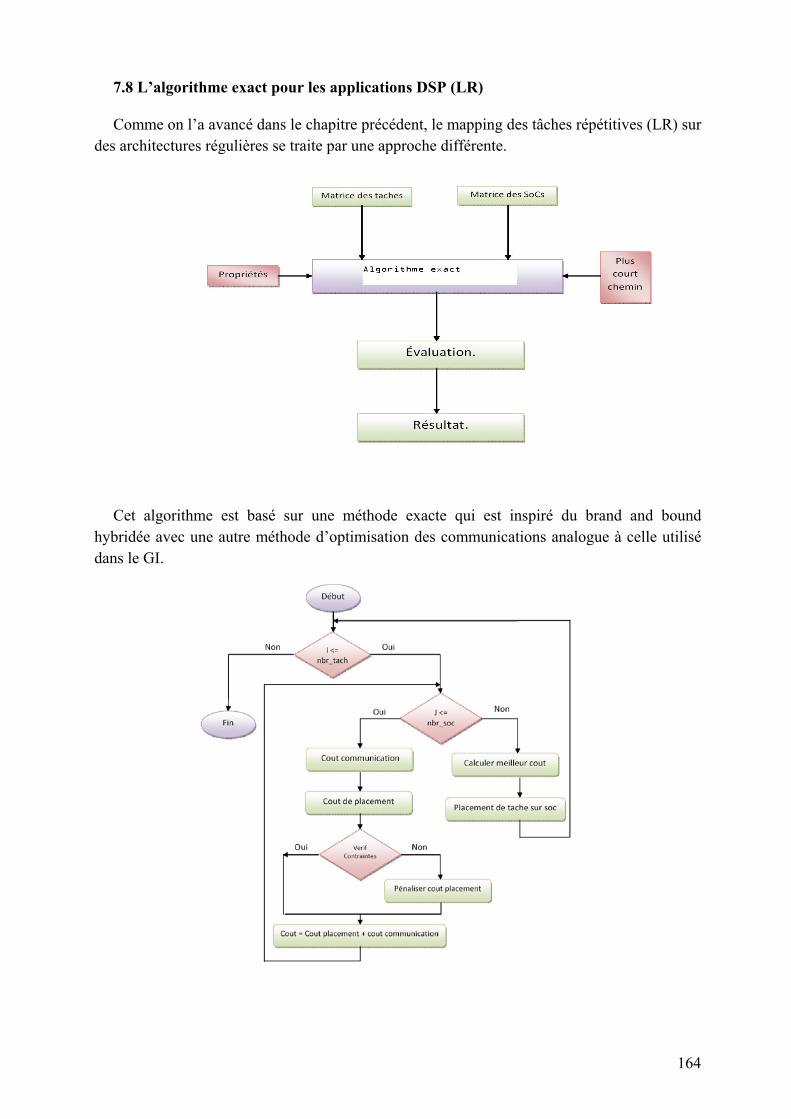
7.8 L’algorithme exact pour les applications DSP (LR)
Comme on l’a avancé dans le chapitre précédent, le mapping des tâches répétitives (LR) sur des architectures régulières se traite par une approche différente.
Cet algorithme est basé sur une méthode exacte qui est inspiré du brand and bound hybridée avec une autre méthode d’optimisation des communications analogue à celle utilisé dans le GI.
164
Ici, aussi, on a essayé de travailler dans le même environnement de développement pour avoir, à la fin, un produit entièrement intégré. La modélisation par UML et sa translation dans notre contexte de développement a donné lieu à un ensemble de classes dont celle présentée ci-après constitue un exemple.
7.8.1 Résultats
Cet algorithme a été élaboré pour les tâches répétitives afin de pouvoir trouver un motif selon la spécification d’Array-Ol présenté dans le chapitre 3. Donc le but est de trouver un sous ensemble de tâches qui peuvent s’exécuter en exploitant d’une façon optimale les ressources. Cet ensemble de tâches va être répété jusqu’à exécution de toutes les autres tâches. Mais avant de chercher ces résultats, on a essayé de valider nos résultats par rapport à d’autres outils qui font référence dans cette problématique. Le premier outil est Syndex, développé spécialement pour les calculs vectoriels de grandes tailles. Le deuxième outil est celui développé par Menna au sein de l’équipe west et qui donne lui aussi de bons résultats. Donc on a exécuté notre algorithme pour des applications à tâches répétitives sur des architectures de 16, 64, 256 et 1024 processeurs. Ces résultats sont comparés, à ceux obtenus par les deux outils cités auparavant, dans le tableau 8 suivant.
Taille matrice
Syndex (unité de temps)
Flatten Non Flatten
Menna LR
4*4=16 40 78 26 32 8*8=64 98 288 74 56 16*16=256 303 1062 266 126 32*32=1024 1176 4166 1034 2100
Tableau 8 : Résultats comparatifs entre notre approche, Syndex et Menna.
Les expériences suivantes nous ont permis de trouver le motif ayant le meilleur AAS. La figure 7.22 illustre le placement de 12 tâches répétitives ainsi que leurs communications sur 5 processeurs. Ce même profil est répété pour exécuter toutes les autres tâches. Ce placement est optimal car il minimise le temps de repos (slack) des processeurs en permettant par là d’exploiter au maximum les ressources disponibles sur une longue durée.
165

Nous constatons que nos résultats ne sont toujours meilleurs par rapport aux autres outils (Syndex et Hashesh). Syndex est un outil très puissant et il est considéré comme un standard pour ce type d’application. Néanmoins, ces deux outils ne prennent pas en considération les modes différents des éléments d’exécution et de communication. C’est ce qui constitue un plus et un avantage dans notre application LR.
7.9 La méthode
Nous avons dévelooptimal d’un ensembldéveloppé permet d’inl’application, le secondappartenant à un des composés ou répétitifsGILR. Donc dans cetteprécédemment sont urépétitifs ou composéssommet-sommet, à cau
Les Tâches
Les SoC
Figure 7.22 : Recherche du meilleur motif
pour le hiérarchique (ou le GILR)
ppé une application qui permet de calculer le résultat de placement e de tâches hiérarchiques sur une application hiérarchique. L’outil troduire deux graphes hiérarchiques (figure 7.23). Le premier modélise modélise l’architecture. Ces deux graphes sont composés de noeuds trois types de nœud définis dans le chapitre3 : les nœuds simples, . Dans le chapitre précédent on a présenté notre démarche pour le application les deux résultas des deux logiciels ( GI et LR) présentés
tilisés comme entrée à chaque appel selon le traitement de nœuds . L’introduction de ce graphe se fait par une matrice d’incidence se des dépendances et communications entre les tâches.
Meilleur placement des tâches
sur les SoC
GILR Mapping Simulator
Figure 7.23
166

Les différents composants de cet outil sont illustrés par le diagramme de classe de la figure 7.24.
Cout Test_band_passanteplCoCh
GI
Figure 7.24 : Diagramme de classe de l'application
7.9.1 Descriptif de l’application
Nous allons présenter l’interface de notre application. Dans la première fenêtre, on trouve deux zones textuelles où on peut introduire le nombre de tâches et le nombre des SoC’s.
Permet l’accès au résultat (placement)
Champ permettant d’introduire le nombre de SoC’s
Champ permettant d’introduire le nombre de tâche
Figure 7.25 : la fenêtre principale
167

Espace pour introduire la taille des tâches et des messages
Onglet arbre hiérarchique
des tâches Onglet matrice des tâches
Onglet propriétés SoC’s Onglet propriétés messages
7.26 : Saisie d’un graphe hiérarchique
168

Figure 7.27 : saisie d’une architecture hiérarchique
Espace pour introduire des propriétés des SoC’s et de bandes passantes identiques
Onglet arbre hiérarchique des SoC’s
Onglet matrice des SoC’s
Onglet propriétés SoC’s Onglet propriétés bande passantes Onglet vitesse bus
169

Et enfin la dernière fenêtre permet de donner le résultat du placement final représenté par un arbre hiérarchique dont chaque nœud contient une matrice de placement qui est dans l’onglet à droite.
Figure 7.28 : Le mapping GILR sous forme de graphe hiérarchique
7.9.2 Etude de cas et validation expérimentale
Nous allons, ici, exposé une étude de cas à l’aide d’un exemple plus complet, et ainsi valider de manière expérimentale les différentes contributions et leurs intégrations dans le processus complet. Le modèle de SoC qu’on va présenter est un encodeur vidéo H.263 placé sur une architecture multiprocesseur.
7.9.2.1 Application encodeur H.263 sur MPSoC
Nous avons choisi cette application car elle est typique des applications visées par Gaspard : C’est une application gourmande en puissance de calcul effectuant un traitement d’image. Le standard H.263 [ref 28 peil] permet de compresser un flux vidéo. Il a été développé pour la transmission de la vidéo sur des lignes à très bas débits pour les applications de visiophonie, les systèmes de surveillance sans fil, etc tel que chaque image de la vidéo est traitée séparément. L’implémentation que nous visons convertit une vidéo au format QCIF dans le format compressé H.263. L’application est composée de trois tâches exécutées séquentiellement :
- La transformée en cosinus discrète (DCT, pour Discrete Cosine Transform) permet d’éliminer la redondance de données et de transformer les données du domaine spatial en une représentation fréquentielle.
170

- La quantification consiste à diviser chaque coefficient de la DCT par un pas de quantification et mettre les coefficients non significatifs à zéro.
- Le codage permet d’encoder les macro-blocs traités en attribuant à chaque coefficient DCT quantifié un mot binaire dont la longueur est d’autant plus courte que le coefficient est fréquent. La méthode de codage utilisée est celle de Huffman [56 piel].
La taille d’une image d’une séquence QCIF est de 176x144 pixels. Dans l’algorithme d’encodage, les données manipulées sont structurées sous forme de macro-blocs qui représentent un espace de 16x16 pixels d’une image vidéo. Le format de données du macro-bloc est le YCbCr qui contient trois composantes : luminance (Y), chrominance bleu (Cb), et chrominance rouge (Cr). Les blocs de luminance décrivent l’intensité des pixels tandis que les blocs de chrominance contiennent des informations sur les couleurs des pixels. La couleur verte n’est pas explicitement codée, elle peut être dérivée à partir des valeurs des trois composantes. Un macro-bloc contient 6 blocs de 8x8 valeurs : 4 blocs contiennent les valeurs de la luminance, un bloc contient les valeurs de la chrominance bleu et un bloc contient les valeurs de la chrominance rouge.
La figure 7.29 présente l’algorithme tel qu’il a été modélisé à l’aide du profil Gaspard. On peut voir chaque niveau de hiérarchie en parcourant le modèle de haut en bas. VideoSequence est le composant de base, il contient juste une répétition de 400 QCIF2H263. Cela permet de traiter 400 images d’une vidéo. Ce nombre correspond à la séquence vidéo de référence que nous utilisons pour les simulations. Pour la génération finale du SoC le concepteur placerait là une répétition infinie (représentée par le caractère ~ ). Comme à chaque fois pour les tâches de base, elle ne contient aucun port, étant donné qu’elle ne nécessite pas d’être connectée à d’autres tâches : les entrées et sortie se font via des sous tâches dédiées.
QCIF2H263 est le composant qui traite une image, il est composé de trois sous tâches. La tâche QCIFReader se charge de lire une séquence vidéo au format QCIF et produit trois tableaux, chacun correspondant à une composante YCbCr. Dans le cadre de la simulation, nous déploierons cette tâche sur une fonction lisant un fichier, mais dans la réalité cette tâche sera chargée de l’acquisition des données depuis une caméra. Quant à la tâche CompressFileSave, elle se charge de sauvegarder le flux compressé. Le format utilisé est choisi pour accommoder la restriction posée par le modèle de calcul : il oblige à connaître à l’avance toutes les tailles des tableaux de données. Les données sont transmises via un tableau dont la première dimension est de 384 éléments, tandis qu’un second tableau spécifie le nombre réel d’éléments utilisés (si la compression a été efficace, largement inférieur à 384). 384 correspond à la taille maximale d’éléments que peut générer l’encodeur à partir d’un macro-bloc (8x8x6).
Entre ces deux tâches la tâche d’encodage H263Encoder est appelée. Elle contient réellement tout l’algorithme pour encoder une image. C’est une tâche répétitive qui a pour sous tâche H263MacroBlock. La répétition consiste à travailler sur chacun des 11x9 macro-blocs composant l’image. Comme on peut le voir par la taille des ports d’entrée de H263MacroBlock, un macro-bloc correspond à 16x16 pixels de la luminance et 8x8 pixels des chrominances. La découpe de l’image d’entrée se fait à l’aide des Tilers. Par Exemple, le Tiler
171
pour la chrominance bleu a un ajustage de ((1,0), (0,1)) indiquant une tuile compacte : lorsque l’on avance d’un élément dans la première dimension du motif, on avance également d’un élément dans la première dimension du tableau et lorsque l’on avance d’un élément dans la seconde dimension du motif, on avance d’un élément dans la seconde dimension du tableau.
Figure la fenêtre de placement
172

Figure 7.29 : Vue principale de l’implémentation de l’encodeur H.263 en mode Gaspard.
Le pavage est de ((8,0),(0,8)) : pour lire le motif suivant dans la première dimension de la répétition il faudra se décaler de 8 pixels dans la première dimension du tableau, de même pour la seconde dimension. Cela est illustré dans la figure 7.30. Les motifs ayant une taille de 8x8, les tuiles dans le tableau sont bord à bord. Enfin, l’espace de répétition est de 11x9, on va donc lire l’ensemble des 88x72 éléments du tableau.
cl
lpac
hau
tlrc
udulqf
Figure 7.30 : Vue partielle du tableau des éléments de chrominance. Chaque lecteur de motif orrespond à une tuile compacte de 8x8 éléments du tableau. Ici sont représentés les éléments us pour trois répétitions de tâche différentes.
Pour l’écriture du flot compressé, les deux dimensions de l’espace de répétitions sont inéarisées. Ainsi le Tiler entre les ports size a un pavage de ((1),(11)) indiquant que pour la remière dimension de la répétition il faut placer chacun des 11 éléments lus les uns après les utres et que pour la seconde dimension de la répétition il faut se décaler de 11 éléments à haque fois, écrivant ainsi chaque bloc de 11 éléments l’un après l’autre.
Le composant H263MacroBlock correspond à l’algorithme tel que nous l’avons décris plis aut : un appel à la DCT (Dct2MacroBlock), puis à la quantification (Quan2MacroBlock), et u codage (Coding). Cette dernière tâche est une tâche élémentaire, nous l’avons déployé sur n adaptateur appelant une fonction de code de Huffman.
Le composant Dct2MacroBlock se charge d’appeler pour chaque bloc de 8x8 éléments la âche élémentaire Dct2Block qui effectue une DCT bi-dimensionnelle. Ainsi, pour traiter la uminance, des Tilers permettent de découper le bloc de 16x16 en quatre motifs puis de econstituer le bloc complet. Similairement, le composant Quan2MacroBlock appelle pour haque bloc de 8x8 éléments la tâche élémentaire Quan2Block qui effectue une quantification.
Les fonctions auxquelles correspondent les tâches élémentaires n’étant pas disponibles dans ne bibliothèque de composants (telle GaspardLib), nous avons décrit entièrement le éploiement de chaque tâche élémentaire directement dans le modèle. La figure 7.31 présente ne partie du déploiement des tâches élémentaires. Quan2Block est déployée sur ’implémentation abstraite quantization, qui ne contient qu’une seule implémentation d’IP : uantization-c. Cette implémentation utilise un fichier (quantization.c) et fait appel à la onction quant_2d().
173

Le type des ports de l’implémentation défini le type des données traitées, il est unsignedchar pour l’entrée comme pour la sortie. Remarquons que ce type de données est élément explicite du modèle, on retrouve sa définition comme type primitive en bas à droite dans la figure. Enfin, il faut également noter que la dépendance ImplementedBy porte deux spécialisations : X_SIZE et Y_SIZE. Elles sont utilisées par la quant_2d() pour connaître la taille des tableaux de donnée, elle peut être adaptée à n’importe quelle taille de données. La caractéristique executionTime qui permettra à la simulation PA de simuler le temps de traitement a été mesurée manuellement dans une simulation du processeur au niveau CABA.
Similairement, la tâche élémentaire QCIF correspond à une taille d’image spécifique de 176x144 pixels, l’implémentation d’IP contenue, qcif-from-file-c ne permet pas au concepteur de spécifier la taille des données qu’elle génère : chaque port a une taille fixée.
Figure 7.31 : vue du déploiement des tâches élémentaires Quan2Block et QCIFReader. En bas à droite est présenté le type des données traitées par les fonctions : unsigned char.
174

7.9.2.2 Architecture matérielle
L’architecture matérielle modélisée est relativement simple (figure 7.32). Elle a pour composant principal HardwArchit. Ce composant est composé de deux mémoires, un réseau d’interconnexion et quatre processeurs MIPS. Le réseau d’interconnexion est un crossbar modélisé à l’aide de deux ports multiples. L’un de ces ports est de type In et permet de connecter les composants ayant des ports initiateurs de transaction (tels que les processeurs). En fonction du nombre de composants à brancher le concepteur peut faire varier sa multiplicité. Similairement, l’autre port est de type Out, auquel on peut connecter les composants ayant des ports esclaves lors des transactions.
C’est sur ce second port que sont connectées les deux mémoires. L’une des mémoires est destinées aux données et l’autre aux instructions mais même si les noms choisis sont expliites, vis-à-vis du code généré ce n’est pas dans le modèle d’architecture que cette sémantique est spécifiée, elle sera spécifiée lors de l’association. Les deux composants sont élémentaires, ils sont déployés sur une implémentation abstraite de RAM disponible dans la bibliothèque de composant GaspardLib. Pour relier ces composants sur un port différent du réseau d’interconnexion, nous utilisons deux Reshapes qui indiquent comment distribuer le port d’une mémoire sur le slave de multiplicité 2. Ainsi les deux Reshapes sont pratiquement identiques : ils sélectionnent le port de la mémoire grâce au Tiler tin puis le lace dans le tableau du port slave gâce à l’autre Tiler. Pour la mémoire i, l’origine du Tiler est 0, tandis que pour d l’origine est 1. Les mémoires sont ainsi connectées respectivement au port slave d’indice 0 et 1.
Le composant MultiMips a une interface avec un port de multiplicité 4, il est donc possible de le connecter directement au réseau d’interconnexion. Ce composant est un composant répétitif : il contient un sous-composant ProcessingUnit répété quatre fois. C’est ainsi que l’on spécifie que l’architecture est quadriprocesseur. Le composant ProcessingUnit est lui-même composé de deux sous-composants. Il contient un processeur nommé mips et un cache nommé c qui fait l’interface entre le processeur et l’extérieur de ‘unité de calcul.
Même si les types des composants élémentaires indiquent leur fonction générique (processeur, réseau de communication, RAM) et que les noms des composants élémentaires ont été choisis de manière à refléter au mieux la fonctionnalité des composants, pour la transformation ils ne signifient rien tant qu’ils n’ont pas été déployé sur IP. La figure 7.33 présente le déploiement des composants Cache et MIPS. Nous avons pu utiliser des IP définis dans la bibliothèque GaspardLIb présenté dans les chapitres précédents. Ainsi, après importation de cette bibliothèque dans le modèle, Cache a été déployé sur une implémentation abstraite d’un cache de 32Ko. MIPS a été déployé sur une implémentation abstraite de processeur MIPS. La caractéristique selectdFrequency=100 a été ajoutée afin de choisir la vitesse d’exécution du processeur. Notons que dans le cadre de la génération vers une simulation PA, l’implémentation du processeur n’est utilile que pour connaître l’interface des ports, les IP ne sont pas utilisés à ce niveau d’abstraction.
175

Figure 7.32 : Vue principale de l’architecture matérielle du MPSoC en modèle Gaspard
Figure 7.33 : Vue du déploiement des composants Cache et MIPS
176

Le diagramme de l’application (figure 7.29) nous permet d’extraire le graphe de tâche hiérarchique (figure 7.34). On peut faire de même pour le graphe d’application hiérarchique à partir de la figure 7.33.
CSoCtousrépé
Ohiéraprécplacl’hiéprocl’app
Figure 7.34 : Graphe de tâche hiérarchique de l’encodeur H.263
’est un graphe de tâche hiérarchique type aux graphes d’applications placées dans les . En particulier Gaspard prend bien en charge ce type de graphe et permet de les traiter à les niveaux de son flot de conception. On remarque que la tâche H263mb est une tâche titive qui se répète 11x9 fois. De même pour dctlum et quanlum qui se répètent 2x2 fois.
n a essayé, à travers cette expérimentation de monter la pertinence de traiter des graphes rchiques lors d’un placement. Les qualités des placements ont déjà été discutées
édemment pour le GI et le LR. Ce graphe mis à plat est constitué de 110 tâches. Le ement de ces tâches comme un graphe non hiérarchique c'est-à-dire qu’on a enlevé rarchisation a trouvé la solution dans un temps de 75 ut. Le meilleur placement sur les esseurs, mais cette fois ci en prenant en considération l’aspect hiérarchique de lication, a été trouvé dans un temps de 67ut (figure 7.36).
177

Figure 7.35
Placement hiérarchique (67 ut)
Placement non hiérarchique (75 ut)
Temps de recherche
Figure 7.36
En essayant de généraliser pour d’autres problèmes, on a fait des expérimentations sur des applications ayant un nombre de tâches différents pour des niveaux différents. C'est-à-dire qu’on a pris une application ayant un nombre de tâches égal à 50 par exemple qu’on a essayé de placer sur une architecture en considérant son HTG dans la première phase à un seul niveau. Ensuite à deux niveaux, etc. On a procédé de la même manière pour les autres applications ayant des nombres de tâches différents (tableau 9).
178

Nombre de taches Niveau1 Niveau2 Niveau3 Niveau4 10 37 32 33 29 20 64 59 58 54 30 75 72 69 63 40 80 75 76 71 50 86 82 79 73
Tableau 9 : Les évolutions des temps de recherche selon les tailles des applications et le nombre de niveaux u HTG
Figure 7.37 : évapplication et du no
100
Un autre résultahiérarchisation desQuand on est en faplus à partir des réquand on a des grale temps de rechconsidération propl’espace de recheNéanmoins la hiéraniveau important inexpérimentations adans laquelle l’algo
7.10 Conclusi
Ce chapitre on lest d’expérimenter L’équipe DaRT dade ces système. Gadans ce flot. Ce sotout travail académde faire d’autres domaine.
d
olution des temps de recherche du GILR en fonction de la taille des mbre de niveau
X10
0
1020
3040
50
6070
8090
1 2 3 4 5
nombre de tâches
tem
ps d
e re
cher
che
Série2Série3Série4Série5
t qu’on peut déduire suite à l’implémentation de notre approche est que la applications facilite leurs représentations, modélisations et traitements. ce d’applications de très grandes tailles cet argument est très important. En sultats obtenus on a constaté que la cherche de solutions est plus rapide phes hiérarchiques à plusieurs niveaux. Ceci peut s’explique par le fait que erche, de n’importe quel algorithme de placement, est en première ortionnel à la taille de l’espace de recherche. En effet plus la taille de rche est grande plus le temps de recherche des solutions est grand. rchisation a des limite, car on a aussi constaté d’un autre coté un nombre de flue inversement sur le temps de recherche. Donc il faut encore pousser les
fin de déterminer une plage de niveau en fonction des tailles des problèmes rithme est efficace.
on
’a complètement dédié à la mise en ouvre de notre approche. Notre souci cette approche dans un contexte spécifique qui est dans notre cas les NOC. ns la quelle j’ai mené ce travail est spécialisée dans les flots de conception pard est son produit et notre travail on a essayé en premier de le placer uci ne doit pas aussi nous éloigner des autres objectifs que doit atteindre ique et en particulier une thèse d’état. C’est dans cet esprit qu’on a essayé expérimentations plus larges pour des problèmes réels divers dans le
179

CONCLUSION GENERALE
180

Conclusion générale
Durant la conception des systèmes informatiques beaucoup de contraintes doivent être prises en considération par les concepteurs. Ces contraintes deviennent encore plus importantes et pertinentes dans les systèmes distribués et spécialement les systèmes distribués embarqués (NoC). En effet, dans ces derniers où en parle de co-modeling pendant la conception; les contraintes matérielles et logicielles ne sont plus prises séparément comme dans les systèmes traditionnelles mais elles sont considérées en même temps. Dans ce type de système où on fait du logiciel dédié et inversement pour le matériel, les deux types de contraintes sont vérifiées en même temps. Ces dernières, du fait de la nature du système, sont diverses. On parle de contrainte de consommation d’énergie, de contrainte temps réel, de surface, de mémoire, etc. Donc pendant la co-conception et surtout lors de la phase de mapping on doit les prendre en considération. Par mapping on parle d’assignation, d’affectation et d’ordonnancement d’éléments d’applications sur des éléments d’architectures. Ce problème est souvent désigné dans la communauté par l’AAS (Assignation, Affectation et Scheduling). Les contraintes dont on a parlé ne peuvent être traitées séparément d’où pour que l’AAS soit réaliste on doit considérer certaines d’entre elles comme des objectifs qu’on doit atteindre simultanément. C’est ce qui rend ce problème, un problème d’optimisation combinatoire multi-objectif (MOP).
Plusieurs approches on été proposées pour résoudre ce problème (l’ASS), mais la plupart l’ont traité comme un SOP, c’est à dire un problème à un seul objectif. Donc notre première contribution se situe à ce niveau en essayant de traiter le problème de mapping dans les NoC Comme un MOP et non pas comme un SOP. Dans notre travail on a plutôt traité deux objectifs et des contraintes mais qui peut être facilement étendu à plusieurs objectifs. Pour cette démarche et à cause de la nature du problème on a proposé un algorithme hybride. Une partie de l’algorithme se base sur une méthode évolutionnaire pour la recherche de solutions acceptables en trouvant l’ensemble du front Pareto. Le choix de cette méthode est surtout du, d’une part à proposer une solution pour des problèmes de grandes tailles, et d’autre part, avoir une démarche multi-objectif. L’autre partie de l’algorithme est basée sur une heuristique d’optimisation des communications. Cette dernière est très importante car d’elle dépend en partie la qualité de la solution. Dans un NoC, où les chemins de communication peuvent varier, la recherche du chemin permettant d’optimiser, et la latence, et l’énergie consommée durant le transfert des données ne peut qu’améliorer sensiblement et qualitativement la solution finale. L’implémentation des algorithmes proposés a été faite dans un environnement basé sur l’approche IDM permettant l’interopérabilité des IP logiciels. Les résultats obtenus peuvent être considérés satisfaisants et qui peuvent être améliorés surtout sur le volet du temps de convergence en essayant avec d’autres travaux de bien cerner les paramètres des algorithmes proposés, notamment l’algorithme évolutionnaire. On peut aussi essayer de revoir les algorithmes proposés pour plus d’optimalité et les rendre plus efficaces.
Une autre partie très importante de notre travail consistait à proposer une solution pour le mapping des applications DSP sur des architectures régulières. Ce problème ne peut être traité de la même manière que celui précédemment évoqué même si on doit considérer les mêmes objectifs et les même contraintes. Tel que on les a vu dans le chapitre 3, les applications DSP qu’on a présenté avec le langage Array-ol présentent une spécificité particulière. Elles traitent
181

de grande quantité de données mais de la même manière, c'est-à-dire qu’il y a répétition dans les calculs. Donc même si la taille des données est importante, l’espace de décision est réduit. C’est ce qu’on a exploité en proposant une méthode exacte qui nous permet d’atteindre plusieurs objectifs à optimiser. Le motif trouvé est constitué d’un nombre réduit de tâches qui exécutent des données différentes et qu’on réitère l’exécution à l’infini sans que ceci n’augmente la complexité de la méthode.
Le dernier volet de notre travail et qui constitue une contribution très importante par son originalité, car il n’a jamais été traité par les chercheurs travaillant dans ce domaine, consiste à faire le mapping des applications hiérarchiques. Ce problème consiste à placer une application hiérarchisée sur une architecture ayant la même structuration. C’est ce qu’on appelle le GILR (Globalement Irrégulier Localement Régulier). La démarche proposée et après expérimentation nous a permis de constater que la hiérarchisation des applications et des architectures permet de réduire considérablement la complexité.
182

BIBLIOGRAPHIE
183

[1] Ivan Doynov Petkov. « Conception des bibliographies des systèmes multiprocesseurs de la simulation vers la réalisation », thèse de doctorat 2006
[2] J.Jannotti, D.Gifford, K.Johnson, M.Kaashoek, and J.O’Toole. Overcast :Reliable multicasting with an overlay network. In Proc. Of USENIX OSDI’00, San Diego, California, pages 197-212, October 2000.
[3] Wikipedia. Informatique embarqué. Wikipédia l’encyclopédie libre. http://fr.wikipedia.org/wiki/informatique embarqué.
[4] EETIMES.RONW, « Is SoC really different ? ». EETIMES 1999. http://WWW.eetimes.com/story/OEG1999110850009.
[5] Hamond L.Olokotun K. “ Consideration in the design of hydra : A multiprocessor-On-Chip micro-architecture”, Stanford Technical Report CSL-TR-98-749, Stanford University, 1998.
[6] Amer Baghdadi : “L’exploitation est conception systématique d’architecture multiprocesseurs monopuces dédiées à des applications spécifiques », thèse de doctorat 2002.
[7] P.Guerrier et A.Greiner, « A generic Architecture for On Chip Packet-Switched Interconnections », Proceedings of the design automation and Test in Europe (Date), Paris France, 2002.
[8] M.Benes, “Design and implementation of communication and switching techniques for the Pleiades family of processors”, Master of science, University of California and Berkley, 2000. Directeur de these : J.M.Rabaey.
[9] L.Fesquet, “Integration de sous-systems photoniques dans les architectures de communications multiporcesseurs”, Electronique, Paul Sabatier, Toulouse, 1997. Directeur de thèse : J.Collet.
[10] D.Lyonnard, « Approche d’assemblage systématique d’éléments d’interface pour la génération d’architecture multiprocesseur », thèse de Doctorat, Institut national Polytechnique de Grenoble, 2003. Directeur de thèse : AA.Jerraya.
[11] M.C.Herbordt, « the evaluation of massively parallel array architectures ». Technical report, M-CS-1995-007,1995.
[12] these hashish 2007
[13] J.Rabaey, K.Kentze, M.Sheets, S.Malik, A.Mihal, A.Sangionanni-vencentelle, and M.Sgroi. Addressing the system-On-Chip interconnected woes through communication-based eesign. Dac, 00:667-672,2001.
[14] M.Horowitz, R.Ho, ad K.Mai. The future of wires, 1999.
184

[15] Kanishka Lahiri, Anaud Raghunathan, Ganesh Lakshiminarayana. “Communication architectures : methodology for he design of high-performance communication architectures for systems-on-chip. In design automation Conference, pages 513-518, 2000.
[16] Tobras Bjerregaard and shnkai Mahadevan. A survey of research and pratices of network-on-chip. ACM Comput. Surv. 38(1):1, 2006.
[17] Reiner Hartenstein. Coarse grain reconfigurable architecture (embedded tutorial). In ASP-DAC’01: Proceedings of the 2001 conference on Ascia South Pacific design automation, pages 564-570, NewYork, NY, USA, 2001. ACM Press
[18] Shashi Kumar, Axel Jantsch, Mikael Millberg, Johny Oberg, Juha-Pekka Sornner, Marhi Forsell, Kari Tiensyria, and Ahmed Hemani. A network on chip architecture and design methodology. In VLSI’02 : Proceedings of the IEEE computer society symposium on VLSI, pages 105-112, Washington, DC, USA, 25-26 April 2002. IEEE Computer Society.
[19] Luca benini and Giovanni De Micheli. Networks on chips: A new SoC paradigm. Computer, 35(1): 70-78,2002.
[20] Arteris, “Enabling Network-On-Chip for SoC Design”, http:\\WWW.arteris.net/document/Arteris-backgrounds-28.pdf,2004.
[21] Projet MopCom.Modeling and specialization of platform and components MDA. http://www.mopcom/doku.php.4.2
[22] Jean Bezini. On the unification power of models. Software and System Modeling (SoSym), 4(2): 171-188, 2005.3.1.1
[23] Hubert Tardien, Arnlod Rochfeld, and Colleti. La methode Merise: Principes et outils. Editions d’organisation, 1991.
[24] Object Management Group, Inc.,editor. UML2 Infrastructure (Final Adopted Specificatio). http://www.org/cgi-bin/doc.ptc/ 2003-09-15, September 2003.
[25] Eclipse Consortium. EMF. http://www.eclipse.org/emf,2007.
[26] Stuart Kent. Model driven engineering. In IFM, pages 286-298, 2002.
[27] Thèse lebbani
[28] Object Management Group. Mof qvt final adopted specification.OMG document final/05-11-01, novembre 2005. http://www.omg.org/docs/ptc/05-11-01-pdf.
[29] Matthieu moy, Florence Maraninchi, and Laurent Maillet-Contoz. Pinapa: An extraction tool for systemc descriptions of systems-on-chip. In EMSOFT, September 2005-8-2-5.
[30] WESTTeam LIFL, LIlle, France. Graphical Array Specification for Parallel and Distributed Computing (GASPARD-2). http://www.lfl.fr/west/ gaspard/,2005.
185

[31] A.Benveniste, P.caspi, S.Edwards, N.Halbwachs, P.L.Guernic, and R.de Simone. Synchronous languages Twelve Years Later. Proceeding of the IEEE, January 2003.
[32] P.Caspi, D.Pilard, N.Halbwachs, and J-A.Plarce.LUSTRE: a declarative language for real-Time programming. ACM Pres, 1987.
[33] Paul le Guernic, Jean-Pierre Talpin, and Jean-christophe le Lann. Polychrony for system design. Journal for Circuits, Systems and Computers, Special Issue on Application Specific Hardware Design, apr 2003.
[34] Object Management Group, Inc., editor. (UML) Profile for Schedulality, performance, and Time version 11. http://www.omg.org/technology/documents/formal/schedulability.htm, January 2005.
[35] mémoire nocolas
[36] Pierre Boulet, Jean-Luc Dekeyser, Cédric Dumoulin, and Philipe Marquet. MDA for System-On-Chip design, intensive signal processing expriment. I.FDL’03, Fankfurt, Germany, September 2003.
[37] Arnaud Curruru, Jean-Luc Dekeyser, Philipe Marquet, and Pierre Boulet. Towars UML2 extension for compact modeling of regular complex topologies. In MODELS.UML.2005, ACM.IEEE 8th International Conference On Model Driven Engeneering Langages ans Systems, MontegoBay, Jamaica, October 2005.
[38] Alain Demeure and Yannick Del Gallio. An Arraqy Approach for Signal Processing Design. In Sophia-Antipolis Conference on Micro-Electronics (SAME 98), France, October 1998.
[39] Alain demeure, Anne Lafarge, Emmanuel Boutillor, Didier Rozzonellu, Jean Claude Dufourd, and Jean-louis Marros. Array-Ol : Proposition d’un formalisme tableau pour le traitement de signal multidimensionnel. In Gretsi, Juan les pins, France, September 1995.
[40] Pierre Boulet. Contribution aux environnements de programmation pour le calcul intensif. Habilitation à diriger des recherches, université des Sciences et technologies de Lille, Decembre 2002.
[41] 27 thèse lebbani
[42] Thèse sebastien
[43] Radu Cornea, Shijairt Mohapatra, Nikil Dutt, Alex Nicolau, and Nalini Venkatasubramanian. Power-aware multimedia-streaming in heterogenous multi-use environents. In Concurrent Information Processing and Computing Advanced Research Workshop, Sinaia, Romaina, uly 5-10 2003.
186

[44] Christophe Manas. Alpha : un langage équationnel pour la conception et la programmation d’architectures parallèles synchrones. PHD thesis, Université de Rennes, Décembre 1989.
[45] Praveen K.Murthy and Edward A.lee. Multidimensional synchronous data flow. IEEE Transaction on signal Processing, juillet 2002.
[46] P.K.Murthy and Edward A.lee. A generalization of multidimensional synchronous dataflow to arbitrary sampling Lattices. Technical Report UCB/ERL M95/59, EECS Department of University of California, Berkeley, mais 1995.
[47] Projet Inria-CNRS COSI. ALPHA home page. http://www.irisa.fr/Cosi/Alpha
[48] Tanguy Risset. Contribution à la compilation de nids de boucle sur silicium. Habilitation à diriger des recherches, Université de Rennes1, Octobre 2000.
[49] Richard M.Karp, Raymond E.Miller, and Shmmel winograd. The organization of compilations for uniform recurrence equations. J.ACM, 14(3): 563-590, Juillet 1967.
[50] Edward A.lu and David G.Messerschmitt. Synchronous Data Flow. In proceedings of the IEEE, volume 75, pages 1235-1245, September 1987.
[51] Edward A.lee and David G.Messerschmitt. Static scheduling of synchronous data Flow programs for digital signal processing. IEEE Trans. On Computers, 36(1) : 24-35, Janvier 1987.
[52] P.K.Murthy and Edward A.lee. A extension of multidimensional synchronous dataflow to arbitrary sampling Lattices. Technical Report UCB/ERL M95/59, EECS Department of University of California, Berkeley, mais 1995.
[53] Article Pirre Boulet
[54]-38 Alain Demeure and Yannick Del Gallo. An Array approach for signal processing design. In Sophia. Antipolis conference on Micro-Electronics (SAME 98), France, Octobre 1998.
[55] Alain Demeure, Anne Lafarge, Emmanuel Bouttillon, Didier Rozzonelli, Jean-Claude Dufourd, and jean-louis Marros. Array-OL : Proposition d’un formalisme tableau pour le traitement de signal multi-dimensionnel. In Gretsy Juan-les-Pins, France, September 1995.
[56] Abdelkader Amar, Pierre Boulet, and Philippe Dumond. Projection of the Array-OL specification langage onto the Kahn process network computation model. In international symposium on parallel Architecture, Algorithms, and NetWorks, Las Vegas, Nevada, USA, December 2005.
[57] Julien Soula. Principe de Compilation d’un langage de traitement de signal. Thèse de doctorat, Laboratoire d’informatique fondamentale de Lille, Université des sciences et technologies de Lille, December 2001.
187

[58] P.Ruxandra, S.Kumar, A Survey of Techniques for Mapping and Scheduling Applications to Network on Chip Systems, Research Report, ISSN 1404-0018, 2004
[59] G.Varatkar, R.Marculescu, Communication, Complexity and Criticaly issue in Designing Silicon Networks, Date 2006.
[60] Y.Zhang, X.Hu, and D.Chen, task Scheduling and Voltage Selection for Energy Minimization, DAC 2002.
[61] T.Lei, S. Kumar, A two-step Genetic Algorithm for Mapping Task Graphs to a NoC Architecture, DSD 2003.
[62] S.Krishnan, S.Chatha, G.Konjevod, Linear-Programming-Based Techniques for Synthesis of Network-on-Chip Architectures, IEEE Transaction on very large scale integration (VLSI) systems, vol.14,No.4, April 2006.
[63] J.Hu, R.Marculescu, Energy-Aware Communication and Task Scheduling for Network-on-Chip Architectures under Real-Time Constraints, in Proc. Design, Automation and Test in Europe Conf., Paris, France, Feb. 2004.
[64] D. Shin, J. Kim, Power-Aware Communication Optimization for Networks-on-Chips with Voltage Scalable Links, in Proc. CODES+ISSS’04, pp.170-175, Sep. 2004
[65] L.Benini, D.Bertozzi, A.Guerri, M.Milano, Allocation, Scheduling and Voltage Scaling on Energy aware MPSoC, In Proc. Of CPAIOP-2006, pp.44-58, 2006.
[66] M.Armin, S.Saeidi, A.Khademzadeh, Spiral : A heuristic mapping algorithm for network on chip, IEICE Electronics Express, Vol;4, No.15, 478-484. August 2007, pp 478-484, 2007.
[67] C.Chou, C.Wu and J.Lee. Integrated Mapping and Scheduling for Circuit-Switched Network-on-Chip Architectures, 4th IEEE International Symposium on Electronic Design, Test & Application, IEEE Computer Society. 2008.
[68] M.T.Schmitz, B.M.Al-Hashimi, P.Eles, Iterative Schedule Optimization for Voltage Scalable Distributed Embedded Systems, ACM Transactions on Embedded Computing Systems, Vol.3, No.1, 182-217,Feb.2004.
[69] M.T.Schmitz, B.M.Al-Hashimi,P.Eles,A Co-Design Methodology for Energy-Efficient Multi-Mode Embedded Systems with Consideration of Mode Execution Probabilities, In Proc. Design, Automation and Test Europe Conference (DATE2003), pp. 960-965, Munich, 2003.
[70] Andrei, M.T.Schmitz, P.Eles, Z.Peng, B.M.Al-Hashimi, Overhead-Conscious Voltage Selection For Dynamic and Leakage Power Reduction of Time-Constraint Systems, In Proc. Design, Automation and Test Europe Conference (DATE2004), accepted for publication, Paris, 2004.
[71] F.Gruian, K.Kuchcinski, LensS: Task Scheduling for Lower-energy Systems Using Variable Supply Voltage Processors, ASP-DAC 2001.
188

[72] L.A.Cortes, P.Eles, Z.Peng, Static Scheduling of Monoprocessor Real-Time Systems composed of Hard and Soft Tasks, The IEEE International Workshop on Electronic Design, Test and Applications (DELTA2004), Perth, Australia, January 28-30, 2004, pp.115-120.
[73] L.A.Cortes, P.Eles, Z.Peng, Quasi-Static Scheduling for Multiprocessor Real-Time Systems with Hard and Soft Tasks, Technical Report, Embedded Systems Lab, Dept. of Computer and Information Science, beDesign, Linkoping University, September 2003.
[74] R.Szymanek Memory Aware Task Assignment and Scheduling for Multiprocessor Embedded Systems, Licentiate Thesis No.13, ISSN 1404-1219, Lund, June 2001.
[75] R.Szymanek, K.Kuchcinski, Design Space Exploration in System Level Synthesis under Memory Constraints, Euromicro 25, Milan, September 8-10, 1999.
[76] Umit Y.Ogras and J.Hu, Key Research Problems in NOC Design: A Holistic Perspective, in Proc CODES+ISSS’05, NewJersey, USA, pp.69-74, Sept. 1921, 2005.
[77] F.Y.Edgeworth. Mathematical physics. P.Keagn, London, England, 19881. [78] V.Pareto. Cours d’Economie Politique, volume 1-2. Rouge, Lausane, switzerland, 1896. [79] A.Geoffrion. Proper efficiency and theory of vector maximization. Journal of
Mathematical Analysis and Applications, 22: 618-630, 1968. [80] R.Stever. Multiple Criteria optimization : Theory, computation and Application. Wiley,
NewYork, 1986. [81] M.Zeleny. Multiple criteria problem solving. McGraw- Hill, NewYork, 1982. [82] R.L.Carraway, T.L.Morin, and H.Moskowitz. Generalizd dynamic programming for
Multicriteria optimization. European Journal of operational Research, 44:95-104,1990. [83] F.BenAbdelaziz, S.Krichen, and J.Chaouchi. Meta-heuristics : Advances and trends in
local search paradigms for optimization, chapter A hybrid heuristic for multi-objective knapsack problems, pages 205-212. Kluwer Academic Publishers, 1999.
[84] A.Nagar, J.Haddock, and S.Heragu. Multiple and bicriteria scheduling : A literature survey. Eurpean Journal of operational Research, 81,88-104,1995.
[85] S.Sayin and S.Karabati. A bicriteria approach to the two-machine flow shop scheduling
problem. Eurpean Journal of operational Research, 113: 435-449,1999. [86] A.Warburton. Approximationof pareto optima in multiple-objective shortest-path
problems. Operations research, 35:70-79, 1987. [87] G.Zhou and M.Gen; Genetic algorithm approach on multicriteria minimum spanning tree
problem. European Journal of operational research, 114: 141-152, 1999. [88] E.L.Ulungu, J.Teghem. Multi-objective combinatorial optimization problems: A survey.
JMCDA, 3:83-104, 1994.
189

[89] P.Serafini. Simulated annealing for multiple objective optimization problems. In Tenth Int. Conf. on multiple criteria decision making, pages 87-96, Taipei, July 1992.
[90] Y.B. Park and C.P. Koelling. An interactive computerized algorithm for multicreteria
vehicle routing problems. Computers and Industrial Engineering, 16: 477-490, 1989. [91] D.A.Van Veldhuizen and G.B.Lamont. Multiobjective evolutionary algorithm research :
A history and analysis. Technical Report TR-98-03, Graduate School of Engineering, Air Force Institute of Technology, Wright-Patterson, USA, Dec 1998.
[92] E.L.Ulungu and J.Teghem. The two phase method: An efficient procedure to solve bi-
objective combinatorial optimisation problems. In Foundations of Computing and Decision Sciences, volume 20, pages 149-165. 1995.
[93] B.S.Stewart and C.C.white. Multiobjective A*. Journal of the ACM, 38(4): 775-814,
1991. [94] D.J.White. The set of efficient solutions for multiple-objectives shortest path problems.
Computers and Operations Research, 9: 101-107, 1982. [95] M.P.Fourman. Compaction of symbolic layout using genetic algorithms. In proceedings
of the first international Conference on genetic algorithms (ICGA), pages 141-153, 1985. [96] Y.Haimes, W.Hall, and H.Freedman. Multiobjective Y.Haimes, W.Hall, and H.Freedman.
Elservier Scientific Publishing edition, NewYork, 1975. [97]Dorigo, M., Maniezzo, V. and Colorni, A.(1996). The Ant System : Opitmization by a
colony of cooperating agents. IEEE Transaction on System, Man, and Cybernetics- Part B, Vol.26, No.1, PP.1-13.
[98]Hallam, N., (2005). Diversity Preservation Techniques in Multiobjective Evolutionnary
Algorithms : Analysis and Proposal. Research Report CSIT-RR-200507-001, University of Nottingham.
[99] Coello Coello, Carlos A. ( 2004). A Comprehensive Survey of Evolutionary-Based
Multiobjective Optimization Techniques. Knowledge and Information Systems, Vol.1, No.3, pp.269-308.
190