pagerank for anomaly detection - hadoop summit
TRANSCRIPT

© Hortonworks Inc. 2015
PageRank for Anomaly Detection
Hadoop Summit Europe, 2015
Ofer Mendelevitch, Hortonworks

© Hortonworks Inc. 2015 Page 2
About Us
Ofer Mendelevitch
Director, Data Science @ Hortonworks
Previously: Nor1, Yahoo!, Risk Insight, Quiver
blog: http://hortonworks.com/blog/author/ofermend/
Joint work with Jiwon Seo
(could not make it last minute)
Ph.D Candidate @ Stanford
Software Engineer @ Pinterest
Designed SociaLite (w/ professor Monica Lam)

© Hortonworks Inc. 2015 Page 3
What is this talk about?
•Why is fraud detection important in healthcare?
•The Medicare-B dataset
•Our approach: Similarity and PageRank
• Implementation: Apache Pig and SociaLite
•Some Results
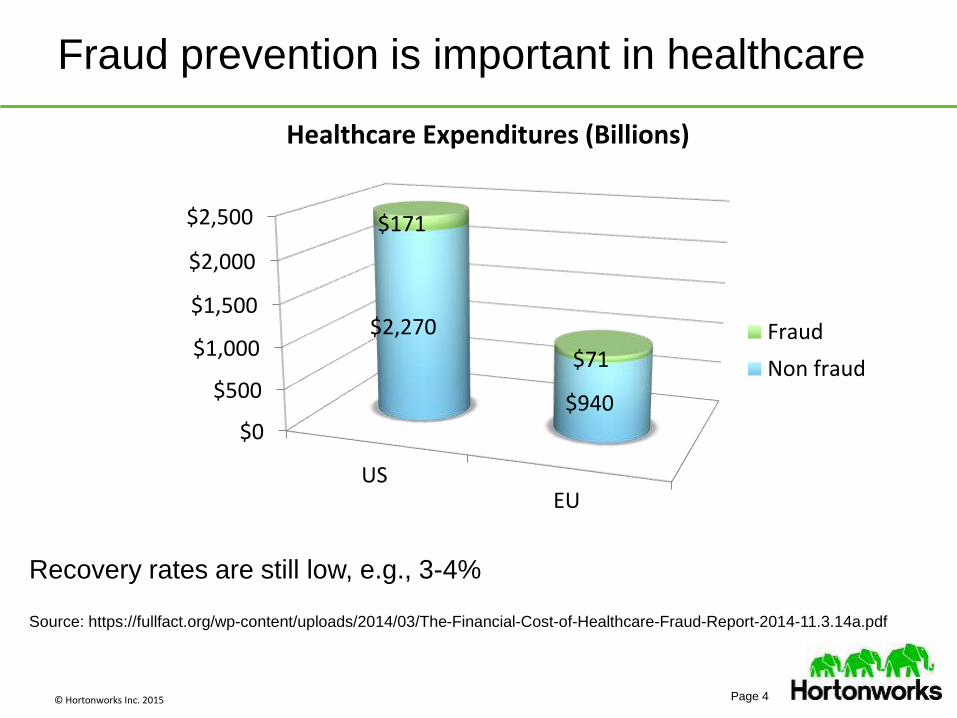
© Hortonworks Inc. 2015 Page 4
Fraud prevention is important in healthcare
Recovery rates are still low, e.g., 3-4%
Source: https://fullfact.org/wp-content/uploads/2014/03/The-Financial-Cost-of-Healthcare-Fraud-Report-2014-11.3.14a.pdf
$0
$500
$1,000
$1,500
$2,000
$2,500
USEU
$2,270
$940
$171
$71
Healthcare Expenditures (Billions)
Fraud
Non fraud

© Hortonworks Inc. 2015 Page 5
Example fraud cases in healthcare…
•A doctor billing too often for most expensive office
visitshttp://www.dallasnews.com/investigations/20140515-medicare-data-
reveals-unusual-billing-patterns-by-nearly-80-texas-doctors-medical-
practitioners.ece
•Medical supply stores paid off local doctors to
prescribe motorized wheelchairs worth $7500 but
instead provided scooters worth $1500http://blog.operasolutions.com/bid/388511/Data-Science-As-the-
Panacea-for-Healthcare-Fraud-Waste-and-Abuse

© Hortonworks Inc. 2015 Page 6
What are some fraud patterns?
•Billing for services that were not actually
performed
•Performing unnecessary services
•Using stolen patient IDs to submit claims
•Unbundling: billing each stage of a procedure as
if it is performed separately
•Upcoding: billing for more expensive services
than were actually performed
•Billing cosmetic surgeries as necessary repairs
•Etc…

© Hortonworks Inc. 2015 Page 7
Most healthcare providers have some type
of system in place to identify such fraud
•Rules based:
–Business rules catch known fraud patterns
•Machine-learning based:
–Automated learning catches difficult to characterize fraud patterns
•What are “good features” in the model that
increase the accuracy?
–Claim features, e.g. total amount
–Provider features, e.g., total payment last year
–Patient features, e.g., current set of diagnoses

© Hortonworks Inc. 2015 Page 8
Why PageRank for fraud detection?
•Most approaches apply supervised learning
–Graph algorithms not as widely-used
•The main idea:
–Produce new “features” for the existing model
–Specifically, a score per provider reflecting its degree of anomaly relative to a medical specialty

© Hortonworks Inc. 2015 Page 9
Our Dataset
•Medicare-B – real world public healthcare dataset
–Released by CMS (US Centers for Medicare and Medicaid Services) in 2014
–Includes provider payment information for 2012
–9.5M records; 880K+ providers; 5616 CPT (procedure) codes
•We will only use 4 fields:–NPI: provider ID
–Specialty: e.g. Internal Medicine, Dentist, etc
–CPT code: medical procedure code
–Count: # of procedures performed (normalized)

© Hortonworks Inc. 2015 Page 10
Example rows from the dataset
1003000126 ENKESHAFI ARDALAN M.D. M I 900 SETON DR CUMBERLAND 215021854 MD US Internal Medicine
Y F99222 Initial hospital care 115 112 115 135.25 0 199 0 108.11565217 0.9005883395
1003000126 ENKESHAFI ARDALAN M.D. M I 900 SETON DR CUMBERLAND 215021854 MD US Internal Medicine
Y F99223 Initial hospital care 93 88 93 198.59 0 291 9.5916630466 158.87 0
1003000134 CIBULL THOMAS L M.D. M I 2650 RIDGE AVE EVANSTON HOSPITAL EVANSTON 602011718 IL US
Pathology Y F88304 Tissue exam by pathologist 226 207 209 11.64 0 115 0 8.9804424779 1.7203407716
1003000134 CIBULL THOMAS L M.D. M I 2650 RIDGE AVE EVANSTON HOSPITAL EVANSTON 602011718 IL US
Pathology Y F88305 Tissue exam by pathologist 6070 3624 4416 37.729960461 0.0012569747 170 0 28.984504119
5.6268316462
1003000134 CIBULL THOMAS L M.D. M I 2650 RIDGE AVE EVANSTON HOSPITAL EVANSTON 602011718 IL US
Pathology Y F88311 Decalcify tissue 13 13 13 12.7 0 39 0 7.8153846154 4.2806624494
We use only 4 fields: NPI, specialty, CPT code and count:
1003000126, Internal Medicine, Initial hospital care (F99222), 115
1003000126, Internal Medicine, Initial hospital care (F99223), 88
1003000134, Pathology, Tissue exam by pathologist (F88304), 209
1003000134, Pathology, Tissue exam by pathologist (F88305), 4416
1003000134, Pathology, Decalcify tissue (F88311), 13

© Hortonworks Inc. 2015 Page 11
Our approach – the steps
•Step 1: Data Preparation/cleansing
•Step 2: Compute similarities, build graph
•Step 3: Compute PageRank, identify anomalies

© Hortonworks Inc. 2015 Page 12
Step 1: Data cleansing
1003000126 ENKESHAFI ARDALAN M.D. M I 900 SETON DR CUMBERLAND 215021854 MD US Internal Medicine Y F99222 Initial hospital care 115 112 115 135.25 0 1990 108.11565217 0.9005883395
1003000126 ENKESHAFI ARDALAN M.D. M I 900 SETON DR CUMBERLAND 215021854 MD US Internal Medicine Y F99223 Initial hospital care 93 88 93 198.59 0 2919.5916630466 158.87 0
1003000134 CIBULL THOMAS L M.D. M I 2650 RIDGE AVE EVANSTON HOSPITAL EVANSTON 602011718 IL US Pathology Y F88304 Tissue exam by pathologist 226 207 209 11.64 0 115 0 8.9804424779 1.7203407716
10030126 Internal Medicine Initial care(F99222) 115
10030126 Internal Medicine Initial care(F99223) 88
10030134 Pathology Tissue exam(F88304) 209Filter columns, data
cleansing
•Extract needed data fields from dataset
–NPI (National Provider ID), Specialty, CPT (procedure) code, count
–For count, we chose: “bene_day_srvc_cnt” (number of distinct Medicare beneficiary per day services)
•Re-compute “specialty” due to data quality issues

© Hortonworks Inc. 2015 Page 13
Specialty Lookup: NPI and NUCC datasets
•Problem:
–Some “specialty” values are inaccurate or not specific enough
•Solution: pre-processing step
–NPI data: maps NPI to specialty code
–NUCC data: maps specialty code to taxonomy

© Hortonworks Inc. 2015 Page 14
Step 2: build graph by similarities
10030126 Internal Medicine Initial care(F99222) 115
10030126 Internal Medicine Initial care(F99223) 88
10030134 Pathology Tissue exam(F88304) 209
•Two providers are “similar” if they have the same
“procedure code patterns”
•We use “Cosine Similarity”
–Each provider represented as vector of 5949 CPT codes

© Hortonworks Inc. 2015 Page 15
Example: similar providers
•NPI1
•NPI2
CPT 93042 99283 99284 99285 99291
Count 280 29 265 410 28
CPT 99283 99284 99285 99291
Count 118 151 270 37
CPT Description
93042 Rhythm Ecg report
99283 Emergency dept visit (1)
99284 Emergency dept visit (2)
99285 Emergency dept visit (3)
99291 Critical care first hour

© Hortonworks Inc. 2015 Page 16
Computing similarity at large scale…
• Number of providers: ~880,000
• 880K * 880K = 77,440,000,000 similarity computations
• Each one a “dot product” between vectors of length 5949
(but sparse)

© Hortonworks Inc. 2015 Page 17
How do we address scalability?
•Our Implementation:
–Heuristics:
–Only compute similarity between NPI1 and NPI2 if they share their most important CPT codes
–Filter out NPIs with less than 3 CPT codes
–Use Apache PIG on a Hadoop cluster (with UDFs) to compute in parallal
•Alternatives:
–DIM-SUM (map-reduce or Spark)
–Locality Sensitive Hashing (DataFu)

© Hortonworks Inc. 2015 Page 18
PIG code: compute similarityGRP = group DATA by npi parallel 10;
PTS = foreach GRP generate group as npi, DATA.(cpt_inx, count) as cpt_vec;
PTS_TOP = foreach PTS generate npi, cpt_vec, FLATTEN(udfs.top_cpt(cpt_vec)) as (cpt_inx: int, count: int);
PTS_TOP_CPT = foreach PTS_TOP generate npi, cpt_vec, cpt_inx;
CPT_CLUST = foreach (group PTS_TOP_CPT by cpt_inx parallel 10) generate PTS_TOP_CPT.(npi, cpt_vec) as clust_bag;
RANKED = RANK CPT_CLUST;
ID_WITH_CLUST = foreach RANKED generate $0 as clust_id, clust_bag;
ID_WITH_SMALL_CLUST = foreach ID_WITH_CLUST generate clust_id, FLATTEN(udfs.breakLargeBag(clust_bag, 2000)) as clust_bag;
ID_WITH_SMALL_CLUST_RAND = foreach ID_WITH_SMALL_CLUST generate clust_id, clust_bag, RANDOM() as r;
ID_WITH_SMALL_CLUST_SHUF = foreach (GROUP ID_WITH_SMALL_CLUST_RAND by r parallel 240)
generate FLATTEN($1) as (clust_id, clust_bag, r);
NPI_AND_CLUST_ID = foreach ID_WITH_CLUST generate FLATTEN(clust_bag) as (npi: int, cpt_vec), clust_id;
CLUST_JOINED = join ID_WITH_SMALL_CLUST_SHUF by clust_id, NPI_AND_CLUST_ID by clust_id using 'replicated';
PAIRS = foreach CLUST_JOINED generate npi as npi1, FLATTEN(udfs.similarNpi(npi, cpt_vec, clust_bag, 0.85)) as npi2;
OUT = distinct PAIRS parallel 20;
Things to highlight:
• Using “replicated” joins (map-side joins) where possible
• Handling Data Skew
• Using Python UDFs to compute similarity, break large
bags, etc
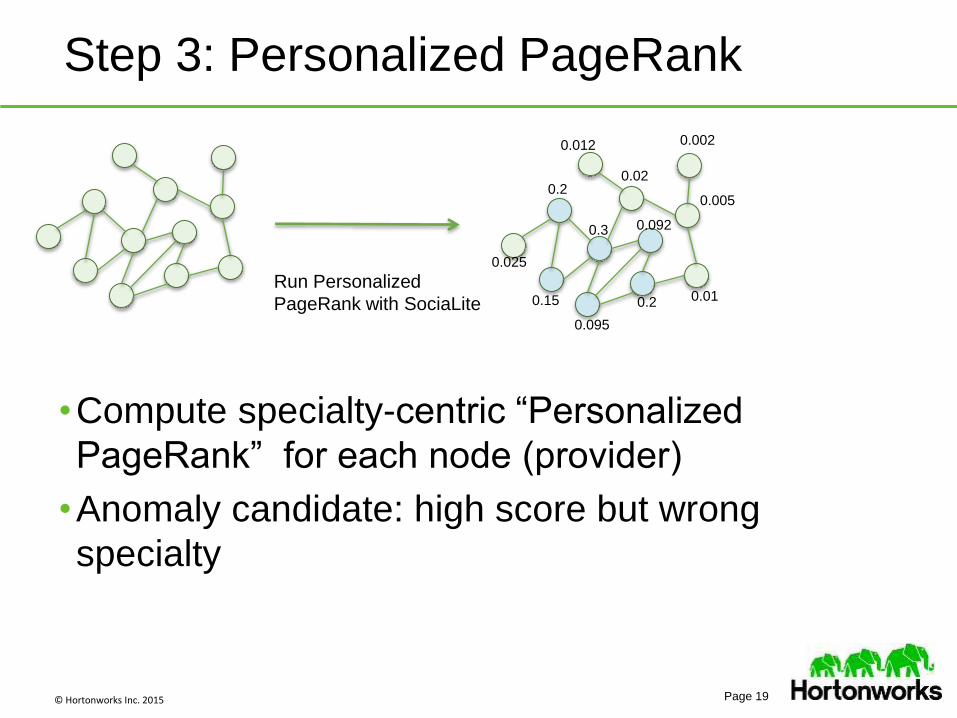
© Hortonworks Inc. 2015 Page 19
Step 3: Personalized PageRank
Run Personalized
PageRank with SociaLite
•Compute specialty-centric “Personalized
PageRank” for each node (provider)
•Anomaly candidate: high score but wrong
specialty
0.025
0.3 0.092
0.095
0.15
0.2
0.002
0.005
0.02
0.01
0.012
0.2

© Hortonworks Inc. 2015 Page 20
PageRank – a quick overview
• Random walk over the graph
• Start from any (randomly selected)
node
• At each step, walker can:
– Move to an adjacent node
(probability d = 80%)
– Randomly jump (or “teleport”) to any node in the graph
(probability 1-d = 20%)
All doctor names are fictitious

© Hortonworks Inc. 2015 Page 21
Personalized PageRank – focused on a
given specialty (Ng, Miller, Jones)
• Random walk over the graph
• Start from any random node IN THE
SPECIALTY GROUP
• At each step, walker can:
– Move to an adjacent node
(probability d = 80%)
– Randomly jump (or “teleport”) to any node OF THE GIVEN SPECIALTY GROUP
(probability 1-d = 20%)
All doctor names are fictitious

© Hortonworks Inc. 2015 Page 22
Personalized PageRank with SociaLite
`Rank(int npi:0..$MAX_NPI_ID, int i:iter, float rank).`
`Rank(source_npi, 0, pr) :- Source(source_npi), pr=1.0f/$N.`
for i in range(10):
`Rank(node, $i+1, $sum(pr)) :- Source(node), pr = 0.2f*1.0f/$N ;
:- Rank(src, $i, pr1), pr1>1e-8, EdgeCnt(src, cnt),
pr = 0.8f*pr1/cnt, Graph(src, node).`
Initialize PageRank value of source providers to be 1/N
In each iteration:
• Teleport to source providers (w/ probability 0.2) ;
• Random walk to one of neighbors (w/ probability 0.8)

© Hortonworks Inc. 2015 Page 23
What’s so cool about SociaLite?
•PageRank in 3 lines of code
•Python integration
•You don’t have to “think like a node”. Declarative
language – “looks like” the formula
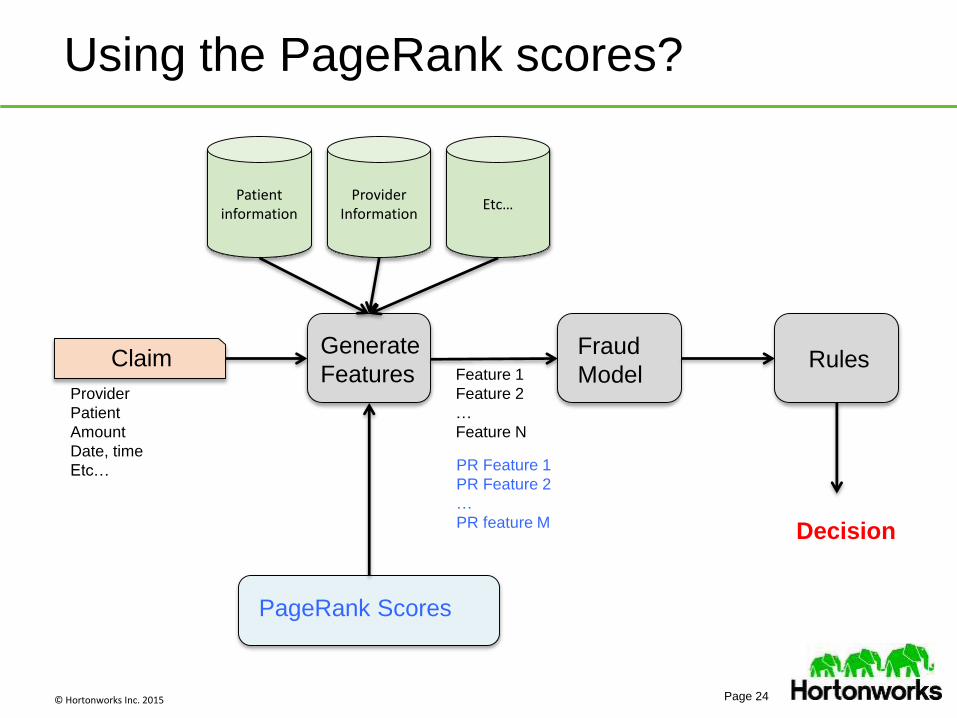
© Hortonworks Inc. 2015 Page 24
Using the PageRank scores?
RulesFraud
ModelClaim
Generate
Features
PageRank Scores
Decision
Provider
Patient
Amount
Date, time
Etc…
Patient information
Provider Information
Etc…
Feature 1
Feature 2
…
Feature N
PR Feature 1
PR Feature 2
…
PR feature M

© Hortonworks Inc. 2015 Page 25
Example result #1: Ophthalmology
Found internist with high score, but these CPT codes:
• Internal eye photography
• Cmptr ophth img optic nerve
• Echo exam of eye thickness
• Cptr ophth dx img post segmt
• Revise eyelashes
• Ophthalmic biometry
• Eye exam new patient
• Eye exam established pat
• After cataract laser surgery
• Eye exam & treatment
• Eye exam with photos
• Cataract surg w/iol 1 stage
• Visual field examination(s)

© Hortonworks Inc. 2015 Page 26
Example result #2: Plastic Surgery
Found Otolaryngologist with high score, but these CPT codes:
• Skin tissue rearrangement (multiple variants)
• Biopsy skin lesion

© Hortonworks Inc. 2015 Page 27
Thank you!
Any Questions?
Ofer Mendelevitch, [email protected], @ofermend
Code available here:
https://github.com/ofermend/medicare-demo/
Blog post series: http://hortonworks.com/blog/using-pagerank-detect-anomalies-fraud-healthcare/