paradigmas de procesamiento en big data: arquitecturas y tecnologías aplicadas
TRANSCRIPT


“Bigdata”serefiereatodolorelacionadoconlacaptura,almacenamiento,procesamiento,análisisyvisualizacióndeconjuntosdedatoscaracterizadosporsu
Volumen,VelocidadyVariedad
3iessonlacuasadelbigData
¿QuéesBigData?
2

¿QuéesBigData?§ ¿BigDataesunproblemadeIngenieríaodeCiencia?
§ Cómomontarunaarquitecturaquedesoporteabigdatayseaescalableesunproblemadeingeniería
§ Cómodarvaloralosdatosesunproblemadeciencia
IngenieroInformáMco
CienNficodedatos
3

Paradigmasdelprocesamiento
3problemas 3soluciones
4

§ Lasgrandesbasesdedatosnosoncarasdealmacenarperosenecesitaunsupercomputadorparasuprocesamiento
§ LaparalelizaciónahorramuchoMempo§ NosóloesúAlenconsultassinotambiénenlaejecucióndealgoritmoso
analíAcas
5
Procesamientodistribuidoyparalelo
Costede1TB=50€
Tiempodeacceso(lectura)de1TB
Unsoloservidor1000servidores6horas 20s

Paradigmasdelprocesamiento§ Procesamientoporlotes(batchprocessing)
§ Soluciónparaelproblemadelvolumen§ SecentraenelprocesamientodegrancanAdaddedatosestáAcos§ Escalable§ Procesamientodistribuidoyparalelo§ Toleranciaafallos§ Altalatencia§ Sistemacompletamentemaduro
§ ProcesamientoenMemporeal(streamingprocessing)§ Soluciónparaelproblemadelavelocidad§ SecentraenelprocesamientodeunflujoilimitadoyconAnuode
datos§ ComputacióndedatosenAemporeal§ Procesamientodistribuidoyparalelo§ Toleranciaafallos§ Bajalatencia
§ Procesamientohíbrido§ ArquitecturaLambda§ Soluciónparaelproblemadelvolumenylavelocidad§ CombinalosresultadosdeanalizardatosestáAcosydatosenAempo
real6

Tecnologíasparaelprocesamientoenbigdata
20132012 2014
NathanMarzdefinelaarquitecturaLambda
Lambdoop&SumminbgirdPrimerospasos
LinkedlnpresentaKaVa
LinkedlnpresentaSamzaCloudera
presentaFlume
NathanMarzcreaStorm
Yahoo!CreaS4
20112008
Sparkescódigolibre
Stratospherepresenta
ApacheFlink
2009 20102006200520042003
Yahoo!CreaPig
ApacheHadoopEstaenproducción
Yahoo!empiezaatrabajarconHadoop
Ar]culoGoogleFileSystem
Ar]culodeGoogleMapReduce
DougCu`ngempiezaadesarrollar
Hadoop
FacebookcreaHive
GoogledesarrollaBigTable
Batch Streaming Hibrida
scribe(porFacebook)códigolibre
7

§ SehanidodesarrollandodisAntasherramientasparacadaunadelasfasesyparacadaunodelosAposdeprocesamiento
Pipelinedelprocesamiento
8
Almacenamientodedatos
Análisisdedatos
Presentaciónresultados
Adquisicióndedatos

Procesamientoporlotes

§ Hadoophasidolaherramientaestrellaenlaimplementacióndelaarquitecturabatchprocessing
§ SehanidodesarrollandodisAntasherramientasparacadaunadelasfasesycondisMntosnivelesdeabstracción→EcosistemaHadoop
Procesamientoporlotes
q ComandosHDFSq Sqoopq Flumeq Chukwaq Scribe
q HDFSq HBase
q Map–Reduceq Hiveq Pigq Cascadingq Sparkq SparkSQL(Shark)
10
Almacenamientodedatos
Análisisdedatos
Presentaciónresultados
Adquisicióndedatos

¿QuéesHaddop?§ Libreríasogwarequepermitemanejargrandesvolúmenesdeinformacióndeforma
distribuida§ Creadoen2006porDougCu`ngcomoproyectoApacheso$wareparacomputación
distribuida
11
(HadoopDistributedFileSystem)

HadoopHDFS§ SoawareencargadodealmacenarygesMonardatosenunClúster
§ Diseñadopara:§ SeruAlizadoencomputadorasbaratasydebajagama(Commodityhardware)§ Sercapazdealmacenargrandesficherosdedatos(PetaBytes)§ SercapazdeprocesarungranvolumendeinformaciónuAlizandoMapReduce
§ FuecreadoaparArdelGoogleFileSystem(GFS)
§ CaracterísMcas:§ Elevadoanchodebanda
§ Másimportanteelanchodebandaquelalatenciadeaccesoalosdatos(procesobatch)
§ Toleranciaafallos(mediantereplicación)
§ Modelodecoherenciasimple
§ EsportableentredisAntasplataformas
§ Escalamientohorizontaldinámicoyconrebalanceo
§ TrabajaenunentornoseparadodelosficherosdelSOlocal
§ EscritoenJava
Almacenamientodedatos
BATCH
12

HDFS
§ ArquitecturadeHDFS
Cluster
ComputadoresBaratos,degamabaja
NodoMaestro
Nodosesclavos
ComputadorMaspotente
MásmemoriaRAM
Metadata
NameNode
13Enelejm,Tamañodelboque=64MB,unficherode100MBsealmacenaríaen2bloques
Almacenamientodedatos
BATCH
F1-B2
F2-B1 F2-B2F1-B1
DataNode1 DataNode2 DataNode3 DataNode4

MapReduce§ Modelodeprogramaciónparaelprocesamientoparalelodegrandes
conjuntosdedatos§ DiseñadoydesarrolladooriginalmenteporGoogle(2004)§ PopularizadoporlaimplementaciónopensourceApacheHadoop
§ CaracterísMcas:§ Basadoen:
§ Laprogramaciónfuncional§ ElalgoritmoDivideyVencerás
§ PermitealdesarrolladorexpresarsusalgoritmosuAlizandoúnicamentedosfuncionesmapyreduce
§ Facilitaunpatróndedesarrolloparaleloparasimplificarlaimplementacióndeaplicacionesenentornosdistribuidos
§ LosprogramasescritossonautomáAcamenteparalelizadosyejecutadosenunclústerdemáquinas
§ Puedeaplicarsetantosobredatosalmacenadosensistemasdeficheros,comoenbasesdedatos
§ Existenlibreríaspara§ C++,Java,RubyyPhython
Análisisdedatos
BATCH
14

§ Esquema
§ FaseInput§ Dividelosdatos§ Preparalosdatos→claves/valor
§ FaseMap§ Ejecutalafunciónmapparacada
parclave/valor
§ FasesShuffle&Sort§ Ordenayagrupaporclavelos
resultadosdelafasemap
§ FaseReduce§ Ejecutalafunciónreduce§ PuedehaberunaomúlAples
funcionesReduce
§ FaseOutput§ Almacenael/losresultadosenun
sistemadeficheros,unabasededatos… 15
Análisisdedatos
BATCH
MapReduce

EjemploMapReduce
en,1
la,1mancha,1
vale,1
la,1pena,1
un,1lugar,1de,1más,1
EnunlugardelamanchaMasvalelapenaenelrostroquelamanchaenelcorazónElamoresdeseodebelleza MAP
MAP
MAP
Reduce
Reduce
Entrada Salida
§ Contarelnúmerodevecesqueaparececadapalabraenunfichero
16
Análisisdedatos
BATCH
PseudocódigodelafunciónMapClave=nombredelficherooelnúmerodelínea,peroenestecasonosenecesitaValor=líneadetexto
Map(Clave,valor)foreachwordwinvalueemit(w,1)

EjemploMapReduce
EnunlugardelamanchaMasvalelapenaenelrostroquelamanchaenelcorazónElamoresdeseodebelleza MAP
MAP
MAP en,1rostro,1
la,1mancha,1
en,1
el,1que,1
Reduce
Reduce
Entrada Salida
17
Análisisdedatos
BATCH
§ Contarelnúmerodevecesqueaparececadapalabraenunfichero

EjemploMapReduce
EnunlugardelamanchaMasvalelapenaenelrostroquelamanchaenelcorazónElamoresdeseodebelleza MAP
MAP
MAP
corazón,1
amor,1
deseo,1
el,1el,1es,1de,1belleza,1
Reduce
Reduce
Entrada Salida
18
Análisisdedatos
BATCH
§ Contarelnúmerodevecesqueaparececadapalabraenunfichero

EjemploMapReduce
Reduce
Shuffl
e&Sort
Reduce
amor,1corazón,1deseo,1en,1,1,1la,1,1,1mancha,1,1pena,1rostro,1vale,1
belleza,1de,1,1el,1,1,1es,1lugar,1más,1que,1un,1
EnunlugardelamanchaMasvalelapenaenelrostroquelamanchaenelcorazónElamoresdeseodebelleza MAP
MAP
MAP
Entrada Salida
19
Análisisdedatos
BATCH
§ Contarelnúmerodevecesqueaparececadapalabraenunfichero

EjemploMapReduce
Reduce
Shuffl
e&Sort
Reduce
EnunlugardelamanchaMasvalelapenaenelrostroquelamanchaenelcorazónElamoresdeseodebelleza MAP
MAP
MAP
amor,1corazón,1deseo,1en,3la,3mancha,2pena,1rostro,1vale,1belleza,1de,2el,3es,1lugar,1más,1que,1un,1
Entrada Salida
20
Análisisdedatos
BATCH
PseudocódigodelReduceClave=palabra;Valor=uniteradorsobrelos1sReduce(Clave,Valor)
emit(Clave,suma(valores))
§ Contarelnúmerodevecesqueaparececadapalabraenunfichero

EjemploMapReduce§ CalidaddelairedeAsturias
§ EstacionesestáAcas,sensoresmóvilesenvíandatosenAemporeal§ Históricodedatosdesdehace10años§ Monitorización,idenAficacióndetendencias,predicción…..
21
Análisisdedatos
BATCH

EjemploMapReduce
<1,6><1,2><3,1><1,9>…
<3,9><2,6><2,6><1,6>…
MAP<2,0><2,8><1,2><3,9>…
MAP
MAP<1,{1
,0,4,…}>
<2,{2,3,0,…
}>
… ID-Estación,MediaSO21 2,0132 2,6953 3,562
.
.
.
Datosshuffl
e
Estación;Nombre;LaAtud;Longitud;Fecha,SO2;NO;CO;PM10;O3;dd;vv;TMP;HR;PRB;
§ ObtenerlamediadeSO2decadaestación
22
Análisisdedatos
BATCH
Clave=nombredelfichero,Valor=líneadelficheroMap(Clave,Valor)
foreachValoremit(idestación,SO2)
Clave=Iddelaestación,Valor=listadecanAdadesdeCO2Reduce(Clave,Valor)
emit(Clave,average(Valor))
ReduceHacelamedia
ReduceHacelamedia

ModelodeejecuciónMapReduce
§ Minimizarelmovimientodelosdatos§ Llevarlacomputaciónalosdatos§ Lasfuncionesmap()yreduce()seejecutanenlosnodosdondeseencuentranlos
datos
§ FacilitaralprogramadorsinexperienciaensistemasdistribuidosyparalelosuAlizarlosrecursos§ Elsistemaseencargarde:
§ Distribuireltrabajo§ LosdetallesdeparAcionamientodelosdatosdeentrada§ Elcontroldelasinstanciasdelprogramaenlasmáquinas§ Manipularlosfallosylacomunicación
§ ElprogramadorsóloseAenequeencargardeprogramarlasfuncionesmap()yreduce()
§ Toleranteafallos
§ Altamenteescalable
23
Análisisdedatos
BATCH

§ ImplementacióndeMapReducesobreHDFS
ImplementacióndeMapReduce
TaskTracker
ReduceMap
DataNode1
ReduceMap ReduceMapReduceMap
JobTracker
Metadata
ClusterHadoop
ComputadoresBaratos,degamabaja
NodoMaestro
Nodosesclavos
Computadormaspotente,másmemoriaRAM
DataNode2 DataNode3 DataNod4
NameNode
24
Análisisdedatos
BATCH
TaskTracker TaskTracker TaskTracker

Tecnologíasparaelprocesamientoporlotes
Almacenamientodedatos
Análisisdedatos
Presentaciónresultados
Adquisicióndedatos
q ComandosHDFSq Sqoopq Flumeq Chukwaq Scribe
q HDFSq HBase
q Map–Reduceq Hiveq Pigq Cascadingq Sparkq SparkSQL(Shark)
25

§ Transforma los registros de la base de datos relacionales en información que se puedealmacenarenbasesdedatosdistribuidas
§ EstádesarrolladoenJavayusaMapReduceparatransferirdatosenparalelo§ Trabajaconconectores:
§ Estándares(basadosenJDBC)§ Directos,paramejorarelrendimiento,parabasesdedatoscomoMySQL,Oracle,SQL
Server,…PostgreSQLDB2§ SecreóenunhackathonenClouderayluegosetransfirióacódigoabierto
Sqoop§ ProyectopensadoparafacilitarlaimportaciónyexportacióndedatosentreHadoop
(HDFSoHbase)ybasesdedatosrelacionales
26
Adquisicióndedatos
BATCH

Sqoop§ MoverdatosdeHDFShaciaunabasededatosrelacionalesuncasodeusocomún
§ HDFSyMap-Reducesonmagníficospararealizareltrabajopesado§ Paraconsultassencillasoalmacenamientodeback-endparaunsiAoweb,sepasalasalidade
Map-Reduceaunalmacenamientorelacional
27
Adquisicióndedatos
BATCH

Flume
“ApacheFlumeesunsistemadistribuidoyseguropararecoger,agregarymovergrandesvolúmenesdedatosprovenientesdelogsdesdedisAntasfuentesaun
almacéndedatosCentralizado”def.weboficialdelproyectoApacheFlume
§ ProyectoiniciadoporClouderayactualmentebajoladireccióndeApache
§ CaracterísAcas:fiable,toleranteafallos,escalable
§ LanovedadqueincorporaesquepermiteimportardatosaHDFSdesdeunafuentequelosgeneradeformaconMnua(flujosdedatosenstreaming)
§ Nosóloagregadatosdesdelogs,tambiénpermiterecogerdatosdesdeeventosligadosaltráficodered,redessociales,mensajesdecorreoelectrónico…
§ PermitelaautomaAzacióndelacargadedatos
28
Adquisicióndedatos
BATCH

Flume§ ArquitecturadeFlume:
§ Fuenteexterna:§ Aplicaciónomecanismo,comounservidorwebouna
consoladecomandos,desdelacualsegeneraneventosdedatosquevanaserrecogidosporlafuente
§ Fuente:§ Seencargaderecogereventosdesdelafuenteexternaenun
formatoreconocibleporflumeypasárselostransaccionalmentealcanal
§ Canal:§ Actúadealmacénintermedioentrelafuenteyelsumidero.
Losdatospermaneceránenelcanalhastaqueelsumiderouotrocanallosconsuman
§ Estoesmuyimportanteyaquehacequeelflujodedatosseafiableytoleranteafallos
§ Sumidero:§ Seencargaderecogerlosdatosdesdeelcanaldentrodeuna
transacciónydemoverlosaunrepositorioexterno,otrafuenteoauncanal
§ Repositorioexterno:§ Paraalmacenarenunsistemadeficheroscomopuede
serHDFSlosdatosprocesadosenflume
Canal
fuente sumidero
Agente
HDFS
Servidorweb
29
Adquisicióndedatos
BATCH

Flume§ Ejemplo:Unaestacióndedatosdecalidaddeaireenvíadatosaunservidor
§ LaaplicaciónflumelosrecolectaylosenvíaaHDFSparasuposterioranálisis
Canal
fuente sumidero
AgenteCalidad-AireHDFS
30
Adquisicióndedatos
BATCH

Flume§ EjemplodeconfiguraciónunagenteFlume
§ Definirelagentea1quetendráunafuenter1queestaráescuchandoenelpuerto4444,unsumiderok1queseráHDFSyuncanalintermedioc1quealmacenaráenmemorialosdatosescuchadosporlafuente
//Nombredelascomponentesdelagentea1.sources=r1a1.sinks=k1a1.channels=c1
//Descripción/Configuracióndelafuentea1.sources.r1.type=Sysloga1.sources.r1.host=localhosta1.sources.r1.port=44444
//Descripcióndelsumideroa1.sinks.k1.type=hdfs
//Descripcióndelcanal:bufferenmemoriaa1.channels.c1.type=memorya1.channels.c1.capacity=1000a1.channels.c1.transacMonCapacity=100
//Enlazarlafuenteyelsumideromedianteelcanala1.sources.r1.channels=c1a1.sinks.k1.channel=c1
31
Adquisicióndedatos
BATCH
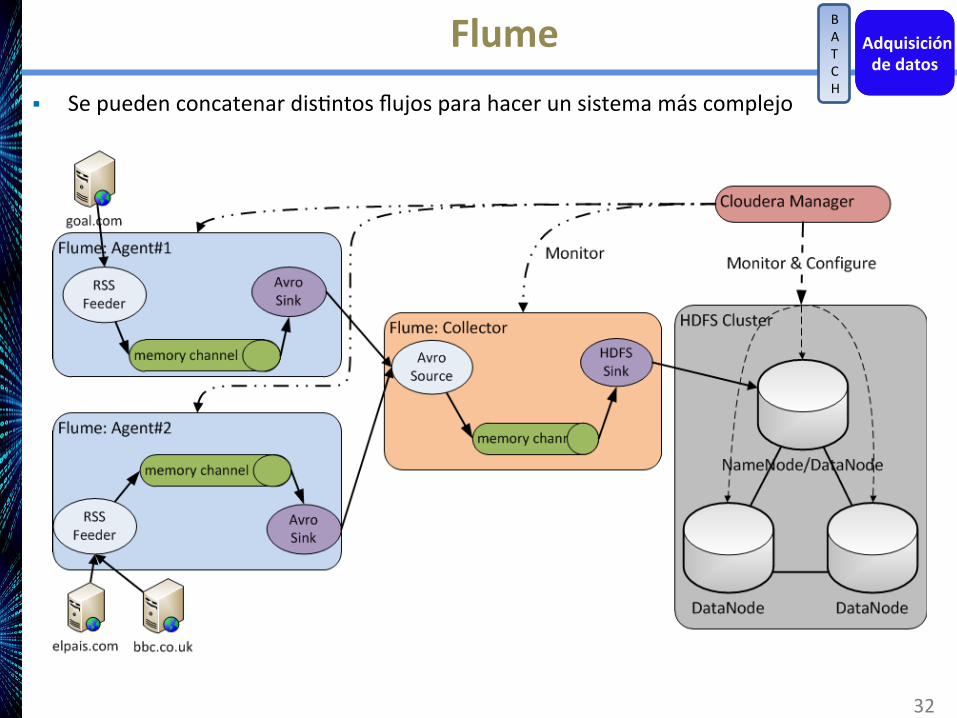
Flume§ SepuedenconcatenardisAntosflujosparahacerunsistemamáscomplejo
32
Adquisicióndedatos
BATCH

Chukwa
§ EsunsistemadecapturadedatosyframeworkdeanálisisquetrabajaconHadoopparaprocesaryanalizargrandesvolúmenesdelogs§ Incluyeherramientasparamostraryanalizarlosdatoscapturados
§ PrincipalescaracterísMcas:
§ Puederecogerunagranvariedaddemétricasyrecibirdatosatravésdevariosprotocolosdered,incluyendosyslog
§ TrabajaconHDFSyMapReduceparaprocesarsusdatosyporlotantopuedeescalarfácilmenteamilesdenodosenlarecolecciónyanálisis
§ Proporcionaunmarcofamiliarparaelanálisisdelosdatosrecogidos
§ Suscomponentessonplugeablesypuedenpersonalizarseymejorarse
§ Soportalarecuperaciónantefallos,usandolascopiaslocalesdelosarchivosderegistro,enlasmáquinasdondesegeneran
33
Adquisicióndedatos
BATCH

Chukwa§ ArquitecturadeChukwa
§ Agentes:procesosquecorrenencadamáquinaenlaquesegeneranloslogsquesequierentransferir
§ RecolectanloslogsdesdelacapadeaplicaciónusandoAdaptadores§ UnAgentepuedetenervariosadaptadores,cadaunorealizandounatareaseparadaderecolectar
logs§ Colectores:seencarganderecolectarloslogsdevariosagentesyescribirlosenunfichero
DataSinkenHDFS§ CadaSinkFileesunficheroHadoopqueconAeneungrupodeclaves-valorymarcadorespara
facilitarelaccesoMapReduce§ SielficheroAeneextensión.chukwaesqueaúnestáprocesándose,cuandoelcolectorcierrael
ficheroleponeextensión.done
§ LosJobsMapReducedeChukwaseencargandeprocesarlosficheros.done§ Muevetodoslosficheros.donefueradelSinkycorreunjobMapReduceparaagruparlosenArchive
Files
34
Adquisicióndedatos
BATCH

Scribe
§ Sielservidorcentralnoestádisponiblesepersisteelmensajeenlocalparasuposteriorenvío
§ LosservidorescentralespuedenpasarlosmensajesaundesAnofinaloaotracapasuperiordeservidores
§ SepuededescribircomounservidorparairagrupandologstransmiAdosenMemporealdesdeungrannúmerodeservidores
§ Estádiseñadoparaescalaragrannúmerodenodosyserrobustoafallosderedonodos
§ EsunproyectoconorigenenFacebook§ LoAeneninstaladoenmilesdemáquinasyprocesandomilesdemillonesde
mensajesaldía
§ Seinstalaencadanododelsistemaconfigurándoloparaagruparmensajesyenviarlosaunservidorcentral(oungrupodeservidores)
Adquisicióndedatos
BATCH
35

Hbase§ EslabasededatosdeHadoop
§ Nosigueunesquemarelacional§ NoadmiteSQL§ Distribuida
§ ParAcionadoautomáAcodelastablas
§ Orientadaporcolumnas§ DiseñadaaparArdeGoogleBigTable
§ Tablet~region§ Masterserver~HBasemaster§ Tabletserver~HBaseRegionserver§ Chubby~Zookeeper§ GFS~HDFS§ SSTablefile~MapFilefile
§ EstámontadasobreHDFSdeHadoop§ Estáenunniveldeabstracciónporencima§ PermitecargarprogramasenJavapararealizar
MapReducespersonalizados
§ NoAeneunlenguajedeconsultaintuiAvo§ UAlizaunlenguajepseudo-javascriptparacreartablasy
realizarconsultas
36
Almacenamientodedatos
BATCH
APIsparaelaccesoalabasededatos

Hive
§ EsunsistemadeDataWarehouseparaHadoopquefacilitaelusodelaagregacióndelosdatos,consultasyelanálisisdegrandesdatasetsalmacenadosenHadoop
§ DesarrolladoporFacebookenenerode2007§ Sepasaacódigoabiertoenagostode2008
§ ProporcionamétodosdeconsultadelosdatosusandoellenguajeHiveQL,parecidoalSQL§ LasconsultasrealizadasdesdeHiveQLseejecutansiguiendoelmodeloMap-Reduce§ HiveseencargadetraducirlaconsultaescritaconHiveQLentareasMap-Reduce§ Permitealprogramadorescribirsuspropiasfuncionesmapyreducecuandoelrendimientonoesel
correcto§ Lalatenciadelasconsultassuelesermayorquelasrealizadasenlasbasesdedatosrelacionales
debidoalainicializacióndeMap/Reduce
§ PermitehacerconsultasatablasqueseencuentrenenHbase
§ TieneinterfacesJDBC/ODBC,porloquese`puedeintegrarconherramientasdeBI
37
Análisisdedatos
BATCH

Hive§ Arquitectura
§ Interfazdeusuario:métododeentradadelusuariopararealizarlasconsultas
§ Driver:recibelasconsultasyseencargadeimplementarlassesiones§ Compilador:parsealaconsultayrealizaanálisissemánAcosyotrascomprobacionesdelenguaje
paragenerarunplandeejecuciónconlaayudadelmetastore§ Motoresdeejecución:seencargandellevaracaboelplandeejecuciónrealizadoporelcompilador
§ Metastore:almacenatodalainformación-metadatos-delaestructuraquemanAenenlosdatosdentrodeHive-esdecir,Aeneelesquemadelasbasesdedatos,tablas,parAciones…
38
Análisisdedatos
BATCH

§ Ejemplo:ObtenerlamediadeSO2decadaestación
Hive
//CrearunatablacondatosalmacenadosenHDFS:CREATETABLECalidad-Aire(Estaciónint,Titulostring,LaAtuddouble,….,SO2int,NOint,..)ROWFORMATDELIMITEDFIELDSTERMINATEDBY';'LINESTERMINATEDBY'\n'STOREDASTEXTFILE;
//Cargardatosenlatabla:LOADDATAINPATH'/CalidadAire_Gijon'OVERWRITEINTOTABLECalidad-Aire;
//ConsultaatablaparahacerlamediadeSO2decadaestación:
SELECTTitulo,avg(SO2)FROMCalidad-AireGROUPBYEstacion;
39
Análisisdedatos
BATCH

Pig§ Esunlenguajedeprogramacióndeflujosdedatos,dealtonivel,desarrolladopara
facilitarlaprogramacióndeMapReducesobrehadoop
§ Unlenguajepropio:PigLa5n§ EsrelaAvamentefácildeaprenderpuesesmuyexpresivoylegible§ Programasejecutadoscomo:
§ ScriptsenPigLaAn§ Grunt:shellinteracAvoparaejecutarcomandosPig§ ComandosPigejecutadosdesdeJava
§ PigPen:entornodedesarrolloparaEclipse
§ Eseficientefrenteagrandesflujosdedatos
§ PermitealosusuariosdeHadoopcentrarseenel“qué”envezdeenel“cómo”
§ InicialmentedesarrolladoporYahoo,en2006§ En2007fueincorporadoalproyectoApache
40
Análisisdedatos
BATCH

Cargarusuario
Filtrarporedad
Unirpornombre
AgruparporURL
Contarclicks
Ordenarclicks
Tomarlos5primeros
Cargarpáginas
Pig
§ Ejemplo:SeAeneunFicherocondatosdeusuarios(“user”)yunFicheroconlistadepáginasvisitadasporlosusuarios(“pages”).Buscarlas5páginasmásvisitadasporusuariosconedadesentre18y25años
Pages=load“pages”as(user,url);Users=load“user”as(name,age);Filtered=filterUsersbyage>=18andage<=25;Joined=joinFilteredbyname,Pagesbyuser;Grouped=groupJoinedbyurl;Summed=foreachGroupedgenerategroupcount(Joined)asclicks;Sorted=orderSummedbyclicksdesc;Top5=limitSorted5;storeTop5into’top5sites’;
41
Análisisdedatos
BATCH

Cascading§ UnsoawaredecapadeabstracciónparaHadoop
§ PermitealosusuarioscrearyejecutarflujosdetrabajodeprocesamientodedatosenclústeresHadoopusandocualquierlenguajebasadoenJVM
§ SuobjeAvoesocultarlacomplejidadsubyacentedelostrabajosdeMapReduce
§ DiseñadoporChrisWenselcomoalternaAvaAPIaMapReduce§ ElsoportecomercialparaCascadingesofrecidoporConcurrent,unaempresafundada
porWensel§ EstádisponiblebajolaGeneralPublicLicensedeGNU
§ EntrelasempresasqueuAlizanCascadingestánTwi�eryEtsy
§ HayotrasherramientasquenosonJavaporencimadeCascadingqueseusancomúnmentecomoCascalogoScalding
42
Análisisdedatos
BATCH

Spark
§ EsunafamilianuevadetecnologíasquesurgecomoalternaMvaalframeworkdemapreduce§ SeincubóenBerkeleyAmpLabscomopartedelatesisdoctoral
§ 2009primerpaper§ SurgecomounproyectoparajusAficarotroproyecto,(Mesos,sistemadegesAóndeclústers)
§ Opensourceen2010§ Primeroenlafasedeincubadorayen2014esunodelostresproyectosmasacAvosdeApache
SogwareFundaAon
§ SecreoDatabricks,unastartupquedesarrollaSpark
§ Hayunacomunidaddedesarrolladores§ MadridApacheSparkMeetup
§ EstádesarrolladoenScala§ ProporcionaAPI´sparaJava,Scala&Python
43
Análisisdedatos
BATCH

Spark§ Modelodeprogramación:“ResilientDistributedDatasets”(RDDs)
§ AbstracciónbásicadeSparkparatrabajarconcualquierMpodedato§ Esunacoleccióndistribuidadeelementos,objetos
§ SobrelosRDDsehacentodaslastransformacionesnecesariaspararesolverelproblema§ Ademásdelosdatos,losRDDconAenentodaslasoperacionesdetransformaciónquesevana
ejecutarsobreellos
§ CadaRDDsedivideenmúlAplesparAcioneslascualespuedenserejecutadasenparaleloendiferentesnodosdelclúster
§ ElRDDtambiénguardainformaciónsobrelasparAcionesyaquénodoAenequeir
§ Soninmutables§ Unavezextraídoslosdatosseasumequenovanacambiarporloquenosevuelvenaleerdedisco§ LastransformacionesaplicadasaunRDDcreanotroRDDconelresultadodeesastransformaciones
44
Análisisdedatos
BATCH
Transformacion RDDRDDRDDRDDAcción ValorRDD

§ Ejemplo:Leeunficherolocalyrealizaunaseriedeoperacionessobreél
Spark
//CrearunRDDconelcontenidodelficheroval:docs=sc.texfile(“..\don-quijote.txt.gz”)
//Sedefinen5transformaciones
valdocsMin=docs.map(_.toLowerCase)valpalabras=docsMin.map(_.split(“”))valpares=palabras.map(word=>(word,1))valfreq=pares.reduceByKey(_+_)valinvFrec=frec.map(_.swap)//Acción:imprimelas20mayores
invFrec.top(20).foreach(prinln)
45
Análisisdedatos
BATCH

Spark§ EcosistemadeSpark
§ SparkSQL:CapadeaccesoSQLaparaejecutaroperacionesdobrelosdatosquehayenRDD
§ EquivalenteaHiveenhadoop
§ SparkStreaming:Móduloquefacilitalaconstruccióndeaplicacionesdeflujocontoleranciaafallosyescalable.paraprocesarenAemporealgrandescanAdadesdedatosentreclústeres.
§ Permiteintegrardentrodelsistemadeprocesamientodatosquevenganenformadestreaming
§ Mllib:MódulodeaprendizajeautomáAcodeApacheSpark.§ GraphX:APIdeApacheSparkparagrafosycomputaciónparaleladegrafos§ SparkR:PermiteconectarRconspark
SparkSQL
SQLSparkR
RsobreSparkGraphX
Computoengrafos
SparkStreaming
MLLibMachinelearning
SparkCoreEngine
46
Análisisdedatos
BATCH

EcosistemaHadoop
HadoopHDFS
Zookeeper
...
47

EcosistemaHadoop§ EnHadoop2.0incorporaYARN(YetAnotherResourceNegociator)
§ EsunmotordegesAónderecursosyaplicacionesoprocesosdistribuidos§ SeparalasdosfuncionalidadesdelJobTrackerendemoniosseparados:
§ GesMónderecursos§ Planificación/monitorización
§ PermitequediferentesAposdeaplicaciones(nosoloMapReduce)seejecutenenelcluster
HadoopHDFS2
YARN
...
...
48

DistribucionesdelecosistemaHaddop§ Tecnologíasdecódigoabierto
§ SudesarrolloesadministradoporApacheSoawareFoundaMon§ Sepuedendescargardeformagratuita
§ ExistenproveedoresdeHadoopqueproporcionan:§ Versionesconlafuncionalidadbásicaquesepuedendescargardeformagratuitaeinstalaren
unavariedaddeplataformasdehardware§ DistribucionesdeHadoopcomercialesqueagrupanelsogwarecondiferentesnivelesde
serviciosdemantenimientoysoporte§ MejorasderendimientoyfuncionalidadsobrelabasedelatecnologíaApache:
§ HerramientasdesogwareadicionalesparafacilitarlaconfiguracióndelclústerylagesAón,olaintegracióndedatosconplataformasexternas
49
...

ProcesamientoenAemporeal
TecnologíasparaelprocesamientoenMemporeal
q Flume q KaVaq Kestrel
q Stormq Sparkstreamingq Flumeq Tridentq S4
51
Almacenamientodedatos
Análisisdedatos
Presentaciónresultados
Adquisicióndedatos

Flume
§ Sistemadistribuidoparacapturar,agregarymovergrandescuanMdadesdedatoslog§ Diferenciarespectoalusoenbatchprocessing:lafuenteexternaesdadatosenstreamingy
elrepositorioexternoesunsistemadealmacenamientotemporalcomoKaVa,…
Adquisicióndedatos
STREAM
Ka�aCanal
fuente Sumidero
Agente
Streamingdata
Procesamiento
52

Ka�a§ Esunsistemademensajeríadistribuidodealtorendimiento
§ Naciócomouncolectordelog,ahoraesunsistemademensajería
§ DesarrolladaporLinkedIn
§ ModeloProductor/Consumidor
§ Seejecutacomounclusterdeunoomásservidores(Brokers)§ ManAenetodoslosdatospublicados(seanconsumidosono)porunAempoconfigurable
§ SeintegrasinproblemasconmuchasherramientasdeApache
Almacenamientodedatos
STREAM
RDDRDDProductor(Otros)
Productor(Adaptador)
Ka�a
Productor(Interfaz)
Productor(Servicio)
Consumidor(MonitorMempo–real)
Consumidor(HadoopClúster)
Consumidor(Storm)
RDDRDDConsumidor
(Otros)
53

Ka�a
§ Ejemplo:AlmacenartemporalmentelainformaciónrecogidadeunsensormóvilquemidelaCalidaddelaire,paraenviarlaalosconsumidoresdondeseanalizar᧠Sedefineelproductor
//definimoselproductor
Producer<String,String>producer=newProducer<String,String>(Config);//Abrirelficherodelogdelsensor
BufferedReaderbr=newBufferedReader(newFileReader(“……”))Stringline;While(true){
Line=br.readLine();If(line==null)
….;//esperaelse
producer.send(newKeyedMessage<String,String>(topic,line));}
Nombredelfichero
54
Almacenamientodedatos
STREAM

Ka�a
§ Ejemplo:§ Sedefineelconsumidor
ConsumerConnectorconsumer=consumer.createJavaConsumerConnector(config);Map<String,Integer>topicCountMap=newHashMap<String,Integer()>;
topicCountMap.put(topic,newInteger(1));
Map<String,List<KaVaMessageStream>>consumerMap= consumer.createMessageStream(topicCountMap);
KaVaMessageStreamstream=consumerMap.get(topic).get(0);consumerIteratorit=stream.iterator();While(it.hasNext()){
It.next();..
55
Almacenamientodedatos
STREAM

Kestrel
§ Unsistemademensajeríadistribuido
§ DesarrolladoporTwi�er
§ Basadoencolas
§ Seejecutacomounclusterdeunoomásservidores§ UnservidorAeneunconjuntodecolasestrictamenteordenadas(FIFO)§ LosservidoresnoAenenningunacomunicaciónentresi
§ ComparadoconKaVa
§ Operacionalmentemássencillo§ Tienepeorrendimiento
56
Almacenamientodedatos
STREAM

Flume
§ Permiteanálisissencillosdatos§ SebasaendefinirInterceptores:
§ Losinterceptoressonclasesqueimplementanlainterfaz§ Packageorg.apache.flume.interceptor
§ Sedefinencomopartedelaconfiguracióndeunafuente
§ Analizanlosdatosamedidaquepasanentrelafuenteyelcanal§ Permitenfiltrar,modificaroinclusoeliminarbasándose��encualquiercriterio
§ Sepuedenencadenarentresí
Análisisdedatos
STREAM
Canal
fuente sumidero
Agente
Interceptor1
Interceptorn…
57

Flume
§ Ejemplo:filtrarlosdatosqueprovienendelsensordelaestación2§ Hayquedefiniruninterceptorqueseencarguedefiltrarlainformación
Ka�a
Canal
fuentesumidero
AgenteCalidadAire
Interceptor
58
Análisisdedatos
STREAM

Flume
§ Ejemplo:filtrarlosdatosqueprovienendelaestación2§ Hayquedefiniruninterceptorqueseencarguedefiltrarlainformación
ClassStaAonFilterimplementsInterceptor…If(!”StaAon”.equals(“2”))
discarddata;Else
savedata;
//definimoslafuentea1.sources=s1
//definimoselinterceptora1.sources.s1.interceptors=i1a1.sources.s1.interceptors.i1.type=org.apache.flume.interceptor.StaMonFilter
//definimoselcanal…
//definimoselsumidero……
59
Análisisdedatos
STREAM

Storm
§ SistemadecomputacióndistribuidaparaprocesamientodedatosenTiempoReal§ DesarrolladoporNathanMarzparaTwi�er§ LicenciaApacheenSepAembredel2011
§ 2014StormhapasadoaserconsideradocomounTop-LevelProjectdeApache
§ UnclusterStormes,aunaltonivel,similaraunclusterHadoopMapReduce
60
Análisisdedatos
STREAM
Hadoop-MapReduce
JobTrackerTaskTrackerJobü Hayestadosü Cuandounatareaseacaba,elhilodeejecucióntermina
Storm
NimbusSupervisorTopology
ü Nohayestadosü Sequedaesperandodatosdeentradaeternamenteü Separamatandolatopología

Storm
§ Modelodeprogramación:Topologías§ Definenungrafodecomputaciónqueprocesaflujosdedatos
61
Análisisdedatos
STREAM
§ Spout:nodosqueseencargandelaentradadelosdatos§ Leelosdatosdelafuentedeorigenylosemitehacialosbolt
enmododestream
§ Bolt:nodosqueseencargadelprocesadodelosstreams§ Puedenrealizaroperacionesdemapreduce,filtrado,
funciones,agregados,conexionesconbasesdedatosexternas
§ Streamesunasecuenciailimitadadetuplas§ Lastuplassonlistasdevaloresconunnombreespecífico§ Elvalorasociadopuedeserunobjetoodatodecualquier
Apo§ Estándar(integers,longs,shorts,bytes,strings,doubles,floats,
booleans,andbyte)§ Definidosporelusuario
SpoutBolt
Stream

Storm
§ Ejemplo:ObtenerlamediadeSO2yNOdecadaestación§ Paso1:construirlatopología
TopologyBuilder AirAVG = new TopologyBuilder();
AirAVG.setSpout("ca-reader ", new CAReader());
AirAVG.setBolt("ca-avg-processor ", new LineProcessor(), 3).shuffleGrouping(“ca-reader")
AirAVG.setBolt(“ca-avg-values", new AvgValues(), 2).fieldsGrouping("ca-avg-processor ", new Fiel
ds( “id"));
Spout“ca-reader”
Bolt“ca-avg-processor”
LineProcessor
Bolt“ca-avg-values”
AvgValuesCAReader Shuffle
“id”
62
Análisisdedatos
STREAM

§ Ejemplo:ObtenerlamediadeSO2yNOdecadaestación§ Paso2:ImplementarlaclaseCAReader(IRichSpoutInterfece)
Storm
63
Análisisdedatos
STREAM

§ Ejemplo:ObtenerlamediadeSO2yNOdecadaestación§ Paso3:ImplementarlaclaseLineProcesor(IBasicBoltInterfece)
Storm
64
Análisisdedatos
STREAM

§ Ejemplo:ObtenerlamediadeSO2yNOdecadaestación§ Paso4:ImplementarlaclaseAvgValues(IBasicBoltInterfece)
Storm
65
Análisisdedatos
STREAM

§ StormseintegrasinproblemasconmuchasherramientasdeApache§ Ejemplo
Storm
Flume
...
66
Análisisdedatos
STREAM

Trident
§ EsunaabstraccióndealtonivelqueofreceStorm
§ Losboltssereemplazancompletamenteporcomponentesmenosgenéricos,comofiltros,proyeccionesyfunciones
§ SeestáconvirAendoenlaformamáscomúndeuAlizarStorm
67
Análisisdedatos
STREAM
Pros§ Facilitalacreacióndelastopologías
§ PermiteconfigurarunatopologíaqueproceseunaentradadedatoasemejándolaaunaquerySQL
§ Permitehacermicro-baches
Contras§ Menorrendimiento§ latenciamásaltaquestorm

§ Plataformadepropósitogeneral,distribuida,quepermiteeldesarrollodeaplicacionesparaelprocesamientodeflujosconMnuoseilimitadosdedatos
§ S4(SimpleScalableStreamingSystem)
§ DesarrolladaporYahoo§ SevolviódecódigoabiertoparaApacheen2010antesdepresentarStormcomocódigoabierto
§ EscritoenJava
§ Fácildeprogramar§ Exponenunainterfazdeprogramaciónsencillaparalosdesarrolladoresdeaplicaciones§ LasaplicacionespuedenserescritasydesplegadasusandounaAPIsencilla§ Existegrannúmerodeaplicacionesbásicasdisponibles
§ SistemasbasadosenS4estánactualmentedesplegadosenlossistemasdeproduccióndeYahoo!paraprocesarmilesdeconsultasdebúsquedaporsegundo
S4
68
Análisisdedatos
STREAM

§ ModelodeProgramación
§ Elprocesamientodedatossebasaenelementosdeproceso(PE)correspondientealmodelodeactordelacomputaciónconcurrente
§ LosdatossetransmitenenformadeeventoshaciaunconjuntoPEs§ CadaeventoestáidenAficadoporunaclave
§ LoseventossonconsumidosporlosPE.Estospueden§ EmiArnuevoseventosparaqueseanconsumidosporotrosPE§ Publicarlosresultados
S4
PE
PE
PE
PEevento
evento
evento
evento
publicar
publicar
publicar
69
Análisisdedatos
STREAM

§ S4versusStorm S4
ü Conceptualmentemáspotente
ü Programaciónmássencilla
ü Recuperacióndelestado
ü BalanceodecargaautomáAco
S4
STORM
ü DistribuciónautomáAcadetareas
ü Depuraciónsencilla
ü ComunidadmuyacAva,Ecosistema
ü Altorendimiento
ü Mayorcontrol
ü Soportaprogramaciónconthreads
70
Análisisdedatos
STREAM
o NoAenebalanceodecargaautomáAco
o Muchotrabajoparaeldesarrollador
o Endesarrollo
o Configuracióncompleja
o ProcesamientoOpaco
o Complicadodedepurar
o EnincubaciónenApacheo ComunidadpocoacAva

Samoa
§ EsunframeworkparamachinelearningensistemasdeprocesamientodistribuidosenMemporeal§ EselequivalenteaApacheMahoutparaMemporeal
§ Esunaabstraccióndealtonivel§ Permiteeldesarrollodenuevosalgoritmossintratardirectamenteconlacomplejidad
delosmotoresdestorm,s4ysamza
§ CorresobreStorm,S4ySamza
71
Análisisdedatos
STREAM

§ FrameworkdeprocesamientoenMemporealdelecosistemaSpark
SparkStreaming
Batchprocessing
Streamingprocessing
Microbatches
SparkSQLSQL
SparkRRsobreSpark
GraphXComputoen
grafos
SparkStreaming
MLLibMachinelearning
SparkCoreEngine
§ EjecutacomputaciónenAemporealcomosifueraunaseriedetrabajosenpequeñoslotes§ TransformaunflujoconMnuodedatosenlotesdeXsegundos
§ AbreunaventanadeAempoenlaqueestárecibiendodatos,yconestosconstruyeRDDs
72
Análisisdedatos
STREAM

Sparkstreaming
-Transformalafuentestreamingenunconjuntodepequeños“batches”(“mini-batch”)-Defineunaventanatemporal-Pasadestreamingapodertrabajarenelmodo
batchhabitual
-Comotrabajacon“mini-batch”estámásopAmizadopararendimientoqueparalatencia
73
Análisisdedatos
STREAMDstream(discreMzadstream)RepresentaunasecuenciadeRDD
§ ManAenetodaslascaracterísAcasdellosRDD§ RepresentaunflujodedatosconstanteenelAempo
DatosdesdeelMempo0hastael1
RDD@t1
DatosdesdeelMempo1hastael2
RDD@t2

ArquitecturasHibridas

Procesamientohíbrido
Volumen Velocidad
Modelocomputacionalhíbrido
problemas
solución
75
§ Cadavezmás,lasempresasquierenmezclarlosdatosenMemporealconloshistóricos

SupongamosquequeremosunsistemadeanálisiswebquepermitaconsultarelnúmerodepáginasvisitadasdeunaURLencualquierrangodedías
Necesidaddelprocesamientohíbrido
76
§ Paraobtenerelresultado§ HayquemirartodaslaspáginasvisitadasporesaURL§ BuscarlasqueestándentrodeeserangodeAempoycontarlas
§ PorcadaconsultaquesehagahayquerepeArelprocesoanterior
§ ProcesandosololosdatosalmacenadosnoseMenenencuentalasvisitasqueestánocurriendomientrassehacelaconsulta
§ Ennúmerodeconsultasporminutoeselevado§ EstacanAdaddedatosnuevosnoestánanalizadosnicontabilizados
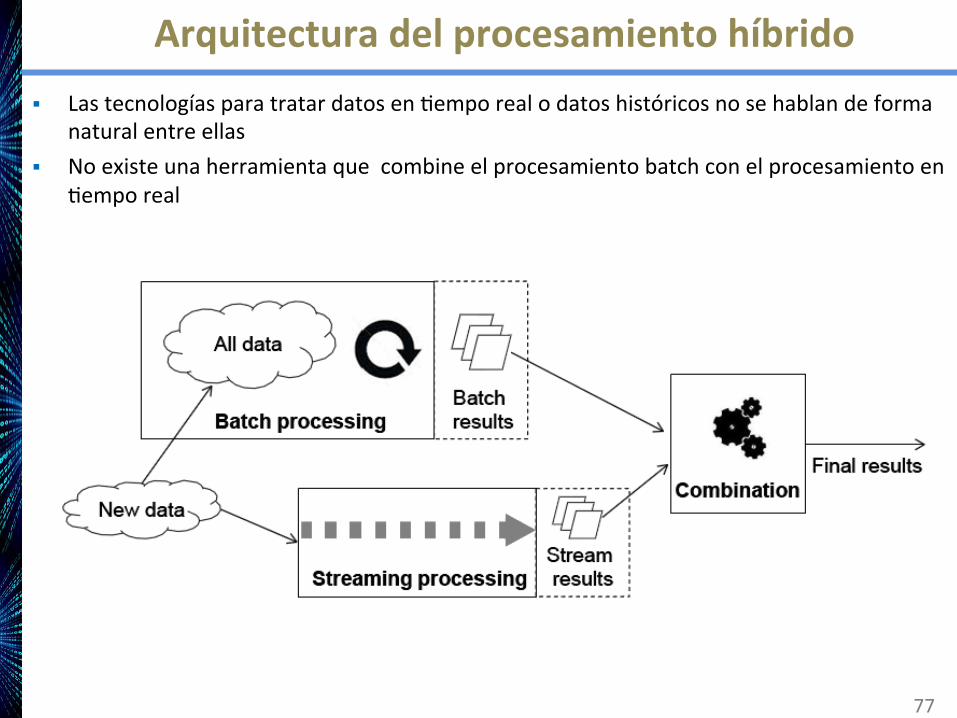
Arquitecturadelprocesamientohíbrido§ LastecnologíasparatratardatosenAemporealodatoshistóricosnosehablandeforma
naturalentreellas§ Noexisteunaherramientaquecombineelprocesamientobatchconelprocesamientoen
Aemporeal
77

ArquitecturaLambda§ DefinidaporNathanMarzen2012
§ Publicación§ h�p://www.databasetube.com/database/big-data-lambda-architecture/
§ Libro:§ h�p://www.manning.com/marz/
§ Proponentrescapas:
§ CapadeBatch(oPorLotes)
§ CapadeVelocidad§ CapadeServicio
78

§ ArquitecturaLambdadefinidaporNathanMarz
ArquitecturaLambda
CapaBatch
VistasBatch
VistasBatch
Capadeservicios
Datosnuevos
PeMción
PeMción
Todoslosdatos
Capadevelocidad
VistaMemporeal
VistaMemporeal
79

ArquitecturaLambda§ EjemploanteriorejecutadosobreunaarquitecturaLambda
“SupongamosquequeremosunsistemadeanálisiswebquepermitaconsultarelnúmerodepáginasvisitadasdeunaURLencualquierrangodedías”
80
LacapabatchEjecutapreviamentelapeAciónsobretodaslaspáginasvisitadasycalculauníndiceconunaclave[url,día]
LacreacióndelavistabatchAenealtalatencia,porqueseestáejecutandosobretodoslosdatosqueseAenen
LacapadevelocidadPermiteanalizarlosdatosqueestánllegandomientrassegeneralasvistasbatchyserealizanlasconsultas
ü Yanosepierdendatos
ü Estosnuevosdatosademássevanalmacenadoenelconjuntodedatostotal
VistabatchProporcionalasrespuestasalasconsultasdemaneraeficienteü SebuscaenelconjuntodeclavesysecuentanlasclavesquetenganeldíaentrerangodeAemposeleccionado
Lacapadeservicio

§ CapadeabstracciónSoawaresobretecnologíasOpenSource§ Hadoop,HBase,Sqoop,Flume,KaVa,Storm,Trident,Spark
§ DesarrolladoporLambdoop,startupdebigdatalanzadaporlaasturianaTreelogic§ hFp://www.lambdoop.com/
81
§ LibreríaparadesarrollarprocesosMpoMapReducequepuedenserejecutadosenHadoop,StormyelmodeloHíbrido
§ Desarrolladaportwi�er§ h�ps://github.com/twi�er/summingbird
§ CaracterísAcas§ DesarrolladaenScala§ ModelodeprogramaciónparalostresMposdeparadigmadeprocesamiento§ NoAeneelniveldeabstraccióncomoalusuariolegustaría

GuadalupeMiñanaropero
82