parallel tsp with branch and bound presented by akshay patil rose mary george
TRANSCRIPT

Parallel TSP with branch and bound
Presented by
Akshay Patil
Rose Mary George

2
Roadmap
Introduction
Motivation
Sequential TSP
Parallel Algorithm
Results
References

3
Introduction
What is TSP?
Given a list of cities and the distances between each pair of cities, find the shortest possible route that visits each city exactly once and returns to the original city.

4
Introduction
Problem Representation
Undirected weighted graph, such that the cities are graph vertices and paths are graph edges and a path's distance is the edge's weight.
0 1 2 3 40 00 17 04 10 131 17 00 01 14 052 04 01 00 04 103 10 14 04 00 064 13 05 10 06 00

5
Roadmap
Introduction
Motivation
Sequential TSP
Parallel Algorithm
Results
References

6
Motivation
Travelling salesperson problem with branch and bound is one of the algorithms which is difficult to parallelize.
Branch and bound technique can incorporate application specific heuristic techniques
One of the earliest applications of dynamic programming is the Held-Karp algorithm that solves the problem in O( n22n)
Greedy algorithm, may or may not obtain the optimal solution with O( n2 logn) complexity.
Parallel branch and bound optimization problems are large and computationally intensive.
Increasing availability of multicomputers, multiprocessors and network of workstations

7
Applications
TSP has several application even in its purest formulation such as :
Planning
Logistics
Manufacture of microchips
Genetics
UPS saves 3 million gallons of gasoline per year.

8
Roadmap
Introduction
Motivation
Sequential TSP
Parallel Algorithm
Results
References

9
Sequential TSP with branch and bound
Best_solution_node = null
Insert start city node into priority queue (Q)
While Q is not empty: node = Q.top() // Node with least cost
If node.cost >= Best_solution_node.cost // Bound
continue
If node is solution better than Best_solution_node
Best_solution_node = node
Else
Explore children of node and insert in Q //Branch
Display best_solution_node

10
Sequential TSP with branch and boundnoOfVertices = 5
Children Generated = (5-1 )! With No bounding
11
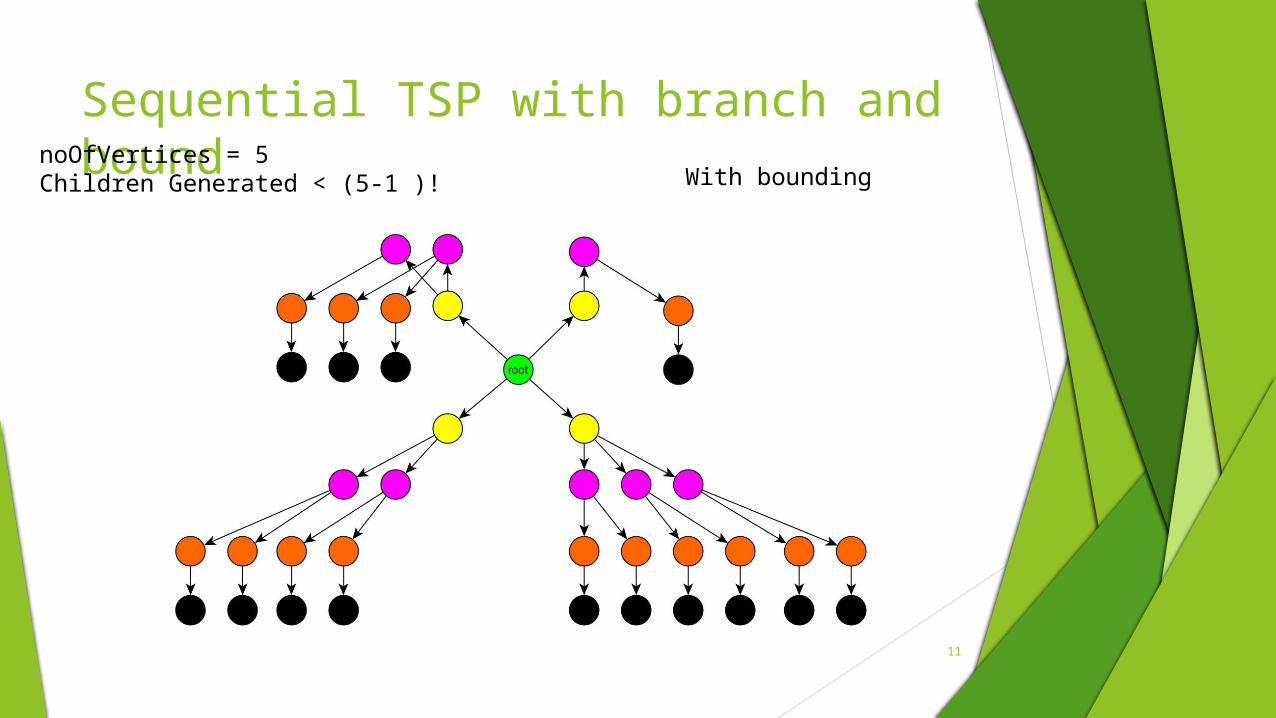
Sequential TSP with branch and boundnoOfVertices = 5
Children Generated < (5-1 )! With bounding

12
Lower Bound Estimate
Cost of any node = path_cost + lower_bound_estimate
lower_bound_estimate = MST ( unvisitied cities, startcity, currentcity)
MST is calculated using Prim’s algorithm which takes O(n2) if implemented using adjacency matrix.
Why MST is a good estimate?

13
Roadmap
Introduction
Motivation
Sequential TSP
Parallel Algorithm
Results
References

14
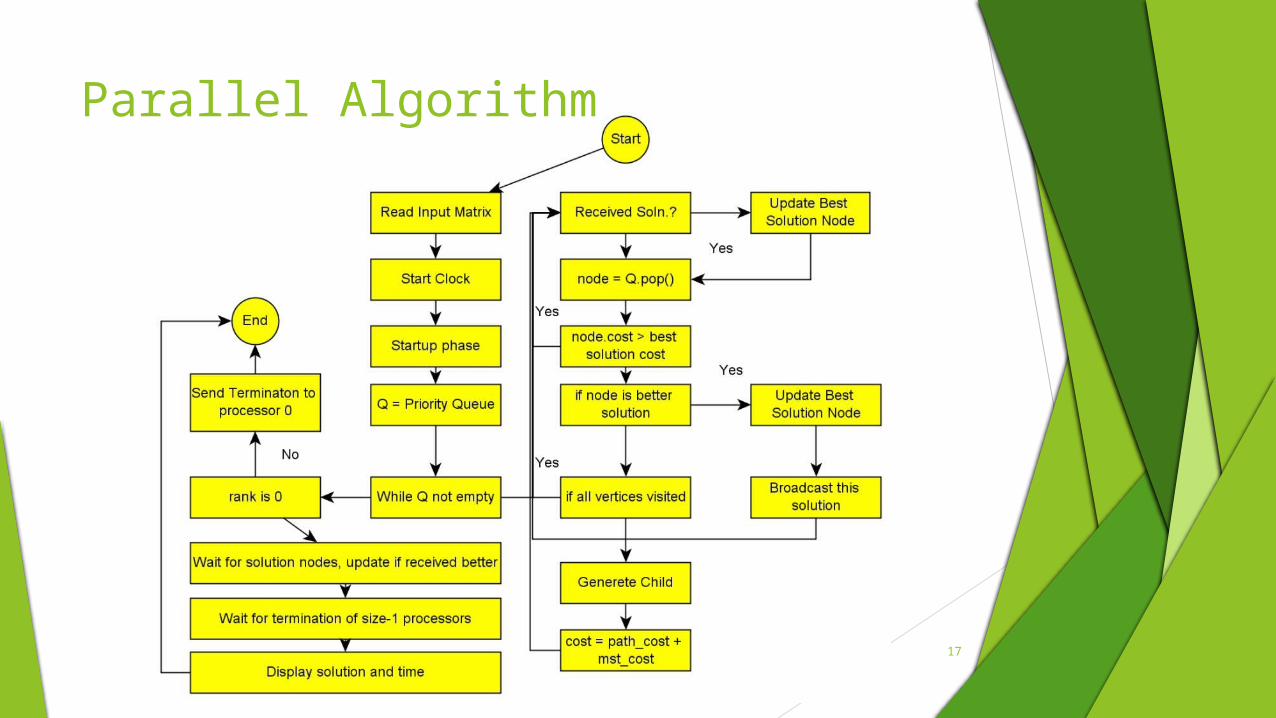
Parallel Algorithm
Datatype Creation for Solution Node
MPI_Datatype mpinode;
MPI_Datatype type[3] = {MPI_INT,MPI_INT,MPI_INT};
MPI_Aint disp[3];
disp[0] = (int)&root.nvisited - (int)&root;
disp[1] = (int)&root.cost - (int)&root;
disp[2] = (int)&root.path[0] - (int)&root;
int blocklen[3] = { 1, 1, GRAPHSIZE };
MPI_Type_create_struct(nodeAttributes,blocklen, disp, type, &mpinode // Resulting datatype.
);
struct Node{int nvisited;int cost;int path[GRAPHSIZE];
}// GRAPHSIZE = no.of.vertices

15
Parallel Algorithm
Send & Receive
At sender
MPI_Isend(&node, 1, mpinode,i,50,MPI_COMM_WORLD,&req);
node = variable of type Node
1 = send 1 variable
Dataype = mpinode
At Receiver
MPI_Irecv(buffer, size, mpinode, MPI_ANY_SOURCE, 50, MPI_COMM_WORLD,&req);
MPI_Wait(&req, &status);
MPI_Get_count(&status, mpinode, &noOfNodesReceivedInBuffer);

16
Startup phase
Distribution of initial nodes to processors.
For noOfProcessors = 4
Round 1 (start round = 1)
0 generates children of start city, sends half to 1, keeps half in startupNodes
Round 2 (last round = log(noOfProcessors)) 0 generates children nodes in startupNode, sends half to 2
1 generates children nodes in startupNode, sends half to 3
17
Parallel Algorithm

18
Roadmap
Introduction
Motivation
Sequential TSP
Parallel Algorithm
Results
References

19
Results
Processors Time Speedup1 7.97 -- 2 10.34 0.774 19.82 0.48 57.99 0.13
Processors Time Speedup1 9.137 -- 2 7.83 1.164 12.5 0.738 44 0.2
For n = 12 For n = 12, all edge weights=10 except 1

20
Current State of the Art Algorithms
LKH(Lin-Kernighan heuristic), was used to solve the World TSP problem which uses data for all the cities in the world.
The best lower bound on the length of a tour for the World TSP is 7,512,218,268
The tour of length 7,515,778,188 was found on October 25, 2011.

21
References
MPI Dynamic receive and Probe, http://www.mpitutorial.com/dynamic-receiving-with-mpi-probe-and-mpi-status/
TSP Test Data, http://www.tsp.gatech.edu/data/
World TSP, http://www.tsp.gatech.edu/world/index.html
LKH(Lin-Kernighan heuristic), http://www.akira.ruc.dk/~keld/research/LKH/
Used to solved the World TSP problem