part-of-speech (pos) tagging - classes.ischool.syr.edu -...
TRANSCRIPT

Part-Of-Speech (POS) Tagging
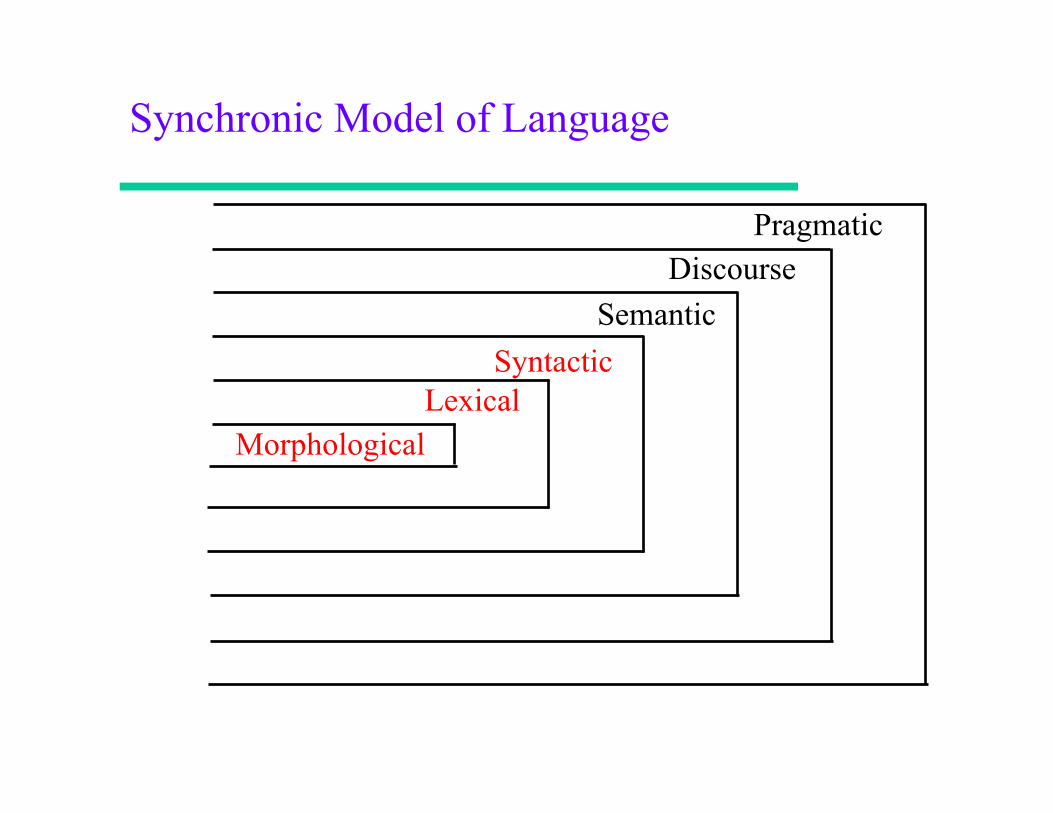
Synchronic Model of Language
Pragmatic Discourse
Semantic Syntactic
Lexical Morphological

What is Part-Of-Speech Tagging?
• The general purpose of a part-of-speech tagger is to associate each word in a text with its correct lexical-syntactic category (represented by a tag)
03/14/1999 (AFP)… the extremist Harkatul Jihad group, reportedly backed by Saudi dissident Osama bin Laden ...
… the|DT extremist|JJ Harkatul|NNP Jihad|NNP group|NN ,|, reportedly|RB backed|VBD by|IN Saudi|NNP dissident|NN Osama|NNP bin|NN Laden|NNP …

Why is Part-Of-Speech Tagging Needed?
• Words may be ambiguous in different ways: – A word may have multiple meanings as the same part-
of-speech • file – noun, a folder for storing papers • file – noun, instrument for smoothing rough edges
– A word may function as multiple parts-of-speech • a round table: adjective • a round of applause: noun • to round out your interests: verb • to work the year round: adverb

Applications that Profit from Part-Of-Speech Tagging
• Internally, next higher levels of NL Processing: – Phrase Bracketing – Parsing – Semantics
• Externally: – Speech synthesis — pronunciation – Speech recognition — class-based N-grams – Information retrieval — stemming, selection high-content words – Word-sense disambiguation – Corpus analysis of language & lexicography – Information Extraction – Question & Answering (Q & A) (QA) – Machine Translation

Overview of Approaches
• Rule-based Approach – ENGTWOL (ENGlish TWO Level analysis)
• Stochastic Approach – Refers to any approach which incorporates frequencies or
probabilities – Requires a tagged corpus to learn frequencies – N-gram taggers – Hidden Markov Model (HMM) taggers
• Transformation-Based Learning Approach (Brill) – Combines rules with learning patterns from a tagged corpus
• Other Issues: unknown words and evaluation
6

What are Parts-of-Speech?
• Approximately 8 traditional basic words classes, sometimes called lexical classes or types – N noun chair, bandwidth, pacing – V verb study, debate, munch – ADJ adjective purple, tall, ridiculous – ADV adverb unfortunately, slowly – P preposition of, by, to – PRO pronoun I, me, mine – DET determiner the, a, that, those
7

Open Class Words
• Open classes – can add words to these basic word classes: • Nouns, Verbs, Adjectives, Adverbs.
– Every known human language has nouns and verbs
• Nouns: people, places, things – Classes of nouns
• proper vs. common • count vs. mass
– Properties of nouns: can be preceded by a determiner, etc.
• Verbs: actions and processes • Adjectives: properties, qualities • Adverbs: hodgepodge!
– Unfortunately, John walked home extremely slowly yesterday
• Numerals: one, two, three, third, …

Closed Class Words
• Closed classes– words are not added to these classes: – determiners: a, an, the – pronouns: she, he, I – prepositions: on, under, over, near, by, …
– over the river and through the woods – particles: up, down, on, off, …
• Used with verbs and have slightly different meaning than when used as a preposition
– she turned the paper over
• Closed class words are often function words which have structuring uses in grammar:
– of, it , and , you
• Differ more from language to language than open class words
– determiners: a, an, the, …

Prepositions from CELEX
• From the CELEX on-line dictionary with frequencies from the COBUILD corpus
Charts from Jurafsky and Martin text

English Single-Word Particles

Pronouns in CELEX

Conjunctions
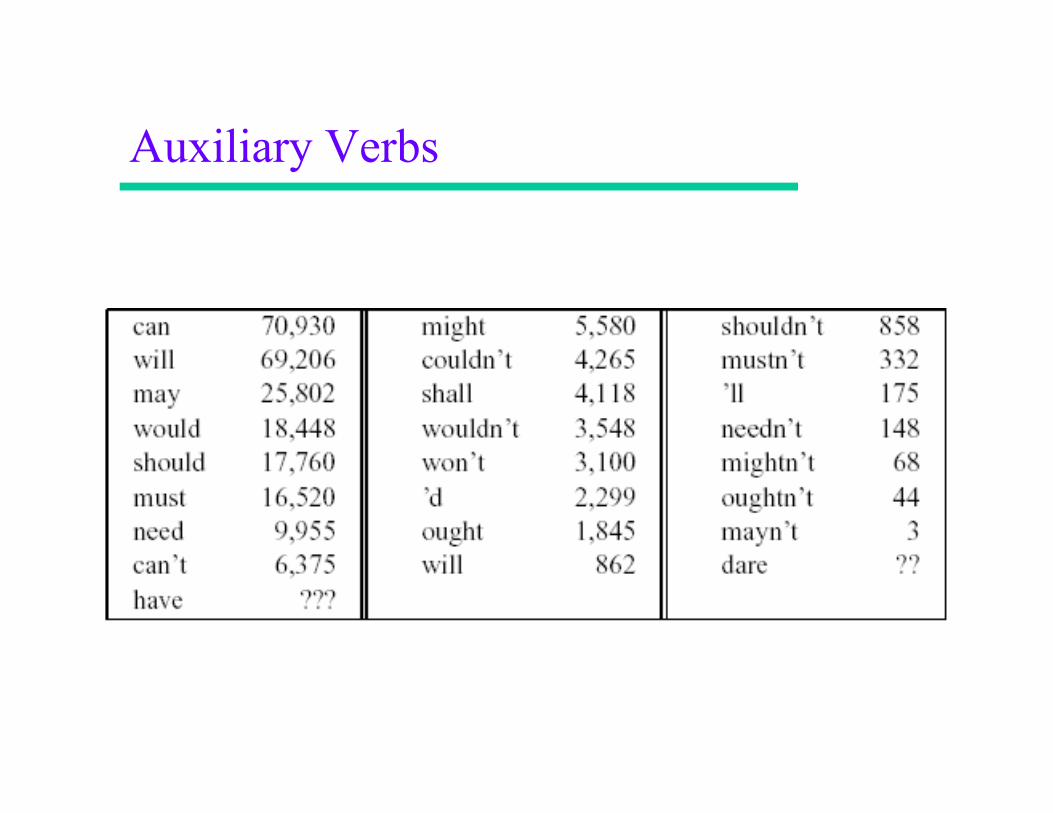
Auxiliary Verbs

Possible Tag Sets for English
• Kucera & Brown (Brown Corpus) – 87 POS tags
• C5 (British National Corpus) – 61 POS tags – Tagged by Lancaster’s UCREL project
• Penn Treebank – 45 POS tags – Most widely used of the tag sets today

Penn Treebank
• A corpus containing: – over 1.6 million words of hand-parsed material from the
Dow Jones News Service, plus an additional 1 million words tagged for part-of-speech.
– the first fully parsed version of the Brown Corpus, which has also been completely retagged using the Penn Treebank tag set.
– source code for several software packages which permits the user to search for specific constituents in tree structures.
• Costs $1,250 to $2,500 for research use
• Separate licensing needed for commercial use

Word Classes: Penn Treebank Tag Set
PRP PRP$

Example of Penn Treebank Tagging of Brown Corpus Sentence
• The/DT grand/JJ jury/NN commented/VBD on/IN a/DT number/NN of/IN other/JJ topics/NNS ./.
• VB DT NN . Book that flight .
• VBZ DT NN VB NN ? Does that flight serve dinner ?

The Problem
• Words often have more than one word class: this – This is a nice day = PRP – This day is nice = DT – You can go this far = RB
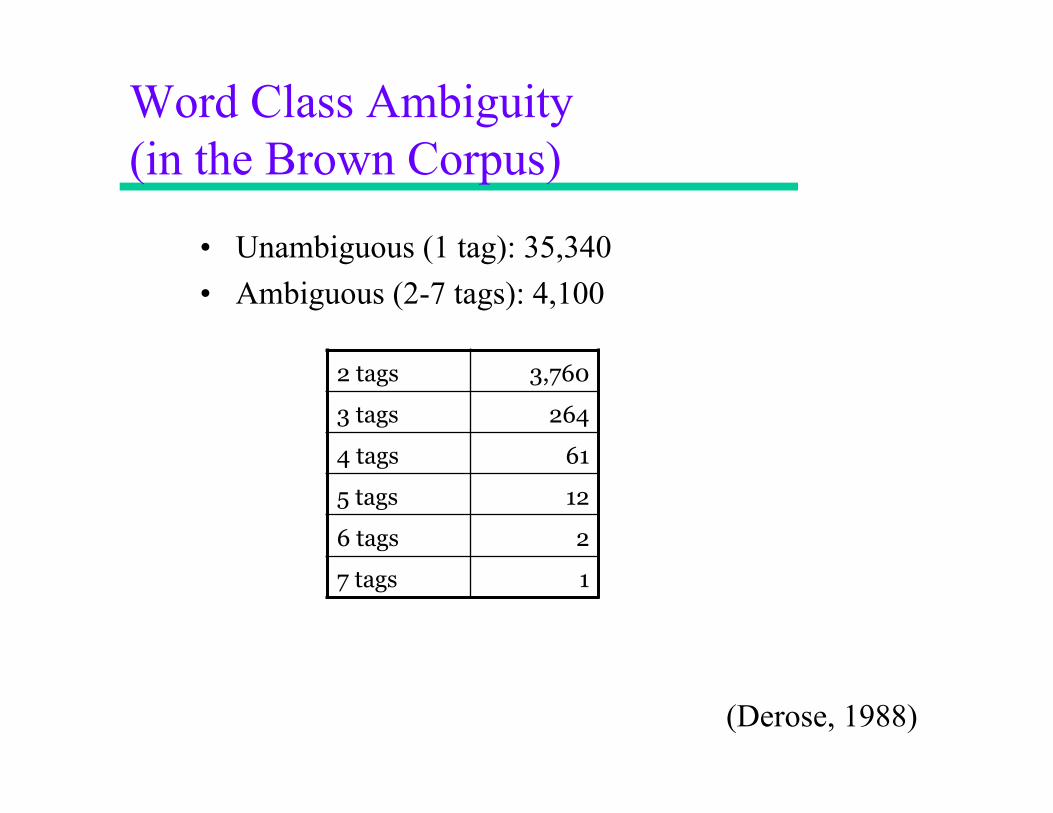
Word Class Ambiguity (in the Brown Corpus)
• Unambiguous (1 tag): 35,340 • Ambiguous (2-7 tags): 4,100
2 tags 3,760
3 tags 264
4 tags 61
5 tags 12
6 tags 2
7 tags 1
(Derose, 1988)

Rule-Based Tagging
• Uses a dictionary that gives possible tags for words • Basic algorithm
– Assign all possible tags to words – Remove tags according to set of rules of type:
• Example rule: – if word+1 is an adj, adv, or quantifier and the following is a
sentence boundary and word-1 is not a verb like “consider” then eliminate non-adv else eliminate adv.
– Typically more than 1000 hand-written rules, but may be machine-learned
• Rule-based tagger: ENGTWOL
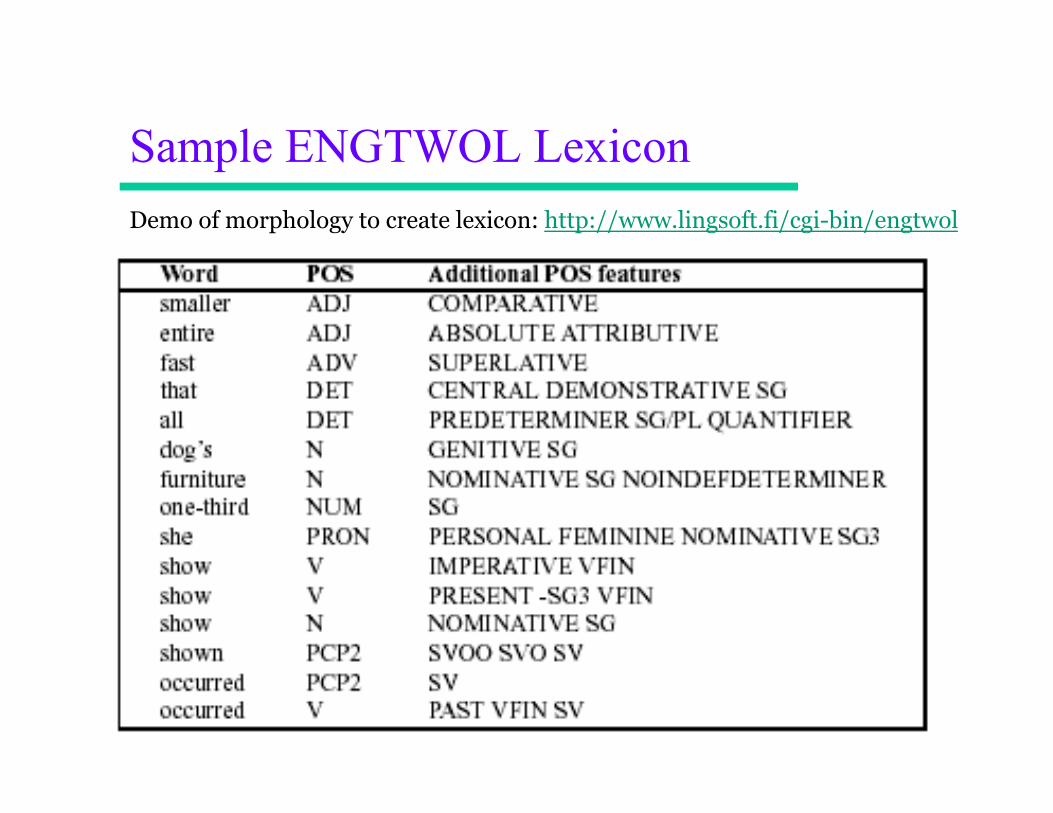
Sample ENGTWOL Lexicon Demo of morphology to create lexicon: http://www.lingsoft.fi/cgi-bin/engtwol

N-gram Approach
• N-gram approach to probabilistic POS tagging: – calculates the probability of a given sequence of tags occurring – the best tag for a given word is determined by the probability that it
occurs with the n previous tags – may be bi-gram, tri-gram, etc
wordn-1 … word-2 word-1 word tagn-1 … tag-2 tag-1 ??
• Presented here as an introduction to HMM tagging – And given in more detail in the NLTK – In practice, bigram and trigram probabilities have the problem that
the combinations of words are sparse in the corpus – Combine the taggers with a backoff approach

N-gram Tagging
• Initialize a tagger by learning probabilities from a tagged corpus
wordn-1 … word-2 word-1 word tagn-1 … tag-2 tag-1 ??
– Probability that the sequence … tag-2 tag-1 word gives tag XX – Note that initial sequences will include a start marker as part of the
sequence
• Use the tagger to tag word sequences (usually of length 2-3) with unknown tags – Sequence through the words:
• To determine the POS tag for the next word, use the previous n-1 tags and the word to look up probabilities and use the highest probability tag
24

25
Need Longer Sequence Classification
• A more comprehensive approach to tagging considers the entire sequence of words – Secretariat is expected to race tomorrow
• What is the best sequence of tags which corresponds to this sequence of observations?
• Probabilistic view: – Consider all possible sequences of tags – Out of this universe of sequences, choose the tag
sequence which is most probable given the observation sequence of n words w1…wn.
Thanks to Jim Martin’s online class slides for the examples and equation typesetting in this section on HMM’s.

26
Road to HMMs • We want, out of all sequences of n tags t1…tn the single tag
sequence such that P(t1…tn|w1…wn) is highest.
• Hat ^ means “our estimate of the best one” • Argmaxx f(x) means “the x such that f(x) is maximized”
*

27
Road to HMMs • This equation is guaranteed to give us the best tag sequence
• But how to make it operational? How to compute this value?
• Intuition of Bayesian classification: – Use Bayes rule to transform into a set of other probabilities that are
easier to compute

Using Bayes Rule
• Bayes rule:
• Apply Bayes Rule:
• Note that this is using the conditional probability, given a tag, what is the most likely word with that tag. – Eliminate denominator as it is the same for every sequence
28

Likelihood and Prior • Further simplify
• Likelihood: assume that the probability of the word depends only on its tag
• Prior: use the bigram assumption that the tag only depends on the previous tag
29

30
Two Sets of Probabilities (1)
• Tag transition probabilities p(ti|ti-1) (priors) – Determiners likely to precede adjs and nouns
• That/DT flight/NN • The/DT yellow/JJ hat/NN • So we expect P(NN|DT) and P(JJ|DT) to be high
– Compute P(NN|DT) by counting in a labeled corpus:

31
Two Sets of Probabilities (2)
• Word likelihood probabilities p(wi|ti) – VBZ (3sg Pres verb) likely to be “is” – Compute P(is|VBZ) by counting in a labeled corpus:

32
An Example: the verb “race”
• Secretariat/NNP is/VBZ expected/VBN to/TO race/VB tomorrow/NR
• People/NNS continue/VB to/TO inquire/VB the/DT reason/NN for/IN the/DT race/NN for/IN outer/JJ space/NN
• How do we pick the right tag?

33
Disambiguating “race”

34
Example
• P(NN|TO) = .00047 • P(VB|TO) = .83 • P(race|NN) = .00057 • P(race|VB) = .00012 • P(NR|VB) = .0027 • P(NR|NN) = .0012
• P(VB|TO)P(NR|VB)P(race|VB) = .00000027 • P(NN|TO)P(NR|NN)P(race|NN)=.00000000032 • So we (correctly) choose the verb tag.
Tag sequence probability for the likelihood of an adverb occurring given the previous tag verb or noun
The tag transition probabilities P(NN|TO) and P(VB|TO)
Lexical likelihoods from the Brown corpus for ‘race’ given a POS tag NN or VB.

35
Hidden Markov Models
• What we’ve described with these two kinds of probabilities is a Hidden Markov Model – The Markov Model is the sequence of words and the hidden states
are the POS tags for each word.
• When we evaluated the probabilities by hand for a sentence, we could pick the optimum tag sequence
• But in general, we need an optimization algorithm to most efficiently pick the best tag sequence without computing all possible combinations of probabilities

Tag Transition Probabilities for an HMM
• The HMM hidden states can be represented in a graph where the edges are the transition probabilities between POS tags.
36

Observation likelihoods for POS HMM • For each POS tag, give words with probabilities
37

The A matrix for the POS HMM
• Example of tag transition probabilities represented in a matrix, usually called the A matrix in an HMM: – The probability that VB follows <s> is .019, …
38

The B matrix for the POS HMM
• Word likelihood probabilities are represented in a matrix, where for each tag, we show the probability that a word has that tag
39

Using HMMs for POS tagging
• From the tagged corpus, create a tagger by computing the two matrices of probabilities, A and B – Straightforward for bigram HMM – For higher-order HMMs, efficiently compute matrix by the forward-
backward algorithm
• To apply the HMM tagger to unseen text, we must find the best sequence of transitions – Given a sequence of words, find the sequence of states (POS tags)
with the highest probabilities along the path – This task is sometimes called “decoding” – Use the Viterbi algorithm
40
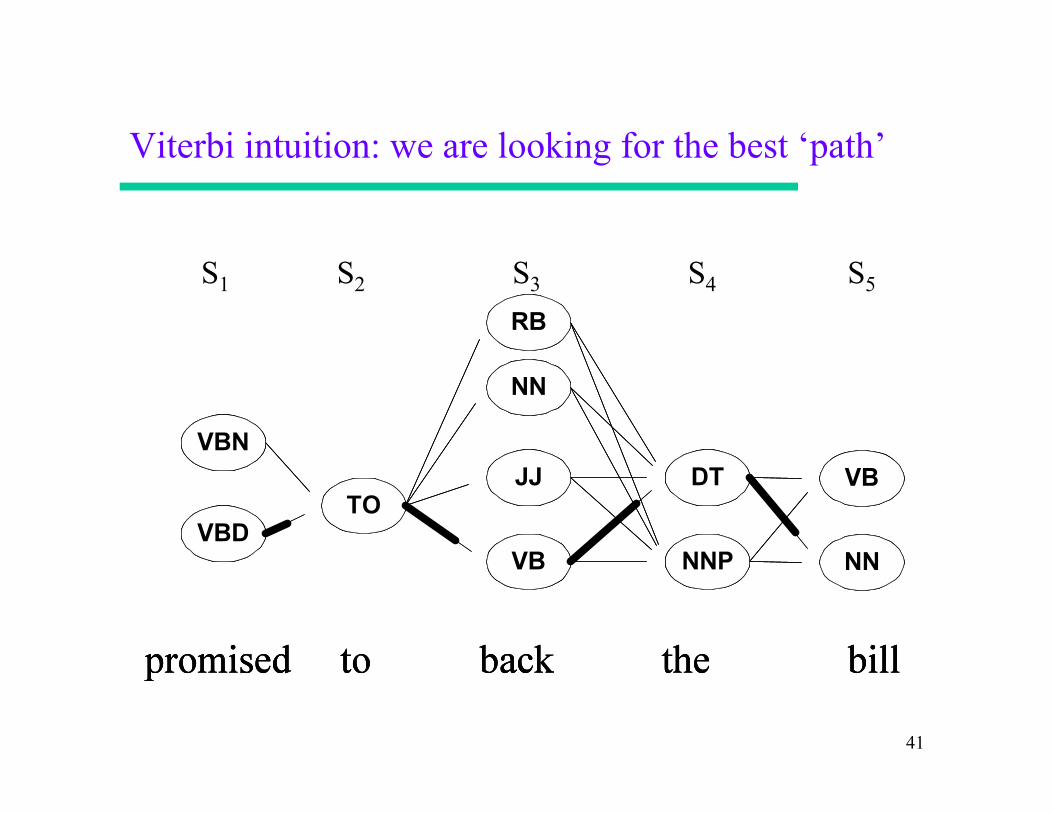
41
Viterbi intuition: we are looking for the best ‘path’
S1 S2 S4 S3 S5

2/16/10 42
Viterbi example

Viterbi Algorithm sketch
• This algorithm fills in the elements of the array viterbi in the previous slide (cols are words, rows are states (POS tags)) function Viterbi for each state s, compute the initial column
viterbi[s, 1] = A[0, s] * b[s, word1] for each word w from 2 to N (length of sequence)
for each state s, compute the column for w viterbi[s, w] = max over s’ ( viterbi[s’,w-1] * A[s’,s] * B[s,w]) <save back pointer to trace final path>
return the trace of back pointers
where A is the matrix of state transitions and B is the matrix of state/word likelihoods 43

Other Issues: Unknown Words
• How can one calculate the probability that a given word occurs with a given tag if that word is unknown to the tagger? – Points out the importance of a sufficient lexicon from a corpus
• Several potential solutions to this problem: – 1. Use morphological information:
• The tagger calculates the probability that a suffix on an unknown word occurs with a particular tag.
• If an HMM is being used, the probability that a word containing that suffix occurs with a particular tag in the given sequence is calculated

Unknown Words: (cont’d)
• 2. Assign a set of default tags to unknown words, and then disambiguate using the probabilities that those tags occur at the end of the n-gram in question – typically the open classes: N, V, Adj, Adv
• 3. Calculate the probability that every tag in the tag set occurs at the end of the n-gram, and to select the path with the highest probability – not the optimal solution if working with a large tag set

The Brill Tagger
• “Transformation-Based Error-Driven Learning” (TBL)
– A machine-learning approach that has been used for part-of-speech tagging, prepositional phrase attachment, disambiguation, syntactic parsing, and letter-to-sound speech generation
– Brill, Eric. “Transformation-Based Error-Driven Learning and Natural Language Processing: A Case Study in Part of Speech Tagging.” Computational Linguistics, Dec. 1995.
• Learns symbolic rules that can be applied to the text to transform it for the given task
• The task is defined by rule templates that give the form of the transformation rules

Operation of the Tagger
• After the tagger is “learned” from annotated text, it consists of an initial tagger and a sequence of transformation rules
• To perform the tagging of some text – First give the text an initial assignment of POS tags – Then apply the transformation rules in order
• The resulting text should have correct POS tags
47

Transformation Rules
• Consist of 2 components: 1. A triggering environment, e.g.
– The preceding word is a determiner 2. A re-write rule, e.g.
• Change the tag from modal to noun • Simple example of TBL rule format:
– if [triggering environment] then [re-write rule] – if [tag of word n-1 = det] then [tag of n = noun]
• The|det can|modal rusted|verb .|. ---> • The|det can|noun rusted|verb .|.

Algorithm to learn the transformation rules
• The annotated corpus is used both as the (raw text) training corpus and as the gold standard
• The training corpus is given an initial tagging • Then trial rules are formed that would change the training
corpus to the gold standard • The trial rule that would give the fewest errors is picked as a
transformation rule and is added to the ordered transformation list
• The training corpus is updated by applying this transformation
• The learning of new transformation rules continues until no transformation can be found whose application results in an improvement in the annotated corpus
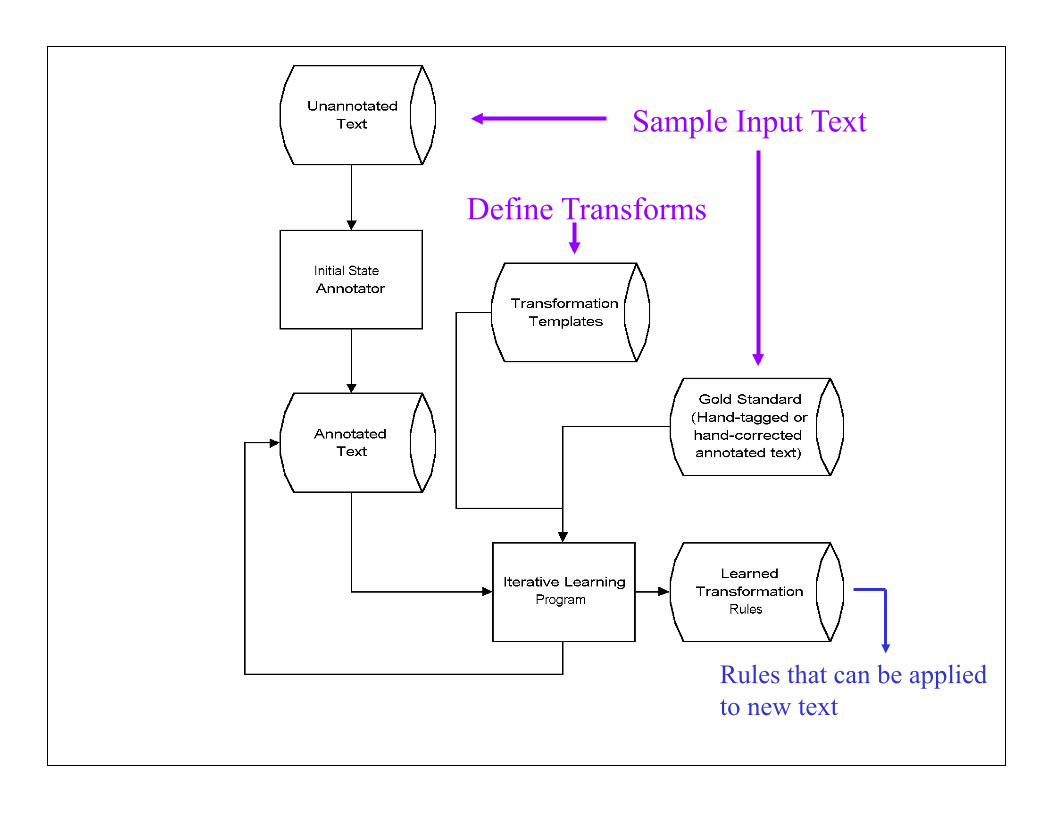
Sample Input Text
Define Transforms
Rules that can be applied to new text

1. Closed World, Non-Lexicalized Rules
• Every word in the corpus is entered into the system’s lexicon, marked for most frequent part-of-speech – half: CD DT JJ NN PDT RB VB
• Transformations do not make reference to specific words, but parts of speech tags.
• Transformation templates are of the format: change tag a to b when any of condition exists involving tags before and after:
1. The preceding (following) word is tagged z. 2. The word 2 before (after) is tagged x. 3. One of the 2 preceding (following) words is tagged z. 4. One of the 3 preceding (following) words is tagged y. 5. The preceding word is tagged z and the following word is
tagged w. 6. The preceding (following) word is tagged z and the 2 before
(after) is tagged w.

Examples of non-lexicalized rules
Change Tag # From To Condition 1 NN VB Previous tag is TO 2 VBP VB One of the previous 3 tags is MD 3 NN VB One of the previous 2 tags is MD 4 VB NN One of the previous 2 tags is DT 5 VBD VBN One of the previous 3 tags is VBZ 6 VBN VBD Previous tag is PRP 7 VBN VBD Previous tag is NNP 8 VBD VBN Previous tag is VBD 9 VBP VB Previous tag is TO 10 POS VBZ Previous tag is PRP

2. Closed World Lexicalized Rules
• Adds contextual transformation templates that refer to words as well as part-of-speech tags – change tag a to b when:
1. The preceding (following) word is w. 2. The word 2 before (after) is w. 3. One of the 2 preceding (following) words is w. 4. The current word is w and the preceding (following) word is x. 5. The current word is w and the preceding (following) word is
tagged z. 6. The current word is w. 7. The preceding (following) word is w and the preceding
(following) tag is t. 8. The current word is w, the preceding (following) word is w2
and the preceding (following) tag is t.

Example of Closed World Lexicalized Rule
• For the phrase: as tall as
• Frequency table will say ‘as’ is most commonly used as a preposition (IN)
as/IN tall/JJ as/IN • If you apply the lexicalized rule:
Change the tag from IN to RB if the word 2 positions to the right is as
• Results in correct tagging of as/RB tall/JJ as/IN

3. Transformation-Based Unknown-Word Rules
• Automatically learns cues to predict the most likely tag for words not seen in the corpus
• Initial state annotator labels the most likely tag for unknown words as Proper Noun if capitalized, common noun otherwise – Change the tag of an unknown word (from X) to Y if:
1. Deleting the prefix (suffix) x, |x| <= 4, results in a known word.
2. The first (last) (1,2,3,4) characters of the word are x. 3. Adding the character string x as a prefix (suffix) results
in a word (|x| <= 4). 4. Word W ever appears immediately to the left (right) of
the word. 5. Character Z appears in the word.

Sample Transformations for Unknown Words
Change Tag # From To Condition 1 NN NNS Has suffix –s 2 NN CD Has character . 3 NN JJ Has character – 4 NN VBN Has suffix –ed 5 NN VBG Has suffix –ing 6 NN JJ Has suffix –al 7 NN JJ The word be appears to the left 8 NNS VBZ The word it appears to the left

Transformation-Based Tagging
• The tagger model consists of the lexicon and the transformation rules – Much smaller than the statistical taggers – May be more understandable to humans
• Training time can be long, depending on the complexity of the templates – But the tagging time is not longer
• Accuracy is quite high, depending on corpora and part-of-speech tag set
– Wall Street Journal, Penn tags 96.6 %
– Wall Street Journal, Brown tags 96.3 %
– Brown, Brown tags 96.5 %

2/15/10 58
Evaluation for POS Taggers
• The result is compared with a manually coded “Gold Standard” – Typically accuracy reaches 96-97% – This may be compared with result for a baseline tagger (one that
uses no context).
• Important: 100% is impossible even for human annotators. • The tagged data should be separated into a training set and a
test set. – The tagger is trained on the training set and evaluated on the test set
• May also hold out some data for development – Evaluation numbers are not prejudiced by the training set

2/15/10 59
Error Analysis
• Confusion matrix show how many correct tags (row labels) were incorrectly tagged by the tagger (column labels)
• See what errors are causing problems – Noun (NN) vs ProperNoun (NNP) vs Adj (JJ) – Preterite (VBD) vs Participle (VBN) vs Adjective (JJ)

Conclusions
• Part of Speech tagging is a doable task with high performance results
• Contributes to many practical, real-world NLP applications and is now used as a pre-processing module in most systems
• Computational techniques learned at this level can be applied to NLP tasks at higher levels of language processing