performance analysis of algorithms for virtualized environments on cloud computing
TRANSCRIPT

Performance Analysis of Algorithms for Virtualized Environments on Cloud Computing
R. S. Bôaventura, Member, IEEE, K. Yamanaka and G. P. Oliveira
1Abstract— Cloud computing emerges as a new dominant paradigm for distributed systems, as a model that allows users to access the network on demand to a shared pool of computing resources that can be configured, e.g., networks, servers, storage, applications and services. In cloud computing the infrastructure can become available as a service through virtualization using hypervisors. Virtualization is a mechanism to abstract hardware resources and system of a given operating system. Therefore, this type of technology is used in cloud environments through a large set of servers using virtual machine monitors that are located between the hardware and the operating system. However there is a wide spread of hypervisors, each with its own advantages and disadvantages. Therefore, this study is one of the proposals, conducting experiments with algorithms among different classes of algorithms available to virtual environments in a cloud. The goal of these experiments is to determine which factors (virtual machines, operating system and hardware) with of its configurations influence the performance of a deterministic algorithm. These experiments were planned and executed with a basic theory of experimental design. The experimental design is a set of tests using pre-established criteria and scientific statistical mostly with the aim of determining the influence of various factors on the results of a system or process, identifying and noting the reasons that led to changes in the expected response. All experiments results will be analyzed and will assist cloud computing users in the discovery of a possible virtual environment configuration that will allow and to avoid programming execution deft, computational resources loss and monthly costs.
Keywords— Virtualization, Cloud computing, Experimental Design, Algorithms Design and Analysis, Experiments with Algorithms.
I. INTRODUÇÃO NTIGAMENTE, os primeiros computadores eram gigantescos, muito caros e ligados via uma rede interna,
por onde trafegavam dados e informações de uma mesma organização. Devido à grande demanda por uso, os computadores rapidamente se tornaram indispensáveis.
Aliado ao surgimento da Internet e a redução dos custos de interligação das redes de computadores, o avanço da padronização de protocolos de comunicação possibilitaram interligar redes de diferentes organizações [1]. Ao mesmo tempo, a capacidade de processamento dos computadores pessoais aumentou substancialmente, devido ao
1 R. S. Bôaventura, Instituto Federal do Triângulo Mineiro (IFTM), Uberlândia, Minas Gerais, Brasil, [email protected] K. Yamanaka, Universidade Federal de Uberlândia (UFU), Uberlândia, Minas Gerais, Brasil, [email protected] G. P. Oliveira, Instituto Federal do Triângulo Mineiro (IFTM), Uberlândia, Minas Gerais, Brasil, [email protected]
desenvolvimento de novos hardwares e às novas técnicas de programação. Entretanto, toda a capacidade adquirida não tem sido muito bem aproveitada. Com isso, em boa parte do tempo, ocorre um grande desperdício de recursos computacionais por não serem utilizados de forma correta e desejada [2]. Baseado nesse problema, a virtualização surgiu com um novo conceito de utilização de máquinas de grande porte, definindo uma técnica que possibilita a divisão de um mesmo hardware em diversas máquinas virtuais [3, 4]. A virtualização foi utilizada nos mainframes e, atualmente, com a evolução de recursos computacionais (memória, armazenamento, entre outros), permitiu também que os servidores de pequeno porte e computadores pessoais pudessem utilizar dessa tecnologia [4]. Com a virtualização pode-se, então, adequar o hardware à carga de trabalho originada pela aplicação. Ou seja, se uma determinada aplicação demandar um grande recurso computacional pode-se, então, alterar o recurso computacional do datacenter dinamicamente. Em outro momento, pode-se novamente restabelecer a configuração original ou até expandir o uso do recurso. Com isso, a virtualização passa a ser a base para a infraestrutura, pois permite alterá-la rapidamente utilizando instrumentos lógicos e não físicos e, ao mesmo tempo, tornando as aplicações independentes de hardwares [1]. Dentro desse cenário surge a computação em nuvem como um novo paradigma para o fornecimento de infraestrutura de computação disponibilizada na rede, reduzindo os custos associados com a gestão de recursos de hardware e de software [5,6,7]. Porém, segundo Zhang & Zhou [8], não existe um padrão para definição e especificação de uma computação em nuvem, mas esse paradigma se baseia em décadas de pesquisa em virtualização, computação distribuída, computação utilitária, serviços Web, redes e softwares [9,10]. Esse trabalho tem como objetivo construir uma nuvem privada, usando infraestrutura como serviço, que permitirá a realização de experimentos com algoritmos em diferentes ambientes virtuais. Para cada ambiente foram coletados os tempos de execução dos algoritmos para análise. Os resultados foram analisados e utilizados para auxiliar a criação e uma infraestrutura virtual em nuvem evitando o desperdício de recursos computacionais.
II. MATERIAIS E MÉTODOS O processo utilizado para conduzir os experimentos foi
proposto por Antony et al. [11], porém adaptado por Barr et al. [12] para conduzir os experimentos com algoritmos.
A. Objetivo dos exeperimentos
O objetivo dos experimentos é determinar quais fatores influenciam o desempenho de um determinado algoritmo determinístico na resolução de problemas. Busca-se descobrir
A
792 IEEE LATIN AMERICA TRANSACTIONS, VOL. 12, NO. 4, JUNE 2014

como, quanto e quando ocorre o aumento de desempenho do algoritmo em ambientes virtualizados em nuvem, ou seja, se é determinado pela configuração de uma máquina virtual, sistema operacional e/ou hardware e como esses parâmetros podem influenciar-se mutualmente.
B. Instâncias dos testes
Para os testes foram escolhidos 4 (quatro) algoritmos muito utilizados em ambientes computacionais para auxiliar problemas reais. Cada um desses algoritmos pertencem a uma classe relativa a notação O [13]. Os dados manipulados pelos algoritmos são da grandeza do tipo long long int que possui 64bits, segundo o padrão ISO C99. Os algoritmos testados foram: classe constante (verificação de par/impar), classe logarítmica (busca binária), classe linear (busca sequencial) e classe linear logarítmica (heapsort). Para cada algoritmo, foi sempre analisado o pior caso.
C. Ambiente Computacional
O ambiente físico onde foram realizados os ensaios é composto por 10 computadores. Cada computador possui um processador Intel(R) Core(TM)2 Quad CPU, Socket 775, 4 GB de memória DIMM DDR2 Synchronous 800 MHz (1.2 ns), placa de vídeo NVIDIA GeForce 7300 SE/ 7200 GS (256 MB) e dois discos rígidos de 320 GB, 7200 RPM, SATA-II (Samsung HD322HJ ATA Device). Um desses computadores é denominado de servidor, e possui instalado o sistema operacional Ubuntu 10.04.4 LTS (Lucid Lynx), cujo é Kernel Linux - 2.6.32-47-generic. Por fim, o compilador G++ 4.4.3..
Para o desenvolvimento da nuvem privada foi instalado no servidor o software OpenQRM 5.0, como plataforma para o gerenciamento de toda a infraestrutura computacional de forma totalmente integrada. O OpenQRM permite que seja criado ambientes virtuais em Citrix XenServer, VMWare ESX/ESXi, Xen, Linux KVM, VirtualBox, Linux LXC Containers e OpenVZ. Para realizar a medição de tempo (wall clock) de execução dos ensaios foi utilizada a biblioteca Chrono 1.53.0.
D. Resposta
A cada execução dos algoritmos foi medido o tempo total de processamento (wall clock) em nanossegundos.
E. Planejamento Experimental
O planejamento experimental é uma técnica de caráter exploratório que permite representar um conjunto de ensaios estabelecidos com critérios estatísticos e científicos com o objetivo de determinar as influências de vários fatores nos resultados de um determinado sistema ou processo [16]. Segundo Rodrigues and Iemma [17], essa técnica associada à análise de superfícies de respostas é uma ferramenta fundamentada na teoria estatística, que fornece informações seguras sobre o processo, minimizando o empirismo que envolve técnicas de tentativa e erro.
O planejamento experimental utilizado foi o planejamento fatorial completo 25. Ou seja, um planejamento composto por 5 fatores que serão avaliados em dois níveis, sendo um nível – e outro nível +.
F. Fatores e Níveis Analisados
Inicialmente foram listados quais possíveis variáveis poderiam influenciar no desempenho de um algoritmo. O custo de um algoritmo é dependente do hardware, compilador e quantidade de memória [8,14,15]. Já segundo Ziviani [8], a quantidade de dados a ser processada também afeta o tempo de execução de um algoritmo de forma mais significativa.
Por fim, Barr et al. [12] informa que, fatores do ambiente de teste devem ser informados, como: tipo de processador, tamanho da memória, frequência do clock, sistema operacional, linguagem de programação, compilador, programas executados em segundo plano e habilidades do programador. Mas, o ideal seria que alguns desses fatores fossem idênticos ou isolados.
Nos ensaios realizados, alguns fatores foram fixados, como: o tipo de processador, a frequência do clock, a linguagem de programação e o compilador. Já os programas executados em segundo plano não foram isolados, porém para controlar esse fator, os algoritmos foram executados 35 vezes de forma aleatória e no final foi calculado o tempo médio das execuções. Os fatores e os seus níveis estão listados na Tabela I.
TABELA I. FATORES E NÍVEIS DOS FATORES.
Fatores Níveis dos fatores
Nível - Nível +
1. Tamanho da entrada 103 elementos do tipo long long int
108 elementos do tipo long long int
2. Quantidade de memória 1GB 3GB
3. Quantidade de núcleos 1 4
4. Sistema Operacional Ubuntu 12.04 CentOS 6.3
5. Máquina Virtual KVM VirtualBox
G. Análise dos dados
Para cada experimento foram construídas as matrizes de sinais para a realização dos calculados dos efeitos dos fatores e suas interações. A análise de variância (ANOVA) [18] foi executada para confirmar a significância dos efeitos. A análise de variância é a melhor abordagem quando se quer comparar várias médias. Nos relatos apresentados dos resultados obtidos são mostrados nas tabelas somente quando significativos (efeitos principais e interações entre os efeitos).
III. ANÁLISE DOS DADOS E REPRESENTAÇÃO DOS RESUTALDOS
A. Análise dos dados para o algoritmo constante
O cálculo dos efeitos dos fatores obteve os valores listados na Tabela II. Dos 5 fatores principais analisados apenas os fatores 3 (Núcleo) e 5 (VM) são considerados com significância prática e seus ajustes causam variação significativa no tempo de resposta do algoritmo. O valor do efeito apresentado no fator 3 (Núcleo) mostra que, ao sair do nível - para o nível + aumenta o tempo de execução do algoritmo analisado em média 2944,04 ns. Para o valor do efeito apresentado no fator 5 (VM) mostra que, também, ao sair do nível - (KVM) para o nível + aumenta o tempo de execução do algoritmo em média 2703,51 ns. Por meio da análise de variância - ANOVA, esses
SOARES BOAVENTURA et al.: PERFORMANCE ANALYSIS 793
fatores foram estatisticamente significativos, a um nível de significância de 5%, ou seja, os p-valores foram respectivamente 0,017948, 0,025133 e 0,019130.
TABELA II. TABELA DE ESTIMATIVA DOS EFEITOS PARA O ALGORITMO CONSTANTE.
Fatores Efeito p-valor
3 (Núcleo) 2944,04 0,017948
5 (VM) 2703,51 0,025133
3 (Núcleo) X 5 (VM) 2897,90 0,019130
O gráfico de Pareto (Fig. 1) mostra de forma clara que os efeitos 3 (Núcleo), 5 (VM) e a interação entre Núcleo e VM estão a direita da linha divisória (p = 0,05). O gráfico mostra que o fatores tem alta significância no tempo de execução do algoritmo analisado. Os demais fatores foram muito pouco significativos, ficando longe do p = 0,05 e sendo considerados sem influência prática.
Figura 1. Gráfico de pareto para o algoritmo constante.
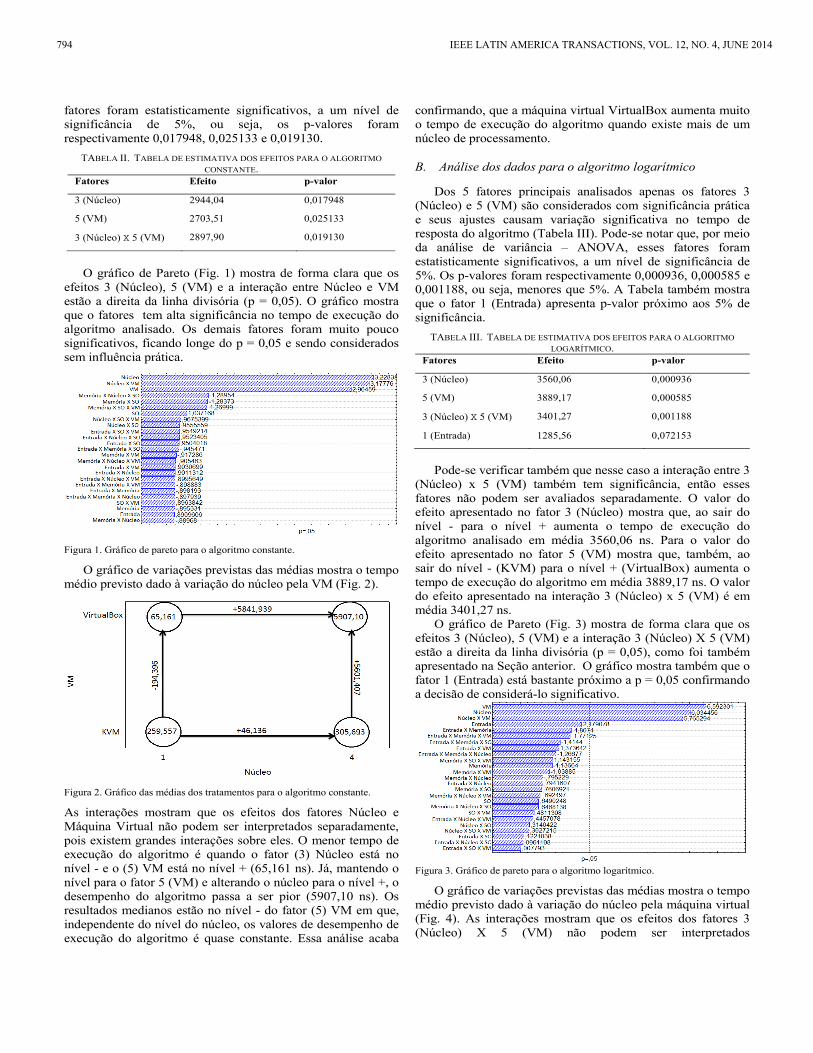
O gráfico de variações previstas das médias mostra o tempo médio previsto dado à variação do núcleo pela VM (Fig. 2).
Figura 2. Gráfico das médias dos tratamentos para o algoritmo constante.
As interações mostram que os efeitos dos fatores Núcleo e Máquina Virtual não podem ser interpretados separadamente, pois existem grandes interações sobre eles. O menor tempo de execução do algoritmo é quando o fator (3) Núcleo está no nível - e o (5) VM está no nível + (65,161 ns). Já, mantendo o nível para o fator 5 (VM) e alterando o núcleo para o nível +, o desempenho do algoritmo passa a ser pior (5907,10 ns). Os resultados medianos estão no nível - do fator (5) VM em que, independente do nível do núcleo, os valores de desempenho de execução do algoritmo é quase constante. Essa análise acaba
confirmando, que a máquina virtual VirtualBox aumenta muito o tempo de execução do algoritmo quando existe mais de um núcleo de processamento.
B. Análise dos dados para o algoritmo logarítmico
Dos 5 fatores principais analisados apenas os fatores 3 (Núcleo) e 5 (VM) são considerados com significância prática e seus ajustes causam variação significativa no tempo de resposta do algoritmo (Tabela III). Pode-se notar que, por meio da análise de variância – ANOVA, esses fatores foram estatisticamente significativos, a um nível de significância de 5%. Os p-valores foram respectivamente 0,000936, 0,000585 e 0,001188, ou seja, menores que 5%. A Tabela também mostra que o fator 1 (Entrada) apresenta p-valor próximo aos 5% de significância.
TABELA III. TABELA DE ESTIMATIVA DOS EFEITOS PARA O ALGORITMO LOGARÍTMICO.
Fatores Efeito p-valor
3 (Núcleo) 3560,06 0,000936
5 (VM) 3889,17 0,000585
3 (Núcleo) X 5 (VM) 3401,27 0,001188
1 (Entrada) 1285,56 0,072153
Pode-se verificar também que nesse caso a interação entre 3 (Núcleo) x 5 (VM) também tem significância, então esses fatores não podem ser avaliados separadamente. O valor do efeito apresentado no fator 3 (Núcleo) mostra que, ao sair do nível - para o nível + aumenta o tempo de execução do algoritmo analisado em média 3560,06 ns. Para o valor do efeito apresentado no fator 5 (VM) mostra que, também, ao sair do nível - (KVM) para o nível + (VirtualBox) aumenta o tempo de execução do algoritmo em média 3889,17 ns. O valor do efeito apresentado na interação 3 (Núcleo) x 5 (VM) é em média 3401,27 ns. O gráfico de Pareto (Fig. 3) mostra de forma clara que os efeitos 3 (Núcleo), 5 (VM) e a interação 3 (Núcleo) X 5 (VM) estão a direita da linha divisória (p = 0,05), como foi também apresentado na Seção anterior. O gráfico mostra também que o fator 1 (Entrada) está bastante próximo a p = 0,05 confirmando a decisão de considerá-lo significativo.
Figura 3. Gráfico de pareto para o algoritmo logarítmico.
O gráfico de variações previstas das médias mostra o tempo médio previsto dado à variação do núcleo pela máquina virtual (Fig. 4). As interações mostram que os efeitos dos fatores 3 (Núcleo) X 5 (VM) não podem ser interpretados
794 IEEE LATIN AMERICA TRANSACTIONS, VOL. 12, NO. 4, JUNE 2014

separadamente, pois existem grandes interações sobre eles. O menor tempo de execução do algoritmo é quando o fator 3 (Núcleo) está no nível - e o fator 5 (VM) está no nível - (531,143 ns). Porém e o nível do fator 5 (VM) e alterar o 3 (Núcleo) para no nível +, o desempenho do algoritmo passa a ser o pior (671,936 ns). Os melhores resultados estão no nível - do fator 5 (VM) na máquina virtual KVM, em que independente da quantidade de núcleos de processamento o desempenho de execução do algoritmo é quase constante. Já os piores resultados estão quando o nível do fator VM está no nível + (VirtualBox).
Figura 4. Gráfico das médias dos tratamentos para o algoritmo logarítmico.
C. Análise dos dados para o algoritmo linear
Dos 5 fatores principais analisados apenas os fatores 1 (Entrada), 2 (Memória) e 5 (VM) são considerados com significativos estatisticamente e seus ajustes causam variação significativa no tempo de resposta do algoritmo (Tabela IV). Pode-se verificar também que nesse caso as interações entre Entrada x Memória, Entrada x Máquina Virtual, Memória x Máquina Virtual e Entrada x Memória x Máquina Virtual também tem significância. Esses fatores não podem ser avaliados separadamente. Os p-valores foram respectivamente 0,017739, 0,043130, 0,046529, 0,043130, 0,046529, 0,042505, 0,042505, ou seja, menores que 5%. A Tabela também mostra que o fator 4 (SO) e as interações entre 1 (Entrada) X 4 (SO), 2 (Memória) X 4 (SO) e 4 (SO) X 5 (VM) apresentam p-valores próximos aos 5% de significância.
TABELA IV. TABELA DE ESTIMATIVA DOS EFEITOS PARA O ALGORITMO LINEAR.
Fatores Efeito p-valor
1 (Entrada) 22,44545 x 108 0,017739
2 (Memória) -17,72102 x 108 0,043130
5 (VM) 17,33146 x 108 0,046529
1 (Entrada) x 2 (Memória) -17,72102 x 108 0,043130
1 (Entrada) x 5 (VM) 17,33145 x 108 0,046529
2 (Memória) x 5 (VM) -17,79619 x 108 0,042505
1 (Entrada) x 2 (Memória) x 5 (VM) -17,79619 x 108 0,042505
4 (SO) 15,84492 x 108 0,062322
1 (Entrada) x 4 (SO) 15,84491 x 108 0,062322
2 (Memória) x 4 (SO) -16,31830 x 108 0,056759
4 (SO) x 5 (VM) 16,48136 x 108 0,054965
O valor do efeito apresentado no fator 1 (Entrada) mostra que, ao sair do nível - para o nível + aumenta o tempo de execução do algoritmo analisado em média 22,445 x 108 ns. Para o valor do efeito apresentado no fator 5 (VM) mostra que, ao sair do nível - para o nível + aumenta o tempo de execução do algoritmo analisado em média 17,331 x 108 ns. Já, o valor do efeito apresentado no fator 2 (Memória) mostra que, ao sair do nível - para o nível + diminui o tempo de execução do algoritmo analisado em média 17,721 x 108 ns. O gráfico de Pareto (Fig. 5) mostra de forma clara que os efeitos 1 (Entrada), 2 (Memória), 5 (VM) e as interações entre os fatores Entrada x Memória, Entrada x Máquina Virtual, Memória x Máquina Virtual e Entrada x Memória x Máquina Virtual estão a direita da linha divisória (p = 0,05). O gráfico mostra também que o fator 4 (SO) e as interações entre 1 (Entrada) x 4 (SO), 2 (Memória) x 4 (SO) e 4 (SO) x 5 (VM) estão bastante próximos a p = 0.05, confirmando a decisão de considerá-los significantes.
Figura 5. Gráfico de pareto para o algoritmo linear
O gráfico de variações previstas das médias mostra o tempo médio previsto dado à variação da memória pela máquina virtual e pela entrada (Fig. 6).
Figura 6. Gráfico das médias dos tratamentos para o algoritmo linear.
As interações mostram que os efeitos desses três fatores não podem ser interpretados separadamente, pois existem grandes interações sobre eles. O menor tempo de execução do algoritmo é quando o fator 1 (Entrada) no nível - e a melhor configuração é máquina virtual KVM com 1GB de memória. Já quando o fator 1 (Entrada) estiver no nível + a melhor
SOARES BOAVENTURA et al.: PERFORMANCE ANALYSIS 795

configuração é a máquina virtual VirtualBox com 3GB de memória.
D. Análise dos dados para o algoritmo linear logarítmico
Dos 5 fatores principais analisados apenas os fatores 1 (Entrada) e 2 (Memória) são considerados com significância prática e seus ajustes causam variação significativa no tempo de resposta do algoritmo (Tabela V). Pode-se verificar também que nesse caso as interações entre 1 (Entrada) x 2 (Memória), também tem significância, os quais, esses fatores não podem ser avaliados separadamente. O valor do efeito apresentado no fator 1 (Entrada) mostra que, ao sair do nível - para o nível + aumenta o tempo de execução do algoritmo analisado em média 55,759 x 1014 ns. Já, o valor do efeito apresentado no fator 2 (Memória) mostra que, ao sair do nível - para o nível + diminui o tempo de execução do algoritmo analisado em média 14,091 x 1014 ns. Os p-valores foram respectivamente 0,000064, 0,047435 e 0,047435, ou seja, menores que 5%. A Tabela também mostra que os fatores 4 (SO) e 5 (VM) e as interações entre 1 (Entrada) x 4 (SO), 1 (Entrada) x 5 (VM), 2 (Memória) x 4 (SO), 2 (Memória) x 5 (VM) e 4 (SO) x 5 (VM) apresentam p-valores próximos aos 5% de significância.
TABELA V. TABELA DE ESTIMATIVA DOS EFEITOS PARA O ALGORITMO LINEAR LOGARÍTMICO.
Fatores Efeito p-valor
1 (Entrada) 557,5956 x 1013 0,000064
2 (Memória) -140,9105 x 1013 0,047435
1 (Entrada) x 2 (Memória) -140,9105 x 1013 0,047435
4 (SO) 131,7668 x 1013 0,059089
5 (VM) 114,5166 x 1013 0,089883
1 (Entrada) x 4 (SO) 131,7668 x 1013 0,059089
1 (Entrada) x 5 (VM) 114,5166 x 1013 0,089883
2 (Memória) x 4 (SO) -136,7319 x 1013 0,052429
2 (Memória) x 5 (VM) -125,5290 x 1013 0,068726
4 (SO) x 5 (VM) 120,9453 x 1013 0,076833
O gráfico de Pareto (Fig. 7) mostra de forma clara que os efeitos 1 (Entrada), 2 (Memória) e a interação entre os fatores Entrada X Memória estão a direita da linha divisória (p = 0,05).
Figura 7. Gráfico de pareto para o algoritmo linear logarítmico.
O gráfico mostra também que os fatores 4 (SO) e 5 (VM) e as interações entre 1 (Entrada) X 4 (SO), 1 (Entrada) X 5
(VM), 2 (Memória) X 4 (SO), 2 (Memória) X 5 (VM) e 4 (SO) X 5 (VM) estão bastante próximos a p = 0.05, confirmando a decisão de considerá-los significantes. O gráfico de variações previstas das médias mostra o tempo médio previsto dado a variação da entrada pela memória (Fig. 8). As interações mostram que os efeitos desses dois fatores não podem ser interpretados separadamente, pois existem grandes interações sobre eles. Pode-se verificar que em média, os menores tempos de execução, estão no nível + do fator 2 (Memória).
Figura 8. Gráfico das médias dos tratamentos para o algoritmo linear logarítmico.
IV. CONSIDERAÇÕES FINAIS Esse trabalho possui como objetivo construir uma nuvem
privada, usando infraestrutura como serviço, que permitirá a realização de experimentos com algoritmos em diferentes ambientes virtuais. Para cada ambiente virtual, são coletados os tempos de execução dos algoritmos. Esses tempos serão analisados. Os resultados serão utilizados para desenvolver uma ferramenta que será executada em um ambiente Web. Essa ferramenta permitirá ao usuário analisar, de acordo com as necessidades da empresa, qual é a configuração (quantidade de núcleo de processamento, quantidade de memória, máquina virtual e sistema operacional) de um ambiente virtualizado que permitirá usar todos os aplicativos de forma mais ágil sem perda de recursos computacionais.
Neste trabalho foi utilizada a técnica de planejamento fatorial completo 25. O planejamento experimental representa um conjunto de ensaios estabelecidos com critérios científicos e estatísticos, com o objetivo de determinar a influência de diversas variáveis nos resultados de um sistema ou processo.
Os experimentos preliminares foram realizados e os resultados irão orientar o planejamento dos novos testes propostos para responder as questões que este trabalho se propõe a investigar. De acordo com os algoritmos analisados pertencentes a cada classe, os resultados preliminares mostram em relação ao planejamento fatorial completo 25 e com 5% de significância, que:
• Os fatores e interações influentes no desempenho dos algoritmos determinísticos são diferentes para cada uma das classes;
• O efeito do fator 1 (Quantidade de Entrada) é significativo estatisticamente em problemas computacionais das classes linear e linear logarítmica. Ou seja, quanto maior a quantidade de elementos de
796 IEEE LATIN AMERICA TRANSACTIONS, VOL. 12, NO. 4, JUNE 2014

entrada o tempo de execução desses algoritmos, em média, aumenta;
• O efeito do fator 2 (Quantidade de Memória) é significativo estatisticamente também em problemas das classes linear e linear logarítmica. Ou seja, quanto maior a quantidade de memória utilizada o tempo de execução, em média, diminui;
• O efeito do fator 3 (Quantidade de Núcleos de processamento) é significativo estatisticamente para algoritmos pertencentes às classes constante e logarítmica. O núcleo nesses dois tipos de algoritmos causa, em média, um impacto negativo quando estiver no nível positivo, ou seja, o tempo de execução desses algoritmos, em média, aumenta com o aumento da quantidade de núcleos de processamento;
• O efeito do fator 4 (Sistema operacional) não apresentou significância prática em nenhum dos testes realizados, porém durante o cálculo dos efeitos mostrou-se que o sistema operacional apresentou p-valor muito próximo aos 5% de significância, confirmando a decisão de considerá-los significante para os algoritmos constante, linear e linear logarítmico;
• O efeito do fator 5 (Máquina virtual) é significativo estatisticamente para as classes de algoritmos constante, logarítmica e linear. Para as máquinas virtuais analisadas, a escolha deve ser levada em consideração para conseguir os melhores desempenhos dos algoritmos no espaço estudado. Para a classe linear logarítmica a máquina virtual não influencia estatisticamente em média o tempo de execução do algoritmo;
• A interação entre as variáveis que influenciam os tempos de execução dos algoritmos analisados são diferentes entre si. Em toda interação estatisticamente significativa, o fator máquina virtual estava presente.
Para os algoritmos analisados a máquina virtual KVM obteve os melhores tempos de execução, em média, para todas as variações dos níveis dos fatores, para os algoritmos constante e linear logarítmico. Para o algoritmo da classe linear, a máquina virtual KVM obteve o melhor desempenho para entrada no nível -- e em qualquer nível de quantidade de memória; já para a quantidade de elementos no nível +, quando a memória estiver no nível -- a máquina virtual KVM executará os algoritmos em média num tempo menor que a máquina virtual VirtualBox e no nível + da memória a máquina VirtualBox desempenhará melhor que a máquina virtual KVM.
REFERÊNCIAS [1] M. Veras, Virtualização: Componente Central do Datacenter, Rio de
Janeiro: Brasport, 2011. [2] M. F. Mergen, V. Uhlig, O. Krieger and J. Xenidis, Virtualization for
highperformance computing, ACM SIGOPS Operating Systems Review, Vol. 40, 2006.
[3] G. J. Popek and R. P. Goldberg, Formal requirements for virtualizable third generation architectures, In Commun. ACM, Vol. 17, pp. 412–421, 1974.
[4] F. B. Souza, Uma arquitetura para monitoramento e medição de desempenho para ambientes virtuais, Tese de Doutorado, Universidade Federal de Minas Gerais, 2006.
[5] M. Armbrust, A. Fox, R. Griffith, A. Joseph, R. Katz, A. Konwinski, G. Lee, D. Patterson, A. Rabkin and I. Stoica, A view of cloud computing., Communications of the ACM , Vol. 53, 2010.
[6] B. Hayes, Cloud computing., Communications of the ACM , Vol. 7, 2008. [7] L. M. Vaquero, L. Rodero-Merino, J. Caceres and M. Lindner, A break in
the clouds: towards a cloud definition., In ‘ACM SIGCOMM - Computer Communication Review’, Vol. 39, pp. 50–55, 2009.
[8] L. Zhang and Q. Zhou, CCOA: Cloud computing open architecture, In ICWS 2009: Procedings of the IEEE International Conference on Web Services’, Los Angeles, CA, pp. 607–616, 2009.
[9] I. Foster, Y. Zhao, I. Raicu and S. Lu, Cloud computing and grid computing 360-degree compared, In ‘IEEE Grid Computing Environments Workshop, 2008. GCE’08’, Cornell University Library, Ithaca NY, pp. 1–10, 2008.
[10] M. A. Vouk, Cloud computing - issues, research and implementations, In ‘IEEE 30th International Conference on Information Technology Interfaces’, Vol. 4, Croatia, pp. 31–40, 2008.
[11] J. Antony, M. Kate and A. Frangou, A strategic methodology to the use of advanced statistical quality improvement techniques, In ‘The TQM Magazine’, Vol. 10, pp. 169–176, 1998.
[12] R. S. Barr, B. L. Golden, J. P. Kelly, M. G. C. Resende and W. R. Stewart, Designing and reporting on computational experiments with heuristic methods., Journal of Heuristics , Vol. 1, pp. 9–32, 1995.
[13] N. Ziviani, Projeto de Algoritmos: com implementações em Pascal e C, 2 ed, Pioneira Thomson Learning, São Paulo, SP, 2004.
[14] M. H. Alsuwaiyel, Algorithms Design Techniques and Analysis, World Scientific, King Fahd University of Petroleum Minerals (KFUPM), Saudi Arabia, 1999.
[15] T. H. Cormen, C. E. Leiserson, R. L. Rivest and C. Stein, Algorithms, 3 ed, The MIT Press, New York, USA, 2009.
[16] C. E. Rolz, Statistical design and analysis of experiments., In ‘Computer and Information Science Applications in Bioprocess Engineering NATO ASI Series’, Vol. 305, pp. 143–156, 1996.
[17] M. I. Rodrigues and A. F. Iemma, Planejamento de experimentos e otimização de processos, Casa do Espírito Amigo Fraternidade Fé e Amor, Campinas, SP, 2009.
[18] D. Montgomery, Design and Analysis of Experiments, John Wiley and Sons, 7th edition, 2009.
Ricardo Soares Bôaventura é doutorando do Programa de Pós-graduação da Engenharia Elétrica, possui mestrado em Ciência da Computação pela Universidade Federal de Uberlândia (2008) e graduação em Ciência da Computação pela Universidade Federal de Lavras (2003). Atualmente é professor efetivo do Instituto Federal de Educação Ciência e Tecnologia do Triângulo Mineiro.
Keiji Yamanaka é doutor em Engenharia Elétrica e de Computação - Nagoya Institute Of Technology, Japão (1999). Atualmente é professor associado 3 da Universidade Federal de Uberlândia. Tem experiência na área de Engenharia Elétrica, com ênfase em Inteligência Computacional, atuando principalmente nos seguintes temas: redes neurais artificiais, algoritmos genéticos, e em reconhecimento de padrões.
Gustavo Prado Oliveira possui graduação em Ciência da Computação pela Universidade Federal de Goiás (2003) e mestrado em Engenharia Mecânica pela Universidade Federal de Uberlândia (2007). Atualmente é prof. do ensino basico tecnico e tecnologico do Instituto Federal de Educação Ciência e Tecnologia do Triângulo Mineiro. Tem experiência na área de Ciência da Computação, com ênfase em Programaçao e
Engenharia de software, atuando principalmente nos seguintes temas: programação, tecnologia da inforamção, programação comercial, engenharia de Software e sistemas para internet.
SOARES BOAVENTURA et al.: PERFORMANCE ANALYSIS 797