クラウド時代だからこそ見直したいphpアプリケーションのパフォーマンスチューニング...
TRANSCRIPT


Masashi Terui @ marcy_teruiI’m a Developer and Cloud Architect.
I’m a full-time employee at JIG-SAW Inc. But, I’m a part-time freelance engineer. I’m a member of GCPUG and JAWS-UG.
I'm the organizer on the some of events with the theme of "Infrastructure as Code”. I’m around 30 years old. I’m a father of my son and daughter.
2

3
∀

4
なぜパフォーマンスチューニングが重要なのか
有名な言葉
単一サーバ構成におけるポイント 複数サーバ構成におけるポイント
スケールアウト構成におけるポイント
まとめ

5

6
100msのレイテンシは1%の売上に相当する(by Amazon)https://news.ycombinator.com/item?id=273900 検索ランキングの判定条件にサイトの速度を使用するhttps://webmasters.googleblog.com/2010/04/using-site-speed-in-web-search-ranking.html クラウドのコストの大半はサーバ料金俺調べ(そこそこ色々見てきたつもり)

7

8
System metricsCPU, Memory, Disk, Network, Load Average etc… Response timeApacheの設定でLogFormatに%Dを付ける、Nginxだと$request_time
Slow query log (後述)
External metricsRequest counts, Latency etc…

9
10
または

11
スケールアップには限界がある
CPUはどちらかというと処理能力よりコア数が大事
高速化 ≒ キャパシティ向上
アプリケーション・ミドルウェアチューニング

12

13
c4.8xlarge 36vCPU 60GB $2.122/1h
r3.8xlarge 32vCPU 244GB $3.192/1h
高い
変更しにくい(停止を伴う)
大きくなるほど性能を使い切るのは難しい

14

15
PHPはシングルスレッド・同期IO マルチプロセスで複数のリクエストを捌く シングルプロセス非同期IO(Node.jsとか)の場合は逆
コアが少ないと専有されたら死亡・・・ 重たいクエリ バッチ処理 バグ(無限ループ等)

16
コアが増えても1コア当たりの性能は変わらない
スケールアップで高速化はたかが知れてる
スペックが変われば適切なミドルウェアの設定も変わる
コアが多いと有効に使い切れない可能性

17

18
処理時間が半分になれば単位時間あたりの処理数は約2倍になる
1リクエストの処理に1秒かかるのは遅いと思いますか?
特定の遅いページがあるのは問題
リクエストが集中するとあっという間に全体が詰まる
バランス良く高速化が必要

19

20
Apache + mod_phpの弱点→prefork
MaxClientsとか大事だけど限界がある
1ページ見るためにアセットをたくさん取得しなければならない
↑をpreforkで捌くのが問題で必然的にプロセス過多になる
逆に言うとAPI専用とかならpreforkでも良いということ

21
Nginx + php-fpmが理想
Event driven web server
Proxy Cacheは超強力
Cookieで制御したりもできるからかなりの範囲で使える
複雑化するのでご利用は計画的に

22
Apache + event_mpm + mod_proxy_fcgi + php-fpmもアリ
Event driven web server
.htaccessが使える
php_valueとかは使えないので注意

23
CDNを導入する
拡張子等でキャッシュ有無を決めれば、
動的サイトでも問題にならない
クラウドだと通常の通信もアウトバウンド通信料がかかり、
CDNを使っても大差なかったりするので積極的に使うと良い

24
ここを解決すると性能が一気に上る場合が多い
語りだすと長くなるので基本だけ
@soudai1025 さんの発表を聞くと良いと思います :-)
とりあえずできるだけ新しいバージョンを使おう
MySQLはアホの子という時代は終わりつつある

25
今はInnoDB一択の時代
MyISAMを使う理由はほぼ無い
innodb_buffer_pool_sizeはとりあえず覚えとけ
クラスターインデックス
REPEATABLE_READおよびインデックスロック

26
Query Cache
更新時の性能劣化が無視できないレベルである
OFF or DEMAND
例外的に更新の極端に少ないCMSとかならONでも良い

27
とりあえずできるだけ新しいバージョンを使おう オペコードキャッシュはもう当たり前 APC (< 5.5) Opcache (5.5 <=) Blue/Green deploymnet等ができるなら apc.stat = 0 opcache.validate_timestamps = 0

28
キリがないのでインフラ目線でこれくらいはやっとけってやつ
DB等のコネクションのSingleton実装
ロック粒度の見直し
N+1問題
→ 特にクラウド環境では地理的分散(Multi-AZ)時に大きな問題になる

29
何はともあれSlow query logを取ろう
long_query_time = 0.1
log-queries-not-using-indexes
pt-query-digest便利
→ Slow query log(以外も可)の集計・ランキング

30
Explain要注意項目 type/ALL, type/index
DEPENDENT SUBQUERY
UNCACHEABLE SUBQUERY Using temporary
Using filesort

31

32
ステート(セッション)共有・キャッシング
リードレプリカ
ファイル置き場
バッチ処理

33

34
なんだかんだ、Memcachedが良いよね PECL::Memcachedで設定のみでセッション格納可 キャッシュとしても 大抵は消えても良いはず(無かったら再作成的な)
冗長化だけが目的ならDBでもOK WAFなら大抵DBセッションの機能を持ってる 自作したこともあるけどそんなに難しくない

35
RedisとMemcachedは併せて語られることが多いが別物 Memcachedの方が運用が楽 本当に永続化しないといけないか考えよう Redisは多様なデータ型やデータ操作という観点で選ぶ Sorted set など Increment, Decrementなど アトミックなデータ操作、Pub/Subなど

36

37
DB読み込みの分散
重いクエリの分割(集計バッチ系など)
冗長化
できれば2台以上ほしい
レプリカ追加や再作成時にマスターに触らなくて済む

38
Master, ReadReplicaのコネクションは明示的に使い分ける SQL見て切り替えるみたいな実装もあるけど、整合性とか色々大変
フェイルオーバー時に接続先を連動して切り替える VIP(使えないクラウドが多い) Domainベース NIC付け替え
ReadReplicaの接続先振り分け マネージドなInternal LBがあるならそれを使う HAProxyなどで冗長化頑張るか個々に入れるとかもアリ(要自動化)

39

40
NFSは単一障害点になるからダメ
運用で死ねるからダメなやつ
GlusterFS → 双方向レプリケーション
s3fs → オブジェクトストレージを無理やりファイルシステム化
オブジェクトストレージをAPIで操作するのが一番確実
一時URLを発行して直接アクセスさせたりする手も

41

42
複数台構成における悩みの一つ
冗長化が難しい バッチ専用サーバというリソースの無駄
その定期バッチほんとうに必要ですか?
オンライン処理からキューイングしてバックエンドで処理できないか? 夜間バッチはリソースが固定なので空きの多い夜間にという発想→ リソースが柔軟に変更できるクラウドではどうなの?

43
マネージドサービスの活用
Elastic Beanstalk worker tier
CloudWatch Events
Azure Scheduler
AppEngine scheduled task

44
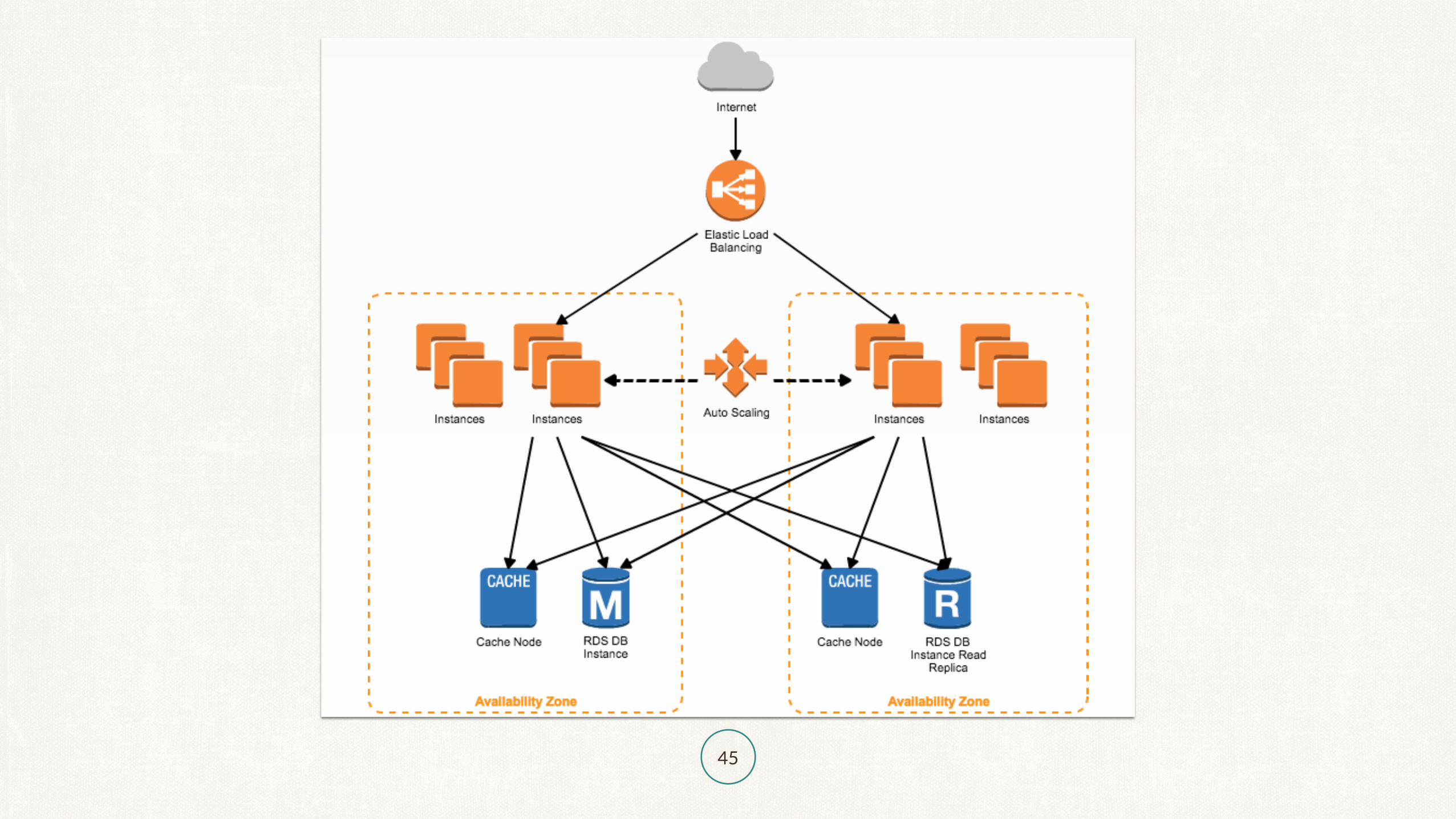
45

46
スケールアウト構成のやつを確実に実行していれば基本大丈夫
GlusterFS使っちゃうとか微妙なことをするとここで困る
運用の変化(若干趣旨がズレるけど) サーバプロビジョニング
アプリケーションデプロイ
サーバメトリクスとログの収集・集約

47

48

49
テンプレート化
VMイメージ
Dockerコンテナ
cloud-initなどによる起動時の自動構成変更
コード化
シェルスクリプト
Chef, Puppet, Ansible, Itamae など

50

51
自動で増減する台数が固定ではない、対象が変わる
Blue/Green deployment
オートディスカバリ
Pull型デプロイ

52

53
収集と集約
サーバ単位よりも役割単位で見れると良い
可視化が重要

54
エージェント型
監視ミドルウェアの運用がしんどい問題
時系列DBの運用がしんどい問題
サービスの活用
CloudWatch, Stackdriver, Mackerel, Datadog etc…

55
収集 rsyslog Fluentd
集約 Elasticsearch + Kibana MongoDB(Capped collection) + Rockmongo, mongo-express オブジェクトストレージ(保管用) BigQuery(分析用)

56

57
パフォーマンスチューニングは様々な観点から行う必要がある
安易にスケールアップ・アウトする前にできることはいっぱいある
とはいえ、大きな人的コストを欠けるのが適切ではない場面ももちろんある
トレードオフなのでどちらかに偏らずにバランス良く見極めていこう
困ったら相談してください :-)
