point estimation module - facultyfaculty.nps.edu/rdfricke/oa3102/point estimation.pdf · point...
TRANSCRIPT

Revision: 1-12 1 1 1
Module 4: Point Estimation Statistics (OA3102)
Professor Ron Fricker Naval Postgraduate School
Monterey, California
Reading assignment:
WM&S chapter 8.1-8.4

Revision: 1-12 2 2
Goals for this Module
• Define and distinguish between point
estimates vs. point estimators
• Discuss characteristics of good point
estimates
– Unbiasedness and minimum variance
– Mean square error
– Consistency, efficiency, robustness
• Quantify and calculate the precision of an
estimator via the standard error
– Discuss the Bootstrap as a way to empirically
estimate standard errors
2

Revision: 1-12 3
Welcome to Statistical Inference!
• Problem:
– We have a simple random sample of data
– We want to use it to estimate a population quantity
(usually a parameter of a distribution)
– In point estimation, the estimate is a number
• Issue: Often lots of possible estimates
– E.g., estimate E(X) with , , or ???
• This module: What’s a “good” point estimate?
– Module 5: Interval estimators
– Module 6: Methods for finding good estimators
3
x x

Revision: 1-12 4
Point Estimation
• A point estimate of a parameter q is a single
number that is a sensible value for q
– I.e., it’s a numerical estimate of q
– We’ll use q to represent a generic parameter – it
could be m, s, p, etc.
• The point estimate is a statistic calculated
from a sample of data
– The statistic is called a point estimator
– Using “hat” notation, we will denote it as
– For example, we might use to estimate m, so in
this case
q̂
x
4
ˆ xm

Definition: Estimator
An estimator is a rule,
often expressed as a formula,
that tells how to calculate the
value of an estimate
based on the measurements
contained in a sample
Revision: 1-12 5

Revision: 1-12 6
An Example
• You’re testing a new missile and want to estimate the
probability of kill (against a particular target under
specific conditions)
– You do a test with n=25 shots
– The parameter to be estimated is pk, the fraction of kills out of
the 25 shots
• Let X be the number of kills
– In your test you observed x=15
• A reasonable estimator and estimate is
6
15ˆestimate: 0.6
25k
xp
n ˆestimator: k
Xp
n
Revision: 1-12 7
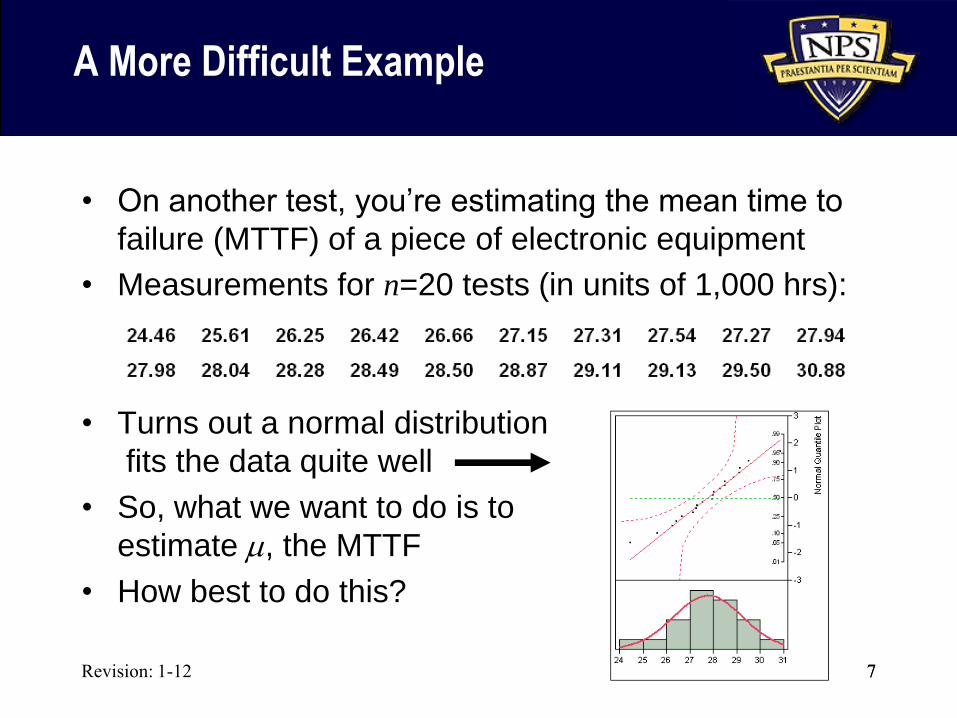
A More Difficult Example
• On another test, you’re estimating the mean time to
failure (MTTF) of a piece of electronic equipment
• Measurements for n=20 tests (in units of 1,000 hrs):
• Turns out a normal distribution
fits the data quite well
• So, what we want to do is to
estimate m, the MTTF
• How best to do this?
7

Revision: 1-12 8
Example, cont’d
• Here are some possible estimators for m and their
values for this data set:
• Which estimator should you use?
– I.e., which is likely to give estimates closer to the true (but
unknown) population value?
8
20
1
1ˆ(1) , so 27.793
20i
i
X x xm
27.94 27.98ˆ(2) , so 27.960
2X xm
min( ) max( ) 24.46 30.88ˆ(3) , so 27.670
2 2
i ie e
X XX xm
18
(10) (10) ( )
3
1ˆ(4) , so 27.838
16tr tr i
i
X x xm

Revision: 1-12 9
Another Example
• In a wargame computer simulation, you want to
estimate a scenario’s run-time variability (s 2)
• The run times (in seconds) for eight runs are:
• Two possible estimates:
• Why prefer (1) over (2)?
9
22 2 2
1
1ˆ(1) , so 0.25125
1
n
i
i
S X X sn
s
22
1
1ˆ(2) , so estimate 0.220
n
i
i
X Xn
s

• Definition: Let be a point estimator for a q
– is an unbiased estimator if
– If is said to be biased
• Definition: The bias of a point estimator is
given by
• E.g.:
Revision: 1-12 10
Bias
q̂
q̂ ˆE q q
ˆ ˆ, E q q q
q̂
ˆ ˆB Eq q q
* Figures from Probability and Statistics for Engineering and the Sciences, 7th ed., Duxbury Press, 2008.

Revision: 1-12 11
Proving Unbiasedness
• Proposition: Let X be a binomial r.v. with
parameters n and p. The sample proportion
is an unbiased estimator of p.
• Proof:
p̂ X n
11

Revision: 1-12 12
Remember: Rules for Linear
Combinations of Random Variables
• For random variables X1, X2,…, Xn
– Whether or not the Xis are independent
– If the X1, X2,…, Xn are independent
1 1 2 2
1 1 2 2
n n
n n
E a X a X a X
a E X a E X a E X
1 1 2 2
2 2 2
1 1 2 2
Var
Var Var Var
n n
n n
a X a X a X
a X a X a X

Revision: 1-12 13
Example 8.1
• Let Y1, Y2,…, Yn be a random sample with
E(Yi)=m and Var(Yi)=s2. Show that
is a biased estimator for s2, while S2 is an
unbiased estimator of s2.
• Solution:
22
1
1'
n
i
i
S Y Yn
13

Revision: 1-12 14
Example 8.1 (continued)
14

Revision: 1-12 15
Example 8.1 (continued)
15

Revision: 1-12 16
Another Biased Estimator
• Let X be the reaction time to a stimulus with
X~U[0,q], where we want to estimate q based
on a random sample X1, X2,…, Xn
• Since q is the largest possible reaction time,
consider the estimator
• However, unbiasedness implies that we can
observe values bigger and smaller than q
• Why?
• Thus, must be a biased estimator
16
1 1 2ˆ max , , , nX X Xq
1q̂

Revision: 1-12 17
Fixing the Biased Estimator
• For the same problem consider the estimator
• Show this estimator is unbiased
17
2 1 2
1ˆ max , , , n
nX X X
nq

Revision: 1-12 18 18

Revision: 1-12 19
One Criterion for
Choosing Among Estimators
• Principle of minimum variance unbiased
estimation: Among all estimators of q that are
unbiased, choose the one that has the
minimum variance
– The resulting estimator is called the minimum
variance unbiased estimator (MVUE) of q
19
q̂
1 2ˆ ˆEstimator is preferred to q q
* Figure from Probability and Statistics for Engineering and the Sciences, 7th ed., Duxbury Press, 2008.

Revision: 1-12 20
• Let X1, X2,…, Xn be a random sample from a
normal distribution with parameters m and s.
Then the estimator is the MVUE for m
– Proof beyond the scope of the class
• Note this only applies to the normal
distribution
– When estimating the population mean E(X)=m for
other distributions, may not be the appropriate
estimator
– E.g., for Cauchy distribution E(X)=!
20
ˆ Xm
X
Example of an MVUE

Revision: 1-12 21
How Variable is My Point Estimate?
The Standard Error
• The precision of a point estimate is given by its
standard error
• The standard error of an estimator is its standard
deviation
• If the standard error itself involves unknown
parameters whose values are estimated, substitution
of these estimates into yields the estimated
standard error
– The estimated standard error is denoted by or
21
q̂
ˆˆVar
qs q
q̂s
ˆˆ
qs ˆs
q

Revision: 1-12 22
Deriving Some Standard Errors (1)
• Proposition: If Y1, Y2,…, Yn are distributed iid
with variance s2 then, for a sample of size n,
. Thus .
• Proof:
22
2Var Y nsY
ns s

Revision: 1-12 23
Deriving Some Standard Errors (2)
• Proposition: If Yi~Bin(n,p), i=1,…,n, then
, where q=1-p and .
• Proof:
23
p̂ pq ns p̂ Y n

Expected Values and Standard Errors
of Some Common Point Estimators
Target
Parameter
q
Sample
Size(s)
Point
Estimator
Standard
Error
m n m
p n p
m1-m2 n1 and n2 m1-m2
p1-p2 n1 and n2 p1-p2
Revision: 1-12 24 24
ˆE qq̂ q̂
s
Y
ˆY
pn
1 2Y Y
1 2ˆ ˆp p
n
s
pq
n
1 1 2 2
1 2
p q p q
n n
2 2
1 2
1 2n n
s s
If p
op
ula
tio
ns a
re
ind
ep
en
de
nt

Revision: 1-12 25
• Sometimes an estimator with a small bias can
be preferred to an unbiased estimator
• Example:
• More detailed discussion beyond scope of
course – just know unbiasedness isn’t
necessarily required for a good estimator
25
However, Unbiased Estimators
Aren’t Always to be Preferred

Mean Square Error
• Definition: The mean square error (MSE) of a
point estimator is
• MSE of an estimator is a function of both its
variance and its bias
– I.e., it can be shown (extra credit problem) that
– So, for unbiased estimators
Revision: 1-12 26
q̂
22
ˆ ˆ ˆ ˆVarMSE E Bq q q q q
ˆ ˆVarMSE q q
2
ˆ ˆMSE Eq q q
q̂

Error of Estimation
• Definition: The error of estimation e is the
distance between an estimator and its target
parameter:
– Since is a random variable, so it the error of
estimation, e
– But we can bound the error:
Revision: 1-12 27
ˆe q q
q̂
ˆ ˆPr Pr
ˆPr
b b b
b b
q q q q
q q q

Bounding the Error of Estimation
• Tchebysheff’s Theorem. Let Y be a random
variable with finite mean m and variance s2.
Then for any k > 0,
– Note that this holds for any distribution
– It is a (generally conservative) bound
– E.g., for any distribution we’re guaranteed that the
probability Y is within 2 standard deviations of the
mean is at least 0.75
• So, for unbiased estimators, a good bound to
use on the error of estimation is
Revision: 1-12 28
2Pr 1 1Y k km s
ˆ2bq
s

Example 8.2
• In a sample of n=1,000 randomly selected
voters, y=560 are in favor of candidate Jones.
• Estimate p, the fraction of voters in the
population favoring Jones, and put a 2-s.e.
bound on the error of estimation.
• Solution:
Revision: 1-12 29

Example 8.2 (continued)
Revision: 1-12 30

Example 8.3
• Car tire durability was measured on samples
of two types of tires, n1=n2=100. The number
of miles until wear-out were recorded with the
following results:
• Estimate the difference in mean miles to
wear-out and put a 2-s.e. bound on the error
of estimation
Revision: 1-12 31
1 2
2 2
1 2
26,400 miles 25,100 miles
1,440,000 miles 1,960,000 miles
y y
s s

Example 8.3
• Solution:
Revision: 1-12 32

Example 8.3 (continued)
Revision: 1-12 33

Revision: 1-12 34
Other Properties of Good Estimators
• An estimator is efficient if it has a small
standard deviation compared to other
unbiased estimators
• An estimator is robust if it is not sensitive to
outliers, distributional assumptions, etc.
– That is, robust estimators work reasonably well
under a wide variety of conditions
• An estimator is consistent if
For more detail, see Chapter 9.1-9.5
nq̂
nP n as 0ˆ eqq
34
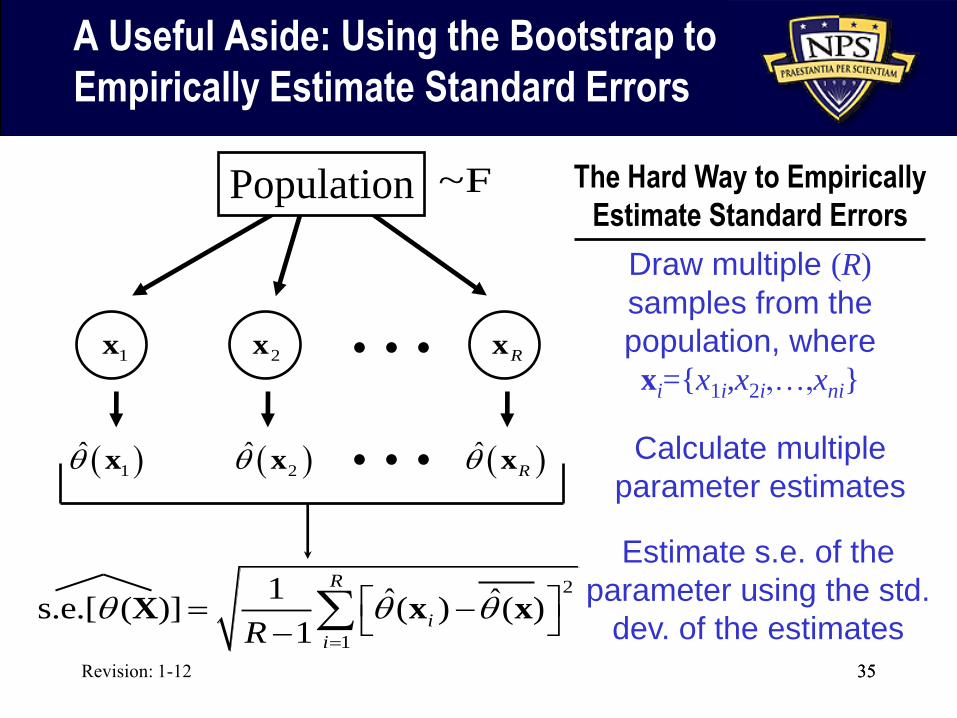
Revision: 1-12 35
A Useful Aside: Using the Bootstrap to
Empirically Estimate Standard Errors
35
1x 2x Rx
1q̂ x 2q̂ x ˆRq x
Draw multiple (R)
samples from the
population, where
xi={x1i,x2i,…,xni}
Calculate multiple
parameter estimates
Estimate s.e. of the
parameter using the std.
dev. of the estimates
Population
2
1
1 ˆ ˆs.e.[ ( )] ( ) ( )1
R
i
iRq q q
X x x
~F The Hard Way to Empirically
Estimate Standard Errors

Revision: 1-12 36
The Bootstrap
• The “hard way” is either not possible or is
wasteful in practice
• Bootstrap is:
– Useful when you don’t know or, worse, simply
cannot analytically derive sampling distribution
– Provides a computer-intensive method to
empirically estimate sampling distribution
• Only feasible recently with the widespread
availability of significant computing power
36

Revision: 1-12 37
Plug-in Principle
• We’ve been doing this throughout the class
• If you need a parameter for a calculation, simply “plug in” the equivalent statistic
• For example, we defined
and then we sometimes did the calculation using for
• Relevant for the bootstrap as we will “plug in” the empirical distribution in place of the population distribution
2
Var( ) ( )X E X E X
( )E XX
37
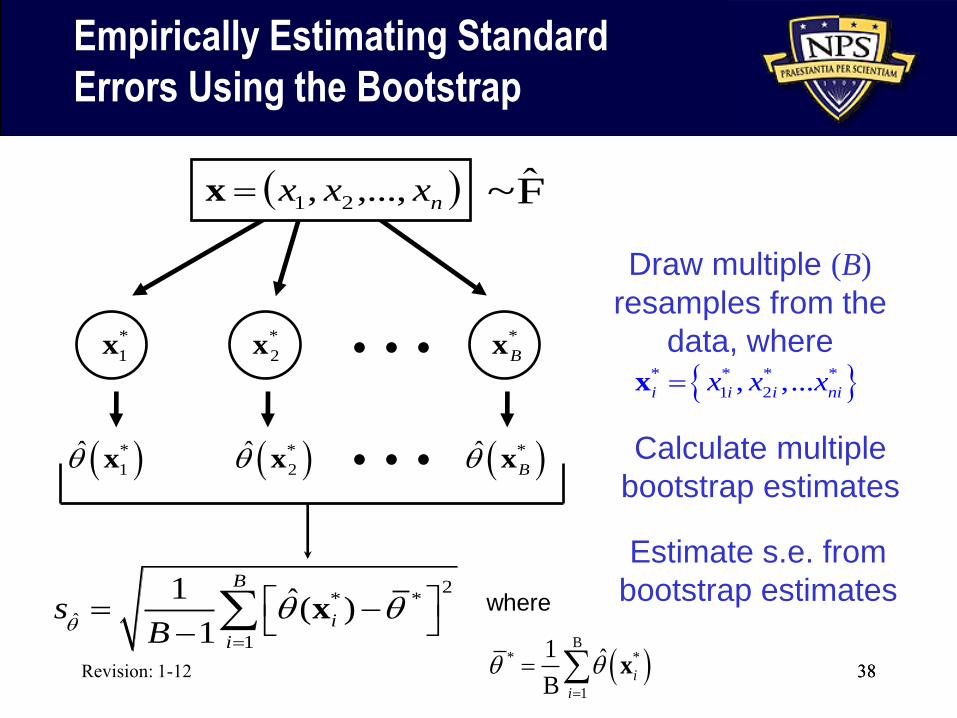
Revision: 1-12 38
Empirically Estimating Standard
Errors Using the Bootstrap
38
*
1x*
2x*
Bx
*
1q̂ x *
2q̂ x *ˆBq x
Draw multiple (B)
resamples from the
data, where
Calculate multiple
bootstrap estimates
Estimate s.e. from
bootstrap estimates 2* *
ˆ
1
1 ˆ( )1
B
i
i
sBq
q q
x
nxxx ,...,, 21x ˆ~F
B
* *
1
1 ˆB
i
i
q q
x
where
* * * *
1 2, ,...i i i nix x xx

Revision: 1-12 39
Some Key Ideas
• Bootstrap samples are drawn with replacement from
the empirical distribution
– So, observations can actually occur in the bootstrap sample
more frequently than they occurred in the actual sample
• Empirical distribution substitutes for the actual
population distribution
– Can draw lots of bootstrap samples from the empirical
distribution to calculate the statistic of interest
• Make B as big as can run in a reasonable timeframe
– Bootstrap resamples are of same size as orignal sample (n)
• Because this is all empirical, don’t need to analytically
solve for the sampling distribution of the statistic of
interest 39

Revision: 1-12 40 40
• Defined and distinguished between point
estimates vs. point estimators
• Discussed characteristics of good point
estimates
– Unbiasedness and minimum variance
– Mean square error
– Consistency, efficiency, robustness
• Quantified and calculated the precision of an
estimator via the standard error
– Discussed the Bootstrap as a way to empirically
estimate standard errors 40
What We Covered in this Module

• WM&S chapter 8.1-8.4 – Required exercises: 2, 8, 21, 23, 27
– Extra credit: 1, 6
• Useful hints: Problem 8.2: Don’t just give the obvious answer, but show
why it’s true mathematically
Problem 8.8: Don’t do the calculations for the estimator
Extra credit problem 8.6: The a term is a constant with
Revision: 1-12 41 41
Homework
4q̂
0 1a