potential-based agnostic boosting varun kanade harvard university (joint work with adam tauman kalai...
TRANSCRIPT

Potential-Based Agnostic Boosting
Varun Kanade
Harvard University
(joint work with Adam Tauman Kalai (Microsoft NE))

Outline
PAC Learning, Agnostic Learning, Boosting
Boosting Algorithm and applications
(Some) history of boosting algorithms

Learning ...
PAC Learning [Valiant '84]
Learning from examples e.g. halfspaces Learning from membership queries. eg. DNF
(x1 ٨ x
7 ٨ x
13) ۷ (x
2 ٨ x
7) ۷ (x
3 ٨ x
8 ٨ x
10)
Agnostic Learning [Haussler '92, Kearns, Schapire, Sellie '94]
No assumptions about correctness of labels Challenging Noise Model
+ ++
++ +
+
++
-
-
---
--
----
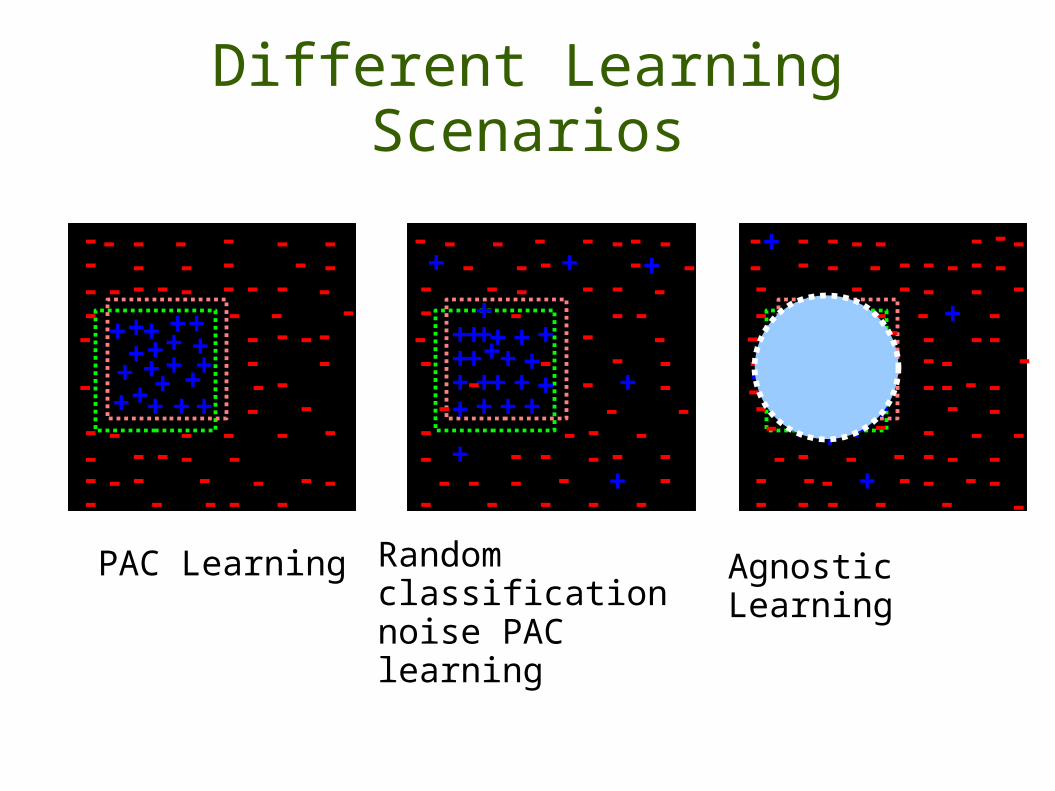
Different Learning Scenarios
PAC Learning Random classification noise PAC learning
Agnostic Learning
+
+ ++ +
+++
++++
++
++
+ +++
--
-
-
- -
-
-
--
--
--
-
-
--
--
--
-
- -
- -
- -
----
-
- --
---
-
-
--
--
-
-
-
--
-
- -
--
-
-
-
-
- +++
+
++
+
+
+
+
++
+ +
+
+
+
+
++
+
+
++ +
++
-
-- --
- -
--
-
-
-
-
-
-
-
-
- -
-
-
--
--
-
--
-
--
--
-
-
-
---
-
-
-
-
-
--
-
-
--
-
-
-
-
-- +
+
+
++
++++ ++
+
+++ ++++
+++++
+ ++++ +++++
-
-
-
-
--
-
-
-
-
-
-
-
-
-
--
-
--
--
-
-
-
-
--
-
-
-
---
-
- -
-
--
-
-
-
-
--
- -
--
-
-
--
-- -
-
-
-
-
-
-
-
-
-
-
--
- -

Boosting ...
Weak learning → Strong Learning(accuracy 51% → accuracy 99%) Great for proving theory results [Schapire '89]
Potential-based algorithms work great in practice e.g Adaboost [Freund and Schapire '95]
But, suffer in the presence of noise.

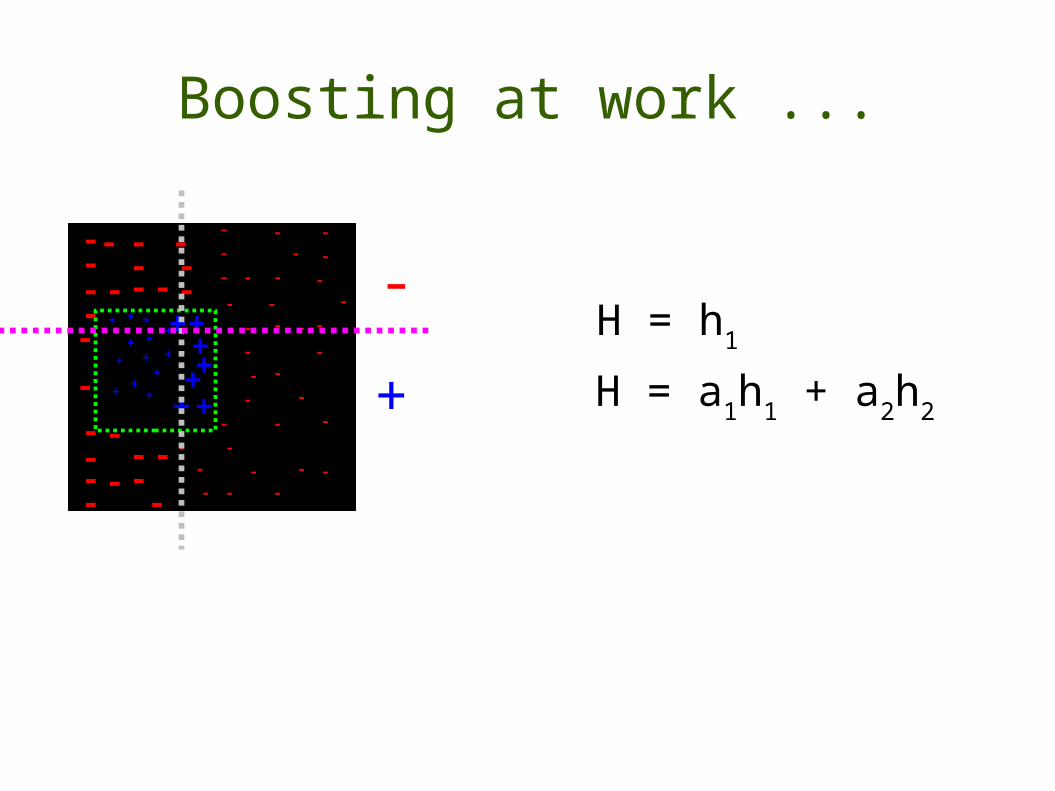
Boosting at work ...
H = h1
+
+ ++ +
+++
++++
++
++
+ +++
--
-
-
- -
-
-
--
--
--
-
-
--
--
--
-
- -
- -
- -
----
-
- --
---
-
-
--
--
-
-
-
--
-
- -
--
-
-
-
-
-
+ -
Boosting at work ...
H = a1h
1 + a
2h
2
H = h1
+
+
+
+ ++
+
+
+
++
+
++
+
+
+
++ +
-
-
-
-
- --
-
-
-
--
-
-
-
-
-
-
--
--
-
- -
- -
- -
----
-
- --
----
-
--
--
-
-
-
--
-
- -
--
-
-
-
-
-
+
-
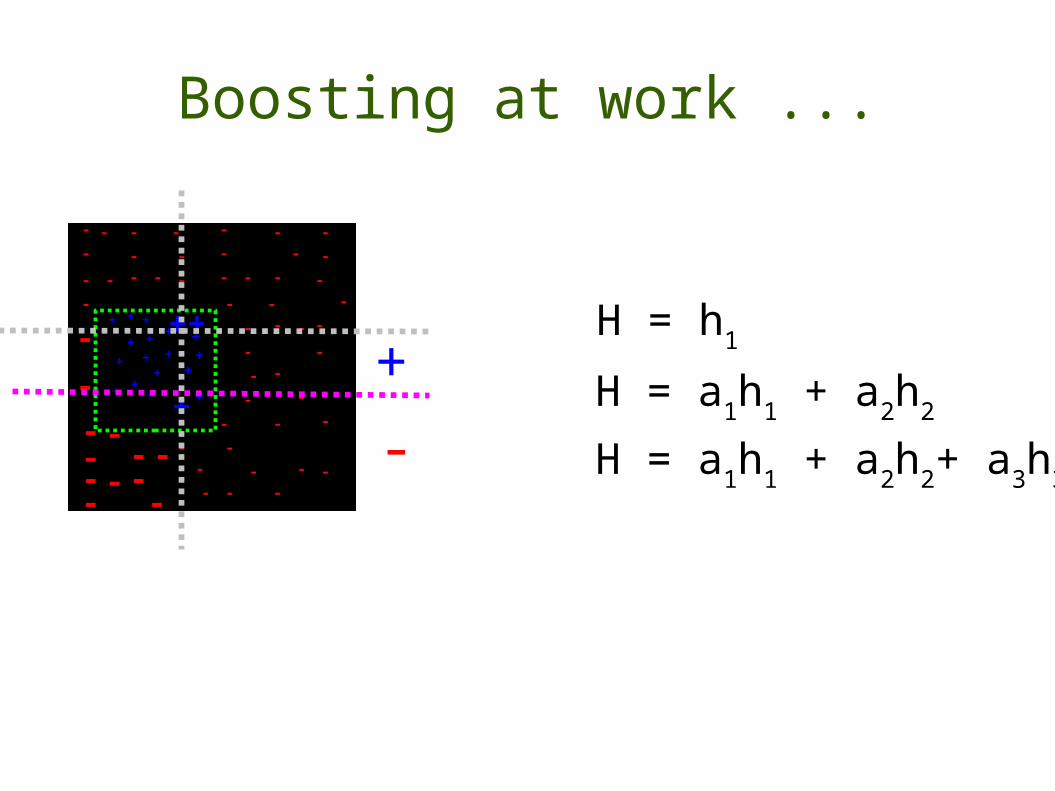
Boosting at work ...
H = a1h
1 + a
2h
2
H = h1
H = a1h
1 + a
2h
2+ a
3h
3
+
++
+ ++
+
+
+
++
+
+
+
+
+
+++ +
-
-
-
-
- -
-
-
-
-
--
-
-
-
-
-
-
--
--
-
- -
- -
- -
--
-
-
-
- --
---
-
-
--
--
-
-
-
--
-
- -
--
-
-
-
-
- +
-
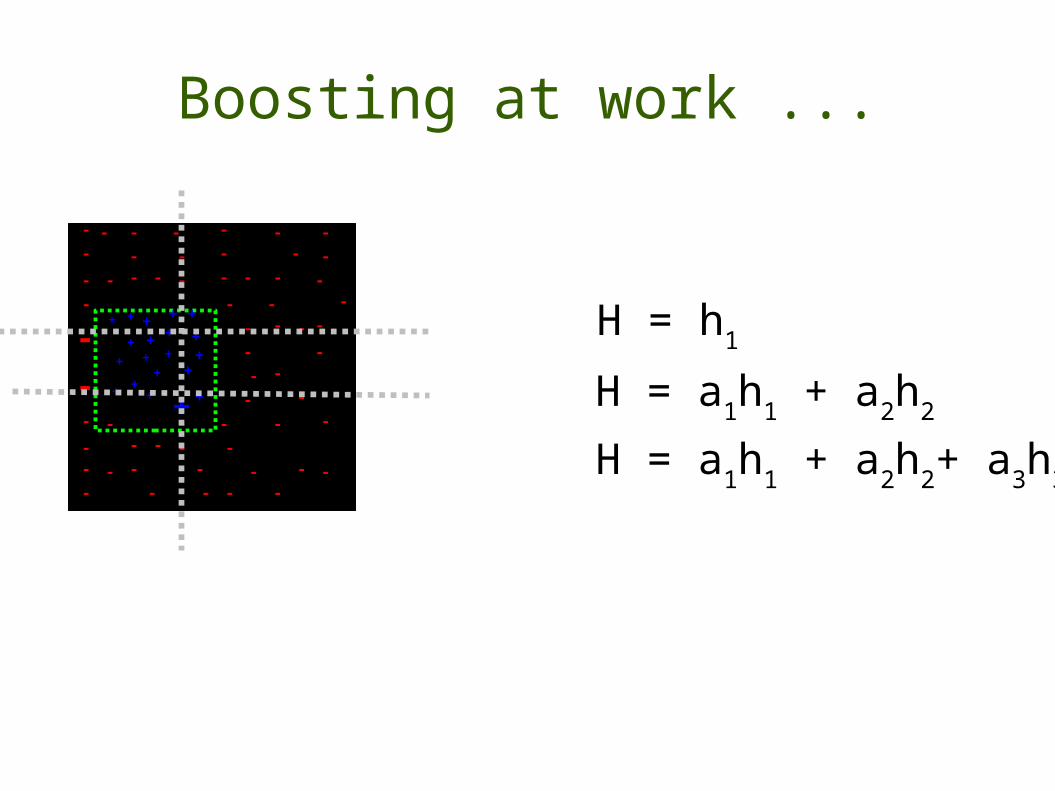
Boosting at work ...
H = a1h
1 + a
2h
2
H = h1
H = a1h
1 + a
2h
2+ a
3h
3
+
++
+ +
+
+
+
+
++
+
+
+
+
+
++++
--
-
-
- -
-
-
-
-
-
-
-
-
-
-
-
-
--
--
-
- -
- -
- -
--
-
-
-- -
-
---
-
-
--
--
-
-
-
--
-
- -
-
-
-
-
-
-
-

Boosting Algorithms
Repeat Find a weakly accurate hypothesis Change weights of examples
Take “weighted majority” of weak classifiers to obtain a highly accurate hypothesis
Guaranteed to work when labelling is correct.

Our Work
New simple boosting algorithm
Better Theoretical Guarantees – agnostic setting
Does not change weights of examples
Application: Simplifies agnostic learning results

Independent Work
Distribution-specific agnostic boosting. - Feldman (ICS 2010)

Agnostic Learning
Assumption that data is perfectly labelled is unrealistic
Make no assumption on how the data is labelled
Goal: Try to fit as well as best from a concept class

Agnostic Learning
Instance Space X
Distribution μ over X
f : X → [-1, 1] (labelling function)
D = (μ, f) over X × {-1, 1} f(x) = E
(x, y)~D [y | x]
Oracle Access
+
-+
+
+
+
+
++
+
++
+
+++
++
+
+
+
+
+
++
+
++
- -
--
--
-
-
-
-- -
- -
--
-
--
--
-
-----
-

Agnostic Learning
errD
(c) = Pr(x, y)~D
[c(x) != y]
cor(c, D) = E(x, y)~D
[c(x)y] = E
x ~ D [c(x) f(x)]
opt = maxc є C
cor(c, D)
Find h satisfyingcor(h, D) ≥ opt - ε
+
-+
+
+
+
+
++
+
++
+
+++
++
+
+
+
+
+
++
+
++
- -
--
--
-
-
-
-- -
- -
--
-
--
--
-
-----
-
PAC Learning is the special case when labels match exactly with a concept in C (f є C), (opt = 1)

Key def: Weak Agnostic Learning
opt may be as low as 0
Algorithm W is a (γ,ε0)-weak agnostic learner for
distribution μ if for every f: X → [-1, 1] and access to D = (μ, f) it outputs a hypothesis w such
cor(w,D) ≥ γ opt – ε0
Weak learner for specific distribution gives strong learner for same distribution

Boosting Theorem
If C is (γ, ε0)-weakly agnostically learnable under
distribution μ over X, then AgnosticBoost returns hypothesis h such that
cor(h) ≥ opt – ε – (ε0/γ)
The boosting algorithm makes O(1/(γε)2) calls to weak learner

Boosting Algorithm
Input: (x1, y
1), ...., (x
mT, y
mT)
1. Let H0 = 02. For t = 1, … , T
Relabel (x(t-1)m+1
, y(t-1)m+1
), … , (xtm
, ytm
)Let gt be the output of weak learner W on relabelled data by weights wt(x,y)
ht = Either gt or – sign(Ht-1)γt = 1/m ∑
i ht(x
i) y
i wt(x
i,y
i)
Ht = Ht-1 + γt ht

Boosting Algorithm
Input: (x1, y
1), ...., (x
mT, y
mT)
1. Let H0 = 02. For t = 1, … , T
Relabel (x(t-1)m+1
, y(t-1)m+1
), … , (xtm
, ytm
)Let gt be the output of weak learner W on relabelled data by weights wt(x,y)
ht = Either gt or – sign(Ht-1)γt = 1/m ∑
i ht(x
i) y
i wt(x
i,y
i)
Ht = Ht-1 + γt ht
Relabelling idea: [Kalai K Mansour '09]

Potential Function
φ(z) = 1 – z if z ≤ 0
φ(z) = e-z otherwise
Ф(H,D) = E(x,y)~D
[φ(yH(x))]
Ф(H0,D) = 1; Ф ≥ 0
(same potential function as Madaboost)
Proof Strategy
Relabelling weights: w(x, y) = -φ'(yH(x))
RD, w
– draw (x,y) from D return (x, y) with probability
(1+w(x,y))/2 else return (x, -y)
cor(h, RD, w
) = E(x, y)~D
[h(x) y w(x, y)]
++
+-+-
+
+-
+-+-+-+
--+
--
- -
-+
-
-
++
++
+
+
+--
-
-
-
--
- --
-
++
+ +
+
++---
--
--
- --

Analysis Sketch ...
φ(yH(x))-φ(yH(x) + γ(yh(x))) ≥ γh(x)y(-φ'(yH(x)))- γ2/2
Taking expectations we get the required result.
Lemma: For any x and δ in reals |φ(x+ δ) - φ(x) – φ'(x) δ| ≤ δ2
/2
Let H: X → R, h: X → [-1, 1], γ є R and distribution μ over X. Relabel according to w(x, y) = - φ'(yH(x))
Φ(H, D) – Φ(H + γ h, D) ≥ γ cor(h, RD, w
) – γ2 /2

Analysis Sketch ...
Only relabelling data points correctly classified by h – so advantage of c only increases …
For distribution D over X × {-1, 1} and c, h : X → {-1, 1} and relabelling function w(x,y) satisfying w(x, -h(x))=1
cor(c,RD,w
) – cor(h,RD,w
) ≥ cor(c, D) – cor(h, D)

Analysis Sketch …
Suppose cor(sign(Ht),D) ≤ opt – ε – (ε0/γ) and let
c є C achieve opt
Relabel using w(x,y) = - φ'(yHt(x)) .. and hence
cor(c, R
D, w) – cor(sign(Ht), R
D, w) ≥ ε + ( ε
0 / γ )
If cor(c, RD, w
) ≥ ε/2 + ε0 / γ … weak learning
else cor(-sign(Ht), RD, w
) ≥ ε/2

Analysis Sketch …
Can always find a hypothesis h satisfying .. cor(h, R
D, w) ≥ (εγ/ 2)
Reduces potential at least by Ω( (εγ)2)
In less that T = O(1 /(εγ)2) steps it must be the case that
cor (sign(Ht), D) ≥ opt – ε - (ε
0/γ)

Applications
Finding low degree Fourier coefficients is a weak learner for halfspaces under the uniform distribution. [Klivans, O'Donnell, Servedio '04]
Get agnostic halfspace algorithm [Kalai, Klivans, Mansour, Servedio '05]
Goldreich-Levin/Kushilevitz-Mansour algorithm for parities is a weak learner for decision trees.Get agnostic decision tree learning algorithm [Gopalan, Kalai, Klivans '08]

Applications
Agnostically learning C under a fixed distribution μ gives PAC learning of disjunctions of C, under same distribution μ [Kalai, K, Mansour '09]
Agnostically learning decision trees gives a PAC learning algorithm for DNF. [Jackson '95]

(Some) History of Boosting Algorithms
Adaboost [Freund and Schapire '95] works in practice!
Also simple, adaptive and has other nice properties.
Random noise worsens performance considerably
Madaboost [Domingo and Watanabe '00] corrects for this somewhat by limiting penalty for wrong labels.

(Some) History of Boosting Algorithms
Random Classification Noise: Boosting using branching programs. [Kalai and Servedi '03]
No potential-based boosting algorithm. [Long and Servedio '09]

(Some) History of Boosting Algorithms
Agnostic Boosting [Ben-David, Long, Mansour '01] - different definition of weak learner
- no direct comparison, full boosting not possible
Agnostic Boosting and Parity Learning. [Kalai, Mansour and Verbin '08]
- uses branching programs - give algorithm to learn parity with noise under all
distributions in time 2O(n/log n)

Conclusion
Simple potential-function based boosting algorithm for agnostic learning
“Right” definition of weak agnostic learning
Boosting without changing distributions
Applications: simplifies agnostic learning algorithms for halfspaces and decision trees, a different way to view PAC-learning DNFs

Boosting
W is a γ-weak learner for concept class C for all distributions μ
Can W be used as a black-box to strongly learn C under every distribution μ? [Kearns and Valiant '88]
Yes – boosting. [Schapire '89, Freund '90, Freund and Schapire '95]

Agnostic Learning Halfspaces
Low-degree algorithm is a (1/nd, ε0)-agnostic weak-
learner for halfspaces under uniform distribution over the boolean cube. [Klivans-O'Donnell-Servedio '04]
Halfspaces over boolean cube are agnostically learnable using examples only for constant ε. [Kalai-Klivans-Mansour-Servedio '05]

Learning Decision Trees
Kushilevitz-Mansour (Goldreich-Levin) algorithm for learning parities using membership queries is a (1/ t, ε
0)-agnostic weak learner for decision trees.
[Kushilevitz-Mansour '91]
Decision trees can be agnostically learned under uniform distribution using membership queries. [Gopalan-Kalai-Klivans '08]

PAC Learning DNFs
Theorem: If C is agnostically learnable under distribution μ then disjunctions of C is PAC-learnable under μ. [Kalai-K-Mansour '09]
DNFs are PAC-learnable under uniform distribution using membership queries. [Jackson 95]

PAC Learning
Instance Space X
Distribution μ over X
Concept class C c є C
Oracle access
-
+ --
-
-
-- -
-
- -
-
-
-
-
-
- -
--
-
-
---
--
+
+
+
+
++
+
++
+
+
+
++
+

PAC Learning
Output hypothesis h
error = Prx ~ μ
[h(x) != c(x)]
With high probability (1–δ) h is approximately (error ≤ ε) correct
-
+ --
-
-
-- -
-
- -
-
-
-
-
-
- -
--
-
-
---
--
+
+
+
+
++
+
++
+
+
+
++
+

PAC Learning
Instance space X, distribution μ over X, concept class C over X
corμ (h, c) = E
x ~ μ [h(x) c(x)] = 1 – 2 err
μ (h, c)
C is PAC learnable under distribution μ, if for all c є C, ε, δ > 0, exists algorithm A which in polytime outputs h such that cor
μ (h, c) ≥ 1- ε with probability at least 1 – δ
strongly
errD(h, c) ≤ ε/2

Weak PAC Learning
Instance space X, distribution μ over X, concept class C over X
Algorithm W is a γ-weak PAC learner for distribution μ if it outputs a hypothesis w such cor
μ (w, c) ≥ γ
errμ(w, c) ≤ (1– γ)/2 : somewhat
better than random guessing

Key def: Weak Agnostic Learning
opt = minc є C
Pr(x, y) ~D
[ c(x) != y]cor(c, D) = E
(x, y) ~D [ c(x) y] = E
x ~ μ [c(x) f(x)]
cor(C, D) = maxc є C
cor(c, D) = 1 – 2 opt
opt may be as low as 0
Algorithm W is a (γ,ε0)-weak agnostic learner for
distribution μ if for every f: X → [-1, 1] and access to D = (μ, f) it outputs a hypothesis w such
cor(w,D) ≥ γ cor(C,D) – ε0

$\gamma$ → γ$\times$ → ×$\mu$ → μ$\epsilon$ → ε$\gequal$ → ≥$\sum$ → ∑$\phi$ → φ$\Bigphi$ → Ф$\lequal$ → ≤$\delta$ → δ$\in$ → ∈$\wedge$ → ٨$\vee$ → ۷