practices: deduplicación en el backup de datos- openexpo day 2015
TRANSCRIPT

Deduplicación en el backup de datos OpenExpo Day 2015
16 de junio 2015
Martín Domínguez Fernández Responsable de Consultoría y Preventa
en WhiteBearSolutions

Objetivos del taller
Entender qué es la deduplicación y porque se necesita…
Entender qué opciones tecnológicas tenemos y cuál debemos elegir…
Dimensionar correctamente un sistema de backup con deduplicación…
Presentar alternativas Open y sus ventajas frente a las soluciones cerradas…

La deduplicación

El escenario... Las organizaciones almacenan
gran cantidad de datos.
El respaldo de los datos es necesario, pero es caro.
Los datos siguen creciendo, entre un 50 – 60 % anual!!
Se hace necesario recurrir a cintas para el almacenamiento de grandes cantidades de datos, pero....
Las cintas son lentas!!
Las cintas fallan!!
Las cintas ocupan espacio!!

La deduplicación…
La deduplicación es una tecnología que elimina los datos duplicados reduciendo considerablemente el tamaño de los datos almacenados.
Se mantiene un listado de referencias a los bloques con datos
No es compresión ni thin provisioning , pero tiene un poco de ambas y se puede combinar con ellas
Reduce los costes de almacenamiento
El backup es un candidato ideal!!

Qué puede hacer por mi…
Nuestra organización tiene 20TB de datos almacenados
Mensualmente se crean 2TB de datos nuevos
¿Cuanto almacenamiento necesitamos? Sin deduplicación:
tamaño = (datos almacenados + cambio semanal) x retención
Con deduplicación: tamaño = (datos almacenados + cambio semanal) x retención
0 TB
50 TB
100 TB
150 TB
Week 1 Week 2 Week 3 Week 4 Week 5
20 TB 22 TB 24 TB 26 TB 28 TB 20 TB
42 TB
66 TB
92 TB
120 TB
with dedup
without dedup Datos en 5 semanas de retención:
Información única: 28TB Información duplicada: 92TB

¿Cómo funciona?

La unidad…
A nivel de fichero: A nivel de software Mejor rendimiento general Falta de granularidad Peores ratios de deduplicación
SOLUCIÓN:
Dividir los ficheros en pequeñas partes: “chunks”
A nivel de bloque: A nivel de filesystem Necesidad de más recursos Buenos ratios de dedupliación menor tamaño de bloque
+ ratio + recursos
MEJORA:
Bloque de tamaño variable

9
El momento…
deduplicación off-line: no afecta al rendimiento R/W requiere espacio para alojar los
datos antes de ser deduplicados requiere más I/O
deduplicación in-line
aporta el ahorro de espacio de forma instantánea puede afectar al rendimiento
R/W Más trabajo en RAM, menos I/O

10
El lugar…
en origen “source”: la carga está en el cliente su objetivo es enviar la mínima
cantidad de datos, pero hay que tener cuidado con el proceso
en destino “target”
la carga está en el servidor permite deduplicar los datos de varios
clientes, lo cual hace que se consigan mejores ratios

11
Qué elegir…
(File-level + chunks) ≈ Block-level
(in-line + recursos) > off-line
¿target vs source? Lo ideal sería contar con ambas tecnologías…
Global data deduplication Deduplica en el origen
Antes de enviar un bloque, comprueba si está en destino
Deduplica entre varios clientes
Maximiza el uso del ancho de banda
Mejora los tiempos de restauración
Reparte el trabajo entre clientes y servidor

12
Dimensionando el sistema…

13
Información clásica que recopilar…
Datos de origen: conoce cuanta información vas a respaldar, eso te dará un punto de partida para dimensionar el sistema.
Numero de copias a guardar: establece tu RPO y tu RTO para tus necesidades y define una retención.
Incremento de datos por copia: te dará el dato definitivo de dimensionamiento teórico del sistema.
0 TB
50 TB
100 TB
150 TB
Week 1 Week 2 Week 3 Week 4 Week 5
20 TB
42 TB
66 TB
92 TB
120 TB
20 TB 22 TB 24 TB 26 TB 28 TB
with dedup
without dedup Estimación para 5 semanas:
Tamaño necesario: 28TB Con compresión (2:1): 14TB

14
¿Es suficiente…?
NO. Muchos sistemas de backup con deduplicación fracasan y las principales causas son dos:
las tasas de deduplicación no son las esperadas y el almacenamiento dimensionado no es suficiente, haciéndonos invertir más dinero del esperado
el rendimiento de la solución es muy bajo, tanto en backup como en restauración y hace que incumplamos nuestras ventanas

15
Cuál es el problema…
La deduplicación no es gratis, tiene unos costes:
Posibilidad de colisiones: corrupción de datos
Uso intensivo de CPU: hashing, indexación…
Uso de grandes cantidades de memoria: tablas de referencia a bloques
Fragmentación de la información: bloques dispersos en disco
Planificación de sistemas en función de los datasheets comerciales de los fabricantes: dimensionamiento erróneo

16
Conoce la tecnología…
El hashing consume CPU
Las tablas de índices consumen memoria
Los sistemas de caché consumen memoria
Los accesos a disco son lentos. Si algo no cabe en memoria, mejor en SSD
El tamaño del bloque importa:
Muy grande, baja deduplicación
Muy pequeño, bajo rendimiento
Opciones de bloque variable

17
El tipo de dato… ¿Qué deduplica bien? En general, conjuntos de datos que cambian
poca información
Directorios de usuarios, sistemas de log, Directorios de OS, sistemas de
archivado…
¿Qué deduplica mal? Conjuntos de datos muy cambiantes, comprimidos o cifrados.
BBDD relacionales, Datawharehouses / BI, Sistemas de correo maildir, Sistemas que comprimen o cifran datos…
Backups incrementales
A mayor numero de copias, mejor tasa de deduplicación
Es importante es probar que los datos deduplican tal como esperamos

18
WBSAirback® &
Bacula Enterprise Edition

19
WBSAirback: ZFS on Linux...
Es un appliance de backup que ofrece “target deduplication”.
Integra Bacula Enterprise como motor de backup y su plugin “Aligned volumes”
ZOL es un porting de ZFS de SUN para Linux
Deduplica a nivel de bloque, de tamaño variable
Ofrece deduplicación in-line y compresión LZ4
Utiliza un sistema de caché multinivel que hace que el rendimiento del sistema sea muy alto

20
WBSAirback: ZFS on Linux...

21
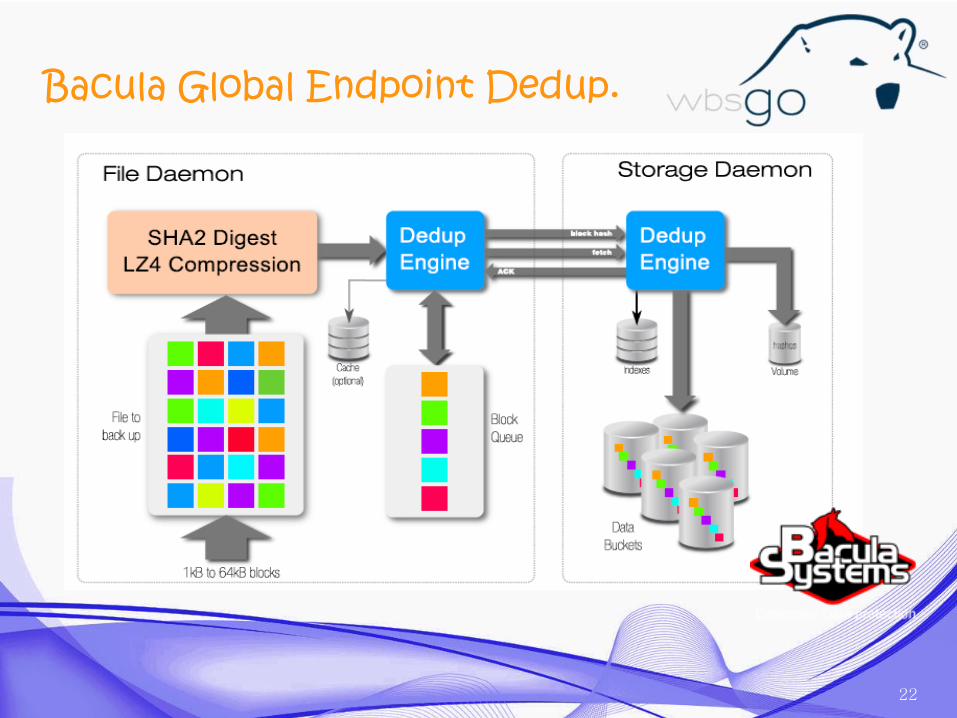
Bacula Global Endpoint Dedup.
Permite aplicación en origen y destino
Trabaja con “chunks” de ficheros de tamaño variable
Mantiene una tabla de hash por “chunk”, residente en SSD
Utiliza sistemas de caché en memoria para más rápido acceso
Implementa la funcionalidad “Client Rehydration” que permite utilizar los datos residentes en el cliente para no enviarlos de nuevo.
22
Bacula Global Endpoint Dedup.

¿Preguntas?

¡Muchas gracias! http://www.whitebearsolutions.com
@WhiteBear_WBSgo
@mtindominguez