praveen yedlapalli emre kultursay mahmut kandemir the pennsylvania state university
TRANSCRIPT

Cooperative Parallelization
Praveen YedlapalliEmre Kultursay
Mahmut Kandemir
The Pennsylvania State University

Motivation Introduction Cooperative Parallelization Programmer’s Input Evaluation Conclusion
Outline

Program parallelization is a difficult task
Automatic parallelization helps in parallelizing sequential applications
Most of the parallelizing techniques focus on array based applications
Limited support for parallelizing pointer-intensive applications
Motivation

Example
void traverse_tree (Tree *tree) { if (tree−>left) traverse_tree(tree->left); if (tree->right) traverse_tree(tree->right);
process(tree);}
void traverse_list (List * list) { List * node = list;
while ( node != NULL ) { process(node);
node = node−>next; }}Tree Traversal
List Traversal

Program Parallelization is a 2-fold problem
First Problem: Finding where parallelism is available in the application if any
Second Problem: Deciding how to efficiently exploit the available parallelism
Introduction

Use static analysis to perform dependence checking and identify independent parts of the program
Target regular structures like arrays and for loops
Pointer intensive codes cannot be analyzed accurately with static analysis
Finding Parallelism

Pointer intensive applications typically have◦Data structures built from input◦and while loops to traverse the data
structures Without the points-to information and with out loop counts there is very little we can do at compile time
Pointer Problem

In array based applications with for loops sets of iterations are distributed to different threads
In pointer intensive applications information about the data structure is needed to run the parallel code
Exploiting Parallelism

The programmer has high level view of the program and can give hints about the program
Hints can indicate things like◦If a loop can be parallelized◦If function calls are independent◦Structure of the working data
All of these bits of information are vital in program parallelization
Programmer’s Input

To efficiently exploit parallelism in pointer intensive applications we need runtime information◦Size and shape of data structure
(dependent on input)◦Points-to information
Using the points-to information we determine the work distribution
Application Runtime Information
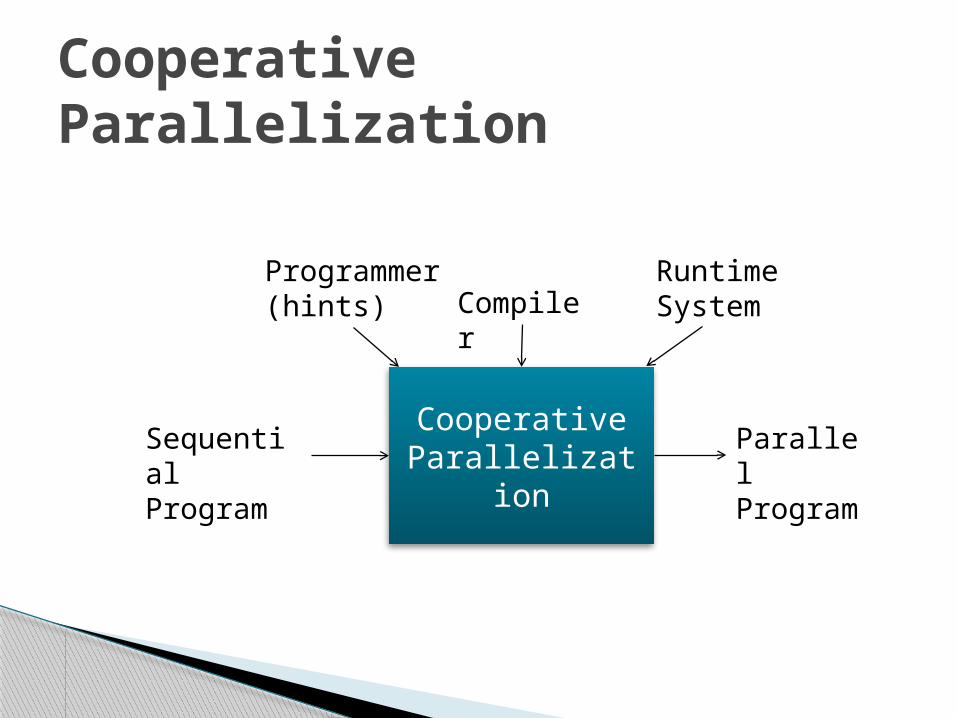
Cooperative Parallelization
CooperativeParallelization
Programmer(hints)
Compiler
RuntimeSystem
SequentialProgram
Parallel Program

Cooperation between the programmer, the compiler and the runtime system to identify and efficiently exercise parallelism in pointer intensive applications
The task of identifying parallelism in the code is delegated to the programmer
Runtime system is responsible for monitoring the program and efficiently executing parallel code
Cooperative Parallelization

Pointer-intensive applications◦A data structure is built from the input◦The data structure is traversed several
times and nodes are processed The operations on nodes are typically independent
This fact can be obtained from the programmer as a hint
Application Characteristics
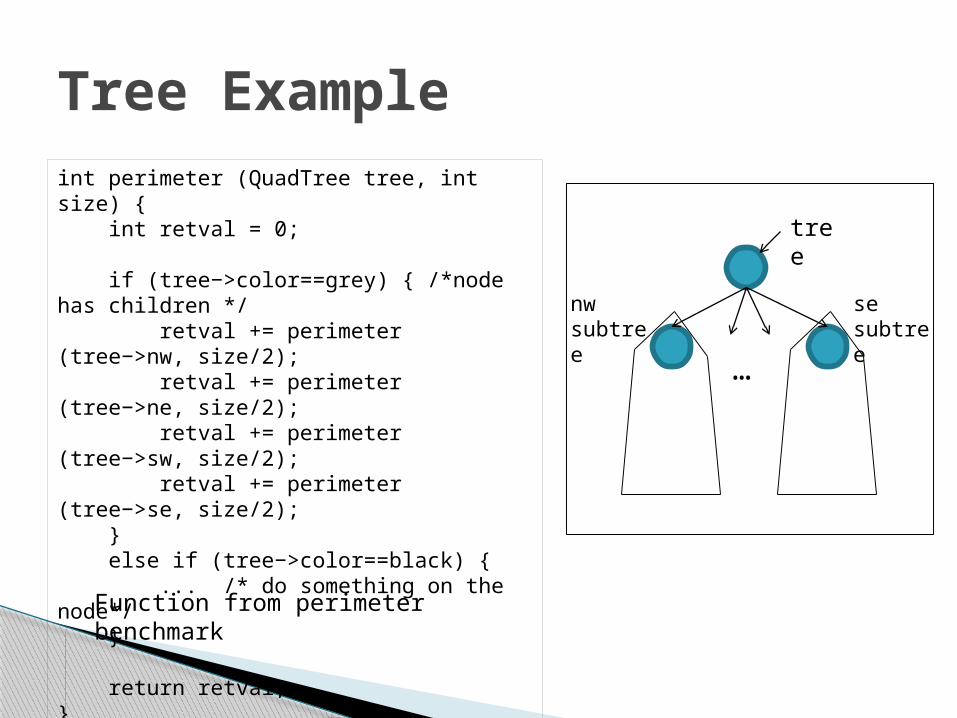
Tree Exampleint perimeter (QuadTree tree, int size) { int retval = 0;
if (tree−>color==grey) { /*node has children */ retval += perimeter (tree−>nw, size/2); retval += perimeter (tree−>ne, size/2); retval += perimeter (tree−>sw, size/2); retval += perimeter (tree−>se, size/2); } else if (tree−>color==black) { ... /* do something on the node*/ }
return retval;}
tree
nwsubtree
sesubtree
…
Function from perimeter benchmark

List Examplevoid compute_node (node_t * nodelist) { int i; while ( nodelist != NULL ) { for (i=0; i < nodelist−>from_count; i++) { node_t *other_node = nodelist−>from_nodes[i]; double coeff = nodelist−>coeffs[i]; double value = other_node−>value; nodelist−>value −= coeff * value; } nodelist = nodelist−>next }}
Function from em3d benchmark
sublist 1 sublist n
. . .
head

Processing of different parts of the data structure (sub problems) can be done in parallel
Needs access to multiple sub problems at runtime
The task of finding these sub problems in the data structure is done by a helper thread
Runtime System

The helper thread goes over the data structure and finds multiple independent sub problems
The helper thread doesn’t need to traverse the whole data structure to find the sub problems
Using a separate thread for finding the sub problems reduces the overhead
Helper Thread

Approach
loop
Sequential Execution
Parallel Execution
helperthread
applicationthreads
loop

Code Structurehelper thread:wait for signal from main threadfind subproblems in the data structuresignal main threadapplication thread:wait for signal from main threadwork on the subproblems assigned to this threadsignal main threadmain thread:signal helper thread when data structure is readywait for signal from helper threaddistribute subproblems to application threadssignal application threadswait for signal from application threadsmerge results from all the application threads

The runtime information collected is used to determine the profitability of parallelization
This decision can be driven by the programmer using a hint
The program is parallelized only if the data structure is “big” enough
Profitability

Interface between the programmer and the compiler
Should be simple to use with minimal essential information
Programmer Hints
#parallel tree function (threads) (degree) (struct) {children} threshold [reduction]
#parallel llist function (threads) (struct) (next_node) threshold [number]

Implemented a source-to-source translator
Modified C language grammar to understand the hints
Automation
ParserGenerato
r
Modified C grammar
Translator
C program with hints
Parallel program

Experimental Setup
Platform
Simics Simulator
16 core hardware
32-bit Linux OS
Benchmarks Data Structure
bisort Binary Tree
treeAdd Binary Tree
tsp Binary Tree
perimeter Quad Tree
em3d Singly Linked List
mst Singly Linked List
otter Singly Linked List
All benchmarks except otter are from olden suite

Evaluation
bisort treeadd tsp perimeter em3d mst otter0
2
4
6
8
10
12
14
16OpenMP 2 threads
OpenMP 4 threads
OpenMP 8 threads
OpenMP 16 threads
Cooperative 2 threads
Cooperative 4 threads
Cooperative 8 threads
Cooperative 16 threads
Sp
eed
up
15x speedu
p

Helper thread can be invoked before the main thread reaches the computation to overlap the overhead of finding the sub problems
Helper thread in general traverses a part of the data structure and takes very less time compared to the original function
Overheads

Open MP 3.0 supports task parallelism◦Directives can be added in the code to
parallelize while loops and recursive functions
Open MP tasks doesn’t take application runtime information into consideration
Tasks tend to be fine grain Significant performance overhead
Comparison to OpenMP

Speculative parallelization can help in parallelizing programs that are difficult to analyze
That comes at the cost of executing instructions which might not be useful◦Power and Performance overhead
Our approach is a non-speculative way of parallelization
Related Work

Traditional parallelization techniques cannot efficiently parallelize pointer intensive codes
Combining programmer’s knowledge and application runtime information we can exploit parallelism in such codes
The idea presented is not limited to trees and linked lists and can be extended to other dynamic structures like graphs
Conclusion

Questions ?
Thanks You