principal component analysis (pca) · pdf file• in pca we assume that x has zero mean ......
TRANSCRIPT

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 1
Principal Component AnalysisPrincipal Component Analysis(PCA)(PCA)
• PCA is an unsupervised signal processing method. There are two views of what PCA does:• it finds projections of the data with maximum
variance;• it does compression of the data with minimum mean
squared error.• PCA can be achieved by certain types of neural
networks. Could the brain do something similar?• Whitening is a related technique that transforms the
random vector such that its components are uncorrelated and have unit variance
Thanks to Tim Marks for some slides!

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 2
Maximum Variance ProjectionMaximum Variance Projection• Consider a random vector x with arbitrary joint pdf• in PCA we assume that x has zero mean• we can always achieve this by constructing x’=x-µ
• Scatter plot and projection y onto a “weight” vector w
• Motivating question: y is a scalar random variable that depends on w; for which w is the variance of y maximal?
( )αcos1
××=
== ∑=
xw
xwyn
iii
Txww
xy

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 3
Example:• consider projecting x onto the red wr and blue wb who
happen to lie along the coordinate axes in this case:
∑
∑
=
=
==
==
n
iibi
Tbb
n
iiri
Trr
xwy
xwy
1
1
xw
xw
• clearly, the projection onto wb has the higher variance, but is there a w for which it’s even higher?

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 4
• First, what about the mean (expected value) of y?
• so we have:
since x has zero mean, meaning that E(xi) = 0 for all i.
• This implies that the variance of y is just:
• Note that this gets arbitrarily big if w gets longer and longer, so from now on we restrict w to have length 1, i.e. (wTw)1/2=1
∑=
==n
iii
T xwy1
xw
0)()()()(111
==== ∑∑∑===
n
iii
n
iii
n
iii xEwxwExwEyE
( )( )( ) ( )222 )()()var( xwTEyEyEyEy ==−=

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 5
• continuing with some linear algebra tricks:
where Cx is the correlation matrix (or covariance matrix) of x.
• We are looking for the vector w that maximizes this expression
• Linear algebra tells us that the desired vector w is the eigenvector of Cx corresponding to the largest eigenvalue
( )( )( )( ) ( )wCw
wxxwwxxwxw
xT
TTTT
T
EEEyEy
=
==
== 22 )()()var(

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 6
Reminder: Eigenvectors and Eigenvalues• let A be an nxn (square) matrix. The n-component vector
v is an eigenvector of A with the eigenvalue λ if:
i.e. multiplying v by A only changes the length by a factor λ but not the orientation.
Example:• for the scaled identity matrix is every vector is an
eigenvector with identical eigenvalue s
vAv λ=
vv ss
s=
L
MOM
L
0
0

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 7
Notes:• if v is an eigenvector of a matrix A then any scaled
version of v is an Eigenvector of A, too
• if A is a correlation (or covariance) matrix, then all the eigenvalues are real and nonnegative; the eigenvectors can be chosen to be mutually orthonormal:
(δik is the so-called Kronecker delta)
• also, if A is a correlation (or covariance) matrix, then A is positive semidefinite:
0vAvv ≠∀≥ 0T
≠=
==kiki
ikkTi :0
:1δvv

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 8
The PCA SolutionThe PCA Solution• The desired direction of maximum variance is the
direction of the unit-length eigenvector v1 of Cx with the largest eigenvalue
• Next, we want to find the direction whose projection has the maximum variance among all directions perpendicular to the first eigenvector v1. The solution to this is the unit-length eigenvector v2 of Cx with the 2nd
highest eigenvalue.• In general, the k-th direction whose projection has the
maximum variance among all directions perpendicular to the first k-1 directions is given by the k-th unit-length eigenvector of Cx. The eigenvectors are ordered such that:
• We say the k-th principal component of x is given by:
xvTkky =
nn λλλλ ≥≥≥ −121 L

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 9
What are the variances of the PCA projetions?
• From above we have:
• Now utilize that w is the k-th eigenvector of Cx:
where in the last step we have exploited that vk has unit length. Thus, in words, the variance of the k-th principal component is simply the eigenvalue of the k-theigenvector of the correlation/covariance matrix.
( ) wCwxw xTTEy == 2)()var(
( )( ) kk
Tkkkk
Tk
kxTkkx
Tky
λλλ ===
==
vvvv
vCvvCv)var(

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 10
To summarize:• The eigenvectors v1, v2, …, vn of the covariance matrix have
corresponding eigenvalues λ1 ≥ λ2 ≥ … ≥ λn. They can be found with standard algorithms.
• λ1 is the variance of the projection in the v1 direction, λ2 is the variance of the projection in the v2 direction, and so on.
• The largest eigenvalue λ1 corresponds to the principal component with the greatest variance, the next largest eigenvalue corresponds to the principal component with the next greatest variance, etc.
• So, which eigenvector (green or red) corresponds to the smaller eigenvalue in this example?

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 11
PCA for multinomial GaussianPCA for multinomial Gaussian
• We can think of the joint pdf of the multinomial Gaussian in terms of the (hyper-) ellipsoidal (hyper-) surfaces of constant values of the pdf.
• In this setting, principle component analysis (PCA) finds the directions of the axes of the ellipsoid.
• There are two ways to think about what PCA does next:• Projects every point perpendicularly onto the axes of
the ellipsoid.• Rotates the ellipsoid so its axes are parallel to the
coordinate axes, and translates the ellipsoid so its center is at the origin.

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 12
Two views of what PCA doesTwo views of what PCA does
x
yPC1
PC2
c 2 c 1
a) projects every point x onto the axes of the ellipsoid to give projection c.
b) rotates space so that the ellipsoid lines up with the coordinate axes, and translates space so the ellipsoid’s center is at the origin.
→
2
1
cc
yx
cx

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 13
Transformation matrix for PCATransformation matrix for PCA• Let V be the matrix whose columns are the eigenvectors
of the covariance matrix, Σ.• Since the eigenvectors vi are all normalized to have length
1 and are mutually orthogonal, the matrix V is orthonormal(VV T = I), i.e. it is a rotation matrix
• the inverse rotation transformation is given by the transpose V T of matrix V
→←
→←→←
n
V
v
vv1
M2
T
↓↓↓
↑↑↑
n
V
vvv1 L2

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 14
Transformation matrix for PCATransformation matrix for PCA• PCA transforms the point x (original coordinates) into the
point c (new coordinates) by subtracting the mean from x(z = x – m) and multiplying the result by V T
• this is a rotation because V T is an orthonormal matrix• this is a projection of z onto PC axes, because v1 • z is
projection of z onto PC1 axis, v2 • z is projection onto PC2 axis, etc.
⋅
⋅⋅
=
↓
↑
→←
→←→←
zv
zvzv
z
v
vv
cz
11
nn
V
MM22
T

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 15
• PCA expresses the mean-subtracted point, z = x – m, as a weighted sum of the eigenvectors vi . To see this, start with:
• multiply both sides of the equation from the left by V:VV Tz = Vc | exploit that V is orthonormal
z = Vc | i.e. we can easily reconstruct z from c
=
↓
↑
→←
→←→←
DD c
cc
V
MM2
1
2
T
z
v
vv
cz1
↓
↑++
↓
↑+
↓
↑=
↓↓↓
↑↑↑=
↓
↑
=
nn
n
n ccc
c
cc
V
vvvvvvz
cz
11 LM
L 2212
1
2

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 16
PCA for data compressionPCA for data compression
x
yPC1
PC2
c 2 c 1
height
weight
What if you wanted to transmit someone’s height and weight, but you could only give a single number?
• Could give only height, x— = (uncertainty when height is known)
• Could give only weight, y— = (uncertainty when weight is known)
• Could give only c1, the value of first PC— = (uncertainty when first PC is known)
• Giving the first PC minimizes the squared error of the result.
To compress n-dimensional data into k dimensions, order the principal components in order of largest-to-smallest eigenvalue, and only save the first k components.

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 17
• Equivalent view: To compress n-dimensional data into k<ndimensions, use only the first k eigenvectors.
• PCA approximates the mean-subtracted point, z = x – m, as a weighted sum of only the first k eigenvectors:
• transforms the point x into the point c by subtracting the mean: z = x – m and multiplying the result by V T
=
↓
↑
→←
→←
→←→←
n
k
n
k
c
c
cc
V
M
M
M
M
2
1
2
T
z
v
v
vv
cz
1
↓
↑++
↓
↑+
↓
↑=
↓↓↓
↑↑↑=
↓
↑
=
kk
k
k ccc
c
cc
V
vvvvvvz
cz
11 LM
L 2212
1
2
=
↓
↑
→←
→←→←
MM
kk c
cc
V
2
1
2
T
z
v
vv
cz
1

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 18
PCA vs. Discrimination• variance maximization or compression are different from
discrimination!• consider this data coming stemming from two classes?• which direction has max. variance, which discriminates
between the two clusters?
PCA vs. Discrimination

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 19
Application: PCA on face imagesApplication: PCA on face images
• 120 × 100 pixel grayscale 2D images of faces. Each image is considered to be a single point in face space (a single sample from a random vector):
• How many dimensions is the vector x ?n = 120 • 100 = 12000
• Each dimension (each pixel) can take values between 0 and 255 (8 bit grey scale images).
• You can easily visualize points in this 12000 dimensional space!
↓
↑x

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 20
The original images (12 out of 97)The original images (12 out of 97)

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 21
The mean faceThe mean face

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 22
• Let x1, x2, …, xp be the p sample images (n-dimensional).• Find the mean image, m, and subtract it from each
image: zi = xi – m• Let A be the matrix whose columns are the
mean-subtracted sample images.
• Estimate the covariance matrix:
matrix2 pnA p ×
↓↓↓
↑↑↑= zzz1 L
T
11)Cov( AAp
A−
==Σ
What are the dimensions of Σ ?

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 23
The transpose trickThe transpose trickThe eigenvectors of Σ are the principal component directions.Problem:
• Σ is a nxn (12000×12000) matrix. It’s too big for us to find its eigenvectors numerically. In addition, only the first p eigenvalues are useful; the rest will all be zero, because we only have p samples.
Solution: Use the following trick. • Eigenvectors of Σ are eigenvectors of AAT; but instead
of eigenvectors of AAT, the eigenvectors of ATA are easy to find
What are the dimensions of ATA ? It’s a p×p matrix: it’s easy to find eigenvectors since p is relatively small.

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 24
• We want the eigenvectors of AAT, but instead we calculated the eigenvectors of ATA. Now what?
• Let vi be an eigenvector of ATA, whose eigenvalue is λi
(ATA)vi = ? λiviA (ATAvi) = A(λivi)AAT (Avi) = λi (Avi)
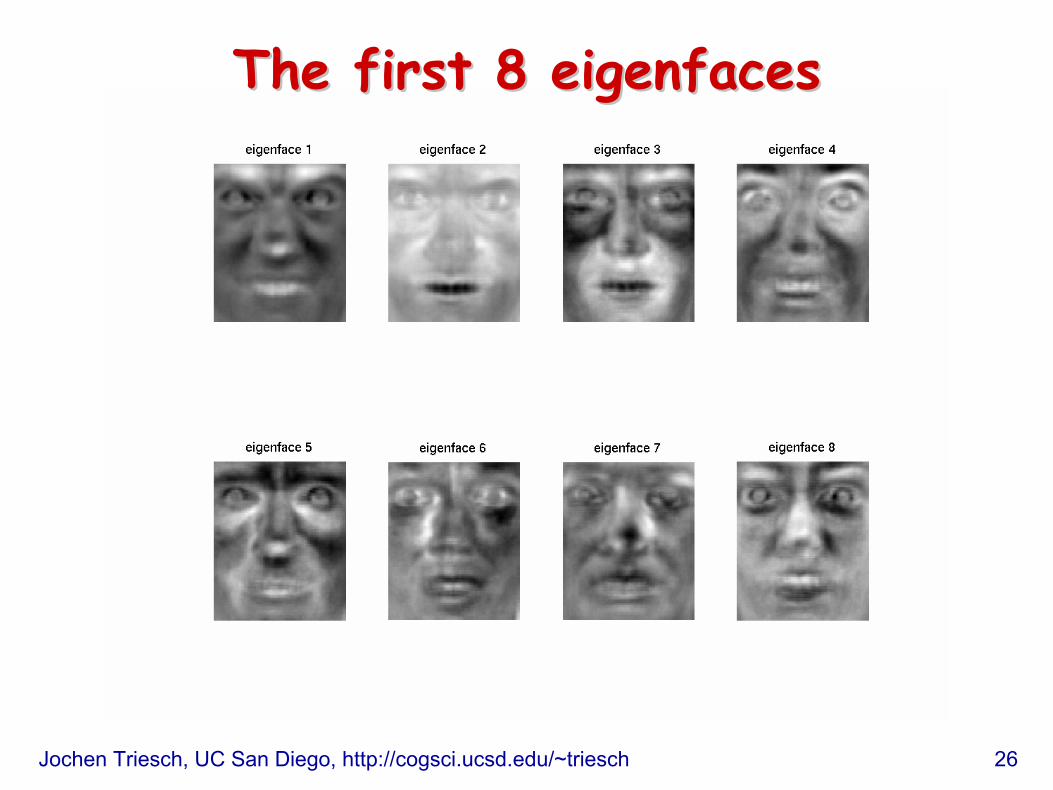
• Thus if vi is an eigenvector of ATA , Avi is an eigenvector of AAT , with the same eigenvalue.Av1 , Av2 , … , Avn are the eigenvectors of Σ. u1 = Av1 , u2 = Av2 , …, un = Avn are called eigenfaces.

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 25
EigenfacesEigenfaces
• Eigenfaces (the principal component directions of face space) provide a low-dimensional representation of any face, which can be used for:• Face image compression and reconstruction• Face recognition• Facial expression recognition
Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 26
The first 8 The first 8 eigenfaceseigenfaces

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 27
PCA for lowPCA for low--dimensional face dimensional face representationrepresentation
↓
↑++
↓
↑+
↓
↑=
↓↓↓
↑↑↑=
↓
↑
=
kk
k
k ccc
c
cc
U
uuuuuuz
cz
11 LM
L 2212
1
2
=
↓
↑
→←
→←→←
MM
kk c
cc
U
2
1
2
T
z
u
uu
cz
1
• To approximate a face using only k dimensions, order the eigenfaces in order of largest-to-smallest eigenvalue, and only use the first k eigenfaces.
• PCA approximates a mean-subtracted face, z = x – m, as a weighted sum of the first k eigenfaces:

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 28
↓
↑+
↓
↑++
↓
↑+
↓
↑=
↓
↑+
↓↓↓
↑↑↑=
+=
+=
muuu
muuu
mcmz
1
1
kk
k
k
ccc
c
cc
Ux
L
ML
221
2
1
2
• To approximate the actual face we have to add the mean face m to the reconstruction of z:
• The reconstructed face is simply the mean face with some fraction of each eigenface added to it

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 29
The mean faceThe mean face

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 30
Approximating a face using the Approximating a face using the first 10 first 10 eigenfaceseigenfaces

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 31
Approximating a face using the Approximating a face using the first 20 first 20 eigenfaceseigenfaces

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 32
Approximating a face using the Approximating a face using the first 40 first 40 eigenfaceseigenfaces

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 33
Approximating a face using all Approximating a face using all 97 97 eigenfaceseigenfaces

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 34
Notes:
• not surprisingly, the approximation of the reconstructed faces gets better when more eigenfaces are used
• In the extreme case of using no eigenface at all, the reconstruction of any face image is just the average face
• In the other extreme of using all 97 eigenfaces, the reconstruction is exact, if the image was in the original training set of 97 images. For a new face image, however, its reconstruction based on the 97 eigenfaceswill only approximately match the original.
• What regularities does each eigenface capture? See movie.

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 35
Eigenfaces in 3DEigenfaces in 3D
• Blanz and Vetter (SIGGRAPH ’99). The video can be found at:
http://graphics.informatik.uni-freiburg.de/Sigg99.html

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 36
Whitening TransformWhitening Transform• zero-mean random vector x is white if its elements are
uncorrelated and have unit variance:
• this directly implies that the covariance matrix is the identity matrix:
• Problem statement: in whitening we are trying to find a linear transformation W such that y=Wx is white
• Solution: if V is the matrix of Eigenvectors of Cx, and D is the diagonal matrix of Eigenvalues of Cx then the whitening transform is given by:
( ) ijji xxE δ=
( ) IxxCx == TE
),,(diag where, 21
21
12
12
1 −−−−== n
T λλ LDVDW

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 37
• to see that y is white:
• where in the 5th step we utilized that Cx = VDVT, which holds for any symmetric and positive definite matrix Cx
• Note: in the Gaussian case, the hyper-ellipsoids describing the contours of equal pdf become spheres; we say we are sphering the data.
• Note: the solution W is not unique. Any matrix UW, where U is an orthogonal matrix is also a solution
( ) ( )( )( ) ( )IVDVDVVDWWVDV
WWCWxxWWxWxyyC
===
====−− 2
12
1 TTTT
Tx
TTTTy EEE
xVDWxy T21−==

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 38
Whitening example:
-2.5 -2 -1.5 -1 -0.5 0 0.5 1 1.5 2 2.5
-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
after whitening-1.5 -1 -0.5 0 0.5 1 1.5
-1
-0.5
0
0.5
1
before whitening
Sigma_before =
0.4365 0.2439
0.2439 0.3283
Sigma_after =
0.9879 -0.0069
-0.0069 0.9334

Jochen Triesch, UC San Diego, http://cogsci.ucsd.edu/~triesch 39
Matlab code for example: (file: whitening.m)
% whitening demo
% generate data and plot itsamples = 1000;x = unifrnd(-1, 1, [2 samples]);T = [1 0.6; 0.2 1];x = T*x;x = x - repmat(mean(x,2),1,samples);figure(1)scatter(x(1,:), x(2,:), 'x');axis equal
% apply whitening transformSigma_x = cov(x')[V D] = eig(Sigma);W = diag(1./sqrt(diag(D)))*V';y = W*x;
% plot resultfigure(2)scatter(y(1,:), y(2,:), 'x');axis equalSigma_y= cov(y')