programming model for network processing on fpgas eric keller october 8, 2004 m.s. thesis defense
TRANSCRIPT

Programming Model for Network Processing on FPGAs
Eric Keller October 8, 2004M.S. Thesis Defense

2
Abstract
• Programming model for implementing network processing applications on an FPGA
• Present an API to higher level tools – Programming Language: Presents an abstraction in
terms of resources more suitable to the networking domain
– Compiler: Generate hardware from this description
• Demonstrate through four applications– Aurora to GigE Bridge, RPC, IP Router, NAT

3
Outline of Talk
• Background• Design Flow• User Interface• Compilation to Hardware• High Level Tools• Experiments/Results• Conclusions

4
Outline of Talk
• Background• Design Flow• User Interface• Compilation to Hardware• High Level Tools• Experiments/Results• Conclusions

5
Tools for FPGAs
• Hardware Description Languages– Verilog, VHDL
• Structural High-Level Languages– JHDL, JBits
• Behavioral High-Level Languages– Handel-C, Forge
• Domain Specific Languages– Cliff, Snort, Ponder

6
Cliff
• Maps Click to Xilinx FPGAs• Click is a domain specific language
for Networking– Modular router on Linux– Elements of common operations
• e.g. Decrement TTL
• Elements written in Verilog• Script to put system together
Lookup
Queue
Simple op
Input
Output

7
Networking on FPGAs
• Routing and Switching– MIR, IP Lookup, Crossbar Switch
• Protocol Boosters– Error coding, encryption, compression
• Security– Virus Scanning, Firewall
• Web Server– TCP/IP in Hardware– 50-300x speedup over Sun/Intel based workstations

8
Outline of Talk
• Background• Design Flow• User Interface• Compilation to Hardware• High Level Tools• Experiments/Results• Conclusions

9
Motivation
• Goal: Create a design environment that allows networking experts to use FPGAs
• Several point solutions have shown FPGAs to be a good solution
• Domain specific languages – There is not a standard high-level tool
• Use MIR as a starting framework– Collaborating threads processing a message– Flexible architecture for memory and communication

10
Design API
• Present an API to higher level tools – No leading high-level design entry for networking domain
• Presents an abstraction in terms of resources suitable to the networking domain– e.g. threads
• Allow specification of architecture as well as functionality• Generate hardware from this description
– Generate VHDL– rely on existing back-end tools for mapping to FPGA
• Present an intermediate textual format– XML

11
Design Hierarchy
High Level Tools
Programming Interface
Platform FPGAs
Teja Click Novalit
. . .
soft architecture- mapping
Back-end tools
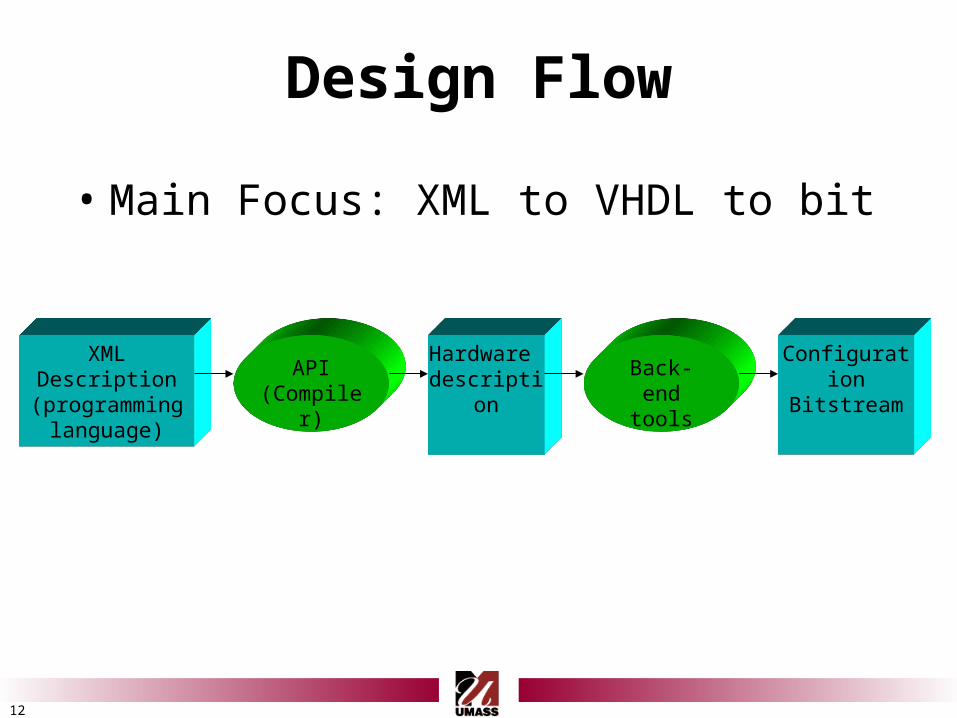
12
Design Flow
• Main Focus: XML to VHDL to bit
XMLDescription
(programming language)
API(Compiler)
Hardware description Back-end
tools
Configuration Bitstream

13
Outline of Talk
• Background• Design Flow• User Interface• Compilation to Hardware• High Level Tools• Experiments/Results• Conclusions
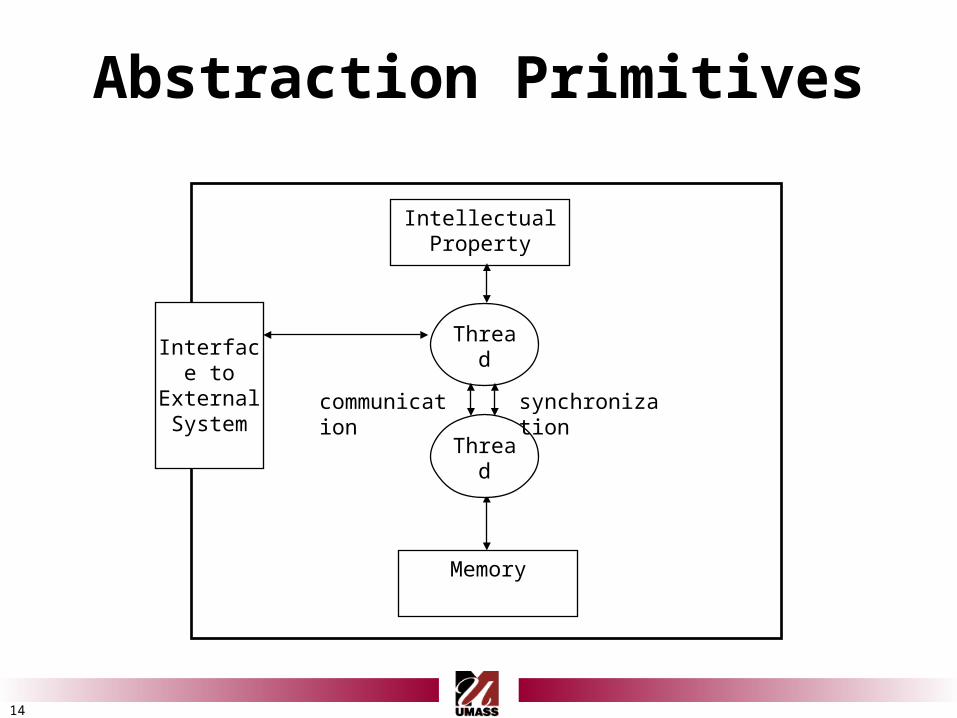
14
Abstraction Primitives
Interface to External System
Intellectual Property
Memory
Thread
Thread
communication synchronization

15
Threads
• Micro-engines with instruction level parallelism– Instruction set and conditionals used to program– User defined variables
• Implemented as custom hardware– Not a microprocessor with fetch, decode, execute
• Synchronization– Activate, Deactivate
• Communication– lightweight, channels

16
Intellectual Property
• Allow for users to make use of pre-designed intellectual property (also called cores)
• Not all algorithms are best expressed as a finite state machine– e.g. encryption, compression
• User must:– define the interface– instantiate using an “include” type statement– associate with a thread

17
Interfaces
• Perimeter of the defined system– System can be whole FPGA or part of larger design
• Exists as pre-defined netlist– Gigabit Ethernet, Aurora
• Interface includes:– Grouping of signals into ports– Extra functionality
• e.g. perform framing and error detection– Protocol to get the message
• Threads interact with the interface
• Instantiate involves an “include” type statement

18
Memory
• Provide buffering of messages, tables for lookup, storage of state
• Parameterizable– Selection of different memories
• exists as pre-defined netlist (…for now)• each possibly being parameterizable
• Instantiate through “include” type statement• Associate a memory port with a thread

19
Memory (cont’d)
• FIFO• PutGet
– Queue of objects, commit mechanism
• SharedMemory– Single memory shared by multiple accessors– locking mechanism via BRAMs “READ_FIRST”
• DPMem– Multiple memories shared by multiple accessors– Allocation mechanism

20
Outline of Talk
• Background• Design Flow• User Interface• Compilation to Hardware• High Level Tools• Experiments/Results• Conclusions

21
Hardware Generation
• Process of mapping between system resources to the hardware
• Generate VHDL– One module per thread– Top level module hooking all components together– Memories, interfaces, channels exist as predefined netlists
• Rely on back-end tools to create bitstream

22
Top Level
entity SYSTEM isport ( -- interface)end SYSTEM;architecture struct of SYSTEM is
-- signals
begin
-- synchronization logic
-- instantiate each component -- (interfaces, memories, threads, externally defined IP, channels)
end struct;

23
Clocks
• Interfaces determine clock domains
I/FX A
B
C
D
Port A Port B
memory
F
G
HEI/FY
Clock Domain 1 Clock Domain 2

24
Threadentity THREAD isport ( -- interface)end THREAD;architecture behavioral of THREAD is
-- signals
begin
-- control logic
-- combinatorial process
-- synchronous process
-- special circuitry for memory reads and channel gets
end behavioral;

25
Special Case Circuitry
• Memory– READ(var, address)– User wants to work with var, not the memory signals– Need extra circuitry to enable this
• Channels– CHAN_GET(var, address)
• Extra conditional testing to see when address matches– START(thread, offset)
• Extra circuitry to align the data• e.g. Ethernet header is 14 bytes

26
Outline of Talk
• Background• Design Flow• User Interface• Compilation to Hardware• High Level Tools• Experiments/Results• Conclusions

27
Click• Click is a language for creating modular software routers
– CLIFF is a tool that will map to FPGAs– Using XML instead
• Create a base system– each element is a thread– each thread connects to one port of a DPMem– each thread can have state storage through SharedMemory memory
element
• Series of optimizations– some pre-base system, some post-base system

28
Click (cont’d)
Clickgraph
Sub-graphmatch and
replace.clk Move
elements.clk
SplitPaths
.clk
Create base
System
RunElementsin parallel
MergeElements
Lib. Ofelements(XML)
system.xml

29
Teja• Teja is a development environment for NPUs• SW Lib - define constructs
– Events, Data Structures, Components (state machine)
• SW Arch - instantiate constructs• HW Arch - define the hardware resources
– import for fixed defined (like NPUs)– create new one for FPGA target
• HW Mapping– map constructs from SW arch to resources in HW Arch

30
Teja (cont’d)
State MachineGUI (C code)
Software Arch. GUI
compile
Data Struct.Library (XML)
ThreadLibrary (XML)
SoftwareArch file(internal format)
(next slide)

31
Teja (cont’d)
Hardware Arch.GUI
Hardware Mapping GUI
Map
(prev slide)
Thread, DPMem, Aurora, etc.
HardwareArch file(internal format)
Insert libcode
System.xml

32
Outline of Talk
• Background• Design Flow• User Interface• Compilation to Hardware• High Level Tools• Experiments/Results• Conclusions

33
Gigabit Ethernet to Aurora Bridge
• Two flows that will convert a frame from one protocol to the other
• Ethernet – broadcast protocol (needs addressing)– Coarse grain flow control
• Aurora– Xilinx proprietary protocol for point to point
communication over multi-gigabit transceivers– Fine grain flow control

34
Bridge Architecture
Aurora Aurora RX thread
Aurora TX thread
TX
RX
GMAC
RX
TX
GMACTX thread
GMACRX thread
Put16Get8 Memory
Put8Get16 Memory

35
Bridge Test Setup

36
Bridge Results
Device LUT FF BRAM Freq. Throughput Latency(ns)
XML XC2VP7-6 2,159 1,492 2 152.8 1 Gbps 40-48VHDL XC2VP7-6 2,091 1,494 2 144.9 1 Gbps 40-48
• Compared result to VHDL code from XAPP777– latency = time from last bit received to first bit sent

37
Remote Procedure Call
• Mechanism to invoke a procedure on a remote computer– used in NFS– Almost exclusive to workstations
• Message with the parameters to the function as well as information about the function being called
• Implement an RPC server with the functions add(x,y) and mult(x,y)

38
RPC Architecture
RX TXGMAC
ADD
broadcastthread
MULT
ETHthread
IPthread
UDPthread
RPCthread
TXthread
RXthread
Put/GetMemories

39
RPC Test Setup
Workstation to Workstation Workstation to FPGA

40
FPGA vs Workstation• Perform several RPC calls to each from client
workstation• Each server system connected directly to the
client through an optical gigabit Ethernet cable
Device LUT FF BRAM Freq. Throughput ResponseTime
XML XC2VP7-6 4,345 2,084 5 127 /31.5MHz
1 Gbps 2.16 us
LinuxStack
Pentium 4(512 MBRAM)
2 GHz 1 Gbps 18.80 us

41
Click Based Applications
IPFilter DropIPaddrrewriter
ToDevice
FromDevice
queue
FromDevice
queueTo
Device
FromDevice
FromDevice
CheckIPHeader
Lookup
DropBrodcasts
DecIPTTL ToDevice
DropBrodcasts
DecIPTTL ToDevice
NAT
IP Router- 2 Port (shown)- 16 Port (not shown)

42
Click ResultsDesign Device LUT FF BRAM Freq.
MHzThru.
(Gbps)Lat.(ns)
XML IP Router2 port
XC2VP7-6 4,052 2,402 8 138.7 1.000 8
CLIFF (org 1) IP Router2 port
XC2VP7-6 7,385 9,063 2 144.3 1.000 224 to248
Click IP Router2 port
Pentium III N/A N/A N/A 700.0 0.228 2500
Click IP Router2 port
AMDAthlon-MP
N/A N/A N/A 1600.0 0.379 NotReported
XML IP Router16 port
XC2VP70-7 50,201 25,111 57 77.4 0.619 25.8 to232.2
Hand Coded inIXP-C
IP Router16 port
IXP1200 N/A N/A N/A 232.0 0.088 NotReported
XML NAT XC2VP7-6 3,970 2,369 4 139.9 1.000 8CLIFF NAT XC2VP7-6 7,304 7,650 2 144.1 1.000 160

43
Outline of Talk
• Background• Design Flow• User Interface• Compilation to Hardware• High Level Tools• Experiments/Results• Conclusions

44
Conclusions
• Presented a programming model for mapping networking applications to FPGAs– An API of abstractions (user interface)– Generate VHDL from the description (compiler)
• Summary– Domain specific languages as a target design entry – FPGAs as a target for implementation – Platform based on threads and flexible memory architecture
• MIR as a starting framework
• Demonstrate efficient mappings/designs through four application examples