pseudo-supervised clustering for text documents marco maggini, leonardo rigutini, marco turchi...
TRANSCRIPT

Pseudo-supervised Clustering for Pseudo-supervised Clustering for Text DocumentsText Documents
Marco Maggini, Leonardo Rigutini, Marco Turchi
Dipartimento di Ingegneria dell’InformazioneUniversità degli Studi di Siena
Siena - Italy

WI 2004Pseudo-Supervised Clustering for
Text Documents 2
Outline
Document representation
Pseudo-Supervised Clustering
Evaluation of cluster quality
Experimental results
Conclusions

WI 2004Pseudo-Supervised Clustering for
Text Documents 3
Vector Space Model Representation with a term-weight vector in the
vocabulary space
di = [ wi,1, wi,2 , wi,3 , … , wi,v]’
A commonly used weight scheme is TF-IDF
Documents are compared using the cosine correlation
wi,k f (tk ,di)
maxtd i f (t,di)log
|D |
f (tk ,D)

WI 2004Pseudo-Supervised Clustering for
Text Documents 4
Vector Space Model: Limitations
High dimensionality Each term is an independent component in the
document representation the semantic relationships between words are not
considered Many irrelevant features
feature selection may be difficult especially for unsupervised tasks
Vectors are very sparse

WI 2004Pseudo-Supervised Clustering for
Text Documents 5
Vector Space Model: Projection
Projection to a lower dimensional space
Definition of a basis for the projection
Use of statistical properties of the word-by-document matrix on a given corpus
SVD decomposition (Latent Semantic Analysis) Concept Matrix Decomposition
[Dhillon & Modha, Machine Learning,2001]
Data partition + SVD/CMD for each partition (Partially) supervised partitioning

WI 2004Pseudo-Supervised Clustering for
Text Documents 6
Singular Value Decomposition
SVD of the |V|x|D| word-by-document matrix (|D|>|V|)
The orthonormal matrix U represents a basis for document representation
The k columns corresponding to the largest singular values in ∑ form the basis for the projected space
UkTXZ k
X UV T

WI 2004Pseudo-Supervised Clustering for
Text Documents 7
Concept Matrix Decomposition-1
Use a basis which describes a set of k concepts represented by k reference term distributions
The projection into the concept space is obtained by solving
2* minargFZ
ZCXZk
Ck c1 c2 ..ck wk

WI 2004Pseudo-Supervised Clustering for
Text Documents 8
Concept Matrix Decomposition-2
The k concept vectors ci can be obtained as the normalized centroids of a partition of the document collection D
D = {D1 , D2 , …., Dk}
CMD exploits the prototypes of certain homogenous sets of documents

WI 2004Pseudo-Supervised Clustering for
Text Documents 9
Pseudo-Supervised Clustering
Selection of the projection basis using a supervised partition of the document set
Determine a partition of a reference subset T of the document corpus
Select a basis Bi for each set i in the partition using SVD/CMD
Project the documents using the basis B=Ui Bi
Apply a clustering algorithm to the document corpus represented using the basis B
Eventually iterate refining the choice of the reference subset

WI 2004Pseudo-Supervised Clustering for
Text Documents 10
Pseudo SVD-1
The SVD is computed for the documents in each subset i in
The basis Bi is composed of the vi left singular vectors Ui
The new basis B is represented by the matrix
*21 kUUUS

WI 2004Pseudo-Supervised Clustering for
Text Documents 11
Pseudo SVD-2
The Pseudo-SVD representation of the word-by-document matrix of the corpus is the matrix Z* computed as
The projection requires the solution of a least mean square problem
2minarg*
FZSZXZ

WI 2004Pseudo-Supervised Clustering for
Text Documents 12
Pseudo CMD-1 An orthogonal basis is computed as follows
Compute the centroid (concept vector) of each subset i in
Compute the word cluster for each concept vector A word belongs to the word cluster Wi of subset i if its
weight in the concept vector ci is greater then its weights in the other concept vectors
Each word is assigned to only one subset i
Represent the documents in i using only the features in the corresponding word cluster Wi
Compute the partition of i into vi clusters and compute the word vectors of each centroid

WI 2004Pseudo-Supervised Clustering for
Text Documents 13
Pseudo CMD-2
Each partition i is represented by a set of vi directions obtained from the concept vectors c’ij
These vectors are orthogonal since each word belongs to only one cij
Document projection
'*
'1*k
'1v
'11 *1
cccckvk
S
ZXST

WI 2004Pseudo-Supervised Clustering for
Text Documents 14
Evaluation of cluster quality
Experiments on pre-classified documents Measure of the dispersion of the classes
among the clusters Contingency table: the matrix H, whose element
h(Ai,Cj) is the number of items with label Ai assigned to the cluster Cj.
Accuracy “classification using majority voting”
Conditional Entropy “confusion” in each cluster
Human Evaluation

WI 2004Pseudo-Supervised Clustering for
Text Documents 15
Experimental results-1
Data Preparation Parsing of PDF file Term filtering using the Aspell-0.50.4.1 library Removal of the stop words Application of the Luhn Reduction to remove
common words
WI 2004Pseudo-Supervised Clustering for
Text Documents 16
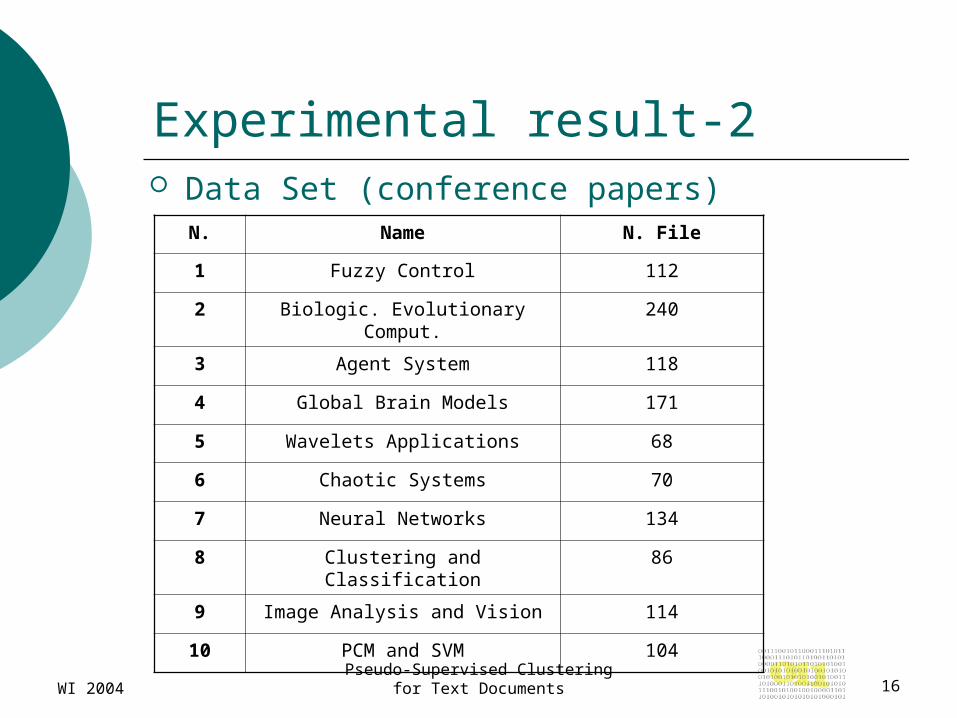
Experimental result-2 Data Set (conference papers)
N. Name N. File
1 Fuzzy Control 112
2 Biologic. Evolutionary Comput. 240
3 Agent System 118
4 Global Brain Models 171
5 Wavelets Applications 68
6 Chaotic Systems 70
7 Neural Networks 134
8 Clustering and Classification 86
9 Image Analysis and Vision 114
10 PCM and SVM 104

WI 2004Pseudo-Supervised Clustering for
Text Documents 17
Experimental result-3 We applied k-means using three different
document representations: original vocabulary basis Pseudo-SVD (PSVD) Pseudo-CMD (PCMD)
Each algorithm was applied setting the number of clusters to 10
For PSVD and PCMD, we varied the number of principal components
10,7,4v
WI 2004Pseudo-Supervised Clustering for
Text Documents 18
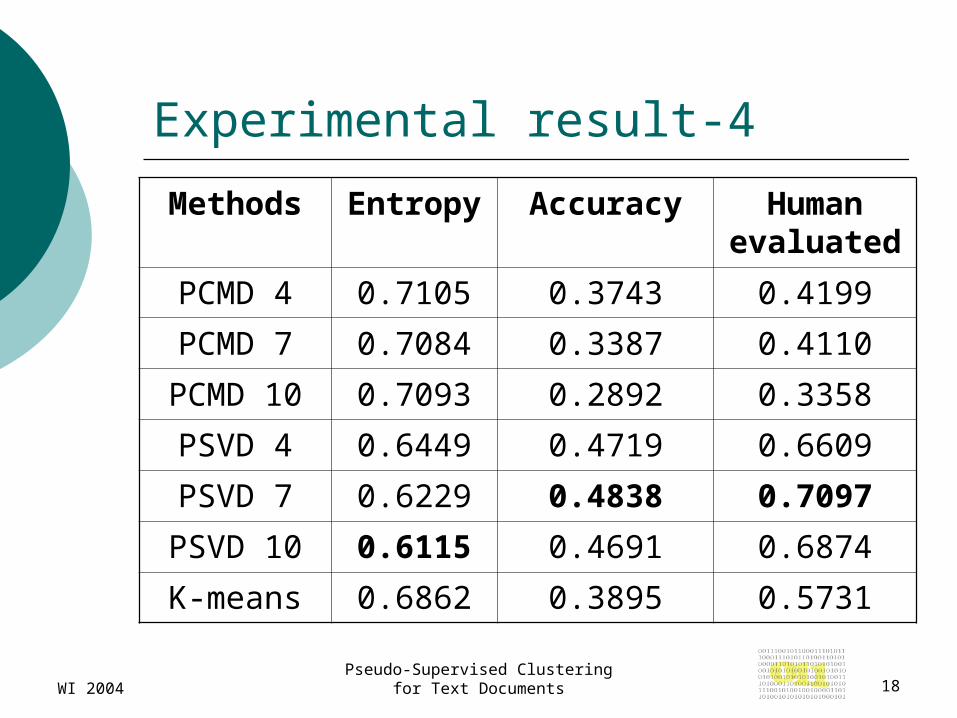
Experimental result-4
Methods Entropy Accuracy Human evaluated
PCMD 4 0.7105 0.3743 0.4199
PCMD 7 0.7084 0.3387 0.4110
PCMD 10 0.7093 0.2892 0.3358
PSVD 4 0.6449 0.4719 0.6609
PSVD 7 0.6229 0.4838 0.7097
PSVD 10 0.6115 0.4691 0.6874
K-means 0.6862 0.3895 0.5731
WI 2004Pseudo-Supervised Clustering for
Text Documents 19
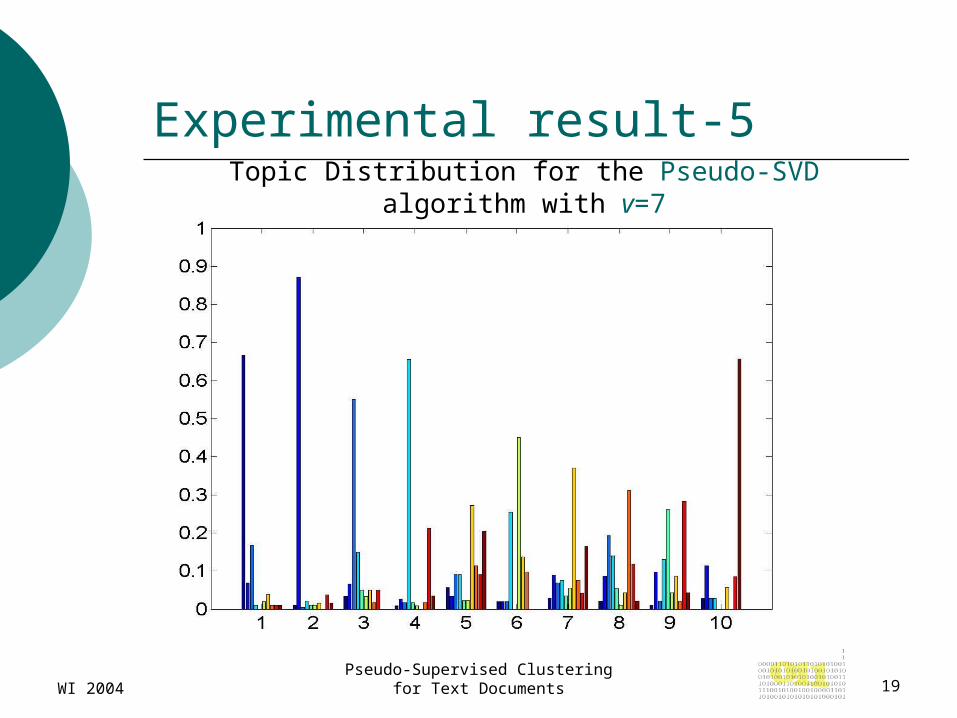
Experimental result-5Topic Distribution for the Pseudo-SVD
algorithm with v=7

WI 2004Pseudo-Supervised Clustering for
Text Documents 20
Experimental result-6
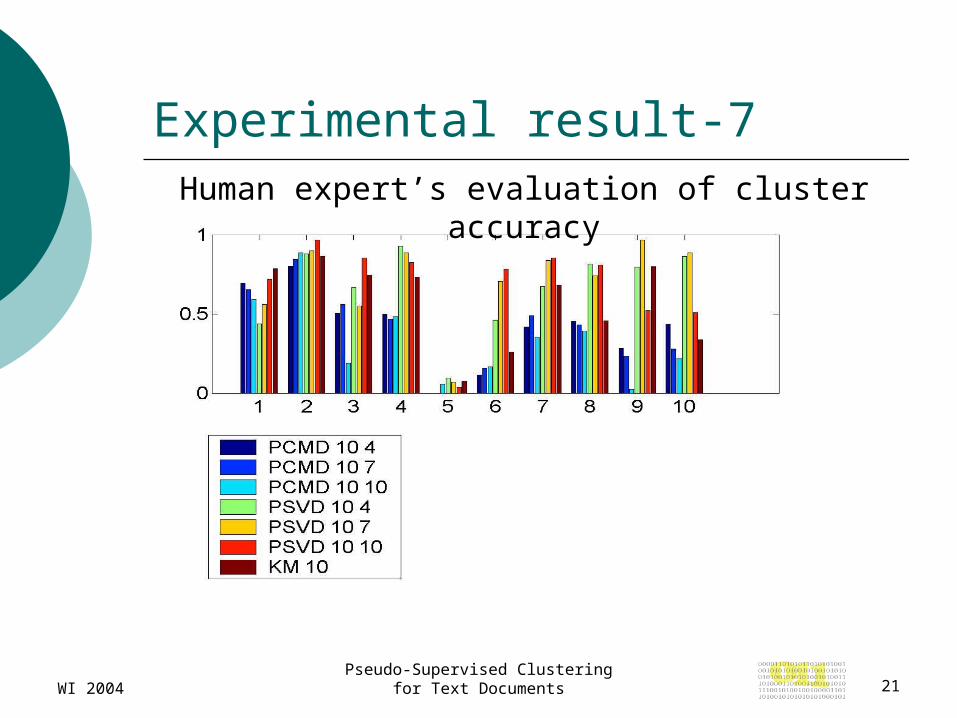
Analyzing the results: Low Accuracy High Entropy
Due to: Data set has many transversal topics (for es.
Class 5 ->Wavelets) We have evaluated the accuracy using the expert’s evaluations.
WI 2004Pseudo-Supervised Clustering for
Text Documents 21
Experimental result-7Human expert’s evaluation of cluster accuracy

WI 2004Pseudo-Supervised Clustering for
Text Documents 22
Conclusions We have presented two clustering algorithms
for text documents which use a clustering step also in definition of the basis for the document representation
We can exploit the prior knowledge of human expert about the data set and bias the feature reduction step towards a more significant representation
The results show that PSVD algorithm is able to perform better than vocabulary Tf-Idf representation and PCMD

WI 2004Pseudo-Supervised Clustering for
Text Documents 23
Thanks for your attention!!!
WI 2004Pseudo-Supervised Clustering for
Text Documents 24
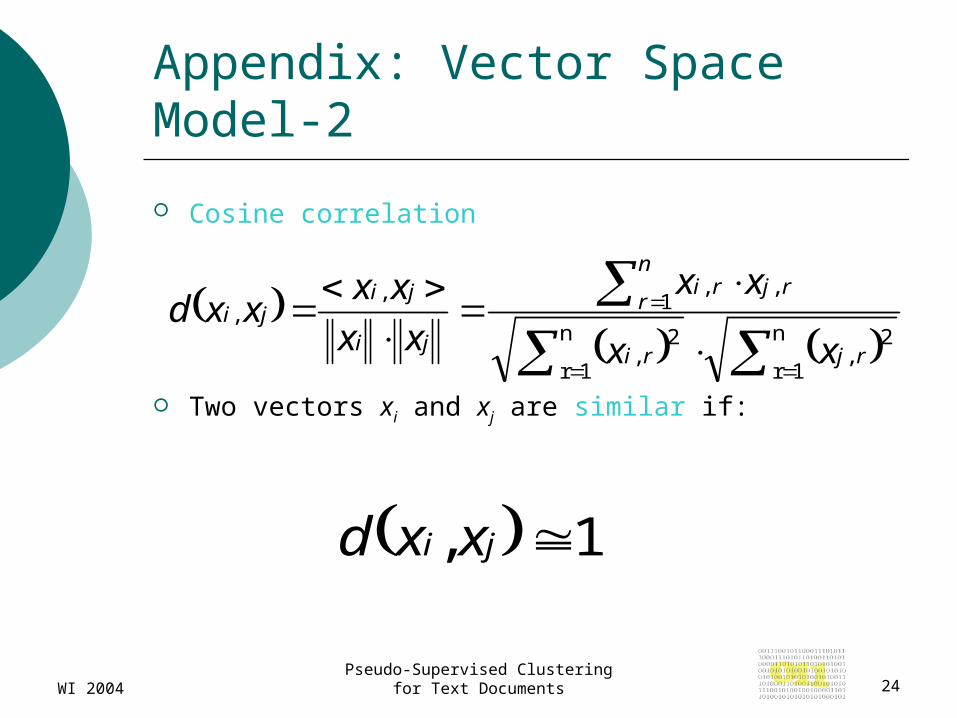
Appendix: Vector Space Model-2
Cosine correlation
Two vectors xi and xj are similar if:
n
1r
2,
n
1r
2,
1,,,
,
rjri
n
rrjri
ji
jiji
xx
xx
xx
xxxxd
1, ji xxd

WI 2004Pseudo-Supervised Clustering for
Text Documents 25
Appendix: Contingency and Confusion Matrix
If you associate the cluster Cj to the topic Am(j) for which Cj has the maximum number of documents and you rearrange the column of H such that j’=m(j), you obtain the confusion matrix Fm

WI 2004Pseudo-Supervised Clustering for
Text Documents 26
Appendix: Pseudo CMD-2
For each word-by-document matrix for cluster i, we keep only the components related to the words in the word cluster Wj
We sub-partition each new matrix to obtain more than one direction for each original partition

WI 2004Pseudo-Supervised Clustering for
Text Documents 27
Appendix: Evaluation of cluster quality-2
Accuracy
Classification Error
j
jjj
Ch
CAhAcc
,
j
k
jiji
jjCh
CAhAccErr
,1

WI 2004Pseudo-Supervised Clustering for
Text Documents 28
Evaluation of cluster quality-3
Conditional Entropy
Where
A
i
k
jjiji CAPCAPCAE
1 1|log,|
d
CAhCAP
jiji
,,
jji
jiCh
CAhCAP
,|

WI 2004Pseudo-Supervised Clustering for
Text Documents 29
Thanks for your attention!!!

Pseudo-supervised Clustering for Pseudo-supervised Clustering for Text DocumentsText Documents
Marco Maggini, Leonardo Rigutini, Marco Turchi
Dipartimento di Ingegneria dell’InformazioneUniversità degli Studi di Siena
Siena - Italy