pseudo two-dimensional shape normalization methods for handwritten chinese character recognition
TRANSCRIPT

Pattern Recognition 38 (2005) 2242–2255www.elsevier.com/locate/patcog
Pseudo two-dimensional shapenormalizationmethodsfor handwrittenChinese character recognition
Cheng-Lin Liu, Katsumi Marukawa∗Central Research Laboratory. Hitachi, Ltd., 1-280 Higashi-koigakubo, Kokubunji-shi, Tokyo 185-8601, Japan
Received 1 July 2004; received in revised form 11 April 2005; accepted 11 April 2005
Abstract
The nonlinear normalization (NLN) method based on line density equalization is popularly used in handwritten Chinesecharacter recognition. To overcome the insufficient shape restoration capability of one-dimensional NLN, a pseudo two-dimensional NLN (P2DNLN) method has been proposed and has yielded higher recognition accuracy. The P2DNLN method,however, is very computationally expensive because of the line density blurring of each row/column. In this paper, we propose anew pseudo 2D normalization method using line density projection interpolation (LDPI), which partitions the line density mapinto soft strips and generate 2D coordinate mapping function by interpolating the 1D coordinate functions that are obtained byequalizing the line density projections of these strips. The LDPI method adds little computational overhead to one-dimensionalNLN yet performs comparably well with P2DNLN. We also apply this strategy to extending other normalization methods,including line density projection fitting, centroid-boundary alignment, moment, and bi-moment methods. The latter threemethods are directly based on character image instead of line density map. Their 2D extensions provide real-time computationand high recognition accuracy, and are potentially applicable to gray-scale images and online trajectories.� 2005 Pattern Recognition Society. Published by Elsevier Ltd. All rights reserved.
Keywords:Handwritten Chinese character recognition; Pseudo 2D nonlinear normalization; Line density projection interpolation; Pseudo2D centroid-boundary alignment; Pseudo 2D moment normalization; Pseudo 2D bi-moment normalization
1. Introduction
The performance of handwritten character recognition islargely dependent on the normalization of character shapes.In addition to transforming the character image to a stan-dard size so as to give a representation of fixed dimension-ality for classification, it is hoped that the deformation ofcharacters can be restored so as to reduce the within-classshape variation. The conventional linear normalization is notsufficient to restore this kind of deformation. To improvethe recognition performance, many methods have been pro-posed for normalizing handwritten characters. The moment
∗ Corresponding author. Tel.: +81423231111;fax: +81423277746.
E-mail address:[email protected](K. Marukawa).
0031-3203/$30.00� 2005 Pattern Recognition Society. Published by Elsevier Ltd. All rights reserved.doi:10.1016/j.patcog.2005.04.019
normalization method of Casey[1] and the geometric pro-jection method of Nagy and Tuong[2] were proposed fornormalizing alphanumeric characters. For normalizing Chi-nese characters that contain multiple strokes, the nonlinearnormalization (NLN) method based on line density equal-ization is proven very efficient[3]. The line density can becomputed in various ways yet the methods of Tsukumo andTanaka[4] andYamada et al.[5] have been widely adopted.The line density-based NLN method is popularly used inhandwritten Chinese character recognition systems and hasyielded superior recognition results[6].Despite its popularity, the line density-based NLNmethod
is complicated in implementation and the normalized shapesare not smooth due to the local transformation nature. Onthe contrary, global transformation methods estimate veryfew parameters efficiently from global shape features and

C.-L. Liu, K. Marukawa / Pattern Recognition 38 (2005) 2242–2255 2243
generate smooth normalized shapes. Recent results showedthat one-dimensional moment normalization (centroid align-ment without rotation or shearing, as a simplification ofCasey’s method) performs comparably well with NLN, anda newly proposed bi-moment method, performs slightly bet-ter than the moment method[7]. Another new method thataligns both centroid and character boundary, called modi-fied centroid-boundary alignment (MCBA), also performscomparably well[8].The NLN method efficiently regulates the stroke spacing
and greatly improves the recognition accuracy of Chinesecharacters as compared to linear normalization. Some meth-ods have been proposed to overcome its insufficiency of cor-recting the imbalance of inclination, local width or heightin handwritten characters. Suzuki et al.[9] added a partialinclination correction procedure prior to normalization bypartitioning the character image both vertically and horizon-tally at the geometric center. Horiuchi et al.[10] extended theone-dimensional coordinate transformation of NLN to two-dimensional by blurring the line density functions of eachrow/column, Lin and Leou[11] combined multiple normal-ized images produced by different normalization methodsand use the genetic algorithm (GA) to optimize the weightsof combination. This method and the method of Horiuchiet al. are very computationally expensive, though they yieldhigher recognition accuracies than one-dimensional NLN.The above normalization methods estimate the transfor-
mation parameters solely from the input character image.The advantage of this approach is that each input image isnormalized only once. On the other hand, class-dependentnormalization methods select a normalized image from mul-tiple versions[12] or deform the input image once for eachclass by matching with a class-dependent template[13–15].This class of methods needs a pre-classification procedureto select a number of candidate classes such that the inputimage is matched with the templates of the candidate classesonly. The computational complexity of matching with mul-tiple candidate classes is still considerable. Moreover, thedesign or selection of template for each class is not trivial.Among the class-independent normalization meth-
ods, the pseudo two-dimensional nonlinear normalization(P2DNLN) method of Horiuchi et al.[10] has yieldedhigher recognition accuracies than one-dimensional NLN(1DNLN) but its computation is extremely expensive. Inthis paper, we propose some alternative pseudo 2D nor-malization methods that perform comparably well withP2DNLN while their computational complexity is onlyslightly higher than their 1D counterparts. Considering thatthe line density function of each row or column is notarbitrary but heavily dependent on the neighboring rowsor columns, we softly partition the rows or columns intothree strips. This partitioning is akin to low-pass filteringwith down-sampling. The horizontal or vertical projectionof line density of each strip is equalized and then the 1Dcoordinate mapping functions of the strips are interpolatedto generate 2D coordinate functions. We call this strategy
line density projection interpolation (LDPI). Since the blur-ring of line density functions is avoided, the computationalcomplexity of LDPI is significantly lower than P2DNLN.We have demonstrated in experiments that LDPI performscomparably well with P2DNLN in handwritten Chinesecharacter recognition.We have also applied the strategy of 1D coordinate
function interpolation to extending other 1D normalizationmethods, including line density projection fitting (LDPF),MCBA, moment, and bi-moment methods. The LDPFmethod transforms pixel coordinates by fitting the linedensity projection using quadratic and sine functions as theMCBA method fits pixel intensity projection. The MCBA,moment and bi-moment methods are directly based on char-acter image projections instead of line density projections.The resulting pseudo 2D methods, named pseudo 2D LDPF(P2DLDPF), pseudo 2D Centroid-boundary alignment(P2DCBA), pseudo 2D moment normalization (P2DMN),and pseudo 2D bi-moment normalization (P2DBMN),perform comparably with LDPI and P2DNLN.We evaluated the recognition performance of the pro-
posed methods on two large image databases of handwrittenChinese characters collected in Japan: ETL9B and JEITA-HP. On character shape normalization by each method,we extracted various features and classified using differentclassifiers. The results show that all the pseudo 2D normal-ization methods outperform their 1D counterparts signif-icantly. The proposed pseudo 2D normalization methodsperform comparably well with P2DNLN at very low com-putational overhead, and therefore, they enable real-timeapplications.The rest of this paper is organized as follows. Section
2 reviews the related previous works; Section 3 describesthe proposed pseudo 2D normalization method LDPI; Sec-tion 4 describes other pseudo 2D normalization methods;Section 5 presents our experimental results, and Section 6offers our concluding remarks. Since this paper involvesmany normalization methods, we provide a glossary in theAppendix.
2. Related works
We first introduce the implementation issues of char-acter image normalization, and then briefly review one-dimensional normalization methods and P2DNLN method.
2.1. Implementation of normalization
Normalization is to regulate the size, position, and shapeof character images so as to reduce the shape variation be-tween the images of same class. Generally, normalizationis performed by mapping the input character image onto astandard image plane such that all the normalized imageshave the same dimensionality. Denote the input image and

2244 C.-L. Liu, K. Marukawa / Pattern Recognition 38 (2005) 2242–2255
the normalized image byf (x, y) andg(x′, y′), respectively,normalization is implemented by coordinate mapping
x′ = x′(x, y),
y′ = y′(x, y). (1)
The mapped coordinates(x′, y′) are discretized and interpo-lated to generate the normalized imageg(x′, y′) = f (x, y).Most normalization methods use 1D coordinate mapping:
x′ = x′(x),
y′ = y′(x). (2)
Under 1D normalization, the pixels at the same row or col-umn in the input image are mapped to the same row or col-umn in the normalized image. The shape restoration capa-bility of 1D normalization is limited but the 1D coordinatemapping functions are easy to estimate.Given coordinate mapping functions (1) or (2), the nor-
malized imageg(x′, y′) can be generated by pixel valueand coordinate interpolation. In our implementation of 1Dnormalization, we map the coordinates forwardly from (bi-nary) input image to normalized image and use coordinatediscretization to generate binary normalized image whileuse pixel value interpolation to generate gray-scale normal-ized image[16]. By discretization, the mapped coordinates(x′, y′) are approximated with the closest integer numbers([x′], [y′]). The discrete coordinates(x, y) scan the pix-els of the input image and the pixel valuef (x, y) is as-signed to all the pixels ranged from([x′(x)], [y′(x)]) to([x′(x+1)], [y′(x+1)]) in the normalized plane. For gener-ating gray-scale image, each pixel in the input image and thenormalized image is viewed as a square of unit area. By co-ordinate mapping, the unit square of input image is mappedto a rectangle in the normalized plane and each pixel (unitsquare) overlapped with the mapped rectangle is assigned agray level proportional to the overlapping area.In the case of 2D normalization, the mapped shape of a
unit square in the input image onto the normalized planeis a quadrilateral. To compute the overlapping areas of thisquadrilateral with the pixels (unit squares) in the normal-ized plane, we decompose the quadrilateral into trapezoids(Fig. 1, triangles are degenerate trapezoids) with parallelhorizontal sides such that each trapezoid is within a row ofunit squares. Each trapezoid in a row is further decomposedinto trapezoids with parallel vertical sides such that eachtrapezoid is within a unit square. After generating the nor-malized gray-scale image, the binary normalized image isobtained by thresholding the gray-scale image. By intuition,the threshold is set to 0.5.In our experiments, the normalized image plane is set
to a square of side lengthL. The normalized plane is notnecessarily fully occupied, however. For some charactersthat are inherently long-shaped, transforming the image tosquare shape yields excessive distortion and will deterioratethe recognition performance. To alleviate this problem, wepartially preserve the aspect ratio of the input image, using
Fig. 1. Decomposition of quadrilateral into trapezoids each withina row of unit squares.
the so-called aspect ratio adaptive normalization (ARAN)strategy[16,17]. InARAN, the aspect ratioR2 of normalizedimage is a continuous function of the aspect ratioR1 ofinput image. We adopt the aspect ratio function
R2 =√sin
(�
2R1
). (3)
R1 is calculated by
R1 = W1/H1 if W1< H1,
R1 = H1/W1 otherwise,
whereW1 andH1 are the width and height of the input image(spreads of projections of stroke pixels or spans of re-setboundaries). The widthW2 and heightH2 of the normalizedimage are related by the aspect ratioR2. If the input imageis vertically elongated, then in the normalized plane, thevertical dimension is filled (heightL) and the horizontaldimension is centered and scaled according to the aspectratio (widthL · R2); otherwise the horizontal dimension isfilled (width L) and the vertical dimension is centered andscaled (heightL · R2).
2.2. 1D normalization methods
Given the sizes of input and normalized images, the coor-dinate mapping functions of linear normalization are simplygiven by
x′ = W2
W1x,
y′ = H2
H1y. (4)

C.-L. Liu, K. Marukawa / Pattern Recognition 38 (2005) 2242–2255 2245
Both the linear normalization and NLN methods align thephysical boundaries (ends of stroke projections) of input im-age to the boundaries of normalized image. The coordinatemapping of line density-based NLN is obtained by accumu-lating the normalized line density projections (line densityequalization):
x′ = W2
x∑u=0
hx(u),
y′ = H2
y∑v=0
hy(v), (5)
wherehx(x) andhy(y) are the normalized line density his-tograms ofx direction andy direction, respectively, whichare obtained by normalizing the projections of local linedensities into unity of sum:
hx(x) = px(x)∑x px(x)
=∑
y dx(x, y)∑x
∑y dx(x, y)
,
hy(y) = py(y)∑y py(y)
=∑
x dy(x, y)∑x
∑y dy(x, y)
, (6)
wherepx(x) andpy(y) are the line density projections ontox axis andy axis, respectively, anddx(x, y) and dy(x, y)
are local line density functions.By Tsukumo and Tanaka[4], the local line densitiesdx
anddy are taken as the reciprocal of horizontal/vertical run-length in background area, or a small constant in strokearea. While by Yamada et al.[5] dx anddy are calculatedby considering both background run-length and stroke run-length, and are unified to renderdx(x, y) = dy(x, y). Thetwo methods provide comparable performance in recogni-tion but the method of Tsukumo and Tanaka is simpler incomputation[3,6]. We have given slight modifications tothem. Tsukumo and Tanaka did not specify the line den-sity computation of marginal and stroke areas. We adjustedthe values of marginal and stroke areas empirically so as toachieve high recognition accuracy. Yamada et al. elaboratedthe density computation for all configurations. For improv-ing the recognition performance, we adopted the modifi-cation of Yoshida and Hongo[18], that re-defined the lineinterval of marginal area to be dependent on the marginalrun-length and re-defined the unified density as the averageof horizontal and vertical densities instead of the maximum.We refer to the NLN methods with line density computedaccording to Tsukumo and Tanaka[4] andYamada et al.[5](with modifications) as NLN-T and NLN-Y, respectively.The 1Dmoment normalization method aligns the centroid
of input image(xc, yc) to the geometric center of normal-ized image(x′
c, y′c) = (W2/2, H2/2), and re-bound the in-
put image according to second-order 1D moments. Let thesecond-order moments be�20 and�02, the width and heightof input image are re-set to�x = �
√�20 and�y = �
√�02,
respectively. Accordingly, the boundaries of input image are
re-set to[xc −�x/2, xc +�x/2] and[yc −�y/2, yc +�y/2].The coordinate mapping is then given by
x′ = W2
�x(x − xc) + x′
c,
y′ = Hx
�y(y − yc) + y′
c. (7)
The bi-moment normalization method aligns the centroidof input image as moment normalization does, but the widthand height are treated asymmetric with respect to the cen-troid. The second-order moments are split into two partsby the centroid:�−
x , �+x , �−
y , and �+y . The boundaries of
input image are re-set to[xc − �√
�−x , xc + �
√�+x ] and
[yc −�√
�−y , yc +�
√�+y ]. For thex axis, a quadratic func-
tion u(x) = a1x2 + b1x + c1 is used to align three points
(xc −�√
�−x , xc, xc +�
√�+x ) to normalized coordinates (0,
0.5, 1), and similarly, a quadratic functionv(y) = a2y2 +
b2y + c2 is used for they axis. Finally, the coordinate map-ping functions are
x′ = W2u(x),
y′ = H2v(y). (8)
The details of moment normalization and bi-moment nor-malization can be found in[7], where we set the constantsto � = 4 and� = 2.The quadratic functions can also be used to align the
physical boundaries and centroid, i.e., map(0, xc, W1) and(0, yc, H1) to (0, 0.5, 1). We call this method centroid-boundary alignment (CBA) (abbreviated as centr-boundmethod in[7]). An improved CBA method, called MCBA[8], was later proposed to adjust the stroke density in cen-tral area by combining a sine function with the quadraticfunctionsu(x) andv(y):
x′ = W2[u(x) + �x sin(2�u(x))],y′ = H2[v(y) + �y sin(2�v(y))]. (9)
The amplitudes of sine waves,�x and�y , are estimated fromthe extent of the central area delimited by the local centroidsof half images (partitioned by the global centroid)[8].The functions of (9) were also applied to fit the normal-
ized coordinates of line density-based NLN. To do this, thecoordinates in input image corresponding to
∑xu=0 hx(u)=
0,0.5,1 are picked up and mapped to normalized coordi-nates (0, 0.5, 1) by quadratic curve fitting. The coordinatescorresponding to
∑xu=0 hx(u) = 0.25,0.75 are used to es-
timate the amplitude of the sine wave. We call this methodline LDPF [8].
2.3. Pseudo 2D NLN
The basic idea of P2DNLN is to equalize the line den-sity functions of each rowdx(x, y0) or columndy(x0, y)

2246 C.-L. Liu, K. Marukawa / Pattern Recognition 38 (2005) 2242–2255
Fig. 2. Input image and normalized images by P2DNLN with� = 4,8,16,32, and∞ (1DNLN).
instead of the line density projections. To control the de-formation of the normalized image from the input image,Horiuchi et al.[10] blurred the line density functions suchthat the equalization of each row/column is dependent on itsneighboring rows/columns. The blurred horizontal densityfunction is (similarly for vertical density)
�x(x, y0) =∑y
dx(x, y) · 1√2��
e−(y−y0)2/2�2, (10)
where�2 is the variance of a Gaussian function (low-pass fil-ter), which controls the rigidity of shape deformation in nor-malization.When�2 → ∞, the blurred line density functionis equivalent to the projection onx axis ory axis, and con-sequently, the normalization is equivalent to 1DNLN. Theblurred line density functions are then equalized for eachrow/column independently to generate 1D coordinate map-ping functionsx′(x, y0) or y′(x0, y). Horiuchi et al. alsoused a row/column density-dependent term to smooth theequalization but we observed in our experiments that the ef-fect of this term is not significant. We incorporated this termin our experiments however.Some examples of P2DNLN using different variance val-
ues are shown inFig. 2, where the input image of the firstrow has unbalanced local height while that of the secondrow has unbalanced local width. We can see that P2DNLNeffects in reducing this kind of imbalance, but there is atradeoff between shape restoration and shape feature pre-serving.
3. Line density projection interpolation
By P2DNLN, the coordinate mapping function of eachrow/column is dependent on the neighboring rows/columnsby line density blurring. To alleviate the distortion ofcharacter shape, the variance of the (low-pass) Gaussianfilter is fairly large, i.e., the bandwidth of the low-passfilter is rather narrow. Therefore, instead of equalizing theblurred line density functions of each row/column, we canequalize for sampled rows/columns only and interpolate thesampled coordinate mapping functions to generate the 2Dcoordinate function. According to the Sampling Theorem,if the sampling rate is larger than two times the bandwidth
of low-pass filter, the interpolation of sampled functions canrestore the filtered function at full rate.Let the impulse response function of Gaussian filter be
f (x) = 1√2��x
e−(�2/2�2x),
its frequency response function is
F(f ) = 1√2��f
e−(f 2/2�2f ),
where�f = 1/2��x . If we approximate the bandwidth of
Gaussian filter as√2�f (the majority of energy is contained
in this bandwidth), to equalize the blurred density functionof one row/column sampled from every 1/2
√2�f =�/
√2�x
rows/columns can generate reasonable 2D coordinate map-ping function by interpolation. When the variance of Gaus-sian is set to�x = 16, we can sample one row/column fromevery 35. This implies, for a character image of 64×64 pix-els, we only have to equalize the blurred density functionsof two rows/columns.Under the strategy of line density function sampling and
interpolation, we herein propose an efficient pseudo 2D nor-malization method, called LDPI. Instead of Gaussian filter-ing, we use a triangular filter which is more computationallyefficient because its impulse response function is piecewiselinear. The computation of blurred line density functions ofsampled rows/columns can be viewed as partitioning the 2Dline density map into soft strips and the impulse responsefunction becomes a weight function. Considering that thecentroid of character images plays an important role in shapenormalization (especially in the moment, bi-moment, CBA,and MCBA methods), we partition the input image horizon-tally/vertically into three strips with a strip centered at thecentroid. Specifically, let the width and height of the inputimage beW1 andH1, the centroid be(xc, yc), we partitionthe horizontal density mapdx(x, y) into three horizontalstrips using weight functions iny axis:
dnx (x, y) = wi(y)dx(x, y), i = 1,2,3, (11)
wherewi(y) are weight functions:
w1(y) = yc − y
yc, y < yc,
w2(y) = 1− w1(y), y < yc,
w2(y) = 1− w3(y), y �yc,
w3(y) = y − yc
H1 − yc, y �yc. (12)
Similarly, the vertical density mapdy(x, y) is partitionedinto three vertical strips using weight functions inx axis.The weight functions ofy axis are depicted graphically inFig. 3.

C.-L. Liu, K. Marukawa / Pattern Recognition 38 (2005) 2242–2255 2247
w
0 yc H1
2 w3w1
Fig. 3. Weight functions for partitioning line density map into softstrips.
Fig. 4. Three strips of character image and their coordinate mappingfunctions.
The horizontal density functions of three strips are equal-ized and interpolated as follows. First, the density values areprojected onto thex axis:
pix(x)
∑y
dix(x, y), i = 1,2,3.
The line density projections are then normalized to sumof unity and accumulated to give 1D coordinate mappingfunctions as in (5) and (6). Denote the three 1D coordinatemapping functions byx′i (x), i = 1,2,3, the 2D coordinatefunction is obtained by interpolation:
x′(x, y) ={
w1(y)x′1(x) + w2(y)x′2(x), y < yc,
w3(y)x′3(x) + w2(y)x′2(x), y �yc,(13)
The vertical density functionsdiy(x, y), i = 1,2,3, are sim-
ilarly equalized and interpolated to generate the 2D coordi-nate functiony′(x, y).Fig. 4 shows an example of partitioning character image
into soft horizontal strips. For visual convenience, we dis-play the character image instead of the line density map.The right graph ofFig. 4shows the 1D coordinate mapping
1w
1w
3w
3w
2w
2
H1cy0
H1cy0
w
Fig. 5. Varying weight functions withw0 = 0.5 (upper graph) andw0 = 2 (lower graph).
functions corresponding to the three line density strips, ob-tained by line density projection equalization. We can seethat the strokes of the upper strip are apparently biased tothe left, so its coordinate mapping function has large slopein the left, which effects in stretching the left part and com-pressing the right part in normalization. In the normalizedimage with interpolated 2D coordinate mapping function,the upper part of this character image will be expanded morethan the central and lower parts.Still, to control the rigidity of shape deformation of LDPI.
we modify the weight functions of (12) to
w1(y) = t
[w0
yc − y
yc
], y < yc,
w2(y) = 1− w1(y), y < yc,
w2(y) = 1− w3(y), y �yc,
w3(y) = t
[w0
y − yc
H1 − yc
], y �yc, (14)
wherew0 controls the strength of the upper/lower part of linedensity map andt (·) truncates the weight into the domain[0,1]:
t (v) ={1 if v >1,0 if v <0,v otherwise.
A small value ofw0 implies that the central part of characterimage is close to the whole image and the interpolated 2Dcoordinate mapping function is close to that of 1D normal-ization. The normalization by LDPI withw0=0 is equivalentto 1DNLN. With a large value ofw0, the interpolated 2Dcoordinate mapping function will be more sensitive to theline density of the upper/lower partial image.Fig. 5 showsthe weight functions withw0 = 0.5 andw0 = 2.

2248 C.-L. Liu, K. Marukawa / Pattern Recognition 38 (2005) 2242–2255
Fig. 6. Input image and normalized images by LDPI withw0 = 0(1DNLN), 0.5, 1, and 2.
An implementation issue of LDPI is the control of im-age width or height according to aspect ratio mapping. Ingenerating the 1D coordinate mapping functions, we makethe three horizontal strips have the same normalized widthW2 and the three vertical strips have the same normalizedheightH2. W2 andH2 are related by the aspect ratioR2,which is related to the aspect ratioR1 of input image by(3). In computingR1, W1 andH1 are the width and heightof the whole input image.Fig. 6 shows some examples of character image normal-
ization by LDPI. The first input image has unbalanced localwidth (the upper part is narrower than the lower part) whilethe second one has both imbalanced width and imbalancedheight (the left part is narrower than the right). We cansee that LDPI alleviates this kind of imbalance as com-pared to 1DNLN, and a large value ofw0 yields excessivedistortion.
4. Other pseudo 2D normalization methods
The strategy of LDPI can be applied to extending other1D normalization methods, including the LDPF, momentnormalization, bi-moment normalization, CBA, and MCBA.Since it was proven that the MCBA outperforms the CBA,we only extend the MCBA method to pseudo 2D normal-ization, and call the extended method P2DCBA. The exten-sions of LDPF, moment and bi-moment methods are calledP2DLDPF, P2DMN, and P2DBMN, respectively.The P2DLDPF method is almost the same as the LDPI
except that the line density projection of a strip of line den-sity map is fitted using quadratic and sine functions afterequalized. The 1D coordinate mapping functions of threestrips are then interpolated to generate the 2D coordinatefunction.The P2DCBA, P2DMN, and P2DBMN methods do not
rely on the computation of local line density map. Instead,they are directly based on the pixel intensity of characterimage. As the soft partitioning of line density map in LDPI,the input character imagef (x, y) is softly partitioned intothree horizontal stripsf i
x(x, y), i = 1,2,3, as inFig. 4, orthree vertical stripsf i
y(x, y), i=1,2,3. The horizontal strips
are projected onto thex axis:
pix(x) =
∑y
f ix(x, y), i = 1,2,3.
Similarly, the vertical strips are projected onto they axis.From each projection functionpi
x(x), the coordinate ofcentroid is computed:
xic =
∑xxpi
x(x)∑xpi
x(x). (15)
For P2DCBA, the coordinates of local centroids of left andright halves are computed by
xi1 =
∑x<xi
cxpi
x(x)∑x<xi
cpi
x(x),
xi2 =
∑x>xi
cxpi
x(x)∑x>xi
cpi
x(x).
The centroidxic and the width of the input image are used
to estimate the quadratic function, and the local centroidsxi1 and xi
2 are used to estimate the amplitude of the sinewave. The combination of the quadratic and sine functionsgives the 1D coordinate mapping functionx′i (x) of the stripf ix(x.y). The three 1D coordinate functions of the horizontalstrips are interpolated to generate the 2D coordinate func-tion x′(x, y). Similarly, the three 1D coordinate functionsy′i (y), i = 1,2,3, of the vertical strips are interpolated togenerate the 2D coordinate functiony′(x, y).For P2DMN, the second-order moment is computed from
the projection of a strip:
�i20=
∑x(x − xi
c)2pi
x(x)∑xpi
x(x). (16)
The width of this strip is re-set to�ix =�
√�i20, which is used
to determine the scaling factor of 1D coordinate mapping:
x′i (x) = W2
�ix
(x − xic) + W2
2.
The 1D coordinate mapping functions of vertical strips arecomputed similarly.For P2DBMN, the second-order moment of a horizontal
strip is split into two parts:
�i−20 =
∑x<xi
c(x − xi
c)2pi
x(x)∑x<xi
cpi
x(x),
�i+20 =
∑x>xi
c(x − xi
c)2pi
x(x)∑x>xi
cpi
x(x). (17)
The bounds of this strip is re-set to[xic − �
√�i−20, xi
c +�√
�i+20], which, together with the centroidxi
c, are used to es-
timate the quadratic 1D coordinate mapping functionx′i (x).

C.-L. Liu, K. Marukawa / Pattern Recognition 38 (2005) 2242–2255 2249
The 1D coordinate mapping functions of vertical strips arecomputed similarly.For P2DMN and P2DBMN, the widthW2 and heightH2
of normalized image are determined from the moments ofthe whole input image according to aspect ratio mapping.They are used in computing the 1D coordinate mappingfunctions of all the horizontal/vertical strips. Since the 1Dcoordinate functions of the strips have different scaling fac-tors depending on the second-order moments of the stripimage, the mapped coordinate of a strip may go beyond therange[0, W2] or [0, H2] of normalized plane. In this case,we truncate the mapped coordinate into the range.All the pseudo 2D normalization methods based on the in-
terpolation of 1D coordinate mapping functions are slightlymore intensive in computation than their 1D counterparts.Compared to 1D normalization, pseudo 2N normalizationcomputes six 1D coordinate functions instead of two. Thethree 1D coordinate functions of three horizontal/verticalstrips are representative of local stroke distribution and aresmoothly interpolated to generate a 2D coordinate function.Thus, the imbalance of stroke distribution can be mitigatedwithout excessive distortion.Fig. 7 shows some normalized images produced by
pseudo 2D normalization methods and their 1D counter-parts. Each group (two rows) of images include an inputimage (upper left) and 11 normalized images producedby five 1D normalization methods (upper row: NLN-T,LDPF, MCBA, moment, and bi-moment) and six pseudo2D normalization methods (lower row: LDPI, P2DNLN,P2DLDPF, P2DCBA, P2DMN, and P2DBMN). The linedensity maps of LDPF, LDPI, P2DNLN, and P2DLDPF arecomputed by NLN-T (Tsukumo and Tanaka[4] with ourmodifications). The blurring parameter of P2DNLN wasset to� = 16 (as favored by Horiuchi et al.[10]), and theweights of other pseudo 2D methods were set tow0= 0.75(favored by our experiments).In Fig. 7, the first input image and the second one have
imbalanced local width, the third and the fourth ones haveimbalanced local height. Further, the second input image isapparently skewed horizontally and the third one is skewedvertically. We can see that all the pseudo 2D normalizationmethods can alleviate this kind of imbalance and skew, whiletheir 1D counterparts are not sufficient in this respect. TheP2DNLN, LDPI, and P2DLDPF methods generate similarnormalized shapes. By fitting normalized coordinates withsmooth functions, the P2DLDPF avoids the abrupt changeof stroke width by P2DNLN (as be evident for the last inputimage). The P2DCBA, P2DMN, and P2DBMN methodsalso generate smooth normalized shapes.
5. Experimental results
We demonstrated the performance of the pseudo 2D nor-malization methods in experiments of handwritten Chinesecharacter recognition and compare with their 1D counter-
Fig. 7. Examples of character shape normalization. Each groupof two rows include an input image and 11 normalized imagesgenerated by different methods (five 1D methods and six pseudo2D methods).
parts in respect of recognition accuracy and computationalcomplexity.
5.1. Experimental setup
We conducted experiments on two large image databases:ETL9B and JEITA-HP. The ETL9B database was collectedand released by the Electro-Technical Laboratory (ETL) ofJapan (currently named the National Institute of AdvancedIndustrial Science and Technology (AIST)). It contains thebinary images of 3036 characters (including 71 hiraganaand 2965 JIS level-1 Kanji), 200 images per category. Weuse the first 20 images and the last 20 images of each classfor testing, and the rest 160 images for learning classifierparameters. This scheme of data partitioning has been testedby, e.g., Nakajima et al.[19].The JEITA-HP database was originally collected by
Hewlett–Packard Japan and later released by JEITA (JapanElectronics and Information Technology Association). Itcontains the character images of 580 writers, including 480writers (A0-492 with 13 numbers absent) in DATASET-Aand 100 writers (B0-99) in DATASET-B. The writers of

2250 C.-L. Liu, K. Marukawa / Pattern Recognition 38 (2005) 2242–2255
Fig. 8. Samples of JEITA-HP database (writers A-492 and B-99).
DATASET-B were taught to write carefully, but no con-straint was imposed onto the writers of DATASET-A. Inprinciple, the dataset of each writer contains 3306 imagesof 3214 categories, in which each Kanji character was writ-ten once, while each of hiragana/Katakana/alphanumericwas written twice.Experimental results on JEITA-HP database have been
reported by Kawatani et al.[20,21]. They experimented withall the 3214 categories but the specification of training andtest data is not clear. In addition, in the non-Kanji characters,some categories (typically, “O”, “o” and “0”) have identicalshapes. To compare the results of JEITA-HP with those ofETL9B, we have figured out the 3036 categories of ETL9Bfrom JEITA-HP, and for the hiragana characters, we useone sample from each writer[7]. Let us refer to the 3036images of one writer as a set. We use the first 400 setsof DATASET-A and the first 80 sets of DATASET-B fortraining, and the rest 80 sets of DATASET-A and 20 setsof DATASET-B for testing. Note that for some writers, thedataset does not contain all the 3036 characters. The totalnumbers of images of training set and test set are 1,441,906and 303,334, respectively. Fig.8 shows some images of twowriters in DATASET-A and DATASET-B, respectively.From a character image, we extracted chaincode direction
features using normalization-base feature extraction (NBFE)or normalization-cooperated feature extraction (NCFE). ByNBFE, the normalized image is generated, then the con-
tour pixels are assigned to four orientation planes, fromeach plane feature measurements are computed by blurring(Gaussian filtering and sampling)[22]. While by NCFE, thecontour pixels of the original image are assigned to orienta-tion planes incorporating coordinate mapping while the nor-malized image is not necessarily generated[23]. We haveimproved the performance of NCPE by generating continu-ous orientation planes instead of discrete ones[16]. We referto the chaincode feature extracted by NBFE and the fea-ture by continuous NCFE aschnandncf-c, respectively. Wehave also tested gradient direction feature (grd-g) from gray-scale normalized image (transformed from binary characterimage)[16]. The size of normalized image and orientationplanes is 64× 64 pixels, and from each orientation plane,we extract 8× 8= 64 measurements. We thus obtain 256measurements and store in a feature vector.On feature extraction, variable transformation is im-
posed on each measurement to improve the Gaussianityof feature distribution[24–26]. Variable transformationis also called Box-Cox transformation[27]. We set thepower of variable transformation to 0.5 without attempt tooptimize it.We present the results of two classifiers, namely, Eu-
clidean distance to class mean and modified quadratic dis-criminant function (MQDF2)[28], both on reduced featurespace by Fisher linear discriminant analysis (FLDA)[24].FLDA has been successfully used in handwritten characterrecognition of large category set by, e.g.[26,29]. We re-duced the dimensionality of feature vector to 160 and gaineda little improvement of classification accuracy. The MQDF2was proposed by Kimura et al.[28] to reduce the storageand computation of ordinary QDF and to improve the clas-sification performance. In MQDF2, the covariance matrix ofeach class is regularized by replacing the minor eigenvalueswith a constant. Denote thed-dimensional feature vector byx, the MQDF2 of classi is computed by
g2(x, i ) =k∑
j=1
1
ij[(x − �i )
T�ij ]2
+ 1
�i
‖x − �i‖2 −
k∑j=1
[(x − �i )T�ij ]2
+k∑
j=1
logij + (d − k) log�i ,
where�i is the mean vector of classi , ij and�ij , j =1, . . . , d, are the eigenvalues and eigenvectors of the covari-ance matrix of classi . The eigenvalues are sorted in de-creasing order and the eigenvectors are sorted accordingly.k denotes the number of principal axes, and the minor eigen-values are replaced with a constant�i . In our experiments,k was set to 50. The classification of MQDF2 is speeded upby selecting 100 candidate classes using Euclidean distance.The MQDF2 is then computed on the candidate classes only.
C.-L. Liu, K. Marukawa / Pattern Recognition 38 (2005) 2242–2255 2251
Table 1Recognition rates (%) on LDPI with various weights
Euclidean MQDF2
chn ncf-c grd-g chn ncf-c grd-g
ETL9Bw0 = 0.5 97.13 97.50 97.44 98.96 99.16 99.13w0 = 0.75 97.22 97.65 97.54 99.01 99.18 99.14w0 = 1 97.28 97.74 97.57 98.97 99.20 99.14
JEITA-HPw0 = 0.5 94.03 94.78 94.49 97.86 98.20 98.08w0 = 0.75 94.15 95.00 94.61 97.93 98.27 98.11w0 = 1 94.19 95.10 94.62 97.90 98.28 98.09
Table 2Recognition rates (%) on ETL9B test set
Classifier Euclidean MQDF2
Feature chn ncf-c grd-g chn ncf-c grd-g
NLN-T 96.59 97.06 97.06 98.82 99.03 98.98NLN-Y 96.44 96.75 96.83 98.76 98.88 98.89Moment 96.84 97.06 97.12 98.81 98.95 98.99Bi-moment 96.90 97.10 97.18 98.85 98.96 99.01MCBA 96.59 96.89 96.97 98.76 98.93 98.94LDPF 96.39 96.78 96.85 98.73 98.94 98.94
P2DNLN-T 97.37 97.66 97.66 99.06 99.19 99.18P2DNLN-Y 96.92 97.14 97.13 98.92 99.01 99.00LDPI 97.22 97.65 97.54 99.01 99.18 99.14P2DLDPF 96.95 97.32 97.27 98.91 99.10 99.09P2DCBA 97.17 97.44 97.42 98.94 99.12 99.12P2DMN 97.24 97.62 97.52 98.96 99.14 99.13P2DBMN 97.34 97.70 97.60 98.98 99.17 99.15
Previously, we set the class-independent constant�i ofMQDF2 heuristically to be proportional to the average fea-ture variance. To optimize the classification performance,we have turned to select the multiplier which maximizesthe accuracy on a holdout set randomly extracted from thetraining set while the other parameters are estimated on theremaining training data.1 On determining the multiplier,the classifier parameters are then re-estimated on the wholetraining set.
5.2. Test accuracies
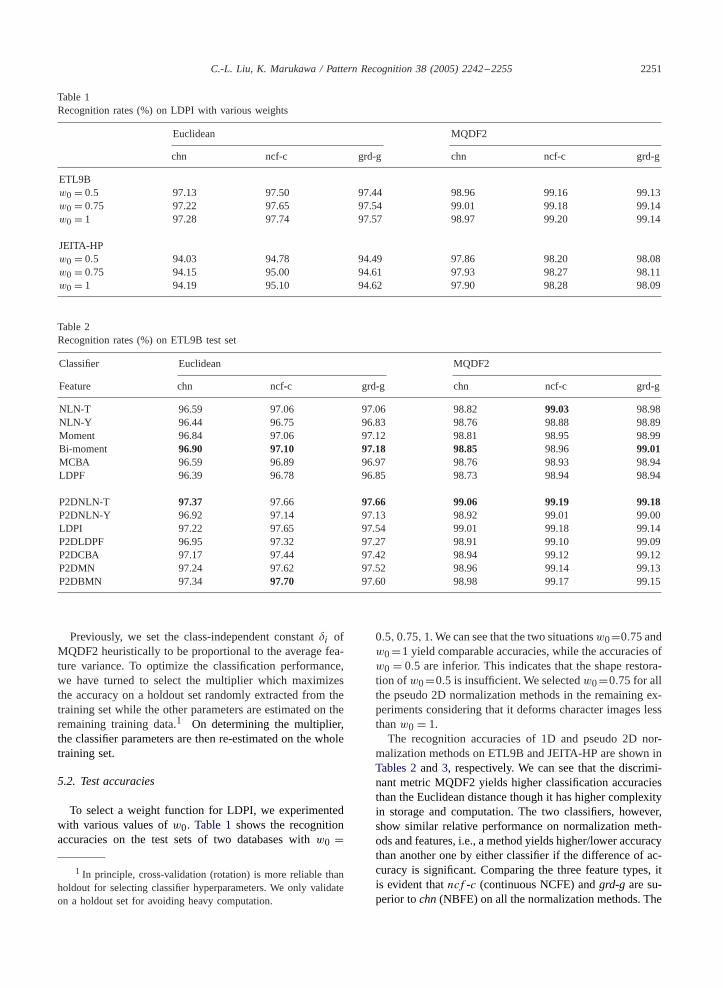
To select a weight function for LDPI, we experimentedwith various values ofw0. Table 1shows the recognitionaccuracies on the test sets of two databases withw0 =
1 In principle, cross-validation (rotation) is more reliable thanholdout for selecting classifier hyperparameters. We only validateon a holdout set for avoiding heavy computation.
0.5,0.75,1.We can see that the two situationsw0=0.75 andw0=1 yield comparable accuracies, while the accuracies ofw0 = 0.5 are inferior. This indicates that the shape restora-tion ofw0=0.5 is insufficient. We selectedw0=0.75 for allthe pseudo 2D normalization methods in the remaining ex-periments considering that it deforms character images lessthanw0 = 1.The recognition accuracies of 1D and pseudo 2D nor-
malization methods on ETL9B and JEITA-HP are shown inTables 2and3, respectively. We can see that the discrimi-nant metric MQDF2 yields higher classification accuraciesthan the Euclidean distance though it has higher complexityin storage and computation. The two classifiers, however,show similar relative performance on normalization meth-ods and features, i.e., a method yields higher/lower accuracythan another one by either classifier if the difference of ac-curacy is significant. Comparing the three feature types, itis evident thatncf -c (continuous NCFE) andgrd-g are su-perior tochn(NBFE) on all the normalization methods. The

2252 C.-L. Liu, K. Marukawa / Pattern Recognition 38 (2005) 2242–2255
Table 3Recognition rates (%) on JEITA-HP test set
Classifier Euclidean MQDF2
Feature chn ncf-c grd-g chn ncf-c grd-g
NLN-T 93.18 94.05 93.88 97.57 97.93 97.83NLN-Y 92.95 93.51 93.48 97.47 97.76 97.68Moment 93.68 94.14 94.21 97.70 97.93 97.91Bi-moment 93.76 94.25 94.28 97.76 98.00 97.98MCBA 93.52 94.05 94.14 97.74 98.00 97.97LDPF 93.01 93.66 93.68 97.53 97.88 97.80
P2DNLN-T 94.35 95.02 94.80 97.99 98.27 98.18P2DNLN-Y 93.65 94.09 93.93 97.75 97.96 97.88LDPI 94.15 95.00 94.61 97.93 98.27 98.11P2DLDPF 93.76 94.53 94.28 97.80 98.13 98.06P2DCBA 94.29 94.92 94.73 97.99 98.26 98.16P2DMN 94.42 95.19 94.86 97.95 98.28 98.18P2DBMN 94.51 95.30 94.99 98.00 98.33 98.23
comparison of features and classifiers are not the intentionof this paper, however.In comparing the normalization methods, let us focus on
the accuracies given by MQDF2. Comparing pseudo 2Dmethods with their 1D counterparts, i.e., P2DNLN versusNLN, P2DLDPF versus LDPF, P2DCBA versus MCBA,P2DMN versus 1D moment method, and P2DBMN versus1D bi-moment method, we can see that the pseudo 2Dmeth-ods yield significantly higher recognition accuracies thantheir 1D counterparts. For example, using the featurencf-c,the accuracy of ETL9B test set was improved from 99.03%by NLN-T to 99.19% by P2DNLN, with error reduced bya factor of 0.97− 0.81/0.97= 16.5%, and the accuracy ofHEITA-HP test set was improved from 97.93% by NLN-Tto 98.27% by P2DNLN, with error reduced by a factor of2.07− 1.73/2.07= 16.4%.Comparing the accuracies of the pseudo 2D normaliza-
tion methods, first the accuracy of LDPI is comparable tothat of P2DNLN-T on either ETL9B or JEITA-HP. Othermethods that yield comparable accuracies are the P2DCBA,P2DMN, and P2DBMN. On ETL9B, the highest accuracieswere given by the P2DNLN, while the highest accuracies onJEITA-HP were given by the P2DBMN. However, the dif-ference of accuracy among these methods is not significant.Though our methods were evaluated on public databases,
it is hard to compare our results with those reported in theliterature since the partition of test data is often different. Ourutilization of JEITA-HP database is much different from thatof Kawatani et al.[20,21]. On the ETL9B database, Kimuraet al. [26] and Kato et al.[30] have reported the highestaccuracies in the literature: 99.15% and 99.42%. They bothrotated the partitions of data for testing while we fixed thetest set. We did not refine the features and classifiers as theydid, but focused on the shape normalization of characterimages.
Table 4CPU time (ms) of normalization on JEITA-HP test set
Method 1D P2D
NLN-T 0.271 4.195NLN-Y 0.387 4.330Moment 0.049 0.134Bi-moment 0.051 0.140MCBA 0.067 0.174LDPF 0.283 0.390LDPI 0.341
5.3. CPU time of normalization
To evaluate the computational complexity of the meth-ods, we profiled the CPU times of coordinate mapping bythe 1D and pseudo 2D normalization methods. On an inputcharacter image, the CPU time is counted until the trans-formed coordinates are computed. It does not cover eitherthe normalized image generation or the feature extractionprocedure, unlike in our previous presentation[7]. We im-plemented the experiments on Pentium4-1.90GHz and aver-aged the CPU time over the samples of JEITA-HP test set.The CPU times of the 1D and pseudo 2D normalization
methods are shown inTable 4. First, it is evident that amongthe 1D normalization methods, the ones based on local linedensity computation (NLN-T, NLN-Y, and LDPF) are morecomputationally intensive than the ones based on image pro-jections (moment, bi-moment, and MCBA). The extensionof 1DNLN to P2DNLN by line density blurring is very ex-pensive, in the sense that the CPU time of P2DNLN is morethan 10 times as many that of 1DNLN. The new methodLDPI, on the other hand, only adds a little computation to1DNLN, and its CPU time is less than one tenth as many

C.-L. Liu, K. Marukawa / Pattern Recognition 38 (2005) 2242–2255 2253
Fig. 9. Samples misclassified by MQDF2 onncf-cwith normaliza-tion methods NLN-T, P2DNLN, LDPI, P2DCBA, and P2DBMN.The character right to each box denotes the ground-truth, and thecharacters below denote the classification results of five methods.
that of P2DNLN. The pseudo 2D extensions of moment, bi-moment, and MCBA methods are even much less expensivethan LDPI because they do not compute local line densities.Overall, the pseudo 2D methods P2DCBA, P2DMN, andP2DBMN provide superior real-time computability whilethe complexity of LDPI and P2DLDPF is acceptable forreal-time applications.
5.4. Examples of mis-recognition
We observed that on some samples misclassified by1DNLN, the pseudo 2D normalization methods classifiedcorrectly. However, some difficult samples were misclas-sified by all the methods. Still, on some samples, thepseudo 2D normalization methods show complementaryperformance.Fig. 9 shows some samples of JEITA-HP testset that were given different results by 1DNLN and fourpseudo 2D normalization methods (the computation of linedensity for 1DNLN, P2DNLN, and LDPI follows NLN-T)with classifier MQDF2 on featurencf-c. We do not showsamples for P2DMN because its performance is similar toP2DBMN even on specific samples.The upper two rows ofFig. 9were mis-recognized by all
the five methods. This is due to the inherent shape confu-sion between similar classes, miswriting (like the last threesamples of the first row), or image degradation (like the lastone of the second row). The samples of the third row weremisclassified by 1DNLN but correctly classified by all the
pseudo 2D normalization methods. This justifies the effec-tiveness of extending normalization to pseudo 2D. The left-most sample of this row is typical of unbalanced local height.On the samples of the remaining three rows, the pseudo 2Dnormalization methods gave complementary classificationresults. The last sample of the fifth row shows the noise im-munity of moment-based methods, which rebound characterimages. The last two samples of the bottom row shows thatthe minor stroke protrusions were better preserved by curvefitting-based normalization (P2DCBA and P2DBMN) thanby local line density-based methods.
6. Conclusion
We proposed a new pseudo 2D normalization methodfor handwritten Chinese character recognition and havedemonstrated its superior performance on two large imagedatabases. This method is based on line density projectioninterpolation (LDPI). Compared to the previous pseudo 2Dmethod (P2DNLN) of Horiuchi et al.[10], LDPI providesreal-time computability while yields comparable recogni-tion accuracies with P2DNLN. We have also applied thestrategy of LDPI to extending the 1D normalization meth-ods that do not rely on line density computation and haveachieved comparable accuracies to LDPI at even lowercomputational overhead. Considering the tradeoff betweenrecognition performance and computational complexity, werecommend to use the P2DCBA and P2DBMN methods,which are comparable in recognition accuracy but generatedifferent normalized shapes on specific samples. The per-formance of P2DMN is similar to P2DBMN. P2DLDPFperforms similarly to LDPI, and both are acceptable forreal-time applications.Our proposed normalized methods were experimented on
binary character images, but they are potentially applica-ble to on-line trajectories[31] and gray-scale images[32]as well. The 1D and pseudo 2D versions of MCBA, mo-ment, and bi-moment methods are based on the projectionsof image intensity. Unlike that for line density-based NLN,the on-line character trajectory should be converted to a2D image, projections and strip projections can be directlyobtained from the trajectory efficiently. The application ofprojection-based normalization methods to gray-scale im-ages is straightforward. The partitioning of either on-linetrajectory or gray-scale image into soft strips can be circum-vented by generating the projections of the strips directly.We will test these methods for recognizing on-line trajecto-ries and gray-scale images in the future.
Acknowledgements
The authors are grateful to the National Institute of Ad-vanced Industrial Science and Technology (AIST) of Japan

2254 C.-L. Liu, K. Marukawa / Pattern Recognition 38 (2005) 2242–2255
and Japan Electronics and Information Technology Associ-ation (JEITA) for providing the image databases.
Appendix A. Glossary
• Shape normalization: To transform character images intothe same dimensionality (size normalization) and mean-while attempt to regulate the character shape so as to re-duce the within-class shape variation. The normalizationmethods can be grouped into 2D methods (Eq. (1)) and1D methods (Eq. (2)) according to the coordinate map-ping functions.
• Linear normalization: Pixel coordinates are mapped us-ing two separate linear functions (Eq. (4)) that align theboundary of input image to that of normalized plane.
• Nonlinear normalization(NLN): Pixel coordinates aremapped using line density equalization (Eq. (5)) on theprojections of local line densities, which are usually com-puted according to Tsukumo and Tanaka[4] (NLN-T) orYamada et al.[5] (NLN-Y).
• Line density projection fitting(LDPF): To generatesmoother normalized image than NLN, the normalizedline density projections (Eq. (6)) are fitted to generatecoordinate mapping functions combining quadratic andsine functions (Eq. (9)).
• Centroid-boundary alignment(CBA): In addition toaligning the character boundary, the centroid of inputimage is aligned to the geometric center of normalizedplane using quadratic functions. In the modified CBA(MCBA) method, the density of central area is furtheradjusted using a sine function (Eq. (9)).
• Moment normalization: The original moment normaliza-tion method of Casey[1] involves 2D coordinate func-tions to perform rotation or shearing. We use a simplified1D moment normalization method to align the centroidof character image and re-set the boundary (Eq. (7)).
• Bi-moment normalization: The bounds of character im-age are treated asymmetric with respect to the centroidand are re-set according to splitted second-order mo-ments. The pixel coordinates are then mapped usingquadratic functions (Eq. (8)).
• Pseudo 2D normalization: The coordinate mapping func-tions of pseudo 2D normalization methods are composedof row-wise/column-wise 1D functions or are generatedby interpolating 1D coordinate functions.
• Pseudo 2D nonlinear normalization(P2DNLN): TheP2DNLN method of Horiuchi et al.[10] generates the2D coordinate function by equalizing the line densityfunctions of each row/column after blurring instead ofequalizing the line density projections.
• Line density projection interpolation(LDPI): To avoidthe heavy computation of line density blurring, the linedensity map is partitioned into three horizontal/verticalstrips and the line density projection of each strip givesa 1D coordinate mapping function. The 2D coordinate
function is then obtained by interpolating the 1D coordi-nate functions.
• Pseudo 2D line density projection fitting(P2DLDPF):On partitioning the line density map into strips, the 1Dcoordinate mapping function of each strip is estimatedby fitting the normalized line density projection usingquadratic and sine functions.
• Pseudo 2D CBA(P2DCBA): On partitioning the inputimage into strips, the 1D coordinate mapping function ofeach strip is estimated by the 1D MCBA method on theprojection of the strip.
• Pseudo 2D moment normalization(P2DMN): On parti-tioning the input image into strips, the 1D coordinatemapping function of each strip is estimated by the 1Dmoment method on the projection of the strip.
• Pseudo 2D Bi-moment normalization(P2DBMN): Onpartitioning the input image into strips, the 1D coordi-nate mapping function of each strip is estimated by the1D bi-moment method on the projection of the strip.
References
[1] R.G. Casey, Moment normalization of handprinted character,IBM J. Res. Dev. 14 (1970) 548–557.
[2] G. Nagy, N. Tuong, Normalization techniques for handprintednumerals, Commun. ACM 13 (8) (1970) 475–481.
[3] S.-W. Lee, J.-S. Park, Nonlinear shape normalization methodsfor the recognition of large-set handwritten characters, PatternRecognition 27 (7) (1994) 895–902.
[4] J. Tsukumo, H. Tanaka, Classification of handprinted Chinesecharacters using non-linear normalization and correlationmethods, Proceedings of the Ninth International Conferenceon Pattern Recognition, Roma, Italy, 1988, pp. 168–171.
[5] H. Yamada, K. Yamamoto, T. Saito, A nonlinear normalizationmethod for handprinted Kanji character recognition—linedensity equalization, Pattern Recognition 23 (9) (1990) 1023–1029.
[6] M. Umeda, Advances in recognition methods for handwrittenKanji characters, IEICE Trans. Information Systems E79-D(5) (1996) 401–410.
[7] C.-L. Liu, H. Sako, H. Fujisawa, Handwritten Chinesecharacter recognition: alternatives to nonlinear normalization,Proceedings of the Seventh International Conference onDocument Analysis and Recognition, Edinburgh, Scotland,2003, pp. 524–528.
[8] C.-L. Liu, K. Marukawa, Global shape normalization forhandwritten Chinese character recognition: a new method,Proceedings of the Ninth International Workshop onFrontiers of Handwriting Recognition, Tokyo, Japan, 2004,pp. 300–305.
[9] M. Suzuki, N. Kato, H. Aso, Y. Nemoto, A handprintedcharacter recognition system using image transformationbased on partial inclination detection, IEICE Trans.Information Systems E79-D (5) (1996) 504–509.
[10] T. Horiuchi, R. Haruki, H. Yamada, K. Yamamoto, Two-dimensional extension of nonlinear normalization methodusing line density for character recognition, Proceedings ofthe Fourth International Conference on Document Analysisand Recognition, Ulm, Germany, 1997, pp. 511–514.

C.-L. Liu, K. Marukawa / Pattern Recognition 38 (2005) 2242–2255 2255
[11] D.-S. Lin, J.-J. Leou, A genetic algorithm approach to Chinesehandwriting normalization, IEEE Trans. Syst. Man Cybern.Part B 27 (6) (1997) 999–1007.
[12] J. Guo, N. Sun, Y. Nemoto, M. Kimura, H. Echigo, R.Sato, Recognition of handwritten characters using patterntransformation method with cosine function, Trans. IEICEJapan J76-D-II (4) (1993) 835–842 (in Japanese).
[13] T. Wakahara, K. Odaka, Adaptive normalization ofhandwritten characters using global/local affine transform-ation, IEEE Trans. Pattern Anal. Mach. Intell. 20 (12) (1998)1332–1441.
[14] T. Wakahara, Y. Kimura, M. Sano, Handwritten Japanesecharacter recognition using adaptive normalization by globalaffine transformation, Proceedings of the Sixth InternationalConference on Document Analysis and Recognition, Seattle,WA, 2001, pp. 424–428.
[15] M. Nakagawa, T. Yanagida, T. Nagasaki, An off-line characterrecognition method employing model-dependent patternnormalization by an elastic membrane model, Proceedings ofthe Fifth International Conference on Document Analysis andRecognition, Bangalore, India, 1999, pp. 495–498.
[16] C.-L. Liu, K. Nakashima, H. Sako, H. Fujisawa, Handwrittendigit recognition: investigation of normalization and featureextraction techniques, Pattern Recognition 37 (2) (2004) 265–279.
[17] C.-L. Liu, M. Koga, H. Sako, H. Fujisawa, Aspect ratioadaptive normalization for handwritten character recognition,in: T. Tail, Y. Shi, W. Gao (Eds.), Advances in MultimodalInterfaces—ICMI2000, LNCS vol. 1948, Springer, Berlin,2000, pp. 418–425.
[18] A. Yoshida, Y. Hongo, Handprinted Kanji recognition by thebackground feature pattern matching method with a non-linearnormalization, IEICE Technical Report, PRU92-34 (1992-09)(in Japanese).
[19] T. Nakajima, T. Wakabayashi, F. Kimura, Y. Miyake,Accuracy improvement by compound discriminant functionsfor resembling character recognition, Trans. IElCE Japan J-83-D-II (2) (2000) 623–633 (in Japanese).
[20] T. Kawatani, H. Shimizu, Handwritten Kanji recognitionwith the LDA method, Proceedings of the 14th InternationalConference on Pattern Recognition, Brisbane, 1998, vol. 2,pp. 1031–1035.
[21] T. Kawatani, Handwritten Kanji recognition with determinantnormalized quadratic discriminant function, Proceedings of
the 15th International Conference on Pattern Recognition,Barcelona, Spain, 2000, vol. 2, pp. 343–346.
[22] C.-L. Liu, Y.-J. Liu, R.-W. Dai, Preprocessing andstatistical/structural feature extraction for handwritten numeralrecognition, in: A.C. Downton, S. Impedovo (Eds.), Progressof Handwriting Recognition, World Scientific, Singapore,1997, pp. 161–168.
[23] M. Hamanaka, K. Yamada, J. Tsukumo, Normalization-cooperated feature extraction method for handprinted Kanjicharacter recognition, Proceedings of the Third InternationalWorkshop on Frontiers of Handwriting Recognition, Buffalo,NY, 1993, pp. 343–348.
[24] K. Fukunaga, Introduction to Statistical Pattern Recognition,second ed., Academic Press, New York, 1990.
[25] T. Wakabayashi, S. Tsuruoka, F. Kimura, Y. Miyake, Onthe size and variable transformation of feature vector forhandwritten character recognition, Trans. IEICE Japan J76-D-II (12) (1993) 2495–2503.
[26] F. Kimura, T. Wakabayashi, S. Tsuruoka, Y. Miyake,Improvement of handwritten Japanese character recognitionusing weighted direction code histogram, Pattern Recognition30 (8) (1997) 1329–1337.
[27] R.V.D. Heiden, F.C.A. Gren, The Box-Cox metric for nearestneighbor classification improvement, Pattern Recognition 30(2) (1997) 273–279.
[28] F. Kimura, K. Takashina, S. Tsuruoka, Y. Miyake, Modifiedquadratic discriminant functions and the application toChinese character recognition, IEEE Trans. Pattern Anal.Mach. Intell. 9 (1) (1987) 149–153.
[29] M.-K. Tsay, K.-H. Shyu, P.-C. Chang, Feature transformationwith generalized LVQ for handwritten Chinese characterrecognition, IEICE Trans. Information Systems E82-D (3)(1999) 687–692.
[30] N. Kato, M. Suzuki, S. Omachi, H. Aso, Y. Nemoto, Ahandwritten character recognition system using directionalelement feature and asymmetric Mahalanobis distance, IEEETrans. Pattern Anal. Mach. Intell. 21 (3) (1999) 258–262.
[31] C.-L. Liu, S. Jaeger, M. Nakagawa, Online handwrittenChinese character recognition: the state of the art, IEEE Trans.Pattern Anal. Mach. Intell. 26 (2) (2004) 198–213.
[32] S.-Y. Kim, S.-W. Lee, Nonlinear shape normalization methodsfor gray-scale handwritten character recognition, Proceedingsof the Fourth International Conference on Document Analysisand Recognition, Ulm, Germany, 1997, pp. 479–482.
About the Author—CHENG-LIN LIU received the B.S. degree in electronic engineering from Wuhan University, Wuhan, China, the M.E.degree in electronic engineering from Beijing Polytechnic University, Beijing, China, the Ph.D. degree in pattern recognition and artificialintelligence from the Institute of Automation, Chinese Academy of Sciences, Beijing, China, in 1989, 1992 and 1995, respectively. Hewas a postdoctoral fellow at Korea Advanced Institute of Science and Technology (KAIST) and later at Tokyo University of Agricultureand Technology from March 1996 to March 1999. From 1999 to 2004, he was a research staff member and later a senior researcher atthe Central Research Laboratory, Hitachi, Ltd., Tokyo, Japan. From 2005, he has been a research professor at the National Laboratory ofPattern Recognition (NLPR), Institute of Automation, Chinese Academy of Sciences, Beijing, China. His research interests include patternrecognition, image processing, neural networks, machine learning, and especially the applications to character recognition and documentanalysis.
About the Author—KATSUMI MARUKAWA received the B.E. and M.E. degrees in Information Science from Tsukuba University in1986 and 1988, respectively. In 1988, he joined the Central Research Laboratory, Hitachi, Ltd., Tokyo, Japan. His research interests includedocument analysis, information retrieval, and image processing. He received the Young Researcher Award from Information ProcessingSociety of Japan in 1993.