purification, homology modeling and structural analysis of
TRANSCRIPT

Purification, homology modeling and
structural analysis of pathogenesis
related class I chitinase from seed coat
of Glycine max [L.] Merr
By
Manvendra Singh
Institute of agricultural sciences,
Banaras Hindu University,
Varanasi-221005, Uttar Pradesh, India

Purification, homology modeling and structural
analysis of pathogenesis related class I chitinase
from seed coat of Glycine max [L.] Merr
By
Manvendra Singh
Institute of agricultural sciences,
Banaras Hindu University,
Varanasi-221005, Uttar Pradesh, India
(This research work was submitted by Manvendra Singh as a M.Sc. (Plant Biotechnology)
student for the partial fulfillment of M.Sc. (Plant Biotechnology) degree, in Institute of
Agricultural Sciences, Banaras Hindu University, Varanasi-221005, Uttar Pradesh, India)
2017
International E - Publication www.isca.co.in

International E - Publication 427, Palhar Nagar, RAPTC, VIP-Road, Indore-452005 (MP) INDIA
Phone: +91-731-2616100, Mobile: +91-80570-83382
E-mail: [email protected] , Website: www.isca.co.in
© Copyright Reserved
2017
All rights reserved. No part of this publication may be reproduced, stored, in a
retrieval system or transmitted, in any form or by any means, electronic,
mechanical, photocopying, reordering or otherwise, without the prior permission
of the publisher.
ISBN: 978-93-84659-94-3

Page | iii
ACKNOWLEDGEMENT
At the outset, being the student of this great Institute, I bow my head with great reverence
to the lotus feet of Mahamana Pandit Madan Mohan Malviya Ji, the founder of the Banaras
Hindu University, whose everlasting desire was to serve mankind. I am fortunate to perceive the
prodigious path to tread upon precisely through precious guidance in this university.
At the outset I would like to express my profound sense of reverence and indebtness to
my Supervisor, Shri. V. K. Singh, Assistant professor, Department of Genetics and Plant
breeding, Institute of Agricultural Sciences, Banaras Hindu University for his meticulous
guidance, compassionate initiation, congenial discussion, constructive criticism and soothing
affection during the course of this investigation and preparation of this manuscript. It was a
matter of sheer luck and opportunity to work under his guidance.
I offer my heartfelt gratitude to my co-supervisor Prof. R.P.singh, Department Of
Genetics and Plant Breeding, Institute of Agricultural Sciences, Banaras Hindu University for
their constant encouragement, critical suggestions and inspiration during entire period of
investigation and the members of the advisory committee Dr. A. Singh, Assistant Professor,
Plant Biotechnology, Genetics and Plant Breeding, R.G.S.C. (BHU) Barkachha, Mirzapur,
Institute of Agricultural Sciences, Banaras Hindu University and Dr. Ravindra Prasad, Assistant
professor, Department of Genetics and Plant Breeding, Institute of Agricultural Sciences,
Banaras Hindu University.
My profound gratefulness and thanks are to Prof. Rajesh Singh, and all staff of
Department of Genetics And Plant Breeding, Institute of Agricultural Sciences, Banaras Hindu
University and all the respected teachers of the Department of Genetics and Plant Breeding, for
their valuable suggestions and criticism during the course of this study.
I express my sincere thanks to Dr. Ram Dhari, Professor and Head, Department of
Genetics and Plant Breeding, Institute of Agricultural Sciences, Banaras Hindu University, for
providing all facilities needed for completion of the research work.
I express my sincere thanks to non – teaching staff, RGSC, Barkachha, research scholars,
of the Department of Genetics and Plant Breeding, for their helping hands, encouragement and
cooperation during the tenure of my studies and research work.
Words with me are insufficient to express my fillings of my heart to acknowledge and
gratitude to my bellowed father Shri. Mantu Lal, mother Smt. Rama Devi, my brother Shri.
Shailendra Kumar, Shri Niraj, my sister in law Smt. Saroj Verma and my nephew Aditya and
other family members who are providing all kind of help of need.
My friends Ranaveer, Jitendra, Bholashanker, Dhirendra, Surendra, Dr. Kaushal Kumar
Bhati, Alok Rai, Chandan, , Pravin, Dr. Alok Kumar Gupta, Dr. Anoop Singh Chauhan, Lalit
Kumar, Swati Verma, Jamalluddin Ansari, Alok Raj, Jay Singh and others deserves my
appreciation for their cooperation and help at various stages of the investigations.

Page | iv
I express my deep and warm feelings of gratitude to my seniors Dr. Chandra Prakash
Patel, Dr. Babloo Sharma and Mr. Ashutosh Nath Mani Tripathi, for their vital support and
sparing their valuable time to complete this manuscript.
Last but not the least, I record my sincere thanks to all beloved and respected people who
helped and could not find separate mentions. I still solicit their benediction to proceed at every
step of respected destined life.
It’s like drop in the ocean by my all regards to Baba Vishwanath, for providing me
energy and patience without which I would have been none.
Manvendra Singh

Page | v
ABBREVIATIONS
ChBD Chitin-binding domain
CatD Catalytic domain
SCP Single-cell protein
PPAP Plant Protein Annotation Program
ExPASy Expert Protein Analysis System
TrEMBL Translation of the EMBL nucleotide sequence
PIR–PSD Resource–Protein Sequence Database
Chi Chitinase
AACC Amino acid class covering
API Application programming interface
CASP Critical assessment in structure prediction
3-D Three-dimensional
EBI European Bioinformatics Institute
EM Expectation-maximization
e-value Expectation value
EVD Extreme value distribution
PDF Fast data finder
FN False negative
HMM Hidden Markov model
ILP Inductive logic programming
LAMA Local alignment of multiple alignments
MAST Multiple alignment searching tool
MDL Minimum description length
MP Membrane protein
NCBI National Centre for Biotechnology Information
NCGR National Centre for Genomic Research
NNSSP Nearest neighbour secondary structure prediction
PD Pattern driven
PDB Protein data bank
PHD Profile secondary structure predictions from Heidelberg

Page | vi
PPV Positive predictive value
PSSM Position-specific scoring matrices
QOS Quality of service
RMSD Root mean square deviation
RTT Round trip time
SAP Structure alignment program
SD Sequence driven
SP Sum of pairs
SRS Sequence retrieval system

Page | vii
Contents
Chapter 1 Introduction 1
Chapter 2 Review of literature 5
2.1 Fungal disease and their impact 5
2.2 Fungal cell wall 5
2.3 Cell wall degrading enzymes 6
2.4 Chitinase 6
2.4.1 Seed chitinase 7
2.5 Classification of chitinases 9
2.6 Regulation of chitinases 11
2.7 Structure and mechanism 12
2.8 The roles of chitinases 13
2.9 Biotechnological Applications of chitinases 14
2.9.1 Production of single-cell protein 15
2.9.2 Isolation of protoplasts 15
2.9.3 Production of chitooligosaccharides, glucosamine, and
GlcNAc
15
2.9.4 Chitinase as a target for biopesticides 16
2.9.5 Estimation of fungal biomass 17
2.9.6 Mosquito control 17
2.9.7 Morphogenesis 17
2.9.8 Defense and Transgenes in Plants 18
2.9.9 Control of plant pathogenic fungi 18
2.10 Bioinformatics tools 19
2.10.1 Protein sequence databases 19
2.10.1.1 GenPept 19
2.10.1.2 Entrez protein 20
2.10.1.3 UniProt 20
2.11 Protein family classification and functional annotation 21
2.12 The Swiss-Prot protein knowledgebase and ExPASy 23
2.12.1 Analysis of Protein Sequence/Structure Similarity
Relationships
24
2.13 Multiple protein sequence alignment 24
2.14 Profunc 26
2.15 Structure analysis 26
Chapter 3 Results and discussion 28
3.1 Purification of the enzyme 28
3.2 Electrophoretic analysis of chitinase 29
3.3 Primary Structure 30
3.4 Multiple sequence Alignment 30
3.5 Homology modelling 32
3.6 Ramachandran plot 32
3.7 Conserved Domain Detection 34
3.8 Secondary structure 34
Page | viii
3.9 Tertiary Structure 36
3.10 Cleft analysis and accessible and buried region 37
3.11 Structural comparison with chitinase using DALI data base 39
3.12 Ligand binding template analysis 40
Chapter 4 Summary and conclusion 43
Chapter 5 References 44

Page | 1
Chapter-1
Introduction
Soybean (Glycine max [L.] Merr) originated in China and was introduced to India
centuries ago through the Himalayan routes, and also brought in via Burma (now Myanmar) by
traders from Indonesia. As a result, soybean has been traditionally grown on a small scale in
Himachal Pradesh, the Kumaon Hills of Uttar Pradesh (now Uttaranchal), eastern Bengal, the
Khasi Hills, Manipur, the Naga Hills, and parts of central India covering Madhya Pradesh.
Because of its high protein and oil content, and other attributes such as its beneficial effects on
soil fertility, several attempts were made in the past to popularize soybean cultivation in India.
However, these initiatives were far from successful, mainly because of the inadequate knowledge
about its cultivation, lack of high-yielding varieties, lack of marketing, and unfamiliarity with its
utilization. Through the well-coordinated and collaborative efforts of a number of national,
international, and private-sector organizations over the years, soybean has now become an
important crop in India. Soybean (Glycine max), otherwise known as a ‘miracle crop’ with over
40% protein and 20% oil, originated in China. Thus, soybean has been cultivated in China for
more than 4,000 years (Hymowitz and Bernard, 1970). With its introduction into USA in the
18th century, and its systematic breeding in that country in the 1940s and 1950s, soybean was
transformed from an inefficient fodder type crop to a highly productive erect plant type, and
USA became the largest producer of soybean in the world ever since (Hymowitz and Harlan,
1983). The average yield of soybean in India is about 1 t ha
-1, compared with 2.3–2.8 t ha
-1 in
other countries. Therefore, the greatest challenge for Indian scientists and development programs
is to increase the average yield of soybean. The other challenges include exploitation of
biotechnological innovations in crop management using herbicide-tolerant and disease tolerant
soybeans and diversification of soybean uses through the development of high-value and health-
oriented food products.

Page | 2
Investigations studies on the lytic activity among biocontrol agents have focused largely
on the characterization of enzyme systems capable of degrading fungal cell wall components, of
which chitinase are among the most intensively studied (Chernin et al., 1997; Zhang and Yuen,
2001)
Chitin, an unbranched homopolymer of 1, 4- b-linked N-acetyl-D-glucosamine
(GlcNAc), is widely distributed in nature. It is believed to be the second most abundant and
renewable polymer on earth, next to cellulose. Chitinases are chitin- degrading enzymes, and
hydrolyze the b-(1, 4) linkages of chitin. The enzymes occur in a wide range of organisms
including viruses, bacteria, fungi, insects, plant, and animals. The roles of chitinases in these
organisms are diverse. In fungi, chitinases are thought to have autolytic, nutri-tional, and
morphogenetic roles (Adams et al., 2004).
Chitinases in mycoparasitic fungi are most commonly suggested to be involved in
mycoparasitism (Haran and Schickler, 1996). Chitinases in bacteria are shown to play a role in
the digestion of chitin for utilization as a carbon and energy source and recylcling chitin in nature
(Svitil et al., 1997). In insects, chitinases are associated with postembry-onic development and
degradation of old cuticle (Merzendorfer and Zimoch, 2003). Plant chitinases are involved in
defence and development (Graham and Sticklen, 1994). Chitinases encoded by viruses have roles
in pathogenesis (Patil et al., 2000). Human chitinases are suggested to play a role in defense
against chtinous human pathogens (Boot et al., 2001). On the other hand, chitinases have shown
an immense potential application in agricultural, biological and envi-ronmental fields.
Due to important biophysiological functions and applications of chitinase, a considerable
amount of research on fungal chitinases has been carried out in recent years. Therefore, the
present review will focus on fungal chitinases, containing their nomenclature and assays,
purification and characterization,molecular cloning and expression, family and structure,
regulation, and function and application (Li Duo-Chuan, 2006).
The complete genome sequences of rice (Nature, 2005) and Arabidopsis (Nature, 2000),
which are non-leguminous model species, are available and provide insight into many
fundamental aspects of plant biology; however, they do not address some important aspects of
legume biology. Legumes are important for maintenance of human health and as crops for
sustainable agriculture. Because this species has genome duplications, self-incompatibilities, and

Page | 3
a long generation time. In this case, the proteomics approach could be a powerful tool for
analyzing the functions of the plant's genes/proteins. Gaining an understanding of the biological
function of any novel gene is a more ambitious goal than merely determining its sequence. The
wealth of information on nucleotide sequences that is being generated through genome projects
far outweighs that which is currently available on the amino acid sequences of known
proteins(Lockhart JD et al., 2000; Pandey et al.,2000). Genome-sequence data and inferred
protein-sequence data can be used to identify proteins and to follow temporal changes in protein
expression in an organism. Recently, M. truncatula has been the subject of several proteomic
studies. (Lei et al., 2005). Furthermore, a proteomic study of M. truncatula protoplast cultures
has been conducted to analyze the molecular changes that take place during protoplast
proliferation (Mathesius et al., 2007). To date these works represent the most extensive
proteomic description of M. truncatula suspension cells and provide a reference map for future
comparative proteomics and functional genomics studies of responses to biotic and abiotic
stresses. Proteomic approach has also been applied in some of other legumes such as pea (Schiltz
et al., 2004; Curto et al., 2006) and/or Lotus species (Wienkoop et al., 2003; Boukli et al., 2007)
to get much information on host-pathogen interaction, nutrition mobilization and/or to gain better
understanding of the molecular basis of symbiosis in legumes.
Despite the importance of soybean in agriculture, increments in yields of this crop
through conventional breeding over the past few decades have lagged behind those that have
been achieved with cereal crops. Yields of soybean are reduced by numerous abiotic and biotic
factors, including flooding, drought, salinity, acidity, nutrient limitation, and various pests and
diseases. Proteomics a promising and powerful approach offers a new platform for studies of
complex biological functions involving large numbers and networks of proteins can be used as a
key tool in analyzing the gene response of non-model plants, particularly that genome has not yet
been completely sequenced such as legumes in response to several biotic and abiotic factors
(Carpentier et al., 2008). The major advantage of proteomics is that it focuses on the functional
translated portion of the genome. Although research on M. truncatula, pea and Lotus provides
insight into some fundamental aspects of molecular biology, it cannot address important aspects
relating to food legumes such as soybean.
Pairwise (BLASTP) and multiple sequence alignment (clustalW2) carried on chitinase
and significant homology with plant and less homology with bacteria is observed. The NCBI

Page | 4
BLAST for primary structure comparison shows similarity between amino acid sequences of
Glycine max and other crops. Functional motifs search using SIB Myhits (Expasy) detected that
besides active chitinase motifs some other conserved and some other functional domains with
variable repetitive frequencies with highly significant E values. Homology modeling (SWISS-
MODEL) and Threading (HHpred) were used for the 3-D structure prediction and the structure
was analyzed on PDBSUM.
In this study, it is shown that a class I chitinase is an abudent protein in soluble extracts
from soybean seed coat tissue. The 32 kDa protein was cataltically active and could be purified
in one step by affinity chromatography on chitin beads. Isolation, sequence analysis, homologous
modeling and comperative analysis of the seed coat class I chitinase precursor protein of 320
amino acids encoded within three exons. Expression of this chitinase gene was associated with
senescence, ripening, and response to pathogen infection (Gijzen et al., 2001).
In many regions of the world, microbial pathogens and pests continue to cause huge crop
losses. Controlling crop diseases is very difficult and requires intensive use of potentially unsafe
and environmentally harmful chemical plant protectants. Concern has been raised about both the
environmental and the potential risk related to the use of these compounds. Therefore,
considerable efforts have been made towards the development of alternative crop protectants.
Studies have shown that transgenic crop encoding chitinases, a pathogen related proteins are
highly resistant to pathogens. The objective of this work is to find and make a detail study on
such important chitinases which can be used to develop pathogen resistant agriculturally
important plant.
Keeping above in the view the present investigation was undertaken with following
objective.
1) Isolation and purification of chitinase from soybean seed coat.
2) Using bioinformatics tools to retrieve the sequence and search homology.
3) Structure prediction of the chitinase using homologous modelling.
4) Structural analysis of the chitinase to identify the key features.

Page | 5
Chapter 2
Review of literature
2.1 Fungal disease and their impact
Fungal pathogen cause significant crop losses amounting to several billion dollars per
annum, control disease in agricultural and horticultural crops is vital with food shortages
experienced in many region as well as demand for improved efficiency in food production
coupled with environmental protection in others (Johnson 1992). Loss of fertile soil s due to
improper management and erosion threatens to limit production of vital food crops in many areas
of the world (Longmann and Schell 1993).
Disease management expenses constitute one of the major costs associated with crop
production (Bridge et al., 2004). Several general approaches taken to control fungal disease are
(a) management/quarantine of agricultural land, (b) use of fungicides (c) breeding of resistance
crop varieties. Management includes chemical fallow, or soil cultivation that are expensive to
implement and may cause undesirable side effects such as soil erosion(Leong et al., 2004).
Furthermore despite the great advances in chemical management of fungal diseases some
of important plant pathogen causing vascular wilt, anthrocinose, take all of wheat and other root
infectious remain uncontrolled by current fungicide chemicals( Knight et al., 1997). In addition
fungicide may become less effective due to the evolution of resistance among the pathogen
(Faize et al., 2003).
2.2 FUNGAL CELL WALL
Chitin and β-glucan are the main components of fungal cells of filamentous fungi. Chitin
forms the back bone and laminair(β-1,3 glucan) is the filling material (Cohen kupiec et al.,
1999).
Chitin is linear polysachcharides composed of β-1,4 linked N-acetylaglucosamide units
and is found in nature as α and β chitin.
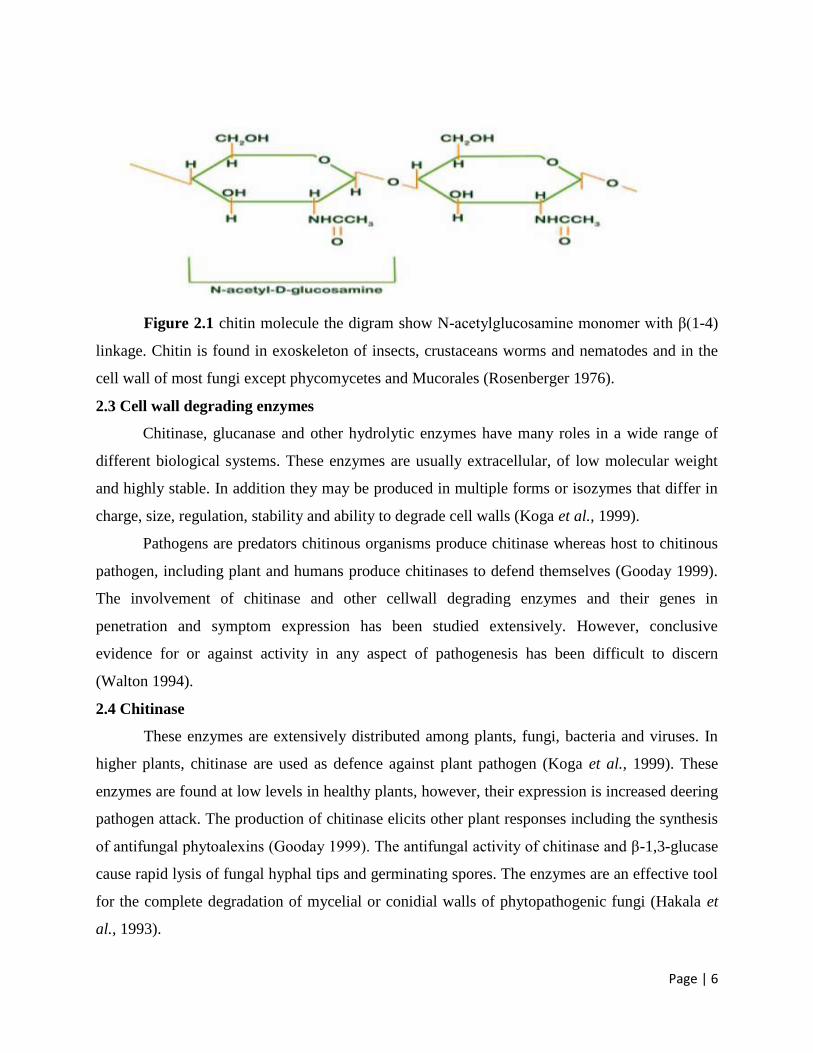
Page | 6
Figure 2.1 chitin molecule the digram show N-acetylglucosamine monomer with β(1-4)
linkage. Chitin is found in exoskeleton of insects, crustaceans worms and nematodes and in the
cell wall of most fungi except phycomycetes and Mucorales (Rosenberger 1976).
2.3 Cell wall degrading enzymes
Chitinase, glucanase and other hydrolytic enzymes have many roles in a wide range of
different biological systems. These enzymes are usually extracellular, of low molecular weight
and highly stable. In addition they may be produced in multiple forms or isozymes that differ in
charge, size, regulation, stability and ability to degrade cell walls (Koga et al., 1999).
Pathogens are predators chitinous organisms produce chitinase whereas host to chitinous
pathogen, including plant and humans produce chitinases to defend themselves (Gooday 1999).
The involvement of chitinase and other cellwall degrading enzymes and their genes in
penetration and symptom expression has been studied extensively. However, conclusive
evidence for or against activity in any aspect of pathogenesis has been difficult to discern
(Walton 1994).
2.4 Chitinase
These enzymes are extensively distributed among plants, fungi, bacteria and viruses. In
higher plants, chitinase are used as defence against plant pathogen (Koga et al., 1999). These
enzymes are found at low levels in healthy plants, however, their expression is increased deering
pathogen attack. The production of chitinase elicits other plant responses including the synthesis
of antifungal phytoalexins (Gooday 1999). The antifungal activity of chitinase and β-1,3-glucase
cause rapid lysis of fungal hyphal tips and germinating spores. The enzymes are an effective tool
for the complete degradation of mycelial or conidial walls of phytopathogenic fungi (Hakala et
al., 1993).

Page | 7
Chitinases are glycosyl hydrolases that catalyse the hydrolytic cleavage of the β-1,4-
glycoside bond present in bioplolymers of N-acetylglucosamine (Collinge et al., 1993). The main
substrate of chitinases is chitin, an insoluble homopolymer of β-1,4-linked N-acetylglucosamine
(GlcNAc) residues which is the second most abundant polymer in nature after cellulose (Brzeski,
1987; Ornum, 1992), and serves a structural role in fungal cell walls and arthropod cuticles
including those of insects, nematodes and crustaceans (Merzendorfer and Zimoch, 2003; Kramer
and Muthukrishnan, 2005). However, chitin has not been found in higher plants, vertebrates and
procaryotes (Cohen-Kupiec and Chet, 1998).
Chitinase genes are found in a range of bacteria (actinomycetes in particular) (Saito et al.,
1999), fungi (Rast et al., 2003), plants (Gomez et al., 2002) but also in viruses (Young et al.,
2005) and humans (Boot et al., 2001). Depending on the organism of origin, these enzymes have
different functions. Bacteria produce chitinases to meet nutritional needs. They usually produce
several chitinases, probably to hydrolyze the diversity of chitins found in nature (Ruiz-Sanchez
et al., 2005). In animals and plants, chitinases mainly play a role in the defence against pathogen
attacks (Patil et al., 2000).
2.4.1 Seed chitinase
Seed chitinase in soybean, little attention has been paid to the physiological and
biochemical basis underlying its defence mechanisms in response to pathogen and herbivore
attack (Vega-sa nchez et al., 2005). A recent investigation on the proteomics of seed filling in
soybean showed that >600 proteins are expressed during five key stages of seed development.
However, most of them, including 7% involved in plant defence, have not been purified and their
biological properties evaluated experimentally (Hajduch et al., 2005).
In soybean seed coat, a 41-kDa peroxidise (Buttery et al., 1968) and a 32-kDa class I
chitinase (Gijzen et al., 2001) have been identified, but their functions were not established. Choi
et al., 2008, showed that SE60, a member of the g-thionin family in soybean seeds, confers
resistance to transgenic tobacco plants against Pseudomonas syringae and might function as a
defence chemical against invading pathogens.
The soybean P. sojae infection site EST matching protein IV was sequenced and used to
probe a seed coat cDNA library to identify transcripts expressed in the seed coat. This resulted in
the isolation of several seed coat cDNA transcripts identical in sequence to the original soybean
(P. sojae) infection site cDNA. The 1.2 kb cDNA transcript encoded a preprotein of 320 amino

Page | 8
acids that shares features of class I chitinases isolated from other plant species. A signal peptide
leader sequence of 23 amino acids followed by a chitin binding domain, a proline hinge region,
and a catalytic domain were all represented in the peptide sequence. The mature protein of 297
amino acids has a calculated molecular mass of 31.9 kDa and does not possess any obvious
vacuolar targeting signals or N-glycosylation sites. Two crucial Glu residues required for
catalytic activity for this class of glycosyl hydrolases are conserved in the soybean chitinase and
correspond to Glu146 and Glu168 of the precursor protein (Gijzen et al., 2001). The soybean
chitinase peptide sequence was most similar (74% identity) to a chitinase (GenBank Accession
no. X63899) isolated from pea (Chang et al., 1995). The best Arabidopsis match (62% identity)
corresponded to a basic chitinase encoded by the T2E22.18 gene on chromosome 3 (Samac et
al., 1990).
The rice class I chitinase OsChia1b, also referred to as RCC2 or Cht-2, is composed of an
N-terminal chitin-binding domain (ChBD) and a C-terminal catalytic domain (CatD), which are
connected by a proline- and threonine-rich linker peptide. Because of the ability to inhibit fungal
growth, the OsChia1b gene has been used to produce transgenic plants with enhanced disease
resistance. As an initial step toward elucidating the mechanism of hydrolytic action and
antifungal activity, the full-length structure of OsChia1b was analyzed by X-ray crystallography
and small-angle X-ray scattering (SAXS). We determined the crystal structure of full-length
OsChia1b at 2.00-A resolution, but there are two possibilities for a biological molecule with and
without inter domain contacts. The SAXS data showed an extended structure of OsChia1b in
solution compared to that in the crystal form. This extension could be caused by the
conformational flexibility of the linker. A docking simulation of ChBD with tri-N-
acetylchitotriose exhibited a similar binding mode to the one observed in the crystal structure of
a two-domain plant lectin complexed with a chitooligosaccharide. A hypothetical model based
on the binding mode suggested that ChBD is unsuitable for binding to crystalline alpha-chitin,
which is a major component of fungal cell walls because of its collisions with the chitin chains
on the flat surface of alpha-chitin. This model also indicates the difference in the binding
specificity of plant and bacterial ChBDs of GH19 chitinases, which contribute to antifungal
activity (Kezuka et al., 2010).
Rye seed chitinase -a ( RSC-a) is abasic class I chitinase consisting of an N-terminal
chitin-binding domain and a catalytic domain is similar sequence to hevein, wheat germ

Page | 9
agglutinin, and poke weed lectin, which are refered to as chitin-binding proteins. Rye seed
chitinase-c ( RSC-c) is basic class II chitinase with 92% sequence to the cat domain of RSC-a,
but lacking the N-terminal chitin binding domain and a linker (Yamagami et al., 1994). RSC-a
has three times more chitinase activity than that of RSC-c when using colloidal chitin as an
insoluble substrate (Yamagami et al.,1993). Yamagami et al., 1996, have previously isolated the
chitin binding domain and the Cat domain after limited thermolysin hydrolysis of RSC-a. The
chitinase activity of the Cat domain, using colloidal chitin, was decreased to the level of RSC-c.
2.5 Classification of chitinases
The chitinolytic enzymes are traditionally divided into two main categories.
Endochitinases (EC 3.2.1.14) cleave chitin randomly at internal sites, generating soluble low
molecular mass multimers of GlcNAc (Botha et al., 1998) and exochitinases that can be divided
into two subcategories: chitobiosidases (EC 3.2.1.29), that catalyze the progressive release of di-
acetylchitobiose and 1,4-β-N-acetylglucosaminidases (EC3.2.1.30), which cleave the oligomeric
products of endochitinases and chitobiosidases generating monomers of GlcNAc (Sahai and
Manocha, 1993). The types of chitinases most extensively studied in plants are endochitinases
(Roberts and Selitrennikoff, 1988) of which many show some degree of lysozyme (EC 3.2.1.17)
activity, i.e. they can hydrolyse β-1,4-linkages between N-acetyl-muramic acid and GlcNAc
residues in peptidoglucan (Schultze et al., 1998).
Different classes have been defined within each family. Classes I and IV are
characterized by the presence of an N-terminal, cystein rich, usually referred to as hevein-like
domain or chitin-binding domain (CBD), which is important for binding chitin but not for
catalytic activity (Iseli et al., 1993). When present, the CBD is separated from the catalytic
domain by a hinge region, variable in length and amino-acid sequence. Most class I chitinases
have molecular masses of around 32 kDa and are defined into two subclasses class Ia and Ib.
Class Ia involves basic chitinases possessing a leucine- or valine-rich carboxy-terminal signal
peptide that is essential for targeting into the plant cell vacuole (Neuhaus et al., 1991), whereas
class Ib chitinases are acidic, lack the signal peptide and are therefore, extracellular (Flach et al.,
1992). Class II chitinases, mainly found in dicolyledons, have molecular masses of 27 to 28 kDa.
Plants express a large number of chitinase isozymes, mostly in the course of defence
reactions against pathogen, and so they have been classified as pathogenesis-related proteins
(PR). The plant chitinases have been classified according to their sequences into four families

Page | 10
within the families of PR-proteins (Neuhaus et al., 1996). Based on biological properties,
enzyme activity and coding sequence similarities, PR proteins are divided into 17 classes.
Chitinases belong to three classes. Class PR-3 includes chitinases of class Ia, Ib, II, IV, VI and
VII, and forms the family 19 glycosyl hydrolases. Chitinases of class III belong to PR-8, and
chitinases of class V to PR-11. They, both, belong to family 18 glycosyl hydrolases.
Additionally, in class PR-4, some proteins with low endochitinase activity were found among the
chitin-binding proteins (Theis et al., 2004).
Based on their primary structure and similarities in amino acid sequences, chitinases can
be classified into two families of glycosyl hydrolases, 18 and 19. Family 18 chitinases break the
β-1,4-glycoside bond in G1cNac- G1cNAc and G1cNAc- G1cN, while family 19 chitinases
break G1cNac- G1cNAc and G1cN- G1cNAc linkage. These two families can be separated into
six smaller classes which class I, II, IV and V chitinases form the family 19, whereas class III
and VI form the family 18. Most of the classes in family 19 are chitinases that only can be found
in plants. While the classes in family 18 refer to chitinases for all fungal, animal and bacterial as
well as plant chitinases (Iseli et al., 1996).
These six classes are identified according to the chitinases characteristics that based on
isoelectic pH, signal peptide, location of enzyme, N- terminal sequence, and the inducers. Class I
chitinases are endochitinases, whereas Class II chitinases are exochitinases. Class III chitinases
do show any similarity to Class I and II chitinases. Although Class IV chitinases show similar
characteristics as Class I chitinases, but they are smaller than enzymes Class I. Class V chitinases
are nettle lectin precursor that show two chitin binding domain in tandem whereas, Class VI
chitinases are all chitinases that no included in Class I, II, III, IV and V chitinases (Theis et al.,
2004).
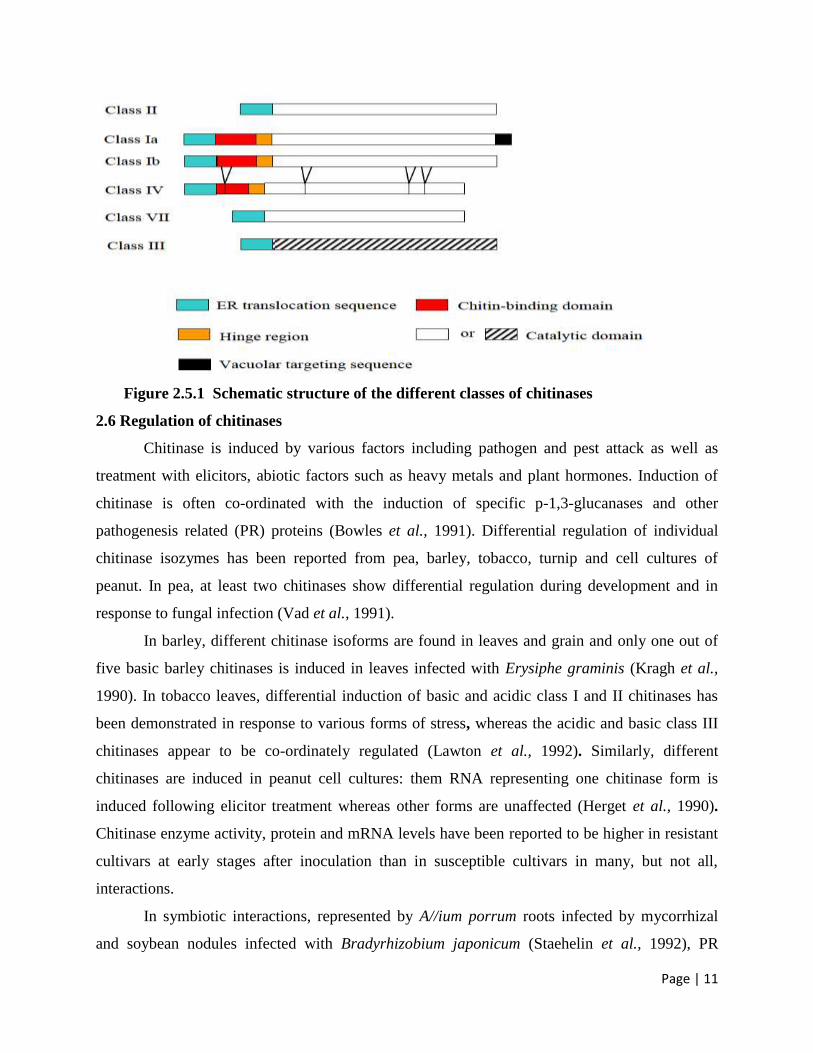
Page | 11
Figure 2.5.1 Schematic structure of the different classes of chitinases
2.6 Regulation of chitinases
Chitinase is induced by various factors including pathogen and pest attack as well as
treatment with elicitors, abiotic factors such as heavy metals and plant hormones. Induction of
chitinase is often co-ordinated with the induction of specific p-1,3-glucanases and other
pathogenesis related (PR) proteins (Bowles et al., 1991). Differential regulation of individual
chitinase isozymes has been reported from pea, barley, tobacco, turnip and cell cultures of
peanut. In pea, at least two chitinases show differential regulation during development and in
response to fungal infection (Vad et al., 1991).
In barley, different chitinase isoforms are found in leaves and grain and only one out of
five basic barley chitinases is induced in leaves infected with Erysiphe graminis (Kragh et al.,
1990). In tobacco leaves, differential induction of basic and acidic class I and II chitinases has
been demonstrated in response to various forms of stress, whereas the acidic and basic class III
chitinases appear to be co-ordinately regulated (Lawton et al., 1992). Similarly, different
chitinases are induced in peanut cell cultures: them RNA representing one chitinase form is
induced following elicitor treatment whereas other forms are unaffected (Herget et al., 1990).
Chitinase enzyme activity, protein and mRNA levels have been reported to be higher in resistant
cultivars at early stages after inoculation than in susceptible cultivars in many, but not all,
interactions.
In symbiotic interactions, represented by A//ium porrum roots infected by mycorrhizal
and soybean nodules infected with Bradyrhizobium japonicum (Staehelin et al., 1992), PR

Page | 12
proteins including chitinase can be induced. This may reflect a need to protect the symbiotic host
from external pathogenic invasion, or pathogenic development of the symbiont.
Treatment of the plants with abiotic elicitors such as heavy metal or salt solutions induces
chitinase activity. Systemic induction of chitinase activity was found in the leaves of barley and
rape 2 days after the roots were exposed to Cr(VI) (Cr03), although not following Cr(lll) (CrCI3)
treatment (Jacobsen et al., 1992). It has been demonstrated that systemically induced resistance
occurs following infection with pathogens or treatment with methyl-2,6-dichloroisonicotinic acid
and salicylic acid. The latter is a well known abiotic elicitor which also acts as a systemic
endogenous signal for induction of PR proteins in tobacco (Yalpani et al., 1991).
2.7 Structure and mechanism
On the basis of their primary structure, most chitinolytic enzymes are grouped into two
families of glycosyl hydrolases, 18 and 19 (Henrissat and Bairoch, 1993). So far family 19
chitinases have only been found in plants and some Streptomyces species (Ohno et al., 1996) and
recently in Aeromonas sp. (Ueda et al., 2003). Class III and V belong to family 18 and classes I,
II, IV, VI, and VII belong to family 19. Both families do not share any sequence similarity, and
have completely different three dimensional structure and hydrolysis mechanisms (Fukamizo et
al., 2000).
The structures for both families were determined by X-ray crystallography analysis of a
barley (Hordeum vulgare L.) and a jack bean chitinase belonging to family 19 (Hahn et al.,
2000) and chitinases from Serratia marcescence, Hevea brasiliensis (rubber tree) and the
pathogenic fungus Coccidioides immitis which are family 18 members (Papanikolau et al.,
2001). The overall fold of family 19 chitinases corresponds to a compact α-helical domain with
three conserved disulfide bridges. The hypothetical binding cleft is composed of two α- helices
and three-stranded β-sheet (Hart et al., 1995). The folding as well as substrate specificities of
family 19 were reported to be very similar to those of lysozyme (Holm and Sander, 1994)
leading to the proposal that both families have related catalytic mechanisms. On the other hand,
family 18 chitinases have a typical (α/β)8 barrel structure composed of eight α- helices and an
eight stranded β-sheet, with an additional N-terminal β-strand-rich domain and a small (α+β)
domain (Terwisscha van Scheltinga and Dijikstra, 1996).
Most, if not all, glycosyl hydrolases are thought to act by general acid catalysis involving
carboxylic residues. Such an acid-catalyzed glycosidic hydrolysis may proceed either through the

Page | 13
double-displacement mechanism to yield a hydrolyzed product with retention of the anomeric
configuration (at C1) (relative to the starting conformation), or through the single displacement
mechanism resulting in the inversion of the latter (Perrakis et al., 1996). All of the family 18
chitinases reported to date proceed through the retaining mechanism yielding a β-anomer
hydrolysis product, whereas family 19 chitinases result in the inverted α-anomer (Iseli et al.,
1996). Glu 89) in the active site separated by 9.3 Å (Andersen et al., 1997). In the course of
hydrolysis, the Glu 67 residue acts as a general acid and protonates the glycosidic oxygen atom
forming an oxocarbonium ion intermediate, and then the water molecule activated by the general
base Glu 89 attacks the C1 atom of the intermediate state from the α-side to complete the
reaction. Despite the structural similarities of hen egg-white lysozyme (HEWL) with the family
19 barley chitinase, their catalytic mechanisms are different since HEWL retains the anomeric
configuration after hydrolysis. The difference in catalytic activity between the two enzymes is
attributed to the distance between the two catalytic residues (9.3 Å), which in case of HEWL are
within just a few Å (4.6 Å) (Brameld and Goddard, 1998a) In contrast to family 19 chitinases,
the enzymes of family 18 operate through a substrate-assisted mechanism with a single glutamic
acid acting as the single catalytic residue (Tews et al., 1996). During the course of hydrolysis an
oxazoline intermediate forms through an anchimeric assistance of the neighbouring N-acetyl
group. The mechanism does not require the second carboxylate and can rationalize the anomer
retaining reaction of the enzymes without the second carboxylate (Fukamizo, 2000).
2.8 The roles of chitinases
Plants do not contain chitin in their cell walls, whereas major agricultural pests such as
most fungi (ascomycetes, basidiomycetes, and deuteromycetes) and insects do (Collinge et al.,
1993), leading to the assumption that plant chitinases are involved in defence mechanism against
pathogens either directly through their antifungal properties or indirectly through the release of
chitin oligomers capable of eliciting plant defensive responses (Suarez et al., 2001; Gomez et al.,
2002). Evidence has been reported that chitinases can degrade fungal cellwalls and inhibit fungal
growth particularly in combination with class I 1,3-β-glucanases (Arlorio et al., 1992). The
expression of a number of chitinase genes appeared to be induced upon fungal infection and they
were shown to accumulate around hyphal walls of infection sites in planta (Wubben et al., 1992).
Moreover, plants over expressing chitinases showed decreased susceptibility to infection by
some fungi that have chitin-containing cell walls (Jongedijk et al., 1995).

Page | 14
A model of the roles of chitinases in plant defence response, proposed by (Mauch and
Staehelin 1989) suggests that these enzymes are involved at different stages of pathogenesis. The
apoplastic chitinases play a role in early stages of infection by releasing elicitor molecules
involved in the transfer of information about the infection of the hyphae that penetrate the
intercellular space (de A Gerhardt et al., 1997). Subsequently, these elicitors bind to particular
receptors switching on the active defence mechanisms, e.g. a higher rate of chitinase synthesis,
additional plant PR-proteins (osmotin, zeamatin, thaumatin–like proteins), phytoalexins and
other compounds (El Gueddari, 2003). During the following phase of pathogenesis, when fungal
enzymes digest the host cell wall causing the protoplast to burst, the vacuolar chitinases and 1,3-
β-glucanases enter into action by flooding the invading fungus with lethal concentrations of the
enzymes. In addition to their well established anti-fungal activity, the specificity of expression of
some chitinase genes suggest that they could play a role in developmental processes, such as
senescence, root and root nodule development, seed germination and somatic embryogenesis
(Gomez et al., 2002; Kasprzewka, 2003).
Plant chitinases also take part in legume nodulation by degrading and deactivating part of
the bacterial lipochitooligosacharide (Nod factors), thus repressing the intensity of root nodule
formation (Cullimore et al., 2001). Finally, some cold-inducible chitinases from winter rye
leaves possess anti-freeze activity which could be important to protect seed tissues from frost
(Hiilvoaara-Teijo et al., 1999; Yeh et al., 2000).
2.9 Biotechnological Applications of chitinases
Chitinases as well as the chitooligosacharides resulting from chitin and chitosan
degradation have shown immense potentials in several fields. Chitinases are reported to dissolve
cell walls of various fungi, a property that has been used for the generation of fungal protoplasts
proving to be an effective tool for studying cell wall synthesis, secretion, as well as strain
improvement (Dahiya et al., 2005).
Chitin and chitosan are the most ubiquitous polymers of fungal cell walls. Although
biochemical analysis can provide precise information about their structures, cytochemical
localization studies can reveal the functional specialization of these polymers. Wheat germ
agglutinin–gold complex and chitinase gold complex have been used as probes for the detection
of GlcNAc residues in the secondary cell walls of plants and in pathogenic fungi (Benhamou and
Asselin 1989).

Page | 15
2.9.1 Production of single-cell protein
The solid waste from shellfish processing is mainly composed of chitin, CaCO3, and
protein. Revah-Moiseev and Carrod (1981) suggested the use of shellfish waste for the
bioconversion of chitin to yeast single-cell protein (SCP) using chitinolytic enzymes. They used
the S. marcescens chitinase system to hydrolyze the chitin and Pichia kudriavazevii to yield SCP
(with 45% protein and 8–11% nucleic acids). The commonly used fungi as the source of SCP are
Hansenula polymorpha, Candida tropicalis, Saccharomyces cerevisiae, and Myrothecium
verrucaria. Vyas and Deshpande (1991) utilized the chitinolytic enzymes of M. verrucaria and
S. cerevisiae for the production of SCP from chitinous waste. The total protein content was
reported to be 61%, with very low contents of nucleic acids (3.1%). Cody et al., (1990)
suggested the enzymatic conversion of chitin to ethanol. The criteria used to evaluate SCP
production are growth yield, total protein, and nucleic acid contents. The protein content in
organisms used was between 39 and 73%, whereas the nucleic acid contents were 1–11%. The
best reported was that of S. cerevisiae, which exhibited more than 60% proteins and 1–3%
nucleic acid contents.
2.9.2 Isolation of protoplasts
Fungal protoplasts have been used as an effective experimental tool in studying cell wall
synthesis, enzyme synthesis, and secretion, as well as in strain improvement for biotechnological
applications. Since fungi have chitinin their cell walls, the chitinolytic enzyme seems to be
essential along with other wall-degrading enzymes for protoplast formation from fungi. Dahiya
et al., (2005) reported the effectiveness of Enterobacter sp. NRG4 chitinase in the generation of
protoplasts from Trichoderma reesei, Pleurotus florida, Agaricus bisporus, and A. niger. Mizuno
et al., (1997) isolated protoplast from Schizophyllum commune using the culture filtrate of B.
circulans KA-304. An enzyme complex from B. circulans WL-12 with high chitinase activity
was effective in generating protoplasts from Phaffia rhodozyme (Johnson et al., 1979).
2.9.3 Production of chitooligosaccharides, glucosamine, and GlcNAc
Chitooligosaccharides, glucosamines, and GlcNAc have an immense pharmaceutical
potential. Chitooligosaccharides are potentially useful in human medicines. A chitinase
preparation from S. griseus was used for the enzymatic hydrolysis of colloidal chitin. The
chitobiose produced was subjected to chemical modifications to give novel disaccharide

Page | 16
derivatives of 2-acetamido 2-deoxy D-allopyranose moieties that are potential intermediates for
the synthesis of an enzyme inhibitor, that is, N,N′-diacetyl-β- chitobiosyl allosamizoline
(Terayama et al., 1993).
Specific combinations of chitinolytic enzymes would be necessary to obtain the desired
chain length of the oligomer. For example, the production of chitooligosaccharides requires high
levels of endochitinase and low levels of N-acetylglucosaminidase and exochitinase, whereas the
production of GlcNAc requires higher proportion of exochitinase and N-acetylglucosaminidase
(Aloise et al., 1996).
Nanjo et al., (1989) observed the accumulation of hexamer when tetramer or pentamer
was incubated with Nocardia orientalis chitinase. A chitinase from T. reesei also exhibited a
similar type of efficient transglycosylation reaction. They reported the accumulation of hexamer
and dimer as the major product when the enzyme was reacted with tetramer (Usui et al., 1990).
They also observed a chain elongation from dimer to hexamer and heptamer using lysozyme
catalysis in the presence of 30% ammonium sulfate in a buffered medium. Chi-26 from
Streptomyces kurssanovii showed the accumulation of hexamer in the reaction mixture
containing tetramer and pentamer (Stoyachenko et al., 1994).
The transglycosylation reaction of Mucor hiemalis endo-β-N-acetyl glucosaminidase was
used for the preparation of sugar derivatives modified at C-1 or C-2 for the synthesis of
glycopeptides (Yamanoi et al., 2004).
Crude bacterial chitinases from Burkholderia cepacia TU09 and B. licheniformis SK-1
were used for the hydrolysis of α- chitin (from crab shells) and β-chitin (from squid pens) to
produce GlcNAc (Pichyangkura et al., 2002). Sashiwa et al., (2002) produced GlcNAc from α-
chitin using crude chitinolytic enzymes from Aeromonas hydrophila H-2330.
2.9.4 Chitinase as a target for biopesticides
Chitin is present in the exoskeleton and gut lining of insects. The molting enzyme
chitinase has been described from Bombyx mori (silkworm), Manduca sexta (tobacco
hawkmoth), and several other species. Similarly, chitinases have been implicated in different
morphological events in fungi (Villagomez-Castro and Lopez-Romero, 1996). Allosamidin, a
potent inhibitor of chitinase, was found to be inhibitory to the growth of mite (Tetranychus
urticae) and a housefly larva (Musca domestica) after ingestion (Sakuda et al., 1987). Chitinase
inhibitors can be explored as potential biopesticides.

Page | 17
2.9.5 Estimation of fungal biomass
A variety of methods have been described to quantify fungi in soil. The techniques
include direct microscopic observation and extraction of fungus-specific indicator molecules
such as glucosamine ergosterol. A strong correlation has been reported between chitinase activity
and fungal population in soils. Such correlation was not found for bacteria and actinomycetes.
Thus, chitinase activity appears to be a suitable indicator of actively growing fungi in soil. Miller
et al., (1998) reported the correlation of chitinase activity with the content of fungus-specific
indicator molecules 18:2ωb phospholipid fatty acid and ergosterol using specific
methylumbelliferyl substrates. Similarly, chitinase and chitin- binding proteins can be used for
the detection of fungal infections in humans (Laine and Lo 1996).
2.9.6 Mosquito control
The worldwide socioeconomic aspects of diseases spread by mosquitoes made them
potential targets for various pest control agents. In case of mosquitoes, entomopathogenic fungus
such as Beauveria bassiana could not infect the eggs of Aedes aegypti, a vector of yellow fever
and dengue, and other related species due to the aquatic environment. The scarabaeid eggs laid in
the soil were found to be susceptible to B. bassiana (Ferron, 1985). M. verrucaria, a saprophytic
fungus, produces a total complex of an insect cuticle-degrading enzyme (Shaikh and Desphande,
1993). It has been seen that both first and fourth instar larvae of mosquito A. aegypti can be
killed within 48 h with the help of the crude preparation from M. verrucaria (Mendonsa et al.,
1996). Though 100% mortality was observed within 48 h, purified endochitinase lethal times
(LT50) were 48 and 120 h for first and fourth instar larvae, respectively. However, the time
period was found to be decreased, corresponding to 24 h and 48 h, when the purified chitinase
was supplemented with lipolytic activity.
2.9.7 Morphogenesis
Chitinases play an important role in yeast and insect morphogenesis. Kuranda and
Robbins (1991) reported the role of chitinases in cell separation during growth in S. cerevisiae,
and Shimono et al., (2002) studied the functional expression of chitinase and chitosanase and
their effects on morphogenesis in the yeast S. pombe. When the chiA gene was expressed in S.
pombe, yeast cells grow slowly and cells become elongated, but when the choA gene was

Page | 18
expressed, cells become swollen. Expression of both chiA and choA genes resulted in elongated
and fat cells.
2.9.8 Defense and Transgenes in Plants
Numeros plant chitinase genes or cDNAs have been cloned. In a successful case,
transgenic tobacco under the control of the cauliflower mosaic virus 35S promoter. The
transgenic tobacco plants were less susceptible to infection by Rhizoctonia solani and either the
disease development was delayed or they were not affected at all. Evaluation of disease
development in hybrids plants, heterozygous for each transgenes and homozygous self progeny,
showed that combination of the two trangenes gave substantially greater protection against the
fungal pathogen Cercospors nicotianae than either gene. These data led to the suggestion that
combinatorial expression of antifungal genes could be an effective approach to engineering
enhanced crop protection against fungal disease (Muzzarelli R, 1999).
2.9.9 Control of plant pathogenic fungi
Biological control or the use of microorganisms or their secretions to prevent plant
pathogens and insect pests offers an attractive alternative or supplement for the control of plant
diseases. Therefore, biological control tactics have become an important approach to facilitate
sustainable agriculture (Wang et al., 2002).
Chitin application increased the population of chitinolytic actinomycetes, fungi, and
bacteria. The increase is shown to be correlated with the reduction in pathogenic fungi and
nematodes and, more importantly, with the reduction of infectivity and, hence, crop damage
(Wang et al., 2002). A biological control agent of fungal root pathogen should exert a sufficient
amount of antagonistic activity.
The chitinase produced by Enterobacter sp. NRG4 was highly active toward Fusarium
moniliforme, A. niger, Mucor rouxi, and Rhizopus nigricans (Dahiya et al., 2005). The chitinase
from Alcaligenes xylosoxydans inhibited the growth of Fusarium udum and Rhizoctonia
bataticola (Vaidya et al., 2001).
Mahadevan and Crawford (1997) reported the antagonistic action of Streptomyces lydicus
WXEC108 against Pythium ultimum and Rhizoctonia solani, which cause disease in cotton and
pea. Horsch et al., (1997) suggested the use of N-acetylhexosaminidase as a target for the design
of low molecular weight antifungals. Chitinases can be added as a supplement to the commonly

Page | 19
used fungicides and insecticides not only to make them more potent but also to minimize the
concentration of chemically synthesized active ingredients of the fungicides and insecticides that
are otherwise harmful to the environment and health. Bhushan and Hoondal, (1998) studied the
compatibility of a thermostable chitinase from Bacillus
sp. BG-11 with the commonly used fungicides and insecticides.
A Fusarium chlamydosporum strain, a mycoparasite of groundnut rust (Puccinia
arachidis), produces endochitinase that inhibits germination of uredospores of rust fungus
(Mathivanan et al., 1998). Chitinolytic enzymes of T. harzianum were found to be inhibitory to a
wide range of fungi than similar enzymes from other sources (Lorito et al., 1993). Govindsamy
et al., (1998) reported the use of purified preparation of M. verrucaria chitinase to control a
groundnut rust, P. arachidis. Penicillium janthinellum P9 caused mycelial damage in Mucor
plumbus and Cladosporium cladosporiodes (Giambattista et al., 2001).
Partially purified chitinase from T. harzianum destroys the cell wall of Crinipellis
perniciosa, the casual agent of witches’ broom disease of cocoa (DeMarco et al., 2000).
Chitinase from B. cereus YQ 308 inhibited the growth of plant pathogenic fungi such as
Fusarium oxysporum, Fusarium solani, and P. ultimum (Chang et al., 2003).
2.10 BIOINFORMATICS TOOLS
2.10.1 Protein sequence databases
Several protein sequence databases act as repositories of protein sequences and, like the
primary nucleotide sequence databases, these are essential to provide the sequences to the user as
quickly as possible. These databases add little or no additional information to the sequence
records they contain and generally make no effort to provide a non-redundant collection of
sequences to users. Expert biologists validate such curated data before being added to the
databases to ensure that the data in these collections is highly reliable. There is also a large effort
invested in maintaining non-redundant datasets by compiling all reports for a given protein
sequence into a single record.
2.10.1.1 GenPept
The GenBank Gene Products data bank (GenPept) (Wheeler et al., 2005) is produced by
the NCBI. Entries in the database are derived from translations of the coding sequences
contained in the collaborative nucleotide database and contain minimal annotation. The

Page | 20
annotation in a GenPept entry has been extracted from the corresponding nucleotide entry and
the database does not contain proteins derived from amino acid sequencing. The database is
redundant as multiple records may represent each protein; no attempt is made to group these
records into a single database entry.
2.10.1.2 Entrez protein
Entrez protein, a sequence repository also produced by NCBI, is compiled from a variety
of sources. It also contains sequence data from translations of the coding sequences contained in
the collaborative nucleotide database as well as protein sequences submitted to Protein
Information Resource (PIR), UniProtKB/Swiss-Prot, Protein Research Foundation (PRF) and
Protein Data Bank (PDB). Additional information exists as it has been extracted from the
manually curated databases such as UniProtKB/Swiss-Prot. As with GenPept, thesequence
collection is redundant.
2.10.1.3 UniProt
The Universal Protein Resource (UniProt) (Bairoch et al., 2005) is a comprehensive
catalogue of data on protein sequence and function, maintained by the
UniProt consortium. The consortium is a collaboration of the Swiss Institute of Bioinformatics
(SIB), the European Bioinformatics Institute (EBI), and the Protein Information Resource (PIR).
UniProt is comprised of three components. Firstly, the expertly curated UniProt Knowledgebase
(UniProtKB) which will continue the work of UniProtKB/Swiss-Prot, UniProtKB/TrEMBL
(Boeckmann et al., 2003) and PIR (Wu et al., 2003).
UniProtKB/Swiss-Prot is a manually annotated database with information extracted from
literature and curator-evaluated computational analysis. It contains a minimal level of
redundancy and a high level of integration with other databases. UniProtKB/TrEMBL contains
the translations of all coding sequences present in the collaborative nucleotide database and also
protein sequences extracted from the literature or submitted to UniProtKB. Entries are enriched
with automated classification and annotation. Records are awaiting full manual annotation. PIR
produced the Protein Sequence Database (PSD) of functionally annotated protein sequences,
which grew out of the Atlas of Protein Sequence and Structure (1965–1978) edited by Margaret
Dayhoff. PIR-PSD is now an archive database as all sequences and annotations have been
integrated into UniProtKB. Secondly, the UniProt archive (UniParc), into which new and
updated sequences are loaded on a daily basis. UniParc (Leinonen et al., 2004) is a

Page | 21
comprehensive repository of protein sequences, providing a mechanism by which the historical
association of database records and protein sequences can be tracked. It is non-redundant at the
level of sequence identity, but may contain semantic redundancies. Thirdly, the non-redundant
UniProt Reference clusters (UniRef) that provide non-redundant reference data collections based
on the UniProt knowledgebase in order to obtain complete coverage of sequence space at several
resolutions: 100, 90 and 50% sequence similarity. Updates of UniProt are publicly available on a
biweekly schedule. The UniProt Release 6.1 consists of: UniProtKB/Swiss-Prot Protein
Knowledgebase Release 48.1 of 27-September- 2005 (contains 195,058 sequence entries,
comprising
70,674,903 amino acids abstracted from 134,132 references) and UniProtKB/TrEMBL Protein
Database Release 31.1 of 27-September-2005 (2,105,517 sequence entries comprising
680,464,593 amino acids).
2.11 Protein family classification and functional annotation
The high-throughput genome projects have resulted in a rapid accumulation of genome
sequences for a large number of organisms. To fully realize the value of the data, scientists need
to identify proteins encoded by these genomes and understand how these proteins function in
making up a living cell. With experimentally verified information on protein function lagging far
behind, computational methods are needed for reliable and large-scale functional annotation of
proteins. A general approach for functional characterization of unknown proteins is to infer
protein functions based on sequence similarity to annotated proteins in sequence databases.
(Bork and Koonin, 1998).
Indeed, numerous genome annotation errors have been detected (Brenner, 1999; Devos
and Valencia, 2001), many of which have been propagated throughout other molecular
databases. There are several sources of errors. Since many proteins are multifunctional, the
assignment of a single function, which is still common in genome projects, results in incomplete
or incorrect information. Errors also often occur when the best hit in pairwise sequence similarity
searches is an uncharacterized or poorly annotated protein, or is itself incorrectly predicted, or
simply has a different function.
The Protein Information Resource (PIR) (Wu et al., in press) provides an integrated
public resource of protein informatics to support genomic and proteomic research and scientific

Page | 22
discovery. PIR produces the Protein Sequence Database (PSD) of functionally annotated protein
sequences, which grew out of the Atlas of Protein Sequence and Structure edited by Dayhoff
(1965-1978).
Protein family classification of proteins provides valuable clues to structure, activity, and
metabolic role. Protein family classification has several advantages as a basic approach for large-
scale genomic annotation: (1) it improves the identification of proteins that are difficult to
characterize based on pairwise alignments; (2) it assists database maintenance by promoting
family-based propagation of annotation and making annotation errors apparent; (3) it provides an
effective means to retrieve relevant biological information from vast amounts of data; and (4) it
reflects the underlying gene families, the analysis of which is essential for comparative genomics
and phylogenetics.
In recent years, a number of different classification systems have been developed to
organize proteins. Scientists recognize the value of these independent approaches, some highly
automated and others curated. Among the variety of classification schemes are: (1) hierarchical
families of proteins, such as the superfamilies/families (Barker et al., 1996) in the PIR-PSD, and
protein groups in ProtoMap (Yona et al., 2000); (2) families of protein domains, such as those in
Pfam
(Bateman et al., 2002) and ProDom (Corpet et al., 2000); (3) sequence motifs or conserved
regions, such as in PROSITE (Falquet et al., 2002) and PRINTS (Attwood
et al., 2002); (4) structural classes, such as in SCOP (Lo Conte et al., 2002) and CATH (Pearl et
al., 2001); as well as (5) integrations of various family classifications, such as iProClass (Huang
et al., in press) and InterPro (Apweiler et al., 2001).
While each of these databases is useful for particular needs, no classification
scheme is by itself adequate for addressing all genomic annotation needs. The PIR
superfamily/family concept (Dayhoff, 1976), the original such classification based on sequence
similarity, is unique in providing comprehensive and non-overlapping clustering of protein
sequences into a hierarchical order to reflect their evolutionary relationships. Proteins are
assigned to the same superfamily/family only if they share end-to-end sequence similarity,
including common domain architecture (i.e. the same number, order, and types of domains), and
do not differ excessively in overall length (unless they are fragments or result from alternate
splicing or initiators). Other major family databases are organized based on similarities of

Page | 23
domain or motif regions alone, as in Pfam and PRINTS. There are also databases that consist of
mixtures of domain families and families of whole proteins, such as SCOP and TIGRFAMs
(Haft et al., 2001).
2.12 The Swiss-Prot protein knowledgebase and ExPASy
The Swiss-Prot protein knowledgebase provides manually annotated entries for all
species, but concentrates on the annotation of entries from model organisms to ensure the
presence of high quality annotation of representative members of all protein families. A specific
Plant Protein Annotation Program (PPAP) was started to cope with the increasing amount of data
produced by the complete sequencing of plant genomes. Its main goal is the annotation of
proteins from the model plant organism Arabidopsis thaliana. As protein families and groups of
plant-specific proteins are regularly reviewed to keep up with current scientific findings, we hope
that the wealth of information of Arabidopsis origin accumulated in our knowledgebase, and the
numerous software tools provided on the Expert Protein Analysis System (ExPASy) web site
might help to identify and reveal the function of proteins originating from other plants. Recently,
a single, centralized, authoritative resource for protein sequences and functional information,
UniProt, was created by joining the information contained in Swiss-Prot, Translation of the
EMBL nucleotide sequence (TrEMBL), and the Protein Information Resource–Protein Sequence
Database (PIR–PSD). A rising problem is that an increasing number of nucleotide sequences are
not being submitted to the public databases, and thus the proteins inferred from such sequences
will have difficulties finding their way to the Swiss-Prot or TrEMBL databases. Exploitation of
the overwhelming amount of data produced by large-scale genomic and proteomic studies
necessitates the development of integrative platforms that regroup information from several
disparate sources.
The Expert Protein Analysis System (ExPASy) World Wide Web server
(http://www.expasy.org) (Gasteiger et al., 2003) is such a hub that provides access to a variety of
databases and analytical tools dedicated to proteins and proteomics.
Following the publication of the first complete plant genome sequence, from Arabidopsis
thaliana (Nature, 2000) in December 2000, and the prediction of 25,498 protein-encoding genes,
the Swiss-Prot group initiated the Plant Proteome Annotation program (PPAP). This Program is
devoted to the annotation of plant-specific protein families. Our major effort is directed towards

Page | 24
A. thaliana, without neglecting annotation of proteins from other plant species, with an emphasis
on species that are the target of genomic, proteomic or transcriptomic projects (rice, maize,
wheat, soybean, Medicago, etc.).
2.12.1 Analysis of Protein Sequence/Structure Similarity Relationships
Proteins display diverse sequence/structure similarity relationships. Understanding
protein similarity relationships is vital for the annotation of genome sequences (Todd et al.,
2001). Proteins with high sequence identity and high structural similarity tend to possess
functional similarity and evolutionary relationships, yet examples of proteins deviating from this
general relationship of sequence/structure/ function homology are well-recognized. For example,
high sequence identity but low structure similarity can occur due to conformational plasticity,
mutations, solvent effects, and ligand binding. Despite this protein diversity most current surveys
have focused on the expected similarity relationship where the proteins have significant sequence
and structural similarity (Levitt and Gerstein, 1998; Wood and Pearson, 1999).
The physical basis of the expected sequence/structure similarity relationship remains
unexplored. To survey and examine the basis of protein relationships, we report here a
representative, broader sequence/structure map that captures known similar/dissimilar protein
relationships (Schlick, 2002).
2.13 Multiple protein sequence alignment
A variety of sequence and structural analysis methods relyon multiple sequence
alignments, including methods for similarity searches, structure modeling, function prediction,
and phylogenetic analysis. Construction of a multiple sequence alignment aims at arranging
residues with inferred common evolutionary origin or structural/functional equivalence in the
same column position for a set of sequences. Position-specific information about residue usage,
conservation and correlation can be deduced from a multiple sequence alignment for various
applications. Thus, the quality of alignments is a crucial factor for their proper usage. Accurate
and fast construction of multiple sequence alignments has been under extensive research in
recent years, and a variety of methods have been developed (Edgar et al.,2006; Notredame,
2007; Wallace 2005).

Page | 25
While pairwise alignment has simple and tractable algorithms using dynamic
programming (Needleman et al., 1970; Smith and Waterman, 1981), direct extension of these
algorithms to aligning multiple sequences is computationally expensive and infeasible for more
than a few sequences (Lipman et al., 1989; Wang and Jiang, 1994). Therefore, many
approximate algorithms have been developed for multiple sequence alignments, including the
commonly used progressive alignment technique (Feng et al., 1987). Progressive methods
assemble a multiple alignment by making a series of pairwise alignments of sequences or pre-
aligned groups. The order of these pairwise alignments is guided by a tree or dendrogram so that
similar sequences tend to be aligned before divergent sequences. Progressive methods cannot
guarantee an optimal solution, and do not correct for errors made in each pairwise alignment
step. Using scoring functions based on general residue substitution models, classic progressive
methods such as ClustalW (Thompson et al., 1994) are fast and can produce reasonable results
for relatively similar sequences (e.g., sequence identity above 30%).
To correct or minimize errors made in progressive alignment steps, two techniques are
frequently used: iterative refinement and consistency scoring. Iterative refinement is often
carried out after progressive assembly of a multiple sequence alignment. This strategy usually
involves repeatedly dividing the aligned sequences into sub-alignments and realigning the sub-
alignments. With scoring based on general amino acid substation models, MAFFT (Kotoh et al.,
2002) and MUSCLE (Edgar, 2004) are two recent programs that mainly rely on iterative
refinement to enhance alignment quality. Fine-tuning of various parameters in progressive
methods with iterative refinement is important to achieve optimal results (Wheeler et al., 2007).
Exploration of consistency information in progressive alignment was pioneered by the program
T-Coffee (Notredame et al., 2000).
Most available alignment methods assume all the sequences are globally alignable, and
they do not perform well for sequences with repeats or different domain architectures. Low-
complexity or disordered regions can also cause alignment problems, since the concept of
alignable positions does not apply for them. POA (Lee et al., 2002) and ABA (Raphael et al.,
2004) handles the cases of repeats or shuffled domains better by representing alignments using
more informative graphic models. ProDA (Phuong et al., 2006) is another program that is
specifically designed to deal with repeats and shuffled domains by exhaustive searching of
locally alignable regions among sequences. Global trace graph (Heger et al., 2007) is an

Page | 26
approach that organizes non-redundant representatives of all known protein sequences into a
graph of aligned positions based on consistency and transitivity of locally alignable residues,
which has been effective in searching for distant homologs.
2.14 Profunc
A large proportion of the structures deposited at the PDB (Bernstein et al., 1977) by the
various structural genomics initiatives (Berman et al., 2001) are of ‘hypothetical proteins’, i.e.
proteins of unknown function. These are classed as hypothetical when sequence search methods
have failed to match them to proteins that have been functionally characterized. However,
knowing the 3D structure of a protein opens up the possibility of ascertaining its function from
an analysis of that structure. Recently, many methods have been developed for predicting protein
function from structure.
These range from global comparisons, such as matching the protein’s fold against other
proteins of known 3D structure, to identification of more local features, such as active site
residues or DNA-ligand-binding motifs (Berman, 1999). None of these structure-based methods
can expect to be successful in all cases. For example, methods that are able to detect catalytic
residues in a 3D structure will give no useful information if the protein in question is not an
enzyme. Therefore, a prudent approach is to use as many methods as possible, both structure-
based and sequence-based, not only to increase the chances of obtaining a helpful match, but also
to benefit from cases where several methods arrive at the same or similar conclusions.
This is the principle behind the ProFunc server (Laskowski et al., 1977), which runs a
number of different methods to analyse both the sequence and the structure of a submitted
protein and provide a single, convenient summary of what each method has found.
In bringing together a number of sequence and structure-based methods, the ProFunc
server is a convenient tool for use in structural genomics. One submits a new structure to the
server and, within a couple of hours, gets a number of complementary
analyses relating to the protein’s possible function. It is also likely to be useful for general
analysis of newly solved structures as it can speedily identify sequence, structural and possibly
functional relationship between the new structure and those already in the PDB.
2.15 Structure analysis
To date, the 3D structures of over 13,000 biological macro molecules have been determined
experimentally, principally by X-ray crystallography and NMR spectroscopy. The majority of

Page | 27
these are protein structure, including protein-DNAand protein ligand complexes. Together with
sequence, physiochemical and functional and fuctinal annotations they provide awealth of
information crucial for the understanding of biological process.
PDBsum (Laskowski et al., 2005), which was set up in 1995, is one of a number of web-
based databases that provide information on all experimentally determined structural models
released by the Protein Data Bank, PDB (Berman et al., 2000). Other databases include the MSD
(Tagari et al., 2006), the Jena Library of Biological Macromolecules (Reichert and Su¨ hnel,
2002).
A primary aim of PDBsum has always been to represent the structural information for
each 3D model in as pictorial a manner as possible, providing schematic diagrams both of the
molecules making up each PDB entry i.e. protein/DNA/RNA chains, ligands and metals and of
the interactions between them. Over the years many new and unique features have been added.
PDBsum does contain some functional annotation. Data from the Gene Ontology (The
Gene Ontology Consortium, 2000) annotations for the corresponding UniProt sequence are
provided where available as is functional annotation from the UniProt Knowledgebase (The
UniProt Consortium, 2007).

Page | 28
Chapter 3
Results and discussion
3.1 Purification of the enzyme
A 32 kDa chitinase has been purified to homogeneity by simple procedure using
ammonium sulphate and hydrophobic interaction chromatography from the seed hull of
soyabean. The crude (devoid of any insoluble material) was subjected to ammonium sulphate
precipitation in 0.1 M NaHPO4, pH 6.0 buffer and applied to ether-Toyopearl fast flow column
pre-equilibrated in the same buffer. The unbound material to column as well as buffer wash of
the column did not show any activity.
Figure 1. Column chromatography of crude lafter removal of insoluble material. Elution
profile of soyabean by hydrophobic interaction chromatography on ether-Toypearl
column. The bound protein was eluted with linear gradient of ammonium sulphate
1.5 M to 0.0 M in 0.05 M MES buffer (pH 6.0). All fractions of elution in the two
chromatographies were assayed for activity () and protein content ().
Fraction number0 20 40 60 80 100 120 140
Ab
so
rba
nc
e a
t 2
80
nm
0.0
0.5
1.0
1.5
2.0
Ch
itin
as
e a
cti
vit
y
0.0
0.5
1.0
1.5
2.0
III
III a
1.5 - 0.0 M Am
SO4
Pool I : 25-60Pool II : 65-95Pool III : 96-110
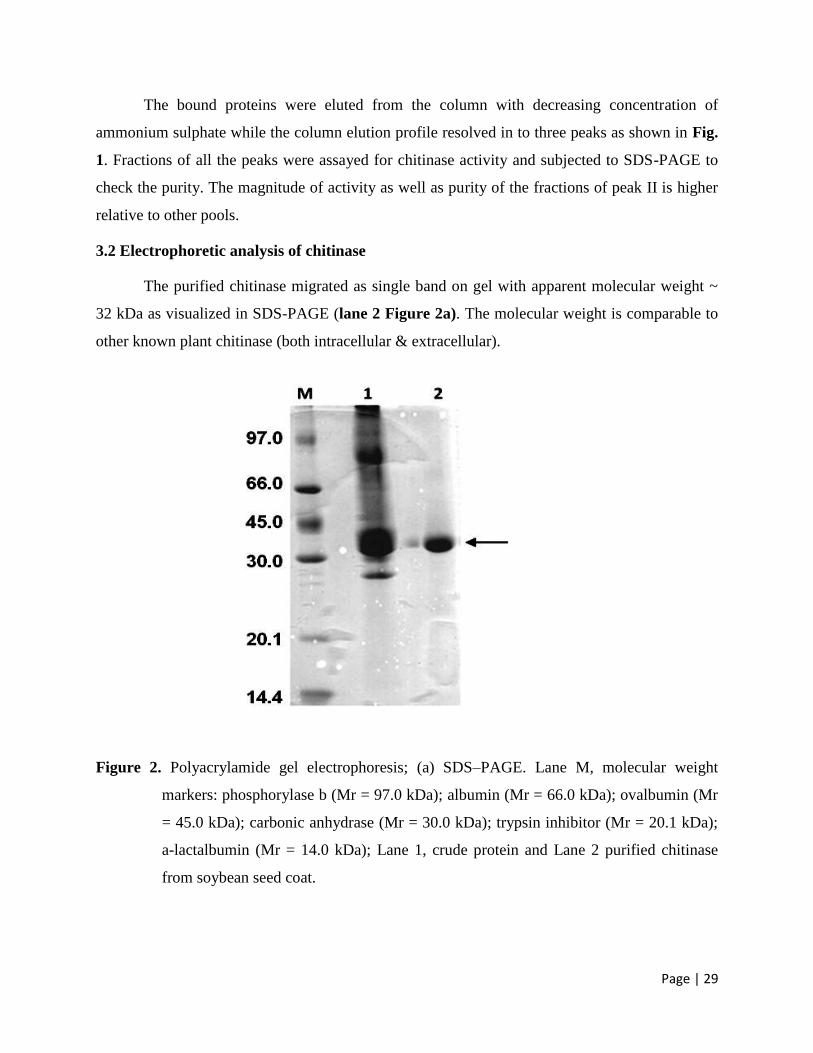
Page | 29
The bound proteins were eluted from the column with decreasing concentration of
ammonium sulphate while the column elution profile resolved in to three peaks as shown in Fig.
1. Fractions of all the peaks were assayed for chitinase activity and subjected to SDS-PAGE to
check the purity. The magnitude of activity as well as purity of the fractions of peak II is higher
relative to other pools.
3.2 Electrophoretic analysis of chitinase
The purified chitinase migrated as single band on gel with apparent molecular weight ~
32 kDa as visualized in SDS-PAGE (lane 2 Figure 2a). The molecular weight is comparable to
other known plant chitinase (both intracellular & extracellular).
Figure 2. Polyacrylamide gel electrophoresis; (a) SDS–PAGE. Lane M, molecular weight
markers: phosphorylase b (Mr = 97.0 kDa); albumin (Mr = 66.0 kDa); ovalbumin (Mr
= 45.0 kDa); carbonic anhydrase (Mr = 30.0 kDa); trypsin inhibitor (Mr = 20.1 kDa);
a-lactalbumin (Mr = 14.0 kDa); Lane 1, crude protein and Lane 2 purified chitinase
from soybean seed coat.

Page | 30
3.3 Primary Structure
Chitinase from soyabean seed coat is a monomeric enzyme and it plays a role as a
defense protein.The linear amino acid sequence of chitinase class I [Glycine max] derived
protein database with protein Id >gi|12698917|gb|AAK01734.1|AF335589_1 contains 320 amino
acid residues (Fig. 3). The theoretical pI and extinction coefficient obtained from Protparam are
7.40 and 60360 M-1
cm-1
respectively. Total number of positively charged residues (Asp & Glu)
and negatively charged residue (Lys and Arg) are 25 and 26 respectively. The chitinase has
unusual glycine composition ~12%.
Figure 3. The primary sequence obtained from protein sequence database. The protein Id is
>gi|12698917|gb|AAK01734.1|AF335589_1 chitinase class I (Glycine max) and it
contains 320 amino acid.
3.4 Multiple sequence Alignment
The sequence with known PDB structure was taken for multiple sequence alignment. The
sequence were compared with BLOSUM 62 matrix and coloured based on conservation of
residues (Fig. 4). The sequence similarity among these chitinases varied between 30 to 70 %,
with maximum similarity exists between soyabean seed coat chitinase and rice chitinase as
shown in the neighbour joining tree (Fig. 5).

Page | 31
Figure 4. Multiple sequence alignment of soybean seed coat chitinase with other class I
realted chitinases using CLUSTAL W. The Boxes dark grey, light grey and pale grey
corresponds to the conserved residues, substitution by a similar type of amino acid and
substitution by a non-similar type of amino acid residues, respectively.
Figure 5. Neighbour joining tree using BLOSUM62 scores for the residue pair at each
aligned position to measure of similarity between each pair of sequences in the
alignment.
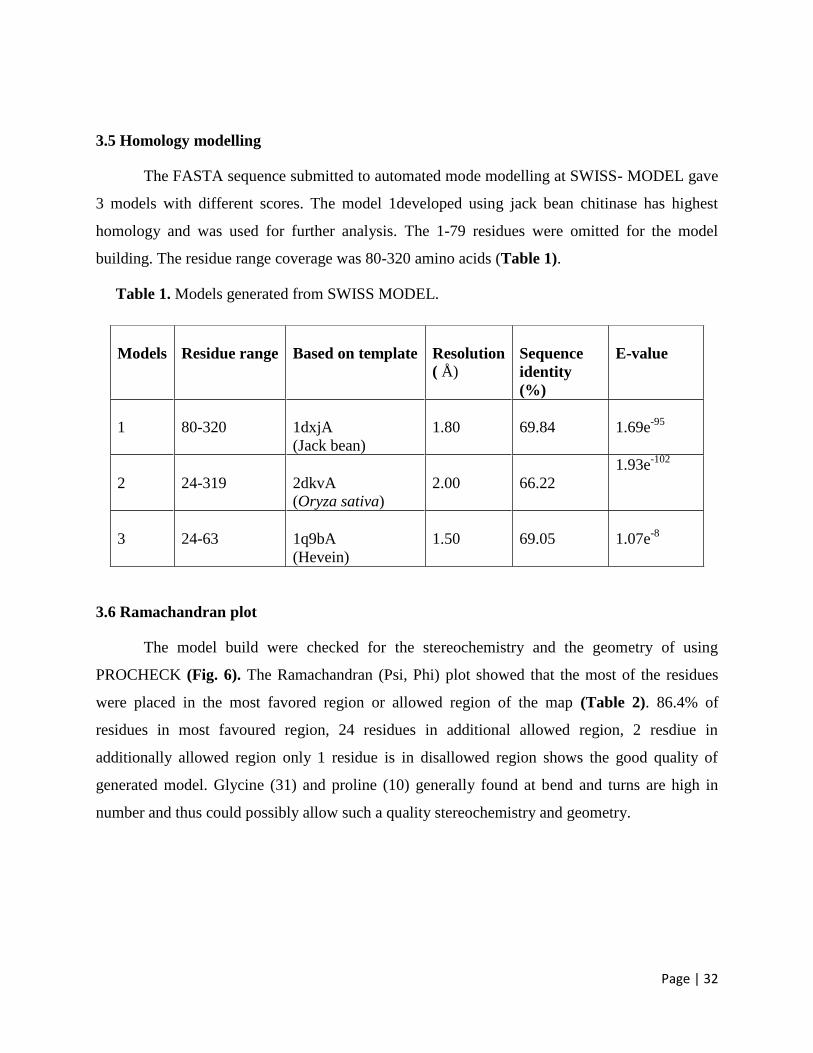
Page | 32
3.5 Homology modelling
The FASTA sequence submitted to automated mode modelling at SWISS- MODEL gave
3 models with different scores. The model 1developed using jack bean chitinase has highest
homology and was used for further analysis. The 1-79 residues were omitted for the model
building. The residue range coverage was 80-320 amino acids (Table 1).
Table 1. Models generated from SWISS MODEL.
3.6 Ramachandran plot
The model build were checked for the stereochemistry and the geometry of using
PROCHECK (Fig. 6). The Ramachandran (Psi, Phi) plot showed that the most of the residues
were placed in the most favored region or allowed region of the map (Table 2). 86.4% of
residues in most favoured region, 24 residues in additional allowed region, 2 resdiue in
additionally allowed region only 1 residue is in disallowed region shows the good quality of
generated model. Glycine (31) and proline (10) generally found at bend and turns are high in
number and thus could possibly allow such a quality stereochemistry and geometry.
Models
Residue range
Based on template
Resolution
( Å)
Sequence
identity
(%)
E-value
1
80-320
1dxjA
(Jack bean)
1.80
69.84
1.69e-95
2
24-319
2dkvA
(Oryza sativa)
2.00
66.22
1.93e-102
3
24-63
1q9bA
(Hevein)
1.50
69.05
1.07e-8
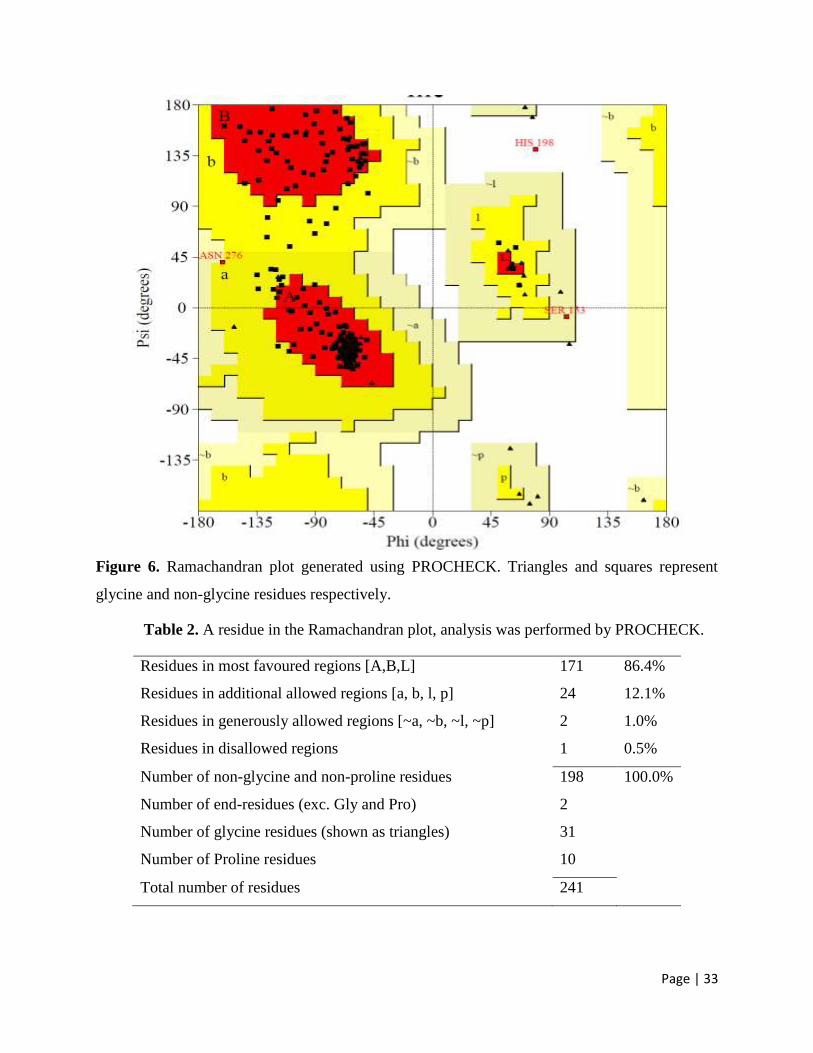
Page | 33
Figure 6. Ramachandran plot generated using PROCHECK. Triangles and squares represent
glycine and non-glycine residues respectively.
Table 2. A residue in the Ramachandran plot, analysis was performed by PROCHECK.
Residues in most favoured regions [A,B,L] 171 86.4%
Residues in additional allowed regions [a, b, l, p] 24 12.1%
Residues in generously allowed regions [~a, ~b, ~l, ~p] 2 1.0%
Residues in disallowed regions 1 0.5%
Number of non-glycine and non-proline residues 198 100.0%
Number of end-residues (exc. Gly and Pro) 2
Number of glycine residues (shown as triangles) 31
Number of Proline residues 10
Total number of residues 241

Page | 34
3.7 Conserved Domain Detection
Two conserved domain ChtBD1 [cd00035], Chitin binding domain, involved in
recognition or binding of chitin subunits and Glycoside chitinase_glyco_hydro_19[cd00325],
Glycoside hydrolase family 19 chitinase domain were detected in the sequence using Conserved
domain detection tool at NCBI (Fig. 7). Through a sequence comparison with homologous plant
chitinases as well as a structural comparison with the active sites of other glycosidases, key
catalytic residues have been identified and the active site has been located in the three-
dimensional structure of the soybean seed coat chitinase.
Figure 7. Conserved domain detection of the chitinase class I [Glycine max]. Two conserved
domain chitin binding domain and Glycoside hydrolase family 19 chitinase domain were
detected in the sequence using CDD.
3.8 Secondary structure
The secondary structure of the protein is inferred from the Ramachandran angles and the
intra-molecular hydrogen bonding of peptide backbone.The 12 alpha helices forms most of the
protein structure as seen in the topology diagram (Fig. 8). The alpha helices forming amino acid
are shown in Table 3. The secondary structure of seed coat class I chitinase consists of 12
helices, 22 beta turns and 3 gamma turns. It contains two right handed spiral disulfide bond Cys
102- Cys 164 and Cys 281- Cys 313 (Fig. 9). Disulfide bridges are very well conserved
structural features in extracellular and other class I chitinases synthesized at the rough
endoplasmic reticulum in the plant.

Page | 35
Figure 8. The topology of a chitinase generated by PROMOTIF showing 12 helices.
Figure 9. Secondary structural elements and connectivity of the chitinase. The sequence is
shown below the structure. The alpha helices strand is shown as helices. The yellow
line indicates disulfide bonds.
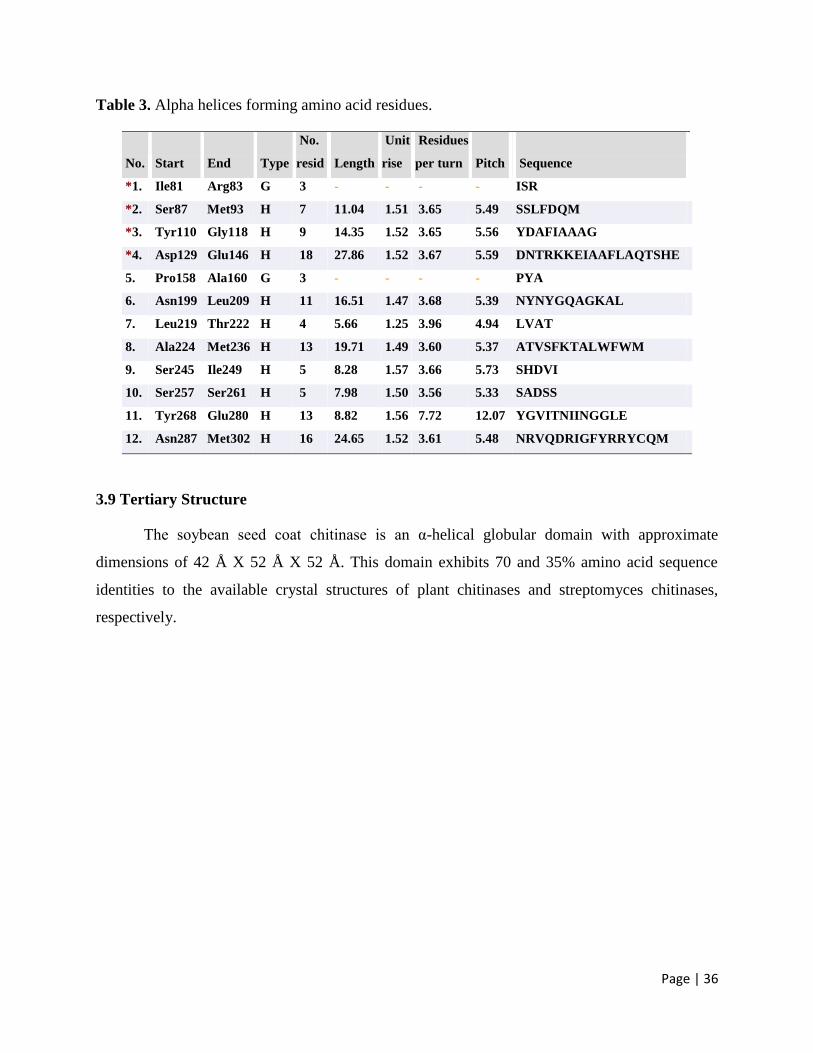
Page | 36
Table 3. Alpha helices forming amino acid residues.
No.
Start
End
Type
No.
resid
Length
Unit
rise
Residues
per turn
Pitch
Sequence
*1. Ile81
Arg83
G
3
-
-
-
-
ISR
*2.
Ser87
Met93
H
7
11.04
1.51
3.65
5.49
SSLFDQM
*3.
Tyr110
Gly118
H
9
14.35
1.52
3.65
5.56
YDAFIAAAG
*4.
Asp129
Glu146
H
18
27.86
1.52
3.67
5.59
DNTRKKEIAAFLAQTSHE
5.
Pro158
Ala160
G
3
-
-
-
-
PYA
6.
Asn199
Leu209
H
11
16.51
1.47
3.68
5.39
NYNYGQAGKAL
7.
Leu219
Thr222
H
4
5.66
1.25
3.96
4.94
LVAT
8.
Ala224
Met236
H
13
19.71
1.49
3.60
5.37
ATVSFKTALWFWM
9.
Ser245
Ile249
H
5
8.28
1.57
3.66
5.73
SHDVI
10.
Ser257
Ser261
H
5
7.98
1.50
3.56
5.33
SADSS
11.
Tyr268
Glu280
H
13
8.82
1.56
7.72
12.07
YGVITNIINGGLE
12.
Asn287
Met302
H
16
24.65
1.52
3.61
5.48
NRVQDRIGFYRRYCQM
3.9 Tertiary Structure
The soybean seed coat chitinase is an α-helical globular domain with approximate
dimensions of 42 Å X 52 Å X 52 Å. This domain exhibits 70 and 35% amino acid sequence
identities to the available crystal structures of plant chitinases and streptomyces chitinases,
respectively.

Page | 37
Figure 10. Tertiary structure of class I seed coat chitinase showing 12 helices. The image was
generated using PYMOL.
The α-helix rich fold of this domain was, as expected, very similar to that of rice
chitinase. The RMS deviations from barley chitinase and rice and barley chitinase are 0.5 Å (279
atoms) and 0.7 Å (238 atoms), respectively, with overlapping of the Cα atoms of the helices,
indicating that the spatial position and orientation of the helices are strictly conserved.
3.10 Cleft analysis and accessible and buried region
Accessibility of each residue and its relative accessibility, defined as percentage of its
accessibility compared to the accessibility of that residue type in an extended Ala-X-Ala
tripeptide, were computed for the subunit using NACCESS program. 33 residues were found to
have relative accessibility values less than 5 % and constitute the hydrophobic core of the
molecule. The Cleft analysis using PROCFUNC shows that most of the residues are easily
accessible to solvent (Fig. 11). There are 10 gap regions in the protein with different degree of
accessibility to the surface (Table 4). Thus protein is globular which is required for accessibility
and binding of different kind of ligand.

Page | 38
B A
Figure 11. Cleft analysis, A. Surface structure generated using pymol B. Surface analyzed
using PROCFUNC showing the residues and the 10 cleft, colored in different
color.
Table 4. Cleft and the accessibility in the tertiary structure.
Gap
region
Volume Accessible
vertices
Buried
vertices
Ave.
depth
1 3225.66 66.11% 10.23% 1
2 494.86 66.61% 6.26% 8
3 386.44 61.70% 4.32% 7
4 377.16 59.93% 6.43% 2
5 280.55 64.44% 8.81% 3
6 356.06 65.96% 6.46% 9
7 266.20 54.30% 4.75% 5
8 282.66 54.05% 4.05% 4
9 241.73 59.67% 3.77% 10
10 198.70 72.63% 5.35% 6
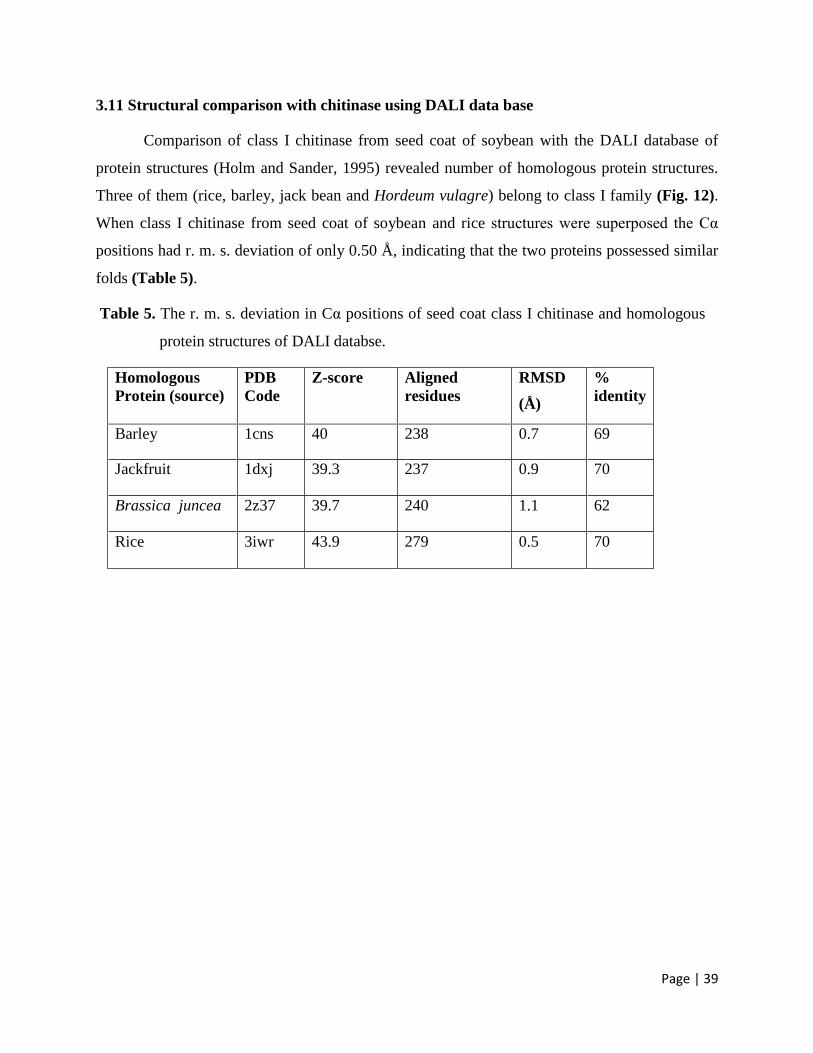
Page | 39
3.11 Structural comparison with chitinase using DALI data base
Comparison of class I chitinase from seed coat of soybean with the DALI database of
protein structures (Holm and Sander, 1995) revealed number of homologous protein structures.
Three of them (rice, barley, jack bean and Hordeum vulagre) belong to class I family (Fig. 12).
When class I chitinase from seed coat of soybean and rice structures were superposed the Cα
positions had r. m. s. deviation of only 0.50 Å, indicating that the two proteins possessed similar
folds (Table 5).
Table 5. The r. m. s. deviation in Cα positions of seed coat class I chitinase and homologous
protein structures of DALI databse.
Homologous
Protein (source)
PDB
Code
Z-score Aligned
residues
RMSD
(Å)
%
identity
Barley 1cns 40 238 0.7 69
Jackfruit 1dxj 39.3 237 0.9 70
Brassica juncea 2z37 39.7 240 1.1 62
Rice 3iwr 43.9 279 0.5 70

Page | 40
Figure 12. Structural aligment (Cα backbone) of soybean class I chitinase (red) with blue.
A. barley B. rice C. jackbean D. B.juncea. Soybean class I chitinase is
structurally similar to most of the known class I chitinase from plant.
3.12 Ligand binding template analysis
Ligand binding template results using Profunc shows a single PDB match with 0.19Å
root mean square deviation in their active site (Table 6). The residue Glu146, Glu168 and
Thr197 showed a closed match with Glu67, Glu89 and Ser120 of barley chitinase. The active site
of soybean class I chitinase contains polar residue for binding of chitin.

Page | 41
Table 6. Ligand binding template analysis.
The template matching is shown in Fig. 13. The residues surrounding the matched
residues are aromatic and thus they may provide the ideal hydrophobic condition for binding of
chitin.
Figure 13. The proposed ligand binding site Glu146, Glu168, Thr197 shown in green is
surrounded by number of aromatic residues (grey) and thus may provide the
Matched PDB
entry
Matched
residues
template
residues
RMSD Similarity
score
Matched
residues
identical/similar
1cns Crystal
structure of
chitinase at 1.91a
resolution
Glu146,
Glu168,
Thr197
Glu67,
Glu89,
Ser120
0.19Å
487.50
24/4

Page | 42
hydrophobic environment for chitin binding. The image was generated using
PYMOL.

Page | 43
Chapter 4
Summary and conclusion
In our investigation on the relevance of plant defense-related proteins, a novel enzyme
having remarkable properties was purified by combining several chromatographic procedures.
We achieved high purity and homogeneity for their biochemical. Such an economic purification
procedure combined with the easy availability of the seed makes large-scale preparation of the
enzyme possible allowing a broad study of its various aspects and hence probable applications.
In summary, soybean seed coats are particularly rich in defence‐related proteins and
peptides, although there are abundant proteins that have yet to be identified. Besides the
biological role of providing defence and protection of the seed until germination occurs, seed
coat tissues affect the overall quality and value of soybean food and feed products. Thus,
characterization of seed coat constituents and their corresponding genes is important from a
biological, nutritional, and economic standpoint in a widely grown crop species such as soybean
.In addition to their role in plant defence, class I chitinases are emerging as a distinct
group of panallergens causing cross‐sensitization to different foods and materials in susceptible
persons. Sensitization is usually limited to raw or uncooked foods, since IgE‐mediated
recognition of the chitin binding domain is lost upon heat denaturation. Several different
allergenic proteins have been identified from soybeans including those that cause food and
inhalant allergies, but chitinases have not been included among these to date. The finding that a
class I chitinase is an abundant component of the soluble protein fraction from seed coats
indicates that this protein should be considered as a potential determinant of allergenicity to raw
or uncookedsoybean products.
Structure prediction of chitinase from soyabean seed coat has shown that it belonged to
Class I family and shared close structural and sequence similarity with rice and jackbean class I
chitinase. The mechanism of chitin hydrolysis is still not clear. In conclusion, the three-
dimensional structure of Class I from soyabean seed coat provides structure for another member
of Class I chitinase and chitinase in general. The structure could account for the specificity and
affinity of the chitinase for its ligands. The structure determined with bound ligand may be
helpful in evaluating the exact specificity of the purified chitinase.

Page | 44
References
Adams DJ. Fungal cell wall chitinases and glucanases. Microbiology (2004) 150: 2029–2035.
Aloise PA, Lumme M, Haynes CA (1996) N-acetyl D-glucosamine production from chitin waste
using chitinase from Serratia marcescens. In: Muzzarelli RAA (ed) Chitin enzymology,
vol 2. Eur Chitin Soc, Grottammare, pp 581–594
Andersen M., Jensen A., Robertus J.D., Leah R., and Skriver K. (1997) Heterologous expression
and characterization of wild-type and mutant forms of a 26 kDa endochitinase from
barley (Hordeum vulgare L.). Biochem. J., 322: 815-822.
Apweiler, R., et al., 2001. The InterPro database, an integrated documentation resource for
protein families, domains and functional sites. Nucleic Acids Res. 29, 37-/40
Arlorio M., Ludwig A. Boller T., and Bonafonte P. (1992) Inhibition of fungal growth by plant
chitinases and β-1,3-glucanases: a morphological study. Protoplasma, 171: 34-43.
Attwood, T.K., et al., 2002. PRINTS and PRINTS-S shed light on protein ancestry. Nucleic
Acids Res. 30, 239-/241.
Bairoch, A., Apweiler, R.,Wu, C.H., Barker,W.C., Boeckmann, B., Ferro, S., Gasteiger, E.,
Huang, H., Lopez, R., Magrane, M., Martin, M.J., Natale, D.A., O’Donovan, C.,
Redaschi, N., Yeh, L.-S.L., 2005. The universal protein resource (UniProt). Nucl. Acids
Res. 33, D154–D159.
Barker, W.C., Pfeiffer, F., George, D.G., 1996. Superfamily classification in PIR-International
Protein Sequence Database. Methods Enzymol. 266, 59_/71.
Bateman, A., et al., 2002. The Pfam protein families database. Nucleic Acids Res. 30, 276-/280.
Benhamou N, Grenier J, Asselin A (1991) Colloidal goldcomplexed chitosanase: a new probe
for ultrastructural localization of chitosan in fungi. J Gen Microbiol 137:2007–2015.
Berman, H.M., Westbrook,J., FEng,Z., Gilliland,G., Bhat,T.N., Weissing,H., Shindyalov,I.N.
and Bourne,P.E. (2000) The Protein Data Bank. Nucleic AcidsRes., 28, 235-242.
Updated article in the issue: nucleic Acids res. (2001), 29, 214-218.
Berman,H.M. (1999) The past and future of structure databases. Curr. Opin. Struct. Biol., 10, 76-
80.
Berman,H.M. et al. (2000) The Protein Data Bank. Nucleic Acids Res., 28, 235–242.

Page | 45
Bernstein,F.C., Koetzle,T.F., Williams,G.J.B., Meyer,E.F.,Tr, Brice,M.D., Rogers,J.R.,
Kennard,O., Shimanouchi, T. and Tasumi,M.(1977) The protein Data Bank: a computer
based archival file for macromolecular structures. J. Mol. Biol., 112, 535-542.
Bhushan B, Hoondal GS (1998) Isolation, purification and properties of a thermostable chitinase
from an alkalophilic Bacillus sp. BG-11. Biotechnol Lett 20:157–159 Biotechnol.
Boeckmann, B., Bairoch, A., Apweiler, R., Blatter, M.-C., Estreicher, A., Gasteiger, E., Martin,
M.J., Michoud, K., O’Donovan, C., Phan, I., et al., 2003. The Swiss-Prot protein
knowledgebase and its supplement TrEMBL in 2003. Nucl. Acids Res. 31, 365–370
Boot R:G., Blommaart E.F.C:, Swart E., Ghauharali-van der Vlugt K., Bijl N., Moe C., Place A.,
and Aerts J.M.F.G. (2001) Identification of a novel acidic mammalian chitinase distinct
from chitobiosidase. J. Biol. Chem., 276: 6770-6778.
Bork, P., Koonin, E.V., 1998. Predicting functions from protein sequences/where are the
bottlenecks? Nat. Genet. 18, 313-/318.
Botha A-M., Nagel M.A.C., Van der Westhuizen, and Botha F.C. (1998) Chitinase isoenzymes
in near-isogenic wheat lines challenged with Russian wheat aphid, exogenous ethylene,
and mechanical wounding. Bot. Bull. Acad. Sin., 39: 99-106.
Boukli NM, Sunderasan E, Bartsev A, Hochstrasser D, Perret X, Bjourson AJ, et al. Early
legume responses to inoculation with Rhizobium sp. NGR234. J Plant Physiol
2007;164:794–806.
Bowles, D.J., Gurr, S.J., Scollan, C., Atkinson, H.J. and Harnmond-Kosack, K.E. (1991)
Local and systemic changes in plant gene expression following root infection by cyst
nema- todes. In Biochemistry and Molecular Biology of Planf- Pathogen lnteractions
(Smith, C.J., ed.). Oxford: Clarendon Press, pp. 225-236.
Brameld K.A., and Goddard III W.A. (1998a) The role of enzyme distortion in the single
displacement mechanism of family 19 chitinases. Proc. Natl. Acad. Sci. USA, 95: 4276-
4281.
Brenner, S.E., 1999. Errors in genome annotation. Trends Genet. 15, 132_/133.
Bridge PD, Singh T, Arora DK (2004) The application of molecular markers in the epidemiology
of plant pathogenic fungi. In ‘Fungal Biotechnology in Agricultural, Food and
Environmental application.’ (Ed Arora). (Marcel Dekker, Inc: New York).
Brzeski, M.M. (1987) Chitin and chitosan-putting waste to good use. Infofish Int., 5:31-33

Page | 46
Buttery BR, Buzzel RI. (1968) Peroxidase activity in seeds of soybean varieties. Crop Sci,
8:722–5.Carbohydr Res 337:557–559
Carpentier SC, Panis B, Vertommen A, Swennen R, Sergeant K, Renaut J, et al. (2008) Proteome
analysis of non-model plants: a challenging but powerful approach. Mass Spectrom Rev
27:354–77.
Chang MM, Horovitz D, Culley D, Hadwiger LA. (1995). Molecular cloning and
characterization of apea chitinase gene expressed in response to wounding, fungal
infection and the elicitor chitosan. Plant Molecular Biology 28, 105-111.
Chang WT, Chen CS, Wang SL (2003) An antifungal chitinase produced by Bacillus cereus with
shrimp and crab shell powder as carbon source. Curr Microbiol 47:102–108
Chernin L., Gafni A., Mozes-Koch R., Gerson U., and Sztejnberg A. (1997) Chitinolytic activity
of the acaropathogenic fungi Hirsutella thompsonii and Hisuthella necatrix. Can. J.
Microbiol., 43: 440-446.
Choi Y, Choi YD, Lee JS (2008). Antimicrobial activity of g-thionin-like soybean SE60 in
Escherichia coli and tobacco plants. Biochem Biophys Res Commun 375:230–4.
Cody RM, Davis ND, Lin J, Shaw D (1990) Screening microorganisms for chitin hydrolysis and
production of ethanol from aminosugars. Biomass 21:285–295
Cohen-Kupiec R, Broglie K, Friesem D, Broglie R, Chet I (1999) Molecular characterisation of a
novel β-1,3-exoglucanase related to mycoparasitism of Trichoderma harzianum. Gene
226, 147-154.
Cohen-Kupiec R., and Chet I. (1998) The molecular biology of chitin digestion. Curr. Opin.
Biotechnol., 9: 270-277.
Collinge D.B., Kragh K.M., Mikkelsen J.D., Nielsen K.K., Rasmussen U., and Vad K. (1993)
Plant chitinases. The Plant Journal, 3: 31-40.
Collinge D.B., Kragh K.M., Mikkelsen J.D., Nielsen K.K., Rasmussen U., and Vad K. (1993)
Plant chitinases. The Plant Journal, 3: 31-40.
Corpet, F., Servant, F., Gouzy, J., Kahn, D., (2000). ProDom and ProDom-CG: tools for protein
domain analysis and whole genome comparisons. Nucleic Acids Res. 28, 267_/269.
Cullimore J.V., Ranjeva R., and Bono J.J. (2001) Perception of lipochitooligosaccharidic Nod
factors in legumes. Trends Plant Sci., 6: 24-30.

Page | 47
Curto M, Camafeita E, Lopez JA, Maldonado AM, Rubiales D, Jorrín JV (2006). A proteomic
approach to study pea (Pisum sativum) responses to powdery mildew (Erysiphe pisi).
Proteomics 6:S163–174.
Dahiya N, Tewari R, Tiwari RP, Hoondal GS (2005a) Production of an antifungal chitinase from
Enterobacter sp. NRG4 and its application in protoplast production. World J Microbiol
Dayhoff, M.O., (1976). The origin and evolution of protein superfamilies. Fed. Proc. 35, 2132-
2138.
Dayhoff, M.O., 1965_/1978. Atlas of Protein Sequence and Structure. vol. 1_/5, supplements 1-
/3. National Biomedical Research Foundation, Washington, DC.
de A. Gerhardt L.B., Sachetto–Martins G., Contarini M.G., Sandorini M., de P. Ferreira R., de
Lima V.M., Cordeiro M.C., de Oliveira D.E., and Margis-Pinheiro M. (1997)
Arabidopsis thaliana class IV chitinase is early induced during the interaction with
Xanthomonas campestris. FEBS Lett., 419: 69-75.
de Jong F, Mathesius U, Imin N, Rolfe BG (2007). A proteome study of the proliferation of
cultured Medicago truncatula protoplasts. Proteomics 7:722–36.
DeMarco JL, Lima CLH, Desousa MV, Felix CR (2000) A Trichoderma harzianum chitinase
destroys the cell walls of the phytopathogen Crinipellis pernicosa, the casual agent of the
witches broom disease of cocoa. World J Microbiol Biotechnol 16:383–386.
Devos, D., Valencia, A., (2001). Intrinsic errors in genome annotation. Trends Genet. 17,
429_/431.
E. Gasteiger, A. Gattiker, C. Hoogland, I. Ivanyi, R.D. Appel, A. Bai-roch, ExPASy: the
proteomics server for in-depth protein knowledge and analysis, Nucleic Acids Res 31
(2003) 3784–3788.
Edgar RC (2004): MUSCLE: multiple sequence alignment with high accuracy and high
throughput. Nucleic Acids Res, 32:1792-1797.
Edgar RC, Batzoglou S, (2006): Multiple sequence alignment. Curr Opin Struct Biol, 16:368-
373.
El Gueddari N.E., Moerschbacher B.M. (2003) A bioactivity matrix for chitosans as elicitors of
disease resistance reactions in wheat. In “Advances in chitin science” (I. Boucher, K.
Jamieson, A. Retnakaran, eds), Proceedings of the 9th ICCC, Vol.VII, pp. 56-57.

Page | 48
Faize M, Faize L, Koike N, Ishii H (2003) Acibenzolar-S-methyl-induced resistance to Japanese
pear scab is associated with potentiation of multiple defense responses. In. (Ed.
GenBank).
Falquet, L., et al., (2002). The PROSITE database, its status in 2002. Nucleic Acids Res. 30,
235-238.
Feng DF, Doolittle RF (1987): Progressive sequence alignment as a prerequisite to correct
phylogenetic trees. J Mol Evol, 25:351-360.
Ferron P (1985) Fungal control. In: Kerkut GA, Gilbert LI (eds) Comprehensive insect
biochemistry and pharmacology, vol 12. Pergamon, Oxford, pp 313–346.
Flach J., Pilet P.E., and Jollés P. (1992) What’s new in chitinase research?. Experientia, 48:701-
716.
Fukamizo T. (2000) Chitinolytic enzymes: Catalysis, substrate binding, and their Application.
Curr. Prot. Pept. Sci., 1: 105-124..
Giambattista RD, Federici F, Petruccioli M, Fence M (2001) The chitinolytic activity of
Penicillium janthinellum P9: purification, partial characterization and potential
application. J Appl Microbiol 91:498–505
Gijzen M, Kuflu K, Qutob D, Chernys JT (2001). A class I chitinase from soybean seed coat. J
Exp Bot;52:2283–9.
Gomez L., Allona I., Casado R., and Aragoncillo C. (2002) Seed chitinases. Seed Sciences
Research, 12: 217-230.
Gooday GW (1999) ‘Aggressive and Defensive role of Chitinase.’ (Birkhauser, Verlag:
Basel/Switzerland).
Govindsamy V, Gunaratna KR, Balasubramanian R (1998) Properties of extracellular chitinase
from Myrothecium verrucaria, an antagonist to the groundnut rust Puccinia arachidis.
Can J Plant Pathol 20:62–68.
Graham LS, Sticklen MB. Plant chitinases. Can J Bot (1994); 72: 1057–1083.
Haft, D.H., et al., (2001). TIGRFAMs: a protein family resource for the functional identification
of proteins. Nucleic Acids Res. 29, 41-/43.
Hahn M., Henning M., Schlesier B., and Höhne W. (2000) Structure of jack bean chitinase. Acta
Crystallogr. D Biol. Crystallogr., 56: 1096-1099.

Page | 49
Hajduch M, Ganapathy A, Stein JW, Thelen J (2005). A systematic proteomic study of seed
filling in soybean: establishment of high-resolution two-dimensional reference maps,
expression profiles, and an interactive proteome database. Plant Physiol;137:1397–419.
Hakala B.E., White C., and Recklies A.D. (1993) Human cartilage gp-39, a major secretory
product of articular chondrocytes and synovial cells, is a mammalian member of a
chitinase protein family. J. Biol. Chem., 268:25803-25810
Haran S, Schickler H, Chet I (1996). Molecular mechanisms of lytic enzymes involved in the
biocontrol activity of Trichoderma harzianum. Microbiology; 142: 2321–2331.
Hart P.J., Heather D.P., Monzingo A., Hollis T., and Robertus J.D. (1995) The refined crystal
structure of an endochitinase from Hordeum vulgare L. seeds at 1.8 Å resolution. J. Mol.
Biol., 248: 402-413.
Heger A, Mallick S, Wilton C, Holm L (2007): The global trace graph, a novel paradigm for
searching protein sequence databases. Bioinformatics, 23:2361-2367.
Herget, T., Schell, J. and Schreier, P.H. (1990) Elicitor-specifi induction of one member of the
chitinase gene family in Arachi hypogaea. Mol. Gen. Genet. 224,469-476.
Hiilovaara-Teijo M., Hannukkala A., Griffith M., Yu X.M., and Pihakaski-Maunsbach K. (1999)
Snow-mold-induced apoplatic proteins in winter rye leaves lack antifreeze activity. Plant
Physiol., 121: 665-673.
Holm L., and Sander C. (1994) Structural similarity of plant chitinase and lysozymes from
animals and phage: An evolutionary connection. FEBS Lett., 340: 129-132.
Horsch M, Mayer C, Sennhauser U, Rast DM (1997) β-Nacetylhexosaminidase: a target for the
design of antifungal agents. Pharma 76:187–218.
Huang, H., Barker, W.C., Chen, Y., Wu, C.H., 2003. iProClass: an integrated database of protein
family, function, and structure information. Nucleic Acids Res. 31 (in press).
Hymowitz, T. and Bernard, R.L. (1991) Origin of the soybean and germplasm introduction and
development in North America. In: H.L. Shands and L.E. Wiesner (Eds.), Use of Plant
intro-ductions in cultivar development, pp. 147–164. Part 1. CSSA Spec. Publ. No. 17.
Madison,WI.
Hymowitz, T., and Harlan, J. R. (1983) Introduction of soybean to North America by Samuel
Bowen in 1765. Economic Botany. 37, 371–379.

Page | 50
International Rice Genome Sequencing Project. The map-based sequence of the rice genome.
Nature 2005;436:793–800.
Iseli B., Armand S., Boller T., Neuhaus J.M., and Henrissat B. (1996) Plant chitinases use two
different hydrolytic mechanisms. FEBS Lett., 382: 186-188.
Iseli B., Armand S., Boller T., Neuhaus J.M., and Henrissat B. (1996) Plant chitinases use two
different hydrolytic mechanisms. FEBS Lett., 382: 186-188.
Iseli B., Boller T., and Neuhaus J.M. (1993) The N-terminal cystein-Rich domain of tobacco
class I chitinase is essential for chitin binding but not for catalytic or antifungal activity.
Plant Physiol., 103: 221-226.
Jacobsen, S., Hauschild, M.Z. and Rasmussen, U. (1992) Induction by chromium ions of
chitinases and polyamines in barley (Hordeum vulgare L.) and rape (Brassica napus L.
ssp. oleifera). Plant Sci. 84, 1 19-1 28.
Johnson (1992) past, present and future opportunities in breeding for disease resistance
with example from wheat.’ (Kluwer Academic Publishers: Dordecht/The Netherlands).
Johnson EA, Villa TG, Lewis MJ, Phaff HJ (1979) Lysis of the cell wall of yeast Phaffia
rhodozyme by lytic complex from Bacillus circulans WL-12. J Appl Biochem 1:273–282
Jongedijk E., Tigelaar H., van Roekel J.S.C., Bres-Vloemans S.A., Dekker I., van den Elzen
P.J.M., Cornelissen B.J.C., and Melchers L.S. (1995) Synergistic activity of chitinases
and β-1,3-glucanases enhances fungal resistance in transgenic tomato plants. Euphytica,
85: 173-177.
Kasprzewska A. (2003) Plant chitinases-Regulation and function. Cell. Mol. Biol. Lett., 8: 809-
824.
Katoh K, Misawa K, Kuma K, Miyata T (2002): MAFFT: a novel method for rapid multiple
sequence alignment based on fast Fourier transform. Nucleic Acids Res, 30:3059-3066.
Kezuka Y, Kojima M, Mizuno R, Suzuki K, Watanabe T, Nonaka T. (2010) Structure of full-
length class I chitinase from rice revealed by X-ray crystallography and small-angle X-
ray scattering. Proteins, 78(10): 2295-2305.
Knight SC, Anthony VM, Brady AM, Greenland AJ, Heaney SP, Murray DC, Powell KA,
Schulz MA, Sinks CA, Worthington PA, Youle D (1997) Rationale and perspectives on
the development of fungicides. Annual Review Phytopathology 35, 349-372.

Page | 51
Koga D, Mitsutomi M, Kono M, Matsumiya M (1999) ‘Biochemistry of chitinase.’( Birkhauser
Veerlag: Basel/Switzerland).
Kragh, K.M., Jacobsen, S. and Mikkelsen, J.D. (1990) Induc- tion, purification and
characterization of barley leaf chitinases. Plant Sci. 71, 5548.
Kramer K.J., and Muthukrishnan S. (2005) Chitin metabolism in insects. In: Gilbert L.I., Latrou
K., and Gill S., eds., Comprehensive Molecular Insect Science. Vol. 4, Biochemistry and
Molecular Biology, Chapter 3, Elsevier Press, Oxford, UK, pp. 111-144.
Kuranda MJ, Robbins PW (1991) Chitinase is required for cell separation during growth of
Saccharomyces cerevisiae. J Biol Chem 266:19707–19758
Laine LA, Lo CJ (1996) Diagnosis of fungal infections with a chitinase. PCT Int Appl Wo
9802742 A122 (CA 128, 86184)
Laskowski,R.A. et al. (2005) PDBsum more: new summaries and analyses of the known 3D
structures of proteins and nucleic acids. Nucleic Acids Res., 33, D266–D268.
Laskowski,R.A., Hutchinson,E.G., Michie,A.D., Wallace,A.C., Jones,M.L. and
Thornton,J.M.(1997). PDBsum: aweb-based database of summeries and analyses of all
PDB structures. Trends Biochem. Sci., 22, 488-490.
Lawton, K., Ward E., Payne, G., Moyer, M. and Ryals, J. (1992) Acidic and basic class 111
chitinase mRNA accumulation in response to TMV infection of tobacco. Planr Mol.
Biol. 19735-743.
Lee C, Grasso C, Sharlow MF: Multiple sequence alignment using partial order graphs.
Bioinformatics 2002, 18:452-464.
Lei Z, Elmer AM,Watson BS, Dixon RA, Mendes PJ, Sumner LW (2005). A two-dimensional
electrophoresis proteomic reference map and systematic identification of 1367 protein
from a cell suspension culture of the model legume Medicago truncatula. Mol Cell
Proteomics;4: 1812–25.
Leinonen, R., Diez, F.G., Binns, D., Fleischmann, W., Lopez, R., Apweiler, R.,( 2004). UniProt
archive. Bioinformatics 20, 3236–3237.
Leong SA (2004) Biotechnological Approaches in Plant Protection: Achievements, New
Initiatives and Prospects. In ‘Fungal Biotechnology in Agricultural, Food and
Environmental Application.’ (Ed. DK Arora) pp. 1-18. (Marcel Dekker Inc.: New York).
Lett 18:373–376

Page | 52
Levitt, M., and M. Gerstein. (1998). A unified statistical framework for sequence comparison
and structure comparison. Proc. Natl. Acad. Sci. U.S.A. 95:5913–5920.
Li Duo-Chuan, Review of fungal chitinases, Mycopathologia (2006) 161: 345–360.
Lipman DJ, Altschul SF, Kececioglu JD (1989): A tool for multiple sequence alignment. Proc
Natl Acad Sci U S A, 86:4412-4415.
Lo Conte, L., Brenner, S.E., Hubbard, T.J.P, Chothia, C., Murzin, A.G., (2002). SCOP database
in 2002: refinements accommodate structural genomics. Nucleic Acids Res. 30, 264-267.
Lockhart JD, Winzeler AE (2000). Genomics, gene expression and DNA arrays. Nature;405:
827–35.
Logemann J, Schell (1993). The impact of biotechnology on plant breeding, or how to combine
increases in agricultural productivity with an improved protection of the environment. In
Biotechnology in plant disease control.’ (Ed. I Chet) pp. 2-14. (John Wiley and sons Inc.:
New York).
Lorito M, Harman GE, Hayes CK, Broadway RM, Tronsmo A, Woo SL, DiPietro A (1993)
Chitinolytic enzymes produced by Trichoderma harzianum: antifungal activity of
purified endochitinase and chitobiosidase. Phytopathology 83:302–307.
Mahadevan B, Crawford DL (1997) Properties of the antifungal biocontrol agent Streptomyces
lydicus WYEC 108. Enzyme Microb Technol 20:489–493.
Mathivanan N, Kabilan V, Murugesan K (1998) Purification, characterization and anti-fungal
activity from Fusarium chlamydosporum, a mycoparasite to groundnut rust, Puccinia
arachidis. Can J Microbiol 44:646–651.
Mauch F. and Staehelin A.L. (1989) Functional implications of the subcellular localization of
ethylene-induced chitinase and β-1,3-glucanase in bean leaves. Plant Cell, 1: 447-457.
Mendonsa ES, Vartak PH, Rao JU, Deshpande MV (1996) An enzyme from Myrothecium
verrucaria that degrades insect cuticle for biocontrol of Aedes aegypti mosquito.
Biotechnol
Merzendorfer H, Zimoch L (2003). Chitin metabolism in insects: structure, function and
regulation of chitin synthases and chitinases. J Exp Biol; 206: 4393–4412.
Merzendorfer H., and Zimoch L. (2003) Chitin metabolism in insects: structure, function and
regulation of chitin synthases and chitinases. J. Exp. Biol., 206: 4393-4412.

Page | 53
Miller M, Palofarvi A, Rangger A, Reeslev M, Kjoller A (1998) The use of fluorogenic
substrates to measure fungal presence and activity in soil. Appl Environ Microbiol
64:613–617
Mizuno K, Kimura O, Tachiki T (1997) Protoplast formation from Schizophyllum commune by
a culture filtrate of Bacillus circulans KA-304 grown on a cell-wall preparation of S.
commune as a carbon source. Biosci Biotechnol Biochem 61:852–857
Muzzarelli R (1999) Native, industrial, and fossil chitins. In: Jolles P, Muzzarelli R (eds) Chitin
and chitinases. Birkhauser, Basel
Nanjo F, Sakai K, Ishikawa M, Isobe K, Usui T (1989) Properties and transglycosylation
reaction of a chitinase from Nocardia orientalis. Agric Biol Chem 53:2189–2195
Needleman SB, Wunsch CD (1970): A general method applicable to the search for similarities in
the amino acid sequence of two proteins. J Mol Biol, 48:443-453.
Neuhaus J.M., Fritig B., Linthorst H.J.M., Meins F., Mikkelsen J.D., and Ryals J. (1996) A
revised nomenclature for chitinase genes. Plant Mol. Biol. Rep., 14: 102-104.
Neuhaus J.M., Sticher L., Meins F.Jr., and Boller T. (1991) A short C-terminal sequence is
necessary and sufficient for the targeting of chitinases to the plant vacuole. Proc. Natl.
Acad. Sci. U.S.A., 88: 10362-1066.
Notredame C (2007): Recent evolutions of multiple sequence alignment algorithms. PLoS
Comput Biol, 3:e123.
Notredame C, Higgins DG, Heringa J (2000): T-Coffee: a novel method for fast and accurate
multiple sequence alignment. J Mol Biol, 302:205-217.
Ohno T., Armand S., Hata T., Nikaidou N., Henrissat B., Mitsutomi M., and Watanabe T. (1996)
A modular family 19 chitinase found in the procaryotic organism Streptomyces griseus
HUT 6037. Journal of Bacteriology, 178: 5065-5070.
Ornum J.V. (1992) Shrimp waste-must it be wasted. Infofish Int., 6: 48-52.
Pandey A, Mann M. Proteomics to study genes and genomics. Nature 2000;405: 837-45.
Papanikolau Y., Prag G., Tavlas G., Vorgias C.E., Oppenheim A.B., and Petratos K. (2001) High
resolution structural analyses of mutant chitinase A complexes with substrates provide
new insight into the mechanism of catalysis. Biochemistry, 40: 11338-11343.
Patil SR, Ghormade V, Deshpande MV. Chitinolytic enzymes: an exploration. Enzyme Microb
Technol 2000; 26: 473–483.

Page | 54
Pearl, F.M.G., et al., 2001. A rapid classification protocol for the CATH domain database to
support structural genomics. Nucleic Acids Res. 29, 223-/227.
Perrakis A., Tews I., Dauter Z., Oppenheim A.B., Chet I., Wilson K.S., and Vogias E. (1994)
Crystal structure of a bacterial chitinase at 2.3-Angstrom resolution. Structure, 2: 1169-
1180.
phagocyte-derived chitotriosidase, a component of innate immunity. Int Immunol 2005; 17:
1505–1512.
Phuong TM, Do CB, Edgar RC, Batzoglou S: Multiple alignment of protein sequences with
repeats and rearrangements. Nucleic Acids Res 2006, 34:5932-5942.
Pichyangkura R, Kudan S, Kultiyawong K, Sukwattanasinitt M, Aiba SI (2002) Quantitative
production of 2-acetamido-2-deoxy-D-glucose from crystalline chitin by bacterial
chitinase.
Raphael B, Zhi D, Tang H, Pevzner P: A novel method for multiple alignment of sequences with
repeated and shuffled elements. Genome Res 2004, 14:2336-2346.
Rast D.M., Baumgartner D., Mayer C., and Hollenstein G.O. (2003) Cell wall-associated
enzymes in fungi. Phytochemistry, 64: 339-366.
Reichert,J. and Su¨ hnel,J. (2002) The IMB Jena Image Library of Biological Macromolecules:
2002 update. Nucleic Acids Res., 30, 253–254.
Revah-Moiseev S, Carrod PA (1981) Conversion of the enzymatic hydrolysate of shellfish waste
chitin to single cell protein. Biotechnol Bioeng 23:1067–1078
Roberts W.K., and Selitrennikoff C.P. (1988) Plant and bacterial chitinases differ in antifungal
activity. J. Gen. Microbiol., 134: 169-176.
Rosenberger RF (1976) The Cell Wall. In ‘Filamentous fungi’. (Ed. BDR Smith J.E.) pp. 328-
344. (Edward Arnold: London)
Ruiz-Sanchez A., Cruz-Camarillo R., Salcedo-Hernandez R., Ibarra J.E., and Barboza-Corona
J.E. (2005) Molecular cloning and purification of an endochitinase from Serratia
marcescens (Nima). Mol. Biotechnol., 31: 103-111.
Sahai A.S., and Manocha M.S. (1993) Chitinases of fungi and plants: their involvement in
morphogenesis and host-parasite interaction. FEMS Microbiol. Rev., 11:317-338.

Page | 55
Saito A., Fujii T., Yoneyama T., Redenbach M., Ohne T., Watanabe T., and Miyashita K. (1999)
High-multiplicity of chitinase genes in Streptomyces coelicolor A3(2). Biosci.
Biotechnol. Biochem., 63: 710-718.
Sakuda S, Isogai A, Matsumoto S, Suzuki A (1987) Search for microbial insect growth
regulators. II. Allosamidin, a novel insect chitinase inhibitor. J Antibiot 40:296–300.
Samac DA, Hironaka CM, Yallaly PE, Shah DM. 1990. Isolation and characterization of genes
encoding basic and acidic chitinases in Arabidopsis thaliana. Plant Physiology 93, 907-
914.
Sashiwa H, Fujishima S, Yamano N, Kawasaki N, Nakayama A,Muraki E, Hiraga K, Oda K,
Aiba S (2002) Purification of NacetylD-glucosamine from alpha-chitin by crude enzymes
from Aeromonas hydrophila H-2330. Carbohydr Res 337: 761–763.
Schiltz S, Gallardo K, Huart M, Negroni L, Sommerer N, Burstin J (2004). Proteome reference
maps of vegetative tissues in pea. An investigation of nitrogen mobilization from leaves
during seed filling. Plant Physiol;135: 2241–60..
Schlick, T. (2002). Molecular Modeling and Simulation: An Interdisciplinary Guide. Springer-
Verlag, New York.
Schultze M., Staehelin C., Brunner F., Genetet I., Legrand M., Fritig B., Kondorosi E., and
Kondorosi A. (1998) lant chitinase/lysozyme isoforms show distinct substrate specificity
and cleavage site preference towards lipochitooligosaccharide Nod signals. Plant J., 16:
571-580.
Shaikh SA, Desphande MV (1993) Chitinolytic enzymes their contribution to basic and applied
research. World J Microbiol Biotechnol 9:468–475
Shimono K, Matsuda H, Kawamukai M (2002) Functional expression of chitinase and
chitosanase, and their effects on morphologies in the yeast Schizosaccharomyces pombe.
Biosci Biotechnol Biochem 66:1143–1147
Smith TF, Waterman MS: Identification of common molecular subsequences. J Mol Biol 1981,
147:195-197.
Staehelin, C., Muller, J., Mellor, R.B., Wiernken, A. and Boller, T. (1992) Chitinase and
peroxidase in effective (fix+) and in- effective (fix-) soybean nodules. Planta, 187, 295-
300.

Page | 56
Stoyachenko IA, Varlamov VP, Davankov VA (1994) Chitinases of Streptomyces kurssanovii:
purification and some properties. Carboydr Polym 24:47–54
Suarez V., Staehelin C., Arango R., Holtorf H., Hofsteenge J., and Meins F. Jr. (2001) Substrate
specificity and antifungal activity of recombinant tobacco class I chitinases. Plant Mol.
Biol., 45: 609-618.
Svitil AL, Chadhain SMN, Moore JA, Kirchman DC. Chitin degradation proteins produced by
the marine bacterium Vibrio harveyi growing on different forms of chitin. Appl Environ
Microbiol 1997; 63: 408–413.
Tagari,M. et al. (2006) E-MSD: improving data deposition and structure quality. Nucleic Acids
Res., 34, D287–D290.
Terayama H, Takahashi S, Kuzuhara H (1993) Large scale preparation of N,N′-
diacetylchitobiose by enzymatic degradation of chitin and its chemical modification. J
Carbohydr Chem 12:81–93
Terwisscha van Scheltinga A.C., and Dijkstra B.W. (1996) Three-dimensional structure and
mechanism of chitinase. In Chitin Enzymology, Vol. 2, Muzzarelli R.A.A., ed., pp. 143-
146.
Tews I., Perrakis A., Oppenheim A., Dauter Z., Wilson K.S., and Vorgias C.E. (1996) Bacterial
chitobiase structure provides insight into catalytic mechanism and the basis of Tay-Sachs
disease. Nature Struct. Biol., 3: 638-648..
The Arabidopsis Genome Initiative,Analysis of the genome sequence of the flowering plant
Arabidopsis thaliana, Nature 408 (2000) 796–815.
The Arabidopsis Genome Initiative. Analysis of the genome sequence of the flowering plant
Arabidopsis thaliana. Nature 2000;408: 796–815.
The Gene Ontology Consortium. (2000) Gene Ontology: tool for the unification of biology.
Nature Genet., 25, 25–29.
The UniProt Consortium. (2007) The Universal Protein Resource (UniProt). Nucleic Acids Res.,
35, D193–D197.
Theis T., and Stahl U. (2004) Antifungal proteins: targets, mechanisms and prospective
applications. Cell. Mol. Life Sci., 61: 437-455.

Page | 57
Thompson JD, Higgins DG, Gibson TJ: CLUSTALW: improving the sensitivity of progressive
multiple sequence alignment through sequence weighting, position-specific gap penalties
and weight matrix choice. Nucleic Acids Res 1994, 22:4673-4680.
Todd, A. E., C. A. Orengo, and J. M. Thornton. 2001. Evolution of function in protein
superfamilies, from a structural perspective. J. Mol. Biol. 307:1113–1143.
Ueda M., Kojima M., Yoshikawa T., Mitsuda N., Araki K., Kawaguchi T., Miyatake K., Arai
M., and Fukamizo T. (2003) A novel type of family 19 chitinase from Aeromonas sp.
No.10S-24. Cloning, sequence, expression and the enzymatic properties. Eur. J.
Biochem., 270: 2513-2520
Usui T, Matsui H, Isobe K (1990) Enzymic synthesis of chitooligosaccharides utilizing
transglycosylation by chitinolytic enzymes in a buffer containing ammonium sulfate.
Carbohydr Res 203:65–77
Vad, K. (1991) Molecular studies of the interaction between pea and thepathogenic fungus
Asochyta pisi. Ph.D. Thesis. Copen- hagen: Royal Veterinary and Agricultural
University.
Vaidya RJ, Shah IM, Vyas PR, Chhatpar HS (2001) Production of chitinase and its optimization
from a novel isolate Alcaligenes xylosoxydans: potential antifungal biocontrol. World J
Microbiol Biotechnol 1:62–69.
van Loon L.C., Pierpoint W.S., Boller T., and Conejero V. (1994) Recommendations for naming
plant pathogenesis-related proteins. Plant Mol. Biol. Rep., 12: 245-264.
Vega-Sa´nchez ME, Redinbaugh MG, Costanzo S, Dorrance AE. Spatial and temporal
expression analysis of defense-related genes in soybean cultivars with different levels of
partial resistance to Phytophthora sojae. Physiol Mol Plant Pathol 2005;66: 175–82.
Villagomez-Castro JC, Lopez-Romero E (1996) Identification and partial characterization of
three chitinases from Entamoeba invadans with emphasis on their inhibition by
allosamidin. Antonie Van Leeuwenhoek 70:41–48.
Vyas PR, Deshpande MV (1991) Enzymatic hydrolysis of chitin by Myrothecium verrucaria
chitinase complex and its utilization to produce SCP. J Gen Appl Microbiol 37:267–275.
Wallace IM, Blackshields G, Higgins DG: Multiple sequence alignments. Curr Opin Struct Biol
2005, 15:261-266.

Page | 58
Walton JD, Schaeffer HJ, Leykam J (1994) Cloning and targeted gene disruption of EXG1,
encoding exo-beta 1,3-glucanase, in the phytopathogenic fungus Cochiobolus carbonum.
Appl. And Env. Microbiol. 60, 594-598.
Wang L, Jiang T: On the complexity of multiple sequence alignment. J Comput Biol 1994,
1:337-348.
Wang SL, Yen YH, Tsiao WJ, Chang WT, Wang CL (2002) Production of antimicrobial
compounds by Monascus purpureus CCRC31499 using shrimp and crab shell powder as
a carbon source. Enzyme Microb Technol 31:337–344.
Wheeler TJ, Kececioglu JD: Multiple alignment by aligning alignments. Bioinformatics 2007,
23:i559-i568.
Wheeler, D.L., Barrett, T., Benson, D.A., Bryant, S.H., Canese, K., Church, D.M., DiCuccio, M.,
Edgar, R., Federhen, S., Helmberg, W., et al., 2005. Database resources of the National
Centre for Biotechnology Information. Nucl. Acids Res. 33, D39–D45.
Wienkoop S, Saalbach G. Proteome analysis. Novel proteins identified at the peribacteroid
membrane from Lotus japonicas root nodules. Plant Physiol 2003;131:1080–90.
Wood, T. C., and W. R. Pearson. 1999. Evolution of protein sequences and structures. J. Mol.
Biol. 291:977–995.
Wu, C.H. et al., 2003. The Protein Information Resource. Nucleic Acids Res. 31 (in press).
Wu, C.H., Yeh, L.S., Huang, H., Arminski, L., Castro-Alvear, J., Chen, Y., Hu, Z., Kourtesis, P.,
Ledley, R.S., Suzek, B.E., et al., 2003. The protein information resource. Nucl. Acids
Res. 31, 345–347.
Wubben J.P., Joosten M.H.A.J., van Kan J.A.L., and De Wit P.J.G.M. (1992) Subcellular
localization of plant chitinases and 1,3-beta-glucanases in Cladosporium fulvum (syn.
Fulvia fulva) infected tomato leaves. Phys. Mol. Path., 41: 23-32.
Yalpani, N., Silverman, P., Wilson, T.M.A., Kieer, D.A. an Raskin, 1. (1991) Salicylic acid
is a systemic signal and a inducer of pathogenesis-related proteins in virus-infected
tobacco. Plant Cell, 3, 809-818.
Yamagami, t. and Funatsu, G., Limited proteolysis and reduction-carboxymethylation of rye seed
chitinase-a: role of the chitin-binding domain in its chitinase action. Biosci. Biotechnol.
Biochem., 60, 1081-1086, (1996).

Page | 59
Yamagami, t. and Funatsu, G., Purification and some properties of three chitinases from the seed
of rye (Secale cereale). Biosci. Biotechnol. Biochem., 57, 643-647 (1993).
Yamagami, t. and Funatsu, G., The complete amino acid sequence of chitinase-a from the seed of
rye(Secale cereale). Biosci. Biotechnol. Biochem., 58, 322-329 (1994).
Yamagami, t. and Funatsu, G., The complete amino acid sequence of chitinase-c from the seed of
rye (Secale cereale). Biosci. Biotechnol. Biochem., 58, 1854-1861 (1993).
Yamanoi T, Tsutsumida M, Oda Y, Akaike E, Osumi K, Yamamamoto K, Fujita K (2004)
Transglycosylation reaction of Mucor hiemalis endo-β-N-acetylglucosaminidase using
sugar derivatives modified at C-1 or C-2 as oligosaccharide acceptors. Carbohydr Res
339:1403–1406
Yeh S., Moffat B.A., Griffith M., Xiong F., Yang D.S.C., Wiseman S.B., Sarhan F., Danyluk J.,
Xue Y.Q., Hew C.L., Deherty-Kirby A., and Lajoie G. (2000) Chitinase genes responsive
to cold encode antifreeze proteins in winter cereals. Plant Physiol., 124: 1251-1263.
Yona, G., Linial, N., Linial, M., 2000. ProtoMap: automatic classification of protein sequences
and hierarchy of protein families. Nucleic Acids Res. 28, 49_/55.
Young V.L., Simpson R.M., and Ward V.K. (2005) Characterization of an exochitinase from
Epiphyas postvittana nucleopolyhedrovirus (family Baculoviridae). J. Gen. Virol., 86:
3253-3261.
Zhang, Z., and Yuen, G. Y., 2001, Chitinases from the plant disease biocontrol agent,
Stenotrophomonas maltophilia C3. Phytopathology, 91: 204–211.
Kyoung-Ja Kim, Yong-Joon Yang and Jong-Gi Kim (2003) Purification and Characterization of
Chitinase from Streptomyces sp. M-20. J. Biochem. Mol. Biol. 36(2): 185-189
Bradford, M. M. 1976 A rapid and sensitive method for the quantitation of microgram quantities
of protein utilizing the principle of protein-dye binding. Anal. Biochem., 72, 248-254.
Laemmli, U. K., 1970 Cleavage of structural proteins during the assembly of the head of
bacteriophage T4. Nature, 227, 6850-6855.

Page | 60
ABOUT AUTHOR
Dr. Manvendra Singh having his graduation in Agriculture From Narendra
Deva University of Agriculture and Technology, Faizabad, U.P. than Post
graduation M.Sc. in Plant biotechnology from Institute of Agricultural
Sciences, BHU Varanasi, U.P. He has completed his Ph.D. in Molecular
Biology and Biotechnology from Rajathan College of Agriculture, MPUAT,
Udaipur, Rajasthan. He has published 4 research paper in plant tissue culture
for commercial exploitation, bioinformatics, molecular biology and 3 book chapters in reputed
books. He has keen interest in medicinal plant biotechnology and bioinformatics.