qmda review session. things you should remember 1. probability & statistics
Post on 21-Dec-2015
216 views
TRANSCRIPT

QMDA
Review Session

Things you should remember

1. Probability & Statistics

the Gaussian or normal distribution
p(x) = exp{ - (x-x)2 / 22 ) 1(2)
expected value
variance

x
p(x)
x x+2x-2
95%
Expectation =
Median =
Mode = x
95% of probability within 2 of the expected value
Properties of the normal distribution

Multivariate Distributions
The Covariance Matrix, C, is very important
Cij
the diagonal elements give the variance of each x i
xi2 = Cii

The off-diagonal elemements of C indicate whether pairs of x’s are correlated. E.g.
C12
x2
x1
x1
x2
C12<0negative correlationx2
x1
x1
x2
C12>0positive correlation

the multivariate normal distribution
p(x) = (2)-N/2 |Cx|-1/2 exp{ -1/2 (x-x)T Cx-1 (x-x) }
has expectation x
covariance Cx
And is normalized to unit area

if y is linearly related to x, y=Mx then
y=Mx (rule for means)
Cy = M Cx MT
(rule for propagating error)
These rules work regardless of the distribution of x
2. Least Squares

Simple Least SquaresLinear relationship between data, d, and model, m
d = Gm
Minimize prediction error E=eTe with e=dobs-Gm
mest = [GTG]-1GTd
If data are uncorrelated with variance, d2, then
Cm = d2 [GTG]-1

Least Squares with prior constraints
Given uncorrelated with variance, d2, that satisfy a
linear relationship d = Gm
And prior information with variance, m2, that satisfy a
linear relationship h = Dm
The best estimate for the model parameters, mest, solves
G
D
d
h m =
Previously, we discussed only the special case h=0
With = m/d.

Newton’s Method for Non-Linear Least-Squares Problems
Given data that satisfies a non-linear relationship d = g(m)
Guess a solution m(k) with k=0 and linearize around it:
m = m-m(k) and d = d-g(m(k)) and d=Gm
With Gij = gi/mj evaluated at m(k)
Then iterate, m(k+1) = m(k) + m withm=[GTG]-1GTd
hoping for convergence

3. Boot-straps

Investigate the statistics of y by
creating many datasets y’and examining their statistics
each y’ is created throughrandom sampling with replacement
of the original dataset y
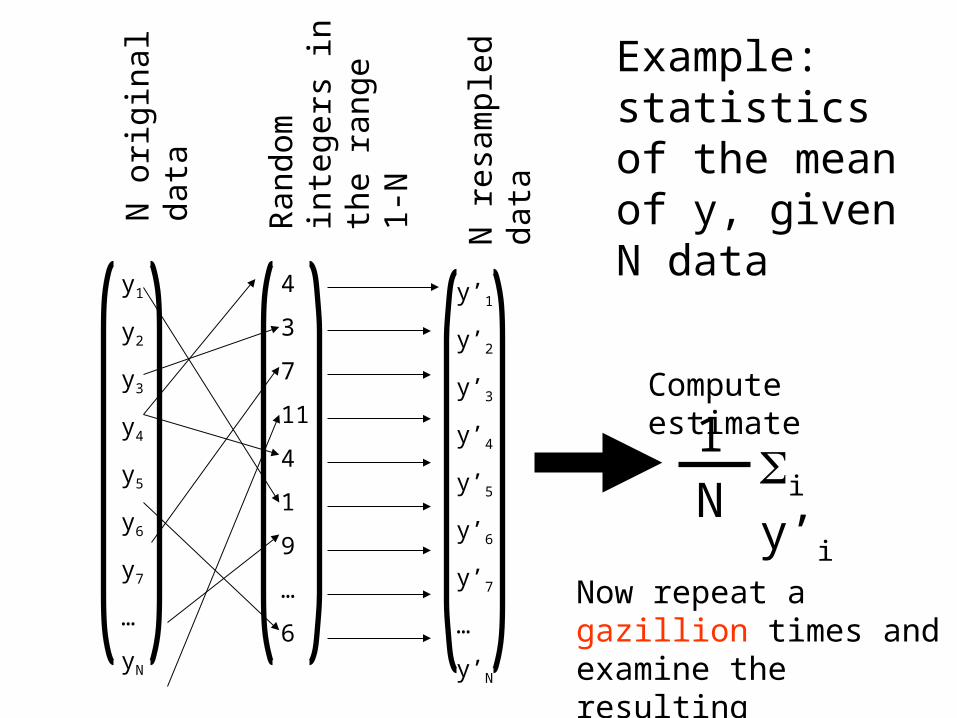
y1
y2
y3
y4
y5
y6
y7
…
yN
y’1
y’2
y’3
y’4
y’5
y’6
y’7
…
y’N
4
3
7
11
4
1
9
…
6
N o
rigi
nal d
ata
Ran
dom
inte
gers
in
the
rang
e 1-
N
N r
esam
pled
dat
aN1
i y’i
Compute estimate
Now repeat a gazillion times and examine the resulting distribution of estimates
Example: statistics of the mean of y, given N data

4. Interpolation and Splines
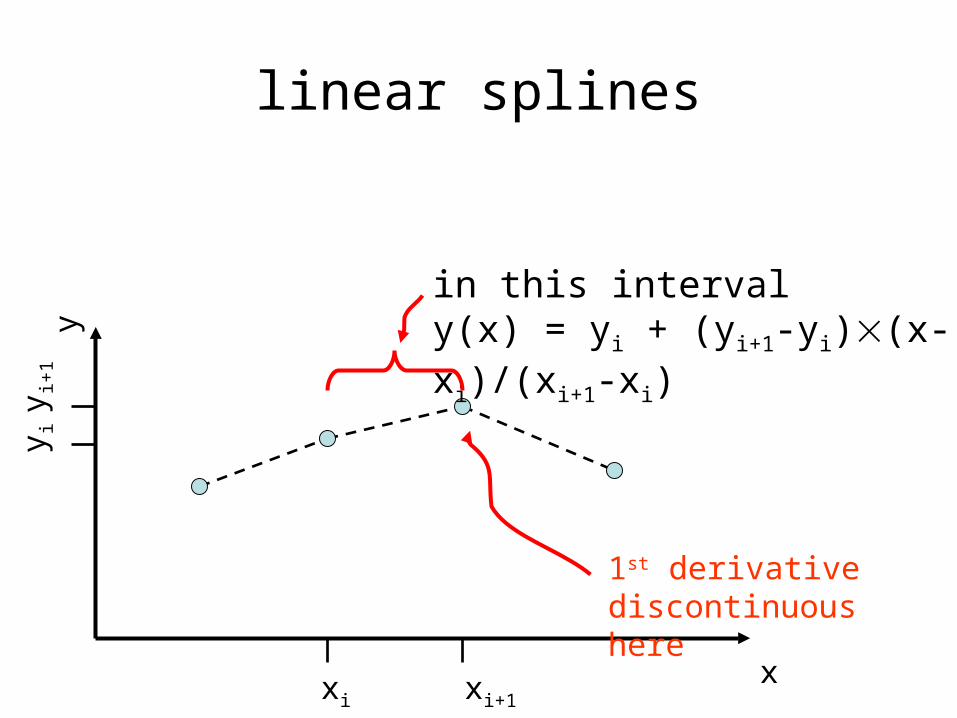
linear splines
xxi xi+1
y iy i+
1y
in this intervaly(x) = yi + (yi+1-yi)(x-xi)/(xi+1-xi)
1st derivative discontinuous here
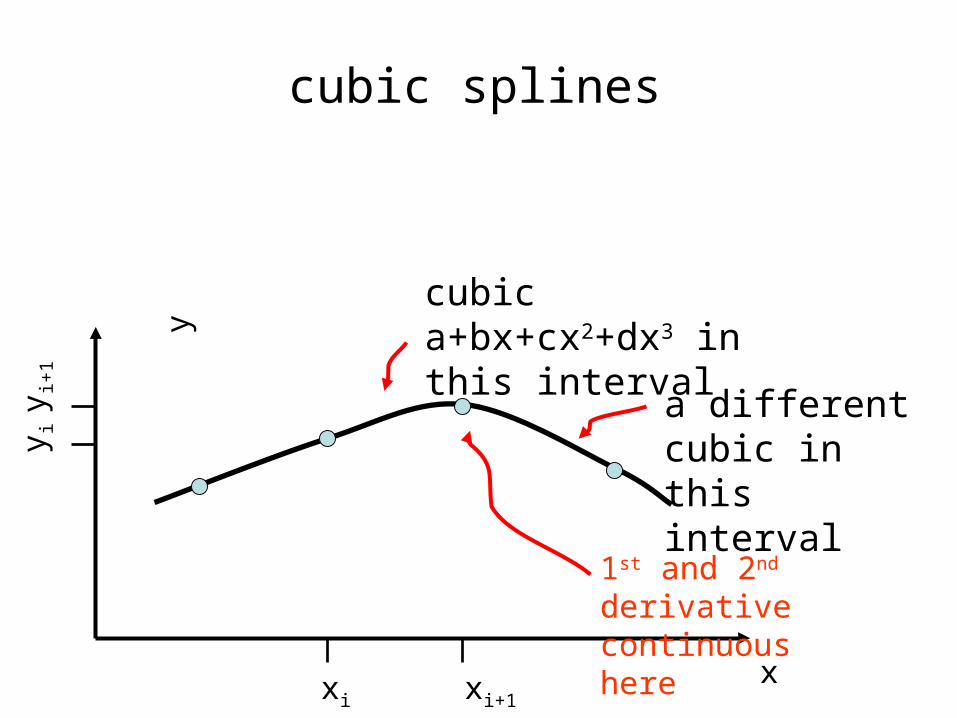
cubic splines
xxi xi+1
y iy i+
1
y
cubic a+bx+cx2+dx3 in this interval
a different cubic in this interval
1st and 2nd derivative continuous here

5. Hypothesis Testing

The Null Hypothesisalways a variant of this theme:
the results of an experiment differs from the expected value only because
of random variation

Test of Significance of Resultssay to 95% significance
The Null Hypothesis would generate the observed result less than 5% of
the time

Four important distributions
Normal distribution
Chi-squared distribution
Student’s t-distribution
F-distribution
Distribution of 2 = i=1Nxi
2
Distribution of xi
Distribution of t = x0 / { N-1 i=1Nxi
2 }
Distribution of F = { N-1i=1N xi
2} / { M-1i=1M xN+i
2 }

5 testsmobs = mprior when mprior and prior are known
normal distribution
obs = prior when mprior and prior are knownchi-squared distribution
mobs = mprior when mprior is known but prior is unknownt distribution
1obs =
obs when m1prior and m2
prior are knownF distribution
m1obs = m
obs when 1prior and
prior are unknownmodified t distribution

6. filters

g(t) = -
t f(t-) h() dgk = t p=-
k fk-p hp
g(t) = 0
f() h(t-) dgk = t p=0
fp hk-p
or alternatively
Filtering operation g(t)=f(t)*h(t)
“convolution”

How to do convolution by handx=[x0, x1, x2, x3, x4, …]T and y=[y0, y1, y2, y3, y4, …]T
x0, x1, x2, x3, x4, …… y4, y3, y2, y1, y0
x0y0
Reverse on time-series, line them up as shown, and multiply rows. This is first element of x*y
[x*y]2=
x0, x1, x2, x3, x4, …… y4, y3, y2, y1, y0
x0y1+x1y0
Then slide, multiply rows and add to get the second element of x*y
And etc …
[x*y]1=

g0
g1
…gN
h0
h1
…hN
f0 0 0 0 0 0f1 f0 0 0 0 0…fN … f3 f2 f1 f0
= t
g = F h
Matrix formulations of g(t)=f(t)*h(t)
g0
g1
…gN
f0
f1
…fN
h0 0 0 0 0 0h1 h0 0 0 0 0…hN … h3 h2 h1 h0
= t
g = H f
and
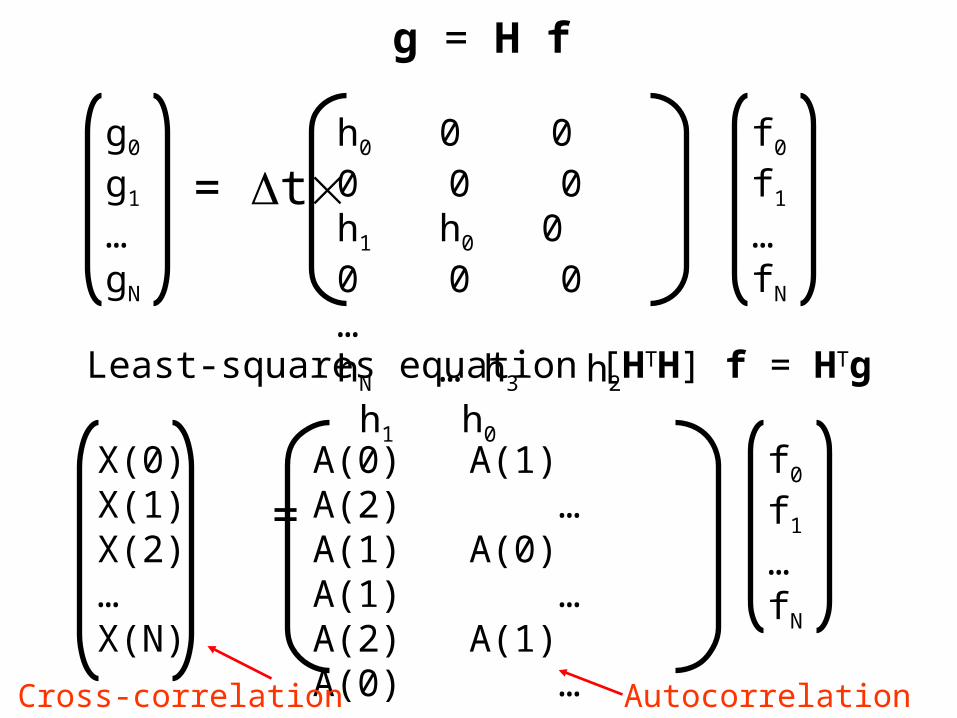
X(0)X(1)X(2)…X(N)
f0
f1
…fN
A(0) A(1) A(2) …A(1) A(0) A(1) … A(2) A(1) A(0) ……A(N) A(N-1) A(N-2) …
=
Least-squares equation [HTH] f = HTg
g = H f
g0
g1
…gN
f0
f1
…fN
h0 0 0 0 0 0h1 h0 0 0 0 0…hN … h3 h2 h1 h0
= t
Autocorrelation of hCross-correlation of h and g

Ai and Xi
Auto-correlation of a time-series, T(t)
A() = -+
T(t) T(t-) dt
Ai = j Tj Tj-i
Cross-correlation of two time-series T(1)(t) and T(2)(t)
X() = -+
T(1)(t) T(2)(t-) dt
Xi = j T(1)j T(2)
j-i

7. fourier transforms and spectra

Integral transforms:
C() = -+
T(t) exp(-it) dt
T(t) = (1/2) -+
C() exp(it) d
Discrete transforms (DFT)
Ck = n=0N-1 Tn exp(-2ikn/N ) with k=0, …, N-1
Tn = N-1k=0N-1 Ck exp(+2ikn/N ) with n=0, …, N-1
Frequency step: t = 2/N
Maximum (Nyquist) Frequency max = 1/ (2t)

Aliasing and cyclicity
in a digital world n+N = n
andsince time and frequency play symmetrical roles in exp(-it)
tk+N = tk

One FFT that you should know:
FFT of a spike at t=0 is a constant
C() = -+
(t) exp(-it) dt = exp(0) = 1

Error Estimates for the DFTAssume uncorrelated, normally-distributed data, dn=Tn, with
variance d2
The matrix G in Gm=d is Gnk=N-1 exp(+2ikn/N )
The problem Gm=d is linear, so the unknowns, mk=Ck, (the coefficients of the complex exponentials) are also normally-distributed.
Since exponentials are orthogonal, GHG=N-1I is diagonaland Cm= d
2 [GHG]-1 = N-1d2I is diagonal, too
Apportioning variance equally between real and imaginary parts of Cm, each has variance 2= N-1d
2/2.The spectrum sm
2= Crm
2+ Cim
2 is the sum of two uncorrelated, normally distributed random variables and is thus
2-distributed.
The 95% value of 2 is about 5.9, so that to be significant, a
peak must exceed 5.9N-1d2/2

Convolution Theorem
transform[ f(t)*g(t) ] =
transform[g(t)] transform[f(t)]

Power spectrum of a stationary time-series
T(t) = stationary time series
C() = -T/2
+T/2 T(t) exp(-it) dt
S() = limT T-1 |C()|2
S() is called the power spectral density, the spectrum normalized by the length of the time series.

Relationship of power spectral density to DFT
To compute the Fourier transform, C(), you multiply the DFT coefficients, Ck, by t.
So to get power spectal densityT-1 |C()|2 =
(Nt)-1 |t Ck|2 =
(t/N) |Ck|2
You multiply the DFT spectrum, |Ck|2, by t/N.

Windowed Timeseries
Fourier transform of long time-series
convolved with the Fourier Transform of the windowing function
is Fouier transform of windowed time-series

Window FunctionsBoxcar
its Fourier transform is a sinc functionwhich has a narrow central peakbut large side lobes
Hanning (Cosine) taperits Fourier transform
has a somewhat wider central peakbut now side lobes

8. EOF’s and factor analysis

SamplesNM
(f1 in s1) (f2 in s1) (f3 in s1)
(f1 in s2) (f2 in s2) (f3 in s2)
(f1 in s3) (f2 in s3) (f3 in s3)
…
(f1 in sN) (f2 in sN) (f3 in sN)
(A in s1) (B in s1) (C in s1)
(A in s2) (B in s2) (C in s2)
(A in s3) (B in s3) (C in s3)
…
(A in sN) (B in sN) (C in sN)
=
(A in f1) (B in f1) (C in f1)
(A in f2) (B in f2) (C in f2)
(A in f3) (B in f3) (C in f3)
S = C F
Coefficients NM
Factors MM
Representation of samples as a linear mixing of factors

SamplesNM
(f1 in s1) (f2 in s1)
(f1 in s2) (f2 in s2)
(f1 in s3) (f2 in s3)
…
(f1 in sN) (f2 in sN)
(A in s1) (B in s1) (C in s1)
(A in s2) (B in s2) (C in s2)
(A in s3) (B in s3) (C in s3)
…
(A in sN) (B in sN) (C in sN)
=
(A in f1) (B in f1) (C in f1)
(A in f2) (B in f2) (C in f2)
S C’ F’
selectedcoefficients
Np
selectedfactors pM
ignore f3
igno
re f
3
data approximated with only most important factors
p most important factors = those with the biggest coefficients

Singular Value Decomposition (SVD)
Any NM matrix S and be written as the product of three matrices
S = U VT
where U is NN and satisfies UTU = UUT
V is MM and satisfies VTV = VVT
and is an NM diagonal matrix of singular values, i

SVD decomposition of S
S = U VT
write as
S = U VT = [U ] [VT] = C F
So the coefficients are C = U
and the factors are
F = VT
The factors with the biggest i’s are the most important

Transformations of FactorsIf you chose the p most important factors, they define both a
subspace in which the samples must lie, and a set of coordinate axes of that subspace. The choice of axes is not unique, and could be changed through a transformation, T
Fnew = T Fold
A requirement is that T-1 exists, else Fnew will not span the same subspace as Fold
S = C F = C I F = (C T-1) (T F)= Cnew Fnew
So you could try to implement the desirable factors by designing an appropriate transformation matrix, T

9. Metropolis Algorithm and Simulated Annealing

Metropolis Algorithm
a method to generate a vector x of realizations of the distribution p(x)

The process is iterativestart with an x, say x(i)
then randomly generate another x in its neighborhood, say x(i+1), using a distribution
Q(x(i+1)|x(i))
then test whether you will accept the new x(i+1)
if it passes, you append x(i+1) to the vector x that you are accumulating
if it fails, then you append x(i)

a reasonable choice for Q(x(i+1)|x(i)) normal distribution with mean=x(i) and x
2 that quantifies the sense of neighborhood
The acceptance test is as followsfirst compute the quantify:
If a>1 always accept x(i+1)
If a<1 accept x(i+1) with a probability of a and accept x(i) with a probability of 1-a
p(x(i+1)) Q(x(i)|x(i+1))
p(x(i)) Q(x(i+1)|x(i))a =

Simulated Annealing
Application of Metropolis to Non-linear optimization
find m that minimizes E(m)=eTewhere e = dobs-g(m)

Based on using the Boltzman distribution for p(x) in the Metropolis
Algorithm
p(x) = exp{-E(m)/T}
where temperature, T, is slowly decreased during the iterations

10. Some final words

Start Simple !
Examine a small subset of your data and looking them over carefully
Build processing scripts incrementally, checking intermediated results at each stage
Make lots of plots and look them over carefully
Do reality checks