quantitative analysis of randomized distributed...
TRANSCRIPT

Quantitative Analysis ofRandomized Distributed Systems
and Probabilistic Automata
Christel BaierTechnische Universitat Dresden
joint work with Nathalie BertrandFrank CiesinskiMarcus Großer
1 / 124

Probability elsewhere int-01
• randomized algorithms [Rabin 1960]
breaking symmetry, fingerprints, input sampling, . . .. . .. . .
• stochastic control theory [Bellman 1957]
operations research
• performance modeling [Markov, Erlang, Kolm., ∼∼∼ 1900]
emphasis on steady-state and transient measures
• biological systems, resilient systems, security protocols.........
2 / 124

Probability elsewhere int-01
• randomized algorithms [Rabin 1960]
breaking symmetry, fingerprints, input sampling, . . .. . .. . .models: discrete-time Markov chains
Markov decision processes
• stochastic control theory [Bellman 1957]
operations researchmodels: Markov decision processes
• performance modeling [Markov, Erlang, Kolm., ∼∼∼ 1900]
emphasis on steady-state and transient measuresmodels: continuous-time Markov chains
• biological systems, resilient systems, security protocols.........
3 / 124

Model checking int-02
requirements(safety, liveness)
specification, e.g.,temporal formula ΦΦΦ
reactive system
abstractmodelMMM
model checking
“doesM |= ΦM |= ΦM |= Φ hold ?”
no yes4 / 124

Probabilistic model checking int-03
quantitativerequirements
specification, e.g.,temporal formula ΦΦΦ
probabilisticreactive system
probabilisticmodelMMM
probabilistic model checking
“doesM |= ΦM |= ΦM |= Φ hold ?”
probability for “bad behaviors” is < 10−6< 10−6< 10−6
probability for “good behaviors” is 111expected costs for ....
5 / 124

Probabilistic model checking int-03
quantitativerequirements
linear temporal formula ΦΦΦ(path event)
probabilisticreactive system
Markov decisionprocessMMM
probabilistic model checking
quantitative analysis ofMMM against ΦΦΦ
probability for “bad behaviors” is < 10−6< 10−6< 10−6
probability for “good behaviors” is 111
6 / 124

Outline overview
• Markov decision processes (MDP) andquantitative analysis against path events
• partial order reduction for MDP
• partially-oberservable MDP
• conclusions
7 / 124

Markov decision process (MDP) mdp-01
operational model with nondeterminism and probabilism
8 / 124

Markov decision process (MDP) mdp-01
operational model with nondeterminism and probabilism
• modeling randomized distributed systemsby interleaving
sss121212
121212
121212
121212
process 111tosses a
coin
process 222tosses acoin
process 111tosses acoin
process 222tosses a
coin
121212
121212
121212
121212
9 / 124
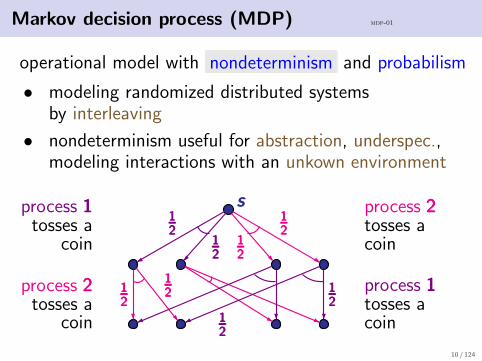
Markov decision process (MDP) mdp-01
operational model with nondeterminism and probabilism
• modeling randomized distributed systemsby interleaving
• nondeterminism useful for abstraction, underspec.,modeling interactions with an unkown environment
sss121212
121212
121212
121212
process 111tosses a
coin
process 222tosses acoin
process 111tosses acoin
process 222tosses a
coin
121212
121212
121212
121212
10 / 124

Markov decision process (MDP) mdp-02-r
M = (S , Act, P, . . .)M = (S , Act, P, . . .)M = (S , Act, P, . . .)
11 / 124

Markov decision process (MDP) mdp-02-r
M = (S , Act, P, . . .)M = (S , Act, P, . . .)M = (S , Act, P, . . .)
• finite state space SSS
12 / 124

Markov decision process (MDP) mdp-02-r
M = (S , Act, P, . . .)M = (S , Act, P, . . .)M = (S , Act, P, . . .)
• finite state space SSS
• ActActAct finite set of actions
13 / 124

Markov decision process (MDP) mdp-02-r
M = (S , Act, P, . . .)M = (S , Act, P, . . .)M = (S , Act, P, . . .)
• finite state space SSS
• ActActAct finite set of actions
• P : S × Act × S → [0, 1]P : S × Act × S → [0, 1]P : S × Act × S → [0, 1] s.t.∑s ′∈S
P(s, α, s ′)∑s ′∈S
P(s, α, s ′)∑s ′∈S
P(s, α, s ′) = 1= 1= 1
sssααα βββ
141414
343434
121212
161616
131313
nondeterministic choice
probabilistic choice
14 / 124

Markov decision process (MDP) mdp-02-r
M = (S , Act, P, . . .)M = (S , Act, P, . . .)M = (S , Act, P, . . .)
• finite state space SSS
• ActActAct finite set of actions
• P : S × Act × S → [0, 1]P : S × Act × S → [0, 1]P : S × Act × S → [0, 1] s.t.
∀s ∈ S∀s ∈ S∀s ∈ S ∀α ∈ Act...∀α ∈ Act...∀α ∈ Act...∑s ′∈S
P(s, α, s ′)∑s ′∈S
P(s, α, s ′)∑s ′∈S
P(s, α, s ′) ∈ {0, 1}∈ {0, 1}∈ {0, 1}
sssααα βββ
141414
343434
121212
161616
131313
nondeterministic choice
probabilistic choice
↗↗↗α /∈ Act(s)α /∈ Act(s)α /∈ Act(s)
↖↖↖α ∈ Act(s)α ∈ Act(s)α ∈ Act(s)
Act(s) =Act(s) =Act(s) = set of actionsthat are enabledin state sss
15 / 124

Markov decision process (MDP) mdp-02-r
M = (S , Act, P, s0, AP , L, rew , . . .)M = (S , Act, P, s0, AP, L, rew , . . .)M = (S , Act, P, s0, AP, L, rew , . . .)
• finite state space SSS
• ActActAct finite set of actions
• P : S × Act × S → [0, 1]P : S × Act × S → [0, 1]P : S × Act × S → [0, 1] s.t.
∀s ∈ S∀s ∈ S∀s ∈ S ∀α ∈ Act...∀α ∈ Act...∀α ∈ Act...∑s ′∈S
P(s, α, s ′)∑s ′∈S
P(s, α, s ′)∑s ′∈S
P(s, α, s ′) ∈ {0, 1}∈ {0, 1}∈ {0, 1}
• s0s0s0 initial state
• APAPAP set of atomic propositions
• labeling L : S → 2APL : S → 2APL : S → 2AP
• reward function rew : S × Act → Rrew : S × Act → Rrew : S × Act → R
↗↗↗α /∈ Act(s)α /∈ Act(s)α /∈ Act(s)
↖↖↖α ∈ Act(s)α ∈ Act(s)α ∈ Act(s)
16 / 124

Randomized mutual exclusion protocol mdp-05
• 222 concurrent processes P1P1P1, P2P2P2 with 333 phases:
ninini noncritical actions of process PiPiPi
wiwiwi waiting phase of process PiPiPi
cicici critical section of process PiPiPi
• competition of both processes are waiting
17 / 124

Randomized mutual exclusion protocol mdp-05
• 222 concurrent processes P1P1P1, P2P2P2 with 333 phases:
ninini noncritical actions of process PiPiPi
wiwiwi waiting phase of process PiPiPi
cicici critical section of process PiPiPi
• competition of both processes are waiting
• resolved by a randomized arbiter who tosses a coin
18 / 124

Randomized mutual exclusion protocol mdp-05
n1n2n1n2n1n2
w1n2w1n2w1n2 n1w2n1w2n1w2
w1w2w1w2w1w2c1n2c1n2c1n2 n1c2n1c2n1c2
c1w2c1w2c1w2 w1c2w1c2w1c2
MDP
request2
request2
request2
releas
e 1re
leas
e 1re
leas
e 1
enter1
enter1
enter1
reques
t1req
uest1
reques
t1 request2
request2
request2
request2
request2
request2 reques
t1req
uest1
reques
t1 enter2enter2enter2
reques
t1
reques
t1
reques
t1
release2
release2
release2
toss atoss atoss acoincoincoin
release2
release2
release2 re
leas
e 1
releas
e 1
releas
e 1
121212
121212
• interleaving of the request operations
• competition if both processes are waiting
• randomized arbiter tosses a coin if both are waiting
19 / 124
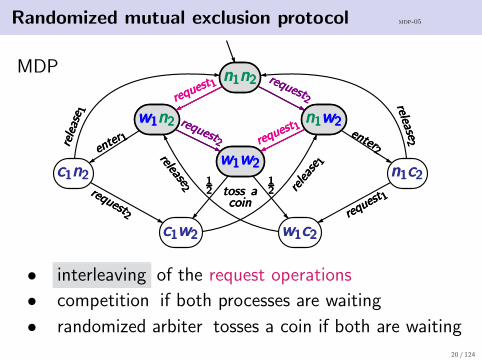
Randomized mutual exclusion protocol mdp-05
n1n2n1n2n1n2
w1n2w1n2w1n2 n1w2n1w2n1w2
w1w2w1w2w1w2c1n2c1n2c1n2 n1c2n1c2n1c2
c1w2c1w2c1w2 w1c2w1c2w1c2
n1n2n1n2n1n2
w1n2w1n2w1n2 n1w2n1w2n1w2
w1w2w1w2w1w2
MDP
request2
request2
request2
releas
e 1re
leas
e 1re
leas
e 1
enter1
enter1
enter1
reques
t1req
uest1
reques
t1 request2
request2
request2
request2
request2
request2 reques
t1req
uest1
reques
t1 enter2enter2enter2
reques
t1
reques
t1
reques
t1
release2
release2
release2
toss atoss atoss acoincoincoin
release2
release2
release2 re
leas
e 1
releas
e 1
releas
e 1
121212
121212
• interleaving of the request operations
• competition if both processes are waiting
• randomized arbiter tosses a coin if both are waiting
20 / 124

Randomized mutual exclusion protocol mdp-05
n1n2n1n2n1n2
w1n2w1n2w1n2 n1w2n1w2n1w2
w1w2w1w2w1w2c1n2c1n2c1n2 n1c2n1c2n1c2
c1w2c1w2c1w2 w1c2w1c2w1c2
w1w2w1w2w1w2
MDP
request2
request2
request2
releas
e 1re
leas
e 1re
leas
e 1
enter1
enter1
enter1
reques
t1req
uest1
reques
t1 request2
request2
request2
request2
request2
request2 reques
t1req
uest1
reques
t1 enter2enter2enter2
reques
t1
reques
t1
reques
t1
release2
release2
release2
toss atoss atoss acoincoincoin
release2
release2
release2 re
leas
e 1
releas
e 1
releas
e 1
121212
121212
• interleaving of the request operations
• competition if both processes are waiting
• randomized arbiter tosses a coin if both are waiting
21 / 124

Randomized mutual exclusion protocol mdp-05
n1n2n1n2n1n2
w1n2w1n2w1n2 n1w2n1w2n1w2
w1w2w1w2w1w2c1n2c1n2c1n2 n1c2n1c2n1c2
c1w2c1w2c1w2 w1c2w1c2w1c2
w1w2w1w2w1w2
c1w2c1w2c1w2 w1c2w1c2w1c2
MDP
request2
request2
request2
releas
e 1re
leas
e 1re
leas
e 1
enter1
enter1
enter1
reques
t1req
uest1
reques
t1 request2
request2
request2
request2
request2
request2 reques
t1req
uest1
reques
t1 enter2enter2enter2
reques
t1
reques
t1
reques
t1
release2
release2
release2
toss atoss atoss acoincoincoin
release2
release2
release2 re
leas
e 1
releas
e 1
releas
e 1
121212
121212
• interleaving of the request operations
• competition if both processes are waiting
• randomized arbiter tosses a coin if both are waiting
22 / 124

Reasoning about probabilities in MDP mdp-10
• requires resolving the nondeterminism by schedulers
23 / 124

Reasoning about probabilities in MDP mdp-10
• requires resolving the nondeterminism by schedulers
• a scheduler is a function D : S+ −→ ActD : S+ −→ ActD : S+ −→ Act s.t.action D (s0 . . . sn)D (s0 . . . sn)D (s0 . . . sn) is enabled in state snsnsn
24 / 124

Reasoning about probabilities in MDP mdp-10
• requires resolving the nondeterminism by schedulers
• a scheduler is a function D : S+ −→ ActD : S+ −→ ActD : S+ −→ Act s.t.action D (s0 . . . sn)D (s0 . . . sn)D (s0 . . . sn) is enabled in state snsnsn
• each scheduler induces an infinite Markov chain
MDP
βββ
γγγααα131313
232323
σσσ
δδδ
. . .. . .. . . . . .. . .. . . . . .. . .. . .
232323
13 α13 α13 α
δδδ βββ
γγγ σσσ
α 23
α 23α 23
131313 σσσ
25 / 124

Reasoning about probabilities in MDP mdp-10
• requires resolving the nondeterminism by schedulers
• a scheduler is a function D : S+ −→ ActD : S+ −→ ActD : S+ −→ Act s.t.action D (s0 . . . sn)D (s0 . . . sn)D (s0 . . . sn) is enabled in state snsnsn
• each scheduler induces an infinite Markov chain���yields a notion of probability measure PrDPrDPrD
on measurable sets of infinite paths
26 / 124

Reasoning about probabilities in MDP mdp-10
• requires resolving the nondeterminism by schedulers
• a scheduler is a function D : S+ −→ ActD : S+ −→ ActD : S+ −→ Act s.t.action D (s0 . . . sn)D (s0 . . . sn)D (s0 . . . sn) is enabled in state snsnsn
• each scheduler induces an infinite Markov chain���yields a notion of probability measure PrDPrDPrD
on measurable sets of infinite paths
typical task: given a measurable path event EEE ,
∗∗∗ check whether EEE holds almost surely, i.e.,
PrD(E ) = 1PrD(E) = 1PrD(E ) = 1 for all schedulers DDD
27 / 124

Reasoning about probabilities in MDP mdp-10
• requires resolving the nondeterminism by schedulers
• a scheduler is a function D : S+ −→ ActD : S+ −→ ActD : S+ −→ Act s.t.action D (s0 . . . sn)D (s0 . . . sn)D (s0 . . . sn) is enabled in state snsnsn
• each scheduler induces an infinite Markov chain���yields a notion of probability measure PrDPrDPrD
on measurable sets of infinite paths
typical task: given a measurable path event EEE ,
∗∗∗ check whether EEE holds almost surely
∗∗∗ compute the worst-case probability for EEE , i.e.,
supD
PrD(E )supD
PrD(E)supD
PrD(E ) or infD
PrD(E )infD
PrD(E)infD
PrD(E )28 / 124

Quantitative analysis of MDP mdp-15
given: MDPM = (S , Act, P, . . .)M = (S , Act, P, . . .)M = (S , Act, P, . . .) with initial state s0s0s0
ωωω-regular path event EEE ,e.g., given by an LTL formula
task: compute PrMmax(s0, E ) = supD
PrD(s0, E)PrMmax(s0, E ) = supD
PrD(s0, E)PrMmax(s0, E) = supD
PrD(s0, E )
29 / 124

Quantitative analysis of MDP mdp-15
given: MDPM = (S , Act, P, . . .)M = (S , Act, P, . . .)M = (S , Act, P, . . .) with initial state s0s0s0
ωωω-regular path event EEE ,e.g., given by an LTL formula
task: compute PrMmax(s0, E ) = supD
PrD(s0, E)PrMmax(s0, E ) = supD
PrD(s0, E)PrMmax(s0, E) = supD
PrD(s0, E )
method: compute xs = PrMmax(s, E)xs = PrMmax(s, E )xs = PrMmax(s, E) for all s ∈ Ss ∈ Ss ∈ S
via graph analysis and linear program
[Vardi/Wolper’86][Courcoubetis/Yannakakis’88][Bianco/de Alfaro’95][Baier/Kwiatkowska’98]
30 / 124

probabilisticsystem
“bad behaviors”
31 / 124

probabilisticsystem
“bad behaviors”
MDPMMM
32 / 124

probabilisticsystem
“bad behaviors”
MDPMMMLTL formula ϕϕϕ
deterministicautomaton AAA
33 / 124

probabilisticsystem
“bad behaviors”
MDPMMMLTL formula ϕϕϕ
deterministicautomaton AAA
quantitative analysisin the product-MDPM×AM×AM×A
PrMmax(s, ϕ)PrMmax(s, ϕ)PrMmax(s, ϕ) === PrM×Amax
(〈s, inits〉,PrM×Amax
(〈s , inits〉,PrM×Amax
(〈s , inits〉, acceptance
cond. of AAA)))
34 / 124

probabilisticsystem
“bad behaviors”
MDPMMMLTL formula ϕϕϕ
deterministicautomaton AAA
quantitative analysisin the product-MDPM×AM×AM×A
PrMmax(s, ϕ)PrMmax(s, ϕ)PrMmax(s, ϕ) === PrM×Amax
(〈s, inits〉,PrM×Amax
(〈s , inits〉,PrM×Amax
(〈s , inits〉, ♦accEC♦accEC♦accEC
)))
maximal probabililityfor reaching anaccepting endcomponent
35 / 124
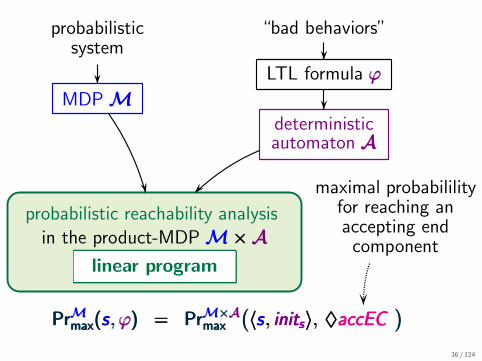
probabilisticsystem
“bad behaviors”
MDPMMMLTL formula ϕϕϕ
deterministicautomaton AAA
probabilistic reachability analysisin the product-MDPM×AM×AM×A
linear program
PrMmax(s, ϕ)PrMmax(s, ϕ)PrMmax(s, ϕ) === PrM×Amax
(〈s, inits〉,PrM×Amax
(〈s , inits〉,PrM×Amax
(〈s , inits〉, ♦accEC♦accEC♦accEC
)))
maximal probabililityfor reaching anaccepting endcomponent
36 / 124

probabilisticsystem
“bad behaviors”
MDPMMMLTL formula ϕϕϕ
deterministicautomaton AAA
probabilistic reachability analysisin the product-MDPM×AM×AM×A
linear program
PrMmax(s, ϕ)PrMmax(s, ϕ)PrMmax(s, ϕ) === PrM×Amax
(〈s, inits〉,PrM×Amax
(〈s , inits〉,PrM×Amax
(〈s , inits〉, ♦accEC♦accEC♦accEC
)))
polynomialin |M| · |A||M| · |A||M| · |A|
37 / 124
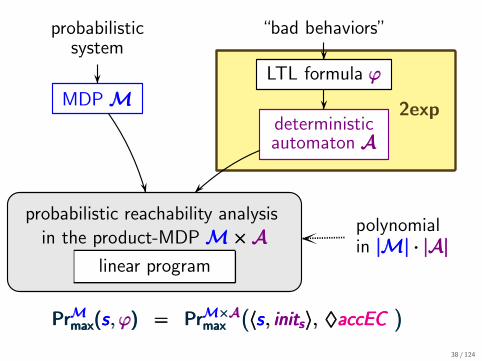
2exp
probabilisticsystem
“bad behaviors”
MDPMMMLTL formula ϕϕϕ
deterministicautomaton AAA
probabilistic reachability analysisin the product-MDPM×AM×AM×A
linear program
PrMmax(s, ϕ)PrMmax(s, ϕ)PrMmax(s, ϕ) === PrM×Amax
(〈s, inits〉,PrM×Amax
(〈s , inits〉,PrM×Amax
(〈s , inits〉, ♦accEC♦accEC♦accEC
)))
polynomialin |M| · |A||M| · |A||M| · |A|
38 / 124

stateexplosionproblem
probabilisticsystem
“bad behaviors”
MDPMMMLTL formula ϕϕϕ
deterministicautomaton AAA
probabilistic reachability analysisin the product-MDPM×AM×AM×A
linear program
PrMmax(s, ϕ)PrMmax(s, ϕ)PrMmax(s, ϕ) === PrM×Amax
(〈s, inits〉,PrM×Amax
(〈s , inits〉,PrM×Amax
(〈s , inits〉, ♦accEC♦accEC♦accEC
)))
polynomialin |M| · |A||M| · |A||M| · |A|
39 / 124

Advanced techniques for PMC por-01-cs
••• symbolic model checking with variants of BDDse.g., in PRISM [Kwiatkowska/Norman/Parker]
••• state aggregation with bisimulatione.g., in MRMC [Katoen et al]
••• abstraction-refinemente.g., in RAPTURE [d’Argenio/Jeannet/Jensen/Larsen]
PASS [Hermanns/Wachter/Zhang]
••• partial order reductione.g., in LiQuor [Baier/Ciesinski/Großer]
40 / 124

Advanced techniques for PMC por-01-cs
••• symbolic model checking with variants of BDDse.g., in PRISM [Kwiatkowska/Norman/Parker]
randomized distributed algorithms,communication and multimedia protocols,power management, security, . . .. . .. . .
••• state aggregation with bisimulatione.g., in MRMC [Katoen et al]
••• abstraction-refinemente.g., in RAPTURE [d’Argenio/Jeannet/Jensen/Larsen]
PASS [Hermanns/Wachter/Zhang]
••• partial order reductione.g., in LiQuor [Baier/Ciesinski/Großer]
41 / 124

Advanced techniques for PMC por-01-cs
••• symbolic model checking with variants of BDDse.g., in PRISM [Kwiatkowska/Norman/Parker]
randomized distributed algorithms,communication and multimedia protocols,power management, security, . . .. . .. . .
••• state aggregation with bisimulatione.g., in MRMC [Katoen et al]
••• abstraction-refinemente.g., in RAPTURE [d’Argenio/Jeannet/Jensen/Larsen]
PASS [Hermanns/Wachter/Zhang]
••• partial order reductione.g., in LiQuor [Baier/Ciesinski/Großer]
42 / 124

Partial order reduction por-02
technique for reducing the state space of concurrentsystems [Godefroid,Peled,Valmari, ca. 1990]
• attempts to analyze a sub-system by identifying“redundant interleavings”
• explores representatives of paths that agree up tothe order of independent actions
43 / 124

Partial order reduction por-02
technique for reducing the state space of concurrentsystems [Godefroid,Peled,Valmari, ca. 1990]
• attempts to analyze a sub-system by identifying“redundant interleavings”
• explores representatives of paths that agree up tothe order of independent actions
e.g., x := x+yx := x+yx := x+y︸ ︷︷ ︸action ααα
‖‖‖ z := z+3z := z+3z := z+3︸ ︷︷ ︸action βββ
has the same effect as α; βα; βα; β or β; αβ; αβ; α
44 / 124

Partial order reduction por-02
technique for reducing the state space of concurrentsystems [Godefroid,Peled,Valmari, ca. 1990]
• attempts to analyze a sub-system by identifying“redundant interleavings”
• explores representatives of paths that agree up tothe order of independent actions
DFS-based on-the-fly generation of a reduced system
for each expanded state sss
• choose an appropriate subset Ample(s)Ample(s)Ample(s) of Act(s)Act(s)Act(s)
• expand only the ααα-successors of sss for α ∈ Ample(s)α ∈ Ample(s)α ∈ Ample(s)(but ignore the actions in Act(s) \ Ample(s)Act(s) \ Ample(s)Act(s) \ Ample(s))
45 / 124

Ample-set method [Peled 1993] por-03
given: processes PiPiPi of a parallel system P1‖. . .‖PnP1‖. . .‖PnP1‖. . .‖Pn
with transition system T = (S , Act,→, . . .)T = (S , Act,→, . . .)T = (S , Act,→, . . .)
task: on-the-fly generation of a sub-system TrTrTr s.t.
(A1) stutter condition . . .. . .. . .(A2) dependency condition . . .. . .. . .
(A3) cycle condition . . .. . .. . .
46 / 124

Ample-set method [Peled 1993] por-03
given: processes PiPiPi of a parallel system P1‖. . .‖PnP1‖. . .‖PnP1‖. . .‖Pn
with transition system T = (S , Act,→, . . .)T = (S , Act,→, . . .)T = (S , Act,→, . . .)
task: on-the-fly generation of a sub-system TrTrTr s.t.
(A1) stutter condition(A2) dependency condition(A3) cycle condition
}π � πrπ � πrπ � πr
by permutations ofindependent actions
Each path πππ in TTT is represented by an “equivalent”path πrπrπr in TrTrTr
47 / 124

Ample-set method [Peled 1993] por-03
given: processes PiPiPi of a parallel system P1‖. . .‖PnP1‖. . .‖PnP1‖. . .‖Pn
with transition system T = (S , Act,→, . . .)T = (S , Act,→, . . .)T = (S , Act,→, . . .)
task: on-the-fly generation of a sub-system TrTrTr s.t.
(A1) stutter condition(A2) dependency condition(A3) cycle condition
}π � πrπ � πrπ � πr
by permutations ofindependent actions
Each path πππ in TTT is represented by an “equivalent”path πrπrπr in TrTrTr������
TTT and TrTrTr satisfy the same stutter-invariant events,e.g., next-free LTL formulas
48 / 124

Ample-set method for MDP por-04
given: processes PiPiPi of a probabilistic system P1‖. . .‖PnP1‖. . .‖PnP1‖. . .‖Pn
with MDP-semanticsM = (S , Act, P, . . .)M = (S , Act, P, . . .)M = (S , Act, P, . . .)
task: on-the-fly generation of a sub-MDPMrMrMr s.t.
MrMrMr andMMM have the same extremal probabilitiesfor stutter-invariant events
49 / 124

Ample-set method for MDP por-04
given: processes PiPiPi of a probabilistic system P1‖. . .‖PnP1‖. . .‖PnP1‖. . .‖Pn
with MDP-semanticsM = (S , Act, P, . . .)M = (S , Act, P, . . .)M = (S , Act, P, . . .)
task: on-the-fly generation of a sub-MDPMrMrMr s.t.
For all schedulers DDD forMMM there is a scheduler DrDrDr forMrMrMr s.t. for all measurable, stutter-invariant events EEE :
PrDM(E) = PrDr
Mr(E)PrDM(E ) = PrDr
Mr(E )PrDM(E ) = PrDr
Mr(E )������
MrMrMr andMMM have the same extremal probabilitiesfor stutter-invariant events
50 / 124

Example: ample set method por-08-new
sss
ααα
βββ γγγ
βββ γγγααα ααα
δδδ δδδ
original system TTT
ααα independentfrom βββ and γγγ
51 / 124

Example: ample set method por-08-new
sss
ααα
βββ γγγ
βββ γγγααα ααα
δδδ δδδ
βββ γγγ
δδδ δδδ
P1 ‖ P2P1 ‖ P2P1 ‖ P2
ααα
original system TTT
ααα independentfrom βββ and γγγ
action ααα: x := 1x := 1x := 1
action δδδ:IF x > 0x > 0x > 0 THEN y := 1y := 1y := 1 FI
52 / 124

Example: ample set method por-08-new
sss
ααα
βββ γγγ
βββ γγγααα ααα
δδδ δδδ
sss
βββ γγγ
ααα ααα
δδδ δδδ
original system TTT reduced system TrTrTr
(A1)-(A3) are fulfilled
ααα independentfrom βββ and γγγ
53 / 124

Example: ample set method fails for MDP por-08-new
sss
121212
ααα
121212
βββ γγγ
βββ γγγγγγβββ
ααα
121212
121212
121212 1
21212
ααα
δδδ δδδ
sss
βββ γγγ
ααα
121212
121212
121212 1
21212
ααα
δδδ δδδ
original MDPMMM reduced MDPMrMrMr
(A1)-(A3) are fulfilled
ααα independentfrom βββ and γγγ
54 / 124

Example: ample set method fails for MDP por-08-new
sss
121212
ααα
121212
βββ γγγ
βββ γγγγγγβββ
ααα
121212
121212
121212 1
21212
ααα
δδδ δδδ
sss
βββ γγγ
ααα
121212
121212
121212 1
21212
ααα
δδδ δδδ
original MDPMMM reduced MDPMrMrMr
PrMmax(s,♦green) = 1PrMmax(s,♦green) = 1PrMmax(s,♦green) = 1 ♦♦♦ “eventually”
55 / 124

Example: ample set method fails for MDP por-08-new
sss
121212
ααα
121212
βββ γγγ
βββ γγγγγγβββ
ααα
121212
121212
121212 1
21212
ααα
δδδ δδδ
sss
βββ γγγ
ααα
121212
121212
121212 1
21212
ααα
δδδ δδδ
original MDPMMM reduced MDPMrMrMr
PrMmax(s,♦green) = 1PrMmax(s,♦green) = 1PrMmax(s,♦green) = 1 > 12 = PrMr
max(s,♦green)> 12 = PrMr
max(s,♦green)> 12 = PrMr
max(s,♦green)
56 / 124

Partial order reduction for MDP por-09
extend Peled’s conditions (A1)-(A3) for the ample-sets
(A1) stutter condition . . .. . .. . .
(A2) dependency condition . . .. . .. . .
(A3) cycle condition . . .. . .. . .
(A4) probabilistic condition
If there is a path sβ1−→ β2−→ . . .
βn−→ α−→sβ1−→ β2−→ . . .
βn−→ α−→sβ1−→ β2−→ . . .
βn−→ α−→ inMMM s.t.
β1, . . . , βn, α /∈ Ample(s)β1, . . . , βn, α /∈ Ample(s)β1, . . . , βn, α /∈ Ample(s) and ααα is probabilistic
then |Ample(s)| = 1|Ample(s)| = 1|Ample(s)| = 1.
57 / 124

Partial order reduction for MDP por-09
extend Peled’s conditions (A1)-(A3) for the ample-sets
(A1) stutter condition . . .. . .. . .
(A2) dependency condition . . .. . .. . .
(A3) cycle condition . . .. . .. . .
(A4) probabilistic condition
If there is a path sβ1−→ β2−→ . . .
βn−→ α−→sβ1−→ β2−→ . . .
βn−→ α−→sβ1−→ β2−→ . . .
βn−→ α−→ inMMM s.t.
β1, . . . , βn, α /∈ Ample(s)β1, . . . , βn, α /∈ Ample(s)β1, . . . , βn, α /∈ Ample(s) and ααα is probabilistic
then |Ample(s)| = 1|Ample(s)| = 1|Ample(s)| = 1.
If (A1)-(A4) hold thenMMM andMrMrMr have the sameextremal probabilities for all stutter-invariant properties.
58 / 124

Probabilistic model checking por-ifm-32
quantitativerequirements
LTL\©\©\© formula ϕϕϕ(path event)
probabilisticsystem
Markov decisionprocessMMM
quantitative analysisofMMM against ϕϕϕ
maximal/minimalprobability for ϕϕϕ
59 / 124
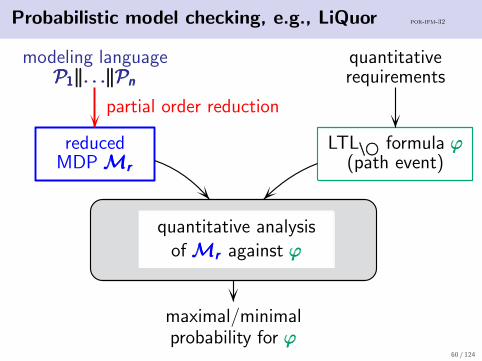
Probabilistic model checking, e.g., LiQuor por-ifm-32
quantitativerequirements
LTL\©\©\© formula ϕϕϕ(path event)
modeling languageP1‖. . .‖PnP1‖. . .‖PnP1‖. . .‖Pn
reducedMDPMrMrMr
partial order reduction
quantitative analysisofMrMrMr against ϕϕϕ
maximal/minimalprobability for ϕϕϕ
60 / 124

Probabilistic model checking, e.g., LiQuor por-ifm-32a
quantitativerequirements
LTL\©\©\© formula ϕϕϕ(path event)
modeling languageP1‖. . .‖PnP1‖. . .‖PnP1‖. . .‖Pn
reducedMDPMrMrMr
partial order reduction
quantitative analysisofMrMrMr against ϕϕϕ
maximal/minimalprobability for ϕϕϕ
}worst-case
analysis61 / 124

Example: extremal scheduler for MDP por-08-copy
sss
121212
ααα
121212
βββ γγγ
βββ γγγγγγβββ
ααα
121212
121212
121212 1
21212
ααα
δδδ δδδ
original MDPMMM
ααα independentfrom βββ and γγγ
62 / 124
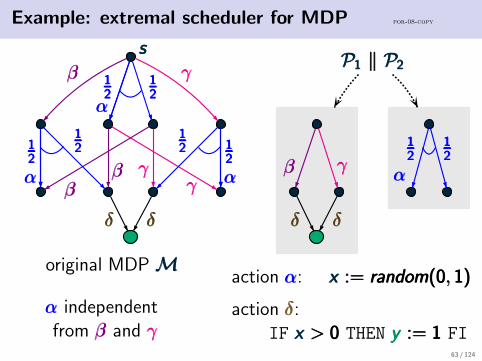
Example: extremal scheduler for MDP por-08-copy
sss
121212
ααα
121212
βββ γγγ
βββ γγγγγγβββ
ααα
121212
121212
121212 1
21212
ααα
δδδ δδδ
βββ γγγ
δδδ δδδ
P1 ‖ P2P1 ‖ P2P1 ‖ P2
ααα
121212
121212
original MDPMMM
ααα independentfrom βββ and γγγ
action ααα: x := random(0, 1)x := random(0, 1)x := random(0, 1)
action δδδ:IF x > 0x > 0x > 0 THEN y := 1y := 1y := 1 FI
63 / 124

Example: extremal scheduler for MDP por-08-copy
sss
121212
ααα
121212
βββ γγγ
βββ γγγγγγβββ
ααα
121212
121212
121212 1
21212
ααα
δδδ δδδ
βββ γγγ
δδδ δδδ
P1 ‖ P2P1 ‖ P2P1 ‖ P2
ααα
121212
121212
scheduler chooses action βββ or γγγ of process P1P1P1,depending on P2P2P2’s internal probabilistic choice
64 / 124

Outline overview-pomdp
• Markov decision processes (MDP) andquantitative analysis against path events
• partial order reduction for MDP
• partially-oberservable MDP ←−←−←−• conclusions
65 / 124

Monty-Hall problem pomdp-01
333 doorsinitially closed
candidateshowmaster
66 / 124

Monty-Hall problem pomdp-01
no prize prize no prize333 doorsinitially closed
candidateshowmaster
67 / 124

Monty-Hall problem pomdp-01
no prize prize no prize333 doorsinitially closed
candidateshowmaster
1. candidate chooses one of the doors
68 / 124

Monty-Hall problem pomdp-01
no prize prize no prize333 doorsinitially closed
candidateshowmaster
1. candidate chooses one of the doors
2. show master opens a non-chosen, non-winning door
69 / 124

Monty-Hall problem pomdp-01
no prize prize no prize333 doorsinitially closed
candidateshowmaster
1. candidate chooses one of the doors
2. show master opens a non-chosen, non-winning door
3. candidate has the choice:• keep the choice or• switch to the other (still closed) door
70 / 124

Monty-Hall problem pomdp-01
no prize 100.000100.000100.000Euro no prize
333 doorsinitially closed
candidateshowmaster
1. candidate chooses one of the doors
2. show master opens a non-chosen, non-winning door
3. candidate has the choice:• keep the choice or• switch to the other (still closed) door
4. show master opens all doors71 / 124
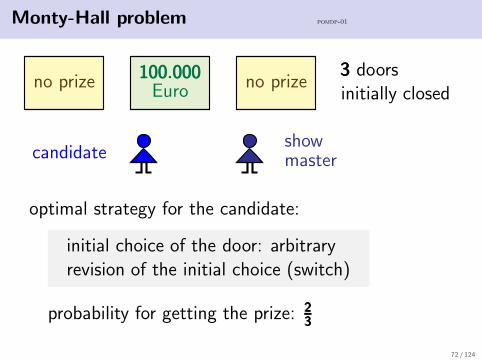
Monty-Hall problem pomdp-01
no prize 100.000100.000100.000Euro no prize
333 doorsinitially closed
candidateshowmaster
optimal strategy for the candidate:
initial choice of the door: arbitraryrevision of the initial choice (switch)
probability for getting the prize: 232323
72 / 124

MDP for the Monty-Hall problem pomdp-02
73 / 124

MDP for the Monty-Hall problem pomdp-02
no prize prize no prize333 doorsinitially closed
candidate’s actions1. choose one door3. keep or switch ?
show master’s actions2. opens a non-chosen,
non-winning door4. opens all doors
74 / 124

MDP for the Monty-Hall problem pomdp-02
no prize prize no prize333 doorsinitially closed
candidate’s actions1. choose one door3. keep or switch ?
show master’s actions2. opens a non-chosen,
non-winning door4. opens all doors������������������������������������������������������������������������������start
door111 door222 door333
lost won
131313 1
31313
131313
keep switch
keep switch
keep switch
75 / 124

MDP for the Monty-Hall problem pomdp-02
no prize prize no prize333 doorsinitially closed
candidate’s actions1. choose one door3. keep or switch ?
Prmax(start,♦won),♦won),♦won) = 1Prmax(start,♦won),♦won),♦won) = 1Prmax(start,♦won),♦won),♦won) = 1
optimal scheduler requirescomplete information
on the states
start
door111 door222 door333
lost won
131313 1
31313
131313
wonswitch
keep switch
76 / 124

MDP for the Monty-Hall problem pomdp-02
no prize prize no prize333 doorsinitially closed
candidate’s actions1. choose one door3. keep or switch ?
cannot be distinguishedby the candidate
start
door111 door222 door333
lost won
131313 1
31313
131313
wonswitch
keep switchkeep switch
keep77 / 124
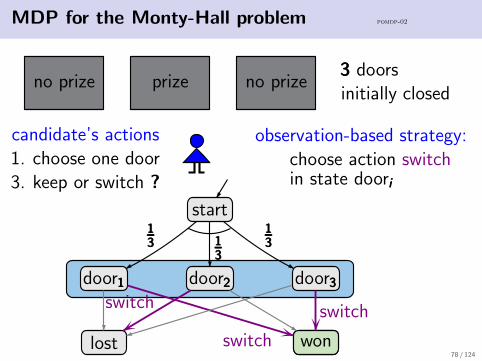
MDP for the Monty-Hall problem pomdp-02
no prize prize no prize333 doorsinitially closed
candidate’s actions1. choose one door3. keep or switch ?
observation-based strategy:choose action switchin state dooriii
start
door111 door222 door333
lost won
131313 1
31313
131313
wonswitch
switchswitch
78 / 124

MDP for the Monty-Hall problem pomdp-02
no prize prize no prize333 doorsinitially closed
candidate’s actions1. choose one door3. keep or switch ?
observation-based strategy:choose action switchin state dooriii
probability for ♦won♦won♦won: 232323start
door111 door222 door333
lost wonwon
131313 1
31313
131313
switch
switchswitch
79 / 124

Partially-observable Markov decision process pomdp-05
A partially-observable MDP (POMDP for short)is an MDPM = (S , Act, P, . . .)M = (S , Act, P, . . .)M = (S , Act, P, . . .) together withan equivalence relation ∼∼∼ on SSS
80 / 124

Partially-observable Markov decision process pomdp-05
A partially-observable MDP (POMDP for short)is an MDPM = (S , Act, P, . . .)M = (S , Act, P, . . .)M = (S , Act, P, . . .) together withan equivalence relation ∼∼∼ on SSS���
if s1 ∼ s2s1 ∼ s2s1 ∼ s2 then s1, s2s1, s2s1, s2 cannot be distinguishedfrom outside (or by the scheduler)
observables: equivalence classes of states
81 / 124

Partially-observable Markov decision process pomdp-05
A partially-observable MDP (POMDP for short)is an MDPM = (S , Act, P, . . .)M = (S , Act, P, . . .)M = (S , Act, P, . . .) together withan equivalence relation ∼∼∼ on SSS���
if s1 ∼ s2s1 ∼ s2s1 ∼ s2 then s1, s2s1, s2s1, s2 cannot be distinguishedfrom outside (or by the scheduler)
observables: equivalence classes of states
observation-based scheduler:
scheduler D : S+ → ActD : S+ → ActD : S+ → Act such that for all π1, π2 ∈ S+π1, π2 ∈ S+π1, π2 ∈ S+:
D(π1) = D(π2)D(π1) = D(π2)D(π1) = D(π2) if obs(π1) = obs(π2)obs(π1) = obs(π2)obs(π1) = obs(π2)
where obs(s0 s1 . . . sn) = [s0] [s1] . . . [sn]obs(s0 s1 . . . sn) = [s0] [s1] . . . [sn]obs(s0 s1 . . . sn) = [s0] [s1] . . . [sn]82 / 124

Extreme cases of POMDP pomdp-11
extreme cases of an POMDP:
• s1 ∼ s2s1 ∼ s2s1 ∼ s2 iff s1 = s2s1 = s2s1 = s2
• s1 ∼ s2s1 ∼ s2s1 ∼ s2 for all s1s1s1, s2s2s2
83 / 124

Extreme cases of POMDP pomdp-11
extreme cases of an POMDP:
• s1 ∼ s2s1 ∼ s2s1 ∼ s2 iff s1 = s2s1 = s2s1 = s2 ←−←−←− standard MDP
• s1 ∼ s2s1 ∼ s2s1 ∼ s2 for all s1s1s1, s2s2s2
84 / 124

Probabilistic automata are special POMDP pomdp-11
extreme cases of an POMDP:
• s1 ∼ s2s1 ∼ s2s1 ∼ s2 iff s1 = s2s1 = s2s1 = s2 ←−←−←− standard MDP
• s1 ∼ s2s1 ∼ s2s1 ∼ s2 for all s1s1s1, s2s2s2 ←−←−←− probabilistic automata
note that for totally non-observable POMDP:
observation-basedscheduler
===function
D : N→ ActD : N→ ActD : N→ Act===
infinite wordover ActActAct
85 / 124

Undecidability results for POMDP pomdp-11
extreme cases of an POMDP:
• s1 ∼ s2s1 ∼ s2s1 ∼ s2 iff s1 = s2s1 = s2s1 = s2 ←−←−←− standard MDP
• s1 ∼ s2s1 ∼ s2s1 ∼ s2 for all s1s1s1, s2s2s2 ←−←−←− probabilistic automata
note that for totally non-observable POMDP:
observation-basedscheduler
===function
D : N→ ActD : N→ ActD : N→ Act===
infinite wordover ActActAct
undecidability results for PFA carry over to POMDP
maximum probabilisticreachability problem
“does Probsmax(♦F ) > pProbsmax(♦F ) > pProbsmax(♦F ) > p hold ?”
===non-emptinessproblem for
PFA86/124

Undecidability results for POMDP pomdp-30-new
• The model checking problem for POMDP andquantitative properties is undecidable, e.g.,probabilistic reachability properties.
87 / 124

Undecidability results for POMDP pomdp-30-new
• The model checking problem for POMDP andquantitative properties is undecidable, e.g.,probabilistic reachability properties.
• There is no even no approximation algorithm forreachability objectives.
[Paz’71], [Madani/Hanks/Condon’99], [Giro/d’Argenio’07]
88 / 124

Undecidability results for POMDP pomdp-30-new
• The model checking problem for POMDP andquantitative properties is undecidable, e.g.,probabilistic reachability properties.
�♦�♦�♦ === “infinitely often”
• There is no even no approximation algorithm forreachability objectives.
• The model checking problem for POMDP and severalqualitative properties is undecidable, e.g.,
repeated reachability with positive probability
“does Probsmax(�♦F )Probsmax(�♦F )Probsmax(�♦F ) > 0> 0> 0 hold ?”
89 / 124

Undecidability results for POMDP pomdp-30-new
• The model checking problem for POMDP andquantitative properties is undecidable, e.g.,probabilistic reachability properties.
• There is no even no approximation algorithm forreachability objectives.
• The model checking problem for POMDP and severalqualitative properties is undecidable, e.g.,
repeated reachability with positive probability
“does Probsmax(�♦F )Probsmax(�♦F )Probsmax(�♦F ) > 0> 0> 0 hold ?”
Many interesting verification problems for distributedprobabilistic multi-agent systems are undecidable.
90 / 124

Undecidability results for POMDP pomdp-30-new
• The model checking problem for POMDP andquantitative properties is undecidable, e.g.,probabilistic reachability properties.
• There is no even no approximation algorithm forreachability objectives.
• The model checking problem for POMDP and severalqualitative properties is undecidable, e.g.,
repeated reachability with positive probability
“does Probsmax(�♦F )Probsmax(�♦F )Probsmax(�♦F ) > 0> 0> 0 hold ?”
... already holds for totally non-observable POMDP︸ ︷︷ ︸probabilistic Buchi automata
91 / 124

Probabilistic Buchi automaton (PBA) pba-01
P = (Q, Σ, δ, µ, F )P = (Q, Σ, δ, µ, F )P = (Q, Σ, δ, µ, F )
• QQQ finite state space
• ΣΣΣ alphabet
• δ : Q × Σ× Q → [0, 1]δ : Q × Σ× Q → [0, 1]δ : Q × Σ× Q → [0, 1] s.t. for all q ∈ Qq ∈ Qq ∈ Q, a ∈ Σa ∈ Σa ∈ Σ:∑p∈Q
δ(q, a, p) ∈ {0, 1}∑p∈Q
δ(q, a, p) ∈ {0, 1}∑p∈Q
δ(q, a, p) ∈ {0, 1}• initial distribution µµµ
• set of final states F ⊆ QF ⊆ QF ⊆ Q
92 / 124

Probabilistic Buchi automaton (PBA) pba-01
POMDP where Σ = ActΣ = ActΣ = Actand ∼∼∼ === Q × QQ × QQ × Q
P = (Q, Σ, δ, µ, F )P = (Q, Σ, δ, µ, F )P = (Q, Σ, δ, µ, F ) ←−←−←−• QQQ finite state space
• ΣΣΣ alphabet
• δ : Q × Σ× Q → [0, 1]δ : Q × Σ× Q → [0, 1]δ : Q × Σ× Q → [0, 1] s.t. for all q ∈ Qq ∈ Qq ∈ Q, a ∈ Σa ∈ Σa ∈ Σ:∑p∈Q
δ(q, a, p) ∈ {0, 1}∑p∈Q
δ(q, a, p) ∈ {0, 1}∑p∈Q
δ(q, a, p) ∈ {0, 1}• initial distribution µµµ
• set of final states F ⊆ QF ⊆ QF ⊆ Q
93 / 124

Probabilistic Buchi automaton (PBA) pba-01
POMDP where Σ = ActΣ = ActΣ = Actand ∼∼∼ === Q × QQ × QQ × Q
P = (Q, Σ, δ, µ, F )P = (Q, Σ, δ, µ, F )P = (Q, Σ, δ, µ, F ) ←−←−←−• QQQ finite state space
• ΣΣΣ alphabet
• δ : Q × Σ× Q → [0, 1]δ : Q × Σ× Q → [0, 1]δ : Q × Σ× Q → [0, 1] s.t. for all q ∈ Qq ∈ Qq ∈ Q, a ∈ Σa ∈ Σa ∈ Σ:∑p∈Q
δ(q, a, p) ∈ {0, 1}∑p∈Q
δ(q, a, p) ∈ {0, 1}∑p∈Q
δ(q, a, p) ∈ {0, 1}• initial distribution µµµ
• set of final states F ⊆ QF ⊆ QF ⊆ Q
For each infinite word x ∈ Σωx ∈ Σωx ∈ Σω:
Pr(x) =Pr(x) =Pr(x) = probability for the accepting runs for xxx↑↑↑
accepting run: visits FFF infinitely often
94 / 124

Probabilistic Buchi automaton (PBA) pba-01
POMDP where Σ = ActΣ = ActΣ = Actand ∼∼∼ === Q × QQ × QQ × Q
P = (Q, Σ, δ, µ, F )P = (Q, Σ, δ, µ, F )P = (Q, Σ, δ, µ, F ) ←−←−←−• QQQ finite state space
• ΣΣΣ alphabet
• δ : Q × Σ× Q → [0, 1]δ : Q × Σ× Q → [0, 1]δ : Q × Σ× Q → [0, 1] s.t. for all q ∈ Qq ∈ Qq ∈ Q, a ∈ Σa ∈ Σa ∈ Σ:∑p∈Q
δ(q, a, p) ∈ {0, 1}∑p∈Q
δ(q, a, p) ∈ {0, 1}∑p∈Q
δ(q, a, p) ∈ {0, 1}• initial distribution µµµ
• set of final states F ⊆ QF ⊆ QF ⊆ Q
For each infinite word x ∈ Σωx ∈ Σωx ∈ Σω:
Pr(x) =Pr(x) =Pr(x) = probability for the accepting runs for xxx↑↑↑
probability measure in the infinite Markov chaininduced by xxx viewed as a scheduler
95 / 124

Accepted language of a PBA pba-03
P = (Q, Σ, δ, µ, F )P = (Q, Σ, δ, µ, F )P = (Q, Σ, δ, µ, F )
• QQQ finite state space, ΣΣΣ alphabet
• δ : Q × Σ× Q → [0, 1]δ : Q × Σ× Q → [0, 1]δ : Q × Σ× Q → [0, 1] s.t. . . .. . .. . .
• initial distribution µµµ
• set of final states F ⊆ QF ⊆ QF ⊆ Q
three types of accepted language:
L>0(P)L>0(P)L>0(P) ==={x ∈ Σω : Pr(x) > 0
}{x ∈ Σω : Pr(x) > 0
}{x ∈ Σω : Pr(x) > 0
}probable semantics
L=1(P)L=1(P)L=1(P) ==={x ∈ Σω : Pr(x) = 1
}{x ∈ Σω : Pr(x) = 1
}{x ∈ Σω : Pr(x) = 1
}almost-sure sem.
L>λ(P)L>λ(P)L>λ(P) ==={x ∈ Σω : Pr(x) > λ
}{x ∈ Σω : Pr(x) > λ
}{x ∈ Σω : Pr(x) > λ
}threshold semanticswhere 0 < λ < 10 < λ < 10 < λ < 1
96 / 124

Example for PBA pba-05
111 222aaa, 1
21212
bbbaaaaaa, 1
21212
initial state (probability 1)
final state
nonfinal state
97 / 124

Example for PBA pba-05
111 222aaa, 1
21212
bbbaaaaaa, 1
21212
accepted language:
L>0(P)L>0(P)L>0(P) === (a + b)∗aω(a + b)∗aω(a + b)∗aω
initial state (probability 1)
final state
nonfinal state
98 / 124

Example for PBA pba-05
111 222aaa, 1
21212
bbbaaaaaa, 1
21212
accepted language:
L>0(P)L>0(P)L>0(P) === (a + b)∗aω(a + b)∗aω(a + b)∗aω
L=1(P)L=1(P)L=1(P) === b∗aωb∗aωb∗aω
initial state (probability 1)
final state
nonfinal state
99 / 124

Example for PBA pba-05
111 222aaa, 1
21212
bbbaaaaaa, 1
21212
accepted language:
L>0(P)L>0(P)L>0(P) === (a + b)∗aω(a + b)∗aω(a + b)∗aω
L=1(P)L=1(P)L=1(P) === b∗aωb∗aωb∗aω
Thus: PBA>0>0>0 are strictly more expressive than DBA
100/124

Example for PBA pba-05
111 222aaa, 1
21212
bbbaaaaaa, 1
21212
accepted language:
L>0(P)L>0(P)L>0(P) === (a + b)∗aω(a + b)∗aω(a + b)∗aω
L=1(P)L=1(P)L=1(P) === b∗aωb∗aωb∗aω
Thus: PBA>0>0>0 are strictly more expressive than DBA
333222
111
a, 12
a, 12a, 12 a, 1
2a, 1
2a, 12
bbb
cccbbb
101 / 124

Example for PBA pba-05
111 222aaa, 1
21212
bbbaaaaaa, 1
21212
accepted language:
L>0(P)L>0(P)L>0(P) === (a + b)∗aω(a + b)∗aω(a + b)∗aω
L=1(P)L=1(P)L=1(P) === b∗aωb∗aωb∗aω
Thus: PBA>0>0>0 are strictly more expressive than DBA
333222
111
a, 12
a, 12a, 12 a, 1
2a, 1
2a, 12
bbb
cccbbb
NBA accepts ((ac)∗ab)ω((ac)∗ab)ω((ac)∗ab)ω
102 / 124

Example for PBA pba-05
111 222aaa, 1
21212
bbbaaaaaa, 1
21212
accepted language:
L>0(P)L>0(P)L>0(P) === (a + b)∗aω(a + b)∗aω(a + b)∗aω
L=1(P)L=1(P)L=1(P) === b∗aωb∗aωb∗aω
Thus: PBA>0>0>0 are strictly more expressive than DBA
333222
111
a, 12
a, 12a, 12 a, 1
2a, 1
2a, 12
bbb
cccbbb
accepted language:
L>0(P)L>0(P)L>0(P) === (ab + ac)∗(ab)ω(ab + ac)∗(ab)ω(ab + ac)∗(ab)ω
but NBA accepts ((ac)∗ab)ω((ac)∗ab)ω((ac)∗ab)ω
103 / 124

Example for PBA pba-05
111 222aaa, 1
21212
bbbaaaaaa, 1
21212
accepted language:
L>0(P)L>0(P)L>0(P) === (a + b)∗aω(a + b)∗aω(a + b)∗aω
L=1(P)L=1(P)L=1(P) === b∗aωb∗aωb∗aω
Thus: PBA>0>0>0 are strictly more expressive than DBA
333222
111
a, 12
a, 12a, 12 a, 1
2a, 1
2a, 12
bbb
cccbbb
accepted language:
L>0(P)L>0(P)L>0(P) === (ab + ac)∗(ab)ω(ab + ac)∗(ab)ω(ab + ac)∗(ab)ω
L=1(P)L=1(P)L=1(P) === (ab)ω(ab)ω(ab)ω
but NBA accepts ((ac)∗ab)ω((ac)∗ab)ω((ac)∗ab)ω
104 / 124

Expressiveness of PBA with probable semantics pba-10a
PBA>0>0>0 are strictly more expressive than NBA
105/124

Expressiveness of PBA with probable semantics pba-10a
PBA>0>0>0 are strictly more expressive than NBA
• from NBA to PBA: via deterministic-in-limit NBA
106 / 124

Expressiveness of PBA with probable semantics pba-10a
PBA>0>0>0 are strictly more expressive than NBA
• from NBA to PBA: via deterministic-in-limit NBA
• PBA can accept non-ωωω-regular languages
222111
aaa,121212
aaaaaa, 121212
bbb
107 / 124

Expressiveness of PBA with probable semantics pba-10a
PBA>0>0>0 are strictly more expressive than NBA
• from NBA to PBA: via deterministic-in-limit NBA
• PBA can accept non-ωωω-regular languages
222111
aaa,121212
aaaaaa, 121212
bbb
accepted language (probable semantics):
L>0(P) ={
ak1bak2bak3b. . . |L>0(P) ={
ak1bak2bak3b. . . |L>0(P) ={
ak1bak2bak3b. . . | . . .. . .. . .}}}
108 / 124

Expressiveness of PBA with probable semantics pba-10a
PBA>0>0>0 are strictly more expressive than NBA
• from NBA to PBA: via deterministic-in-limit NBA
• PBA can accept non-ωωω-regular languages
222111
aaa,121212
aaaaaa, 121212
bbb
accepted language (probable semantics):
L>0(P) ={
ak1bak2bak3b. . . |L>0(P) ={
ak1bak2bak3b. . . |L>0(P) ={
ak1bak2bak3b. . . |∞∏i=1
(1−
(12
)ki
)> 0
∞∏i=1
(1−
(12
)ki
)> 0
∞∏i=1
(1−
(12
)ki
)> 0
}}}109 / 124

Expressiveness of PBA pba-15
PBA>0>0>0
DBA
110/124

Expressiveness of PBA pba-15
PBA>0>0>0
DBA
NBA
111/124

Expressiveness of PBA pba-15
PBA>0>0>0
DBA
NBA
PBA with thresholds
112 / 124

Expressiveness of PBA pba-15
PBA>0>0>0
DBA
NBA
PBA with thresholds
PBA=1=1=1
almost-suresemantics
113 / 124

Expressiveness of PBA pba-15
PBA>0>0>0
DBA
NBA
PBA with thresholds
PBA=1=1=1
almost-suresemantics
(a + b)∗aω(a + b)∗aω(a + b)∗aω
114 / 124

Expressiveness of PBA pba-15
PBA>0>0>0
DBA
NBA
PBA with thresholds
PBA=1=1=1
almost-suresemantics
(a + b)∗aω(a + b)∗aω(a + b)∗aω
{ak1bak2b. . . :
∞∏i=1
(1− (12)ki) > 0
}{ak1bak2b. . . :
∞∏i=1
(1− (12)
ki) > 0}{
ak1bak2b. . . :∞∏i=1
(1− (12)ki) > 0
}
115 / 124

Expressiveness of PBA pba-15
PBA>0>0>0
DBA
NBA
PBA with thresholds
PBA=1=1=1
almost-suresemantics
(a + b)∗aω(a + b)∗aω(a + b)∗aω
{ak1bak2b. . . :
∞∏i=1
(1− (12)ki) > 0
}{ak1bak2b. . . :
∞∏i=1
(1− (12)
ki) > 0}{
ak1bak2b. . . :∞∏i=1
(1− (12)ki) > 0
}{ak1bak2b. . . :
∞∏i=1
(1− (12)
ki) = 0}{
ak1bak2b. . . :∞∏i=1
(1− (12)
ki) = 0}{
ak1bak2b. . . :∞∏i=1
(1− (12)
ki) = 0}
116 / 124

Expressiveness of PBA pba-15
PBA>0>0>0
DBA
NBA
PBA with thresholds
PBA=1=1=1
almost-suresemantics
(a + b)∗aω(a + b)∗aω(a + b)∗aω
emptiness problem: undecidable for PBA>0>0>0
decidable for PBA=1=1=1
117 / 124

Outline overview-conc
• Markov decision processes (MDP) andquantitative analysis against path events
• partial order reduction for MDP
• partially-oberservable MDP
• conclusions ←−←−←−
118 / 124

Conclusion conc
• worst/best-case analysis of MDP solvable by
∗∗∗ numerical methods for solving linear programs
∗∗∗ known techniques for non-probabilistic systems
graph algorithms, LTL-2-AUT translators, . . .. . .. . .techniques to combat the state explosion problem(such as partial order reduction)
119 / 124

Conclusion conc
• worst/best-case analysis of MDP solvable by
∗∗∗ numerical methods for solving linear programs
∗∗∗ known techniques for non-probabilistic systems
graph algorithms, LTL-2-AUT translators, . . .. . .. . .techniques to combat the state explosion problem(such as partial order reduction)
but: strongly simplified definition of schedulers���assumption “full knowledge of the history” is
inadequate, e.g., for agents of distributed systems
120 / 124

Conclusion conc
• worst/best-case analysis of MDP solvable by
∗∗∗ numerical methods for solving linear programs
∗∗∗ known techniques for non-probabilistic systems
• more realistic model: partially-observable MDPand multi-agents variants with distributed schedulers
121 / 124

Conclusion conc
• worst/best-case analysis of MDP solvable by
∗∗∗ numerical methods for solving linear programs
∗∗∗ known techniques for non-probabilistic systems
• more realistic model: partially-observable MDPand multi-agents variants with distributed schedulers
−−− many algorithms for “finite-horizon properties”
−−− few decidability results for qualitative properties
−−− undecidability for quantitative properties and, e.g.,repeated reachability with positive probability
122 / 124

Conclusion conc
• worst/best-case analysis of MDP solvable by
∗∗∗ numerical methods for solving linear programs
∗∗∗ known techniques for non-probabilistic systems
• more realistic model: partially-observable MDPand multi-agents variants with distributed schedulers
−−− many algorithms for “finite-horizon properties”
−−− few decidability results for qualitative properties
−−− undecidability for quantitative properties and, e.g.,repeated reachability with positive probability
���proof via probabilistic language acceptors (PFA/PBA)
123 / 124

Conclusion conc
• worst/best-case analysis of MDP solvable by
∗∗∗ numerical methods for solving linear programs
∗∗∗ known techniques for non-probabilistic systems
• more realistic model: partially-observable MDPand multi-agents variants with distributed schedulers
−−− many algorithms for “finite-horizon properties”
−−− few decidability results for qualitative properties
−−− undecidability for quantitative properties and, e.g.,repeated reachability with positive probability
• probabilistic Buchi automata interesting in their own . . .. . .. . .
124 / 124