quantum chemistry (qc) on gpus - nvidia · • gaussian is a top ten hpc (quantum chemistry)...
TRANSCRIPT

Feb. 2, 2017
Quantum Chemistry (QC) on GPUs

2
Overview of Life & Material Accelerated Apps
MD: All key codes are GPU-accelerated
Great multi-GPU performance
Focus on dense (up to 16) GPU nodes &/or large # of
GPU nodes
ACEMD*, AMBER (PMEMD)*, BAND, CHARMM, DESMOND, ESPResso,
Folding@Home, GPUgrid.net, GROMACS, HALMD, HOOMD-Blue*,
LAMMPS, Lattice Microbes*, mdcore, MELD, miniMD, NAMD,
OpenMM, PolyFTS, SOP-GPU* & more
QC: All key codes are ported or optimizing
Focus on using GPU-accelerated math libraries,
OpenACC directives
GPU-accelerated and available today:
ABINIT, ACES III, ADF, BigDFT, CP2K, GAMESS, GAMESS-
UK, GPAW, LATTE, LSDalton, LSMS, MOLCAS, MOPAC2012,
NWChem, OCTOPUS*, PEtot, QUICK, Q-Chem, QMCPack,
Quantum Espresso/PWscf, QUICK, TeraChem*
Active GPU acceleration projects:
CASTEP, GAMESS, Gaussian, ONETEP, Quantum
Supercharger Library*, VASP & more
green* = application where >90% of the workload is on GPU

3
MD vs. QC on GPUs
“Classical” Molecular Dynamics Quantum Chemistry (MO, PW, DFT, Semi-Emp)Simulates positions of atoms over time;
chemical-biological or chemical-material behaviors
Calculates electronic properties; ground state, excited states, spectral properties,
making/breaking bonds, physical properties
Forces calculated from simple empirical formulas (bond rearrangement generally forbidden)
Forces derived from electron wave function (bond rearrangement OK, e.g., bond energies)
Up to millions of atoms Up to a few thousand atoms
Solvent included without difficulty Generally in a vacuum but if needed, solvent treated classically (QM/MM)
or using implicit methods
Single precision dominated Double precision is important
Uses cuBLAS, cuFFT, CUDA Uses cuBLAS, cuFFT, OpenACC
Geforce (Accademics), Tesla (Servers) Tesla recommended
ECC off ECC on

4
Accelerating Discoveries
Using a supercomputer powered by the Tesla
Platform with over 3,000 Tesla accelerators,
University of Illinois scientists performed the first
all-atom simulation of the HIV virus and discovered
the chemical structure of its capsid — “the perfect
target for fighting the infection.”
Without gpu, the supercomputer would need to be
5x larger for similar performance.

5
GPU-Accelerated Quantum Chemistry Apps
Abinit
ACES III
ADF
BigDFT
CP2K
GAMESS-US
Gaussian
GPAW
LATTE
LSDalton
MOLCAS
Mopac2012
NWChem
Green Lettering Indicates Performance Slides Included
GPU Perf compared against dual multi-core x86 CPU socket.
Quantum SuperChargerLibrary
RMG
TeraChem
UNM
VASP
WL-LSMS
Octopus
ONETEP
Petot
Q-Chem
QMCPACK
Quantum Espresso

ABINIT

ABINIT on GPUS
Speed in the parallel version:
For ground-state calculations, GPUs can be used. This is based on
CUDA+MAGMA
For ground-state calculations, the wavelet part of ABINIT (which is BigDFT) is
also very well parallelized : MPI band parallelism, combined with GPUs

BigDFT

Courtesy of BigDFTteam @ CEA

Courtesy of BigDFTteam @ CEA

Courtesy of BigDFTteam @ CEA

Courtesy of BigDFTteam @ CEA
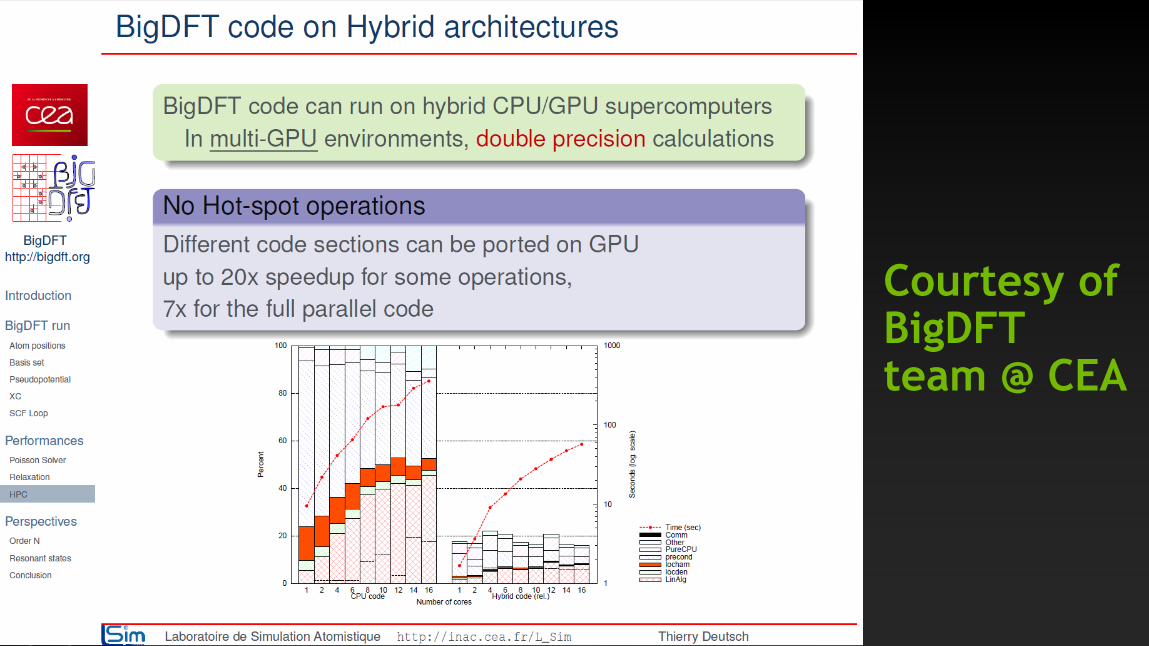
Courtesy of BigDFTteam @ CEA

Courtesy of BigDFTteam @ CEA

April 2017
Gaussian 16

16
GPU-ACCELERATED GAUSSIAN 16 AVAILABLE
• Gaussian is a Top Ten HPC (Quantum Chemistry) Application.
• 80-85% of use cases are GPU-accelerated (Hartree-Fock and DFT: energies, 1st derivatives (gradients) and 2nd derivatives). More functionality to come.
• K40, K80 support; P100 support coming as a minor release, performance “good”, faster wall clock times. Early P100 results promising.
• No pricing difference between Gaussian CPU and GPU versions.
• Existing Gaussian 09 customers under maintenance contract get (free) upgrade.
• Existing non-maintenance customers required to pay upgrade fee.
• To get the bits or to ask about the upgrade fee, please contact Gaussian, Inc.’s Jim Hess, Operations Manager; [email protected].
100% PGI OpenACC Port (no CUDA)

17
rg-a25 on K80s
Running Gaussian version 16
The blue node contains Dual Intel Xeon E5-2698 [email protected] (Haswell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] (Haswell) CPUs + Tesla K80 (autoboost) GPUs
Alanine 25. Two steps: Force and Frequency. APFD 6-31G*
nAtoms = 259, nBasis = 2195
7.4 hrs 6.4 hrs 5.8 hrs 5.1 hrs0.0x
0.2x
0.4x
0.6x
0.8x
1.0x
1.2x
1.4x
1.6x
1 Haswell node 1 node +1x K80 per node
1 node +2x K80 per node
1 node +4x K80 per node
Speed-u
p v
s D
ual H
asw
ell
rg-a25

18
rg-a25td on K80s
Running Gaussian version 16
The blue node contains Dual Intel Xeon E5-2698 [email protected] (Haswell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] (Haswell) CPUs + Tesla K80 (autoboost) GPUs
Alanine 25. Two Time-Dependent (TD) steps: Force and Frequency. APFD 6-31G*
nAtoms = 259, nBasis = 2195
27.9 hrs 25.8 hrs 22.6 hrs 20.1 hrs0.0x
0.2x
0.4x
0.6x
0.8x
1.0x
1.2x
1.4x
1.6x
1 Haswell node 1 node +1x K80 per node
1 node +2x K80 per node
1 node +4x K80 per node
Speed-u
p v
s D
ual H
asw
ell
rg-a25td

19
rg-on on K80s
Running Gaussian version 16
The blue node contains Dual Intel Xeon E5-2698 [email protected] (Haswell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] (Haswell) CPUs + Tesla K80 (autoboost) GPUs
GFP ONIOM. Two steps: Force and Frequency. APFD/6-
311+G(2d,p):amber=softfirst)=embednAtoms = 3715 (48/3667), nBasis = 813
2.5 hrs 2.1 hrs 1.7 hrs 1.5 hrs0.0x
0.2x
0.4x
0.6x
0.8x
1.0x
1.2x
1.4x
1.6x
1.8x
1 Haswell node 1 node +1x K80 per node
1 node +2x K80 per node
1 node +4x K80 per node
Speed-u
p v
s D
ual H
asw
ell
rg-on

20
rg-ontd on K80s
Running Gaussian version 16
The blue node contains Dual Intel Xeon E5-2698 [email protected] (Haswell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] (Haswell) CPUs + Tesla K80 (autoboost) GPUs
GFP ONIOM. Two Time-Dependent (TD) steps: Force and Frequency. APFD/6-311+G(2d,p):amber=softfirst)=embed
nAtoms = 3715 (48/3667), nBasis = 813
55.4 hrs 43.6 hrs 33.7 hrs 26.8 hrs0.0x
0.5x
1.0x
1.5x
2.0x
2.5x
1 Haswell node 1 node +1x K80 per node
1 node +2x K80 per node
1 node +4x K80 per node
Speed-u
p v
s D
ual H
asw
ell
rg-ontd

21
rg-val on K80s
Running Gaussian version 16
The blue node contains Dual Intel Xeon E5-2698 [email protected] (Haswell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] (Haswell) CPUs + Tesla K80 (autoboost) GPUs
Valinomycin. Two steps: Force and Frequency. APFD 6-311+G(2d,p)
nAtoms = 168, nBasis = 2646
229.0 hrs 168.4 hrs 141.7 hrs 101.5 hrs0.0x
0.5x
1.0x
1.5x
2.0x
2.5x
1 Haswell node 1 node +1x K80 per node
1 node +2x K80 per node
1 node +4x K80 per node
Speed-u
p v
s D
ual H
asw
ell
rg-val

22
Effects of using K80s7.4
hrs
27.9
hrs
2.5
hrs
55.4
hrs
229.0
hrs
6.4
hrs
25.8
hrs
2.1
hrs
43.6
hrs
168.4
hrs
5.8
hrs
22.6
hrs
1.7
hrs
33.7
hrs
141.7
hrs
5.1
hrs
20.1
hrs
1.5
hrs
26.8
hrs
101.5
hrs
0.0x
0.3x
0.5x
0.8x
1.0x
1.3x
1.5x
1.8x
2.0x
2.3x
2.5x
rg-a25 rg-a25td rg-on rg-ontd rg-val
Speed-u
p o
ver
run w
ithout
GPU
s
Number of K80 boards
Effects of using K80 boardsHaswell E5-2698 [email protected]
0 1 2 4

23
Gaussian 16 Supported Platforms
• 4-way collaboration; Gaussian, Inc., PGI, NVIDIA and HPE
• HPE, NVIDIA and PGI is the development platform
• All released/certified x86_64 versions of Gaussian 16 use the PGI compilers
• Certified versions of Gaussian 16 use Intel only for Itanium, XLF for some IBM platforms, Fujitsu compilers for some SPARC-based machines and PGI for the rest (including some Apple products)
• GINC is collaborating with IBM, PGI (and NVIDIA) to release an OpenPower version of Gaussian that also uses the PGI compiler
• See Gaussian Supported Platforms for more details: http://gaussian.com/g16/g16_plat.pdf

24
CLOSING REMARKS
Significant Progress has been made in enabling Gaussian on GPUs with OpenACC
OpenACC is increasingly becoming more versatile
Significant work lies ahead to improve performance
Expand feature set:
PBC, Solvation, MP2, ONIOM, triples-Corrections

25
ACKNOWLEDGEMENTS
Development is taking place with:
Hewlett-Packard (HP) Series SL2500 Servers (Intel® Xeon® E5-2680 v2 (2.8GHz/10-core/25MB/8.0GT-s QPI/115W, DDR3-1866)
NVIDIA® Tesla® GPUs (K40 and later)
PGI Accelerator Compilers (16.x) with OpenACC (2.5 standard)
5/10/2017

GPAW

Increase Performance with Kepler
Running GPAW 10258
The blue nodes contain 1x E5-2687W CPU (8
Cores per CPU).
The green nodes contain 1x E5-2687W CPU (8
Cores per CPU) and 1x or 2x NVIDIA K20X for
the GPU.
0
0.5
1
1.5
2
2.5
3
3.5
Silicon K=1 Silicon K=2 Silicon K=3
Sp
eed
up
Co
mp
are
d t
o C
PU
On
ly
1.4
2.5
1.5
2.7
1.6
3.0
1 1 1

Increase Performance with Kepler
0
0.5
1
1.5
2
2.5
3
Silicon K=1 Silicon K=2 Silicon K=3
Sp
eed
up
Co
mp
are
d t
o C
PU
On
ly
1.7x
2.2x
2.4x
Running GPAW 10258
The blue nodes contain 1x E5-2687W CPU (8
Cores per CPU).
The green nodes contain 1x E5-2687W CPUs (8
Cores per CPU) and 2x NVIDIA K20 or K20X for
the GPU.

Increase Performance with Kepler
Running GPAW 10258
The blue nodes contain 2x E5-2687W CPUs (8
Cores per CPU).
The green nodes contain 2x E5-2687W CPUs (8
Cores per CPU) and 2x NVIDIA K20 or K20X for
the GPU.
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
Silicon K=1 Silicon K=2 Silicon K=3
Sp
eed
up
Co
mp
are
d t
o C
PU
On
ly
1.3x
1.4x
1.4x

Used with
permission from
Samuli Hakala




34

35

36

37

38

39

NWChem

NWChem 6.3 Release with GPU Acceleration
Addresses large complex and challenging molecular-scale scientific
problems in the areas of catalysis, materials, geochemistry and
biochemistry on highly scalable, parallel computing platforms to
obtain the fastest time-to-solution
Researchers can for the first time be able to perform large scale
coupled cluster with perturbative triples calculations utilizing the
NVIDIA GPU technology. A highly scalable multi-reference coupled
cluster capability will also be available in NWChem 6.3.
The software, released under the Educational Community License
2.0, can be downloaded from the NWChem website at
www.nwchem-sw.org

System: cluster consisting
of dual-socket nodes
constructed from:
• 8-core AMD Interlagos
processors
• 64 GB of memory
• Tesla M2090 (Fermi)
GPUs
The nodes are connected
using a high-performance
QDR Infiniband interconnect
Courtesy of Kowolski, K.,
Bhaskaran-Nair, at al @
PNNL, JCTC (submitted)
NWChem - Speedup of the non-iterative calculation for various configurations/tile sizes

Kepler, Faster Performance (NWChem)
0
20
40
60
80
100
120
140
160
180
CPU Only CPU + 1x K20X CPU + 2x K20X
Tim
e t
o S
olu
tio
n (
sec
on
ds
)
165
81
54
Uracil
Uracil Molecule
Performance improves by 2x with one GPU and by 3.1x with 2 GPUs

December 2016
Quantum Espresso 5.4.0

45
AUSURF112 on K80s
Running Quantum Espresso version 5.4.0
The blue node contains Dual Intel Xeon E5-2690 [email protected] [3.5GHz Turbo]
(Broadwell) CPUs
The green node contains Dual Intel Xeon E5-2690 [email protected] [3.5GHz Turbo]
(Broadwell) CPUs + Tesla K80 (autoboost) GPUs
606.00
528.20
480
500
520
540
560
580
600
620
1 Broadwell node 1 node +4x K80 per node
seconds
AUSURF112*Lower is better
1.1X

46
AUSURF112 on P100s PCIe
606.00
515.70
486.90
0
100
200
300
400
500
600
700
1 Broadwell node 1 node +4x P100 PCIe per node
1 node +8x P100 PCIe per node
seconds
AUSURF1120
Running Quantum Espresso version 5.4.0
The blue node contains Dual Intel Xeon E5-2690 [email protected] [3.5GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2690 [email protected] [3.5GHz Turbo]
(Broadwell) CPUs + Tesla P100 PCIe GPUs
*Lower is better
1.2X 1.2X

Speaker, Date
TeraChem 1.5K

48
TERACHEM 1.5K; TRIPCAGE ON TESLA K40S
0
40
80
120
160
200
2 x Xeon E5-2697 [email protected] + 1 xTesla K40@875Mhz (1 node)
2 x Xeon E5-2697 [email protected] + 2 xTesla K40@875Mhz (1 node)
2 x Xeon E5-2697 [email protected] + 4 xTesla K40@875Mhz (1 node)
2 x Xeon E5-2697 [email protected] + 8 xTesla K40@875Mhz (1 node)
TeraChem 1.5K; TripCage on Tesla K40s & IVB CPUs(Total Processing Time in Seconds)

49
TERACHEM 1.5K; TRIPCAGE ON TESLA K40S & HASWELL CPUS
0
40
80
120
160
200
2 x Xeon E5-2698 [email protected] + 1 x TeslaK40@875Mhz (1 node)
2 x Xeon E5-2698 [email protected] + 2 x TeslaK40@875Mhz (1 node)
2 x Xeon E5-2698 [email protected] + 4 x TeslaK40@875Mhz (1 node)
TeraChem 1.5K; TripCage on Tesla K40s & Haswell CPUs(Total Processing Time in Seconds)

50
TERACHEM 1.5K; TRIPCAGE ON TESLA K80S & IVB CPUS
0
40
80
120
2 x Xeon E5-2697 [email protected] + 1 x Tesla K80 board(1 node)
2 x Xeon E5-2697 [email protected] + 2 x Tesla K80 boards(1 node)
2 x Xeon E5-2697 [email protected] + 4 x Tesla K80 boards(1 node)
TeraChem 1.5K; TripCage on Tesla K80s & IVB CPUs(Total Processing Time in Seconds)

51
TERACHEM 1.5K; TRIPCAGE ON TESLA K80S & HASWELL CPUS
0
30
60
90
120
2 x Xeon E5-2698 [email protected] + 1 x Tesla K80board (1 node)
2 x Xeon E5-2698 [email protected] + 2 x Tesla K80boards (1 node)
2 x Xeon E5-2698 [email protected] + 4 x Tesla K80boards (1 node)
TeraChem 1.5K; TripCage on Tesla K80s & Haswell CPUs(Total Processing Time in Seconds)

52
TERACHEM 1.5K; BPTI ON TESLA K40S & IVB CPUS
0
2000
4000
6000
8000
10000
12000
2 x Xeon E5-2697 [email protected] + 1 xTesla K40@875Mhz (1 node)
2 x Xeon E5-2697 [email protected] + 2 xTesla K40@875Mhz (1 node)
2 x Xeon E5-2697 [email protected] + 4 xTesla K40@875Mhz (1 node)
2 x Xeon E5-2697 [email protected] + 8 xTesla K40@875Mhz (1 node)
TeraChem 1.5K; BPTI on Tesla K40s & IVB CPUs(Total Processing Time in Seconds)

53
TERACHEM 1.5K; BPTI ON TESLA K80S & IVB CPUS
0
2000
4000
6000
8000
2 x Xeon E5-2697 [email protected] + 1 x Tesla K80board (1 node)
2 x Xeon E5-2697 [email protected] + 2 x Tesla K80boards (1 node)
2 x Xeon E5-2697 [email protected] + 4 x Tesla K80boards (1 node)
TeraChem 1.5K; BPTI on Tesla K80s & IVB CPUs(Total Processing Time in Seconds)

54
TERACHEM 1.5K; BPTI ON TESLA K40S & IVB CPUS
0
2000
4000
6000
8000
10000
12000
2 x Xeon E5-2698 [email protected] + 1 x TeslaK40@875Mhz (1 node)
2 x Xeon E5-2698 [email protected] + 2 x TeslaK40@875Mhz (1 node)
2 x Xeon E5-2698 [email protected] + 4 x TeslaK40@875Mhz (1 node)
TeraChem 1.5K; BPTI on Tesla K40s & Haswell CPUs(Total Processing Time in Seconds)

55
TERACHEM 1.5K; BPTI ON TESLA K80S & HASWELL CPUS
0
2000
4000
6000
2 x Xeon E5-2698 [email protected] + 1 x Tesla K80 board(1 node)
2 x Xeon E5-2698 [email protected] + 2 x Tesla K80boards (1 node)
2 x Xeon E5-2698 [email protected] + 4 x Tesla K80boards (1 node)
TeraChem 1.5K; BPTI on Tesla K80s & Haswell CPUs(Total Processing Time in Seconds)

TeraChemSupercomputer Speeds on GPUs
0
10
20
30
40
50
60
70
80
90
100
4096 Quad Core CPUs ($19,000,000) 8 C2050 ($31,000)
Tim
e (
Seco
nd
s)
Time for SCF Step
TeraChem running on 8 C2050s on 1 node
NWChem running on 4096 Quad Core CPUs
In the Chinook Supercomputer
Giant Fullerene C240 Molecule
Similar performance from just a handful of GPUs

TeraChemBang for the Buck
1
493
0
100
200
300
400
500
600
4096 Quad Core CPUs ($19,000,000) 8 C2050 ($31,000)
Pri
ce/P
erf
orm
an
ce r
ela
tiv
e t
o S
up
erc
om
pu
ter
Performance/Price
Dollars spent on GPUs do 500x more science than those spent on CPUs
TeraChem running on 8 C2050s on 1 node
NWChem running on 4096 Quad Core
CPUs
In the Chinook Supercomputer
Giant Fullerene C240 Molecule
Note: Typical CPU and GPU node pricing
used. Pricing may vary depending on node
configuration. Contact your preferred HW
vendor for actual pricing.

Kepler’s Even Better
Kepler performs 2x faster than Tesla
TeraChem running on C2050 and K20C
First graph is of BLYP/G-31(d)
Second is B3LYP/6-31G(d)
0
100
200
300
400
500
600
700
800
C2050 K20C
Seco
nd
s
Olestra BLYP 453 Atoms
0
200
400
600
800
1000
1200
1400
1600
1800
2000
C2050 K20C
Seco
nd
s
B3LYP/6-31G(d)

February 2017
VASP 5.4.1

60
Interface on K80s
Running VASP version 5.4.1
The blue node contains Dual Intel Xeon E5-2699 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2699 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla K80 (autoboost) GPUs
➢ 1x K80 is paired with Single Intel Xeon E5-2699 [email protected] [3.6GHz
Turbo] (Broadwell)
Interface between a platinum slab Pt(111) (108 atoms) and liquid water (120 water
molecules) (468 ions)
1256 bands762048 plane waves
ALGO = Fast (Davidson + RMM-DIIS)
0.00171 0.00173
0.00238
0.00317
0.0000
0.0010
0.0020
0.0030
0.0040
0.0050
1 Broadwell node 1 node +1x K80 per node
1 node +2x K80 per node
1 node +4x K80 per node
1/se
conds
Interface
1.0X1.4X
1.9X

61
Interface on P100s PCIe
Running VASP version 5.4.1
The blue node contains Dual Intel Xeon E5-2699 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2699 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla P100 PCIe GPUs
➢ 1x P100 PCIe is paired with Single Intel Xeon E5-2699 [email protected]
[3.6GHz Turbo] (Broadwell)
Interface between a platinum slab Pt(111) (108 atoms) and liquid water (120 water
molecules) (468 ions)
1256 bands762048 plane waves
ALGO = Fast (Davidson + RMM-DIIS)
0.00171
0.00228
0.00308
0.00359
0.00434
0.00000
0.00050
0.00100
0.00150
0.00200
0.00250
0.00300
0.00350
0.00400
0.00450
0.00500
1 Broadwell node 1 node +1x P100 PCIe
per node
1 node +2x P100 PCIe
per node
1 node +4x P100 PCIe
per node
1 node +8x P100 PCIe
per node
1/se
conds
Interface
1.3X
1.8X2.1X
2.5X

62
Interface on P100s SXM2
Running VASP version 5.4.1
The blue node contains Dual Intel Xeon E5-2699 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla P100 SXM2 GPUs
➢ 1x P100 SXM2 is paired with Single Intel Xeon E5-2698 [email protected]
[3.6GHz Turbo] (Broadwell)
Interface between a platinum slab Pt(111) (108 atoms) and liquid water (120 water
molecules) (468 ions)
1256 bands762048 plane waves
ALGO = Fast (Davidson + RMM-DIIS)
0.00171
0.00228
0.00270
0.00326
0.00462
0.00000
0.00050
0.00100
0.00150
0.00200
0.00250
0.00300
0.00350
0.00400
0.00450
0.00500
1 Broadwell node 1 node +1x P100 SXM2
per node
1 node +2x P100 SXM2
per node
1 node +4x P100 SXM2
per node
1 node +8x P100 SXM2
per node
1/se
conds
Interface
1.3X1.6X
1.9X
2.7X
63
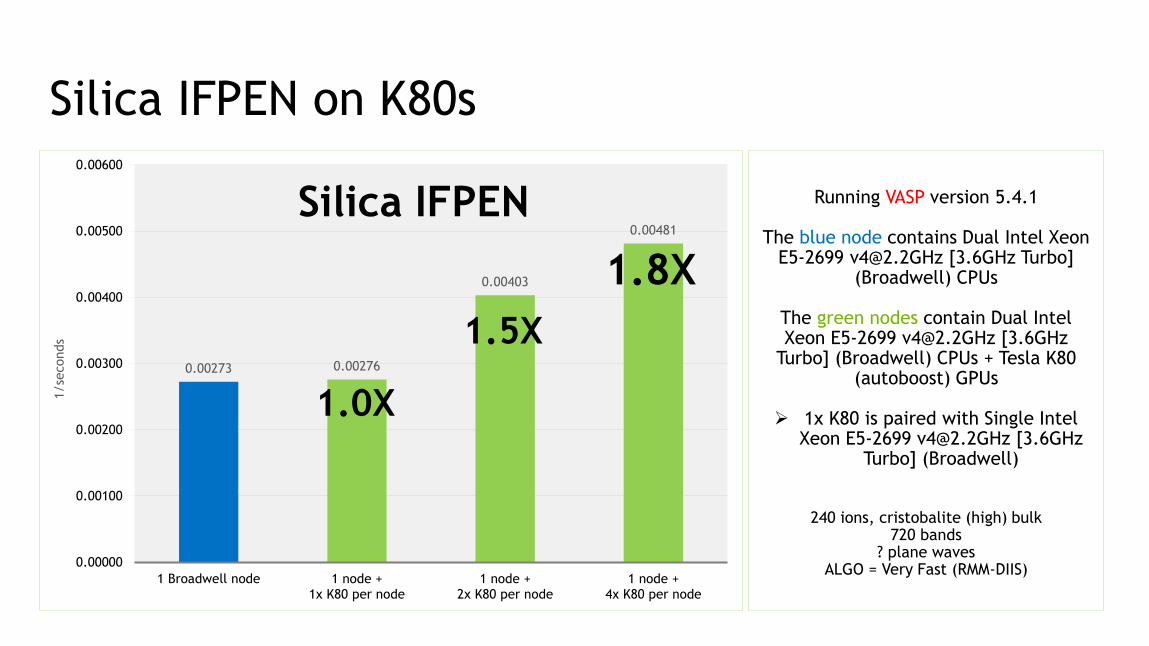
Silica IFPEN on K80s
Running VASP version 5.4.1
The blue node contains Dual Intel Xeon E5-2699 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2699 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla K80 (autoboost) GPUs
➢ 1x K80 is paired with Single Intel Xeon E5-2699 [email protected] [3.6GHz
Turbo] (Broadwell)
240 ions, cristobalite (high) bulk720 bands
? plane wavesALGO = Very Fast (RMM-DIIS)
0.00273 0.00276
0.00403
0.00481
0.00000
0.00100
0.00200
0.00300
0.00400
0.00500
0.00600
1 Broadwell node 1 node +1x K80 per node
1 node +2x K80 per node
1 node +4x K80 per node
1/se
conds
Silica IFPEN
1.0X
1.5X
1.8X

64
Silica IFPEN on P100s PCIe
Running VASP version 5.4.1
The blue node contains Dual Intel Xeon E5-2699 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2699 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla P100 PCIe GPUs
➢ 1x P100 PCIe is paired with Single Intel Xeon E5-2699 [email protected]
[3.6GHz Turbo] (Broadwell)
240 ions, cristobalite (high) bulk720 bands
? plane wavesALGO = Very Fast (RMM-DIIS)
0.00273
0.00380
0.00474
0.00616
0.00674
0.00000
0.00100
0.00200
0.00300
0.00400
0.00500
0.00600
0.00700
0.00800
1 Broadwell node 1 node +1x P100 PCIe
per node
1 node +2x P100 PCIe
per node
1 node +4x P100 PCIe
per node
1 node +8x P100 PCIe
per node
1/se
conds
Silica IFPEN
1.4X
1.7X
2.3X
2.5X

65
Silica IFPEN on P100s SXM2
Running VASP version 5.4.1
The blue node contains Dual Intel Xeon E5-2699 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla P100 SXM2 GPUs
➢ 1x P100 SXM2 is paired with Single Intel Xeon E5-2698 [email protected]
[3.6GHz Turbo] (Broadwell)
240 ions, cristobalite (high) bulk720 bands
? plane wavesALGO = Very Fast (RMM-DIIS)
0.00273
0.00352
0.00475
0.00616
0.00692
0.00000
0.00100
0.00200
0.00300
0.00400
0.00500
0.00600
0.00700
0.00800
1 Broadwell node 1 node +1x P100 SXM2
per node
1 node +2x P100 SXM2
per node
1 node +4x P100 SXM2
per node
1 node +8x P100 SXM2
per node
1/se
conds
Silica IFPEN
1.3X
1.7X
2.3X2.5X

66
Si-Huge on K80s
Running VASP version 5.4.1
The blue node contains Dual Intel Xeon E5-2699 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2699 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla K80 (autoboost) GPUs
➢ 1x K80 is paired with Single Intel Xeon E5-2699 [email protected] [3.6GHz
Turbo] (Broadwell)
512 Si atoms1282 bands
864000 Plane WavesAlgo = Normal (blocked Davidson)
0.00019
0.00024
0.00032
0.00047
0.00000
0.00005
0.00010
0.00015
0.00020
0.00025
0.00030
0.00035
0.00040
0.00045
0.00050
1 Broadwell node 1 node +1x K80 per node
1 node +2x K80 per node
1 node +4x K80 per node
1/se
conds
Si-Huge

67
Si-Huge on P100s PCIe
Running VASP version 5.4.1
The blue node contains Dual Intel Xeon E5-2699 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2699 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla P100 PCIe GPUs
➢ 1x P100 PCIe is paired with Single Intel Xeon E5-2699 [email protected]
[3.6GHz Turbo] (Broadwell)
512 Si atoms1282 bands
864000 Plane WavesAlgo = Normal (blocked Davidson)
0.00019
0.00034
0.00044
0.00058
0.00074
0.00000
0.00010
0.00020
0.00030
0.00040
0.00050
0.00060
0.00070
0.00080
1 Broadwell node 1 node +1x P100 PCIe
per node
1 node +2x P100 PCIe
per node
1 node +4x P100 PCIe
per node
1 node +8x P100 PCIe
per node
1/se
conds
Si-Huge
1.8X
2.3X
3.1X
3.9X

68
Si-Huge on P100s SXM2
Running VASP version 5.4.1
The blue node contains Dual Intel Xeon E5-2699 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla P100 SXM2 GPUs
➢ 1x P100 SXM2 is paired with Single Intel Xeon E5-2698 [email protected]
[3.6GHz Turbo] (Broadwell)
512 Si atoms1282 bands
864000 Plane WavesAlgo = Normal (blocked Davidson)
0.00019
0.00033
0.00040
0.00045
0.00066
0.00000
0.00010
0.00020
0.00030
0.00040
0.00050
0.00060
0.00070
1 Broadwell node 1 node +1x P100 SXM2
per node
1 node +2x P100 SXM2
per node
1 node +4x P100 SXM2
per node
1 node +8x P100 SXM2
per node
1/se
conds
Si-Huge
1.7X
2.1X2.4X
3.5X

69
SupportedSystems on K80s
Running VASP version 5.4.1
The blue node contains Dual Intel Xeon E5-2699 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2699 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla K80 (autoboost) GPUs
➢ 1x K80 is paired with Single Intel Xeon E5-2699 [email protected] [3.6GHz
Turbo] (Broadwell)
267 ions788 bands
762048 plane wavesALGO = Fast (Davidson + RMM-DIIS)
0.00413 0.00414
0.00519
0.00599
0.00000
0.00100
0.00200
0.00300
0.00400
0.00500
0.00600
0.00700
1 Broadwell node 1 node +1x K80 per node
1 node +2x K80 per node
1 node +4x K80 per node
1/se
conds
SupportedSystems
1.0X
1.3X
1.5X

70
SupportedSystems on P100s PCIe
Running VASP version 5.4.1
The blue node contains Dual Intel Xeon E5-2699 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2699 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla P100 PCIe GPUs
➢ 1x P100 PCIe is paired with Single Intel Xeon E5-2699 [email protected]
[3.6GHz Turbo] (Broadwell)
267 ions788 bands
762048 plane wavesALGO = Fast (Davidson + RMM-DIIS)
0.00413
0.00518
0.00651
0.00794 0.00796
0.00000
0.00200
0.00400
0.00600
0.00800
0.01000
1 Broadwell node 1 node +1x P100 PCIe
per node
1 node +2x P100 PCIe
per node
1 node +4x P100 PCIe
per node
1 node +8x P100 PCIe
per node
1/se
conds
SupportedSystems
1.3X
1.6X
1.9X 1.9X

71
SupportedSystems on P100s SXM2
Running VASP version 5.4.1
The blue node contains Dual Intel Xeon E5-2699 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla P100 SXM2 GPUs
➢ 1x P100 SXM2 is paired with Single Intel Xeon E5-2698 [email protected]
[3.6GHz Turbo] (Broadwell)
267 ions788 bands
762048 plane wavesALGO = Fast (Davidson + RMM-DIIS)
0.00413
0.00516
0.00570
0.00692
0.00938
0.00000
0.00100
0.00200
0.00300
0.00400
0.00500
0.00600
0.00700
0.00800
0.00900
0.01000
1 Broadwell node 1 node +1x P100 SXM2
per node
1 node +2x P100 SXM2
per node
1 node +4x P100 SXM2
per node
1 node +8x P100 SXM2
per node
1/se
conds
SupportedSystems
1.2X1.4X
1.7X
2.3X

72
NiAl-MD on K80s
Running VASP version 5.4.1
The blue node contains Dual Intel Xeon E5-2699 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2699 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla K80 (autoboost) GPUs
➢ 1x K80 is paired with Single Intel Xeon E5-2699 [email protected] [3.6GHz
Turbo] (Broadwell)
500 ions3200 bands
729000 plane wavesALGO = Fast (Davidson + RMM-DIIS)
0.003470.00359
0.00537
0.00614
0.00000
0.00100
0.00200
0.00300
0.00400
0.00500
0.00600
0.00700
1 Broadwell node 1 node +1x K80 per node
1 node +2x K80 per node
1 node +4x K80 per node
1/se
conds
NiAl-MD
1.0X
1.5X
1.8X

73
NiAl-MD on P100s PCIe
Running VASP version 5.4.1
The blue node contains Dual Intel Xeon E5-2699 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2699 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla P100 PCIe GPUs
➢ 1x P100 PCIe is paired with Single Intel Xeon E5-2699 [email protected]
[3.6GHz Turbo] (Broadwell)
500 ions3200 bands
729000 plane wavesALGO = Fast (Davidson + RMM-DIIS)
0.00347
0.00577
0.00731
0.009020.00936
0.00000
0.00100
0.00200
0.00300
0.00400
0.00500
0.00600
0.00700
0.00800
0.00900
0.01000
1 Broadwell node 1 node +1x P100 PCIe
per node
1 node +2x P100 PCIe
per node
1 node +4x P100 PCIe
per node
1 node +8x P100 PCIe
per node
1/se
conds
NiAl-MD
1.7X
2.1X2.6X
2.7X

74
NiAl-MD on P100s SXM2
Running VASP version 5.4.1
The blue node contains Dual Intel Xeon E5-2699 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla P100 SXM2 GPUs
➢ 1x P100 SXM2 is paired with Single Intel Xeon E5-2698 [email protected]
[3.6GHz Turbo] (Broadwell)
500 ions3200 bands
729000 plane wavesALGO = Fast (Davidson + RMM-DIIS)
0.0035
0.0057
0.0074
0.0081
0.0090
0.0000
0.0010
0.0020
0.0030
0.0040
0.0050
0.0060
0.0070
0.0080
0.0090
0.0100
1 Broadwell node 1 node +1x P100 SXM2
per node
1 node +2x P100 SXM2
per node
1 node +4x P100 SXM2
per node
1 node +8x P100 SXM2
per node
1/se
conds
NiAl-MD
1.6X
2.1X2.3X
2.6X
75
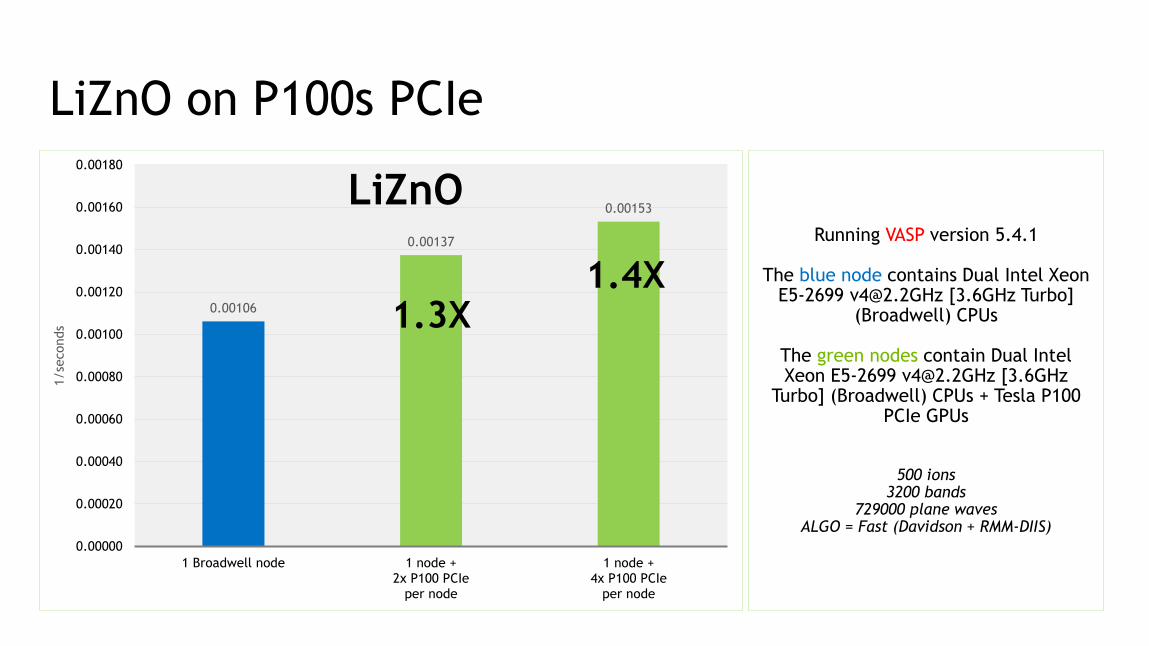
LiZnO on P100s PCIe
Running VASP version 5.4.1
The blue node contains Dual Intel Xeon E5-2699 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2699 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla P100 PCIe GPUs
500 ions3200 bands
729000 plane wavesALGO = Fast (Davidson + RMM-DIIS)
0.00106
0.00137
0.00153
0.00000
0.00020
0.00040
0.00060
0.00080
0.00100
0.00120
0.00140
0.00160
0.00180
1 Broadwell node 1 node +2x P100 PCIe
per node
1 node +4x P100 PCIe
per node
1/se
conds
LiZnO
1.3X1.4X

76
LiZnO on P100s SXM2
Running VASP version 5.4.1
The blue node contains Dual Intel Xeon E5-2699 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla P100 SXM2 GPUs
➢ 1x P100 SXM2 is paired with Single Intel Xeon E5-2698 [email protected]
[3.6GHz Turbo] (Broadwell)
500 ions3200 bands
729000 plane wavesALGO = Fast (Davidson + RMM-DIIS)
0.00110.0011
0.0013
0.0015
0.0018
0.0000
0.0002
0.0004
0.0006
0.0008
0.0010
0.0012
0.0014
0.0016
0.0018
0.0020
1 Broadwell node 1 node +1x P100 PCIe
per node
1 node +2x P100 PCIe
per node
1 node +4x P100 PCIe
per node
1 node +8x P100 PCIe
per node
1/se
conds
LiZnO
1.0X1.2X
1.4X1.6X

77
B.hR105 on P100s PCIe
Running VASP version 5.4.1
The blue node contains Dual Intel Xeon E5-2699 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2699 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla P100 PCIe GPUs
➢ 1x P100 PCIe is paired with Single Intel Xeon E5-2699 [email protected]
[3.6GHz Turbo] (Broadwell)
105 Boron atoms (β-rhombohedral structure)216 bands
110592 plane wavesHybrid Functional with blocked Davicson
(ALGO=Normal)LHFCALC=.True. (Exact Exchange)
0.00090
0.00223
0.00371
0.00560
0.00702
0.00000
0.00100
0.00200
0.00300
0.00400
0.00500
0.00600
0.00700
0.00800
1 Broadwell node 1 node +1x P100 PCIe
per node
1 node +2x P100 PCIe
per node
1 node +4x P100 PCIe
per node
1 node +8x P100 PCIe
per node
1/se
conds
B.hR105
2.5X
4.1X
6.2X
7.8X

78
B.hR105 on P100s SXM2
Running VASP version 5.4.1
The blue node contains Dual Intel Xeon E5-2699 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla P100 SXM2 GPUs
➢ 1x P100 SXM2 is paired with Single Intel Xeon E5-2698 [email protected]
[3.6GHz Turbo] (Broadwell)
105 Boron atoms (β-rhombohedral structure)216 bands
110592 plane wavesHybrid Functional with blocked Davicson
(ALGO=Normal)LHFCALC=.True. (Exact Exchange)
0.0009
0.0024
0.0039
0.0059
0.0078
0.0000
0.0010
0.0020
0.0030
0.0040
0.0050
0.0060
0.0070
0.0080
0.0090
1 Broadwell node 1 node +1x P100 SXM2
per node
1 node +2x P100 SXM2
per node
1 node +4x P100 SXM2
per node
1 node +8x P100 SXM2
per node
1/se
cpnds
B.hR105
2.7X
4.3X
6.6X
8.7X

79
B.aP107 on P100s PCIe
Running VASP version 5.4.1
The blue node contains Dual Intel Xeon E5-2699 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2699 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla P100 PCIe GPUs
➢ 1x P100 PCIe is paired with Single Intel Xeon E5-2699 [email protected]
[3.6GHz Turbo] (Broadwell)
107 Boron atoms (symmetry broken 107-atom β′ variant)
216 bands110592 plane waves
Hybrid functional calculation (exact exchange) with blocked Davidson. No KPoint parallelization.
Hybrid Functional with blocked Davidson (ALGO=Normal)
LHFCALC=.True. (Exact Exchange)
0.00003
0.00012
0.00021
0.00031
0.00041
0.00000
0.00005
0.00010
0.00015
0.00020
0.00025
0.00030
0.00035
0.00040
0.00045
1 Broadwell node 1 node +1x P100 PCIe
per node
1 node +2x P100 PCIe
per node
1 node +4x P100 PCIe
per node
1 node +8x P100 PCIe
per node
1/se
conds
B.aP107
4.0X
7.0X
10.3X
13.7X

80
B.aP107 on P100s SXM2
Running VASP version 5.4.1
The blue node contains Dual Intel Xeon E5-2699 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla P100 SXM2 GPUs
➢ 1x P100 SXM2 is paired with Single Intel Xeon E5-2698 [email protected]
[3.6GHz Turbo] (Broadwell)
107 Boron atoms (symmetry broken 107-atom β′ variant)
216 bands110592 plane waves
Hybrid functional calculation (exact exchange) with blocked Davidson. No KPoint parallelization.
Hybrid Functional with blocked Davidson (ALGO=Normal)
LHFCALC=.True. (Exact Exchange)
0.00003
0.00011
0.00020
0.00027
0.00044
0.00000
0.00005
0.00010
0.00015
0.00020
0.00025
0.00030
0.00035
0.00040
0.00045
0.00050
1 Broadwell node 1 node +1x P100 SXM2
per node
1 node +2x P100 SXM2
per node
1 node +4x P100 SXM2
per node
1 node +8x P100 SXM2
per node
1/se
conds
B.aP107
3.7X
6.7X9.0X
14.7X

Dec, 19, 2016
Quantum Chemistry (QC) on GPUs