radial basis function neural network with incremental learning for face recognition
TRANSCRIPT

940 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 41, NO. 4, AUGUST 2011
Radial Basis Function Neural Network WithIncremental Learning for Face Recognition
Yee Wan Wong, Kah Phooi Seng, and Li-Minn Ang
Abstract—Conventional face recognition suffers from problemssuch as extending the classifier for newly added people andlearning updated information about the existing people. The wayto address these problems is to retrain the system which willrequire expensive computational complexity. In this paper, a radialbasis function (RBF) neural network with a new incrementallearning method based on the regularized orthogonal least square(ROLS) algorithm is proposed for face recognition. It is designedto accommodate new information without retraining the initialnetwork. In our proposed method, the selection of the regressorsfor the new data is done locally, hence avoiding the expensivereselecting process. In addition, it accumulates previous experi-ence and learns updated new knowledge of the existing groups toincrease the robustness of the system. The experimental resultsshow that the proposed method gives higher average recognitionaccuracy compared to the conventional ROLS-algorithm-basedRBF neural network with much lower computational complexity.Furthermore, the proposed method achieves higher recognitionaccuracy as compared to other incremental learning algorithmssuch as incremental principal component analysis and incrementallinear discriminant analysis in face recognition.
Index Terms—Face recognition, incremental learning, neuralnetwork, orthogonal least square, radial basis function (RBF),visual variation.
I. INTRODUCTION
THE recognition performance of the face recognition sys-tem deteriorates when the system is exposed to the real-
world scenario. This problem happens because we do not havea complete set of training samples that consists of all types ofvisual variations. Furthermore, the extendability of the systemto recognize more new people who join the existing groups inthe future may cause a problem to the system. A conventionalway to solve this problem is to retrain the system to learn thenew information. However, this will cause high computationalcomplexity. A more practical and faster way to solve this prob-lem is by embedding incremental learning in feature selectionand classification.
In recent years, several incremental learning methods havebeen developed independently [1]–[4]. As for incrementallearning in feature selection, principal component analysis(PCA) [5] was extended to incremental PCA (IPCA) [2], [3]and was applied in the face recognition systems [6], [8]. If
Manuscript received February 24, 2010; revised June 7, 2010 andSeptember 21, 2010; accepted November 27, 2010. Date of publicationJanuary 17, 2011; date of current version July 20, 2011. This paper wasrecommended by Associate Editor J. Su.
The authors are with The University of Nottingham Malaysia Campus,43500 Semenyih, Malaysia (e-mail: [email protected]).
Color versions of one or more of the figures in this paper are available onlineat http://ieeexplore.ieee.org.
Digital Object Identifier 10.1109/TSMCB.2010.2101591
the labels of the data are available, the incremental lineardiscriminant analysis (ILDA) [4], [7], which maximizes thebetween-class scatter and minimizes the within-class scatter,can be used to optimize the class separability incrementally.Since the feature space of these methods is updated everytime a new training sample is available, the dimension of thefeature space might be increased. This will cause a problem inmost neural network classifiers as the networks should also beupdated to adapt to the dimension extension of the input data.
As for incremental learning in classification, neural-network-based approaches are developed in [1], [6], [26], and [27].More recently, a new multiclass online boosting strategy toincrementally add new classes to a previously learned facerecognition model has been proposed [1]. This method wastested in the face recognition system, and it achieved promisingrecognition accuracy. However, this method does not includethe ability to update the network using updated training datathat belong to the existing groups. This is a drawback of thismethod as we realize that an updated sample of existing groupscontains information that can help to improve the robustness ofthe system.
In this paper, we propose a new incremental learning methodfor the regularized orthogonal least square (ROLS)-based [9]radial basis function (RBF) neural network. This proposed al-gorithm is named as the incremental ROLS (IROLS) algorithm.The IROLS algorithm is designed to accommodate a new classand updated new data while avoiding retraining the network.The IROLS algorithm combines the zero-order regularizationwith the orthogonal least square to construct a parsimoniousRBF network to improve the generalization ability of thesystem. This algorithm is capable of constructing small RBFnetworks which generalize well and requires low computationalcomplexity [9]. For the conventional ROLS algorithm, it firstselects the basis vector that provides the most significant errorreduction among all the basis vectors and orthogonalizes all theremaining basis vectors into a Euclidean space formed by theselected basis vector. This process will be repeated until theerror reduction ratio is lower than a predetermined threshold.Unlike the conventional ROLS algorithm, the proposed IROLSreduces the computational complexity of the ROLS algorithmby selecting the basis vector which corresponds to the newclass of training data locally instead of globally. For updatingdata, the incremental learning of the updated training sample isachieved by reinforcing the positions of hidden neurons to thenew information, and this avoids the retraining process.
The proposed IROLS-algorithm-based RBF neural networkis then applied to address the face recognition problems: theability to add a new class to the existing classifier and to
1083-4419/$26.00 © 2011 IEEE

WONG et al.: RBF NEURAL NETWORK WITH INCREMENTAL LEARNING FOR FACE RECOGNITION 941
Fig. 1. IROLS framework for face recognition system.
accumulate new knowledge without retraining the system. Asshown in Fig. 1, we allow the new information to appear intwo forms: the new classes that need to be included in theexisting groups and the updated training samples of the existinggroups in the system. Compared to [1], the proposed learningscheme not only allows the addition of new classes but alsoallows the addition of new updating samples to existing groupsto accumulate knowledge to help future recognition processes.During the training stage, each of the training samples willbe first transformed into feature representation. The trainingsamples which belong to the initial classes will be first trainedby the ROLS-based neural network. When new class samplesappear, the IROLS-based neural network will add the newclass data to the existing network without retraining the wholenetwork. For new updated samples, the IROLS will learn thenew information in the updated samples, together with theprevious knowledge in the network. In addition, we investigatehow the updated new knowledge that contains different visualvariations from the training samples can help to improve therecognition performance of the system. To the best of ourknowledge, this is the first study that specifically focuses on theinfluence of incremental learning of various visual variations tothe face recognition performance. The recognition performanceof the proposed algorithm will be tested on three face databasesand compared with that of other state-of-the-art methods.
This paper is organized as follows. In Section II, the detailsof the proposed IROLS-based neural network will be presented.Then, the implementation of the proposed neural network inthe face recognition system will be discussed in Section III.The experimental results of the proposed IROLS-based neuralnetwork will be given in Section IV. Section V describes theconclusion of this paper.
II. IROLS-ALGORITHM-BASED NEURAL NETWORK
The ROLS algorithm is used to build a global scheme wherea new class or updated data can be added after the initial set ofclasses is trained. The proposed IROLS comprises two majorsteps: First, the ROLS algorithm is run to create the initialmodel which contains the knowledge of the initial classes, andsecond, the training samples which can be the training samples
for the new classes or updated data are presented to the IROLSfor incremental learning.
A. ROLS Algorithm for RBF Neural Network
The RBF neural network is formulated as a linear regressionmodel as follows [9]–[11]:
fr(x) =ns∑i=1
θiφ (‖x − ci‖) (1)
where x = {x1 · · ·xm} is the training data of the initial trainingset with the desired outputs y = {y1 · · · ym}, m is the totalnumber of training samples, θi represents the weights, c ={c1 · · · cns
} represents the RBF centers, ‖ · ‖ refers to theEuclidean norm, φ(·) is the nonlinearity of the hidden neurons,and ns is the total number of selected hidden neurons. At thefirst stage of the selection procedure l = 1 of the algorithm,ns = m. The ROLS algorithm for the RBF neural network isdiscussed hereinafter.
Assuming that we have every training sample x ={x1 · · ·xm} as the center cj = xj , for 1 ≤ j ≤ m, we computethe regressor matrix Φ as follows:
Φj = exp(−‖x − cj‖2
2σ2
), 1 ≤ j ≤ m (2)
where σ is the width of the Gaussian function.
1) For 1 ≤ j ≤ m: Test: Conditioning number check. If(Φ(l−1)
j )T Φ(l−1)j < Tz , the jth candidate is not consid-
ered, where Tz is a very small positive value. This check-ing is to avoid ill-conditioning or singular situations [10].The Tz term is set as 0.02 in this paper. Compute
g(j)l =
((Φ(l−1)
j
)T
y(l−1)
)/((Φ(l−1)
j
)T
Φ(l−1)j +λ
)(3)
[rerr](j)l =(g(j)l
)2((
Φ(l−1)j
)T
Φ(l−1)j +λ
)/yT y (4)
where λ is the regularization parameter, g is the orthogo-nalized weight, y is the desired output matrix, and Φ(l−1)
j

942 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 41, NO. 4, AUGUST 2011
is the jth column of the regressor matrix of selection stagel − 1.
2) Select the significant regressors by using the regularizederror reduction ratio
[rerr]l = max{
[rerr](j)l , l ≤ j ≤ m, jpassesTest}
. (5)
Equation (5) selects the significant regressors that havethe maximum error reduction ratio among the regressorsthat pass the test at the selection stage l. The selectedregressor will be assigned as the center of the lth se-lection stage. For l = 1, the jlth column of Φ(l−1)
j isinterchanged with the lth column of Φ(l−1)
j .3) Perform the orthogonalization as follows. For l =
1, 2, . . . ,m − 1
wl =Φ(l−1)l (6)
al,j =wTl Φ(l−1)
j /(wT
l wl
), l + 1 ≤ j ≤ m (7)
Φ(l)j =Φ(l−1)
l − al,jwl, l + 1 ≤ j ≤ m (8)
where al,j is substituted to the lth row of A. A is anm × m triangular matrix with 1’s on the diagonal and 0’sbelow the diagonal. A and W are as follows:
A =
⎡⎢⎢⎢⎣1 a1,2 · · · a1,m
0 1. . .
......
. . .. . . am−1,m
0 · · · 0 1
⎤⎥⎥⎥⎦ (9)
W = [w1 · · ·wm] (10)
with orthogonal columns that satisfy
wTi wj = 0, if i �= j. (11)
Then, calculate gl and update y(l−1)l into yl in the way
shown hereinafter. For 1 ≤ l ≤ m
gl =(wT
l y(l−1))/
wTl wl + λ (12)
y(l) =y(l−1) − glwl. (13)
When l > 1, the selection procedure repeats, the jlthcolumn of Φ(l−1)
j is interchanged with the lth column ofΦ(l−1)
j , and the jlth column of A is interchanged up tothe (l − 1)th row with the lth column of A. This selectsthe jlth candidate as the lth regressor in the subset model.
The selection is terminated at the ns stage when
1 −ns∑
k=1
[rerr]k < ξ (14)
is satisfied, where 0 ≤ ξ ≤ 1 is a chosen tolerance. Al-ternatively, the selection will be terminated when thereare no more candidates which would not cause an ill-conditioning or singular problem [10].
B. IROLS Algorithm for RBF Neural Network
After ns stages, an ns-dimensional Euclidean spaceEns is established which has the orthogonal basis vectors{w1,w2, . . . ,wns
}. The original data that correspond tothe selected basis vectors can be referred to as the centersc = {x1, x2, . . . , xns
} = {c1, c2, . . . , cns} of the initial net-
work. Assuming that the new training samples are xNEW ={x1, . . . , xnM
}, where nM is the number of new trainingsamples, we perform the following procedure. The new inputtraining samples are first determined manually whether thesamples are an additional new class or samples that belongto the existing class (updated sample). If the input trainingsamples are from a new class, go to Step 1). Otherwise, go toStep 7).
Step 1) Let the new training samples of that class bexNEW = {x1, . . . , xnM
}, where nM is the totalnumber of new training samples which belong toa new class. Calculate the mean x̄NEW, and findthe three centers from cj ∈ {c1, . . . , cns
} which areclosest to x̄NEW as follows:
dj = ‖x̄NEW − cj‖, 1 ≤ j ≤ ns. (15)
Then, the first three jth centers that are closestto x̄NEW will be selected. The three closest centersare chosen based on an experimental result whichtested on the influence of the number of centers tothe recognition accuracy. The results show that theproposed algorithm achieves the highest recognitionaccuracy when the number of centers is three.
Step 2) Assuming that the corresponding training sam-ples which belong to the three centers are xc ={x1, . . . , xno
} and concatenating them with thenew training samples form x̃ = {xc,xNEW} ={x1, . . . , xnT
}. Since x̃ = cs, then the regressors ofthe input x̃ are as follows:
Φs = exp(−‖x̃ − cs‖2
2σ2
), 1 ≤ s ≤ nT . (16)
Compute
gs =((Φs)T y
)/((Φs)T Φs + λ
), 1≤s≤nT (17)
[rerr]s = (gs)2((Φs)T Φs + λ
)/yT y, 1≤s ≤ nT (18)
where y is the local desired output of the trainingsamples. This step is important to compute the errorreduction ratio of the new training samples with thethree closest classes.
Step 3) The regressor for the new class is selected accordingto the scalar measure of [rerr] where only the re-gressors that correspond to the new class are chosento be the candidates
[rerr]p = max {[rerr]p, no + 1 ≤ p ≤ nT } . (19)
This is to choose the regressor Φp belongingto the new class locally instead of reselectingall the regressors as in the conventional ROLS

WONG et al.: RBF NEURAL NETWORK WITH INCREMENTAL LEARNING FOR FACE RECOGNITION 943
algorithm. The number of selected regressors is now{Φ1,Φ2, . . . ,Φns
,Φp} = {Φ1,Φ2, . . . ,Φnk},
where nk = ns + 1.Step 4) Compute the regressors of input training set x′ =
{x,xNEW} with c = x′ as follows:
ΦNewj = exp
(−‖x′ − cj‖2
2σ2
), 1 ≤ j ≤ nH (20)
where nH = m + nM .Step 5) Perform the orthogonalization with the regressors
{Φ1,Φ2, . . . ,Φns,Φp} in which the first nsth re-
gressors correspond to the regressors chosen dur-ing the training of the initial network. For l =1, 2, . . . , nk
wl =Φ(l−1)l (21)
al,j =wTl Φ(l−1)
j
/ (wT
l wl
), l+1 ≤ j ≤ nH (22)
Φ(l)j =Φ(l−1)
l − al,jwl, l+1 ≤ j ≤ nH . (23)
Then, the elements of g and y are computed asfollows:
gl =wTl y(l−1)
/wT
l wl + λ (24)
y(l) =y(l−1) − glwl. (25)
The jlth column of Φ(l−1)j is interchanged with
the lth column of Φ(l−1)j , and the jlth column of A
is interchanged up to the (l − 1)th row with the lthcolumn of A.
Step 6) Calculate the output of the network y = wlgl. If thejth output is not equal to the desired output, thenSteps 1)–3) are repeated to select the three centerswhich are nearest to the center of a class that xj be-longs to. Note that the “new class” and “new trainingsample” referred to in Steps 1)–3) should now bereferred to as the class of the misclassified trainingsample xj . Then, add a hidden unit (i.e., nk ←nk + 1) to the network if the selected regressorhas not been selected before Φnk
(nj /∈ nk). Then,Steps 4)–6) are computed. This step is repeated onceto reduce the training error. Otherwise, the followingprocedure is carried out.
Step 7) Let the updated data be xNEW = xup and the centercorrespond to the class of the updated data that areselected from cup ∈ {c} or cup ∈ {cNEW}. If thereis more than one center which belongs to the updatedclass, the center which has the closest distance to theupdated sample will be selected as the cup. The cup
is updated as follows:
c(New)up = c(old)
up + η(xup − c(old)
up
)(26)
where η is a positive learning rate. Then, repeatSteps 4)–6).
Fig. 2. Data scatter diagram for (a) the initial training samples and selectedcenters and (b) the updated samples and the adjustment of the old centers to thenew updated samples.
The proposed algorithm avoids the retraining of the networkby using the initial network architecture. The regressor whichcorresponds to the new training data will be selected locallywith the data that have the minimum distance to the newtraining data. The incremental learning of the updated trainingsample is achieved by reinforcing the old center to the updatedtraining samples. Fig. 2 shows how (26) works. The η parameterdetermines how much the old centers have moved toward theupdated samples.
III. PROPOSED IROLS-ALGORITHM-BASED NEURAL
NETWORK FOR FACE RECOGNITION
In the previous section, the details of the proposed IROLS-based RBF neural network are presented. In this section, theproposed IROLS will be implemented in the face recognitionsystem. In this paper, we employ the dual optimal multibandfeature (DOMF) fusion method [12] as the feature extractionmodule. This method is suitable for incremental learning be-cause it provides a fixed input dimension to the neural network,and it extracts the optimal sets of wavelet subbands that are

944 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 41, NO. 4, AUGUST 2011
Fig. 3. Block diagram of the DOMF for face recognition.
invariant to facial expression and illumination. It uses an adap-tive fusion method to avoid the adverse effect caused by com-bining the optimal feature sets. Fig. 3 shows the block diagramof the DOMF in the face recognition system. The waveletpacket transform [13] decomposes the image into frequencysubbands to represent the facial features of the face image.The multiband feature fusion technique [14] is incorporated tosearch for subbands that are invariant to illumination and facialexpression variations separately. The optimal multiband fea-tures that are invariant to illumination and facial expression areused and named as optimal multiband feature for illumination(OMF_I) and optimal multiband feature for facial expression(OMF_E). The proposed IROLS-based RBF neural networksare then used to classify the OMF_I and OMF_E features togenerate scoreI and scoreE, respectively.
During the testing stage, the decision scores are linearly com-bined through a set of fusion weights. In the DOMF method, theweights are determined by the illumination variation estimatorwhere the illumination variation factor will be assigned basedon the illumination variation level of the input testing image.For example, the weight assigned to scoreI is higher thanthat assigned to scoreE if the input image is influenced byhigh illumination variation. The illumination variation estima-tor uses morphological opening to remove the facial featuresand then estimates the level of illumination variation of theimage. The level of illumination variation can be describedas the illumination variation factor k. Assuming that the faceimage that contains illumination variation has one side ofthe image brighter than the other, the k can be determined asthe difference between the mean pixel values at the left and theright sides of the image. The weight of the system can thenbe determined adaptively based on the k value of the testingimage. The sum rule is incorporated to combine the scores. Thesum rule computes the final score from [15]
s =J∑
i=1
fweightisi (27)
where J is the number of modalities (which is two in thiscase), fweight is the fusion weight, and si represents the scoresobtained from the J modalities (scoreI or scoreE). The fusion
weights are adaptive in the sense that the weights assigned tothe modalities are based on the illumination variation factorof the testing image. The weight fweighti for each image isdetermined with the following definition:
fweighti ={
fweight, k ≥ T1 − fweight, k < T .
(28)
T denotes the threshold of the illumination variation factorwhere it is determined as the mean value of the illuminationvariation factors of the training images. The value of fweight isfixed and is obtained experimentally.
During the training stage, the illumination variation factorof the updated training sample will be computed to help theincremental learning in the proposed IROLS algorithm. As wehave seen in the previous section, the learning of the updatedtraining sample is achieved by reinforcing the old center tothe updated training samples as described in (26). Only the oldcenters will be moved toward the updated samples based on thefollowing criteria:
ηOMF_Ii=
{η, k ≥ T0, k < T
(29)
ηOMF_Ei=
{0, k ≥ Tη, k < T
(30)
where ηOMF_Iiand ηOMF_Ei
refer to the learning rates for theneural network for OMF_I and OMF_E features, respectively.The first criterion explains that, if the updated sample i has anillumination variation level that is higher than the T thresholdvalue, the old center which belongs to the class of updatedsample i will be moved toward the updated sample in thenetwork that corresponds to the OMF_I features. Otherwise, theold center remains stagnant. The same theory will be applied tothe network that corresponds to the OMF_E feature which isshown on the second criterion: The updated samples that donot contain illumination variation only will be learned by thenetwork that corresponds to OMF_E features.
WONG et al.: RBF NEURAL NETWORK WITH INCREMENTAL LEARNING FOR FACE RECOGNITION 945
Fig. 4. Examples of images from the AR database.
IV. EXPERIMENTAL RESULTS
In this section, we evaluate the performance of the pro-posed IROLS-based RBF neural network with different facedatabases. The databases used include the AR database [16],the Yale database [17], and The University of NottinghamMalaysia Campus Visual Information Engineering Research(UNMC-VIER) database [18]. All the experiments are per-formed on a PC with a Pentium Core 2 Duo 2.66-GHz CPUand 2.97 GB of RAM. The experiments included in this sectionare as follows.
1) Evaluate the recognition performance of the IROLS-based RBF neural network. The recognition accuracy ofthe IROLS-based RBF neural network is compared withthat of the conventional ROLS-based RBF neural networkand other incremental learning methods.
2) Evaluate the effect of knowledge accumulation of theIROLS-based RBF neural network on the recognitionaccuracy in various visual variations. The recognitionaccuracy of the IROLS is compared with that of other facerecognition methods.
A. Recognition Performance of IROLS-Based RBFNeural Network
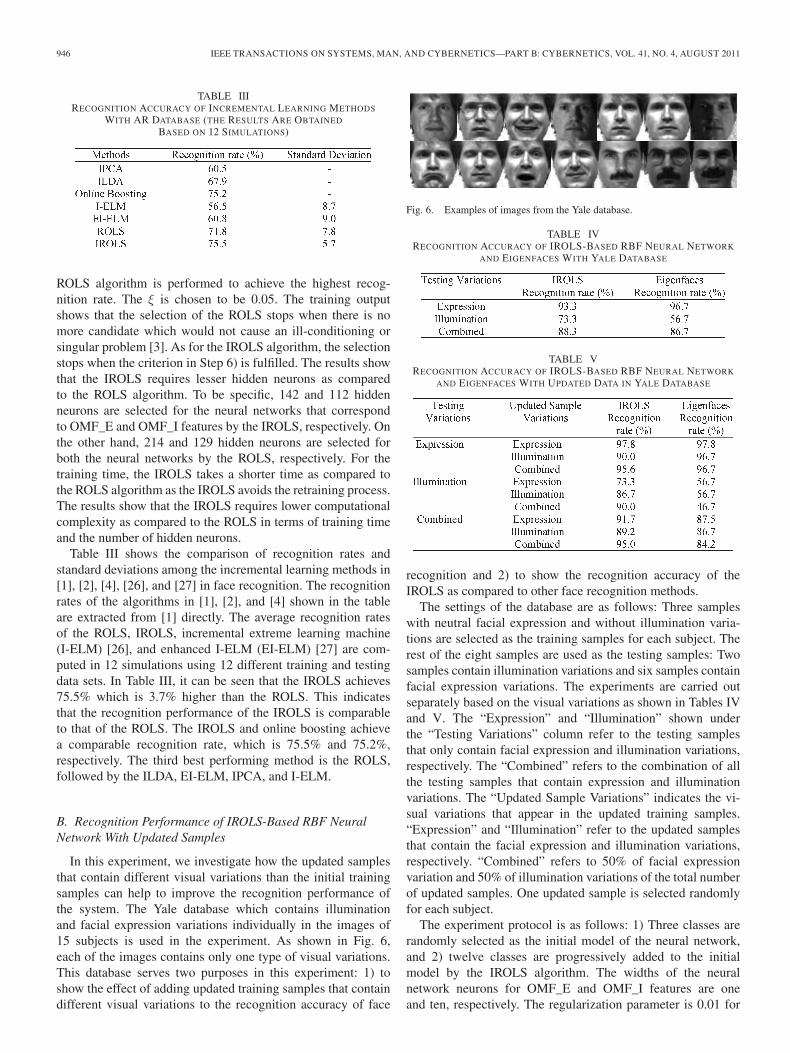
In this experiment, the AR face database is used. The AR facedatabase consists of images that are taken under various visualvariations such as occlusion, illumination, facial expression,and aging. Fig. 4 shows some of the example images fromthe AR database. The images were acquired in two differentsessions. There is a total of 26 images for each subject in thedatabase. The experiment setting is similar to the experimentsetting in [1]. The first 86 people out of 100 people are selectedas the samples in this experiment. However, instead of using13 training samples and 13 testing samples as in [1], we use6 training samples and 13 testing samples for each subject.We take only 6 instead of 13 training samples because wedo not train the system with the samples with illuminationvariations and drastic facial expression variations. They areexcluded from the training set to show the recognition per-formance of the proposed method in illumination and facialexpression variations. The remaining 14 people are used for theexperiments conducted to select optimal values for fweight, λ,and η. Fig. 5 shows the recognition rates of IROLS and ROLS
Fig. 5. Recognition rate against fweight for IROLS- and ROLS-based RBFneural network in AR database.
TABLE IRECOGNITION ACCURACY OF IROLS AGAINST LAMBDA
WITH AR DATABASE
TABLE IIHIDDEN NEURONS AND TRAINING TIMES REQUIRED FOR ROLS-AND
IROLS-BASED RBF NEURAL NETWORK WITH AR DATABASE
against fweight values. The result shows that both the algo-rithms achieve the optimal fweight value at 0.8. The recognitionaccuracies versus regularization parameter λ with the values of0, 0.01, 0.1, and 1 [9] are shown in Table I. The λ = 0.01 ischosen to be the optimal value as the highest recognition rate isachieved at this point of the λ value. The experiment has beencarried out to find the optimal η value in the AR database. Wefound that the most suitable η value for all the testing samplesthat we have tested is 0.4.
The experiment protocol is as follows: 1) Twenty classes arerandomly selected as the initial model of the neural network,and 2) sixty-six classes are progressively added to the initialmodel by the IROLS algorithm. The widths of the neural net-work neurons for the OMF_E and OMF_I features are chosento be twice the mean distance between the training samples[25], which are two and ten, respectively. The regularizationparameter is 0.01 for both the neural networks. The weightfweight for the DOMF is set as 0.8.
The IROLS is first compared with the conventional ROLS.Table II shows the number of hidden neurons and the trainingtime required by the ROLS and IROLS algorithms for trainingthe OMF_E and OMF_I features. As in our experiments, crossvalidation on the recognition performance against ξ of the
946 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 41, NO. 4, AUGUST 2011
TABLE IIIRECOGNITION ACCURACY OF INCREMENTAL LEARNING METHODS
WITH AR DATABASE (THE RESULTS ARE OBTAINED
BASED ON 12 SIMULATIONS)
ROLS algorithm is performed to achieve the highest recog-nition rate. The ξ is chosen to be 0.05. The training outputshows that the selection of the ROLS stops when there is nomore candidate which would not cause an ill-conditioning orsingular problem [3]. As for the IROLS algorithm, the selectionstops when the criterion in Step 6) is fulfilled. The results showthat the IROLS requires lesser hidden neurons as comparedto the ROLS algorithm. To be specific, 142 and 112 hiddenneurons are selected for the neural networks that correspondto OMF_E and OMF_I features by the IROLS, respectively. Onthe other hand, 214 and 129 hidden neurons are selected forboth the neural networks by the ROLS, respectively. For thetraining time, the IROLS takes a shorter time as compared tothe ROLS algorithm as the IROLS avoids the retraining process.The results show that the IROLS requires lower computationalcomplexity as compared to the ROLS in terms of training timeand the number of hidden neurons.
Table III shows the comparison of recognition rates andstandard deviations among the incremental learning methods in[1], [2], [4], [26], and [27] in face recognition. The recognitionrates of the algorithms in [1], [2], and [4] shown in the tableare extracted from [1] directly. The average recognition ratesof the ROLS, IROLS, incremental extreme learning machine(I-ELM) [26], and enhanced I-ELM (EI-ELM) [27] are com-puted in 12 simulations using 12 different training and testingdata sets. In Table III, it can be seen that the IROLS achieves75.5% which is 3.7% higher than the ROLS. This indicatesthat the recognition performance of the IROLS is comparableto that of the ROLS. The IROLS and online boosting achievea comparable recognition rate, which is 75.5% and 75.2%,respectively. The third best performing method is the ROLS,followed by the ILDA, EI-ELM, IPCA, and I-ELM.
B. Recognition Performance of IROLS-Based RBF NeuralNetwork With Updated Samples
In this experiment, we investigate how the updated samplesthat contain different visual variations than the initial trainingsamples can help to improve the recognition performance ofthe system. The Yale database which contains illuminationand facial expression variations individually in the images of15 subjects is used in the experiment. As shown in Fig. 6,each of the images contains only one type of visual variations.This database serves two purposes in this experiment: 1) toshow the effect of adding updated training samples that containdifferent visual variations to the recognition accuracy of face
Fig. 6. Examples of images from the Yale database.
TABLE IVRECOGNITION ACCURACY OF IROLS-BASED RBF NEURAL NETWORK
AND EIGENFACES WITH YALE DATABASE
TABLE VRECOGNITION ACCURACY OF IROLS-BASED RBF NEURAL NETWORK
AND EIGENFACES WITH UPDATED DATA IN YALE DATABASE
recognition and 2) to show the recognition accuracy of theIROLS as compared to other face recognition methods.
The settings of the database are as follows: Three sampleswith neutral facial expression and without illumination varia-tions are selected as the training samples for each subject. Therest of the eight samples are used as the testing samples: Twosamples contain illumination variations and six samples containfacial expression variations. The experiments are carried outseparately based on the visual variations as shown in Tables IVand V. The “Expression” and “Illumination” shown underthe “Testing Variations” column refer to the testing samplesthat only contain facial expression and illumination variations,respectively. The “Combined” refers to the combination of allthe testing samples that contain expression and illuminationvariations. The “Updated Sample Variations” indicates the vi-sual variations that appear in the updated training samples.“Expression” and “Illumination” refer to the updated samplesthat contain the facial expression and illumination variations,respectively. “Combined” refers to 50% of facial expressionvariation and 50% of illumination variations of the total numberof updated samples. One updated sample is selected randomlyfor each subject.
The experiment protocol is as follows: 1) Three classes arerandomly selected as the initial model of the neural network,and 2) twelve classes are progressively added to the initialmodel by the IROLS algorithm. The widths of the neuralnetwork neurons for OMF_E and OMF_I features are oneand ten, respectively. The regularization parameter is 0.01 for

WONG et al.: RBF NEURAL NETWORK WITH INCREMENTAL LEARNING FOR FACE RECOGNITION 947
TABLE VIMETHOD COMPARISON WITH YALE DATABASE
both the neural networks. The total number of hidden neuronsselected for the neural networks that correspond to OMF_E andOMF_I features are 15 and 17, respectively. The weight fweightfor the DOMF is set as 0.8.
Table IV shows the recognition accuracy of the IROLS andeigenface [5] method without updated training samples. TheIROLS achieves an overall high recognition rate in all threetesting variations. It obtains the highest recognition rate whenit is tested on testing samples that contain facial expressionvariations only. When all the testing samples are combined,the highest recognition rate achieved is 88.3%. Compared tothe eigenface method in testing samples that contain expressionvariation, the eigenface method outperforms the IROLS by3.4%. However, the IROLS shows better robustness in illumi-nation and combined visual variation conditions as comparedto eigenfaces.
Table V shows the effect of adding updated training samplesthat contain various variations to the recognition performancefor the IROLS and eigenface method. It can be observed that therecognition rate increases drastically when the updated samplecontains visual variations that appear in the testing samples.For example, the recognition rate of the IROLS increases from73.3% to 86.7% when the updated samples which contain illu-mination variations are added to the network. The improvementin the recognition performance is more obvious when the net-work is trained by the updated samples that contain different vi-sual variations. The overall recognition accuracy of the IROLS(in “combined” testing variation) increases from 88.3% to 95%which is the highest, whereas the overall recognition accuracyof the eigenfaces increases from 86.7% to 87.5% which isthe highest. This shows that the proposed IROLS achieves animprovement in the robustness of the face recognition systemto visual variations.
In Table VI, the recognition performance of the proposedIROLS is compared with that of some of the existing facerecognition methods published in the literature. The recognitionrates shown in the table are extracted from the correspondingreference directly. The results of all the methods except theIROLS shown in the table are tested on the Yale databaseusing the “leave-one-out” strategy. In this strategy, an imageof a person is classified, this image is removed from the dataset, and the dimensionality reduction matrix is computed. Allthe images in the database, excluding the test image, are thenprojected down into the reduced space to be used for classi-fication [19]. The “leave-one-out” strategy is not used in the
Fig. 7. Examples of images from the UNMC-VIER database.
TABLE VIIRECOGNITION ACCURACY OF IROLS-BASED RBF NEURAL NETWORK
AND EIGENFACES WITH UNMC-VIER DATABASE
proposed IROLS as the samples with illumination and facialexpression variations are not included in the training. This isto show the robustness of our proposed algorithm in visualvariation conditions. The proposed IROLS outperforms almostall the methods tested in terms of recognition accuracy. Theresults show that the regularized discriminant analysis (RDA)[20] achieves the highest recognition rate of 97.6% which is2.6% higher than our proposed algorithm (95%). This result canbe explained by the advantage of the “leave-one-out” strategyemployed in [20] that uses almost all the sample images as thetraining samples.
We then continue with the experiment of the IROLS-basedneural network in a video-based face recognition system.Video-based face recognition is known to be exposed to variousvisual variations at the same time. For example, a person whois talking in a dim light environment contains visual variationssuch as facial expression, illumination, and head pose varia-tions. The purpose of this experiment is to show how the IROLSbenefits the recognition performance when the testing imagescontain more than one visual variation.
The audiovisual UNMC-VIER database is used in this ex-periment. It consists of 123 speakers recorded in two sessions:one in a controlled environment and another in an uncontrolledenvironment. In the controlled environment, the lighting isuniform, whereas in the uncontrolled environment, the subjectsare exposed to lighting changes. Fig. 7 shows the sample imagesin the UNMC-VIER database. Three images for training andthree images for testing for each subject are snapshots fromthe video sequences. All the images are first being cropped andresized to 120 × 120. The training images are captured underthe controlled environment, which are frontal and taken underuniform lighting condition with a neutral talking expression.

948 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 41, NO. 4, AUGUST 2011
TABLE VIIIRECOGNITION ACCURACY OF IROLS-BASED RBF NEURAL NETWORK
AND EIGENFACES WITH UPDATED DATA IN UNMC-VIER DATABASE
The testing images are chosen according to Tables VII and VIII.It is worth noting that the “Expression+Illumination” shown inTables VII and VIII refers to the existence of expression andillumination variations which both appear in the same testingimage. One updated sample is selected for each subject.
The experiment protocol is as follows: 1) Ten classes arerandomly selected as the initial model of the neural network,and 2) one hundred thirteen classes are progressively added tothe initial model by the IROLS algorithm. The widths of theneural network neurons for OMF_E and OMF_I features are1 and 15, respectively. The regularization parameter is 0.01 forboth the neural networks. The total number of hidden neuronsselected for the neural networks that correspond to OMF_E andOMF_I features are 124. The weight fweight for the DOMF isset as 0.8.
To test the recognition performance of the video-based facerecognition, the equal-weight fusion approach [24] is used tocombine the scores obtained by each frame. In the equal-weightfusion approach, the mean score is used for decision making,which is defined as
S =1F
F∑f=1
sf (31)
where F is the total number of frames which is three in thisexperiment, f is the frame number, and sf refers to the resultantscore for that particular frame.
Table VII shows the recognition accuracy of the IROLS-based RBF neural network and eigenface method without up-dated samples. The recognition performance is clearly degradedwhen the system is tested with testing samples that containillumination and expression+illumination variations. This isbecause there is more than one visual variation that appearsin the same testing image. On the other hand, the overallrecognition performance of both the methods is improved whenupdated samples are added (see Table VIII). The most obviousimprovement in the recognition performance can be observedwhen the system is tested with testing samples that containillumination and expression+illumination variations. It can beseen that the proposed IROLS-based RBF neural network out-performs eigenfaces in terms of recognition accuracy. Hence,we can conclude that, with the additional information that existsin the updated samples, the proposed IROLS improves the
robustness of the face recognition system to testing images thatcontain more than one visual variation.
V. CONCLUSION
In this paper, we have proposed the IROLS algorithm forRBF neural networks to solve the problems in the face recog-nition. The conventional ROLS involves retraining the wholeneural network when new training data are added. In ourproposed algorithm, the selection of the regressors for the newdata is done locally, hence avoiding the expensive reselectingprocess. In addition, it accumulates previous experience andlearns updated new knowledge of the existing groups to in-crease the robustness of the system. The proposed algorithmachieves comparable recognition accuracy and requires lessertraining time and hidden neurons compared to the conventionalROLS-based RBF neural network. The experimental resultshave shown that the proposed method achieves higher recog-nition accuracy as compared to the IPCA, ILDA, I-ELM, andEI-ELM. It also achieves a comparable recognition rate to theonline boosting in the AR database. Moreover, the recognitionperformance of the proposed method in visual variations istested on the Yale and UNMC-VIER databases. The resultshave shown that the proposed method outperforms most of thestate-of-the-art face recognition methods in terms of recogni-tion accuracy. We have also shown that improvement in therobustness of the face recognition system to real-world facerecognition challenges is achieved by the proposed algorithm.
REFERENCES
[1] D. Masip, A. Lapedriza, and J. Vitria, “Boosted online learning for facerecognition,” IEEE Trans. Syst., Man, Cybern. B, Cybern., vol. 39, no. 2,pp. 530–538, Apr. 2009.
[2] M. Artac, M. Jogan, and A. Leonardis, “Incremental PCA for on-linevisual learning and recognition,” in Proc. ICPR, 2002, vol. 3, pp. 781–784.
[3] P. Hall and R. Martin, “Incremental eigenanalysis for classification,” inProc. Brit. Mach. Vis. Conf., 1998, vol. 1, pp. 286–295.
[4] S. Pang, S. Ozawa, and N. Kasabov, “Incremental linear discriminantanalysis for classification of data stream,” IEEE Trans. Syst., Man,Cybern. B, Cybern., vol. 35, no. 5, pp. 905–914, Oct. 2005.
[5] M. Turk and A. Pentland, “Eigenfaces for recognition,” J. Cogn.Neurosci., vol. 3, no. 1, pp. 71–86, Mar. 1991.
[6] S. Ozawa, S. L. Toh, S. Abe, S. Pang, and N. Kasabov, “Incrementallearning of feature space and classifier for face recognition,” Neural Netw.,vol. 18, no. 5/6, pp. 575–584, Jul./Aug. 2005.
[7] H. Zhao and P. C. Yuen, “Incremental linear discriminant analysis for facerecognition,” IEEE Trans. Syst., Man, Cybern. B, Cybern., vol. 38, no. 1,pp. 210–221, Feb. 2008.
[8] I. Dagher and R. Nachar, “Face recognition using IPCA–ICA algorithm,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 28, no. 6, pp. 996–1000,Jun. 2006.
[9] S. Chen, E. S. Chng, and K. Alkadhimi, “Regularized orthogonal leastsquares algorithm for constructing radial basis function networks,” Int. J.Control, vol. 64, no. 5, pp. 829–837, Jul. 1996.
[10] S. Chen, “Local regularization assisted orthogonal least squares regres-sion,” Neurocomputing, vol. 69, no. 4–6, pp. 559–585, Jan. 2006.
[11] S. Chen, S. A. Billings, and W. Luo, “Orthogonal least squares methodsand their application to non-linear system identification,” Int. J. Control,vol. 50, no. 5, pp. 1873–1896, Nov. 1989.
[12] Y. W. Wong, K. P. Seng, and L.-M. Ang, “Dual optimal multiband featurefor face recognition,” Expert Syst. Appl., vol. 37, no. 4, pp. 2957–2962,Apr. 2010.
[13] A. Primer, Introduction to Wavelet and Wavelet Transform. EnglewoodCliffs, NJ: Prentice-Hall, 1998.

WONG et al.: RBF NEURAL NETWORK WITH INCREMENTAL LEARNING FOR FACE RECOGNITION 949
[14] Y. W. Wong, K. P. Seng, and L.-M. Ang, “Audio-visual recognition sys-tem insusceptible to illumination variation over Internet protocol,” Int. J.Comput. Sci. (IAENG), vol. 36, no. 1, pp. 167–174, 2009.
[15] L. A. Alexandre, A. C. Campilho, and M. Kamel, “On combining clas-sifiers using sum and products rules,” Pattern Recognit. Lett., vol. 22,no. 12, pp. 1283–1289, Oct. 2001.
[16] A. M. Martinez and R. Benavente, “The AR face data base,” Comput. Vis.Center, Barcelona, Spain, Tech. Rep. 24, Jun. 1998.
[17] Yale Face Database, 1997. [Online]. Available: http://cvc.yale.edu/projects/yalefaces/yalefaces.html
[18] Y. W. Wong, S. I. Ch’ng, K. P. Seng, L. M. Ang, S. W. Chin,W. J. Chew, and K. H. Lim, “A new audio-visual data base,” in Proc.Int. Conf. Embedded Syst. Intell. Technol., 2010, [CD-ROM].
[19] P. N. Belhumeur, J. P. Hespanha, and D. J. Kriegman, “Eigenfaces vs. fish-erfaces: Recognition using class specific linear projection,” IEEE Trans.Pattern Anal. Mach. Intell., vol. 19, no. 7, pp. 711–720, Jul. 1997.
[20] D.-Q. Dai and P. C. Yuen, “Face recognition by regularized discriminantanalysis,” IEEE Trans. Syst., Man, Cybern. B, Cybern., vol. 37, no. 4,pp. 1080–1085, Aug. 2007.
[21] Y. Gao and M. K. Leung, “Face recognition using line edge map,” IEEETrans. Pattern Anal. Mach. Intell., vol. 24, no. 6, pp. 764–779, Jun. 2002.
[22] M.-H. Yang, “Face recognition using kernel methods,” in Advances ofNeural Information Processing Systems, vol. 14. Cambridge, MA: MITPress, 2002, pp. 215–220.
[23] N. Kwak, C. Choi, and N. Ahuja, “Face recognition using feature extrac-tion based on independent component analysis,” in Proc. Int. Conf. ImageProcess., 2002, vol. 2, pp. 337–340.
[24] S. K. Kung, M. W. Mak, and S. H. Lin, Biometric Authentication.Englewood Cliffs, NJ: Prentice-Hall, 2005.
[25] C. M. Bishop, Neural Networks for Pattern Recognition. London, U.K.:Oxford Univ. Press, 2003, pp. 116–163.
[26] G.-B. Huang, L. Chen, and C.-K. Siew, “Universal approximation us-ing incremental constructive feedforward networks with random hiddennodes,” IEEE Trans. Neural Netw., vol. 17, no. 4, pp. 879–892, Jul. 2006.
[27] G.-B. Huang and L. Chen, “Enhanced random search based incremen-tal extreme learning machine,” Neurocomputing, vol. 71, no. 16–18,pp. 3460–3468, Oct. 2008.
[28] X. He and P. Niyogi, “Locality preserving projections,” in Advances inNeural Information Processing Systems. Cambridge, MA: MIT Press,2003.
[29] X. He, S. Yan, Y. Hu, P. Niyogi, and H.-J. Zhang, “Face recognition usingLaplacianfaces,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 27, no. 3,pp. 328–340, Mar. 2005.
Yee Wan Wong received the B.S. degree fromthe Faculty of Engineering, The University ofNottingham Malaysia Campus, Semenyih, Malaysia,in 2006, where she is currently working toward thePh.D. degree.
Her research interests include image processing,intelligent visual processing, audiovisual recogni-tion, artificial intelligence, and image compression.
Kah Phooi Seng received the B.S. degree (withfirst class honors) and the Ph.D. degree from theUniversity of Tasmania, Hobart, Australia, in 1997and 2001, respectively.
She is currently a Member of the School ofElectrical and Electronic Engineering, The Univer-sity of Nottingham Malaysia Campus, Semenyih,Malaysia. Her research interests include the fieldsof intelligent visual processing, biometrics andmultibiometrics, artificial intelligence, and signalprocessing.
Li-Minn Ang received the B.Eng. and Ph.D. degreesfrom Edith Cowan University, Perth, Australia, in1996 and 2001, respectively.
He was a Professor at Monash University,Melbourne, Australia. Since 2004, he has been withThe University of Nottingham Malaysia Campus,Semenyih, Malaysia. His research interests includethe fields of signal, image, and vision processing andreconfigurable computing.