deeplearning nlp
TRANSCRIPT

A not-so-short introduction to Deep Learning NLP
Francesco Gadaleta, PhD
1
worldofpiggy.com

What we do todayNLP introduction (<5 min)Deep learning introduction (10 min)What do we want (5 min)How do we get there (15 min)Demo (5 min)What’s next (5 min)Demo (5 min)Questions (10 min)
2

A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
The Goals of NLP
Analysis of (free) text
Extract knowledge/abstract concepts from textual data (text understanding)
Generative models (chat bot, AI assistants, ...)
Word/Paragraph similarity/classification
Sentiment analysis
3

A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
Traditional ML andNLP
4

A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
Traditional NLP word representation
0 0 0 0 1 0 0 0 0 0
One-hot encoding of words: binary vectors of <vocabulary_size> dimensions
0 0 0 0 0 0 0 0 1 0
0 1 0 0 0 0 0 0 0 0
0 0 0 0 1 0 0 0 0 0
“book”
“chapter”
“paper”
AND
AND
= 0
5

A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
Traditional soft-clustering word representation
Soft clustering models learn for each cluster/topic a distribution over words of how likely that word is in each cluster
• Latent Semantic Analysis (LSA/LSI), Random projections
• Latent Dirichlet Analysis (LDA), HMM clustering
6
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
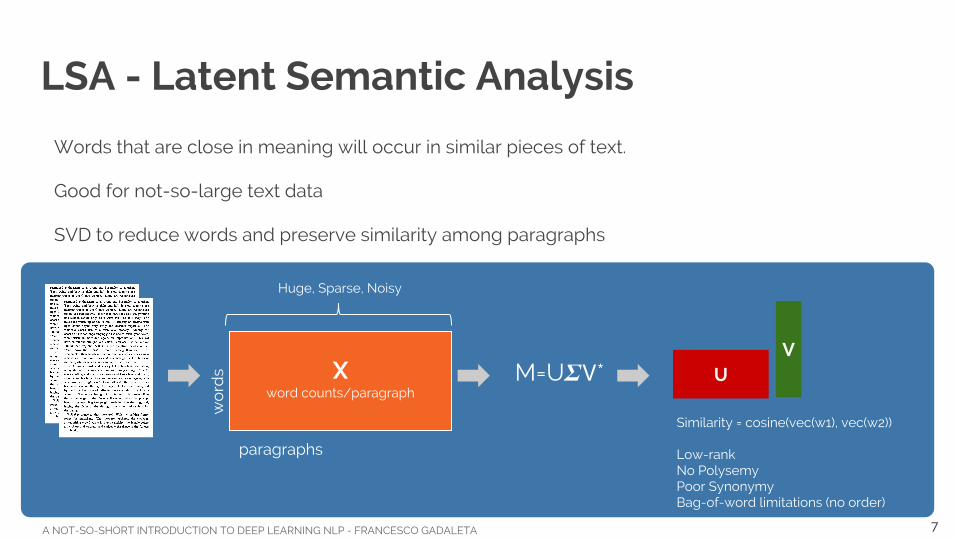
LSA - Latent Semantic Analysis
Words that are close in meaning will occur in similar pieces of text.
Good for not-so-large text data
SVD to reduce words and preserve similarity among paragraphs
paragraphs
wo
rds
Similarity = cosine(vec(w1), vec(w2))
Low-rankNo PolysemyPoor SynonymyBag-of-word limitations (no order)
UV
M=U *
Huge, Sparse, Noisy
7
X word counts/paragraph

A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
Traditional ML andDeep Learning
8
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
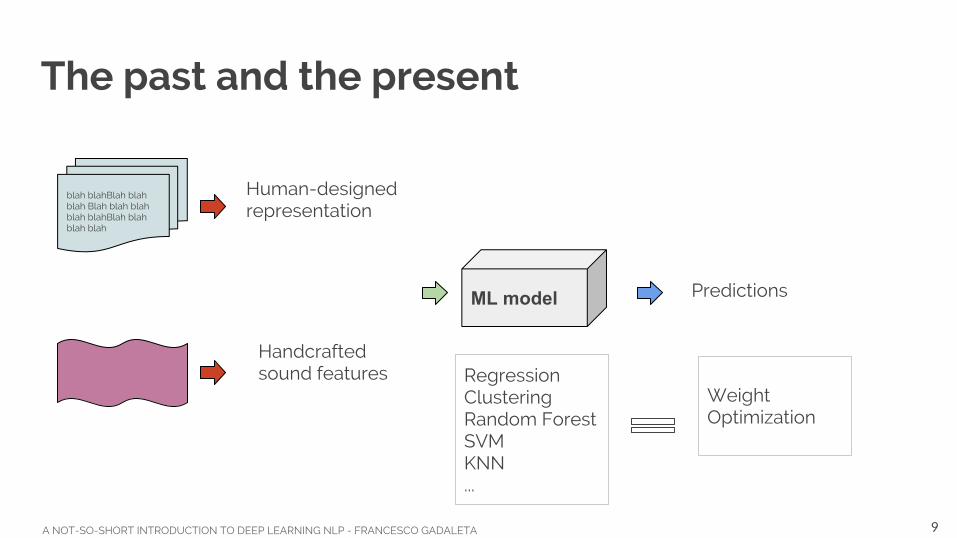
The past and the present
Human-designed representation
blah blahBlah blah blah Blah blah blah blah blahBlah blah blah blah
Handcrafted sound features
ML model Predictions
RegressionClusteringRandom ForestSVMKNN...
Weight Optimization
9

A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
The future
Representation Learning automatically learn good features or representations
Deep Learning learn multiple levels of representation with increasing complexity and abstraction
10

A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
The promises of AI (1969-2016)
11
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
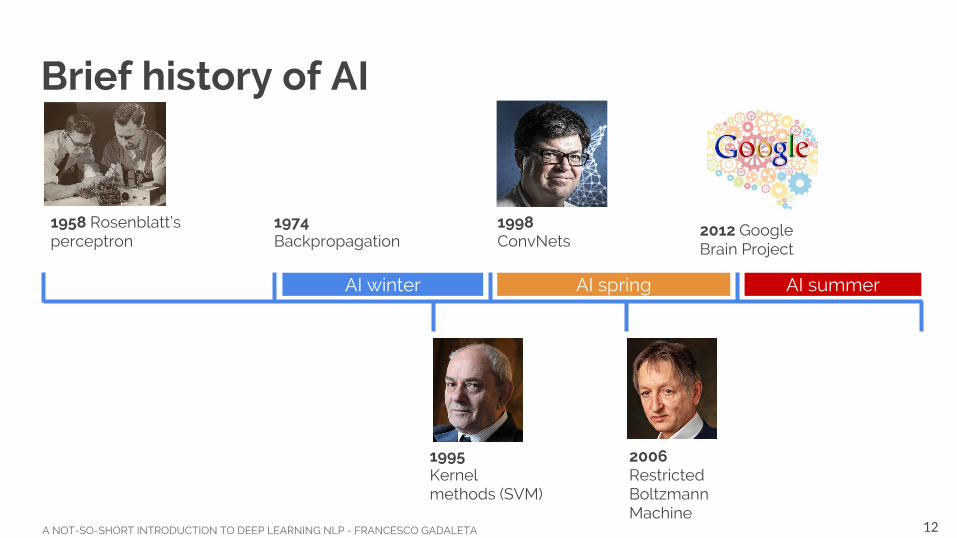
Brief history of AI
1958 Rosenblatt’s perceptron
1974 Backpropagation
1998 ConvNets
2012 Google Brain Project
1995 Kernel methods (SVM)
2006 Restricted Boltzmann Machine
AI winter AI spring AI summer
12
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
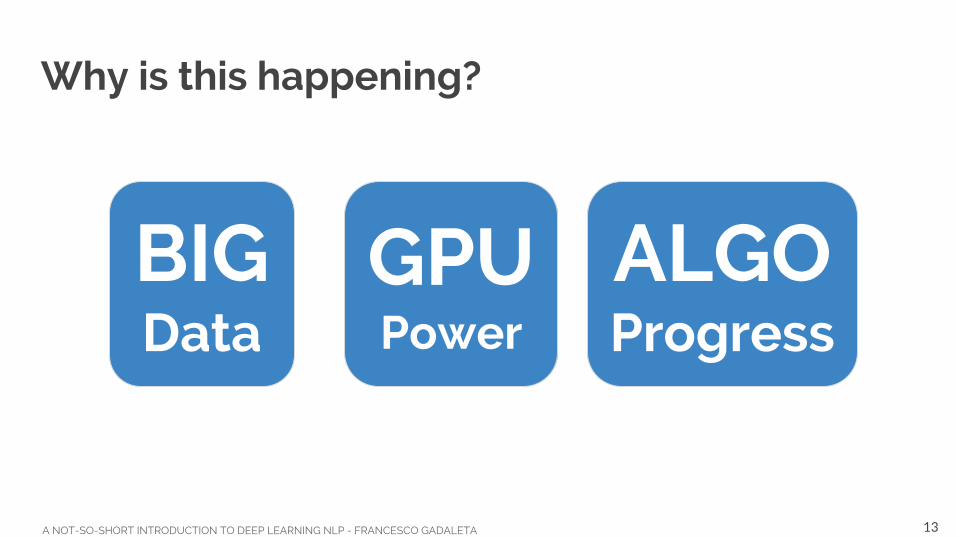
Why is this happening?
BIGData
GPUPower
ALGOProgress
13

Geoffrey Hinton
Cognitive psychologist AND Professor
at University of Toronto AND one of
the first to demonstrate the use of
generalized backpropagation to train
multi-layer networks.
Known for Backpropagation OR
Boltzmann machine AND great-great-
grandson of logician George Boole
14

Yann LeCun Postdoc at Hinton’s lab. Developed DJVu format.
Father of Convolutional Neural Networks and Optical Character Recognition (OCR).
Proposed bio inspired ML methods like “Optimal Brain Damage” a regularization method.
LeNet-5 is now state-of-the-art in artificial vision.
15

Yoshua Bengio
Professor at University Montreal. Many contributions in Deep Learning.
Known for Gradient-based learning, word representations and representation learning for NLP.
16

A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
Some reasons to apply Deep Learning (non-exhaustive list)
17
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
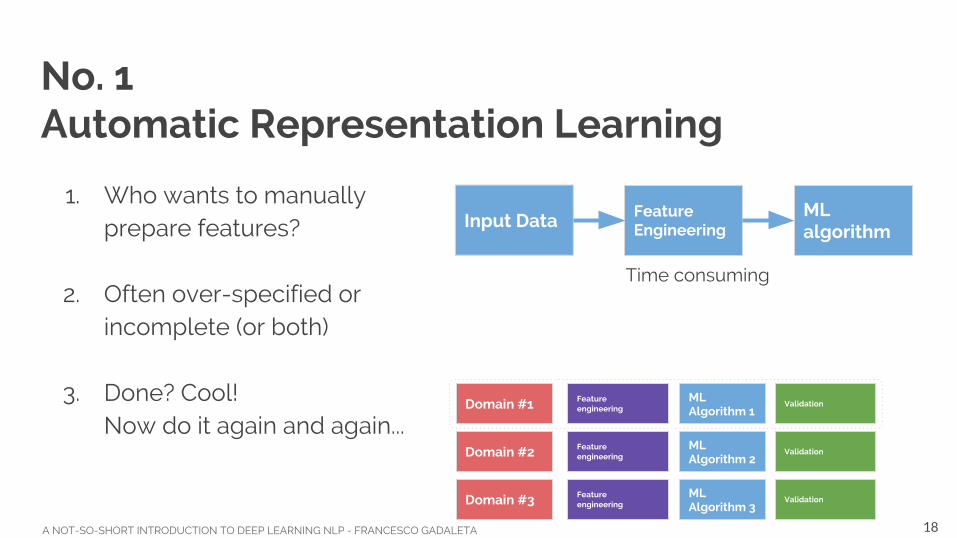
No. 1 Automatic Representation Learning
1. Who wants to manually prepare features?
2. Often over-specified or incomplete (or both)
3. Done? Cool!Now do it again and again...
Input Data Feature Engineering
ML algorithm
Time consuming
MLAlgorithm 1
MLAlgorithm 2
MLAlgorithm 3
Domain #1
Domain #2
Domain #3
Validation
Validation
Validation
18
Featureengineering
Featureengineering
Featureengineering

A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
No. 2Learning from unlabeled data
Traditional NLP requires labeled training data
Guess what? Almost all data is unlabeled
Learning how data is generated is essential to ‘understand’ data[Demo]
19

A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
No. 3Metric Learning
Similarity
Dissimilarity
Distance matrix
Kernel
Define please!
20
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
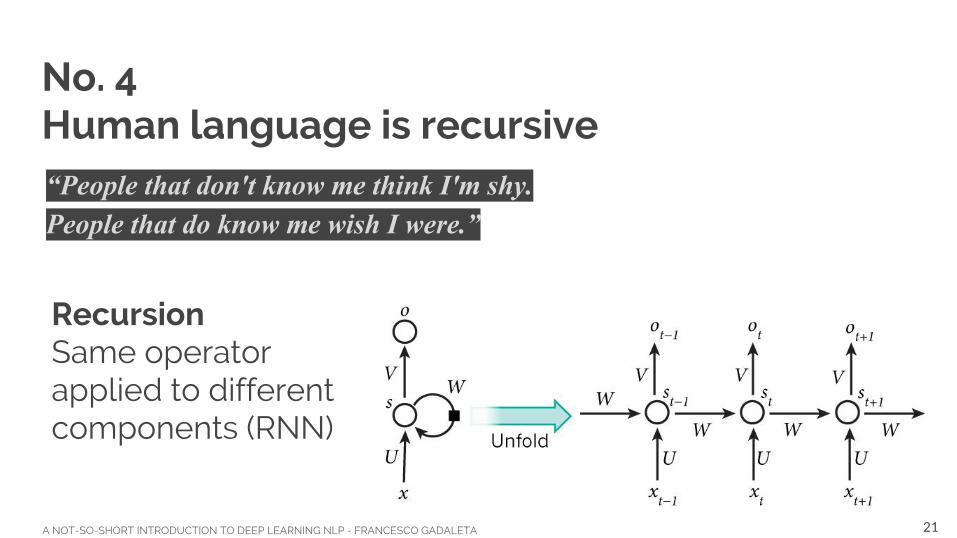
No. 4Human language is recursive“People that don't know me think I'm shy.People that do know me wish I were.”
RecursionSame operator applied to different components (RNN)
21

A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
Some examples
22
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
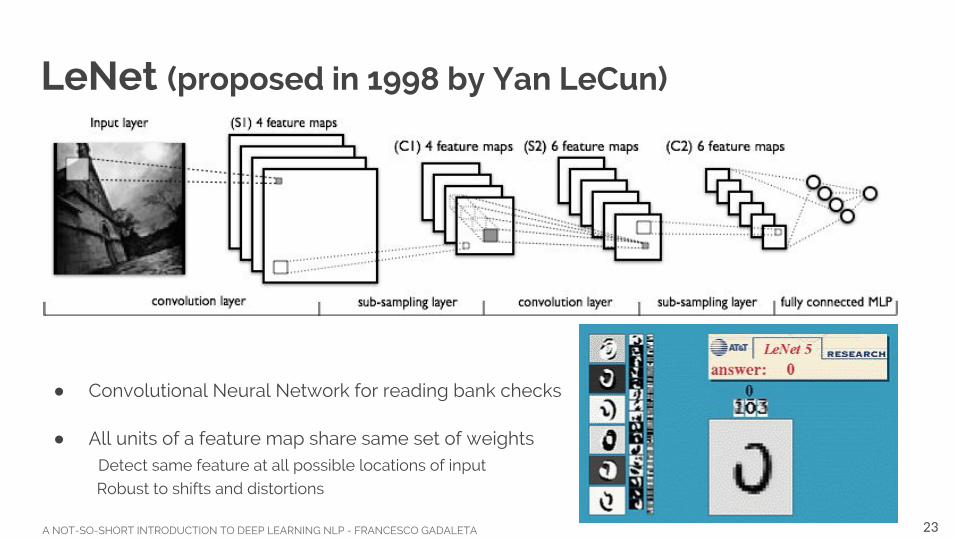
LeNet (proposed in 1998 by Yan LeCun)
● Convolutional Neural Network for reading bank checks
● All units of a feature map share same set of weights Detect same feature at all possible locations of input
Robust to shifts and distortions
23

A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
GoogLeNet (proposed in 2014 by Szegedy et al.)
Specs22 layers 12x less parameters than winning network ILSVRC 2012 challengeIntroduced Inception module (filters similar to the primate visual cortex) to find out how a local sparse structure can be approximated by readily available dense componentsToo deep => gradient propagation problems => classifiers added in the middle of the network :)
Object recognition
Captioning
Classification
Scene description (*)
(*) with semantically valid phrases.
24
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
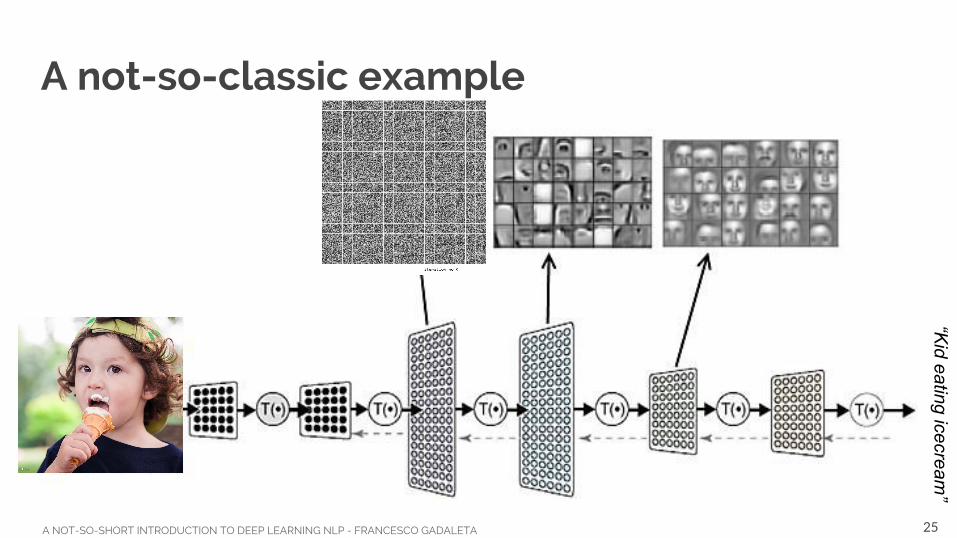
A not-so-classic example
“Kid eating icecream
”
25
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
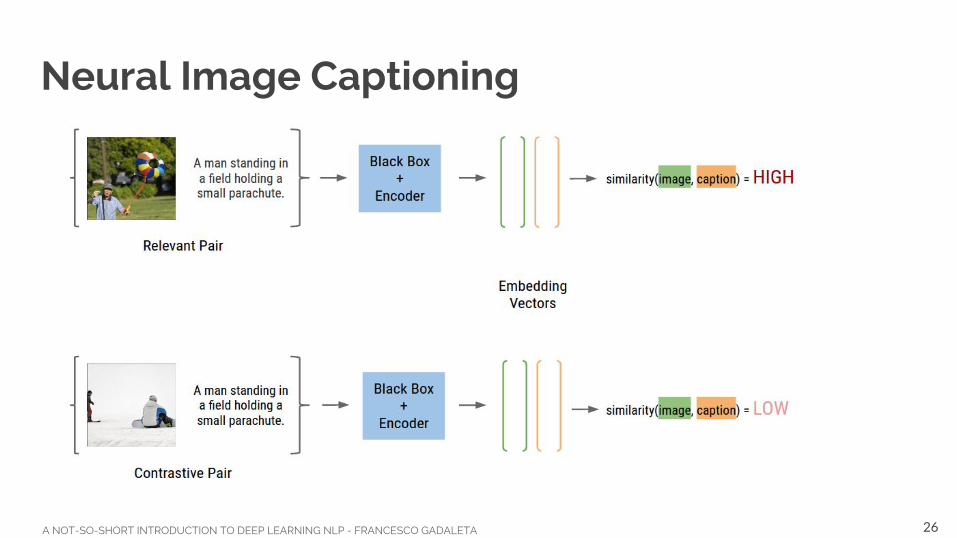
Neural Image Captioning
26
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
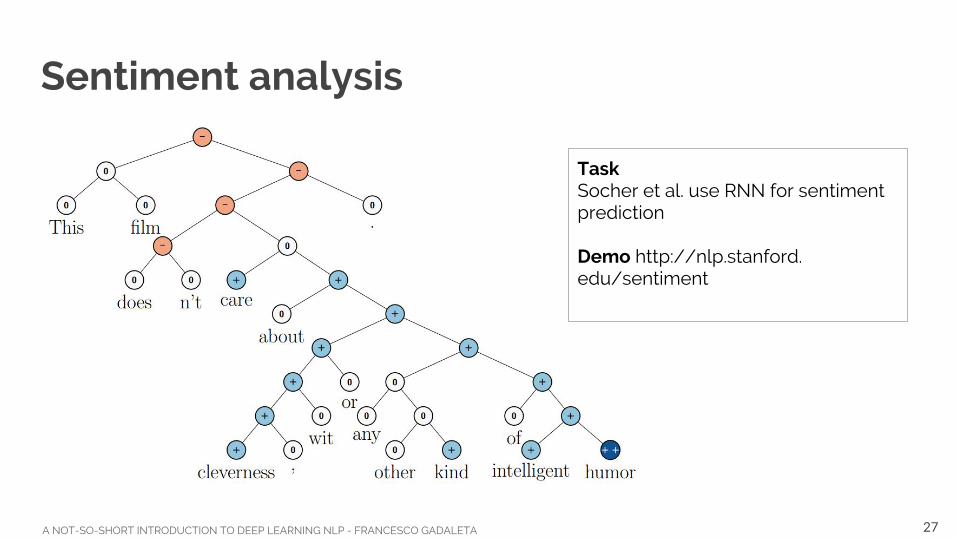
Sentiment analysis
TaskSocher et al. use RNN for sentiment prediction
Demo http://nlp.stanford.edu/sentiment
27

A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
Neural Generative Model Character-based RNN
Text Alice in Wonderland
Corpus len 167546
Unique chars 85
# sequences 55842
Context chars 20
Epochs 280
CPU Intel i7
GPU NVIDIA 560M
RAM 16 GB
neural networks are fun
neural networks are fun
neural networks are fun
neural networks are fun neural networks are fun
INPUT <20x85> OUTPUT <1x85>
orrfe
28

A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
demo
29
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
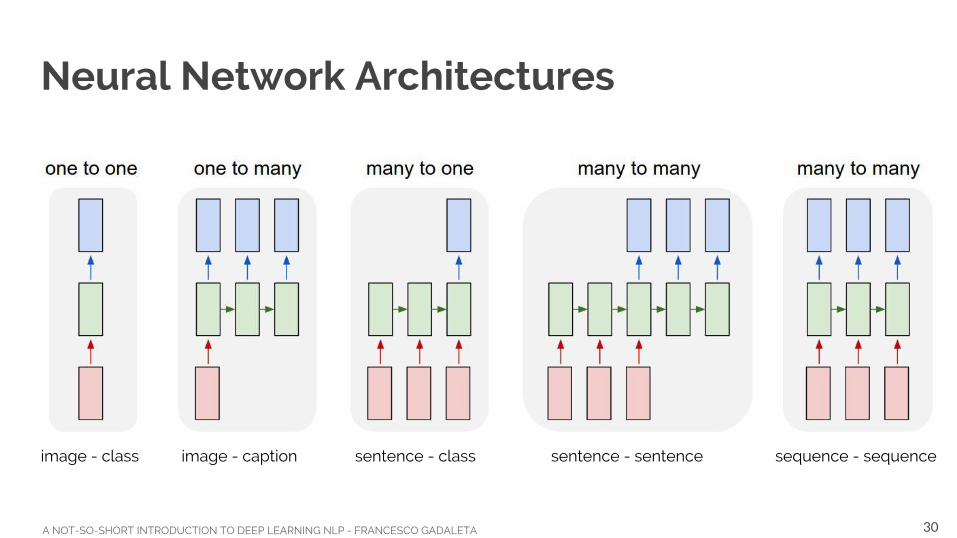
Neural Network Architectures
image - class image - caption sentence - class sentence - sentence sequence - sequence
30

How many neural networks for speech recognition and NLP tasks?
31
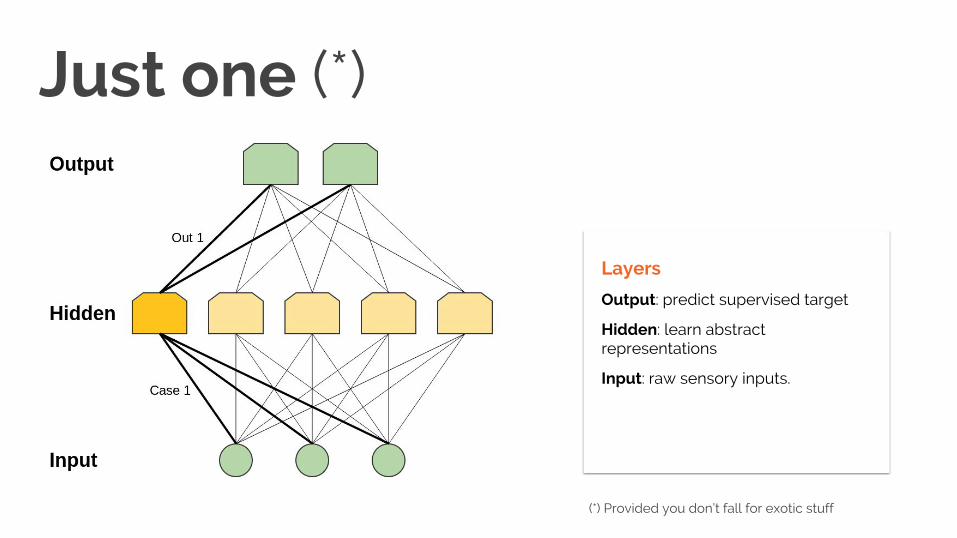
Just one (*)
Layers
Output: predict supervised target
Hidden: learn abstract representations
Input: raw sensory inputs.
(*) Provided you don’t fall for exotic stuff 32
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
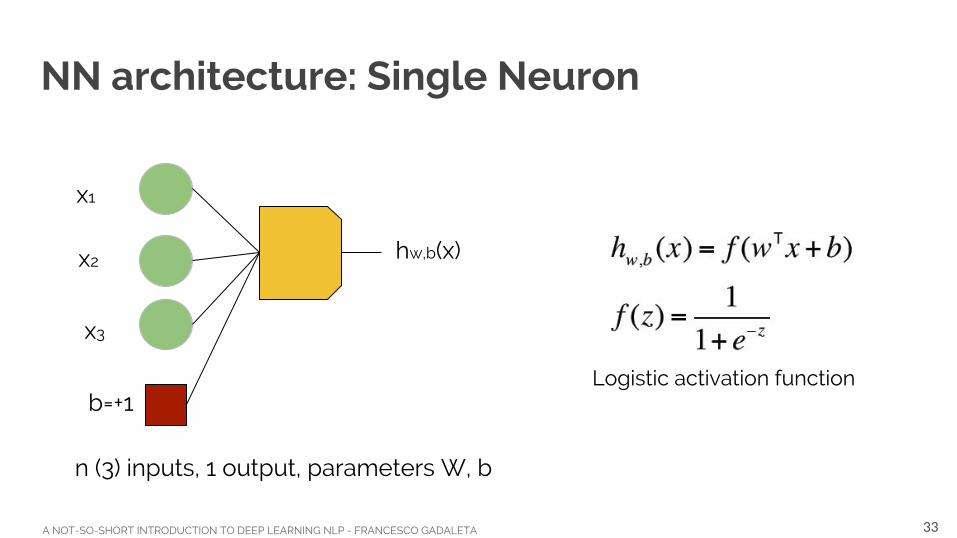
NN architecture: Single Neuron
n (3) inputs, 1 output, parameters W, b
x1
x2
x3
b=+1
hw,b(x)
Logistic activation function
33
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
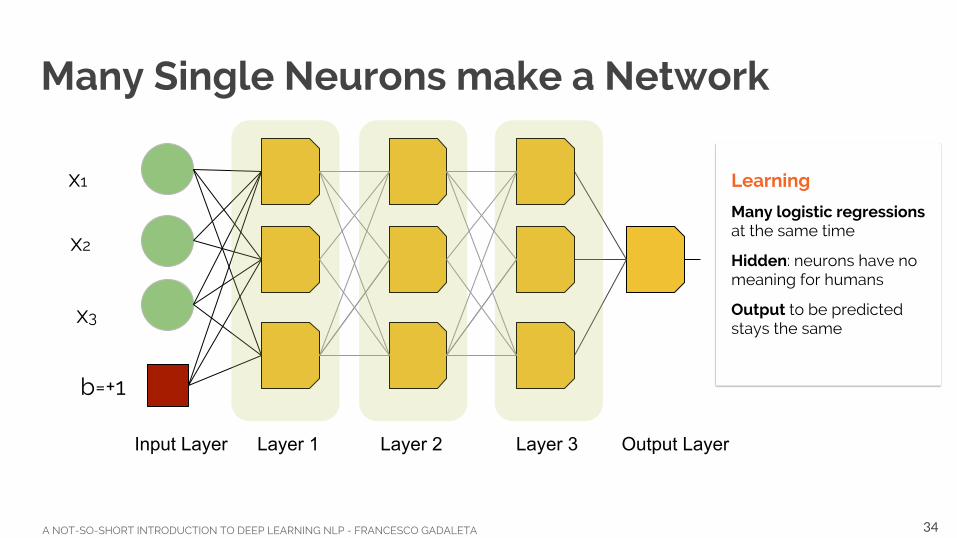
Many Single Neurons make a Network
Input Layer Layer 1 Layer 2
Learning
Many logistic regressions at the same time
Hidden: neurons have no meaning for humans
Output to be predicted stays the same
Layer 3 Output Layer
x1
x2
x3
b=+1
34

A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
Neural Networks in a (not-so-small) nutshell
*** DISCLAIMER ***
After this section the charming and fascinating halo surrounding Neural Networks and Deep Learning will be gone.
35
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
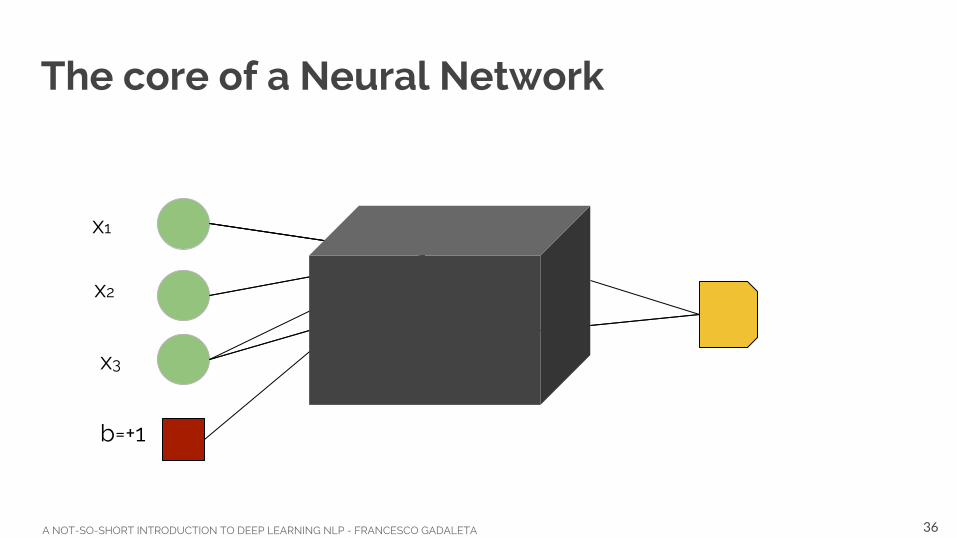
The core of a Neural Network
x1
x2
x3
b=+1
36
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
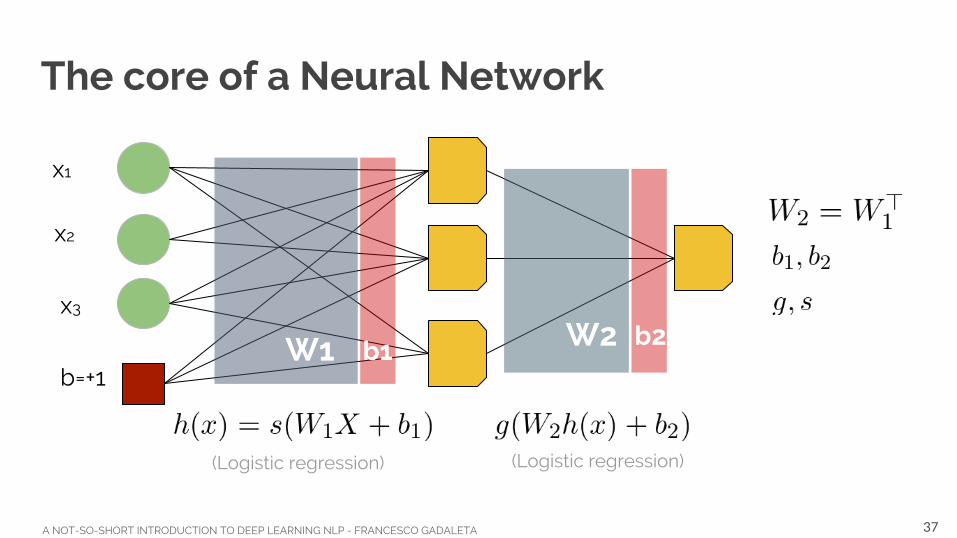
The core of a Neural Network
x1
x2
x3
b=+1W1 W2
(Logistic regression) (Logistic regression)
b1 b2
37

A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
The core of a Neural Network
(Logistic regression)
SGD Stochastic Gradient Descent
Backpropagation (at each layer)
38
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
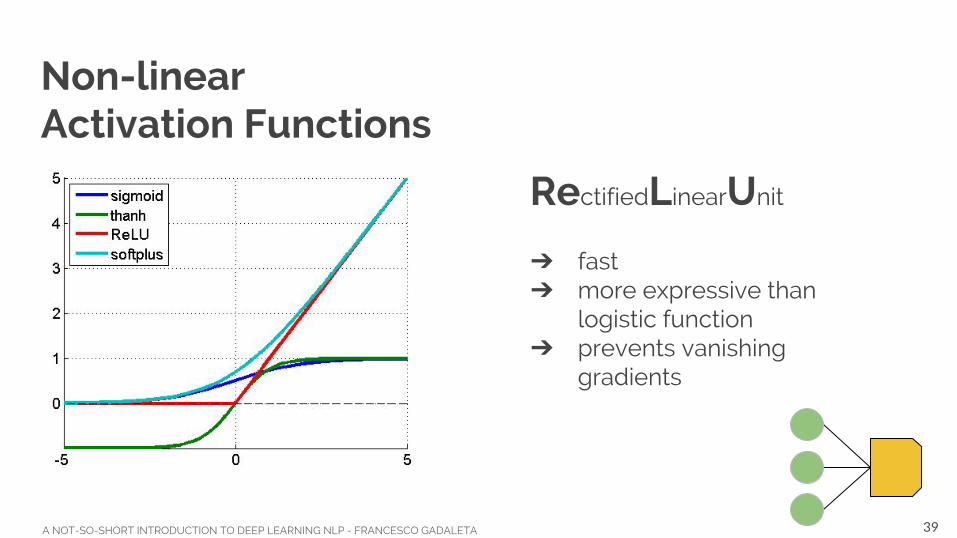
Non-linear Activation Functions
RectifiedLinearUnit
➔ fast➔ more expressive than
logistic function➔ prevents vanishing
gradients
39
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
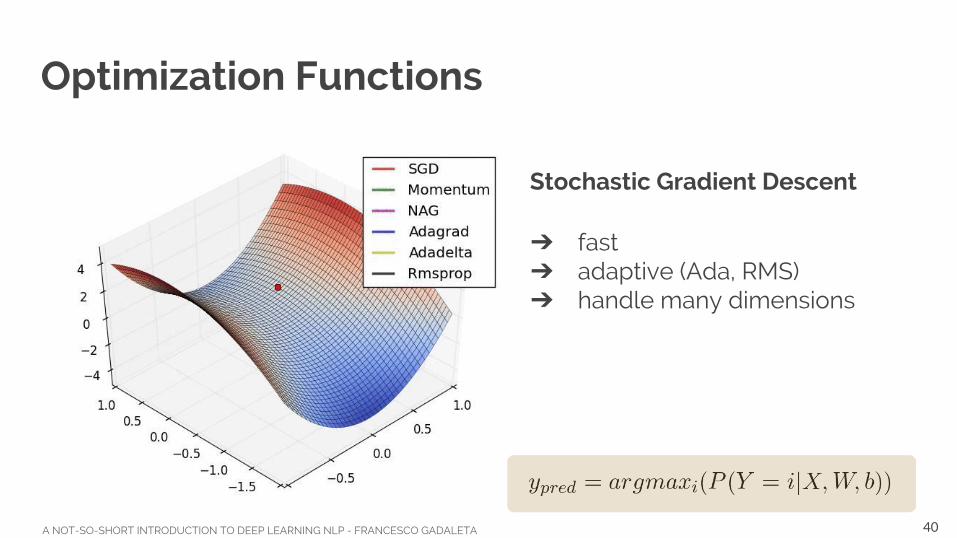
Optimization Functions
Stochastic Gradient Descent
➔ fast➔ adaptive (Ada, RMS)➔ handle many dimensions
40
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
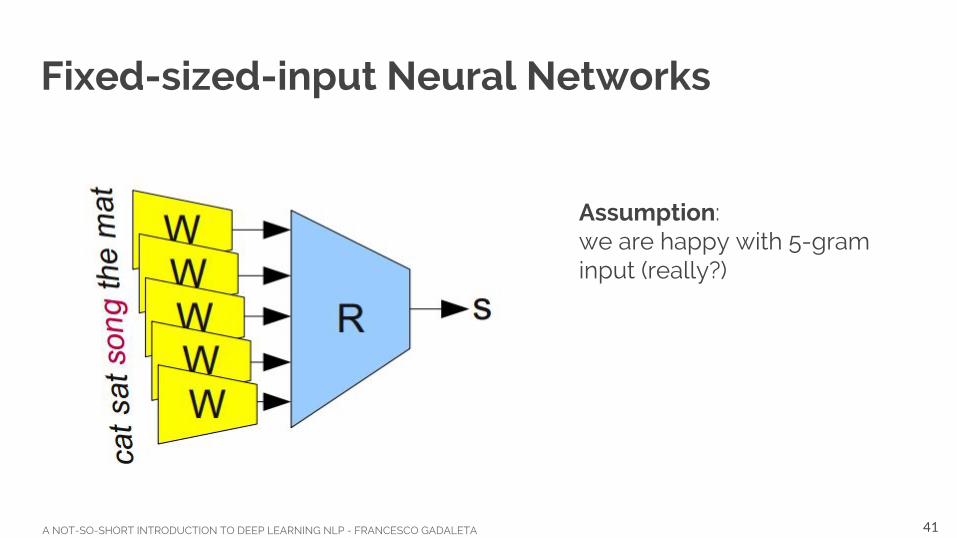
Fixed-sized-input Neural Networks
Assumption: we are happy with 5-gram input (really?)
41
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
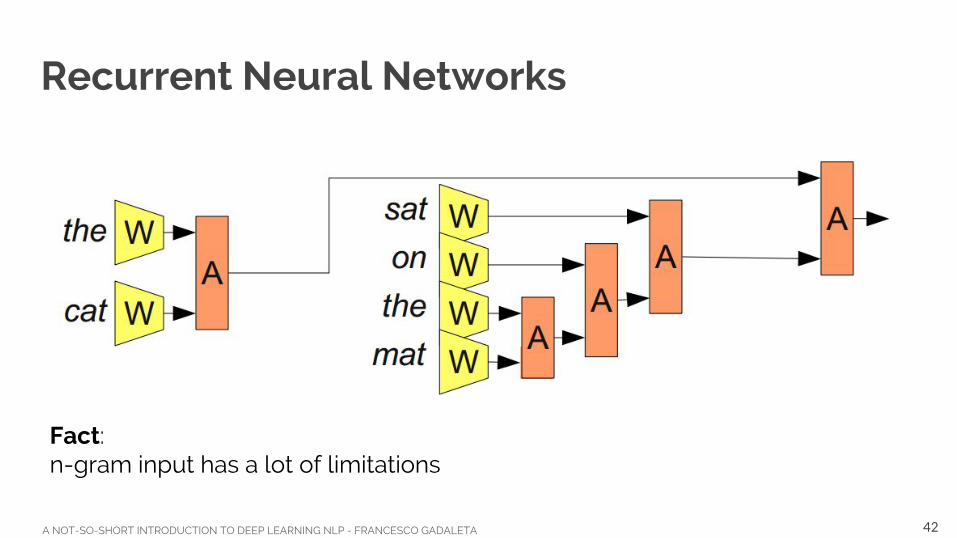
Recurrent Neural Networks
Fact: n-gram input has a lot of limitations
42
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
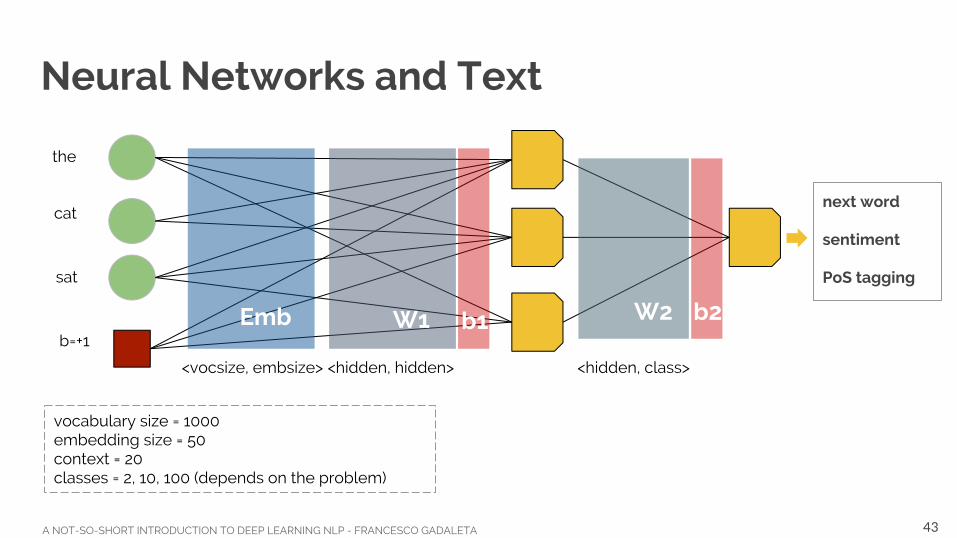
Neural Networks and Text
the
cat
sat
b=+1W1 W2b1 b2Emb
<vocsize, embsize> <hidden, class><hidden, hidden>
vocabulary size = 1000embedding size = 50context = 20classes = 2, 10, 100 (depends on the problem)
next word
sentiment
PoS tagging
43

A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
Neural Networks and Text
Emb
<vocsize, embsize>
Words are represented as numeric vectors(can subtract, add, group, cluster,...)
Similarity kernel (learned)
This is “knowledge” that can be transferred
+1.4% F1 Dependency Parsing 15.2% error reduction (Koo & Collins 2008, Brown clustering)
+3.4% F1 Named Entity Recognition 23.7% error reduction (Stanford NER, exchange clustering)
44
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
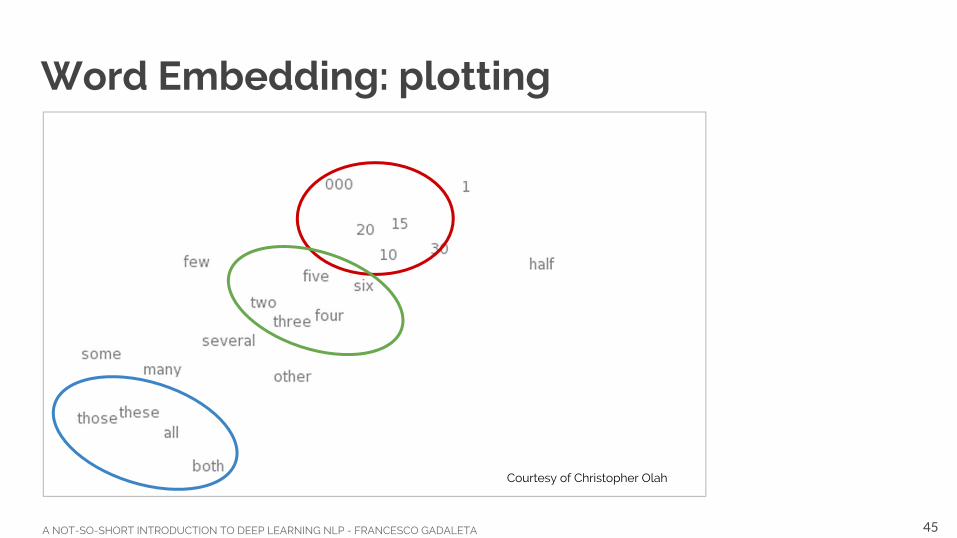
Word Embedding: plotting
Courtesy of Christopher Olah
45
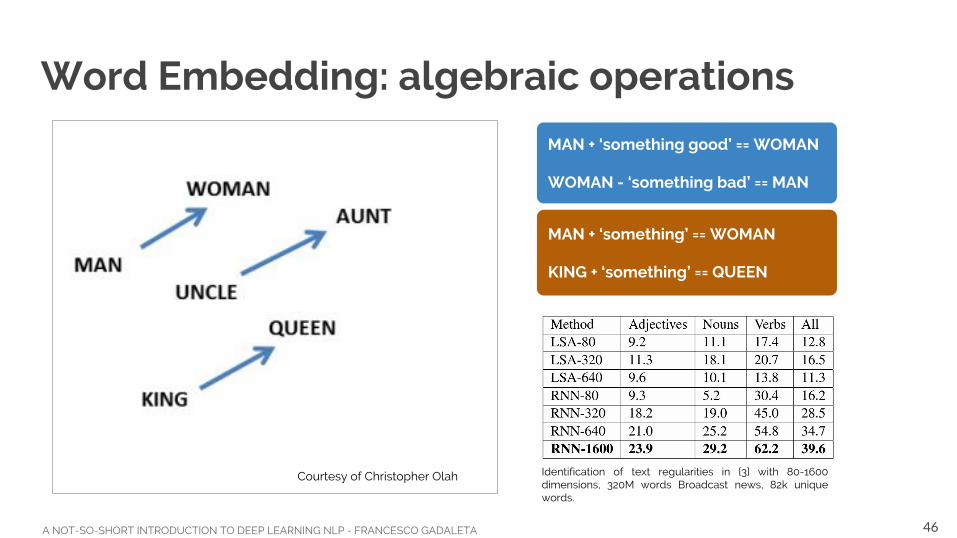
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
Courtesy of Christopher Olah
Word Embedding: algebraic operations
MAN + ‘something good’ == WOMAN
WOMAN - ‘something bad’ == MAN
MAN + ‘something’ == WOMAN
KING + ‘something’ == QUEEN
Identification of text regularities in [3] with 80-1600 dimensions, 320M words Broadcast news, 82k unique words.
46
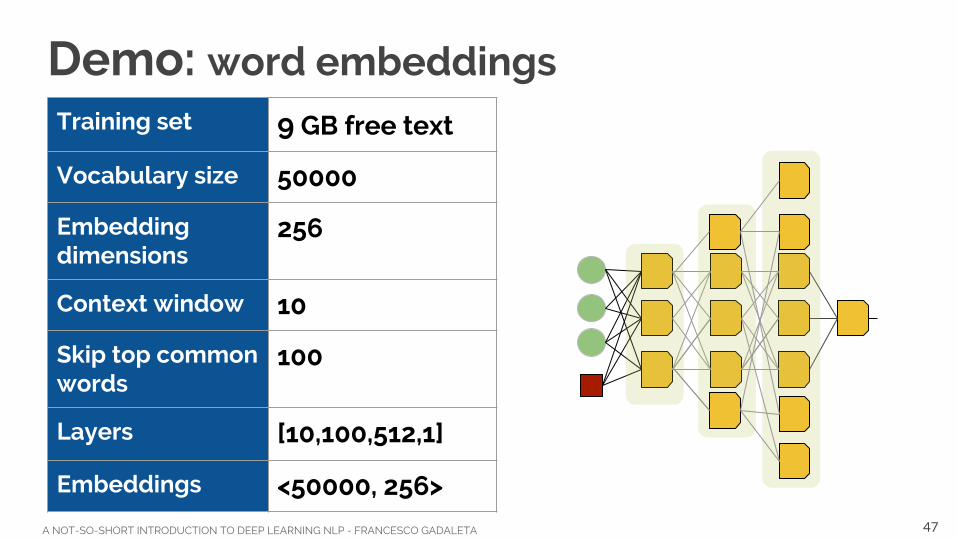
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
Demo: word embeddingsTraining set 9 GB free text
Vocabulary size 50000
Embedding dimensions
256
Context window 10
Skip top common words
100
Layers [10,100,512,1]
Embeddings <50000, 256>47
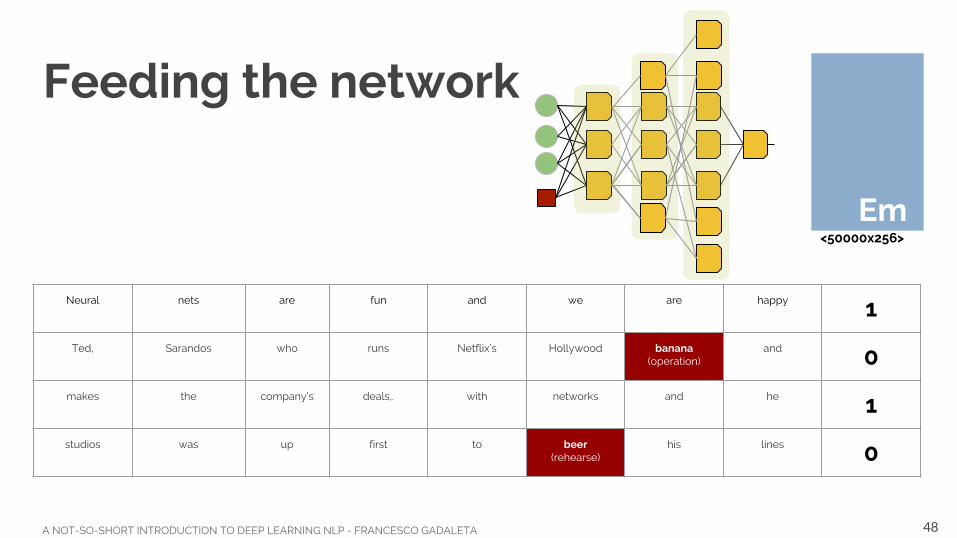
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
Feeding the network
Neural nets are fun and we are happy 1
Ted, Sarandos who runs Netflix’s Hollywood banana(operation)
and 0
makes the company’s deals,. with networks and he 1
studios was up first to beer(rehearse)
his lines 0
48
Emb<50000x256>

A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
Demo word embeddings: pre-processing
Remove HTML tags
replace unicode
utf-8 encode
tokenize
4-node Spark cluster
49

A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA 50
demo
A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
What’s Nextfrom word to document embeddings
Distributed Representations of Sentences and DocumentsQuoc Le, Tomas Mikolov, Google Inc
Skip-Thought Vectors Ryan Kiros, Yukun Zhu, Ruslan Salakhutdinov, Richard S. Zemel, Antonio Torralba, Raquel Urtasun, Sanja Fidler
51

Who is ‘deep learning’?
Twitter, Pinterest, News delivery, broadcast
Google Self Driving car, Smart Reply, Ads.Google, Alphabet
Facebook automatic tagging, text understandingFacebook, Inc.
52

Deep learning has simplified feature engineering in many cases (it certainly hasn't removed it)
Less feature engineering is leading to more complex machine learning architectures
Most of the time, these model architectures are as specific to a given task as feature engineering used to be.
Conclusion
The job of the data scientist will stay sexy for a while (keep your fingers crossed on this one).
53

A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
References[1] Recursive Deep Models for Semantic Compositionality Over a Sentiment TreebankRichard Socher, Alex Perelygin, Jean Y. Wu, Jason Chuang, Christopher D. Manning, Andrew Y. Ng and Christopher Potts Stanford University, Stanford, CA 94305, USA
[2] Document Embedding with Paragraph Vectors Andrew M. Dai, Christopher Olah, Quoc V. Le Google
[3] Linguistic Regularities in Continuous Space Word RepresentationsTomas Mikolov, Wen-tau Yih, Geoffrey Zweig, Microsoft Research
[4] Distributed Representations of Sentences and DocumentsQuoc Le, Tomas Mikolov, Google Inc
[5] Skip-Thought Vectors Ryan Kiros, Yukun Zhu, Ruslan Salakhutdinov, Richard S. Zemel, Antonio Torralba, Raquel Urtasun, Sanja Fidler
[6] Text Understanding from Scratch Xiang Zhang, Yann LeCun Computer Science Department, Courant Institute of Mathematical Sciences, New York University
[7] World of Piggy - Data Science at Home Podcast - History and applications of Deep Learning http://worldofpiggy.com/history-and-applications-of-deep-learning-a-new-podcast-episode/
54

A NOT-SO-SHORT INTRODUCTION TO DEEP LEARNING NLP - FRANCESCO GADALETA
Thank you
55
github.com/worldofpiggy @worldofpiggy [email protected] worldofpiggy.com