recurrent neural networks1 recurrent networks some problems require previous history/context in...
TRANSCRIPT

Recurrent Neural Networks 1
Recurrent Networks Some problems require previous history/context in order to
be able to give proper output (speech recognition, stock forecasting, target tracking, etc.
One way to do that is to just provide all the necessary context in one "snap-shot" and use standard learning
How big should the snap-shot be? Varies for different instances of the problem.

Recurrent Networks
Another option is to use a recurrent neural network which lets the network dynamically learn how much context it needs in order to solve the problem– Speech Example – Vowels vs Consonants, etc.
Acts like a state machine that will give different outputs for the current input depending on the current state
Recurrent nets must learn and use this state/context information in order to get high accuracy on the task
2Recurrent Neural Networks

Recurrent Networks
Partially and Fully recurrent networks – feed forward vs. relaxation nets
Elman Training – simple recurrent networks, can use standard BP training
BPTT – Backpropagation through time – can learn further back, must pick depth
Real-time recurrent learning, etc.
3Recurrent Neural Networks

4Recurrent Neural Networks

Recurrent Network Variations
This network can theoretically learn contexts arbitrarily far back
Many structural variations– Elman/Simple Net– Jordan Net– Mixed– Context sub-blocks, etc.– Multiple hidden/context layers, etc.– Generalized row representation
How do we learn the weights?
Recurrent Neural Networks 5

Simple Recurrent Training – Elman Training
Can think of net as just being a normal MLP structure where part of the input happens to be a copy of the last set of state/hidden node activations. The MLP itself does not even need to be aware that the context inputs are coming from the hidden layer
Then can train with standard BP training While network can theoretically look back arbitrarily far in
time, Elman learning gradient goes back only 1 step in time, thus limited in the context it can learn– Would if current output depended on input 2 time steps back
Can still be useful for applications with short term dependencies
Recurrent Neural Networks 6

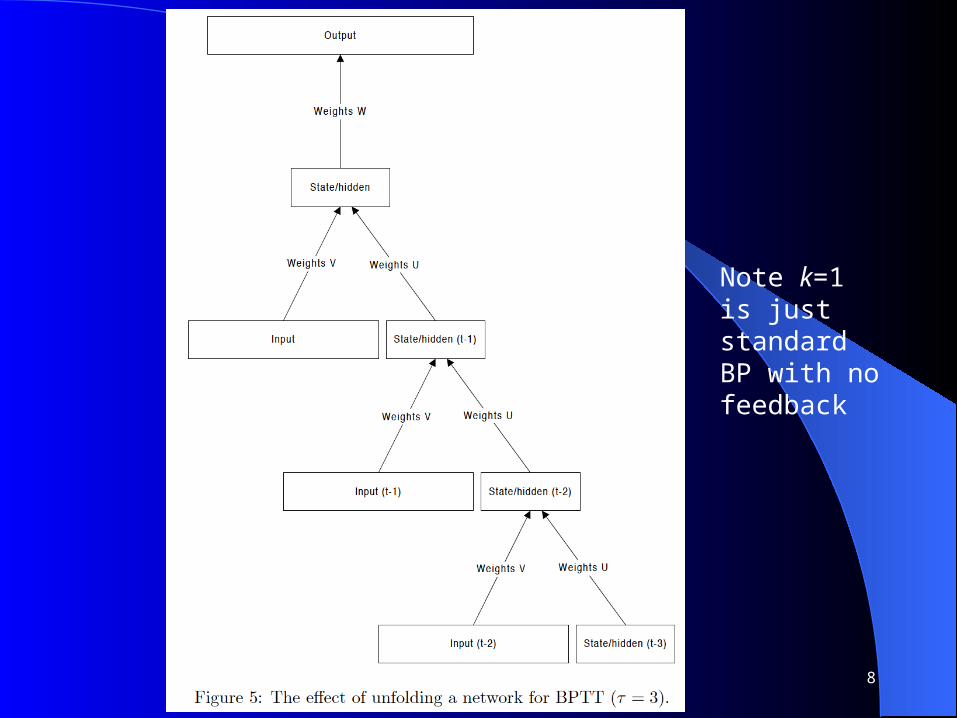
BPTT – Backprop through time
BPTT allows us to look back further as we train However we have to pre-specify a value k, which is the
maximum that learning will look back During training we unfold the network in time as if it were
a standard feedfoward network with k layers– But where the weights of each unfolded layer are the same
We then train the unfolded k layer feedforward net with standard BP
Execution still happens with the actual recurrent version Is not knowing k apriori that bad? How do you choose it?
– Cross Validation, just like finding best number of hidden nodes, etc., thus we can find a good k fairly reasonably for a given task
Recurrent Neural Networks 7
8Recurrent Neural Networks
Note k=1is just standardBP with nofeedback
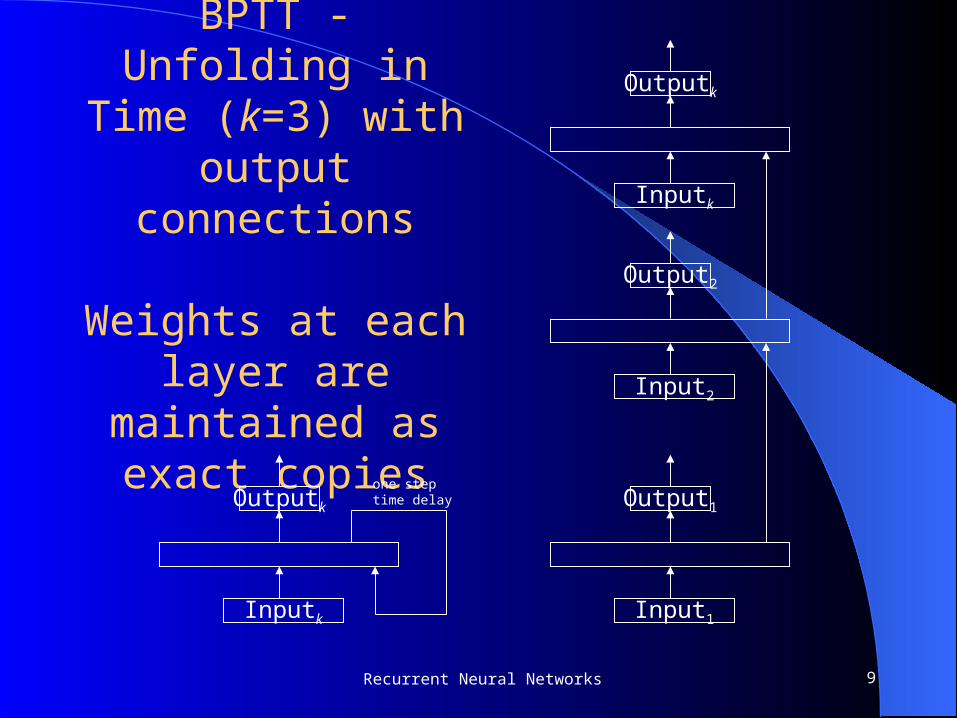
BPTT - Unfolding in Time (k=3) with
output connections
Weights at each layer are maintained
as exact copies
Inputk
Outputk
Input2
Output2
Input1
Output1
Inputk
Outputk
one steptime delay
9Recurrent Neural Networks
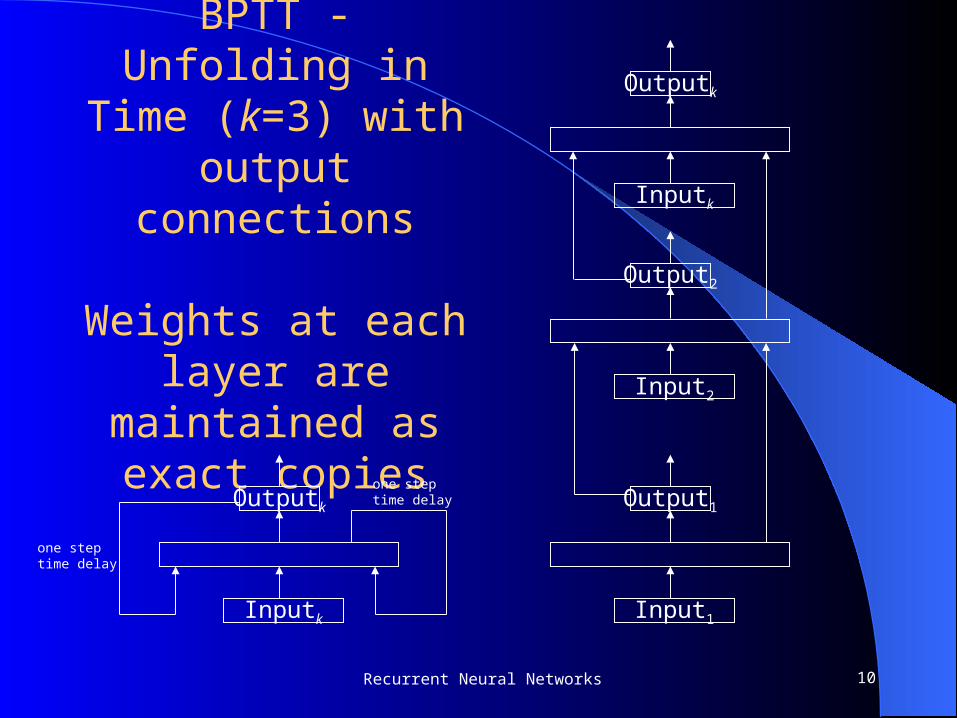
BPTT - Unfolding in Time (k=3) with
output connections
Weights at each layer are maintained
as exact copies
Inputk
Outputk
Input2
Output2
Input1
Output1
Inputk
Outputk
one steptime delay
one steptime delay
10Recurrent Neural Networks

Synthetic Data Set
Delayed Parity Task - Dparity– This task has a single time series input of random bits. The output
label is the parity (even) of n arbitrarily delayed (but consistent) previous inputs. For example, for Dparity(0,2,5) the label of each instance would be set to the parity of the current input, the input 2 steps back, and the input 5 steps back.
– Dparity(0,1) is the simplest version where the output is the XOR of the current input and the most recent input
Dparity-to-ARFF app– User enters # of instances wanted, random seed, and a vector of
the n delays (and optionally a noise parameter?)– The app returns an ARFF file of this task with a random input
stream based on the seed, with proper labels
11Recurrent Neural Networks

BPTT Learning/Execution
Consider Dparity(0,1) and Dparity(0,2) For Dparity(0,1) what would k need to be? For learning and execution we need to start the input
stream at least k steps back to get reasonable context How do you fill in initial activations of context nodes
– 0 vector common, .5 vector, typical/average vector
For Dparity(0,2) what would k need to be?– Note k=1 is just standard non-feedback BP– And k=2 is simple Elman training looking back one step
Let's do an example and walk through it – HW
Recurrent Neural Networks 12

BPTT Training Example/Notes How to select instances from the training set
– Random start positions– Input and process for k steps (could start a few further back to get
more representative example of initial context node activations – Burn in)
– Use the kth label as the target– Any advantage in starting next sequence at the last start + 1?
Would already have good approximations for initial context activations
– Don't shuffle training set (targets of first k-1 instances are ignored) Unfold and propagate error for the k layers
– Backpropagate error just starting from the kth target – else hidden node weight updates would be dominated by earlier less attenuated target errors
– Accumulate the weight changes and make one update at the end – thus all unfolded weights are proper exact copies
13Recurrent Neural Networks

BPTT Issues/Notes
Typically an exponential drop-off in effect of prior inputs – only so much that a few context nodes can be expected to remember
Error attenuation issues of multi-layer BP learning as k gets larger
Learning less stable and more difficult to get good results, local optima more common with recurrent nets
BPTT – Common approach, finding proper depth k is important
Recurrent Neural Networks 14

BPTT Project
Implement BPTT Experiment with the Delayed Parity Task
– First test with Dparity(0,1) to make sure that works. Then try other variations including ones which stress BPTT.
Analyze the results of learning a Real World recurrent task of your choice
15Recurrent Neural Networks

BPTT Project Sequential/Time series with and without separate labels
– These series often do not have separate labels– Recurrent nets can support both variations
Possibilities in the Irvine Data Repository Detailed Example – Localization Data for Person Activity
Data Set – Let's set this one up exactly – some subtleties Which features should we use as inputs
Recurrent Neural Networks 16

Localization Example
Time stamps are not that regular Thus just one sensor reading per time stamp Could try to separate out learning of one sensor at a time,
but the combination of sensors is critical, and just keeping the examples in temporal order would be sufficient for learning
What would the network structure and data representation look like?
What value for k? Typical CV graph? Stopping criteria (e.g. validation set, etc.) Remember basic BP issues: normalization, nominal value
encoding, don’t know values, etc.
Recurrent Neural Networks 17

Localization Example
Note that you might think that there would be a synchronized time stamp showing the x,y,z coordinates for each of the 4 sensors – in which case the feature vector would look like what?
And could then do k ≈ 3 vs k ≈ 10 for current version (and k ≈ 10 will struggle due to error attenuation)
Recurrent Neural Networks 18

BPTT Project Hints
Dparity(0,1)– Needs LOTS of weights updates (e.g. 20 epochs with 10,000
instances, 10 epochs with 20,000 instance, etc.)– Learning can be negligible for a long time, and then suddenly rise
to 100% accuracy– k must be at least 2 – Larger k should just slow things down and lead to potential overfit– Need enough hidden nodes
Struggles to learn with less than 4, 4 or more does well more hidden nodes can bring down epochs, but may still increase wall
clock time (i.e. # of weight updates) Not all hidden nodes need to be state nodes Explore a bit
Recurrent Neural Networks 19

BPTT Project Hints
Dparity(x,y,z)– More weight updates needed– k should be at least z+1, try different values– Burn-in helpful? – inconclusive so far– Need enough hidden nodes, at least 2*z might be a conservative
heuristic, more can be helpful, but too many can slow things down
LR between .1 and .5 seemed reasonable– Could try momentum to speed things up
Use a fast computer language/system!
Recurrent Neural Networks 20

BPTT Project Hints
Real world task Unlike Dparity(), the recurrence requirement for different
instances may vary– Sometimes may need to look back 4-5 steps– Other times may not need to look back at all– Thus, first train with k=1 (standard BP) as the baseline, and then
you can see how much improvement is obtained when using recurrence
– Then try k = 2, 3, 4, etc.– Too big of k (e.g. > 10, will usually take too long to see any
benefits since the error is too attenuated to gain much benefit)
Recurrent Neural Networks 21

Other Recurrent Approaches
LSTM – Long short term memory RTRL – Real Time Recurrent Learning
– Do not have to specify a k, will look arbitrarily far back– But note, that with an expectation of looking arbitrarily far back,
you create a very difficult problem expectation– Looking back more requires increase in data, else overfit – Lots of
irrelevant options which could lead to minor accuracy improvements
– Have reasonable expectations– n4 and n3 versions – too expensive in practice
Relaxation networks – Hopfield, Boltzmann, Multcons, etc. - Later
22Recurrent Neural Networks