reducing false sharing and improving spatial locality … · reducing false sharing and improving...
TRANSCRIPT

Reducing False Sharing and ImprovingSpatial Locality in a
Unified Compilation FrameworkMahmut Kandemir, Member, IEEE, Alok Choudhary, Member, IEEE Computer Society,
J. Ramanujam, Member, IEEE, and Prith Banerjee, Fellow, IEEE
Abstract—The performance of applications on large shared-memory multiprocessors with coherent caches depends on the
interaction between the granularity of data sharing, the size of the coherence unit, and the spatial locality exhibited by the applications,
in addition to the amount of parallelism in the applications. Large coherence units are helpful in exploiting spatial locality, but worsen
the effects of false sharing. A mathematical framework that allows a clean description of the relationship between spatial locality and
false sharing is derived in this paper. First, a technique to identify a severe form of multiple-writer false sharing is presented. The
importance of the interaction between optimization techniques aimed at enhancing locality and the techniques oriented toward
reducing false sharing is then demonstrated. Given the conflicting requirements, a compiler-based approach to this problem holds
promise. This paper investigates the use of data transformations in addressing spatial locality and false sharing, and derives an
approach that balances the impact of the two. Experimental results demonstrate that such a balanced approach outperforms those
approaches that consider only one of these two issues. On an eight-processor SGI/Cray Origin 2000 multiprocessor, our approach
brings an additional 9 percent improvement over a powerful locality optimization technique that uses both loop and data
transformations. Also, the presented approach obtains an additional 19 percent improvement over an optimization technique that is
oriented specifically toward reducing false sharing. This study also reveals that, in addition to reducing synchronization costs and
improving the memory subsystem performance, obtaining large granularity parallelism is helpful in balancing the effects of enhancing
locality and reducing false sharing, rendering them compatible.
Index Terms—Data reuse, cache locality, false sharing, loop and memory layout transformations, shared-memory multiprocessors.
æ
1 INTRODUCTION
PROCESSOR speeds have continued to advance at a muchhigher pace than memory speeds. This has led to the
deep memory hierarchies that are found in modernuniprocessor and multiprocessor systems. Although anumber of hardware-based techniques are available toexploit these deep memory hierarchies [19], compileroptimizations have come to play an increasingly impor-tant role in exploiting the potential performance of thesemachines. In recent years, there has been a significantamount of work on compiler optimizations aimed atrestructuring programs to use the memory hierarchybetter, leading to improved performance [51]. In principle,this can be achieved by modifying the access patterns inthe program control structures (e.g., loop nests) or bymodifying the memory layouts of large data structures(e.g., multidimensional arrays), or through a combinationof the two. It has been shown that techniques along theselines are quite successful in enhancing the overall
memory performance on uniprocessors [49], [39], [40],[41], [42], [38], [32], [26].
However, there is another critical issue to be consideredin the case of shared-memory parallel machines, namely,false sharing [8], [46]. False sharing arises when two or moreprocessors that are executing parallel parts of a programaccess distinct data elements in the same coherence unit[15], [22]. In other words, some form of synchronization isrequired between the two processors even though there isno data dependence between the computations on theprocessors. The negative impact of false sharing on thememory performance can be devastating. Eggers andJeremiassen [15] show that a number of programs—thatexhibit good spatial locality on uniprocessors—performvery poorly on multiprocessors. The main reason is theadded set of invalidations incurred on updates and theextra invalidation misses that occur when processors rereaddifferent data that belong to the invalidated block. Similarobservations have been made by others as well [47], [46].
The interaction between locality and false sharing onshared-memory parallel machines is quite well-known. Forexample, it is known that with smaller cache lines,improving spatial locality also results in a reduction offalse sharing. But, at the page level (where the coherenceunit is much larger), just targeting spatial locality may notbe sufficient [18]. In this paper, we present a mathematicalframework that allows us to succinctly represent and studythe interaction between the two. More importantly, forarray-based regular floating-point scientific codes, thisframework enables the derivation of data transformations toaddress the conflicting effects of techniques that improvelocality and the techniques that reduce false sharing.
IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 14, NO. 4, APRIL 2003 337
. M. Kandemir is with the Department of Computer Science andEngineering, The Pennsylvania State University, 220 Pond Laboratory,University Park, PA 16802. E-mail: [email protected].
. A. Choudhary and P. Banerjee are with the Department of Electrical andComputer Engineering, Northwestern University, 2145 Sheridan Road,Evanston, IL 60208. E-mail: {choudhar, banerjee}@ece.nwu.edu.
. J. Ramanujam is with the Department of Electrical and ComputerEngineering, 102 Electrical Engineering Building, S. Campus Drive,Louisiana State University, Baton Rouge, LA 70803-5901.E-mail: [email protected].
Manuscript received 18 Sept. 2000; revised 1 Nov. 2001; accepted 1 Feb. 2002.For information on obtaining reprints of this article, please send e-mail to:[email protected], and reference IEEECS Log Number 112878.
1045-9219/03/$17.00 ß 2003 IEEE Published by the IEEE Computer Society

False sharing can be studied at the level of a cache line aswell as at the memory page level; our approach does notdistinguish between these two types of false sharing.Instead, our interest is in identifying those cases in whichoptimizations aimed at enhancing locality and optimiza-tions for reducing false-sharing do not conflict with eachother. For this purpose, we first represent the potentialmultiple-writer false sharing in a given loop nest in theform of vectors. Although this representation is approx-imate, it gives the compiler some idea about the referencesthat may cause a severe form of multiple-writer falsesharing if not addressed correctly. We then show howlocality optimizations and parallelization techniques affectfalse sharing. In order to do that, we represent the availablelocality in a loop nest and the available parallelism optionsalso in mathematical terms. Then, we present an analysis ofthe cases in which locality optimizations and false sharingoptimizations conflict with each other and the cases wherethey do not. We believe that such an analysis is very usefulfor compiler writers as well as for the end-users of shared-memory parallel architectures. Our results emphasize theimportance of obtaining large-granularity (outermost loop)parallelism. Experimental results on an eight-processorSGI/Cray Origin 2000 machine demonstrate significantimprovements. While the importance of outermost loopparallelism has been shown by previous researchers alongthe lines of reducing synchronization costs [51], reducinginterprocessor communication [48], and enhancing memoryperformance [47], in this paper, we show that obtainingoutermost loop parallelism is also important to ensure thatenhancing locality and reducing false sharing are notincompatible.
The remainder of this paper is organized as follows:Section 2 presents the relevant background and shows howa specific form of false sharing can be represented in amathematical framework. Section 3 discusses the impact ofloop and data transformations in reducing false sharing andin optimizing locality. In Section 4, we present our heuristicto obtain a balance between enhancing locality andreducing false sharing. Section 5 presents our experimentalplatform and discusses performance numbers obtained onan eight-processor Origin 2000 distributed-shared-memorymultiprocessor. In Section 6, we discuss related work andwe conclude in Section 7, with a summary and a briefoutline of ongoing and planned research.
2 PRELIMINARIES
Self temporal reuse is said to occur when a reference in a loopnest accesses the same data in different iterations. Similarly,if a reference accesses nearby data, i.e., data residing in thesame coherence unit, in different iterations, we say thatthere is self spatial reuse [51]. It should be emphasized thatthe most useful forms of reuse (temporal or spatial) arethose exhibited by the innermost loop. If the innermost loopexhibits temporal reuse for a reference, then the accessedelement can be placed in a register for the entire duration ofthe innermost loop (provided that there is no aliasing [51]).Similarly, spatial reuse is most beneficial when it occurs inthe innermost loop since, in that case, it may enable unit-stride accesses, leading to repeated accesses to the samecoherence unit.
False sharing occurs when two or more processors access(and at least one of them writes) different data elements in thesame coherence unit (cache line, memory page, etc.) [22], [8],[46], [15]. In this section, we show how to identify a severe
form of false sharing that occurs when an array dimensionthat exhibits spatial reuse is accessed by multiple writers, i.e.,multiple processors that write to data in the same coherenceunit. For example, this form of false sharing might occur wheneach processor updates a different row of a two-dimensionalarray stored in column-major order. Note that, depending onthe array and the size of the coherence units, multiple-writerfalse sharing can also occur if each processor updates adifferent column of the said array. However, this type of falsesharing occurs only at the boundaries of columns and is not assevere. Now, we introduce two key concepts, namely, theparallelism vector and the reuse summary vector. Note that, inthis paper, we sometimes write a column vector �xx asðx1; . . . ; xnÞT when there is no confusion.
The parallelism vector indicates which loops in a loop nestwill be executed in parallel. These loops are a subset of theloops that may be executed in parallel; this parallelisminformation is typically obtained through data dependenceanalysis [51]. Assuming a loop nest of depth n, an elementpi of the parallelism vector �pp ¼ ðp1; . . . ; pnÞT is one if theiterations of the corresponding loop will be executed inparallel, otherwise pi is zero.
Consider an access to an m-dimensional array in a loopnest of depth n. We assume that the array subscriptfunctions and loop bounds are affine functions of enclosingloop indices and symbolic loop-independent parameters[51]. Let �II denote the iteration vector consisting of loopindices starting from the outermost loop to the innermost.Under these assumptions, a reference to an m-dimensionalarray is represented as L�II þ �oo; where the m� n matrix L iscalled the access (or reference) matrix [49] and the m-elementvector �oo is referred to as the offset (or constant) vector. Thedata reuse theory introduced by Wolf and Lam [49] andlater refined by Li [39] is used to identify the types of reusein a given loop nest. Two iterations represented by vectors�II1 and �II2 (where �II1 precedes �II2 in sequential execution)access the same data element using the reference repre-sented as L�II þ �oo if L�II1 þ �oo ¼ L�II2 þ �oo: In this case, thetemporal reuse vector is defined as �rr ¼ �II2 ÿ �II1, and it can becomputed from the relation L�rr ¼ �00. Assuming column-majormemory layouts, spatial reuse can occur if the accesses aremade to the same column. We can compute the spatial reusevector �ss from the equation Ls�ss ¼ �00, where Ls is L with allelements of the first row replaced by zero [49], [39].
A collection of individual reuse vectors is referred to as areuse matrix. We now focus on spatial reuse vectors. We callthe matrix built from these vectors the spatial reuse matrix.For a given reuse vector, the first nonzero element from thetop (also called the leading element) corresponds to the loopthat carries the associated reuse. A reuse summary vector for agiven reuse vector is a vector in which all the elements arezero except the element that corresponds to the loopcarrying the reuse (in the associated reuse vector); thiselement is set to one. The reuse summary matrix and thespatial reuse summary matrix are defined analogously. Fig. 1shows an example loop nest and illustrates these concepts.As an example computation, since
Lv ¼1 0 00 1 11 1 0
0@ 1A;
338 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 14, NO. 4, APRIL 2003

the spatial reuse vector should be selected from the nullset of
0 1 11 1 0
� �:
Consequently,
�ssv ¼1ÿ11
0@ 1A:Since the first nonzero element in this vector is the firstelement, the reuse summary vector is
�ss0v ¼100
0@ 1A:In this paper, we focus on self-reuses (i.e., reuses thatoriginate from individual references to the same array), butour approach can be extended to include group-reuses (i.e.,reuses that occur when multiple references access the samedata element [49]) as well. Unless stated otherwise, all thememory layouts are assumed to be column-major.
2.1 Identifying False Sharing Due to anLHS Reference
We begin by noting that a common cause of false sharing isthe parallel execution of a loop that carries spatial reuse[39]. For example, in Fig. 2a, parallelizing the i-loop cancause false sharing of array U . The reason is that the spatialreuse for the reference Uði; jÞ is carried by the i-loop, andparallelizing this loop can cause multiple processors towrite to each column of this array. Note that false sharingoccurs as a result of the interplay between memory layouts,array subscript functions, coherence unit size, sharinggranularity, and parallelization decisions.
We now express the condition for the existence of thisform of multiple-writer false sharing in mathematical terms.Let �ss0 be a spatial reuse summary vector for a given lefthand side (LHS) reference in a nest and let �pp be theparallelism vector for the nest. A severe form of multiple-writer false sharing can occur if �ppT �ss0 6¼ 0, i.e., if the loopcarrying the spatial reuse is parallelized. Considering all theLHS references in the nest, multiple-writer false sharing can
occur if �ppTS0 6¼ �00; where S0 is the spatial reuse summarymatrix comprised of the reuse summary vectors for the LHSreferences. We define the false sharing vector �ff as
�ppTS0 ¼ �ffT : ð1Þ
The nonzero entries in the false sharing vector �ff identify thereferences that can cause false sharing. Based on previouswork in compilers, one can suggest the desired values for�ppT , S0, and �ffT . For example, it is well-known that a desiredform of �ppT has nonzero elements only at the beginning [51].In effect, most commercial compilers attempt to obtain asingle 1 in the leftmost position, which corresponds toparallelizing only the outermost loop in the nest. This helpsto reduce the synchronization costs [51], reduce interpro-cessor communication [48], and improve memory perfor-mance [47]. On the other hand, previous work onoptimizing locality [49], [40], [39] tells us that for each�ss0 2 S0, the index of the first nonzero element (starting with1 corresponding to the outermost loop going to n for theinnermost loop in an n-nested loop) should be as high aspossible. This will ensure that inner loops carry the reuse. Inthe ideal case, we would prefer the leading element to bethe last element in each �ss0, i.e., �ss0 ¼ ð0; . . . ; 0; 1ÞT . Thiscorresponds to the case where the spatial reuse is carried bythe innermost loop. In practice, it may not be possible toobtain this ideal reuse summary vector for every referencebecause of conflicts. Finally, as we have hinted above, theideal false sharing vector should be a zero vector and thelikelihood of multiple-writer false sharing increases withthe number of ones in the false sharing vector.
Our focus is on false sharing that is due to one referenceper array (self-variable false sharing [11]). It is relativelystraightforward to extend the approach presented here toaddress false sharing due to multiple references to the samearray. In this case, we need to consider every pair ofreferences to an array that can cause false sharing and, for ksuch reference pairs, the resulting false sharing vector havek elements. On the other hand, false sharing due to differentarrays (multiple-variable false sharing [11]) is, in general,not severe and can be eliminated by the alignment of arrayvariables on coherence unit boundaries; therefore, it is notinvestigated in this study. Also, we focus mainly onmultiple-writer false sharing; reader-writer false sharingcan be avoided on machines that employ weak memory
KANDEMIR ET AL.: REDUCING FALSE SHARING AND IMPROVING SPATIAL LOCALITY IN A UNIFIED COMPILATION FRAMEWORK 339
Fig. 1. An example loop nest and the concepts used in this paper. Notice that the reference to array V does not have temporal reuse. Lu and Lv are
the access matrices and �oou and �oov are the offset vectors, �rru is the temporal reuse vector, �ssu and �ssv are the spatial reuse vectors, and �ss0u and �ss0v denote
the spatial reuse summary vectors. And, S is the spatial reuse matrix and S0 is the spatial reuse summary matrix.

consistency models [11], [19]. However, our approachcan be extended to deal with reader-writer false sharingas well.1
2.2 ExamplesThe main issue that we investigate in this paper, is one ofsimultaneously obtaining large granularity of parallelism,improving spatial locality, and reducing false sharing. Wewill derive the kind of data transformations useful forachieving this goal. We note that, if we can optimize an LHSreference (which may cause false sharing) such that only theinnermost loop carries the spatial reuse for it, then thepossibility of multiple-writer false sharing can be reduced ifthe compiler can derive outermost parallelism after thelocality optimization. This strategy works fine as long asoutermost loop parallelism is available. If this is not thecase, then the interplay between locality, parallelism, andfalse sharing merits further study.
Let us now consider again, the code in Fig. 2a, and showhow the false sharing vector is computed. Assume that thenest shown is enclosed by a sequential timing loop and thei-loop is to be parallelized,2 i.e., �pp ¼ ð1; 0; 0ÞT . Since
Lu¼1 0 0
0 1 0
� �;Lv¼
1 0 0
0 0 1
� �; and Lw¼
0 0 1
0 1 0
� �:
The spatial reuse vectors for U , V , and W can be selected
from the null sets of ð0; 1; 0Þ, ð0; 0; 1Þ, and ð0; 1; 0Þ,respectively. If we eliminate the candidate vectors that
are also temporal reuse vectors (note that we do notconsider temporal reuse here), the spatial reuse summary
vectors (and also spatial reuse vectors) are �ss0u ¼ ð1; 0; 0ÞT ,�ss0v ¼ ð1; 0; 0ÞT , and �ss0w ¼ ð0; 0; 1ÞT ; note that we do not
consider temporal reuse here. This means that the spatialreuse for arrays U and V are carried by the i-loop and thespatial reuse for W is carried by the k-loop. Thus, thespatial reuse summary matrix is
S0 ¼1 1 00 0 00 0 1
0@ 1A:Hence,
�ffT ¼ �ppTS0 ¼ ð1; 0; 0Þ1 1 00 0 00 0 1
0@ 1A ¼ ð1; 1; 0Þ:This means that, if the i-loop is parallelized, then both thereferences Uði; jÞ and V ði; kÞmay incur multiple-writer falsesharing (as they have nonzero entries in the false sharingvector). We also note that, in our example loop nest, if weparallelize the j-loop (instead of the i-loop), then the falsesharing vector will be a zero vector (the ideal case), but wewill not have outermost loop parallelism anymore. There-fore, there is a trade-off between optimizing for parallelismand reducing false sharing. Ideally, the best parallelismvector is one that enables outermost loop parallelism andmaximizes the number of zeroes in the false sharing vector.From �ffT ¼ �ppTS0 ¼ �00, we obtain S0T �pp ¼ �00) �pp 2 KerfS0Tg. Inother words, KerfS0Tg includes all those parallelism vectorsthat lead to the ideal false sharing vector, namely, the zerovector. From among these candidate parallelism vectors, weneed to choose one that is legal and that enables themaximum degree of outermost loop parallelism.
We now concentrate on the loop nest shown in Fig. 2b.For the only reference shown, the spatial reuse vector is�ss ¼ ð0; 1;ÿ1ÞT , which implies the spatial reuse summaryvector �ss0 ¼ ð0; 1; 0ÞT . In order to reduce the extent of falsesharing, the parallelism vector �pp should be either ð1; 0; 0ÞT
340 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 14, NO. 4, APRIL 2003
1. In fact, multiple-writer false sharing can also be handled by weakmemory consistency models. However, it is always better for a compiler todo it since there is cache coherence overhead at runtime.
2. This does not mean that the j and k loops cannot be run in parallel, itjust means that the compiler decides to parallelize only the outermost loop.
Fig. 2. Several example loop nests that can incur false sharing depending on the parallelization strategy used.

or ð0; 0; 1ÞT (assuming only one loop will be parallelized).To exploit outermost loop parallelism, it is better to select�pp ¼ ð1; 0; 0ÞT , i.e., parallelize the i-loop.
Let us suppose that (for some reason) we want toparallelize the j-loop in this example nest. Further, assumethat ði1; j1; k1Þ and ði2; j2; k2Þ are two iterations executed intwo different processors. Assuming column-major memorylayouts, multiple-writer false sharing can occur if thefollowing system has a solution:
loop bounds condition :
il � i1; i2 � iujl � j1; j2 � jukl � k1; k2 � ku
8><>:9>=>;
parallelism condition :fj1 6¼ j2gstride condition :fjk2 ÿ k1j < �glocality condition :fi1 ¼ i2; j1 þ k1 ¼ j2 þ k2g;
where � is the coherence unit size (specified in number ofarray elements). The loop bounds conditions ensure that thetwo iterations are within the loop bounds. The parallelismcondition indicates that we parallelize only the j-loop. Thelocality condition guarantees that the two iterations men-tioned will access the same column; therefore, all thesubscript positions (dimensions), except maybe the first,should have the same value. And, finally, the stridecondition requires that the two accesses fall into the samecoherence block (assuming perfect alignment). Assumingthat il ¼ jl ¼ kl ¼ 1 and iu ¼ ju ¼ ku ¼ N and � > 1, theabove system has many solutions, e.g., iterations ð1; 1; 2Þand ð1; 2; 1Þ. In other words, if we parallelize the j-loop,multiple-writer false sharing is likely to occur.
If, instead, we assume that the i-loop is parallelized, thenthe parallelism condition will be i1 6¼ i2. Since this conditionis in conflict with the locality condition (which requires i1and i2 to be equal), the system will not have a solution,meaning that false sharing is unlikely to occur. Thisformulation of the false sharing problem as a system ofequalities and inequalities is very promising (especiallywith the success of polyhedral algebra tools like the Omegalibrary [30]). However, in this paper, we use a matrixframework and postpone the full treatment of the poly-hedral algebraic formulation to a future work. Here, weassume that the loop bounds condition is always satisfied.Also (for portability concerns), we conservatively assumethat the stride condition always holds. Thus, what is left toconsider are the parallelism and locality conditions.
3 IMPACT OF TRANSFORMATIONS ON FALSE
SHARING
Given a loop nest with a single LHS reference, thecompiler’s task is to determine suitable values for thevectors �pp, �ss0, and �ff . In order to realize this goal, we considerboth loop transformations and data transformations. Wefirst briefly evaluate the effect of loop transformations and,then, make a case for using data transformations.
3.1 Loop Transformations
We assume that the set of applicable loop transformationsfor an n-deep loop nest are those that can be represented byn� n nonsingular integer transformation matrix T . From
data reuse theory [39], we know that, if �ss is the spatial reusevector before the transformation, then �ssþ ¼ T �ss is the newspatial reuse vector after the transformation. From �ssþ, wecan easily compute �ss0þ, the new spatial reuse summaryvector. Unfortunately, finding �ppþ, the new parallelismvector after the transformation is not as easy. In most cases,we need to run the dependence analyzer to find it. Now,from a loop transformation point of view, we can take threedifferent approaches to the problem.
Parallelism-oriented approach. Using one of the algo-rithms in the literature (e.g., [50], [40]), we can find atransformation T that results in the best possible parallelismvector �ppþ. Then, from T �ss, we find the new spatial reusevector and, finally, using (1), we can check whether thereference incurs false sharing.
Locality-oriented approach. Using one of the algorithmsin the literature (e.g., [39], [49]), we can find a transforma-tion T that gives us the best spatial reuse vector �ssþ. Then,using dependence analysis, we can find the new parallelismvector and, as before, using (1), we can check whether thereference incurs false sharing.
False sharing-oriented approach. We can try to deter-mine a T that will make the dot-product of �ppþ and �ssþ zero.Unfortunately, it does not seem trivial to find such a looptransformation matrix.3
Although we present the alternative strategies here interms of a reuse summary vector �ss0, they can easily be statedusing reuse summary matrices by substituting S0 for �ss0. Aproblem with loop transformation techniques is that looptransformations impact both the parallelism vector and thespatial reuse vector (matrix). That is, in most cases, eithersome parallelism or some locality must be sacrificed for thesake of the other. What we need is a less intrusiveoptimization technique such as data transformation, whichis explained next.
3.2 Data Transformations
Recently, a number of researchers have proposed datatransformations (or, also called memory layout transformations)as an alternative to loop transformations for optimizinglocality (see [42], [26], [38], [12] and the references therein). Incontrast to loop transformations, memory layout transforma-tions are not constrained by data dependences and can beapplied to imperfectly-nested loops as well as explicitly-parallelized codes [12]. Moreover, in a given loop nest, thememory layout of each array can be chosen independent ofthe memory layouts of other arrays. We first summarize ourmemory layout representation framework presented in [26],[25], and utilized in this work, and then show the effect of datatransformations on spatial locality and false sharing.
The working of our framework can be summarized asfollows: Each potential layout for an array can berepresented using a matrix (explained below). We thenconstruct two different sets of equalities involving thesematrices: layout equalities and false sharing equalities(based on false sharing vectors). The objective of theframework is to select a suitable layout (that is, thecorresponding matrix) for each array such that both setsof equalities are satisfied as much as possible. This isbecause we would like to both enhance locality and
KANDEMIR ET AL.: REDUCING FALSE SHARING AND IMPROVING SPATIAL LOCALITY IN A UNIFIED COMPILATION FRAMEWORK 341
3. To see the problem here, assume that �ppþ ¼ T �pp (see [3] for the caseswhere this holds) . Then, the new false sharing vector isðT �ppÞT TS0 ¼ �ppTTTTS0. Since TTT involves nonlinearity, a trivial solutionprocess is unlikely unless very strict assumptions are made.

eliminate false sharing. In this section, we give the details ofthis data space oriented optimization strategy.
In our framework, we represent the memory layouts ofmultidimensional arrays using hyperplanes. In two dimen-sions, a hyperplane defines a set of array elements ð�1; �2ÞTthat satisfy the relation
g1�1 þ g2�2 ¼ c ð2Þfor some constant c. In this equation, g1 and g2 are rationalnumbers called hyperplane coefficients and c is a rationalnumber referred to as the hyperplane constant [20], [44]. Thehyperplane coefficients in (2) can be written as a hyperplanevector �gg ¼ ðg1; g2ÞT . A hyperplane family is a set of hyper-planes defined by the same �gg and different values of c.
A hyperplane family can be used to partially define the
memory layout of a multidimensional array [25]. In a two-
dimensional data (array) space, a hyperplane family defines
parallel hyperplanes (lines), each corresponding to a different
value of c. We assume that the array elements on a specific
hyperplane are stored in consecutive memory locations. As
an example, for an array whose memory layout is column-
major, each column represents a hyperplane (a line) whose
elements are stored in consecutive locations in memory.
Given a large array, the relative storage order of the columns
(with respect to each other) is not important to us in this
paper. Therefore, we represent the column-major layout with
the hyperplane vector �gg ¼ ð0; 1ÞT , which simply indicates the
orientation of the hyperplanes. Similarly, the vectors ð1; 0ÞT ,
ð1;ÿ1ÞT , and ð1; 1ÞT correspond to row-major, diagonal, and
antidiagonal memory layouts, respectively. Two array ele-
ments ��� ¼ ð�1; �2ÞT and ���0 ¼ ð�01; �02ÞT belong to the same
hyperplane �gg ¼ ðg1; g2ÞT if and only if
ðg1; g2Þð�1; �2ÞT ¼ ðg1; g2Þð�01; �02ÞT : ð3Þ
As an application of (3), consider an array stored in column-major order, i.e., the layout hyperplane vector is ð0; 1ÞT . Here,the array elements ð2; 3ÞT and ð5; 3ÞT belong to the samehyperplane (i.e., same column), whereas the elements ð2; 3ÞTand ð2; 4ÞT do not. We say that two array elements that belongto the same hyperplane have spatial locality [25]. Although thisdefinition of spatial locality is somewhat coarse (e.g., does nothold at the array boundaries) and is different from thedefinitions used in previous work [49], [39], it is sufficient forthe purposes of this paper.
In a two-dimensional space, a single hyperplane familyis sufficient to partially define a memory layout. In higherdimensions however, we may need to use more hyperplanefamilies. Let us concentrate on a three-dimensional array Uwhose layout is column-major. Such a layout can berepresented using two hyperplanes: �gg ¼ ð0; 0; 1ÞT and�gg0 ¼ ð0; 1; 0ÞT . We can write these two hyperplanes collec-tively as a layout constraint matrix or simply a layout matrix
Gu ¼ �ggT
�gg0T
� �¼ 0 0 1
0 1 0
� �:
In that case, two data elements ��� and ���0 have spatial localityif both of the following conditions are satisfied: �ggT ��� ¼ �ggT ���0
and �gg0T ��� ¼ �gg0T ���0. The elements that have spatial localityshould be stored in consecutive memory locations. Notehow this layout representation matches the column-major
layout of a three-dimensional array in Fortran. For such anarray, in order for two elements to have spatial locality(according to our definition), all the array indices, exceptmaybe the first one, should be equal. Notice that the twoconditions given above ensure that these index equalitieshold. This representation framework can easily accommo-date higher-dimensional arrays. We refer the interestedreader to [26] and [25] for an indepth discussion ofhyperplane-based layout representations.
It is important to note that memory layout transforma-tions do not have any effect on the parallelism vector. This isan important advantage over loop transformations. As aresult, we can start with the best possible parallelization strategyand then use data transformations to strike a balance betweenspatial locality and false sharing without disturbing the availableparallelism. This is the approach taken in this paper. Let �IIand �II 0 be two iteration vectors and let �ss denote �II 0 ÿ �II: Thedata elements accessed by these two vectors through areference represented by L and �oo to a two-dimensionalarray are L�II þ �oo and L�II 0 þ �oo, respectively. Using (3) givenabove, these two elements have spatial locality if (where �ssdenotes the spatial reuse vector)
�ggT ðL�II þ �ooÞ ¼ �ggT ðL�II 0 þ �ooÞ ) �ggTLð�II 0 ÿ �IIÞ ¼ 0 or �ggTL�ss ¼ 0:
ð4Þ
Now, we have two important equations, (1) and (4), bothrelated to locality. The former gives the relationshipbetween parallelization decisions and locality, whereas thelatter shows the relationship between locality and memorylayout. Let us concentrate on a single LHS reference withone spatial reuse vector in an n-deep loop nest. Assume thatwe want to parallelize only the outermost loop in the nest,i.e., �pp ¼ ð1; 0; . . . ; 0ÞT . In order to reduce the chances formultiple-writer false sharing due to this reference, �ppT �ss0
should be zero. Substituting the value for �pp, we getð1; 0; . . . ; 0Þ�ss0 ¼ 0) �ss0 ¼ ð0;�; . . . ;�;�ÞT , where � standsfor dont-care.4 A simple spatial reuse vector �ss that satisfiesthe �ss0 vector above is ð0; . . . ; 0; 1ÞT . If we substitute thisspatial reuse vector in (4), we can find an appropriatememory layout using �ggT 2 KerfL�ssg, or �ggT 2 Kerf�llng,where �lln is the last column of L.
What we have done here is (assuming outermost loopparallelism) to find a spatial reuse vector and, then, byusing that vector to find a memory layout. Notice that thespatial reuse vector that we derived reduces false sharing. Itis important to note that such a vector is ideal from thespatial locality point of view as well. Li [39] has observedthat the form of the ideal spatial reuse vector is ð0; . . . ; 0; 1ÞTsince it exploits spatial locality in the innermost loop. Tosum up, in this case, we are able to reduce false sharing andoptimize spatial locality together. In general (after obtainingmaximum granularity parallelism using loop transforma-tions), from a data transformation point of view, we candefine the problem as one of finding a memory layout suchthat
1. false sharing will be reduced and2. spatial locality will be enhanced.
Once we determine a suitable layout, it is relatively easy toimplement it (see [38], [42]) in a compiler that assumes a
342 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 14, NO. 4, APRIL 2003
4. � can be 0 or 1; there can be only a single 1 according to our definitionof a reuse summary vector.

default memory layout, e.g., column-major layout in
Fortran. This is achieved by transforming the default layout
matrix (e.g., that represents column-major layout) to the
desired layout matrix. The linear transformation matrix that
achieves this is then used to transform the subscript
expressions (of array references) as well as array declara-
tions. Determining the transformation matrix and trans-
forming subscript expressions are relatively easy; they are
similar to the code modifications caused by loop transfor-
mations. Modifying array declarations is in general more
difficult as such modifications might increase the overall
data space requirements of the code. These extra data space
requirements can be reduced significantly using the
techniques discussed in Leung and Zahorjan [38].Let us now consider the loop nest shown in Fig. 2c.
Assuming that the outermost loop i is parallelized, from
ð1; 0Þ�ss0 ¼ 0, we obtain �ss0 ¼ ð0;�ÞT . Using this summary
vector, we can select �ss ¼ ð0; 1ÞT for all the references in the
nest.
For array U : �ggT1 0
0 1
� �0
1
� �¼ 0 )
�ggT 2 Ker0
1
� �� �) �gg ¼
1
0
� �For array V : �ggT
0 1
1 0
� �0
1
� �¼ 0 )
�ggT 2 Ker1
0
� �� �) �gg ¼
0
1
� �For array W : �ggT
1 1
0 1
� �0
1
� �¼ 0 )
�ggT 2 Ker1
1
� �� �) �gg ¼
1
ÿ1
� �For array X : �ggT
1 0
1 1
� �0
1
� �¼ 0 )
�ggT 2 Ker0
1
� �� �) �gg ¼
1
0
� �:
With these hyperplane vectors, it is clear that the arrays
U and X should be row-major, array V should be column-
major, and array W should have a diagonal memory layout
(see the discussion in Section 3.2). Note that (provided the
i-loop is parallel) these layouts do not incur severe multiple-
writer false sharing and lead to good spatial locality in the
innermost j-loop.An important question now is, under what circum-
stances we cannot optimize spatial locality and reduce false
sharing without any conflict. Before answering this ques-
tion, consider the loop nest shown in Fig. 2d. Assume that
we parallelize both the i and j loops (provided it is legal to
do so). Thus, in mathematical terms, �pp ¼ ð1; 1; 0ÞT . Such a
two-level parallelization might be useful in architectures
like Convex Exemplar where there are two levels of
processor hierarchies (interhypernode and intrahypernode).
From ð1; 1; 0Þ�ss0 ¼ 0, we obtain �ss0 ¼ ð0; 0;�ÞT . Using this
summary vector, we can select �ss ¼ ð0; 0; 1ÞT for both the
references in the nest. Therefore,
For array U : �ggT1 0 0
0 1 0
0 0 1
0B@1CA 0
0
1
0B@1CA ¼ 0 )
�ggT 2 Ker0
0
1
0B@1CA
8><>:9>=>; ) Gu ¼
1 0 0
0 1 0
� �
For array V : �ggT1 1 0
1 0 1
0 1 1
0B@1CA 0
0
1
0B@1CA ¼ 0 )
�ggT 2 Ker0
1
1
0B@1CA
8><>:9>=>; ) Gv ¼
1 0 0
0 1 ÿ1
� �:
As in the previous example, with these layouts,5 we areable to reduce false sharing and optimize spatial localitytogether. In fact, it is easy to see that a parallelism vectorsuch as ð1; . . . ; 1; 0; . . . ; 0ÞT can always be treated asð1; 0; . . . ; 0ÞT ; that is, all the outermost parallel loops canbe collapsed into one loop. Thus, we can conclude thefollowing:
In a given parallelism vector, if all the ones are in theleftmost positions consecutively (without a zero in betweenthem), then it is possible to reduce false sharing andoptimize locality together for a given left-hand sidereference.
It is also useful to verify the solution proposed for theexample in Fig. 2d, using a system of constraints. Let usfocus on just array V . The following system should have atleast two iterations ði1; j1; k1Þ and ði2; j2; k2Þ as a solution inorder for multiple-writer false sharing to occur through thereference V ðiþ j; iþ k; jþ kÞ in the original loop nest.
loop bounds condition :
1 � i1; i2 � N1 � j1; j2 � N1 � k1; k2 � N
8><>:9>=>;
parallelism condition :i1 6¼ i2j1 6¼ j2
� �stride condition :fjði2 þ j2Þ ÿ ði1 þ j1Þj < �glocality condition :fi1 þ k1 ¼ i2 þ k2; j1 þ k1 ¼ j2 þ k2g;
where � is the coherence unit size in array elements. It iseasy to see that this system has many solutions. On theother hand, if we apply our layout transformations, the newreference will be V ðiþ k; iþ j; iÿ jÞ.6 Now, the layoutcondition becomes fi1 þ j1 ¼ i2 þ j2 and i1 ÿ j1 ¼ i2 ÿ j2g;which implies i1 ¼ i2. This, in turn, conflicts with theparallelism condition i1 6¼ i2. That is, the new system has nosolution meaning that the possibility of multiple-writerfalse sharing is reduced.
3.3 Outer and Inner Loop Parallelization
It may not always be possible to obtain outermost loopparallelism in loop nests [36]. For an n-nested loop, let Ddenote the dependence distance matrix [50], the columns of
KANDEMIR ET AL.: REDUCING FALSE SHARING AND IMPROVING SPATIAL LOCALITY IN A UNIFIED COMPILATION FRAMEWORK 343
5. Here, Gu here, corresponds to a row-major layout and Gv represents anonconventional layout. See [25] and [26] for a precise interpretation oflayout matrices for three and higher dimensional arrays.
6. See [38], [42], [26] for details of rewriting access matrices and arraydeclarations after layout transformations.

which are the (constant) dependence distance vectors [51].If rankðDÞ < n, then the outermost nÿ rankðDÞ loops canbe run in parallel. If rankðDÞ ¼ n; then the loop nest can betransformed such that the outermost is sequential, but theinner nÿ 1 loops can be run in parallel [36]. As noted earlierin this paper, in the case of an outermost parallel loop, weset the parallelism vector to ð1; 0; . . . ; 0; 0ÞT and thenoptimize each reference using ð0; 0; . . . ; 0; 1ÞT as the spatialreuse vector. This allows us to optimize spatial locality andreduce false sharing together. If rankðDÞ ¼ n, then outermostloop parallelism is not available and, therefore, optimizingfor improving spatial locality and optimizations for redu-cing false sharing will conflict.
Consider now, the loop nest shown in Fig. 2e. This nestrepresents the core computation in the successive-over-relaxation (SOR) code. Both the i and the j loops carry datadependences, so, as it is, none of the loops can be executedin parallel. By skewing the inner loop with respect to theouter loop, followed by interchanging the loops, we derivethe code shown in Fig. 2f. Now, the innermost loop (i0) canrun in parallel, giving a parallelism vector ð0; 1ÞT . In orderto reduce false sharing, we need to choose �ss ¼ ð1; 0ÞT . Usingthis reuse vector,
�ggT0 11 ÿ1
� �10
� �¼ 0;
i.e., �ggT 2 Kerfð0; 1ÞTg, or �gg ¼ ð1; 0ÞT . Thus, the layout of the
array should be row-major. With this choice, there is no
false sharing due to multiple writes to the LHS reference,
but spatial locality is very poor as successive iterations of
the local portion of a processor touch different rows of the
array.Let us now find the result of using a locality-oriented
approach for the same nest. We use �ss ¼ ð0; 1ÞT as our (best)spatial reuse vector. From
�ggT0 11 ÿ1
� �01
� �¼ 0;
we get �ggT 2 Kerfð1;ÿ1ÞTg, or �gg ¼ ð1; 1ÞT . Here, the layoutof the array should be antidiagonal. Now, we have spatiallocality exploited in the innermost loop since successiveiterations of the innermost loop access a given antidiagonal,but we incur false sharing at the coherence block bound-aries. This example clearly shows the potential conflictbetween optimizing spatial locality and reducing falsesharing.
4 HEURISTIC FOR REDUCING FALSE SHARING AND
ENHANCING SPATIAL LOCALITY
In this section, we propose a solution for enhancingspatial locality and reducing false sharing together. Notethat, while false sharing is an issue for arrays that have atleast one reference on the LHS, spatial locality is an issuefor all the arrays referenced in the nest. Therefore, wedivide the arrays referenced in the nest being analyzedinto two groups: 1) arrays referenced on the RHS onlyand 2) arrays referenced on both sides. Supposing thatthere is a total of arrays referenced in the nest,A1; A2; . . . ; A�; Að�þ1Þ; . . . ; Að ÿ1Þ; A . Without loss of gener-ality, we can assume that � of these arrays fall into thefirst group and ÿ � fall into the second. In thefollowing, we do not distinguish between spatial reuse
vector and spatial reuse summary vector, as these twovectors are usually the same for most loop nests that wecome across in practice.
The first group is easy to handle. Since false sharing isnot an issue for this group, all we need is to use (4) foroptimizing locality. Specifically, let us consider an array jwhere 1 � j � �. Assume that the number of references tothis array is tj. We can use the constraint �ggTj Ljk�ssjk ¼ 0 tofind the optimal layout for this array where Ljk is the kthreference to this array and �ssjk is the kth spatial reuse vector.In the ideal case, we want to choose �ssjk ¼ ð0; . . . ; 0; 1ÞT foreach reference k (1 � k � tj). However, given a largenumber of references, this may not be possible. That is,different references to the same array may impose conflict-ing layout requirements. In that case, using profile informa-tion, we favor some references over the others and optimizefor only those favored references. In the following, webriefly discuss a profile-based reference selection scheme;see [25] for an alternative method. For each reference Ljk,we associate a weight function weight (Ljk), which gives thenumber of times this reference is touched in a typicalexecution of the program at hand. We use profiling to getthe values of weight (Ljk). Then, the solution process is asfollows:
1. Set �ssjk ¼ ð0; . . . ; 0; 1ÞT for each reference k (1 � k � tj).2. Sort the reference according to their weights in
nonincreasing order.3. Attempt to solve �ggTj Ljk�ssjk ¼ 0 for each k.4. If there is a solution, return; else omit the reference
with the smallest weight, and go to Step 3.
When the process terminates, we will have �j � tj refer-ences optimized for the locality in the innermost loop. Thisprocess is independently repeated for all � arrays in the firstgroup (1 � j � �).
As for the second group, false sharing might be animportant issue especially at the page-level. Let us nowfocus again on a single array j where � þ 1 � j � . Wedivide the references for this array into two groups:
1. the LHS references, Ljk where 1 � k � � and2. the RHS references, Ljk0 where �þ 1 � k0 � tj.
The constraints to be satisfied for each group are differentand can be listed as follows:
In this case, we try the following two options and select theone that performs better.
. In the first option, we set:
�ssj1 ¼ �ssj2 ¼ . . . ¼ �ssj� 2 Kerf�ppTg and
�ssjð�þ1Þ ¼ �ssjð�þ2Þ ¼ �ssjtj ¼ ð0; . . . ; 0; 1ÞT :
In other words, in this option, for the LHSreferences, we favor reducing false sharing overenhancing locality and, for the RHS references, weare trying to maximize locality. After these settings,we attempt to solve the constraints given above for
344 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 14, NO. 4, APRIL 2003

�ggj. As before, if there is no solution, we omit the
(constraints belonging to the) reference with the
smallest weight and try to solve the system again.. In the second option, we set:
�ssj1 ¼ �ssj2 ¼ . . . ¼ �ssj� ¼ �ssjð�þ1Þ ¼ �ssjð�þ2Þ ¼�ssjtj ¼ ð0; . . . ; 0; 1ÞT :
That is, we favor optimizing locality over reducing
false sharing for both LHS and RHS references. The
rest of the process is the same as in the previous
option.
We compare the solutions from these two options and selectthe best one. Our comparison scheme is rather simple. Foreach option, we calculate a cumulative weight, which is thesum of the weights of the references that are satisfied (i.e.,not omitted during the solution process). We prefer theoption with the larger cumulative weight. The overallalgorithm is given in Fig. 3.
Note that, in general, a layout that is suitable for onearray in one loop nest may not be suitable for the samearray in another loop nest. This means that, in contrast toloop-based transformation techniques that can handle asingle loop nest at a time, an optimization strategy based onlayout transformations should consider all the nested loopsthat access the array whose layout is to be manipulated. Our
KANDEMIR ET AL.: REDUCING FALSE SHARING AND IMPROVING SPATIAL LOCALITY IN A UNIFIED COMPILATION FRAMEWORK 345
Fig. 3. A balanced algorithm that reduces false sharing while improving locality.

solution to this global optimization problem is as follows:First, we determine an order of processing the nests; that is,if a nest is more important (costly) than another, weoptimize the more important nest first. Again, profiling isused to determine the estimated cost of a nest, which can bedefined as the sum of the weights (number of runtimeoccurrences) of the references it encloses. Then, for the mostimportant nest, we optimize it using the approachexplained in this paper. After optimizing this nest, thememory layouts of some of the arrays referenced in it willbe fixed. Then, we consider the next important nest, andoptimize it using a slightly different version of ourapproach that takes the layouts found in the most importantnest into account.7 Then, we move to the third mostimportant nest and, in optimizing it, we take all the layoutsdetermined so far (in the most important and the secondmost important nests) into account, and so on. The details ofthe global layout propagation algorithm is outside the scopeof this paper; it is similar to those presented in [28], [27]. Itshould also be noted that a more sophisticated optimizationstrategy could use loop transformations (in addition to datatransformations) during the optimization of the nests forfalse sharing.
4.1 Example Application of the Algorithm
We now present an example application of our heuristic.Consider the program fragment given in Fig. 4a. Let us firstfocus on the first loop nest. Our approach starts withoptimizing parallelism. In this nest, we can achieve amaximum granular parallelism by interchanging the loops iand j. The resulting nest is shown in Fig. 4b. The accessmatrices for the arrays referenced in this nest in Fig. 4b are
Lu1 ¼0 11 0
� �;Lv1 ¼ Lv2 ¼
1 00 1
� �; and Lw1 ¼
1 10 1
� �:
We next parallelize the outer i-loop; that is, �ppT ¼ ð1; 0Þ.The array W belongs to the first group mentioned above,i.e., it has no reference on the LHS. Therefore, the onlyconstraint that should be satisfied is �ggTwLw1�ssw1 ¼ 0.Selecting �ssw1 ¼ ð0; 1ÞT , we have
�ggTw1 10 1
� �01
� �¼ 0) �ggTw
11
� �¼ 0) �ggTw ¼ ð1;ÿ1Þ:
This means that this array should have a diagonal (skewed)memory layout. Note that, since the loop i is the innermost,this layout will maximize the locality for this array.
For the array U , we need to satisfy �ppT �ssu1 ¼ 0 and
�ggTuLu1�ssu1 ¼ 0. Selecting �ssu1 ¼ ð0; 1ÞT , we reach
�ggTu0 11 0
� �01
� �¼ 0) �ggTu
10
� �¼ 0) �ggTu ¼ ð0; 1Þ;
meaning that the array U should be column-major.The array V has both LHS and RHS references. We need
to satisfy the following constraints:
�ppT �ssv1 ¼ 0; �ggTv Lv1�ssv1 ¼ 0; and �ggTv Lv2�ssv2 ¼ 0:
Since �ppT ¼ ð1; 0Þ, the two options mentioned above are thesame. Consequently, we select �ssv1 ¼ �ssv2 ¼ ð0; 1ÞT and obtainthe following two equations:
�ggTv1 00 1
� �01
� �¼ 0 and �ggTv
1 00 1
� �01
� �¼ 0;
respectively, for the two references to array V . Therefore,from
�ggTv1 00 1
� �01
� �¼ 0) �ggTv
01
� �¼ 0) �ggTv ¼ ð1; 0Þ;
we find that the layout of V should be row-major. To sumup, the layouts of the arrays U , V , and W should be column-major, row-major, and diagonal, respectively. These layoutshelp us to exploit locality in the innermost loop whilereducing the amount of potential false sharing.
We next move to the second nest. Now, suppose that,due to possible dependences arising from references toarrays other than X, only the innermost loop k can beparallel, meaning that �ppT ¼ ð0; 0; 1Þ. Let us concentrate onarray X. The two access matrices are
Lx1 ¼1 0 10 1 1
� �and Lx2 ¼
1 1 00 ÿ1 1
� �:
We have three constraints to be satisfied:
346 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 14, NO. 4, APRIL 2003
Fig. 4. (a) An example program fragment. (b) Parallelism-optimized version of (a) with parallel loops identified using dopar.
7. To be specific, the global strategy just omits the arrays whose layoutshave already been determined and focuses on the remaining arrays.

�ppT �ssx1 ¼ 0; �ggTxLx1�ssx1 ¼ 0; and �ggTxLx2�ssx2 ¼ 0:
Considering the first option, we can set �ssx1 ¼ ð0; 1; 0ÞT and�ssx2 ¼ ð0; 0; 1ÞT . Then,
�ggTx1 0 10 1 1
� � 010
0@ 1A ¼ 0) �ggTx01
� �¼ 0) �ggTx ¼ ð1; 0Þ;
which implies that the layout of X should be row-major.Similarly, from
�ggTx1 1 00 ÿ1 1
� � 001
0@ 1A ¼ 0) �ggTx01
� �¼ 0) �ggTx ¼ ð1; 0Þ;
we also find that the preferred layout is row-major.Therefore, in this option, we are able to satisfy both theconstraints by selecting a row-major memory layout for thearray X.
We now focus on the second option. We try to satisfy thetwo constraints by setting �ssx1 ¼ �ssx2 ¼ ð0; 0; 1ÞT . Therefore,
�ggTx1 0 10 1 1
� � 001
0@ 1A ¼ 0) �ggTx11
� �¼ 0) �ggTx ¼ ð1;ÿ1Þ;
which implies that the layout of X should be diagonal. Onthe other hand, from
�ggTx1 1 00 ÿ1 1
� � 001
0@ 1A ¼ 0) �ggTx01
� �¼ 0) �ggTx ¼ ð1; 0Þ;
we find that the second constraint prefers a row-majorlayout. Assuming a profile information prefers one refer-ence (constraint) over the other, using this option, we cansatisfy only a single constraint.
Comparing these two options, it is clear that the firstoption is preferable, therefore, we set the layout of thearray X to row-major.
5 EXPERIMENTAL RESULTS
We now present preliminary experimental results obtainedon an eight-processor SGI/Cray Origin 2,000 distributedshared memory multiprocessor [37] at Northwestern Uni-versity. The SGI Origin uses R10K processors, each ofwhich is a 4-way superscalar microprocessor operating at aclock frequency of 195 MHz. Each processor has a 32 KBon-chip instruction cache and can issue instructions to itsfour functional units out-of-order. It also has a 32 KB two-way set-associative on-chip data cache and a 4 MB unifiedexternal cache, which are called the primary and thesecondary cache, respectively. The latency ratio betweenthe first-level (on-chip) data cache, second-level (off-chip)cache, and main memory is approximately 1 : 5 : 60. Thecache line size is 128 bytes and the page size is 16 KB. Thelocal memory of each node (which consists of twoprocessors) is made up of 128 MB SDRAM.
We conducted extensive experiments to measure theimpact of our approach on locality and false sharing using20 programs from different domains (benchmarks, librarycodes, and real application codes). Table 1 gives theimportant features of these codes. The size column gives(in terms of double precision elements) the maximum sizeof a dimension of any array used in the program and theiter column shows how many times the outermost timingloop has been executed for each code. The max-dim columnon the other hand, shows the maximum dimensionality ofany array used in the respective code. The last two columnswill be explained later.
When necessary (to eliminate a constraint duringoptimization), we used profile data to select the constraintto be dropped from consideration. Since our constraints(false sharing or locality) are obtained from array refer-ences, we can easily associate a constraint with one or morearray references. Consequently, eliminating a constraint canbe reexpressed as eliminating an array reference(s). Tomeasure how important each array reference is, weinstrumented each code to keep track of how many timeseach array reference is touched during execution. When this
KANDEMIR ET AL.: REDUCING FALSE SHARING AND IMPROVING SPATIAL LOCALITY IN A UNIFIED COMPILATION FRAMEWORK 347
TABLE 1Programs in Our Experimental Suite and Their Important Characteristics

instrumented version is executed, we can order thereferences in the code according to their importance. Usingthis profiling strategy, the references in inner loop levels areconsidered more important than the references in outerloop levels. Similarly, the references in loops with large tripcounts (number of iterations) are considered more impor-tant than the references in loops with small trip counts. Wealso performed experiments with different input data(keeping the data size fixed). However, since in array-intensive codes the runtime execution path is largelydetermined by loop bounds and array sizes (rather thanspecific values of input arrays), we did not observe anysignificant dependence on input. Even with smaller inputsizes, the relative importance of different array referenceswith respect to each other did not change too much.
Table 2 shows the versions used in our experiments.The optimized versions can be divided into severalgroups. In the first group consisting of LOL, LOD, andLOU, the optimizations used are aimed only at enhancingspatial locality. Among these versions, LOU is the mostpowerful as it employs both loop and data transforma-tions to improve locality. In the second group (consistingof FOL, FOD, and FOU), the optimizations attempt toreduce false sharing rather than optimizing spatiallocality exclusively, therefore, they are most useful onmultiprocessors. In this group, the most powerfultechnique is FOU, which uses both loop and datatransformations for minimizing false sharing. For eachversion, we tried to use as many published techniques aspossible (listed under the referencescolumn in Table 2)and selected the one that performs best.8 In all these sixversions, only linear loop and data transformations wereused. For example, tiling or loop unrolling [51] were notused. The BAL version refers to the approach discussed inthis paper, and HND is the hand-optimized version usingboth linear and nonlinear (e.g., tiling) loop and datatransformations. Note that, with the hand-optimizedversion (HND), we did not pay great attention to choosingtile sizes; the use of tile size selection heuristics [14], [34]may further improve the performance of the HND version.
For all the versions, before transforming the code forlocality and/or false sharing, we detected the largestgranularity parallelism using the native Fortran compiler(MIPSpro version 7.20) with locality optimizations turnedoff.9 Note that FOL, FOD, FOU, BAL, and HND takeparallelism decisions explicitly into account, whereasLOL, LOD, and LOU can reduce false sharing only as aside effect of improving locality. After the differentversions were obtained, we again used the nativecompiler (with the -O2 option and all the scalaroptimizations turned on) to generate the executables.
The results for single processor case are presented inTable 3, and the results for the eight processor case areshown in Table 4. In these tables, the second column (ORI)gives the total execution times in seconds. Columns threethrough 10 show the percentage improvement obtained byusing the respective versions over ORI. The improvementhere means reduction in the overall execution time and anegative entry indicates an increase in the execution timewith respect to ORI.
From Table 3, we can conclude the following: The purelocality oriented techniques are able to improve theoverall performance significantly. In 14 of our 20programs, the LOD version had the opportunity forapplying some kind of data transformation. Similarly, in12 of our codes, the LOL version chose to apply somekind of loop transformation. We observe that in nineprograms the LOU and FOU version generated the sameresults. We also observe that LOU brings on average23.44 percent improvement over the original codes.However, three is a large variance between applications.For example, btrix and vpenta show very largeimprovements (mostly due to layout transformations).The btrix benchmark, for instance, accesses four-dimen-sional arrays and the original access pattern is very poor.Loop transformations eliminate some of the problems, butin particular, two loop nests in this code cannot be fullyoptimized due to data dependences. A framework thatuses both loop and data transformations in concert on theother hand, achieve large performance benefits. Incontrast, in hydro2d/fct, mxm, cholsky, qzhes, andhnd_int_1e_studd, the default memory layout isappropriate for the default access pattern. For example,in mxm, the original code is both unrolled and looptransformed for locality. Consequently, neither loop nordata transformations are effective. In addition, we alsoobserve that in some cases data transformations actuallydegrade performance. This is because in some cases thecompiler can decide to apply a data transformation,
348 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 14, NO. 4, APRIL 2003
TABLE 2Different Versions Used in Our Experiments
8. Our own approaches [26], [28] as well as the heuristic presented in thispaper are implemented using Parafrase-2 [43]. For the approaches of otherresearchers, we hand coded the optimizations relying on the explanations inthe respective papers; also, in those cases, we used only the techniques thatare applicable to array-based codes. For example, from [18] we used onlyloop and array alignment, from [46] we used only array alignment, andfrom [13] we used software caching where applicable. For each version, weselected the result of the best performing version. As an example, the LOL
version used the best of the output codes of native compiler [29] and [39].The entry authors denotes our own techniques that have not beenpublished yet. Also, note that all array dimensions were padded [45], [2] bya small amount to eliminate power-of-two sizes.
9. The locality optimizations are turned on for generating the LOL
version.
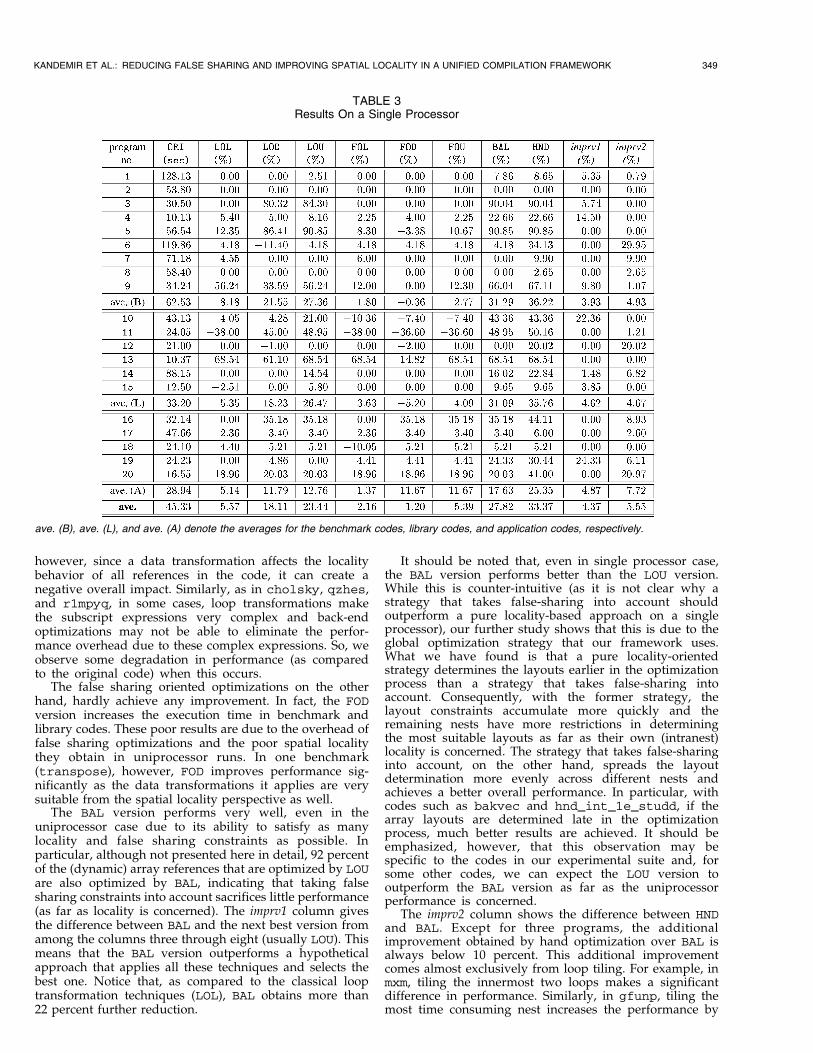
however, since a data transformation affects the localitybehavior of all references in the code, it can create anegative overall impact. Similarly, as in cholsky, qzhes,and r1mpyq, in some cases, loop transformations makethe subscript expressions very complex and back-endoptimizations may not be able to eliminate the perfor-mance overhead due to these complex expressions. So, weobserve some degradation in performance (as comparedto the original code) when this occurs.
The false sharing oriented optimizations on the otherhand, hardly achieve any improvement. In fact, the FOD
version increases the execution time in benchmark andlibrary codes. These poor results are due to the overhead offalse sharing optimizations and the poor spatial localitythey obtain in uniprocessor runs. In one benchmark(transpose), however, FOD improves performance sig-nificantly as the data transformations it applies are verysuitable from the spatial locality perspective as well.
The BAL version performs very well, even in theuniprocessor case due to its ability to satisfy as manylocality and false sharing constraints as possible. Inparticular, although not presented here in detail, 92 percentof the (dynamic) array references that are optimized by LOUare also optimized by BAL, indicating that taking falsesharing constraints into account sacrifices little performance(as far as locality is concerned). The imprv1 column givesthe difference between BAL and the next best version fromamong the columns three through eight (usually LOU). Thismeans that the BAL version outperforms a hypotheticalapproach that applies all these techniques and selects thebest one. Notice that, as compared to the classical looptransformation techniques (LOL), BAL obtains more than22 percent further reduction.
It should be noted that, even in single processor case,the BAL version performs better than the LOU version.While this is counter-intuitive (as it is not clear why astrategy that takes false-sharing into account shouldoutperform a pure locality-based approach on a singleprocessor), our further study shows that this is due to theglobal optimization strategy that our framework uses.What we have found is that a pure locality-orientedstrategy determines the layouts earlier in the optimizationprocess than a strategy that takes false-sharing intoaccount. Consequently, with the former strategy, thelayout constraints accumulate more quickly and theremaining nests have more restrictions in determiningthe most suitable layouts as far as their own (intranest)locality is concerned. The strategy that takes false-sharinginto account, on the other hand, spreads the layoutdetermination more evenly across different nests andachieves a better overall performance. In particular, withcodes such as bakvec and hnd_int_1e_studd, if thearray layouts are determined late in the optimizationprocess, much better results are achieved. It should beemphasized, however, that this observation may bespecific to the codes in our experimental suite and, forsome other codes, we can expect the LOU version tooutperform the BAL version as far as the uniprocessorperformance is concerned.
The imprv2 column shows the difference between HND
and BAL. Except for three programs, the additionalimprovement obtained by hand optimization over BAL isalways below 10 percent. This additional improvementcomes almost exclusively from loop tiling. For example, inmxm, tiling the innermost two loops makes a significantdifference in performance. Similarly, in gfunp, tiling themost time consuming nest increases the performance by
KANDEMIR ET AL.: REDUCING FALSE SHARING AND IMPROVING SPATIAL LOCALITY IN A UNIFIED COMPILATION FRAMEWORK 349
TABLE 3Results On a Single Processor
ave. (B), ave. (L), and ave. (A) denote the averages for the benchmark codes, library codes, and application codes, respectively.
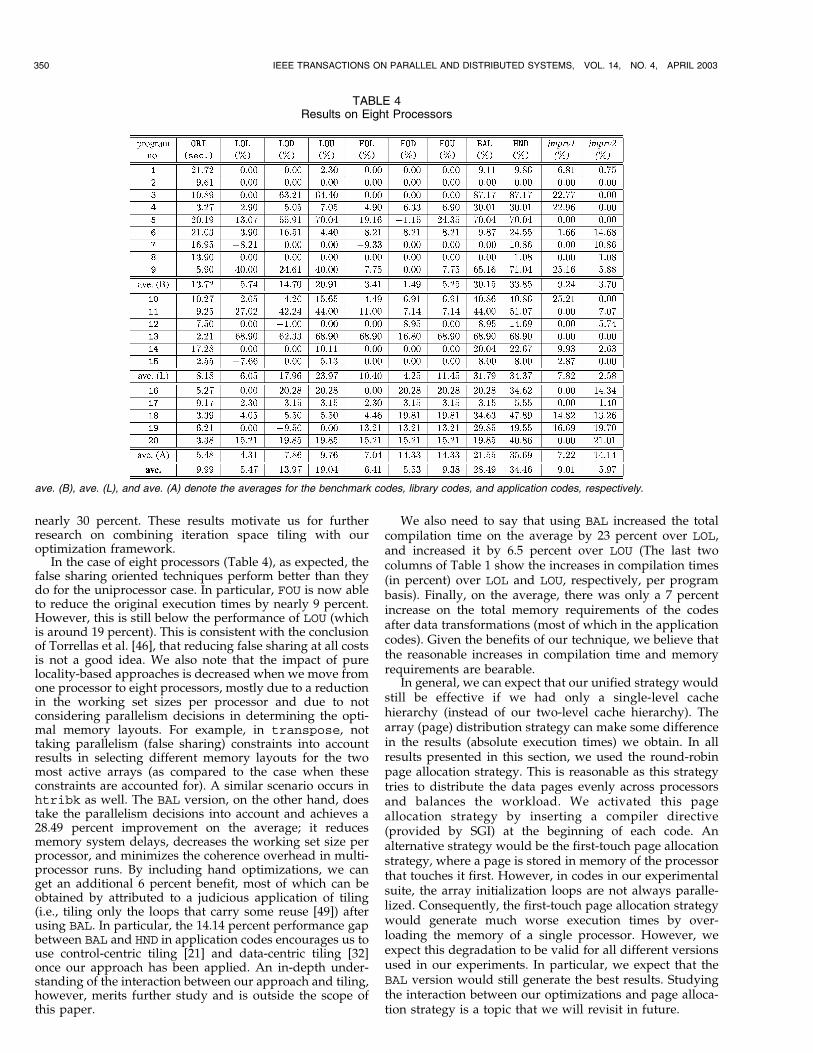
nearly 30 percent. These results motivate us for furtherresearch on combining iteration space tiling with ouroptimization framework.
In the case of eight processors (Table 4), as expected, thefalse sharing oriented techniques perform better than theydo for the uniprocessor case. In particular, FOU is now ableto reduce the original execution times by nearly 9 percent.However, this is still below the performance of LOU (whichis around 19 percent). This is consistent with the conclusionof Torrellas et al. [46], that reducing false sharing at all costsis not a good idea. We also note that the impact of purelocality-based approaches is decreased when we move fromone processor to eight processors, mostly due to a reductionin the working set sizes per processor and due to notconsidering parallelism decisions in determining the opti-mal memory layouts. For example, in transpose, nottaking parallelism (false sharing) constraints into accountresults in selecting different memory layouts for the twomost active arrays (as compared to the case when theseconstraints are accounted for). A similar scenario occurs inhtribk as well. The BAL version, on the other hand, doestake the parallelism decisions into account and achieves a28.49 percent improvement on the average; it reducesmemory system delays, decreases the working set size perprocessor, and minimizes the coherence overhead in multi-processor runs. By including hand optimizations, we canget an additional 6 percent benefit, most of which can beobtained by attributed to a judicious application of tiling(i.e., tiling only the loops that carry some reuse [49]) afterusing BAL. In particular, the 14.14 percent performance gapbetween BAL and HND in application codes encourages us touse control-centric tiling [21] and data-centric tiling [32]once our approach has been applied. An in-depth under-standing of the interaction between our approach and tiling,however, merits further study and is outside the scope ofthis paper.
We also need to say that using BAL increased the totalcompilation time on the average by 23 percent over LOL,and increased it by 6.5 percent over LOU (The last twocolumns of Table 1 show the increases in compilation times(in percent) over LOL and LOU, respectively, per programbasis). Finally, on the average, there was only a 7 percentincrease on the total memory requirements of the codesafter data transformations (most of which in the applicationcodes). Given the benefits of our technique, we believe thatthe reasonable increases in compilation time and memoryrequirements are bearable.
In general, we can expect that our unified strategy wouldstill be effective if we had only a single-level cachehierarchy (instead of our two-level cache hierarchy). Thearray (page) distribution strategy can make some differencein the results (absolute execution times) we obtain. In allresults presented in this section, we used the round-robinpage allocation strategy. This is reasonable as this strategytries to distribute the data pages evenly across processorsand balances the workload. We activated this pageallocation strategy by inserting a compiler directive(provided by SGI) at the beginning of each code. Analternative strategy would be the first-touch page allocationstrategy, where a page is stored in memory of the processorthat touches it first. However, in codes in our experimentalsuite, the array initialization loops are not always paralle-lized. Consequently, the first-touch page allocation strategywould generate much worse execution times by over-loading the memory of a single processor. However, weexpect this degradation to be valid for all different versionsused in our experiments. In particular, we expect that theBAL version would still generate the best results. Studyingthe interaction between our optimizations and page alloca-tion strategy is a topic that we will revisit in future.
350 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 14, NO. 4, APRIL 2003
TABLE 4Results on Eight Processors
ave. (B), ave. (L), and ave. (A) denote the averages for the benchmark codes, library codes, and application codes, respectively.

6 RELATED WORK
Compiler researchers have attacked the locality optimiza-tion problem from several points of view. Most of theresearch has focused on enhancing the cache locality ofscientific computations using loop transformations. Wolfand Lam [49] presented formal definitions of several typesof reuse and offered a framework that uses unimodularloop transformations as well as tiling. Li [39] also focusedon cache locality, but considered general nonsingular looptransformation matrices. McKinley et al. [41] presented asimple algorithm that unifies loop permutation, fusion, anddistribution. Other researchers have also considered tiling[14], [21], [32], [49], [9]. All of these approaches use onlyiteration space transformations and, consequently, they areconstrained by intrinsic data dependences in the program.Since it might be difficult to find a loop transformation thatsatisfies all the references in a loop nest, these approachesare limited in their ability to improve locality for all thearrays referenced in a nest. Moreover, since most of thesetechniques are specifically for optimizing the performanceof uniprocessor caches, they do not take false sharing intoaccount.
Recently, techniques based on memory layout transfor-mations for improving locality have been proposed. Leungand Zahorjan [38], O’Boyle and Knijnenburg [42], andKandemir et al. [26], [25] proposed techniques that changememory layouts. Although such techniques can improvethe spatial locality characteristics of the programs signifi-cantly, they may not be as effective on multiprocessors dueto false sharing as they do not take parallelism informationinto account. In contrast, Cierniak and Li [12] and Kandemiret al. [27] offered techniques that employ both loop and datatransformations to improve locality. Besides suffering fromdisadvantages of loop transformations, these techniquesalso suffer from the effects of false sharing in those caseswhere outermost loop parallelism is not available. Ander-son et al. [1] also propose data transformations to improvelocality and eliminate false sharing; they use permutationsand strip-mining for possible data transformations. Ourwork is more general as we consider a larger search spacefor possible layout transformations.
Kennedy and McKinley [31] explore the tradeoffsbetween effectively utilizing parallelism and memoryhierarchy on shared memory parallel machines. They usestrip-mining and loop permutation in order to exploit bothparallelism and data locality. There is also considerablework on reducing false sharing in shared-memory parallelmachines. Torrellas et al. [46] applied a number of datatransformations such as array padding and block alignmentto eliminate false sharing. They hypothesize that falsesharing is not the major source of cache misses on shared-memory machines; instead, most of the misses are due topoor spatial locality. However, they offer no systematicapproach that can be automated for balancing spatiallocality and false sharing for array-based codes. Jeremiassenand Eggers [22], [15] also proposed data transformations toreduce false sharing. Their optimizations either group datathat is accessed by the same processor or separateindividual data items that are shared. Although some oftheir transformations help improve spatial locality, othersmay adversely affect locality. In comparison, we focus moreon structured codes and demonstrate how spatial localityand false sharing can be treated in an optimizing compilerframework.
Bianchini and LeBlanc [5], Eggers and Katz [17], and Juand Dietz [23] also observe the impact of false sharing onparallel programs and propose several techniques tomanage it. None of these works explicitly studied theinteraction between optimizing locality and reducing false
sharing. In contrast, Bolosky et al. [8] proposed coalescingdifferent data into a larger data set and padding data topage boundaries to eliminate false sharing at the page level.Since padding to page boundaries can be very expensiveand distorts spatial locality, it is not clear to us howsuccessful this method will be on modern cache-coherentarchitectures. Granston and Wijshoff [18] discussed loopand data transforms for eliminating false sharing in sharedvirtual memory systems, however, they do not propose acomplete methodology and no experimental results arepresented. Bodin et al. [6], [7] also proposed looptransformation techniques for reducing page-level multi-ple-writer false sharing. However, they do not investigatethe interaction between parallelism decisions, spatiallocality, and false sharing. Another drawback of theprevious work on false sharing specific optimizations isthat, in reality, the number of processors available for a runmay not be known at compile time. If it happens to be justone processor, then all these false sharing-oriented page-level transformations may introduce significant overhead atruntime. In comparison, we take a more balanced view ofthe problem and do not eliminate false sharing at all costs.Cierniak and Li [13] proposed software caching anddynamic layout modifications to reduce false sharing. Theyfound that false sharing optimizations improve spatiallocality as well. Their results can be attributed to theavailable outermost loop parallelism in the small kernelsthat they used. Finally, Chow and Sarkar [11] proposed themodification of runtime scheduling parameters for elim-inating multiple-writer false sharing. We believe that theirsolution is complementary to our approach.
Finally, there is some work on developing cache-conscious applications and scientific libraries. Frens andWise [16] give a recursive matrix-multiply algorithm thatuses nonlinear array layouts. LaMarca and Ladner investi-gate the influence of caches on the performance of heaps[35] and present a cache performance analysis of well-known algorithms [33]. Bilmes et al. present a locality-optimized matrix-multiply routine [4]. Chatterjee et al. [10]consider nonlinear memory layouts for optimizing cachelocality in some matrix computations.
7 SUMMARY AND FUTURE WORK
The performance of programs on current shared-memorymultiprocessors with coherent caches depends on severalfactors such as the interaction between the granularity of datasharing, the size of the coherence unit, and the spatial localityexhibited by the applications, in addition to the amount ofparallelism in the applications. In this paper, we havepresented a mathematical framework for studying theinteraction between false sharing and locality for programson shared-memory multiprocessors. We have found that, inthose cases where the compiler can obtain outermost loopparallelism, it is possible to simultaneously enhance spatiallocality and reduce false sharing using memory layouttransformations, while honoring the parallelism decisionsalready made by the compiler. On a collection of 20 programsdrawn from various sources, the balanced approach pre-sented in this paper, brings about an additional 9 percentimprovement over powerful loop and data transformationsaimed specifically at locality and shows a 19 percentimprovement over techniques aimed only at reducing falsesharing. This clearly demonstrates the benefits of balancinglocality and false sharing. In those cases where outermostloop parallelism is not possible, we need to favor eliminatingfalse sharing over optimizing locality or vice-versa; detailedprofile informations might be useful in making this decision.
KANDEMIR ET AL.: REDUCING FALSE SHARING AND IMPROVING SPATIAL LOCALITY IN A UNIFIED COMPILATION FRAMEWORK 351

In the future, we plan to embed loop transformations(other than those aimed only at deriving parallel loops) intoour framework. Although, in principle, such a frameworkshould be more powerful than the one discussed in thispaper; including loop transformations brings a number ofother issues into the picture. In addition, we plan toenhance our data transformation framework so that it canwork in an interprocedural setting where the arrays may bereshaped across procedure boundaries.
ACKNOWLEDGMENTS
The authors would like to thank the anonymous referees forproviding helpful comments. The material presented in thispaper is based on research supported in part by the USNational Science Foundation grants CCR-9357840 and CCR-9509143, and the Air Force Materials Command undercontract F30602-97-C-0026. P. Banerjee is supported in partby the Defense Advanced Research Projects Agency(DARPA) under contract F30602-98-2-0144. J. Ramanujamis supported in part by a US National Science FoundationYoung Investigator Award CCR-9457768, a US NationalScience Foundation grant CCR-0073800, and a US NationalScience Foundation Information Technology Research grantCHE-0121706.
REFERENCES
[1] J. Anderson, S. Amarasinghe, and M. Lam, “Data and Computa-tion Transformations for Multiprocessors,” Proc. Fifth ACMSIGPLAN Symp. Principles and Practice of Parallel Programming,pp. 166-178, July 1995.
[2] D.F. Bacon, J. Chow, D.R. Ju, K. Muthukumar, and V. Sarkar, Proc.CASCON ’94 Conf., Nov. 1994.
[3] U. Banerjee, “Unimodular Transformations of Double Loops,”Advances in Languages and Compilers for Parallel Processing,A. Nicolau et al., eds., MIT Press, 1991.
[4] J. Bilmes, K. Asanovic, C.-W. Chin, and J. Demmel, “OptimizingMatrix-Multiply Using PHiPAC: A Portable, High-PerformanceANSI C Coding Methodology,” Proc. Int’l Conf. Supercomputing,pp. 340-347, July 1997.
[5] R. Bianchini and T. LeBlanc, “Software Caching on Cache-Coherent Multiprocessors,” Proc. Fourth IEEE Symp. Parallel andDistributed Processing, Dec. 1992.
[6] F. Bodin, E. Granston, and T. Montaut, “Evaluating Two LoopTransformations for Reducing Multiple-Writer False Sharing,”Proc. Seventh Ann. Workshop Languages and Compilers for ParallelComputing, Aug. 1994.
[7] F. Bodin, E. Granston, and T. Montaut, “Page-Level AffinityScheduling for Eliminating False Sharing,” Proc. Fifth WorkshopCompilers for Parallel Computing, June 1995.
[8] W. Bolosky, R. Fitzgerald, and M. Scott, “Simple But EffectiveTechniques for NUMA Memory Management,” Proc. 12th ACMSymp. Operating Systems Principles, Dec. 1989.
[9] L. Carter, J. Ferrante, S. Flynn Hummel, B. Alpern, and K. Gatlin,“Hierarchical Tiling: A Methodology for High Performance,”UCSD Technical Report CS96-508, Nov. 1996.
[10] S. Chatterjee, V.V. Jain, A.R. Lebeck, S. Mundhra, and M.Thottethodi, “Nonlinear Array Layouts for Hierarchical MemorySystems,” Proc. ACM Int’l Conf. Supercomputing (ICS ’99), June1999.
[11] J. Chow and V. Sarkar, “False Sharing Elimination by Selection ofRuntime Scheduling Parameters,” Proc. 26th Int’l Conf. ParallelProcessing, Aug. 1997.
[12] M. Cierniak and W. Li, “Unifying Data and Control Transforma-tions for Distributed Shared Memory Machines,” Proc. SIGPLAN’95 Conf. Programming Language Design and Implementation, pp. 205-217, June 1995.
[13] M. Cierniak and W. Li, “A Practical Approach to the Compile-Time Elimination of False Sharing for Explicitly Parallel Pro-grams,” Proc. 10th Ann. Int’l Conf. High Performance Computers,June 1996.
[14] S. Coleman and K. McKinley, “Tile Size Selection Using CacheOrganization and Data Layout,” Proc. SIGPLAN ’95 Conf.Programming Language Design and Implementation, June 1995.
[15] S. Eggers and T. Jeremiassen, “Eliminating False Sharing,” Proc.Int’l Conf. Parallel Processing, vol. I, pp. 377-381, Aug. 1991.
[16] J.D. Frens and D.S. Wise, “Auto-Blocking Matrix Multiplication orTracking BLAS3 Performance with Source Code,” Proc. Sixth ACMSIGPLAN Symp. Principles and Practice of Parallel Programming,pp. 206-216, June 1997.
[17] S. Eggers and R. Katz, “The Effect of Sharing on the Cache and BusPerformance of Parallel Programs,” Proc. Third Int’l Conf.Architectural Support for Programming Languages and OperatingSystems, pp. 257-270, Apr. 1989.
[18] E. Granston and H. Wijshoff, “Managing Pages in Shared VirtualMemory Systems: Getting the Compiler Into the Game,” Proc. Int’lConf. Supercomputing, pp. 11-20, 1993.
[19] J. Hennessy and D. Patterson, Computer Architecture: A QuantitativeApproach. Morgan Kaufmann, 1995.
[20] C.-H. Huang and P. Sadayappan, “Communication-Free Partition-ing of Nested Loops,” J. Parallel and Distributed Computing, vol. 19,pp. 90-102, 1993.
[21] F. Irigoin and R. Triolet, “Supernode Partitioning,” Proc. 15th Ann.ACM Symp. Principles of Programming Languages, pp. 319-329, Jan.1988.
[22] T. Jeremiassen and S. Eggers, “Reducing False Sharing on SharedMemory Multiprocessors Through Compile Time Data Transfor-mations,” Proc. Fifth ACM SIGPLAN Symp. Principles and Practice ofParallel Programming, July 1995.
[23] Y. Ju and H. Dietz, “Reduction of Cache Coherence Overhead byCompiler Data Layout and Loop Transformation,” Proc. WorkshopLanguages and Compilers for Parallel Computing, U. Banerjee et al.,eds., pp. 344-358, 1992.
[24] M. Kandemir, A. Choudhary, J. Ramanujam, and P. Banerjee, “AGraph-Based Framework to Detect Optimal Memory Layouts forImproving Data Locality,” Proc. 1999 Int’l Parallel Processing Symp.,Apr. 1999.
[25] M. Kandemir, A. Choudhary, N. Shenoy, P. Banerjee, and J.Ramanujam, “A Linear Algebra Framework for AutomaticDetermination of Optimal Data Layouts,” IEEE Trans. Paralleland Distributed Systems, vol. 10, no. 2, Feb. 1999.
[26] M. Kandemir, A. Choudhary, N. Shenoy, P. Banerjee, and J.Ramanujam, “A Hyperplane Based Approach for OptimizingSpatial Locality in Loop Nests,” Proc. 1998 ACM Int’l Conf.Supercomputing, pp. 69-76, July 1998.
[27] M. Kandemir, A. Choudhary, J. Ramanujam, and P. Banerjee,“Improving Locality Using Loop and Data Transformations in anIntegrated Framework,” Proc. 31st Ann. ACM/IEEE Int’l Symp.Microarchitecture, vol. 31, pp. 285-296, Dec. 1998.
[28] M. Kandemir, A. Choudhary, J. Ramanujam, and P. Banerjee, “AMatrix-Based Approach to the Global Locality OptimizationProblem,” Proc. 1998 Int’l Conf. Parallel Architectures and Compila-tion Techniques, Oct. 1998.
[29] M. Kandemir, J. Ramanujam, A. Choudhary, and P. Banerjee, “AnIteration Space Transformation Algorithm Based on Explicit DataLayout Representation for Optimizing Locality,” Proc. WorkshopLanguages and Compilers for Parallel Computing, Aug. 1998.
[30] W. Kelly, V. Maslov, W. Pugh, E. Rosser, T. Shpeisman, and D.Wonnacott, “The Omega Library Interface Guide,” TechnicalReport CS-TR-3445, CS Dept., Univ. of Maryland, College Park,Mar. 1995.
[31] K. Kennedy and K.S. McKinley, “Optimizing for Parallelism andData Locality,” Proc. 1992 ACM Int’l Conf. Supercomputing (ICS ’92),July 1992.
[32] I. Kodukula, N. Ahmed, and K. Pingali, “Data-Centric Multi-LevelBlocking,” Proc. SIGPLAN ’97 Conf. Programming Language Designand Implementation, June 1997.
[33] R. Ladner, J. Fix, and A. LaMarca, “Cache Performance Analysisof Algorithms,” Proc. 10th Ann. ACM-SIAM Symp. DiscreteAlgorithms, Jan. 1999.
[34] M. Lam, E. Rothberg, and M. Wolf, “The Cache Performance ofBlocked Algorithms,” Proc. Fourth Int’l Conf. Architectural Supportfor Programming Languages and Operating Systems (ASPLOS ’91),Apr. 1991.
[35] A. LaMarca and R. Ladner, “The Influence of Caches on thePerformance of Heaps,” The ACM J. Experimental Algorithms, vol. 1,1996.
352 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 14, NO. 4, APRIL 2003

[36] L. Lamport, “The Parallel Execution of DO Loops,” Comm. ACM,vol. 17, no. 2, pp. 83-93, Feb. 1974.
[37] J. Laudon and D. Lenoski, “The SGI Origin: A CC-NUMA HighlyScalable Server,” Proc. 24th Ann. Int’l Symp. Computer Architecture(ISCA ’97), May 1997.
[38] S.-T. Leung and J. Zahorjan, “Optimizing Data Locality by ArrayRestructuring,” Technical Report TR 95-09-01, Dept. of ComputerScience and Eng., Univ. of Washington, Sept. 1995.
[39] W. Li, “Compiling for NUMA Parallel Machines,” PhD thesis,Cornell Univ., Ithaca, New York, 1993.
[40] W. Li and K. Pingali, “Access Normalization: Loop Restructuringfor NUMA Compilers,” ACM Trans. Computer Systems, vol. 11, no.4, pp. 353-375, 1993.
[41] K. McKinley, S. Carr, and C.W. Tseng, “Improving Data Localitywith Loop Transformations,” ACM Trans. Programming Languagesand Systems, vol. 18, no. 4, pp. 424-453, July 1996.
[42] M. O’Boyle and P. Knijnenburg, “Non-Singular Data Transforma-tions: Definition, Validity, Applications,” Proc. Sixth WorkshopCompilers for Parallel Computers, pp. 287-297, 1996.
[43] C. Polychronopoulos, M. Girkar, M. Haghighat, C. Lee, B. Leung,and D. Schouten, “Parafrase-2: An Environment for Parallelizing,Partitioning, Synchronizing, and Scheduling Programs on Multi-processors,” Int’l J. High Speed Computing, vol. 1, no. 1, 1989.
[44] J. Ramanujam and P. Sadayappan, “Compile-Time Techniques forData Distribution in Distributed Memory Machines,” IEEE Trans.Parallel and Distributed Systems, vol. 2, no. 4, pp. 472-482, Oct. 1991.
[45] G. Rivera and C.-W. Tseng, “Data Transformations for Eliminat-ing Conflict Misses,” Proc. 1998 ACM SIGPLAN Conf. ProgrammingLanguage Design and Implementation (PLDI ’98), June 1998.
[46] J. Torrellas, M. Lam, and J. Hennessey, “False Sharing and SpatialLocality in Multiprocessor Caches,” IEEE Trans. Computers, vol. 43,no. 6, pp. 651-663, June 1994.
[47] E. Torrie, C-.W. Tseng, M. Martonosi, and M. Hall, “Evaluatingthe Impact of Advanced Memory Systems on Compiler-Paralle-lized Codes,” Proc. Int’l Conf. Parallel Architectures and CompilationTechniques, June 1995.
[48] C.-W. Tseng, J. Anderson, S. Amarasinghe, and M. Lam, “UnifiedCompilation Techniques for Shared and Distributed AddressSpace Machines,” Proc. 1995 Int’l Conf. Supercomputing, July 1995.
[49] M. Wolf and M. Lam, “A Data Locality Optimizing Algorithm,”Proc. ACM SIGPLAN ’91 Conf. Programming Language Design andImplementation, pp. 30-44, June 1991.
[50] M. Wolf and M. Lam, “A Loop Transformation Theory and anAlgorithm to Maximize Parallelism,” IEEE Trans. Parallel andDistributed Systems, vol. 2, no. 4, pp. 452-471, 1991.
[51] M. Wolfe, High Performance Compilers for Parallel Computing.Addison Wesley, CA, 1996.
Mahmut Kandemir received the BSc and MSc
degrees in control and computer engineering
from Istanbul Technical University, Istanbul,
Turkey, in 1988 and 1992, respectively. He
received the PhD from Syracuse University,
New York, in electrical engineering and compu-
ter science in 1999. He has been an assistant
professor in the Computer Science and En-
gineering Department at the Pennsylvania State
University since August 1999. His main research interests are optimizing
compilers, I/O intensive applications, embedded systems, and power-
aware computing. He is a member of the IEEE and the ACM.
Alok Choudhary received the PhD degree fromthe University of Illinois, Urbana-Champaign, inelectrical and computer engineering in 1989, theMS degree from the University of Massachu-setts, Amherst, in 1986, and the BE degree(Hons.) from the Birla Institute of Technologyand Science, Pilani, India in 1982. He is aprofessor of electrical and computer engineeringat Northwestern University. From 1993 to 1996he was an associate professor in the Electrical
and Computer Engineering Department at Syracuse University, andfrom 1989 to 1993 he was an assistant professor in the samedepartment. He has worked in industry for computer consultants priorto 1984. Alok Choudhary received the US National Science Founda-tion’s Young Investigator Award in 1993 (1993-1999). He has alsoreceived an IEEE Engineering Foundation award, an IBM FacultyDevelopment award, and an Intel Research Council award. His mainresearch interests are in high-performance computing and communica-tion systems and their applications in many domains including multi-media systems, information processing, and scientific computing. Inparticular, his interests lie in the design and evaluation of architecturesand software systems (from system software such as runtime systems,compilers, and programming languages to applications), high-perfor-mance servers, high-performance databases, and input-output. He haspublished more than 130 papers in various journals and conferences inthe above areas. He has also written a book and several book chapterson the above topics. His research has been sponsored by (past andpresent) the Defense Advanced Research Projects Agency (DARPA),US National Science Foundation, NASA, Air Force Office of ScientificResearch (AFOSR), Office of Naval Research (ONR), US Departmentof Energy (DOE), Intel, IBM, and TI. Alok Choudhary served as theconference cochair for the International Conference on ParallelProcessing and as a program chair and general chair for theInternational Workshop on I/O Systems in Parallel and DistributedSystems. He also served a program vice-chair for HiPC ’1999. He is aneditor of the Journal of Parallel and Distributed Computing and anassociate editor of IEEE Transactions on Parallel and DistributedSystems. He has also served as a guest editor for IEEE Computer andIEEE Parallel and Distributed Technology. He serves (or has served) onthe program committee of many international conferences in architec-tures, parallel computing, multimedia systems, performance evaluation,distributed computing, etc. He is a member of the IEEE ComputerSociety and the ACM. He also serves in the High-Performance FortranForum, a forum of Academia, industry, and government labs working onstandardizing programming languages for portable programming onparallel computers.
KANDEMIR ET AL.: REDUCING FALSE SHARING AND IMPROVING SPATIAL LOCALITY IN A UNIFIED COMPILATION FRAMEWORK 353

J. Ramanujam (Ram) received the BTech
degree in electrical engineering from the Indian
Institute of Technology, Madras, India, in 1983,
and the MS and PhD degrees in computer
science from The Ohio State University, Colum-
bus, in 1987 and 1990, respectively. He is a
professor of electrical and computer engineering
at Louisiana State University, Baton Rouge. His
research interests are in embedded systems,
compilers for high-performance computer systems, software optimiza-
tions for low-power computing, high-level hardware synthesis, parallel
architectures, and algorithms. He has published more than 90 papers in
refereed journals and conferences in these areas in addition to several
book chapters. Dr. Ramanujam received the US National Science
Foundation’s Young Investigator Award in 1994. He has served on the
Program Committees of several conferences and workshops such as
the ACM SIGPLAN Workshop on Languages, Compilers, and Tools for
Embedded Systems (LCTES ’2001), the Workshop on Power Manage-
ment for Real-Time and Embedded Systems, (IEEE Real-Time
Applications Symposium, 2001), the International Conference on
Parallel Architectures and Compilation Techniques (PACT 2000), the
International Symposium on High Performance Computing (HiPC 99),
and the 1997 International International Conference on Parallel
Processing. He initiated and has coorganized the annual workshop on
Compilers and Operating Systems for Low Power, which has been held
in conjunction with PACT (Conference on Parallel Architectures and
Compilation Techniques) since 2000. He has taught tutorials on
compilers for high-performance computers at several conferences such
as the International Conference on Parallel Processing (1998, 1996),
Supercomputing 94, Scalable High-Performance Computing Confer-
ence (SHPCC 94), and the International Symposium on Computer
Architecture (1993 and 1994). He has been a frequent reviewer for
several journals and conferences. He is a member of the IEEE.
Prith Banerjee received the BTech degree inelectronics and electrical engineering from theIndian Institute of Technology, Kharagpur, India,in August 1981, and the MS and PhD degrees inelectrical engineering from the University ofIllinois at Urbana-Champaign in December1982 and December 1984, respectively. Dr.Banerjee is currently the Walter P. MurphyProfessor and Chairman of the Department ofElectrical and Computer Engineering, and Di-
rector of the Center for Parallel and Distributed Computing at North-western University in Evanston, Illinois. During 1985-1996, he was onthe faculty of the University of Illinois. During that time, he was theDirector of the Computational Science and Engineering program andProfessor of Electrical and Computer Engineering and the CoordinatedScience Laboratory at the University of Illinois at Urbana-Champaign.Prith Banerjee has also served as Founder, President, and CEO of acompany called AccelChip during 2000-2002 while he was on leave fromNorthwestern University. This company was founded based ontechnology developed as part of a DARPA sponsored research on theMATCH compiler at Northwestern. Prith is continuing to serve asChairman and Chief Technology Officer of AccelChip, Inc., in a part-timemanner. His research interests are in parallel algorithms for VLSI designautomation, distributed memory parallel compilers, and compilers forVLSI systems such as FPGAs and ASICs, and is the author of morethan 300 papers in these areas. He lead the PARADIGM compilerproject for compiling programs for distributed memory multicomputers,the ProperCAD project for portable parallel VLSI CAD applications, theMATCH project on a MATLAB compilation environment for adaptivecomputing, and the PACT project on power aware compilation andarchitectural techniques. He is also the author of a book entitled “ParallelAlgorithms for VLSI CAD” published by Prentice Hall, Inc., 1994. He hassupervised 30 PhD and 35 MS student theses so far. Dr. Banerjee hasreceived numerous awards and honors during his career. He receivedthe IEEE Taylor L. Booth Education Award from the IEEE ComputerSociety in 2001. He became a Fellow of the ACM in 2000. He was therecipient of the 1996 Frederick Emmons Terman Award of ASEE’sElectrical Engineering Division sponsored by Hewlett-Packard. He waselected to the fellow grade of IEEE in 1995. He received the UniversityScholar award from the University of Illinois for in 1993, the Senior XeroxResearch Award in 1992, the IEEE Senior Membership in 1990, the USNational Science Foundation’s Presidential Young Investigators’ Awardin 1987, the IBM Young Faculty Development Award in 1986, and thePresident of India Gold Medal from the Indian Institute of Technology,Kharagpur, in 1981. The company that he has started called AccelChiphas received the award for the “One of 50 emerging new technologycompanies in Illinois” in 2001. Prith has served as an Associate Editor ofthe IEEE Transactions on Parallel and Distributed Systems, the IEEETransactions on Computers, the Journal of Parallel and DistributedComputing, the IEEE Transactions on VLSI Systems, and the Journal ofCircuits, Systems, and Computers. He has served on the program andorganizing committees of at least 30 conferences overview the past fewyears. He has also served as the Program Chair of the High-Performance Computing Conference in 1999, and the InternationalConference on Parallel Processing for 1995. He has served as GeneralChairman of the International Conference on Parallel and DistributedComputing Systems in 1997, and the International Workshop onHardware Fault Tolerance in Multiprocessors 1989. He has been aconsultant to many companies and was on the Technical AdvisoryBoard of many companies such as Ambit Design Systems and Atrenta.
. For more information on this or any other computing topic,please visit our Digital Library at http://computer.org/publications/dlib.
354 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 14, NO. 4, APRIL 2003