reflected intelligence evolving self-learning data systems
TRANSCRIPT

Reflected Intelligence: Evolving self-learning data systems
Trey Grainger SVP of Engineering
Khalifeh AlJadda Lead Data Scientist

Agenda• Introductions• Key Technologies
○ Hadoop, Spark, Solr, Cloud/AWS
• Information Retrieval Overview○ Overview○ Feedback Loops
• Reflected Intelligence Use Cases○ Recommendations○ Semantic Search / Query Intent○ Learning to Rank○ Search QA
• Conclusion

Introductions

Trey Grainger SVP of Engineering
• Previously Director of Engineering @ CareerBuilder• MBA, Management of Technology – Georgia Tech• BA, Computer Science, Business, & Philosophy – Furman University• Mining Massive Datasets (in progress) - Stanford University
Fun outside of CB: • Co-author of Solr in Action, plus a handful of research papers• Frequent conference speaker• Founder of Celiaccess.com, the gluten-free search engine• Lucene/Solr contributor
About Us

Khalifeh AlJadda Lead Data Scientist, Search Data Science
• Joined CareerBuilder in 2013
• PhD, Computer Science – University of Georgia• BSc, MSc, Computer Science, Jordan University of Science and Technology
Activities: • Founder and Chairman of CB Data Science Council• Invited speaker “The Data Science Conference 2016”• Creator of GELATO (Glycomic Elucidation and Annotation Tool)
About Us


Search-Driven Everything
Customer Service
Customer Insights
Fraud Surveillance
Research Portal
Online Retail Digital Content
The standard for enterprise search.
of Fortune 500 uses Solr.
90%

Lucidworks enables Search-Driven Everything
Data Acquisition
Indexing & Streaming
Smart Access API
Recommendations & Alerts
Analytics & InsightsExtreme Relevancy
CUSTOMER SERVICE
RESEARCH PORTAL
DIGITAL CONTENT
CUSTOMER INSIGHTS
FRAUD SURVEILLANCE
ONLINERETAIL
• Access all your data in a number of ways from one place.
• Secure storage and processing from Solr and Spark.
• Acquire data from any source with pre-built connectors and adapters.
Machine learning and advanced analytics turn all of your apps into intelligent data-driven applications.


Bay Area Search
At CareerBuilder, Search Powers...At CareerBuilder, Search Powers...

Search by the Numbers
14
Powering 50+ Search Experiences Including:
100 million +Searches per day
30+Software Developers, Data
Scientists + Analysts
500+Search Servers
1,5 billion +Documents indexed and
searchable
1Global Search
Technology platform
...and many more

Big Data Platform by the Numbers
Big Data Technologies:
47Data Nodes
1.5Petabyte Storage
1504
Hyperthread CPU Cores
6
TB RAM

what is “reflected intelligence”?

The Three C’s
Content:Keywords and other features in your documents
Collaboration:How other’s have chosen to interact with your system
Context:Available information about your users and their intent
Reflected Intelligence “Leveraging previous data and interactions to improve how new data and interactions should be interpreted”

Feedback Loops
User Searches
User Sees
ResultsUser
takes an action
Users’ actions inform system improvements

● Recommendation Engines● Building user profiles from past searches, clicks, and other actions● Identifying correlations between keywords/phrases● Building out automatically-generated ontologies from content and queries● Determining relevancy judgements (precision, recall, nDCG, etc.) from click
logs● Learning to Rank - using relevancy judgements and machine learning to
train a relevance model● Identifying misspellings, synonyms, acronyms, and related keywords● Disambiguation of keyword phrases with multiple meanings● Learning what’s important in your content
Examples of Reflected Intelligence

big data ecosystem

Bay Area Search
• Massive data volume • Can’t fit on single machine’s memory• Can’t be processed on multi-core single machine in reasonable time• The “1000 genomes” project will produce 1 petabyte of data per year
from multiple sources in multiple countries.○ One algorithm used in this project will need 9 years to converge
with 300 cores computing power.• Facebook’s daily log 60 TB
○ Time to read 1TB from disk ~3 hours
The Big Data Problem

Hadoop● Distributed computing framework● Simplify hardware requirements (commodity computers), but move complexity to
software.● Can run on multi-core single machine as well as on a cluster of commodity
machines.● Hadoop basic components:
○ HDFS○ Map/Reduce
● Hadoop echo system:○ Workflow engine (oozie)○ SQL-like language (Hive)○ Pig○ Zoo Keeper○ Machine Learning Library (Mahout)

Apache Spark
Features Hadoop Map/Reduce Spark
Storage Disk Memory & Disk
Operations Map/Reduce Map/Reduce/Join/Filter/Sample
Execution Model Batch Batch/Interactive/Streaming
Programming Language Java Java/Scala/Python/R

Solr is the popular, blazing-fast,
open source enterprise search
platform built on Apache Lucene™.

Key Solr Features:
● Multilingual Keyword search● Relevancy Ranking of results● Faceting & Analytics● Highlighting● Spelling Correction● Autocomplete/Type-ahead
Prediction● Sorting, Grouping, Deduplication● Distributed, Fault-tolerant, Scalable● Geospatial search● Complex Function queries● Recommendations (More Like This)● … many more
*source: Solr in Action, chapter 2

Cloud Computing / Amazon Web Services
● On-demand Storage
● On-demand Processing
● Auto-scaling


Reference Architecture (Lucidworks Fusion)

Traditional Keyword Search
The mechanics of querying and ranking search results

What is an “inverted index”?
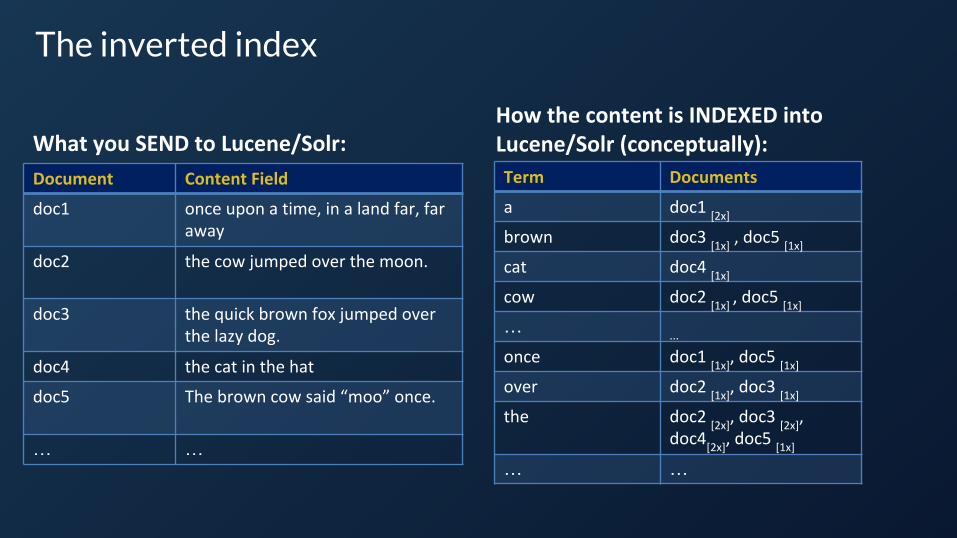
Term Documents
a doc1 [2x]
brown doc3 [1x]
, doc5 [1x]
cat doc4 [1x]
cow doc2 [1x]
, doc5 [1x]
…...
once doc1 [1x]
, doc5 [1x]
over doc2 [1x]
, doc3 [1x]
the doc2 [2x]
, doc3 [2x]
, doc4
[2x], doc5
[1x]
… …
Document Content Field
doc1 once upon a time, in a land far, far away
doc2 the cow jumped over the moon.
doc3 the quick brown fox jumped over the lazy dog.
doc4 the cat in the hat
doc5 The brown cow said “moo” once.
… …
What you SEND to Lucene/Solr:How the content is INDEXED into Lucene/Solr (conceptually):
The inverted index

Matching text queries to text fields
/solr/select/?q=jobcontent:“software engineer”
Job Content Field Documents
… …engineer doc1, doc3, doc4,
doc5…mechanical doc2, doc4, doc6… …software doc1, doc3, doc4,
doc7, doc8… …
doc5
doc7 doc8
doc1 doc3 doc4
engineer
software
software engineer

relevancy
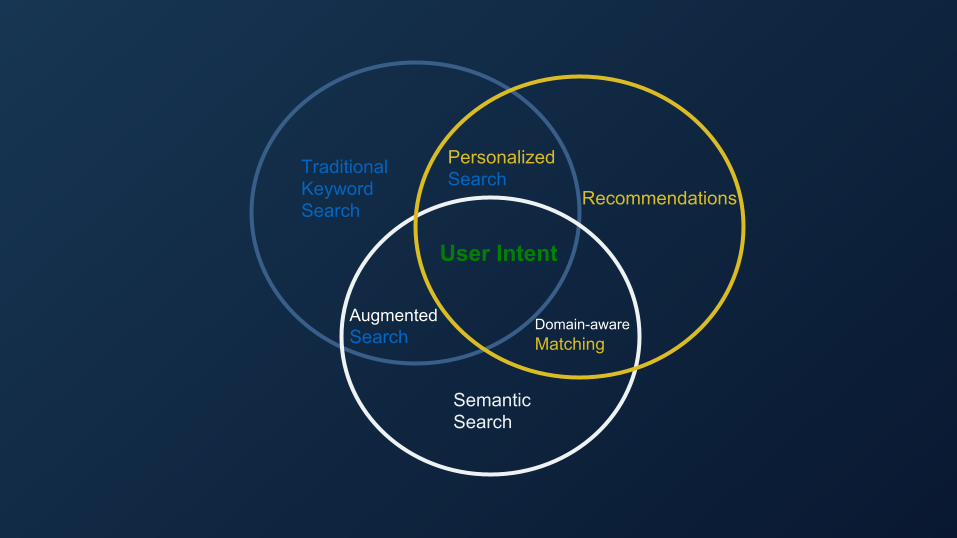
Traditional Keyword Search
Recommendations
SemanticSearch
User Intent
Personalized Search
Augmented Search
Domain-awareMatching

Classic Lucene Relevancy Algorithm (though BM25 to be default soon):
*Source: Solr in Action, chapter 3
Score(q, d) = ∑ ( tf(t in d) · idf(t)2 · t.getBoost() · norm(t, d) ) · coord(q, d) · queryNorm(q) t in q
Where: t = term; d = document; q = query; f = field tf(t in d) = numTermOccurrencesInDocument ½ idf(t) = 1 + log (numDocs / (docFreq + 1)) coord(q, d) = numTermsInDocumentFromQuery / numTermsInQuery queryNorm(q) = 1 / (sumOfSquaredWeights ½ ) sumOfSquaredWeights = q.getBoost()2 · ∑ (idf(t) · t.getBoost() )2 t in q norm(t, d) = d.getBoost() · lengthNorm(f) · f.getBoost()

• Term Frequency: “How well a term describes a document?”– Measure: how often a term occurs per document
• Inverse Document Frequency: “How important is a term overall?”– Measure: how rare the term is across all documents
TF * IDF

News Search : popularity and freshness drive relevanceRestaurant Search: geographical proximity and price range are criticalEcommerce: likelihood of a purchase is keyMovie search: More popular titles are generally more relevantJob search: category of job, salary range, and geographical proximity matter
TF * IDF of keywords can’t hold it’s own against good domain-specific relevance factors!
That’s great, but what about domain-specific knowledge?
Recommendations
Leveraging context to automatically suggest relevant results

John lives in Boston but wants to move to New York or possibly another big city. He is currently a sales manager but wants to move towards business development.
Irene is a bartender in Dublin and is only interested in jobs within 10KM of her location in the food service industry.
Irfan is a software engineer in Atlanta and is interested in software engineering jobs at a Big Data company. He is happy to move across the U.S. for the right job.
Jane is a nurse educator in Boston seeking between $40K and $60K
Consider what you know about users

http://localhost:8983/solr/jobs/select/? fl=jobtitle,city,state,salary& q=( jobtitle:"nurse educator"^25 OR jobtitle:(nurse educator)^10 ) AND ( (city:"Boston" AND state:"MA")^15 OR state:"MA") AND _val_:"map(salary, 40000, 60000,10, 0)”
*Example from chapter 16 of Solr in Action
Query for Jane
Jane is a nurse educator in Boston seeking between $40K and $60K

{ ... "response":{"numFound":22,"start":0,"docs":[ {"jobtitle":" Clinical Educator (New England/ Boston)", "city":"Boston", "state":"MA", "salary":41503},
…]}}
*Example documents available @ http://github.com/treygrainger/solr-in-action/
Search Results for Jane
{"jobtitle":"Nurse Educator", "city":"Braintree", "state":"MA", "salary":56183},
{"jobtitle":"Nurse Educator", "city":"Brighton", "state":"MA", "salary":71359}

We built a recommendation engine!
What is a recommendation engine?“A system that uses known information (or derived information from that known information) to automatically suggest relevant content”
Our example was just an attribute based recommendation… but we can also use any behavioral-based features, as well (i.e. collaborative filtering).
What did we just do?

For full coverage of building a recommendation engine in Solr…
See Trey’s talk from Lucene Revolution 2012 (Boston):

Personalized Search
Why limit yourself to JUST explicit search or JUST automated recommendations?
By augmenting your user’s explicit queries with information you know about them, you can personalize their search results.
Examples:A known software engineer runs a blank job search in New York…
Why not show software engineering higher in the results?
A new user runs a keyword-only search for nurseWhy not use the user’s IP address to boost documents geographically closer?

Willingness of a job seeker to relocate for a job

Bay Area Search
Collect the locations from a user’s job applications.
Find a centric point with radius <= 50 miles
Compute the coverage within radius 50 miles
If the coverage > 60% of jobs’ locations, then use that centric point as preferred location
25% of the job seekers provided outdated preferred location in their resumes
Where is a jobseeker actually applying to jobs?

Semantic Search
Understanding the meaning of documents and queries

Bay Area Search
What’s the problem we’re trying to solve today?
User’s Query:
machine learning research and development Portland, OR software engineer AND hadoop, java
Traditional Query Parsing: (machine AND learning AND research AND development AND portland) OR (software AND engineer AND hadoop AND java)
Semantic Query Parsing:"machine learning" AND "research and development" AND "Portland, OR" AND "software engineer" AND hadoop AND java
Semantically Expanded Query:("machine learning"^10 OR "data scientist" OR "data mining" OR "artificial intelligence")AND ("research and development"^10 OR "r&d") AND AND ("Portland, OR"^10 OR "Portland, Oregon" OR {!geofilt pt=45.512,-122.676 d=50 sfield=geo})
AND ("software engineer"^10 OR "software developer") AND (hadoop^10 OR "big data" OR hbase OR hive) AND (java^10 OR j2ee)
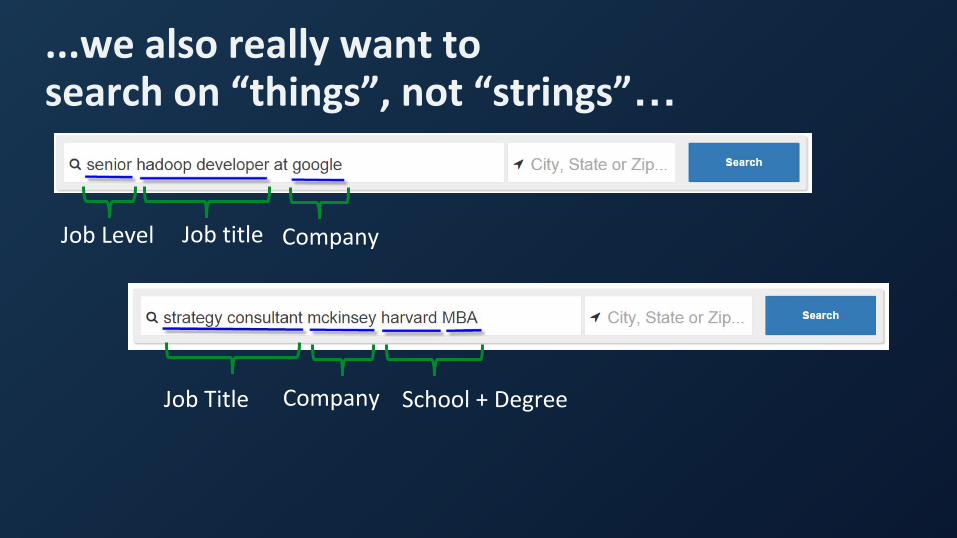
...we also really want to search on “things”, not “strings”…
Job Level Job title Company
Job Title Company School + Degree
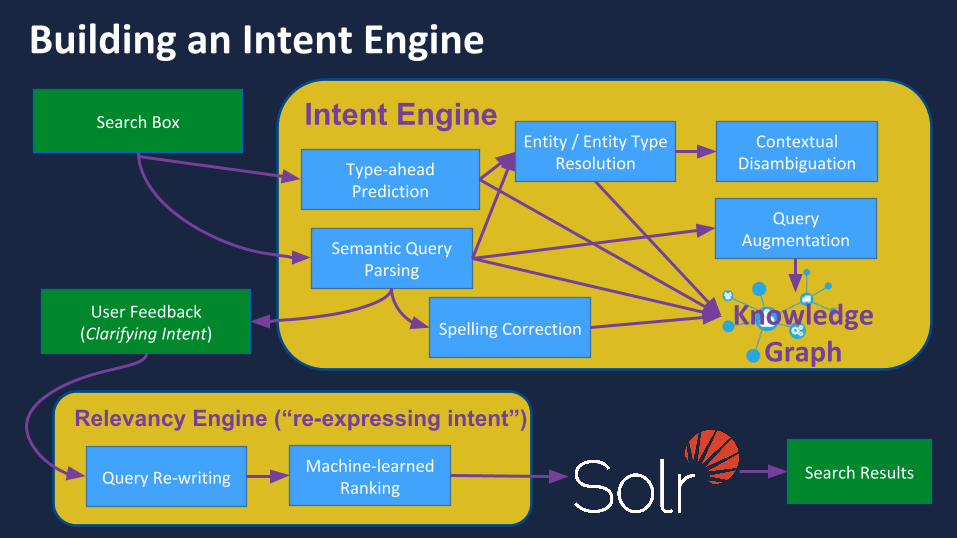
Bay Area Search
Type-aheadPrediction
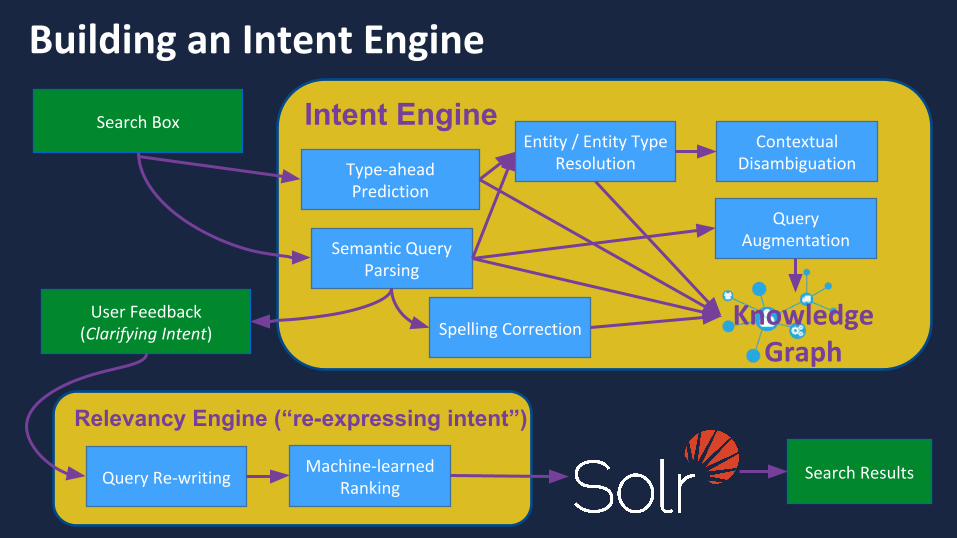
Building an Intent Engine
Search Box
Semantic Query Parsing
Intent Engine
Spelling Correction
Entity / Entity Type Resolution
Machine-learned Ranking
Relevancy Engine (“re-expressing intent”)
User Feedback (Clarifying Intent)
Query Re-writing Search Results
Query Augmentation
Knowledge Graph
Contextual Disambiguation

entity recognition

Differentiating related terms
Synonyms: cpa => certified public accountant rn => registered nurse r.n. => registered nurse
Ambiguous Terms*: driver => driver (trucking) ~80% likelihood
driver => driver (software) ~20% likelihood
Related Terms: r.n. => nursing, bsn hadoop => mapreduce, hive, pig
*differentiated based upon user and query context

Bay Area Search
Building a Taxonomy of Entities
Many ways to generate this:• Topic Modelling• Clustering of documents• Statistical Analysis of interesting phrases• Buy a dictionary (often doesn’t work for
domain-specific search problems)• …
CareerBuilder’s strategy:Generate a model of domain-specific phrases by mining query logs for commonly searched phrases within the domain
[1]
[1] K. Aljadda, M. Korayem, T. Grainger, C. Russell. "Crowdsourced Query Augmentation through Semantic Discovery of Domain-specific Jargon," in IEEE Big Data 2014.

Bay Area Search
Proposed strategy1. Mine user search logs for a list of common phrases (“jargon”)
within our domain.
2. Perform collaborative filtering on the common jargon (“user’s who searched for that phrase also search for this phrase”)
3. Remove noise through several methodologies:– Segment search phrases based upon the
classification of users
– Consider shared jargon used by multiple sides of our two-sided market (i.e. both Job Seekers and Recruiters utilize the same phrase)
– Validate that the two “related” phrases actually co-occur in real content (i.e. within the same job or resume) with some frequency

Job Seeker Search Terms Extractor
Employer Search Terms Extractor
Combine a user’s search terms
Combine a user’s search terms
Crowdsourcing Latent Semantic Discovery Engine
Content-Based Filtering
Find Intersection
Job Seeker search logs
Recruiter search logs
Latent Semantic Discovery System
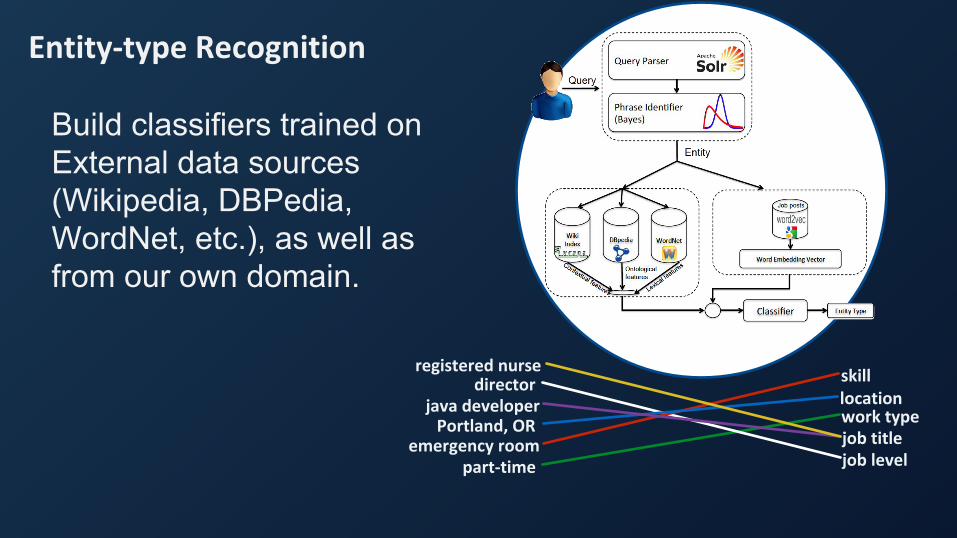
Entity-type Recognition
Build classifiers trained onExternal data sources(Wikipedia, DBPedia, WordNet, etc.), as well asfrom our own domain.
java developer
registered nurse
emergency room
director
job title
skill
job level
locationwork typePortland, OR
part-time

typ
type-ahead predictionhandling typostypical use cases

Semantic Autocomplete
• Shows top terms for any search
• Breaks out job titles, skills, companies, related keywords, and other categories
• Understands abbreviations, alternate forms, misspellings
• Supports full Boolean syntax and multi-term autocomplete
• Enables fielded search on entities, not just keywords

spelling corection
Did you mean: spelling correction?


contextual disambiguation

How do we handle phrases with ambiguous meanings?
Example Related Keywords (representing multiple meanings)driver truck driver, linux, windows, courier, embedded, cdl,
deliveryarchitect autocad drafter, designer, enterprise architect, java
architect, designer, architectural designer, data architect, oracle, java, architectural drafter, autocad, drafter, cad, engineer
… …

Discovering ambiguous phrases
1) Classify users who ran each search in the search logs (i.e. by the job title classifications of the jobs to which they applied)
3) Segment the search term => related search terms list by classification, to return a separate related terms list per classification
2) Create a probabilistic graphical model of those classifications mapped to each keyword phrase.

Disambiguated meanings (represented as term vectors)
Example Related Keywords (Disambiguated Meanings)architect 1: enterprise architect, java architect, data architect, oracle, java, .net
2: architectural designer, architectural drafter, autocad, autocad drafter, designer, drafter, cad, engineer
driver 1: linux, windows, embedded2: truck driver, cdl driver, delivery driver, class b driver, cdl, courier
designer 1: design, print, animation, artist, illustrator, creative, graphic artist, graphic, photoshop, video2: graphic, web designer, design, web design, graphic design, graphic designer
3: design, drafter, cad designer, draftsman, autocad, mechanical designer, proe, structural designer, revit
… …

Using the disambiguated meanings
In a situation where a user searches for an ambiguous phrase, what information can we use to pick the correct underlying meaning?
1. Any pre-existing knowledge about the user: • User is a software engineer• User has previously run searches for “c++” and “linux”
2. Context within the query:• User searched for windows AND driver vs. courier OR driver
3. If all else fails (and there is no context), use the most commonly occurring meaning.
driver 1: linux, windows, embedded2: truck driver, cdl driver, delivery driver, class b driver, cdl, courier

query parsing

Bay Area Search
Probabilistic Query Parser
Goal: given a query, predict which combinations of keywords should be combined together as phrases
Example: senior java developer hadoop
Possible Parsings:senior, java, developer, hadoop"senior java", developer, hadoop"senior java developer", hadoop"senior java developer hadoop”"senior java", "developer hadoop”senior, "java developer", hadoopsenior, java, "developer hadoop"

Input: senior hadoop developer java ruby on rails perl

Bay Area Search
Semantic Search Architecture – Query Parsing
Identification of phrases in queries using two steps:
1) Check a dictionary of known terms that is continuously built, cleaned, and refined based upon common inputs from interactions with real users of the system [1]
2) Also invoke a statistical phrase identifier to dynamically identify unknown phrases using statistics from a corpus of data (language model)
Shown on next slides:Pass extracted entities to a Query Augmentation phase to rewrite the query with enhanced semantic understanding
[1] K. Aljadda, M. Korayem, T. Grainger, C. Russell. "Crowdsourced Query Augmentation through Semantic Discovery of Domain-specific Jargon," in IEEE Big Data 2014.

query augmentation
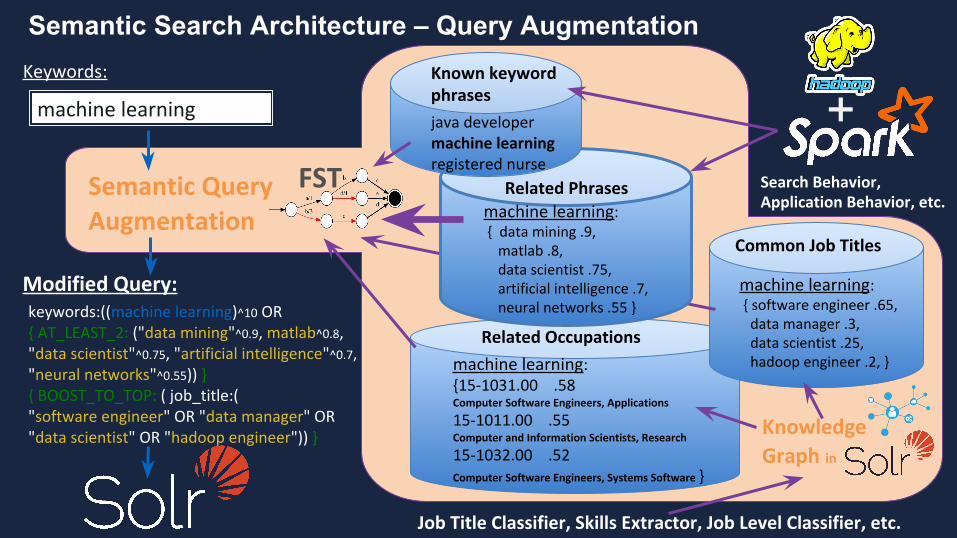
Bay Area Search
machine learning
Keywords:
Search Behavior,Application Behavior, etc.
Job Title Classifier, Skills Extractor, Job Level Classifier, etc.
Semantic Query Augmentation
keywords:((machine learning)^10 OR { AT_LEAST_2: ("data mining"^0.9, matlab^0.8, "data scientist"^0.75, "artificial intelligence"^0.7, "neural networks"^0.55)) }{ BOOST_TO_TOP: ( job_title:("software engineer" OR "data manager" OR "data scientist" OR "hadoop engineer")) }
Modified Query:
Related Occupations
machine learning: {15-1031.00 .58Computer Software Engineers, Applications
15-1011.00 .55Computer and Information Scientists, Research
15-1032.00 .52 Computer Software Engineers, Systems Software }
machine learning: { software engineer .65, data manager .3, data scientist .25, hadoop engineer .2, }
Common Job Titles
Semantic Search Architecture – Query Augmentation
Related Phrases
machine learning: { data mining .9, matlab .8, data scientist .75, artificial intelligence .7, neural networks .55 }
Known keyword phrases
java developermachine learningregistered nurse
FST
Knowledge Graph in
+

Bay Area Search
Query Enrichment
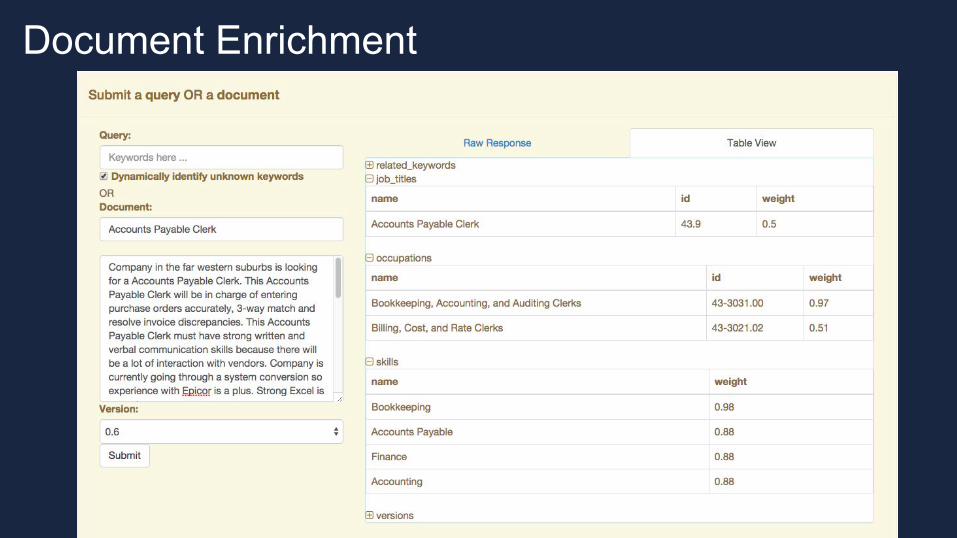
Bay Area Search
Document Enrichment

Bay Area Search
Document Enrichment

Bay Area Search

measuring & improving relevancy
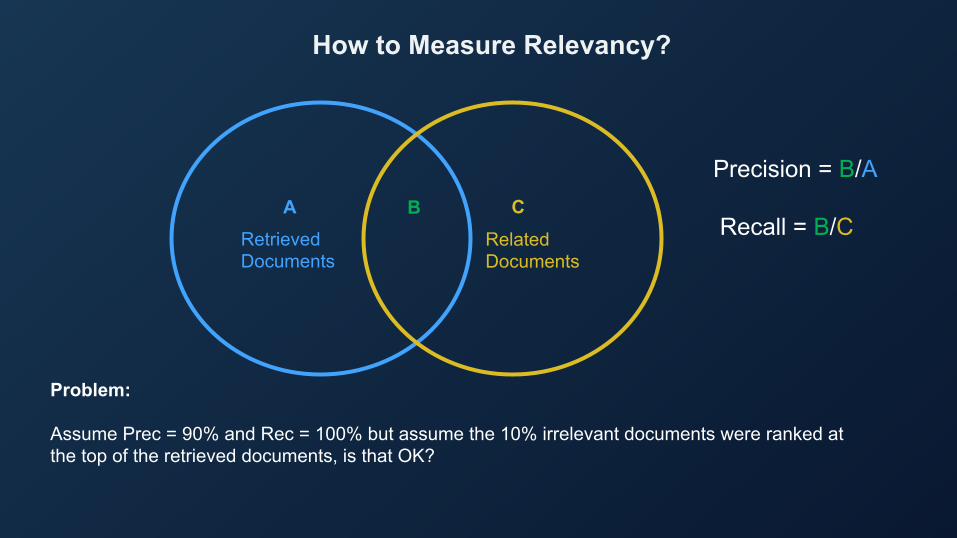
How to Measure Relevancy?
A B CRetrieved Documents
Related Documents
Precision = B/A
Recall = B/C
Problem:
Assume Prec = 90% and Rec = 100% but assume the 10% irrelevant documents were ranked at the top of the retrieved documents, is that OK?

Discounted Cumulative Gain
Rank Relevancy
1 0.95
2 0.65
3 0.80
4 0.85
Rank Relevancy
1 0.95
2 0.65
3 0.80
4 0.85
Ranking
IdealGiven
• Position is considered in quantifying relevancy.
• Labeled dataset is required.
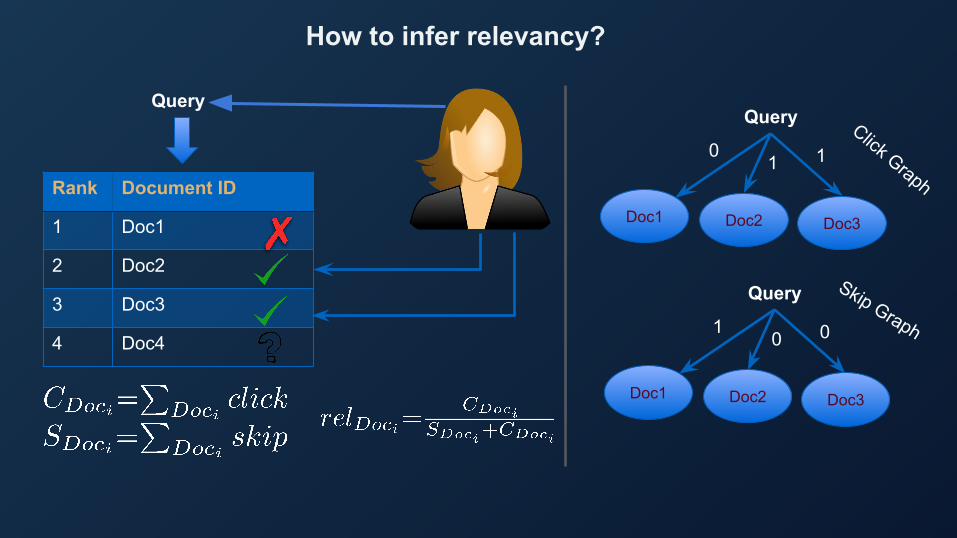
How to infer relevancy?
Rank Document ID
1 Doc1
2 Doc2
3 Doc3
4 Doc4
QueryQuery
Doc1 Doc2 Doc3
01 1
Query
Doc1 Doc2 Doc3
10 0
Click Graph
Skip Graph

How to get labeled data?
● Manually○ Pros:
■ Accuracy○ Cons:
■ Not scalable (cost or man-power wise)■ Expensive, Data become stale
○ Methodology:■ Hire employees, contractors, or interns■ Crowdsourcing
● Less cost● Less accuracy
● Infer relevancy utilizing Reflected Intelligence (RI)

Search QA System:
Traditional Keyword Search Semantic Search Algorithms

learning to rank

How to improve relevancy?
Relevancy
Matching Ranking
Matching score calculation can’t be computationally expensive
Matching score is not always the best for ranking
FEATURES

Learning to Rank (LTR)
● It applies machine learning techniques to discover the best combination of features that provide best ranking.
● It requires labeled set of documents with relevancy scores for given set of queries
● Features used for ranking are usually more computationally expensive than the ones used for matching
● It works on subset of the matched documents (e.g. top 100)

Common LTR Algorithms
• RankNet* (Neural Network, boosted trees)
• LambdaMart* (set of regression trees)
• SVM Rank** (SVM classifier)
** http://research.microsoft.com/en-us/people/hangli/cao-et-al-sigir2006.pdf
* http://research.microsoft.com/pubs/132652/MSR-TR-2010-82.pdf

LambdaMart Example
Bay Area Search
Type-aheadPrediction
Building an Intent Engine
Search Box
Semantic Query Parsing
Intent Engine
Spelling Correction
Entity / Entity Type Resolution
Machine-learned Ranking
Relevancy Engine (“re-expressing intent”)
User Feedback (Clarifying Intent)
Query Re-writing Search Results
Query Augmentation
Knowledge Graph
Contextual Disambiguation

Additional References:

Bay Area Search
2014 - 2015 Publications & PresentationsBooks:Solr in Action - A comprehensive guide to implementing scalable search using Apache Solr
Research papers:● Crowdsourced Query Augmentation through Semantic Discovery of Domain-specific jargon - 2014● Towards a Job title Classification System - 2014● Augmenting Recommendation Systems Using a Model of Semantically-related Terms
Extracted from User Behavior - 2014● sCooL: A system for academic institution name normalization - 2014● PGMHD: A Scalable Probabilistic Graphical Model for Massive Hierarchical Data Problems - 2014● SKILL: A System for Skill Identification and Normalization – 2015● Carotene: A Job Title Classification System for the Online Recruitment Domain - 2015● WebScalding: A Framework for Big Data Web Services - 2015● A Pipeline for Extracting and Deduplicating Domain-Specific Knowledge Bases - 2015● Macau: Large-Scale Skill Sense Disambiguation in the Online Recruitment Domain - 2015● Improving the Quality of Semantic Relationships Extracted from Massive User Behavioral Data – 2015● Query Sense Disambiguation Leveraging Large Scale User Behavioral Data - 2015● Entity Type Recognition using an Ensemble of Distributional Semantic Models to Enhance Query Understanding - 2016
Speaking Engagements:● Over a dozen in the last year: Lucene/Solr Revolution 2014, WSDM 2014, Atlanta Solr Meetup, Atlanta Big Data Meetup, Second
International Symposium on Big Data and Data Analytics, RecSys 2014, IEEE Big Data Conference 2014 (x2), AAAI/IAAI 2015, IEEE Big Data 2015 (x6), Lucene/Solr Revolution 2015, and Bay Area Search Meetup
Bay Area Search
Contact Info
Trey Grainger [email protected] @treygrainger
Other presentations: http://www.treygrainger.com http://www.aljadda.com
Khalifeh AlJadda [email protected]
@aljadda