regresión múltiple - uam.es · menores presupuestos escolares Œ y mayor str: z estÆ...
TRANSCRIPT

5-1
Regresión Múltiple (SW Capítulo 5)
Estimación MCO de la relación entre las notas y el número de estudiantes por profesor: !Notas = 698.9 � 2.28¥STR, R2 = .05, SER = 18.6
(10.4) (0.52) ¿es ésta una estimación creíble del efecto causal de un cambio en el número de estudiantes por profesor sobre las notas?
No: existen factores omitidos (como la renta familiar o si los estudiantes hablan un inglés nativo) que sesgan el estimador MCO: STR podría �recoger� el efecto de dichos factores.

5-2
Sesgo de Variables Omitidas (SW Sección 5.1)
El sesgo en el estimador MCO que ocurre como consecuencia de un factor omitido se denomina sesgo de variables omitidas. Para que ocurra el sesgo de variables omitidas, el factor omitido �Z� debe ser:
1. un determinante de Y; y 2. correlacionado con el regresor X.
Ambas condiciones deben cumplirse para que la omisión de Z produzca un sesgo de variables omitidas.

5-3
En el ejemplo anterior: 1. La habilidad para hablar en inglés (si el inglés es la
segunda lengua del estudiante) plausiblemente afectará a las notas: Z es un determinante de Y.
2. Las comunidades de inmigrantes tienden a tener menores presupuestos escolares � y mayor STR: Z está correlacionada con X.
• Por tanto, 1�β será sesgado
• ¿Cuál es la dirección del sesgo? • ¿qué sugiere el sentido común? • Si el sentido común se equivoca, existe una
fórmula...

5-4
Fórmula del sesgo de variables omitidas:
1�β � β1 = 1
2
1
( )
( )
n
i ii
n
ii
X X u
X X
=
=
−
−
∑
∑ = 1
2
1
1
n
ii
X
vnn s
n
=
−
∑
donde vi = (Xi � X )ui ≅ (Xi � µX)ui.
La hipótesis #1 de MCO,
E[(Xi � µX)ui] = cov(Xi,ui) = 0.
Pero ¿qué ocurre si E[(Xi � µX)ui] = cov(Xi,ui) = σXu ≠ 0?

5-5
Entonces
1�β � β1 = 1
2
1
( )
( )
n
i ii
n
ii
X X u
X X
=
=
−
−
∑
∑ = 1
2
1
1
n
ii
X
vnn s
n
=
−
∑
por tanto
E( 1�β ) � β1 = 1
2
1
( )
( )
n
i ii
n
ii
X X uE
X X
=
=
− −
∑
∑ ≅ 2
Xu
X
σσ
= u Xu
X X u
σ σσ σ σ
×
donde ≅ es = cuando n es grande; en concreto,
1�β
p→ β1 + u
XuX
σ ρσ
, donde ρXu = corr(X,u)

5-6
Fórmula del sesgo de variables omitidas:
1�β
p→ β1 + u
XuX
σ ρσ
.
Si un factor omitido Z es simultáneamente: (1) un determinante de Y (contenido en u); y (2) correlacionado con X,
entonces ρXu ≠ 0 y el estimador MCO 1�β será sesgado.
Aquellos distritos con un menor número de estudiantes de inglés (EL), (1) obtienen mejores notas y (2) tienen mayor presupuesto escolar; por tanto, ignorar el factor EL sesga hacia arriba el efecto del STR.
¿Es esto cierto en los datos CA?
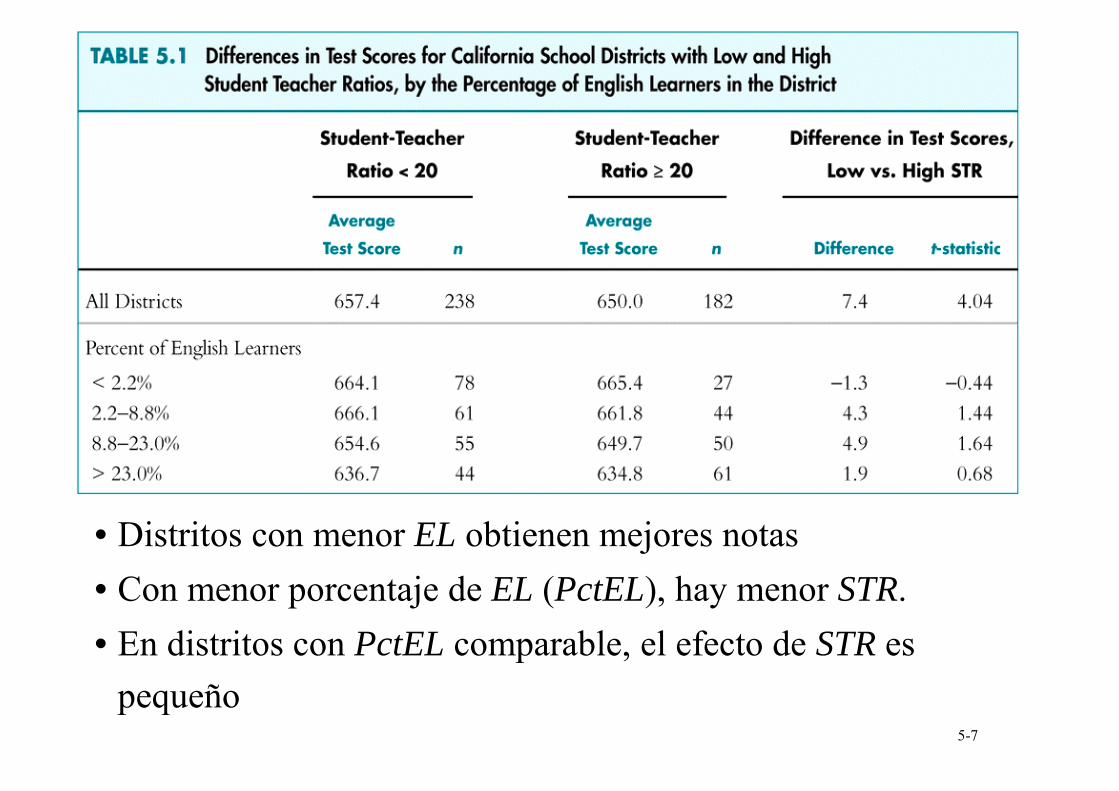
5-7
• Distritos con menor EL obtienen mejores notas • Con menor porcentaje de EL (PctEL), hay menor STR. • En distritos con PctEL comparable, el efecto de STR es
pequeño

5-8
Tres formas de evitar el sesgo de variables omitidas 1. Llevar a cabo un experimento controlado aleatorio en
el que STR esté asignado aleatoriamente: entonces PctEL sería todavía un determinante de las notas, pero estaría incorrelacionada con STR. (Esta situación no es realista en la práctica.)
2. �Tabulación cruzada�, con mayor graduación de STR y PctEL ( pronto nos quedaremos sin datos y ¿qué ocurre con otros determinantes como la renta familiar y la educación de los padres?)
3. Incluir PctEL como un regresor adicional en una regresión múltiple.

5-9
El Modelo de Regresión Poblacional Múltiple (SW Section 5.2)
Considerar la situación con dos regresores: Yi = β0 + β1X1i + β2X2i + ui, i = 1,�,n
• X1, X2 son las variables independientes (regresores) • (Yi, X1i, X2i) es la i-ésima observación en Y, X1, y X2. • β0 = ordenada en el origen • β1 = efecto en Y de un cambio en X1, manteniendo X2
constante • β2 = efecto en Y de un cambio en X2, manteniendo X1
constante • ui = �término de error� (factores omitidos)

5-10
Interpretación de los coeficientes Yi = β0 + β1X1i + β2X2i + ui, i = 1,�,n
Cambiemos X1 en ∆X1 manteniendo X2 constante: Recta de regresión poblacional antes del cambio:
Y = β0 + β1X1 + β2X2 Recta de regresión poblacional, después del cambio:
Y + ∆Y = β0 + β1(X1 + ∆X1) + β2X2

5-11
Antes: Y = β0 + β1X1 + β2X2 Después: Y + ∆Y = β0 + β1(X1 + ∆X1) + β2X2 Diferencia: ∆Y = β1∆X1
Entonces,
β1 = 1
YX
∆∆
, manteniendo X2 constante
también,
β2 = 2
YX
∆∆
, manteniendo X1 constante
y β0 = predicción de Y cuando X1 = X2 = 0.

5-12
El Estimador MCO en una Regresión Múltiple (SW Section 5.3)
Con dos regresores, el estimador MCO resuelve:
0 1 2
2, , 0 1 1 2 2
1
min [ ( )]n
b b b i i ii
Y b b X b X=
− + +∑
• El estimador MCO minimiza la media de las diferencias al cuadrado entre los valores de Yi y sus predicciones a partir de la recta de regresión estimada.
• El problema de minimización se resuelve empleando cálculo matemático
• El resultado son los estimadores MCO de ββββ0 y ββββ1.

5-13
Ejemplo: Datos de CA
!Notas = 698.9 � 2.28¥STR Ahora, incluimos PctEL:
!Notas = 696.0 � 1.10¥STR � 0.65PctEL • ¿Qué ocurre con el coeficiente de STR? • ¿Por qué? (Pista: corr(STR, PctEL) = 0.19)
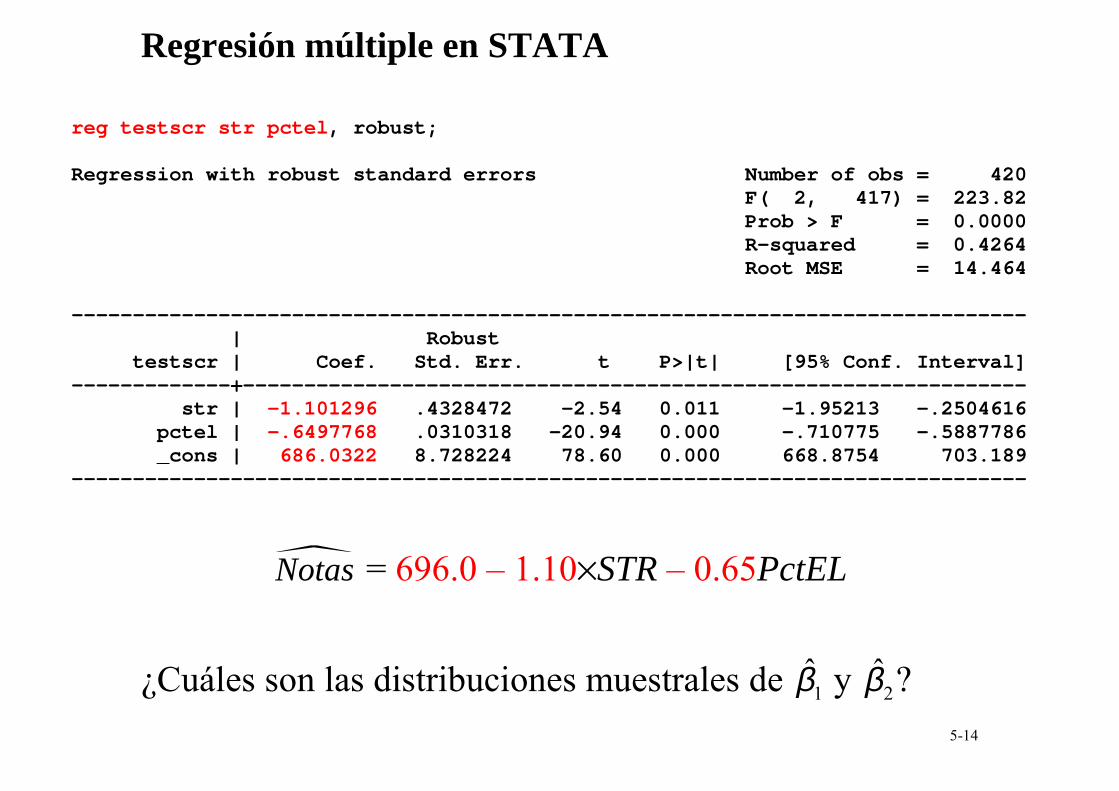
5-14
Regresión múltiple en STATA reg testscr str pctel, robust;
Regression with robust standard errors Number of obs = 420 F( 2, 417) = 223.82 Prob > F = 0.0000 R-squared = 0.4264 Root MSE = 14.464 ------------------------------------------------------------------------------ | Robust testscr | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------- str | -1.101296 .4328472 -2.54 0.011 -1.95213 -.2504616 pctel | -.6497768 .0310318 -20.94 0.000 -.710775 -.5887786 _cons | 686.0322 8.728224 78.60 0.000 668.8754 703.189 ------------------------------------------------------------------------------
!Notas = 696.0 � 1.10¥STR � 0.65PctEL
¿Cuáles son las distribuciones muestrales de 1
�β y 2�β ?

5-15
Hipótesis del MCO en la Regresión Múltiple (SW Section 5.4)
Yi = β0 + β1X1i + β2X2i + � + βkXki + ui, i = 1,�,n
1. La distribución condicional de u dadas las X�s posee
media cero, es decir, E(u|X1 = x1,�, Xk = xk) = 0. 2. (X1i,�,Xki,Yi), i =1,�,n, son i.i.d. 3. X1,�, Xk, y u poseen momentos de cuarto orden:
E( 41iX ) < ∞,�, E( 4
kiX ) < ∞, E( 4iu ) < ∞.
4. No existe multicolinealidad perfecta.

5-16
Hipótesis #1: la media condicional de u dadas la X’s incluidas es cero.
• Posee la misma interpretación que en la regresión con un único regresor.
• Si una variable omitida (1) pertenece a la ecuación (por tanto está en u) y (2) está correlacionada con una variable incluida X, entonces esta condición no se cumple
• Incumplimiento de esta condición lleva al sesgo de variables omitidas
• La solución � si es posible � es incluir la variable omitida en la regresión.

5-17
Hipótesis #2: (X1i,…,Xki,Yi), i =1,…,n, son i.i.d. Se cumple automáticamente con el muestreo aleatorio simple.
Hipótesis #3: momentos de cuarto orden finitos
Esta es una hipótesis técnica que se satisface automáticamente para variables con un dominio acotado (notas, PctEL, etc.)
Hipótesis #4: No existe de multicolinealidad perfecta Multicolinealidad Perfecta se produce cuando uno de los regresores es una función lineal exacta de otros regresores.
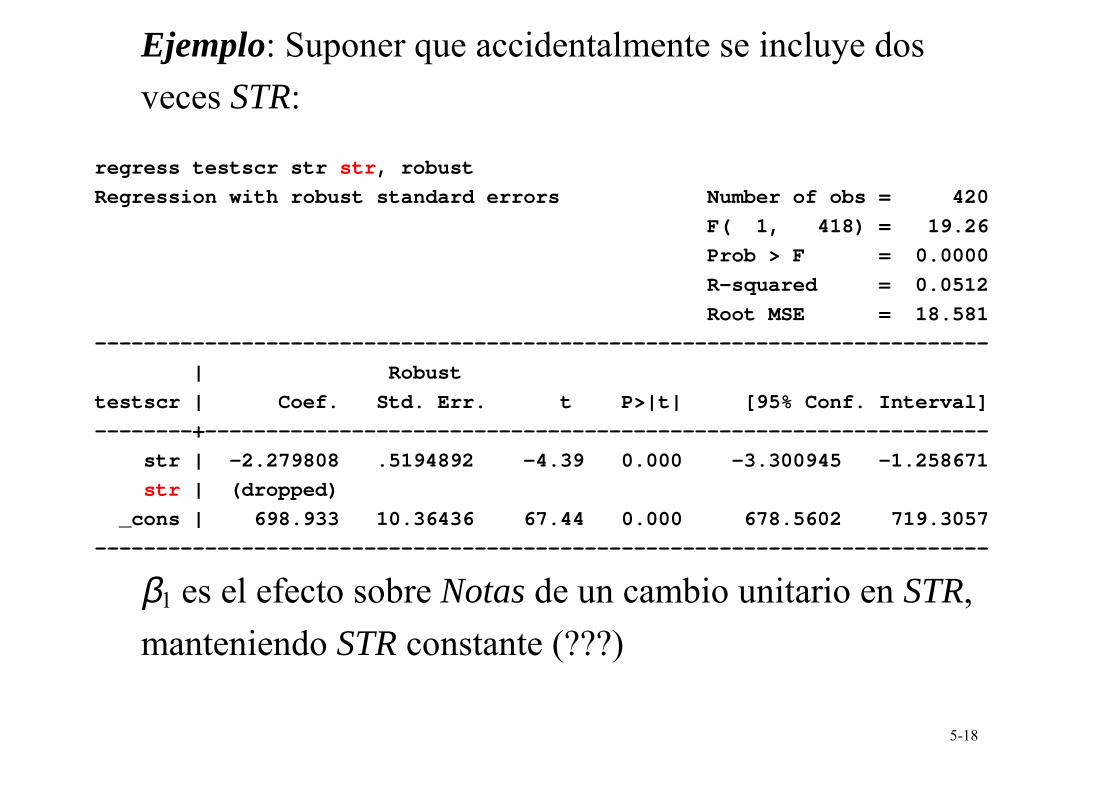
5-18
Ejemplo: Suponer que accidentalmente se incluye dos veces STR:
regress testscr str str, robust
Regression with robust standard errors Number of obs = 420
F( 1, 418) = 19.26
Prob > F = 0.0000
R-squared = 0.0512
Root MSE = 18.581
-------------------------------------------------------------------------
| Robust
testscr | Coef. Std. Err. t P>|t| [95% Conf. Interval]
--------+----------------------------------------------------------------
str | -2.279808 .5194892 -4.39 0.000 -3.300945 -1.258671
str | (dropped)
_cons | 698.933 10.36436 67.44 0.000 678.5602 719.3057
-------------------------------------------------------------------------
β1 es el efecto sobre Notas de un cambio unitario en STR, manteniendo STR constante (???)

5-19
Segundo ejemplo: Llevar a cabo la regresión de Notas sobre una constante, D, y B, donde: Di = 1 si STR ≤ 20, = 0 caso contrario; Bi = 1 si STR >20, = 0 caso contrario; por tanto, Bi = 1 � Di y existe multicolinealidad perfecta • ¿Existiría multicolinealidad perfecta si la ordenada en
el origen se eliminara de la regresión? • Multicolinealidad Perfecta generalmente refleja un
error en las definiciones de los regresores, o un problema en los datos

5-20
La Distribución Muestral del Estimador MCO (SW Section 5.5)
Considerando las cuatro Hipótesis del MCO, • 1
�β posee media β1 y var( 1�β ) inversamente
proporcional a n. • La distribución exacta es muy complicada
• 1�β es consistente: 1
�β p
→ β1 (LLN)
• 1 1
1
� �( )�var( )
Eβ β
β
− se distribuye aproximadamente como
N(0,1) (CLT) • Igualmente para 2
�β ,�, �kβ

5-21
Contrastes de Hipótesis e Intervalos de Confianza para un Coeficiente de la Regresión Múltiple
(SW Section 5.6)
• 1 1
1
� �( )�var( )
Eβ β
β
− se distribuye aproximadamente N(0,1)
• Por tanto, es posible contrastar hipótesis sobre β1 mediante el estadístico habitual t, y los intervalos de
confianza mediante { 1�β ± 1.96×SE( 1
�β )}.
• Igual para β2,�, βk. • 1
�β y 2�β , en general, no se distribuyen
independientemente� tampoco lo están sus estadísticos t.

5-22
Ejemplo: Datos de CA
(1) !Notas = 698.9 � 2.28¥STR (10.4) (0.52)
(2) !Notas = 696.0 � 1.10¥STR � 0.650PctEL (8.7) (0.43) (0.031)
• El coeficiente de STR en (2) representa el efecto sobre Notas de un cambio unitario en STR, manteniendo constante PctEL.
• El coeficiente de STR disminuye a la mitad • 95% intervalo de confianza para el coeficiente de STR
en (2) es {�1.10 ± 1.96×0.43} = (�1.95, �0.26)

5-23
Contrastes de Hipótesis Conjuntas (SW Section 5.7)
Expn = gastos por estudiante. Considerar el modelo de regresión poblacional:
Notasi = β0 + β1STRi + β2Expni + β3PctELi + ui Hipótesis nula: �los recursos escolares no importan,�
H0: β1 = 0 y β2 = 0
vs. H1: bien β1 ≠ 0 ó β2 ≠ 0 ó ambas

5-24
Notasi = β0 + β1STRi + β2Expni + β3PctELi + ui H0: β1 = 0 y β2 = 0
vs. H1: bien β1 ≠ 0 ó β2 ≠ 0 ó ambas
Una hipótesis conjunta especifica un valor para dos o más coeficientes; es decir, impone una restricción en dos o más coeficientes.
• Un contraste de �sentido común� consistiría en rechazar cuando cualesquiera de los estadísticos individuales t excediera de 1.96 en valor absoluto.
• ¡Pero el �sentido común� no funciona! El contraste resultante no posee el nivel de significación adecuado!

5-25
Explicación: Cálculo de la probabilidad de rechazar incorrectamente la hipótesis nula empleando el contraste de �sentido común� a partir de dos estadísticos t individuales. Para simplificar los cálculos, suponer que 1
�β y 2�β están independientemente
distribuidos. Sean t1 y t2 los estadísticos t:
t1 = 1
1
� 0�( )SE
ββ− y t2 = 2
2
� 0�( )SE
ββ−
El contraste de �sentido común� es: rechazar H0: β1 = β2 = 0 si |t1| > 1.96 y/o |t2| > 1.96 ¿Cuál es la probabilidad de que este contraste de �sentido común� rechace H0, cuando H0 es en realidad verdadera? (Debería ser 5%.)

5-26
Probabilidad de rechazar incorrectamente la nula =
0PrH [|t1| > 1.96 y/o |t2| > 1.96]
= 0
PrH [|t1| > 1.96, |t2| > 1.96]
+ 0
PrH [|t1| > 1.96, |t2| ≤ 1.96]
+ 0
PrH [|t1| ≤ 1.96, |t2| > 1.96] (eventos disjuntos)
= 0
PrH [|t1| > 1.96] × 0
PrH [|t2| > 1.96]
+ 0
PrH [|t1| > 1.96] × 0
PrH [|t2| ≤ 1.96]
+ 0
PrH [|t1| ≤ 1.96] × 0
PrH [|t2| > 1.96]
(t1, t2 son independientes por hipótesis)
= .05×.05 + .05×.95 + .95×.05
= .0975 = 9.75% � que no es el deseado 5%!!

5-27
El tamaño de un contraste es la tasa de rechazo bajo la hipótesis nula.
• ¡El tamaño del contraste de �sentido común� no es 5%!
• Su tamaño en realidad depende de la correlación entre t1 y t2 (y por tanto, de la correlación entre 1
�β y 2�β ).
Dos Soluciones: • Emplear un valor crítico diferente en este
procedimiento, � no 1.96 (este es el método de �Bonferroni� � ver App. 5.3)
• Emplear un contraste estadístico diferente, que contraste ambos β1 y β2 a la vez: el estadístico F.

5-28
El estadístico F El estadístico F contrasta todos los elementos de una hipótesis conjunta a la vez. Fórmula para el caso especial de la hipótesis conjunta β1 = β1,0 y β2 = β2,0 en una regresión con dos regresores:
F = 1 2
1 2
2 21 2 , 1 2
2,
�21�2 1
t t
t t
t t t tρρ
+ − −
donde 1 2,�t tρ estima la correlación entre t1 y t2.
Rechazar cuando F es �grande�

5-29
El estadístico F,
F = 1 2
1 2
2 21 2 , 1 2
2,
�21�2 1
t t
t t
t t t tρρ
+ − −
• El estadístico F es grande cuando t1 y/o t2 es grande • El estadístico F corrige (de forma adecuada) la
correlación entre t1 y t2. • La formula para más de dos β�s es complicada a
menos que se emplee álgebra matricial. • Proporciona al estadístico F una distribución
aproximada en muestras-grandes, que es�

5-30
Distribución de muestras grandes del estadístico F Considerar el caso especial en el que t1 y t2 son
independientes, por tanto 1 2,�t tρ
p→ 0; en muestras grandes
la fórmula se convierte en
F = 1 2
1 2
2 21 2 , 1 2
2,
�21�2 1
t t
t t
t t t tρρ
+ − −
≅ 2 21 2
1 ( )2
t t+
• Bajo la hipótesis nula, t1 y t2 poseen distribuciones normales estándar; en este caso especial, serían independientes
• La distribución de muestras grandes del estadístico F es la distribución de la media de dos variables aleatorias normales independientes al cuadrado.

5-31
La distribución chi-cuadrado con q grados de libertad ( 2
qχ ) se define como la distribución de la suma de q variables aleatorias independientes normales al cuadrado. En grandes muestras, F se distribuye como 2
qχ /q. Selección de valores críticos de 2
qχ /q q 5% valor crítico 1 3.84 (¿por qué?) 2 3.00 (el caso q=2 anterior) 3 2.60 4 2.37 5 2.21

5-32
p-valor empleando el estadístico F:
p-valor = probabilidad de la cola derecha de 2qχ /q a
partir del valor calculado del estadístico F. Implementación en STATA
Emplear el comando �test� después de la regresión Ejemplo: Contrastar la hipótesis conjunta de que los coeficientes poblacionales de STR y gastos por estudiante (expn_stu) son ambos cero contra la alternativa de que al menos uno de ellos es distinto de cero.
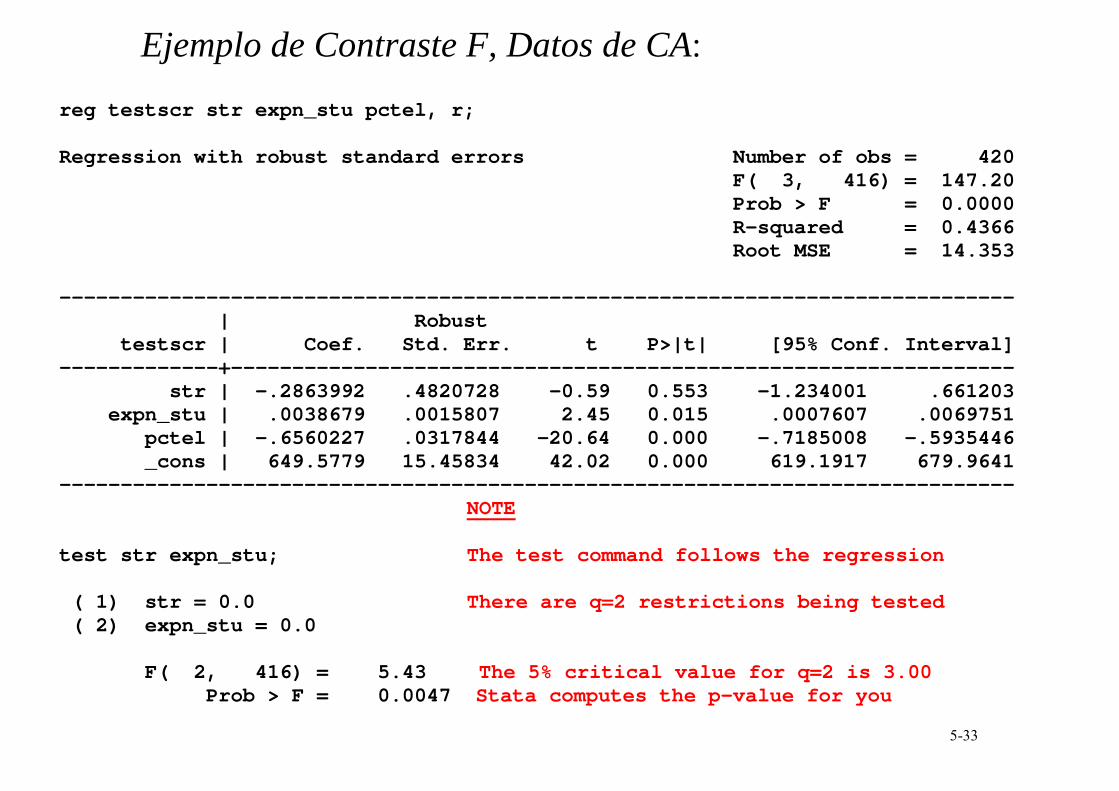
5-33
Ejemplo de Contraste F, Datos de CA: reg testscr str expn_stu pctel, r; Regression with robust standard errors Number of obs = 420 F( 3, 416) = 147.20 Prob > F = 0.0000 R-squared = 0.4366 Root MSE = 14.353 ------------------------------------------------------------------------------ | Robust testscr | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------- str | -.2863992 .4820728 -0.59 0.553 -1.234001 .661203 expn_stu | .0038679 .0015807 2.45 0.015 .0007607 .0069751 pctel | -.6560227 .0317844 -20.64 0.000 -.7185008 -.5935446 _cons | 649.5779 15.45834 42.02 0.000 619.1917 679.9641 ------------------------------------------------------------------------------ NOTE test str expn_stu; The test command follows the regression ( 1) str = 0.0 There are q=2 restrictions being tested ( 2) expn_stu = 0.0 F( 2, 416) = 5.43 The 5% critical value for q=2 is 3.00 Prob > F = 0.0047 Stata computes the p-value for you

5-34
Dos cuestiones (relacionadas) no consideradas: 1. Sólo versiones homoscedásticas del estadístico F 2. La distribución �F�
F con homoscedasticidad (“regla rápida”) Para calcular el estadístico F con homoscedasticidad:
• Emplear la formulas anteriores, pero empleando únicamente errores estándar homoscedásticos; o
• Realizar dos regresiones, una bajo la hipótesis nula (regresión �restringida�) y otra bajo la hipótesis alternativa (regresión �sin restringir�).
• El segundo método posee una fórmula sencilla

5-35
Regresiones “restringidas” y “sin restringir” Ejemplo: ¿son los coeficientes de STR y Expn cero? Regresión poblacional restringida (es decir, bajo H0):
Notasi = β0 + β3PctELi + ui (¿por qué?)
Regresión poblacional sin restringir (bajo H1): Notasi = β0 + β1STRi + β2Expni + β3PctELi + ui
• El número de restricciones bajo H0 = q = 2. • El ajuste será mayor (R2 mayor) en la regresión sin
restricciones (¿ por qué?)

5-36
¿Cuánto deberá incrementar el R2 para que los coeficientes en Expn y PctEL se consideren estadísticamente significativos?
Fórmula sencilla para el estadístico F con homoscedasticidad:
F = 2 2no restringido restringido
2no restringido no restringido
( ) /(1 ) /( 1)
R R qR n k
−− − −
donde: 2restringidoR = R2 en la regresión restringida 2no restringidoR = R2 en la regresión sin restringir
q = número de restricciones bajo la hipótesis nula kno restringido = número de regresores en la regresión sin restringir.

5-37
Ejemplo: Regresión restringida: !Notas = 644.7 �0.671PctEL, 2
restringidoR = 0.4149 (1.0) (0.032) Regresión sin restringir: !Notas = 649.6 � 0.29STR + 3.87Expn � 0.656PctEL (15.5) (0.48) (1.59) (0.032) 2
no restringidoR = 0.4366, kno restringido = 3, q = 2 por tanto:
F = 2 2no restringido restringido
2no restringido no restringido
( ) /(1 ) /( 1)
R R qR n k
−− − −
= (.4366 .4149) / 2(1 .4366) /(420 3 1)
−− − −
= 8.01

5-38
El estadístico F con homoscedasticidad
F = 2 2no restringido restringido
2no restringido no restringido
( ) /(1 ) /( 1)
R R qR n k
−− − −
• Rechaza cuando al añadir las dos variables se incrementa el R2 lo �suficiente� � es decir, cuando al añadir las dos variables se incrementa el ajuste de la regresión �suficientemente�
• Si los errores son homoscedásticos, entonces el estadístico F con homoscedasticidad posee una distribución 2
qχ /q en grandes muestras.
• Si los errores son heteroscedásticos, la distribución en grandes muestras es complicada y no una 2
qχ /q

5-39
La distribución F Si:
1. u1,�,un se distribuyen Normal; y 2. Xi se distribuye independientemente de ui (en
particular ui es homoscedástico) entonces el estadístico F con homoscedasticidad posee una distribución �Fq,n-k–1�, donde q = número de restricciones y k = número de regresores bajo la alternativa (modelo sin restringir).

5-40
La distribución Fq,n–k–1: • La distribución F está tabulada • Cuando n se hace grande, la distribución Fq,n-k–1 tiende
asintóticamente a la distribución 2qχ /q:
Fq,∞ es otro nombre para 2qχ /q
• Para q no muy elevado y n≥100, la distribución Fq,n–k–1
y la distribución 2qχ /q son prácticamente idénticas.
• Muchos programas de regresión calculan los p-valores del estadístico F empleando la distribución F (lo cual es
correcto si el tamaño muestral es ≥100)
• Encontraremos la distribución �F� en los trabajos empíricos publicados.

5-41
Digresión: Un poco de historia en estadística… • La teoría del estadístico F con homoscedasticidad y
las distribuciones de Fq,n–k–1 descansa en hipótesis muy fuertes no verosímiles (¿están los ingresos normalmente distribuidos?)
• Estos estadísticos datan de principios del Siglo XX, cuando �calcular� era un trabajo descriptivo y el número de observaciones escasas.
• El estadístico F y la distribución Fq,n–k–1 constituyeron dos avances significativos: una fórmula sencilla de calcular; un conjunto sencillo de tablas que se podían publicar de una vez, aplicarlas en múltiples ocasiones; y una justificación matemática precisa y elegante.

5-42
Un poco de historia de estadística, continuación… • Las hipótesis tan fuertes parecían un precio menor
comparado con la gran aportación. • Pero con los ordenadores actuales y muestras grandes
podemos emplear estadísticos F robustos a la
heteroscedasticidad y la distribución Fq,∞, que sólo
requiere las cuatro hipótesis de MCO. • Este legado histórico persiste en los programas de
ordenador, en los que los errores estándar con homoscedasticidad (y estadísticos F) constituyen la opción por defecto, y en los que los p-valores se calculan empleando la distribución Fq,n–k–1.

5-43
Resumen: Distribución de F con homoscedasticidad • Se justifican únicamente en situaciones muy estrictas
� más estrictas que realistas en la práctica habitual. • Con todo, son ampliamente empleadas. • Debería emplearse el F robusto, con valores críticos
2qχ /q (es decir, Fq,∞).
• Para n ≥ 100, la distribución F es esencialmente la distribución 2
qχ /q.
• Para pequeños n, la distribución F no tiene por qué ser una aproximación �mejor� a la distribución muestral del estadístico F � sólo si la condiciones fuertes son ciertas.

5-44
Resumen: contrastando hipótesis conjuntas • La aproximación de �sentido común� de rechazar si el
estadístico t excede 1.96 rechaza más del 5% de las veces bajo la hipótesis nula (el tamaño excede el nivel de significación deseado)
• El estadístico robusto F se encuentra construido en STATA (comando�test�); contrasta todas las restricciones a la vez.
• Para n grande, F se distribuye como 2qχ /q (= Fq,∞)
• El estadístico homoscedástico F es importante históricamente y es intuitivamente llamativo, pero inválido cuando existe heteroscedasticidad

5-45
Contraste de Restricciones Simples en los Coeficientes (SW Section 5.8)
Yi = β0 + β1X1i + β2X2i + ui, i = 1,�,n
Considerar las hipótesis nula y alternativa,
H0: β1 = β2 vs. H1: β1 ≠ β2
Esta nula impone una restricción simple (q = 1) sobre múltiples coeficientes � no es una hipótesis conjunta con múltiples restricciones (comparar con β1 = 0 y β2 = 0).

5-46
Dos métodos para contrastar restricciones simples con múltiples coeficientes:
1. transformar la regresión Reagrupar los regresores de forma que la restricción se convierta en una restricción sobre un coeficiente individual en una regresión equivalente
2. Realizar el contraste directamente
Algunos programas (software), incluyendo STATA, permiten contrastar restricciones empleando múltiples coeficientes directamente

5-47
Metodo 1: Transformar la regresión
Yi = β0 + β1X1i + β2X2i + ui
H0: β1 = β2 vs. H1: β1 ≠ β2
Sumar y restar β2X1i:
Yi = β0 + (β1 � β2) X1i + β2(X1i + X2i) + ui ó
Yi = β0 + γ1 X1i + β2Wi + ui donde γ1 = β1 � β2 Wi = X1i + X2i

5-48
(a) Sistema original: Yi = β0 + β1X1i + β2X2i + ui
H0: β1 = β2 vs. H1: β1 ≠ β2
(b) Sistema transformado:
Yi = β0 + γ1 X1i + β2Wi + ui donde γ1 = β1 � β2 y Wi = X1i + X2i por tanto
H0: γ1 = 0 vs. H1: γ1 ≠ 0
El problema de contrastar es ahora una cuestión simple:
Contrastar si γ1 = 0 en la especificación (b).

5-49
Método 2: Realizar el contraste directamente
Yi = β0 + β1X1i + β2X2i + ui
H0: β1 = β2 vs. H1: β1 ≠ β2
Ejemplo: Notasi = β0 + β1STRi + β2Expni + β3PctELi + ui Para contrastar con STATA si β1 = β2:
regress testscore str expn pctel, r
test str=expn

5-50
Regiones de Confianza con Múltiples Coeficientes (SW Section 5.9)
Yi = β0 + β1X1i + β2X2i + � + βkXki + ui, i = 1,�,n ¿Cómo es una región de confianza conjunta de β1 y β2? Una región de confianza del 95% es: • Una función conjunto de los datos que contiene el
verdadero parámetro(s) en el 95% de hipotéticas muestras repetidas.
• El conjunto de valores de los parámetros que no pueden rechazarse para un nivel de significación del 5% cuando se consideran como la hipótesis nula.

5-51
La tasa de cobertura de una región de confianza es la probabilidad de que la región de confianza contenga los verdaderos valores de los parámetros Una región de confianza de �sentido común� es la unión de los intervalos de confianza del 95% de β1 y β2, es decir, el rectángulo:
{ 1�β ± 1.96×SE( 1
�β ), 2�β ± 1.96 ×SE( 2
�β )}
• ¿Cuál es la tasa de cobertura de esta región de confianza?
• ¿Es la tasa de cobertura igual al nivel de confianza deseado del 95%?

5-52
Tasa de Cobertura de �sentido común�:
Pr[(β1, β2) ∈ { 1�β ± 1.96×SE( 1
�β ), 2�β 1.96 ± ×SE( 2
�β )}]
= Pr[ 1�β � 1.96SE( 1
�β ) ≤ β1 ≤ 1�β + 1.96SE( 1
�β ),
2�β � 1.96SE( 2
�β ) ≤ β2 ≤ 2�β + 1.96SE( 2
�β )]
= Pr[�1.96≤ 1 1
1
��( )SE
β ββ
− ≤1.96, �1.96≤ 2 2
2
��( )SE
β ββ
− ≤1.96]
= Pr[|t1| ≤ 1.96 y |t2| ≤ 1.96]
= 1 � Pr[|t1| > 1.96 y/o |t2| > 1.96] ≠ 95% !
¿Por qué? ¡El tamaño no iguala el nivel de significación!

5-53
La probabilidad de rechazar incorrectamente la nula =
0PrH [|t1| > 1.96 y/o |t2| > 1.96]
= 0
PrH [|t1| > 1.96, |t2| > 1.96]
+ 0
PrH [|t1| > 1.96, |t2| ≤ 1.96]
+ 0
PrH [|t1| ≤ 1.96, |t2| > 1.96] (eventos disjuntos)
= 0
PrH [|t1| > 1.96] × 0
PrH [|t2| > 1.96]
+ 0
PrH [|t1| > 1.96] × 0
PrH [|t2| ≤ 1.96]
+ 0
PrH [|t1| ≤ 1.96] × 0
PrH [|t2| > 1.96]
(si t1, t2 son independientes)
= .05×.05 + .05×.95 + .95×.05
= .0975 = 9.75% � no es el deseado 5%!!

5-54
Por el contrario, use un contraste cuyo tamaño sea igual al nivel de significación: Sea F(β1,0,β2,0) el estadístico robusto F para contrastar la hipótesis de que β1 = β1,0 y β2 = β2,0: 95% región de confianza = {β1,0, β2,0: F(β1,0, β2,0) < 3.00}
• 3.00 es el valor crítico al 5% de la distribución F2,∞
• Esta región posee una tasa de cobertura del 95% porque el contaste sobre el que se realiza posee tamaño 5%.

5-55
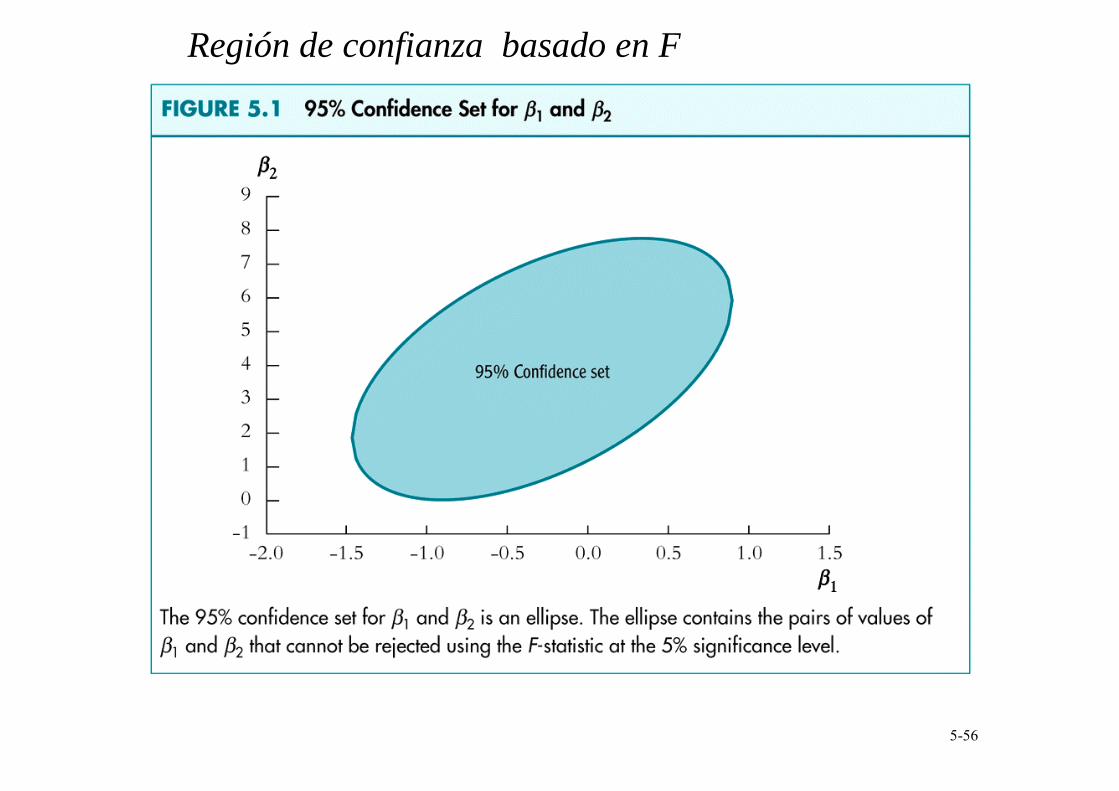
La región de confianza del estadístico F es una elipse
{β1, β2: F = 1 2
1 2
2 21 2 , 1 2
2,
�21�2 1
t t
t t
t t t tρρ
+ − −
≤ 3.00}
Por tanto,
F = 1 2
1 2
2 21 2 , 1 22
,
1 �2�2(1 ) t t
t t
t t t tρρ
× + − −
1 2
1 2
2,
2 2
2 2,0 1 1,0 1 1,0 2 2,0,
2 1 1 2
1�2(1 )
� � � ��2� � � �( ) ( ) ( ) ( )
t t
t tSE SE SE SE
ρ
β β β β β β β βρ
β β β β
= ×−
− − − − + +
Esta es una forma cuadrática en β1,0 y β2,0 � la frontera del conjunto F = 3.00 es una elipse.
5-56
Región de confianza basado en F

5-57
El R2, SER, y 2R en la Regresión Múltiple
(SW Section 5.10)
Real = predicción + residuo: Yi = �iY + �iu
Al igual que en la regresión con un único regresor, el SER (y el RMSE) es una medida de la dispersión de las Y�s alrededor de la recta de regresión:
SER = 2
1
1 �1
n
ii
un k =− − ∑

5-58
El R2 es la fracción de la varianza explicada:
R2 = ESSTSS
= 1 SSRTSS
− ,
donde ESS = 2
1
� �( )n
ii
Y Y=
−∑ , SSR = 2
1
�n
ii
u=∑ , y TSS =
2
1
( )n
ii
Y Y=
−∑ � en una regresión con un regresor.
• El R2 aumenta cuando se añade otro regresor • El 2R corrige este problema �penalizando� la
inclusión de otro regresor:
2R = 111
n SSRn k TSS
− − − − so 2R < R2

5-59
¿Cómo interpretar el R2 y 2R ? • Un elevado R2 (o 2R ) significa que los regresores
explican la variación en Y. • Un elevado R2 (o 2R ) no significa que se haya
eliminado el sesgo de variables omitidas. • Un elevado R2 (o 2R ) no significa que tengamos un
estimador insesgado del efecto causal (β1). • Un elevado R2 (o 2R ) no significa que las variable
incluidas sean estadísticamente significativas � esto debe determinarse empleando contrastes de hipótesis.

5-60
Ejemplo: Estudio más detallado de los datos de CA (SW Section 5.11, 5.12)
Un enfoque general para seleccionar variables y especificación de modelos:
• Especificar un modelo de �base� • Especificar un rango plausible de modelos
alternativos, que incluyan variables alternativas candidatas.
• ¿Cambian estas variables el β1 de interés? • ¿Es la candidata estadísticamente significativa? • Emplear juicio razonado, no una �receta� mecánica �

5-61
Variables que nos gustaría ver en los datos de CA: Características escolares:
• Cociente estudiantes-profesor • Calidad del profesorado • ordenadores por estudiante • diseño curricular�
Características de los Estudiantes: • Nivel de inglés • Disponibilidad de actividades extracurriculares • Ambiente de aprendizaje en casa • nivel de educación de los padres �

5-62
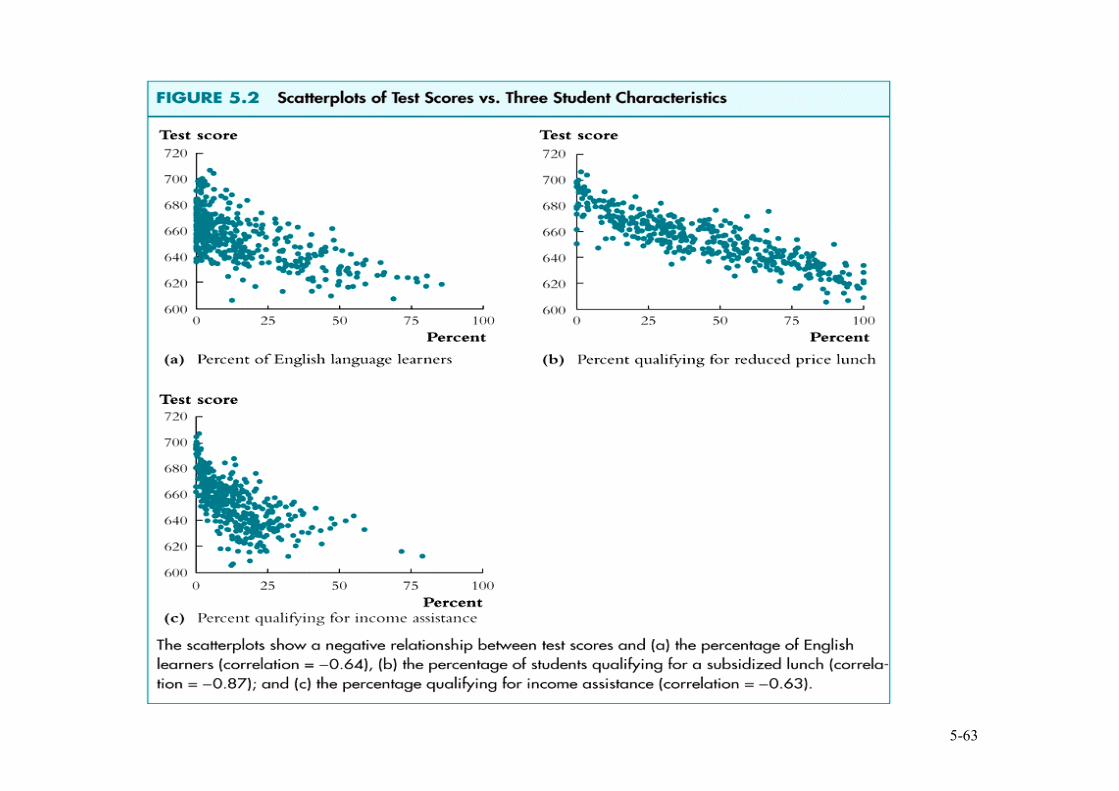
Variables encontradas en los datos de CA:
• cociente estudiantes-profesor (STR) • porcentaje de estudiantes que tienen el inglés como
segunda lengua (PctEL) • porcentaje de personas elegibles para el subsidio de
comida • porcentaje de ayudas públicas de renta • renta promedio del distrito
5-63

5-64
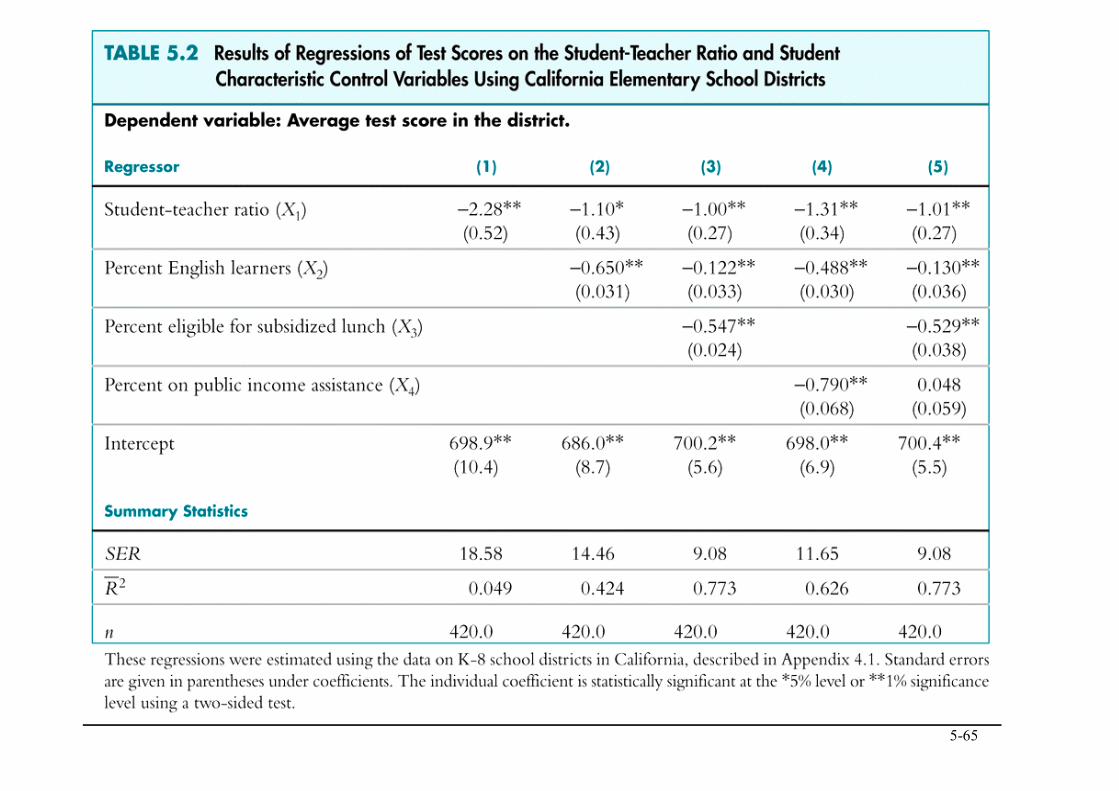
Digresión: presentación de los resultados en una tabla • Hacer un listado de todas las ecuaciones de regresión
puede resultar confuso cuando hay muchos regresores y muchas ecuaciones.
• Tablas con los resultados de forma compacta. • Información a incluir: ! Variables (dependiente e independientes) ! coeficientes estimados ! errores estándar ! resultados de los contrastes F pertinentes ! alguna medida de ajuste ! número de observaciones
5-65

5-66
Resumen: Regresión Múltiple • La regresión múltiple nos permite estimar el efecto en
Y de un cambio en X1, manteniendo X2 constante. • Si una variable es observable, evitaremos el sesgo de
variables omitidas incluyéndola en la regresión. • No hay una receta sencilla para decidir qué variables
incluir en una regresión � emplear sentido común. • Una aproximación consiste en especificar un modelo
de base � fundado en razonamientos a-priori � posteriormente explorar la sensibilidad de las estimaciones con especificaciones alternativas.