relational macros for transfer in reinforcement learning lisa torrey, jude shavlik, trevor walker...
TRANSCRIPT

Relational Macros for Transfer in Reinforcement
LearningLisa Torrey, Jude Shavlik, Trevor Walker
University of Wisconsin-Madison, USA
Richard MaclinUniversity of Minnesota-Duluth, USA

Transfer Learning ScenarioTransfer Learning Scenario
Agent learns Task A
Agent encounters related Task B
Agent recalls relevant knowledge from Task A
Agent uses this knowledge to learn Task B quickly

Goals of Transfer LearningGoals of Transfer Learning
Learning curves in the target task:
perf
orm
ance
training
with transferwithout transfer
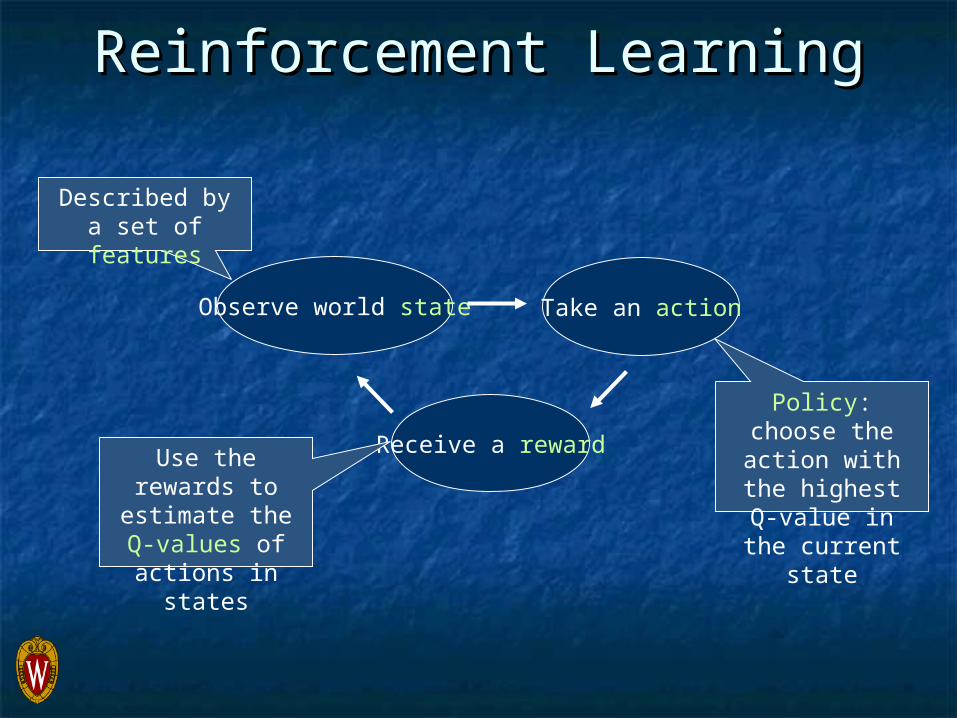
Reinforcement LearningReinforcement Learning
Take an actionObserve world state
Receive a reward
Policy: choose the action with the highest Q-value in the current state
Use the rewards to
estimate the Q-values of actions in
states
Described by a set of features
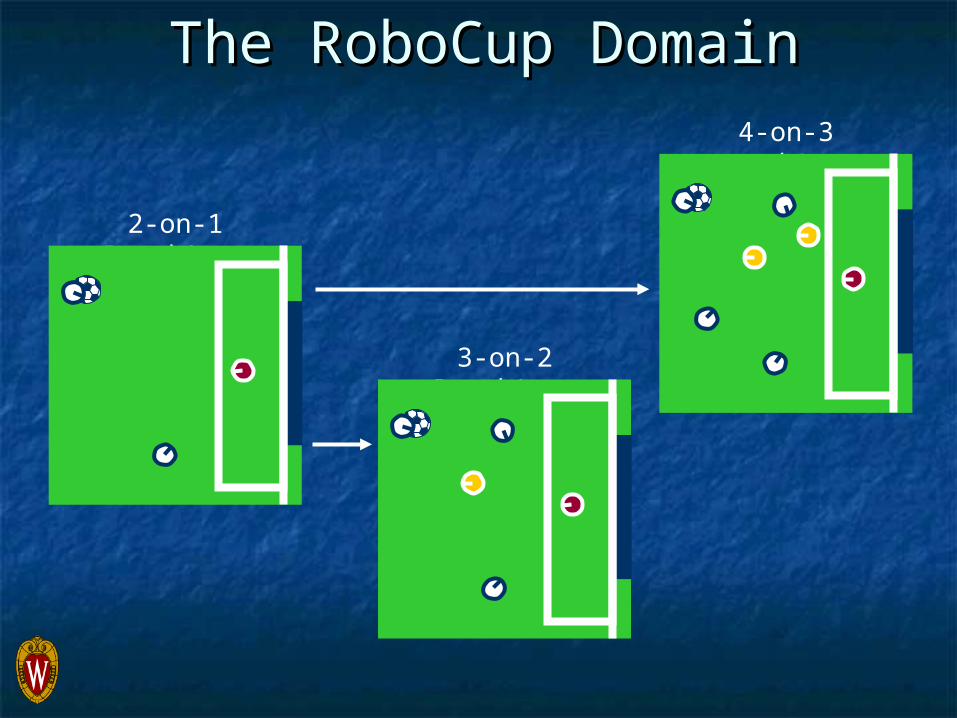
The RoboCup DomainThe RoboCup Domain
2-on-1 BreakAway
3-on-2 BreakAway
4-on-3 BreakAway

Transfer in Reinforcement Transfer in Reinforcement LearningLearning
Related workRelated work Model reuse (Taylor & Stone 2005)Model reuse (Taylor & Stone 2005) Policy reuse (Fernandez & Veloso 2006)Policy reuse (Fernandez & Veloso 2006) Option transfer (Perkins & Precup 1999)Option transfer (Perkins & Precup 1999) Relational RL (Driessens et al. 2006)Relational RL (Driessens et al. 2006)
Our previous workOur previous work Policy transfer (Torrey et al. 2005)Policy transfer (Torrey et al. 2005) Skill transfer (Torrey et al. 2006)Skill transfer (Torrey et al. 2006)
Now we learn a strategy instead of
individual skills
Copy the Q-function
Learn rules that describe when to take
individual actions

Representing a Multi-step Representing a Multi-step StrategyStrategy
A A relational macrorelational macro is a finite-state machine is a finite-state machine NodesNodes represent internal states of agent in represent internal states of agent in
which limited independent policies applywhich limited independent policies apply ConditionsConditions for transitions and actions are in for transitions and actions are in
first-order logicfirst-order logic
Really these are rule sets, not just single
rules
hold ← true pass(Teammate) ← isOpen(Teammate)
isClose(Opponent)
allOpponentsFar
The learning agent jumps between
players

Our Proposed MethodOur Proposed Method
Learn a Learn a relational macrorelational macro that describes that describes a successful strategy in the source taska successful strategy in the source task
Execute the macro in the target task to Execute the macro in the target task to demonstratedemonstrate the successful strategy the successful strategy
Continue learning the target task with Continue learning the target task with standard RL after the demonstrationstandard RL after the demonstration

Learning a Relational MacroLearning a Relational Macro
We use We use ILPILP to learn macros to learn macros Aleph: top-down search in a bottom Aleph: top-down search in a bottom
clauseclause Heuristic and randomized searchHeuristic and randomized search Maximize F1 scoreMaximize F1 score
We learn a macro in We learn a macro in two phasestwo phases The action sequence (node structure)The action sequence (node structure) The rule sets for actions and transitionsThe rule sets for actions and transitions

Learning Macro StructureLearning Macro Structure
Objective: find an Objective: find an action patternaction pattern that that separates good and bad gamesseparates good and bad games
macroSequence(Game) macroSequence(Game) ←←
actionTaken(Game, StateA, move, ahead, StateB),actionTaken(Game, StateA, move, ahead, StateB),
actionTaken(Game, StateB, pass, _, StateC),actionTaken(Game, StateB, pass, _, StateC),
actionTaken(Game, StateC, shoot, _, gameEnd).actionTaken(Game, StateC, shoot, _, gameEnd).
pass(Teammate)move(ahead) shoot(GoalPart)

Learning Macro ConditionsLearning Macro Conditions
Objective: describe when Objective: describe when transitionstransitions and and actionsactions should be taken should be taken For the
transition from move to passtransition(State) transition(State) ←←
feature(State, distance(Teammate, goal)) < 15.feature(State, distance(Teammate, goal)) < 15.
For the policy in the pass
nodeaction(State, pass(Teammate)) action(State, pass(Teammate)) ←←feature(State, angle(Teammate, me, Opponent)) > 30.feature(State, angle(Teammate, me, Opponent)) > 30.
pass(Teammate)move(ahead) shoot(GoalPart)

Examples for ActionsExamples for Actions
Game 1: move(ahead) pass(a1)shoot(goalRight)Game 2: move(ahead) pass(a2)shoot(goalLeft)
Game 3: move(right) pass(a1)
Game 4: move(ahead) pass(a1)shoot(goalRight)
scoring
non-scoring
positiv
e
negative
pass(Teammate)move(ahead) shoot(GoalPart)

Examples for TransitionsExamples for Transitions
Game 1: move(ahead) pass(a1)shoot(goalRight)Game 2: move(ahead) move(ahead)
shoot(goalLeft)
Game 3: move(ahead) pass(a1)shoot(goalRight)
scoring
non-scoring
positiv
e
negative
pass(Teammate)move(ahead) shoot(GoalPart)

Transferring a MacroTransferring a Macro
DemonstrationDemonstration Execute the macro strategy to get Q-value Execute the macro strategy to get Q-value
estimatesestimates Infer low Q-values for actions not taken by macroInfer low Q-values for actions not taken by macro Compute an initial Q-function with these examplesCompute an initial Q-function with these examples Continue learning with standard RLContinue learning with standard RL
Advantage: potential for large immediate Advantage: potential for large immediate jump in performancejump in performance
Disadvantage: risk that agent will blindly Disadvantage: risk that agent will blindly follow an inappropriate strategyfollow an inappropriate strategy

ExperimentsExperiments
Source task: 2-on-1 BreakAwaySource task: 2-on-1 BreakAway 3000 existing games from the learning curve3000 existing games from the learning curve Learn macros from 5 separate runsLearn macros from 5 separate runs
Target tasks: 3-on-2 and 4-on-3 Target tasks: 3-on-2 and 4-on-3 BreakAwayBreakAway Demonstration period of 100 gamesDemonstration period of 100 games Continue training up to 3000 gamesContinue training up to 3000 games Perform 5 target runs for each source runPerform 5 target runs for each source run
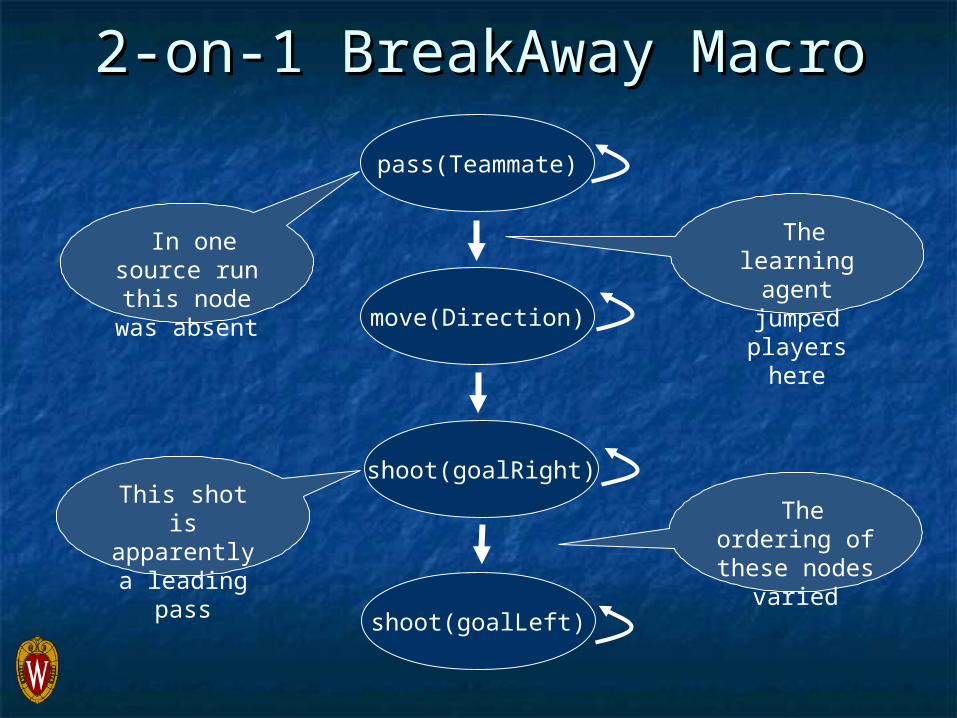
2-on-1 BreakAway Macro2-on-1 BreakAway Macro
pass(Teammate)
move(Direction)
shoot(goalRight)
shoot(goalLeft)
In one source run this node
was absent
The ordering of these nodes
varied
This shot is apparently a leading pass
The learning agent
jumped players here
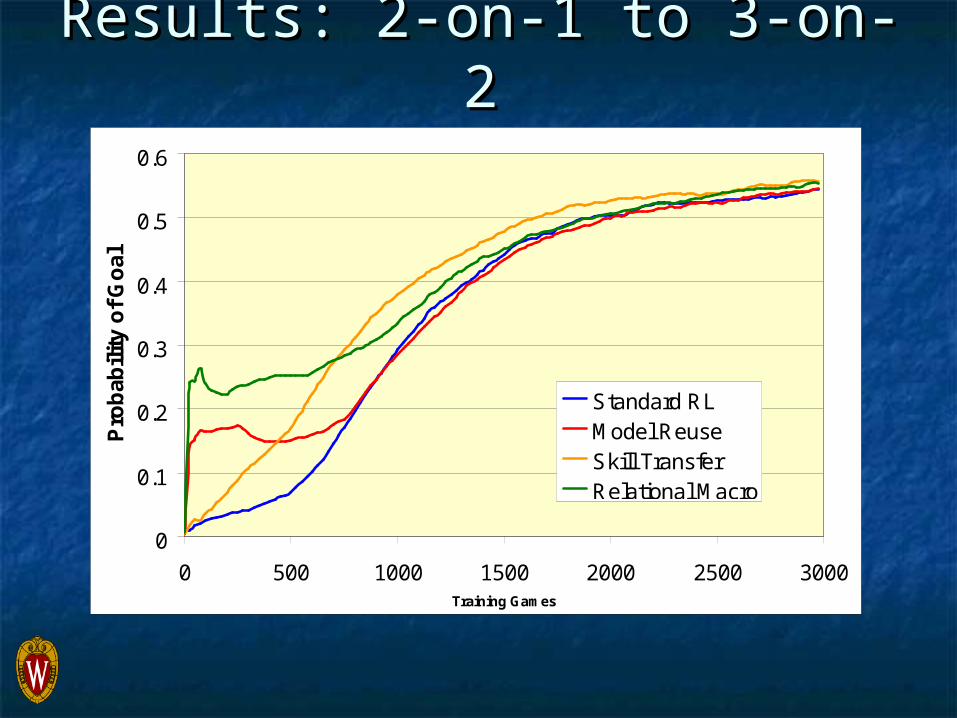
Results: 2-on-1 to 3-on-2Results: 2-on-1 to 3-on-2
0
0.1
0.2
0.3
0.4
0.5
0.6
0 500 1000 1500 2000 2500 3000Training Games
Pro
bab
ility
of
Go
al
Standard RLModel ReuseSkill TransferRelational Macro
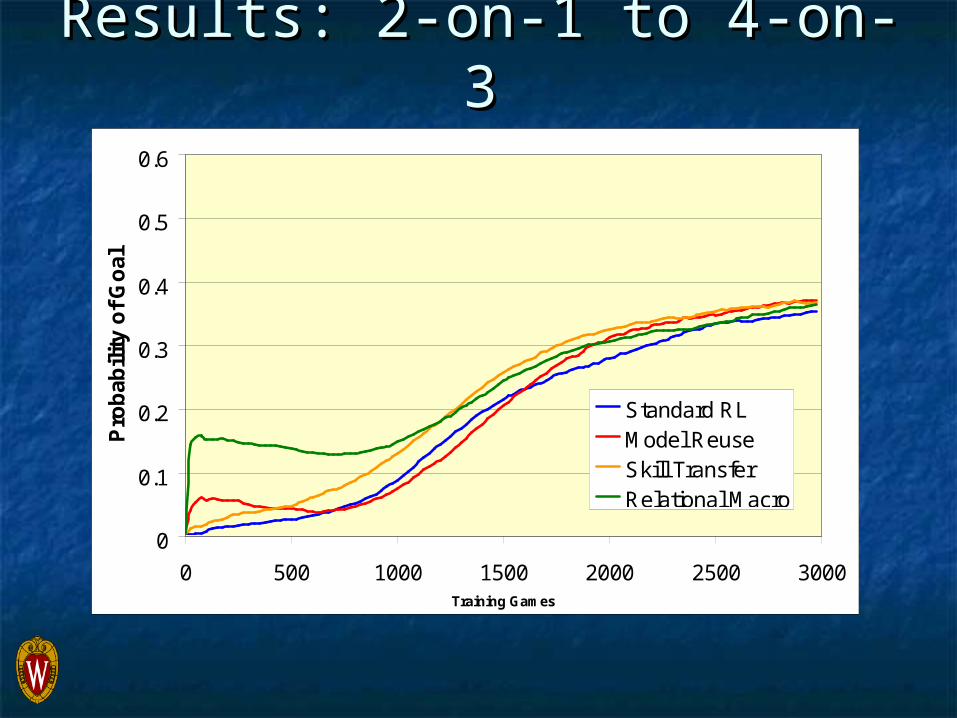
Results: 2-on-1 to 4-on-3Results: 2-on-1 to 4-on-3
0
0.1
0.2
0.3
0.4
0.5
0.6
0 500 1000 1500 2000 2500 3000Training Games
Pro
bab
ility
of
Go
al
Standard RLModel ReuseSkill TransferRelational Macro

ConclusionsConclusions
This transfer method can significantly This transfer method can significantly improve initial target-task performanceimprove initial target-task performance
It can handle new elements being added It can handle new elements being added to the target task, but not new objectivesto the target task, but not new objectives
It is an aggressive approach that is a good It is an aggressive approach that is a good choice for tasks with similar strategieschoice for tasks with similar strategies

Future WorkFuture Work
Alternative ways to apply relational Alternative ways to apply relational macros in the target taskmacros in the target task Keep the initial benefitsKeep the initial benefits Alleviate risks when tasks differ moreAlleviate risks when tasks differ more
Alternative ways to make decisions Alternative ways to make decisions about steps within macrosabout steps within macros Statistical relational learning Statistical relational learning
techniquestechniques

AcknowledgementsAcknowledgements
DARPA Grant HR0011-04-1-0007DARPA Grant HR0011-04-1-0007
DARPA IPTO contract FA8650-06-C-DARPA IPTO contract FA8650-06-C-76067606
Thank You

Rule scoresRule scores
Each Each transitiontransition and and actionaction has a set of has a set of rules, one or more of which may firerules, one or more of which may fire
If multiple rules fire, we obey the one If multiple rules fire, we obey the one with the highest with the highest scorescore
The score of a rule is the The score of a rule is the probabilityprobability that that following it leads to a successful gamefollowing it leads to a successful game
Score = Score = # source-task games that followed the rule and scored# source-task games that followed the rule and scored # source-task games that followed the rule# source-task games that followed the rule