report #1 by team: green ensemble ausdm 2009 ensemble analytical challenge: rules, objectives, and...
TRANSCRIPT

Report #1By Team:
Green Ensemble
AusDM 2009 ENSEMBLE Analytical Challenge: Rules, Objectives, and Our
Approach

What is it all about?The purpose of this challenge is to
somehow combine the individual models to give the best overall model performance.
We call it Ensembling.

What do we mean by Ensembling?Ensembling, Blending, Committee of
Experts are various terms used for the process of improving predictive accuracy by combining models built with different algorithms, or the same algorithm but with different parameter settings. It is a technique frequently used to win predictive modelling competitions, but how it is actually achieved in practice maybe somewhat arbitrary.

Why Ensembling?Remember NETFLIX prize?Over 1,000 sets of predictions have been
providedTaking the mean prediction over all these
models is only slightly worse than the best individual model.
The mean of the best 10 models is significantly better than any individual model.

That’s why we are after Ensembling!

Data (1/2)• RMSE Small - 200 sets of predictions for
15,000 ratings. • AUC Small - 200 sets of prediction for 15,000
ratings. • RMSE Medium - 250 sets of predictions for
20,000 ratings. • AUC Medium - 250 sets of predictions for
20,000 ratings.• RMSE Large - 1,151 sets of predictions for
50,000 ratings. • AUC Large - 1,151 sets of predictions for
50,000 ratings.

Data (2/2)• the predicted ratings values have been
converted to integers by rounding to 3 decimal places and multiplying by 1,000.
1000<Prediction<5000• Targets = { 1000,2000,3000,4000,5000}
for RMSE challenge• Targets={-1,1} for AUC challenge • Each of data sets is split into 2 files, one for
Training (Target/Rating provided) and one for Scoring (Target/Rating withheld)

Our First ApproachWeighted Averaging (1/3)
A: 200 models, 15000 movies ratings predictions
Target: 15000 movies real ratings
How to find such weights?Our approach is to find vector w such as:

Weighted Averaging (2/3)A is not square, so we must find pseudo-
Inverse of A. It’s easy in MATLAB. w= A\target . W is Least-
Square solution of previous equation.Formal mathematical problem:

Weighted Averaging (3/3)The result is above the baselines, good for
us!RMSE = 882.81593589302The problem is, it’s so overfitted to Train
data set. Also We don’t use any information of Test data set. Just multiply w to test matric and get the results.

Our Second ApproachEnsemble Selection(1/3)• Implemented from this paper:Ensemble Selection from Libraries of Models[R.Caruana, A.Niculesco-Mizil, Proceedings of
ICML’04]• Winner team of KDD Orange cup also used
this method.(IBM team)• Just like weighted averaging but they find
weights by hill climbing search. Search for models which improve RMSE.

Ensemble Selection(2/3) ensemble selection procedure
1. Start with the empty ensemble. Initialized with N best models ( N ~5-25)
2. Select a ranodm Bag of models in library. Add to the ensemble the model in the Bag that maximizes the ensemble’s performance to the error metric on a hillclimb (validation) set.
3. Repeat Step 2 for a fixed number of iterations or Until all the models have been used.
4. Return the ensemble from the nested set of ensembles that has
maximum performance on the hillclimb (validation) set.

Ensemble Selection(3/3)• It’s a fast search but we have better
searchs than just simple hill climbing! • RMSE slightly improved. • RMSE = 882.31317521497• Author argued their method have better
performance than many methods such as : SVM, ANN, BAG-DT, KNN,BST-DT.
• We compare Ensemble Selection and ANN in our problem. They were right!

Some Statistics about Data set

How much good are these 200 models?Predicting 1000s

How much good are these 200 models?Predicting 2000s

How much good are these 200 models?Predicting 3000s

How much good are these 200 models?Predicting 4000s

How much good are these 200 models?Predicting 5000s
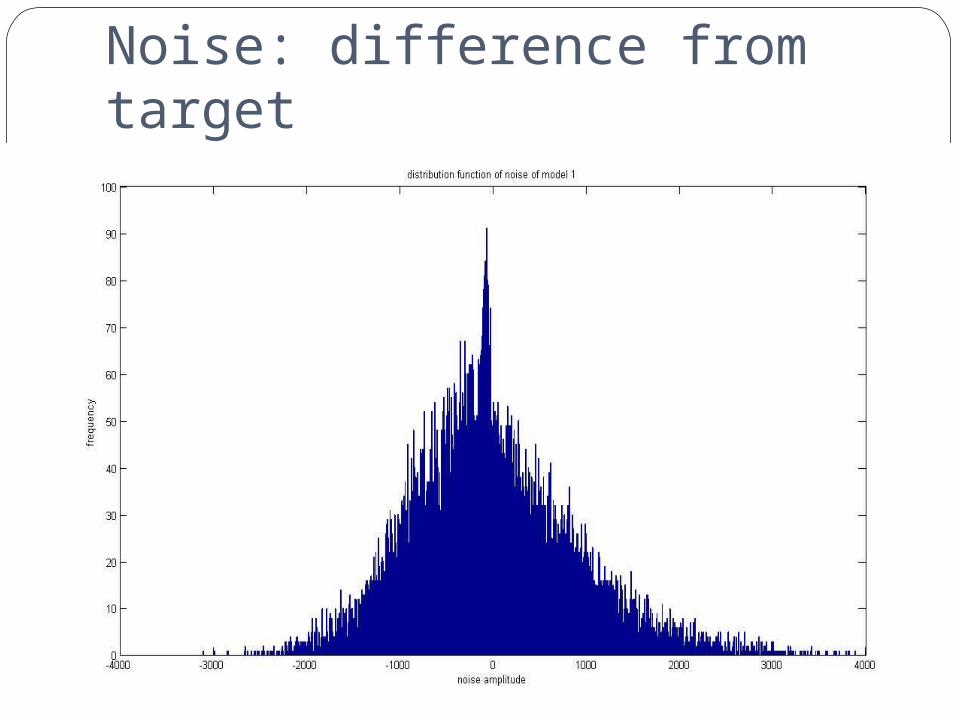
Noise: difference from target

Noise: difference from target

Some other Ideas• Discritize predictions, then find frequent
motifs of each set of movies ranked 1000 to 5000.
• Using GA to search for better weights• Using Estimation theory. (noises are
gaussian or semi gaussin )• Using some metrics for each row of test
data set to determine its distance to some selected rows of data sets. Metrics could be RMSE,KL divergence, cos(θ) ,…

Green Ensemble E.Khoddam MohammadiM.J.MahzoonA.AskariA.Ghaffari Nejad

Thanks for your attention.