reporting on smerp data challenge - dcu school of...
TRANSCRIPT

Reporting on SMERP Data Challenge
Speaker: Saptarshi Ghosh
Department of CST,Indian Institute of Engineering Science and Technology Shibpur, India
Department of CSE,Indian Institute of Technology Khargpur, India

Outline
1 Introduction and Motivation
2 The Test Collection
3 The Challenges
4 Task 1 : Text Retrieval
5 Task 2 : Summarization

Role on Microblogs during Disasters
Lot of useful situational information posted on microblogging sites likeTwitter during disaster events
Challenges in extracting the important information
Important information obscured amongst lot of sentiment, opinion, ...Microblogs are very short and written informallyLarge variation in vocabulary of crowdsourced content

Motivation for the track
Develop a standard data collection for evaluating IR and summarizationmethodologies for microblog retrieval during disasters
Inspired by TREC microblog track (which does not consider disaster scenario)

Outline
1 Introduction and Motivation
2 The Test Collection
3 The Challenges
4 Task 1 : Text Retrieval
5 Task 2 : Summarization

The Microblog dataset
Collected tweets posted during two weeks after the devastating earthquake inItaly in August 2016
Used Twitter Search API with the keyword ‘italy’
About 180,000 tweets in English collected
Removed duplicates and near-duplicates based on presence of common words
Final dataset of 72,220 tweets

Topics for retrieval
Consulted members of NGOs who work in disaster-affected regions – whatare the typical information requirements during a disaster relief operation?
Identified 4 broad information requirements (topics)
SMERP-T1: What resources are availableSMERP-T2: What resources are requiredSMERP-T3: What infrastructure damage, restoration and casualties arereportedSMERP-T4 : What are the rescue activities of various NGOs / governmentorganizations

Examples of relevant tweets
SMERP-T1: What resources are available
Long queues to donate blood after Earthquake strikes Central Italy.#PrayForItaly [url]Earthquake in Central Italy, collection of food in the supermarkets of the ValledAosta
SMERP-T2: What resources are required
#earthquake Avis Rieti hospital Avis ask for blood donors, all blood typeItaly Earthquake: ’No electricity or food’ - Sabarina lives 8 miles from theepicentre [url] via @audioBoom
SMERP-T3: What infrastructure damage, restoration and casualties arereported
A 6.1 quake hit Italy, damaged buildings near Rieti & ppl fleeing homes[url]Death toll rises to 159, over 360 injured after deadly earthquake rocks centralItaly, Army mobilized in rescue

Outline
1 Introduction and Motivation
2 The Test Collection
3 The Challenges
4 Task 1 : Text Retrieval
5 Task 2 : Summarization

The Challenges
Tasks
Task 1 : Text Retrieval
Task 2 : Summarization

The Challenges : Levels
Levels
Level 1 : The tweets collected during the first day (24 hours) – 52,469tweets given
Level 2 : The tweets collected during the second day (24 hours) – 19,751and gold standard of Level 1 given

The Challenges : Format
Participants given
The tweet-ids, and a Python script to download the tweets using Twitter API
The four topics in the format conventionally used for TREC topics (number,title, description, narrative)

The Challenges : Types of methodologies considered
Full-Automatic – No manual intervention at any stage
Semi-automatic – manual intervention involved in query formulation stage(but not in the retrieval/summarization stage)

Outline
1 Introduction and Motivation
2 The Test Collection
3 The Challenges
4 Task 1 : Text Retrieval
5 Task 2 : Summarization

Task 1 : Evaluation
5 teams participated
Runs submitted :
Level 1 : 10 runs; 2 automatic, 8 semi-automaticLevel 2 : 14 runs; 2 automatic, 12 semi-automatic
Primary evaluation measure – Bpref ; ties broken by MAP.
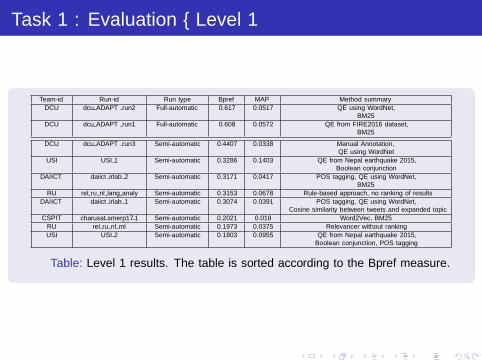
Task 1 : Evaluation – Level 1
Team-id Run-id Run type Bpref MAP Method summaryDCU dcu ADAPT run2 Full-automatic 0.617 0.0517 QE using WordNet,
BM25
DCU dcu ADAPT run1 Full-automatic 0.608 0.0572 QE from FIRE2016 dataset,BM25
DCU dcu ADAPT run3 Semi-automatic 0.4407 0.0338 Manual Annotation,QE using WordNet
USI USI 1 Semi-automatic 0.3286 0.1403 QE from Nepal earthquake 2015,Boolean conjunction
DAIICT daiict irlab 2 Semi-automatic 0.3171 0.0417 POS tagging, QE using WordNet,BM25
RU rel ru nl lang analy Semi-automatic 0.3153 0.0678 Rule-based approach, no ranking of results
DAIICT daiict irlab 1 Semi-automatic 0.3074 0.0391 POS tagging, QE using WordNet,Cosine similarity between tweets and expanded topic
CSPIT charusat smerp17 1 Semi-automatic 0.2021 0.018 Word2Vec, BM25
RU rel ru nl ml Semi-automatic 0.1973 0.0375 Relevancer without ranking
USI USI 2 Semi-automatic 0.1803 0.0955 QE from Nepal earthquake 2015,Boolean conjunction, POS tagging
Table: Level 1 results. The table is sorted according to the Bpref measure.

Task 1 : Evaluation – Level 2
Team-id Run-id Run type Bpref MAP Method summaryDCU dcu ADAPT run2 Full-automatic 0.7767 0.06 Same as Level 1
DCU dcu ADAPT run1 Full-automatic 0.6861 0.0627 Same as Level 1
RU ru nl ml0 Semi-automatic 0.4724 0.1295 Relevancer with ranking
RU rel ru nl lang analy1 Semi-automatic 0.3846 0.1323 Rule-based approach, results ranked
RU rel ru nl lang analy0 Semi-automatic 0.3846 0.0853 Rule-based approach, no ranking of results
DCU dcu ADAPT run3 Semi-automatic 0.3821 0.0399 Same as Level 1
RU ru nl ml1 Semi-automatic 0.3097 0.1093 Combined approach
USI USI 2.1 Semi-automatic 0.3029 0.1549 QE on Level 1 training data, Boolean conjunction
DAIICT daiict irlab l2 2 Semi-automatic 0.2869 0.0635 Same as Level 1
DAIICT daiict irlab l2 1 Semi-automatic 0.2869 0.0571 Same as Level 1
USI USI 2.2 Semi-automatic 0.2425 0.1462 QE on Level 1 training data, Boolean conjunctionNaive Bayes classifier
USI USI 2.3 Semi-automatic 0.1828 0.1266 QE on Level 1 training data, Boolean conjunctionPOS tagging
DAIICT daiict irlab l2 3 Semi-automatic 0.1204 0.0433 POS tagging, QE using WordNet,Language model
CSPIT charusat smerp17 2 Semi-automatic 0.0218 0.0072 Same as Level 1
Table: Level 2 results. The table is sorted according to the Bpref measure.

Outline
1 Introduction and Motivation
2 The Test Collection
3 The Challenges
4 Task 1 : Text Retrieval
5 Task 2 : Summarization

Task 2 : Evaluation
4 teams participated
Summaries submitted :
Level 1 : 7 summaries; 4 automatic, 3 semi-automaticLevel 2 : 4 summaries; all semi-automatic
Primary evaluation measure – ROUGE-L; ties broken by ROUGE-SU4.

Task 2 : Evaluation – Level 1
Team-id Summary-id Summary type ROUGE-L ROUGE-SU4 Method summaryUSI USI 2 1 Full-automatic 0.3029 0.1011 Relevance, Novelty,
Word2Vec, POS,linear interpolation with a specific parameter value
USI USI 2 2 Full-automatic 0.2809 0.0903 Relevance, Novelty using Word2Vec,POS,
linear interpolation with a specific parameter value
USI USI 1 1 Full-automatic 0.2806 0.0947 Relevance, Novelty using Word2Vec,linear interpolation with a specific parameter value
USI USI 1 2 Full-automatic 0.275 0.09 Relevance, Novelty,Word2Vec,
linear interpolation with a specific parameter value
IIEST Kanav Mehra Semi-automatic 0.4885 0.2329 SumBasic summarizer,Naive Bayes classifier
IIEST Kanav Mehra Semi-automatic 0.4375 0.1983 SumBasic summarizer,ensemble classifier
DAIICT daiict irlab summ 1 Semi-automatic 0.3085 0.1055 Relevance,Novelty using Jaccard based word overlap
Table: Level 1 results. The table is sorted according to the ROUGE-L measure.

Task 2 : Evaluation – Level 2
Team-id Summary-id Summary type ROUGE-L ROUGE-SU4 Method summaryIIEST Kanav Mehra Semi-automatic 0.5142 0.2864 Same as Level 1
but with feedback from Level 1 training data
IIEST Kanav Mehra Semi-automatic 0.4796 0.2505 Same as Level 1but with feedback from Level 1 training data
DAIICT daiict irlab summ 1 Semi-automatic 0.3254 0.1194 Same as Level 1
CSPIT Sindur Patel Semi-automatic 0.3233 0.122 Cosine similarity, Jaccard similarity
Table: Level 2 results. The table is sorted according to the ROUGE-L measure.
