rerere: remote embodied referring expressions in real ... · navigating a real environment to a...
TRANSCRIPT

RERERE: Remote Embodied Referring Expressionsin Real indoor Environments
Yuankai Qi1, Qi Wu∗1, Peter Anderson2, Marco Liu3, Chunhua Shen1, and Anton van den Hengel1
1Australia Centre for Robotic Vision, The University of Adelaide2Georgia Institute of Technology
3University of Melbourne
Abstract
One of the long-term challenges of robotics is to enablehumans to communicate with robots about the world. It isessential if they are to collaborate. Humans are visual ani-mals, and we communicate primarily through language, sohuman-robot communication is inevitably at least partly avision-and-language problem. This has motivated both Re-ferring Expression datasets, and Vision and Language Nav-igation datasets. These partition the problem into that ofidentifying an object of interest, or navigating to anotherlocation. Many of the most appealing uses of robots, how-ever, require communication about remote objects and thusto not reflect the dichotomy in the datasets. We thus proposethe first Remote Embodied Referring Expression dataset ofnatural language references to remote objects in real im-ages. Success requires navigating through a previously-unseen environment to select an object identified throughgeneral natural language. This represents a complex chal-lenge, but one that closely reflects one of the core visualproblems in robotics. A Navigator-Pointer model whichprovides a strong baseline on the task is also proposed.
1. Introduction
You can ask a 10-year-old child to bring you a cushioneven in an unfamiliar environment. There’s a good chancethat they will succeed. The probability that a robot willsucceed at the same task is significantly lower. The robotfaces multiple challenges in completing the task, but oneof the most fundamental is that of knowing where to look.Children have a wealth of knowledge about their environ-ment that they can apply to such tasks, including the factthat cushions generally inhabit couches, that couches in-
∗corresponding author; [email protected]
Instruction: Go to the stairs on level one and bring me the bottom picture that is next to the top of the stairs.
Figure 1. Remote Embodied Referring Expression – REREREtask. We focus on following a natural language based naviga-tion instruction (in blue) and detecting the object described by areferring expression (in red). The target object (in red boundingboxes) might be visible from multiple viewpoints and camera an-gles. Blue discs are nearby approachable viewpoints.
habit lounge rooms, and that lounge rooms are often con-nected to the rest of a building through hallways. Robotstypically lack this type of information.
The task we propose is intended to encourage the de-velopment of vision and language models that embody theinformation required to carry out natural language instruc-tions that refer to previously unseen objects in real environ-ments. It represents an extension of existing Referring Ex-pression, Visual Grounding, and Embodied Question An-swering datasets (see [6, 8, 9, 13, 29] for example) to thecase where it cannot be assumed that the object in ques-tion is visible in the current image. This represents a sig-nificant development because solving the problem requires
1
arX
iv:1
904.
1015
1v1
[cs
.CV
] 2
3 A
pr 2
019

navigating a real environment to a position where the objectis likely to be visible, identifying the object in question ifit is there, and adapting if it is not. This is far more chal-lenging than selecting a candidate from amongst the set ofobjects visible in a provided image. We refer to this novelproblem as one of interpreting Remote Embodied ReferringExpressions in Real indoor Environments (RERERE).
Although vision-and-language tasks motivated byrobotics have attracted significant attention previ-ously [5, 8, 15, 26, 30], it is the recent success ofvision-and-language navigation [1, 7, 20, 25] and visualgrounding [6, 9, 29] that motivates the new RERERE taskand dataset. An example from the RERERE dataset isgiven in Fig 1. In carrying out the task an agent is placedat a starting point and given a natural language query thatrefers to an object. The query represents an action a robotmight usefully carry out, and the location where it shouldbe occur. The response is expected to take the form ofan object bounding box encompassing the subject of thequery. This is in contrast to [1], where the query representsdetailed navigational guidance and [5], where the queryrepresents a natural language question with a naturallanguage answer. One example asks that the robot {‘go tothe stairs on level one’, ’bring me the bottom picture thatis next to the top of the stairs.’}, for instance. This requestnot only requires the agent to navigate to ‘the stairs on levelone’, but also that it localises the ‘bottom picture that isnext to the top of the stairs’ in the area. The task posesseveral challenges including visual navigation, naturallanguage understanding, object detection and high-levelreasoning.
The dataset is built upon the Matterport3D Simulator [1]which provides panoramic image sets for multiple locationsaround a building, and a (virtual) means of navigating be-tween them. To enable the agent to receive object-level in-formation about the environment we have extended the sim-ulator to incorporate object annotations including labels andbounding boxes. As the task is intended to be image-based,we have enabled the bounding boxes to be projected ontothe images so as to automatically accommodate differentviewpoints and angles. This particularly enables answersprovided as image-based bounding boxes to be assessedequivalently irrespective of the location of the agent. Thedataset comprises 10,567 panoramas within 90 buildingscontaining 3103 objects, and 1.6k open vocabulary, crowd-sourced expressions with an average length of 19 words.
The natural language commands comprise two parts, oneof which indicates the location of the object. In contrastto [1] wherein the questions tend to provide detailed trajec-tory guidance from start to end, RERERE provides only adescription of the final destination, and the object-centredaction to be carried out. This is a more challenge and re-alistic setting. The second part in the language expression
is a description that can distinguish the target object fromother surrounding objects, for example, ‘the bigger greenpillow on the bed’ and ‘the laptop with an Elsa sticker onit’. As illustrated in Figure 1, the associated task requires anagent to understand natural-language guidance to navigateto the right location and detect the object (by outputting abounding box), in a previously unseen case. The final suc-cessful rate is measured by the IoU (Intersection of Union)between the predicted bounding box and the ground-truth,or whether the model can select the target object from agiven list of candidates.
In this paper, we also investigate the difficulty of theRERERE task by proposing a baseline Navigator-Pointermodel composed of a language-guided visual navigationmodel and a referring expression comprehension model. Ahuman evaluation is also performed to show the gap be-tween the baseline model and human performance.
In summary, our main contributions are:
1. We introduce a new vision-and-language task that re-quires an agent to identify a remote object in a realindoor environment on the basis of a natural languageaction description.
2. We extend the Matterport3D Simulator [1] to includeobject annotation and present the RERERE dataset, thefirst benchmark for Remote Embodied Referring Ex-pression in a real 3D environment.
3. We propose a Navigator-Pointer model for theRERERE dataset, establishing the first baselines underseveral evaluation settings.
The simulator, RERERE dataset and models will be pub-licly available upon the acceptance of this submission.
2. Related WorkReferring Expressions The referring expression taskaims to localise an object in an image given a natural lan-guage description. Recent works cast this task as look-ing for the object that can generate its paired expres-sions [12, 18, 32] or jointly embedding the image and ex-pression for matching estimation [4, 11, 17, 31]. Yu etal. [32] propose to compute the appearance difference ofthe same category objects to enhance the visual features forexpression generation. Instead of treating expressions as aunit, [31] learns a language attention model to decomposeexpressions into appearance, location, and object relation-ship for each component.
In contrast to existing referring expression tasks,RERERE introduces three new challenges: i) the robotagent must first navigate to the target room on the basis ofa high-level command, such as ‘go to the second bedroomon level two’. ii) the agent must select a panoramic imageset to search from the set of panorama locations within the
2

target room. iii) if the target cannot be localised (due toview-angle dependent appearance changes, or absence) theagent must reconsider and try again.
Vision-and-Language Navigation In the vision-and-language navigation (VLN) task, a robot agent is expectedto plot a path to the goal location given natural languagenavigation instructions (‘turn right ... go ahead ... turn left...’). A simulator also provides a representation of visualenvironments at each step of the path. Most of existing sim-ulators roughly fall within two categories: synthetic-photosimulator [2, 15, 27] or realistic-photo simulator [1, 23, 28].These simulators have been employed in a range of VLNmethods [7, 20, 25]. Wang et al. [25] for example proposea look-ahead module to take into account the future agentstate and reward when making action decisions, and in [7], aspeaker model is designed to synthesise new instructions fordata augmentation and to implement pragmatic reasoning.The work [24] designs a cross-modal reasoning network tolearn the trajectory history, the attention of textual instruc-tion, and the local visual attention in environment images.Although the proposed RERERE task also requires an agentto navigate to goal location, it differs from existing VLNtasks in two important aspects: i) the final goal in REREREis to localise the target object specified in a referring ex-pression, this greatly simplifies performance evaluation asno assessment of the path taken is necessary and ii) the nav-igation instructions are semantic-level commands such asmight more naturally be given to a human, such as ‘go tothe first bedroom on level two’ rather than ‘go to the top ofthe stairs then turn left and walk down the hall to the seconddoorway’.
Embodied Vision-and-Langauge Embodied questionanswering (EQA) [5] requires an agent to answer a ques-tion about an object or a room, such as ‘What colour is thecar?’ and ‘What room is the <OBJ> in?’. The subject ofthe question may be invisible from the initial location of theagent, so navigation may be required. The House3D EQAdataset [5] is based on synthetic images and includes ninekinds of predefined question template. Gordon et al. [8] in-troduce an interactive version of the EQA task, where theagent may need to interact with the environment/objects tocorrectly answer questions. Our Remote Embodied Refer-ring Expression task also falls within the area of embodiedvision-and-language, but different from previous works thatonly output a simple answer or a series of actions, we askthe agent to put a bounding box around a target object. Thisis a more challenging but more realistic setting because ifwe want a robot to manipulate an object in an environment,we need its precise location and little more.
Figure 2. We add object bounding box annotations into the Mat-terport simulator. The bounding box size, the length-width ratioof the same object may change after we move to another view-point or change the camera angle. For example, the size of thebounding box (in blue) of the coffee table is bigger after we movecloser to it. The ratio of the bounding box (in yellow) of the sofachanged given a new viewpoint. The bounding box (in red) of TVdisappeared in the lower-left image because it is occluded by thearmchair.
3. Object-level Matterport3D Simulator3.1. Matterport3D Simulator
The Matterport3D Simulator [1] is a large-scale in-teractive environment constructed from the Matterport3Ddataset [3] which includes 10,800 panoramic RGB-D im-ages of 90 real-world building-scale indoor environments.The viewpoints are distributed throughout the entire walk-able floors with an average distance of 2.25m between twoadjacent viewpoints. By default, the simulator captures 36RGB images from 3 pitch angles and 12 yaw angles usingcameras at the approximate height of a standing person.
In the simulator, an embodied agent is able to virtually‘move’ throughout each building by iteratively selecting ad-jacent nodes from the graph of panorama locations and ad-justing the camera pose at each viewpoint. The simulatortakes three parameters (v, θ, φ) and returns the renderedcolour image I , where v is the 3D position of a viewpointof the Matterport3D dataset, θ ∈
[−π2 ,
π2
]is the camera
elevation, and φ ∈ [0, 2π) denotes camera heading.
3.2. Adding Object-level Annotations
The bounding boxes are needed in the proposed task,which are either used to assess the agent’s ability to localisethe object that is referred to by a natural expression or pro-vided as object hypotheses. We exploit the bounding boxesand labels provided by the Matterport3D dataset.
The main challenge in adding the object annotation, es-pecially the object bounding boxes, is that the coordinateand visibility of 2D bounding boxes vary as the viewpointand camera angle change. To address these issues, we cal-culate the bounding box overlap and object depth, i.e., if abounding box is fully covered by another one and it is be-
3

hind it (according to the depth information), we treat it as anoccluded case and it will be removed from the visible objectlist at current viewpoint. Specifically, for each building theMatterport3D dataset [3] provides all the objects appearingin it with centre point position c = 〈cx, cy, cz〉, three axisdirections di = 〈dxi , d
yi , d
zi 〉, i ∈ {1, 2, 3}, and three radii
ri, one for each axis direction. To correctly render objectsin the simulator, we first calculate the eight vertexes usingc,di and ri. Then these vertexes are projected into the cam-era space by the camera pose provided by Matterport3D at acertain viewpoint. Finally, the visibility in the current cam-era view and occlusion relationship among objects are com-puted using OpenGL APIs.
Figure 2 demonstrates an example of projected boundingboxes. We can see there are multiple object bounding boxesappeared in the image and the bounding boxes’ size/ratiois changed after we change to another angle. On average,there are 5 object bounding boxes in every single view.Considering on average each navigation graph (in a singlebuilding) contains 117 viewpoints and each viewpoint has36 camera angles, there are more than 20k bounding boxesprovided in a single building.
4. The RERERE DatasetWe now describe the Remote Embodied Referring Ex-
pression task and dataset, including the data collection pol-icy and analysis of the expressions we collected. We finallyprovide several evaluation metrics which consider both nav-igation and detection accuracy.
4.1. Task
As shown in Figure 1, our RERERE task requires an ar-tificial agent to correctly localise the target object specifiedby a high-level natural language instruction. Since the targetobject is in a different room from the starting, the proposedtask can be decomposed into two parts: high-level languagenavigation and referring expression grounding. The high-level language navigation task requires the agent navigateto the correct room1 while the grounding referring expres-sion task asks the agent to output the bounding box of thetarget object.
Formally, at the beginning of each episode the agentis given as input a high-level natural language in-struction w = 〈wN1 , wN2 , · · · , wNL , wR1 , wR2 , · · · , wRM 〉,where N is a symbol denoting the instruction is relatedto the ‘Navigation’ (such as ‘Go to the bedroomwith the striped wallpaper’) and R is a sym-bol denoting the word is from the ‘Referring expres-sion’ part (such as ‘Bring me the pillow thatis laying next to the ottoman’). L is the
1Please note the navigation instructions provided by our task are quitedifferent from the detailed guidance in [1]. Our instructions are more nat-ural and concise thus more challenging.
Object Referring Expression Length
0 5 10 15 20 25 30Number of Words
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
Norm
aliz
ed F
req
uen
cy
Navigation Instruction Length
0 5 10 15 20 25 30 35 40
Number of Words
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
No
rma
lize
d F
req
ue
ncy
Figure 3. The length distribution of the the collected annotationsfor describing object and trajectory, respectively.
length of navigation instruction and M is the length of thereferring expression. wi is a single word token.
The agent observes an initial RGB image o0, determinedby the agent’s initial pose comprising a tuple of 3D posi-tion, heading and elevation s0 = 〈v0, φ0, θ0〉. To find thetarget object, the agent must execute a sequence of actions〈s0, a0, s1, a1, · · · , sT , aT 〉, with each action at leading toa new pose st+1 = 〈vt+1, φt+1, θt+1〉, and generating anew image observation ot+1. The agent can then chooseto stop here to output the bounding box of the target ob-ject, or continue to move and scan. If the agent chooseto ‘stop and detect’, it is required to output the boundingbox b = 〈bx, by, bw, bh〉 of its selected image region, wherebx and by denote the coordinate of the left-top point of thebounding box, bw and bh denote the width and height of thebounding box, respectively. The b can be either selectedfrom a set of predefined bounding box candidates or fromobject detection results. The episode ends after the agentoutputs the target bounding box.
The performance of a model is measured from twofold.The navigation performance is measured by five kinds ofmetrics including the length of the trajectory and the dis-tance between the stop location and the goal location v∗.The performance of referring expression grounding is mea-sured by whether selected the right object candidate (ifcandidates bounding boxes are given) or by the IoU withground truth. Refer to Section 4.4 for evaluation details.
4.2. Data Collection
Our goal is to collect high-level human daily commandsthat may be assigned to a home robot in future, such as ‘Goto the bedroom and bring me a pillow’ or ‘Open the leftwindow in the kitchen’. As these commands are usuallyvery concise, which will be rather challenging for robot un-derstanding, we prefer to reuse the trajectories of the ex-isting R2R [1] navigation dataset for high-level commandsannotation, so that one can fairly compare our more natu-ral and concise navigation instructions to the detailed onesprovided in R2R, given the same trajectories.
Our embodied referring expression annotations are col-lected on Amazon Mechanical Turk (AMT). To this end, wedevelop an interactive 3D WebGL environment, which willfirst show a path animation and randomly highlight one ob-
4

Figure 4. Distribution of referring expressions based on their firstfour words. Expressions are read from the centre outwards. Arclengths are proportional to the number of instructions containingeach word.
ject at the goal location for workers to provide annotationsto find or operate with. There is no style limitation of thecommand as long as it can lead the robot to the target ob-ject. The workers can look around at the goal location tolearn the environment and facilitate to give feasible com-mands. For each target object, we collect three referringexpressions. We also ask the annotators to label which partof the instruction is about navigation (such as ‘the largestbedroom at level 2’) and which part is related to the re-ferring expression (such as ‘the left window’). A benefitof doing this is that one can only evaluate the ‘navigation’ability of the model by providing the navigation instructiononly, or only evaluate the ‘referring expression comprehen-sion’ by providing the object related instruction with theground truth viewpoint. We encourage researchers to com-bine them as a single task to evaluate, but we provide base-lines for all three cases, namely ‘Navigation-Only’,‘Grounding-Only’ and ‘Navigation-Grounding’in this paper. More details can be found in Section 6.
The full collection interface (see in supplementary) is theresult of several rounds of experimentation. We use onlyUS-based AMT workers, screened according to their per-formance on previous tasks. Over 456 workers took partin the data collection, contributing around 1,324 hours ofannotation time. One example of the collected data can befound in Figure 1. More examples are in supplementary.
4.3. RERERE Dataset Analysis
At the time of submission, there are totally 11,371 in-structions 2 in the version 0.9. The average length of cur-rently collected instructions is 19 words while averagely 10words are from the navigation instruction part. Compar-ing to the detailed navigation instructions provided in theR2R [1] with an average length of 29 words, our naviga-tion command is more concise and natural, in other words,more challenging. At the referring expression side, the pre-
2We target to collect more than 20K annotations in the full version
Figure 5. Distribution of the number of objects mentioned in refer-ring expressions.
vious largest dataset RefCOCOg [32] based on COCO [16]contains an average of 8 words, while we have 9. Figure 3displays the length distribution of the collected annotationsfor describing object and trajectory, respectively. Accord-ing to the instruction vocabulary, we have 1.6k words. Thedistribution of referring expressions based on their first fourwords is depicted in Figure 4, which shows the diversityof expressions. We also compute the number of mentionedobjects in referring expressions and its distribution is pre-sented in Figure 5. It shows that 30% expressions mention3 or more objects, 40% expressions mention 2 objects, andthe remaining 30% expressions mention 1 object.
There are 3103 objects in the dataset, falling into 417 cat-egories, which is much more than the number of categoriesin ReferCOCO [32] that is 80.
Data Splits We follow the same train/val/test split strat-egy as the R2R [1] and Matterport3D [3] datasets. In thecurrent version, the training set consists of 59 scenes and5181 referring expressions over 1605 objects. The valida-tion set including seen and unseen splits totally contains 63scenes, 938 objects and 3842 referring expression, of which10 scenes and 2174 referring expression over 422 objectsare reserved for val unseen split. For the test set, we collect2348 referring expressions involving 560 objects randomlyscattered in 16 scenes. All the test data are unseen duringtraining and validation procedures. The ground truth for thetest set will not be released and we will host an evaluationserver where agent trajectories and detected bounding boxescan be uploaded for scoring.
4.4. Evaluation Metrics
We measure the performance of a robot agent in theRERERE task in terms of both visual navigation and re-ferring expression grounding performance.
Regarding the navigation performance, we adopt fivemetrics from the VLN task [1], namely: trajectory lengthin meters (Len.), navigation error in meters (Err.), successrate (Succ.), oracle success rate (OSuss.), and action steps(Steps). The navigation error is the Euclidean distance be-tween the agent’s final location and the goal location. Weconsider a navigation success if its navigation error is nolarger than 3 meters. The oracle error is defined as the short-
5

go to level one…
…LSTM
𝑤𝑤𝑁𝑁
Navigation instruction
ℎ1 ℎ2 ℎ𝐿𝐿ℎ𝐿𝐿−1
<𝑎𝑎0, >
Attention
<𝑐𝑐1, ℎ1′>
𝑎𝑎1
…
<𝑎𝑎1, >
<𝑐𝑐2, ℎ2′>
𝑎𝑎2
… <𝑎𝑎𝑇𝑇−1, >
<𝑐𝑐𝑇𝑇 , ℎ𝑇𝑇′ >
STOP
Navigator
SCAN
36 imagesfrom different angles
positive expressionbring me the stairs…
…LSTM
𝑤𝑤𝑅𝑅
ℎ1 ℎ2 ℎ𝑀𝑀ℎ𝑀𝑀−1
Pointer
Spatial 𝐹𝐹𝑆𝑆+
<x,y,w,h>
Global 𝐹𝐹𝐺𝐺+ Regional 𝐹𝐹𝑅𝑅+
, ,
positive object
Spatial 𝐹𝐹𝑆𝑆−
<x,y,w,h>
Global 𝐹𝐹𝐺𝐺− Regional 𝐹𝐹𝑅𝑅−
, ,
negative objectclean the upper left …
…LSTM
𝑤𝑤𝑅𝑅
ℎ1 ℎ2 ℎ𝑀𝑀ℎ𝑀𝑀−1
negative expression
𝑂𝑂+
𝑂𝑂−
𝑅𝑅+
𝑅𝑅−
𝐶𝐶𝐶𝐶𝐶𝐶(𝑅𝑅+,𝑂𝑂+)
𝐶𝐶𝐶𝐶𝐶𝐶(𝑅𝑅−,𝑂𝑂+) 𝐶𝐶𝐶𝐶𝐶𝐶(𝑅𝑅+,𝑂𝑂−)
for each image that includes the target object
𝑀𝑀𝑎𝑎𝑀𝑀𝑀𝑀𝑀𝑀𝑀𝑀𝑅𝑅𝑎𝑎𝑀𝑀𝑀𝑀𝑀𝑀𝑀𝑀𝑀𝑀𝑀𝑀𝐶𝐶𝐶𝐶𝐶𝐶
Figure 6. The main architecture of our proposed Navigator–Pointer Model.
est distance to the goal location during one navigation. Sim-ilarly, if the oracle error is no larger than 3 meters, we sayit is a oracle success. Finally, the success rate and the or-acle success rate are defined as the ratio of the number ofsuccess/oracle success navigation over the total dataset.
As to the referring expression grounding measurement,we use the success rate and the overlap ratio metrics. Allthe objects in the simulator have a distinct identification inits scene, so if the grounding task is done using target candi-dates provided by the simulator, it is able to verify whetherthe identifications match. If object proposals obtained fromout of the simulator, such as from object detection, its iden-tification will be inconsistent with that in the simulator. Insuch case, we propose to measure the performance via theIoU (Intersection of Union) IoU =
Bg∩Bgt
Bg∪Bgt, where Bg is
the grounding result and Bgt is the ground truth. Follow-ing the common practice in object detection, we treat it as asuccess if IoU > 0.5.
5. A Navigator – Pointer ModelAs the vast majority of the collected human instructions
are composed of a navigation command and an object re-ferring expression, we design a baseline model having twocounterpart components: a Navigator and a Pointer.
The whole framework of this Navigator-Pointer modelis shown in Figure 6. Given an instruction which includesa navigation part and object referring expression part, inthe Navigator model, we first encode the navigation in-struction with an LSTM. The action predictor is anotherLSTM which takes the previous action and current obser-vation as the input and then predicts the next step action by
jointly considering the attended navigation instruction fea-tures. After the model predicted a ‘STOP’ action, 36 imagescaptured from different camera angles at the stopped view-point are passed to the Pointer model.
For each image, assuming the candidate bounding boxesare given (or provided by an object proposal model suchas RPN [21]), the Pointer model first computes featuresfor each candidate object by concatenating the global im-age CNN features, the regional CNN features and a bound-ing box spatial feature. Cosine similarity is then calcu-lated between each candidate object feature and the natu-ral language referring expression feature, which is obtainedfrom an LSTM encoder. The one with the highest similarityscores among all the candidates from all 36 images is out-putted as the final result. To train the Pointer model, we alsointroduce negative examples and employ a Margin RankingLoss. More details are discussed below.
5.1. Navigator Model
We adopt the sequence-to-sequence LSTM architecturewith an attention mechanism [1] as the navigation baseline.As shown in Figure 6, the navigator is equipped with anencoder-decoder architecture.
The encoder maps the navigation related high-level in-struction wN = 〈wN1 , · · · , wNL 〉 using an LSTM [10] -hi = LSTMenc(w
Ni , hi−1), and maps the current image
observation o0 to o = f(o0) using the pretrained ResNet-152. We use h = 〈h1, · · · , hL〉 as the instruction con-text. Then o and the last hidden hL are concatenated asthe joint representation for the input instruction and imageobservation, denoted as x = cat(hL, o). Based on x, a de-
6

coder LSTM is learned for each action, which is denoted ash
′= LSTMdec(x, h
′
t−1). To predict a distribution over ac-tions at step t, the global general alignment function in [19]is adopted to identify the most relevant parts of the navi-gation instruction. This is achieved by first computing aninstruction context ct = g(h
′
t, h) and then compute an at-tentional hidden state ht = tanh(Wc[ct;h
′
t]). The actiondistribution is finally calculated as at = softmax(ht).
The predicted action at is then sent back to the simulatorto obtain the new observation ot+1. If the at is a ‘STOP’signal, then the agent stopped navigating and the simulatorwill return 36 images captured from different camera anglesat the stopped viewpoint 3. All these images are sent to thenext Pointer model.
5.2. Pointer Model
We formulate the pointer model in a joint-embeddingarchitecture inspired by the success in referring expres-sion [33]. The purpose of this embedding model is toencode the visual information from the target object andsemantic information from the referring expression into ajoint embedding space that embeds vectors that are visuallyor semantically related closer together in the space. Giventhe referring express R = 〈wR1 , · · · , wRM 〉, the pointermodel points to its closest objectO in the embedding space.
Specifically, we use an LSTM to encode the input sen-tence and use the pre-trained ResNet-152 to encode the ob-ject appearance and its context information (i.e. the wholeimage). Then two multi-layer perceptions and two L2 nor-malisation layers following two paths, the object and theexpression. Each perception module is composed of twofully connected layers with ReLUs aiming to transform theobject and the expression into a common space. The cosinedistance of the two normalised representations is calculatedas their similarity score S(R,O). To train the model, Weuse a Margin Ranking Loss over three sample pairs:
Lref =∑i
[max(0,m+ S(R+, O+)− S(R+, O−))
+ max(0,m+ S(R+, O+)− S(R−, O+))] (1)
where (R+, O−) and (R−, O+) are negative matches ran-domly selected from other objects and expressions for thesame viewpoint environment. m is the margin, which weset as 0.1. Because there are multiple images in the returned36 images include the target object, all these images will beused as training examples to train the model.
During the testing, we calculate the similarity score be-tween each candidate object and the natural language refer-ring expression. The highest one among all the candidatesfrom all 36 images is outputted as the final result.
3Our simulator also can return captured images at any viewpoints, evenbefore the ‘stop’. Whether to use the returned images at each viewpointdepending on the model strategy. Our baseline model adapts the easieststrategy, say navigation-stop-detect. Another strategy could be performingdetection at each point. If nothing found at this point, continue to move,scan and detect, until the target is found. But we leave this as further work.
6. ExperimentsIn this section, we first present the implementation de-
tails of our navigator–pointer model and its training. Then,we provide extensive experimental results and analysis.
6.1. Implementation Details
For the navigator, we set the simulator image resolutionto 640×480 with a vertical field of view of 60 degrees. Theamount of hidden units in each LSTM is set to 512. Thesize of the input word embedding is 256, and the size of theaction embedding is 32. A discretized heading of 30 degreesand elevation of 30 degrees are adopted in the simulator.For the pointer, we set the word embedding size to 512, thehidden layer size to 512. Dropout with probability 0.25 isemployed at both the visual and the language embeddingviews. The words in language text for both the navigatorand the pointer models are filtered out if it occurs less thanfive times in the training set.Training As the collected annotation can be divided intothe path-related and object-related parts, we train the nav-igator model and the pointer model separately. It is worthnoting that we adopt the teacher-forcing and student-forcingapproaches as in [1] for the navigator training. With theteacher-forcing strategy, the training is supervised by theground-truth target action from the shortest-path trajectory.However, this leads to a challenging input distribution be-tween training and testing [22]. To address this problem,the student-forcing strategy is also explored, where the nextaction is drawn from the agent’s output probability over theaction space. The student-forcing is equivalent to the on-line DAGGER [22]. The Adam optimiser with weight de-cay [14] is utilised to train the models.
6.2. Results
Experimental settings. We adopt three experimental set-tings: Navigation-Only, Grounding-Only, andNavigation-Grounding, to evaluate the performanceof each component and their combination. We also providehuman performance in these three settings.Navigation–Only. Based on the collected high-level nav-igation instructions, we report the navigation-only experi-mental results in Table 1 with Random, Shortest, and Hu-man performance as baselines. The Random agent at eachstep randomly selects heading and completes a total of 5successful forward actions (if the forward action is un-available the agent selects right) as in [1]. The Shortestagent always follows the shortest path to the goal.
The results in Table 1 show that:
• This is a very challenging task from two aspects: (1)Human can achieve a high success rate of 86.23%,while the baseline model only achieves a success ratearound 12%. Please note that the baselines have in-
7

Table 1. Navigation-only evaluation using the collected high-levelnavigation instructions.
Len. (m) Err. (m) Succ. (%) OSucc. (%) StepsVal SeenShorest 10.31 0 100 100 11.32Random 9.55 9.68 12.32 17.13 15.75T-forcing 10.65 10.01 11.48 21.18 16.10S-forcing 11.63 7.37 24.47 36.37 30.93Val UnSeenShorest 9.56 0 100 100 12.13Random 9.66 9.66 16.21 22.42 15.87T-forcing 10.76 9.82 11.76 20.92 17.93S-forcing 9.47 9.05 10.52 16.14 36.14TestShorest 9.56 0 100 100 11.56Random 9.41 9.53 11.35 15.55 16.29S-forcing 7.99 8.82 12.25 17.67 19.35Human 21.88 1.77 86.23 89.71 38.3
Table 2. Navigation-only evaluation using the detailed instructionsfrom the R2R dataset [1].
Len. (m) Err. (m) Succ. (%) OSucc. (%) StepsVal SeenShorest 10.28 0 100 100 10.87Random 9.57 9.87 12.61 16.64 16.01T-forcing 9.44 8.75 18.15 28.07 13.97S-forcing 9.62 7.28 27.23 36.97 18.46Val UnSeenShorest 9.75 0 100 100 11.94Random 9.98 9.71 13.49 19.19 15.8T-forcing 8.92 9.6 14.91 19.19 13.27S-forcing 7.99 8.52 17 23.14 19.14TestShorest 9.52 0 100 100 11.35Random 9.27 9.37 13.09 17.67 16.22S-forcing 7.83 7.81 17.38 25.32 19.2Huamn 11.9 1.61 86.4 90.2 17.52
tegrated the recent advances in CNNs and RNNs. (2)This task is rather challening for human because wefind that compared to the best case namely the groundtruth shown by Shortest, human takes nearly triplesteps and double trajectory length to get only a successrate of 86.23%.
• The test split is harder than the val seen and val un-seen splits because the best performance achieved byRandom, T-forcing, or S-forcing on the test split dropsabout 5% from that on the val splits.
• The newly collected high-level instructions are harderthan the detailed instructions of the R2R dataset. Aswe collected high-level instructions for the same pathused in the R2R dataset, so it is a fair comparison tothe agent’s performance on the R2R dataset as shownin Table 2. Please note that the agent is retrained onR2R using the same setting.
Grounding-Only. Table 3 presents the performance of thePointer baseline and human (we randomly select one thirdof the test split, 1000 referring expressions, for human per-formance evaluation). The results show that the baseline
Table 3. Success rate (%) of the grounding-only taskVal Seen Val UnSeen Test
Pointer 22.41 21.25 29.5Human – – 100
performs far below human with about a 70% performancegap. This indicates the grounding task in an embedded en-vironment is much challenging due to the aforementionedreasons such as great appearance difference for the samecategory objects caused by different view angels. Here weuse the ground truth candidates, the results of using the Fas-tRCNN [21] as a candidates provider can be found in thesupplementary material.Navigation-Grounding. In the Navigation-Grounding set-ting, we first perform the VLN subtask using the Navigatorbaseline described in Section 5.1. After it stops or reachesthe maximum steps, we then perform the Pointer model de-scribed in Section 5.2.
We present the experimental results in Table 4 with hu-man performance on the test split. The results show thatthe RERERE task is extremely challenging where the base-line performance drops beneath 1% where human perfor-mance also incurs a 25% decrease from 100% shown in Ta-ble 3 to 74.95% shown in Table 4. We believe that such ahuge performance drop is mainly attributed to the the incor-rect navigation. In the case where the navigator stops at awrong room, a perfect pointer cannot find the target objecteither. These results demonstrate that the proposed task isextremely challenging and solutions may take both naviga-tion and grounding referring expression into consideration.
Table 4. Success rate (%) of the Navigation-Grounding taskVal Seen Val UnSeen Test
Navigator-Pointer 1.68 0.57 0.88Human – – 74.95
7. ConclusionEnable human-robots collaboration is a long-term goal.
In this paper, we make a step further towards this goalby proposing a Remote Embodied Referring Expression inReal indoor Environments (RERERE) task and dataset. TheRERERE is the first one to evaluate the capability of anagent to follow high-level natural languages instructions tonavigate and select the target object in previously unseenreal images rendered buildings. We investigate several base-lines and a Navigator-Pointer agent model, which consis-tently demonstrate the significant necessity of further re-searches in this field.
We reach three main conclusions: First, RERERE isinteresting because existing vision and language methodscan be easily plugged in. Second, the challenge of under-standing and executing high-level expressions is significant.Finally, the combination of instruction navigation and re-
8

ferring expression grounding is a challenging task becausethere is still a large gap between the proposed model andhuman performance.
8. AcknowledgmentsWe thank Sam Bahrami for his great help in the building
of the RERERE dataset.
References[1] P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson,
N. Sunderhauf, I. D. Reid, S. Gould, and A. van den Hen-gel. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. InCVPR, pages 3674–3683, 2018.
[2] S. Brodeur, E. Perez, A. Anand, F. Golemo, L. Celotti,F. Strub, J. Rouat, H. Larochelle, and A. C. Courville.Home: a household multimodal environment. CoRR,abs/1711.11017, 2017.
[3] A. X. Chang, A. Dai, T. A. Funkhouser, M. Halber,M. Nießner, M. Savva, S. Song, A. Zeng, and Y. Zhang.Matterport3d: Learning from RGB-D data in indoor environ-ments. In 2017 International Conference on 3D Vision, 3DV2017, Qingdao, China, October 10-12, 2017, pages 667–676, 2017.
[4] K. Chen, R. Kovvuri, and R. Nevatia. Query-guided regres-sion network with context policy for phrase grounding. InICCV, pages 824–832, 2017.
[5] A. Das, S. Datta, G. Gkioxari, S. Lee, D. Parikh, and D. Ba-tra. Embodied question answering. In CVPR, pages 1–10,2018.
[6] C. Deng, Q. Wu, Q. Wu, F. Hu, F. Lyu, and M. Tan. Visualgrounding via accumulated attention. In 2018 IEEE Confer-ence on Computer Vision and Pattern Recognition, CVPR2018, Salt Lake City, UT, USA, June 18-22, 2018, pages7746–7755, 2018.
[7] D. Fried, R. Hu, V. Cirik, A. Rohrbach, J. Andreas,L. Morency, T. Berg-Kirkpatrick, K. Saenko, D. Klein, andT. Darrell. Speaker-follower models for vision-and-languagenavigation. In NeurIPS, pages 3318–3329, 2018.
[8] D. Gordon, A. Kembhavi, M. Rastegari, J. Redmon, D. Fox,and A. Farhadi. IQA: visual question answering in interac-tive environments. In CVPR, pages 4089–4098, 2018.
[9] L. A. Hendricks, R. Hu, T. Darrell, and Z. Akata. Groundingvisual explanations. In Computer Vision - ECCV 2018 - 15thEuropean Conference, Munich, Germany, September 8-14,2018, Proceedings, Part II, pages 269–286, 2018.
[10] S. Hochreiter and J. Schmidhuber. Long short-term memory.Neural Computation, 9(8):1735–1780, 1997.
[11] R. Hu, M. Rohrbach, J. Andreas, T. Darrell, and K. Saenko.Modeling relationships in referential expressions with com-positional modular networks. In CVPR, pages 4418–4427,2017.
[12] R. Hu, H. Xu, M. Rohrbach, J. Feng, K. Saenko, and T. Dar-rell. Natural language object retrieval. In CVPR, pages4555–4564, 2016.
[13] S. Kazemzadeh, V. Ordonez, M. Matten, and T. Berg.Referitgame: Referring to objects in photographs of natu-ral scenes. In Proceedings of the 2014 conference on empiri-cal methods in natural language processing (EMNLP), pages787–798, 2014.
[14] D. P. Kingma and J. Ba. Adam: A method for stochasticoptimization. CoRR, abs/1412.6980, 2014.
[15] E. Kolve, R. Mottaghi, D. Gordon, Y. Zhu, A. Gupta, andA. Farhadi. AI2-THOR: an interactive 3d environment forvisual AI. CoRR, abs/1712.05474, 2017.
[16] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ra-manan, P. Dollar, and C. L. Zitnick. Microsoft coco: Com-mon objects in context. In European conference on computervision, pages 740–755. Springer, 2014.
[17] J. Liu, L. Wang, and M. Yang. Referring expression gen-eration and comprehension via attributes. In ICCV, pages4866–4874, 2017.
[18] R. Luo and G. Shakhnarovich. Comprehension-guided refer-ring expressions. In CVPR, pages 3125–3134, 2017.
[19] M.-T. Luong, H. Pham, and C. D. Manning. Effectiveapproaches to attention-based neural machine translation.arXiv preprint arXiv:1508.04025, 2015.
[20] P. Mirowski, M. K. Grimes, M. Malinowski, K. M. Hermann,K. Anderson, D. Teplyashin, K. Simonyan, K. Kavukcuoglu,A. Zisserman, and R. Hadsell. Learning to navigate in citieswithout a map. In NeurIPS, pages 2424–2435, 2018.
[21] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towardsreal-time object detection with region proposal networks. InAdvances in neural information processing systems, pages91–99, 2015.
[22] S. Ross, G. J. Gordon, and D. Bagnell. A reduction of im-itation learning and structured prediction to no-regret on-line learning. In Proceedings of the Fourteenth InternationalConference on Artificial Intelligence and Statistics, AISTATS2011, Fort Lauderdale, USA, April 11-13, 2011, pages 627–635, 2011.
[23] M. Savva, A. X. Chang, A. Dosovitskiy, T. A. Funkhouser,and V. Koltun. MINOS: multimodal indoor simula-tor for navigation in complex environments. CoRR,abs/1712.03931, 2017.
[24] X. Wang, Q. Huang, A. Celikyilmaz, J. Gao, D. Shen,Y. Wang, W. Y. Wang, and L. Zhang. Reinforced cross-modal matching and self-supervised imitation learning forvision-language navigation. CoRR, abs/1811.10092, 2018.
[25] X. Wang, W. Xiong, H. Wang, and W. Y. Wang. Look beforeyou leap: Bridging model-free and model-based reinforce-ment learning for planned-ahead vision-and-language navi-gation. In ECCV, pages 38–55, 2018.
[26] T. Winograd. Procedures as a representation of data in acomputer program for understanding natural language. PhDthesis, Massachusets Institute of Technology, January 1971.
[27] Y. Wu, Y. Wu, G. Gkioxari, and Y. Tian. Building generaliz-able agents with a realistic and rich 3d environment. CoRR,abs/1801.02209, 2018.
[28] F. Xia, A. R. Zamir, Z. He, A. Sax, J. Malik, and S. Savarese.Gibson env: Real-world perception for embodied agents. InCVPR, pages 9068–9079, 2018.
9

[29] F. Xiao, L. Sigal, and Y. J. Lee. Weakly-supervised visualgrounding of phrases with linguistic structures. In CVPR,pages 5253–5262, 2017.
[30] H. Yu, H. Zhang, and W. Xu. Interactive grounded languageacquisition and generalization in a 2d world. arXiv preprintarXiv:1802.01433, 2018.
[31] L. Yu, Z. Lin, X. Shen, J. Yang, X. Lu, M. Bansal, and T. L.Berg. Mattnet: Modular attention network for referring ex-pression comprehension. In CVPR, pages 1307–1315, 2018.
[32] L. Yu, P. Poirson, S. Yang, A. C. Berg, and T. L. Berg. Mod-eling context in referring expressions. In ECCV, pages 69–85, 2016.
[33] L. Yu, H. Tan, M. Bansal, and T. L. Berg. A joint speaker-listener-reinforcer model for referring expressions. In 2017IEEE Conference on Computer Vision and Pattern Recog-nition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017,pages 3521–3529, 2017.
10

Supplements
1. Typical Samples of The RERERE Task
In Figure 1, we present several typical samples of theproposed RERERE task. It shows the diversity in objectcategory, goal region, path instruction, and target object re-ferring expression.
2. Additional Analysis of The Dataset
We calculate the ratio of regions where the target objectlocates, namely goal region, and show the results in Fig-ure 2. It shows that the bathroom accounts for the largestproportion in all the train/val seen/val unseen/test splits.The remaining regions account for different proportions inthe four splits. For example, the bedroom is the second mostregion type in train/val seen/test splits, while the hallwayranks second in the val unseen split.
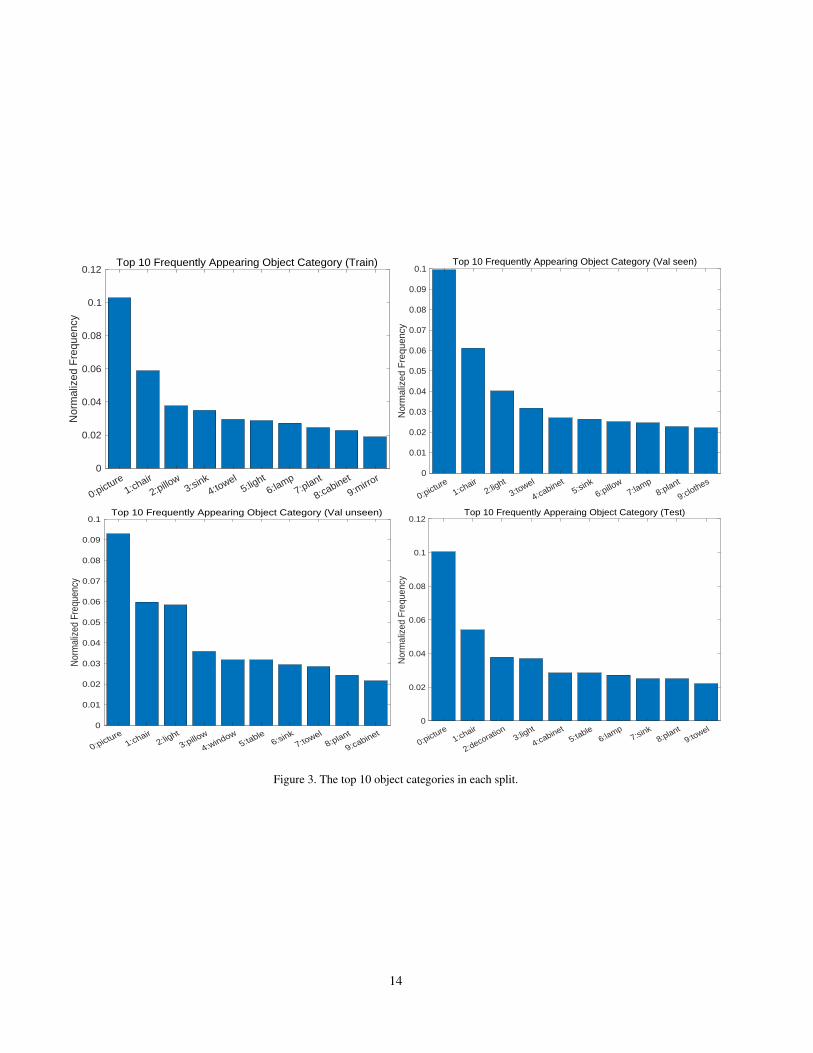
In addition, we compute the most frequently appearingobject category in the train/val seen/val unseen/test splits.As shown in Figure 3, pictures and chairs occupy the toptwo, which is consistent with most of our living scenarios.
3. Additional Evaluation Results
It is a common practice to use object detection tech-nologies to obtain target object proposals. Here we pro-vide evaluation results using proposals achieved by MaskR-CNN, which is one of the state-of-the-art object detectionmethods. We use its best configuration ‘X-101-32x8d-FPN’in the PyTorch framework, which achieves an AP score of42.2% on the COCO test-dev dataset1.
We present results in Table 1 on the Grounding-Only set-ting. A test is considered success if the IoU≥ 0.5 betweenthe selected proposal and the ground truth bounding box.The results in Table 1 show that the baseline only achieves asuccess rate of 2.86% on the test split, which falls far behind29.5 obtained using all the available objects in the simula-tor as target proposals. Similar results are observed on theval seen and val unseen splits. To help understand these re-sults, we calculate the upper bound of success rate when us-ing detection proposals for referring expression grounding,where a test is considered success as long as there exist oneproposal having IoU≥ 0.5. The upper bound is shown inTable 2. It shows that the current detection results achievesonly up to 43.62% on the test split, which indicates a largegap compared to human performance (100%). We also re-port results in the Navigation-Grounding setting in Table 3.The success rate further drops to 1.58% on the test split,which is caused by the introduce of incorrect navigation.
1https://github.com/facebookresearch/maskrcnn-benchmark/blob/master/MODEL ZOO.md
Table 1. Success rate (%) of the Grounding-Only task using objectdetection results as proposals.
Val Seen Val UnSeen TestPointer 2.14 1.71 2.86
Table 2. Upper bound of success rate (%) of the Grounding-Onlytask using object detection results as proposals.
Val Seen Val UnSeen TestPointer 42.54 41.11 43.62
Table 3. Success rate (%) of the Navigation-Grounding task usingobject detection results as proposals
Val Seen Val UnSeen TestPointer 1.12 1.32 1.58
4. Data Collecting ToolTo collect data for the RERERE task, we develop a We-
bGL based data collecting tool as shown in Figure 4. Tofacilitate the workers, we provide real-time updated refer-ence information in the web page according to the loca-tion of the agent, including the current level/total level, thecurrent region, and the number of regions in the build hav-ing the same function. At the goal location, in addition tohighlighting the target object with a red 3D rectangle, wealso provide the label of the target object and the number ofobjects falling in the same category with the target object.Text and video instructions are provided for workers to un-derstand how to make high quality annotations as shown inFigure 5.
11

Enter the bathroom on level 1 with the regal wallpaper and the hatched window. Open the window.
Go to the bathroom on level 1 that has a picture of a woman in a white dress adjacent to the toilet. Gaze out the window.
Walk to the bathroom inside the bedroom with long horizontal bed. Wipe the window.
Go to the living room. Water the potted plant on the coffee table.
Enter the living room on level 1. Pick up the pot with the pink flowers in it.
Go to the living room on level 1. Look closely at the single, small pot in the middle of the room.
Navigate to the bedroom on level 2 with the word "safari" above the door. Wash the towel next to the sink which is hanging
Go to the bedroom with the zebra print chair. Grab the towel that is hanging next to the sink just inside the door.
Go to the bedroom next to the elevator on level 2. Bring me the towel next to the sink.
Head to the laundry room. Take the first picture off the wall.
Go to the second floor laundry room. Pick up the painting opposite the dryer and closest to the door.
Go to the laundry room/mudroom on the second level. Take down the first canvas picture on the left.
Go to the home office room on the first floor. Pick up the phone handset.
Go to the office near the stairs. Answer the phone and take a message.
Go to the office where the computer is. Answer the phone on the desk.
Walk into the living room and stand next to the chaise. Grab a pillow from the chaise.
Bring me the pillow on the chair next to the ottoman in the living room.
Go to the living room. Pick up the pillow on the armchair.
Figure 1. Several typical samples of the collected dataset, which involes various object category, goal region, path instruction, and objectreferring expression. Blue font denotes high level navigation instructions and red font denotes target object referring expressions.
12

Distribution of Goal Region (Train)
bathroom (21%)
bedroom (12%)
hallway (10%)
office (7%) laundryroom (7%)
living (6%)
lounge (6%)
kitchen (5%)
familyroom (4%)
closet (4%)
dining (4%)
entryway (3%)stairs (3%)
porch (2%)others (7%)
Distribution of Goal Region (Val Seen)
bathroom (24%)
bedroom (11%)
living room (9%)
hallway (9%)closet (8%)
office (7%)
dining (4%)
kitchen (4%)
lounge (4%)
meeting room (3%)
familyroom (3%)
entryway (3%)balcony (3%)
porch (2%)others (5%)
Distribution of Goal Region (Val UnSeen)
bathroom (21%)
hallway (14%)
lounge (9%)
dining (9%)living (8%)
spa (6%)
bedroom (5%)
entryway (5%)
laundryroom (4%)
kitchen (4%)
office (4%)familyroom (3%)
balcony (2%)workout (2%)
others (3%)Distribution of Goal Region (Test)
bathroom (19%)
bedroom (16%)
kitchen (7%)
hallway (7%) closet (6%)
stairs (6%)
lounge (5%)
laundryroom (5%)
office (5%)
dining (5%)
porch (4%)
living (3%)spa (3%)
familyroom (2%)others (7%)
Figure 2. Distribution of goal region in each split.
13
Top 10 Frequently Appearing Object Category (Train)
0:picture1:chair
2:pillow
3:sink4:towel
5:light
6:lamp7:plant
8:cabinet
9:mirror
0
0.02
0.04
0.06
0.08
0.1
0.12
Nor
mal
ized
Fre
quen
cy
Top 10 Frequently Appearing Object Category (Val seen)
0:picture1:chair
2:light
3:towel
4:cabinet5:sink
6:pillow
7:lamp8:plant
9:clothes0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
0.1
Nor
mal
ized
Fre
quen
cy
Top 10 Frequently Appearing Object Category (Val unseen)
0:picture1:chair
2:light
3:pillow
4:window5:table
6:sink7:towel
8:plant
9:cabinet0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
0.1
Nor
mal
ized
Fre
quen
cy
Top 10 Frequently Apperaing Object Category (Test)
0:picture1:chair
2:decoration3:lig
ht
4:cabinet5:table
6:lamp7:sink
8:plant9:towel
0
0.02
0.04
0.06
0.08
0.1
0.12
Nor
mal
ized
Fre
quen
cy
Figure 3. The top 10 object categories in each split.
14

Figure 4. Collecting interface with real-time updated reference information.
15

Figure 5. Text and video instructions for workers in the collecting interface
16