reusable data access patterns by gary helmling, hbasecon 2015
TRANSCRIPT

Gary Helmling, Software Engineer @gario
HBaseCon 2015 - May 7
Reusable Data Access Patterns

Agenda• A brief look at data storage challenges • How these challenges have influenced our work at Cask • Exploration of Datasets and how they help • Review of some common data access patterns and how Datasets apply • A look underneath at the tech that makes it work

Data Storage Challenges• Many HBase apps tend to solve similar problems with common needs • Developers rebuild these solutions on their own, sometimes repeated for each app • Effective schema (row key) design is hard
• byte[] conversions, no real native types • No composite keys • Some efforts - Orderly library and HBase types (HBASE-8089) - but nothing complete

Cask Data Application Platform• CDAP is a scale-out application platform for Hadoop and HBase
• Enables easy scaling of application components • Combines real-time and batch data processing • Abstracts data storage details with Datasets
• Built from experience by Hadoop and HBase users and contributors • CDAP and the components it builds on are open source (Apache License v2.0):
• Tephra, a scalable transaction engine for HBase and Hadoop • Apache Twill, makes writing distributed apps on YARN as simple as running threads
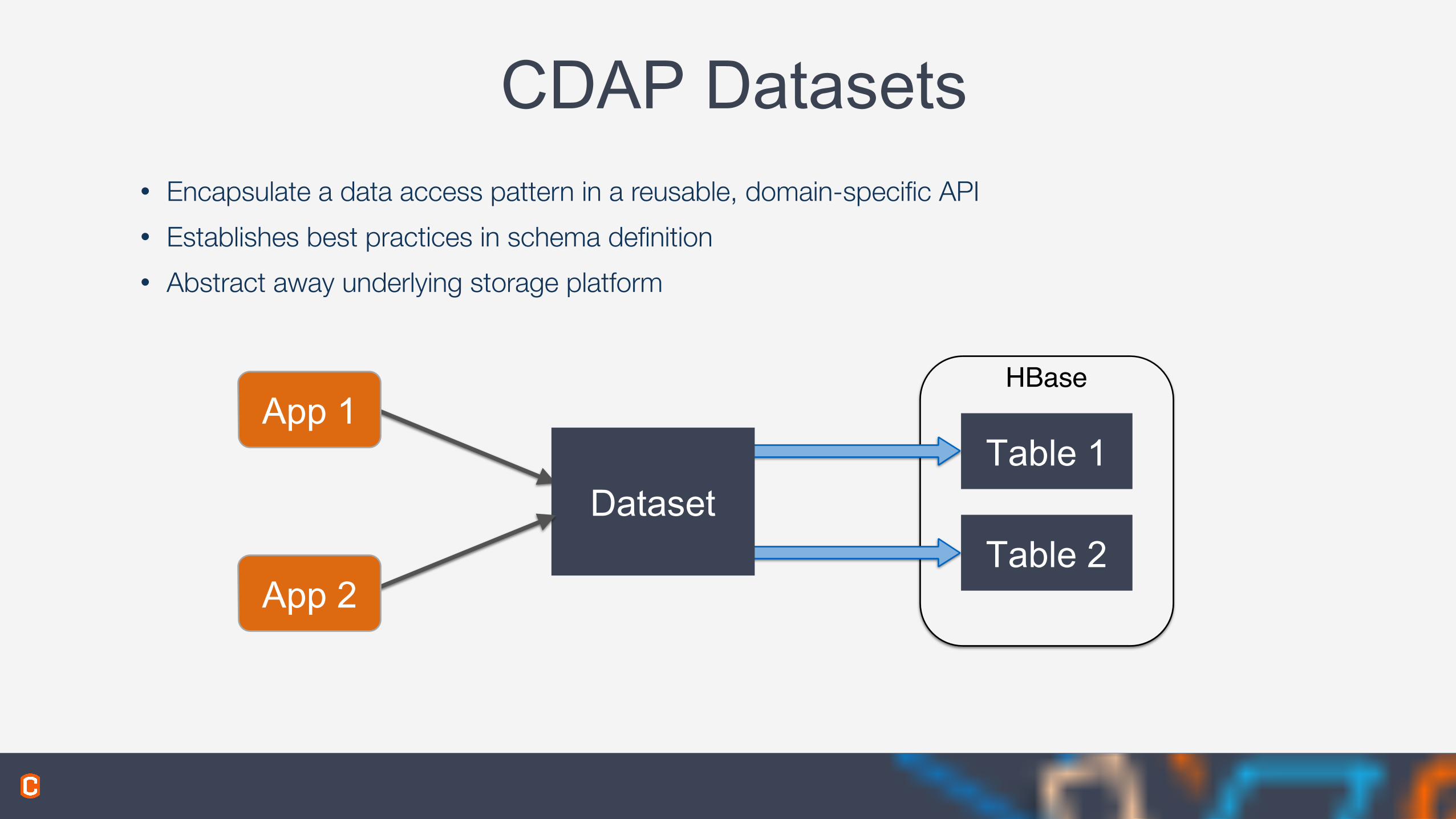
• Encapsulate a data access pattern in a reusable, domain-specific API • Establishes best practices in schema definition • Abstract away underlying storage platform
HBase
CDAP Datasets
Table 1
Table 2Dataset
App 2
App 1

How CDAP Datasets Help• Reusable as data storage templates • Easy sharing of stored data:
• Between applications • Batch and real-time processing
• Integrated testing • Extensible to create your own solutions • Leverage common services to ease development:
• Transactions • Readless increments

Reusing Datasets• CDAP integrates lifecycle management • Centralized metadata provides key configuration • Transparent integration with other systems
• Hive metastore • Map Reduce Input/OutputFormats • Spark RDDs

Reusing Datasets/**
* Counter Flowlet.
*/
public class Counter extends AbstractFlowlet {
@UseDataSet("wordCounts")
private KeyValueTable wordCountsTable;
…
}
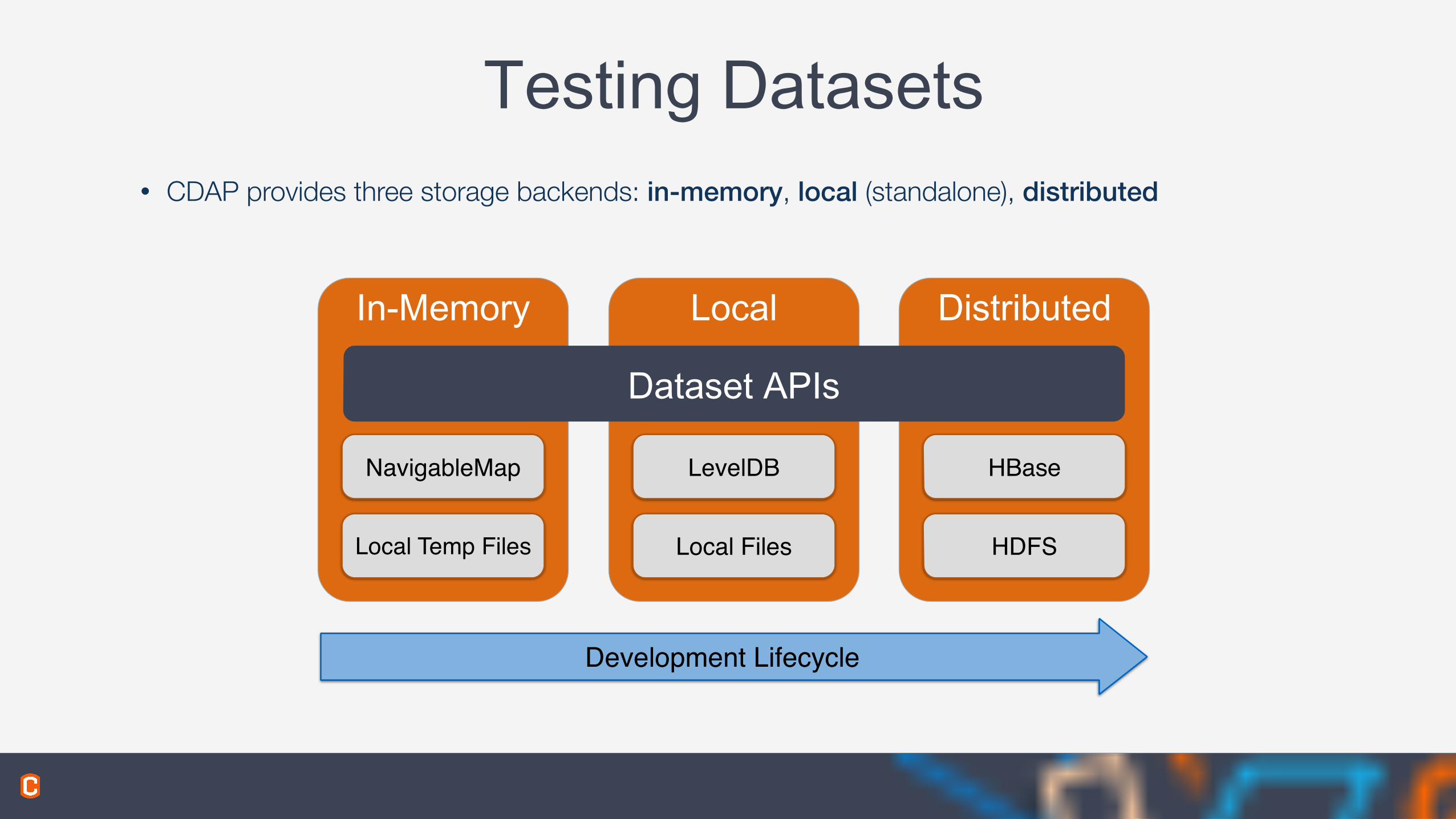
Testing Datasets• CDAP provides three storage backends: in-memory, local (standalone), distributed
In-Memory
NavigableMap
Local Temp Files
Local
LevelDB
Local Files
Distributed
HBase
HDFS
Dataset APIs
Development Lifecycle

Extending Datasets• Existing datasets can be used as building blocks for your own patterns
• @EmbeddedDataset annotation injects wrapped instance in custom code • Operations seamlessly wrapped in same transaction, no need to re-implement
public class UniqueCountTable extends AbstractDataset {
public UniqueCountTable(DatasetSpecification spec,
@EmbeddedDataset("unique") Table uniqueCountTable,
@EmbeddedDataset("entry") Table entryCountTable) {
…
}
}

HBase Data Patterns & Datasets• Secondary Indexes • Object-mapping • Timeseries • Data cube

Secondary Indexing• Example use case: Entity storage - store customer records indexed by location • HBase sorts data by row key
• Retrieving by a secondary value means storing a reference in another table • Two types: global and local
• Global: efficient reads, but updates can be inconsistent • Local: updates can be made consistent, but reads require contacting all servers
• IndexedTable Dataset performs global indexing • Uses two tables: data table, index table • Uses global transactions to keep updates consistent

Object-Mapping• Example use case: Entity storage - easily store User instances for user profiles • Easy serialization / deserialization of Java objects (think Hibernate) • Maps property fields to HBase columns • No defined schemas in HBase
• Accessing data by other means requires knowledge of object structure
• ObjectMappedTable Dataset: automatically persists object properties as columns in HBase • Metadata managed by CDAP
• Stores the object's schema • Automatically registers a table definition in Hive metastore with the same schema

Timeseries Data• Example use case: any data organized around a time dimension
• System metrics • Stock ticker data • Sensor data - smart meters
• Constructing keys to avoid hotspotting and support efficient retrieval can be tricky
• TimeseriesTable Dataset: for each data key, stores a set of (timestamp, value) records • Each stored value may have a set of tags used to filter results • Each row represents a time bucket, individual values in that bucket stored as columns • When reading data, projects entries back into a simple Iterator for easy consumption

Data Cube• Example use case: Retail product sales reports, web analytics • Stores “fact” entries, with aggregated values along configured combinations of the “fact”
dimensions • Pre-aggregation necessary for efficient retrieval
• HBase increments can be costly in write-heavy workload • Querying requires knowledge of pre-aggregation structure
• Reconfiguration can be difficult • Need metadata around configuration
• Cube Dataset: uses readless increments for efficient aggregation • Transactions keep pre-aggregations consistent • Dataset framework manages metadata

Transactions• Provided by Tephra (http://tephra.io), an open-source, distributed, scalable transaction engine
designed for HBase and Hadoop • Each transaction assigned a time-based, globally unique transaction ID • Transaction =
• Write Pointer: Timestamp for HBase writes • Read pointer: Upper bound timestamp for reads • Excludes: List of timestamps to exclude from reads
• HBase cell versions provide MVCC for Snapshot Isolation

Tephra Architecture
Tx Manager (active)
Tx Manager (standby)
HBase
RS 1
start / commitClient
Client
Client
read / write RS 2
Tx CP Tx CP

Transactional Writes• Client sets write pointer (transaction ID) as timestamp on all writes • Maintains set of change coordinates (row-level or column-level granularity depending on needs) • On commit, client sends change set to Transaction Manager
• If any overlap with change sets of commits since transaction start, returns failure • On commit failure, attempts to rollback any persisted changes
• Deletes use special markers instead of HBase deletes • HBase deletes cannot be rolled back

Transactional Reads• TransactionAwareHTable client sets the transaction state as an attribute on all read operations
• Get, Scan • Transaction Processor RegionObserver translates transaction state into request properties
• max versions • time range • TransactionVisibilityFilter - excludes cells from:
• Invalid transactions (failed but not cleaned up) • In-progress transactions • “Delete” markers • TTL’d cells

Increment Performance• HBase increments perform read-modify-write cycle
• Happens server-side, but read operation still incurs overhead • Read cost is unnecessary if we don't care about return value • Not a great fit for write-heavy workloads

HBase Increments
row:col timestamp value
hello:count 1001 1
1002 2
Example: Word count on “Hello, hello, world”
counting 2nd “hello”
1. read: value = 1
2. modify: value += 1
3. write: value = 2

Readless Increments• Readless increments store individual increment values for each write
• Mark cell value as Increment instead of normal Put • Increment values are summed up on read

Readless Increments
row:col timestamp value
hello:count 1001 +1
1002 +1 1. write: increment = 1
Example: Word count on “Hello, hello, world”
counting 2nd “hello”

Readless Increments
row:col timestamp value
hello:count 1001 +1
1002 +1
Example: Word count on “Hello, hello, world”
reading current count for “hello”
read: 1 + 1 = 2 (total value)

Readless Increments• Increments become simple writes • Good for write-heavy workloads (many uses of increments) • Reads incur extra cost from reading all versions up to latest full sum • HBase RegionObserver merges increments on flush and compaction
• Limits cost of coalesce-on-read • Work well with transactions: increments do not conflict!

Want to Learn More?
Open-source (Apache License v2) Website: http://cdap.io
Mailing List: [email protected] [email protected]
Open-source (Apache License v2) Website: http://tephra.io
Mailing List: [email protected] [email protected]

QUESTIONS?
Want to work on these and other challenges?http://cask.co/careers/