review lecture distributed computing systems. what is distributed computin systems distributed...
TRANSCRIPT

Review LectureDistributed Computing systems

What is Distributed Computin Systems
• Distributed system is one in which components located at networked computers communicated and coordinate their actions only by passing message –G. Coulouris
• A collection of independent computers that appears to its users as a single coherent system. - S. Tanenbaum

The Challenges
• Heterogeneity
• Openness
• Security
• Scalability
• Failure handling
• Concurrency
• Transparency

Scalability problems
• Characteristics of decentralized algorithms:
• No machine has complete information about the system state.
• Machines make decisions based only on local information.
• Failure of one machine does not ruin the algorithm.
• There is no implicit assumption that a global clock exists.

transparency, different types of transparency.
Distribution transparency is the phenomenon by which distribution aspects in a system are hidden from users and applications.
• Examples
- access transparency, location transparency, migration transparency, relocation transparency, replication transparency, concurrency transparency, failure transparency, and persistence transparency.

Transparencies
• Access transparency: enables local and remote resources to be accessed using identical operations.
• Location transparency: enables resources to be accessed without knowledge of their physical or network location (for example, which building or IP address).
• Concurrency transparency: enables several processes to operate concurrently using shared resources without interference between them.
• Replication transparency: enables multiple instances of resources to be used to increase reliability and performance without knowledge of the replicas by users or application programmers.

Transparencies
• Failure transparency: enables the concealment of faults, allowing users and application programs to complete their tasks despite the failure of hardware or software components.
• Mobility transparency: allows the movement of resources and clients within a system without affecting the operation of users or programs.
• Performance transparency: allows the system to be reconfigured to improve performance as loads vary.
• Scaling transparency: allows the system and applications to expand in scale without change to the system structure or the application algorithms.

Multitiered Architectures
The simplest organization is to have only two types of machines:
• A client machine containing only the programs implementing (part of) the user-interface level
• A server machine containing the rest, – the programs implementing the processing
and data level

Architectural Styles
• The (a) layered architectural style (vertical)

Architectural Styles
The object-based architectural style.
( horizontal)

vertical distribution and horizontal distribution
• Vertical distribution refers to the distribution of the different layers in a multitiered architectures across multiple machines. In principle, each layer is implemented on a different machine.
• Horizontal distribution deals with the distribution of a single layer across multiple machines, such as distributing a single database and a peer to peer system.

Architectural Styles
Important styles of architecture for distributed systems
• Layered architectures• Object-based architectures• Data-centered architectures• Event-based architectures

Structured overlay network
• messages are routed according to the topology of the overlay.
• Disadvantage-– The problem is that we are dealing only with logical
paths. It may very well be the case that two nodes A and B which are neighbors in the overlay network are physically placed far apart.
– As a consequence, the logically short path between A and B may require routing a message along a very long path in the underlying physical network

Process & Thread
A program in execution
• An instance of a program running on a computer• The entity that can be assigned to and executed on a
processor• A unit of activity characterized by the execution of a
sequence of instructions, a current state, and an associated set of system instructions
-William Stallings
• Threads -The unit of dispatching is referred to as a thread or lightweight process

Multithreaded Servers (1)
• A multithreaded server organized in a dispatcher/worker model.

limiting the number of threads in a server process
• First, threads require memory for setting up their own private stack. Consequently, having many threads may consume too much memory for the server to work properly. Another, more serious reason, is that, to an operating system, independent threads tend to operate in a chaotic manner.
• In a virtual memory system it may be difficult to build a relatively stable working set, resulting in many page faults and thus I/O. Having many threads may thus lead to a performance degradation resulting from page thrashing. Even in those cases where everything fits into memory, we may easily see that memory is accessed following a chaotic pattern rendering caches useless. Again, performance may degrade in comparison to the single-threaded case.

Process & Thread -Thread Implementation
Combining kernel-level lightweight processes and user-level threads.

Problem of single lightweight process per process
• In this scheme, we effectively have only user-level threads, meaning that any blocking system call will block the entire process.

Migration in Heterogeneous Systems
Three ways to handle migration (which can be combined)
• pushing memory pages to the new machine and resending the ones that are later modified during the migration process.
• Stopping the current virtual machine; migrate memory, and start the new virtual machine.
• Letting the new virtual machine pull in new pages as needed, that is, let processes start on the new virtual machine immediately and copy memory pages on demand.

RPC (Remote Procedure Call)
The interaction between client and server in a traditional RPC.

Asynchronous RPC
– When a client calls a remote procedure the client will block until are replies returned
– Unnecessary when there is no result return; adding antries into a database, transferring money from one account to another, batch processing
– To support this situation, RPC systems may provide facilities for what are called asynchronous RPCs.
(Server’s acknowledgement for client requirement)

Asynchronous RPC (2)
• The interaction using asynchronous RPC.

Case of asynchronous RPC and client execute a normal RPC
- Assume a client calls an asynchronous RPC to a server, and subsequently waits until the server returns a result using another asynchronous RPC. Is this approach the same as letting the client execute a normal RPC? -
• This is not the same. An asynchronous RPC returns an acknowledgment to the caller, meaning that after the first call by the client, an additional message is sent across the network.
• Likewise, the server is acknowledged that its response has been delivered to the client.

What if replace the synchronous RPCs with asynchronous RPCs?(2)
• Two asynchronous RPCs may be the same, provided reliable communication is guaranteed.
• This is generally not the case.

25
Network principles
• Mode of transmission
• Switching schemes
• Protocol suites
• Routing
• Congestion control

26
Mode of transmission
• Packets
– messages divided into packets( on Transport Layer)
– packets queued in buffers before sent onto link
– QoS not guaranteed
• Data streaming
– links guarantee QoS (rate of delivery)
– for multimedia traffic
– need higher bandwidth

27
Switching schemes
• Broadcasts (Ethernet, wireless)
– send messages to all nodes
– nodes listen for own messages (carrier sensing)
• Circuit switching (phone networks)
• Packet switching (TCP/IP)
– store-and-forward
– unpredictable delays
• Frame/cell relay (ATM)
– bandwidth & latency guaranteed (virtual path)
– small, fixed size packets (padded if necessary)
• 53bytes= header 5 + body 48
– avoids error checking at nodes (use reliable links)

28
Packet delivery
• In network layer– datagram packet delivery(IP in Ethernet, most wired and wireless LAN
technologies)– virtual circuit packet delivery(ATM)
• In transport layer– connection-oriented transmission(TCP)
• Reliable communication with static routing table(ISO, X.25)• Ex) remote login(Telnet), FTP, HTTP(big-sized file), stream data
– connectionless transmission(UDP)• Unreliable communication with pre-defined routing table• Ex) rcp, rwho, RPC, HTTP(small-sized file), FTP(non-error bulk
file)

29
Routing
• Necessary in non-broadcast networks (cf Internet) : Hop by Hop
• Distance-vector algorithm for each node
– stores table of state & cost information of links, cost infinity for faulty links
– determines route taken by packet (the next hop)
– periodically updates the table and sends to neighbors
– may converge slowly [Bellman-Ford]
• RIP-1(Router Information Protocol) for Internet
– Local router table changes
– use default routes, plus multicast and authentication
– better convergence( routes better route to an existing destination)

30
Congestion control
• When load on network exceeds 80% of its capacity
– packet queues long, links blocked
• Solutions(in datagram-based network layers)
– packet dropping
• reliable of delivery at higher levels
– reduce rate of transmission
• nodes send choke packets (Ethernet)
– A specialized packet that requesting a reduction in transmission rate
• transmission control (TCP)
– transmit congestion information to each node
• QoS guarantees (ATM)

Middleware Overview• 1970s
– By Socket Programming• 1980s
– By RPC (Remote Procedure Call)
RPC on DCE
RPC on DCOM• 1990s
– By ROI (Remote Object Invocation)
ORB on CORBA Platform
RMI on Java Platform
Remote on .NET Platform• 2000s
– By Web Service
Web Service on Java Platform
Web Service on .NET Platform
Web Service on Linux
Network Computing
Distributed Computing

Middleware
• Definition
– software layer that lies between the operating system and the applications on each site of the system.
– Stimulated by the growth of network-based applications, middleware technologies are taking an increasing importance. They cover a wide range of software systems, including distributed objects and components, message-oriented communication, and mobile application support.
• Examples
– ftp, E-mail
– Web browsers
– Database drivers and gateways
– OSF’s DCE (Distributed Computing Environment)
– OMG’s CORBA (Common Object Request Broker Architecture)

Role of middleware
• To enhance the distribution transparency that is missing in network operating systems.
• middleware aims at improving the single-system view that a distributed system should have.

34
Core OS components• Process manager
– creation and operations on processes (= address space+threads)• Threads manager
– threads creation, synchronization, scheduling• Communication manager
– communication between threads (sockets, semaphores)• in different processes(concurrency)• on different computers(parallel)
• Memory manager– physical (RAM) and virtual (disk) memory
• Supervisor– hardware abstraction (dispatching of interrupts, exceptions, system call traps)– control of memory managements and hardware cache

35
Middleware with OS

36
Middleware with OS
• Network OS– ex) UNIX, Windows NT– network transparent access for remote files (NFS)– no task/process scheduling across different nodes– services
• rlogin, telnet, ftp, WWW

37
Middleware with OS
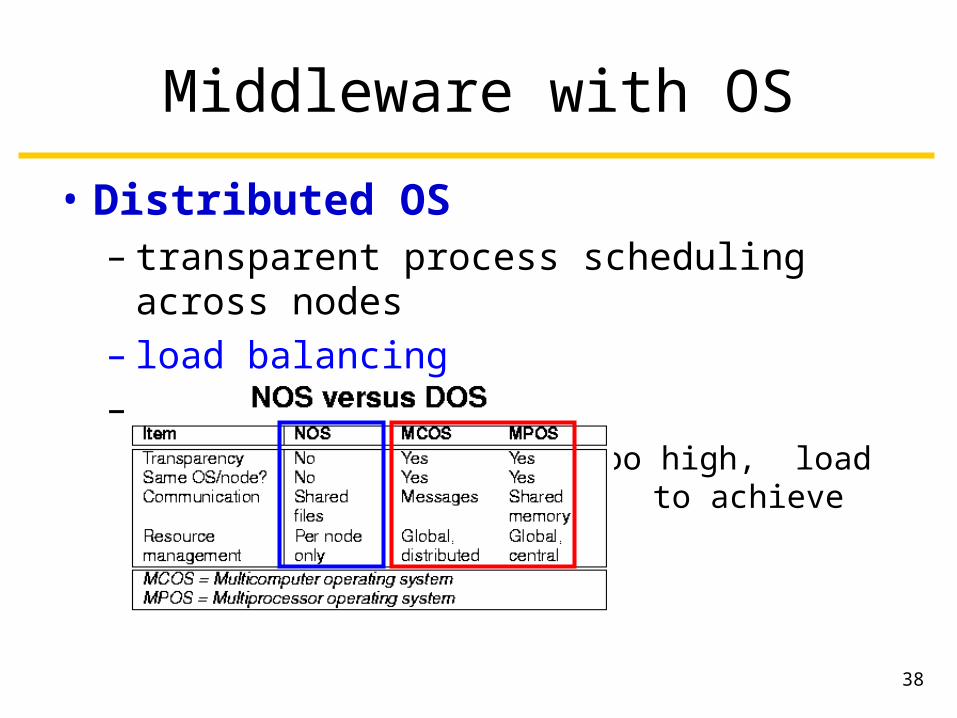
38
Middleware with OS
• Distributed OS– transparent process scheduling across nodes– load balancing– none in use: cost of switching OS too high, load balancing not always
easy to achieve

39
Middleware with OS
: NOS
: DOS
: NOS
Distributed Operating System Services

40
Middleware with OS
• Middleware– built on top of different NOSs– offers distributed resource sharing
• via remote invocations
– Similar to functionalities of DOS possible

41
Movtivation for middleware

Implementation of CORBA's asynchronous method invocation.
This do not affect the server-side implementation of an object.
• The important issue is that the client-side runtime system handles all the calls to the server.
• In particular, the RTS can do a synchronous call to the server, possibly having to wait a long time before an answer is returned. At that moment, it does an upcall to the client application.
• Likewise, the method invocation can be forwarded to a message router, where eventually, the targeted object server is simply called.
• it is the communication subsystem that handles the asynchronous nature of the invocation

How would you implement exceptions in RPCs and RMIs?
• exceptions are initially raised at the server side, the server stub can do nothing else but catch the exception and marshal it as a special error response back to the client.
• The client stub, on the other hand, will have to unmarshal the message and raise the same exception if it wants to keep access to the server transparent. Consequently, exceptions now also need to be described in an interface definition language.

JAVA RMI – Definition
• RMI (Remote Method Invocation) allows a Java program to invoke a method that is being executed on a remote machine
– Character • Transparency Method call• Support Callback from Server to Client
– Action • Stub and Skeleton
– Class allow exchanging data between Client and Server• Remote Reference layer
– Support various hosts in heterogeneous environment • Transport layer
– Path the marshaled stream
Transport Layer
Remote Reference Layer
Stub Skeleton
Client Server

45
RMI Program Procedure① Set a remote interface② Remote interface class③ Complete server program④ Set a client program to use the remote object⑤ Compile ②,③,④⑥ Create stub and skeleton by rmic
⑦ Activate rmiregistry⑧ Run the programs
% rmic Classname

CORBA-RMI
How does CORBA differ from RMI: •RMI is Java-only. •RMI is not an industry standard (it is a product of Sun). •RMI does not provide such a rich set of services and facilities. •RMI is simpler to use and integrates smoothly with Java. •RMI and CORBA can be used together. •(Soon - RMI over IIOP will make this very simple.)

Socket Sample
1)Serverside implementation for UDPsocket open and connetimport java.net.*;import java.io.*;public class UDPServer{public static void main(String args[] ) {try {
DatagramSocket aSocket = new DatagramSocket(6789);byte[] buffer = new byte[100];while(true) {DatagramPacket request =new DatagramPacket(buffer, buffer.length);System.out.println("Client's message : " + newString(request.getData()));aSocket.receive(request);DatagramPacket reply = new DatagramPacket(request.getData(),request.getLength(), request.getAddress(),request.getPort());aSocket.send(reply);
}}catch (SocketException e) {System.out.println("Socket: " +e.getMessage());}catch (IOException e) {System.out.println("IO: " + e.getMessage()); } }}

Socket Sample2)Clientside application for UDPsocketimport java.net.*;import java.io.*;public class UDPClient{public static void main(String args[]) {// args give message contents and server hostnametry {
DatagramSocket aSocket = new DatagramSocket();byte [] m = args[0].getBytes();InetAddress aHost = InetAddress.getByName(args[1]);int serverPort = 6789;DatagramPacket request =new DatagramPacket(m, args[0].length(), aHost,serverPort);aSocket.send(request);byte[] buffer = new byte[100];DatagramPacket reply =new DatagramPacket(buffer, buffer.length);aSocket.receive(reply);System.out.println("Reply: " + new String(reply.getData()));aSocket.close();
}catch (SocketException e) {System.out.println("Socket: " +e.getMessage());}catch (IOException e) {System.out.println("IO: " +e.getMessage()); }}}

CORBA - IDL
//Hello.idl
module HelloApp
{ interface Hello
{
string sayHello();
long sum(in long x);
};
};

CORBA- Server side. //HelloServer.java
import HelloApp.*;import org.omg.CosNaming.*;import org.omg.CosNaming.NamingContextPackage.*;import org.omg.PortableServer.*;import org.omg.CORBA.*;import org.omg.PortableServer.POA;
class HelloImpl extends HelloPOA { public String sayHello( ) { return “The result is\n"; } public int sum(int x) { if (x>0) return(x+sum(x-1)); else return 0; }}
public class HelloServer { public static void main(String args [] ) { try { ORB orb = ORB.init (args, null); POA rootPoa = (POA)orb.resolve_initial_references("RootPOA"); rootPoa.the_POAManager().activate(); HelloImpl hello = new HelloImpl(); org.omg.CORBA.Object ref = rootPoa.servant_to_reference(hello); Hello href = HelloHelper.narrow(ref); org.omg.CORBA.Object oRef = orb.resolve_initial_references("NameService");
NamingContextExt ncRef = NamingContextExtHelper.narrow(oRef); String name= "Hello"; NameComponent path[]=ncRef.to_name(name); ncRef.rebind(path, href); System.out.println("Hello Server Ready"); orb.run(); } catch(Exception e){e.printStackTrace();} System.out.println("Server Exiting"); }}

CORBA - Client side.
//Helloclient.javaimport HelloApp.*;import org.omg.CosNaming.*;import org.omg.CosNaming.NamingContextPackage.*;import org.omg.CORBA.*;
public class HelloClient{ static Hello hello; public static void main(String args[]) { try { ORB orb=ORB.init(args, null); org.omg.CORBA.Object objRef=
orb.resolve_initial_references("NameService");NamingContextExt ncRef = NamingContextExtHelper.narrow(objRef);
hello=HelloHelper.narrow(ncRef.resolve_str("Hello")); System.out.println(hello.sayHello()); System.out.println("the result is " + hello.sum(100)); } catch(Exception e) {e.printStackTrace();} }}