roundtable 2: big data analytics and nosql
TRANSCRIPT

DB Revolution: 2nd RoundtableWednesday, March 14, 12


To conduct an Open Research program that invites the participation of both IT users and technology vendors
To assist IT buyers in understanding database technology and the architecture that surrounds it.
Allow audience members to pose serious questions... and get answers!
Publish all findings
Twitter Tag: #briefrWednesday, March 14, 12

Your Host: Eric Kavanagh
Research Leader: Mark Madsen - Third Nature
Primary Collaborator: Robin Bloor - The Bloor Group
Guest Analyst 1: Colin White - BI Research
Guest Analyst 2: Steve Dine - DataSource Consulting
Wednesday, March 14, 12

Twitter Tag: #briefr
Colin White is the president of DataBase Associates Inc. and founder of BI Research. He is well known for his in-depth knowledge of data management, information integration, and business intelligence technologies. He has consulted for dozens of companies throughout the world and is a frequent speaker at leading IT events. For ten years he was the conference chair of the DCI and Shared Insights Portals, Content Management, and Collaboration conference.
Wednesday, March 14, 12

Colin WhitePresident BI Research
March 2012
Big Data is Bigger than NoSQL
Wednesday, March 14, 12

2Copyright © BI Research, 2012
What is Big Data?
2
A term that represents workloads and data management solutions that could not previously be supported because of cost considerations and/or technology limitations
Three important technologies:•Optimized analytic RDBMSs•Non-relational “NoSQL” systems
•Stream processing systems
Wednesday, March 14, 12

3Copyright © BI Research, 2012
Big Data: The Business Case
Smarter Decisions• Analyze new sources of data e.g., sensor data, web content,
systems logs, text, XML files, graph data, map data, etc. • More sophisticated analyses - advanced analytics
Faster Decisions• Supports workloads that were difficult to implement previously in
a timely or cost-effective manner • Faster data analysis, e.g., analysis of large detailed data stores,
dramatic increase in analytic model execution
Faster Time to Value• Analyze data that is outside of the enterprise data warehouse,
e.g., machine-generated data such as sensor data
3
Wednesday, March 14, 12

4Copyright © BI Research, 2012
Non-Relational Solutions
Some organizations have developed their own non-relational (NoSQL) systems to support extreme workloads
• Google: MapReduce + BigTable DBMS + Google File System
Non-relational systems are not new, but modern versions are often available to the open source community
• Often support commodity hardware in a large-scale distributed computing environment
• Several types of data stores (key value, graph, document, indexed file/DB systems)
• A key vendor focus area is the Hadoop distributed computing system
4
Wednesday, March 14, 12

5Copyright © BI Research, 2012
Hadoop versus an RDBMS
This debate is reminiscent of the object versus relational database debates of the 1980s, and the reasons are similar
• Programmers prefer procedural programmatic approaches for accessing and manipulating data, e.g., MapReduce
• Non-programmers prefer declarative languages, e.g., RDBMSs and SQL
Adding the Hive SQL-like language to Hadoop, and MR functions to RDBMSs, however, complicates the debate
Key requirements are:• The ability for organizations to easily analyze large volumes of multi-
structured data with good price/performance• The need to make technologies for developing and running these
analyses more usable by data scientists
Organizations will likely use Hadoop and an RDBMS - the challenges are deciding which to use when and interconnecting the systems
5
Wednesday, March 14, 12

11
Wednesday, March 14, 12

7Copyright © BI Research, 2012
The Value of Big Data: McKinsey Report
7
www.mckinsey.com/Insights/MGI/Research/Technology_and_Innovation/Big_data_The_next_frontier_for_innovation
Wednesday, March 14, 12

Twitter Tag: #briefr
Robin Bloor is Chief Analyst at The Bloor Group.
Wednesday, March 14, 12

The Hardware LandscapeCPUs go multicoreMemory/Disk cost ratio fallsSpeed of random reads lag speed of serial readsFaster networking and fast switchesParallelism becomes more importantCommodity serversCloud computing cuts H/W costs
Wednesday, March 14, 12

That MapReduce ThingThere are two fundamental approaches to parallelism
Data PartitioningProcess partitioning
MapReduce implements an approach which is oriented to data partitioningThis relates to data processing rather than to databaseHadoop is often used for ETL
Wednesday, March 14, 12

The Devil Is In The Workload
NoSQL is a distractionBig Data can be Big US Data or Big SDATAUnstructured workloads are rarely suited to traditional RDMBS-type enginesAnalytical workloads span both
Database Database
DATA
VOLUME
MoreStructured
LessStructured
ColumnStore
BigTable
RDBMS ODBMS
DocumentStore
XMLStore
Wednesday, March 14, 12

If you don’t know the expected workloads, you shouldn’t be
selecting a database
Wednesday, March 14, 12

Twitter Tag: #briefr
Steve Dine is the founder of Datasource Consulting, LLC. He has extensive experience delivering and managing successful, highly scalable and maintainable data integration and business intelligence solutions. Steve combines hands-on technical experience across the entire BI project lifecycle with strong business acumen. He currently works as a consultant for Fortune 500 companies. Steve is a faculty member at TDWI and a judge for the Annual TDWI Best Practices Awards. He teaches courses and presents on many BI topics. Contact info: Twitter: @steve_dineEmail: [email protected] Web: http://www.datasourceconsulting.com
Wednesday, March 14, 12

The State of NoSQL & BIFrom the trenches…
19
Confiden)al, Datasource Consul)ng, LLC
“Hey Bob, seems like a no brainer. So, what’s the catch?”
* Graphic from h=p://[email protected]/category/booksbook-‐reviews/c-‐s-‐lewis/page/2/
Wednesday, March 14, 12

Why NoSQL?
20
Confiden)al, Datasource Consul)ng, LLC
More dataMore different types of data (semi-‐structured, unstructured)
More frequent changes to the structure of the data we need to store and analyze
More demand for the long tail analysisMore “affordable”, commodity hardware available (blade servers, “cheap” storage, cloud)
More buzz!
* Graphic from h=p://www.fredberinger.com/musings-‐on-‐nosql/
Wednesday, March 14, 12

Why Not Not NoSQL?
21
Confiden)al, Datasource Consul)ng, LLC
RelaCvely immature (0.x – 2.x)Difficult to describe to decision makersNot fit for purpose (low latency, update heavy, complex joins)
In many organizaCons it’s a soluCon looking for a problem Lack of “BI” supportSkills gap!
* Graphic based on h=p://www.fredberinger.com/musings-‐on-‐nosql/
Wednesday, March 14, 12

BI-NoSQL Skills Gap
22
Confiden)al, Datasource Consul)ng, LLC
“SQL” Skills
• GUI’s (mostly)• Rela)onal Data Modeling • RDBMS • SQL• Stored procedures• LDAP• Javascript• Batch/Shell Scripts
NoSQL Skills
• Command Line• Key-‐Value / Column Family Modeling• Distributed Data Store• Programming (Java, Jscript, Python, etc)• MapReduce (Hive)• JSON• Shell Scripts
* Graphic based on h=p://www.beckshome.com/index.php/2007/09/the-‐soa-‐chasm/
Wednesday, March 14, 12

Conclusions?
23
Confiden)al, Datasource Consul)ng, LLC
• Best to evaluate your true data size, data growth, data formats, data structure and analyCc requirements before deciding on soluCon
• Make sure to evaluate your available skills• Experienced NoSQL resources with BI experience not always easy to find
• Need to plan for addiConal technology risk in project plan • Consider starCng out with one part of your DW architecture (i.e. staging)
• POC POC POC
• NoSQL maturing quickly and will likely conCnue to evolve into a hybrid soluCon
Wednesday, March 14, 12

Twitter Tag: #briefr
Mark Madsen is founder of Third Nature, a research and consulting firm focused on analytics, BI and decision-making. Mark spent the past two decades working on analysis and decision support in many industries and countries. He is an award-winning architect and former CTO whose work has been featured in numerous industry publications. Over the past ten years Mark received awards for his work from the American Productivity & Quality Center, TDWI, and the Smithsonian Institute. He is an international speaker, a contributing editor at Intelligent Enterprise, and manages the open source channel at the Business Intelligence Network. For more information or to contact Mark, visit http://ThirdNature.net.
Wednesday, March 14, 12

One Size Doesn’t Fit AllChoosing which big data, NoSQL or database technology to use
March 14, 2012
Mark R. Madsenhttp://ThirdNature.net
Wednesday, March 14, 12

Wednesday, March 14, 12

Unstructured data isn’t really unstructured.
The problem is that this data is unmodeled.
The real challenge is complexity.
Big data?
Wednesday, March 14, 12

The holy grail of databases under current market hype
A key problem is that we’re talking mostly about computa?on over data when we talk about “big data” and analy?cs, a poten?al mismatch for both rela?onal and nosql.
Wednesday, March 14, 12

Solving the Problem Depends on the Diagnosis
Wednesday, March 14, 12

You must understand your workload -‐ throughput and response =me requirements aren’t enough.▪ 100 simple queries accessing month-‐to-‐date data
▪ 90 simple queries accessing month-‐to-‐date data plus 10 complex queries using two years of history
▪Hazard calculaCon for the enCre customer master
▪ Performance problems are rarely due to a single factor.
Wednesday, March 14, 12

Workload: One big query or many small queries?
Retrieval: small return set or large?
Selectivity: large volume of data scanned or small?Wednesday, March 14, 12

Important workload parameters to know
• Read-‐intensive vs. write-‐intensive
Wednesday, March 14, 12

Important workload parameters to know
• Read-‐intensive vs. write-‐intensive•Mutable vs. immutable data
Wednesday, March 14, 12

Important workload parameters to know
• Read-‐intensive vs. write-‐intensive•Mutable vs. immutable data
• Immediate vs. eventual consistency
Wednesday, March 14, 12

Important workload parameters to know
• Read-‐intensive vs. write-‐intensive•Mutable vs. immutable data
• Immediate vs. eventual consistency
• Short vs. long access latency
Wednesday, March 14, 12

Important workload parameters to know
• Read-‐intensive vs. write-‐intensive•Mutable vs. immutable data
• Immediate vs. eventual consistency
• Short vs. long access latency• Predictable vs. unpredictable data access paEerns
Wednesday, March 14, 12

Types of workloads
Write-‐biased: ▪OLTP▪OLTP, batch▪OLTP, lite▪Object persistence▪Data ingest, batch▪Data ingest, real-‐Cme
Read-‐biased:Query
Query, simple retrieval
Query, complex
Query-‐hierarchical / object / network
AnalyCc
Mixed?Inline analytic execution, operational BI
Wednesday, March 14, 12
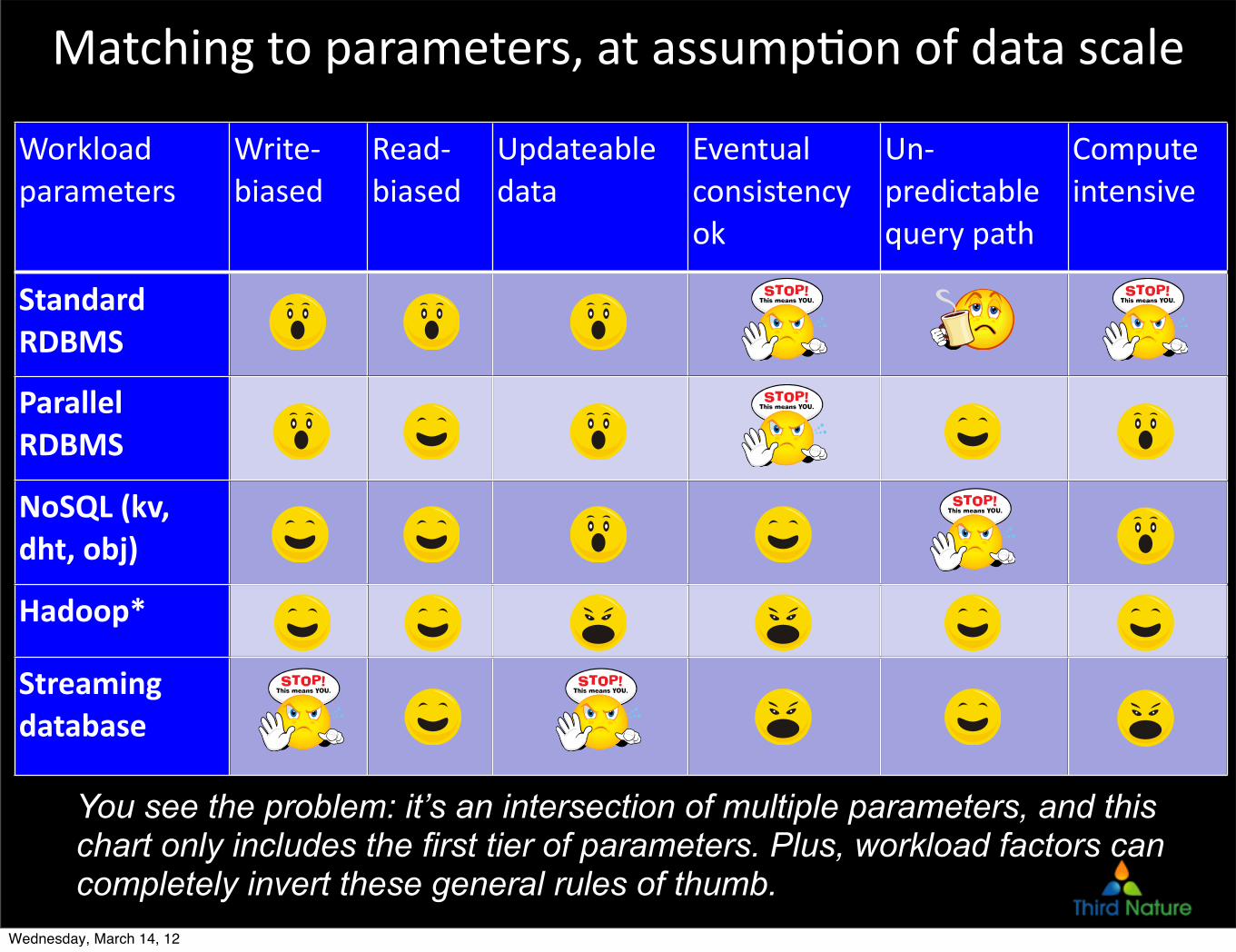
Matching to parameters, at assumpCon of data scale
Workload parameters
Write-‐biased
Read-‐biased
Updateable data
Eventual consistency ok
Un-‐predictable query path
Compute intensive
Standard RDBMS
Parallel RDBMS
NoSQL (kv, dht, obj)
Hadoop*
Streaming database
You see the problem: it’s an intersection of multiple parameters, and this chart only includes the first tier of parameters. Plus, workload factors can completely invert these general rules of thumb.
Wednesday, March 14, 12

Matching to parameters, at assumpCon of data scale
Workload parameters
Complex queries
SelecCve queries
Low latency queries
High concurrency
High ingest rate
Standard RDBMS
Parallel RDBMS
NoSQL (kv, dht, obj)
Hadoop
Streaming database
You have to look at the combination of workload factors: data scale, concurrency, latency & response time, then chart the parameters.
Wednesday, March 14, 12

Always build a proof of concept!
Wednesday, March 14, 12

Disection & Discussion
Twitter Tag: #briefrWednesday, March 14, 12

Wednesday, March 14, 12

March:Vendor ResearchMarch 14th: Second Round Table focusing on No SQL databases and their applicationDB Revolution Survey conducted
April:Vendor ResearchPublishing of Round Table Transcripts, with comments
May:Authoring of White PaperPublishing of White PaperPublishing of survey activity
Twitter Tag: #briefrWednesday, March 14, 12

March Briefing Room: Integration
April Briefing Room: Discovery
May Briefing Room: Analytics
Twitter Tag: #briefrWednesday, March 14, 12

Thank YouFor YourAttention
Wednesday, March 14, 12