rozpoznawanie i synteza mowy - eti.pg.edu.pl · 2 alicja nagórko, zarys gramatyki polskiej, pwn,...
TRANSCRIPT

Rozpoznawanie i synteza mowy
Jan Daciuk
Katedra Inteligentnych Systemów Interaktywnych, Wydział ETI, Politechnika Gdanska
Multimedialne systemy interaktywne
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 1 / 189

Literatura
1 Marek Wisniewski, Zarys fonetyki i fonologii współczesnegojezyka polskiego, Wydawnictwo Uniwersytetu Mikołaja Kopernika,wydanie IV, Torun 2001.
2 Daniel Jurafsky, James H. Martin, Speech and LanguageProcessing. An Introduction to Natural Language Processing,Computational Linguistics, and Speech Recognition, secondedition, Prentice-Hall, 2008.
3 Bartosz Ziółko, Mariusz Ziółko, Przetwarzanie mowy,Wydawnictwa AGH, Kraków 2011.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 2 / 189

Literatura uzupełniajaca
1 Danuta Ostaszewska, Jolanta Tambor, Fonetyka i fonologiawspółczesnego jezyka polskiego, PWN, Warszawa, 2002.
2 Alicja Nagórko, Zarys gramatyki polskiej, PWN, Warszawa, 1996.3 Paul Taylor, Text-to-speech synthesis, Cambridge University
Press, 2009.4 Xuedong Huang, Alex Acero, Hsiao-Wuen Hon, Spoken
Language Processing: A Guide to Theory, Algorithm and SystemDevelopment, Prentice Hall, 2001.
5 Stefan Breuer, Multifunktionale und MultilingualeUnit-Selection-Sprachsynthese. Designprinzipien für Architekturund Sprachbausteine, rozprawa doktorska, RheinischenFriedrich-Wilhelms-Universität Bonn, 2009. Dostepna podadresem:http://hss.ulb.uni-bonn.de/2009/1650/1650.pdf
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 3 / 189

Literatura uzupełniajaca
6 Zygmunt Ciota, Metody przetwarzania sygnałów akustycznych wkomputerowej analizie mowy, Akademicka Oficyna WydawniczaEXIT, Warszawa 2010.
7 Ryszard Tadeusiewicz, Sygnał mowy, Wydawnictwa Komunikacji iŁacznosci, Warszawa 1988, ksiazka dostepna pod adresem:http://winntbg.bg.agh.edu.pl/skrypty/0004/
8 Tomasz Zielinski, Cyfrowe przetwarzanie sygnałów. Od teorii dozastosowan, Wydawnictwa Komunikacji i Łacznosci, 2009.
9 Peter Birkholz, 3D-Artikulatorische Sprachsynthese, rozprawadoktorska, Universität Rostock, 2005. Dostepna pod adresem:http://www.vocaltractlab.de/publications/birkholz-2005-dissertation.pdf
10 Takashi Masuko, HMM-Based Speech Synthesis and ItsApplications, rozprawa doktorska, Tokyo Institute of Technology,2002. Dostepna pod adresem:http://www.kbys.ip.titech.ac.jp/masuko/masuko-doctor.pdf
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 4 / 189

1 litera – 1 dzwiek
Alfabet jezyka polskiego składa sie z 32 liter: a, a, b, c, c, d, e, e, f, g,h, i, j, k, l, ł, m, n, n, o, ó, p, r, s, s, t, u, w, y, z, z, z. Łacinskie litery q, vi x wystepuja jedynie w pisowni wyrazów obcych.Alfabet fonetyczny jezyka polskiego składa sie z około 78 dzwieków.Dokładna liczba głosek zalezy od sposobu traktowania wariantów.Relacja litera – głoska jest typu wiele – wiele. Tak jest takze w wieluinnych jezykach.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 5 / 189

Alfabety fonetyczne
Miedzynarodowy Alfabet Fonetyczny – International PhoneticAlphabet (IPA). Moze byc stosowany do opisu róznych jezyków.Niektóre głoski jezyka polskiego zapisuje sie w nim w doscskomplikowany sposób, np. [
>dz,].
Slawistyczny Alfabet Fonetyczny. Powszechnie stosowany doopisu jezyków słownianskich, w tym polskiego. Prostszy zapisgłosek jezyka polskiego, np. [Z].
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 6 / 189

1 litera – 1 dzwiek
Głoski zapisywane z litera z i ew. znakami diakrytycznymi:[c] – cz (np. czapa), [s] – sz (np. sznur), [z] – rz (np. rzeka, ale zona).W wyrazach pochodzenia obcego moga pojawiac sie miekkie wariantyspółgłosek dziasłowych: [Ťc] (np. Chile), [Ťs] (np. Sziwa), [Ťz] (np. zigolo).[Z] – dz (np. pieniadze), [Z] – dz i dzi (np. dzwiek i dzien), [Z] – dz (np.dzem, dzungla, ale nie drzem, drzewo). Warianty [ŤZ] (np. dzinsy) i [Z’](wystepuje tylko w gwarze).
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 7 / 189

1 litera – 1 dzwiek
Głoski zapisywane na dwa rózne sposoby – kiedys rózne głoski:[x] wymawiana jest przez wiekszosc Polaków w wyrazach pisanychzarówno z ch (np. chleb, Chełm), jak i z h (np. hełm, hustawka, hardy).Nieliczni Polacy wymawiaja h inaczej – jako [G]. Warianty: [x’] (np.chichot, Chiny) i [G’] (np. historia).Głoska [u] jest zapisywana zarówno jako u (np. lub, lud), jak i ó (np.chłód, lód).Głoska [z] jest zapisywana zarówno jako rz (np. rzeka), jak i z (np.zaba).
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 8 / 189

1 litera - 1 dzwiek
Spółgłoski miekkie i zmiekczone, zapis z kreseczka lub z i :[c], [Z], [n], [s], [z] moga byc zapisywane jako c, dz, n, s i z przedspółgłoskami i na koncu wyrazu, jako ci, dzi, ni, si i zi przedsamogłoska rózna od i oraz jako c, dz, n, s i z przed samogłoska i.[x’], [g’], [G’], [k’] zapisywane sa wyłacznie w postaci połaczenia z i(np. chichot, drugi).[b’], [f’], [p’], [v’], [l’], [m’], a w wyrazach pochodzenia obcego takze[d’], [r’], i [t’], takze zapisywane sa za pomoca połaczenia z litera i,której nie powtarza sie przed głoska [i].
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 9 / 189

Reguły transkrypcji – inne jezyki
Angielski: (corpse, corps), (horse, worse), (speak, break), (read,read).Francuski: (chanter, chanté), (chantais, chantait, chantaient). Leprésident. Ils président.Jezyki semickie: zapisywane sa wyłacznie spółgłoski.
Oprócz pisma alfabetycznego istnieje tez pismo ideograficzne (np.chinskie), gdzie kazdy znak oznacza pewne pojecie, i pismosylabiczne, np. japonskie alfabety kana (hiragana i katakana) czygreckie pismo linearne B.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 10 / 189

Podstawowe pojecia
Głoska (ang. phone) – najprostszy element dzwiekowy mowy ludzkiej,niepodzielny artykulacyjnie i słuchowo.Fonem (ang. phonem) – funkcjonalne jadro głoski, na które składa siezbiór cech rozrózniajacych (dysktynktywnych).Dzwieczny (ang. voiced) – powiazany z okresowymi drganiamiwiazadeł głosowych.Samogłoska (ang. vowel) – głoska, dla której jedynym zródłemdzwieku sa okresowe drgania wiazadeł głosowych.Spółgłoska (ang. consonant) – głoska, przy której wymawianiuwystepuje przeszkoda w obrebie jamy ustno-gardłowej, wskutek czegonie jest mozliwy przepływ powietrza przez kanał głosowy bez zakłócen.Sylaba (zgłoska) – odcinek wypowiedzi stanowiacy jednoscwydechowa, ruchowa i akustyczna, posiadajacy jedno maksimumdonosnosci, który potencjalnie moze byc fonetycznie samodzielnawypowiedzia.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 11 / 189

Po co klasyfikowac głoski?
Rozróznianie jednych głosek od drugichZnajdowanie głosek podobnych w przypadku błedów rozpoznaniaWymagane w regułach fonologicznych dla prawidłowej syntezymowy
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 12 / 189

Klasyfikacja głosek
Kryterium funkcjonalne: samogłoski i spółgłoski.
Kryterium akustyczne: tony – dzwieki o regularnej czestotliwoscidrgan (samogłoski) i szumy – dzwieki o nieregularnej czestotliwoscidrgan (spółgłoski).
Kryterium artykulacyjne: dzwieki otwarte – brak wyraznej zapory dlapowietrza z płuc (samogłoski sa otwarte) i dzwieki, które nie sa otwarte(spółgłoski nie sa otwarte).
Dzwieki [i“] i [u
“] z funkcjonalnego punktu widzenia sa spółgłoskami, ale
z artykulacyjnego – samogłoskami (sa otwarte).
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 13 / 189

Samogłoski polskie
a
u
o
i
e
ywysokie: i, y i usrednie: e i oniskie: a
Na diagramie za-znaczono tylkosamogłoski ustne.
przednie: i, y i e, srodkowe: a, tylne: u i o.Samogłoski nosowe (a i e) w jezyku polskim sa złozeniem samogłoskaustna + spółgłoska nosowa.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 14 / 189

Półsamogłoski
Zdanie w jezyku czeskimstrc prst skrz krk
W jezyku polskim nie jest mozliwe tworzenie sylab bez samogłosek.Ograniczenie to nie dotyczy niektórych innych jezyków słowianskich.Dzwieki [l] (np. w wyrazie vlk) i [r] sa w jezyku czeskim (i słowackim, atakze serbsko-chorwackim) pół-samogłoskami (ang. semivowel).Umozliwiaja tworzenie sylab.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 15 / 189

Klasyfikacja spółgłosek
Ruch wiazadeł głosowych: dzwieczne (wiazadła drgaja) ibezdzwieczne (wiazadła nie biora udziału w powstawaniu dzwieku).Na przykład [b], [v] i [z] sa dzwieczne, a odpowiadajace im [p], [f] i [s]– bezdzwieczne.
Ruchy jezyczka podniebienia miekkiego (ang. velum): ustne, np.[b], [s] itp. – ogromna wiekszosc spółgłosek i nosowe (ang. nasal),[m], [n] i ich warianty.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 16 / 189

Klasyfikacja spółgłosek
Typ zapory: półotwarte (ang. approximants) (powietrze w jednymmiejscu nasady napotyka na całkowita blokade utworzona przezzwarte artykulatory, a w innym płynie przez szczeline utworzona przezinna pare artykulatorów) – np. [m], [n], [n], [N], [l], [r] i spółgłoskiwłasciwe. Spółgłoski własciwe dzielimy na zwarte (ang. stops) iartykułowane bez udziału zwarcia. Zwarte dzielimy nazwarto-szczelinowe (ang. africates) (artykułowane takze z udziałemszczeliny – „afrykaty”, czyli „nie w pełni trace”) – np. [c], [Z] itp. orazzwarto-wybuchowe (ang. plosives) (powietrze po napotkaniu blokadypokonuje ja) – np. [p], [d]. Artykułowane bez udziału zwarcia tospółgłoski szczelinowe (ang. fricatives) („trace” lub „frykatywne”) – np.[v], [z].
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 17 / 189
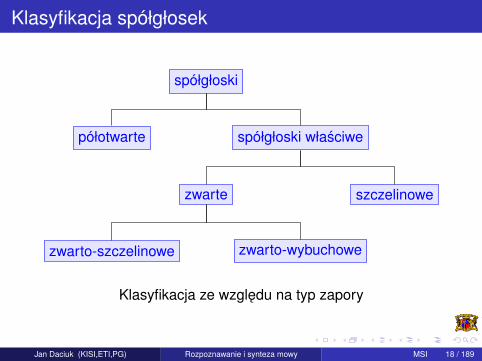
Klasyfikacja spółgłosek
spółgłoski
półotwarte spółgłoski własciwe
zwarte
zwarto-szczelinowe zwarto-wybuchowe
szczelinowe
Klasyfikacja ze wzgledu na typ zapory
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 18 / 189

Klasyfikacja spółgłosek
Miejsce artykulacji: artykułowane z udziałem warg i bez udziałuwarg. Te pierwsze dziela sie dwuwargowe (ang. bilabials) (tylko wargitworza zapore) – np. [b], [m] i wargowo-zebowe (ang. labiodental) (nietylko wargi tworza zapore) – np. [f]. Te drugie dziela sie na takie, wktórych przód jezyka tworzy zapore – przedniojezykowe (ang. coronal)i te, w których sytuacja ta nie zachodzi. Przedniojezykowe dziela siena przedniojezykowo-zebowe (ang. dentals) (przód jezyka tworzyzapore z zebami) – np. [d], [Z] i przedniojezykowo-dziasłowe (ang.alveolar) (przód jezyka tworzy zapore z dziasłami) – np. [l], [r].
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 19 / 189

Klasyfikacja spółgłosek
Spółgłoski, które nie sa przedniojezykowe, dziela sie na tylnojezykowe(ang. velar) (srodek jezyka nie tworzy zapory) – np. [g], [x],prepalatalne (srodek jezyka tworzy zapore z tylna czesciapodniebienia twardego) – np. [n] i postpalatalne (srodek jezyka nietworzy zapory z tylna czescia podniebienia twardego) – np. [G’].
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 20 / 189

Klasyfikacja spółgłosek
spółgłoski
wargowe
dwuwargowe wargowo-zebowe
niewargowe
przedniojezykowe
przedniojezykowo-zebowe przedniojezykowo-dziasłowe
nieprzedniojezykowe
tylnojezykowe prepalatalne postpalatalne
Klasyfikacja ze wzgledu na miejsce artykulacji
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 21 / 189

Klasyfikacja spółgłosek
Udział jezyka w artykulacji: twarde (bez udziału srodka jezyka, któryzalega dno jamy ustnej) – np. [b], [z] i artykułowane z udziałemsrodka jezyka: miekkie (srodek jezyka jest głównym miejscemartykulacji, tzn. tworzy jedna zapore) – np. [z] i zmiekczone (srodekjezyka nie tworzy jednej zapory) – np. [b’] czy [z’].
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 22 / 189

Klasyfikacja spółgłosek
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 23 / 189

Klasyfikacja spółgłosek
Wargowosc Przedniojezykowosc Srodkowo- Tylno--zebowosc Dwu- -zebowosc -dziasłowosc jezykowosc jezyko-
Tw Zm Tw Zm Tw Zm Tw Zm Prepal. Postpal wosc
Zwarcie [b],[p] [b’],[p’] [d],[t] [d’],[t’] [d˙],[t
˙] [g’],[k’] [g],[k]
Zwarto-szczelinowosc [Z],[c] [Z’],[c’] [Z],[c] [Z’],[c’] [Z],[c]
Szczelina [v],[f] [v’],[f’] [z],[s] [z’],[s’] [z],[s] [z’],[s’] [z],[s] [G’],[x’] [G],[x]
Półotwarcie [M] [n] [n˙]
nosowe [m],[m›] [m’] [n],[n
›] [n’] [n
˙] [n],[n
›] [N],[N
›]
Półotwarcieustne-boczne [ł],[ł
›] [l],[l
›] [l’]
Półotwarcieustne-drzace [r],[r
›] [r’]
Nagłówki kolumn okreslaja miejsce zapory. Nagłówki wierszy okreslajatyp zapory.Kropka pod litera oznacza dziasłowosc: [d
˙],[t
˙], np. drzewo. Kreska
pod litera oznacza bezdzwieczna wymowe głoski: [m›], [n
›], [n
›], [N
›], [ł
›],
[l›], np. basn.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 24 / 189
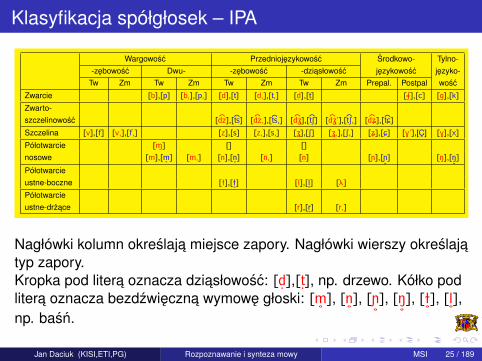
Klasyfikacja spółgłosek – IPA
Wargowosc Przedniojezykowosc Srodkowo- Tylno--zebowosc Dwu- -zebowosc -dziasłowosc jezykowosc jezyko-
Tw Zm Tw Zm Tw Zm Tw Zm Prepal. Postpal wosc
Zwarcie [b],[p] [b,],[p,] [d],[t] [d,],[t,] [d˙],[t
˙] [S],[c] [g],[k]
Zwarto-szczelinowosc [
>dz],[
>ts] [
>dz,],[
>ts,] [
>dÿ],[
>tS] [
>dÿ’],[
>tS,] [
>dý],[
>tC]
Szczelina [v],[f] [v,],[f,] [z],[s] [z,],[s,] [ÿ],[S] [ÿ,],[S,] [ý],[C] [G’],[Ç] [G],[x]
Półotwarcie [M] [] []
nosowe [m],[m˚
] [m,] [n],[n˚] [n,] [n
˙] [ñ],[ñ
˚] [N],[N
˚]
Półotwarcieustne-boczne [ë],[ë
˚] [l],[l
˚] [ń]
Półotwarcieustne-drzace [r],[r
˚] [r,]
Nagłówki kolumn okreslaja miejsce zapory. Nagłówki wierszy okreslajatyp zapory.Kropka pod litera oznacza dziasłowosc: [d
˙],[t
˙], np. drzewo. Kółko pod
litera oznacza bezdzwieczna wymowe głoski: [m˚
], [n˚], [ñ
˚], [N
˚], [ë
˚], [l
˚],
np. basn.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 25 / 189

Koartykulacja
Tendencja do łagodzenia kontrastów: dochodzi do upodobnien(asymilacji). Upodobnienia moga byc martwe lub zywe.W jezyku polskim istnieja upodobnienia wsteczne: głoski mocniejwiaza sie z głoska poprzedzajaca, zmieniaja jej cechy.Redukcja (np. szescset, królewski, martwe miejski, półtora),ubezdzwiecznienie (np. babka, dab, wóz, martwe postepowe krzak,swój, swieto, przód), udzwiecznianie (np. prosba).
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 26 / 189

Koartykulacja
półtrzecia talentu — talent = 60 min, miewał rozmaita wagelokalna 20-30 kg; lidyjski talent wazył ponad 25 kg.
Herodot - „Dzieje”. Z jezyka greckiego przełozył i opracował SewerynHammer. Czytelnik. Warszawa 2003, str. 548. Tekst oparto na drugimwydaniu z 1959 roku. Zachowano wszystkie charakterystyczne cechystylu i pisowni przekładu Seweryna Hammera.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 27 / 189

Prozodia
Prozodia bada funkcje spełniana przez cechy foniczne o charakterzeponadsegmentalnym, nie bedace atrybutami fonemów, lecz sylab lubciagów sylab. Obejmuje akcent, iloczas i ton (intonacje).Akcent moze byc wyrazowy i zdaniowy (kontur intonacyjny zdania).Akcent wyrazowy moze byc:– iloczasowy (kwantytatywny, rytmiczny) – dłuzsze wymawianiesamogłoski– tonalny (melodyczny, muzyczny) – podwyzszenie tonu samogłoski– przyciskowym (dynamicznym, ekspiracyjnym) – wieksza energiaartykulacyjna i intensywnosc wymowy samogłoski.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 28 / 189

Prozodia
Ze wzgledu na wyrózniane miejsce akcent moze byc stały – gdy padana jedna, okreslona pozycje sylaby lub swobodny. Akcent stały mozebyc:– oksytoniczny - pada na ostatnia sylabe, jak np. we francuskim– paroksytoniczny – pada na przedostatnia sylabe, np. w polskim– proparoksytoniczny – pada na trzecia sylabe od konca, np. wewspółczesnym macedonskim– inicjalny – pada na pierwsza sylabe, np. w czeskim.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 29 / 189

Prozodia
Akcent swobodny moze byc:– nieruchomy – powiazany ze scisle okreslonym morfemem, np. wangielskim – ruchomy – nie jest powiazany ze scisle okreslonymmorfemem, np. w rosyjskim.Poza wyrazami o własnym akcencie (ortotonicznymi) istnieja wyrazyatoniczne (niesamodzielne akcentowo), czyli klityki (proklityki ienklityki). Łacznie tworza wyraz fonetyczny.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 30 / 189

Prozodia
Polski akcent wyrazowy jest przyciskowy, jednostajny (niewprowadza intonacji sylabowej) i stały (pada w tym samym miejscu).Pada na przedostatnia sylabe, czyli pozwala przewidziec granicewyrazu (np. kochanadaremnie); jest zatem akcentemparoksytonicznym. Istnieja wyjatki w wymowie wyrazów pochodzeniaobcego. Proklityki to przyimki i partykuła nie, enklityki – wyrazy mu, go,sie, no, ze oraz morfemy trybu przypuszczajacego i czasu przeszłego.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 31 / 189

Prozodia
Intonacja w jezyku polskim słuzy przede wszystkim do wyrazeniatrybu zdania. Ze wzgledu na typy zmian tonu podstawowego, w jezykupolskim wyrózniamy nastepujace trzy podstawowe (mozna wyróznicjeszcze cztery inne) typy intonacji:
opadajaca – zwana tez kadencja lub intonacja twierdzaca,rosnaca – zwana tez antykadencja lub intonacja pytajna irówna – zwana tez progrediencja.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 32 / 189

Reguły fonologiczne
Reguły fonologiczne maja postac A→ B/C _ D. A zostaje zamienionena B w kontekscie C _ D, czyli majac po lewej stronie C, a po prawejD. +spółgłoska
+nosowa+dzwieczna
→ +spółgłoska
+nosowa-dzwieczna
/ [ +spółgłoska-dzwieczna
]_ #
Reguły fonologiczne mozna realizowac za pomoca automatówskonczonych.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 33 / 189

Teoria Optymalnosci
W Stanach Zjednoczonych szczególnie popularna jest teoriaoptymalnosci (ang. Optimality Theory) zastepujaca tradycyjne regułyfonologiczne. Wykorzystuje dwie funkcje: GEN i EVAL orazuszeregowany zbiór ograniczen CON. Funkcja GEN tworzy wszystkiemozliwe i niemozliwe formy powierzchniowe, natomiast funkcja EVALstosuje ograniczenia według ustalonej kolejnosci. Ograniczenie niejest stosowane, jesli całkowicie blokuje tworzenie formpowierzchniowych; w przeciwnym wypadku działa jako filtr.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 34 / 189

Rozpoznawanie mowy – motywacja
Mowa:Naturalny sposób przekazywania wiadomosci, polecen, prósb itp.przez ludzi – dane wejsciowe dla komputeraZnacznie szybszy niz pisanie (odreczne lub za pomocaklawiatury)Mozliwosc uzywania wtedy, gdy rece sa zajeteDo niedawna jedyny sposób komunikacji przez telefon, nadalszybciej jest zadzwonic niz napisac SMS
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 35 / 189

Rozpoznawanie mowy – rodzaje zadan
Słownictwomałe, ograniczoneduze, nieograniczone
Ciag słówz przerwami (ang. isolated word)bez przerw (ang. continuous speech)
Powiazanie z mówcazalezne od mówiacego (ang. speaker-dependent)niezalezne od mówiacego (ang. speaker-independent)
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 36 / 189

Skutecznosc
Skutecznosc rozpoznawania mowy zalezy od rodzaju zadania. Zalezytez od innych czynników:
rodzaju tekstu (rozmowa miedzy ludzmi czy rozmowa zkomputerem, tekst spontaniczny czy czytany),srodowiska (zakłócenia, hałas),mówcy (gwara, obca wymowa).
Procent błednie rozpoznanych słów w idealnych warunkach siega dlajezyka angielskiego od 0.5 dla rozpoznawania cyfr do 20 dlarozpoznawania słów w rozmowach telefonicznych z nieograniczonymsłownictwem. Hałas (np. samochodowy) zmniejsza skutecznoscrozpoznania 2 do 4 razy, obca wymowa – 3 do 4 razy (hiszpanska lubjaponska wymowa angielskiego). Co dekade skutecznosc rozpoznaniarosnie o ok. 10%.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 37 / 189

Model zaszumionego kanału
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 38 / 189

Model jezyka i model akustyczny
Wejsciowy ciag akustyczny – ciag symboli: O = o1,o2, . . . ,otWyjscie – ciagiem słów: W = w1,w2, . . . ,wnSzukamy najbardziej prawdopodobnego ciagu słów przy danychobserwacjach akustycznych:
W = arg maxW∈L
P(W |O)
W = arg maxW∈L
P(O|W )P(W )
P(O)
P(O) jest stałe dla jednego ciagu obserwacji, wiec
W = arg maxW∈L
P(O|W )P(W )
P(O|W ) to model akustyczny, P(W ) to model jezyka
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 39 / 189

Schemat przetwarzania
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 40 / 189

Wybór cech
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 41 / 189

Wzmocnienie wstepne
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 42 / 189

Wzmocnienie wstepne
W widmie mowy wiecej energii znajduje sie w niskichczestotliwosciach. To niekorzystne z punktu przetwarzania sygnałówzjawisko nazywane jest przekrzywieniem widma (ang. spectral tilt). Wfazie wzmocnienia wstepnego (ang. preemphasis) filtr realizowany zapomoca równania:
y [n] = x [n]− αx [n − 1]
(gdzie x to wejscie, y – wyjscie, a 0.9 ≤ α ≤ 1 to współczynnik) usuwaskutki przekrzywienia. Jest to filtr górnoprzepustowy.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 43 / 189

Wzmocnienie wstepne
oryginalne widmo
α = 0.9
α = 1.0
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 44 / 189
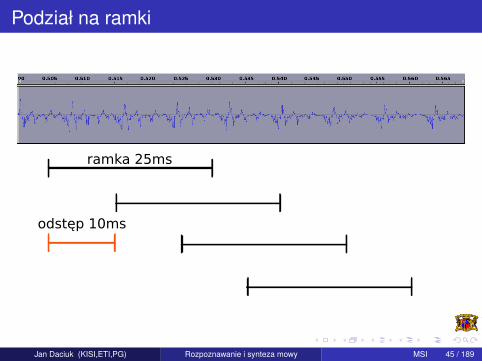
Podział na ramki
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 45 / 189

Podział na ramki
Sygnał wejsciowy jest dzielony na nakładajace sie na siebie ramkiwycinane przez przesuwajace sie nad sygnałem okno. Parametrami sadługosc okna (ramki) i odstep pomiedzy kolejnymi ramkami(dokładniej: miedzy poczatkami ramek). Okno w :
y [n] = w [n]s[n]
wycina sygnał s, tak ze poza oknem jest (prawie) całkowiciewytłumiony, ale moze tez wpływac na jego kształt. Moze bycprostokatne:
w [n] =
{1 0 ≤ n ≤ L− 10 w przeciwnym wypadku
ale okno prostokatne ma kiepskie własciwosci.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 46 / 189

Podział na ramki
Okno prostokatne
−2 0 20
0.5
1
n/L
w[n
]
w [n] =
{1 0 ≤ n ≤ L− 10 w przeciwnym wypadku
−4 −2 0 2 4
0
1
f/Tw
[f]
w [f ] =sin 2πfT
πf
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 47 / 189

Podział na ramki
Wytnijmy oknem prostokatnym przedział [−4,4] sygnałus(t) = cos(2πf0t)
−2 −1.5 −1 −0.5 0 0.5 1 1.5 2
−2
0
2
4
6
8
f/f0
s[f]∗
w[f
]
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 48 / 189
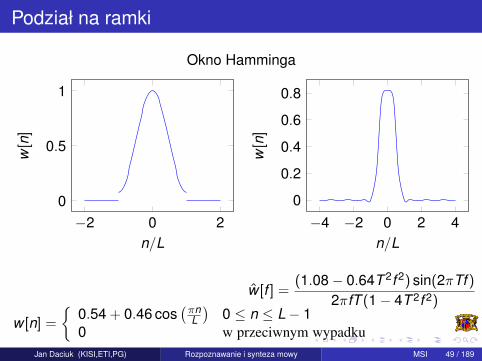
Podział na ramki
Okno Hamminga
−2 0 20
0.5
1
n/L
w[n
]
w [n] =
{0.54 + 0.46 cos
(πnL
)0 ≤ n ≤ L− 1
0 w przeciwnym wypadku
−4 −2 0 2 40
0.2
0.4
0.6
0.8
n/Lw
[n]
w [f ] =(1.08− 0.64T 2f 2) sin(2πTf )
2πfT (1− 4T 2f 2)
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 49 / 189

Dyskretne przekształcenie Fouriera
Przekształcenie Fouriera przenosi sygnał z dziedziny czasu dodziedziny czestotliwosci. Sygnał okresowy przyblizany jest za pomocakombinacji liniowej sygnałów harmonicznych:
X [k ] = F(x [n]) =N−1∑n=0
x [n]e−j 2πkN n
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 50 / 189

Zespół filtrów mel
Mel jest jednostka tonu zdefiniowana w taki sposób, by dzwiekiodczuwane jako równoodległe pod wzgledem tonu rózniły sie takasama liczba jednostek mel. Człowiek róznie odczuwa dzwieki o róznejwysokosci. Te wyzsze sa słabiej odczuwane; granica jest ok. 1 kHz.Czestotliwosc mel moze byc obliczona jako:
B(f ) = 1127 ln(1 +f
700)
lub równowaznieB(f ) = 2595 lg(1 +
f700
)
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 51 / 189

Zespół filtrów mel
Zespół M filtrów trójkatnych zdefiniowanych w nastepujacy sposób:
Hm[k ] =
0 k < f [m − 1]
2(k−f [m−1])(f [m+1]−f [m−1])(f [m]−f [m−1]) f [m − 1] ≤ k ≤ f [m]
2(f [m+1]−k)(f [m+1]−f [m−1])(f [m+1]−f [m]) f [m] ≤ k ≤ f [m + 1]
0 k > f [m + 1]
gdzie
f [m] =
(NFs
)B−1
(B(fl) + m
B(fh)− B(fl)M + 1
)gdzie Fs to czestotliwosc próbkowania, N to rozmiar FFT i
B−1(b) = 700(
eb
1125 − 1)
W uproszczonym podejsciu filtry mel to trójkatne filtry rozmieszoneliniowo ponizej 1 kHz i logarytmicznie powyzej tej czestotliwosci.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 52 / 189

Zespół filtrów mel
Liczba filtrów M i czestotliwosci graniczne fl i fh zaleza odczestotliwosci próbkowania Fs. Typowe wartosci to:
Fs [Hz] 8000 11025 16000M 31 36 40fl [Hz] 200 130 130fh [Hz] 3500 5400 6800
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 53 / 189

Zespół filtrów Mel
Istnieje inne, popularne skale odczuwanej wysokosci dzwieku, któreoceniane sa jako dokładniejsze. Sa to skala Barka:
B = 13arctg(0.76 · 10−3f ) + 3.5arctg((f/7500)2)
i skala ERB (ang. equivalent regular bandwidth):
B = 6.23 · 10−6f 2 + 9.339 · 10−2f + 28.52
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 54 / 189

Logarytm
Natezenie dzwieku tez jest odczuwane przez ludzi w skalilogarytmicznej (dlatego m.in. natezenie dzwieku mierzy sie wdecybelach). Dlatego przy obliczaniu cepstrum sygnał otrzymany poprzejsciu przez zespół filtrów mel jest logarytmowany.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 55 / 189

Cepstrum – odwrotne przekształcenie Fouriera
Sygnał po zlogarytmowaniu zostaje poddany odwrotnemuprzekształceniu Fouriera. Otrzymany sygnał nazywa sie cepstrum.Nazwa powstała przez odwrócenie pierwszej połowy angielskiegosłowa spectrum (po polsku: widmo). Pomijajac zespół filtrów melmozemy napisac:
c[n] = F−1 (log |F(x [n])|)
czyli:
c[n] =N−1∑n=0
log
(∣∣∣∣∣N−1∑n=0
x [n]e−j 2πN kn
∣∣∣∣∣)
ej 2πN kn
Zamiast odwrotnego przekształcenia Fouriera stosuje sie czestopokrewne dyskretne przekształcenie kosinusowe.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 56 / 189

Cepstrum
Dzieki zastosowaniu filtrów i logarytmowaniu wynik odwrotnegoprzekształcenia Fouriera nie jest sygnałem wejsciowym. Sygnał mowymozna przedstawic jako splot:
y [n] = u[n]⊗ v [n]⊗ r [n]
gdzie u[n] to zródło (drgania wiazadeł głosowych lub szum), v [n] tofiltry modelujace trakt artykulacyjny i r [n] to model uwzgledniajacywargi, zeby itp. Operacja logarytmowania skaluje harmoniczne wsposób uwypuklajacy ich „okresowosc” w widmie, a takze umozliwiaoddzielenie zródła od filtrów v i r . Poniewaz splot po przekształceniuFouriera staje sie iloczynem, a logarytm iloczynu jest sumalogarytmów, po odwrotnym przekształceniu dostajemy sume.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 57 / 189

Cepstrum
Okazuje sie, ze rózne współczynniki cepstrum nie sa (w odróznieniuod widma) od siebie zalezne. Jest to szczególnie wazne przystosowaniu w dalszym ciagu przetwarzania modelu sumy rozkładówGausowskich. Niskie czestotliwosci cepstrum odpowiadaja filtrowitraktu artykulacyjnego (pozycja jezyka, rozwarcie ust itp.), wyzszezawieraja informacje o czestotliwosci podstawowej. Do dalszegoprzetwarzania bierzemy na ogół pierwsze 12 współczynnikówuzyskanych z odwrotnego przekształcenia Fouriera. Nazywane saMFCC (ang. mel frequency cepstral coefficients).
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 58 / 189

Inne cechy obliczane do wektorów cech
Do wektorów cech obliczmy takze energie. Energia jest liczona jakosuma mocy próbek w ramce, wiec dla ramki trwajacej od t1 do t2mamy:
E =
t2∑t=t1
x2[t ]
Ponadto ciekawi nas nie tylko energia i współczynniki MFCC, ale tezich zmiennosc w czasie. Ich róznice pokazuja, o ile te cechy zmieniajasie w czasie. Róznice róznic (odpowiadajace drugim pochodnym dlasygnałów ciagłych) pokazuja tempo zmian. Na ogół zamiast zwykłychróznic dla kolejnych ramek liczone sa róznice obejmujace kilka ramek.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 59 / 189
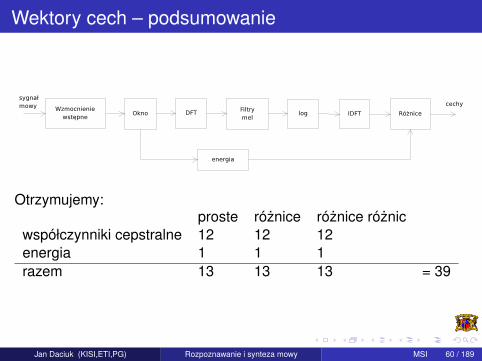
Wektory cech – podsumowanie
Otrzymujemy:proste róznice róznice róznic
współczynniki cepstralne 12 12 12energia 1 1 1razem 13 13 13 = 39
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 60 / 189

Modelowanie akustyczne / rozpoznawanie głosek
Otrzymalismy ciag wekto-rów cech – po jednym wek-torze na ramke. Nie mamyzwiazku miedzy wektoramicech a głoskami. Tenzwiazek bedzie wyrazonyjako prawdopodobienstwowysłania okreslonego sym-bolu przy przejsciu miedzyokreslonymi stanami nie-jawnego modelu Markowa.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 61 / 189

Niejawne modele Markowa – wprowadzenie
q1 q2 q3 · · ·
a1,2 a2,3 a3,4
a2,1 a3,2 a4,3
a1,1 a2,2 a3,3
o1
b1
o2
b1
o3
b3
qi – stanaij – prawdpodo-bienstwo przejsciaze stanu qi do qjot – symbol obser-wowany w czasie tbi(ot) – prawdopo-dobienstwo wysła-nia symbolu ot wstanie qi
Nas interesuja prawdopodobienstwa bi uzyskiwane na podstawiewektorów MFCC.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 62 / 189

Kwantyzacja wektorów
Potrzebujemy funkcji, która oszacowałaby prawdopodobienstwowystapienia wektorów o wartosciach rzeczywistych. Najprostszerozwiazanie:
Ustalamy liste symboli reprezentujacych mozliwe wartosciwektorów cech (ang. codebook). Dokonuje sie tego za pomocaalgorytmów grupowania.Dla kazdej klasy ustalamy jej przedstawiciela (ang. codeword).Liczymy prawdopodobienstwa bi(ot ) zliczajac wystapieniaprzedstawiciela klasy (pojedynczego symbolu) zamiastwystapienia róznych wektorów nalezacych do tej samej klasy.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 63 / 189

Kwantyzacja wektorów
Poniewaz poszczególne cechy w wektorach MFCC maja róznawariancje σ2
i , zamiast odległosci euklidesowej liczymy kwadratodległosci Mahalanobis, która uwzglednia σ2
i :
d2Mahalanobis(x , y) =
D∑i=1
(xi − yi)2
σ2i
gdzie D jest rozmiarem wektora (w naszym przypadku 39). W zapisiemacierzowym:
d2Mahalanobis(x , y) = (x − y)T Σ−1(x − y)
gdzie Σ to macierz kowariancji.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 64 / 189

Model sumy rozkładów Gaussowskich
Kwantyzacja wektorów okazuje sie niewystarczajaca do potrzebrozpoznawania mowy. Najczesciej uzywana metoda do otrzymaniaprawdopodobienstwa głoski na podstawie wektorów MFCC jest modelsumy rozkładów Gaussowskich, chociaz uzywa sie takze siecineuronowych, SVMs (ang. support vector machines) i CRFs (ang.conditional random fields).
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 65 / 189

Model sumy rozkładów Gaussowskich
Funkcja gestosci prawdopodobienstwa w rozkładzie Gaussowskimdana jest wzorem:
f (x) =1√
2πσ2e−
(x−µ)2
2σ2
gdzie µ to srednia zdefiniowana jako:
µ = E(X ) =N∑
i=1
p(Xi)Xi
zas wariancja σ2 to kwadrat odchylenia standardowego σ:
σ2 = E(Xi − E(X ))2 =N∑
i=1
p(Xi)(Xi − E(X ))2
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 66 / 189

Model sumy rozkładów Gaussowskich
Poniewaz obserwowane wartosci nie sa pojedynczymi symbolami, awektorami, to powinnismy w zasadzie uzywac rozkładuwielowariancyjnego, w którym posługujemy sie macierza kowariancjizamiast pojedynczej wariancji dla pojedynczej zmiennej losowej.
Jednak cecha charakterystyczna cepstrum jest to, ze poszczególnecechy w wektorze sa od siebie (w duzym stopniu) niezalezne.Oznacza to, ze macierz kowariancji jest macierza diagonalna. Dlategorozkład prawdopodobienstwa mozemy liczyc dla poszczególnychskładowych niezaleznie od pozostałych.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 67 / 189

Model sumy rozkładów Gaussowskich
Zakładajac (niepoprawnie), ze rozkład gestosci prawdopodobienstwapojedynczych składowych wektorów MFCC jest rozkładem normalnymi dla danego stanu j HMM reprezentujacego głoske lub czesc głoskiposiada srednia µi i wariancje σ2
j , przyjmujac tez, ze ot ma rozmiar 1,otrzymamy rozkład:
bj(ot ) =1√
2πσ2j
e(−
(ot−µj )2
2σ2j
)
Tak obliczonego prawdopodobienstwa mozna by było uzyc wdekodowaniu, ale musimy najpierw policzyc srednia i wariancje. Majacoznaczone próbki, w których kazdej obserwacji ot przyporzadkowanyjest stan i , mozemy policzyc:
µi =1T
T∑t=1
ot tak ze qt = qi , σ2i =
1T
T∑t=1
(ot − µi)2 tak ze qt = qi
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 68 / 189

Model sumy rozkładów Gaussowskich
Nie majac odpowiednio oznaczonego zbioru uczacego, mozemyprzyporzadkowac wektor ot kazdemu stanowi i zprawdopodobienstwiem równym prawdopodobienstwu γt (i) bycia wstanie i w czasie t . Mozemy wtedy policzyc:
µi =
∑Tt=1 γt (i)ot∑T
t=1 γt (i)σ2
i =
∑Tt=1 γt (i)(ot − µi)
2∑Tt=1 σt (i)
Prawdopodobienstwo γt (i) moze byc obliczone w ramach algorytmuBaum-Welch.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 69 / 189

Model sumy rozkładów Gaussowskich
Uwzgledniajac fakt, ze ot jest wektorem, a srednia i wariancja dotyczakazdej z D jego składowych, otrzymujemy:
bj(ot ) =D∏
d=1
1√2πσ2
jd
e(−
(otd−µjd )2
2σ2jd
)
Wzory na srednia i wariancje sa podobne, ale wartosci te sa terazwektorami:
µi =
∑Tt=1 γt (i)ot∑T
t=1 γt (i)σ2
i =
∑Tt=1 γt (i)(ot − µi)(ot − µi)
T∑Tt=1 γt (i)
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 70 / 189
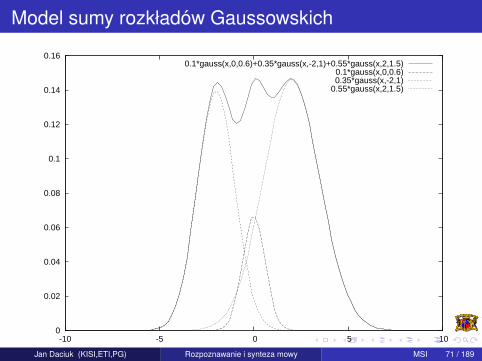
Model sumy rozkładów Gaussowskich
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
-10 -5 0 5 10
0.1*gauss(x,0,0.6)+0.35*gauss(x,-2,1)+0.55*gauss(x,2,1.5)0.1*gauss(x,0,0.6)0.35*gauss(x,-2,1)
0.55*gauss(x,2,1.5)
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 71 / 189

Model sumy rozkładów Gaussowskich
Poniewaz rozkład prawdopodobienstwa cech MFCC nie jest rozkłademnormalnym, nie mozna go dobrze opisac takowym. Mozna jednakdowolna funkcje przyblizyc za pomoca kombinacji liniowej róznychrozkładów normalnych:
f (x) =M∑
k=1
ck1√
2π |Σk |e(x−µk )T Σ−1(x−µk )
stad prawdopodobienstwo bj(ot ) pojedynczej obserwowanej cechy(pomijamy tu dla uproszczenia indeks cechy) majac dany stan qj :
bj(ot ) =M∑
m=1
cjm1√
2π∣∣Σjm
∣∣e(ot−µjm)T Σ−1jm (ot−µjm)
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 72 / 189

Model sumy rozkładów Gaussowskich
Aby skorzystac z podanych wzorów, musimy znac wartosci cjm, µjm iΣjm. Nie mozemy ich policzyc zliczajac wystapienia kazdej wartoscicechy dla kazdego stanu, bo nie znamy stanu!Mozemy jednak uzyc algorytmu Bauma-Welcha do obliczeniaprawdopodobienstwa γtm(j) bycia w stanie qj w czasie t z m-taskładowa sumy rozkładów. Wtedy mozemy policzyc:
cjm =
∑Tt=1 γtm(j)∑T
t=1∑M
k=1 γtk (j)
µjm =
∑Tt=1 γtm(j)ot∑T
t=1∑M
k=1 γtk (j)
Σjm =
∑Tt=1 γtm(j)(ot − µjm)(ot − µjm)T∑T
t=1∑M
k=1 γtk (j)
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 73 / 189

Logarytmy prawdopodobienstwa
Poniewaz mnozac prawdopodobienstwa otrzymuje sie bardzo małeliczby, w obliczeniach pojawiałoby sie stałe zagrozenie niedomiarem.Rozwiazaniem czesto stosowanym nie tylko w rozpoznawaniu mowy,ale tez ogólnie w obliczeniach statystycznych, jest stosowanielogarytmów wartosci.Dodatkowa zaleta jest przyspieszenie obliczen:
log(ex ) = x
log(xy) = log(x) + log(y)
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 74 / 189

Słownik
Słownik jest przechowywany w postaci automatu skonczonego. Kazdejgłosce odpowiada ciag 3 stanów (poczatek głoski, stan ustalony,koniec głoski):
Przejscia sa zwiazane z okreslonym prawdopodobienstwem. Wartozauwazyc brak przejsc wstecz. Rysunek pokazuje jedno słowo –słownik ma takowych wiele. Taka siec petla prowadzaca do tegosamego stanu i z pojedynczym przejsciem do nastepnego stanunazywa sie siecia Bakisa.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 75 / 189

Niejawne modele Markowa
Mar Roz
0.7 0.40.3
0.6
0.1 0.9
ng prz bdbMar Mar 0.2 0.7 0.1Mar Roz 0.1 0.3 0.6Roz Mar 0.2 0.7 0.1Roz Roz 0.1 0.3 0.6
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 76 / 189
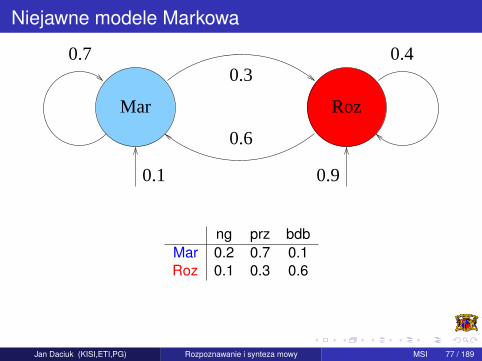
Niejawne modele Markowa
Mar Roz
0.7 0.40.3
0.6
0.1 0.9
ng prz bdbMar 0.2 0.7 0.1Roz 0.1 0.3 0.6
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 77 / 189

Niejawne modele Markowa
zbiór stanów S = {s1, . . . , sN}alfabet wyjsciowy K = {k1, . . . , kM} = {1, . . . ,M}poczatkowe pp. stanów Π = {πi}, i ∈ Spp. przejsc A = {aij}, i , j ∈ Spp. wysłania symbolu B = {bijk , i , j ∈ S, k ∈ K}ciag stanów X = (X1, . . . ,XT +1)
Xt : S 7→ {1, . . . ,N}ciag symboli wyjsciowych O = (o1 . . . ,oT ), ot ∈ K
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 78 / 189

Niejawne modele Markowa
1 Modele MarkowaOgraniczony horyzont
P(Xt+1 = sk |X1, . . . ,Xt ) = P(Xt+1 = sk |Xt )
Niezmiennosc w czasie (stacjonarnosc):
= P(X2 = sk |X1)
Parametry:aij = P(Xt+1 = sj |Xt = si ), πi = P(X1 = si )
2 (Dodatkowo) niejawne modele MarkowaPrawdopodobienstwo wysłania symbolu:
P(Ot = k |Xt = si ,Xt+1 = sj ) = bijk
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 79 / 189

Niejawne modele Markowa
1 Jak wydajnie obliczyc prawdopobienstwo obserwacji P(O|µ)majac dany model µ = (A,B,Π)?
2 Majac dane ciag obserwacji O i model µ, jak wybrac ciag stanów(X1, . . . ,XT +1) najlepiej wyjasniajacy obserwacje?
3 Majac dane ciag obserwacji O i przestrzen mozliwych modelipowstała w wyniku zmian parametrów modelu µ = (A,B,Π), jakznalezc najlepszy model, który objasnia obserwowane dane?
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 80 / 189

HMMs – prawdopodobienstwo obserwacji
Jakie jest prawdopodobienstwo, ze zaobserwowano ciag symboli bdb ing?
Mar Roz
0.7 0.40.3
0.6
0.1 0.9
ng prz bdbMar Mar 0.2 0.7 0.1Mar Roz 0.1 0.3 0.6Roz Mar 0.2 0.7 0.1Roz Roz 0.1 0.3 0.6
Najbardziej prawdopodobna wydaje sie sytuacja, ze ten ciag symbolizostał wysłany w ciagu stanów Roz, Roz i Mar :
Roz0.9 Roz Mar0.4 0.6
bdb ng
0.6 0.2 P(bdb,ng|Roz,Roz,Mar, µ) == 0.6 · 0.2 = 0.12
Prawdopodobienstwo ciagu symboli i ciagu stanów przy danymmodelu µ:P(bdb,ng,Roz,Roz,Mar|µ) = 0.9 · 0.4 · 0.6 · 0.6 · 0.2 = 0.02592
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 81 / 189
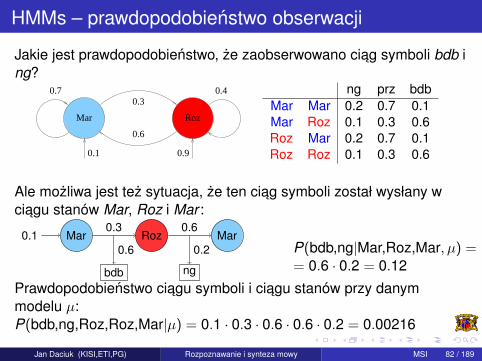
HMMs – prawdopodobienstwo obserwacji
Jakie jest prawdopodobienstwo, ze zaobserwowano ciag symboli bdb ing?
Mar Roz
0.7 0.40.3
0.6
0.1 0.9
ng prz bdbMar Mar 0.2 0.7 0.1Mar Roz 0.1 0.3 0.6Roz Mar 0.2 0.7 0.1Roz Roz 0.1 0.3 0.6
Ale mozliwa jest tez sytuacja, ze ten ciag symboli został wysłany wciagu stanów Mar, Roz i Mar :
Mar0.1 Roz Mar0.3 0.6
bdb ng
0.6 0.2 P(bdb,ng|Mar,Roz,Mar, µ) == 0.6 · 0.2 = 0.12
Prawdopodobienstwo ciagu symboli i ciagu stanów przy danymmodelu µ:P(bdb,ng,Roz,Roz,Mar|µ) = 0.1 · 0.3 · 0.6 · 0.6 · 0.2 = 0.00216
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 82 / 189

HMMs – prawdopodobienstwo obserwacji
Jakie jest prawdopodobienstwo, ze zaobserwowano ciag symboli bdb ing?
Mar Roz
0.7 0.40.3
0.6
0.1 0.9
ng prz bdbMar Mar 0.2 0.7 0.1Mar Roz 0.1 0.3 0.6Roz Mar 0.2 0.7 0.1Roz Roz 0.1 0.3 0.6
Dla ciagu stanów Mar, Mar, Mar otrzymamyP(bdb,ng|Mar,Mar,Mar, µ) = 0.1 · 0.2 = 0.02 iP(bdb,ng,Mar,Mar,Mar|µ) = 0.1 · 0.7 · 0.1 · 0.7 · 0.2 = 0.00098.
Ogólnie mozemy miec 23 ciagów stanów i aby policzycprawdpodobienstwo P(bdb,ng|µ) musimy zsumowac P(bdb,ng,X |µ)dla kazdego ciagu stanów X .
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 83 / 189

Niejawne modele Markowa – P(O|µ)
Naiwne obliczanie prawdopodobienstwa obserwacji
P(O|X , µ) =∏T
t=1 P(ot |Xt ,Xt+1, µ)= bX1X2o1bX2X3o2 · · · bXT XT +1oT
P(X |µ) = πX1aX1X2aX2X3 · · · aXT XT +1
P(O,X |µ) = P(O|X , µ)P(X |µ)
P(O|µ) =∑
X P(O|X , µ)P(X |µ)
=∑
X1···XT +1πX1
∏Tt=1 aXt Xt+1bXt Xt+1ot
Bezposrednie wykorzystanie tego wzoru wymaga (2T + 1) · NT +1
mnozen.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 84 / 189
Niejawne modele Markowa – do przodu
Mar
Roz
Mar
Roz
Mar
Roz
0.1
0.9
0.7 · 0.1
0.3 · 0.60.6· 0.1
0.4 · 0.6
bdb
0.7 · 0.2
0.3 · 0.10.6· 0.2
0.4 · 0.1
ng
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 85 / 189

Niejawne modele Markowa – do przodu
Mar
Roz
Mar
Roz
Mar
Roz
0.1
0.9
0.7 · 0.1
0.3 · 0.60.6· 0.1
0.4 · 0.6
bdb
0.7 · 0.2
0.3 · 0.10.6· 0.2
0.4 · 0.1
ng
Liczac P(bdb,ng,Roz,Roz,Mar|µ) i P(bdb,ng,Roz,Roz,Roz|µ) musimypoliczyc wspólny czynnik:
P(bdb,ng,Roz,Roz,Mar|µ) = P(bdb,Roz,Roz|µ)·aRoz Mar ·bRoz Mar , ng+. . .
P(bdb,ng,Roz,Roz,Roz|µ) = P(bdb,Roz,Roz|µ)·aRoz Roz ·bRoz Roz, ng+. . .
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 86 / 189
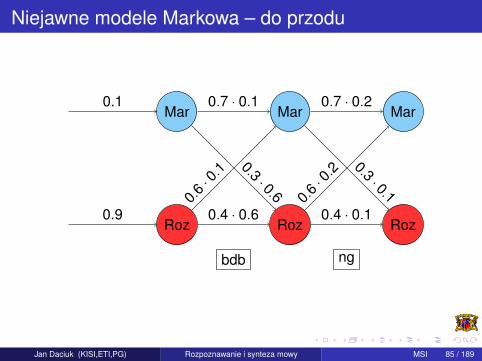
Niejawne modele Markowa – do przodu
Mar
Roz
Mar
Roz
Mar
Roz
0.1
0.9
0.7 · 0.1
0.3 · 0.60.6· 0.1
0.4 · 0.6
bdb
0.7 · 0.2
0.3 · 0.10.6· 0.2
0.4 · 0.1
ng
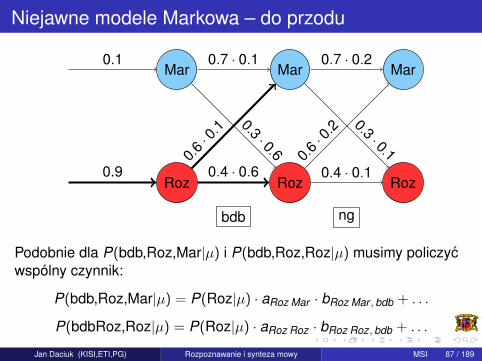
Podobnie dla P(bdb,Roz,Mar|µ) i P(bdb,Roz,Roz|µ) musimy policzycwspólny czynnik:
P(bdb,Roz,Mar|µ) = P(Roz|µ) · aRoz Mar · bRoz Mar , bdb + . . .
P(bdbRoz,Roz|µ) = P(Roz|µ) · aRoz Roz · bRoz Roz, bdb + . . .
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 87 / 189

Niejawne modele Markowa – do przodu
αi(t) = P(o1o2 · · · ot−1,Xt = i |µ)
1 Wartoscipoczatkowe
αi(1) = πi , 1 ≤ i ≤ N
2 Indukcja
αj(t+1) =N∑
i=1
αi(t)aijbijot , 1 ≤ t ≤ T ,1 ≤ j ≤ N
3 Całosc
P(O|µ) =N∑
i=1
αi(T +1)
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 88 / 189
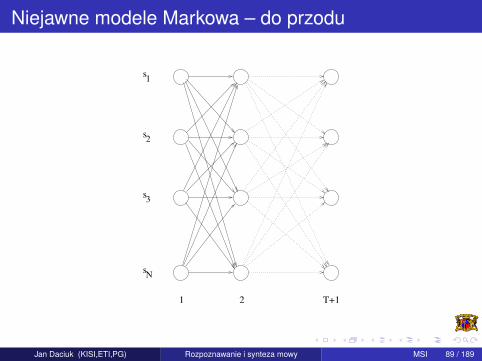
Niejawne modele Markowa – do przodu
s
s
s
s
1
2
3
N
1 2 T+1
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 89 / 189

Niejawne modele Markowa – do przodu
Mar
Roz
Mar
Roz
Mar
Roz
0.1
0.9
0.7 · 0.1
0.3 · 0.60.6· 0.1
0.4 · 0.6
bdb
0.7 · 0.2
0.3 · 0.10.6· 0.2
0.4 · 0.1
ng
Policzmy:
αMar (1) = πMar = 0.1αRoz(1) = πRoz = 0.9
}Wartosci poczatkowe
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 90 / 189
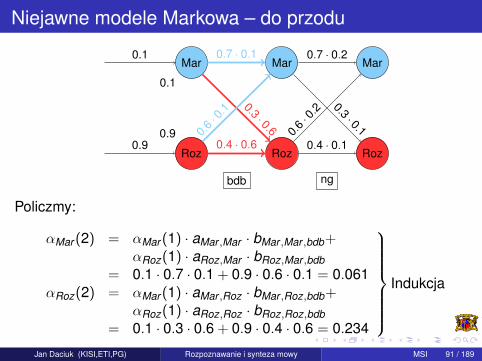
Niejawne modele Markowa – do przodu
Mar
0.1
Roz
0.9
Mar
Roz
Mar
Roz
0.1
0.9
0.7 · 0.1
0.3 · 0.60.6· 0.1
0.4 · 0.6
bdb
0.7 · 0.2
0.3 · 0.10.6· 0.2
0.4 · 0.1
ng
Policzmy:
αMar (2) = αMar (1) · aMar ,Mar · bMar ,Mar ,bdb+αRoz(1) · aRoz,Mar · bRoz,Mar ,bdb
= 0.1 · 0.7 · 0.1 + 0.9 · 0.6 · 0.1 = 0.061αRoz(2) = αMar (1) · aMar ,Roz · bMar ,Roz,bdb+
αRoz(1) · aRoz,Roz · bRoz,Roz,bdb= 0.1 · 0.3 · 0.6 + 0.9 · 0.4 · 0.6 = 0.234
Indukcja
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 91 / 189

Niejawne modele Markowa – do przodu
Mar
Roz
Mar
0.061
Roz
0.234
Mar
Roz
0.1
0.9
0.7 · 0.1
0.3 · 0.60.6· 0.1
0.4 · 0.6
bdb
0.7 · 0.2
0.3 · 0.10.6· 0.2
0.4 · 0.1
ng
Policzmy:
αMar (3) = αMar (2) · aMar ,Mar · bMar ,Mar ,ng+αRoz(2) · aRoz,Mar · bRoz,Mar ,ng
= 0.061 · 0.7 · 0.2 + 0.234 · 0.6 · 0.2 = 0.03662αRoz(3) = αMar (2) · aMar ,Roz · bMar ,Roz,ng+
αRoz(2) · aRoz,Roz · bRoz,Roz,ng= 0.061 · 0.3 · 0.1 + 0.234 · 0.4 · 0.1 = 0.01119
Indukcja
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 92 / 189

Niejawne modele Markowa – do przodu
Mar
Roz
Mar
Roz
Mar
Roz
0.1
0.9
0.7 · 0.1
0.3 · 0.60.6· 0.1
0.4 · 0.6
bdb
0.7 · 0.2
0.3 · 0.10.6· 0.2
0.4 · 0.1
ng
Policzmy:
αMar (3) = 0.03662αRoz(3) = 0.01119
}⇒ P(bdb,ng|µ) = αMar (3)+αRoz(3) = 0.04781
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 93 / 189

Niejawne modele Markowa – do tyłu
βi(t) = P(ot · · · oT ,Xt = i |µ)
1 Wartoscipoczatkowe
βi(T +1) = 1, 1 ≤ i ≤ N
2 Indukcja
βi(t) =N∑
j=1
aijbijotβj(t+1), 1 ≤ t ≤ T ,1 ≤ j ≤ N
3 Całosc
P(O|µ) =N∑
i=1
πiβi(1)
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 94 / 189

Niejawne modele Markowa – do tyłu
Mar
Roz
Mar
Roz
Mar
Roz
0.1
0.9
0.7 · 0.1
0.3 · 0.60.6· 0.1
0.4 · 0.6
bdb
0.7 · 0.2
0.3 · 0.10.6· 0.2
0.4 · 0.1
ng
Policzmy:βMar (3) = 1.0βRoz(3) = 1.0
}Wartosci poczatkowe
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 95 / 189

Niejawne modele Markowa – do tyłu
Mar
Roz
Mar
Roz
Mar
Roz
0.1
0.9
0.7 · 0.1
0.3 · 0.60.6· 0.1
0.4 · 0.6
bdb
0.7 · 0.2
0.3 · 0.10.6· 0.2
0.4 · 0.1
ng
Policzmy:
βMar (2) = βMar (3) · aMar ,Mar · bMar ,Mar ,ng+βRoz(3) · aMar ,Roz · bMar ,Roz,ng =
= 1.0 · 0.7 · 0.2 + 1.0 · 0.3 · 0.1 = 0.17βRoz(2) = βMar (3) · aRoz,Mar · bRoz,Mar ,ng+
βRoz(3) · aRoz,Roz · bRoz,Roz,ng == 1.0 · 0.6 · 0.2 + 1.0 · 0.4 · 0.1 = 0.16
Indukcja
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 96 / 189

Niejawne modele Markowa – do tyłu
Mar
Roz
Mar
0.17
Roz
0.16
Mar
Roz
0.1
0.9
0.7 · 0.1
0.3 · 0.60.6· 0.1
0.4 · 0.6
bdb
0.7 · 0.2
0.3 · 0.10.6· 0.2
0.4 · 0.1
ng
Policzmy:
βMar (1) = βMar (2) · aMar ,Mar · bMar ,Mar ,bdb+βRoz(2) · aMar ,Roz · bMar ,Roz,bdb =
= 0.17 · 0.7 · 0.1 + 0.16 · 0.3 · 0.6 = 0.0407βRoz(1) = βMar (2) · aRoz,Mar · bRoz,Mar ,bdb+
βRoz(2) · aRoz,Roz · bRoz,Roz,bdb == 0.17 · 0.6 · 0.1 + 0.16 · 0.4 · 0.6 = 0.0486
Indukcja
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 97 / 189
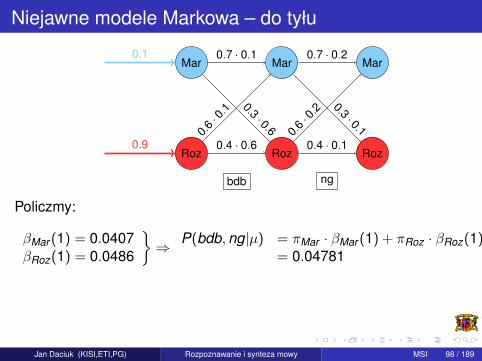
Niejawne modele Markowa – do tyłu
Mar
Roz
Mar
Roz
Mar
Roz
0.1
0.9
0.7 · 0.1
0.3 · 0.60.6· 0.1
0.4 · 0.6
bdb
0.7 · 0.2
0.3 · 0.10.6· 0.2
0.4 · 0.1
ng
Policzmy:
βMar (1) = 0.0407βRoz(1) = 0.0486
}⇒ P(bdb,ng|µ) = πMar · βMar (1) + πRoz · βRoz(1)
= 0.04781
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 98 / 189

Niejawne modele Markowa – w obie strony
P(O,Xt = i |µ) = P(o1 · · · oT ,Xt = i |µ)= P(o1 · · · ot−1,Xt = i ,ot · · · oT |µ)= P(o1 · · · ot−1,X = i |µ) ·
·P(ot · · · oT |o1 · · · ot−1,Xt = 1|µ)= P(o1 · · · ot−1,Xt = i |µ)·
·P(ot · · · oT |Xt = i , µ)= αi(t)βi(t)
P(O|µ) =N∑
i=1
αi(t)βi(t), 1 ≤ t ≤ T + 1
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 99 / 189

Niejawne modele Markowa – najlepszy ciag stanów
Mar
Roz
Mar
Roz
Mar
Roz
0.1
0.9
0.7 · 0.1
0.3 · 0.60.6· 0.1
0.4 · 0.6
bdb
0.7 · 0.2
0.3 · 0.10.6· 0.2
0.4 · 0.1
ng
Jak moglismy znalezc sie w stanie Mar po zaobserwowaniu symbolubdb? Sa dwie mozliwosci: wczesniej bylismy w stanie Mar lub w stanieRoz. Poniewaz:
0.1 · 0.7 · 0.1 = 0.007 < 0.054 = 0.9 · 0.6 · 0.1wiec sciezka ze stanu Roz jest bardziej prawdopodobna.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 100 / 189
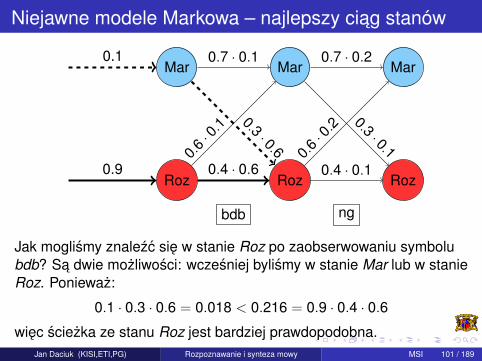
Niejawne modele Markowa – najlepszy ciag stanów
Mar
Roz
Mar
Roz
Mar
Roz
0.1
0.9
0.7 · 0.1
0.3 · 0.60.6· 0.1
0.4 · 0.6
bdb
0.7 · 0.2
0.3 · 0.10.6· 0.2
0.4 · 0.1
ng
Jak moglismy znalezc sie w stanie Roz po zaobserwowaniu symbolubdb? Sa dwie mozliwosci: wczesniej bylismy w stanie Mar lub w stanieRoz. Poniewaz:
0.1 · 0.3 · 0.6 = 0.018 < 0.216 = 0.9 · 0.4 · 0.6wiec sciezka ze stanu Roz jest bardziej prawdopodobna.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 101 / 189

Niejawne modele Markowa – najlepszy ciag stanów
Mar
Roz
Mar
Roz
Mar
Roz
0.1
0.9
0.7 · 0.1
0.3 · 0.60.6· 0.1
0.4 · 0.6
bdb
0.7 · 0.2
0.3 · 0.10.6· 0.2
0.4 · 0.1
ng
Jak moglismy znalezc sie w stanie Mar po zaobserwowaniu ciagusymboli bdb i ng? Sa dwie mozliwosci: wczesniej bylismy w stanie Marlub w stanie Roz. Poniewaz:
0.054 · 0.7 · 0.2 = 0.00756 < 0.02592 = 0.216 · 0.6 · 0.2wiec sciezka ze stanu Roz jest bardziej prawdopodobna.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 102 / 189

Niejawne modele Markowa – najlepszy ciag stanów
Mar
Roz
Mar
Roz
Mar
Roz
0.1
0.9
0.7 · 0.1
0.3 · 0.60.6· 0.1
0.4 · 0.6
bdb
0.7 · 0.2
0.3 · 0.10.6· 0.2
0.4 · 0.1
ng
Jak moglismy znalezc sie w stanie Roz po zaobserwowaniu ciagusymboli bdb i ng? Sa dwie mozliwosci: wczesniej bylismy w stanie Marlub w stanie Roz. Poniewaz:
0.054 · 0.3 · 0.1 = 0.00162 < 0.00864 = 0.216 · 0.4 · 0.1wiec sciezka ze stanu Roz jest bardziej prawdopodobna.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 103 / 189

Niejawne modele Markowa – najlepszy ciag stanów
Mar
Roz
Mar
Roz
Mar
Roz
0.1
0.9
0.7 · 0.1
0.3 · 0.60.6· 0.1
0.4 · 0.6
bdb
0.7 · 0.2
0.3 · 0.10.6· 0.2
0.4 · 0.1
ng
Poniewaz sciezka konczaca sie w stanie Mar jest bardziejprawdopodobna (0.00864) niz sciezka konczaca sie w stanie Roz(0.00162), wiec najlepsza sciezka jest Roz, Roz, Mar.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 104 / 189

Niejawne modele Markowa – najlepszy ciag stanów
Chcemy znalezc arg maxX P(X |O, µ), czyli dla stałego O:arg maxX P(X ,O|µ). Zdefiniujmy:
δj(t) = maxX1···Xt−1
P(X1 · · ·Xt−1,o1 · · · ot−1,Xt = j |µ)
1 Wartosci poczatkowe
δj(1) = πj , 1 ≤ j ≤ N
2 Indukcjaδj(t + 1) = max
1≤i≤Nδi(t)aijbijot , i ≤ j ≤ N
3 i zachowanie sladu
ψj(t + 1) = arg max1≤i≤N
δi(t)aijbijot , i ≤ j ≤ N
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 105 / 189

Niejawne modele Markowa – najlepszy ciag stanów
Zakonczenie i odczytanie sciezki (wstecz):
XT +1 = arg max1≤i≤N δi(T + 1)
Xt = ΨXt+1(t + 1)
P(X ) = max1≤i≤N δi(T + 1)
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 106 / 189

Niejawne modele Markowa – uczenie modelu
Mamy dane ciag zaobserwowanych symboli oraz zbiór mozliwychstanów modelu µ. Musimy nauczyc sie parametrów Π, A i B.Formalnie szukamy modelu µ = (Π,A,B), który daje najwiekszeprawodpodobienstwo P(O|µ):
arg maxµ
P(O|µ)
Nie istnieje zadna znana metoda analityczna znalezienia optymalnegoµ. Mozna za to znalezc lokalne minimum. Robi sie to w kolejnychprzyblizeniach. Zaczynamy od jakiegos modelu i sprawdzamy, któreprzejscia i wysłania symboli sa czesciej uzywane.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 107 / 189

Niejawne modele Markowa – uczenie modelu
...
...
...
...
...
...
si
...
...
...
sj
...
...
...
tt − 1 t + 2t + 1
aij bijot
αi(t) βj(t + 1)
Oszacujmy prawdopodobienstwoξt (i , j) przejscia ze stanu i do stanuj w chwili t przy danym ciaguobserwacji O:
ξt (i , j) = P(Xt = i ,Xt+1 = j |O, µ)
= P(Xt =i,Xt+1=j,O|µ)P(O|µ)
=αi (t)aij bijot βj (t+1)∑N
m=1 αm(t)βm(t)
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 108 / 189

Niejawne modele Markowa – uczenie modelu
Mamy wiec prawdopodobienstwo przejscia ze stanu i do stanu j wchwili t przy danym ciagu obserwacji O:
ξt (i , j) =αi(t)aijbijotβj(t + 1)∑N
m=1 αm(t)βm(t)
Oznaczmy tez:
γi(t) =N∑
j=1
ξt (i , j)
Teraz sumujac po wszystkich chwilach czasu dostajemy:T∑
t=1γi(t) = oczekiwana liczba przejsc ze stanu i dla O
T∑t=1
ξt (i , j) = oczekiwana liczba przejsc ze stanu i do stanu j dla O
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 109 / 189

Niejawne modele Markowa – uczenie modelu
Mozemy teraz policzyc nowe oszacowania parametrów modelu µ:1 Szacowana czestosc bycia w stanie i w chwili t = 1
πi = γi(1)
2 Szacowany iloraz oczekiwanej liczby przejsc ze stanu i do stanu jprzez oczekiwana liczbe przejsc ze stanu i :
aij =
∑Tt=1 ξt (i , j)∑Tt=1 γi(t)
3 Szacowany iloraz oczekiwanej liczby przejsc ze stanu i do stanu jprzy obserwacji k przez szacowanej liczby przejsc ze stanu i dostanu j :
bijk =
∑(t :ot =k ,1≤t≤T ) ξt (i , j)∑T
t=1 ξt (i , j)
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 110 / 189

Niejawne modele Markowa – uczenie modelu
Z modelu µ = (A,B,Π) otrzymalismy model µ = (A, B, Π) taki ze:
P(O|µ) ≥ P(O|µ)
Nowy model podstawiamy w miejsce starego i szacujemy parametrykolejnego, lepszego modelu. Obliczenia moga zakonczyc sie wlokalnym maksimum, ale zwykle ten algorytm – Baum-Welch –dostarcza dobrych wyników.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 111 / 189

MEMM – Maximum Entropy Markov Model
W niejawnych modelach Markowa (HMMs) liczymyprawdopodobienstwo ciagu stanów wykorzystujac prawo Bayesa iprawopodobienstwo P(Oi |Xi):
X = arg maxX
P(X |O)
= arg maxX
P(O|X )P(O)
= arg maxX
∏i
P(Oi |Xi)∏i
P(Xi |Xi−1)
W MEMMs prawdopodobienstwo P(X |O) liczymy bezposrednio:
X = arg maxX
P(X |O)
= arg maxX
∏i
P(Xi |Oi ,Xi−1)
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 112 / 189

MEMM – Maximum Entropy Markov Model
W MEMMs mozemy wykorzystac wiecej cech:
P(Xt+1|Xt ,ot ) =1
Z (Ot ,Xt )exp
(∑i
wi fi(ot ,Xt )
)
Dekodowanie jest podobne. W zwykłych HMMs mielismy:
δj(t) = max1≤i≤N
δi(t)aijbijot , i ≤ j ≤ N
W MEMMs mamy:
δj(t) = max 1 ≤ i ≤ Nδi(t)P(Xt+1 = sj |Xt = si ,ot ), i ≤ j ≤ N
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 113 / 189

Niejawne modele Markowa – uczenie modelu
W rozpoznawaniu mowy nie zmieniamy wartosci parametrów Bbezposrednio. Pamietamy, ze do ich szacowania uzywalismy sumy Mrozkładów Gaussowskich. Dlatego wartosci ξ i γ liczymy dla kazdejskładowej sumy rozkładów i uzywamy ich do szacowania parametrówsumy rozkładów, jak widzielismy to juz wczesniej:
cjm =
∑Tt=1 γtm(j)∑T
t=1∑M
k=1 γtk (j)
µjm =
∑Tt=1 γtm(j)ot∑T
t=1∑M
k=1 γtk (j)
Σjm =
∑Tt=1 γtm(j)(ot − µjm)(ot − µjm)T∑T
t=1∑M
k=1 γtk (j)
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 114 / 189

LMSF i WIP
Wrócmy jeszcze do naszego podstawowego równania:
W = arg maxW
P(O|W )P(W )
Poniewaz liczymy prawdopodobienstwa dla kazdej ramki i je mnozymy,powaznie niedoszacowujemy model akustyczny. Wprowadzamy wiecczynnik LMSF (ang. language model scaling factor) jako wykładnikP(W ), przyjmujacy zwykle wartosci miedzy 5 a 15. PoniewazP(W ) ≤ 0, wiec waga modelu jezyka P(W ) sie zmniejsza. Poniewazmodel jezyka faworyzuje mniejsza liczbe dłuzszych słów, musimywprowadzic dodatkowa kare za wstawianie słów WIP (ang. wordinsertion penalty):
W = arg maxW
P(O|W )P(W )LMSF WIPN
N to liczba słów.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 115 / 189

Problemy z algorytmem Viterbiego
Algorytm Viterbiego daje dobre wyniki, ale nie jest idealny. Stosujac gospotykamy dwa problemy:
1 Słowa z róznymi wariantami wymowy sa traktowane przez tenalgorytm jako mniej prawdopodobne.
2 Nie mozna stosowac modeli wyzszych rzedów.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 116 / 189

Problemy z algorytmem Viterbiego
Prawdopodobienstwo ciagu obserwacji przy danym ciagu słówpowinnismy liczyc jako:
P(O|W ) =∑
X
P(O,X |W )
Tymczasem w algorytmie Viterbiego liczymy:
P(O|W ) ≈ maxX
P(O,X |W )
Najlepszy ciag słów powinien wyjsc taki sam, poza przypadkami, gdyjakies słowa maja rózne, alternatywne wymowy.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 117 / 189
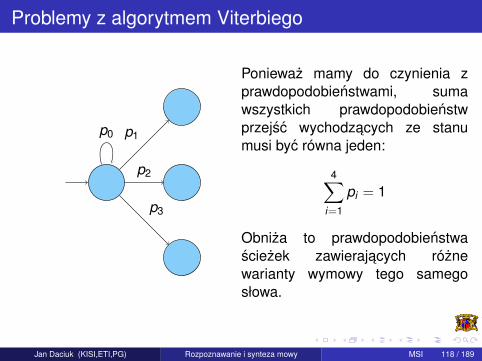
Problemy z algorytmem Viterbiego
p1
p2
p3
p0
Poniewaz mamy do czynienia zprawdopodobienstwami, sumawszystkich prawdopodobienstwprzejsc wychodzacych ze stanumusi byc równa jeden:
4∑i=1
pi = 1
Obniza to prawdopodobienstwasciezek zawierajacych róznewarianty wymowy tego samegosłowa.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 118 / 189

Problemy z algorytmem Viterbiego
W algorytmie Viterbiego zakładamy, ze jesli najlepsza sciezkaprzechodzi przez pewien stan qi , to musi zawierac najlepsza sciezkedo stanu qi . Jezeli uzywamy bigrams, to tak zawsze jest.
Jesli uzywamy trigrams, czy modeli jeszcze wyzszych rzedów, tak bycnie musi!
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 119 / 189

Rozwiazania
Dwa najczesciej uzywane rozwiazania obu wymienionych problemówto:
1 Dekodowanie wieloprzebiegowe.2 Algorytm A∗.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 120 / 189

Dekodowanie wieloprzebiegowe
W dekodowaniu wieloprzebiegowym najpierw korzystamy z wydajnych,ale mniej dokładnych metod do wstepnego wyboru kandydatów.Nastepnie uzywamy metod bardziej złozonych obliczeniowo, aledokładniejszych.
wektoryMFCC N-best
N najlepszychrozwiazan
ponowneprzeliczanie
najlepszerozwiazanie
W pierwszej fazie korzystamy z modyfikacji algorytmu Viterbiego, którazamiast jednej odpowiedzi, zwróci ich zadana liczbe. W fazieponownego przeliczania korzystamy z róznych metod, które pozwalajadokładniej, na podstawie wiekszej ilosci danych, policzycprawdopodobienstwo ciagu słów. Zastepujemy wczesniej policzoneprawdopodobienstwa nowymi i wybieramy najlepszy ciag wedługnowych kryteriów.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 121 / 189

Dekodowanie wieloprzebiegowe
W algorytmie Viterbiego zamiast przechowywac jedno rozwiazanie(jedna sciezke), przechowujemy ich wieksza liczbe (5÷ 10%przestrzeni poszukiwan). Jednak stany (lub przejscia miedzy nimi) niesa odwzorowane 1-1 w głoski lub czesci głosek. Dlatego nalezypamietac rozpoznawane słowa dla kazdej ze sciezek i przechowywactylko rózne rozwiazania.
Lista N rozwiazan zawiera pary prawdopodobienstw pochodzace zmodelu akustycznego i modelu jezyka. Ta lista nie jestprzechowywana jako lista, ale jako tzw. krata (ang. lattice). Nie jest tokrata w sensie matematycznym.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 122 / 189

Dekodowanie wieloprzebiegowe
ta
nie
panie
łap
mnie
ładnie
bede
W kracie zapisywane sa czasy roz-poczecia i zakonczenia, stad wielewersji dla tego samego słowa.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 123 / 189
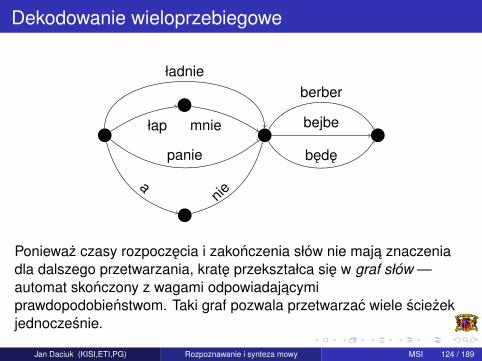
Dekodowanie wieloprzebiegowe
anie
panie
łap mnie
ładnie
bede
bejbe
berber
Poniewaz czasy rozpoczecia i zakonczenia słów nie maja znaczeniadla dalszego przetwarzania, krate przekształca sie w graf słów —automat skonczony z wagami odpowiadajacymiprawdopodobienstwom. Taki graf pozwala przetwarzac wiele sciezekjednoczesnie.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 124 / 189

Algorytm A∗
Jest to algorytm znany ze sztucznej inteligencji. Wybiera sciezke onajlepszej ocenie.
Algorytm A∗
1: utwórz pusta kolejke priorytetowa2: repeat3: Pobierz najlepsza sciezke z kolejki4: Jesli koniec zdania to wypisz i zakoncz5: for all nastepne mozliwe słowa do6: Utwórz nowa sciezke dodajac do biezacej dane słowo7: Policz prawdopodobienstwo akustyczne i modelu jezyka8: Wstaw do kolejki9: end for
10: until pusta kolejka
Kolejne słowa pobierane sa z grafu słów.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 125 / 189
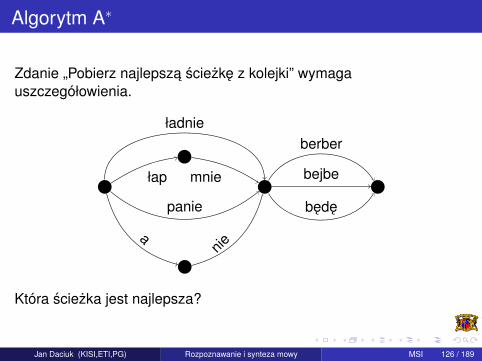
Algorytm A∗
Zdanie „Pobierz najlepsza sciezke z kolejki” wymagauszczegółowienia.
anie
panie
łap mnie
ładnie
bede
bejbe
berber
Która sciezka jest najlepsza?
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 126 / 189

Algorytm A∗
Wybranie sciezki o najwiekszym prawdopodobienstwie nie jestnajlepszym rozwiazaniem:
1 Dodanie słowa do sciezki zmniejsza jej prawdopodobienstwo2 Im dłuzsza sciezka, tym mniejsze prawdopodobienstwo3 Algorytm usiłowałby rozpoznawac zdania jednosłowowe
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 127 / 189

Algorytm A∗
Uzywa sie funkcji oceny postaci:
f ∗(p) = g(p) + h∗(p)
gdzie:f ∗(p) jest szacowana ocena całej, pełnej sciezki, dla którejsciezka p jest przedrostkiemg(p) jest ocena biezacej sciezki p (daje sie oszacowac zP(O|W )P(W ))h∗(p) jest szacowana ocena najlepszego dokonczenia danejsciezki
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 128 / 189

Triphones
jem jen cel cep
Poniewaz wymowa głosek rózni sie w zaleznosci od kontekstu,wiekszosc systemów rozpoznawania mowy zastepuje głoskiniezalezne od kontekstu (ang. context-independend phone, CI-phone)głoskami zaleznymi od kontekstu (ang. context-dependent phone,CD-phone). Do modelowania tych ostatnich nadaja sie triphones.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 129 / 189

Triphones
Problem: rzadkosc danych.
W danych uczacych zwykle jest za mało przykładów modeli rzedówwyzszych niz dwa. Niektórych dozwolonych kombinacji głosek mozepo prostu brakowac (np. około połowy dla angielskiego).
Skad wziac brakujace dane? Rozwiazanie: grupowanie danych.Najczesciej uzywa sie drzew decyzyjnych.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 130 / 189

Triphones
Budujemy drzewo decyzyjne dla kazdego stanu (w wariancie Moore’a)lub kazdego przejscia (w wariancie Mealy’ego). Pytania dotycza cechfonetycznych poprzedzajacej i nastepnej głoski.
Zaczynamy od korzenia drzewa, zawierajacego wszystkie wariantygłoski. W kazdym wierzchołku zadajemy jedno pytanie, które dzielizbiór na dwie czesci.
W uczeniu wypróbowujemy kazde mozliwe pytanie i wybieramy te,które daje nam najwiekszy wzrost prawdopodobienstwa danych popodziale. Konczymy wtedy, gdy kazdy wierzchołek ma minimalnadozwolona liczbe przykładów.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 131 / 189

Synteza mowy – motywacja
Przesyłanie tekstu jest prostsze, szybsze i wymaga przesłaniamniejszej ilosci informacji niz przesyłanie mowy.Informacje z baz danych, baz wiedzy, informacje pochodzace zautomatycznej interpretacji danych (np. z systemów orientacjigeograficznej itp.) maja postac tekstowa.Komunikat głosowy łatwiej dotrze na czas np. do pasazerów nadworcach, portach i lotniskach.Komunikat głosowy moze wykorzystac kanał głosowy w sytuacji,gdy wzrok jest zajety, np. w trakcie prowadzenia pojazdu lubstatku (takze powietrznego).Synteza mowy umozliwia rozmowe przez telefon osobom niemogacym mówic.Czytanie przez człowieka kosztuje.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 132 / 189

Synteza mowy – główne moduły
Analiza tekstu – fazy:1 Normalizacja tekstu2 Analiza fonetyczna3 Analiza prozodyczna
Synteza fali dzwiekowej – metody:Synteza oparta o sklejanie(Concatenative synthesis)Synteza formantów (Formantsynthesis)Synteza modelujaca traktartykulacyjny (Articulatory synthesis)Synteza oparta o niejawne modeleMarkowa (HMM Speech synthesis)
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 133 / 189

Normalizacja tekstu
Tekst8. marca w ajencji PKO przy ul. Władysława IV 17/1 dr inz. Kowalskiwypłacił 371,20 zł.
Tekst po normalizacji
Ósmego marca w ajencji pe ka o przy ulicy Władysława Czwartegosiedemnascie mieszkania jeden doktor inzynier Kowalski wypłaciłtrzysta siedemdziesiat jeden złotych i dwadziescia groszy.
1 Podział na zdania2 Słowa niestandardowe
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 134 / 189

Normalizacja tekstu – podział na zdania
Zdanie moze konczyc sie kropka, wykrzyknikiem, znakiem zapytania,srednikiem, dwukropkiem. Najwieksze trudnosci sprawia kropka:
12. stycznia 2008 r. przy ul. Kopernika 13 inz. J. Kowalski znalazłportfel, który zgubił w 2007 r.
Kropka moze konczyc zdanie, ale tez konczyc skrót, oznaczacliczebnik porzadkowy. . .
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 135 / 189

Normalizacja tekstu – podział na zdania
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 136 / 189

Normalizacja tekstu – podział na zdania
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 137 / 189

Normalizacja tekstu – podział na zdania
Wiekszosc programów dokonujacych podziału na zdania wykorzystujeuczenie maszynowe na podstawie zbiorów tekstów. Przykładowecechy przydatne w uczeniu:
przedrostek – czesc elementu przed mozliwym podziałemprzyrostek – czesc elementu po mozliwym podzialeczy przedrostek lub przyrostek jest skrótem z listypoprzednie słowonastepne słowoczy poprzednie słowo jest skrótemczy nastepne słowo jest skrótemwielkosc liter
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 138 / 189

Słowa niestandardowe
Niektóre typy:
liter
owe
rozwijane skróty prof., inz., gen., w.rozwijane skróty nr, dra, zł, gr, grozwijane skrótowce lp., itd., sp., m.in.ciag liter skrótowce PKP, PTTK, PKO, BHP, WSPjak słowa skrótowce NATO, PAP, MON, ETI
liczb
y
liczby liczby 12, 3.14, 3/4, 0,25porzadk. liczeb. porz. dzis jest 8. marca, Władysław IVodmienione liczeb. porz. dnia 8. marca, ul. Władysława IVciag cyfr cyfry kod dostepu 746532, kontociagi cyfr rózne tel. 347-2689, kod 80-952daty daty 2008-03-10, 11.03.2008czas czas 21:54, 712
adres adres Warszawska 24/7
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 139 / 189

Słowa niestandardowe
Rozpoznawac i klasyfiko-wac słowa niestandardowemozna jak obok lub zapomoca uczenia maszyno-wego, uwzgledniajac ce-chy jak wielkosc liter, obec-nosc znaków niealfanume-rycznych, sasiednie słowaitp.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 140 / 189

Słowa niestandardowe – rozwijanie
prof. Kowalski ⇒ profesor Kowalskiprof. Kowalskiego ⇒ profesora Kowalskiego
1 mezczyzna ⇒ jeden mezczyzna1 kobieta ⇒ jedna kobieta
1 1/2 l ⇒ półtora litra1 1/2 h ⇒ półtorej godziny
PKP ⇒ pe ka pe11.03.2008 ⇒ jedenasty marca dwa tysiace osiem
m.in. ⇒ miedzy innymi3,2 tys. zł ⇒ trzy tysiace dwiescie złotych
Łódzka 24/7 ⇒ Łódzka dwadziescia cztery mieszkania siedem
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 141 / 189

Słowa niestandardowe – homografy
W jezyku polskim rózna wymowa tych samych napisów dotyczygłównie skrótów. W innych jezykach bywa gorzej:
angielskiI bought it at a discount. They never discount this product.
francuskiIls président. C’est monsieur le président.
Przykłady pokazuja przypadek, kiedy czesc mowy wpływa nawymowe. Ustalenie czesci mowy pozwala na ustalenie wymowy. Winnych przypadkach konieczne jest ustalenie znaczenia słowa.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 142 / 189

Analiza fonetyczna
W ramach analizy fonetycznej, rozwiazywane sa trzy problemy:1 słowniki wymowy2 nazwy własne3 zamiana grafemów na fonemy
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 143 / 189

Słowniki wymowy
Gerard Nolst Trenité - The Chaos (1922)
Dearest creature in creationStudying English pronunciation,I will teach you in my verseSounds like corpse, corps, horse and worse.I will keep you, Susy, busy,Make your head with heat grow dizzy;Tear in eye, your dress you’ll tear;Queer, fair seer, hear my prayer.Pray, console your loving poet,Make my coat look new, dear, sew it!Just compare heart, hear and heard,Dies and diet, lord and word. . . .
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 144 / 189

Słowniki wymowy
Dla jezyków takich jak angielski, potrzeba słowników wymowy jestoczywista. Przechowuja nie tylko ciagi fonemów, ale tez miejscaakcentu wyrazowego. Dla jezyka polskiego:
wydział
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 145 / 189

Słowniki wymowy
Dla jezyków takich jak angielski, potrzeba słowników wymowy jestoczywista. Przechowuja nie tylko ciagi fonemów, ale tez miejscaakcentu wyrazowego. Dla jezyka polskiego:
wydziałpodziemny
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 146 / 189

Słowniki wymowy
Dla jezyków takich jak angielski, potrzeba słowników wymowy jestoczywista. Przechowuja nie tylko ciagi fonemów, ale tez miejscaakcentu wyrazowego. Dla jezyka polskiego:
wydziałpodziemny
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 147 / 189

Słowniki wymowy
Dla jezyków takich jak angielski, potrzeba słowników wymowy jestoczywista. Przechowuja nie tylko ciagi fonemów, ale tez miejscaakcentu wyrazowego. Dla jezyka polskiego:
podziałpodziemnypodzielony
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 148 / 189

Słowniki wymowy
Dla jezyków takich jak angielski, potrzeba słowników wymowy jestoczywista. Przechowuja nie tylko ciagi fonemów, ale tez miejscaakcentu wyrazowego. Dla jezyka polskiego:
podziałpodziemnypodzielony
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 149 / 189

Słowniki wymowy
Dla jezyków takich jak angielski, potrzeba słowników wymowy jestoczywista. Przechowuja nie tylko ciagi fonemów, ale tez miejscaakcentu wyrazowego. Dla jezyka polskiego:
podziałpodziemnypodzielony?podczerwony
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 150 / 189

Nazwy własne
W zwykłym słowniku nazwy własne nie wystepuja, jednak na ogółstanowia 70-80% tych słów wystepujacych w tekstach, których nie maw zwykłym słowniku. Mozna je podzielic na:
nazwy osób (imiona i nazwiska)nazwy geograficzne (kraje, miasta, ulice, góry, rzeki itp.)nazwy handlowe (nazwy firm i wyrobów)
Dla nieznanych nazwisk mozna próbowac znajdowac nazwiskapodobne ze wzgledu na np. podobna koncówke.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 151 / 189

Zamiana grafemów na fonemy
Ten sposób dokonywania transkrypcji fonetycznej wykonuje sie dlasłów, których brak w słowniku. Mozna stosowac recznie pisane regułytakie jak poznane juz wczesniej reguły fonologiczne. Sa onewykonywane w okreslonej kolejnosci. Nowsze systemy uzywajauczenia maszynowego do pozyskiwania takich reguł. Dla danegociagu liter L staramy sie uzyskac najbardziej prawdopodobny ciaggłosek P:
P = arg maxP
P(P|L)
Wystepuja tu dwa zagadnienia:1 wyrównywanie grafemów z głoskami2 wybieranie najlepszej wymowy
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 152 / 189

Wyrównywanie grafemów z głoskami
Do uczenia potrzebne sa wyrównane dane (najczesciej ze słowników):
ł ó dz| | |u“
u Z
Do uzyskania takiego wyrównania uzywa sie róznych technik. Jedna znajprostszych wymaga list dozwolonych transkrypcji grafemów nagłoski. Dla kazdego słowa ze zbioru uczacego znajdujemy wszystkiedozwolone transkrypcje słowa (uzywajace dozwolonych transkrypcjigrafemów). Nastepnie dla wszystkich głosek pi i wszystkich grafemówlj liczy sie:
P(pi |lj) =liczba(pj , lj)
liczba(lj)
i uzywa algorytmu Viterbiego dla znalezienia najlepszego wyrównania.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 153 / 189

Wybieranie najlepszego ciagu głosek
W wyrównywaniu obecny był zarówno ciag liter, jak i odpowiadajacymu ciag głosek. Teraz dla nieznanego słowa mamy tylko ciag liter – niemamy głosek. Ciag głosek uzyskujemy na podstawie klasyfikatoranauczonego na wyrównanych ciagach. Typowym klasyfikatorem sadrzewa decyzyjne. Prawdopodobienstwa głosek sa na ogół szacowanena podstawie:
biezacej litery,okna k poprzedzajacych i k nastepnych liter,k poprzednich głosek (oszacowanych w poprzednich krokach).
Mozna tez uzywac innych cech, np. kategorii głosek itp. Wiekszoscsystemów syntezy mowy ma dwa rózne drzewa decyzyjne: jedno dlanieznanych nazw osób i jedno dla pozostałych słów.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 154 / 189

Analiza prozodyczna
Analiza prozodyczna:ustala strukture prozodycznaustala wage prozodycznaustala intonacje
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 155 / 189

Struktura prozodyczna
Zdania obok struktury składniowej maja strukture prozodyczna;wystepuja w niej frazy intonacyjne i (mniejsze) frazy posrednie.
zdanie – bez podziału na frazyPrzerwijmy na chwile nasze maltuzjanskie rozwazania, aby wrócic dosprawy przerywania ciazy i do Komisji Kodyfikacyjnej.
Czesto wstawiamy przerwe po frazie intonacyjnej, ostatniasamogłoska frazy jest na ogół dłuzsza niz zwykle, F0 czesto obniza siew trakcie frazy.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 156 / 189

Struktura prozodyczna
Zdania obok struktury składniowej maja strukture prozodyczna;wystepuja w niej frazy intonacyjne i (mniejsze) frazy posrednie.
frazy intonacyjnePrzerwijmy na chwile nasze maltuzjanskie rozwazania, z aby wrócic dosprawy przerywania ciazy i do Komisji Kodyfikacyjnej.
Czesto wstawiamy przerwe po frazie intonacyjnej, ostatniasamogłoska frazy jest na ogół dłuzsza niz zwykle, F0 czesto obniza siew trakcie frazy.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 157 / 189

Struktura prozodyczna
Zdania obok struktury składniowej maja strukture prozodyczna;wystepuja w niej frazy intonacyjne i (mniejsze) frazy posrednie.
frazy posredniePrzerwijmy na chwile z nasze maltuzjanskie rozwazania, z aby wrócic z
do sprawy przerywania ciazy z i do Komisji Kodyfikacyjnej.
Czesto wstawiamy przerwe po frazie intonacyjnej, ostatniasamogłoska frazy jest na ogół dłuzsza niz zwykle, F0 czesto obniza siew trakcie frazy.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 158 / 189

Struktura prozodyczna
Przewidywanie granicy frazy jest przykładem klasyfikacji dwójkowej.Mozna korzystac z podziału na zdania omawianego juz wczesniej,mozna dodatkowo wstawiac granice frazy przed słowem pomocniczym(np. przyimkiem), po którym nastepuje słowo niosace samodzielneznaczenie. Bardziej zaawansowane programy uzywaja uczeniamaszynowego. Jest takze istotna współzaleznosc pomiedzy strukturaprozodyczna a składniowa. Cechy uzywane w klasyfikacji:
długosci:całkowita liczba słów i sylab w wypowiedzeniu,odległosc miejsca od poczatku i konca zdania (w słowach lubzgłoskach)odległosc w słowach od ostatniego znaku interpunkcyjnego;
sasiednie czesci mowy i interpunkcja:czesci mowy w oknie (na ogół po dwa słowa) wokół miejsca,rodzaj nastepnego znaku interpunkcyjnego.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 159 / 189

Waga prozodyczna
Słowa, które sa wazne, lub słowa, które mówiacy chce podkreslic, saakcentowane – wymawiane głosniej, wolniej (czyli dłuzej), lubzmieniajac ton podstawowy. Mozna wyróznic do czterech poziomówakcentowania poszczególnych słów – od emfazy do braku akcentu(wyrazów atonicznych). Akcentowanie słowa zalezy od jegoznaczenia, tego, czy jest nowe w danej wypowiedzi, wagi zawartej wnim informacji.Na akcent danego słowa wpływa tez akcent słów w jego otoczeniu.Słowa akcentowane nie moga byc zbyt blisko, ani zbyt daleko siebie.Np. kiedy słowa akcentowane miałyby byc zbyt blisko siebie, akcentbywa przenoszony na dalsze słowa.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 160 / 189

Waga prozodyczna
Waga prozodyczna na ogół jest przydzielana na podstawiealgorytmów uczenia maszynowego (zwykle drzewa decyzyjne). W jakisposób oceniac, czy argument jest nowy i wnosi wiele do znaczenia?
TF ∗ IDF(w) = Nw × log(
Nk
)TF – term frequencyIDF – inverse document frequencyNw – czestosc słowa w w danym dokumencieN – liczba dokumentówk – liczba dokumentów zawierajacych słowo w
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 161 / 189

Intonacja
W praktyce systemy syntezy mowy realizuja na ogół tylko trzy zjawiskadotyczace intonacji:
1 zwiekszanie czestotliwosci podstawowej przy wyliczeniach pokolejnym elemencie,
2 zwiekszenie czestotliwosci podstawowej na koncu pytania i3 opadanie czestotliwosci podstawowej przy koncu innych
wypowiedzi.Istnieja bardziej skomplikowane modele prozodii, jak ToBI i TILT.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 162 / 189

Dodatkowe informacje dla syntezy fali dzwiekowej
Do syntezy opartej na wyborze jednostek nic wiecej nie trzeba juzliczyc. Dane dla syntezy fali dzwiekowej stanowia:
informacja o akcencie,ciag głosek.
Jednak w syntezie formantów i syntezie polegajacej na sklejaniujednostek diphone nalezy okreslic takze:
długosc trwania jednostki,czestotliwosc podstawowa.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 163 / 189

Obliczanie długosci odcinków mowy
W metodzie Klatta długosc głosek oblicza sie korzystajac ze wzoru:
d = dmin +N∏
i=1
fi × (d − dmin)
gdzie d – długosc głoski,dmin – minimalna długosc głoski,d – srednia długosc głoski,N – liczba reguł okreslajacych długosc głoski,fi – waga danej reguły.Przykładowe wartosci fi dla niektórych reguł dla j. angielskiego:
1.4 wydłuzenie samogłoski lub półsamogłoski przed przerwa-0.6 odcinków, które nie sa na koncu frazy1.4 wydłuzenie konczacych fraze [l] i [ô] po samogłoskach
oraz głosek nosowych
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 164 / 189

Obliczanie czestotliwosci podstawowej
Czestotliwosc podstawowa (F0) wyrazana jest nie w hercach, alewzgledem zakresu czestotliwosci przez okreslonego mówce. Jejwartosc zalezy od modelu prozodii, np. w jednym systemów opartychna modelu ToBI akcent H∗ ma 100% zakresu, a L∗ – 0%. Wartosc F0jest ustalana dla konkretnych kilku miejsc w obrebie sylaby. Miejscamozna okreslic recznie, lecz mniej pracochłonne jest zastosowanieuczenia maszynowego, np. regresji liniowej, na cechachzawierajacych:
typ akcentu biezacej sylaby oraz dwóch poprzednich i dwóchnastepnych,liczba sylab od poczatku i do konca frazyliczba akcentowanych sylab do konca frazy
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 165 / 189

Synteza fali dzwiekowej
Podstawowe metody:Synteza w oparciu o reguły (rule-based synthesis) – regułyopisuja wzajemny wpływ głosek w oparciu o modele wymowy.Bardzo duza liczba parametrów trudnych do oszacowania.Synteza formantów.Synteza w oparciu o sklejanie (concatenative synthesis) –mowa tworzona jest przez sklejanie mniejszych zapisanychfragmentów: diphones (zaczynajacych sie w stabilnym staniejednej głoski i konczacych w stabilnym stanie drugiej), półsylab,triphones (jak diphones, ale obejmuja jedna pełna głoske) itp.Synteza oparta o niejawne modele Markowa (HMM-basedsynthesis) — parametry mowy sa generowane bezposrednioprzez rozszerzone, niejawne modele Markowa.Synteza traktu artykulacyjnego – modeluje połozenie narzadówmowy i na tej podstawie tworzy dzwiek.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 166 / 189

Synteza traktu artykulacyjnego
W odróznieniu od syntezy formantów ta forma syntezy modelujefizyczne własciwosci poszczególnych narzadów uczestniczacych wwymowie.
Systemy wykorzystujace ten model daja obecnie gorsze wyniki nizsystemy wykorzystujace synteze konkatenacyjna z wyboremjednostek.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 167 / 189

Synteza traktu artykulacyjnego
Mozna wyróznic trzy czesci systemu:1 model sterowania – odpowiada za sterowanie ruchem narzadów
mowyodcinkowy (ang. segmental) – wypowiedz dzielimy na odcinki ookreslonym czasie trwania i etykietachoparty o działania (ang. action based) – ruchy sa zapisywane naczyms w rodzaju partytury
2 model kanału głosowego – przekształca informacje o ruchu nazmiany kształtu kanału głosowego: statystyczny,biomechaniczny, geometryczny
3 model akustyczny – tworzy dzwiek na podstawie kształtu kanaługłosowego
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 168 / 189

Synteza traktu głosowego – model kanału głosowego
Kanał głosowy jest modelowanyjako ciag rur o pewnych długo-sciach i przekrojach.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 169 / 189

Synteza traktu głosowego – modele akustyczne
modele odbiciowych odpowiedników przewodu (ang.reflection type line analog models) – fale cisnienia sa liczone wdziedzinie czasu dla kazdego odcinka rur na podstawie równanuwzgledniajacych nieciagłosci na granicy rur. Wada jestniemoznosc modelowania zmiany długosci odcinków rur w czasie.modele odpowiedników układów przewodzacych (ang.transmission line circuit analog models) – zmiany cisnienia saliczone przez cyfrowa symulacje obwodów elektrycznych.Długosci odcinków traktu artykulacyjnego moga sie zmieniac, aletrudno jest przyblizac straty wynikajace z wibracji scian, tarcia,wypływu powietrza przez usta i nos.modele hybrydowe w dziedzinach czasu i czestotliwosci (ang.hybrid time-frequency domain models)modele propagacji fal metoda elementów skonczonych (ang.finite element wave propagation models)
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 170 / 189

Synteza w oparciu o reguły
Zwana jest takze synteza formantów, poniewaz jej celem jesttworzenie formantów odpowiadajacych rezonansom w poszczególnychmiejscach drogi głosowej. Osiaga sie to przez zastosowanie filtrów doszumu i tetnien głosu. Filtry drugiego stopnia stosuje sie szeregowo irównolegle. Filtry ustawione szeregowo dobrze modeluja głoskinienosowe, równolegle – nosowe i trace.Podstawowa trudnoscia jest znalezienie reguł i ustalenie ichparametrów. Próbuje sie to robic przez analize za pomoca syntezy.Tego typu syntezatory maja niewielkie wymagania sprzetowe. Mogabyc wiec uzywane w sprzecie takim jak telefony komórkowe, palmtopy,zegarki, zabawki itp. Zrozumiałosc jest wysoka nawet przy bardzoduzej szybkosci, ale głos jest sztuczny i trudno mu nadac cechy głosukonkretnej osoby.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 171 / 189

Syntetyzator formantów
Zródło modeluje sygnał powstały po przejsciu powietrza z płuc przezstruny głosowe. Moga byc to szumy lub sygnał okresowy lub obanaraz (np. dla dzwiecznych spółgłosek tracych). Struny głosoweotwieraja sie i zamykaja z czestotliwoscia ok. 80 Hz do 250 Hz dlamezczyzn i 120 Hz do 400 Hz dla kobiet.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 172 / 189

Formanty
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 173 / 189

Formanty
Pojedynczy formant moze byc tworzony przez filtr drugiego stopnia,którego funkcja przenoszenia dana jest wzorem:
H(z) =1
(1− p1z )(1− p2
z )
Filtr tworzacy wiecej formantów moze byc uzyskany przezwymnozenie funkcji przenoszenia wielu formantów. Zaleta jestpojedyncza funkcja tworzenia. Wada tego rozwiazania jest wzajemnywpływ na siebie blisko połozonych formantów.W syntezatorze równoległym łatwiej sterowac czestotliwosciaformantów, ale mamy mniejszy wpływ na amplitude. Nie mamy tezpojedynczej funkcji przenoszenia.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 174 / 189

Synteza w oparciu o sklejanie
Najprostszym rodzajem tego typu systemów sa systemy sklejajacegotowe fragmenty wypowiedzi – słowa, zwroty, czasem nawet zdania.Znajduja zastosowanie w ograniczonych dziedzinach, np. prognozapogody, zapowiedzi na dworcu (kolejowym w Poznaniu). Sprawdzajasie tylko w jednym, konkretnym srodowisku. Nie moga wypowiadactekstów, dla których nie zostały zaprogramowane.Troche bardziej zaawansowane sa systemy uzywajace fragmentówtakich jak diphones, triphones i półsylab. Uzywa sie nagran od jednegostanu stabilnego do drugiego takiego stanu po to, by modelowacprzejscia miedzy głoskami. Im dłuzszy fragment, tym trudniej jestznalezc odpowiednie wzorce w zapisanej mowie, ale tymnaturalniejsze brzmienie głosu sie otrzymuje. Charakterystyczne dlatakich systemów sa róznego rodzaju specjalne efekty dzwiekowe nagranicy sklejanych fragmentów.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 175 / 189

Synteza sklejana z uzyciem diphones
Do tego rodzaju syntezy nalezy przede wszystkim przygotowac bazediphones. Odbywa sie to w kilku krokach:
1 Utworzenie zbioru diphones, które maja zostac nagrane.2 Znalezienie odpowiedniego lektora.3 Stworzenie tekstu do odczytania przez lektora.4 Nagranie głosu lektora czytajacego przygotowany tekst.5 Podział, oznaczenie i wyciecie diphones.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 176 / 189

Synteza sklejana z uzyciem diphones – TD-PSOLA
Brzegi sklejanych jednostek rzadko idealnie do siebie pasuja. Wmiejscach łaczenia słychac klikniecia. TD-PSOLA (ang. Time-DomainPitch-Synchronous OverLap-and-Add) zmienia ton i długosc głosekprzez wyciaganie poszczególnych ramek, zmienianie ich i połaczenieprzez nakładanie.Długosc głosek mozna zmieniac wstawiajac lub usuwajac ramki(wiecej o ramkach przy rozpoznawaniu mowy). Mozna zmieniacczestotliwosc podstawowa sciesniajac (zwiekszanie) lubrozrzedzajac (zmniejszanie) ramki, tzn. zmieniajac odległosc miedzyramkami. Poniewaz taka operacja zmieniłaby takze długosc ramek,konieczne moze byc dodanie lub usuniecie ramek dla zrównowazeniaskutków tych operacji.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 177 / 189

Synteza z wyborem jednostek
Wybór jednostek jest forma syntezy sklejanej, ale w odróznieniu odsyntezy z uzyciem diphones:
baza danych zawiera wiele godzin nagran zawierajacych wieleróznych kopii diphones (a nie dokładnie po jednym ichegzemplarzu),obróbka sklejonych fragmentów jest znacznie mniej intensywna.
Celem syntezy jest wybranie z bazy danych takiego ciagu jednostek,który minimalizowałby koszt syntezy:
U = arg minU
(N∑
i=1
T (si ,ui) +N−1∑i=1
J(ui ,ui+1))
gdzie N to liczba jednostek,T (ui , si) – koszt okreslajacy, jak dobrze wybrana jednostka uiodpowiada specyfikacji si ,J(ui ,ui+1) – koszt łaczenia jednostek ui i ui+1.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 178 / 189

Koszty w syntezie z wyborem jednostek
Koszt T (st ,uj) liczony jest jako suma wagowa poszczególnych cechdopasowania jednostek do specyfikacji docelowych diphones:
T (si ,uj) =
p∑p=1
wpTp(st [p],uj [p])
gdzie cechy obejmuja akcent, połozenie we frazie intonacyjnej,czestotliwosc podstawowa, rodzaj słowa.Koszt łaczenia takze liczony jest jako suma wazona:
J(ut ,ut+1) =P∑
p=1
wpJp(ut [p],ut+1[p])
gdzie koszty składowe to odległosc cepstralna w punkcie łaczenia,róznica logarytmów mocy sygnału i róznica czestotliwoscipodstawowej.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 179 / 189

Koszty w syntezie z wyborem jednostek
Koszt łaczenia jest zerowy jesli łaczy sie nastepujace po sobiejednostki z bazy danych (przylegajace do siebie fragmenty tegosamego nagrania).W obu kosztach wagi najczesciej ustalane sa doswiadczalnie, recznie,chociaz istnieja tez algorytmy uczenia maszynowego.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 180 / 189

Wybór jednostek
W jaki sposób znalezc takie ciag jednostek, który minimalizuje kosztydopasowania i koszty łaczenia? Najczesciej wykorzystuje sie niejawnemodele Markowa (HMMs). Specyfikacje obiektów docelowych saciagiem obserwacji, natomiast stanami sa jednostki, które nalezywybrac. Celem jest wybranie najlepszego ciagu stanów. Stosuje sie dotego algorytm Viterbiego.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 181 / 189

Hidden Semi-Markov Model
Jest to rozszerzenie HMM, w którym modeluje sie bezposrednio czas(dyskretny, czyli liczbe razy) pozostawania w okreslonym stanie.
X0 X0 X0 X1 X1 X1 · · · Xl Xl Xl · · ·
o1 o2 o3 o4 o5 ot ot+1
d1 d2 dl
Inaczej mówiac przejscie z jednego stanu do drugiego wysyła nawyjscie cały ciag obserwacji. W wersji Moore’a jeden stan wysyła nawyjscie cały ciag obserwacji.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 182 / 189

Hidden Semi-Markov Model
Liczac prawdopodobienstwo ciagu obserwacji, wartosci poczatkowe iprawdopodobienstwo obserwacji liczymy tak jak poprzednio, natomiastkrok indukcyjny wyglada nastepujaco:
αj(t + 1) =t∑
d=1
∑i=1i 6=j
αi(t − d)aijpj(d)t∏
s=t−d+1
bijos ,1 ≤ t ≤ T ,≤ j ≤ N
gdzie pj(d) to prawdopodobienstwo pozostawania w stanie j przez djednostek czasu.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 183 / 189

Synteza mowy z uzyciem niejawnych modeli Markowa
W tym rodzaju syntezy sygnał mowy generowany jest bezposrednio napodstawie danych statystycznych. Wiaza sie z tym nastepujace cechy:
Dane do syntezy zajmuja duzo mniej miejsca niz w syntezie zwyborem jednostek.Łatwiej jest zmienic parametry głosu, np. uzyskac głos konkretnejosoby w okreslonym stanie emocjonalnym.Mozna łatwo uzyskac spiewMozna uzyskac płynne przejscie z głosu jednej osoby w głos innejosoby (odpowiednik morfingu z grafiki)
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 184 / 189

Synteza mowy z uzyciem niejawnych modeli Markowa
W tym rodzaju syntezy:1 Kazda głoska modelowana jest w postaci ciagu kilku stanów, z
petlami na stanach i przejsciami do nastepnego stanu w ciagu.2 Parametry cepstralne uzyskuje sie bezposrednio z modelu
Markowa.3 Długosci głosek modeluje sie bezposrednio korzystajac z HSMM.4 Oddzielnie modeluje sie czestotliwosc podstawowa F0.5 Ze wzgledu na braki w danych stosuje sie drzewa decyzyjne, po
jednym drzewie dla cech spektralnych (wykorzystuje sietriphones), czestotliwosci podstawowej i długosci głosek.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 185 / 189

Kryteria oceny syntezy mowy
Sa dwa podstawowe kryteria oceny syntezatorów mowy:1 zrozumiałosc2 naturalnosc
W róznych zastosowaniach wazne moga byc dodatkowe cechy głosu,np. stanowczy, niski, meski głos dominujacego samca w systemach,które maja kierowac grupa osób lub zalotny, kobiecy głos w reklamachi szczególnego rodzaju programach rozrywkowych.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 186 / 189

Speech Synthesis Markup Language – SSML
SSML jest jezykiem pozwalajacym zapisywac informacje wazne dlaprawidłowej wymowy tekstu. Uzywany jest przez przegladarki(przesłuchanki?) głosowe. Tekst pisany jest wzbogacony o wymowewyrazów, głosnosc, barwe głosu, intonacje itp. Celem jest poprawieniejakosci syntezy mowy. W SSML moze byc zapisany cały dokument lubtylko jego czesc. Oprócz SSML istnieja tez SABLE i wywodzacy sie zniego REQS, ale sa mniej popularne. Dokument zapisany w SSMLmoze byc stworzony przez człowieka lub przez program.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 187 / 189

Speech Synthesis Markup Language – SSML
Na poziomie analizy struktury elementy p – paragraph (akapit) i s –sentence (zdanie) oznaczaja wyraznie te jednostki tekstu, które sawymawiane w okreslony sposób, według okreslonego wzorca. Napoziomie normalizacji tekstu elementy say-as (wypowiedz jako)pomagaja w wymowie takich fragmentów tekstu jak daty, liczebniki itp.Skróty moga byc rozwijane bezposrednio przez autora za pomocaelementów sub, w angielskim CIA jako C I A i IEEE jako I triple E. Napoziomie przekształcania tekstu na ciag fonemów uzywa sieelementów say-as i sub, a takze lexicon, który pozwala odwołac siedo zewnetrznego wzorca wymowy.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 188 / 189

Speech Synthesis Markup Language – SSML
Na poziomie prozodii uzywa sie elementów emphasis, break iprosody. Na poziomie tworzenia fali głosowej element voice pozwalazazadac głosu o okreslonej charakterystyce, np. młodej kobiety oniskim głosie, zas element audio pozwala na wykorzystaniezapisanych danych dzwiekowych.
Jan Daciuk (KISI,ETI,PG) Rozpoznawanie i synteza mowy MSI 189 / 189