scalable distributed computing hierarchy: cloud, fog and ... · distributed computing paradigms:...
TRANSCRIPT

c© 2015 by the authors; licensee RonPub, Lubeck, Germany. This article is an open access article distributed under the terms and conditions ofthe Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Open Access
Open Journal of Cloud Computing (OJCC)Volume 2, Issue 1, 2015
http://www.ronpub.com/ojccISSN 2199-1987
Scalable Distributed Computing Hierarchy:Cloud, Fog and Dew Computing∗
Karolj SkalaA, Davor DavidovicA, Enis AfganA,B, Ivan SovicA, Zorislav SojatA
A Centre for Informatics and Computing, Rudjer Boskovic Institute, Bijencka cesta 54,10000 Zagreb, Croatia, {skala, ddavid, isovic, eafgan, sojat}@irb.hr
B Johns Hopkins University, 3400 N. Charles Street, Baltimore, MD 21218, USA, [email protected]
ABSTRACT
The paper considers the conceptual approach for organization of the vertical hierarchical links between the scalabledistributed computing paradigms: Cloud Computing, Fog Computing and Dew Computing. In this paper, the DewComputing is described and recognized as a new structural layer in the existing distributed computing hierarchy.In the existing computing hierarchy, the Dew computing is positioned as the ground level for the Cloud and Fogcomputing paradigms. Vertical, complementary, hierarchical division from Cloud to Dew Computing satisfies theneeds of high- and low-end computing demands in everyday life and work. These new computing paradigms lowerthe cost and improve the performance, particularly for concepts and applications such as the Internet of Things(IoT) and the Internet of Everything (IoE). In addition, the Dew computing paradigm will require new programmingmodels that will efficiently reduce the complexity and improve the productivity and usability of scalable distributedcomputing, following the principles of High-Productivity computing.
TYPE OF PAPER AND KEYWORDS
Visionary paper: Distributed computing, grid computing, cloud computing, fog computing, dew computing, high-productivity computing
1 INTRODUCTION
The history of distributed computing dates back to 1960swhen the first distributed system, IBM System/360[17, 12], was introduced. Since then, the distributedparadigm emerged as an alternative to expensive super-computers, powerful but large and inflexible machinesthat were hard to modify and update. This alternativewas required in order to handle new and increasing usersneeds and application demands. Opposed to supercom-puters, distributed computing systems are networks oflarge number of attached nodes or entities (e.g. compu-tational nodes) formed from computers (machines) con-
∗This is a OpenAir FP7 Pilot Granted Paper (www.openaire.eu).
nected through a fast local network [2][3].
This architectural design brings several new features,such as high computational capabilities and resourcesharing. High computational capabilities are achievedby joining together a large number of compute units viaa fast network, while resource sharing allows differentdistributed entities to be shared among different usersbased on the resource availability and user’s require-ments. Moreover, adding, removing and accessing theresource is easy and can be done in a uniform way, al-lowing multiple devices to communicate and share databetween themselves.
The biggest boost in the development of distributedcomputing occurred around year 2000 when the proces-
16

K. Skala, D. Davidovic, E. Afgan, I. Sovic, Z. Sojat: Scalable Distributed Computing Hierarchy: Cloud, Fog and Dew Computing
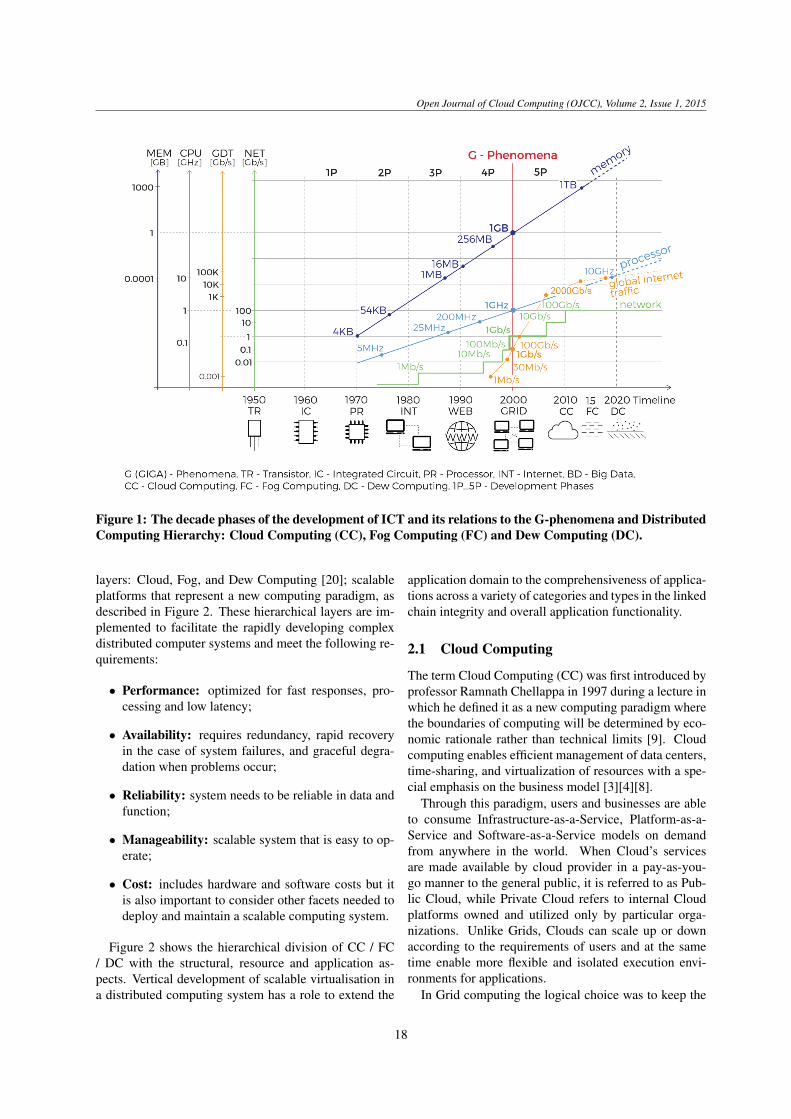
sor clock rate, network bandwidth and RAM (Random-Access Memory) capacity reached the Giga range. Thisoccurrence has been denoted as the G-phenomena [21]and started the fifth phase of development of comput-ing systems (see Figure 1). Specifically, 1 GHz proces-sors were released by Intel and AMD, gigabit Ethernetwas in use and the first computers with 1 GB of RAMbecame available. This alignment made a virtual inte-gration of spatially distributed computers plausible, fur-ther enabling rapid development of distributed systems,thus creating conditions for space-independent conceptof distributed systems.
Started by the Grid and Cloud computing paradigms,the G-phenomena was one of the two main drivingforces (namely, hardware and software) that have ledto the current development of Information and Com-munications Technologies (ICT). The primary predis-position for that development was achieving substantialspeed improvements of processors and their interconnec-tions, and the ability to process more data in memory.High-performance distributed computing systems werefounded on Grid computing paradigm while scalable dis-tributed computing systems evolved through Cloud com-puting paradigm and the Internet of Things.
Today, distributed systems play an important role inalmost every aspect of our everyday living. One of themost popular and widely used distributed systems in theworld is the Internet, without which the contemporaryeveryday life would be hard to imagine. The other ex-amples, more hidden from the public view, are large dis-tributed computational and storage infrastructures calledGrids and Clouds, mostly used to analyze tremendousamounts of data coming from numerous business, re-search and development activities such as DNA sequenc-ing, climate changes, medicine, banking, and telecom-munications. One of the first large-scale distributed com-puting systems developed specifically for many-task ap-plications was the Grid [14][5].
The first grid infrastructures were started in late 1990sthrough several Grid-oriented projects in the UnitedStates, while the two major European projects, startedin early 2000s, the UK e-Science program and EuropeanUnion Data Grid project [10]. These gave shape to whatis known today as the European Grid Initiative [18] -a pan-European distributed research infrastructure. Theavailability of the first public Grid infrastructures stimu-lated the expansion of scientific computing research, andprogressively, Grid computing became one of the majorparadigms for scientific applications. However, high uti-lization of public Grid infrastructures by many differentgroups with different applications and their technical andbureaucratic issues limited their widespread usage.
Following the G-phenomena (Figure 1) over the pastdecade, an increasing number of companies, especially
from telecommunication and IT sector are moving fromstatic, centralized cluster environments to more elastic,scalable and potentially cheaper Cloud distributed plat-forms. Moreover, Cloud computing is becoming attrac-tive to the fast growing Small and Medium-sized Enter-prises (SMEs) [22] as it allows them to allocate, increaseand decrease the required resource on-demand depend-ing on a rise in service demands. In other words, by mov-ing from the capital upfront investment model to an oper-ational expense, Cloud computing promises, especiallyto SMEs and entrepreneurs, to accelerate the develop-ment and adoption of innovative solutions and lower theoperational costs.
Similarly, in many branches of modern research suchas genomics, climate change simulations, drugs dis-covery, and medical research, computational and data-intensive problems have arisen. These problems en-compass the generation, analysis and interpretation ofvast amounts of data and their comparisons against cat-alogues of existing knowledge through complex multi-stage workflows. These workflows, or analyses, are en-abled by a combination of analysis platforms and com-putational infrastructures and can be provided as threemain Cloud services: Infrastructure as a Service (IaaS),Platform as a Service (PaaS) and Software as a Service(SaaS).
However, in order to meet the needs of the currentas well as future research problems, for example real-time human brain simulation, one of the main chal-lenges in the computer science, the scalability, has tobe solved. It is expected that the future computing sys-tems will be highly heterogeneous, consisting of vari-ous devices such as mobile devices, traditional comput-ers, embedded systems, and sensors, that the present-daymodels and paradigms could not efficiently solve. Thus,new challenges will require new computing models andparadigms. As an example, a relatively new computingmodel that can efficiently solve data-intensive problemswith reduced power consumption is based on the FieldProgrammable Gate Arrays (FPGAs) using a data-flowapproach to processing [13].
2 HIERARCHY OF SCALABLE DISTRIBUTEDCOMPUTING
Scalability is the ability of a computer system, networkor application to handle a growing amount of work,both in terms of processing power as well as storage re-sources, or its potential to be easily enlarged in orderto accommodate that growth. Today, we are witnessingthe exponential growth of data (Big Data) and process-ing (application) needs which lead to the necessary scal-ability of resources at multiple levels. In this way wecame to a new hierarchical structure, consisting of three
17
Open Journal of Cloud Computing (OJCC), Volume 2, Issue 1, 2015
Figure 1: The decade phases of the development of ICT and its relations to the G-phenomena and DistributedComputing Hierarchy: Cloud Computing (CC), Fog Computing (FC) and Dew Computing (DC).
layers: Cloud, Fog, and Dew Computing [20]; scalableplatforms that represent a new computing paradigm, asdescribed in Figure 2. These hierarchical layers are im-plemented to facilitate the rapidly developing complexdistributed computer systems and meet the following re-quirements:
• Performance: optimized for fast responses, pro-cessing and low latency;
• Availability: requires redundancy, rapid recoveryin the case of system failures, and graceful degra-dation when problems occur;
• Reliability: system needs to be reliable in data andfunction;
• Manageability: scalable system that is easy to op-erate;
• Cost: includes hardware and software costs but itis also important to consider other facets needed todeploy and maintain a scalable computing system.
Figure 2 shows the hierarchical division of CC / FC/ DC with the structural, resource and application as-pects. Vertical development of scalable virtualisation ina distributed computing system has a role to extend the
application domain to the comprehensiveness of applica-tions across a variety of categories and types in the linkedchain integrity and overall application functionality.
2.1 Cloud Computing
The term Cloud Computing (CC) was first introduced byprofessor Ramnath Chellappa in 1997 during a lecture inwhich he defined it as a new computing paradigm wherethe boundaries of computing will be determined by eco-nomic rationale rather than technical limits [9]. Cloudcomputing enables efficient management of data centers,time-sharing, and virtualization of resources with a spe-cial emphasis on the business model [3][4][8].
Through this paradigm, users and businesses are ableto consume Infrastructure-as-a-Service, Platform-as-a-Service and Software-as-a-Service models on demandfrom anywhere in the world. When Cloud’s servicesare made available by cloud provider in a pay-as-you-go manner to the general public, it is referred to as Pub-lic Cloud, while Private Cloud refers to internal Cloudplatforms owned and utilized only by particular orga-nizations. Unlike Grids, Clouds can scale up or downaccording to the requirements of users and at the sametime enable more flexible and isolated execution envi-ronments for applications.
In Grid computing the logical choice was to keep the
18

K. Skala, D. Davidovic, E. Afgan, I. Sovic, Z. Sojat: Scalable Distributed Computing Hierarchy: Cloud, Fog and Dew Computing
Figure 2: Scalable Distributed Computing Hierarchy.
heterogeneity of the computing equipment to the mini-mum possible (same operating system, processor type,software libraries etc., particularly at a specific Grid site,but also across the entire Grid infrastructure), whereasthe Cloud, via virtualization, allows much wider possi-bility of choices. From the end-users perspective, Clouddelivers a service (IaaS, PaaS or SaaS) that hides theunderlying complexity and heterogeneity which is per-ceived by the user as a single, homogeneous service.That means that the users needs will be processed byan already existing hardware/software combination, withno inherent restriction in the CC paradigm, which woulddisallow (or at least make hard) the usage of very hetero-geneous computing equipment.
The user is not actually aware of the underlying hard-ware, e.g. operating system, processor, memory, or disk,used by a particular part of the Cloud. With the maturityof the Cloud technologies more companies, especiallySMEs, are moving from self-managed, self-provided andself-acquired PaaS and SaaS solutions to more flexible,time-sharing oriented Cloud solutions which facilitatethe development and make their business processes andproducts more competitive.
2.2 Fog Computing
The new generation of smart devices, capable of process-ing data locally rather than sending them to the Cloud orany other computational system for processing, enablesa new area of possibility and applicability for distributedsystems. The Fog Computing (FC) [1] paradigm, first in-troduced by CISCO Systems, Inc., is a distributed com-puting paradigm that provides data, compute, storageand application services closer to client or near-user edgedevices, such as network routers. Furthermore, FC han-dles data at the network level, on smart devices and onthe end-user client side (e.g. mobile devices), instead ofsending data to a remote location for processing.
The goal of the FC is to improve the efficiency by di-rectly processing data on the network (e.g. on networkrouters or smart devices) and thus reducing the amountof data that has to be transferred for processing but alsokeeping data closer to the user thus enhancing the se-curity which is one of the main problems in CC [19].The distinguishing characteristics of FC are its proximityto specific end-users, its dense geographical distribution,the ability to reconfigure itself and its support for mobil-ity as well as its potential to improve security. Services
19

Open Journal of Cloud Computing (OJCC), Volume 2, Issue 1, 2015
in FC are hosted at the network edge, which reduces ser-vice latency and improves the overall Quality of Service(QoS), resulting in a superior level of distributed com-puting functionality.
Today, with the overwhelming abundance of sensorsand devices that generate enormous amounts of data, theFC paradigm is becoming increasingly popular and at-tractive. Moreover, in numerous applications, transfer-ring a large amount of data from sensors to distant pro-cessing systems can be inefficient and possibly leads toan unnecessary network overhead that can result in per-formance and security drops (e.g. real-time vehicle-to-vehicle communication). Following this example, the FCparadigm is well positioned for Big Data and real-timeanalytics and knowledge extraction.
FC is a new conceptual solution to dealing with the de-mands of the increasing number of Internet-oriented (orconnected) devices sometimes referred to as the Internetof Things (IoT) [6][16]. In the IoT scenario, the termthing refers to any natural or artificial data-oriented ob-ject that an Internet Protocol (IP) address can be assignedto, thus providing it with the ability to acquire and trans-fer data over a network to a remote (distributed) comput-ing environment [7]. Moreover, today, a large number ofThings connected to the Internet are capable of produc-ing vast amounts of data, for which FC will play a keyrole in reducing the latency in dynamical network-basedapplications.
2.3 Dew Computing
Dew Computing (DC) goes beyond the concept of a net-work/storage/service, to a sub-platform - it is based ona micro-service concept in vertically distributed comput-ing hierarchy. Compared to Fog Computing, which sup-ports emerging IoT applications that demand real-timeand predictable latency and the dynamic network recon-figurability, DC pushes the frontiers to computing appli-cations, data, and low level services away from central-ized virtual nodes to the end users.
In [23] the author proposes a cloud-dew type of archi-tecture that scatters the information around the end-usersdevices (e.g. laptops or smart-phones) thus enabling dataaccess even when no Internet connection is available.The DC approach also leverages resources that are con-tinuously connected to a network, such as smart phones,tablets and sensors. As a result, DC covers a wide rangeof technologies including wireless sensor networks, mo-bile data acquisition, cooperative applications on dis-tributed peer-to-peer ad hoc networking and processingenvironments. These extend further to autonomic self-healing networks, data intensive and augmented realityapplications that open everyday, general purpose usagein working and living environments, down to the level
of the simple and special purpose equipment and micro-services.
One of the main advantages of the Dew Computingis in its extreme scalability. The DC model is based ona large number of heterogeneous devices and differenttypes of equipment, ranging from smart phones to in-telligent sensors, joined in peer-to-peer ad hoc virtualprocessing environments consisting of numerous micro-services. Although highly heterogeneous, the activeequipment in DC is able to perform complex tasks andeffectively run a large variety of applications and tools.In order to provide such functionality, the devices in DCare ad hoc programmable and self-adaptive, capable ofrunning applications in a distributed manner without re-quiring a central communication point (e.g. a master orcentral device).
3 DISCUSSION ON VISIONARY ASPECTS
In contrast to the CC and FC paradigms, DC is basedon Information-oriented processing rather than Data-oriented, which requires new, more flexible protocolsand more productive programming models. In this sense,(raw) data are context-free, while information is datawith accompanying meta-data. The meta-data places thedata in a specific context enabling more comprehensiveanalyses and knowledge discovery. The existing com-puting paradigms, such as Cloud and Fog Computing,operate on huge amounts of raw data generated by spe-cific Things, via predefined services.
Since the raw data is out of context, the services needto be tailored and application specific, requiring datadriven decisions. Building an integrated scalable het-erogeneous distributed computing environment from thelevel of Cloud or Fog is currently not plausible (or vi-able), as it disallows the generic integration of all pro-cessing elements. On the other hand, in the Dew Com-puting scenario, individual Things are responsible forcolleting/generating the raw data, and are thus the onlycomponents of the computing ecosystem which are com-pletely aware of the context the data were generated in.
As the Dew Computing is placed at the lowest levelof the computing hierarchy, the context therefore needsto propagate from the bottom-level up using well-defined, standardized and information-oriented protocolsof communication. Context-aware communication ser-vices have already been proposed before for application-specific cases such as enhanced IP telephony [15]. Wesuggest that one of the possible directions for the devel-opment of the Dew Computing could be through devel-opment of an extended OSI model (Open Systems Inter-connection), where a new (eight) Context layer would beadded on top of the existing Application layer. The con-
20

K. Skala, D. Davidovic, E. Afgan, I. Sovic, Z. Sojat: Scalable Distributed Computing Hierarchy: Cloud, Fog and Dew Computing
text information could then be propagated through the re-maining layers and automatically communicated by anynetwork-enabled device, making any device which usesthis extended model a Dew-enabled device.
However, not only protocols of communication needto change. The main programming principles of DChave to be of quite a different paradigm, as commonprogramming models cannot cope efficiently with thenecessities of the Internet of Everything. Cloud Com-puting should be further extended to seamlessly copewith the new presence of context in the data (the in-formation), while still providing legacy for existing ser-vices. For example, Cloud Computing could then alsobe extended with a new layer which provides Context-as-a-Service (CaaS) on top of the existing Software-as-a-Service (SaaS) layer.
On the CaaS layer, programming must be completelyoriented on processing and exchanging of information,not only the raw data. New programming models mustbe developed which will allow interplay amongst CaaSservices. Recently, ideas of context graphs and contextmanagement systems were proposed [11]which mightpresent a possible direction in which the development ofthe new Dew-oriented programming models should besteered.
Another important issues that DC has to solve is: Per-sonal High Productivity. To be able to define the ne-cessities of high productivity in the sense of the aim ofCC/FC/DC, the exploration of the concept of High Pro-ductivity Computing, or, maybe better to say, High Pro-ductivity Information Processing and Computing has tobe undertaken. The concept of Productivity is chang-ing through time to encompass some aspects and put lesssignificance on other aspects of the processes involved.The objective of further development is to explore the de-velopment of necessities in the area of high productivityscalable distributed computing. The extended visionaryaspect and strict definition of the concept of High Pro-ductivity in Information and Computing Sciences will bea valuable effort in the next computer science develop-ment phase.
An important aspect of the Personal High Productiv-ity Computing, which may be well exploited inside theprinciples of DC, is High Productivity of the equipment,or something probably best called service efficiency inthe overall distributed computing hierarchy. Althoughthe scientific use of computing equipment was partiallygained from the Giga/Tera/Peta/Exa drive, the expan-sion was not primarily driven from the side of scientificneeds, but from the common consumers. This can beobserved over the past several decades through scientificefforts put in to find alternate computer architectures andprogramming models, specifically adapted to dedicatedneeds or generic types of programming principles.
As a growth of two or more orders of magnitude oftodays computing systems is expected in the near-by fu-ture, including systems with unprecedented amounts ofheterogeneous hardware, numbers of users, and volumesof data, sustainability is critical to ensure the feasibilityof those systems. Due to those needs, currently thereis an emerging cross-domain interaction between high-performance in Clouds and the adoption of distributedprogramming paradigms. The central objective of theprogrammability challenge is the development, defini-tion and standardization of a universal environment fromthe level of hardware up to the level of expression ofcomplex algorithms involving a wide spectrum of avail-able information processing and computing equipment.
This kind of approach will enable wide usage of infor-mation processors to solve a myriad of ad-hoc problemsby common people, i.e. solving problems by not involv-ing specialized computer system programming knowl-edge, but by enabling context and information aware”things” and ”processors” in the immediate or wider sur-rounding (environment) of the common user (dependingon the request/algorithm) to provide, based on the uni-versal information and algorithmic environment, propersolutions.
On a practical level, the Dew Computing paradigmwill be very useful in everyday life. So, for example,a typical part of the Dew could be an integrated trafficcontrol system of a town, where individual simple datacollection/processing units located at all street segmentsbetween traffic lights would exchange information abouttraffic heaviness in their area of responsibility, allowing acollective computerized overview of the whole situation,and enabling auto-adaptive traffic control behavior. Aspart of such a system individual cars and drivers couldalso be involved, as information generators, informationconsumers and information processors. So it would bepossible for example to inform hybrid cars approaching acongested area to switch to conventional fuel until enter-ing the congestion, as to collect as much electrical energyas possible for moving through the congestion, thereforesignificantly reducing the exhaust smoke densities.
The information collected and processed on this levelwould be, through the hierarchy described, available formany advanced studies and analyses. And finally, it isimportant to note that the DC paradigm will have to alsoinvolve, through the Personal High Productivity Com-puting Environment, bilateral co-operation of the Personand the Information System, by enabling not only theHuman user to pose ”questions” to the computing envi-ronment, but also the environment to pose specific ques-tions about possible missing information or solution al-gorithms to the user, as to be able to intelligently processthe user requests.
21

Open Journal of Cloud Computing (OJCC), Volume 2, Issue 1, 2015
4 CONCLUSION
Cloud, Fog and Dew distributed computing systems arethe result of the exponential development rate of com-puting and related technologies over the past 50 years.This development is the most prominent driving forceof the human society. It is expected that new comput-ing technologies will continue to emerge, such as today’sresearched photonic, nanocomputing and quantum com-puting paradigms, that will continue to make distributedcomputer systems more powerful than any standalonecomputer. This predicted development, and the everincreasing heterogeneity span shows that many of thepresent day notions of programmability, user-interactionand ad-hoc definition of user needs will have to be heav-ily adapted, defined and/or re-defined to enable the user-experience of a simple and integrated living environ-ment.
The new computing paradigm, Dew Computing, willfocus on the three major points: Information process-ing (raw data and metadata describing those data), HighProductivity of user-requests (programmability / recon-figurability) and High Efficiency of the equipment (com-plexities of everyday human information environment).
ACKNOWLEDGEMENTS
This work was co-funded by the European Commis-sion through the AIS DC (EU FP7) project, EGI-Engageproject (Horizon 2020) under Grant number 654142and INDIGO DataCloud projects (Horizon 2020) un-der Grant number 653549. This paper was sub-mited to Open Journal Of Cloud Computing (OJCC)on September 17, 2015 and accepted on December14, 2015. It is a OpenAir FP7 Pilot granted paper(https://www.openaire.eu/postgrantoapilot).
REFERENCES
[1] M. Abdelshkour, “IoT, from Cloud to Fog Comput-ing,” http://blogs.cisco.com/perspectives/iot-from-cloud-to-fog-computing, accessed 28th Sep 2015.
[2] E. Afgan, P. Bangalore, and K. Skala, “Applica-tion Information Services for distributed comput-ing environments.” Future Generation Comp. Syst.,vol. 27, no. 2, pp. 173–181, 2011.
[3] E. Afgan, P. Bangalore, and T. Skala, “Schedul-ing and planning job execution of loosely cou-pled applications.” The Journal of Supercomputing,vol. 59, no. 3, pp. 1431–1454, 2012.
[4] M. Armbrust, A. Fox, R. Griffith, A. D. Joseph,R. Katz, A. Konwinski, G. Lee, D. Patterson,A. Rabkin, I. Stoica, and M. Zaharia, “A view of
cloud computing,” Commun. ACM, vol. 53, no. 4,pp. 50–58, Apr. 2010.
[5] F. Berman, G. Fox, and A. J. Hey, Grid computing:making the global infrastructure a reality. JohnWiley and sons, 2003, vol. 2.
[6] F. Bonomi, R. Milito, J. Zhu, and S. Addepalli,“Fog Computing and Its Role in the Internet ofThings,” in Proceedings of the First Edition of theMCC Workshop on Mobile Cloud Computing, ser.MCC ’12. New York, NY, USA: ACM, 2012, pp.13–16.
[7] F. Bonomi, R. A. Milito, P. Natarajan, and J. Zhu,“Fog Computing: A Platform for Internet ofThings and Analytics.” in Big Data and Internet ofThings, ser. Studies in Computational Intelligence,N. Bessis and C. Dobre, Eds. Springer, 2014, vol.546, pp. 169–186.
[8] R. Buyya, C. Yeo, S. Venugopal, and J. B. I.Brandic, “Cloud Computing and Emerging IT Plat-forms: Vision, hype, and reality for delivering com-puting as the 5th utility,” Future Generation Com-puter Systems, vol. 25, no. 6, pp. 599–616, 2009.
[9] R. K. Chellappa, “Intermediaries in Cloud-Computing: A New Computing Paradigm,” IN-FORMS Annual Meeting, Oct. 1997.
[10] A. Chervenak, I. Foster, C. Kesselman, C. Salis-bury, and S. Tuecke, “The Data Grid: Towards anArchitecture For the Distributed Management andAnalysis of Large Scientific Datasets,” 2001.
[11] B. Chihani, “Enterprise context-awareness : em-powering service users and developers,” Soft-ware Engineering [cs.SE]. Institut National desTelecommunications, Tech. Rep., 2013.
[12] ETHW, “IBM System/360,” http://ethw.org/IBMSystem/360, accessed 18th November 2015.
[13] M. J. Flynn, O. Mencer, V. Milutinovic, G. Rakoce-vic, P. Stenstrom, R. Trobec, and M. Valero, “Mov-ing from Petaflops to Petadata,” Communicationsof the ACM, vol. 56, no. 5, pp. 39–42, May 2013.
[14] I. T. Foster and C. Kesselman, The Grid, Blueprintfor a New Computing Infrastructure. San Fran-cisco: Morgan Kaufmann Publishers, 1999. [On-line]. Available: http://www.bibsonomy.org/bibtex/283302c972e4e27f2333c31fc21beaca9/buzz
[15] M. Gortz, R. Ackermann, J. Schmitt, and R. Stein-metz, “Context-aware Communication Services: AFramework for Building Enhanced IP TelephonyServices.” in ICCCN. IEEE, 2004, pp. 535–540.
[16] J. Gubbi, R. Buyya, S. Marusic, andM. Palaniswami, “Internet of Things (IoT): A
22

K. Skala, D. Davidovic, E. Afgan, I. Sovic, Z. Sojat: Scalable Distributed Computing Hierarchy: Cloud, Fog and Dew Computing
Vision, Architectural Elements, and Future Di-rections,” Future Generation Computer Systems,vol. 29, no. 7, pp. 1645–1660, 2013.
[17] IBM, “IBM, System 360 Annoucement,”https://www-03.ibm.com/ibm/history/exhibits/mainframe/mainframe PR360.html, accessed 18thNovember 2015.
[18] D. Kranzlmuller, J. Marco de Lucas, and P. Oster,“The European Grid Initiative (EGI): Towards aSustainable Grid Infrastructure,” in Remote Instru-mentation and Virtual Laboratories. Springer,2010, pp. 61–66.
[19] K. Shenoy, P. Bhokare, and U. Pai, “Fog Com-puting Future of Cloud Computing,” InternationalJournal of Science and Research, vol. 4, no. 6, pp.55–56, Jun. 2015.
[20] K. Skala, D. Davidovic, E. Afgan, I. Sovic,T. Lipic, and E. Cetinic, “Scalable Dis-tributed Computing Common Hierarchy,”https://indico.egi.eu/indico/contributionDisplay.py?contribId=121&confId=2544, EGI CommunityForum, unpublished materials.
[21] K. Skala, D. Davidovic, T. Lipic, and I. Sovic, “G-Phenomena as a Base of Scalable Distributed Com-puting —G-Phenomena in Moore’s Law,” Interna-tional Journal of Internet and Distributed Systems,vol. 2, no. 1, pp. 1–4, 2014.
[22] N. A. Sultan, “Reaching for the ”cloud”: HowSMEs can manage.” Int J. Information Manage-ment, vol. 31, no. 3, pp. 272–278, 2011.
[23] Y. Wang, “Cloud-dew architecture,” InternationalJournal of Cloud Computing, vol. 4, no. 3, pp. 199–210, 2015.
23

Open Journal of Cloud Computing (OJCC), Volume 2, Issue 1, 2015
AUTHOR BIOGRAPHIES
Prof. Karolj Skala is a scientificadvisor at the Rudjer BoskovicInstitute and full professor Uni-versity of Zagreb. Initiator ofthe CRO GRID national pro-gram from which emerged CRONGI. He participated in the EUprojects: COST 254, COST276, COST IC0805 and COSTIC1305 from Croatia. He suc-cessfully completed five EU FP6, seven EU FP7 projects and
provide 3 Horizon 2020 Cloud computing projects.Member of the Croatian Academy of Engineering andan associate member of the Hungarian Academy of Sci-ences.
Dr. Davor Davidovic is aresearch assistant at RudjerBoskovic Institute. He obtainedhis Ph.D. in 2014 from the Fac-ulty of Electrical Engineeringand Computing at the Univer-sity of Zagreb. His researchinterests are in parallel anddistributed computing, with the
emphasis on the high-performance and GPU comput-ing, heterogeneous computing, and numerical linearalgebra. He participated in 4 EU projects: EGEE-III,SEE-GRID-SCI, SCI-BUS, and COST Action IC0805,and is actively involved in 3 projects: Cost ActionIC1305, EGI-Engage, Indigo-Datacloud, and SESAME-Net. He has published 15 original scientific papers ininternational journals and conference proceedings.
Dr. Enis Afgan is a research sci-entist at the Rudjer Boskovic In-stitute in Zagreb, Croatia. Heobtained his Ph.D. in 2009 fromthe Department of Computer andInformation Sciences at the Uni-versity of Alabama at Birming-
ham (UAB). Since 2009 he has been a member of theGalaxy Project team and since 2012 a member of theGenomics Virtual Lab project. He is a recipient of theFP7 Marie-Curie Reintegration Grant, AIS-DC. He leadson the CloudMan project. His research interests focusaround distributed computing, with the current empha-sis on application- and user-level accessibility of cloudcomputing resources.
Ivan Sovic is a research assis-tant at the RBI and a PhD stu-dent at the University of ZagrebFaculty of Electrical Engineer-ing and Computing. He receivedhis M.Sc. in Electrical Engi-neering and Information Tech-nology in 2010, and enrolled ina PhD programme in ComputerScience at the same University
in 2011. His research interests include algorithms forsequence alignment and de novo genome assembly witha focus on third generation sequencing data, machinelearning, signal processing and reconfigurable comput-ing platforms.
Prof. Zorislav Sojat is a profes-sor of General Linguistics andSocio-Humanistic. His mainfield of interest is Cybernetics,and he applies Cybernetic prin-ciples in scientific research inthe area of computer science andintelligence stimulation. From1991 till 2000 he was Assis-tant Professor for APL, Lisp andRobot Languages on the Depart-ment of Information Science at
the Faculty of Philosophy University of Zagreb. He stud-ied Linguistics and Socio-Informatics. He has publishedhundreds of papers in the field of linguistics, ethics, in-formatics, philology, computing, economics, philosophy,as well as several books. He is co-author of severalworld-renowned patents. He speaks fluently Croatian,German, English, Esperanto and actively Italian, Dutchand French.
24