scaling graphite for application metrics
TRANSCRIPT

Application Telemetry at scaleHow to Scale Graphite
!BigData Meetup May 20, 2015

> whoami
• Jim Plush
• Sr Director of Engineering @ CrowdStrike
• twitter: @jimplush

About CrowdStrike
Big Data Security Company
Focus on targeted, state sponsored attacks and attribution
Single enterprise can generate 2+TB of machine data per day
MicroService architecture w/1000’s of VMs running.
We use goodies like AWS, Kafka, Cassandra, Elastic Search, Hadoop, Scala, GoLang

What is Graphite?
• Captures Numeric, Time-Series Data
• Metric: test.myapp.host1.logins
• Value: 64
• Timestamp: 1432077015

echo "test.myapp.host1.logins 64 `date +%s`" | nc 10.10.10.10 2003



Graphite
• Composed of 3 projects
• Carbon - collects and records metrics
• Whisper - Backend storage mechanism
• Graphite-Web - HTTP frontend for graphing API
• Written in Python

What metrics to track?• counters, latencies, error rates • business metrics: sales, order latency, abandoned carts • refactoring, how do you know you’ve succeeded • hadoop metrics via MetricFactory • logins, login failures
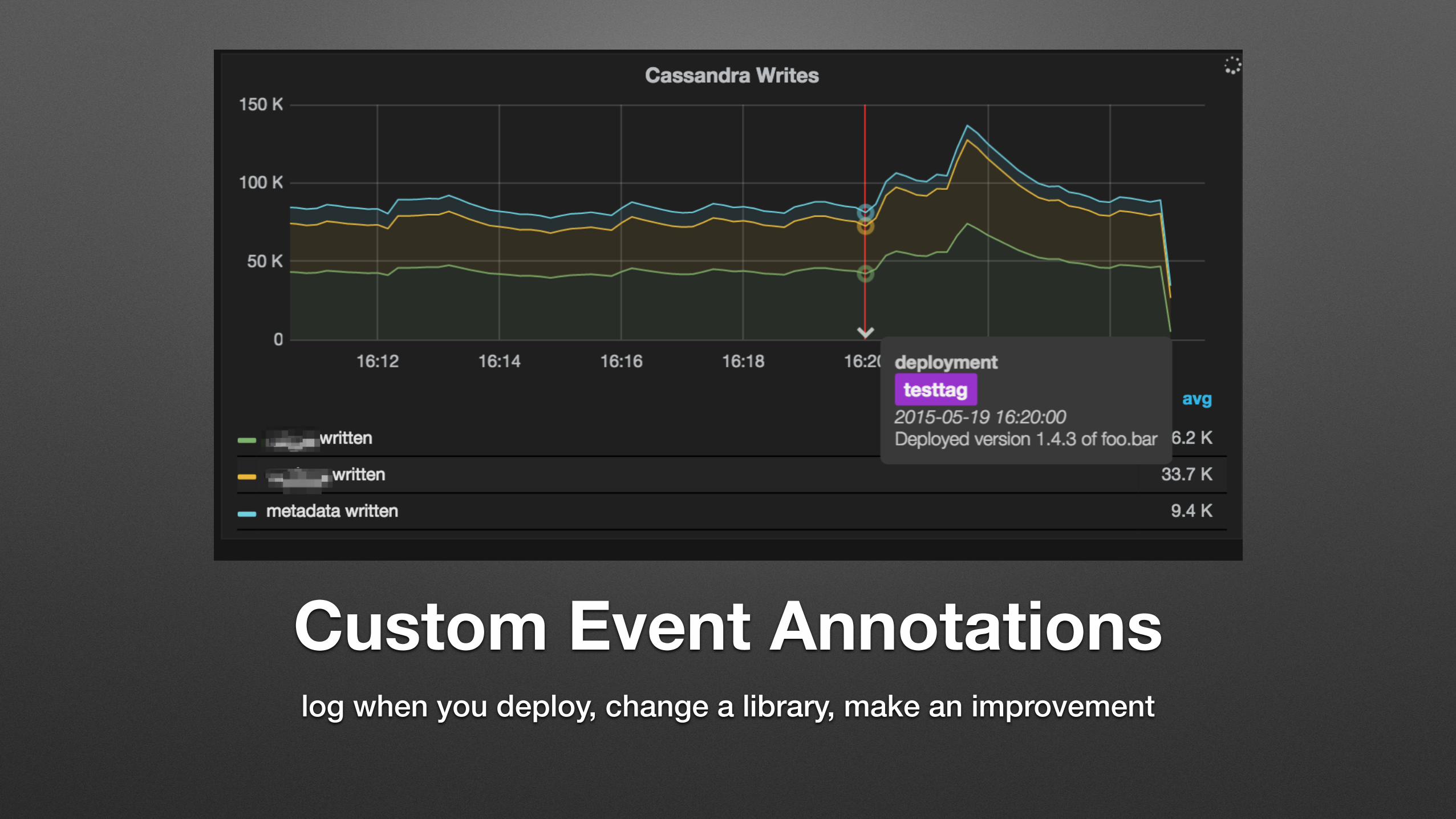
Custom Event Annotationslog when you deploy, change a library, make an improvement

Libraries
• JAVA/Scala: dropwizard.github.io
• Go: github.com/rcrowley/go-metrics

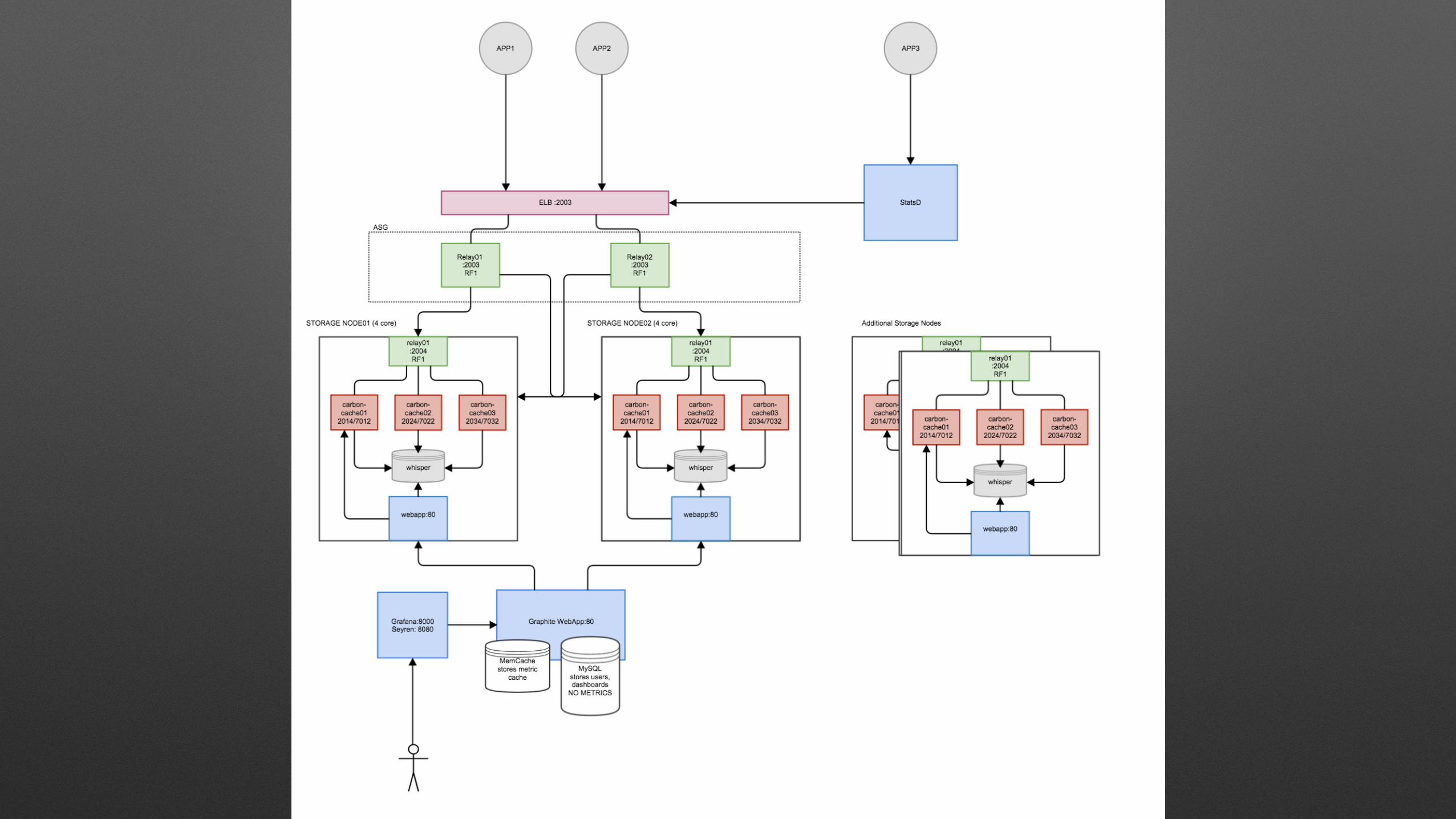




Multi Data Center Replication

Note: Relays may need to be scaled behind a local HAProxy

Specs: AWS biased
NO MAGNETIC: SSD ONLY !
Load Balancer: HAProxy or ELBS
Cache/Whisper: i2.2XL (8 core)
1.6TB RAID0 SSD XFS filesystem
1 cache per core
Relays: c3.large (2 core)
in autoscale group give it CPU#1
taskset -apc 1 PID
Web Tier: M3 memory instances
Use MySQL or Postgres Memcache ON

Data Retention[garbage_collection]
pattern = garbageCollections$
retentions = 10s:7d,60s:90d
!
Data size is fixed, inserted with NULLS, real data overwrites so files don’t grow larger. Makes estimation easier.

How does my data get to the right server?

Old School Sharding hash(key) % numServers

Modern Way Consistent Hashing
• Less shuffling of data when adding or removing nodes
• Graphite utilizes this approach much like Cassandra’s mechanism for distributing data


Graphite Downside: !
unlike Cassandra, re-balancing data isn’t automatic. You’ll need Carbonate or BuckyTools
!
https://github.com/jssjr/carbonate or
https://github.com/jjneely/buckytools

SeyrenAlerting on actionable metrics

Key Resourceshttps://gist.github.com/obfuscurity/63399584ea4d95f921e4 !
http://bitprophet.org/blog/2013/03/07/graphite/ !
ClusterServers vs Destinations https://answers.launchpad.net/graphite/+question/228472 !
Tuning for 3m writes a minute https://answers.launchpad.net/graphite/+question/178969 !
http://www.aosabook.org/en/graphite.html !
https://grey-boundary.io/the-architecture-of-clustering-graphite/ !

WE’RE HIRING :)
•Offices in Irvine / Seattle / DC •Massive Scale •Fast Growing Company •Distributed Systems
An Environment Made For Engineers
•Open Source Friendly •Stock / Bonus plans •GeekDesks
[email protected] twitter: @jimplush
crowdstrike.com/careers
The Tech For All-The-Things!