scientific big data -...
TRANSCRIPT

www.altecspace.it
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
Teramo, 12-03-2015
Scientific Big DataALTEC Data Processing Team

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Definizione
� Data Mining
� Architetture e Piattaforme
� Storage / Data Store
� Processing
� Data Visualization
23/02/2015 Page 2

www.altecspace.it
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
Definizione

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Ogni giorno nel mondo si creano 2,5 exabytes di dati e il 90% dei dati è stato creato solo negli ultimi due anni [fonte IBM].
� Questi dati vengono registrati ovunque: ad esempio sensori per la raccolta di informazioni sul clima, post su siti di social media, video e immagini digitali, record delle transazioni di acquisto e segnali GPS dei cellulari. Questi tipi di dati vengono definiti big data.
� Con il termine scientific big data si indicano i dati utilizzati in progetti con finalità scientifiche sia acquisiti o generati per lo scopo del progetto/missione sia provenienti da sorgenti esterne.
Cosa sono i Big Data
23/02/2015 Page 4

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Il termine BigData comparve per la prima volta in un articolo della NASA nel 1997 che descriveva la problematica di visualizzare grandi quantità di dati.
� La definizione ampiamente citata di McKinsey del 2011 individua con il termine BigData “datasets whose size is beyond the ability of typical database software tools to capture, store, manage, and analyze”.
� Wikipedia 2015:”Big data is a broad term for data sets so large or complex that traditional data processing applications are inadequate. Challenges include analysis, capture, curation, search, sharing, storage, transfer, visualization, and information privacy. The term often refers simply to the use of predictive analytics or other certain advanced methods to extract value from data, and seldom to a particular size of data set.”
Definizioni 1/2
23/02/2015 Page 5

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
Definizioni 2/2
Noting that “there is no rigorous definition of big
data,”... “The ability of society to harness information in
novel ways to produce useful insights or goods and
services of significant value” and “'things one can do
at a large scale that cannot be done at a smaller one,
to extract new insights or create new forms of value.”
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
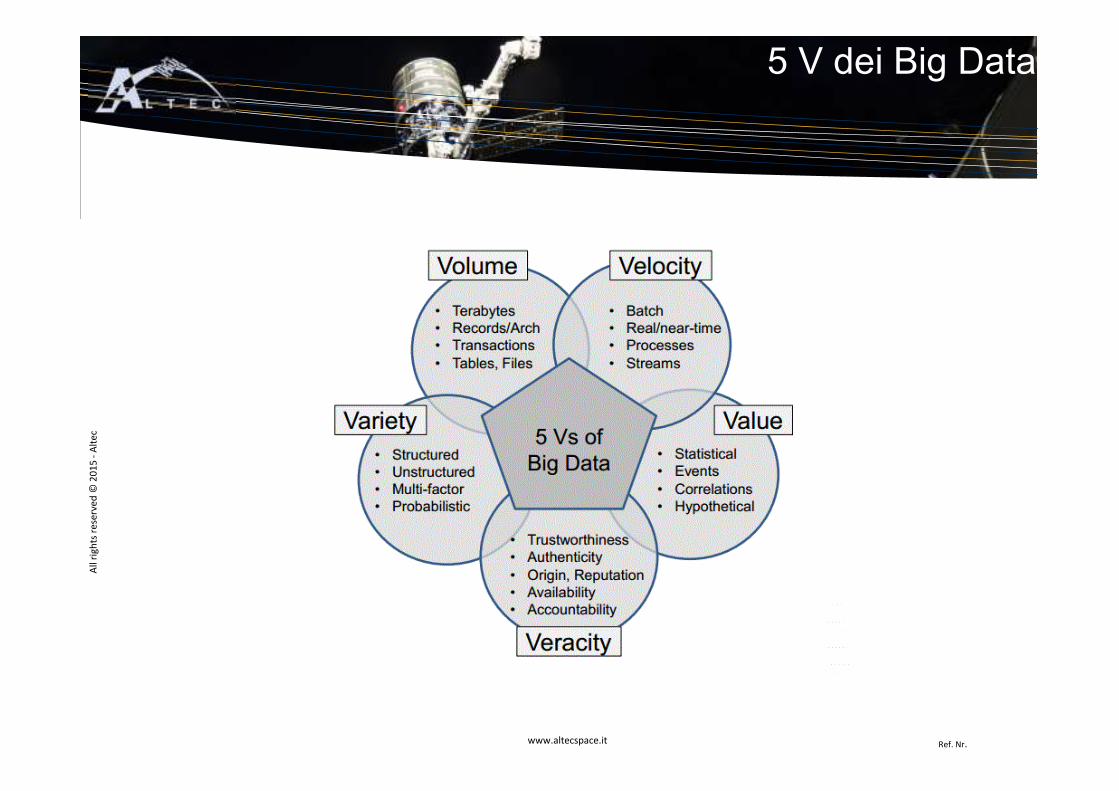
5 V dei Big Data

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
Le caratteristiche principali dei big data si possono riassumere nelle cinque "V":� VOLUME: capacità di acquisire, memorizzare ed accedere a
grandi volumi di dati.� VELOCITÀ: capacità di effettuare analisi dei dati in tempo reale o
quasi.� VARIETÀ: riferita alle varie tipologie di dati, provenienti da fonti
diverse (strutturati, semi-strutturati e non strutturati): ad esempio, dati di testo, dati dei sensori, dati audio, dati video, flussi di clic, file di log, e tutto quello che può provenire dal cosiddetto Internet of Things.
� VERIDICITÀ: la qualità dei dati intesa come correttezza e accuratezza dell’informazione.
� VALORE: ciò che si può ottenere, anche di inaspettato, dalla conoscenza e l’analisi dei dati.
Caratteristiche
23/02/2015 Page 8

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� La crescente maturità del concetto dei big data mette in evidenza le differenze con la business intelligence, in materia di dati e del loro utilizzo:
� La business intelligence utilizza la statistica descrittiva con dati ad alta densità di informazione per misurare cose, rilevare tendenze, ecc., cioè utilizza dataset limitati, dati puliti e modelli semplici;
� I big data utilizzano la statistica inferenziale e concetti di identificazione di sistemi non lineari per ricavare leggi (regressioni, relazioni non lineari, effetti causali) da grandi insiemi di dati, e per rivelare i rapporti, le dipendenze, ed effettuare previsioni di risultati e comportamenti, cioè utilizza dataset eterogenei (non correlati tra loro), dati grezzi e modelli predittivi complessi.
� Approccio induttivo � «regressione creatrice»� Incentrato sulla ricerca di correlazioni rispetto a determinare loro
causalità. Esempio: Studio dell’ambiente L2 correlando i dati di Gaia con i dati solari.
Differenze conbusiness intelligence
23/02/2015 Page 9

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Il volume di dati dei big data e l'ampio uso di dati non strutturati non permette l'utilizzo dei tradizionali RDBMS, che non rendono possibile archiviazione e velocità di analisi. Gli operatori di mercato invece utilizzano sistemi con elevata scalabilità e soluzioni basate sulla NoSQL.
� Nell'ambito della business analytics nascono nuovi modelli di rappresentazione in grado di gestire tale mole di dati con elaborazioni in parallelo dei database.
� Architetture di elaborazione distribuita di grandi insiemi di dati sono offerte dai framework MapReduce like. Con questo sistema le applicazioni sono separate e distribuite con nodi in parallelo, e quindi eseguite in parallelo (funzione map). I risultati vengono poi raccolti e restituiti (funzione reduce).
Modelli
23/02/2015 Page 10

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
Scientific Big Data
� VOLUME � Disponibilità di archivi che raggiungono la dimensione dell’Exabyte.� Array multidimensionali come principale tipo di dato.
� VELOCITA’� Nuovi dati acquisiti constantemente e ad una velocità crescente grazie alla disponibilità di nuove
tecnologie elettroniche che hanno migliorato la sensoristica.� L’analisi dei dati nel tempo assume notevole importanza nel contesto scientifico.� Il processamento in breve tempo di grandi moli di dati è una caratteristica delle missioni
scientifiche.
� VARIETÀ � I dati acquisiti tramite sensoristica sono vari, sono acquisiti sia con strumentazione attiva sia con
strumentazione passiva che lavorano su diverse frequenze dello spettro elettromagnetico.� Utilizza di dati non provenienti da sensori come i dati di simulazione.� Presenza di dati strutturati e semi strutturati.
� VERIDICITA’� La qualità dei dati è associata all’accuratezza della misura.
� VALORE� La capacità di estrarre informazioni dai dati è una costante ricerca in ambito scientifico, spesso
eseguita su dataset inizialmente acquisiti per scopi diversi.
11

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
Progetti Science Big Data

www.altecspace.it
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
Data Mining

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Disponibilità di enormi dataset ma spesso la conoscenza in questi dataset è nascosta:� Non è immediatamente osservabile� Gli analisti umani necessitano di una gran quantità di tempo per
l’analisi� La maggior parte dei dati non è mai analizzata
� Data Mining: Estrazione di informazione utili dai dati disponibili� Implicita� Precedentemente sconosciuta� Potenzialmente utile
� L’estrazione è automatica ed eseguita da appropriati algoritmi.
� L’informazione estratta è rappresentata attraverso un modello astratto, come pattern.
Data Mining
23/02/2015 Page 14
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
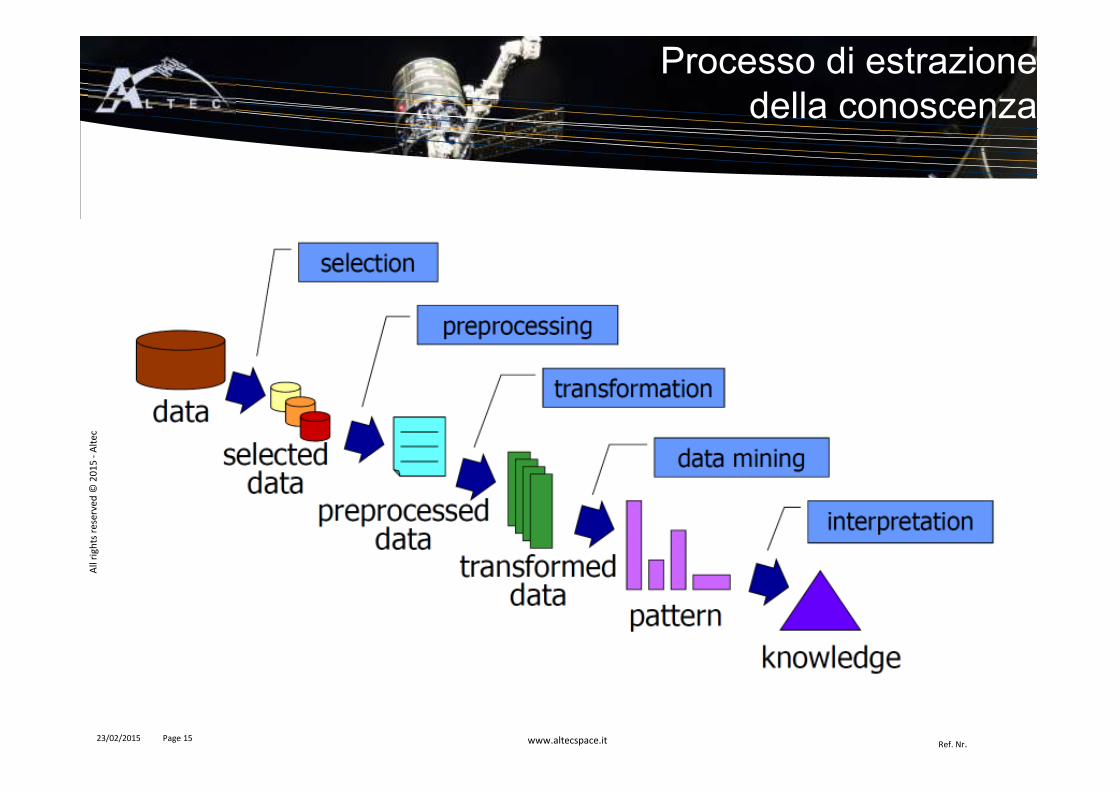
Processo di estrazione della conoscenza
23/02/2015 Page 15

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Pulizia del dato� Riduzione dell’effetto del rumore
� Identificazione e rimozione degli outlier
� Risoluzione inconsistenze
� Integrazione del dato� Unione dei dati estratti da fonti
diverse
� Integrazione metadati
� Identificazione e risoluzione di conflitti nei valori dei dati
� Gestione ridondanze
Preprocessing
23/02/2015 Page 16
• I dati del mondo reale sono «sporchi»
• Senza dati iniziali di buona qualità non si può estrarre un buon pattern: «garbage in, garbage out»
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
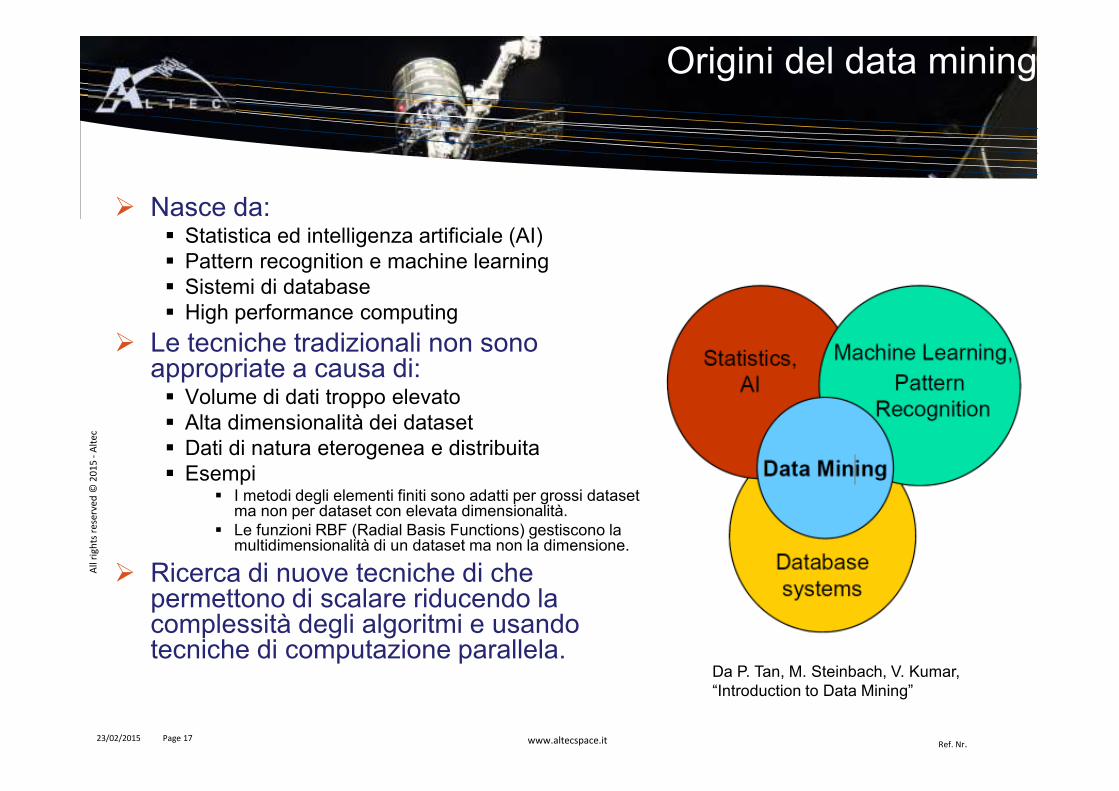
� Nasce da:� Statistica ed intelligenza artificiale (AI)� Pattern recognition e machine learning� Sistemi di database� High performance computing
� Le tecniche tradizionali non sono appropriate a causa di:� Volume di dati troppo elevato� Alta dimensionalità dei dataset� Dati di natura eterogenea e distribuita� Esempi
� I metodi degli elementi finiti sono adatti per grossi dataset ma non per dataset con elevata dimensionalità.
� Le funzioni RBF (Radial Basis Functions) gestiscono la multidimensionalità di un dataset ma non la dimensione.
� Ricerca di nuove tecniche di che permettono di scalare riducendo la complessità degli algoritmi e usando tecniche di computazione parallela.
Origini del data mining
23/02/2015 Page 17
Da P. Tan, M. Steinbach, V. Kumar,“Introduction to Data Mining”

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Metodi descrittivi� Estrazione di modelli interpretabili che descrivono i dati
� Esempi: classificazione della clientela
� Metodi predittivi� Uso di variabili note per predirre valori sconosciuti o futuri di
(altre) variabili
� Esempi: rilevamento di spam nelle email in arrivo
Tecniche di analisi
23/02/2015 Page 18

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Estrazione di frequenti correlazioni o di un pattern da un database transazionale
� Esempio: Analisi della spesa. Il database è formato dagli scontrini di un supermercato.� Regola di associazione: pannolini ⇒ birra
� Il 2% delle transazioni contengono entrambi gli oggetti
� Il 30% delle transazioni che contengono pannolini contengono anche birra
� Applicazioni: layout degli scaffali nei negozi, design dei cataloghi e dei volantini pubblicitari
Regole di associazione
23/02/2015 Page 19

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
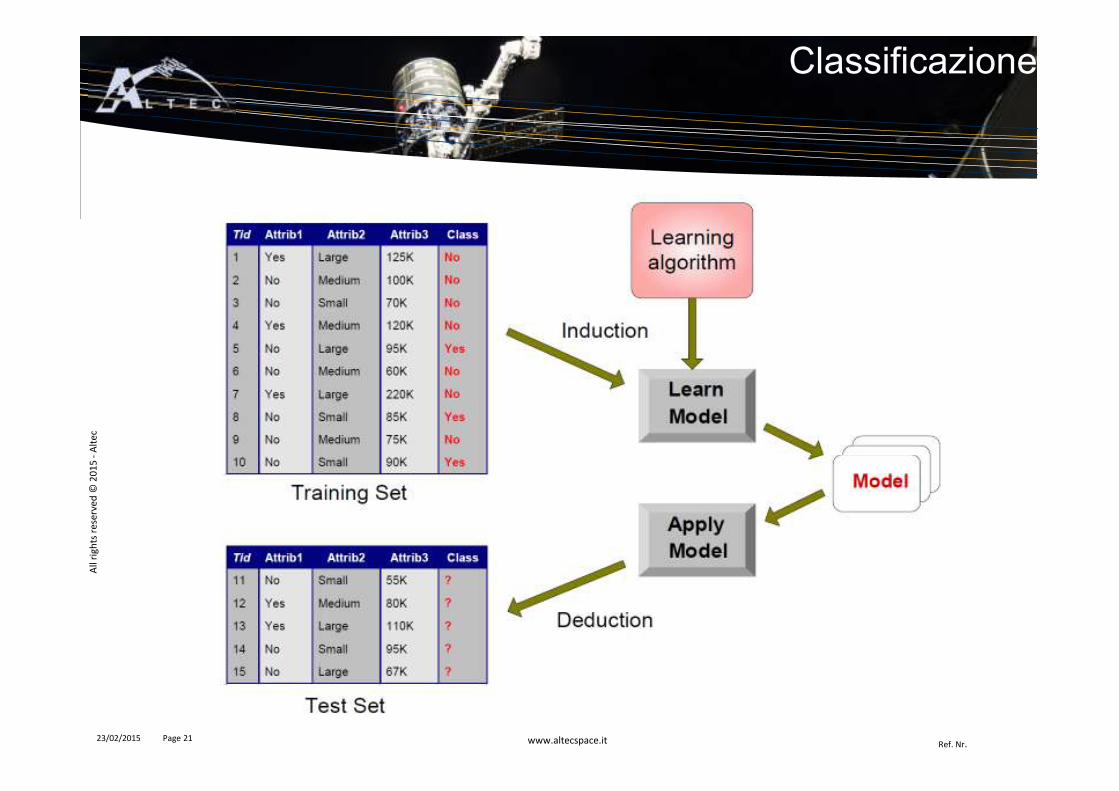
� È data una collezione di oggetti, di cui ognuno contiene un insieme di attributi. Uno di questi attributi è la classe.
� L’attributo di classe viene modellizzato come una funzione degli altri attributi.
� L’obiettivo è assegnare una classe ai nuovi oggetti nel modo più accurato possibile.
� Solitamente il dataset fornito viene diviso in� Training set, usato per costruire il modello
� Test set, usato per validare il modello e determinarne l’accuratezza.
Classificazione
23/02/2015 Page 20
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
Classificazione
23/02/2015 Page 21

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Metodi basati su alberi di decisione
� Metodi basati su regole
� Classificazione bayesiana
� K-nearest neighbors
� altre: reti neurali, Support Vector Machines, ...
La valutazione delle tecniche si basa su:� Accuratezza: qualità della previsione
� Efficienza: tempo di costruzione del modello e tempo di classificazione
� Scalabilità: dimensione del training set e numero di attributi
� Robustezza: rumore e dati mancanti
� Interpretabilità: quanto il modello è compatto e spiegabile
Tecniche di classificazione
23/02/2015 Page 22
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
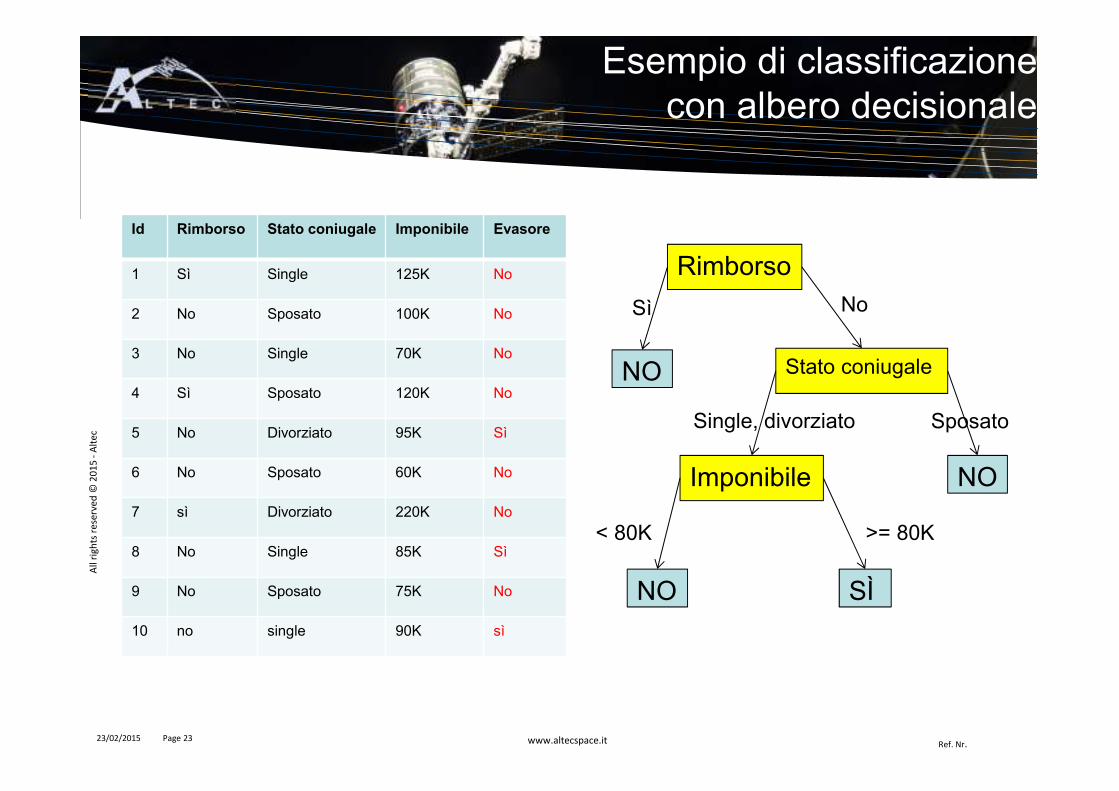
Id Rimborso Stato coniugale Imponibile Evasore
1 Sì Single 125K No
2 No Sposato 100K No
3 No Single 70K No
4 Sì Sposato 120K No
5 No Divorziato 95K Sì
6 No Sposato 60K No
7 sì Divorziato 220K No
8 No Single 85K Sì
9 No Sposato 75K No
10 no single 90K sì
Esempio di classificazionecon albero decisionale
23/02/2015 Page 23
Rimborso
SÌ
Stato coniugale
Imponibile
NO
NO
NO
Sì
>= 80K< 80K
Single, divorziato Sposato
No

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Le entrate sono classificate usando una collezione di clausole «se... allora...»
� Regola: (congiunzione di attributi) → classe
� Esempi:� (Imponibile<50K) e (Rimborso=sì) → Evasore=no
� (Sangue=caldo) e (Depone uova=sì) → Uccelli
� Le regole si possono creare a partire da alberi di decisione
� Vantaggi (analoghi degli alberi decisionali):� Facili da interpretare
� Facili da generare
� Classificano nuove entrate rapidamente
Classificazione basata su regole
23/02/2015 Page 24

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Supponiamo che l’attributo di classe C e tutti gli attributi X dei dati siano variabili casuali.
� Dato x da classificare, si calcola P(C|X=x), cioè la probabilità che x appartenga alla classe C, per ogni possibile classe C. Quindi x si assegna alla classe che massimizza quella probabilità.
� Richiede la conoscenza delle probabilità a priori e condizionali relative al problema
� Per calcolare la probabilità P(C|X) si utilizza il teorema di Bayes con le frequenze calcolate a partire dal training set.
Classificazione bayesiana
23/02/2015 Page 25

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Vantaggi� Classificazione efficiente
� Robusto per isolare rumore e attributi irrilevanti
� Aggiornamento incrementale del modello
� Punti deboli� Il calcolo della probabilità usa l’ipotesi che tutti gli attributi siano
indipendenti fra loro. Ciò non è sempre vero, a discapito della qualità del modello.
� Senza l’ipotesi di indipendenza il modello è irrealizzabile. Si possono però utilizzare le reti bayesiane per specificare sottoinsiemi di dipendenze tra gli attributi.
Classificazione bayesiana
23/02/2015 Page 26
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
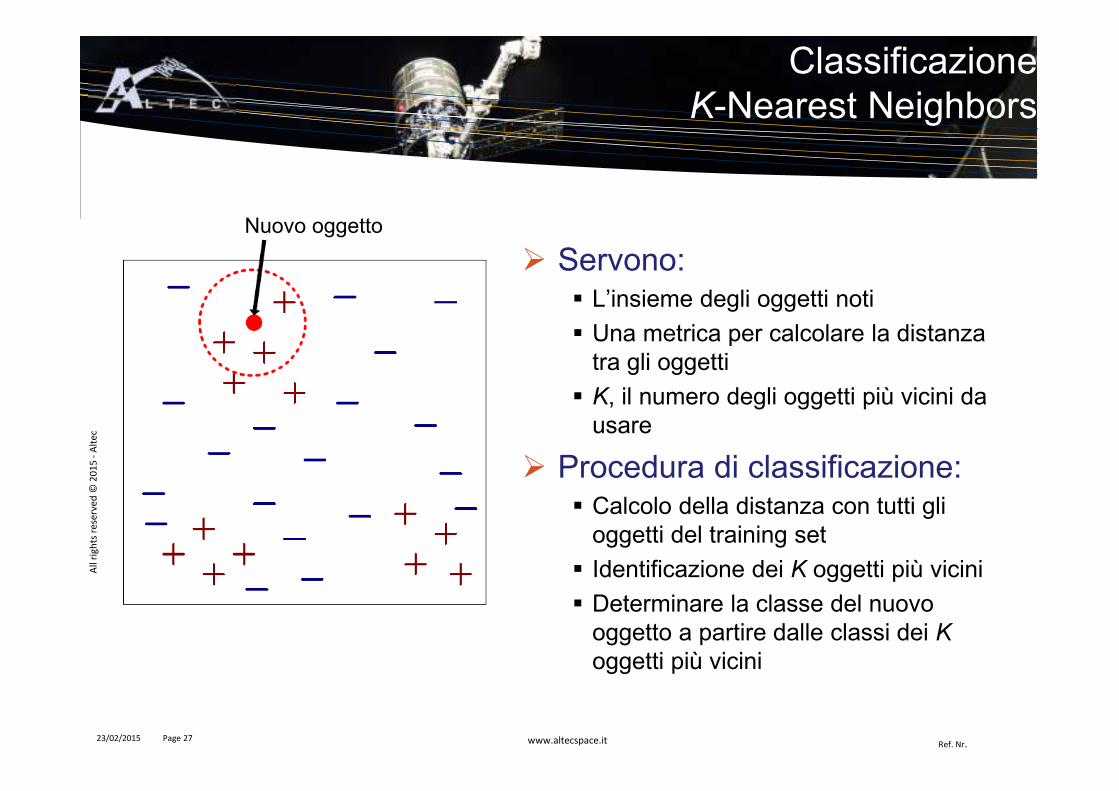
� Servono:� L’insieme degli oggetti noti
� Una metrica per calcolare la distanza tra gli oggetti
� K, il numero degli oggetti più vicini da usare
� Procedura di classificazione:� Calcolo della distanza con tutti gli
oggetti del training set
� Identificazione dei K oggetti più vicini
� Determinare la classe del nuovo oggetto a partire dalle classi dei K
oggetti più vicini
ClassificazioneK-Nearest Neighbors
23/02/2015 Page 27
Nuovo oggetto

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Distanza euclidea:� �, � � ∑ �� ���
� Scelta della classe:� Si sommano le occorrenze di ciascuna classe nei K vicini,
pesate con la distanza (ad esempio con peso �
� )
� Si assegna il nuovo oggetto alla classe con la maggiore somma ottenuta
Esempio di classificazione K-NN
23/02/2015 Page 28
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
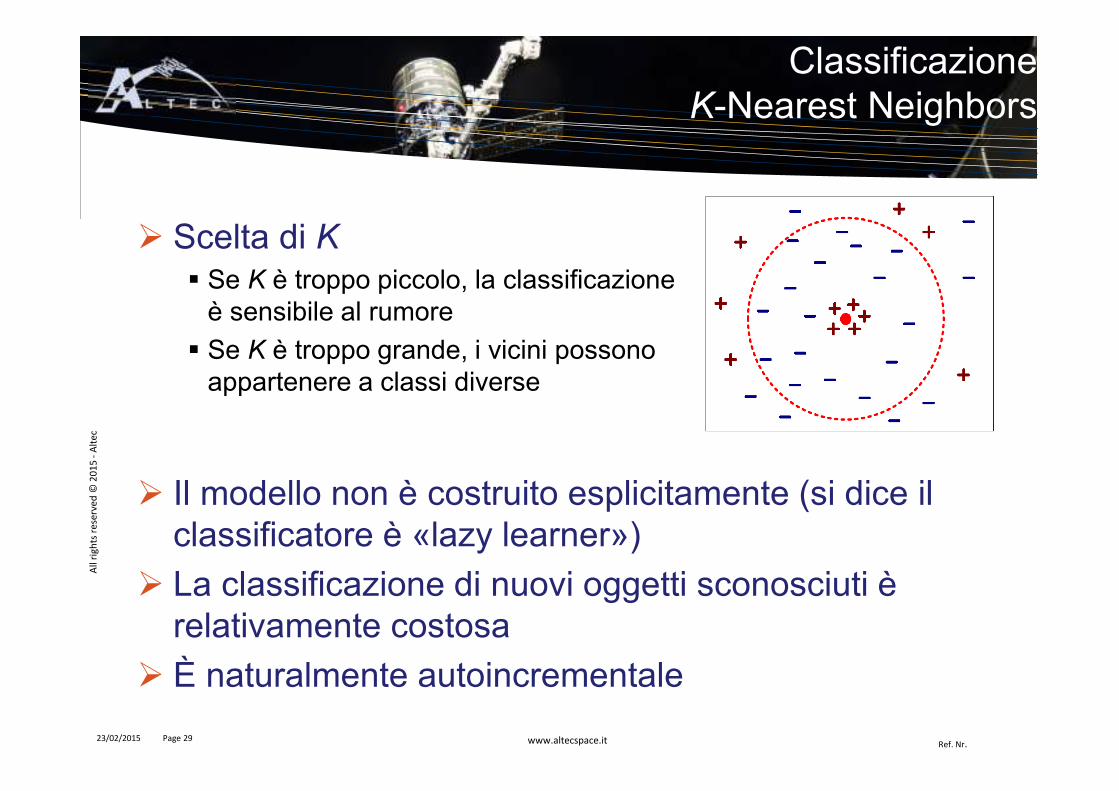
� Scelta di K� Se K è troppo piccolo, la classificazione
è sensibile al rumore
� Se K è troppo grande, i vicini possono appartenere a classi diverse
ClassificazioneK-Nearest Neighbors
23/02/2015 Page 29
� Il modello non è costruito esplicitamente (si dice il classificatore è «lazy learner»)
� La classificazione di nuovi oggetti sconosciuti è relativamente costosa
� È naturalmente autoincrementale
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
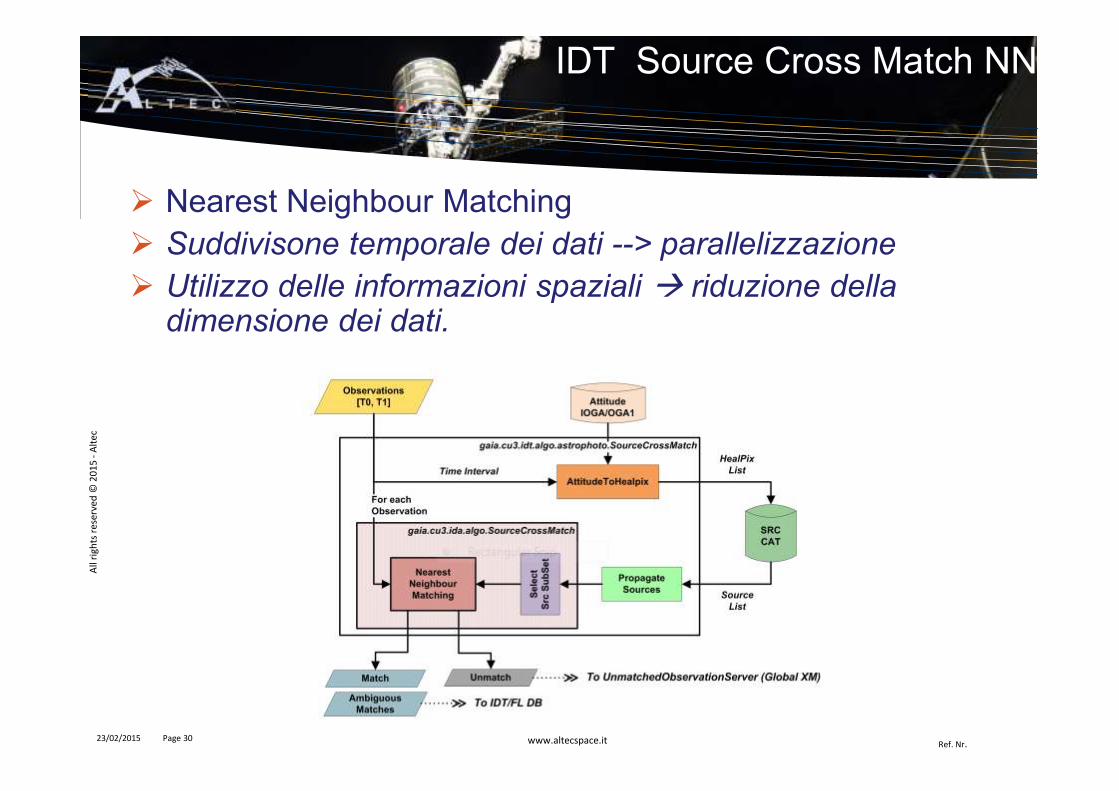
IDT Source Cross Match NN
23/02/2015 Page 30
� Nearest Neighbour Matching� Suddivisone temporale dei dati --> parallelizzazione
� Utilizzo delle informazioni spaziali � riduzione della dimensione dei dati.

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Il clustering è trovare gruppi di oggetti tali che all’interno di un gruppo gli oggetti sono tutti simili (o correlati) tra loro, e sono tanto più diversi (o scorrelati) da quelli degli altri gruppi.
� Ha lo scopo di� Comprendere meglio il dataset
� Ridurre la dimensione del dataset
� Un clustering è un insieme di cluster.
Cluster Analysis
23/02/2015 Page 31
� Un clustering partizionale è una suddivisione del dataset in sottoinsiemi disgiunti, tali che ogni oggetto appartiene esattamente ad un cluster.
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
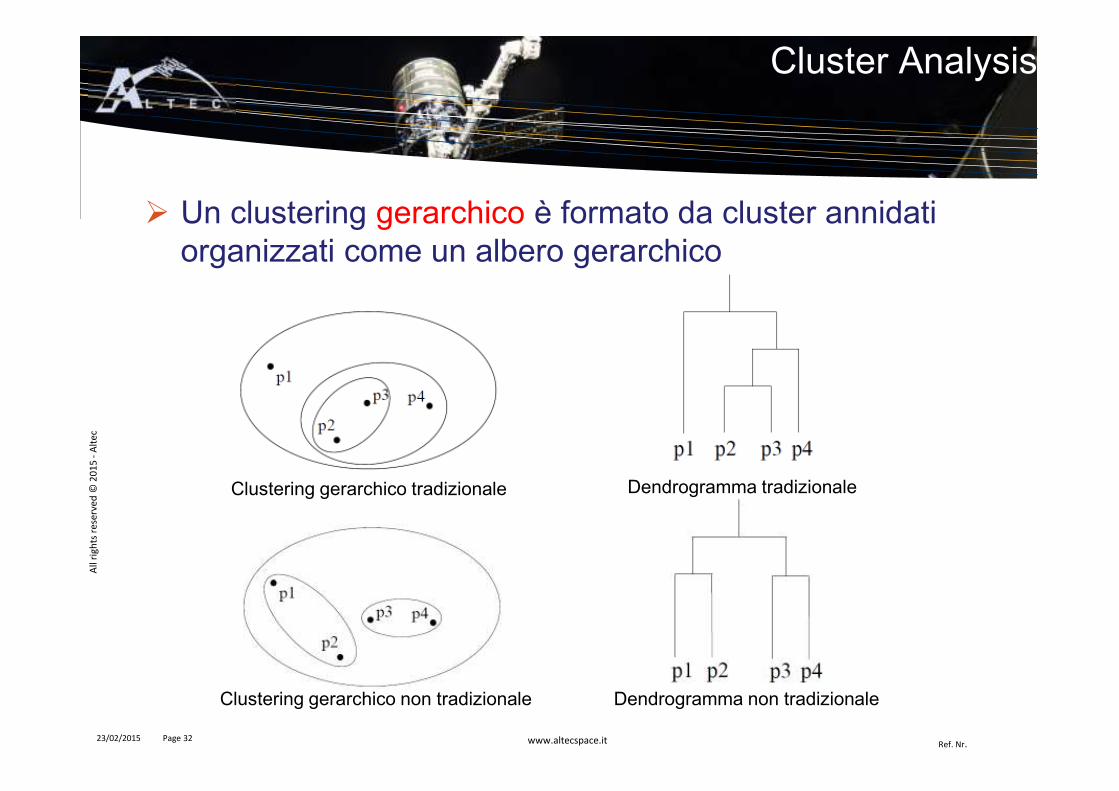
� Un clustering gerarchico è formato da cluster annidati organizzati come un albero gerarchico
Cluster Analysis
23/02/2015 Page 32
Clustering gerarchico tradizionale
Dendrogramma non tradizionaleClustering gerarchico non tradizionale
Dendrogramma tradizionale

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� K-means
� Gerarchico
� Basato sulla densità
Algoritmi di clustering
23/02/2015 Page 33

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Approccio partizionale
� Ogni cluster è associato ad un punto centrale detto centroide
� Ogni punto è assegnato al cluster del centroide più vicino
� Il numero K di cluster è specificato all’inizio.
� Algoritmo:1. Scegliere K punti come centroidi iniziali
2. repeat
3. Formare K cluster assegnando tutti i punti al centroide più vicino
4. Ricalcolare il centroide di ogni cluster
5. until I centroidi non cambiano
Clustering K-means
23/02/2015 Page 34

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� I centroidi iniziali sono spesso scelti casualmente. La scelta può influire sui cluster prodotti.
� Il centroide è calcolato tipicamente come il baricentro del cluster.
� La vicinanza è misurata con la distanza euclidea, la correlazione, ...
� Per le comuni misure di similarità K-means converge. Essendo la convergenza più veloce nelle prime iterazioni, spesso la condizione di stop diventa «relativamente pochi oggetti cambiano cluster».
Clustering K-means
23/02/2015 Page 35
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
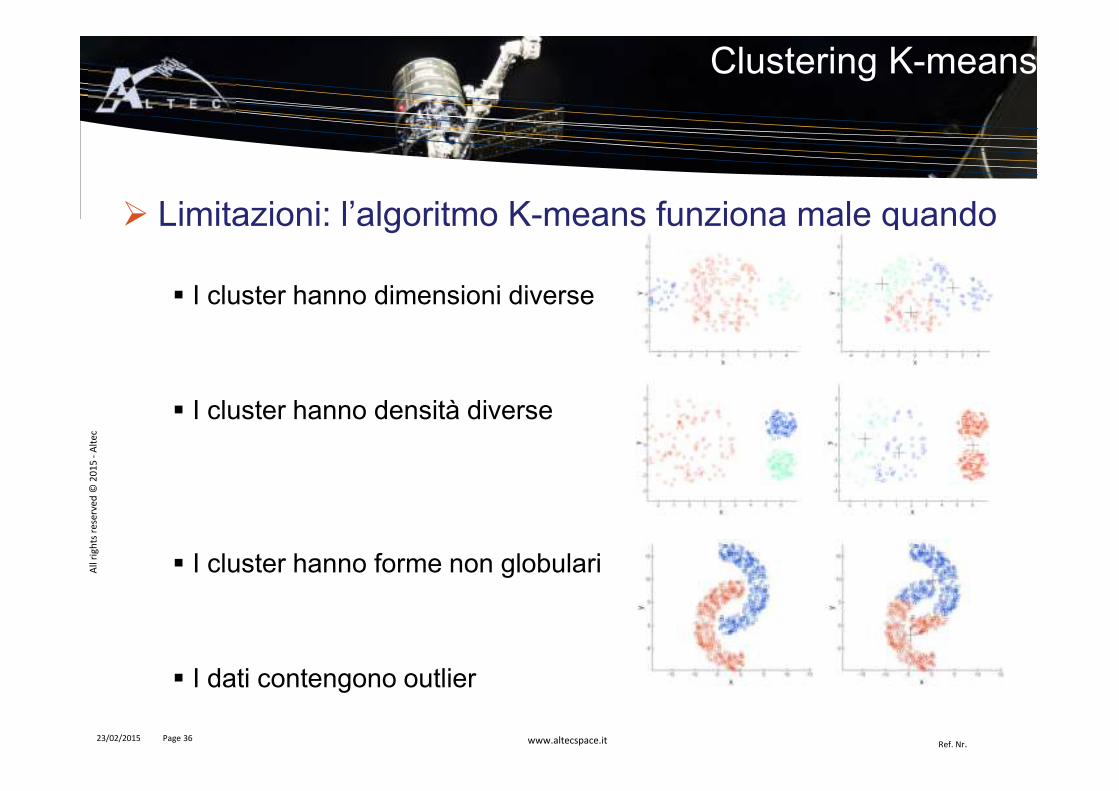
� Limitazioni: l’algoritmo K-means funziona male quando
� I cluster hanno dimensioni diverse
� I cluster hanno densità diverse
� I cluster hanno forme non globulari
� I dati contengono outlier
Clustering K-means
23/02/2015 Page 36

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Possibili soluzioni e migliorìe� Clusterizzare inizialmente con cluster gerarchico per determinare i
centroidi iniziali
� Selezionare più di K centroidi iniziali e poi selezionarne K tra questi (magari quelli più distanti)
� Pre-processing� Normalizzare i dati
� Eliminare gli outlier
� Post-processing� Eliminare piccoli cluster che possono rappresentare outlier
� Spezzare cluster molto «vasti»
� Unire cluster molto «vicinI»
Clustering K-means
23/02/2015 Page 37

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Produce un insieme di cluster annidati organizzati secondo un albero gerarchico
� Si può visualizzare mediante un dendrogramma: diagramma ad albero che descrive le sequenze di unione o divisione
Clustering gerarchico
23/02/2015 Page 38

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Non c’è un numero di cluster fissato. Si può scegliere a posteriori tagliando il dendrogramma ad un opportuno livello.
� Due tipi di clustering gerarchico:� Agglomerativo: all’inizio ogni oggetto è un cluster e ad ogni step
si uniscono i due cluster più vicini
� Divisivo: un cluster unico che include tutti gli oggetti e ad ogni step si divide un cluster, finché tutti i cluster hanno un solo punto.
� Per il calcolo delle vicinanze si usa la matrice di prossimità, contenente le distanze (secondo una certa metrica) tra i cluster.
Clustering gerarchico
23/02/2015 Page 39
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
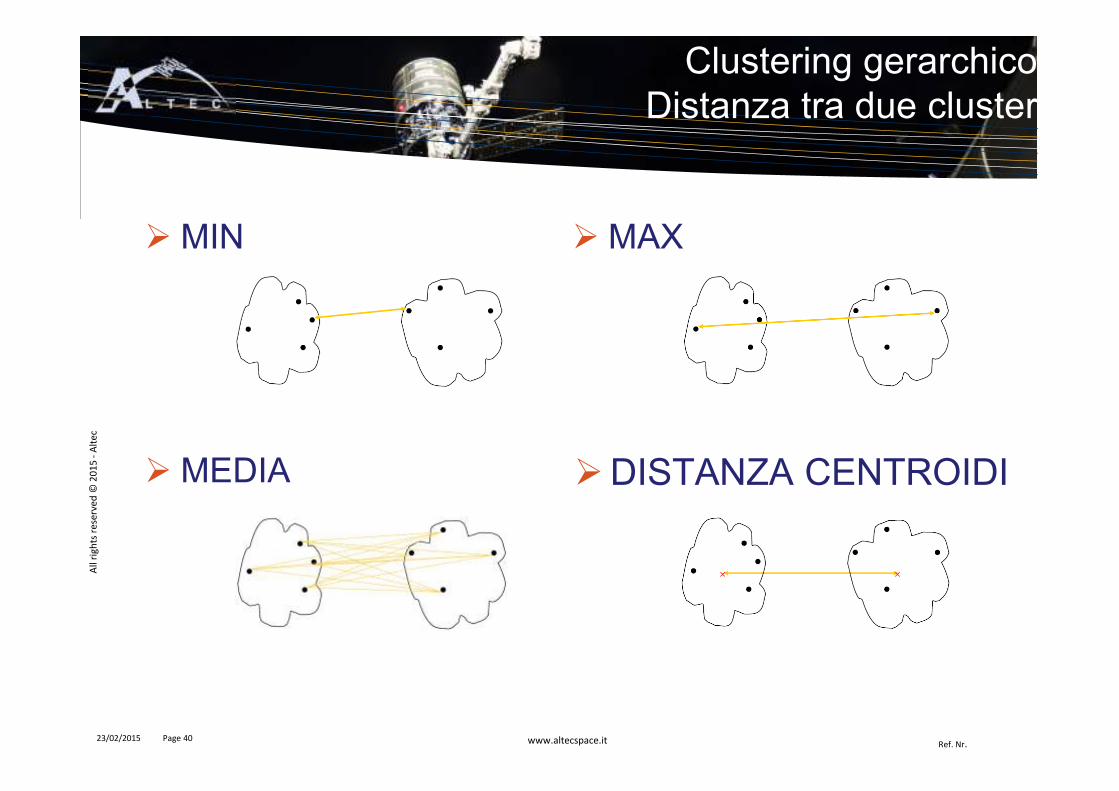
� MIN
Clustering gerarchicoDistanza tra due cluster
23/02/2015 Page 40
� MAX
� MEDIA �DISTANZA CENTROIDI

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Density-Based Spatial Clustering of Applications
with Noise
� Fissato un raggio r e un intero k, si definiscono i punti del dataset come:� Punti di nucleo, se all’interno del raggio r ci sono almeno k punti
� Punti di bordo, se hanno meno di k punti entro r ma sono nell’intorno di un punto di nucleo
� Punti di rumore, altrimenti.
� I punti di nucleo e di bordo i cui intorni si intersecano appartengono allo stesso cluster.
� I punti di rumore vengono raggruppati in un cluster a parte.
DBSCAN
23/02/2015 Page 41

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Vantaggi� Resistente al rumore
� Gestisce cluster di diverse forme e dimensioni
DBSCAN
23/02/2015 Page 42
Dataset originale ClusteringNucleo, bordo, rumore
� Problemi con� Densità variabili
� Dataset ad alte dimensioni

www.altecspace.it
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
Architetture e Piattaforme

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
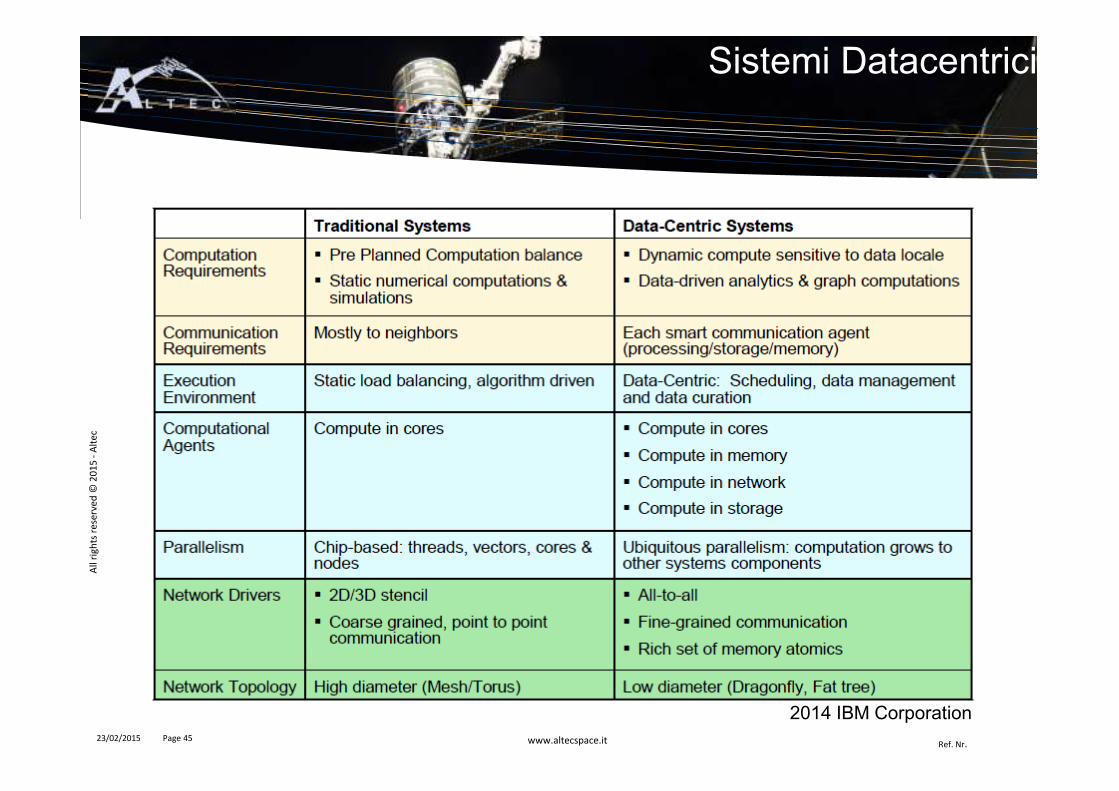
� High Performance Computing� Un sistema HPC permette l’esecuzione di un’istanza di un software parallelo su più processori.� I job di tipo HPC richiedono solitamente grossa potenza di calcolo per un limitato periodo di tempo.
� High Throughput Computing� Un sistema HTC permette di eseguire nello stesso tempo più istanze software indipendenti su più processori.� “..term to describe the use of many computing resources over long periods of time to accomplish a
computational task” (Wikipedia 2015)� “A computing paradigm that focuses on the efficient execution of a large number of loosely-coupled tasks”
(EGI)
� In ambito Big Data le architetture dei grossi sistemi di computazione seguono unapproccio HTC.
� Spesso si hanno architetture ibride o centri di calcolo che integrano sistemi HPC eHTC. L’installazione di PICO al CINECA è un esempio.
� L’integrazione di architetture diverse, anche esistenti, per l’esecuzione di applicazionieterognee è un elemento chiave in progetti di grosse dimensioni.
Da HPC a HTC..
23/02/2015 Page 44
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
Sistemi Datacentrici
23/02/2015 Page 45
2014 IBM Corporation

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
Sistemi Data Centric Principi di Design
23/02/2015 Page 46
2014 IBM Corporation
� Computazione eseguita dove si trovano i datieliminando lo spostamento dei dati verso i nodi dicomputazione.

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
HPC Delivery Evolution
23/02/2015 Page 47

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
CINECA PICO
23/02/2015 Page 48
� Supporta le applicazioni di classe «BigData»� Utilizza Tecnologie Cloud� Composta da server Intel NeXtScale che permettono
un sistema ad ad alta densità e ad elevate prestazioni.� Integra server con componenti hardware eterogenei
per le diverse tipologie di applicazioni.� Utilizzo di elevate quantità di memoria e acceleratori.� Call for Interest per iniziare a provare la piattaforma.

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
Definizione del NIST:
“Cloud computing is a model for enabling ubiquitous, convenient, on- demand network access to a shared pool of configurable computingresources (e.g., networks, servers, storage, applications, andservices) that can be rapidly provisioned and released with minimalmanagement effort or service provider interaction. This cloud modelis composed of five essential characteristics , three service models ,and four deployment models.”
Cloud ComputingDefinizione
23/02/2015 Page 49

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Self-service, on-demand� L’utente può disporre di risorse in modo automatico e senza l’interazione umana.
� Accesso attraverso la rete� Le risorse sono accedute tramite la rete utilizzando diverse piattaforme client.
� Pool di risorse� Le risorse sono gestite in pool in modo da servire più consumatori (multi tenancy).� Risorse fisiche e virtuale assegnate in modo dinamico� L’utente non ha conoscenza sulla localizzazione della risorsa.
� Elasticità� Le capacità di una piattaforma sono fornite e rilasciate in modo elastico spesso in modo
automatico.� Le piattaforme cloud dovrebbero scalare sulla base delle domande dell’utente� Dal punto di vista dell’utente risorse infinite. (In realtà le risorse sono finite)
� Misura dell’utilizzo dei servizi� L’utilizzo della risorse è constantemente monitorato� Pagamento a consumo
Cloud Computing Caratteristiche
23/02/2015 Page 50

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Software as a Service (SaaS)� Consiste nell'utilizzo di programmi installati su una piattaforma cloud non
gestita dall’utente.
� Platform as a Service (PaaS)� Invece che uno o più programmi singoli, l’utente esege in remoto una
applicazione/piattaforma software che può essere costituita da diversi servizi, programmi, librerie, etc.
� Infrastructure as a Service (IaaS)� Utilizzo di risorse hardware o virtuali in remoto in modo autonomo da parte
dell’utente.
Cloud Computing Modelli di Servizio
23/02/2015 Page 51

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Private Cloud� L’infrastruttura Cloud è utilizzata in modo esclusivo da un’organizzazione.
� Community Cloud� L’infrastruttura Cloud è utilizzata in modo esclusivo da una comunità quale ad
esempio un consorzio creato per una missione/progetto.
� Public Cloud� L’infrastruttura Cloud è pubblica ed è gestita da un’organizzazione
� Hibrid Cloud� L’infrastruttura Cloud è costituita da una federazione di infrastrutture che
appartengono ad una delle tre precedenti tipologie. Sono necessari meccanismi per la portabilità tra infrastrutture cloud.
Cloud Computing Deployment Model
23/02/2015 Page 52

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
Cloud Computing
� Tecnologia proveniente dal settore commerciale.
� Totale controllo sulle applicazioni� Maggiore elasticità nella gestione
delle risorse� Esecuzione come composizione di
servizi.� Ridotte attese per l’esecuzione� Multitenancy and multitask
Cloud Computingvs. Grid Computing
23/02/2015 Page 53
Grid Computing
� Enorme successo in ambito scientificoHTC soprattutto per grandicollaborazioni scientifiche
� Impatto sostanzialmente nullo al di fuori dell’ambito della ricerca scientifica �sostenibilità
� Job divisi in piccole parti eseguite su nodi diversi
� Applicazioni sviluppate ad-hoc.� Multitenancy and multitask
Non esclusive

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� EGI Federated Cloud is a seamless grid of academic
private clouds and virtualised resources, built around
open standards and focusing on the requirements of
the scientific community.
� H2020/EINFRA� INDIGO
� DHTCS-IT
� Smart Cities
Iniziative Cloud
23/02/2015 Page 54

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
Secondo INFN (Salomoni Pula 2014):
� Una allocazione sofisticata delle risorse per tenant multipli
� Meccanismi di autenticazione e soprattutto di policy di autorizzazione distribuiti.
� Stabilità e standardizzazione del software
� Meccanismi di “federazione” tra resource providers, in particolare per cloud ibride (pubbliche + private).
� Contorni legislativi chiari (cf. Terms of Contract di public Cloud providers, oppure le normative USA vs. EC vs. nazionali).
Altri:
� Processo di standardizzazione per l’utilizzo del modello di servizio PaaS.
Cosa manca affinchè il Cloud si diffonda in ambito scientico?
23/02/2015 Page 55

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
The Open Source Toolkit for Cloud Computing
23/02/2015 Page 56
Cos’è un Cloud Toolkit:� Fornisce un alto livello di astrazione alle
risorse� Comunica con un insieme di differenti ed
tecnologie:� Hypervisor (Compute)� Storage systems � Network resources (Controller SDN,
virtual switches`)� Esporta North-Bound APIs alle
applicazioni utenti.

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
OpenStack Project
57
Trove Ironic Zaqar Sahara
� Progetto avviato nel 2010 da Rackspace e da NASA.� Progetto Open Source.� Notevole supporto da diversi ed eterogenei attori IT.� Modello di IaaS

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
Utilizzo degli acceleratori
� Secondo nVIDIA la legge di Moore è superata perché continuando ad aumentare il numero di transistors nei chip delle CPU emerge il problema del consumo di energia in quanto le architetture di CPU tradizionali sono inefficienti.
� Nuova architettura che integra, all’interno del chip della CPU, degli acceleratori con core ad alta efficienza energetica.
12/03/2015 58
� Due tecnologie di acceleratori sono presenti sul mercato per computazione massicciamente parallela.� GPGPU (General-purpose
Processing on Graphics Processing Units)
� MIC (Many Integrated Core)
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
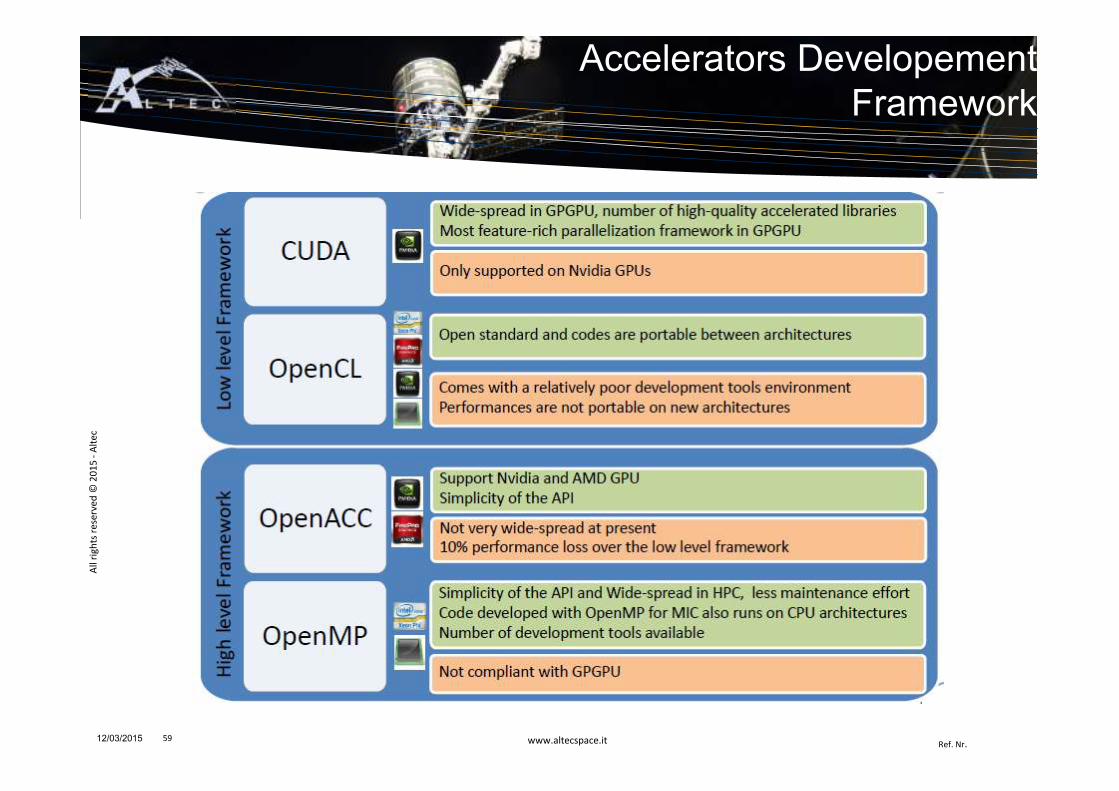
Accelerators Developement Framework
12/03/2015 59

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
CINECA GALILEO
23/02/2015 Page 60
Model: IBM NeXtScaleArchitecture: Linux Infiniband ClusterNodes: 516Processors: 2 8-cores Intel Haswell 2.40 GHz per nodeCores: 16 cores/node, 8256 cores in totalGPU: 2 Intel Phi 7120p per node on 384 nodes (768 in total)RAM: 128 GB/node, 8 GB/coreInternal Network: Infiniband with 4x QDR switchesDisk Space: 2.000 TB of local scratchPeak Performance: 1.000 TFlop/s (to be defined)
..problematica della portabilità delle applicazioni esistenti per utilizzare la potenza di calcolo delle GPU

www.altecspace.it
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
Storage – Data Store

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Contesto� Presenza di dati non strutturati rispetto ai dataset strutturati tipici dei contesti HPC e Data WareHousing.� Necessità di un processamento «real time» oltre al classico processamento batch.� Enormi quantità di dati e necessità di scalare al crescere dei dati.� Necessità di supportare le applicazioni esistenti sviluppate secondo i paradigmi tradizionali.
� Caratteristiche dei componenti Storage� Scalabile
� Storage multilivello
� Gestione autonoma
� Garanzia che il contenuto sia ampiamente disponibile
� Garanzia che il contenuto sia ampiamente accessibile
� Supporto di applicazioni sia di analisi sia di contenuto
� Supporto per l’automazione di workflow
� Integrazione con applicazioni legacy
� Integrazione con ecosistemi pubblici, privati e cloud ibridi
� Risoluzione automatica di problematiche interne
� Soluzioni Architetturali� Hyperscale Computing Environments
� Scale-out or clustered NAS
� Object-based storage
Big Data Storage
23/02/2015 Page 62

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Hyperscale Computing Environments� Server con direct-attached storage (DAS)
� Ridondanza a livello dell’intera unità di storage/processamento
� PCIe flash storage sola nel server o aggiunta al disco per minimizzare lalatenza dello storage
� In questa configurazione non c’è storage condiviso
� Utilizzo di tecnologie quali HDFS per la gestione del dato
Big Data StorageHCE
23/02/2015 Page 63

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Scale-out or clustered NAS� Accesso al dato tramite file
� Accesso ai file tramite storage condiviso
� Filesystemi paralleli distribuiti su più nodi di storage
� Da soluzione di nicchia a soluzione proposta dai principali vendor di storage(NetApp è stata la prima grande azienda che ha spinto su questa tecnologia).
� Altri esempi di implementazioni sono OneFS dell’EMC-Isilon, General ParallelFile System (GPFS) dell’IBM e Ibrix Fusion di HP.
� Soluzione facilmente implementabile in organizzazioni di ridotte dimensioni.
Big Data StorageClustered NAS
23/02/2015 Page 64

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Object-based storage� Dati gestiti come oggetti.
� Un oggetto tipicamente include i dati, un numero variabile di metadati e unidentificativo unico.
� Separazione tra metadata e data
� Lo storage dei metadati è ottimizzato (es. database o key value storage)rispetto allo storage dei dati (es. unstructured binary storage)
� Forniscono le API per operare sugli oggetti
� Il concetto degli oggetti si può applicare a diversi livelli:� Object-based file systems � Lustre
� Cloud Storage � OpenStack-Swiift
� Storage Ibridi � Ceph, GlusterFS, and Scality RIN
� Sistemi “captive" object storage come Haystack di Facebook
Big Data Storage Object Storage
23/02/2015 Page 65

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Hadoop Distributed File System� Ogni file è suddiviso in blocchi (default 64MB)� Ogni blocco è replicato all'interno del cluster (default 3 copie)
� Durability, AvailabilityThroughput� Le copie sono distribuite sia i server sia tra i rack.
� Sistema ottimizzato per il throughput, per le operazione diGet/Delete/Append
Data StoreHDFS
23/02/2015 Page 66
� Pochi sistemi storage supportano HDFS� EMC Isilon e HP Vertica Connector for Hadoop.
Un’alternativa� Esistono protocolli di storage enterprise come, ad
esempio, NFS (NetApp FlexPod Select) chesupporta in maniera nativa la tecnologiadistribuita MapR di Hadoop.
� HDFS può essere sostituito con un altro filesystem che si può anche collegare in Hadoop.Ad esempio, General Parallel File System diIBM (GPFS).
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
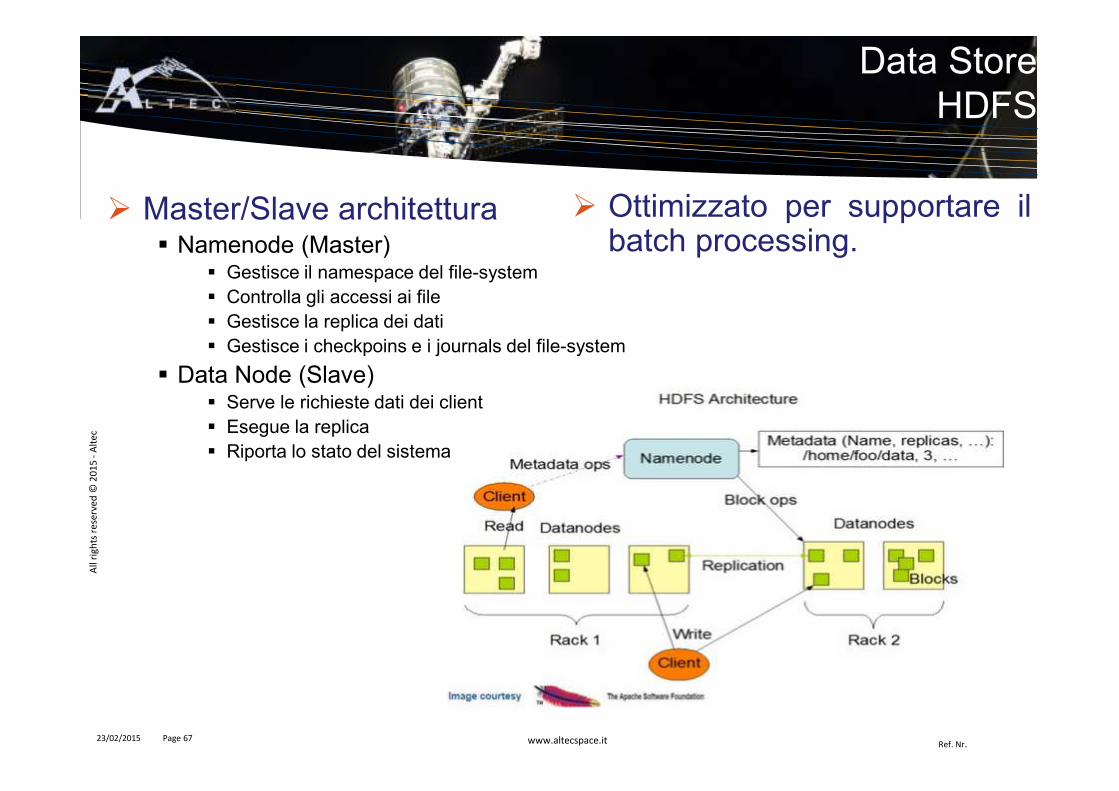
� Master/Slave architettura� Namenode (Master)
� Gestisce il namespace del file-system� Controlla gli accessi ai file� Gestisce la replica dei dati� Gestisce i checkpoins e i journals del file-system
� Data Node (Slave)� Serve le richieste dati dei client� Esegue la replica� Riporta lo stato del sistema
Data StoreHDFS
23/02/2015 Page 67
� Ottimizzato per supportare ilbatch processing.
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
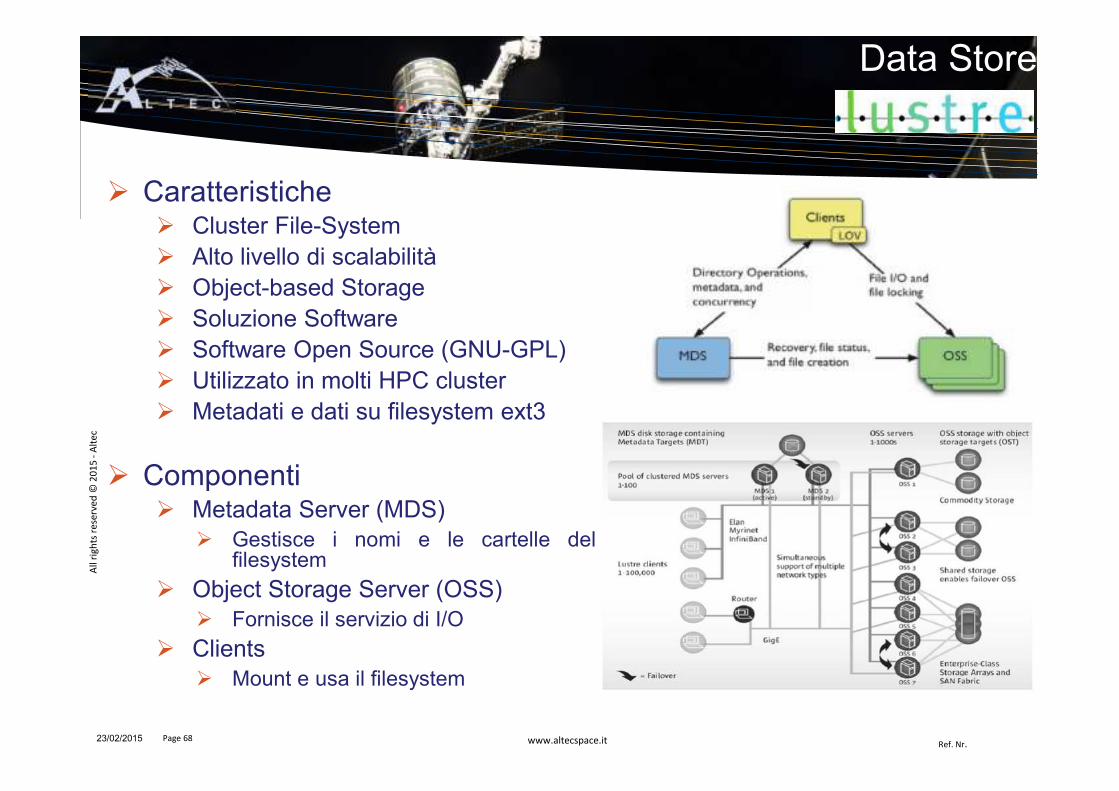
Data Store
� Caratteristiche� Cluster File-System� Alto livello di scalabilità� Object-based Storage� Soluzione Software� Software Open Source (GNU-GPL)� Utilizzato in molti HPC cluster� Metadati e dati su filesystem ext3
� Componenti� Metadata Server (MDS)
� Gestisce i nomi e le cartelle delfilesystem
� Object Storage Server (OSS)� Fornisce il servizio di I/O
� Clients� Mount e usa il filesystem
23/02/2015 Page 68

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Negli ultimi anni si sta avendo un’ampia diffusione didatabase NoSQL che forniscono meccanimi di storage eretrieval per dato modellati differentemente dal normalemodello relazione
� Le motivazioni principali che spingono su questo tipo didatabase sono principalmente legate alla scalabilitàorizzontale e alle performance� Non sono più possibili operazioni di join come nei db relazionali ma si devono effettuare
più query singole� Le performance delle singole query sono tali da consentire un beneficio rispetto
all’utilizzo del join� Anche i più importanti player produttori di RDBMS si stanno cimentando con i NoSQL
database. Es: Oracle con il suo NoSQL Database
� Il prezzo da pagare per una maggiore availability e partitiontollerance è un compromesso sulla consistenza
Data Store - NoSQL
23/02/2015 Page 69

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Esistono molti tipi database NoSQL che si possono classificare in base al data model utilizzato:� Colum families (UniqueName, Value, Timestamp): Cassandra,
Hbase, Accumulo
� Document Store (document oriented db, semistructured-data): MongoDB, OrientDB, CouchDB
� Key-value: Dynamo, Aerospike, Oracle NoSQL Database
� Graph (it uses graph structure for semantic query): MapGraph, Allegro, Virtuoso
� Multi-model (supportano differenti data model): OrientDB, ArangoDB
Data Store - NoSQL
23/02/2015 Page 70

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� I database NoSQL più utilizzati sono:� MongoDB
� Cassandra
� Redis
� HBase
� CouchDB
� Neo4j
Data Store - NoSQL
23/02/2015 Page 71

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� MongoDB� E’ un document store DB con licenza Open Source
� E’ uno dei db nosql più vicini al modello degli RDBMS tradizionali
� Non consente JOIN
� E’ schema free
� Usa un sistema di replica Master-Slave
� Auto-sharding (dati suddivisi in differenti macchine)
� Ottimo sistema di indicizzazione (indici unici, indici, secondari, indici sparsi, indici geospaziali, indici full text)
� Diritti d’accesso per utente e ruoli
� Supporta Stored Procedure
Data Store - NoSQL
23/02/2015 Page 72

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Cassandra� Open Source NoSQL db che usa datamodel Colum Families
� E’ Schema Free
� Auto-Sharding
� Dati replicati
� No Single Point of failure (ogni nodo è identico ad un altro)
� Grande scalabilità
� Alte performance
� Diritti di accesso per utente definibili per oggetto
Data Store - Cassandra
23/02/2015 Page 73

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Neo4j� Open source graph database
� E’ schema free
� Possibile uso di trigger tramite event handler
� Replica master slave (solo nella versione enterprise)
� Chiavi esterne
� Indici
� Non supporta il MapReduce
Data Store - NoSQL
23/02/2015 Page 74

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Array Databases � SciDB, SciQL� E’ in arrivo un’estensione del linguaggio SQL: ISO 9075
Part 15: SQL/MDA (”Multi-Dimensional Arrays”).� Possibilità di eseguire query flessibili su dati di tipo
spazio temporali.� Possibilità di unire dati e metadati.� Fornisce un set di costrutti per creare ed operare sugli
array perfettamente integrati in SQL (subsetting, extending, scaling, encoding, decoding ecc..).
Science SQL
23/02/2015 Page 75
SELECT encode(ARRAY [h(0:255)]VALUES count_cells( scene.band1 = h ),"csv")
FROM LandsatScenesWHERE acquired BETWEEN
"1990-06-01"AND "1990-06-30"
AGGREGATE +OVER [ x(100:200), y(50:350) ]USING a[ x, y ]

www.altecspace.it
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
Processing

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� La programmazione di sistemi distribuiti è un’attività difficile.� Programmazione parallela � Eseguire un programma più velocemente su hardware parallelo.� Programmazione concorrente � Gestire in modo esplicito l’esecuzione concorrente di thread.
� Leggi di Moore superata� Trasportare i dati dalla memoria al processore è il collo di bottiglia delle architetture di processing� Migliorare ulterioremente le prestazioni dei processori non basta per gestire le richeste di processamento
di grandi quantità di dati
� Il calcolo distribuito deve essere utilizzato su due livelli.� Micro scale: multicore processing� Macro scale: cloud computing / distributed data parallel systems
� L’approccio tradizionale di programmazione in ambito distribuito introduce il problema del non determinismo:
non-deterministico= programmazione parallela/concorrente + stato mutabile
� Per avere un processing deterministico bisogna fare in modo di non avere la componente dello stato mutabile.
� Per eliminare lo stato mutabile bisogno passare da un paradigma imperativo ad un paradigma funzionale.
Processing Tradizionale
23/02/2015 Page 77
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
Processing funzionale/parallelo
23/02/2015 Page 78
Many Data-Parallel frameworks

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
Apache Hadoop
� Progetto open source dell’Apache Software Foundation� Progetto derivato da due articoli di Google:
� Google File System (GFS 2003)� MapReduce (2004)
� E’ un sistema di analisi e un sistema di storage affidabile� HDFS� Map Reduce
� Scala orizzontalmente� Dati divisi in blocchi� Un blocco di dati è l’input di una Map task� Le task sono eseguite in parallelo su diversi nodi
� Ogni task lavora solo sulla parte locale dell’intero dataset.
� Rilocazione del carico di lavoro
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
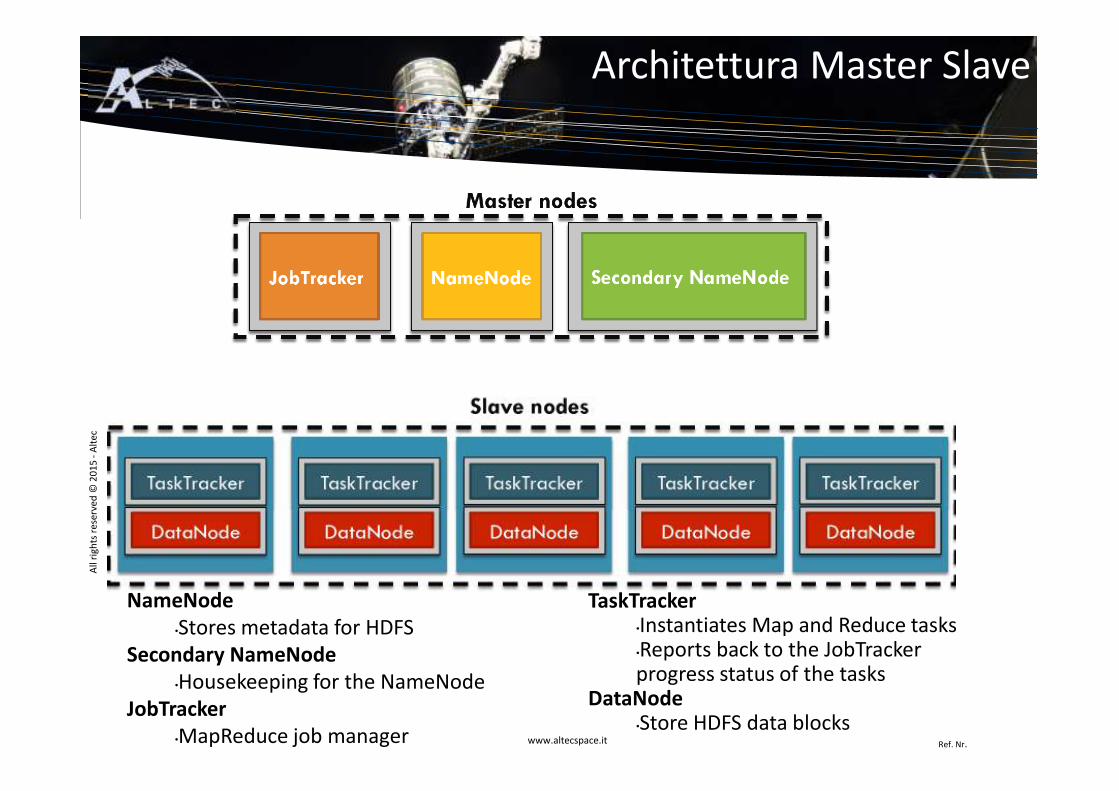
Architettura Master Slave
NameNode
•Stores metadata for HDFS
Secondary NameNode
•Housekeeping for the NameNode
JobTracker
•MapReduce job manager
TaskTracker
•Instantiates Map and Reduce tasks•Reports back to the JobTrackerprogress status of the tasks
DataNode
•Store HDFS data blocks
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
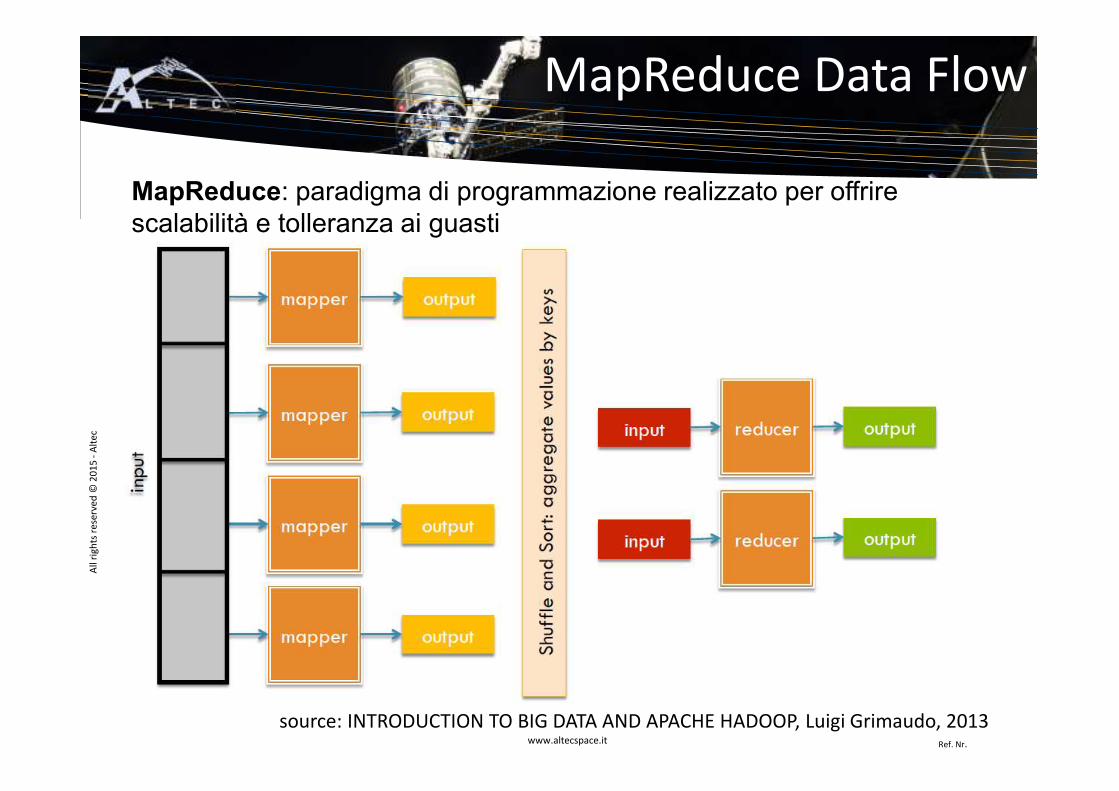
MapReduce Data Flow
source: INTRODUCTION TO BIG DATA AND APACHE HADOOP, Luigi Grimaudo, 2013
MapReduce: paradigma di programmazione realizzato per offrirescalabilità e tolleranza ai guasti

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
Hadoop based projects
� Pig� High level data flow descriptive framework to run MapReduce
jobs,based on Pig Latin Language� Hive
� High level abstraction with SQL-like language to write queriesautomatically converted in MapReduce jobs
� Sqoop� Importing data tool for relational databases
� Flume� Tool to import data as it is generated
� Oozie� Tool to create and manage workflows of MapReduce jobs
� Impala� Same as Hive, but avoiding MapReduce paradigm
� Other� Avro, Tez, Mahout etc.
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
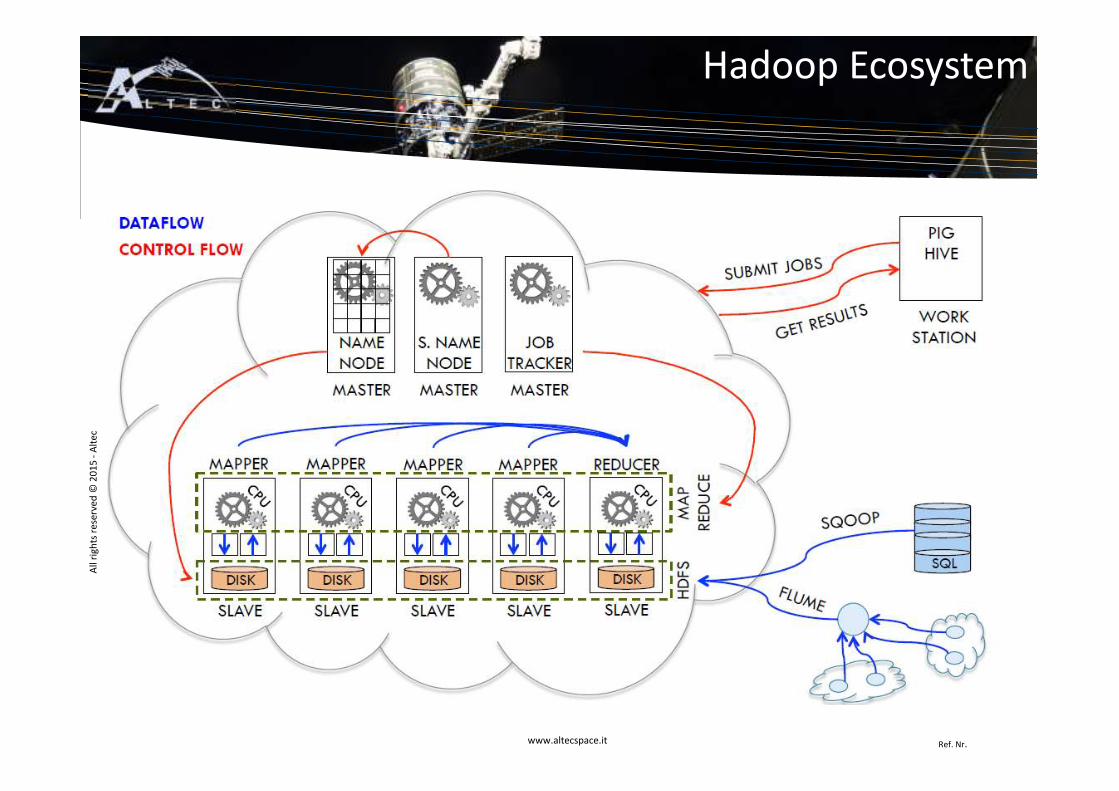
Hadoop Ecosystem

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
Hadoop Suitability
� Hadoop is good for:� Hadoop is basically a batch processing system� Use cases which the data can be partitioned into independent
chunks� Embarrassingly parallel applications� Better with easy data structure� Dataset di grandi dimensioni� Dati strutturati, non strutturati e semi strutturati insieme� Dati che contengono informazioni non ancora estratte� Giant 1 is perfect for Hadoop� All other giants, simpler problems or smaller versions of the
giants are doable in Hadoop
� Hadoop constraints:� Lack of Object Database Connectivity (ODBC)� Hadoop MR is not well-suited for iterative computation� Algorithm needed joins (interrelation/correlation) might not run
efficiently over Hadoop� Hadoop is not well suited for real-time computations� Limited with complex data structure (graphs)� Alternatives for complex problem of the giants (Spark)� In presenza di query complesse e che richiedono costosa
ottimizzazione� Accesso casuale ed interattivo ai dati� Salvataggio di dati sensibili
Computation Paradigms (giants)
Basic statistics
Linear algebraic computations
Generalized N-body problems
Graph theoretic computations
Optimizations
Integrations
Alignment problems
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
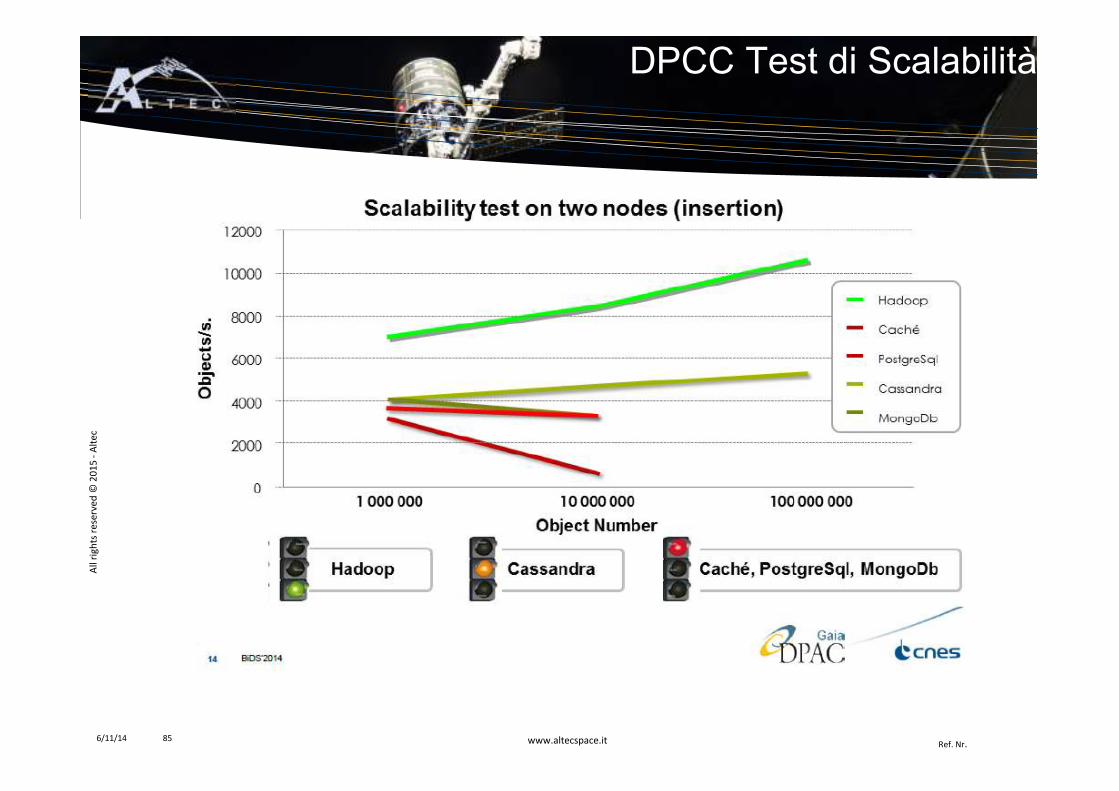
DPCC Test di Scalabilità
6/11/14 85

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
Piattaforma HW del DPCI per Hadoop
6/11/14 86
� 108 Identical nodes Hadoop nodes (storage & processing)� dual 6 core, 2.40GHz� 48GB memory� 9 * 1TB disks (enterprise class)� Centos Linux
� Providing altogether:� 1296 cores
� 5.1TB of memory� ~1PB HDFS disk space
� Current configuration:� Hortonworks Data Platform (HDP) 2.0 (Hadoop 2.2.0)� Replication level : 3� Ganglia for monitoring� Nagios for alerts� xCat for hardware provisioning

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr. 6/11/14 87
� Apache Spark è un framework di computazione openinizialmente sviluppato nel progetto AMPLab dell’università diBerkeley.
� Un solo framework che permette di fare batch, interactive estreaming processing.
� In memory storage
� Fino a 40 volte più veloce di Hadoop� Compatibile con Hadoop� Rich APIs in Java, Scala, Python
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr. 6/11/14 88
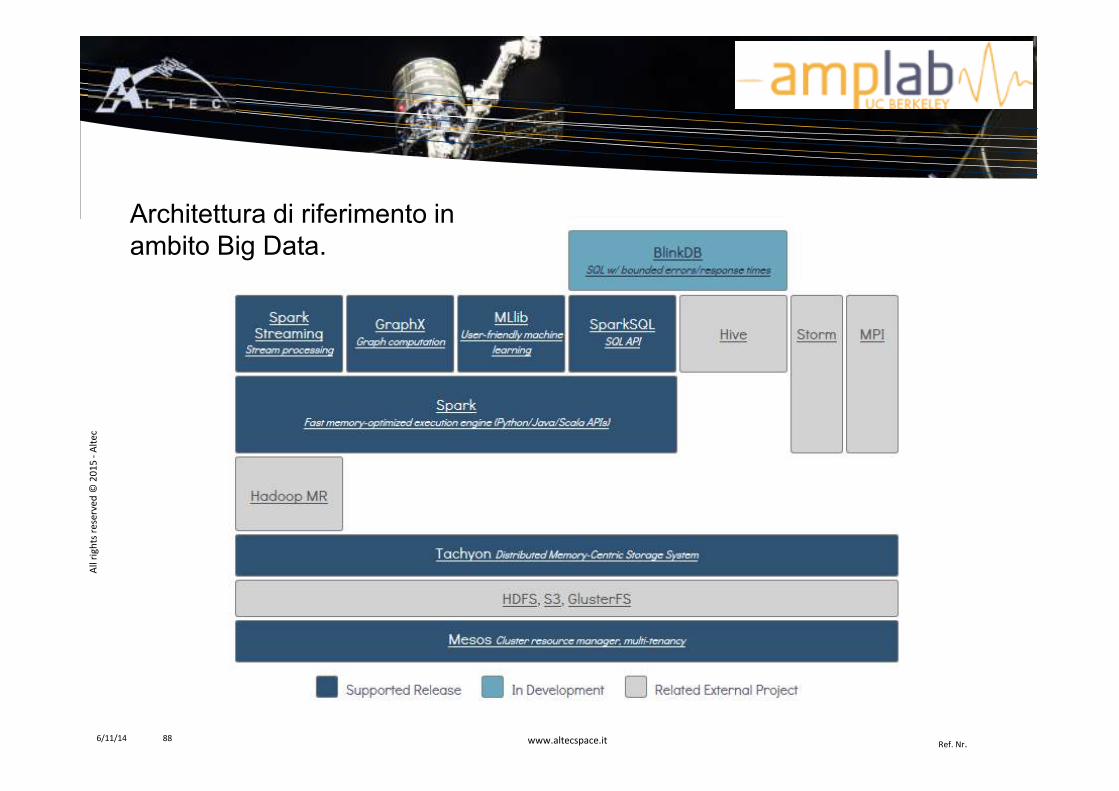
Architettura di riferimento in ambito Big Data.
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
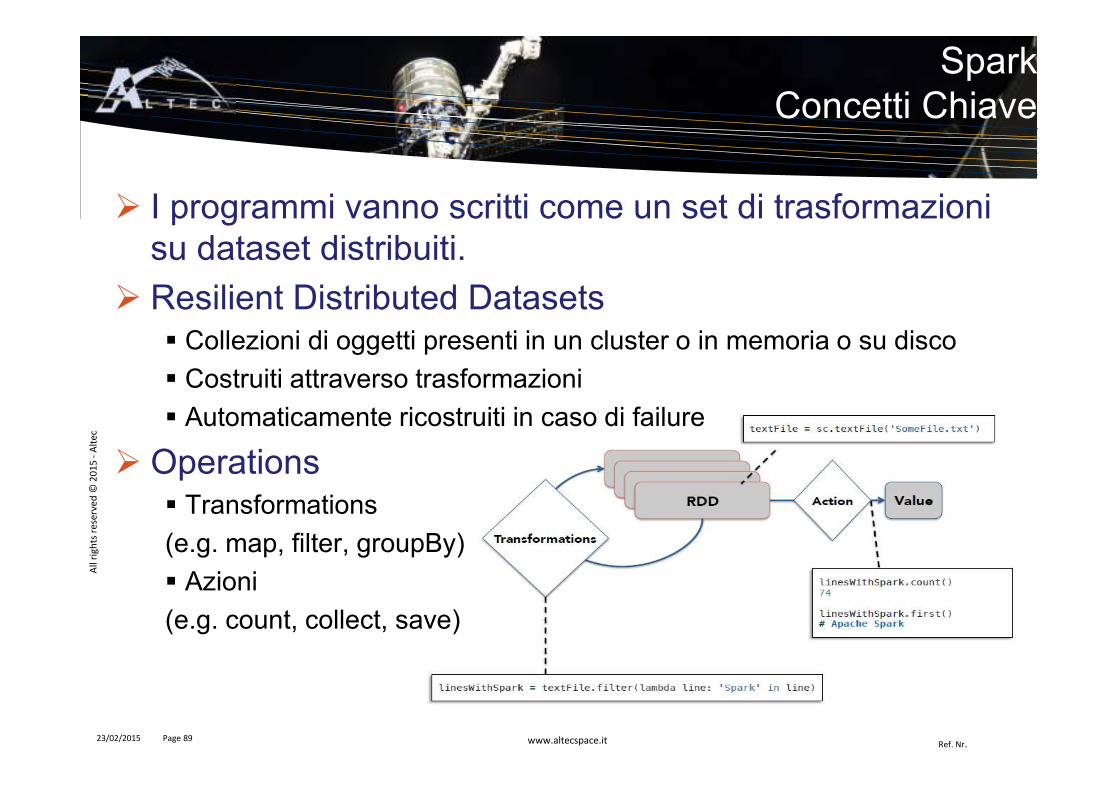
� I programmi vanno scritti come un set di trasformazioni su dataset distribuiti.
� Resilient Distributed Datasets� Collezioni di oggetti presenti in un cluster o in memoria o su disco
� Costruiti attraverso trasformazioni
� Automaticamente ricostruiti in caso di failure
� Operations� Transformations
(e.g. map, filter, groupBy)
� Azioni
(e.g. count, collect, save)
SparkConcetti Chiave
23/02/2015 Page 89

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Spark SQL è un modulo di Spark per lavorare su dati strutturati.� Permette di interrogare dati strutturati come dati in formato RDD.� Permette di caricare dati ed eseguire query su una varietà di sorgenti dati. � SchemaRDDs è un’unica interfaccia per lavorare su dati strutturati structured
data (Apache Hive tables, parquet files e JSON files). � Dispone di una modalità per la connessine tramite JDBC e ODBC
� MLlib è una libreria di Spark per in ambito machine learning� linear SVM and logistic regression� • classification and regression tree� • k-means clustering� • recommendation via alternating least squares� • singular value decomposition� • linear regression with L1- and L2-regularization� • multinomial naive Bayes� • basic statistics� • feature transformations
Moduli SparkSpark SQL MLlib
23/02/2015 Page 90

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Spark Streaming permette di realizzare applicazioniscalabili e fault tolerant che utilizzano flussi di dati real time.
� GraphX è un set di API per la gestione dei grafi e la loro computazione in modalità.� PageRank
� Connected components
� Label propagation
� SVD++
� Strongly connected components
� Triangle count
Moduli SparkSpark Streaming GraphX
23/02/2015 Page 91

www.altecspace.it
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
Data Visualization

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Un obiettivo primario della data visualization è comunicare le informazioni in modo chiaro ed efficiente tramite strumenti quali grafici e tabelle.
� Solo grazie alla visualizzazione, il cervello riesce ad elaborare, assorbire ed interpretare contemporaneamente grandi quantità di informazioni.
� Entrambe le precedenti affermazioni sono valide in ambito scientifico.
� Consiste nella creazione e nello studio della rapresentazione grafica dei dati.
Visualizzazione dei dati
23/02/2015 Page 93
La prima fotografia della
luce come onda e
particella

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� La Data Visualization è definita come l’esplorazione
visuale/interattiva e la relativa rappresentazione
grafica di dati di qualunque dimensione (small e big
data), natura e origine. Permette, in estrema
sintesi, di identificare fenomeni e trend che
risultano invisibili ad una prima analisi dei dati.
� Applicazioni:� analisi di dati al fine di creare e condividere report univoci e
consistenti
� esplorazione dei dati
� ottimizzazione dei processi
� previsioni analitiche per identificare e anticipare trend futuri
Visualizzare per conoscere
23/02/2015 Page 94
Fonte: SAS

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
La visualizzazione di grandi dataset è un problema nonbanale. Diverse tecniche sono state introdotte per visualizzaredataset 2D e 3D.
� Tecniche 2D� Color Mapping� Countor Line� Glyphs� Streamlines � Line integral convolution (LIC)
� Tecniche 3D� Volume Rendering� Isosurface (Marching cubes)
Tecniche
23/02/2015 Page 95
All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
Tipologie di grafici
23/02/2015 Page 96
Scatter plot Tree Map
StreamGraph
Network
Bar chart Heat Map

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� Google Public Data Explorer (Dataset Publishing Language)
� Google Fusion Tables is an experimental data visualization web application to gather, visualize, and share data tables.
� Google Earth
� IDL
Esempi di tool di visualizzazione dati
23/02/2015 Page 97

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.
� In ambito scientifico la disponibilità di nuove tecnologie informatiche offre nuove possibilità di estrazioni di informazioni al costo di una maggiore complessità dei sistemi stessi.
� Le figure dei «data scientist» sono diventate importanti in un contestoscientifico/informatico che preme verso un ulteriore specializzazione dellecompetenze.
� Dal BiD’s 14 è emerso in modo netto l’impulso che le tecnologie dei BigData hanno dato al settore scientifico e sono stati individuati anche alcuni punti su cui porre l’attenzione nel prossimo futuro.� Disponibilità dei dati (Open Data in ambito scientifico)� Federazione delle capacità di processing� Standardizzazione degli accessi� Disponibilità di ambienti collaborativi� Miglioramento della qualità e disponibilità del dato
� Nelle missioni scientifiche di medio e lungo periodo le scelte fatte in fase di design dovrebbero rendere possibile aggiornamenti tecnologici in fase implementativa, le tecnologie informatiche si evolvono e cambiano in modo repentino.
Conclusioni
23/02/2015 Page 98

All
rig
hts
re
serv
ed
© 2
01
5 -
Alt
ec
www.altecspace.it Ref. Nr.