scikit-learn case study - penn state college of...
TRANSCRIPT

scikit-learn Case Study
Professor Patrick McDaniel
Jonathan Price
Fall 2015

Page
More Advanced Usage
• Here, we will do a more advanced usage of scikit
learn to solve an actual security problem. We will
using the Microsoft Malware Classification Kaggle
competition as our test case, and examine the
solution of Nate Lageman (who has previously
given a talk on this subject).
• You will improve upon one of these learning
methods as an assignment.

Page
Malware Classification• "A difficult challenge of anti-malware is the vast number of
files that need to be examined. As the number of files
continues to grow, the need for better malware
classification increases. By successfully classifying
malware into respective families, we can relieve some of
the load caused by the sea of files that need to be
classified. Knowing the family of a particular malicious files
allows us to make predictions about that file. For instance,
we could sort multiple malicious files, assign threat values,
and delegate resources appropriately. The goal of this
project is to classify malicious files into their respective
families of malicious software. There are 9 malicious
families associated with this dataset."

Page
The Workshop
• We will walk through a high level design for
classifying the malware data. We will use two
prior works as a guide, and gain basic experience
in the following:
‣ Binary Analysis
‣ Feature Engineering
‣ Classification methods in scikit-learn
• This will be a high level discussion, to show what
is possible in this field, rather than designing these
solutions from scratch

Page
The Data
• Set of known malware files representing a mix of 9
different families.
• Each malware file has an Id, a 20 character hash
value uniquely identifying the file, and a Class, an
integer representing one of 9 family names to which
the malware may belong.
• Raw data contains the hexadecimal representation of
the file's binary content, without the PE header (to
ensure sterility).
• A metadata manifest, which is a log containing
various metadata information extracted from the
binary, such as function calls, strings, etc.

Page
Feature Extraction
• You’ve looked at sample data as pre-work, lets do
some feature engineering
• What features does the data have that you can
think of?
• What did Nate use?

Page
Feature Extraction
• You’ve looked at sample data as pre-work, lets do
some feature engineering
• What features does the data have that you can
think of?
• What did Nate use?
‣ Byte Frequency
‣ First 10k bytes
‣ Keyword frequency (metadata)

Page
Feature Extraction
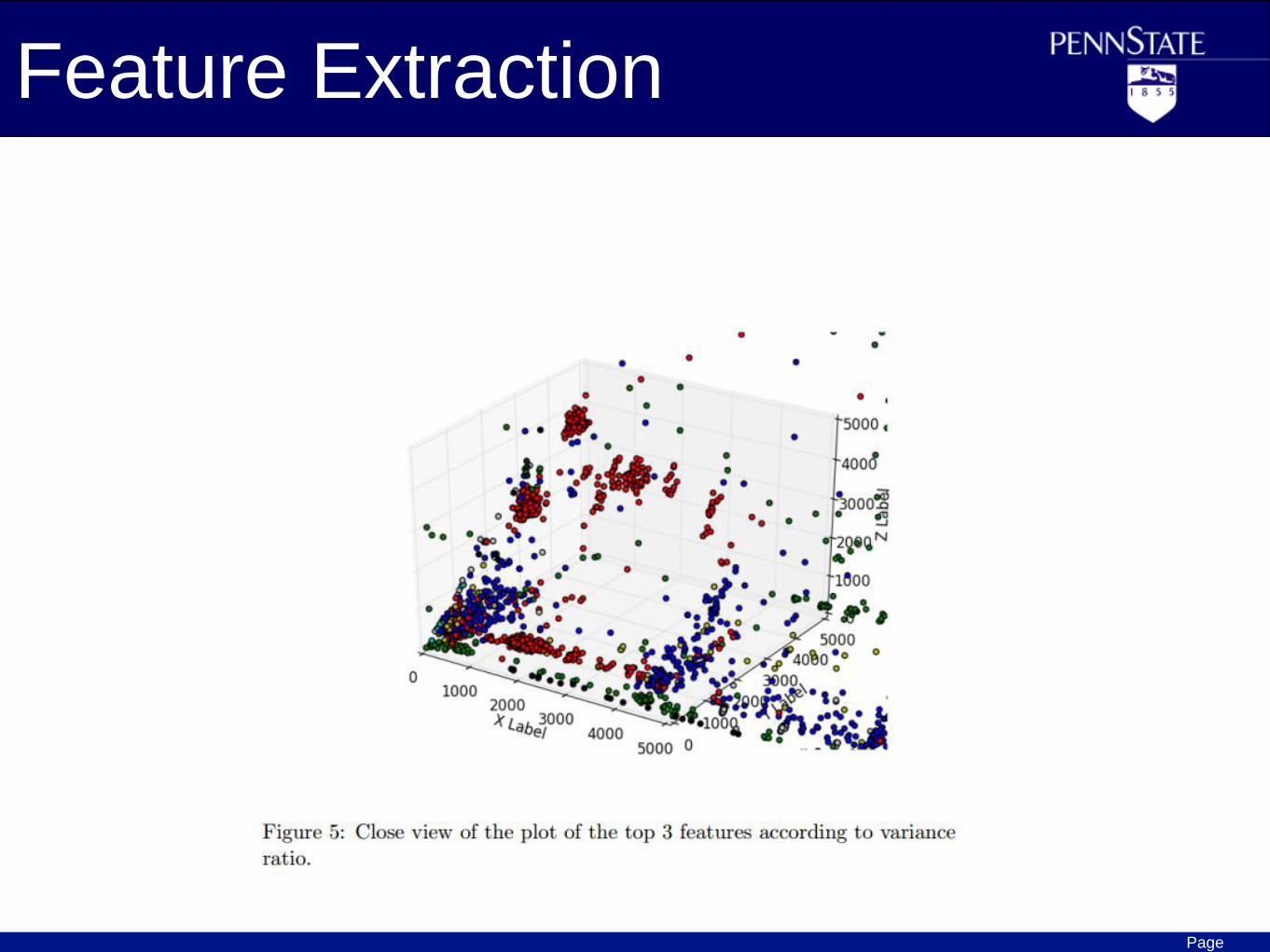
Page
Feature Extraction

Page
Classification
• We will go over the implementation and
effectiveness of five different classification
methods:
‣ Random Forests
‣ Support Vector Machines
‣ K-Nearest Neighbor
‣ Gradient Boosting

Page
Random Forest
• Ensemble learning method
‣ (This means it uses multiple learning methods)
• Collection of decision trees, outputs the mode of
the decided class
• We control:
‣ Max depth of trees
‣ # of Trees
‣ Features per tree
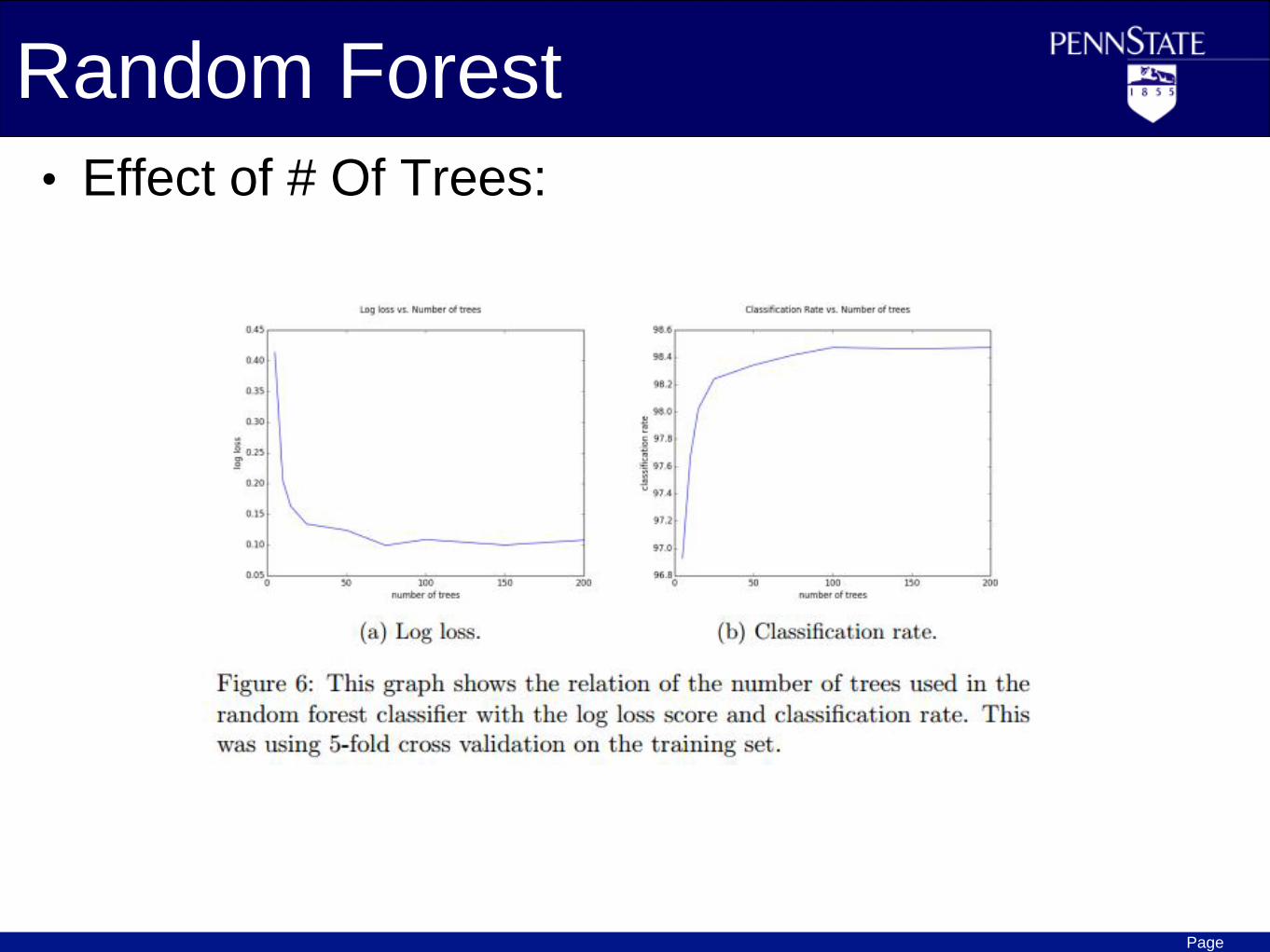
Page
Random Forest
• Effect of # Of Trees:

Page
Random Forest: Results
• 100-Tree forest with no pruning, using 5-fold cross
validation

Page
Support Vector Machine
• Basically the SVC we talked about last lecture
• We control:
‣ Kernel
• Linear
• Polynomial
• Exponential (rbf)
‣ Degree

Page
SVM: Results
• Rbf:
• Polynomial:

Page
K-Nearest Neighbor
• Classified as the majority vote of an objects k-
nearest neighbors
• We control:
‣ Weights (Uniform, distance)
‣ K
• Build model by increasing k by 1, stop when log-
loss stops improving.

Page
KNN
• From Wiki:
• With uniform weights, what class would the new
object be at k=1, 2, 3, 4...?

Page
KNN: Results
• K = 7

Page
Gradient Boosting
• Another ensemble classifier
• Also uses decision trees
‣ But regression trees this time
• We control:
‣ Tree #
‣ Learning Rate
‣ Max Depth of trees

Page
Gradient Boosting: Results

Page
Conclusion
• Random Forest and Gradient Boosting preformed
the best (why?)
• Counting and frequency features preformed the
best (why?)

Page
Assignment
• Improve this!
• Take the script code and improve (one) of the
methods we went over. Pick your favorite.
• Use the modified dataset distributed to the class
(Its smaller, this will take less time)
• Bonus: Read the report of the winning Kaggle
entry and compare it to the methods we went over.