search and retrieval: more on term weighting and document ranking prof. marti hearst sims 202,...
TRANSCRIPT

Search and Retrieval: More onSearch and Retrieval: More onTerm Weighting and Document RankingTerm Weighting and Document Ranking
Prof. Marti HearstProf. Marti Hearst
SIMS 202, Lecture 22SIMS 202, Lecture 22

Marti A. HearstSIMS 202, Fall 1997
TodayToday
Document RankingDocument Ranking term weights similarity measures
vector space model probabilistic models
Multi-dimensional spacesMulti-dimensional spaces ClusteringClustering

Marti A. HearstSIMS 202, Fall 1997
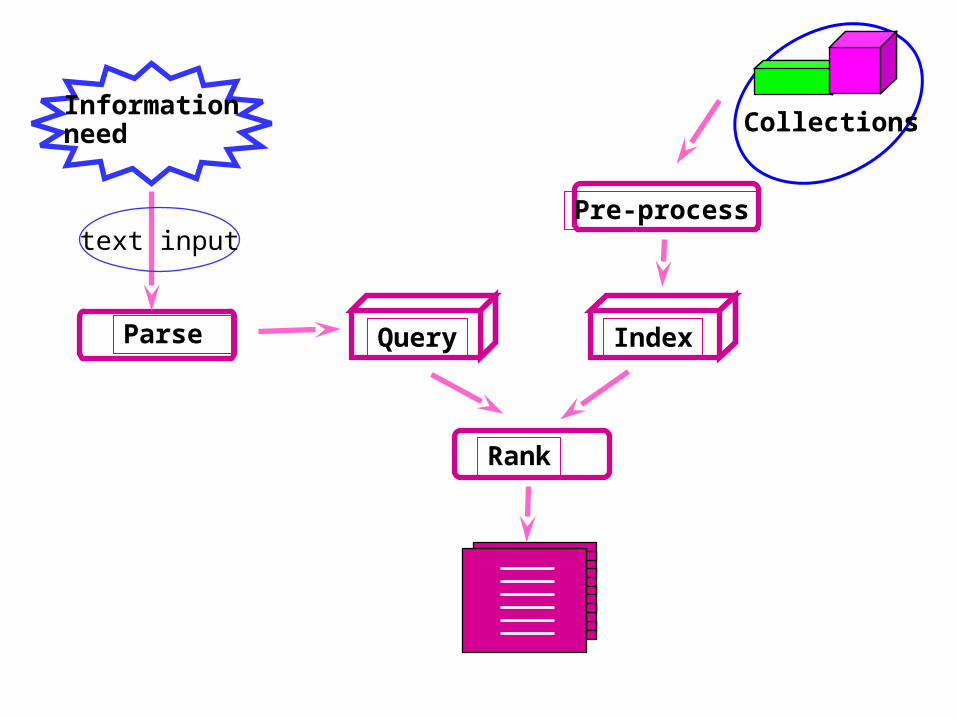
Finding Out AboutFinding Out About
Three phases:Three phases: Asking of a question Construction of an answer Assessment of the answer
Part of an iterative processPart of an iterative process

Marti A. HearstSIMS 202, Fall 1997
Ranking AlgorithmsRanking Algorithms
Assign weights to the terms in the Assign weights to the terms in the query.query.
Assign weights to the terms in the Assign weights to the terms in the documents.documents.
Compare the weighted query terms to Compare the weighted query terms to the weighted document terms.the weighted document terms.
Rank order the results.Rank order the results.
Informationneed
Index
Pre-process
Parse
Collections
Rank
Query
text input

Marti A. HearstSIMS 202, Fall 1997
Vector RepresentationVector Representation (revisited; see Salton article in (revisited; see Salton article in ScienceScience))
Documents and Queries are Documents and Queries are represented as vectors.represented as vectors.
Position 1 corresponds to term 1, Position 1 corresponds to term 1, position 2 to term 2, position t to term tposition 2 to term 2, position t to term t
The weight of the term is stored in each The weight of the term is stored in each positionposition
absent is terma if 0
,...,,
,...,,
21
21
w
wwwQ
wwwD
qtqq
dddi itii

Marti A. HearstSIMS 202, Fall 1997
Assigning Weights to TermsAssigning Weights to Terms
Raw term frequencyRaw term frequency tf x idftf x idf Automatically-derived thesaurus Automatically-derived thesaurus
termsterms

Marti A. HearstSIMS 202, Fall 1997
Assigning Weights to TermsAssigning Weights to Terms
Raw term frequencyRaw term frequency tf x idftf x idf
Recall the Zipf distribution Want to weight terms highly if they are
frequent in relevant documents … BUT infrequent in the collection as a whole
Automatically derived thesaurus Automatically derived thesaurus termsterms

Marti A. HearstSIMS 202, Fall 1997
Assigning WeightsAssigning Weights tf x idf measure:tf x idf measure:
term frequency (tf) inverse document frequency (idf)
Goal: assign a tf * idf weight to Goal: assign a tf * idf weight to each term in each documenteach term in each document

Marti A. HearstSIMS 202, Fall 1997
tf x idftf x idf
)/log(* kikik nNtfw
)/log(
Tcontain that in documents ofnumber the
collection in the documents ofnumber total
in T termoffrequency document inverse
document in T termoffrequency
document in term
Nnidf
Cn
CN
Cidf
Dtf
DkT
kk
kk
kk
ikik
ik

Marti A. HearstSIMS 202, Fall 1997
tf x idf normalizationtf x idf normalization
Normalize the term weights (so longer Normalize the term weights (so longer documents are not unfairly given more documents are not unfairly given more weight)weight) normalize usually means force all values to fall within
a certain range, usually between 0 and 1, inclusive.
t
k kik
kikik
nNtf
nNtfw
1
22 )]/[log()(
)/log(

Marti A. HearstSIMS 202, Fall 1997
Vector space similarityVector space similarity(use the weights to compare the (use the weights to compare the documents)documents)
terms.) thehting when weigdone tion was(Normaliza
product.inner normalizedor cosine, thecalled also is This
),(
:is documents twoof similarity theNow,
1
t
kjkikji wwDDsim

Marti A. HearstSIMS 202, Fall 1997
Vector Space Similarity Vector Space Similarity MeasureMeasurecombine tf x idf into a similarity measurecombine tf x idf into a similarity measure
)()(
),(
:comparison similarity in the normalize otherwise
),( :normalized weights termif
absent is terma if 0 ...,,
,...,,
1
2
1
2
1
1
,21
21
t
jd
t
jqj
t
jdqj
i
t
jdqji
qtqq
dddi
ij
ij
ij
itii
ww
ww
DQsim
wwDQsim
wwwwQ
wwwD

Marti A. HearstSIMS 202, Fall 1997
To Think AboutTo Think About
How does this ranking algorithm How does this ranking algorithm behave?behave? Make a set of hypothetical documents
consisting of terms and their weights Create some hypothetical queries How are the documents ranked,
depending on the weights of their terms and the queries’ terms?

Marti A. HearstSIMS 202, Fall 1997
Computing Similarity ScoresComputing Similarity Scores
2
1 1D
Q2D
98.0cos
74.0cos
)8.0 ,4.0(
)7.0 ,2.0(
)3.0 ,8.0(
2
1
2
1
Q
D
D
1.0
0.8
0.6
0.8
0.4
0.60.4 1.00.2
0.2

Marti A. HearstSIMS 202, Fall 1997
Computing a similarity scoreComputing a similarity score
98.0 42.0
64.0
])7.0()2.0[(*])8.0()4.0[(
)7.0*8.0()2.0*4.0(),(
yield? comparison similarity their doesWhat
)7.0,2.0(document Also,
)8.0,4.0(or query vect have Say we
22222
2
DQsim
D
Q

Marti A. HearstSIMS 202, Fall 1997
Other Major Ranking Other Major Ranking SchemesSchemes
Probabilistic RankingProbabilistic Ranking Attempts to be more theoretically sound
than the vector space (v.s.) model try to predict the probability of a document’s
being relevant, given the query there are many many variations usually more complicated to compute than v.s. usually many approximations are required
Usually can’t beat v.s. reliably using standard evaluation measures

Marti A. HearstSIMS 202, Fall 1997
Other Major Ranking Other Major Ranking SchemesSchemes
Staged Logistic RegressionStaged Logistic Regression A variation on probabilistic ranking Used successfully here at Berkeley in
the Cheshire II system

Marti A. HearstSIMS 202, Fall 1997
Staged Logistic RegressionStaged Logistic Regression
Pick a set of X feature typesPick a set of X feature types sum of frequencies of all terms in query x1 sum of frequencies of all query terms in document x2 query length x3 document length x4 sum of idf’s for all terms in query x5
Determine weights, c, to indicate how important Determine weights, c, to indicate how important each feature type is (use training examples)each feature type is (use training examples)
To assign a score to the document:To assign a score to the document: add up the feature weight times the term weight for
each feature and each term in the query
5
1
),(i
iixcQDscore

Marti A. HearstSIMS 202, Fall 1997
Multi-Dimensional SpaceMulti-Dimensional Space
Documents exist in multi-dimensional space Documents exist in multi-dimensional space What does this mean?What does this mean?
Consider a set of objects with features different shapes different sizes different colors
In what ways can they be grouped? The features define an abstract space that the objects
can reside in.
Generalize this to terms in documents.Generalize this to terms in documents. There are more than three kinds of terms!

Marti A. HearstSIMS 202, Fall 1997
Text ClusteringText Clustering
Clustering isClustering is“The art of finding groups in data.” -- Kaufmann and Rousseeu
Term 1
Term 2

Marti A. HearstSIMS 202, Fall 1997
Text ClusteringText Clustering
Term 1
Term 2
Clustering isClustering is“The art of finding groups in data.” -- Kaufmann and Rousseeu

Marti A. HearstSIMS 202, Fall 1997
Pair-wise Document SimilarityPair-wise Document Similarity
novanova galaxy galaxy heatheat h’woodh’wood film film roleroledietdiet furfur
11 3 3 1 1
55 2 2
22 1 1 5 5
44 1 1
ABCD
How to compute document similarity?

Marti A. HearstSIMS 202, Fall 1997
Pair-wise Document SimilarityPair-wise Document Similarity(no normalization for simplicity)(no normalization for simplicity)
novanova galaxy galaxy heatheat h’woodh’wood film film roleroledietdiet furfur
11 3 3 1 1
55 2 2
22 1 1 5 5
44 1 1
ABCD
t
iii
t
t
wwDDsim
wwwD
wwwD
12121
2,22212
1,12111
),(
...,,
...,,
9)11()42(),(
0),(
0),(
0),(
0),(
11)32()51(),(
DCsim
DBsim
CBsim
DAsim
CAsim
BAsim

Marti A. HearstSIMS 202, Fall 1997
Using ClusteringUsing Clustering
Cluster entire collectionCluster entire collection Find cluster centroid that best Find cluster centroid that best
matches the querymatches the query This has been explored extensivelyThis has been explored extensively
it is expensive it doesn’t work well

Marti A. HearstSIMS 202, Fall 1997
Using ClusteringUsing Clustering
Alternative (scatter/gather): Alternative (scatter/gather): cluster top-ranked documents show cluster summaries to user
Seems usefulSeems useful experiments show relevant docs tend to
end up in the same cluster users seem able to interpret and use the
cluster summaries some of the time More computationally feasibleMore computationally feasible

Marti A. HearstSIMS 202, Fall 1997
ClusteringClustering
Advantages:Advantages: See some main themes
Disadvantage:Disadvantage: Many ways documents could group
together are hidden

Marti A. HearstSIMS 202, Fall 1997
Using ClusteringUsing Clustering
Another alternative:Another alternative: cluster entire collection force results into a 2D space display graphically to give an overview
looks neat but hasn’t been shown to be useful
Kohonen feature maps can be used instead of clustering to produce display of documents in 2D regions

Marti A. HearstSIMS 202, Fall 1997
Clustering Multi-Dimensional Clustering Multi-Dimensional
Document SpaceDocument Space(image from Wise et al 95)(image from Wise et al 95)

Marti A. HearstSIMS 202, Fall 1997
Clustering Multi-Dimensional Clustering Multi-Dimensional Document SpaceDocument Space(image from Wise et al 95)(image from Wise et al 95)

Marti A. HearstSIMS 202, Fall 1997
Concept “Landscapes” from Concept “Landscapes” from Kohonen Feature Maps Kohonen Feature Maps (X. Lin and H. Chen)(X. Lin and H. Chen)
Pharmocology
Anatomy
Legal
Disease
Hospitals

Marti A. HearstSIMS 202, Fall 1997
Graphical Depictions of Graphical Depictions of ClustersClusters
Problems:Problems: Either too many concepts, or too Either too many concepts, or too
coarse coarse Only one concept per documentOnly one concept per document Hard to view titlesHard to view titles Browsing without searchBrowsing without search

Marti A. HearstSIMS 202, Fall 1997
Another Approach to Term Another Approach to Term Weighting:Weighting:Latent Semantic IndexingLatent Semantic Indexing
Try to find words that are similar in Try to find words that are similar in meaning to other words by:meaning to other words by: computing document by term matrix
a matrix is a two-dimensional vector processing the matrix to pull out the
main themes

Marti A. HearstSIMS 202, Fall 1997
Document/Term MatrixDocument/Term Matrix
ntnnn
t
t
t
dddD
dddD
dddD
TTT
...
....
....
...
...
...
21
222212
112111
21
ijij DTd in of value

Marti A. HearstSIMS 202, Fall 1997
Finding Similar TokensFinding Similar Tokens
ntnnn
t
t
t
dddD
dddD
dddD
TTT
...
....
....
...
...
...
21
222212
112111
21
ijij DTd in of value
n
iikijkj ddTTsim
1
),(
Two terms are considered similar if they co-occur often in many documents.

Marti A. HearstSIMS 202, Fall 1997
Document/Term MatrixDocument/Term Matrix
This approach doesn’t work wellThis approach doesn’t work well Problems:Problems:
Word contexts too large Polysemy
Alternative ApproachesAlternative Approaches Use Smaller Contexts
Machine-Readable Dictionaries Local syntactic structure
LSI (Latent Semantic Indexing) Find main themes within matrix