segmentation, content extraction and visualization of ... · pdf filesegmentation, content...
TRANSCRIPT

Segmentation, Content Extraction and Visualization of
Broadcast News Video using Multistream Analysis
Mark Maybury, Andrew Merlino, James Rayson
Advanced Information Systems CenterThe MITRE Corporation
202 Burlington RoadBedford, MA 01730, USA
{ maybury, andy, jrayson } @mitre.org
AbstractThis paper reports the development of a broadcastnews video corpora and novel techniques toautomatically segment stories, extract proper names,and visualize associated metadata. We report storysegmentation and proper name extraction results usingan information retrieval inspired evaluationmethodology, measuring the precision and recallperformance of our techniques. We briefly describeour implementation of a Broadcast News Analysis(BNA’~) system and an associated viewer, BroadcastNews Navigator (BNNTM). We point to current effortstoward more robust processing using multistreamanalysis on imagery, audio, and closed-captionstreams and future efforts in automatic videosummarization and user-tailored presentationgeneration.
1. Problem and Related Research
Content based video access is a valuable capability forseveral important applications including videoteleconference archiving, video mail access, andindividualized video news program generation. The currentstate of the art for commercial video archives focuses onmanual annotation (Davis 1991), which suffers fromproblems of accuracy, consistency (when performed bymore than one operator), timeliness, scalability, and cost.Just as information retrieval techniques are required tomanage large text collections, video sources require similarindexing and storage facilities to support real-time profilingas well as retrospective search. Within the imagery stream,techniques performing in the ninety plus percent accuracyrange have been developed to index video based on visualtransitions (e.g., dissolve, fade, cut) and shot classification(e.g., anchor versus story shots (Zhang et al. 1994). Othershave investigated linguistic streams associated with video(e.g., closed captions, transcripts), indexing keywords andassociated video keyframes to create static and hypertextdepictions of television news (Bender & Chesnais 1988,Shahraray & Gibbon 1995). Unfortunately, inverted
indices of keywords (even when supplemented withlinguistic processing to address complexities such assynonymy, polysemy, and coreference) will only supportmore traditional information retrieval tasks as opposed tosegmentation (required for higher level browsing),information extraction, and summarization. More complexlinguistic processing is reported by (Taniguchi et al. 1995),who use Japanese topic markers such as "ex ni tsuite" and"wa" ("with regard to", "as for"), subject/object markers, well as frequency measures to extract discourse structuresfrom transcripts, which are then used to provide topic-oriented video browsers.
It has become increasingly evident that moresophisticated single and multistream analysis techniqueswill be required not only to improve accuracy but tosupport more fine grained access to content and to provideaccess to higher level structure (Aigraine 1995). (Brown al. 1995), for example, provide content based access tovideo using a large scale, continuous speech recognitionsystem to transcribe associated audio. In the InformediaTM
project, (Hauptmann & Smith 1995) perform a series multistream analyses including color histogram changes,optical flow analysis, and speech transcription (usingCMU’s Sphynx-II System). Similarly, we have found need to correlate events such as subject changes andspeaker changes to improve the accuracy of indexing andretrieval.
In (Mani et al. 1996), we report our initial efforts tosegment news video using both anchor/reporter and topicshifts identified in closed-caption text. In this paper, wereport our more recent results, which include thecorrelation of multiple streams of analysis to improve storysegmentation performance, the extraction of facts from thelinguistic stream, and the visualization of extractedinformation to identify trends and patterns in the news.Through the creation of a manually annotated videocorpora representing ground truth and an associated set ofevaluation metrics and methods, we are able to reportstatistical performance measures of our algorithms.
102
From: AAAI Technical Report SS-97-03. Compilation copyright © 1997, AAAI (www.aaai.org). All rights reserved.

2. Video Corpora
Unlike the image processing, text retrieval, and messageunderstanding communities, there exists no standard set ofdata and evaluation benchmarks for content based videoprocessing. We have therefore created two data sets frommajor network news programs from two time segments:17.5 hours during one week in 1991 (7/15/91 to 7/23/91)and approximately 20 hours over three weeks in 1996(I/22/96-2/14/96). Our database includes the audio, video,and closed captions associated with programs such as CNNPrime News, PBS’s MacNeil Lehrer News Hour (now theJim Lehrer News Hour), ABC World News Tonight, ABCNightline, CBS Evening News, and NBC Evening News.We have manually annotated representative programs withinformation about anchor/reporter handoffs, story start/end,story inserts within larger stories, and commercial initiationand termination. We are in the process of semi-automatingthe markup of this corpora to include not only storysegments but also all mentioned named entities (e.g.,people, organizations, locations, moneys, dates). By usingtraining and test subsets, we can automatically measure theperformance of our automated segmentation andinformation extraction algorithms using scoring programs.
VideoSource
3. System Overview and Multistream Analysis
Figure 1 illustrates the overview of our Broadcast NewsAnalysis BNATM system and our associated viewer,Broadcast News Navigator BNNTM. BNA consists of anumber of multistream analyses. Analysis tools process theimagery, audio, and textual streams and store the gatheredinformation in a relational and a video databasemanagement system (collectively referred to as thevideo/metadata library in the Figure 1).
For the imagery stream associated with video, we usecommercial scene transition detection hardware/software(Scene Stealer TM 1996) together with keyframe selectionheuristics we have engineered based on the structure ofindividual video programs. For example, keyframes for atypical story containing a reporter segment are selectedfrom the center of the reporter segment. For audio analysis,we are experimenting with speaker change detectionalgorithms created at MIT Lincoln Laboratory. For theclosed-caption textual stream, we automatically detectcommercials, story segments, and named entities, detailsand results of which we present below. We are currentlycollaborating with CMU (Hauptmann & Smith 1995) measure how spoken language transcription will effectperformance results of story segmentation and named entitytagging.
Broadcast News Analysis (BNA) Broadcast NewsNavigator (BNN)
Imagery
Text
SegregateVideo
Streams
Analyze and Store Video and Metadata
Figure 1. System Architecture
Web-based Search~Browse byProgram, Person, Location, ...
103

The closed-caption text and the results from the imagery,audio, and text analysis (metadata) are stored in a relationaldatabase management system with associated audio andvideo stored in MPEG-1 format in a video managementsystem to provide real-time, streamed access. To supportevaluation, the relational database includes both manualannotations of ground truth as well as automaticallygenerated analysis. To enable cross stream referencing,data in the database management system is both temporallyannotated and semantically correlated (e.g., speakerchanges in the audio channel are related to speaker andstory changes detected in closed-caption text).
Figure 2 provides a temporal visualization of cross-channel processing results applied to the ABC World NewsTonight broadcast of 22 January 1996. The X-axis ismeasured in seconds from the start of the news program.Human annotations (ground truth) appear in the first row the Y-axis and include the start and end points of anchor,reporter, and commercial segments as well as inserts. Startpoints appear slightly above end points for anchor, reporter,and commercials. An insert is a 10-second or shortersegment of supporting information (typified by a newspeaker or new scene) inserted within an anchor or reportersegment. Commercials (circled in ovals) are simplyindicated by a start and end point per contiguous sequenceof commercials, with no annotation to indicate the start and
end of each commercial nor speaker changes withincommercials. The "all cues" line is the union of the above.
Row two of Figure 2 indicates the results of speakerchange detection software applied to the audio stream. Theaudio stream is subdivided into series of non-overlappingwindows that are 2, 5, 10, and 20 seconds in length.Feature vectors are derived for each window and anentropy distance metric is used to measure the change fromwindow to subsequent window. Changes exceeding athreshold are illustrated.
The third row of the figure indicates scene changes ofimage content derived from video frames extracted at onesecond intervals from the video stream for a thresholdvalue of 10,000. The scene change line illustrates that,without detailed models of anchor and reporter shots as in(Zhang et al. 1995), our image stream segmentor overgenerates. The scene change data appears to lag the otherdata by several seconds. This is due to some limitations inhow clock initialization is performed in the scene changedetection system and will be corrected by our currenttransition to SMPTE time code as the common time source.The fourth row of the figure shows anchor, reporter, andcommercial segments as well as operator cues and blanklines extracted from the closed-caption stream, algorithmicdetails of which we describe next.
ABC 22 Jan 96: Truth + Speech + Scene +Text
¯ 41~140, 488, 41,
II,q~@o
l& ’1600Elapsed Seconds
18
Figure 2. Cross Channel Processing Results
TruthAnchor S/EReporter S/EInsertCommercialsAll Cues
Speech25
1020Scene Change10,000
CC TextAnchor S/EReporter S/EDouble (>>)Triple (>>>)BlankCommercials
~0
104

The upside down U-shaped lines show the anchor segmentspaired with their associated reporter segments. In theground truth they are interspersed by blank spacecorresponding to commercials which, of course, contain noanchor or reporter segments. In the closed-caption datathese "U" shapes are connected by dashed lines whicherroneously show long anchor segments that incorporatethe commercials that have not yet been removed.
Note the correlation of ground truth segments toautomatically derived segments from the closed captions.There is also correlation of both of these to the speech data,particularly when using clusters of events identified in the20-second windows to identify commercials. There is alsosome correlation with the scene change detection and the"all cues" line in the human annotation. In future work weintend to exploit additional information in the audiochannel, such as emphasis detection (via intonation) andmusic detection. We are experimenting with variousmethods of improving this processing, including computingconfidence measures in segments based on the number andstrength of individual channel analyses.
4. Discourse Analysis for Story Segmentation
Human communication is characterized by distinctdiscourse structure (Grosz & Sidner 1986) which is usedfor a variety of purposes including mitigating limitedattention, signaling topic shifts, and as a cue for shift ininterlocutor control. Motivated by this, we haveinvestigated the use of discourse structure to analyzebroadcast news. In (Mani et al. 1996) we report our initialexperiments with topic segmentation and storysegmentation of closed-caption text, the former usingthesaurus based subject assessments (Liddy & Myaeng1992), the latter on explicit turn taking signals (e.g.,anchor/reporter handoffs). We have investigated additionalnews programs, refining our discourse cue detectors tomore accurately detect story segments. Closed-caption textpresent a number of challenges, as exemplified in Figure 3,including errors created by upper case text and during
transcription (e.g., errors of omission, commission, andsubstitution).
We have identified three parallel sources ofsegmentation information within the closed-caption stream:structural analysis, closed-caption operator cues, anddiscourse cues. Together they provide redundantsegmentation cues that can be correlated and exploited toachieve higher precision and recall. For ABC World NewsTonight the structural analysis shows that:
¯ broadcasts always start and end with theanchor,
¯ each reporter segment is preceded by anintroductory anchor segment and togetherthey form a single story, and
¯ commercials serve as story boundaries.In MacNeil-Lehrer, the structure provides not only
segmentation information but also content information foreach segment. The series of segments is consistently:
¯ preview of major stories of the day or in thebroadcast program
¯ sponsor messages¯ summary of the day’s news (only partial
overlap with major stories)¯ four to six major stories¯ recap summary of the day’s news¯ sponsor messages
There is often further discourse structure with the majorstory segments as well as specialized types of stories (e.g.,newsmaker interviews). The above program structure isillustrated in Figure 3, which starts with a news/programpreview followed by a sponsor message, followed by thenews summary, and so on. This means that aftersegmenting the broadcast we can identify summaries of theday’s news, a preview which serves as a summary of themajor stories in the broadcast, and the major storiesthemselves. A user wishing to browse this one-hournewscast needs only to view a four-minute openingsummary and a 30-second preview of the major stories.Similarly, sponsor messages can be eliminated. These arethe building blocks of a hierarchical video table ofcontents.
I05

S . Errors Omission __ Upcase
GOOD EVENING. LEADII~Q THE NEW,THIS THUF~rA~I~T~HE SENATLL.I~t~SED BILLS TO FORCE AIDS.INFECTED HEALTH WORKERS TODISCLOSE THEIR DISF.~E. PRESIDEI~r BUS~IXAIDT~r W~ TO GRANT--SOVIET UNION SPECIAL TRADE BENEFITS AS BOON AS
-- ¯ POESIBLE. AND THF..~.S. AND SYRIA RGBIED ON TER1BG OF"AJMIDEAST PEACE’~Q~IFERENCE. WE’LL HAVE THE DETAILS IN OUR NEWSb, revle.~_.__w
:UFTM:;TR~~TE~ AIDS TESTING FUNDING FOR THESponsor NEWSHOUR/~[IR~EEN P~I~IDED BY~4C~ANO BY THE COR~"A~-.~_QN =e~a m’a’ v" =-SI~ASTING. AND BY THE FINANCIAL
~ SSED TWO BILLS O~EETING FOR KHAERK KWORKERS
Ji ~,4"~.OMETH~,.~J=,NJq’E GAVE ITSELF A 23% PAY RAISE LAST NIGHT. BY A VOTE OF 83-48, SENATORS DID WHAT HOUSE MEMBERS DID AI ~r~NaS, THEY WILL NO LONGER BE ABLE TO ACCEPT MONEY FORI ~P~i~O ENGAGEMENTS~ SAID THE PAY INCREASE WAS LONG OVERDUE.I
ESPONSIBLE AND ACCOUNTABLE PIECE LEGISLATION. IT BANS HONOR ARIA ANO IT MAKES THE PAY OF SENATORS EQUIVALENT OFTHAT THERE THE HOUSE. IN THE OVERALL LEVEL OF COMPENSATION OF SENATORS, INCLUDING ONRARIA, THERE IS NO CHANGE.
TODAY, CONSUMER ADVOCATE RALPH NADER cRmc,zED THE SENATE’S ACTION~ InsertionsNewsRummervTO A HUGE PAY INCREAEE DIRECTLY IN THE FACE OF MALLSIVE GOVERNMENT DE~GIT~, C~BACKS IN CRITICAL PRACTICALS. THE-- "¯ MAJORITY OF SENATORS HAVE STIFFED THE AMERICAN PEOPLE, AND THIS ~HE VOTERS WILL REMEMBER IN NOVEMBER.
BLACK LEADERS SPOKE OUT ABOUT SUPREME COURT NOMINE~JDi~’RENCE THOMAS TODAY. THE CONGRESSIONAL BLACK CAUCUSFORMALLY ANNOUNCED ITS OPPOSmON TO THE NOMINA]]GhI~I~ COALITION OF CONSERVATIVE BLACK LEADERS SAID SUCHATTACKS ARE UNFAIR. THEY ,AI~..TJ;IQMALI~L~B~F~,.tRtE VICTIM OF A "POLmCAL LYNCHING." BOTH GROUPS SPOKE AT NEWS
~s-’~os BUS. TODAY DECKS THE .RET ~.ERIDAN PRE~DE~r TO VISIT GREECE IN MORE TH~ rH,R~ YEARS HECHALI.ENGED GREECE AND TURKEY TO END THEIR LONG DISPUTE OVER THE ISLAND OF CYPRUS BY THE END OF THE YEAR. HE MADETHE REMARKS IN AN ADDRE88 TO THE GREEK PARLIAMENT AND PLEDGED U.S. HELP IN RESOLVING THE FEUD. LATER, RIOT POLICEFOUGHT SEVERAL THOUSAND GREEK 81"UDENTS PROTESTING IN THE STREETS OUTSIDE A STATE DINNER FOR THE PRESIDENT. THEETUDENTIB HURLED GASOLINE BOMBS AND STONES. THE POLICE FIRED BACK WiTH TEAR GAS. OFFICIALS SAID A NUMBER OF PEOPLEWERE INJURED, BUT RELEASED NO FIGURE. WHILE IN GREECE, PRESIDEHT BUSH SAID HE WANTED TO GRANT THE SOVIET UNION8PECIAL TRADE STATUS AS SOON AS PO$81BLE. HE SAID FOR NOW "TECHNICAL PROBLEMS" WITH SOVIET LEGISLATION LOOSENINGTHE COUNTRY’S EMIGRATION LAW8 WERE STANDING IN THE WAY. MR. OORBACHEV ALEO WON NEW PLEDGES OF HELP FROMCANADA AND GREAT BRITAIN AS HE CONTINUED HIS LONDON VIEIT. WE HAVE MORE FROM MARK WEBSTER OF INDEPENDENTTELEVISION NEWS.
Figure 3. Closed-Caption Challenges(MacNeil-Lehrer, July 19, 1991)
The closed-caption operator cues are supplementaryinformation entered by the closed-caption operators as theytranscribe the speech to closed-caption text as an aid toviewers. Most notable is the ">>" cue used to indicate achange in speaker and ">>>" cue used to indicate a changein story. When available, the closed-caption operator cuesare a valuable source of information; however, their use byclosed-caption operators are not standard. While mostbroadcast news sources provide the speaker changeindicator, the story change indicators are present for somesources (ABC, CNN) and absent for others (CBS,MacNeil-Lehrer).
It is important to note that the three types ofsegmentation information identified for closed-caption textalso apply to broadcast sources with no supporting closed-caption data. After speech-to-text processing, the resultingtext stream can be analyzed for both structural anddiscourse cues, of course subject to transcription errors. Inaddition, speaker change identification software can beused to replicate the bulk of the closed-caption operatorcues.
4.1 ABC News SegmentationThe ABC news closed-caption segmentation illustrated atthe bottom of Figure 2 is performed using Perl scripts thatexploit a combination of all three types of segmentationinformation. These build on techniques applied by (Mani
et al. 1996) in which the anchor/reporter andreporter/anchor handoffs are identified through patternmatching of strings such as:
- (word) (word) ", ABC NEWS"- "ABC’S CORRESPONDENT" (word) (word)The pairs of words in parentheses correspond to the
reporter’s first and last names. Broadcasts such as ABCNews have very consistent dialog patterns which ensurethat a small set of these text strings are pervasive withinand across news programs. Combining the handoffs withstructural cues, such as knowing that the first and lastspeaker in the program will be the anchor, allows us todifferentiate anchor segments from reporter segments. Weintend to generalize the text strings we search for bypreprocessing the closed-caption text with MITRE’s part ofspeech tagger. It will allow us to identify proper nameswithin the text in which case the strings we search from willbecome:
- (proper name) ", ABC NEWS"- "ABC’S CORRESPONDENT" (proper name)A combination of structural and closed-caption operator
cues allow us to identify commercials. The end of asequence of commercials in the closed-caption text isindicated by a blank line followed by a line containing achange of speaker (>>) or new story (>>>) indicator. then search backwards to find the beginning of thesequence which is indicated by a ">>" or ">>>", followed
106

by any number of non-blank lines, followed by a blank line.The blank lines correspond to the short (0.5 to 3 seconds)silences which accompany the transitions from news tocommercials and back to news. This approach tocommercial detection works well as shown in Figure 2.Having the ability to identify and extract commercials alsobenefits our proper name extraction and summarizationroutines.
4.2 MacNeil-Lehrer News Segmentation
Hand analysis of multiple programs reveals that regularcues are used to signal these shifts in discourse, althoughthis structure varies dramatically from source to source.For MacNeiI-Lehrer, discourse cues can be classified intothe following categories (numbers in parenthesis indicatefrequency and/or location of examples in one week worthof data, items in square brackets indicate variations):
¯ Start of Preview (of news and program)- GOOD EVENING. LEADING THE NEWS THIS[MONDAY, TUESDAY, WEDNESDAY ...] (almostevery day)- GOOD EVENING. THE OPENING OF THEBUSH- GORBACHEV SUMMIT LEADS THENEWS THIS TUESDAY
¯ End of Preview (~lso start of News Summary)- BY THE CORPORATION FOR PUBLICBROADCASTING AND BY THE FINANCIALSUPPORT OF VIEWERS LIKE YOU.,(every day)
¯ End of News Summary, Start of Main Stories- THAT ENDS OUR SUMMARY OF THE DAY’STOP STORIES. AHEAD ON THE NEWSHOUR,LIFE INSURANCE PROBLEMS,- THAT’S IT FOR THE NEWS SUMMARYTONIGHT. [NOW IT’S ON TO THE MOSCOWSUMMIT]- ON THE NEWSHOUR TONIGHT, THE SUMMITIS OUR MAIN FOCUS.
¯ New,maker Interview- WE GO FIRST TONIGHT TO A NEWSMAKERINTERVIEW WITH THE SECRETARY OFDEFENSE, DICK CHENEY...- WE TURN NOW TO A NEWS MAKERINTERVIEW WITH NICHOLAS BRADY WHOJOINS US FROM LONDON.- NOW IT’S ON TO NEWSMAKER INTERVIEWSWITH- In interview segments, "DR. FISCHER INBOSTON?, MR. SCHULMANN., DR. SHELTON?,R. FISCHER?
¯ Anchor/Ret~orter Transition, Speaker Change- WE’LL HAVE DETAILS IN OUR NEWSSUMMARY IN A MOMENT. [JIM, ROGER MUDDIS IN WASHINGTON TONIGHT. ROGER]- WE’LL HAVE THE DETAILS IN OUR NEWSSUMMARY IN A MOMENT. [ROBIN, JUDYWOODRUFF IS IN NEW YORK TONIGHT.]
¯ Start of a New Main Story- WE TURN NOW TO [ROGER MUDD, THE MAN,A LOOK AT], WE TURN FIRST TONIGHT TO- OUR LEAD [STORY, FOCUS] TONIGHT- FIRST TONIGHT, WE FOCUS ON...- STILL AHEAD, STILL TO COME ON THENEWSHOUR TONIGHT,- NEXT (2), NEXT TONIGHT (2)- NOW, AN OVERVIEW- ROGER MUDD HAS THE DETAILS- MARK, I’M SORRY, WE HAVE TO GO- FINALLY TONIGHT (3), WE CLOSE TONIGHTWITH A
¯ Recap- AGAIN THE MAIN STORIES OF THIS[MONDAY, TUESDAY ..... ]- AGAIN, THE MAJOR STORIES OF THIS[TUESDAY, WEDNESDAY, THURSDAY .... ]
¯ Close- I’M JIM LEHRER. THANK YOU, AND GOODNIGHT (2)- GOOD NIGHT [ROBIN (3) ROGER]- GOOD NIGHT, JIM. THAT’S THE NEWSHOURTONIGHT. WE’LL SEE YOU TOMORROWNIGHT. I’M ROBERT MACNEIL. GOOD NIGHT.FUNDING FOR THE NEWSHOUR- WE’LL SEE YOU TOMORROW NIGHT. (3)- THAT’S OUR NEWSHOUR FOR TONIGHT- FUNDING FOR THE NEWSHOUR HAS BEENPROVIDED BY [2] ... AND BY THE FINANCIALSUPPORT OF VIEWERS LIKE YOU
The regularity of these discourse cues from broadcast tobroadcast provides an effective foundation for discourse-based segmentation routines. However, as mentioned, thisis not the only effective mechanism for segmentation.Figure 4 shows the results of applying a different type ofclosed-caption segmentation information -- that derivedfrom the structural analysis -- to segment the broadcast. Wewere able to not only segment the broadcast, but alsoidentify each segment as a non-news preamble, preview,summary, story, or non-news epilogue. By viewing severalbroadcasts and simultaneously scanning a hard copy of the
107
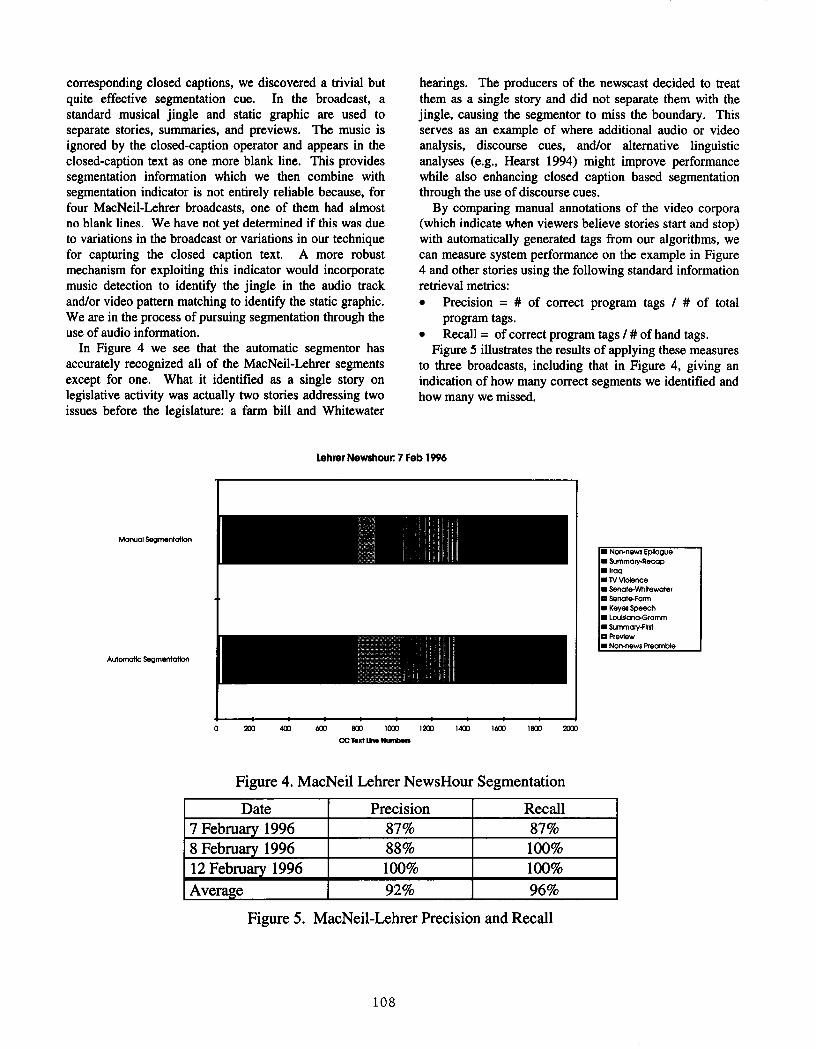
corresponding closed captions, we discovered a trivial butquite effective segmentation cue. In the broadcast, astandard musical jingle and static graphic are used toseparate stories, summaries, and previews. The music isignored by the closed-caption operator and appears in theclosed-caption text as one more blank line. This providessegmentation information which we then combine withsegmentation indicator is not entirely reliable because, forfour MacNeil-Lchrer broadcasts, one of them had almostno blank lines. We have not yet determined if this was dueto variations in the broadcast or variations in our techniquefor capturing the closed caption text. A more robustmechanism for exploiting this indicator would incorporatemusic detection to identify the jingle in the audio trackand/or video pattern matching to identify the static graphic.We are in the process of pursuing segmentation through theuse of audio information.
In Figure 4 we see that the automatic segmentor hasaccurately recognized all of the MacNeil-Lehrer segmentsexcept for one. What it identified as a single story onlegislative activity was actually two stories addressing twoissues before the legislature: a farm bill and Whitewater
hearings. The producers of the newscast decided to treatthem as a single story and did not separate them with thejingle, causing the segmentor to miss the boundary. Thisserves as an example of where additional audio or videoanalysis, discourse cues, and/or alternative linguisticanalyses (e.g., Hearst 1994) might improve performancewhile also enhancing closed caption based segmentationthrough the use of discourse cues.
By comparing manual annotations of the video corpora(which indicate when viewers believe stories start and stop)with automatically generated tags from our algorithms, wecan measure system performance on the example in Figure4 and other stories using the following standard informationretrieval metrics:¯ Precision = # of correct program tags / # of total
program tags.¯ Recall = of correct program tags / # of hand tags.
Figure 5 illustrates the results of applying these measuresto three broadcasts, including that in Figure 4, giving anindication of how many correct segments we identified andhow many we missed.
Lehrer Newshour. 7 Feb 1996
Monuol Segmentation
Automatic Segmentation
¯ Non-news Epilogue¯ Summary.Recap¯ Iraq¯ "IV Violence¯ Senoto-Whh’ewoter¯ Senate-Farm¯ Keyes Speech¯ Loulslona-Gramm¯ Summa~’-Flrst[] Preview¯ Non-news Pi’eomble
0 200 400 600 800 lOOO 1200 1400 1600 1800 2000
CC Text LIM, N~
Figure 4. MacNeil Lehrer NewsHour Segmentation
Date Precision Recall7 February 1996 87% 87%
8 February 1996 88% 100%
12 February, 1996 100% 100%
Average 92% 96%
Figure 5. MacNeil-Lehrer Precision and Recall
108
The only errors in boundary detection were due toerroneously splitting a single story segment into two storysegments, or merging two contiguous story segments into asingle story segment. That means that in all cases for allbroadcasts the segment type labels, which identify thecontent of the segment (e.g,, preview, news summary,story) are correct. The precision and recall values arealready quite good for this small sample size, especiallysince we have only applied the segmentation analysis cues.Applying the discourse and closed caption operator cuesshould improve these results further (a currentimplementation). Our perfect results for segment typesclassification enables us to derive a table of contents for thebroadcast, along with a high quality summary of the entirebroadcast, without the use of complex automatedsummarization algorithms.
5. Named Entity Extraction and StorySummarization
In addition to detecting segments and summarizing stories(for search or browsing), it is also important to extractinformation from video, including who did what to who,when, where and how. For this problem, we have applied aproper name tagger from the Alembic System (Aberdeen etal. 1995). This trainable system applies the same generalerror-reduction learning approach used previously for
generating part-of-speech rules designed by (Brill 1994) the problem of learning phrase identification rules.
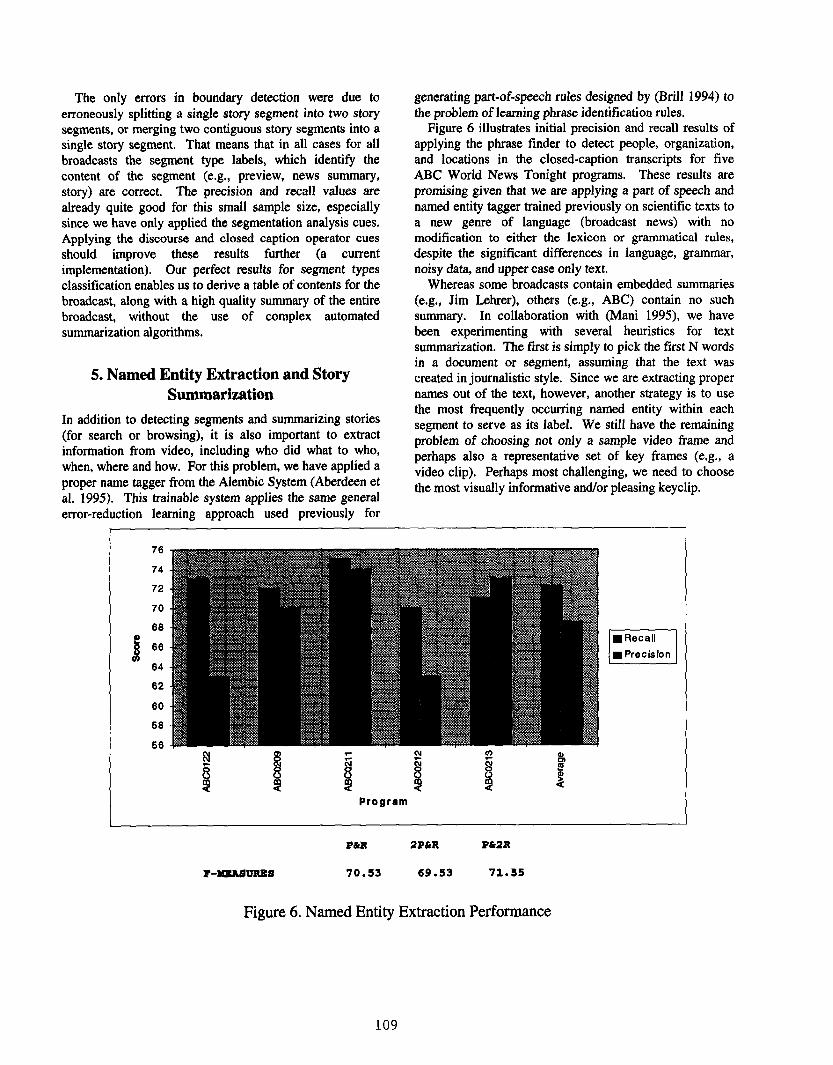
Figure 6 illustrates initial precision and recall results ofapplying the phrase finder to detect people, organization,and locations in the closed-caption transcripts for fiveABC World News Tonight programs. These results arepromising given that we are applying a part of speech andnamed entity tagger trained previously on scientific texts toa new genre of language (broadcast news) with modification to either the lexicon or grammatical rules,despite the significant differences in language, grammar,noisy data, and upper case only text.
Whereas some broadcasts contain embedded summaries(e.g., Jim Lehrer), others (e.g., ABC) contain no summary. In collaboration with (Mani 1995), we havebeen experimenting with several heuristics for textsummarization. The first is simply to pick the first N wordsin a document or segment, assuming that the text wascreated in journalistic style. Since we are extracting propernames out of the text, however, another strategy is to usethe most frequently occurring named entity within eachsegment to serve as its label. We still have the remainingproblem of choosing not only a sample video frame andperhaps also a representative set of key frames (e.g., video clip). Perhaps most challenging, we need to choosethe most visually informative and/or pleasing keyclip.
76
74
72
70
68
66
64
62
60
58
56
Program
I:Recall
Pr e c is ion
P&R 2P&R P&2R
70.53 69.53 71.55
Figure 6. Named Entity Extraction Performance
109

6. Application to Network News AccessUsing the above segmentation and information extractiontechniques, we have developed BNN to enable a user tosearch and/or browse the original video by program, date,person, organization, location or topic of interest. WithinBNN, a web user can first specify particular broadcast newsagencies and time periods they are interested in searching.BNN will generate a list of named entities with theirfrequencies sorted in descending order. Figure 7 illustratessuch a response to a user query indicating, among otherthings, that there were many references to the "FAA","GINGRICH" and "ZAIRE".
With the frequency screen displayed, the user can viewthe stories for one of the values by selecting a value, forexample "ZAIRE". Upon selection of the value, BNNsearches through the 2893 stories discovered in the 163
broadcasts to display the related stories seen in Figure 8.The returned stories are sorted in descending order of keyword occurrence. Each returned story contains the a keyframe, the date, the source, the six most frequent tags, asummary and the ability to view the closed caption, videoand all of the tags found for the story. The summary iscurrently the first line of the segment. In the future, thesystem will extract the sentence, which is most statisticallyrelevant to the query.
While viewing the video, the user has the ability todirectly access the video related to the story segment.Thus, if the story segment starts at six minutes and twelveseconds into the news broadcast, the streaming of the videoto the user will start at that point. While viewing thestreaming video, the user can scroll through out the videowith VCR like controls.
Figure 7. Named Entity (Metadata) Visualization
110

Key ;ource
Closed
6 MostFrequentTags Video
Summary Related Web Sites
Figure 8. Viewing Story Segments that Meet the Query Criteria
8. Limitations and Future Directions
An important area for further research is to createsegmentation and extraction algorithms that are morerobust to signal noise and degradation, perhaps usingconfidence measures across multiple streams as a means forcombining multiple sources of evidence. Ultimately onewould like to automatically acquire both more general andprogram specific segmentation algorithms. In our currentexperiments, we aim to significantly improve the aboveperformance by training both our part of speech and propername tagger on closed-caption and spoken languagetranscripts from our video corpus. We are alsoexperimenting with the accuracy of segmentation andextraction from spoken language transcription (Hauptmann& Smith 1995, Brown et al. 1995) and will contrast theirperformance with that of closed captioned sources. Wefurther seek to evaluate not only segmentation andextraction accuracy, but also efficiency measured in time toperform an information seeking task. We are collaboratingwith (Mani 1995) to extend our system to incorporateautomated story summarization tailored to particular usersinterests as in (Maybury 1995).
information extraction techniques to support news storysegmentation and proper name extraction/visualization. Asin (Taniguchi et al. 1995) work, we report specificperformance results in terms of information retrievalmetrics of precision and recall. These discourse structureand content analyses are an important step toward enablingmore sophisticated customization of automaticallygenerated multimedia presentations that take advantage ofadvances not only in user and discourse modeling (Kobsa& Wahlster 1989) but also in presentation planning, contentselection, media allocation, media realization, and layout(Maybury 1993).
10. Acknowledgments
At MITRE, we are indebted to Inderjeet Mani forproviding text summarization routines, to Marc Vilain andJohn Aberdeen for providing part of speech and propername taggers, and to David Day for customizing these toour domain. We thank Douglas Reynolds of the SpeechSystems Technology Group at MIT Lincoln Laboratory forhis speaker change detection software.
11. References
9. Conclusions
This paper reports on extensions to previous efforts,including automatic discourse structure analysis and
Aigraine, P., Joly, P., and Longueville, V. 1995.Medium Knowledge-based Macro-Segmentationof Video into Sequences. In Maybury, M. (editor)Working notes of IJCAI-95 Workshop on
iii

Intelligent Multimedia Information, 5-16.Retrieval, Montreal.
Aberdeen, J., Burger, J., Day, D., Hirschman, L.,Robinson, P., and Vilain, M. 1995. Description ofthe Alembic System Used for MUC-6. InProceedings of the Sixth Message UnderstandingConference. Advanced Research Projects AgencyInformation Technology Office, 6-8. Columbia,MD.
Bender, W., and Chesnais, P. 1988. NetworkPlus. SPIE Vo1900 Imaging Applications and theWork World 81-86. Los Angeles, CA.
Bender, W., H~tkon, L., Owrant, J., Teodosio, L.,Abramson, N. Newspace: Mass Media andPersonal Computing 329-348. USENIX, Summer’91, Nashville, TN.
Brill, E. Some Advances in Rule-Based Part ofSpeech Tagging. In Proceedings Proceedings ofthe Twelfth National Conference on ArtificialIntelligence, 722-727. Seattle, WA.
Brown, M. G., Foote, J. T., Jones, G.J.F., Sparck-Jones, K., and Young, S. J. Automatic Content-Based Retrieval of Broadcast News. InProceedings of ACM Multimedia 1995 35--44.San Francisco, CA.
Davis, M. Director’s Workshop: Semanticlogging with Intelligent Icons. In Maybury (ed.),In Proceedings of the AAAI Workshop onIntelligent Multimedia Interfaces 122-132.
Mani, I., House, D., Maybury, M. and Green, M.Towards Content-Based Browsing of BroadcastNews Video. to appear in Maybury (editor)Intelligent Multimedia Information Retrieval.Forthcoming.
Grosz, B. J. and Sidner, C. July-September, 1986."Attention, Intentions, and the Structure ofDiscourse." Computational Linguistics 12(3):175-204.
Hauptmann, A. and Smith, M. 1995. Text,Speech, and Vision for Video Segmentation: TheInformedia Project. In Maybury, M. (editor)Working notes of IJCAI-95 Workshop onIntelligent Multimedia Information 17-22.Retrieval, Montreal.
Hearst, M. A. Multi-Paragraph Segmentation ofExpository Text, ACL-94, Las Cruces, NewMexico, 1994.
Kobsa, A., and Wahlster, W. (eds.) 1989. UserModels in Dialog Systems. Berlin: Springer-Verlag.
Liddy, E. and Myaeng, S."DR-LINK’s Linguistic-Conceptual Approach to Document Detection",Proceedings of the First Text RetrievalConference, 1992, pub. National. Institute ofStandards and Technology.
Mani, I. .1995 "Very Large Scale TextSummarization", Technical Note, The MITRECorporation.
Maybury, M. (ed) 1993. Intelligent MultimediaInterfaces, Cambridge, MA: AAAI/MIT Press.
Maybury, M. T. 1995. Generating Summariesfrom Event Data. International Journal ofInformation Processing and Management :Special Issue on Text Summarization. 31(5): 735-751.
Proceedings of the Sixth Message UnderstandingConference. Advanced Research Projects AgencyInformation Technology Office, Columbia, MD,6-8 November, 1995.
Dubner, B. Automatic Scene Detector andVideotape logging system, User Guide, DubnerInternational, Inc., Copyright 1995, 14.
Shahraray, B. and Gibbon, D. 1995. AutomatedAuthoring of Hypermedia Documents of VideoPrograms. In Proceedings of ACM Multimedia’95 401-409. San Francisco, CA.
Taniguchi, Y., Akutsu, A., Tonomura, Y. andHamada, H. "An intuitive and efficient accessinterface to real-time incoming video based onautomatic indexing", Proceedings of ACMMultimedia ’95 25-34. San Francisco, CA.
Zhang, H. J., Low, C. Y., Smoliar, S. W., andZhong, D., "Video Parsing, Retrieval, andBrowsing: An Integrated and Content-BasedSolution", Proceedings of ACM Multimedia ’9515-24. San Francisco, CA.
112