selective dissemination of streaming xml by hyun jin moon, hetal thakkar
Post on 19-Dec-2015
218 views
TRANSCRIPT

Selective Dissemination of Streaming XMLBy Hyun Jin Moon, Hetal Thakkar

Overview Introduction Background XFilter
Architecture Implementation Optimizations Experiments/Analysis Conclusion
Related Work: XTrie

Introduction Information Dissemination
Enormous Amount of Data Lots of Users User Profiles
Bag of Keywords Selective Distribution of Data
Applications Stocks, Sports, Traffic, Electronic Personalized
Newspapers, Entertainment, etc.

Introduction (Cont’d) Emergence of XML as Standard of
Information Exchange on Internet Utilize Structure of XML for Better
Dissemination Use XPath(s) for User Profile
Optimizations for Searching a Streaming XML Document for Many XPaths XFilter XTrie Structure

Background: SDI Structure XPath XML Parsers
DOM SAX
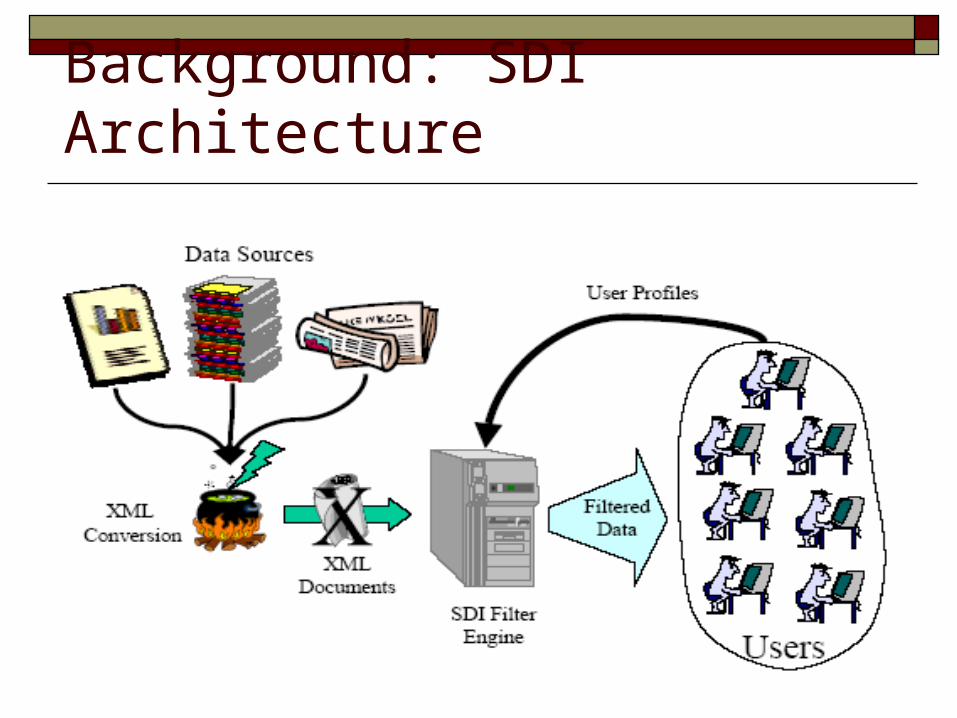
Background: SDI Architecture

Background: XPath Query Structure and Data Enough Complexity for Dissemination Constructs
‘*’ Relative Path
//product[price/msrp<300]/name

Background: XML Parser DOM: Document Object Model SAX: Simple API for XML (SAX)
Standard Interface for Event-Based XML Parsing Suitable for Streaming XML Example:

XFilter Architecture Implementation Optimizations
List Balancing Prefiltering
Experiments/Analysis Conclusions
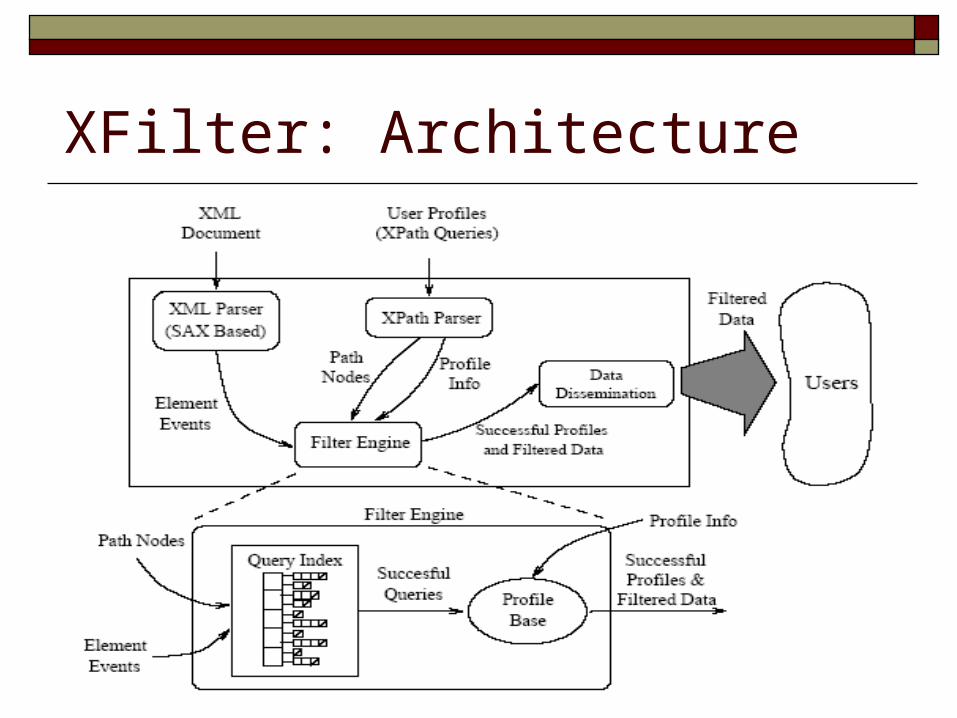
XFilter: Architecture

XFilter: Implementation Filter Engine
Brute Force Approach Instead,
Decompose Queries into Path Nodes Create a Query Index from Path Nodes Build a Finite State Machine on the Query Index As a Document Arrives Traverse the FSM for All
Queries (In One Pass)

XFilter: Implementation Path Nodes:
QueryId Position:
Sequence Number for Path Node in the Query (XPath)
RelativePos: Relative Distance in the Document
Level (Can be Updated During Evaluation): Absolute Level in the XML Document, at Which the
Path Node should be Checked

XFilter: Implmentation Query Index:
Hash Table Key: Element Names that Appear in XPath
Expressions Data: 2 Lists Containing Path Nodes
Candidate List: “Current Node” of Each Query Representing Current State of the Query
Wait List: Path Nodes Representing Future States

XFilter: Implementation

XFilter: Implementation Start Element Handler:
Inputs: Name, Level, and Attribute-Values of the Element Action:
Look-up Element Name in Query Index Examine Nodes in Candidate List
Check Level, etc. If All Checks Succeed AND Final Path Node of Query Then the
Document is Deemed to Match the Query Else If All Checks Succeed Then Move the Query to its Next
State Else Do Nothing

XFilter: Implementation End Element Handler
Input: Element Name Action:
Delete the Corresponding Path Nodes from the Candidate List (for Restoring Purpose)
Element Character Handler Input: Data Action: Similar to Start Element Handler

XFilter: Implementation Example:
Start DocumentStart Element: a Level: 1 Start Element: b Level: 2 Start Element: c Level: 3
End Element: c End Element: bEnd Element: a

XFilter: Implementation

XFilter: Implementation Advanced Features
Attribute Filter Start Element Event Handler
Content Filter Element Character Handler
Nested Path Expression Treat Nested Sub-Queries as Another Query

XFilter: Optimizations List Balancing (LB)
Basic Approach: First Path Node for Each Query in the Candidate List Low Selectivity
Instead, Apply Candidate List Balancing When Adding a New Query to Query Index the Path
Node Who has the Shortest Candidate List is Chosen as the “Pivot” Node
Prefix

XFilter: Optimizations Prefiltering
Eliminate Queries, which have Element Name(s) that are not Present in the Document
Yan and Garcia-Molina’s Key Based Algorithm Assign Key Element of the Queries Create Occurrence Table for Each Arriving Document
Occurrence Table: Hash Table Key: Element Name Data: Queries, Whose Key is this Element
Only Queries in Occurrence Table are Checked Further Thus, Each Input Document is Parsed Twice

XFilter: Experimental SetupParameter Range Description
P 1,000 to 100,000 Number of Profiles
D 1 to 10 Maximum Depth of the XML Document and Queries
W 20% to 80% Probability of a Wildcard (‘*’) in the Element Nodes of the Queries
F 0 to 3 Level of the Element Node Filter in the Queries. 0 Means There is No Element Node Filter.
S 1% to 100% Selectivity of the Element Node Filter
θ 0 and 1 Skewedness of Element Names in Query Generation

Experiment 1.1: The Effect of Number of Profiles Number of Profiles (Standing XPath
Queries) Changes Basic Algorithm Gives the Worst
Performance List Balance Improves Prefiltering Leads to a Greater
Speed-Up Than LB 2.6 % of Profiles Match a Given
Document Basic Algorithm Examines 12% of
Profiles Prefiltering Examines Only 3.5 %
of Profiles

Experiment 1.2: The Effect of Number of Profiles
Number of Profiles Changes – Same as Before
Skewed Selection of Elements – Leads to Unbalanced Query Index (Hash Table) in Basic Algorithm
List Balance is Effective in Balancing the Hash Table

Experiment 2.1:The Effect of Depth Maximum Depth of XML
Documents and Queries Change
More Depth -> More Checking -> Greater Filtering Time
List Balance and Prefiltering Graphs cross at Depth 8. With Higher Depth, Less Prefiltering LB Benefits with More
Choices of Pivot Elements

Experiment 2.2:The Effect of Depth Maximum Depth of XML
Documents and Queries Change
Skewed Selection of Elements LB Effectively Balances the
Skewed Hash Table After Level 4, the Presence of
Element Names in the Queries does not Change Much Due to Skewed Distribution. Workload Characteristics Remain Similar.

Experiment 3:The Effect of Wildcard Wildcard (‘*’) Usage
Probability in Queries Change Prefiltering is Slower with
More Wildcards Prefiltering Takes Extra
Time Trying Filtering, but Prefiltering cannot Filter Out the Wildcards
However, it is Unlikely that Many Profiles will have such a High Proportion of Wildcards.

Experiment 4.1:The Effect of Filter Injected a New Fixed Attribute
Named dummy into the Documents with Certain Probability
Created a Simple Element Node Filter Containing Only that Fixed Attribute
(e.g. [@dummy=“true”]) In this Experiment, a Single
Element Node Filter is Placed in Different Levels of the Query with Fixed Query Selectivity of 10%
The Deeper the Filter, the Longer it Takes to Test

Experiment 4.2:The Effect of Filter Filters are Placed at Level 2,
with Varying Selectivity. Logarithmic Scale on
Selectivity For All Algorithms,
Performance is not Heavily Affected by Filter Selectivity

Summary of Results These Experiments Demonstrate that,
XFilter approach is scalable The Extensions Provide Substantial Improvements
List Balance is Effective When the Distribution of Elements in Queries is Highly Skewed
Prefiltering is Effective in Reducing the Number of Profiles to Examine
Combination of LB-Prefiltering Provides the Best Performance in All Cases
Considering that Distribution of Elements in Queries of SDI Applications is Highly Skewed, and Prefiltering Requires a Space Overhead, Simple LB is Preferable in Many Practical Cases

Conclusions XML Document Filtering System XFilter for
Selective Dissemination of Information (SDI) Expressive Profiles in XPath Query Language Profile Indexing and Matching Algorithms Based
on a FSM Approach Optimization Techniques
List Balancing Prefiltering

Related Work: XTrie Efficient Filtering of XML Documents with
XPath Expression– ICDE 2002 Supports Complex XPath Expressions (As
Opposed to Simple, Single-Path Specifications) e.g. /a/b[c/d//e][g//e/f]//*/*/e/f
Supports Both Ordered and Unordered Matching of XML Data
Ordered Matching: //a//b/*[following-sibling::d]/c Substring-Based Query Indexing 2 to 4 Times Faster Than XFilter