semantic search and intelligence system for the quran · pdf filethe goal of this project is...
TRANSCRIPT

Semantic Search and Intelligence System for the Quran
Karim Ouda
Submitted in accordance with the requirements for the degree of
MSc Advanced Computer Science (Data Analytics)
2014/2015
I
School of ComputingFACULTY OF ENGINEERING

The candidate confirms that the following have been submitted:
Items Format Recipient(s) and Date
Project Report Report SSO (09/09/2015)
Code Software codes Supervisor (08/09/2015)
Type of Project: Exploratory Software
The candidate confirms that the work submitted is their own and the appropriate credit has
been given where reference has been made to the work of others.
I understand that failure to attribute material which is obtained from another source may be
considered as plagiarism.
(Signature of student) ____________________
© 2015 The University of Leeds and Karim Ouda
II

Summary
The goal of this project is to build the first Semantic Search and Intelligence System for the Quran, providing normal users and scholars the ability to search the Quran semantically, analyse all aspects of the text, find hidden patterns and associations using state-of-the-art visualization techniques.
Another aspect of the project is to glue-together previous research done in Leeds University and to provide an opensource framework for Quran Analysis work, paving the way for innovation in this area.
All the above goals were achieved and made accessible through the following website http://www.qurananalysis.com
Acknowledgements
First I would like to thank my supervisor Eric Atwell for his continuous support and guidance,
he gave me all freedom and empowerment I needed to achieve, and he was always there
when I needed help and direction.
Also I would like to acknowledge Sameer Alrehaili for his fruitful discussions and reviews.
Finally I would like to thank my mother whom without her motivation and sacrifice I would not
have been able to achieve this degree.
Dedication
I dedicate this project to whom without their contributions this project would not have been
possible.
• Hamid Zarrabi-Zadeh & Team (Tanzil Project).
• Kais Dukes (Quranic Arabic Corpus).
• Abdul Baqi M. Sharaf (TextMiningTheQuran).
III

مم محي ررر من ال حح ررر مه ال مم الررل حس ممممب
In the name of Allah, the Entirely Merciful, the Especially Merciful.
[All] praise is [due] to Allah, Lord of the worlds. The Entirely Merciful, the Especially Merciful.
Sovereign of the Day of Recompense. It is You we worship and You we ask for help. Guide
us to the straight path - The path of those upon whom You have bestowed favor, not of
those who have evoked [Your] anger or of those who are astray.
Alif, Lam, Meem. This is the Book about which there is no doubt, a guidance for those
conscious of Allah.
- Quran, [1:1 to 2:2] The Opening (Al-Faatiha), The Cow (Al-Baqara) -
Allah will raise those who have believed among you and those who were given knowledge,
by degrees.
- Quran, [58:11] The Pleading Woman (Al-Mujaadila) -
And they ask you, [O Muhammad], about the soul. Say, "The soul is of the affair of my Lord.
And mankind have not been given of knowledge except a little”.
- Quran, [17:85] The Night Journey (Al-Israa) -
So high [above all] is Allah, the Sovereign, the Truth. And, [O Muhammad], do not hasten
with [recitation of] the Qur'an before its revelation is completed to you, and say, "My Lord,
increase me in knowledge”.
- Quran, [20:114] Taa-Haa -
When a human being dies, all of his deeds are terminated except for three types: an
ongoing charity, knowledge from which others benefit, and a righteous child who makes
prayer for him.
- Prophet Mohamed [Sahih Muslim] -
IV

Table of Contents
Summary..............................................................................................................................
Acknowledgements.............................................................................................................
Dedication............................................................................................................................
Table of Contents.................................................................................................................
1 - Introduction & Background............................................................................................
1.1 Terminologies..................................................................................................1
1.2 Overview.........................................................................................................1
1.3 Motivation........................................................................................................2
1.4 Goals...............................................................................................................2
1.5 Problem...........................................................................................................3
1.5.1 Research Questions............................................................................4
1.5.2 Challenges..........................................................................................5
1.6 Methodology....................................................................................................6
1.7 Data Sources..................................................................................................6
1.8 Project Management.......................................................................................7
1.9 Deliverables....................................................................................................7
2 - Literature Review............................................................................................................
2.1 NLP & Data Mining..........................................................................................8
2.2 Semantic Search & Ontology Extraction..........................................................8
2.3 Visualization....................................................................................................9
2.4 Question Answering........................................................................................9
3 - Ontology Extraction........................................................................................................
3.1 Introduction.....................................................................................................9
3.2 Iteration 1......................................................................................................11
3.2.1 Term Extraction & Concept Formation...............................................11
3.2.2 Phrase Concepts...............................................................................13
3.2.3 Concepts Extraction From Pronoun Antecedents..............................14
3.2.4 Final List of Concepts........................................................................15
3.2.5 Non-Taxonomical Relations...............................................................16
3.2.6 Extracting New Concepts from Relations..........................................25
3.2.7 Basic Taxonomical Relations.............................................................26
3.2.8 Translation and Transliteration...........................................................27
3.2.9 Concept Enrichment using DBpedia..................................................28
V

3.2.10 Custom and Realtime Translations..................................................29
3.2.11 Concept Enrichment Using Wordnet................................................30
3.2.12 Exclusions.......................................................................................32
3.2.13 Final Post-processing......................................................................34
3.2.14 Generating Ontology OWL File........................................................35
3.3 Iteration 2......................................................................................................36
4 - Quran Analysis Website – Qurananalysis.com...........................................................
4.1 Website Design.............................................................................................36
4.1.1 Logo & Domain Name.......................................................................36
4.1.2 Structure............................................................................................37
4.2 Technology....................................................................................................38
4.3 Data Models..................................................................................................38
4.4 Search...........................................................................................................38
4.4.1 Search Engine...................................................................................39
4.4.2 Search Flow......................................................................................39
4.4.3 Relevance.........................................................................................40
4.5 Explore..........................................................................................................41
4.6 Analyze.........................................................................................................41
4.7 Opensource Initiative.....................................................................................41
5 - Analysis Tools...............................................................................................................
5.1 Basic Statistics..............................................................................................42
5.2 Word Frequency............................................................................................42
5.3 Word Clouds.................................................................................................43
5.4 Full Text.........................................................................................................43
5.5 Charts...........................................................................................................43
5.6 N-Grams.......................................................................................................44
5.7 PoS Patterns.................................................................................................44
5.8 PoS Query....................................................................................................44
5.9 Repeated Verses...........................................................................................44
5.10 Repeated Phrases......................................................................................45
5.11 Ontology Data.............................................................................................45
5.12 Ontology Graph...........................................................................................45
5.13 Uthmani to Simple.......................................................................................45
5.14 Word Information.........................................................................................46
5.15 Collocation..................................................................................................46
VI

5.16 Concordance...............................................................................................47
5.17 Pause Marks...............................................................................................47
5.18 Buckwalter to Arabic Transliteration Mapping..............................................48
5.19 Word Similarity............................................................................................48
5.20 Quran Initials...............................................................................................48
6 - Visualization..................................................................................................................
6.1 Search Results Graph...................................................................................49
6.1.1 Ontology Graph.................................................................................49
6.1.2 Word Cloud........................................................................................52
6.1.3 Distribution Chart...............................................................................53
6.2 Exploratory Search........................................................................................54
6.2.1 Experiments......................................................................................54
6.2.2 Final Solution.....................................................................................55
7 - Question Answering......................................................................................................
7.1 Detecting Question........................................................................................57
7.2 PoS Tagging..................................................................................................57
7.3 Question Enrichment.....................................................................................57
7.4 Extract Answer from Ontology.......................................................................59
7.4.1 Searching Ontology Concepts...........................................................59
7.4.2 Searching Ontology Verbs.................................................................59
7.5 Extract Answer from Verses..........................................................................60
7.6 Answer Presentation.....................................................................................61
7.7 Second Level Question Answering................................................................62
7.5.1 Red Labels in Verses.........................................................................62
7.5.2 Graph................................................................................................62
7.5.3 Word Cloud........................................................................................62
8 - Evaluation......................................................................................................................
8.1 QA Website User Feedback..........................................................................63
8.1.1 Answers to Questions........................................................................63
8.1.2 Personal Observations......................................................................64
8.2 Ontology........................................................................................................64
8.2.1 Application Approach.........................................................................65
8.2.2 Gold Standard...................................................................................65
8.3 Question Answering......................................................................................66
8.4 Reviews........................................................................................................68
VII

9 - Conclusion.....................................................................................................................
9.1 Achievements................................................................................................68
9.2 Future Work..................................................................................................69
9.2.1 Sentiment Analysis............................................................................69
9.2.2 Ontology Extraction...........................................................................69
9.2.3 Ontology Enrichment.........................................................................69
9.2.4 Quran Wordnet..................................................................................69
9.2.5 Question Answering...........................................................................69
9.2.6 New Analysis Tools............................................................................70
9.2.7 Additional Corpora.............................................................................70
9.2.8 Website Enhancements.....................................................................70
9.2.9 Writing Papers...................................................................................70
9.2.10 Marketing.........................................................................................71
9.3 Personal Reflection & Project Evaluation......................................................71
List of References..............................................................................................................
Appendix A - NEON Ontology Requirements Specification............................................
Appendix B - Illustrations..................................................................................................
Appendix B.1.......................................................................................................78
Appendix B.2.......................................................................................................79
Appendix B.3.......................................................................................................79
Appendix B.4.......................................................................................................80
Appendix B.5.......................................................................................................81
Appendix B.6.......................................................................................................81
Appendix B.7.......................................................................................................82
Appendix B.8.......................................................................................................83
Appendix B.9.......................................................................................................84
Appendix B.10.....................................................................................................85
Appendix B.11.....................................................................................................86
Appendix B.12.....................................................................................................86
Appendix B.13.....................................................................................................87
Appendix B.14.....................................................................................................88
Appendix B.15.....................................................................................................89
Appendix B.16.....................................................................................................89
Appendix B.17.....................................................................................................90
Appendix B.18.....................................................................................................90
VIII

Appendix B.19.....................................................................................................91
Appendix B.20.....................................................................................................92
Appendix B.21.....................................................................................................93
Appendix B.22.....................................................................................................94
Appendix B.23.....................................................................................................95
Appendix B.24.....................................................................................................96
Appendix B.25.....................................................................................................97
Appendix B.26.....................................................................................................98
Appendix B.27.....................................................................................................99
Appendix B.28...................................................................................................100
Appendix B.29...................................................................................................101
Appendix B.30...................................................................................................102
Appendix B.31...................................................................................................103
Appendix B.32...................................................................................................104
Appendix B.33...................................................................................................105
Appendix B.34...................................................................................................106
Appendix B.35...................................................................................................107
Appendix B.36...................................................................................................107
Appendix B.37...................................................................................................108
Appendix B.38...................................................................................................109
Appendix C - Concluding Thoughts, Experiments & Observations.............................
Appendix C.1 – Term Extraction........................................................................110
Appendix C.2 – Phrase Concepts......................................................................113
Appendix C.3 – Qurana Issues..........................................................................116
Appendix C.4 – Arabic Wordnet Evaluation & Comparison................................117
Appendix C.5 – OWLLib Modifications..............................................................119
Appendix C.6 – DBPedia Enrichment Details....................................................119
Appendix D - Data.............................................................................................................
Appendix D.1 - Question Answering Test Questions.........................................122
Appendix D.2 - Concepts PoS Tags Frequency Experiment Results.................122
Appendix E - Data Models................................................................................................
Appendix E.1 - QAC..........................................................................................125
Appendix E.2 - Qurana......................................................................................127
Appendix E.3 - Wordnet....................................................................................129
Appendix E.4 - QA Ontology.............................................................................136
IX

Appendix E.5 - Quran Core Simple...................................................................139
Appendix E.6 - Quran Core Uthmani.................................................................141
Appendix E.7 - Quran Core English..................................................................141
Appendix E.8 - Uthmani to Simple Mapping......................................................141
Appendix E.9 - Quran Words Translation..........................................................141
Appendix E.10 - Transliteration.........................................................................143
Appendix E.11 - Stop-words Lists......................................................................143
English lists..............................................................................................143
Arabic lists................................................................................................143
Appendix E.12 - Inverted Index.........................................................................145
Appendix F - External Materials......................................................................................
Appendix G - Ethical Issues............................................................................................
Appendix H - Personal Reflection...................................................................................
X

1 - Introduction & Background
1.1 Terminologies
Terminology Description
QA Qurananalysis.com website
QAC Quranic Arabic Corpus
Segments Segments (words and parts of a word) in QAC
PoS Part of Speech
Simple text Quran text in modern Arabic script (Imla'ei script)
Uthmani text Quran text in uthmani script
Qurana Corpus of the Quran annotated with Pronominal Anaphora
WN Wordnet
AWN Arabic Wordnet
CTT Custom Translation Table
FDG Force Directed Graph
Table 1 Terminologies
1.2 Overview
“It would be nice in theory to be able to ask questions in plain English, like How long should I breastfeed my child for ? and have an AI system which computes the meaning, and finds the versewhich has relevant meaning to answer the question” [54] that was a sentence I found in one of my my supervisor's documents which I believe can summarize the whole thesis.
1

This project is about building the first “Semantic Search” and “Intelligence System” for the Quran,
providing normal users and scholars the ability to search (semantically), explore the Quranic
domain, analyse all aspects of the text, find hidden patterns and associations and provide answers
to user questions, all of which is aided by high quality modern visualization techniques.
1.3 Motivation
The Quran is the holy book and the core of Islam where Muslims believe is a revelation from God
and the main Miracle of Prophet Mohammed. Through more than 1400 years this book has been
documented, studied and memorized and lately digitized. The Quran is of much importance and
influence on the daily life of Muslims. It is the main source of values, morals, rules, law and wisdom
for a practising Muslim. On the other side, Islam is currently the fastest growing religion in the
world with an estimate of reaching 2.7 billion people in 2050 [55] which is 73% growth in 40 years
with current population size of 1.6 billion. that said, making the Quran easy to search, understand
and learn from is a growing need for billions of Muslims and also Non-muslims whom would like to
know more about Islam either due to personal interest of changing religion or curiosity sparked by
the current world political conflicts.
In addition to the obvious need for a smart search for the Quran, such project would have a strong
scientific impact. First, it will be an additional proof of concept on the applicability of “semantic
technologies” for web search specially for Arabic language. Also a project with such bold goals will
definitely extend the boundary of knowledge in the area of Arabic and Quranic research specially in
the following areas “Visualization”, “Question Answering” and “Semantics”.
Finally, it was decided to release the project as open-source code on GitHub Repository [56] in
November 2015. The code-base that will be released will definitely speed up and boost scientific
research in this area and can also be used to enhance current Quranic applications (such as
mobile apps and Quran-based websites) in terms of functionality and smartness.
1.4 Goals
The initial targets of the project are listed below sorted by priority (high priority first)
1. Semantic Search: providing smart semantic search engine for normal users.
2

2. Intelligence & Analytics: implementing data analysis system for the Quran.
3. Visualization: Enhancing the overall visualization of the results and finding new ways to
present semantically related data.
4. Question Answering: implementing a question answering system on the top of previous
layers.
5. Sentiment Analysis: providing the capability to detect, search by sentiment, and producing
the first fully sentiment-labelled Quran corpus.
It is worth noting that point number 5 was dropped due to time shortage.
1.5 Problem
The problem lies in the fact that; to implement the goals mentioned earlier, multiple scientific fields
and technologies needs to be harnessed and integrated together in one place to serve one
purpose. To make a computer respond to user queries and questions in a smart way and
understanding the semantics of both the user input and the target text, the following have to be
done:
1. Data should be processed and annotated with as much tags and features as possible, for
example the Quran heavily refers to concepts using pronouns, so if there is no corpus to
resolve such pronouns the system will miss huge information that is hidden by those
pronouns (fortunately this is already solved [3]).
2. An Ontology has to be created to describe and link the concepts in the the target domain
(Quran). This means that ontology extraction from text has to be done in an automated or
semi-automated approach which is already an open challenging problem.
3. Custom Question Answering system for the Quran has to be implemented based on the
ontology.
4. Domain knowledge is needed to understand the text and to facilitate research observations,
experiments and evaluation.
5. Much coding, language handling, data model loading and integration, memory/performance
optimization and technical experience is needed to implement such system and integrate all
modules together.
3

6. Sound visualization techniques needs to be used to encode and present all semantic
information, relations, patterns, insights and answers to the user.
7. In addition to all the above, since the project is targeting normal users; the online system
has to be appealing and usable and self descriptive.
More details are discussed in the next two sections about the challenges and questions to be
answered.
1.5.1 Research Questions
To achieve target research goals, the following questions needs to be answered.
1.5.1.1 Ontology Extraction
1. Can Full Semantic Ontology be extracted from Quranic text ?
2. Which ontology learning approach works best for religious texts: linguistic, statistical,
machine learning or hybrid ?
3. How to choose the level of granularity of information in the ontology, for example should
verse pointers be added to concepts ?
4. How to enrich the ontology from external sources, is it important ? does it add any value ?
5. How to validate the ontology ?
6. If the ontology is extracted successfully, will it really add value to the intelligence application
being built ? is it the best option ? other alternatives ?
1.5.1.2 Visualization
1. How to visualize an ontology ?
2. Which presentation is better for search results visualization after integrating the ontology,
Graph ? Tree ?
3. How much information should be shown to the user in the visualization ?
4. How to give the user the ability to navigate from the visualization ?
5. How to serve a user who doesn't know exactly what he/she is looking for ?
1.5.1.3 Question Answering
4

1. How to understand user questions in natural language ?
2. What is an acceptable answer confidence-level for religious texts ?
3. What is the best approach to answer the question ? how much will the ontology help in
finding an answer to user questions? what other data sources can be used to facilitate
question answering ?
4. In cases when the system can't find a direct answer, how to assist the user and get him/her
closer to the answer ?
1.5.1.4 Analytics and Intelligence
1. How to provide the user the ability to analyse and find new patterns and insights from the
data ?
2. How to present patterns and insight to the user ?
1.5.1.5 General Questions
1. How to support and cater for the needs of both normal users and researchers on the same
website ?
2. Which corpora to use, Quran Translation ? Quran Original Text ? Simple or Uthmani
scripts ?
3. Should the website support multiple or a single language and which one should be the
default ?
4. What custom search operators and relevance factors are needed for the Quran ? what are
the expectations of target users ?
1.5.2 Challenges
This project is so challenging in many ways. Actually a project with the same goals was jointly
proposed by the University of Leeds and 6 other Universities in Proceedings of the GCCR'2010
Grand Challenges in Computing Research in 2010 “Understanding the Quran:a new grand
challenge for computer science and artificial intelligence“ [57].
The main challenges of this project can be summarized in the following points:
1. Complexity of Arabic language
5

Arabic is much more complex than English in terms of number of words, morphology and
grammar rules. Also the Quran is written in a script that is slightly different from the modern
Arabic script. Finally Arabic unicode characters requires different handling in applications
specially for the fact that it is written from right to left.
2. Shortage of Arabic and Quranic research.
3. Shortage of Arabic corpora compared to English.
Resources like wordnet and ontologies are much more in terms of count, richness and
maturity in English compared to Arabic.
4. Shortage of similar applications to assess, learn from and compare with.
5. Multi-disciplinary project.
This project needs understanding and application of multi-disciplinary fields such as
Linguistics, Data Mining & Analytics, Semantic Technologies, Knowledge Representation
and NLP.
1.6 Methodology
I used an “iterative constructive/application” methodology for research & software development
where the following is repeated on each of the goals mentioned earlier:
1. Identifying the current problem/challenge.
2. Read latest research about the suggested solutions.
3. Analyse both problem and current solutions then trying to extend the boundary and find a
new solution.
4. Technically implement and try the new solution.
5. Evaluate the results. Learn from experiment and handle new problems.
6. Start again from point number one for a different goal.
1.7 Data Sources
The following corpora were used in the project:
6

1. Tanzil Project - Quran Text: Authentic Simple/Uthmani text of the the Quran [1].
2. Tanzil Project - Quran Translation: English translation corpus of the Quran [1].
3. Tanzil Project - Quran Transliteration: English transliteration corpus of the Quran [1].
4. Quranic Arabic Corpus: PoS tagged corpus of the Quran with morphological annotations [2].
5. Quranic Arabic Corpus Word-by-Word: Word by word Arabic-English translation corpus of the Quran [2].
6. Qurana: Corpus of the Quran annotated with pronominal anaphora [3].
7. Brown corpus lexicon for English PoS Tagging [25].
8. Stopwords list gathered from various sources [section Appendix E.11].
9. Wordnet: English dictionary and thesaurus corpus [30].
10. DBPedia: semantic structured-data extracted from Wikipedia [23].
1.8 Project Management
Initial preparatory work has been started early in Feb 2015 but was paused due to study
commitments. The full-time focused effort spent on this project is 3 full months (June to
September) in addition to 20 days effort scattered between Feb and June.
The Gantt chart of the initial schedule can be found in Appendix B.30 and the revised one in
Appendix B.31.
Risk mitigation plan was decided before starting the project due to apparent limitations in time and
an action was taken to drop goal #5 “Sentiment Analysis” [section 1.4 Goals] since time was not
enough to achieve all goals.
QA GitHub code commit activities from June to September can be seen in Appendix B.38.
1.9 Deliverables
The following was delivered:
1. Website: a working application resulted from all research work and experimentation
www.qurananalysis.com
7

2. Website Code: source code for the whole website.
3. Ontology Extraction Code: The code used to extract the ontology.
4. QA Ontology: OWL file including rich concepts, relations and metadata from the Quran.
5. Stopwords Lists: Quranic stop words lists.
6. Simple to Uthmani Mapping File: A file containing one-to-one mapping between simple
and uthmani words from the Quran.
7. Qurana to QAC segment Mapping File: QAC and Qurana has different segments counts.
The file includes one-to-one mapping between QAC and Qurana segment numbers.
8. Longest Common Substrings in the Quran: A file containing all common substrings in
the Quran - extracted using LCS algorithm [66].
2 - Literature Review
Following are general background about all areas researched. Detailed related-work references
can be found in the dedicated chapter of each topic.
2.1 NLP & Data Mining
Dukes [2] created the Quranic Arabic Corpus, a PoS tagged corpus for the Quran with
morphological annotations. (Sharaf et al, 2012) [7] created a corpus of the Quran annotated with
pronominal anaphora to resolve pronouns mentioned in the Quran to concepts.
2.2 Semantic Search & Ontology Extraction
Despite the fact that there are many papers around Ontology Extraction from the Quran, yet no
complete, reliable and mature ontologies are available. Semantic Quran (Sherif, 2009) [10] created
a multilingual Quranic ontology based on QAC and other resources. Qurany (Abbas, 2009) [11]
built a Quranic ontology by using concepts extracted manually from Mushaf Al Tajuid. Albayan
(Abdelnasser et al, 2014) [13] have built their own ontology based on other ontologies to facilitate
NLP Question Answering. (Sharaf et al, 2012) [5] extracted a list of concepts by resolving pronouns
in the Quran which can be used as a base for ontology extraction. Finally (Alrehaili et al, 2014) [59]
8

made a comparison between 12 ontologies on a 9-criterion basis and concluded that “Most
ontologies built for the Qur’an are incomplete and focused in a specific domain”.
As for Ontology Extraction from English text: (Wong et al, 2012) [4] made a survey on all ontology
extraction methods including current progress and challenges faced. (Kang et al, 2014) [61]
proposed multi-technique approach to extract concepts from text.
2.3 Visualization
(Kboubi et al, 2012) [8] Proposed a semantic visualization and navigation approach which offers 3
search views: precise (normal), connotative (similar concepts to user search) and thematic search
(navigate though a specific theme) while (Brierley et al, 2013) [9] demonstrated a novel corpus
exploration tool which facilitate insights gathering by gisting the whole corpus and proving a unique
navigation system that keeps previous choices in a 3rd dimension while the user navigates through
the corpus. (Balzer et al, 2015) [63] compared and examined many of the available ontology
visualization tools and concluded with recommendations.
2.4 Question Answering
Aside from English question answering endeavours following are some research effort tackling the
same problem for Arabic language. (Trigui et al, 2012) [64] proposed an approach to answer
factoid multiple choice questions from short Arabic texts with accuracy 0.19. (Abdelnasser et al,
2014) [13] proposed a tailored question answering system for the Quran and claimed 85%
accuracy on a top-3 results basis.
3 - Ontology Extraction
3.1 Introduction
In this section, the methodology used to learn ontology automatically from the Quran will be
explained. I used an iterative approach for this task which starts by building a limited ontology,
integrating with QA search engine, evaluating the results and then redo the same process again to
create a full ontology taking into consideration the lessons learned from the first iteration.
9

In general, ontology extraction process should include four steps according to (Wong et al, 2012)
[4] where each step depends on the previous one. below are the steps in order:
1. Term Extraction.
2. Concept Formalization.
3. Discovering Relations.
4. Extracting Axioms.
Term extraction is the initial stage where significant terms are extracted from text using NLP
and/or statistical methods. In the next step concepts are formed by clustering and filtering the
extracted terms from the previous step and also combining terms to find “phrase concepts”. An
example for phrase concept is combining “Leeds” and “University” to form “Leeds University” place
concept. In the following stage, relations between those concepts are discovered using multiple
techniques such as PoS patterns, statistical methods and machine learning. It is worth noting that
there are two types of relations: Taxonomic; which describes hierarchical relations such as “is-a”
relations and non-taxonomic which includes properties and actions such as “Movie hasDirector
Director” (Subject verb Object) and finally extracting axioms – fact sentences – from concepts and
relations using inductive logic or axiom templates.
10
Illustration 1: Ontology Extraction Process - inspired by (Wong et al, 2012) [4]

For this project, the above process taken from (Wong et al, 2012) [4] was followed for ontology learning from text except for the axioms part since it was not part of the initial goals. Also NEON methodology (Suárez-Figueroa et al, 2008) [14] was used for ontology requirement specification and development. see Appendix A for the ontology requirement specification table.
In the next section, all steps done to create the initial version of the ontology including unsuccessful experiments will be listed and explained.
3.2 Iteration 1
In this iteration I followed the process explained in the previous section to produce a limited
ontology to be easy to validate and work on. The 4 stages were broken-down to a 14 stage
process to include other tasks such as enrichment, translation and exclusion.
3.2.1 Term Extraction & Concept Formation
Significant terms were extracted from Quran text by making use of QAC corpus, which is a
complete PoS-tagged corpus for the Quran. It was noted by observation that PN, N and ADJ tags
are good fit for concept extraction. All words tagged with any of the those tags were fetched from
the corpus. the table below shows the results of extraction.
PoS Tag Meaning Terms Count
PN Proper Noun 201
N Noun 6105
ADJ Adjectives 694
Total 7000
Table 2: Term Extraction: Words fetched by chosen PoS Tags and Frequencies
11

3.2.1.1 Grouping
The terms were then grouped by lemma to merge derivations of the same word.
Illustration 2 shows that many words (segments) can be grouped into a single lemma which can beconsidered the best representation for a concept, since it can summarize all segments and derivations. After grouping the list size decreased 53.4% to be 3267 terms instead of 7000.
PoS Tag Meaning Terms Count
PN Proper Noun 106
N Noun 2728
ADJ Adjectives 433
Total 3267
Table 3: Grouped terms PoS Tags and Frequencies
3.2.1.2 List Enrichment and Sorting
The list was enriched with metadata for each term and then sorted by frequency. the following
fields were added to each term in the list as an additional feature to help in taking decisions in later
stages and also to be included in the final ontology.
1. Frequency.
2. TF-IDF weight.
3. Part Of Speech Tag.
4. Simple Representation (mapped from uthmani representation).
5. Lemma.
6. Root and Segments (derivations of the lemma).
3.2.1.3 Manual Validation
12
Illustration 2: Example of terms grouping by lemma

The top 70 terms (by frequency) were manually validated to make sure they represent proper
concepts.
At this stage, terms were extracted using PoS tags then merged and filtered making a list of 3267
concepts. While executing the above process I had some observations and ideas and also
managed to conduct some experiments to test their feasibility. All conclusions and observations
can be found in Appendix C.1 – Term Extraction.
3.2.2 Phrase Concepts
Phrase concepts are phrases of 2 or more words that when combined together can have different
meaning, such concepts are found in many verses in the Quran such as “آل فرعون" (the family of
Pharaoh).
Below is another example of “4 phrase concepts” in one verse.
محررممز ننز مم نلز ميز ِهزنيمنمةز الرل ِههقق نلز ِهه ز قق نز ِهق رر منز ال رطريمبا ِهتز ِهم موال مجز ِهل ِهعمبا ِهد ِههز نخمر منز آممقناوا ز ارل ِهتيز مأ ددننمياز ِهفيز ِهلرل ِهذني محميا ِهةز ال مصةةز انل مخا ِهل مم ِهةز نل ِهقميا ناوممز ا قلمني رص مكز قنمف ذمذ ِهل مك ز من قماو نعمل ناوممز مني نليآمنيا ِهتز ِهلمق ا
Illustration 3: Surat Al-'A`rāf (The Heights) 7:32
The English translations of each concept are listed below in the same order:
1. Aِdornment of Allah.
2. Those who believe.
3. The worldly life.
4. The day of resurrection.
3.2.2.1 Extraction Steps
The following linguistic approach was used to extract phrase concepts. This decision was taken
after conducting some experiments which are explained in Appendix C.2 – Phrase Concepts.
1) First, extracted all bigrams from the Quran (simple text) which makes a list of 43,894 bigrams.
13

2) Then PoS-Tagged all bigrams using the most common tag for each word in the Quran as
shown in the example below.
Bigram English Translation QAC PoS-Tags (pattern)
الذين آمنوا Those who believe REL V PRON
Table 4: Bigram PoS Tagging Example
3) Excluded PoS tags and patterns by manual observation and investigation using QA PoS
patterns tool [explained in Appendix B.14].
Below is the list of QAC tags and patterns for inclusion or exclusion:
• If the bigram is following the pattern below, then include it.
REL V PRON
• If the bigram is following the pattern below, then exclude it.
PN N
ADJ ADJ
• Else if the bigram contains any of the following tags, then exclude it.
CONJ, ACC, CERT, P, NEG, COM, SUB, RES, EXP, CIRC, REM, COND, T, LOC, RSLT,
INTG, SUP, SUB, VOC, DEM, RET, EMPH, REL, PRON, V
The final list after exclusion is 3118 bigrams only, which is almost 14 times less than the original list. Experiments, observations and choices for this phase are discussed in details in Appendix C.2 – Phrase Concepts
3.2.3 Concepts Extraction From Pronoun Antecedents
Pronouns are used heavily in the Quran. Quranic pronouns usually refers to concepts or phrase
concepts. Although such pronouns cannot be easily extracted using automated techniques, they
can't be ignored since they refer to concepts. Fortunately (Sharaf et al, 2012) [5] created a corpus
resolving all pronouns in the Quran (Qurana). This corpus was used to extract 1054 pronoun
concept in this stage.
14

3.2.4 Final List of Concepts
The goal of this iteration was to create a small tractable ontology (V1) so it can be easily integrated
with the search engine to evaluate the effect on search results. that said, the concepts list was
filtered to keep only concepts which can be found in Qurana's concept list [21]. In addition to that,
the first 100 adjectives and a manually generated class concept “Thing” were added.
3.2.4.1 Intersecting with Qurana
Qurana list includes 1054 concepts. 335 of which are one word concepts while 319 are bigrams
and the rest are n-grams phrase concepts. The concept list extracted in the previous steps has
6388 concepts - 3267 word concepts and 3121 bigrams - after intersecting both lists a filtered list
of 348 concepts was reached. Table 5 shows statistics for all lists mentioned.
3.2.4.2 Adjectives
The first 100 out of 433 adjectives were added to the final list of concepts (also called master
concepts list).
3.2.4.3 Thing
“Thing” class was added manually to be used as a parent for any individual concept which does
not have a parent class. This is needed during OWL file generation (last stage).
Qurana Concepts
QA Concepts V1
QA Concepts V1 Filtered(common with Qurana)
All Concepts 1054 6388 348
One-word Concepts
335 3267 219
Adjectives* 75
Two-words concepts
319 3121 54
Table 5: Qurana verses QA Concepts comparison & intersection
* Adjectives are less than 100 since 25% duplicates were found after merging with other concept.
15

The table above shows that the automated concept learning process was able to successfully
extract 41.7% of Qurana manually labelled concepts - 273 (219+54) out of 654 (335+319)
concepts and bigram phrase concepts – the next section is a discussion of why the results seems
not good enough.
3.2.4.4 Issues with Qurana Concepts
The goal of Qurana was to annotate the Quran with pronoun antecedents which then lead to a list
of concepts for all pronouns. A list of points which I think are the reason of low matching
percentage between Qurana and QA concepts lists can be found in Appendix C.3.
3.2.4.5 Notes About Matching Concepts with Qurana
Since QA concepts are lemmas, a rule has been added to match concepts from Qurana in case a
QA concept (lemma) preceded by DET “ال " (the) can be found.
3.2.4.6 Comparing QA and QAC concepts
QAC published an ontology comprised of 256 concepts excluding hierarchical relations. QA full concept list (6388 concepts) was matched against QAC and found to include 64% of the concepts in QAC list (164 out of 256 concepts). No further analysis was made on the mismatches.
3.2.4.7 PoS Syntactic Patterns Experiment
After extracting the full phrase concepts list and matching with Qurana, I thought of conducting
after-the-fact experiment on the result and aggregate the PoS patterns in both QA and Qurana
phrase concepts which can give a “model” of what combinations and order of PoS tags could make
a perfect phrase concept. Results from the experiment are shown in Appendix D.2.
3.2.5 Non-Taxonomical Relations
Two methods have been tried for extracting non-taxonomical (not defining hierarchies or types)
relations from the Quran. both are based on syntactic (and lexico-syntactic) patterns but different in
the way the text is parsed, the size of the pattern and finally the size of the context boundary taken
into consideration by the parser.
3.2.5.1 Method #1: Tri-gram lexico-syntactic rules
16

The Quran was scanned sequentially in trigram units (each 3 words makes one unit) and each unit
is checked against some predefined lexico-syntactic patterns. The patterns are mainly focused on
(subject → verb → object) sequences observed in the Quran. If the unit matches the pattern then it
is added as a new relation - only if the concepts are already in the initial concepts list derived in the
previous sections - if the pattern was not matched, the scan will continue after removing the first
word and first PoS pattern from the context array. An example is shown below.
Verse Words ال يحب المتقينبلى من أوفى بعهده واتقى فإن
Translation But yes, whoever fulfills his commitment and fears Allah - then indeed, Allah loves those who fear Him.
Verse Pattern ANS, COND, V, P N PRON, CONJ V, RSLT ACC, PN, V, DET N
Matched Pattern PN V DET N
+ condition: no “Said” (قال) word in the whole verse
Table 6: Example of Lexico-syntactic rule matching
In the example above the phrase "ال يحب المتقين" (Allah loves those who fear Him) was matched
because its PoS tag sequence matches one of the predefined patterns ”PN V DET N” which represents subject (PN), verb (V) and object (DET N). The section below shows those patterns andexplains how they were derived.
Predefined Patterns
17

Syntactic Pattern & Lexical Conditions
Example Number of Trigrams *
PN V DET NVerb != قال (said)
ال -> يحب -> المتقين
Allah loves “those who fear Him”
32
PN LOC DET NVerb == مع (with)
ال -> مع -> الصابرينAllah is with the patient
5
PN V PN ال-> اصطفى-> آدم
Allah chose Adam
3
PN N PN
The word “قالت" (said) not found in the whole verse
محمد-> رسول-> ال
Muhammad is the Messenger of Allah
17
V PN N PRON ربه-> آدم->وعصىAnd Adam disobeyed his Lord
42
Table 7: Predefined Patterns & Conditions
Notes
• The last column in Table 7 shows the significance of each pattern by calculating how many
times it was found in the Quran.
• The trigram units were reset by the end of each verse and when a pattern was matched.
• One of the challenges faced during concept matching (checking whether the word found in
the Quran is a concept in the derived concepts list) was the difference in morphology. For
example a concept may start with determiner (ال) while the word in the Quran does not,
although both words refer to the same thing. I managed to overcome this problem by
comparing not only the strings but also the lemmas of both words.
3.2.5.2 Method #1 Results
This method has produced only 13 relations. the number is small due to the following reasons: first
the relation is only included if the subject and verb are in the derived concepts lists – which is
already capped as discussed earlier. Second, not too many rules were added to produce more
relations. Finally the method was not flexible enough in terms of context size variability. that said, a
different method was tried to overcome such obstacles and produce better results.
18

3.2.5.3 New Methods: The Rationale
The reason behind the new methods was to be able to extract relations from variable context sizes
with variable size patterns. The first step was to increase the granularity of the parsed units, so
instead of parsing full verses it was decided to split verses on pause marks so that the max context
to be parsed is less in general. it was found that pause marks [discussed in detail in section 5.17
Pause Marks] in most cases are found at end of a phrase and the start of a new one. Below is an
example of an average verse before and after splitting.
Before Splitting
After Splitting
سسللِم.1 ِسل لرهه ِل لصسد سح لر سش هه لي سهِدلي هلل لأن لي لمن هيِرِد ا لف
لماِء.2 لس لصلعهد ِف ي ال لما لي لكلألن ججا لر لح لضييجقا لرهه لصسد سل لع سج هه لي سد لأن هيِضلل لمن هيِر لو
لن.3 سؤِمهنو لن لل هي لعللى اللِذي لس سج ير هلل ال هل ا لع سج لك لي ِل لكذلذ
Illustration 5: Surat Al-'An`ām - Verse (6:125) [22] - after splitting to sub-verses
As shown above, one verse can be slitted into 3 sub-phrases (called sub-verse here after) each
having its own context.
19
* Pause marks marked in redIllustration 4: Surat Al-'An`ām - Verse (6:125) [22] - before splitting to sub-verses

3.2.5.4 Method #2: Blind Matching
In this method, each sub-verse is parsed using syntactic information only. Any word matching a
concept in the concepts list is considered a subject and kept in a special array then any verb is
considered verb, and any later concept is considered an object. pronouns were resolved using
Qurana data model and were also considered concepts. At the end of the sub-verse the register
array is checked; if it contains 2 concepts and a verb, a relations is constructed and added as a
triple (subject → object → verb ). If more than 2 concepts were found, multiple relations were
constructed between all concepts (all possible combinations) with “unknown” as a verb.
This method produced hundreds of relations but most of them were not accurate enough, yet many
points were learned from this endeavour.
1. Relation extraction from the Quran needs to be done in a controlled manner with as much
rules as possible. The text has many cases and exceptions, so a general flexible parser will
never work.
2. In Quran, the text is not always structured as Subject, Verb, Object. Sometimes the verb is
before or after the subject and object. Also one word can include a whole triple as
discussed in the next point.
3. Most of the relations in the Quran are in pronouns cases. Even one pronoun can have a
complete ontology triple as shown in the example below.
Word همناجعلف
Translation We made them
Part of Speech Tags V PRON PRON
TripleSubject → verb → Object
Allah → made → Them (Resolved Pronoun)
Table 8: Example of triple relation in one pronoun
4. Negations (QAC TAGS: NEG and PRO) needs to be handled by adding the negation
words to verbs.
5. Verb features can give clues on the best morphology of the verb to be selected -
specifically QAC features [60] like active/passive (PASS) and imperative (IMPV).
20

6. Sub-verses can be further splitted when one of the following QAC tags are found (REL,
REM, SUB, COND, ACC and CONJ) but I believe more research needs to be done on that.
3.2.5.5 Method #3: Statistically Significant Rules
Building on the lessons learned from the first two methods specially that relation extraction should
be done in a controlled manner, I decided to continue following the syntactic-rules approach and to
choose rules manually whenever they conforms to the following characteristics:
1. The rule should be very common in the Quran - should have high repetition frequency.
2. The rule should represent a full context including a subject, verb and object.
3. The rule should be tested manually first and should show good results in QA PoS Pattern
tool [5.7 PoS Patterns].
Statistical techniques
Three techniques were used to find PoS patterns from the Quran matching the 3 points criteria
above.
Collocation and Concordance
Used QA's concordance and collocation tools [explained in 5.15 Collocation and 5.16
Concordance] to find context for a specific PoS tag. QA's tool has the unique feature of showing
collocation or concordance for PoS in addition to words, so for example the tool user can search
for the context of QAC tag “V” in both tools and find what will probably be the tags after and before
“V” in the Quran. Using these tools I managed to choose the sequence of most repeated tags
which contains “V” (Verb) in addition to subjects and objects (other tags such as: PN, N, DET N,
ADJ).
Below is a screenshot showing the results of the above example from QA website.
21

Shown in the illustration above is the tag “V” with pre/post context. It was obvious when I ran this
for the first time that “V PRON PRON” is a very significant pattern which was also asserted in
previous methods. Below is the same experiment done using the concordance tool.
The same experiment for concordance shows the heavy use of PRON after verbs and also reveal
significant patterns such as “V PRON PRON” and “V PRON DET N”.
22
Illustration 6: Collocation for QAC PoS tag "V" in QA collocation tool
Illustration 7: Concordance for QAC PoS tag "V" in QA concordance tool

Longest Common Substrings
The last technique used for finding statistically significant PoS patterns was applying LCS (Longest
Common Substrings) algorithm [66] on the Quran but instead of applying it on words – which is
already a tool on QA [5.10 Repeated Phrases] - it was applied on the corresponding PoS tags of
all words. All sub-verses (verses splitted on pause marks) PoS tags were considered a list of
strings and the LCS algorithm was applied on that list which resulted in more than 21,000 patterns
of different lengths.
The patterns were filtered to drop any pattern which represent less that 3 words. The resultant
patterns (~19,000) were sorted by their frequency of repetition and the top patterns were inspected
manually [can be found in Appendix B.34].
The results showed that the same patterns were asserted by all techniques; pronouns used heavily
and same patterns from earlier techniques were found such as V PRON PRON” and “V PRON
DET N”.
Final Rules
# Rules/Pattern Example
1 V PRON, P, N, PN تعبدون من دون الWhat you worship instead of Allah
2 V PRON PRON خلقناكم
We created you
3 V PRON, DET N عملوا الصالحات
And those who do righteous deeds
4 V PRON, N PRON ينفقون أموالهم
Spend of their wealth
Table 9: Final rules for Method #3
Each rule is checked against each sub-verse in the Quran. if the rule is found to be a substring of
the sub-verse a special handling is done according to the rule type as discussed below.
3.2.5.6 Rule handling process
23

For each rule the following general process is applied:
1. Keep record of all PoS tags before the pattern.
2. If the sub-verse includes VOC, COND or INTG tags then it is ignored, since if a triple is part
of a condition, conversation or interrogation it can't be considered a fact to be included in
the ontology.
3. Pronouns are resolved.
4. Verb word is extracted from QAC according to the location of the verb in the pattern -
except for “V PRON, P, N, PN" the verb lemma + the second word in pattern are used
instead.
5. If the verb has IMPV (Imperative) feature then the whole pattern sub-verse is ignored since
it is also not a fact, rather it is an order to do something in the future or to say something.
6. Concepts (Subject and Object) are resolved according to the words location for each
pattern, for example for the following rule
“V PRON, P, N, PN”
The subject is the PRON part of the first word and the object is the last 2 words together,
also if the second word features contains “NOM”.
For “V PRON, N PRON” the default is first pronoun considered subject and object is the
second word's noun - with an exception case when the noun features includes “NOM”
(Nominative) instead of “ACC” (Accusative), in this case the default is swapped.
7. If any concept is empty due to any resolution failure then the whole sub-verse is ignored.
8. In-case the verb is preceded with a negation (NEG or PRO tags) then the corresponding
negation word is added to the verb.
9. A new relation is added for the resolved triple.
It is worth noting here that the constraints imposed on previous methods (existence of subject and
object in master list) were removed in this method since the patterns are checked manually and
are guaranteed to include valid concepts.
3.2.5.6 Adjectives
It was observed that there is an obvious PoS tags pattern in the Quran which can be lead to non-
taxonomical relations which is “PN ADJ ADJ”. This pattern usually describes attributes that the
proper noun have.
24

Words هلل لحِكيمم لعِليمم ٱ
Translation Allah is Knowing and Wise
PN (Subject) Allah
First ADJ (Object) Knowing
Second ADJ (Object) Wise
Table 10: Example of PN ADJ ADJ relations
The table above shows how such patterns can produce 2 taxonomical relations each, such as:
“Allah is Knowing” and “Allah is Wise”.
3.2.5.7 Results
This technique was successful in finding many reasonable relations for a different variety of
concepts. The total number of extracted relations is 1,312 some of which are relations between
new concepts that were not in the original concepts list. this will be handled in the next section.
3.2.6 Extracting New Concepts from Relations
The previous stage produced more than 1000 relations without applying the any constraints
regarding concepts existence in the master concepts list. In this phase, all relations' concepts will
be matched against the master list and added if it does not exist there.
3.2.6.1 Process
1. Loop on all relations that are of type non-taxonomical.
2. If the relation's “subject” is not in the master concepts list.
(a) Get metadata for the new subject from the master “terms” list which was extracted
in section 3.2.1. the metadata includes important information such as frequencies.
(b) Translate the new concept using the words translation data model [discussed in
Appendix E.9]. if the concept is a phrase concept which can be found in Qurana
then get translation from Qurana data model.
(c) Add the new concept to the master list.
25

3. Do the same (the last step) for “Objects”.
3.2.6.2 Results
523 new concepts were added to the master list, increasing the total to 871 concepts.
Subjects (Unique) 171
Objects (Unique) 352
Table 11: Distribution of subjects and objects in new concepts
3.2.7 Basic Taxonomical Relations
In this stage, basic taxonomical relations are added to the relations master list. Basic relations are
obvious facts that can be extracted easily. There two kinds of such basic relations: 1) Adjectives
and 2) Parents of phrase concepts. Both relation types will discussed in the next sections.
3.2.7.1 T-BOX and A-BOX
Concepts in an ontology can be divided into two categories T-BOX and A-BOX. T-BOX is explained
by (Paulheim, 2011) [65] as the concept which “contains the definitions of classes and relations”
while the A-Box concept is that which “contains the information about instances of those classes”
(meaning T-BOX classes). Concepts added as classes are considered and marked as T-BOX, for
example “Person” is a class (T-BOX), but “Karim” is an actual person (A-BOX).
3.2.7.2 Adjectives
All adjectives (words marked as PoS tag ADJ in the Quran) in the master concepts list were added
as a instance of a class Attribute -(صفة) in Arabic- which was added manually to the concepts list
with relation verb “is-a”.
3.2.7.3 Phrase Concept Parent
Some of the phrase concepts were found to be a subgroup of a class where that class is in the
same phrase of the concept. Below is an example.
26

Phrase Concept (Arabic) الكتاب اهل
Phrase Concept (Translated) People of the book
Parent Class People
Class instance People of the book
Table 12: Phrase concept taxonomical relation example
The table above shows the fact that “People of the Book” are “People”, thus a taxonomical relation.
All phrase concepts are filtered to select bigrams only, each bigram concept is splitted to two
words, the first is considered parent class and the whole phrase is the instance of the class, if the
parent word PoS is not PN, ADJ or N then it is excluded because it is not considered a concept.
The parent word is translated using the translation data model and added as a class concept. A
taxonomical “is-a” relation is added to link the whole phrase concept and the parent class.
3.2.7.4 Results
131 more relations were extracted from this stage with the following distribution: 100 from
adjectives and 31 from phrase concepts parents.
3.2.8 Translation and Transliteration
In this stage concepts are enriched by adding Translation and Transliteration information. For each
concept the following process is applied:
1. If the concept already has translation information attached, then ignore.
2. Find the corresponding translation for the concept in the translation model [explained in
section 4.2.9] if a translation is not found; the same word is tried again after adding “ال"
Arabic determiner since most of the concepts were added by the lemma presentation while
the translation model uses the actual word in the Quran.
3. The translation is cleaned (replaced special characters with spaces) since most translations
are in the following format “(to)-men” .
4. The last 3 steps are repeated for “Transliteration”.
27

3.2.9 Concept Enrichment using DBpedia
DBpedia [23] is a website and a crowd-sourcing community which managed to extract millions of
Wikipedia articles by processing and storing them in a semantically structured manner offering free
access to the whole dataset which is currently more than 3 billion RDF triples [24]. The amount of
data and the fact that it is based on Wikipedia and includes semantic triples seemed very
promising, so an additional stage was added to the extraction process to enrich concepts using
DBpedia's structured information.
3.2.9.1 Enrichment
DBpedia contains valuable information that can be added to enrich the concepts but only the
following were used for this version of the ontology:
1. Wikipedia link.
2. Abstract about the concept.
3. Hypernyms (types).
4. Concept picture.
5. Synonyms.
The Quran source is in Arabic, so one might expect to search dbpedia for Arabic concept names.
However, this gave very poor results, probably because not all Quranic concepts are on wikipedia
or they may not have been fetched by dbpedia's crawler, so instead; English translation of
concepts were used.
Full details about the enrichment process can be found in Appendix C.6 – DBPedia Enrichment
Details.
3.2.9.2 Results
28

Number of concepts having corresponding resource on dbpedia
132
Concept enriched (added type, abstract and other information)
38
New concepts added to the master list 13
Table 13: Statistical results for DBPedia Enrichment
Unfortunately the results were not good enough due to two reasons 1) English translation name of
the concept may not be found on dbpedia 2) Many of dbpedia's resources are not complete
enough, meaning that it does not have as much information as in the main wikipedia page.
3.2.10 Custom and Realtime Translations
During the concept enrichment phase it was clear that translation and reverse translation can solve
the problem of the scarcity of Arabic corpora compared to English. A strong 2-way translation
system can get us out of the bottle neck of depending on Arabic data sources. that said, English
translations were used to get information from external English sources (ex: DBpedia) and then
translate the information back (Reverse translation) to Arabic before adding to the ontology.
First, a translation memory was created (hereafter called Custom Translation Table) and persisted
in a flat file. Excerpt from the file can be found in Appendix B.36.
While in the extraction process, any translation that can't be found in the Quran words translation
data model [Appendix E.9] are checked in the custom translation table and returned if found, else
real-time translation is done and the translation is stored in the custom translation file. Real-time
translations are discussed in the next section.
3.2.10.1 Realtime translations
There was a need for a mechanism to translate words on-the-fly during the extraction process, for
example a parent concept is extracted from an external source will need to be translated and will
not usually be included in the translation model or in the custom table, so the solution was to use
one of the popular translation APIs available on the internet.
29

I decided to use Microsoft Translator API [27] since it was easy to create account and use, also it
provides a PHP library [28] and the result accuracy was very similar to other APIs (such as Google
translate) after doing a quick comparison.
3.2.10.2 Translation process
1. Find the word in the custom translation table.
2. If found, return.
3. If not found, use Microsoft Translator API to translate it.
4. Add the new translation in the custom translation table.
It was found that the realtime translation provides correct/expected translation around 50% of the
time. The other 50% were corrected manually in the custom translation table file.
3.2.11 Concept Enrichment Using Wordnet
Wordnet (WN) is a general domain knowledge source for English language. It can be considered
as a lexical index, corpus, thesaurus and a structured semantic knowledge source. Although it was
mentioned in (Wong et al, 2012) [4] as a good source of information in many stages in ontology
learning, it wasn't initially considered since it is not in Arabic language. yet I found a project
claiming to build an Arabic version of wordnet (AWN) [31] using interlingua transformation of the
English wordnet with Suggested Upper Merged Ontology (SUMO) as an interlingua bridge.
A complete comparison and evaluation of Arabic Wordnet was conducted [found in Appendix C.4 –
Arabic Wordnet Evaluation] and a decision was made to use wordnet instead of AWN. The reasons
are listed below.
1. Wordnet(WN) is 6 to 10 times richer than AWN.
2. AWN does not have all words in WN and does not have proper glossaries.
3. Cross referencing between AWN and WN requires double effort.
4. WN is an important model which may be needed for other future uses (such as user query enrichment by wordnet synonyms).
3.2.11.1 Enrichment using Wordnet
30

Wordnet files were processed and loaded as a QA data model. wordnet model is discussed in
details in Appendix E.3 - Wordnet. For each concept the following was applied:
1. Get concept English name, clean and trim.
2. Get all information about this word from wordnet. This includes the following:
a) Synonyms.
b) Semantic Types (lexnames in wordnet).
c) Relationships (Hypernyms and derivational pointers .. etc).
This is done by getting the word from the wordnet INDEX model which includes all
synsets and pointers for this word. For each synset; synonyms, glossary and semantic
types are extracted and each pointer is processed to get relation information such as
hypernym relation between the target word and other words.
3. If the word is not found in the index and the last character is “s” then the same word without
“s” -single word- is checked again.
4. If word is found, only the information of a specific PoS is extracted from the array, this is
done by converting QAC PoS to Wordnet PoS representation (ex: N to noun ) since in
wordnet the word may have different senses per PoS. Only information about the PoS
which matches the concepts PoS tag is fetched.
5. Translate the glossary using the custom translation table (CTT) and add both English and
Arabic glossary translation to the concept metadata (MEANING_EN → WORDNET).
6. For each of the semantic types for the current word: if it is one of the following
ppl,all,tops,pert then ignore, else translate it using CTT and add it as a T-BOX concept if it
was not added before. Do all the previous steps for the new concept since it needs
enrichment too. If it was already in the concepts list then add a new “is-a” relation between
the semantic type and the concept (ex: concept is-a “the semantic type”).
7. Add all synonyms in concept metadata in (AKA → EN → WORDNET).
8. For each relation of the current word: if the relation is not “hypernym” ignore, else do the
same steps for the semantic types in step 6.
3.2.11.2 Results
This stage contributed much to the value of the ontology specifically by extracting hypernyms and
glossaries for many concepts. Below are the results of this phase:
31

Concepts Enriched 491
New concept added (Hypernyms)
316
Relations added 688
Table 14: Results for Wordnet Enrichment
Notes
One of the issues that is still open is how to choose a specific word sense in wordnet, for example
the word “land” has many senses (many synsets) even for the “noun” PoS such as “earth”,
“country”, “real-state” and many others. The decision I took was to include all senses and exclude
wrong ones in the exclusion section (next section).
3.2.12 Exclusions
Many relations and concepts have been created in the previous stages, some of which are
incorrect and messy. For example during the enrichments stages some of the concepts and
relations extracted from dbpedia and wordnet were out of the Quranic domain context, specifically
in wordnet due to multiple senses of a word issue that was discussed in the previous section. It is
also worth asserting again that the extraction process needs to be controlled and errors should be
at the minimum in religious domains, so in this stage concepts and relations are excluded using
different techniques.
3.2.12.1 Concepts
A list of concepts to be excluded were created and loaded from a file. The master list is checked for
any of these concepts, if the concept match it will be removed from the list.
Example of excluded concepts which came from wordnet
Arabic رئيس المحكمة العليا
Translation President of the Supreme Court
Table 15: Example of Excluded Concept
32

3.2.12.2 Relations
Flexible rules have been set to exclude any relation which matches. The rules were decided by
manual inspection and can be found below.
1 SUBJECT = OBJECT
2 SUBJECT OR OBJECT WERE EXCLUDED IN THE PREVIOUS PHASE
3 "SUBJECT"=>"*" AND "VERB"=>"ابن" AND "OBJECT"=>"ال"
4 "SUBJECT"=>"ال" AND "VERB"=>"*" AND "OBJECT"=>"الشخص"
5 "SUBJECT"=>"*" AND "VERB"=>"قال" AND "OBJECT"=>"*"
6 "SUBJECT"=>"إنسان" AND "VERB"=>"IS-A" AND "OBJECT"=>"حيوان"
7 "SUBJECT"=>"ناس" AND "VERB"=>"IS-A" AND "OBJECT"=>"حيوان"
8 "SUBJECT"=>"صيد" AND "VERB"=>"*" AND "OBJECT"=>"*"
9 "SUBJECT"=>"أنثى" AND "VERB"=>"IS-A" AND "OBJECT"=>"حيوان"
10 "SUBJECT"=>"مرء" AND "VERB"=>"IS-A" AND "OBJECT"=>"حيوان"
Table 16: Relation Exclusion Patterns
The first two rules are obvious. Other rules are wrong attribution for God such as “God is a
Person”. Later rules are added to drop relations including conversation “someone said so” and
wrong relations between people and animals (mostly from wrong wordnet senses). The star “*”
means if anything found in the place of the star in addition to other conditions being true the whole
relation will be excluded.
3.2.12.3 Metadata
Enriching the ontology from external source other than the Quran has critical implications. Wrong
images, descriptions, synonyms were removed in this stage because of different reasons that are
explained below.
Some images fetched from DBpedia were not appropriate to be included in a website about the
Quran. For example images including depictions of prophets are not accepted by majority of
Muslims, also other images didn't add value or were not good enough in terms of colors and
quality.
33

17 out of 27 images were excluded. Below is a link for one of them.
https://upload.wikimedia.org/wikipedia/commons/thumb/c/cd/StJohnsAshfield_StainedGlass_GoodShepherd-frame_crop.jpg/300px-StJohnsAshfield_StainedGlass_GoodShepherd-frame_crop.jpg
Due to the wrong word senses issue discussed at the end of section 3.2.11 some description and
synonyms were found irrelevant and removed. Overall 79 synonyms and many descriptions
gathered from wikipedia and wordnet were removed.
3.2.13 Final Post-processing
So far the extraction task passed 12 stages where master lists are being added and changed all
the time. This can be considered flexibility but at the same time it can lead to some
inconsistencies. This stage is where such inconsistencies are handled.
3.2.13.1 IS-A relations
Any relation which has “is-a” as a verb the “object” is changed to “T-BOX” concepts to fix any
relation which was not correctly set up.
3.2.13.2 Excluded Relations
Since some relations were excluded in the previous stage, some of the concept lost the reason to
be parent classes, so for all of these concepts the type is changed from “T-BOX” to “A-BOX”. For
example if: 1) the relation “Bee is-a Animal” were removed 2) Animal does not have any other is-a
relation in the master list, then Animal should be changed from class to “instance” (which means
instance of class “Thing”).
3.2.13.3 Re-clustering Concepts
At this stage it was found that there are many duplicate concepts. The same word is added again
but with additional Arabic determiner “ال". An algorithm was devised to merge those concepts by
finding concept names that differ only in determiners then both concepts are checked for richness
(concept which has more metadata) and then the other concept is removed. All relations are
updated by changing the subject and object name of any relation used to contain the removed
concept to the new concept name.
34

100 concepts were found redundant and were removed.
3.2.14 Generating Ontology OWL File
So far the ontology is ready for serialization (writing to file). The master lists were converted to
RDF triples and written to an XML OWL file using a modified version of PHP OWLLib [29].
Documentation of OWLLib modifications can be found in Appendix C.5 – OWLLib Modifications.
3.2.14.1 Concept serialization
Each of the following is applied on each concept before serialization:
1. English name is cleaned and made XML-friendly. Cleaning will remove selected stop words
and will trim the string. Any space in the middle of multi-word concept will be converted to
underscore for XML friendliness.
2. If the concept type is a “T-BOX”; the concept is added to the memory ontology model
(added in memory) as a class, else it is added as an instance of class “Thing”.
3. English and Arabic concept names are added as labels of the concept (in the memory
model).
4. All metadata are flattened (ex: [DESC_EN] → [WORDNET] hierarchy is converted to
desc_en_wordnet ) and added as an AnnotationProperty inside the concept tag.
3.2.14.2 Relation Serialization
1. Subject, verb and object of each relation are made xml-friendly as explained in the previous
stage.
2. If it is taxonomical relation, the” subject” is added as an instance of the “object”.
3. If it is non-taxonomical, an ObjectProperty is created if it does not exist in model, and a new
property is added to the “subject” instance or class in the model with all relation metadata
(such as verb_translation_en and frequency) added as tag attributes.
35

Final the memory model generated from the previous steps are sent to “writeToFile” function to be
serialized to an OWL file. The file is a 3 MB file including all concepts and relation with all of their
metadata.
Excerpt from the OWL file can be found in Appendix B.37.
3.3 Iteration 2
Additional iteration was planned but was not executed due to time limitations thus added as future
work. The plan for this iteration was to produce a new version of the ontology (V1.1) which is richer
than V1.0 (Iteration #1) as described below:
1. Remove all capping and limits that were imposed in iteration 1 to reach a tractable
ontology. It is expected to reach 2,000+ concepts as a result of the limitation removal.
2. Discover and support more lexico-syntactic rules for non-taxonomical relation extraction,
together with removal of concepts cap, the count is expected to pass 5,000 relations.
3. Redo all the 14 steps in iteration 1 to produce QA ontology V1.1 including custom exclusion
and manual validation effort.
4 - Quran Analysis Website – Qurananalysis.com
In this section QA website is described in terms of how it is structured and how it works.
4.1 Website Design
The main design principles followed are simplicity, usability and self descriptiveness, making best
use of available space and choosing lively appealing colors. In the next section the website
structure and the design decisions will be explained.
4.1.1 Logo & Domain Name
Much consideration has been given in almost every detail of the design including the logo.
36

There is a deep concept behind the logo shown in the illustration above. First people will see it as
“Q” letter which is the first letter in the word “Quran”, but also it can be a single story lower-case 'A'
“ɑ” and also it looks like the Arabic letter “ after adding imaginary double dots on top of it - this "ق
letter is the first letter in the word Quran in Arabic (قرآن). Finally and most importantly it looks like a
magnifier which is the most popular symbol for “Searching”.
As for the domain name, the name is simple and descriptive: www.qurananalysis.com and also will
have additional impact on SEO (Search Engine optimization) since it contains both words “Quran”
and “Analysis” which are the words users will probably use in searches to get to QA and QA-like
websites. Having search words in the domain name is one of the factors which affects search
engine's result ranking [53].
4.1.2 Structure
The website is structured into three main sections “Search”, “Explore” and “Analyze” where search
is the default view the user will see when entering the website.
1. Search is mainly for users trying to find verses about a specific word or topic.
2. Explore is an unique exploratory search view for people who are new to the domain (ex:
non-muslims or new-muslims) and would like to explore the Quran.
3. Analyze is a section for religious scholars and computing researchers where they can find
20 research and analysis tools tailored for the Quran.
In addition to the above, there is a menu which links to information, contacts, feedback and
contribution forms for interested users.
37
Illustration 8: QA Logo

4.2 Technology
QA was developed using PHP programming language, Javascript, CSS and HTML.
D3 Library was used for visualization.
PHP APC was used for caching data models in memory.
4.3 Data Models
Full detailed explanation of all 12 data models can be found in Appendix E – Data Models
(including description of the source corpus, file formats and technical details for loading and storing
the data model).
The following models are covered:
1. QAC
2. Qurana
3. Wordnet
4. QA Ontology
5. Quran Core Simple
6. Quran Core Uthmani
7. Quran Core English
8. Uthmani to Simple Mapping
9. Quran Words Translation
10. Transliteration
11. Stop-words Lists
12. Inverted Index
4.4 Search
The main functionality of the website is the search page. In the index page the user will see a
search field and some examples of search queries [Appendix B.33].
The following search types are supported:
1. One Word.
38

2. Multiple Words (OR is assumed).
3. Phrases (Exact Match).
4. Questions (In natural language both English and Arabic).
5. Specific Verse (In the following format “chapter_index:verse_index”).
Real examples of the above types in Arabic and English can be seen in Appendix B.33.
4.4.1 Search Engine
The search engine is built using an inverted index which contains all words in the Quran (both
simple Arabic script and English words) each pointing to all verses where the word can be found.
In addition to normal words: QAC roots, lemmas and Qurana pronoun concepts are added with
pointers to source verses.
The ontology was not added to the index since almost all words in the ontology are extracted from
the Quran, so all words in the ontology are already in the index except for concepts added from
DBpedia and Wordnet, but such concepts are hypernyms and are handled during the search flow
as explained in later section.
The inverted index is explained in details in section 4.2.13.
4.4.2 Search Flow
When the user types a query the following happens:
1. Language detection: detect query language and set it as the default model language.
2. Logging: query is logged for reference and future analysis.
3. Load Models: load models from memory based on query language.
4. Detect Query Type: decide whether the query is a question, phrase, specific verse or a
normal keywords query.
5. Trim: trim by removing special characters and spaces from right and left sides.
6. Script conversion (Arabic only): diacritics are removed using an uthmani-to-simple
conversion algorithm. This is needed to support user searching using both uthmani and
simple scripts since the index is using simple script; uthmani queries should be converted
to simple before scanning the index.
39

7. Clean query: remove special characters from any part of the query since sometimes users
will copy verses from other websites/documents or enter unneeded characters by mistake.
8. Derivation extension: user query is extended by finding word derivations (such as
plural/single variations).
9. Ontology Extension: user query is extended by finding taxonomical relations in the
ontology (ex: if user searched for animal, instances of Animal concept (Dog) will be added).
10. Question Answering: if the query is a question: the question answering module is used to
answer the question.
11. QAC Derivation Extension (Arabic Only): user query is extended by adding roots and
lemmas of current query terms using QAC corpus.
12. Exclude Stop Words: remove any stopword from query terms.
13. Limit Query: limit query terms to 25 terms.
14. Fetch From Index: Fetch verses and metadata (ex:chapter name) from inverted index.
15. Relevance Score: calculate relevance score for each verse.
16. Suggestion: calculate and show nearest words suggestions if the query returned no
results.
17. Show and Highlight: show verses and highlight any word or pronoun found in query
terms.
4.4.3 Relevance
Relevance score of verses is calculated as follows and results are sorted by score in descending
order.
Factor Weight Description
Frequency 0.5 Frequency of occurrence of terms in verse
Coverage 2 Number of query terms found in verse
Pronouns 1 Number of pronoun references found in verse – complementing “coverage”
Phrase Presence 4 Full query phrase is present in the verse
Table 17: Search Result Relevance Factors
40

4.5 Explore
This section is made for users with little knowledge about the Quran and would like to explore and
know more. The idea is explained in details in section 6.2.
The user will see color-coded clustered circles each representing a concept in the Quran, he/she
will notice that related concepts have the same color. When clicking on any concept all verses
related to that concept is shown.
Screenshot of the exploratory search can be seen in Appendix B.1 and Appendix B.7.
4.6 Analyze
The analyze section contains 20 research tools for scholars to facilitate their work. The user will
see the tools menu on the left and description for each tool on the index page.
Detailed description and screenshots for each tool can be found in Chapter 5.
4.7 Opensource Initiative
QA is not only a thesis project, rather it emerged to be an opensource initiative with the intention of
sparking innovation in the area of Quranic Research. The code for the full website including
ontology extraction is already on Github in a private repository [56] and will be released in
November 2015.
Researchers and software developers will be able to make full use of all the effort made in this
project and use the code in their own systems and contribute code to QA.
41

5 - Analysis Tools
This section illustrates the Analysis Tools offered by QA website, these tools are for researchers
and scholars who are interested in analysing Quranic data and finding patterns from text, it is
meant to be the “swiss-knife” of Quran Research aiming to advance and speed up innovation in the
field. Most of the tools were created due to actual need during the research work in this project.
Most of the tools supports both English and Arabic languages. Below is an explanation for each
tool.
5.1 Basic Statistics
This page shows much statistics from the Quran for both Arabic text and English translation.
Statistics shown includes the following:
1. The total number of chapters, verses, words and characters.
2. Minimum and maximum words, verses and word/verse lengths.
3. Breakdown of totals by chapters.
4. Quran pause marks count.
Page screenshot can be viewed in Appendix B.8.
5.2 Word Frequency
This tool lists all words in the Quran with their frequencies and weights calculated using the TFIDF
algorithm. Each chapter is considered a “Document” in TFIDF calculation. The tool also provides a
button to exclude stop words from the list.
Tool screenshot can be viewed in Appendix B.9.
42

5.3 Word Clouds
This tool shows word clouds [Appendix B.10] for each chapter in the Quran in addition to 2 other
clouds for verse endings and beginnings (clouds for first and last words in each verse). The bigger
the word size the more it is mentioned in the Quran.
The rationale behind this tool is allowing the user to understand the digest of chapters by a quick
look and getting to know which words has more emphasis, for example it was found that some
words are often repeating at the end of many verses such as “knowing”, “wrongdoers”,
“punishment” and “merciful” though no further effort has been done to find explanation for this
trend.
It was also found that using unsorted array of words 1) gives better visualization 2) enhance user
interaction compared to sorted words, since the user will invest more effort to scroll and find big
significant words.
5.4 Full Text
This page lists all verses in the Quran in order so users can see the source text used in the
website in one page, it was used during research as a fact page where search results are validated
against.
Page screenshot can be viewed in Appendix B.11.
5.5 Charts
This page shows a collection of charts from Quranic data. The motivation is finding insights using
data visualization. Currently only "Chapter/Verse distribution" is shown. An obvious insight in this
chart is that number of verses in chapters goes down as the number of chapters increase except
for 3 chapters (outliers) and looks like a wave due to temporarily rises.
Page screenshot can be viewed in Appendix B.12.
43

5.6 N-Grams
The n-grams tool gives the user the ability to choose the "N" value in n-grams and produces a list
of N-gram words from the Quran. This tool was used intensively during research work in the
ontology extraction chapter.
Tool screenshot can be viewed in Appendix B.13.
5.7 PoS Patterns
This is a unique tool which gives the user the ability to get verses from the Quran matching a
specific PoS Pattern, for example if the user specified “PN V” the tool will return all verses having a
proper noun followed by a verb, such tool is very useful in choosing syntactic and lexico-syntactic
patterns. The tool supports all QAC patterns in addition to “*” wildcard.
Tool screenshot can be viewed in Appendix B.14.
5.8 PoS Query
This tool lists verses containing any specific PoS Tag from the Quran. QAC tagset [50] is
supported. The tool also supports filtering by QAC features [60], for example the user can search
for “N” as a PoS and “GEN” as a feature, the tool will return verses containing a noun in a genitive
case. The tool will also show the number of verses and all “distinct” words for the specified PoS
Tag.
Tool screenshot can be viewed in Appendix B.15.
5.9 Repeated Verses
This page shows all repeated verses from the Quran. verses are sorted in a descending order by
their repetition. This can be useful since repeated verses may have certain significance.
Page screenshot can be viewed in Appendix B.16.
44

5.10 Repeated Phrases
This page shows all repeated “phrases” (sub-verses or substring of verses) from the Quran.
phrases are sorted in a descending order by their repetition. LCS (Longest Common Substrings)
algorithm [66] was applied on the whole text of the Quran to make up and cache the repeated
phrases list.
This list is valuable for many tasks such as “phrase concept” extraction in ontology learning, finding
lexico-syntactic patterns and finally finding significant n-gram phrases in the Quran.
Page screenshot can be viewed in Appendix B.17.
5.11 Ontology Data
This page shows the data extracted from the ontology. All concepts and relations are shown in
tables including their totals, it is created for researchers who want to check specific relations or
concepts from the ontology online without using OWL ontology viewing tools.
Page screenshot can be viewed in Appendix B.18.
5.12 Ontology Graph
This tool shows the subset ontology [example in Appendix B.19] of any selected chapter in the
Quran, in addition to the visualization of the full QA ontology [Appendix B.6].
The importance of the subset ontology for chapters is that it can be considered a “footprint” or a
“digest” for any chapter since it shows the “concepts” mentioned in the chapter in variable sizes
according to their frequency and the links between them, for example the screenshot shown in
Appendix B.19 shows that “The Iron” chapter has more emphasis on heaven, rewards, bounty,
light, life, people and messengers.
5.13 Uthmani to Simple
The Quran is written in uthmani script which is different from the simple script used in modern
Arabic at present. This page shows all uthmani words in the Quran and their corresponding simple
words.
45

The algorithm used to compile this list from the Quran is described in details in Appendix E.8 -
Uthmani to Simple Mapping.
Page screenshot can be viewed in Appendix B.20.
5.14 Word Information
This tool provides information about any Arabic word in the Quran by gathering data about the
word from all relevant data models [Appendix E - Data Models]. For each word the following is
shown to the user:
1. Simple and Uthmani Word Presentation.
2. Frequency.
3. TF-IDF Weight.
4. Buckwalter Transliteration.
5. Transliteration.
6. English Translation.
7. Word Root.
8. Word Lemma.
9. QAC PoS Tags.
10. QAC Features.
11. Verses.
Tool screenshot can be viewed in Appendix B.21.
5.15 Collocation
The collocation tool shows the context of any word in the Quran Appendix B.22. When a word is
entered by the user, the tool will show all words mentioned before or after the target word up to 3
levels. The tool also supports QAC PoS tags (Collocation of PoS Tags) Appendix B.23 which is a
novel feature that can help in finding linguistic rules and patterns to facilitate different research
tasks such as ontology learning from text.
46

5.16 Concordance
Similar to the collocation tool, the concordance tool shows the context of any word in the Quran
Appendix B.24 with word dependencies considered. When a word is entered by the user the tool
will show all words mentioned before or after the target word up to N levels where N is chosen by
the user. The target word is highlighted in red and the words before and after are also highlighted
but in blue. The tool also supports QAC PoS tags Appendix B.25 which is important as explained in
the previous section.
Another novel feature in this tool compared to other concordance tools I used before is that it
shows the most repeated phrases before and after the target word, for example if the target word is
“eats” and the specified context level is 3 the tool will show the most repeated trigrams (including
target) such as “A and B eats” and “C and D eats” as “pre-context” and “eats X Y” and “eats Y Z”
as “post-context”.
Both the collocation and concordance tools are very important in multiple fields such as linguistics
and computing since it provides the researcher deep insights, patterns and rules from the Quran.
Both tools were built due to strong need in ontology learning research.
Both tools supports only Arabic words (Simple and Uthmani) and QAC PoS Tags.
5.17 Pause Marks
This tool will show all verses containing any chosen pause mark by the user. Pause marks are a
set of 6 marks which directs the reciter of the Quran on when it is permissible, recommended or
not acceptable to stop while reading.
This tool was created to investigate whether pause marks can be considered good positions for
splitting verses into sub-verses.
Tool screenshot can be seen in Appendix B.26.
47

5.18 Buckwalter to Arabic Transliteration Mapping
Buckwalter transliteration [50] is a reversible transliteration scheme used to write Arabic charactersusing Latin ASCII characters. QAC data is encoded using an extended version of Buckwalter transliteration table [51] so a mapping function was needed to translate Arabic to Buckwalter and vice-versa in order to convert QAC segments to Arabic characters.
The tool accepts Arabic or Buckwalter encoded string, it manage to detect the type of the string automatically and will show the result after conversion.
Tool screenshot can be seen in Appendix B.27.
5.19 Word Similarity
This tool shows the top 20 similar words for any word in the Quran. The tool supports both Arabic
and English. The same functionality is currently used to suggest query words for users if their
queries didn't return results. The words are found using an extended min-edit-distance algorithm
discussed in [section 7.3 Arabic Question Handling].
Tool screenshot can be seen in Appendix B.28.
5.20 Quran Initials
Quran Initials [52] are unique dis-joined letters which are found in the Quran in 30 locations. The
letters are treated as one unit and in some cases it make up a full verse and in other cases they
are found at the beginning of a long verse. The meaning of those “letter units” are not clear until
present time and no one can claim having absolute understanding for any of them.
The tool employs visualization and analytics aiming to help in deciphering the meaning of those
letters. The tool shows the following:
1. Totals of each unique initial.
2. A chart showing distribution of initials in the Quran.
3. A cloud of words found in the same verses of the initials, significant words were found such
as “Book”, “Quran” and “These are the verses”.
4. List of all verses - initials marked in blue and second word marked in red.
Tool screenshot can be seen in Appendix B.29.
48

6 - Visualization
The purpose of this section is to explain the novel visualization techniques used in QA website and
the rationale behind them. In general, visualizations were meant to serve multiple goals 1) facilitate
search by visualizing results and enable post-result navigation 2) help in analysing relations and
finding patterns from the Quran 3) enable exploratory search 4) visualize QA ontology and
presenting numerical information in charts and word clouds. Visualizations were used in all three
website sections which will be discussed in details in the following sections.
6.1 Search Results Graph
Search results are visualized in three ways: an ontology graph, verse distribution chart and word
cloud.
6.1.1 Ontology Graph
One of the main reasons for the ontology extraction work in chapter 3 is to visualize search results
to add “context” and “meaning” to plain text results, thus to achieve the semantic search goals
stated in the introduction.
The screenshot below is taken from QA website for search query “Muhammad”. The graph is
placed on the right side of the result page adjacent to the verses returned for that query. The graph
is a subset ontology (part of the complete QA ontology) which includes only concepts that are
either found in query terms or in the text of the returned verses. A quick look on the graph will give
the user an overview of the searched concept and all related concepts (in the ontology) then the
user can start using the graph to navigate through clicking on links and related concepts.
Below is a detailed explanation for each component in the graph.
49

General Graph Presentation
The graph is a force-directed graph (FDG) [40] drawn using D3 JavaScript library [41] and is a
tweaked version of D3 FDG Example [42]. The idea of FDG is to consider graph nodes as magnets
with charge repelling each other and the links as springs keeping the magnets from going far apart
thus when applying appropriate (tunable) node charge and spring gravity forces the graph will
reach an equilibrium state of forces leading to a balanced good looking presentation, this is why
FDG layout was chosen from many alternatives in D3 library.
D3 library was chosen because it is the most popular and widely used web visualization library,
supported by a strong active community, very well documented and includes a rich set of
examples. Currently it has 40,000+ stars on Github, more than 10,000 forks and 97 contributors
[43].
Circles and Words
50
Illustration 9: Search Results Graph

Red circles are the main concepts that were searched for. The blue words are the concepts related
to the main concept. Circle and word sizes and proportional to the frequency of the concept in the
Quran. Clicking on the concepts will show all verses containing the clicked concept.
Links
The grey lines between concept are links which means that “the linked concepts” have one or more
relations between each other. When the mouse is hovered on the link a tooltip appears showing
the “verb” which describe the relation between concepts. Finally the width of the link means the
relation has been found more often in the Quran (this can be seen above between “Muhammad
and Allah).
Clicking on a link will show verses containing the whole relation, that is; verses containing the
subject, the object and the verb. Finally arrows denote the direction of the relation.
Description Layer
When the mouse comes over a concept, the black layer in the bottom of the graph becomes visible
to show more information about the concept such as Wikipedia or Wordnet descriptions, the
concept name and the link – if present in the ontology. It is also worth noting that the background of
that layer will be the depiction of the concept – if present in ontology – finally the layer can be
closed by clicking on “x” on the top right.
Zooming
The graph can be zoomed in and out using the “+” and “-” controls on the top right of the box. The
zooming functionality is implemented by increasing and decreasing the “gravity” force of the FDG.
Challenges Faced
1. Finding the right size for concept fonts and circles: The solution was to find proper values
by trial and error to be proportional with the frequency of the concept in the Quran. Also the
best colours for links, circles and text needed some consideration.
2. The location of description layer was changed many times to provide better user
experience. In general the layer shouldn't be vertical since it will take more space and will
51

mostly be empty. Preferably it should be outside the graph box since it blocks the ability to
click on concepts.
3. How to show the link verb (relation name): Showing the verbs on all links distort the
presentation so it was made hidden except when the use hover on the link, only then it is
shown in the middle of the link. This also didn't look good enough. Finally a decision was
taken to show only one verb beside the mouse position when hovering on the link.
4. Handling multiple relations between 2 concepts: the solution was to aggregate all verbs
together and show only one on hovering but when clicked' all verbs are searched.
5. Finding the right FDG forces for best presentation in the available space: many
experiments were done with different values to reach the best presentation in addition to
basing the forces on other factors like number of nodes and links in the graph.
6. Implementing the zooming functionality: I had 2 options to implement zooming, using SVG
scaling or gravity alteration, the later was chosen since it is more simple and gives more
control and keeps the presentation balanced.
6.1.2 Word Cloud
The word cloud section is placed below the ontology graph, it helps in showing the context of the
results by listing all significant words found in the result verses. It is also useful in cases when the
ontology is missing some concepts that can be found in the search result text, in such case the
missing concept will be found in the word cloud.
The word cloud in the illustration above shows the context for search query “Muhammad”. The
bigger the word the more it is mentioned in the results, for example words like “Allah” “Lord”
52
Illustration 10: Wordcloud of search result verses for "Muhammad"

“People” and “Revealed' are relevant context for the word “Muhammad”, also the bigger the word
the more greenish the colour is.
The cloud is clickable: clicking on any word will get all verses which has the original search query
plus the clicked word, so if “lord” is clicked all verses including Muhammad and Lord will be
retrieved.
The word cloud is rendered using the JQuery Wordcloud library [44].
6.1.3 Distribution Chart
The last visualization component in the search result page is the distribution chart which shows the
distribution of the returned verses across Quran.
The above chart is showing that “Muhammad” was mentioned in almost all chapters (most of the
mentions are through pronouns) with more frequent mentions in the initial chapters, this is
beneficial in finding insights by observing distribution variance across chapters.
The chart is rendered using D3 Library [41].
53
Illustration 11: Verse distribution chart for the query "Muhammad"

6.2 Exploratory Search
Exploratory search is visualization concept by which users are assisted to explore a new domain
without having a clear goal or a specific thing he/she is looking for. As explained by (Janiszewski,
1998) “exploratory search behaviour occurs when consumers are confronted with multiple pieces
of information but have little stored knowledge about how to proceed with the information
gathering”.
In the context of this project, exploratory search is used to help users find new unanticipated
information, for example Non-Muslims wanting to know more about the Quran or Muslims wanting
to search the Quran by topic. This is done by encoding the whole QA ontology in one visual view
where users can scan and find verses by topic.
The explore part was the most challenging visualization problem in the project. The challenge can
be summarized by this question: how to encode more than 1000 concepts in a web page while
showing the user relevant information such as topic significant and relatedness to other topics.
That said, many experiments have been conducted and compared. In the next sections all
experiments will be explained and the final solution will be presented.
6.2.1 Experiments
The experiments were inspired by [47] and [48].
6.2.1.1 Treemap
Treemaps as seen in Appendix B.3 present concepts in boxes with box size denoting the
frequency of the concept, children of a concept are encoded in the same box with box space
splitted among them.
The treemap visualization was applied on QA ontology and the results were not satisfactory since
much size is wasted and when a concept has many children the boxes become too small and
unreadable.
6.2.1.2 Tree Layout
Tree Layout is a normal tree shape structure with the ability to collapse and expand nodes, it didn't
fit in the explore section since it wastes so much space and needs long scrolling to scan. However
54

it was used in the analysis section for full ontology view. The actual Tree Layout can be viewed in
Appendix B.4.
6.2.1.3 Radial Rotating Tree
This is the same as the Tree Layout except that the tree is folded in a way forming a radial shape
so it can show more data in less space.
The experiment was a failure since the ontology was too big to be fitted radially in the allocated
width and height although the allocated diameter was above 900 pixels, the text was not readable
and the orientation of the text depends on the angle. This visualization was found limiting in
general. Actual snapshot can be found in Appendix B.5.
6.2.1.4 Force Directed Graph
FDG is already used to visualized the search results, it works well for small number of concepts.
FDG uses forces to align concepts away from each other. Depending on the force and gravity
settings the concepts will be far apart wasting space between them or will be brought together and
make the presentation vague and unreadable. An experiment was done and my concerns were
validated: the ontology will never fit in a single page view. Also FDG will never scale vertically
because of the link (spring) force pushing towards the gravity. However it was used as one of the
options to visualize the ontology in the analysis section but with 2600x2000 pixel view. Screenshot
can be seen in Appendix B.6.
6.2.2 Final Solution
Inspired by the clustered FDG layout in [49] a modified version was applied and found to be fitting
QA visualization requirements. Clustered FDG are normal force layout but instead of having 1 force
towards the centre (gravity) it will have many centres one for each cluster. The layout implements 2
functions: cluster and collide, the first pushes nodes towards the largest node in the cluster and
collide prevents node from overlapping. The actual visualization can be found in Appendix B.1.
The nodes in the ontology were clustered based on taxonomical relations with each cluster having
a different color (only 10 colors are used with rotation after the 10th cluster). Most of the nodes has
a min fixed size except for very high frequency nodes which will be bigger. nodes of the same
cluster appear beside each other.
55

When a node is clicked a layer appears beside the node showing all verses for the clicked concept
(example in Appendix B.7). If the concept is a long “phrase concept” it will be cut on a fixed length
and “...” added at the end. However, when the user hover on a node the circle is expanded and the
full name is shown.
Many customizations have been added to the new layout to fit in QA. first a function
handleOutOfBoundry was added to handle any node going out of page boundaries - because of
initial charges - and return it back to its cluster. Also initial pre-visualization clustering and
positioning work was done and found important for smooth and good looking visualization. Finally
handling clicks and hovers and adjusting the location of the popup layer so it doesn't go out of
page boundary.
7 - Question Answering
In this chapter, QA's question answering system will be explained in details. There are two levels or
approaches followed for answering user questions 1) finding direct answer from the ontology 2)
answer facilitation through visualization. The first approach was the most challenging. Both
approaches are explained in the following sections and an overview diagram for the whole process
can be found below.
56

7.1 Detecting Question
User queries are checked for “Question” clues. Currently the following clues are supported:
• Question marks.
• What, Who, How much, How many and How long.
• .(Arabic variations of What and Who) من هو, من هم, من هى, من الذى, من الذين, ما هى, ما هو, ماذا
7.2 PoS Tagging
User query is tagged using the PoS tagger described in Appendix C.6 if the language is English,
else if the language is Arabic; a very simple entity extraction algorithm is applied by removing stop
words and then considering remaining words as nouns.
7.3 Question Enrichment
Key terms in questions might be mentioned in a singular form while the word in the Quran (or in
QA Ontology) can be plural. Also there may be synonyms for the same word, thus an algorithm
was implemented to find all possible derivation for the words in the query. The algorithm is
described below.
57
Illustration 12: Question Answering Process

First any word less than 2 characters long is ignored since the below rules will not apply.
7.3.1 English Question Handling
1. If PoS tag is “noun singular” (NN) then add “s”.
2. Else if plural (NNS) then remove last character.
7.3.2 Arabic Question Handling
I was faced with a challenge trying to get all derivations for Arabic words since I didn't find any
corpus or a proper algorithm to do that. I used another approach which is matching the word with
all concepts in the ontology and filtering only words which have the closest distance and then
applying specific Arabic derivation patterns rules on both words to decide whether they are
derivation of each other or not. Similarity was calculated using min-edit-distance algorithm -
Levenshtein distance [46] – in addition to another custom similarity measurement algorithm which
measures “character similarity” between both words, adding more accuracy to the similarity score.
1. Loop on all concepts (and concept synonyms) in the Quran. For each question word apply
min-edit-distance and “character similarity” algorithms and keep a list of similar words with
distance less than or equal 5.
2. Loop on the extracted list from the previous point which has the similar word as key and
distance as value.
3. Compare each word in the list with question terms on the following basis
1. Detect which word is smaller.
2. Apply string diff (difference) algorithm which finds the remaining sub-string after
removing the small word from the longer word.
3. If the remaining characters are one of the 3 pre-set derivational patterns (listed
below) then add the similar word to question terms.
4. If the smaller word does not fit into the larger word (not substring) and the diff is one
character, then only one pattern is checked (second pattern in the table below).
4. Limit added derivations to 10 including question terms since the query shouldn't be
overloaded with terms.
58

Preset Patterns
Difference Word 1 Word 2 Pattern
2 حيوانAnimal
حيوانات
Animals
They are the same if “ات" is added at the end of the smaller word
1 صفةAttribute
صفاتAttributes
The same if last character is removed from the
smaller word and “ات" is added at the end
4 حيوانAnimal
الحيواناتThe Animals
They are the same if “ات" is added at the end and “
at the beginning of the smaller word ”ال
Table 18: Supported Arabic Derivational Patterns
7.4 Extract Answer from Ontology
The question is answered from the ontology by looking for relevant concepts and searching
relation verbs using all noun terms in the question. For example if the user is searching for “What
are the colors mentioned in Quran ?” the algorithm will be able to answer by searching for all
instance concepts of class “Color” (single by derivation) in the ontology.
7.4.1 Searching Ontology Concepts
The algorithm works as follows:
1. For each term in Question, check if it is a concept or not, if not then ignore.
2. Get all inbound relations for the current concept, that is any relations where the current
concept is an object (ex: in “Green is a Color” - color is Object).
3. If the verb is an “is-a” verb then add the subject to the answer list.
4. Do step 2 and 3 for “Outbound” relations such as (Color is-a “Another concept” ).
7.4.2 Searching Ontology Verbs
Sometimes the answer lies in verbs not in concepts. For example to answer the following question
“What Allah Loves” the system will only answer if it looks for relations of the following patterns
59

“Allah loves X”, that said; verb searching was added to complement the question answering
engine. Find details below.
For each term tagged as verb in the question:
1. If the verb is not found in the Ontology verb index (discussed in Appendix E.4 - QA
Ontology) or not part (substring) of any verb word in the index then ignore.
2. Get the subject and object of the verb from Ontology verb index.
3. If language is English, translate both (subject and object) to English.
4. If the subject is found in the question terms list (part of the question) then add the “object”
as the answer and do the same for the object (add subject as an answer in case of object
found in question terms).
7.5 Extract Answer from Verses
In addition to extracting answers from ontology, answers are also extracted by applying question-
verse similarity measurements to find verses from the Quran which are most probably the answer
to the user question. This technique is similar in concept to “search relevance” and is partly
inspired by “Albayan” [13]. This technique is useful in cases where 1) The ontology is not
comprehensive enough 2) The question is complex. Also this technique was found to be more
flexible and can be used and applied on external text such as interpretations (Tafseer). The
process is illustrated below.
1. The Question Type is detected by looking for the supported question clues (ex: “Who”
means “Person”). Knowing the question type help predicting the expected answer.
The following question types (clues) are supported: Person, Time, Quantity and General.
2. All instance concepts for the Question Type class are extracted from the ontology (ex: any
instance of class “Person” in the ontology such as names of prophets).
3. Concepts are extracted from question text by matching each word against the ontology
index.
4. The next points are applied on each scored verse returned by the normal search engine
process as explained in [section 4.4 Search]. The goal is to score each verse as a
candidate answer to the question.
60

5. Concepts are extracted from the verse text and intersected with concepts extracted in point
#3 (Question concepts). The intersection count (number of matching concepts) is added to
the candidate answer score for that verse.
6. Concepts extracted in point #5 (Verse concepts) are also intersected with concepts
extracted in point #2 (Question Type concepts) to find if the verse has concepts related to
the question type (Person name for “who” questions) thus will have more probability of
being the correct answer. The number of intersected concepts are added to the candidate
answer score for the verse.
7. If the question language is English: Word-to-word similarity algorithm is applied on both the
question and the verse as follows:
If the question word is a verb or a noun and is more than 2 characters in length then find if
that word and any other word in the verse are matching or can be substrings to each other,
if so; then add “1” to the verse score to mark a derivational word similarity between the
question and the verse.
8. If the query language Arabic: Get the roots -from QAC- of all nouns in the question -if
possible since words might not be Quranic words- and the verse and intersect them
together. The result of the intersection is added to the candidate answer score for the
verse.
9. After applying the previous points on all verses, the verses are sorted by the new candidate
answer score and the top verse is considered the answer.
7.6 Answer Presentation
The answer is added as a sentence directly after the search field as shown below.
61
Illustration 13: Answer Presentation

7.7 Second Level Question Answering
If the direct question answering system wasn't able to find a clear answer from the ontology or
verses, the system can still help the user get closer to the answer, this is referred to here as
“Second Level Answer”. This is achieved through visualization and search relevance.
To illustrate this concept consider the following example: the user searched for “Who is the brother
of Moses ?” the ontology does not include a link between Moses and Aaron but through
visualization and labelling the user can still find the answer in one of the following 3 locations.
7.5.1 Red Labels in Verses
When a question is not answered, the system will try to find significant words which might include
answer clues, those clues are sometimes the top collocations found in result verses (collocations
for words found in the question).
7.5.2 Graph
The graph can also hold information about the answer. For the query mentioned in the previous
section the graph contains the concept Aaron that when you hover on will show the wikipedia
description which includes the answer to the question.
7.5.3 Word Cloud
Finally sometimes the answer in found in the top terms in the word cloud, but it is usually not as
accurate as the last two views.
An illustration of the above example can be seen in Appendix B.2.
62

8 - Evaluation
8.1 QA Website User Feedback
Feedback sessions have been conducted with 5 Muslim students from different countries and
speaking 3 different languages, each session took more than 1 hour as they were asked to explore
the website. Notes were taken as they navigate and interact with the system. At the end they were
asked the same questions in addition to any other questions arising from their interaction and
expectations. Below is the digest of their feedback.
8.1.1 Answers to Questions
Is the website useful ?
• 4 out of 5 students said that it is useful while the other student said he didn't use other
relevant websites so he can't judge.
• “Amazing, simple, nice, intuitive and interesting” responses were quoted specially when
commenting on the user interface and the “explore” section.
What is special about QA compared to current search engines ?
• Statistics and Graphs.
• Adding variations of the words in user queries to get better results.
• Suggestions when searching for wrong words.
• Helps the user to reach what he/she is looking for.
• Helps the user to learn more.
• The ability to find relations between things.
• The question answering functionality.
What needs to be improved ?
• Question answering needs to be more accurate.
• Phonetic (transliteration) search was expected by one of the non-Arabic speakers.
• Adding descriptions for search results visualization components and help button in the “Analyze” section.
• For verse search, a mapping table of chapter index and chapter name was expected.
63

• Search chapter by name or verse range was expected.
• Some colors needs to be changed and clickable items needs to be more obvious.
• Group word frequencies by lemma to be more meaningful.
Any functionality found broken (not working) ?
• Some concepts in “Explore” didn't show any results when clicked.
• Wrong answers to questions.
8.1.2 Personal Observations
Below are some observation notes I took from users interactions.
1. Most of the students didn't see the answer section [7.6]. users tend to look at the verses
first thing.
2. Most of them didn't click on the examples in the main page. When asked some said they
didn't feel it is clickable and other preferred to search by themselves.
3. Most of the users ignored the graph in search results. When asked they said they didn't
understand it, when they used the graph they didn't know that they can click on the link
between two concepts to see verses related to that link.
4. The explore section seemed to be perfect in terms of usability and self description. Most
users didn't find any difficulty dealing with it.
5. Since it is very processing intensive, the website was not as fast as it should be.
6. Users had higher expectations from the Question Answering functionality.
7. Users appreciated the integration of Qurana in QA where search results include words that
are mentioned in the query but is referred to in the verse as a pronoun, they called it
“smartness”.
8.2 Ontology
There are four types of ontology evaluation techniques according to (Brank et al, 2005) [58] 1) First
Gold standard, which means comparing with other established ontologies 2) Application:
measuring how much the ontology affected the functionality of a specific application 3) Data driven:
which is comparing ontology coverage with a relevant corpus 4) Human expert: validating the
ontology manually.
64

In addition to the above criteria (Alrehaili et al, 2014) [59] proposed 9 custom criterion to evaluate
Quranic Ontologies and applied them on 12 ontologies of the Quran [comparison results can be
seen in Appendix B.32].
The evaluation approach that will be followed is the “ Application” from [58] and the 9-list criteria
from [59] which can also fit as “Gold standard” in [58].
8.2.1 Application Approach
Integrating QA Ontology into QA website (the Application) added much functionality and smartness.
If the ontology is removed the following features will not function.
1. Question Answering.
2. Enriching user query by synonyms and hyponyms.
3. Visualization of search results and graph navigation.
4. The exploratory search section “Explore”.
8.2.2 Gold Standard
Although the current available ontologies can't be considered gold standard (Reference
Ontologies) it is a good idea to do such comparison to know where does QA ontology stands.
Shown below is QA entry if it was added to (Alrehaili et al, 2014) [59] comparison in Appendix
B.32.
QA A Full A OWL Learned FromText
A 1079 Taxonomicnon-taxonomic
Manual
Table 19: QA Entry for Alrehaili comparison
65

After comparing the above entry with other 12 ontologies, it is obvious that QA ontology
outperforms all of them except for the validation criteria since it was not validated by domain
experts. Following is a list of evidence backing my claim.
1. Number of concepts are the highest (1079) compared the second largest ontology
(Mohammad 2012 in Alrehaili's paper) which has 1054 concepts.
2. QA is the only ontology containing non-taxonomical relations (above 2000).
3. QA is the only ontology which covers the whole Quran as opposed to specific domains or
pronouns (Mohammad 2012 in Alrehaili's paper).
In addition to the above, QA scores high in all other factors such as availability, conforming to
standards and being based on the original text.
It is worth noting that there are some other criterion not covered by (Alrehaili et al, 2014) [59] and is
strong in QA such as:
1. Richness of the ontology: for example QA includes much metadata in addition to
concepts and relations such as; frequency, English translation (up to the level of relation
verbs), transliteration, wikipedia links and images, synonyms, weight, descriptions, lemma
and root.
2. Phrase concepts: whether the ontology contains phrase concepts or not.
8.3 Question Answering
This Question Answering module was evaluated by running a batch set of test questions on QA
website and calculating precision and recall measures for the results.
The question set is a list of 12 questions in English language, some of which were gathered during
the feedback sessions – when asked by the users - while other questions were thought of before
implementing the question answering functionality. the list of questions can be found in Appendix
D.1.
66

The evaluation results of the question answering module using QA Ontology V1 is shown below.
Precision 0.33
Recall 1
Table 20: Question Answering Evaluation Results
In the context of this evaluation, precision means: the number of questions answered correctly out
of all questions answered while recall means: the number of answers returned regardless of its
correctness.
Comparing to Albayan [13] which is the latest research effort done in this area (Quranic Expert
Systems) QA didn't reach the precision record claimed in [13] (0.65 overall system precision on
Top-1 answer basis) but there are many other points to be considered when comparing both
systems.
1. QA supports English and Arabic – Evaluation done using English questions - while Albayan
supports Arabic only.
2. Albayan extract answers from interpretations in addition to the Quran while QA only relies
on verses from the Quran in addition to the Ontology (extracted from the Quran).
3. QA ontology V1 which was used for this evaluation. V1 is a capped ontology version that is
expected to be superseded by V1.1 [discussed in section 3.3 Iteration 2] which is 2-3 times
richer than V1. This is expected to make much difference in the results.
4. QA employs three approaches for question answering 1) direct answer from ontology
including verb searching 2) question-verse similarity 3) secondary level answering by
visualization. Albayan only supports the second approach.
5. QA is publicly accessible and can be verified while Albayan is not.
67

8.4 Reviews
This report was reviewed by Leeds 2nd-year PhD student Sameer Alrehaili who is currently
researching ontology extraction from the Quran. Sameer praised the project in general. Following
are statements quoted from his feedback.
"You have done a lot of experimental work and showed interesting results".
“The website produces valuable analysis and knowledge to researchers who are interested in
Islamic studies and computational linguistic”.
9 - Conclusion
9.1 Achievements
The outcomes of the project were more than expected. In addition to achieving 4 out of 5 ambitious
goals, there were many other unplanned additions and contributions. Listed below are all
significant outcomes of the project.
1. Building the first specialized and customized smart semantic search website for the Quran
www.qurananalysis.com.
2. Contributed 20 free accessible research tools for religious scholars and researchers to
advance the Quran research field.
3. Contributed the largest and most rich Quranic Ontology as of writing this thesis.
4. Contributed the first open source initiative and framework for Quranic Research with more
than 20,000 lines of code including many libraries for various tasks such as reading
wordnet lexical database. Also algorithms and functions to process and manipulate Arabic
language and Quranic text.
5. Contributed novel visualization techniques and ideas as described in section 6.
6. Contributed novel ideas and methodologies in ontology extraction and enrichment from
Arabic text.
68

7. Contributed new corpora such as Quranic stop words, uthmani-to-simple and QAC-Qurana
segments mapping files and finally longest common substrings in the Quran.
9.2 Future Work
Since QA is an open source initiative, I will peruse the following goals in the future to add more
value to the users and the research community.
9.2.1 Sentiment Analysis
Create a corpus with all verses in the Quran labelled according to the main sentiment in the verse.
Such corpus will help in Quran research and can have additional value in QA (both in visualization
and search functionality).
9.2.2 Ontology Extraction
Experimenting on using machine learning to extract ontology from text using WEKA. First, Quran
verses will splitted in 5-grams phrases, each phrase will be labelled by whether the middle word is
a “concept” or “not concept”, the labelling will be done using the current QA ontology, each line in
the arff file will be a vector of 10 values, for each word in the 5-grams the PoS of the word and the
word text will be added to the vector, a classification algorithm (ex: JRip) will be applied on the data
to find rules which makes a concept in the middle of a 5-gram context.
9.2.3 Ontology Enrichment
Wikipedia should be used for ontology enrichment instead of dbpedia since it is more rich specially
for Arabic content. Strong Arabic PoS tagger will be needed to extract structured information from
Wikipedia text.
9.2.4 Quran Wordnet
Although QA ontology can be considered a “Quranic wordnet”, it is still missing the synset aspect
of wordnets, so I think some effort should be done in this area.
9.2.5 Question Answering
Enhance the accuracy of the question answering module.
69

9.2.6 New Analysis Tools
The following tools should be added to the “Analyze” section.
1. Quran memorization tool: a tool to help people trying to memorize the Quran by showing
related verses and variations of the same word in different locations in the Quran.
2. Verse PoS Tagger: the user will enter verse text and get it PoS-tagged using QAC
annotations.
3. Statistics about PoS tags distribution in the Quran.
4. Word-by-word translation and transliteration mapping page.
5. Verse similarity (based on the work done by Sharaf [3]).
9.2.7 Additional Corpora
1. Generate 2-5 grams language models from the Quran.
2. A corpus of derivations of all words in the Quran.
9.2.8 Website Enhancements
1. Google-like auto-complete suggestion functionality for search using generated Quran
language models.
2. Enrich user queries using wordnet synsets.
3. Group words by lemma in “Word Frequency” page and all word clouds in the website.
4. Use Arabic PoS tagger to tag Arabic queries.
5. The website needs to be faster. Many parts of the code need to be re-factored and
optimized.
9.2.9 Writing Papers
Some effort will be invested in writing scientific papers to document important parts of QA in
details.
70

9.2.10 Marketing
Marketing both the website and the opensource initiative by communicating and reaching out to
researchers and users through various channels according to the user type (ex: Social Media for
Users and Conferences for Researchers).
9.3 Personal Reflection & Project Evaluation
Personal reflection can be found in Appendix H - Personal Reflection
List of References
1. Tanzil. Tanzil Project Wiki. [Online]. [Accessed August 2015]. Available from:
http://tanzil.net/wiki
2. Quran. The Quranic Arabic Corpus. [Online]. [Accessed August 2015]. Available from:
http:// corpus.quran.com
3. Text Mining The Quran. [Online]. [Accessed August 2015]. Available from:
http://www.textminingthequran.com
4. Wong, W. et al. Ontology learning from text: A look back and into the future. ACM Computing Surveys (CSUR), 2012. http://dl.acm.org/citation.cfm?id=2333115
5. Sharaf, A. B. M. and Atwell, E. QurAna: Corpus of the Quran annotated with Pronominal
Anaphora. LREC. 2012. http://citeseerx.ist.psu.edu/viewdoc/download?
doi=10.1.1.357.2036&rep=rep1&type=pdf
6. Dukes, K. Statistical Parsing by Machine Learning from a Classical Arabic Treebank. Ph.D.
thesis. University of Leeds (School of Computing), 2013.
http://www.kaisdukes.com/papers/thesis-dukes2013.pdf
7. Muhammad, A. B. Annotation of conceptual co-reference and text Mining the Qur'an. Ph.D.
thesis. University of Leeds, 2012. http://etheses.whiterose.ac.uk/4160
8. Kboubi, F. et al. Semantic visualization and navigation in textual corpus. ArXiv, 2012.
http://arxiv.org/abs/1202.1841
71

9. Brierley C. et al. Semantic pathways: a novel visualisation of varieties of English. ICAME
Journal of the International Computer Archive of Modern English. 2013, 37, pp.5-36.
http://clu.uni.no/icame/ij37/Pages_5-36.pdf
10. Sherif, M. A. and Ngonga Ngomo, A. C. Semantic Quran: A multilingual resource for
natural-language processing. Semantic Web. 2003.
http://svn.aksw.org/papers/2014/SWJ_SemanticQuran/public.pdf
11. Abbas, N. H. Quran “Search for a Concept” Tool and Website. Ph.D. thesis. University of
Leeds (School of Computing), 2009. http://citeseerx.ist.psu.edu/viewdoc/download?
doi=10.1.1.225.9215&rep=rep1&type=pdf
12. Islamic Book Store. Mushaf Al Tajuid. [Online]. [Accessed August 2015]. Available from:
http://www.islamicbookstore.com/b8898.html
13. Abdelnasser, H. et al. Al-Bayan: An Arabic Question Answering System for the Holy Quran.
ANLP 2014. http://www.aclweb.org/anthology/W14-36#page=68
14. Suarez-Figueroa, M. C. et al. NeOn methodology for building contextualized ontology
networks. NeOn Deliverable D5. 2008. http://www.neon-project.org/web-
content/images/Publications/neon_2008_d5.4.1.pdf
15. Google Code. Stop-words project. [Online]. [Accessed August 2015]. Available from:
https://code.google.com/p/stop-words
16. Fossies. Openoffice Arabic Dictionary File. [Online]. [Accessed August 2015]. Available
from: http://fossies.org/linux/misc/libreoffice/src/libreoffice-dictionaries-
5.0.0.2.tar.gz/libreoffice-5.0.0.2/dictionaries/ar/ar.dic
17. Github. Ar-PHP project. [Online]. [Accessed August 2015]. Available from:
https://github.com/Shnoulle/Ar-PHP/blob/master/Arabic/data/ar-extra-stopwords.txt
18. TextMiningTheQuran. Quran Stop-words list. [Online]. [Accessed August 2015]. Available
from: http://www.textminingthequran.com/wiki/Stopwords
19. Qِuran. Surat Al-'Insān (The Man). 76:27. [Online]. [Accessed August 2015]. Available from:
http://quran.com/76/27
20. Quran. Surat Al-Baqarah (The Cow). 2:86. [Online]. [Accessed August 2015]. Available
from: http://quran.com/2/86
21. TextMiningTheQuran. Qurana Concepts List. [Online]. [Accessed August 2015]. Available
from: http://www.textminingthequran.com/apps/conceptlist.php
22. Quran. Surat Al-'An`ām (The Cattle). 6:125. [Online]. [Accessed August 2015]. Available
from: http://quran.com/6/125
72

23. DBPedia. DBPedia Wiki. [Online]. [Accessed August 2015]. Available from:
http://wiki.dbpedia.org
24. DBPedia. DBPedia Facts. [Online]. [Accessed August 2015]. Available from:
http://wiki.dbpedia.org/about/facts-figures
25. PHPir. PoS Tagging. [Online]. [Accessed August 2015]. Available from:
http://phpir.com/part-of-speech-tagging
26. Github. Mark Watson Github page. [Online]. [Accessed August 2015]. Available from:
https://github.com/mark-watson?tab=repositories
27. Microsoft. Microsoft Translator API. [Online]. [Accessed August 2015]. Available from:
https://www.microsoft.com/translator/api.aspx
28. Microsoft. Microsoft Translator API PHP code. [Online]. [Accessed August 2015]. Available
from: https://msdn.microsoft.com/en-us/library/ff512421.aspx#phpexample
29. Sourceforge. OWLLib PHP Library. [Online]. [Accessed August 2015]. Available from:
http://phpowllib.sourceforge.net
30. Wordnet. Wordnet Main Page. [Online]. [Accessed August 2015]. Available from:
https://wordnet.princeton.edu
31. Global Wordnet. Arabic WordNet Page. [Online]. [Accessed August 2015]. Available from:
http://globalwordnet.org/arabic-wordnet
32. Adam Pease. Suggested Upper Merged Ontology (SUMO). [Online]. [Accessed August
2015]. Available from: http://www.adampease.org/OP
33. Arabic WordNet Browser. [Online]. [Accessed August 2015]. Available from:
http://sourceforge.net/projects/awnbrowser
34. UPC. Arabic Wordnet XML File. [Online]. [Accessed August 2015]. Available from:
http://nlp.lsi.upc.edu/awn/get_bd.php
35. UPC. Arabic Wordnet Resources. [Online]. [Accessed August 2015]. Available from:
http://www.talp.upc.edu/index.php/technology/resources/multilingual-lexicons-and-machine-
translation-resources/multilingual-lexicons/72-awn
36. Princeton. Wordnet Statistics. [Online]. [Accessed August 2015]. Available from:
https://wordnet.princeton.edu/wordnet/man/wnstats.7WN.html
37. Princeton. Wordnet Index File Format. [Online]. [Accessed August 2015]. Available from:
https://wordnet.princeton.edu/wordnet/man/wndb.5WN.html#sect2
38. Princeton. Wordnet Pointer Types. [Online]. [Accessed August 2015]. Available from:
https://wordnet.princeton.edu/wordnet/man/wninput.5WN.html#sect3
73

39. Princeton. Wordnet Data File Format. [Online]. [Accessed August 2015]. Available from:
https://wordnet.princeton.edu/wordnet/man/wndb.5WN.html#sect3
40. Eades, P. A. Heuristics for graph drawing. Congressus numerantium. 1984, pp.146-160.
41. D3JS. D3 Javascript Library. [Online]. [Accessed August 2015]. Available from:
http://d3js.org
42. Blocks. D3 Force Directed Graph Example. [Online]. [Accessed August 2015]. Available
from: http://bl.ocks.org/mbostock/4062045
43. Github. D3 Github Account. [Online]. [Accessed August 2015]. Available from:
https://github.com/mbostock/d3
44. Github. JQuery Tagcloud Javascript Library. [Online]. [Accessed August 2015]. Available
from: https://github.com/addywaddy/jquery.tagcloud.js
45. Janiszewski, C. The influence of display characteristics on visual exploratory search
behavior. Journal of Consumer Research. 1998, pp.290-301.
http://www.jstor.org/stable/pdf/10.1086/209540.pdf
46. Wikipedia, Levenshtein Distance. [Online]. [Accessed August 2015]. Available from:
https://en.wikipedia.org/wiki/Levenshtein_distance
47. Michelepasin. Messing Around with D3.js. [Online]. [Accessed August 2015]. Available
from: http://www.michelepasin.org/blog/2013/06/21/messing-around-wih-d3-js-and-
hierarchical-data
48. Github. D3 Example Gallery. [Online]. [Accessed August 2015]. Available from:
https://github.com/mbostock/d3/wiki/Gallery
49. Blocks. D3 Clustered Force Layout Example. [Online]. [Accessed August 2015]. Available
from: http://bl.ocks.org/mbostock/1747543
50. Qamus. Buckwalter Transliteration Table. [Online]. [Accessed August 2015]. Available from:
http://www.qamus.org/transliteration.htm
51. Quran. QAC Extended Buckwalter Transliteration. [Online]. [Accessed August 2015].
Available from: http://corpus.quran.com/java/buckwalter.jsp
52. Wikipedia. Quran Initials. [Online]. [Accessed August 2015]. Available from:
https://en.wikipedia.org/wiki/Muqatta%27at
53. Moz. Choosing Domains for SEO. [Online]. [Accessed August 2015]. Available from:
https://moz.com/learn/seo/domain
54. Leeds University. Arabic Language Computing applied to the Quran Presentation. [Online].
[Accessed August 2015]. Available from: www.comp.leeds.ac.uk/arabic/dukes11pgr.doc
74

55. Pew Forum. The Future of World Religions: Population Growth Projections 2010-2050.
[Online]. [Accessed August 2015]. Available from:
http://www.pewforum.org/2015/04/02/religious-projections-2010-2050
56. Github. QA GitHub Repository. [Online]. [Accessed August 2015]. Available from:
https://github.com/karimouda/qurananalysis
57. Atwell ES. et al. Understanding the Quran: a new grand challenge for computer science
and artificial intelligence. In: Proceedings of the GCCR'2010 Grand Challenges in
Computing Research. UKCRC. 2010. http://eprints.whiterose.ac.uk/82244
58. Brank, J. et al. A survey of ontology evaluation techniques. In: Proceedings of the
conference on data mining and data warehouses (SiKDD 2005). 2005.
http://ailab.ijs.si/dunja/sikdd2005/papers/BrankEvaluationSiKDD2005.pdf
59. Alrehaili, S. M. and Atwel E. Computational ontologies for semantic tagging of the Quran: A
survey of past approaches. In: Proceedings of LREC. 2014.
http://eprints.whiterose.ac.uk/78272
60. Quran. QAC Morphological Features. [Online]. [Accessed August 2015]. Available from:
http://corpus.quran.com/documentation/morphologicalfeatures.jsp
61. Kang, Y. B., et al. CFinder: An intelligent key concept finder from text for ontology
development. Expert Systems with Applications. 2014, 41(9), pp.4494-4504.
http://www.sciencedirect.com/science/article/pii/S0957417414000189
62. Dukes, K. et al. Syntactic Annotation Guidelines for the Quranic Arabic Dependency
Treebank. LREC. 2010. http://citeseerx.ist.psu.edu/viewdoc/download?
doi=10.1.1.229.3777&rep=rep1&type=pdf
63. Balzer, L. et al. Comparison and evaluation of ontology visualizations. 2015. http://elib.uni-
stuttgart.de/opus/volltexte/2015/9941
64. Trigui, O, et al. Arabic Question Answering for Machine Reading Evaluation. CLEF (Online
Working Notes/Labs/Workshop). 2012.
http://users.dsic.upv.es/~prosso/resources/TriguiEtAl_QA4MRE_CLEF12.pdf
65. Paulheim, H. Ontology-based application integration. [Online]. Springer Science & Business
Media, 2011. p.182. https://books.google.co.uk/books?
hl=en&lr=&id=TRHNt_VFry8C&oi=fnd&pg=PR3&dq=Ontology-
based+application+integration.&ots=AXkONdSbpp&sig=57DJgjdSqgNgufy7-BPGYkzcfyo
66. Longest Common Substrings Algorithm. [Online]. [Accessed August 2015]. Available from:
https://en.wikibooks.org/wiki/Algorithm_Implementation/Strings/Longest_common_substring
75

67. Sjeiti. Tiny Sort Javascript Library. [Online]. [Accessed August 2015]. Available from:
http://tinysort.sjeiti.com
68. Jquery. JQuery Javascript Library. [Online]. [Accessed August 2015]. Available from:
https://jquery.com
69. Ranks. English and Arabic Stopwords list. [Online]. [Accessed August 2015]. Available from: http://www.ranks.nl/stopwords
76

Appendix A -NEON Ontology Requirements Specification
Ontology Requirements Specification Document
1 Purpose
- Enable and support Semantic Search and Visualization for the Quran.- Enable and support Question Answering/Expert systems for the Quran.
2 Scope
The ontology will include all concepts and all possible taxonomic and non-taxonomic relationsthat can be extracted from text.
3 Implementation Language
The ontology will be coded using OWL.
4 Intended End-Users
- Developers of Qurananalysis.com website.- Researchers interested in building and validating ontologies.- Web and Mobile Developers intending to build smart Quranic applications.
5 Intended Uses
Supporting Semantic Search and Visualization functionalities in Qurananalysis.com website.
6 Ontology Requirements
Functional Requirements: Groups of Competency Questions
Found in Appendix D.1 - Question Answering Test Questions
7 Pre-Glossary of Terms
Terms and concepts will be learned automatically from text.
Table 21: QA Ontology Requirement Specification
77

Appendix B - Illustrations
Appendix B.1
78
Illustration 14: Explore section - English

Appendix B.2
Appendix B.3
79
Illustration 15: Secondary Level Answer - Verses for "Who is Aaron ?" query
Illustration 16: Secondary Level Answer - wordcloud for "Who is Aaron ?" query
Illustration 17: Tree Map Illustration

Appendix B.4
80
Illustration 18: Ontology Visualization using Tree Layout

Appendix B.5
Appendix B.6
81
Illustration 19: Radial Tree Layout
Illustration 20: Full Ontology Visualization using FDG

Appendix B.7
82
Illustration 21: Explore post-click action

Appendix B.8
83
Illustration 22: Analysis tools - basic statistics

Appendix B.9
84
Illustration 23: Analysis tools - word frequency

Appendix B.10
85
Illustration 24: Analysis tools - word clouds

Appendix B.11
Appendix B.12
86
Illustration 25: Analysis tools - full text
Illustration 26: Analysis tools - charts

Appendix B.13
87
Illustration 27: Analysis tools - N-Grams

Appendix B.14
88
Illustration 28: Analysis tools - PoS Patterns

Appendix B.15
Appendix B.16
89
Illustration 29: Analysis tools - PoS Query
Illustration 30: Analysis tools - Repeated Verses

Appendix B.17
Appendix B.18
90
Illustration 31: Analysis tools - Repeated Phrases
Illustration 32: Analysis tools - Ontology Data

Appendix B.19
91
Illustration 33: Analysis tools: Ontology Graph - "The Iron" chapter

Appendix B.20
92
Illustration 34: Analysis tools - Uthmani to Simple
Mapping

Appendix B.21
93
Illustration 35: Analysis tools - Word Information
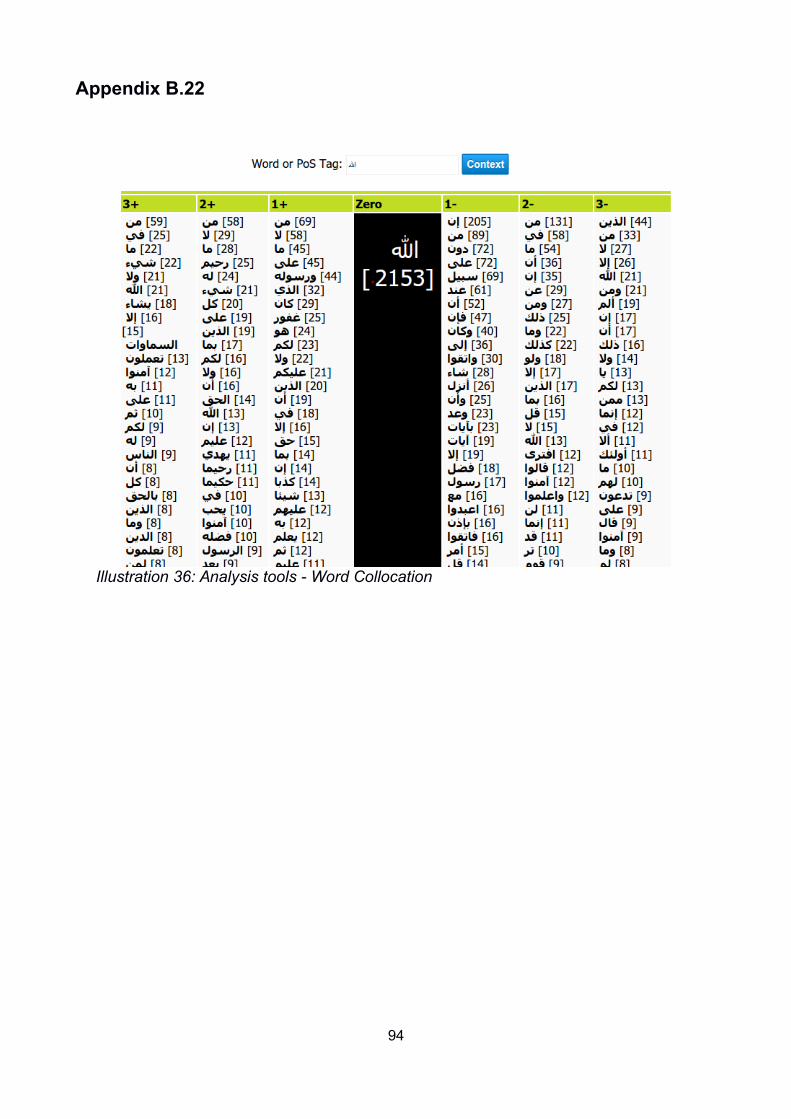
Appendix B.22
94
Illustration 36: Analysis tools - Word Collocation

Appendix B.23
95
Illustration 37: Analysis tools - PoS Collocation

Appendix B.24
96
Illustration 38: Analysis tools - Word Concordance

Appendix B.25
97
Illustration 39: Analysis tools - PoS Concordance

Appendix B.26
98
Illustration 40: Analysis tools - ۘ Pause Marks in the Quran

Appendix B.27
99
Illustration 41: Analysis tools - Buckwalter to Arabic Transliteration Mapping

Appendix B.28
100
Illustration 42: Analysis tools – Word Similarity

Appendix B.29
101Illustration 43: Analysis tools – Quran Initials Analysis

Appendix B.30
102Illustration 44: Initial Pre-June schedule

Appendix B.31
103Illustration 45: Post-June/Final Schedule

Appendix B.32
104
Illustration 46: Quranic Ontology Comparison [59]

Appendix B.33
105
Illustration 47: QA Search Page

Appendix B.34
Below are the top patterns with their frequencies. Please note that the frequencies does not mean
the actual repetition in the Quran but repetition in general even as a sub pattern in a longer pattern.
106
Illustration 48: Top LCS "PoS Patterns" in the Quran

Appendix B.35
Appendix B.36
107
Illustration 49: Excerpt from DBpedia's JSON Response for Ship
Illustration 50: Custom Translation Table file excerpt

Appendix B.37
108
Illustration 51: Excerpt from QA Ontology V1 OWL file

Appendix B.38
109Illustration 52: QA GitHub Commit Activity from June to September

Appendix C - Concluding Thoughts, Experiments &Observations
Appendix C.1 – Term Extraction
1. Concept formation can be done by clustering terms based on their min-edit-
distance.
2. Roots can also be used to convert/cluster terms to concepts but lemma will lead to
better results. Below is an example showing why merging by “root” is not the best
option.
Word English Translation Root Lemma QAC Segments
مم ظظلل Injustice ظلم ظظللم مم,ا مم,ظظلل ظظلل
مم, مم,ظظلل مم,ظظلل ظظلل
مم,ا لظمل ظم Dark ظلم لظِللم ظم مم,ا لظمل من,ظم ظمنو لظمل مم
Table 22: Example of merging terms by roots
The above table shows that grouping by roots will merge words with different meanings
into one concept. Also roots does not make proper words by its own to be used as
concept. For example “عوم" is the root of “عام” - “Year” in English and is obviously not an
understandable Arabic word to be considered a concept. Finally some words does not
have a root like many proper nouns and nouns such as “ججببيلل جزجن " which is “Ginger” in
English.
It is also worth noting that grouping by root will lead to a smaller concept list.
3. Words grouped be lemma can be grouped further like in this example
110

Lemma Meaning Root
ظظللم Injustice ظلم
لظللم لأ More unjust ظلم
م لظللل unjust ظلم
Table 23: Multiple lemmas having the same meaning
Such extra grouping can be done using the root of the words or by the “meaning” of all
words which can be extracted from external corpora.
4. Terms can be merged into concepts using the English translation corpus of the
Quran. It was noted that multiple Arabic words can map to the same English word –
the concept – and this makes sense because the translator made the effort of
understanding the meaning of each Arabic word to translate them to English. Below
is an example for that.
111
Illustration 53: Surat Al-'Insān (The Man) [19]

The two examples above shows that the following Arabic words “العاجلة" and "الدنيا" can
be merged into a single concept “life” by doing Arabic-English word-to-word mapping
between the original Quran text and the available translations.
5. QAC displays Quran text in the classical Uthmani script which is preferred by
Islamic scholars but differs subtly from "Simple" Modern Arabic script. However it
was decided to use “Simple” representation instead of uthmani to avoid multiple
words having same characters but different diacritics (tashkeel) and different
meanings. Instead, the root and lemma of the word will be added as properties in
the final ontology. Below is an example for such words.
112
Illustration 54: Illustration 1: Surat Al-Baqarah (The Cow) [20]

Word Meaning Word Meaning
مم�ة مأ Woman slave مم�ة أأ People
Table 24: Simple-Uthmani ambiguity
Appendix C.2 – Phrase Concepts
N-grams Distribution
Trying to understand the distribution and the significance of n-grams in the Quran: I managed to generate histograms of frequency distributions of bi-grams, tri-grams and quad-grams with a threshold of frequencies above 2. The results were plotted and n-grams sample was checked manually.
The illustration above shows that bigrams are the most used n-grams in the Quran with many bigrams repeated above 100 times. An apparent gap between bigrams and later n-grams can be seen. The bigram trend can be understood as follows: only 6 bigrams are repeated more than 100 times while 1609 bigrams we found repeating 3 times (long tail). This means that fewer bigrams have high frequency while most of the bigrams are repeated 1-3 times.
113
Illustration 55: N-grams distribution in the Quran
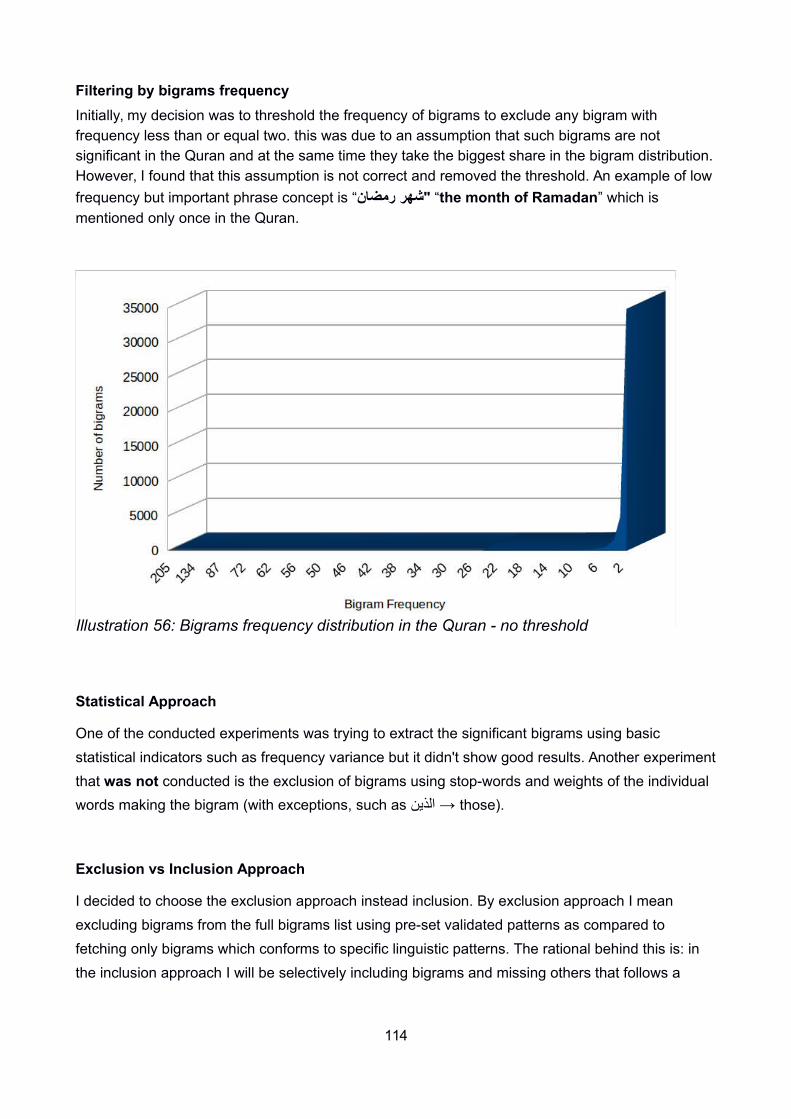
Filtering by bigrams frequency
Initially, my decision was to threshold the frequency of bigrams to exclude any bigram with frequency less than or equal two. this was due to an assumption that such bigrams are not significant in the Quran and at the same time they take the biggest share in the bigram distribution.However, I found that this assumption is not correct and removed the threshold. An example of low
frequency but important phrase concept is “شهر رمضان" “the month of Ramadan” which is
mentioned only once in the Quran.
Statistical Approach
One of the conducted experiments was trying to extract the significant bigrams using basic
statistical indicators such as frequency variance but it didn't show good results. Another experiment
that was not conducted is the exclusion of bigrams using stop-words and weights of the individual
words making the bigram (with exceptions, such as الذين → those).
Exclusion vs Inclusion Approach
I decided to choose the exclusion approach instead inclusion. By exclusion approach I mean
excluding bigrams from the full bigrams list using pre-set validated patterns as compared to
fetching only bigrams which conforms to specific linguistic patterns. The rational behind this is: in
the inclusion approach I will be selectively including bigrams and missing others that follows a
114
Illustration 56: Bigrams frequency distribution in the Quran - no threshold

different pattern which I am not aware of, but in the exclusion approach I am excluding “from the
whole list” after doing quick careful manual check on each exclusion pattern, so in this approach no
information will be missed without noticing.
Ngrams and Quran Pause Marks
Pause marks are a set of 6 marks which directs the reciter of the Quran on when it is permissible, recommended or not acceptable to stop while reading. This gives some clues about sub-sentencesinside verses. I managed to investigate the effect of this feature in the Quran on ngrams extraction and reached the conclusion that ngram extraction code should consider the compulsory pause “م" as an end of a sentence and reset the ngram accumulator. Below is an example why this is important. For other marks it was not clear whether it is significant or not. I think more research needs to be done on that.
Translation (Sahih International)
Only those who hear will respond [pause] But the dead - Allah will resurrect them; then toHim they will be returned.
Without taking into consideration the pause mark, we would get a the following phrase:
والموتى يسمعونإنما يستجيب الذين
Which translates to the following wrong meaning:
Only those who hear will respond AND the dead
115
Illustration 57: Surat Al-'An`ām (The Cattle) 6:36 [22]

Appendix C.3 – Qurana Issues
Following are a list of points which I think is the reason of low matching percentage between
Qurana and QA concepts lists.
1. Qurana author made much use of conjunctions while labelling concepts. Although I
understand that the concept of the pronoun may lead to such labelling, I don't think an
ontology concept should include conjunctions.
Example:
إبراهيم وإبسماعيل وإبسحاق ويعقوب والبسباط
Abraham, Ishmael, Isaac, Jacob and the Descendants
2. Qurana considers long phases as concepts. However, that was not part of the matching
and measurement process since it was focused only on words and bigrams (not long n-
grams).
Example:
قق ويقتلون الذين يأمرون بالقسط من الناس الذين يكفرون بآيات ال ويقتلون النبيين بغير ح
Those who disbelieve in the signs of Allah and kill the prophets without right and kill those who
order justice from among the people
3. Spelling mistakes.
Example: المسلون والمشركون - Muslims and disbelievers
4. Found a “null” concept though i understand the importance of its inclusion.
5. It is not complete since it is focused only on pronouns.
116

Appendix C.4 – Arabic Wordnet Evaluation & Comparison
In my effort evaluating and comparing both Arabic and English Wordnets, I used the supplied AWN
browser [33] and the AWN database XML file [34].
Statistical Comparison
Statistically, it was obvious that AWN is weak compared to WN. Shown below is a comparison
between WN and AWN where data for AWN was taken from AWN browser while data for WN from
[36].
Arabic Wordnet Wordnet
Synsets 11,269 117,659
Words 23,481 155,287
Table 25: Wordnet VS Arabic Wordnet Comparison
Manual Inspection
117
Illustration 58: “Allah” word in Arabic Wordnet Browser

A manual Inspection was made on AWN XML file and it was found that the file includes information
about many concepts and includes hypernyms and synonyms, but many limitations and issues
were found which are listed below:
1. Arabic words includes “general” diacritics (tashkeel) which will probably be different from
same word in the Quran since it will depend on the location of the word in the sentence. A
workaround is to remove tashkeel from the file and use Quran simple words.
2. Most of the glossaries were empty or were in English language not Arabic.
118
Illustration 59: AWN XML File
Illustration 62: AWN XML Hypernyms
Illustration 61: AWN XML English Glossary
Illustration 60: AWN XML File Empty Glossary

3. Initially, I though the offset refers to the original wordnet files but found that this is not true,
so to make cross reference between both wordnets the supplied browser's “dat” files or
provided API should be used.
4. Some words are not found such as “فرعون" (Pharaoh).
Appendix C.5 – OWLLib Modifications
OWLLib was found to be limited in terms of functionality for such big and rich ontology. Listed
below are some of the modifications done to overcome such limitations:
1. OWLLib didn't support owl:AnnotationProperty which was found to be the best option to
inject concept metadata.
2. No support for adding OWL header (which includes ontology title and version).
3. QA ontology is a very rich ontology to the extent that relations also have metadata that
needs to be added in the tags. I decided to add attributes in the relation tag (
owl:ObjectProperty) to hold the relation metadata, to do that the library code was altered to
support such functionality.
4. Addition of owl:ObjectProperty and owl:AnnotationProperty to classes in addition to
instances. This is probably not a best practice in ontologies but it was needed for that case
since classes also have metadata such as frequency and the best place to add them is a
tag inside the class tag.
Appendix C.6 – DBPedia Enrichment Details
Process
The following steps were repeated for each concept:
1. English translation is extracted from concept metadata.
2. If the English translation is empty or the concept is not a single word entry (muti-word
concept) then ignore, else continue.
119

3. Inject concept English name (translation) into DBPedia's URL templates.
Example:
Template: http://live.dbpedia.org/data/{NAME}.json
Actual: http://live.dbpedia.org/data/Ship.json
4. The resultant URL is used to fetch the DBpedia resource corresponding to the concept if it
cached before, else fetch and cache the response of the http call. Excerpt of the returned
results can be found in Appendix B.35.
5. Parse the JSON response and extract the resource type and abstract.
6. If the type or abstract are empty then ignore enriching this concept since the response does
not contain enough enrichment information.
7. Check if the type's URI contains any of the following: “schema.org”, “dbpedia.org/ontology”,
“xmlns.com/foaf”, “umbel.org” or “yago/Person”, if so; then extract the type which is the
string after the last slash.
Example:
Full type URI: http://live.dbpedia.org/ontology/Person
Type name: Person
8. Extract concept image: which is any attribute of the following URIs.
“http://xmlns.com/foaf/0.1/depiction” or “http://live.dbpedia.org/ontology/thumbnail”
9. Extract names (synonyms) using the following URI “http://xmlns.com/foaf/0.1/name”.
10. Add all extracted attributes to the concept metadata (Except Type).
Concept metadata attributes added in this stage
1. DBPEDIA_LINK
2. WIKIPEDIA_LINK
3. IMAGES_DBPEDIA
4. DESC_EN_DBPEDIA
Extracting Types from Abstract
It was noted that not all types are of well suited for being added to the ontology. For example, the
following type URI http://live.dbpedia.org/class/yago/ProphetsOfIslam (expected Prophets not
120

ProphetsOfIslam) so a decision was made to extract additional types from the “abstract” text using
simple entity resolution techniques - specifically PoS syntactic rules.
PoS tagging is applied on the abstract text. The PoS tagger used is a simple tagger published on
PHPir website [25] and is based on implementation of Brill tagger rules by Mark Watson [26]. The
tagger uses a simple lexicon extracted from brown corpus [25].
The result of the tagging is scanned for simple lexico-syntactic patterns that are listed below
First Tag Second Tag
Third Tag
Third Word Fourth Tag
VBZ DT NN Not “name” IN
VBD DT VBG Not “name” IN
Table 26: Type Extraction PoS Tagging Patterns
If any of the above rules are found then the third word is considered a Type. The above is done for
the first 20 words only.
Example
Text Blindness is (VBZ) the (DT) condition (NN) of (IN) poor visual perception
Type Condition
Table 27: Example Application of the PoS Tagging Patterns
Adding Hypernyms
For each type extracted from the “structured information” or the “abstract” the following is done:
1. The Type is translated from English to Arabic.
Since DBpedia resources are in English language, the type needs to be translated back to
Arabic to be added to the ontology so each type name is checked in the custom translation
table, if found then the translation is used, else the type is translated on-the-fly using
Microsoft translation API [explained in section 3.2.10.1].
121

2. A new T-Box class concept for that type is added to the concepts.
3. A new relation between the new parent class (Type) and the initial concept that was being
enriched is also added.
Appendix D - Data
Appendix D.1 - Question Answering Test Questions
1. How long should I breastfeed my child for ?
2. What Allah loves ?
3. What are the attributions of Allah ?
4. When was the Quran Revealed ?
5. Animals in the Quran ?
6. How many signs were sent to Pharaoh ?
7. What did Allah said to Adam ?
8. What are the colors in the Quran ?
9. Who is the prophet whom Allah spoke to ?
10. Fruits in Heaven ?
11. Number of wives allowed in Islam ?
12. Who are the people of the Book ?
Appendix D.2 - Concepts PoS Tags Frequency Experiment Results
The table below shows the frequency of individual PoS tags in all patterns in QA phrase concepts
list (bigrams).
122

PoS Frequency
N 1813
DET 813
ADJ 549
PRON 505
V 505
PN 185
ANS 36
INC 21
EXH 6
FUT 2
Table 28: PoS occurrence frequency in QA phrase concepts list
The table below shows the frequency of the top 20 extracted “PoS Patterns” in QA phrase
concepts.
123

Pattern Frequency
N N 750
REL V PRON 501
N DET N 484
N ADJ 379
DET N N 349
N PN 139
DET N DET ADJ 109
DET N DET N 72
PN DET N 64
DET ADJ N 32
ADJ N 26
N DET PN 24
N DET ADJ 20
DET N ANS 17
N ANS 16
DET N ADJ 13
PN ADJ 11
DET ADJ DET ADJ 10
ANS N 10
DET N INC 9
Table 29: Top 20 extracted “PoS Patterns” in QA phrase concepts
124

The table below shows “PoS patterns” found in the common QA/Qurana phrase concepts which i
believe is more significant.
Tag Frequency
N DET N 19
N PN 19
N DET PN 4
DET N DET ADJ 4
N ADJ 3
N N 2
DET N DET N 1
REL V PRON 1
N DET ADJ 1
Table 30: “PoS patterns” found in common QA/Qurana phrase concepts
Appendix E - Data Models
Appendix E.1 - QAC
QAC is a PoS tagged and morphological annotation corpus for the Quran, it was used heavily in
many sections in this project and is considered as the base layer. Below is a description of the
corpus file.
QAC file version 0.4 (quranic-corpus-morphology-0.4.txt) was downloaded from [2] and loaded.
Each line in the file has the following format:
125

LOCATION FORM TAG FEATURES
(1:1:1:1) bi P PREFIX|bi+
Table 31: QAC File Format
The Location can be decoded as:
(Chapter Index, Verse Index, Word Index, Segment in Word Index).
Form is the Arabic segment (part of a word) in a verse, encoded in Buckwalter transliteration.
Tag is the PoS tag of the segment (ex: proper noun or verb).
Features are additional morphological information about the segment such as root and lemma.
More information about features can be found in [60].
Below is an illustration of the loading process.
1. Each line in the file (which holds information about a single segment) is parsed.
2. Location is parsed to extract verse and word indexes.
3. Form is reversed transliterated (converted back) to Arabic using a one-to-one mapping
table generated from [51].
4. Features are parsed. Roots and lemmas are also reverse transliterated to Arabic.
5. All information from the current line is stored in QAC master table.
6. The last 5 steps are repeated for each line.
Data extracted from QAC corpus are stored in 3 structures to facilitate data access. Structures are
described below.
Master Table
This table contains all information in QAC corpus and is stored in memory. Additionally, the reverse
transliteration (Arabic) of Buckwalter forms are also added.
126

Master ID SEGMENT_
INDEX
FORM_EN FORM_AR TAG SEGMENT_
INDEX
Features
Table 32: QAC Master Table Model Structure
PoS Pointer Table
This table is a hash table with Key=”PoS tag” and Value=”Master ID”, it is used to speed up access
to all verses for a specific PoS tag.
Features Table
A hash table with Key=”Feature Name” and Value=”Master ID” to speed up access to all verses
having a specific Feature.
All structures above can be accessed from memory using 'MODEL_QAC' key.
Appendix E.2 - Qurana
Qurana [3] is a pronoun resolution (pronominal anaphora) corpus for the Quran. Qurana was used
heavily in many sections in QA website and also during research work. The corpus is comprised of
115 files: 1 file contains a listing of all concepts and the other 114 files contains pronouns for each
chapter in the Quran. files structures are described below.
Concepts.xml files
The file contains a list of 1054 concept tags. Each concept has: 1) concept id 2) Arabic concept
name 3) English translation. These concepts are referred-to from other files using the concept id.
Pronxml-N.xml files
N is a number from 1-114 specifying the index of a chapter in the Quran. Each file will include
“verse” tags which includes children “seg” tags. For each segment in the verse; if one of the
segments is a pronoun then a “pron” tag is found to be the parent tag of the “seg” tag. The pron tag
will include details about the concept and the antecedent of the segment pronoun.
127

It was noted that Qurana segments are different from QAC segments thus some alignments needs
to be done to map them. The alignment algorithm is illustrated in the next section.
QAC to Qurana Segment Mapping
To find the QAC segment for any Qurana segment the following is done:
1. Get the following 3 values for the target Qurana segment: Chapter, Verse and Segment
indexes (Segment index is not the one in the file, but rather the local index of the segment
in that specific verse, this is calculated by a counter in the loop).
2. Get all segments from QAC for the same “Chapter and Verse”.
3. Loop on returned QAC segments and increment a QAC segment counter.
4. If QAC segment counter is equal to Qurana segment index (from point #1) then return it.
Qurana Loading
The following steps are followed to load the files:
1. Load the concepts file.
2. Store all entries in an array one-to-one (Concept id, Arabic name, English name).
3. Load the pronouns file for each chapter. For each file do the following points.
4. For each tag in each verse, if the tag name is not “pron” ignore.
5. If tag is “pron” get segment id and convert it to QAC segment id to be able to cross
reference.
6. Store all information in the “resolved pronouns table” as shown below.
Qurana Pronouns Table
The pronouns table contains all pronouns and their antecedent concepts.
Location
(Chapter, Verse, Word index )
Concept ID Segment index Antecedent
segments
Table 33: Qurana Pronouns Model Structure
128

Concepts Table
A lookup table for all concepts in Qurana.
Concept ID EN AR
Table 34: Qurana Concepts Model Structure
Qurana Model can be accessed using 'QURANA_PRONOUNS' and 'QURANA_CONCEPTS' keys
in $MODEL_QURANA model.
Appendix E.3 - Wordnet
Wordnet is a general domain knowledge source for English language. Wordnet files includes
“indexes” which are the entry points to wordnet, it also contains a list of all words for any of the
supported PoS tags (noun, verb, adjectives and adverbs). For example “index.noun” contains
indexes to all noun words in wordnet. Excerpt from the file is shown below.
index.noun file
The index file follows the format [37] below.
lemma pos synset_cnt p_cnt [ptr_symbol...] sense_cnt tagsense_cnt synset_offset [synset_offset...]
As shown below the word” land” is a noun, it has 11 synsets (all senses of the word “land”) those
synsets have 6 types of pointer relations (such as hypernym relation) with other words in wordnet.
The relations are represented by the pointer types (@, ~, #p, %m, %p and +) full list of pointer
types can be found in [38] .The actual pointers are the numbers starting by 13250048 (there are 11
of them but the screenshot was cropped for readability) which is the location (file offset) of the
129
Illustration 63: Wordnet index.noun file

sense in the data.noun file. Pointer locations can be reached using fseek function in any
programming language.
data.noun file
The data includes all senses for all words in the index with extra information like synonyms,
relations and glossaries. The file has the following format [39].
synset_offset lex_filenum ss_type w_cnt word lex_id [word lex_id...] p_cnt [ptr...] [fra
mes...] | gloss
For example, below is the first sense for the word “land”.
In the illustration above: the red part (first underlined part) specifies the semantic type of the word.
The number 21 is a lookup index for a table in another file called lexnames which is discussed in
the next section. The grey part (second underlined part) includes the number of words in this sense
and the words list. Note that any words here are synonyms. The green part (third underlined part)
contains pointers to other words that have any relation with the current word such as Hypernym or
Hyponym relations. The blue part (last underlined part) shows a short description (glossary) for the
current word sense.
lexnames file
The lexnames file shown below contains a table of indexes and semantic types which can be used
to resolve the type of any word. For example, “land” has the type 21 which is “possession”.
130
Illustration 64: Wordnet data.noun file - sense for the word land

QA Wordnet Datamodel
To make use of wordnet in QA, the files had to be integrated and fitted in the datamodels. The files
described above were processed and converted to data structures for each of Wordnet's PoS tags
(ex: index.noun, index.verb, … etc) below is a description of the final Wordnet datamodel in QA.
The mode is comprised of 3 structures loaded in memory which are
1) WORDNET_INDEX
2) WORDNET_LEXICO_SEMANTIC_CATEGORIES
3) WORDNET_DATA
Each can be retrieved using apc_fetch(STRUCTURE_NAME) OR using the
$MODEL_WORDNET[STRUCTURE_NAME].
WORDNET_LEXICO_SEMANTIC_CATEGORIES
131
Illustration 65: Excerpt from
Wordnet lexnames file

Contains the data in lexnames file, it is just a key/value lookup table for semantic types as shown
below.
132

Key Value
0 adj.all
1 adj.pert
2 adv.all
3 noun.Tops
4 noun.act
5 noun.animal
6 noun.artifact
7 noun.attribute
8 noun.body
9 noun.cognition
10 noun.communication
11 noun.event
12 noun.feeling
13 noun.food
14 noun.group
15 noun.location
16 noun.motive
17 noun.object
18 noun.person
19 noun.phenomenon
20 noun.plant
21 noun.possession
22 noun.process
23 noun.quantity
24 noun.relation
25 noun.shape
26 noun.state
133

27 noun.substance
28 noun.time
29 verb.body
30 verb.change
31 verb.cognition
32 verb.communication
33 verb.competition
34 verb.consumption
35 verb.contact
36 verb.creation
37 verb.emotion
38 verb.motion
39 verb.perception
40 verb.possession
41 verb.social
42 verb.stative
43 verb.weather
44 adj.ppl
Table 35: WORDNET_LEXICO_SEMANTIC_CATEGORIES Model
WORDNET_INDEX
Includes all data in index.pos files. The hierarchical structure is shown below.
[LEMMA1] - word text, ex: book
[NOUN]
[SYNSETS] - senses of the word
[INDEX]=[SYNSET_POINTER_IN_DATA_FILE]
134

[0]=[13250048] - pointer to an entry in “WORDNET_DATA”
[..]=[...]
[POINTERS_TYPES] - senses of the word
[POINTER_SYMBOL]=[POINTER_RELATION_DESCRIPTION]
[@]=[HYPERNYM] - pointer description
[…] = [...]
[VERB] - senses of the same word in other PoS
[...]
[land] - next word
[ADJ]
[...]
[...]
[...]
WORDNET_DATA
Includes all data in data.pos files. The hierarchical structure is shown below.
[OFFSET] - synset [word(s)] offset in the file
[GLOSSARY] - short description
[SEMANTIC_CATEGORY_ID] - semantic type
[POS] - pos tag
[WORDS] - synonyms
[WORD_1]=[...]
[POINTERS] - relations with other words
[0]=[POINTER_ARRAY]
[SYMBOL] - pointer symbol
[SYNSET_OFFSET] – synset offset (offset in same structure)
135

[POS] - pos tag
[SOURCE_TARGET] - not used
[SYMBOL_DESC] - pointer symbol description (ex:hypernym)
Appendix E.4 - QA Ontology
The ontology is loaded from the OWL file generated in the ontology extraction phase (section 3.1)
despite the fact that the ontology generation process generates a proprietary file; It was decided to
load the OWL file instead to make sure it is usable by other researchers and that it does not miss
anything from the proprietary cached ontology. Once loaded, the ontology can be fetched from
memory using the following key MODEL_QA_ONTOLOGY or used directly using the variable
$MODEL_QA_ONTOLOGY.
The file is parsed by owllib library. The classes and instances are added as concepts in the
CONCEPTS structure. All their metadata and labels are added as concepts properties. All object
properties are added to another relations structure (RELATIONS).
Quality check and comparison
During the processing of the OWL file, it was noted that there were some discrepancies between
the loaded model from the OWL file and the model loaded from the proprietary file, thus a quality
check technique has been implemented to make sure that the model loaded from the OWL exactly
matches the original model, this is done by making one-to-one check between all concepts and
relations across both models (proprietary file is loaded from file to do this check ).
Graph Indexes
Two additional indexes (GRAPH_INDEX_SOURCES and GRAPH_INDEX_TARGETS) were built
to speed-up access to concepts for graph loading and question answering needs.
GRAPH_INDEX_SOURCES contains all concepts which are “subjects” in any relation, while
GRAPH_INDEX_TARGETS includes all concept which were found in the “object” side of any
relation. In source index, outbound relations are added to each concept, while in target index only
inbound relations are added to concepts.
136

This is beneficial for some cases like “graphing one concept” with all relations coming out from it,
or getting all inbound relations for a specific concepts, without such indexes a full scan needs to be
done on all relations to derive the same information.
Verb Index
Verb index (VERB_INDEX) was created to facilitate verb searching, specifically to support question
answering since for some questions cases, the answer can only be found in the verb.
Translation Table
During ontology integration it was found that an English to Arabic translation table for concept
labels was needed since all indexes and structure keys are in Arabic, so if the user is searching in
English then each English word needs to be translated to Arabic to be checked whether it is a
concept or not. The following simple key/value table structure (CONCEPTS_EN_AR_NAME_MAP)
was created for this purpose.
The Model
QA's 5-structures ontology model is described below.
CONCEPTS
[ARABIC_CONCEPT_NAME]
[label_ar] => أرض
[label_en] => land
[frequency] => 461
[weight] => 7.2742243000426
[pos] => N
[transliteration] => ardin
[lemma] => ررض جأ
[root] => ارض
[meaning_wordnet_en] => agriculture considered as an occupation or way of life
[meaning_wordnet_translated_ar] => الزراعة تعتبر مهنة أو وسيلة للحياة
137

[dbpedia_link] =>
[wikipedia_link] =>
[image_url] =>
[long_description_en] =>
[long_description_ar] =>
[synonym_1] => الرض
[ARABIC_CONCEPT_NAME_2]
[...]
[...]
RELATIONS
[444172b6f7e9be37d478d175a5f9c199] - relation unique hash id
[subject] => أيوب
[verb] => مس
[object] => الضر
[frequency] => 1
[verb_translation_en] => touch
[verb_uthmani] => لس لم
[...]
CONCEPTS_EN_AR_NAME_MAP
[ship] => سفينة
[stand] => قيام
[...]
GRAPH_INDEX_SOURCES
[السموات]
[0]
[link_verb] => هو
138

[target] => ش يء
[..]
[...]
GRAPH_INDEX_TARGETS
[السموات]
[0]
[source] => الناس
[link_verb] => ترونها
[..]
[…]
VERB_INDEX
[يحب]
[0]
[subject] => ال
[object] => المتقين
[..]
[...]
Appendix E.5 - Quran Core Simple
The core datamodel contains general statistical information about the Quran, it is used in almost all
pages in the website. The data structure contains the following.
1. META_DATA
Metadata about chapters in the Quran such as indexes and chapter names (Arabic/English
and Transliterated).
2. TOTALS
139

Statistical information about counts, minimums, maximums of chapters, verses, words up to
the character level.
3. WORDS_FREQUENCY
Frequency of words in the Quran, words per chapter and weights.
4. QURAN_TEXT
The full Quran text in simple Arabic.
Note: the phrase “بسم ال الرحمن الرحيم" was removed from beginning of all chapters except
the first chapter since it is not part of the original text but rather a practice in recitation. It is
worth noting that in one chapter the same phrase was found to be in the middle (ex: إنه من
وإنه بسم ال الرحمن الرحيم سليمان ) so the phrase should be only deleted when in the first verse.
The same was done for Uthmani but it was found that in uthmani there are two versions of
the phrase due to diacritics (the first version can only be found in chapters 95 and 97). Find
both versions below.
لرِحيِم ِن ٱل سحملذ لر ِلل ٱل سسِم ٱ يب
لرِحيِم ِن ٱل سحملذ لر ِلل ٱل سسِم ٱ ِب
5. RESOURCES
Multi-lingual text resource mapping: this is used to change user interface titles on the
website when the user changes language.
6. STOP_WORDS
Quran stopwords (Simple script).
7. STOP_WORDS_STRICT_L2
Very strict list of Arabic stopwords in the Quran.
The data above were gathered in parallel while processing the following files:
1. quran-simple-clean.txt (Tanzil Project [1]).
2. quran-data.xml (Tanzil Project [1]).
3. quran-stop-words.strict.l1.ar and quran-stop-words.strict.l2.ar.
4. english-stop-words.en.
5. resources.ar and resources.en.
140

Appendix E.6 - Quran Core Uthmani
The same as the previous section except for using “quran-uthmani.txt” (Tanzil Project [1]) file.
Appendix E.7 - Quran Core English
The same like previous section except for using “en.sahih” (Tanzil Project [1]) file instead of the
Arabic Quran file.
Appendix E.8 - Uthmani to Simple Mapping
Uthmani to simple mapping table was generated to facilitate uthmani-to-simple conversion which is
important since QAC and Qurana are based on uthmani script while users will normally use simple
script which is why it is the default in the website. The mapping algorithm is described below.
1) Load both the simple and the uthmani Quran corpora.
2) Loop on each verse in both datasets.
3) Remove “pause marks”.
4) If both verses have the same number of words then do one-to-one word mapping (map
each simple word in first verse to its corresponding uthmani word).
5) If word counts for both verses differ then check the following for each word
a) If the simple word is any of the following يا - ها - ويا or the uthmani word is لولأللِو
b) Append the current simple word to the one next to it and map them of the Uthmani
word.
c) If (a) is true but the uthmani word is هؤلم سبلن then merge the current simple word with the لي
next two words instead of one word and map them to the uthmani word.
Appendix E.9 - Quran Words Translation
The data model is based on QAC word-by-word translation file [2]. Some modifications were done
on the file to produce better results for ontology extraction, these modifications are listed below
141

1. Special chars such as “;” were removed.
2. One record was changed since it was not correct. Record “73965|72|18|2|” was changed
from “the” to “the-masajid”.
3. Prophet names were found transliterated from Arabic not translated to the English common
names. For example: prophet “موسى" was translated to “Musa” instead of “Moses” where
“Musa” is how the Arabic word is pronounced if written in English. Changed words are listed
below:
shaitaan, mariam, musa, isa, harun, ibrahim, yaqub, ishaq, ismail, yunus, sulaiman, dawud,
jalut, nuh, yahya, ilyas, lut, talut, yusuf, firaun.
Building the model
The file was scanned line by line and each Arabic word was assigned to its English translation and
vice versa. Two mapping tables were created, from EN to AR and the other from AR to EN.
File structure
Each line in the file has the following format
SEGMENT_ID|CHAPTER_ID|VERSE_ID|WORD_ID_IN_VERSE|ARABIC_WORD_UTHMANI|
ENGLISH-WORD
Final Mapping Table Example
EN AR
created-you هكم لخلللق
you-ask لن لءهلو لسٓا لت
Table 36: Word-by-word Translation Mapping Example
142

Appendix E.10 - Transliteration
To build the transliteration table the “en.transliteration.txt” file (Tanzil Project [1]) was loaded and
each word in each verse is mapped one-to-one with the same verse in uthmani corpus.
Appendix E.11 - Stop-words Lists
Stopwords in QA's context are words that are not significant. They are needed in many cases such
as 1) Filtering user query terms by removing unimportant words 2) Filtering word listings in tables
or word clouds in order not to show the user words that are insignificant.
Multiple levels of stopwords were generated according to the different needs discussed above.
Levels are mainly basic and strict; basic level is used for user queries and strict for words filtering
and list rendering. The stopwords lists were compiled from different sources on the internet as
follows.
English lists
Basic: The following 44 words were extracted from [69].
o,she,he,i,a,an,and,are,as,us,at,be,but,by,for,if,in,into,is,it,no,of,on,we,them,or,such,that,the,their,th
en,there,these,they,this,him,so,to,was,were,will,with,you,have.
Strict: Unique words were fetched from all-english-stopwords.txt file which is part of the stop-
words project [15]. The final generated list (english-stop-words.en file) included 848 stopwords.
Arabic lists
Basic: The following 82 words were extracted from [69].
فى ,ف ي ,كل ,لم ,لن ,له ,من ,هو ,ه ي ,كما ,لها ,منذ ,وقد ,ول ,هناك ,وقال ,وكان ,وقالت ,وكانت ,فيه ,لكن ,وف ي ,ولم ,ومن
,وهو ,وه ي ,يوم ,فيها ,منها ,حيث ,اما ,الت ي ,اكثر ,الذى ,الذي ,الن ,الذين ,ابين ,ذلك ,دون ,حول ,حين ,الى ,انه ,انها ,ف
,و ,قد ,ل ,ما ,مع ,هذا ,قبل ,قال ,كان ,لدى ,نحو ,هذه ,وان ,واكد ,كانت ,عند ,عندما ,على ,عليه ,عليها ,تم ,ضد ,بعد
,بعض ,حتى ,اذا ,احد ,بان ,اجل ,غير ,بن ,به ,ثم ,اف ,ان ,او ,اي ,بها
143

Strict:
For Arabic, two levels of strict stopwords were generated; level 1 and level 2. Level 1 includes
Arabic words that were found in both external stopwords lists and also in the Quran while Level 2
(More strict) includes ALL words in the Quran that are NOT Nouns, Proper Nouns or Adjectives.
Level 1:
Below are the steps used to generate the “strict” level 1 stopwords list:
1. Preprocessed and merged OpenOffice ar.dic [16] with Ar-PHP project [17] Arabic stop
words file.
2. Preprocessed TextMiningTheQuran stop-words list [18].
3. After removing diacritics (tashkeel) from TextMiningTheQuran list (1138 words), the list was
merged with the previous two files making a final list of 11,400 words.
4. A script was used to find if each word in the new list is in the Quran (simple text).
5. If the word was found in QAC in any of the following PoS Tags: PN, N or ADJ then it is
excluded from the list since it is significant (also if any of the tags were preceded by DET).
6. The result was used to form the stop words list of the Quran. Only stop words found in the
Quran were included.
The final list (quran-stop-words.strict.l1.ar file) is made of 809 words. The list still includes verbs
and derivations. The main difference between this list and [18] is that it is in “simple”
representation.
Level 2
This list contains all words in Level 1 in addition to any word which is NOT pure N, PN or ADJ, that
is: not pre-fixed or post-fixed by any morphological derivations except DET (such as CONJ or
PRONOUN). For example, the word “الرض" (The Land) is a noun prefixed with determiner so it will
not be part of the list while “والرض ” (And The Land) is prefixed with CONJ so it will be included
since there is no value in such derivation.
The list is created by retrieving all words from QAC that are not pure N, PN, or ADJ (pure means:
with no derivations) and add them to the following file (quran-stop-words.strict.l2.ar). The final list
contains 10958 words.
144

Appendix E.12 - Inverted Index
The inverted index is built during the loading of all other data models from files.
The index can be accessed from memory using INVERTED_INDEX key or used directly through
the variable $MODEL_SEARCH['INVERTED_INDEX'].
The structure of the inverted index is as follows:
CHAPTER VERSE INDEX_IN_
VERSE
WORD_TYPE EXTRA_INFO
WORD1 114 2 1 NORMAL_WORD
WORD2 2 10 5 PRONOUN_
ANTECEDENT
Table 37: Inverted Index Structure Example
WORD_TYPE can be any of the following
1. NORMAL_WORD
2. PRONOUN_ANTECEDENT
3. ROOT
4. LEM
145

Appendix F - External Materials
The following external resources were used in QA:
1. Tanzil Project - Quran Text: Authentic Simple/Uthmani text of the the Quran [1].
2. Tanzil Project - Quran Translation: English translation corpus of the Quran [1].
3. Tanzil Project - Quran Transliteration: English transliteration corpus of the Quran [1].
4. Quranic Arabic Corpus: PoS tagged corpus of the Quran with morphological annotations [2].
5. Quranic Arabic Corpus Word-by-Word: Word by word Arabic-English translation corpus of the Quran [2].
6. Qurana: Corpus of the Quran annotated with Pronominal Anaphora [3].
7. Wordnet: English dictionary and thesaurus corpus [30].
8. DBPedia: semantic structured data extracted from Wikipedia [23].
9. D3 Javascript Library [41].
10. JQuery [68] and JQuery Tagcloud [44] Javascript Libraries.
11. TinySort Javascript Library [67].
12. OWLLib PHP Library [29].
13. Microsoft Translator API [27].
14. PHPir PoS Tagging Library [25].
15. Brown corpus lexicon for English PoS Tagging [25].
16. English stop-words project [15].
17. OpenOffice ar.dic file [16].
18. Arabic stopwords list from Ar-PHP project [17].
19. TextMiningTheQuran stop-words list [18].
20. Limited number of basic English and Arabic stopwords taken from [69].
Appendix G - Ethical Issues
No significant ethical issues were found. However since QA is handling religious text it was
important to assert that QA cannot be considered as a 100% error free source for the Quran, thus
the following note was added on the website:
“Caution: in addition to the beta-experimental nature of this website it is a human endeavour which
can't be perfect and should NOT be considered as truth or fact source”.
146

Appendix H - Personal Reflection
Everything about this project was above my expectations. I found it extremely challenging and
interesting since it was my first exposure in this area. Actually I didn't expect that so much analysis
and ideas can arise from around 80,000 words text. Whenever I investigated or experimented an
area I used to take notes of my thoughts which then accumulated to make up pages of ideas,
some of which were not included in this thesis. I enjoyed every moment in the project and I always
hoped I had more focused-dedicated time to keep innovating and implementing my ideas.
In terms of learning, I gained deep practical experience in semantic technologies, NLP and
visualization. Also gained fair experience in linguistics and scientific writing.
At the end of this journey I believe that what has been done is just a proof of concept or 10% of
what can be done in this area, and that more innovation is only possible by collaboration. I always
asked myself this question: if one person can build such system in 4 months including research
and writing what can a funded dedicated team do in two or three years ?
Coming from entrepreneurship background, I would advice researchers and MSc students to aim
very high and choose areas and goals of which they have passion for. Trying to do something that
is impossible would at least lead to something novel and unique. Have vision in what you are trying
to do, for example capitalize on your research by pursuing PhD in the same topic or building a
technology company to apply your research. Don't choose or limit yourself by the available time or
your current skills since everything can be compensated by hard-smart effort specifically by finding
ways to speed up the process and being more efficient. I also found that investing much time in
reading other people's approaches can be limiting in some way, rather some lateral out-of-the-box
thinking attitude should be followed in addition to reading. I was told by almost everyone that this
project in its current form can't be done in the available time, even in some moments - specifically
during ontology extraction – I was about to believe so, but at the end it happened.
I advise MSc students in the UK to start as early as possible since 3 months of full time work is not
enough to research, code and do scientific writing. Also as my supervisor always pushed on me; I
advice to write as you go, when you finish a phase stop and write it down when it is still fresh in
your mind so you don't miss any details. Also keep a research log of everything you do or even try.
Make sure you have enough time at the end to revise your writing specially if you are not a native
147

English speaker. Finally be flexible and be prepared to drop goals and change approaches as you
go.
From my experience, I believe supervisor's presence and support is so important if he/she is giving
enough time and care about the project and also maintaining good mood in meetings, this is
important for keeping weekly deadlines and guidance for students who are new to scientific
research like me, and I believe I was lucky to get all that.
148