semi-supervised learning over text tom m. mitchell machine learning department carnegie mellon...
TRANSCRIPT

Semi-Supervised Learning over Text
Tom M. MitchellMachine Learning Department
Carnegie Mellon University
September 2006
Modified by Charles Ling

Statistical learning methods require LOTS of training data
Can we use all that unlabelled text?

Outline
• Maximizing likelihood in probabilistic models– EM for text classification
• Co-Training and redundantly predictive features– Document classification– Named entity recognition– Theoretical analysis
• Sample of additional tasks– Word sense disambiguation– Learning HTML-based extractors– Large-scale bootstrapping: extracting from the web

Many text learning tasks
• Document classification. – f: Doc Class
– Spam filtering, relevance rating, web page classification, ...
– and unsupervised document clustering
• Information extraction. – f: Sentence Fact, f: Doc Facts
• Parsing– f: Sentence ParseTree
– Related: part-of-speech tagging, co-reference res., prep phrase attachment
• Translation– f: EnglishDoc FrenchDoc

1. Semi-supervised Document classification (probabilistic model and EM)

Document Classification: Bag of Words Approach
aardvark 0
about 2
all 2
Africa 1
apple 0
anxious 0
...
gas 1
...
oil 1
…
Zaire 0

Supervised: Naïve Bayes Learner
Train:
For each class cj of documents
1. Estimate P(cj )
2. For each word wi estimate P(wi | cj )
Classify (doc):Assign doc to most probable class
docw
jijj
i
cwPcP )|()(maxarg
* assuming words are conditionally independent, given class
*

For code and data, see www.cs.cmu.edu/~tom/mlbook.html click on “Software and Data”
Accuracy vs. # training examples
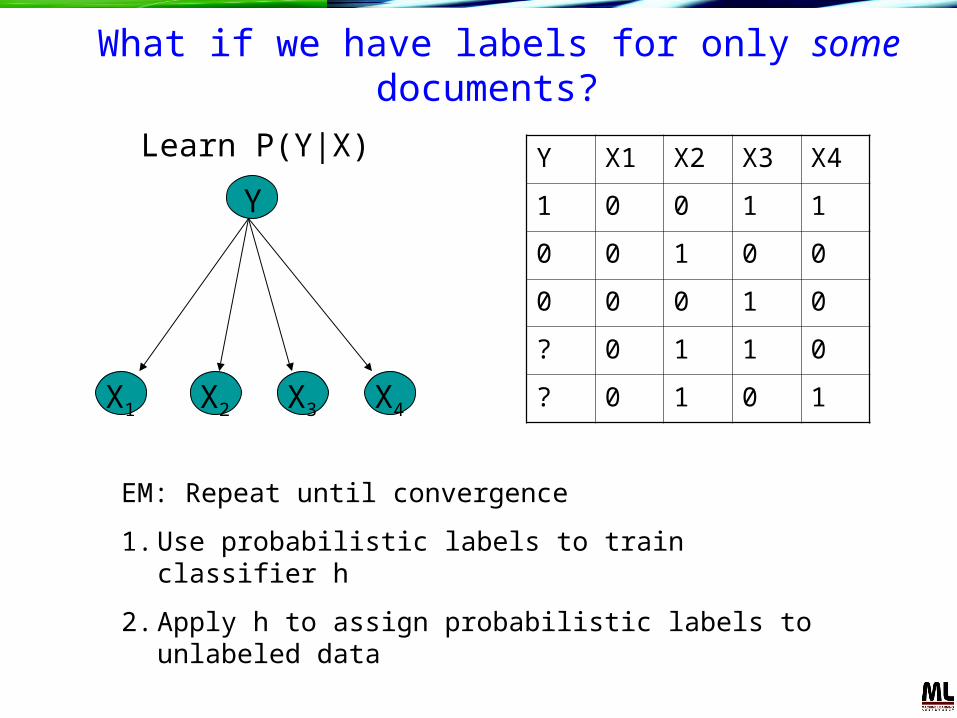
What if we have labels for only some documents?
Y
X1 X4X3X2
Y X1 X2 X3 X4
1 0 0 1 1
0 0 1 0 0
0 0 0 1 0
? 0 1 1 0
? 0 1 0 1
Learn P(Y|X)
EM: Repeat until convergence
1. Use probabilistic labels to train classifier h
2. Apply h to assign probabilistic labels to unlabeled data

From [Nigam et al., 2000]

E Step:
M Step:wt is t-th word in vocabulary

Using one labeled example per class
Words sorted by P(w|course) / P(w| : course)
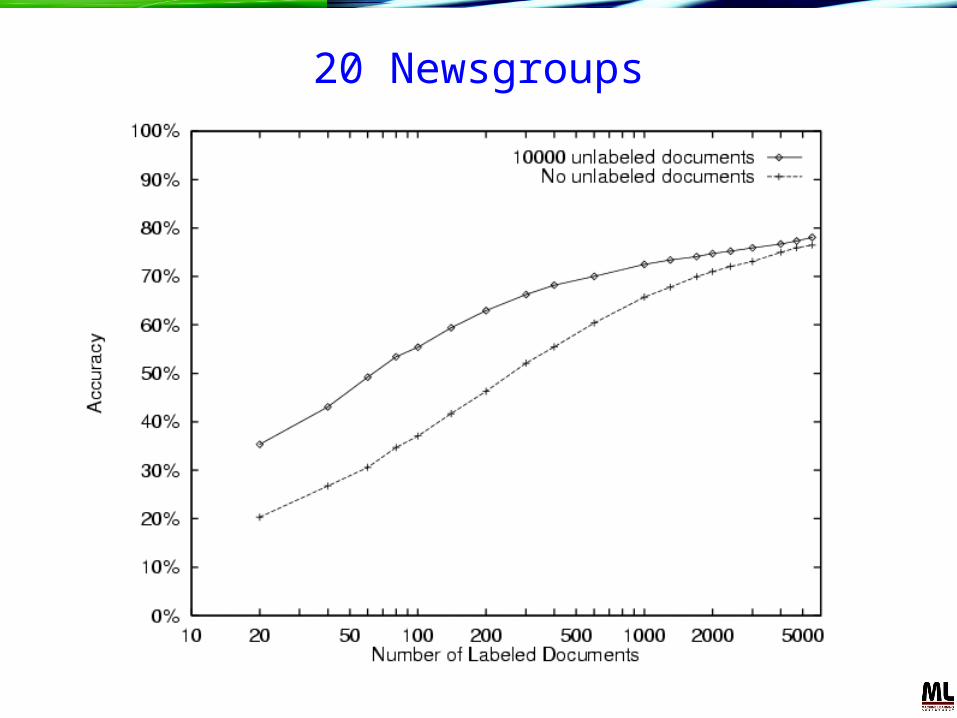
20 Newsgroups
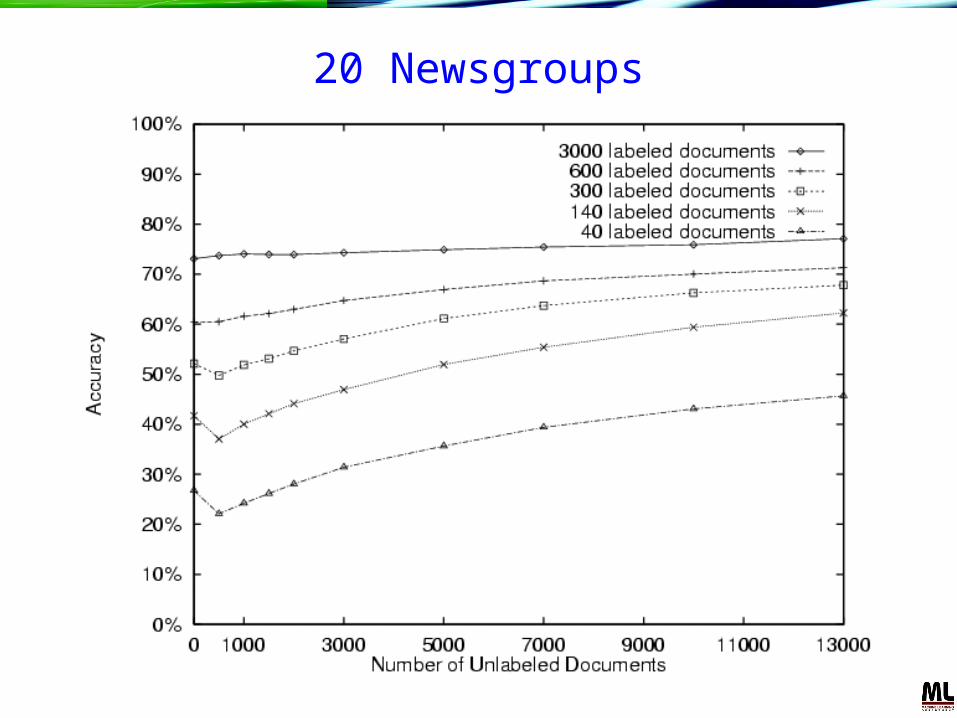
20 Newsgroups

Why/When will this work?
• What’s best case? Worst case? How can we test which we have?

EM for Semi-Supervised Doc Classification
• If all data is labeled, corresponds to supervised training of Naïve Bayes classifier
• If all data unlabeled, corresponds to mixture-of-multinomial clustering
• If both labeled and unlabeled data, it helps if and only if the mixture-of-multinomial modeling assumption is correct
• Of course we could extend this to Bayes net models other than Naïve Bayes (e.g., TAN tree)
• Other extensions: model negative class as mixture of N multinomials

2. Using Redundantly Predictive Features (Co-Training)

Redundantly Predictive Features
Professor Faloutsos my advisor
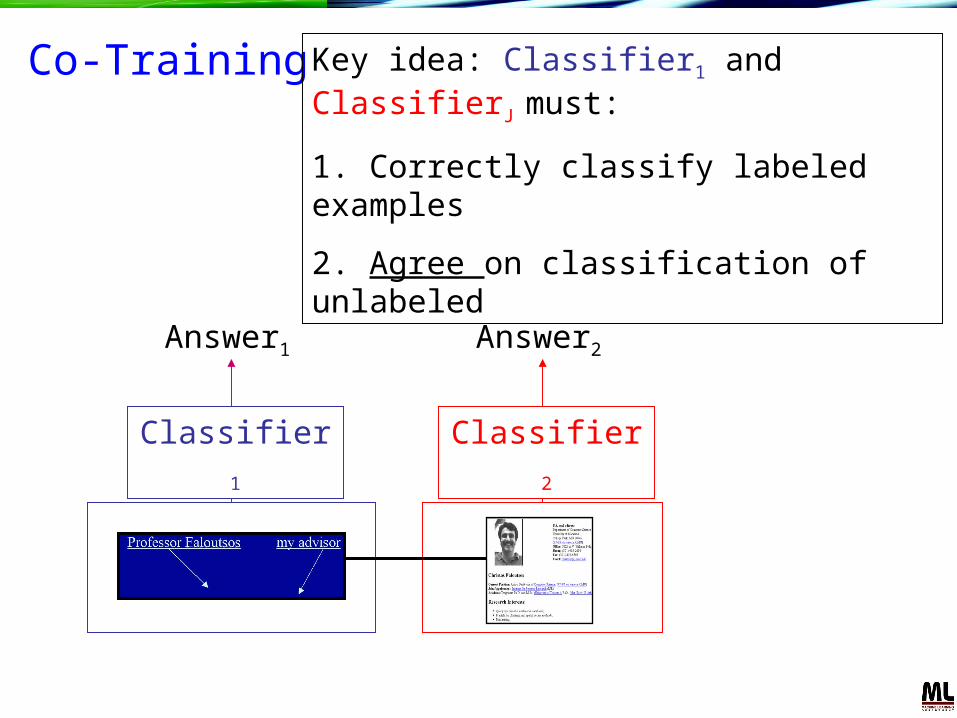
Co-Training
Answer1
Classifier1
Answer2
Classifier2
Key idea: Classifier1 and ClassifierJ must:
1. Correctly classify labeled examples
2. Agree on classification of unlabeled

CoTraining Algorithm #1 [Blum&Mitchell, 1998]
Given: labeled data L,
unlabeled data U
Loop:
Train g1 (hyperlink classifier) using L
Train g2 (page classifier) using L
Allow g1 to label p positive, n negative examps from U
Allow g2 to label p positive, n negative examps from U
Add these self-labeled examples to L

CoTraining: Experimental Results
• begin with 12 labeled web pages (academic course)
• provide 1,000 additional unlabeled web pages
• average error: learning from labeled data 11.1%;
• average error: cotraining 5.0%
Typical run:

Co-Training for Named Entity Extraction(i.e.,classifying which strings refer to people, places, dates, etc.)
Answer1
Classifier1
Answer2
Classifier2
I flew to New York today.
New York I flew to ____ today
[Riloff&Jones 98; Collins et al., 98; Jones 05]

One result [Blum&Mitchell 1998]: • If
– X1 and X2 are conditionally independent given Y– f is PAC learnable from noisy labeled data
• Then– f is PAC learnable from weak initial classifier plus unlabeled
data
CoTraining setting:
• wish to learn f: X Y, given L and U drawn from P(X)
• features describing X can be partitioned (X = X1 x X2)
such that f can be computed from either X1 or X2

Example Bootstrap learning algorithms:
• Classifying web pages [Blum&Mitchell 98; Slattery 99]
• Classifying email [Kiritchenko&Matwin 01; Chan et al. 04]
• Named entity extraction [Collins&Singer 99; Jones&Riloff 99]
• Wrapper induction [Muslea et al., 01; Mohapatra et al. 04]
• Word sense disambiguation [Yarowsky 96]
• Discovering new word senses [Pantel&Lin 02]
• Synonym discovery [Lin et al., 03]
• Relation extraction [Brin et al.; Yangarber et al. 00]
• Statistical parsing [Sarkar 01]

What to Know
• Several approaches to semi-supervised learning– EM with probabilistic model– Co-Training– Graph similarity methods– ...– See reading list below
• Redundancy is important• Much more to be done:
– Better theoretical models of when/how unlabeled data can help– Bootstrap learning from the web (e.g. Etzioni, 2005, 2006)– Active learning (use limited labeling time of human wisely)– Never ending bootstrap learning?– ...

Further Reading
• Semi-Supervised Learning, Olivier Chapelle, Bernhard Sch¨olkopf, and Alexander Zien (eds.), MIT Press, 2006.
• Semi-Supervised Learning Literature Survey, Xiaojin Zhu, 2006.
• Unsupervised word sense disambiguation rivaling supervised methods D. Yarowsky (1995)
• "Semi-Supervised Text Classification Using EM," K. Nigam, A. McCallum, and T. Mitchell, in Semi-Supervised Learning, Olivier Chapelle, Bernhard Sch¨olkopf, and Alexander Zien (eds.), MIT Press, 2006.
• " Text Classification from Labeled and Unlabeled Documents using EM," K. Nigam, Andrew McCallum, Sebastian Thrun and Tom Mitchell. Machine Learning, Kluwer Academic Press, 1999.
• " Combining Labeled and Unlabeled Data with Co-Training," A. Blum and T. Mitchell, Proceedings of the 1998 Conference on Computational Learning Theory, July 1998.
• Discovering Word Senses from Text Pantel & Lin (2002) • Creating Subjective and Objective Sentence Classifiers from Unannotated Texts by
Janyce Wiebe and Ellen Riloff (2005) • Graph Based Semi-Supervised Approach for Information Extraction by Hany Hassan,
Ahmed Hassan and Sara Noeman (2006) • The use of unlabeled data to improve supervised learning for text summarization by
MR Amini, P Gallinari (2002)

Further Reading
• Yusuke Shinyama and Satoshi Sekine. Preemptive Information Extraction using Unrestricted Relation Discovery
• Alexandre Klementiev and Dan Roth. Named Entity Transliteration and Discovery from Multilingual Comparable Corpora.
• Rion L. Snow, Daniel Jurafsky, Andrew Y. Ng. Learning syntactic patterns for automatic hypernym discovery
• Sarkar. (1999). Applying Co-training methods to Statistical Parsing. • S. Brin, 1998. Extracting patterns and relations from the World Wide Web, EDBT'98 • O. Etzioni et al., 2005. "Unsupervised Named-Entity Extraction from the Web: An
Experimental Study," AI Journal, 2005.