semi-supervised speech act recognition in emails and forums
TRANSCRIPT

Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, pages 1250–1259,Singapore, 6-7 August 2009. c©2009 ACL and AFNLP
Semi-supervised Speech Act Recognition in Emails and Forums
Minwoo Jeong†∗ Chin-Yew Lin‡ Gary Geunbae Lee††Pohang University of Science & Technology, Pohang, Korea
‡Microsoft Research Asia, Beijing, China†{stardust,gblee}@postech.ac.kr ‡[email protected]
Abstract
In this paper, we present a semi-supervisedmethod for automatic speech act recogni-tion in email and forums. The major chal-lenge of this task is due to lack of labeleddata in these two genres. Our methodleverages labeled data in the Switchboard-DAMSL and the Meeting Recorder Dia-log Act database and applies simple do-main adaptation techniques over a largeamount of unlabeled email and forum datato address this problem. Our method usesautomatically extracted features such asphrases and dependency trees, called sub-tree features, for semi-supervised learn-ing. Empirical results demonstrate thatour model is effective in email and forumspeech act recognition.
1 Introduction
Email and online forums are important social me-dia. For example, thousands of emails and postsare created daily in online communities, e.g.,Usenet newsgroups or the TripAdvisor travel fo-rum1, in which users interact with each other us-ing emails/posts in complicated ways in discus-sion threads. To uncover the rich interactions inthese email exchanges and forum discussions, wepropose to apply speech act recognition to emailand forum threads.
Despite extensive studies of speech act recogni-tion in many areas, developing speech act recogni-tion for online forms of conversation is very chal-lenging. A major challenge is that emails andforums usually have no labeled data for trainingstatistical speech act recognizers. Fortunately, la-beled speech act data are available in other do-mains (i.e., telephone and meeting conversations
∗This work was conducted during the author’s internshipat Microsoft Research Asia.
1http://tripadvisor.com/
in this paper) and large unlabeled data sets can becollected from the Web. Thus, we focus on theproblem of how to accurately recognize speechacts in emails and forums by making maximumuse of data from existing resources.
Recently, there are increasing interests inspeech act recognition of online text-based con-versations. Analysis of speech acts for onlinechat and instant messages and have been studiedin computer-mediated communication (CMC) anddistance learning (Twitchell et al., 2004; Nastri etal., 2006; Rose et al., 2008). In natural languageprocessing, Cohen et al. (2004) and Feng et al.(2006) used speech acts to capture the intentionalfocus of emails and discussion boards. However,they assume that enough labeled data are availablefor developing speech act recognition models.
A main contribution of this paper is that we ad-dress the problem of learning speech act recog-nition in a semi-supervised way. To our knowl-edge, this is the first use of semi-supervised speechact recognition in emails and online forums. Todo this, we make use of labeled data from spo-ken conversations (Jurafsky et al., 1997; Dhillonet al., 2004). A second contribution is that ourmodel learns subtree features that constitute dis-criminative patterns: for example, variable lengthn-grams and partial dependency structures. There-fore, our model can capture both local featuressuch as n-grams and non-local dependencies. Inthis paper, we extend subtree pattern mining to thesemi-supervised learning problem.
This paper is structured as follows. Section 2reviews prior work on speech act recognition andSection 3 presents the problem statement and ourdata sets. Section 4 describes a supervised methodof learning subtree features that shows the effec-tiveness of subtree features on labeled data sets.Section 5 proposes semi-supervised learning tech-niques for speech act recognition and Section 6demonstrates our method applied to email and on-
1250

line forum thread data. Section 7 concludes thispaper with future work.
2 Related Work
Speech act theory is fundamental to many stud-ies in discourse analysis and pragmatics (Austin,1962; Searle, 1969). A speech act is an illo-cutionary act of conversation and reflects shal-low discourse structures of language. Recent re-search on spoken dialog processing has investi-gated computational speech act models of human-human and human-computer conversations (Stol-cke et al., 2000) and applications of these mod-els to CMC and distance learning (Twitchell et al.,2004; Nastri et al., 2006; Rose et al., 2008).
Our work in this paper is closely related to priorwork on email and forum speech act recognition.Cohen et al. (2004) proposed the notion of ‘emailspeech act’ for classifying the intent of an emailsender. They defined verb and noun categoriesfor email speech acts and used supervised learn-ing to recognize them. Feng et al. (2006) pre-sented a method of detecting conversation focusbased on the speech acts of messages in discus-sion boards. Extending Feng et al. (2006)’s work,Ravi and Kim (2007) applied speech act classifi-cation to detect unanswered questions. However,none of these studies have focused on the semi-supervised speech act recognition problem and ex-amined their methods across different genres.
The speech processing community frequentlyemploys two large-scale corpora for speech actannotation: Switchboard-DAMSL (SWBD) andMeeting Recorder Dialog Act (MRDA). SWBD isan annotation scheme and collection of labeled di-alog act2 data for telephone conversations (Juraf-sky et al., 1997). The main purpose of SWBD isto acquire stochastic discourse grammars for train-ing better language models for automatic speechrecognition. More recently, an MRDA corpus hasbeen adapted from SWBD but its tag set for la-beling meetings has been modified to better reflectthe types of interaction in multi-party face-to-facemeetings (Dhillon et al., 2004). These two corporahave been extensively studied, e.g., (Stolcke et al.,2000; Ang et al., 2005; Galley et al., 2004). Wealso use these for our experiments.
2A dialog act is the meaning of an utterance at the levelof illocutionary force (Austin, 1962), and broadly covers thespeech act and adjacency pair (Stolcke et al., 2000). In thispaper, we use only the term ‘speech act’ for clarity.
This paper focuses on the problem of semi-supervised speech act recognition. The goal ofsemi-supervised learning techniques is to use aux-iliary data to improve a model’s capability to rec-ognize speech acts. The approach in Tur et al.(2005) presented semi-supervised learning to em-ploy auxiliary unlabeled data in call classification,and is closely related to our work. However, ourapproach uses the most discriminative subtree fea-tures, which is particularly attractive for reducingthe model’s size. Our problem setting is closely re-lated to the domain adaptation problem (Ando andZhang, 2005), i.e., we seek to obtain a model thatanalyzes target domains (emails and forums) byadapting a method that analyzes source domains(SWBD and MRDA). Recently, this type of do-main adaptation has become an important topic innatural language processing.
3 Problem Definition
3.1 Problem Statement
We define speech act recognition to be the taskthat, given a sentence, maps it to one of the speechact types. Figure 1 shows two examples of ouremail and forum speech act recognition. E1∼6 areall sentences in an email message. F1∼3, F4∼5,and F6 are three posts in a forum thread. A sen-tence interacts alone or with others, for example,F6 agrees with the previous post (F4∼5). To gaininsight into our work, it is useful to consider thatE2, 3 and F1, 4, 6 are summaries of two dis-courses. In particular, F1 denotes a question andF4 and F6 are corresponding answers. More re-cently, using speech acts has become an appealingapproach in summarizing the discussions (Galleyet al., 2004; McKeown et al., 2007).
Next, we define speech act category based onMRDA. Dhillon et al. (2004) included definitionsof speech acts for colloquial style interactions(e.g., backchannel, disruption, and floorgrabber),but these are not applicable in emails and forums.After removing these categories, we define 12 tags(Table 1). Dhillon et al. (2004) provides detaileddescriptions of each tag. We note that our tag setdefinition is different from (Cohen et al., 2004;Feng et al., 2006; Ravi and Kim, 2007) for tworeasons. First, prior work primarily interested inthe domain-specific speech acts, but our work usedomain-independent speech act tags. Second, wefocus on speech act recognition on the sentence-level.
1251

E1: I am planning my schedule at CHI 2003 (http://www.chi2003.org/) SE2: - will there be anything happening at the conference related to this W3C User interest group? QYE3: I do not see anything on the program yet, but I suspect we could at least have an informal SIG SE4: - a chance to meet others and bring someone like me up to speed on what is happening. SE5: There will be many competing activities, so the sooner we can set this up the more likely I can attend. SE6: Keith SF1: If given a choice, should I choose Huangpu area, or should I choose Pudong area? QRF2: Both location are separated by a Huangpu river, not sure which area is more convenient for sight seeing? QWF3: Thanks in advance for reply! PF4: Stay on the Puxi side of the Huangpu river and visit the Pudong side by the incredible tourist tunnel. ACF5: If you stay on the Pudong side add half an hour to visit the majority of the tourist attractions. SF6: I definitely agree with previous post. AA
Figure 1: Examples of speech act recognition in emails and online forums. Tags are defined in Table 1.
Table 1: Tags used to describe components ofspeech acts
Tag DescriptionA Accept response
AA Acknowledge and appreciateAC Action motivatorP Polite mechanism
QH Rhetorical questionQO Open-ended questionQR Or/or-clause questionQW Wh-questionQY Yes-no questionR Reject responseS StatementU Uncertain response
The goal of semi-supervised speech act recogni-tion is to learn a classifier using both labeled andunlabeled data. We formally define our problemas follows. Let x = {xj} be a forest, i.e., a set oftrees that represents a natural language structure,for example, a sequence of words and a depen-dency parse tree. We will describe this in moredetail in Section 4. Let y be a speech act. Then,we define DL = {xi, yi}n
i=1 as the set of labeledtraining data, and DU = {xi}l
i=n+1 as the set ofunlabeled training data where l = n + m and m isthe number of unlabeled data instances. Our goalis to find a learning method to minimize the clas-sification errors in DL and DU .
3.2 Data Preparation
In this paper, we separate labeled (DL) and un-labeled data (DU ). First we use SWBD3 andMRDA4 as our labeled data. We automatically
3LDC Catalog No. LDC97S624http://www.icsi.berkeley.edu/∼ees/dadb/
map original annotations in SWBD and MRDA toone of the 12 speech acts.5 Inter-annotator agree-ment κ in both data sets is ∼ 0.8 (Jurafsky et al.,1997; Dhillon et al., 2004). For evaluation pur-poses, we divide labeled data into three sets: train-ing, development, and evaluation sets (Table 2).Of the 1,155 available conversations in the SWBDcorpus, we use 855 for training, 100 for devel-opment, and 200 for evaluation. Among the 75available meetings in the MRDA corpus, we ex-clude two meetings of different natures (btr001and btr002). Of the remaining meetings, we use59 for training, 6 for development, and 8 for eval-uation. Then we merge multi-segments utterancesthat belong to the same speaker and then divide alldata sets into sentences.
As stated earlier, our unlabeled data consistsof email (EMAIL) and online forum (FORUM)data. For the EMAIL set, we selected 22,391emails from Enron data6 (discussion threads,all documents, and calendar folders). For the FO-RUM set, we crawled 11,602 threads and 55,743posts from the TripAdvisor travel forum site (Bei-jing, Shanghai, and Hongkong forums). As ourevaluation sets, we used 40 email threads of theBC3 corpus7 for EMAIL and 100 threads selectedfrom the same travel forum site for FORUM. Ev-ery sentences was automatically segmented by theMSRA sentence boundary detector (Table 2). An-notation was performed by two human annotators,and inter-annotator agreements were κ = 0.79 forEMAIL and κ = 0.73 for FORUM.
Overall performance of automatic evaluationmeasures usually depends on the distribution oftags. In both labeled and unlabeled sets, the most
5Our mapping tables are available athttp://home.postech.ac.kr/∼stardust/acl09/.
6http://www.cs.cmu.edu/∼enron/7http://www.cs.ubc.ca/nest/lci/bc3.html
1252

Table 2: Number of sentences in labeled and unlabeled dataSet SWBD MRDATraining 96,553 50,865Development 12,299 8,366Evaluation 24,264 10,492
Set EMAIL FORUMUnlabeled 122,125 297,017Evaluation 2,267 3,711
Figure 2: Distribution of speech acts in the evaluation sets. Tags are defined in Table 1.
frequent tag is the statement (S) tag (Figure 2).Distributions of tags are similar in training and de-velopment sets of SWBD and MRDA.
4 Speech Act Recognition
Previous work in speech act recognition used alarge set of lexical features, e.g., bag-of-words,bigrams and trigrams (Stolcke et al., 2000; Co-hen et al., 2004; Ang et al., 2005; Ravi and Kim,2007). However, these methods create a largenumber of lexical features that might not be nec-essary for speech act identification. For example,a Wh-question “What site should we use to book aBeijing-Chonqing flight?” can be predicted by twodiscriminative features, “(<s>, WRB) → QW”and “(?, </s>) → QW” where <s> and </s>are sentence start and end symbols, and WRB isa part-of-speech tag that denotes a Wh-adverb.In addition, useful features could be of variouslengths, i.e. not fixed length n-grams, and non-adjacent. One key idea of this paper is a novel useof subtree features to model these for speech actrecognition.
4.1 Exploiting Subtree FeaturesTo exploit subtree features in our model, we usea subtree pattern mining method proposed byKudo and Matsumoto (2004). We briefly intro-duce this algorithm here. In Section 3.1, we de-fined x = {xj} as the forest that is a set of trees.More precisely, xj is a labeled ordered tree whereeach node has its own label and is ordered left-to-right. Several types of labeled ordered trees
Figure 3: Representations of tree: (a) bag-of-words, (b) n-gram, (c) word pair, and (d) depen-dency tree. A node denotes a word and a directededge indicates a parent-and-child relationship.
are possible (Figure 3). Note that S-expressioncan be used instead for computation, for example(a(b(c(d)))) for the n-gram (Figure 3(b)).Moreover, we employ a combination of multipletrees as the input of the subtree pattern mining al-gorithm.
We extract subtree features from the forest set{xi}. A subtree t is a tree if t ⊆ x. For exam-ple, (a), (a(b)), and (b(c(d))) are subtreesof Figure 3(b). We define the subtree feature as aweak learner:
f(y, t,x) ,{
+y t ⊆ x,
−y otherwise,(1)
where we assume a binary case y ∈ Y ={+1,−1} for simplicity. Even though the ap-proach in Kudo and Matsumoto (2004) and oursare simiar, there are two clear distinctions. First,our method employs multiple tree structures, anduses different constraints to generate subtree can-didates. In this paper, we only restrict generating
1253

the dependency subtrees which should have 3 ormore nodes. Second, our method is of interestfor semi-supervised learning problems. To learnsubtree features, Kudo and Matsumoto (2004) as-sumed supervised data {(xi, yi)}. Here, we de-scribe the supervised learning method and will de-scribe our semi-supervised method in Section 5.
4.2 Supervised Boosting LearningGiven training examples, we construct a ensem-ble learner F (x) =
∑k λkf(yk, tk,x), where λk
is a coefficient for linear combination. A finalclassifier h(x) can be derived from the ensemblelearner, i.e., h(x) , sgn (F (x)). As an optimiza-tion framework (Mason et al., 2000), the objectiveof boosting learning is to find F such that the costof functional
C(F ) =∑i∈D
αiC[yiF (xi)] (2)
is minimized for some non-negative and monoton-ically decreasing cost function C : R → R andthe weight αi ∈ R+. In this paper, we use theAdaBoost algorithm (Schapire and Singer, 1999);thus the cost function is defined as C(z) = e−z .
Constructing an ensemble learner requires thatthe user choose a base learner, f(y, t,x), tomaximize the inner product −〈∇C(F ), f〉 (Ma-son et al., 2000). Finding f(y, t,x) to maxi-mize −〈∇C(F ), f〉 is equivalent to searching forf(y, t,x) to minimize 2
∑i:f(y,t,xi)6=yi
wi − 1,where wi for i ∈ DL, is the empirical data dis-tribution w
(k)i at step k. It is defined as:
w(k)i = αi · e−yiF (xi). (3)
From Eq. 3, a proper base learner (i.e., subtree)can be found by maximizing weighted gain, where
gain(t, y) =∑i∈DL
yiwif(y, t,xi). (4)
Thus, subtree mining is formulated as the prob-lem of finding (t, y) = arg max
(t,y)∈X×Ygain(t, y). We
need to search with respect to a non-monotonicscore function (Eq. 4), thus we use the monotonicbound, gain(t, y) ≤ µ(t), where
µ(t) = max
2∑
wi
{i|yi=+1,t⊆xi}−
n∑i=1
yif(y, t,xi),
2∑
wi
{i|yi=−1,t⊆xi}+
n∑i=1
yif(y, t,xi)
. (5)
Table 3: Result of supervised learning experiment;columns are micro-averaged F1 score with macro-averaged F1 score in parentheses. MAXENT:maximum entropy model; BOW: bag-of-wordsmodel; NGRAM: n-gram model; +POSTAG,+DEPTREE, +SPEAKER indicate that the com-ponents were added individually onto NGRAM.‘?’ indicates results significantly better than theNGRAM model (p < 0.001).
Model SWBD MRDAMAXENT 92.76 (63.54) 82.48 (57.19)BOW 91.32 (54.47) 82.17 (55.42)NGRAM 92.60 (58.43) 83.30 (57.53)+POSTAG 92.69 (60.07) 83.60 (58.46)+DEPTREE 92.67 (61.75) ?83.57 (57.45)+SPEAKER ?92.86 (63.13) 83.40 (58.20)ALL ?92.87 (63.77) 83.49 (59.04)
The subtree set is efficiently enumerated using abranch-and-bound procedure based on µ(t) (Kudoand Matsumoto, 2004).
After finding an optimal base leaner, f(y, t,x),we need to set the coefficient λk to form a new en-semble, F (xi) ← F (xi) + λkf(t, y,xi). In Ad-aBoost, we choose
λk =12
log(
1 + gain(t, y)1− gain(t, y)
). (6)
After K iterations, the boosting algorithm returnsthe ensemble learner F (x) which consists of a setof appropriate base learners f(y, t,x).
4.3 Evaluation on Labeled Data
We verified the effectiveness of using subtree fea-tures on the SWBD and MRDA data sets. Forboosting learning, one typically assumes αi = 1.In addition, the number of iterations, which relatesto the number of patterns, was determined by adevelopment set. We also used a one-vs.-all strat-egy for the multi-class problem. Precision and re-call were computed and combined into micro- andmacro-averaged F1 scores. The significance of ourresults was evaluated using the McNemar pairedtest (Gillick and Cox, 1989), which is based on in-dividual labeling decisions to compare the correct-ness of two models. All experiments were imple-mented in C++ and executed in Windows XP on aPC with a Dual 2.1 GHz Intel Core2 processor and2.0 Gbyte of main memory.
1254

Figure 4: Comparison of different trees (SWBD)
We show that use of subtree features is ef-fective to solve the supervised speech act recog-nition problem. We also compared our modelwith the state-of-the-art maximum entropy classi-fier (MAXENT). We used bag-of-words, bigramand trigram features for MAXENT, which mod-eled 702k (SWBD) and 460k (MRDA) parameters(i.e., patterns), and produced micro-averaged F1
scores of 92.76 (macro-averaged F1 = 63.54) forSWBD and 82.48 (macro-averaged F1 = 57.19)for MRDA. In contrast, our method generated ap-proximately 4k to 5k patterns on average with sim-ilar or greater F1 scores (Table 3); hence, com-pared to MAXENT, our model requires fewer cal-culations and is just as accurate.
The n-gram model (NGRAM) performed signif-icantly better than the bag-of-words model (Mc-Nemar test; p < 0.001) (Table 3). Unlike MAX-ENT, NGRAM automatically selects a relevant setof variable length n-gram features (i.e., phrasefeatures). To this set, we separately added twosyntax type features, part-of-speech tag n-gram(POSTAG) and dependency parse tree (DEPTREE)automatically parsed by Minipar8, and one dis-course type feature, speaker n-gram (SPEAKER).Although some micro-averaged F1 are not statisti-cally significant between the original NGRAM andthe models that include POSTAG, DEPTREE orSPEAKER, macro-averaged F1 values indicate thatminor classes can take advantage of other struc-tures. For example, in the result of SWBD (Fig-ure 4), DEPTREE and SPEAKER models help topredict uncertain responses (U), whereas NGRAM
and POSTAG cannot do this.
5 Semi-supervised Learning
Our goal is to eventually make maximum useof existing resources in SWBD and MRDA for
8http://www.cs.ualberta.ca/∼lindek/minipar.htm
email/forum speech act recognition. We call themodel trained on the mixed data of these two cor-pora BASELINE. We use ALL features in con-structing the BASELINE for the semi-supervisedexperiments. While this model gave promising re-sults using SWBD and MRDA, language used inemails and forums differs from that used in spo-ken conversation. For example, ‘thanx’ is an ex-pression commonly used as a polite mechanismin online communications. To adapt our model tounderstand this type of difference between spokenand online text-based conversations, we should in-duce new patterns from unlabeled email and fo-rum data. We describe here two methods of semi-supervised learning.
5.1 Method 1: Bootstrapping
First, we bootstrap the BASELINE model using au-tomatically predicted unlabeled examples. How-ever, using all of the unlabeled data results in noisymodels; therefore filtering or selecting data is veryimportant in practice. To this end, we only selectsimilar examples by criterion, d(xi,xj) < r or knearest neighbors where xi ∈ DL and xj ∈ DU .In practice, r or k are fixed. In our method, exam-ples are represented by trees; hence we use a “treeedit distance” for calculating d(xi,xj) (Shashaand Zhang, 1990). Selected examples are evalu-ated using BASELINE, and using subtree patternmining runs on the augmented data (i.e. unla-beled). We call this method BOOTSTRAP.
5.2 Method 2: Semi-supervised Boosting
Our second method is based on a principle ofsemi-supervised boosting learning (Bennett et al.,2002). Because we have no supervised guidancefor DU , our objective functional to find F is de-fined as:
C(F ) =∑i∈DL
αiC[yiF (xi)] +∑
i∈DU
βiC[|F (xi)|]
(7)
This cost functional is non-differentiable. Tosolve it, we introduce pseudo-labels y where y =sgn(F (x)) and |F (x)| = yF (x). Using the samederivation in Section 4.2, we obtain the following
1255

gain function and update rules:
gain(t, y) =∑i∈DL
yiwif(y, t,xi)
+∑
i∈DU
yiwif(y, t,xi), (8)
wi =
{αi · e−yiF (xi) i ∈ DL,
βi · e−yiF (xi) i ∈ DU .(9)
Intuitively, an unlabeled example that has ahigh-confidence |F (x)| at the current step, willprobably receive more weight at the next step.That is, similar instances become more impor-tant when learning and mining subtrees. Thissemi-supervised boosting learning iteratively gen-erates pseudo-labels for unlabeled data and findsthe value of F that minimizes training errors (Ben-nett et al., 2002). Also, the algorithm infers newfeatures from unlabeled data, and these featuresare iteratively re-evaluated by the current ensem-ble learner. We call this method SEMIBOOST.
6 Experiment
6.1 SettingWe describe specific settings used in our exper-iment. Because we have no development set,we set the maximum number of iterations K at10,000. At most K patterns can be extracted, butthis seldom happens because duplicated patternsare merged. Typical settings for semi-supervisedboosting are αi = 1 and βi = 0.5, that is, wepenalize the weights for unlabeled data.
For efficiency, BASELINE model used 10% ofthe SWBD and MRDA data, selected at random.We observed that this data set does not degrade theresults of semi-supervised speech act recognition.For BOOTSTRAP and SEMIBOOST, we selectedk = 100 nearest neighbors of unlabeled exam-ples for each labeled example using tree edit dis-tance, and then used 24,625 (SWBD) and 54,961(MRDA) sentences for the semi-supervised set-ting.
All trees were combined as described in Section4.3 (ALL model). In EMAIL and FORUM data weadded different types of discourse features: mes-sage type (e.g., initial or reply posts), authorship(e.g., an identification of 2nd or 3rd posts writtenby the same author), and relative position of a sen-tence. In Figure 1, for example, F1∼3 is an initialpost, and F4∼5 and F6 are reply posts. Moreover,F1, F4, and F6 are the first sentence in each post.
Table 4: Results of speech act recognition on on-line conversations; columns are micro-averagedF1 score with macro-averaged scores in parenthe-ses. ‘?’ indicates that the result is significantly bet-ter than BASELINE (p < 0.001).
Model EMAIL FORUMBASELINE 78.87 (37.44) 78.93 (35.57)BOOTSTRAP ?83.11 (44.90) 79.09 (44.38)SEMIBOOST ?82.80 (44.64) ?81.76 (44.21)SUPERVISED 90.95 (75.71) 83.67 (40.68)
These features do not occur in SWBD or MRDAbecause these are utterance-by-utterance conver-sations.
6.2 Result and Discussion
First, we show that our method of semi-supervisedlearning can improve modeling of the speechact of emails and forums. As our baseline,BASELINE achieved a micro-averaged F1 scoreof ∼ 79 for both data sets. This implies thatSWBD and MRDA data are useful for our prob-lem. Using unlabeled data, semi-supervised meth-ods BOOTSTRAP and SEMIBOOST perform bet-ter than BASELINE (Table 4; Figure 5). To verifyour claim, we evaluated the supervised speech actrecognition on EMAIL and FORUM evaluationsets with 5-fold cross validation (SUPERVISED inTable 4). In particular, our semi-supervised speechact recognition is competitive with the supervisedmodel in FORUM data.
The difference in performance between super-vised results in EMAIL and FORUM seems toindicate that the latter is a more difficult dataset. However, our SEMIBOOST method were ableto come close to the supervised FORUM results(81.76 vs. 83.67). This is also close to the range ofsupervised MRDA data set (F1 = 83.49 for ALL,Table 3). Moreover, we analyzed a main reason ofwhy transfer results were competitive in the FO-RUM but not in the EMAIL. This might be dueto the mismatch in the unlabeled data, that is, weused different email collections, the BC3 corpus(email communication of W3C on w3.org sites),for evaluation while used Enron data for adaption.We also conjecture that the discrepancy betweenEMAIL and FORUM is probably due to the moreheterogeneous nature of the FORUM data whereanyone can post and reply while EMAIL (Enron or
1256

(a) EMAIL (b) FORUM
Figure 5: Result of the semi-supervised learning method
BC3) might have a more fix set of participants.The improvement of less frequent tags is promi-
nent, for example 25% for action motivator (AC),40% for polite mechanism (P), and 15% for rhetor-ical question (QR) error rate reductions wereachieved in FORUM data (Figure 5(b)). There-fore, the semi-supervised learning method is moreeffective with small amounts of labeled data (i.e.,less frequent annotations). We believe that despitetheir relative rarity, these speech acts are more im-portant than the statement (S) in some applica-tions, e.g., summarization.
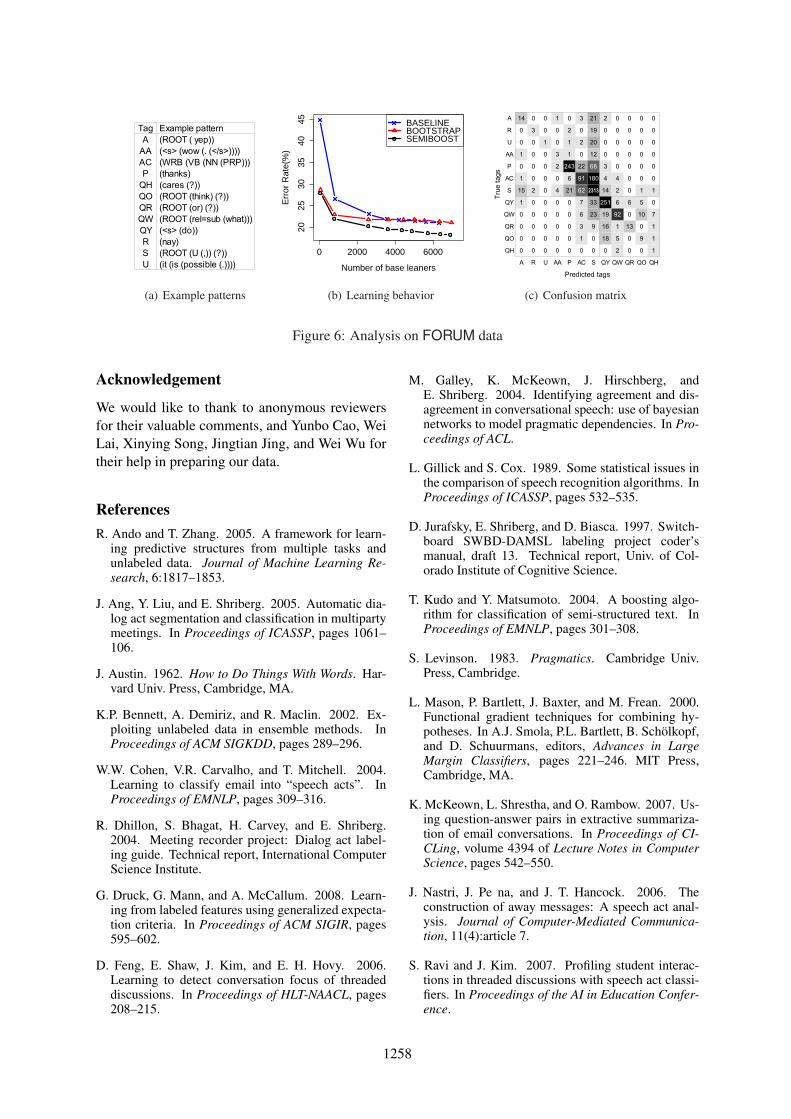
Next, we give a qualitative analysis for betterinterpretation of our problem and results. Due tolimited space, we focus on FORUM data, whichcan potentially be applied to many applications.Of the top ranked patterns extracted by SEMI-BOOST (Figure 6(a)), subtree patterns of n-gram,part-of-speech, dependency parse trees are mostdiscriminative. The patterns from unlabeled datahave relatively lower ranks, but this is not surpris-ing. This indicates that BASELINE model providesthe base knowledge for semi-supervised speechact recognition. Also, unlabeled data for EMAILand FORUM help to induce new patterns or ad-just the model’s parameters. As a result, the semi-supervised method is better than the BASELINE
when an identical number of patterns is modeled(Figure 6(b)). For this result, we conclude that ourmethod successfully transfers knowledge from asource domain (i.e., SWBD and MRDA) to a tar-get domain (i.e., EMAIL and FORUM); hence itcan be a solution to the domain adaption problem.
Finally, we determine the main reasons for error(in SEMIBOOST), to gain insights that may allowdevelopment of better models in future work (Fig-ure 6(c)). We sorted speech act tags by their se-mantics and partitioned the confusion matrix intoquestion type (Q*) and statement, which are two
high-level speech acts. Most errors occur in thesimilar categories, that is, language usage in ques-tion discourse is definitely distinct from that instatement discourse. From this analysis, we be-lieve that more advanced techniques (e.g. two-stage classification and learning with hierarchy-augmented loss) can improve our model.
7 Conclusion
Despite the increasing interest in online text-basedconversations, no study to date has investigatedsemi-supervised speech act recognition in emailand forum threads. This paper has addressed theproblem of learning to recognize speech acts us-ing labeled and unlabeled data. We have also con-tributed to the development of a novel applica-tion of boosting subtree mining. Empirical resultshave demonstrated that semi-supervised learningof speech act recognition with subtree features im-proves the performance in email and forum datasets. An attractive future direction is to exploitprior knowledge for semi-supervised speech actrecognition. Druck et al. (2008) described gen-eralized expectation criteria in which a discrimi-native model can employ the labeled features andunlabeled instances. Using prior knowledge, weexpect that our model will effectively learn usefulpatterns from unlabeled data.
As work progresses on analyzing online text-based conversations such as emails, forums, andonline chats, the importance of developing modelsfor discourse without annotating much new datawill become more important. In the future, weplan to explore other related problems such as ad-jacency pairs (Levinson, 1983) and discourse pars-ing (Soricut and Marcu, 2003) for large-scale on-line forum data.
1257
(a) Example patterns
0 2000 4000 6000
2025
3035
4045
Number of base leaners
Err
or R
ate(
%)
BASELINEBOOTSTRAPSEMIBOOST
(b) Learning behavior (c) Confusion matrix
Figure 6: Analysis on FORUM data
Acknowledgement
We would like to thank to anonymous reviewersfor their valuable comments, and Yunbo Cao, WeiLai, Xinying Song, Jingtian Jing, and Wei Wu fortheir help in preparing our data.
ReferencesR. Ando and T. Zhang. 2005. A framework for learn-
ing predictive structures from multiple tasks andunlabeled data. Journal of Machine Learning Re-search, 6:1817–1853.
J. Ang, Y. Liu, and E. Shriberg. 2005. Automatic dia-log act segmentation and classification in multipartymeetings. In Proceedings of ICASSP, pages 1061–106.
J. Austin. 1962. How to Do Things With Words. Har-vard Univ. Press, Cambridge, MA.
K.P. Bennett, A. Demiriz, and R. Maclin. 2002. Ex-ploiting unlabeled data in ensemble methods. InProceedings of ACM SIGKDD, pages 289–296.
W.W. Cohen, V.R. Carvalho, and T. Mitchell. 2004.Learning to classify email into “speech acts”. InProceedings of EMNLP, pages 309–316.
R. Dhillon, S. Bhagat, H. Carvey, and E. Shriberg.2004. Meeting recorder project: Dialog act label-ing guide. Technical report, International ComputerScience Institute.
G. Druck, G. Mann, and A. McCallum. 2008. Learn-ing from labeled features using generalized expecta-tion criteria. In Proceedings of ACM SIGIR, pages595–602.
D. Feng, E. Shaw, J. Kim, and E. H. Hovy. 2006.Learning to detect conversation focus of threadeddiscussions. In Proceedings of HLT-NAACL, pages208–215.
M. Galley, K. McKeown, J. Hirschberg, andE. Shriberg. 2004. Identifying agreement and dis-agreement in conversational speech: use of bayesiannetworks to model pragmatic dependencies. In Pro-ceedings of ACL.
L. Gillick and S. Cox. 1989. Some statistical issues inthe comparison of speech recognition algorithms. InProceedings of ICASSP, pages 532–535.
D. Jurafsky, E. Shriberg, and D. Biasca. 1997. Switch-board SWBD-DAMSL labeling project coder’smanual, draft 13. Technical report, Univ. of Col-orado Institute of Cognitive Science.
T. Kudo and Y. Matsumoto. 2004. A boosting algo-rithm for classification of semi-structured text. InProceedings of EMNLP, pages 301–308.
S. Levinson. 1983. Pragmatics. Cambridge Univ.Press, Cambridge.
L. Mason, P. Bartlett, J. Baxter, and M. Frean. 2000.Functional gradient techniques for combining hy-potheses. In A.J. Smola, P.L. Bartlett, B. Scholkopf,and D. Schuurmans, editors, Advances in LargeMargin Classifiers, pages 221–246. MIT Press,Cambridge, MA.
K. McKeown, L. Shrestha, and O. Rambow. 2007. Us-ing question-answer pairs in extractive summariza-tion of email conversations. In Proceedings of CI-CLing, volume 4394 of Lecture Notes in ComputerScience, pages 542–550.
J. Nastri, J. Pe na, and J. T. Hancock. 2006. Theconstruction of away messages: A speech act anal-ysis. Journal of Computer-Mediated Communica-tion, 11(4):article 7.
S. Ravi and J. Kim. 2007. Profiling student interac-tions in threaded discussions with speech act classi-fiers. In Proceedings of the AI in Education Confer-ence.
1258

C. Rose, Y. Wang, Y. Cui, J. Arguello, K. Stegmann,A. Weinberger, and F. Fischer. 2008. Analyzingcollaborative learning processes automatically: Ex-ploiting the advances of computational linguistics incomputer-supported collaborative learning. Interna-tional Journal of Computer-Supported Collabora-tive Learning, 3(3):237–271.
R.E. Schapire and Y. Singer. 1999. Improved boostingalgorithms using confidence-rated predictions. Ma-chine Learning, 37(3):297–336.
J. Searle. 1969. Speech Acts. Cambridge Univ. Press,Cambridge.
D. Shasha and K. Zhang. 1990. Fast algorithms for theunit cost editing distance between trees. Journal ofAlgorithms, 11(4):581–621.
R. Soricut and D. Marcu. 2003. Sentence level dis-course parsing using syntactic and lexical informa-tion. In Proceedings of NAACL-HLT, pages 149–156.
A. Stolcke, K. Ries, N. Coccaro, E. Shriberg, R. Bates,D. Jurafsky, P. Taylor, R. Martin, C. Van Ess-Dykema, and M. Meteer. 2000. Dialogue actmodeling for automatic tagging and recognition ofconversational speech. Computational Linguistics,26(3):339–373.
G. Tur, D. Hakkani-Tur, and R. E. Schapire. 2005.Combining active and semi-supervised learning forspoken language understanding. Speech Communi-cation, 45(2):171–186.
D. P. Twitchell, J. F. Nunamaker, and J. K. Burgoon.2004. Using speech act profiling for deception de-tection. In Second Symposium on Intelligence andSecurity Informatics, volume 3073 of Lecture Notesin Computer Science, pages 403–410.
1259