sequence order independent structural alignment joe dundas, andrew binkowski, bhaskar dasgupta, jie...
Post on 20-Dec-2015
216 views
TRANSCRIPT

Sequence order independent structural alignment
Joe Dundas, Andrew Binkowski, Bhaskar DasGupta, Jie LiangDepartment of Bioengineering/Bioinformatics, University of Illinois at Chicago

Backgroundo Extended Central Dogma of molecular biology
DNA RNA primary structure 3D structure function
o Evolution conserves the 3D structure more than amino acid sequence.
o Structural similarity often reflects a common function or origin of proteins.[1]
o It is useful to classify proteins based on their structures. (SCOP, CATH, FSSP).
o Many methods for structure alignment have been reported. (CE, DALI, FAST, Matchprot)

Circular Permutation
o Ligation of the N and C termini, and subsequent cleavage elsewhere.
o In 1979, first natural circular permutation was observed in favin vs. concanavalin A.[2]
o In 1983, the first engineered circular permutation was performed on bovine pancreatic trypsin inhibitor.[3]
o Since, studies have shown that artificially permuted proteins are able to fold into a stable structures that are similar to the native protein.[4]
o Circular permutations have been discovered in lectins, β-glucanases, swaposin…[5]
Uliel S., Fliess A., Amir A., Unger R. (1999)[6]
Uliel S., Fliess A., Unger R. (2001)[7]

Alignment Problem
o Most structural alignment methods rely on the structural units of each protein to align sequentially i.e. CE, FAST.
o Some newer methods will perform non-sequential alignments i.e. Dali, Matchprot.
After explaining our method, will we compare the results against Dali and Matchprot.

Our Method• We exhaustively fragment protein A and protein B
into lengths ranging from 4 to 7 residues. Notation: fragment λa = (a1, a2), where a1 and a2 are the beginning
and ending positions relative to the N termini of protein A.
Πa = {λa,1, λa,2,… λa,n} is the set of all fragments from protein A.
La,i is the length of fragment Πa,I
• Each fragment from protein A is aligned to all fragments of protein B if La,I = Lb,j, forming a set of Aligned Fragment Pairs ( Λ Πa x Πb ).
• A similarity function σ maps Λ

Similarity Function
( ) ( _ ( )* ( )) * _ ( )i i i iss corr rmsd seq sim
H( ) is the percentage of aligned Helical residues. E( ) is the percentage of aligned Strand residues. C( )
_ ( ) = 1.0 * C( ) +5.0 * H( ) +1.25 * E( ) +1.0 * M( )i i i i i
iii
ss corr
is the percentage of algined Other residues. M( ) is the percentage of Mismatched aligned residues. i
( ) is the optimal root mean square distance of the aligned fragment pair.irmsd
_ ( ) is the sequence similarity of the aligned fragment pair.iseq sim
The parameters , , were empirically set to 100, .5, and 1, respectively.
All Λi with σ(Λi) > Threshold are used to create a conflict graph.
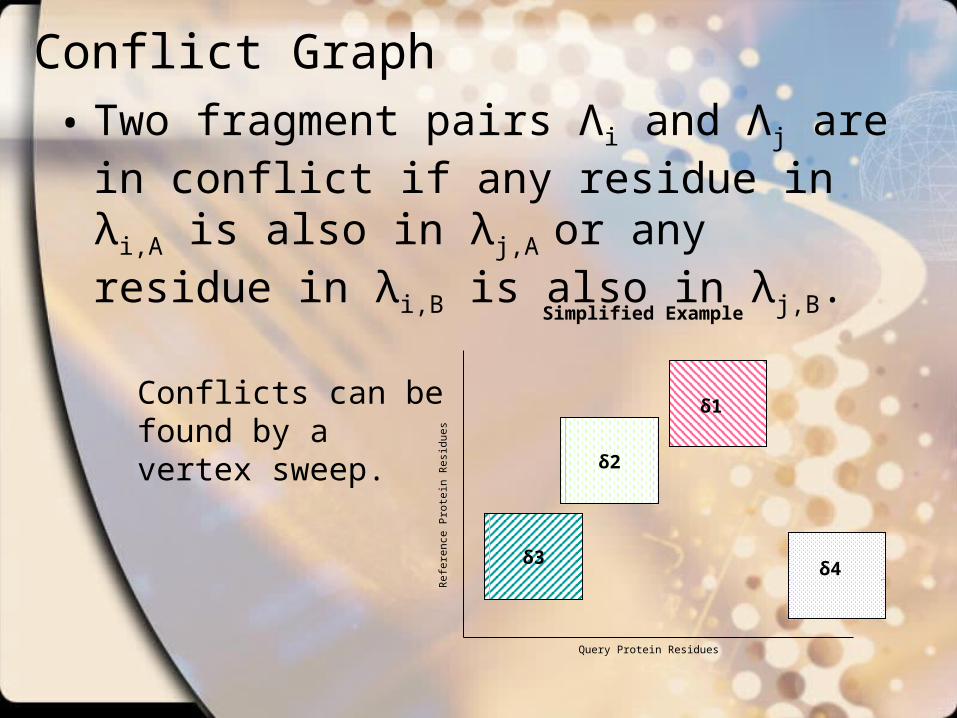
Conflict Graph• Two fragment pairs Λi and Λj are in conflict
if any residue in λi,A is also in λj,A or any residue in λi,B is also in λj,B.
Conflicts can be found by a vertex sweep.
Query Protein Residues
Ref
eren
ce P
rote
in R
esid
ues
δ3
δ2
δ4
δ1
Simplified Example

LP Formulation
i
i
maximize: ( )* ix
a
a
,
t
y 1
,
t
y 1b
b
No conflicting residues inquery or reference protein.
Consistency between variables
All variables are between 0 and 1
x is a relaxed integer between 0 and 10 = don’t use fragment1 = use fragment
Solve using linear programming package
, - x 0ay , - x 0by
a b, ,0 y ,y ,x 1
Subject to:
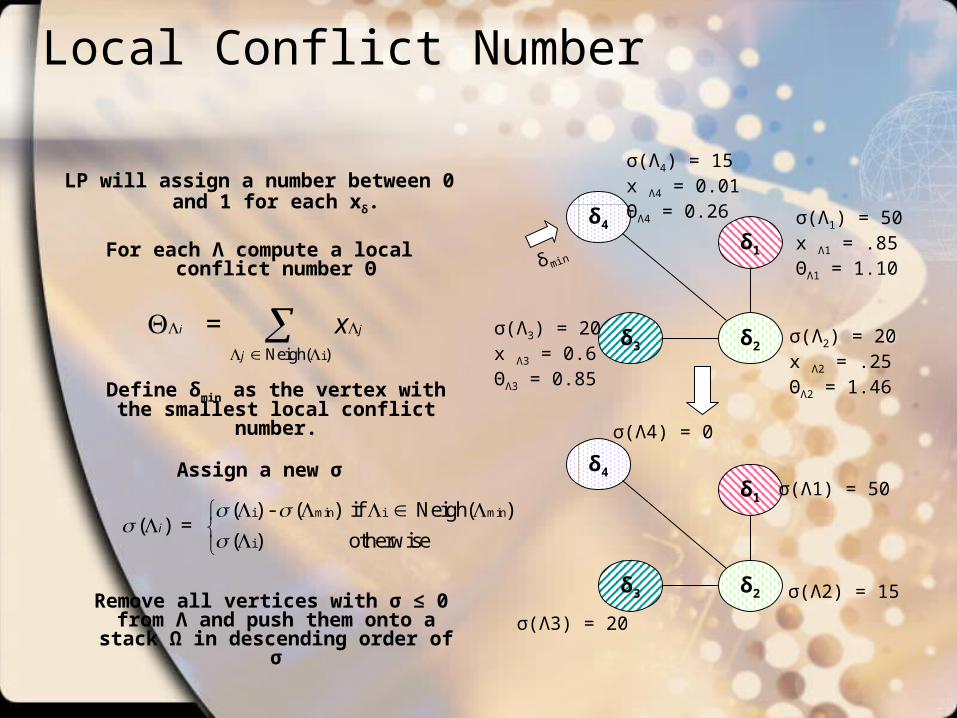
Local Conflict Number
LP will assign a number between 0 and 1 for each xδ.
For each Λ compute a local conflict number Θ
Define δmin as the vertex with the smallest local conflict number.
Assign a new σ
Remove all vertices with σ ≤ 0 from Λ
and push them onto a stack Ω in descending order of σ
i Neigh( )
= i j
j
x
δ4
δ2
δ1
δ3
δ4
δ2
δ1
δ3
σ(Λ1) = 50x Λ1 = .85ΘΛ1 = 1.10
σ(Λ2) = 20x Λ2 = .25ΘΛ2 = 1.46
σ(Λ3) = 20x Λ3 = 0.6ΘΛ3 = 0.85
σ(Λ4) = 15x Λ4 = 0.01ΘΛ4 = 0.26
δmin
σ(Λ1) = 50
σ(Λ2) = 15
σ(Λ4) = 0
σ(Λ3) = 20
i min i min
i
( ) - ( ) if Neigh( )( ) =
( ) otherwisei

Repeat
Repeat LP formulation until all vertices have been pushed onto the stack Ω.
Begin with 5 empty alignments.
While the stack is not empty, retrieve a aligned pair by popping the stack.
Insert it into each non-empty alignment if and only if:
1. No residue conflicts occur.
2. The global RMSD does not change by some threshold.
If it can not be inserted into any alignment, insert it into an available empty alignment.
Determine which alignment with highest similarity score.

Results – Circular Permutation?1jqsC70s ribosome functional complexFold: Ribosome & Ribosomal fragments
2piiPII (Product of glnB)Fold: Ferredoxin-like
RMSD: 2.3194

Results – Circular Permutation1iudAAspartate RacemaseFold: ATC-like
1h0rAType II 3-dehydrogenate dehydralaseFold: Flavodoxin

Results1fe0ATX1 MetallochaperoneFold: ferredoxin-like
1vetMitogen activated protein kinase

Results
1e50Core binding factorFold: Core binding factor beta
1pkvRiboflavin Synthase