service clustering for autonomic clouds using random forest
TRANSCRIPT

Service Clustering for AutonomicClouds Using Random Forest
Rafael Brundo UriarteIMT Lucca
Sotirios Tsaftaris Francesco TiezziIMT Lucca University of Camerino
CCGrid - 7th May 2015 - Shenzhen, China

Contents
1 Introduction
2 Requirements and Existing Solutions
3 RF+PAM
4 Evaluation
5 Conclusions
Uriarte, Tsaftaris and Tiezzi 1/29

Introduction
Introduction Uriarte, Tsaftaris and Tiezzi 2/29

Cloud Computing
I Everything-as-a-Service
I Dynamism
I Heterogeneity
I Virtualization
I Large-Scale
Introduction Uriarte, Tsaftaris and Tiezzi 3/29

Autonomic Computing
Introduction Uriarte, Tsaftaris and Tiezzi 4/29

Autonomic Clouds
I Restricted Knowledge
I Approaches to alleviate the problem:
I Machine LearningI Service Clustering
Introduction Uriarte, Tsaftaris and Tiezzi 5/29

Applications in the Domain
I Anomalous Behaviour Detection
I Service Scheduling
I Application Profiling
I SLA Risk Assessment
Introduction Uriarte, Tsaftaris and Tiezzi 6/29

Requirements and Existing Solutions
Requirements and Existing Solutions Uriarte, Tsaftaris and Tiezzi 7/29

Requirements
Characteristics Requirements
Security, Heterogeneity,Dynamism
Mixed Types ofFeatures
Large-Scale, Dynamism On-line Prediction
Large-Scale, Multi-AgentLoosely-Coupled
Parallelism
HeterogeneityLarge Number of
Features
Requirements and Existing Solutions Uriarte, Tsaftaris and Tiezzi 8/29

Existing Approaches
I Solutions which handle mixed data types usually are notscalable (e.g. HClustream)
I Expert intervention is not feasible due to the dynamism
I Distance Metric Learning Approaches require labelled dataor are computationally expensive.
Requirements and Existing Solutions Uriarte, Tsaftaris and Tiezzi 9/29

RF+PAM
RF+PAM Uriarte, Tsaftaris and Tiezzi 10/29

Random Forest
I Mixed Features
I Large Number of Features
I Efficient and Scales Well
I Easily Parallelizable
RF+PAM Uriarte, Tsaftaris and Tiezzi 11/29

Random Forest
Clustering with Random Forest
I Originally Developed for Classification
I On-Line Random Forest
I Intrinsic Measure of Similarity
I Clustering Algorithm (e.g. PAM)
RF+PAM Uriarte, Tsaftaris and Tiezzi 12/29

Similarity Using RF: Criteria
RF+PAM Uriarte, Tsaftaris and Tiezzi 13/29

Problems
I Similarity Matrix (Big Memory Footprint)
I Re-cluster on Every New Observation
RF+PAM Uriarte, Tsaftaris and Tiezzi 14/29

Solution: RF+PAM
I Off-line Training and On-line Prediction
I Similarity Learning and Standard Clustering
RF+PAM Uriarte, Tsaftaris and Tiezzi 15/29

Solution: RF+PAM
Build Forest, Calculate Similarities, Cluster, Selectthe medoids and Store the references of the leaves.
RF+PAM Uriarte, Tsaftaris and Tiezzi 16/29

Solution: RF+PAM
Parse service and Assign the cluster of the mostsimilar medoid to it.
RF+PAM Uriarte, Tsaftaris and Tiezzi 17/29

Evaluation
Evaluation Uriarte, Tsaftaris and Tiezzi 18/29

Experiments
1. Cluster Quality
2. On-Line Prediction
3. Use Case
Evaluation Uriarte, Tsaftaris and Tiezzi 19/29

Cluster Quality
I Clustering quality compared to 2 otherapproaches (same dataset)
I Better results in all criteria
I Connectivity - Connectedness of the clustersI Dunn Index - Cluster density and SeparationI Silhouette - Confidence in the assignment
Evaluation Uriarte, Tsaftaris and Tiezzi 20/29

On-line Prediction
I On-Line vs Batch Mode
I K-Fold Cross-Validation
I Compared the Adjusted Rand Index (ARI) for 2datasets:
I Monitoring data of Google’s productionclouds - 12500 servers
I Requests of a grid of the Dutch UniversitiesResearch Testbed (DAS-2) - 200 servers
Evaluation Uriarte, Tsaftaris and Tiezzi 21/29
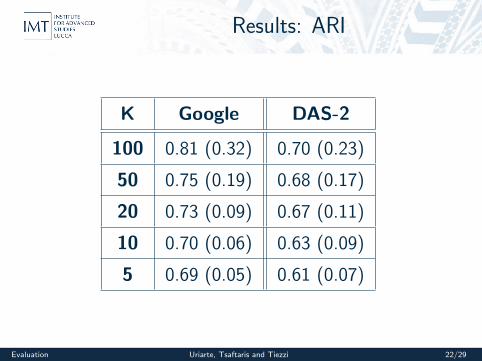
Results: ARI
K Google DAS-2
100 0.81 (0.32) 0.70 (0.23)
50 0.75 (0.19) 0.68 (0.17)
20 0.73 (0.09) 0.67 (0.11)
10 0.70 (0.06) 0.63 (0.09)
5 0.69 (0.05) 0.61 (0.07)
Evaluation Uriarte, Tsaftaris and Tiezzi 22/29

Use Case
I Schedules according to the Dissimilarity
I Similar services separated
I Algorithms:
1. Random2. Dissimilarity3. Isolated
Evaluation Uriarte, Tsaftaris and Tiezzi 23/29

Use Case
I 9 VMs
I Arrival Rates
I Types of Service
I Services’ SLA
Evaluation Uriarte, Tsaftaris and Tiezzi 24/29

Results
Evaluation Uriarte, Tsaftaris and Tiezzi 25/29

Conclusions
Conclusions Uriarte, Tsaftaris and Tiezzi 26/29

Summary
I We propose RF+PAM to alleviate the problemof limited knowledge in AC
I Validated RF+PAM with 3 Experiments
I Scheduling Algorithm
Conclusions Uriarte, Tsaftaris and Tiezzi 27/29

Future Works
I More Use Cases
I Better Implementation
Conclusions Uriarte, Tsaftaris and Tiezzi 28/29

Thank you!Questions?
Rafael Brundo [email protected]
Conclusions Uriarte, Tsaftaris and Tiezzi 29/29

Prune Trees
I Parsing is very fast and efficient
I Prune requires analysis (time consuming)
Conclusions Uriarte, Tsaftaris and Tiezzi 29/29

Retraining
Ratio of predictions/training services (user defined):
I Parallel training
I Trade-off between updating/prediction
Other solutions:
I Dissimilarity to Medoids
I On-line Clustering (Current Limitations andPrediction Speed)
Conclusions Uriarte, Tsaftaris and Tiezzi 29/29