shannon ’ s theory part ii ref. cryptography: theory and practice douglas r. stinson
Post on 21-Dec-2015
227 views
TRANSCRIPT

Shannon’s theory part II
Ref. Cryptography: theory and practice
Douglas R. Stinson

Shannon’s theory
1949, “Communication theory of Secrecy Systems” in Bell Systems Tech. Journal.
Two issues: What is the concept of perfect secrecy? Does
there any cryptosystem provide perfect secrecy?
It is possible when a key is used for only one encryption
How to evaluate a cryptosystem when many plaintexts are encrypted using the same key?
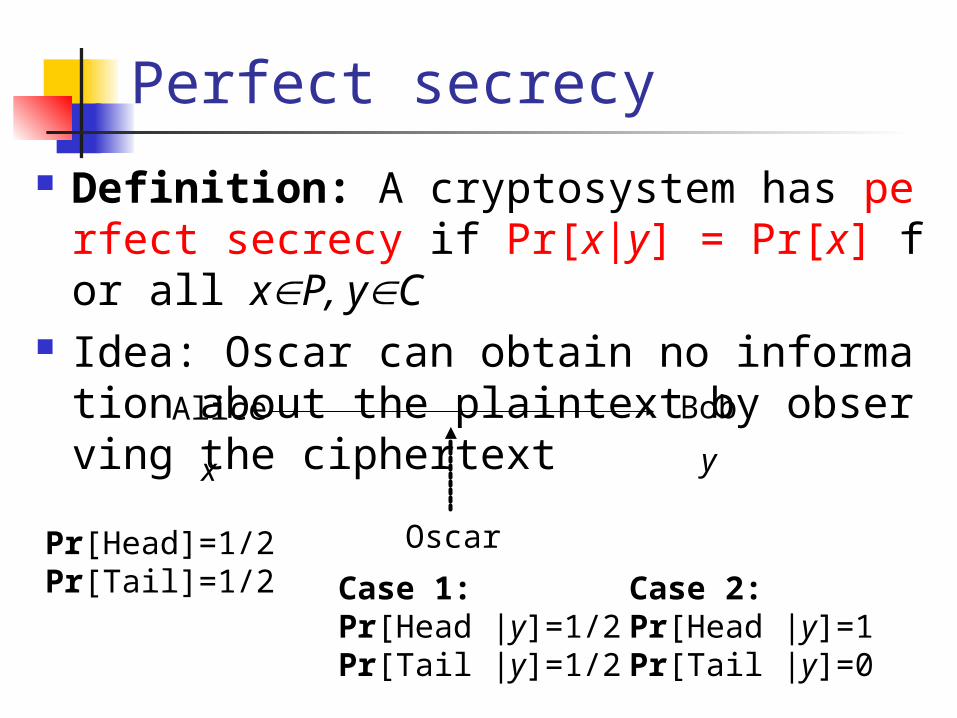
Perfect secrecy
Definition: A cryptosystem has perfect secrecy if Pr[x|y] = Pr[x] for all xP, yC
Idea: Oscar can obtain no information about the plaintext by observing the ciphertext
Alice Bob
Oscar
x y
Pr[Head]=1/2Pr[Tail]=1/2 Case 1:
Pr[Head |y]=1/2Pr[Tail |y]=1/2
Case 2:Pr[Head |y]=1Pr[Tail |y]=0

Perfect secrecy when |K|=|C|=|P|
(P,C,K,E,D) is a cryptosystem where |K|=|C|=|P|.
The cryptosystem provides perfect secrecy iff every keys is used with equal probability 1/|K| For every xP, yC, there is a unique key K suc
h that
Ex. One-time pad in Z2
yxeK )(
P: 010K: 101
P: 111K: 000
C: 111?

Outline
Introduction One-time pad
Elementary probability theory Perfect secrecy Entropy Properties of entropy Spurious keys and unicity distance Product system
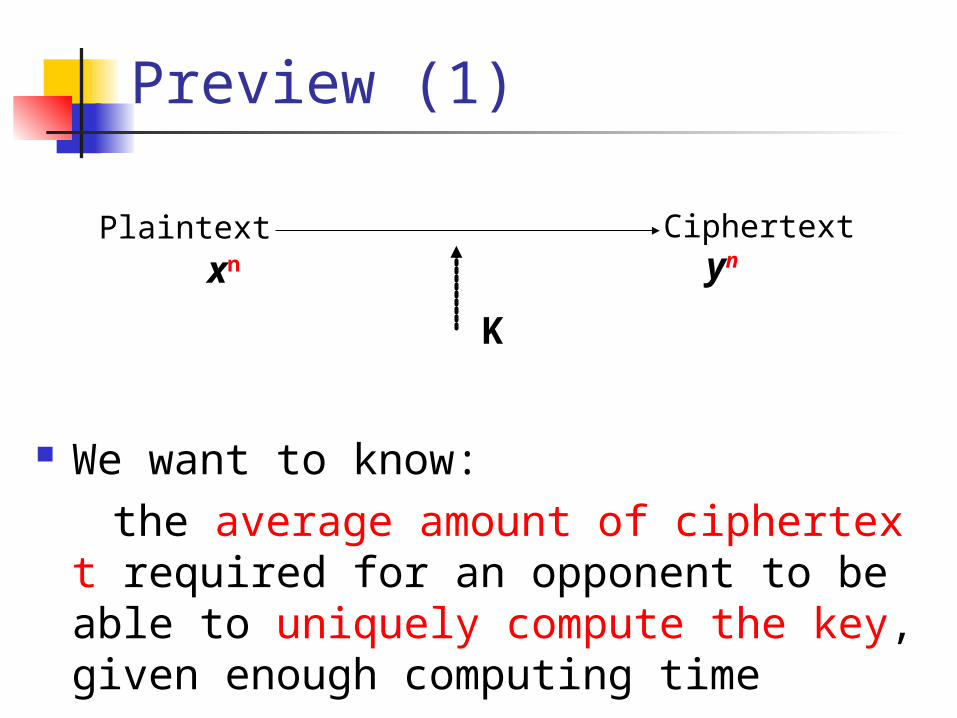
Preview (1)
We want to know: the average amount of ciphertext required
for an opponent to be able to uniquely compute the key, given enough computing time
Plaintext Ciphertextxn yn
K

Preview (2)
That is, we want to know: How much information about the key is rev
ealed by the ciphertext = conditional entropy H(K|Cn)
We need the tools of entropy

Entropy (1)
Suppose we have a discrete random variable X What is the information gained by the outcome
of an experiment? Ex. Let X represent the toss of a coin, Pr[he
ad]=Pr[tail]=1/2 For a coin toss, we could encode head by 1,
and tail by 0 => i.e. 1 bit of information

Entropy (2)
Ex. Random variable X with Pr[x1]=1/2, Pr[x2]=1/4, Pr[x3]=1/4
The most efficient encoding is to encode x1 as 0, x2 as 10, x3 as 11.
Pr[x1]=1/2Pr[x2]=1/4
uncertainty informationcodeword length

Entropy (3)
Notice: probability 2-n => n bits p => -log2 p
Ex.(cont.) The average number of bits to encode X
2
32
4
12
4
11
2
1

Entropy: definition
Suppose X is a discrete random variable which takes on values from a finite set X. Then, the entropy of the random variable X is defined as
Xx
xxH ]Pr[log]Pr[)( 2X

Entropy : example
Let P={a, b}, Pr[a]=1/4, Pr[b]=3/4. K={K1, K2, K3}, Pr[K1]=1/2, Pr[K2]=Pr[K3]= 1/4. encryption matrix: a b
K1 1 2
K2 2 3
K3 3 4
H(P)= 81.04
3log
4
3
4
1log
4
122
H(K)=1.5, H(C)=1.85

Properties of entropy (1)
Def: A real-valued function f is a strictly concave ( 凹 ) function on an interval I if
2
)()(
2
yfxfyxf
x y
f(x)f(y)

Properties of entropy (2)
Jensen’s inequality: Suppose f is a continuous strictly concave function on I,
x1 xn
niaa i
n
ii
1 ,0 ,11
n
i
n
iiiii xafxfa
1 1
)(
Then
Equality hold iff x1 =...=xn

Properties of entropy (3)
Theorem: X is a random variable having a probability distribution which takes on the values on p1, p2,…pn, pi>0, 1 i n.
Then H(X) log2 n with equality iff pi=1/n for all i
* Uniform random variable has the maximum entropy

Properties of entropy (4)
Proof:
i
n
ii p
pH1
log)(1
2
X
n
i ii p
p1
2
1log
n2log

Entropy of a natural language (1)
HL : average information per letter in English
1. If the 26 alphabets are uniform random,
= log2 26 4.70
2. Consider alphabet frequencyH(P) 4.19

Entropy of a natural language (2)
3. However, successive letters has correlationsEx. Digram, trigram
Q: entropy of two or more random variables?

Properties of entropy (5)
Def:
Theorem: H(X,Y) H(X)+H(Y) with equality iff X and Y are independent Proof: Let
YyXx
yxyxH,
2 ],Pr[log],Pr[),( YX
mixXp ii 1 ],Pr[
njyYq jj 1 ],Pr[
njmiyYxXr jiij 1 ,1 ],,Pr[
n
jiji rp
1
m
iijj rq
1

Entropy of a natural language (3)
3. Let Pn be the random variable that has as its probability distribution that of all n-gram of plaintext.
tabulation of digrams => H(P2)/2 3.90 tabulation of trigrams => H(P3)/3 … tabulation of n-grams => H(Pn)/4
n
HH
n
nL
)(lim
P
1.0 HL 1.5

Entropy of a natural language (4)
Redundancy of L is defined as
P
HR L
L2log
1
Take HL =1.25, RL = 0.75
English language is 75% redundant !
We can compress English text to aboutone quarter of its original length

Conditional entropy
Known any fixed value y on Y, information about random variable X
Conditional entropy: the average amount of information about X that is revealed by Y
Theorem: H(X,Y)=H(Y)+H(X|Y)
x
yxyxyH ]|Pr[log]|Pr[)|( 2X
y x
yxyxyH ]|Pr[log]|Pr[]Pr[)|( 2YX

Theorem about H(K|C) (1)
Let (P,C,K,E,D) be a cryptosystem, then H(K|C) = H(K) + H(P) – H(C) Proof:
H(K,P,C) = H(C|K,P) + H(K,P)
Since key and plaintext uniquely determine the ciphertext
H(C|K,P) = 0
H(K,P,C) = H(K,P) = H(K) + H(P)
Key and plaintext are independent

Theorem about H(K|C) (2)
We have Similarly,
Now,
H(K,P,C) = H(K,C) = H(K) + H(C)
H(K,P,C) = H(K,P) = H(K) + H(P)
H(K|C)= H(K,C)-H(C)
= H(K,P,C)-H(C)
= H(K)+H(P)-H(C)

Results (1)
Define random variables as
Plaintext CiphertextPn Cn
K
)()()()|( nnn HHHH CPKCK
n
HH
n
nL
)(lim
P
PRnnHH LLn
2log)1()( P=>
CnnHH n2log)()( CC
Set |P|=|C|, PnRHH Ln
2log)()|( KCK

Spurious( 假 ) keys (1) Ex. Oscar obtains ciphertext WNAJW, whic
h is encrypted using a shift cipher K=5, plaintext river K=22, plaintext arena One is the correct key, and the other is spu
rious
Goal: prove a bound on the expected number of spurious keys

Spurious keys (2)
Given yCn , the set of possible keys
The number of spurious keys |K(y)|-1 The average number of spurious keys
Plaintext CiphertextPn Cn
K
yxexxKyK Kn )(,0]Pr[such that :Κ)( P
1|)(|]Pr[1|)(|]Pr[ nn yy
n yKyyKysCC

Relate H(K|Cn) to spurious keys (1)
By definition
ny
n yHyHC
KCK )|(]Pr[)|(
ny
yKyC
|)(|log]Pr[ 2
ny
n yKyC
|)(|]Pr[log
1log nn s

Relate H(K|Cn) to spurious keys (2)
1log)|( nnn sH CK
PnRHH Ln
2log)()|( KCK
We have derived
PnRHs Ln 22 log)()1(log K
So
LnRLnRP
KPK
||loglog||log 222

Relate H(K|Cn) to spurious keys (3)
Theorem: |C|=|P| and keys are chosen equiprobably. The expected number of spurious keys
As n increases, right hand term => 0
1||
LnRnsP
K

Relate H(K|Cn) to spurious keys (4)
Set
For substitution cipher, |P|=|C|=26, |K|=26!
0ns
P
K
2
20 log
||log
LRn
25)7.475.0/(4.880 n
The average amount of ciphertext required for an opponentto be able to unique compute the key, given enough time
Unicity distance

Product cryptosystem
S1 = (P,P,K1,E1,D1), S2 = (P,P,K2,E2,D2) The product of two cryptosystems is S1 = (P,P, K1K2 ,E,D)
))(()(1221 ),( xeexe KKKK
))(()(2121 ),( yddyd KKKK
Encryption:
Decryption:

Product cryptosystem (cont.)
Two cryptosystem M and S commute if
Idempotent cryptosystem: S2 = S Ex. Shift cipher
If a cryptosystem is not idempotent, then there is a potential increase in security by iterating it several times
MxS = SxM

How to find non-idempotent cryptosystem?
Thm: If S and M are both idempotent, and they commute, then SM will also be idempotent
Idea: find simple S and M such that they do not commute SxM is possibly non-idempotent
(SXM) x (SxM) = S x (M x S) xM =S x (S x M) x M
=(S x S) x (M x M)
=S x M