simonas Šaltenis aalborg...
TRANSCRIPT

Simonas Šaltenis
Aalborg Universitydaisy.aau.dk
Spatial Indexing
Indexing basics (R-trees)

DAT5/DE3 DB seminar, September 27, 2010 2
Outline
• B-tree: a very brief reminder
• Multi-dimensional index structures
• R-trees (Overlapping Region trees) Structure and simple queries Update algorithms Nearest-neighbor queries

DAT5/DE3 DB seminar, September 27, 2010 3
“Rules of the game”• Measure of efficiency – number of I/O operations
One I/O operation reads or writes a page of data (~2Kb – 16Kb) from the disk to memory
A page of data = a node of data structure (index) consisting of a number B of entries
The size of the data set in disk blocks n = N/B CPU cost is mostly neglected
• Operations that have to be supported: Different kind of queries (that's why we want an index) Insertions Deletions Update = Deletion + Insertion Bulk-loading the index

DAT5/DE3 DB seminar, September 27, 2010 4
Multi-dimensional Indexes
• Multidimensional Data Structures are used to answer queries on the set of stationary multidimensional points Range query ([x1, x2], [y1,y2]): find all points (x, y) such that x1<x<x2
and y1<y<y2, and do it faster than a linear scan (Θ(n)) preferably O(log n) in worst-case or at least on average

DAT5/DE3 DB seminar, September 27, 2010 5
1D Range-Searching: B-trees
• B-trees [Bayer & McCreight, 1972] – a balanced disk-based search tree. B+-trees: All data entries (keys) are in leaf-nodes Internal (directory) nodes “direct queries” and point to lower-level
nodes Each entry corresponds to an interval that bounds all data in a
subtree. Based on an ordering “<”
5191
51 60 7780 91 93 9810 25 32 44

DAT5/DE3 DB seminar, September 27, 2010 6
• Guaranteed 50% capacity by insert and delete algorithms split / merge routines
x1 x2
• Range query: find x, such that x1<x<x2 Can be done in O(log n + k) worst-case
time, where k is the size of the answer in disk blocks
B-trees (cont.)

DAT5/DE3 DB seminar, September 27, 2010 7
• Much harder than one-dimensional problem
• A lot of multidimensional index methods have been proposed
• The theoretically optimal ones [Arge et al. 1999] that achieve O(log n + k) worst-case query performance: are unpractically complex, require a little bit more than linear-space
• Easy to implement, linear-space methods: K-D-B-trees, Quadtrees, Grid Files (for points) R-trees and variations (work for non-point objects as well)
Multi-dimensional indexing

DAT5/DE3 DB seminar, September 27, 2010 8
p2
p1
p14
p9
p8
p5
p3
p4
p10
p13
p15
p11
p12
p6
p7
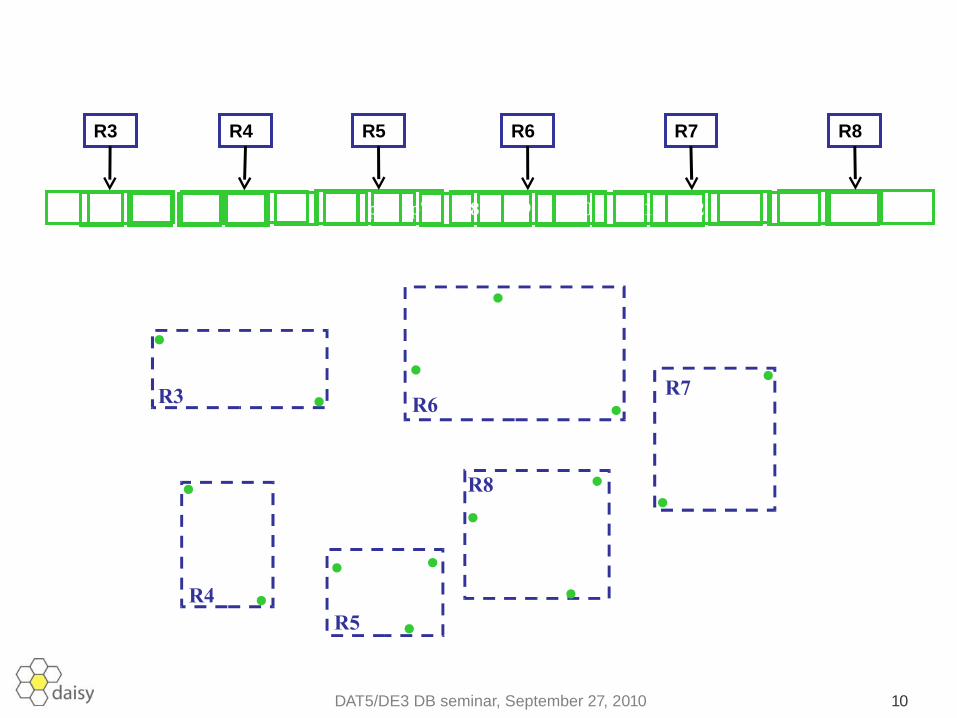
R-tree: an example

DAT5/DE3 DB seminar, September 27, 2010 9
R1
R3 R7R6
R5R4
R8
R2
p2
p1
p7p5
p3
p4
p6
p14
p9
p8
p10
p13
p15
p11
p12
DAT5/DE3 DB seminar, September 27, 2010 10
p11 p12p8 p9 p10p5 p6 p7p3 p4p1 p2 p13 p14 p15
R5
R3 R7R6
R4
R8
p2
p1
p5
p3
p4
p6
p14
p9
p8
p10
p13
p15
p11
p12
p7
p11 p12p8 p9 p10p5 p6 p7p3 p4p1 p2 p13 p14 p15
R3 R4 R5 R6 R7 R8

DAT5/DE3 DB seminar, September 27, 2010 11
R5
R3 R7R6
R4
R8
R1
R2
p2
p1
p5
p3
p4
p6
p14
p9
p8
p10
p13
p15
p11
p12
p7
p11 p12p8 p9 p10p5 p6 p7p3 p4p1 p2 p13 p14 p15
R4 R7R3 R5 R6 R8
R1 R2
R3 R4 R5 R6 R7 R8

DAT5/DE3 DB seminar, September 27, 2010 12
R5
R3 R7R6
R4
R8
R1
R2
p2
p1
p5
p3
p4
p6
p14
p9
p8
p10
p13
p15
p11
p12
p7
p11 p12p8 p9 p10p5 p6 p7p3 p4p1 p2 p13 p14 p15
R4 R7R3 R5 R6 R8
R1 R2R1 R2

DAT5/DE3 DB seminar, September 27, 2010 13
• Query example
QueryR1
R2
R1 R2
R3 R4 R5
p6 p7p5p1 p2
Pointers to data items
p8p3 p4 p9 p10 p11 p12p13
R6 R7
R3 R4
R5
R6
R7
p1p7
p6
p8
p2
p3
p4
p5
p9
p10
p11
p12
p13
R-Tree

DAT5/DE3 DB seminar, September 27, 2010 14
• Strucutre: Leaf entry = <n-dimensional point, rid> Internal entry = <n-dim MBR, ptr to a child>
MBR – a Minimum Bounding Rectangle of all points in the sub-tree pointed to by ptr
MBRs can overlap! R-tree is a balanced tree – all leaves are at same depth from the
root Nodes are kept at least m% full (except root) through insertion and
deletion algorithms m is usually chosen to be 40%. m is the minimum fill factor; depending on the workload the average fill
factor is usually ≈ 70%.
R-tree Properties

DAT5/DE3 DB seminar, September 27, 2010 15
• Note: We may have to search several subtrees at each node! What about B-trees? Worst-case performance O(n)! But in practice, R-trees exhibit good
query performance for various data sets
• How do we insert and delete?
RangeQuery(Q, node) // in a tree rooted at node 01 foreach entry <MBR, ptr> in node do 02 if MBR overalaps Q then03 if node is not leaf then 04 return RangeQuery(Q, ReadNode(ptr))05 else // if node is leaf 06 return ptr // as a row id / pointer to a data
Range Query in R-trees

DAT5/DE3 DB seminar, September 27, 2010 16
Internal Nodes
Leaf Nodes
BP1 BPnBP2...
…..
...
Grow-Post trees (Generalized Search Trees - GiST)
• Penalty• Union • PickSplit
Bounding predicate (BP) = something that describes the entries in a subtree
Building blocks of algorithms: For querying:
For updating:
• Consistent(BP, Q) – returns true if results of query Q can be under BP (in the R-tree, MBR intersects Q)In Overlapin Region trees (OR-trees), Consistent can return true for more than one BP in a node.
Grow-Post trees
DAT5/DE3 DB seminar, September 27, 2010 17
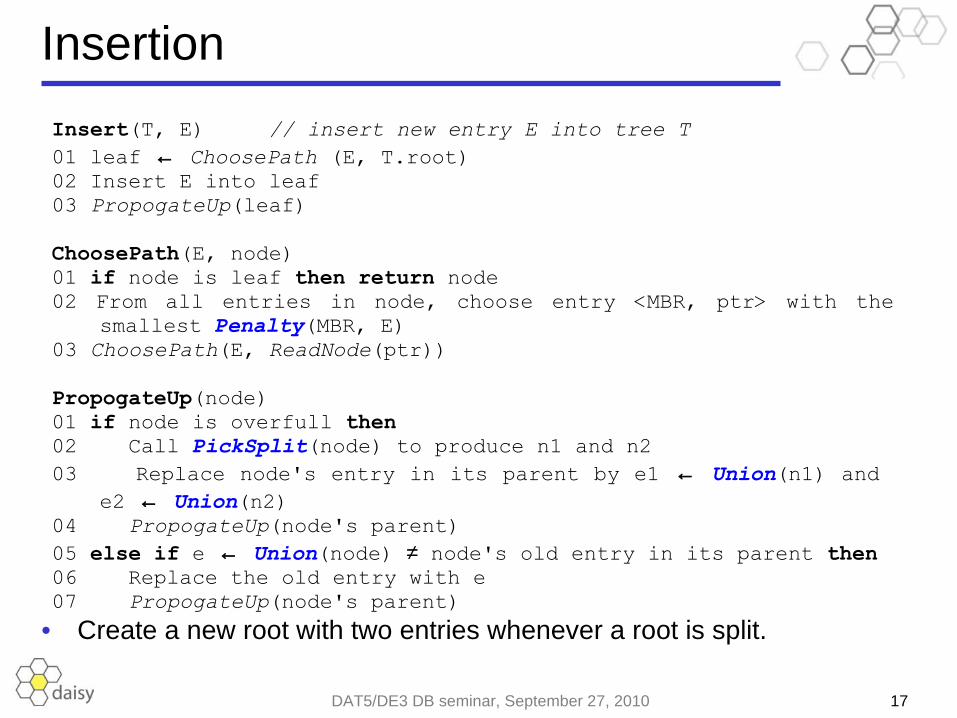
Insertion
• Create a new root with two entries whenever a root is split.
Insert(T, E) // insert new entry E into tree T 01 leaf ← ChoosePath (E, T.root)02 Insert E into leaf03 PropogateUp(leaf)
ChoosePath(E, node)01 if node is leaf then return node02 From all entries in node, choose entry <MBR, ptr> with the
smallest Penalty(MBR, E)03 ChoosePath(E, ReadNode(ptr))
PropogateUp(node)01 if node is overfull then 02 Call PickSplit(node) to produce n1 and n203 Replace node's entry in its parent by e1 ← Union(n1) and
e2 ← Union(n2)04 PropogateUp(node's parent)05 else if e ← Union(node) ≠ node's old entry in its parent then06 Replace the old entry with e07 PropogateUp(node's parent)

DAT5/DE3 DB seminar, September 27, 2010 18
Internal Nodes
Leaf Nodes
BP1 BPnBP2...
…..
...
Grow-Post trees (Generalized Search Trees - GiST)
• Union(node) – computes a BP of a collection of entries (in the R-tree, computes an MBR – minimum and maximum in all dimensions )
• Penalty(BP, E) – returns an estimate how “worse” BP becomes if E is inserted under it
Bounding predicate (BP) = something that describes the entries in a subtree
Building blocks of algorithms For updating:
• PickSplit(node) – splits a page of entries into two groups
Grow-Post trees (cont.)

DAT5/DE3 DB seminar, September 27, 2010 19
Heuristics for Penalty
• Heuristics are used in R-tree’s Penalty: Least area enlargement Smallest area to break ties
R1
R2
R1 R2
R3 R4 R5
p6 p7p5p1 p2
Pointers to data tuples
p8p3 p4 p9 p10 p11 p12p13
R6 R7
R3 R4
R5
R6
R7
p1p7
p6
p8
p2
p3
p4
p5
p9
p10
p11
p12
p13p14

DAT5/DE3 DB seminar, September 27, 2010 20
Heuristics for Penalty
R1
R2
R1 R2
R3 R4 R5
p6 p7p5p1 p2
Pointers to data tuples
p8p3 p4 p9 p10 p11 p12p13
R6 R7
R3 R4
R5
R6
R7
p1p7
p6
p8
p2
p3
p4
p5
p9
p10
p11
p12
p13p14
p14
• Heuristics are used in R-tree’s Penalty: Least area enlargement Smallest area to break ties

DAT5/DE3 DB seminar, September 27, 2010 21
PickSplit
• The entries in a node node plus the newly inserted entry must be distributed between n1 and n2
• The goal is to reduce a likelihood of both n1 and n2 being searched on subsequent queries Again we use heuristics of minimum area. Redistribute so as to minimize the area of n1 plus the area of n2. Freedom to have uneven split in terms of a number of entries (m =
40% < 50%)

DAT5/DE3 DB seminar, September 27, 2010 22
PickSplit (cont.)
Good split
Bad split
• Problem – there is an exponential number of possible distributions. Solution – approximate minimization of area:
Original Guttman's quadratic “gready” algorithm: Consider all pairs of entries and pick a
pair with the largest MBR Consider the two entries as the seeds of
the two new nodes From the remaining entries, choose the
one which, when added to one of the nodes, increases the sum of areas the least
Repeat the last step until all entries are distributed

DAT5/DE3 DB seminar, September 27, 2010 23
Deletion
• No additional heuristics are involved in Delete, underfull nodes are handled using Insert as a subroutine.
Delete(T, E) // Delete entry E from tree T 01 Using a querying algorithm, find a leaf where E is located 02 Remove E from leaf03 PropogateUp(leaf)
PropogateUp(node)01 if node is underfull then 02 Deallocate node03 Remove node's entry from its parent04 PropogateUp(node's parent)05 Reinsert all node's entries using the Insert algorithm06 else if e ← Union(node) ≠ node's old entry in its parent then07 Replace the old entry with e08 PropogateUp(node's parent)

DAT5/DE3 DB seminar, September 27, 2010 24
Comments on R-Trees
• Worst-case: Insertions: O(log n), Deletions: O(n)!
• Works well for 2 - 4 D point/non-point datasets
• Several variants (notably, R+ and R*-trees) have been proposed Concurrency control, recovery protocols for R-trees are well
researched Implemented in Oracle, PostgreSQL, MySQL Not only range queries, but a wide variety of other types of queries
are supported by R-trees (point queries, nearest-neighbor queries, joins)

DAT5/DE3 DB seminar, September 27, 2010 25
Nearest-Neighbor Queries• Nearest-neighbor query:
Given a set of multi-dimensional points S and a query point q, return a point p ∈ S, closest to q:
That is ∀ a∈S d q , pd q , a
q
p

DAT5/DE3 DB seminar, September 27, 2010 26
Nearest-Neighbor Queries• Applications:
Find a closest gas station Similarity search: find an image or a song that is most similar to a
given one. Represent each image (song) as a feature vector (multi-dimensional
point)
• Can we program Consistent(MBR, Q) to get a NN query algorithm for R-trees? Similar to a circular range query, but we don't know the radius of the
circle a priori!

DAT5/DE3 DB seminar, September 27, 2010 27
Depth-First NN Search
R1
R2
R1 R2
R3 R4 R5
p6 p7p5p1 p2
Pointers to data items
p8p3 p4 p9 p10 p11 p12p13
R6 R7
R3 R4
R5
R6
R7
p1p7
p6
p8
p2
p3
p4
p5
p9
p10
p11
p12
p13
Candidate NN: p8 p12
Nodes accessed: 6

DAT5/DE3 DB seminar, September 27, 2010 28
Depth-First Traversal• Branch-and-bound algorithm. Ideas:
Use an upper estimate on the range prunedist, which is infinite initially
Update prunedist, whenever points are retrieved In a node, order entries to be visited by their MINDIST to a data
point
R1
R2R2 R3MINDIST(R3, q) = 0

DAT5/DE3 DB seminar, September 27, 2010 29
Depth-First NN search
• Worst case performance: O(n)
• Prunedist could also be updated after line 9, but this does not help (can be proved...)
prunedist ← ∞ // Prunning distancenncand ← NIL // Best NN candidate found so far
DepthFirstNN(q, node) // in a tree rooted at node 01 if node is leaf then02 foreach entry p in node do 03 if d(p,q) < prunedist then04 prunedist ← d(p,q)05 nncand ← p06 else // node is not leaf 07 foreach entry <MBR, ptr> in node sorted on MINDIST do 08 if MINDIST (MBR,q) < prunedist then 09 DepthFirstNN(q, ReadNode(ptr))

DAT5/DE3 DB seminar, September 27, 2010 30
Optimal algorithm• The depth-first algorithm is not optimal!
• The optimal one should visit only the entries intersecting the NN-circle (Root, R1, R2, R7, R5)
R1
R2
R3 R4
R5
R6
R7
p1p7
p6
p8
p2
p3
p4
p5
p9
p10
p11
p12
p13
DAT5/DE3 DB seminar, September 27, 2010 31
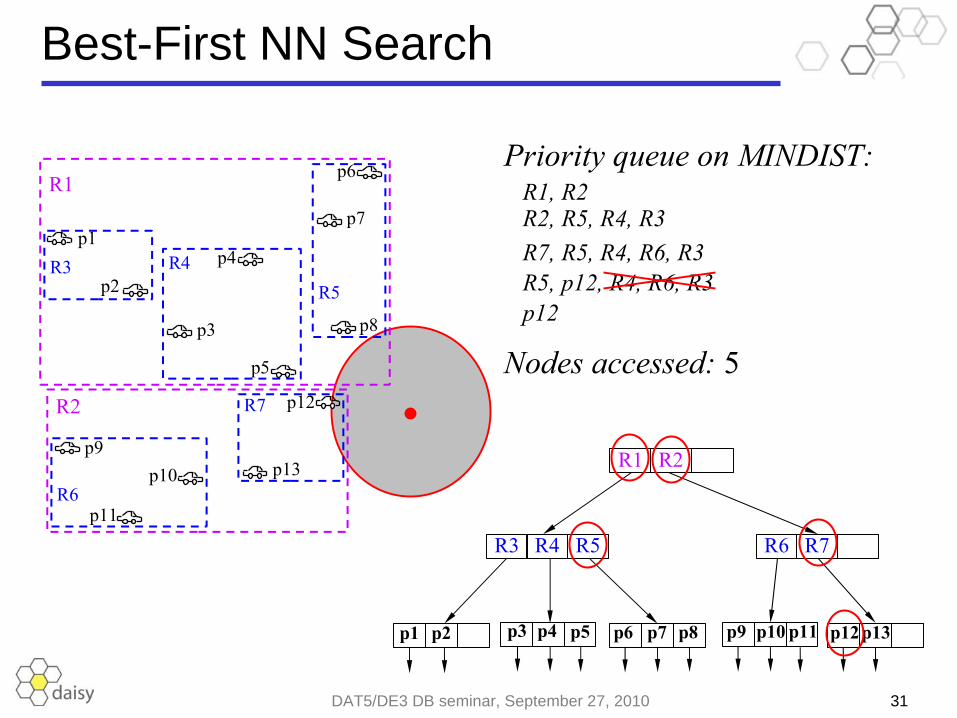
Best-First NN Search
R1
R2
R1 R2
R3 R4 R5
p6 p7p5p1 p2 p8p3 p4 p9 p10 p11 p12p13
R6 R7
R3 R4
R5
R6
R7
p1p7
p6
p8
p2
p3
p4
p5
p9
p10
p11
p12
p13
Nodes accessed: 5
Priority queue on MINDIST: R1, R2 R2, R5, R4, R3 R7, R5, R4, R6, R3 R5, p12, R4, R6, R3 p12

DAT5/DE3 DB seminar, September 27, 2010 32
Best-First NN Search
BestFirstNN(q, T)01 Q ← ∅ // Priority queue ordered on MINDIST to q02 Q.enqueue(T.root)03 while true do04 p ← Q.dequeue() 05 if p is a data point then return p06 else 07 foreach entry e in ReadNode(p) do 08 Q.enqueue(e) 09 Prune Q by removing all entries after the first data point

DAT5/DE3 DB seminar, September 27, 2010 33
NN Querying: Conclusions• Best-first:
Uses O(n) memory in worst-case Is optimal for a given R-tree, but runs in O(n) in worst-case
• Depth-first: Uses only O(log n) memory Runs in O(n) in worst-case
• Both algorithms can be generalized to find not one but k nearest neighbors
• They work also on kd-trees, quadtrees, and other hierarchies of enclosing descriptions