single-chip multiprocessors: redefining the microarchitecture of multiprocessors guri sohi...
TRANSCRIPT

Single-Chip Multiprocessors: Single-Chip Multiprocessors: Redefining the Microarchitecture Redefining the Microarchitecture
of Multiprocessorsof MultiprocessorsGuri Sohi
University of Wisconsin

2
OutlineOutline
Waves of innovation in architecture Innovation in uniprocessors Opportunities for innovation Example CMP innovations
Parallel processing models CMP memory hierarcies

3
Waves of Research and InnovationWaves of Research and Innovation
A new direction is proposed or new opportunity becomes available
The center of gravity of the research community shifts to that direction SIMD architectures in the 1960s HLL computer architectures in the 1970s RISC architectures in the early 1980s Shared-memory MPs in the late 1980s OOO speculative execution processors in the 1990s

4
WavesWaves
Wave is especially strong when coupled with a “step function” change in technology Integration of a processor on a single chip Integration of a multiprocessor on a chip

5
Uniprocessor Innovation WaveUniprocessor Innovation Wave
Integration of processor on a single chip The inflexion point Argued for different architecture (RISC)
More transistors allow for different models Speculative execution
Then the rebirth of uniprocessors Continue the journey of innovation Totally rethink uniprocessor microarchitecture

6
The Next WaveThe Next Wave
Can integrate a simple multiprocessor on a chip Basic microarchitecture similar to traditional
MP Rethink the microarchitecture and usage of
chip multiprocessors

7
Broad Areas for InnovationBroad Areas for Innovation
Overcoming traditional barriers New opportunities to use CMPs for
parallel/multithreaded execution Novel use of on-chip resources (e.g., on-chip
memory hierarchies and interconnect)

8
Remainder of Talk RoadmapRemainder of Talk Roadmap
Summary of traditional parallel processing Revisiting traditional barriers and overheads
to parallel processing Novel CMP applications and workloads Novel CMP microarchitectures

9
Multiprocessor ArchitectureMultiprocessor Architecture
Take state-of-the-art uniprocessor Connect several together with a suitable
network Have to live with defined interfaces
Expend hardware to provide cache coherence and streamline inter-node communication Have to live with defined interfaces

10
Software ResponsibilitiesSoftware Responsibilities
Reason about parallelism, execution times and overheads This is hard
Use synchronization to ease reasoning Parallel trends towards serial with the use of
synchronization Very difficult to parallelize transparently

11
Net ResultNet Result
Difficult to get parallelism speedup Computation is serial Inter-node communication latencies
exacerbate problem Multiprocessors rarely used for parallel
execution Typical use: improve throughput This will have to change
Will need to rethink “parallelization”

12
Rethinking ParallelizationRethinking Parallelization
Speculative multithreading Speculation to overcoming other
performance barriers Revisiting computation models for
parallelization New parallelization opportunities
New types of workloads (e.g., multimedia) New variants of parallelization models

13
Speculative MultithreadingSpeculative Multithreading
Speculatively parallelize an application Use speculation to overcome ambiguous
dependences Use hardware support to recover from mis-
speculation E.g., multiscalar Use hardware to overcome barriers

14
Overcoming Barriers: Memory ModelsOvercoming Barriers: Memory Models
Weak models proposed to overcome performance limitations of SC
Speculation used to overcome “maybe” dependences
Series of papers showing SC can achieve performance of weak models

15
ImplicationsImplications
Strong memory models not necessarily low performance
Programmer does not have to reason about weak models
More likely to have parallel programs written

16
Overcoming Barriers: SynchronizationOvercoming Barriers: Synchronization
Synchronization to avoid “maybe” dependences Causes serialization
Speculate to overcome serialization Recent work on techniques to dynamically
elide synchronization constructs

17
ImplicationsImplications
Programmer can make liberal use of synchronization to ease programming
Little performance impact of synchronization More likely to have parallel programs written

18
Revisiting Parallelization ModelsRevisiting Parallelization Models
Transactions simplify writing of parallel code very high overhead to implement semantics in software
Hardware support for transactions will exist Speculative multithreading is ordered transactions No software overhead to implement semantics
More applications likely to be written with transactions

19
New Opportunities for CMPsNew Opportunities for CMPs
New opportunities for parallelism Emergence of multimedia workloads
• Amenable to traditional parallel processing Parallel execution of overhead code Program demultiplexing Separating user and OS

20
New Opportunities for CMPsNew Opportunities for CMPs
New opportunities for microarchitecture innovation Instruction memory hierarchies Data memory hierarchies
21
Reliable SystemsReliable Systems
Software is unreliable and error-prone Hardware will be unreliable and error-prone Improving hardware/software reliability will
result in significant software redundancy Redundancy will be source of parallelism

22
Software Reliability & SecuritySoftware Reliability & Security
Reliability & Security via Dynamic Monitoring
- Many academic proposals for C/C++ code- Ccured, Cyclone, SafeC, etc…
- VM performs checks for Java/C#
High Overheads!- Encourages use of unsafe code

23
Software Reliability & SecuritySoftware Reliability & Security
- Divide program into tasks
- Fork a monitor thread to check computation of each task
- Instrument monitor thread with safety checking code
A
B
C
D
A’
B’
C’
Monitoring Code
Pro
gram

24
Software Reliability & SecuritySoftware Reliability & Security
- Commit/abort at task granularity
- Precise error detection achieved by re-executing code w/ in-lined checks
C
D
B
B’
A
A’
COMMIT
COMMITC’
ABORT
C’
D

25
Software Reliability & SecuritySoftware Reliability & Security
Fine-grained instrumentation- Flexible, arbitrary safety checkingCoarse-grained verification- Amortizes thread startup latency over many
instructions
Initial Results: Software-based Fault Isolation (Wahbe et al. SOSP 1993)
- Assumes no misspeculation due to traps, interrupts, speculative storage overflow

26
Software Reliability & SecuritySoftware Reliability & Security
0.00
0.50
1.00
1.50
2.00
2.50
gzipvp
r.pvp
r.r mcf
craf
ty
parse
rper
l
vorte
xbzip
2tw
olf
No
rma
lize
d E
xe
cu
tio
n T
ime
Segment Matching:Software
Segment Matching:Hardware Support

27
Program De-multiplexingProgram De-multiplexing
New opportunities for parallelism 2-4X parallelism
Program is a multiplexing of methods (or functions) onto single control flow
De-multiplex methods of program Execute methods in parallel in dataflow
fashion

28
Data-flow ExecutionData-flow Execution
3
1
4
5
2
Data-flow Machines- Dataflow in programs- No control flow, PC- Nodes are instrs. on FU
OoO Superscalar Machines- Sequential programs- Limited dataflow with ROB- Nodes are instrs. on FU
6
7

29
Program DemultiplexingProgram Demultiplexing
3
1
4
5
2 6
7Dem
ux’e
d E
xecu
tion Nodes - methods (M)
Processors - FUs
Seq
uen
tial P
rog
ram

30
Program DemultiplexingProgram Demultiplexing
3
1
4
5
2
6
7
Seq
uen
tial P
rog
ramTriggers
- usually fire after data dep of M- Chosen with software support- Handlers generate params
PD- Data-flow based spec. execution- Differs from control-flow spec.
6
On Trigger-Execute
On Call-UseD
em
ux’e
d e
xec.
(6)

31
Data-flow Execution of MethodsData-flow Execution of MethodsEarl
iest
possib
le E
xec.
tim
e
of
M
Exec.
Tim
e +
overh
ead
s o
f M

32
Impact of ParallelizationImpact of Parallelization
Expect different characteristics for code on each core
More reliance on inter-core parallelism Less reliance on intra-core parallelism May have specialized cores

33
Microarchitectural ImplicationsMicroarchitectural Implications
Processor Cores Skinny, less complex
• Will SMT go away? Perhaps specialized
Memory structures (i-caches, TLBs, d-caches) Different organizations possible

34
Microarchitectural ImplicationsMicroarchitectural Implications
Novel memory hierarchy opportunities Use on-chip memory hierarchy to improve
latency and attenuate off-chip bandwidth Pressure on non-core techniques to tolerate
longer latencies
• Helper threads, pre-execution

35
Instruction Memory HierarchyInstruction Memory Hierarchy
Computation spreading
36
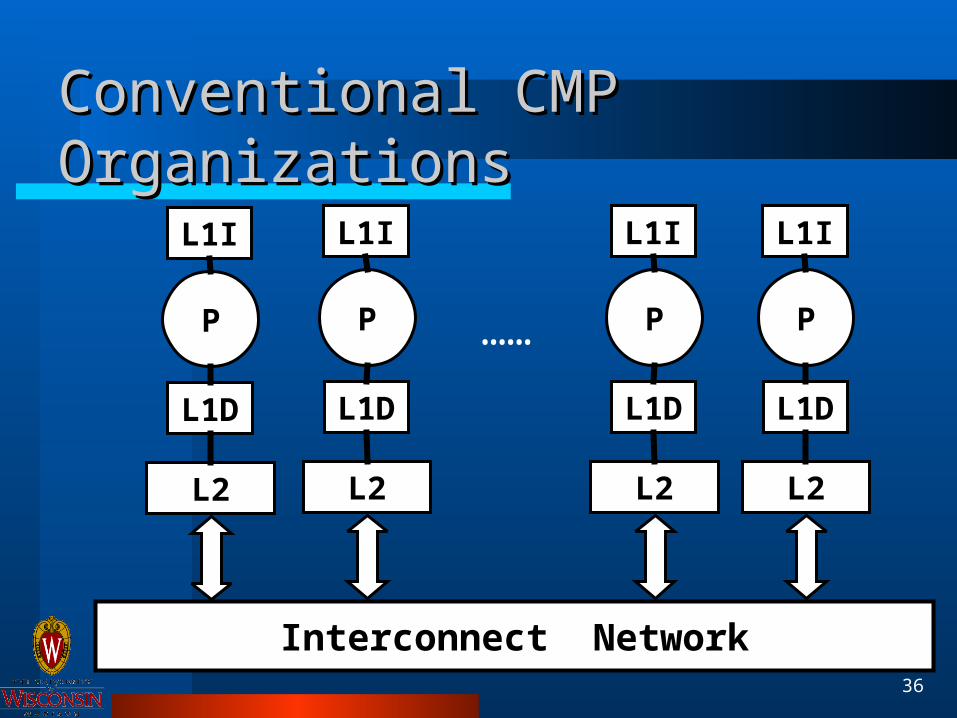
Conventional CMP OrganizationsConventional CMP Organizations
P
L1I
L1D
L2
Interconnect Network
P
L1I
L1D
L2
P
L1I
L1D
L2
P
L1I
L1D
L2
……

37
Code CommonalityCode Commonality
Large fraction of the code executed is common to all the processors both at 8KB page (left) and 64-byte cache block (right) granularity
Poor utilization of L1 I-cache due to replication
38
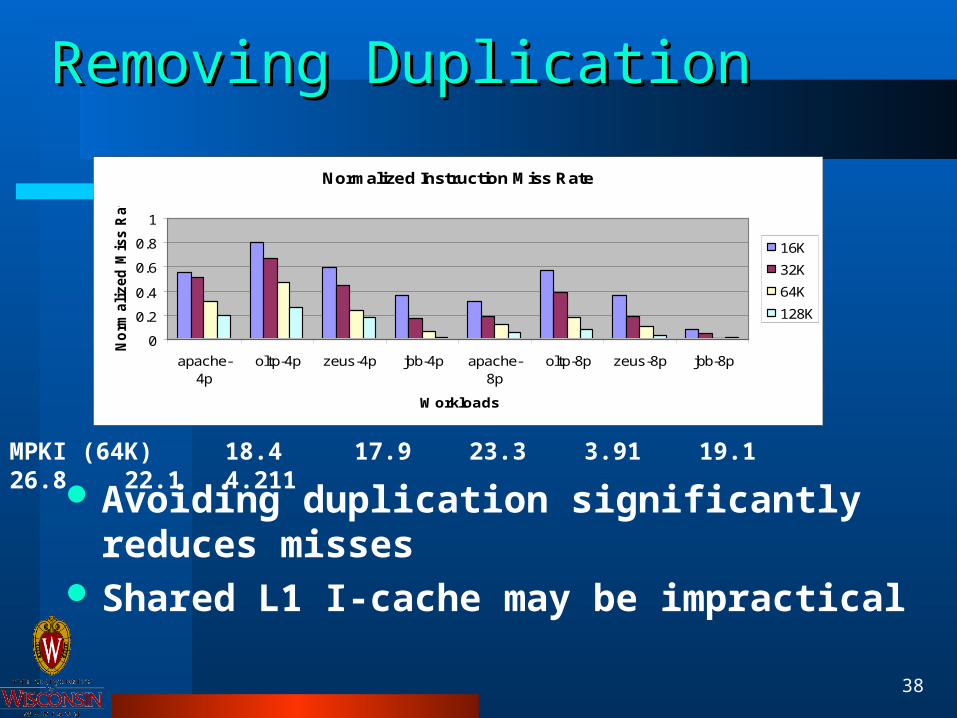
Removing DuplicationRemoving Duplication
Avoiding duplication significantly reduces misses
Shared L1 I-cache may be impractical
MPKI (64K) 18.4 17.9 23.3 3.91 19.1 26.8 22.1 4.211
Normalized Instruction Miss Rate
0
0.2
0.4
0.6
0.8
1
apache-4p
oltp-4p zeus-4p jbb-4p apache-8p
oltp-8p zeus-8p jbb-8p
Workloads
No
rmali
zed
Mis
s R
ate
16K
32K
64K
128K

39
Computation SpreadingComputation Spreading
Avoid reference spreading by distributing the computation based on code regions Each processor is responsible for a particular
region of code (for multiple threads) References to a particular code region is
localized Computation from one thread is carried out in
different processors

P1 P2 P3
A B’ C’’
B C’ A’’
C A’ B’’
P1 P2 P3
A B’ C’’
A’ B C’
A’’ B’’ C
T1 T2 T3
A
B
C
B’
C’
A’
C’’
A’’
B’’
Canonical Model Computation Spreading
Example
TIME

41
L1 cache performanceL1 cache performance
Significant reduction in instruction misses
Data Cache Performance is deteriorated Migration of computation disrupts locality of data reference
Normalized Data Miss Rates
00.51
1.52
2.53
3.54
Workloads
No
rmali
zed
Mis
s R
ate
s
16K
32K
64K
128K
Normalized Instruction Miss Rates
00.10.20.30.40.50.60.70.8
apach
e-4p
oltp-4p
zeus-4
pjbb
-4p
apach
e-8p
oltp-8p
zeus-8
pjbb
-8p
Workloads
No
rmal
ized
Mis
s R
ates
16K
32K
64K
128K

42
Data Memory HierarchyData Memory Hierarchy
Co-operative caching

43
Conventional CMP OrganizationsConventional CMP Organizations
P
L1I
L1D
L2
Interconnect Network
P
L1I
L1D
L2
P
L1I
L1D
L2
P
L1I
L1D
L2
……

44
Conventional CMP OrganizationsConventional CMP Organizations
P
L1I
L1D
Interconnect Network
P
L1I
L1D
P
L1I
L1D
P
L1I
L1D
……
Shared L2

45
A Spectrum of CMP Cache DesignsA Spectrum of CMP Cache DesignsSharedCaches
PrivateCaches
Configurable/malleable Caches(Liu et al. HPCA’04, Huh et al. ICS’05, etc)
Cooperative Caching
Unconstrained capacity sharing;Best capacity
No capacity sharing;
Best latency
Hybrid Schemes
(CMP-NUCA, Victim replication, CMP-NuRAPID, etc)
… …

46
CMP Cooperative CachingCMP Cooperative Caching
Basic idea: Private caches cooperatively form an aggregate global cache
Use private caches for fast access / isolation Share capacity through cooperation Mitigate interference via cooperation throttling
Inspired by cooperative file/web caches
PL1I L1D
L2
PL1IL1D
L2
L2 L2
L1I L1D L1IL1DP P

47
Reduction of Off-chip AccessesReduction of Off-chip Accesses
Trace-based simulation: 1MB L2 cache per core
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
OLTP Apache ECperf JBB Barnes Ocean Mix1 Mix2
C-Clean C-Singlet C-1Fwd Shared
Shared (LRU)Most reduction
C-Clean: good for commercial workloads
C-Singlet: Good for all benchmarks
C-1Fwd: good forheterogeneous workloads
3.21 11.63 5.53 1.67 0.50 5.97 15.84 5.28MPKI (private):
Red
uct
ion
of
off-
chip
acc
ess
rate

48
Cycles Spent on L1 MissesCycles Spent on L1 MissesTrace-based simulation: no miss overlapping
Latencies: 10 cycles Local L2; 30 cycles next L2, 40 cycles remote L2, 300 cycles off-chip accesses
PCFS PCFS PCFS PCFS PCFS PCFS PCFSOLTP Apache ECperf JBB Barnes Ocean Mix1 Mix2
PCFS
P:PrivateC:C-CleanF:C-1FwdS:Shared

49
SummarySummary
Start of a new wave of innovation to rethink parallelism and parallel architecture
New opportunities for innovation in CMPs New opportunities for parallelizing
applications Expect little resemblance between MPs today
and CMPs in 15 years We need to invent and define differences