spatial context learning 1 makovski &...
TRANSCRIPT

Spatial context learning Makovski & Jiang 1
[February 2011; In press, Quarterly Journal of Experimental Psychology]
Investigating the role of response in spatial context learning
Tal Makovski
Yuhong V. Jiang
Department of Psychology and Center for Cognitive Sciences, University of Minnesota
Keywords: contextual cueing, perception and action, visual search, touch response, eye
movement
Running title: Spatial context learning
Send correspondence to:
Tal Makovski
Department of Psychology
University of Minnesota
N218 Elliott Hall
Minneapolis, MN 55455
Email: [email protected]
Tel: 612-624-9483 Fax: 612-626-2079
Acknowledgements This study was supported in part by NIH 071788. We thank Khena Swallow and Ming
Bao for help with eye tracking, Ameante Lacoste, Birgit Fink, and Sarah Rudek for comments,
and Eric Bressler, Jacqueline Caston, and Jen Decker for help with data collection.
Correspondence should be sent to Tal Makovski, N218 Elliott Hall, Minneapolis, MN 55455.
Email: [email protected].

Spatial context learning Makovski & Jiang 2
Abstract Recent research has shown that simple motor actions, such as pointing or grasping, can
modulate the way we perceive and attend to our visual environment. Here we examine the role of
action in spatial context learning. Previous studies using keyboard responses have revealed that
people are faster locating a target on repeated visual search displays (“contextual cueing”).
However, this learning appears to depend on the task and response requirements. In Experiment
1, participants searched for a T-target among L-distractors, and responded either by pressing a
key or by touching the screen. Comparable contextual cueing was found in both response modes.
Moreover, learning transferred between keyboard and touch screen responses. Experiment 2
showed that learning occurred even for repeated displays that required no response and this
learning was as strong as learning for displays that required a response. Learning on no-response
trials cannot be accounted for by oculomotor responses, as learning was observed when eye
movements were discouraged (Experiment 3). We suggest that spatial context learning is
abstracted from motor actions.
Embedded (or “grounded”) cognition theories postulate that cognition should not be
studied independent of the body and environment that accommodates it (cf., Barsalou, 2008).
Instead, body states, motor actions, and their interactions with the environment all take part in
basic cognitive processes. This idea of a unified cognitive system, where an action is more than
the mere outcome of cognition (Song & Nakayama, 2009), also underlies the vision-for-action
hypothesis (Milner & Goodale, 2006). According to this hypothesis, the dorsal visual pathway,
commonly described as carrying “where” information, should be described as carrying “how”
information, as objects are represented in relation to the observer and to the actions directed to
them (Goodale & Milner, 1992). These theories suggest that vision is determined not only by the
visual input, but also by the motor output directed to it. Along a similar theoretical vein, the pre-
motor theory of attention (Rizzolatti, Riggio, Dascola, & Umilta, 1987) states that covert
attention is driven by the need to overtly direct a motor action to an object. In his review on
attention, Allport suggested that perceptual filtering of distractors is not the main function of
attention. Rather, people selectively attend to targets to ensure that a successful response is made
to them (Allport, 1989).
That perception and attention are affected by whether or not an action is carried out raises
the possibility that learning and memory may be modulated by motor actions as well. Indeed, a
few findings indicate that this may be the case. In research on the production effect, memory for
words spoken out loud is enhanced relative to memory for words read silently (MacLeod, Gopie,
Hourihan, Neary & Ozubko, 2010). In addition, it has been shown that negative adjectives were
remembered better when participants shook their heads during encoding, and positive adjectives
were remembered better when participants nodded their heads during encoding (Forster & Stark,
1996). Even a simple motor action can influence cognition as shapes presented after a “go”
response were considered more pleasant than shapes presented after a “no-go” response
(Buttaccio & Hahn, 2010). In the present study we further examine the interaction between
vision and action. In particular, we test how overt motor action made toward a search target
modulates contextual learning between the target and its surrounding spatial context (Chun &
Jiang, 1998).

Spatial context learning Makovski & Jiang 3
The role of action in visual learning People are highly efficient at extracting regularities embedded in the environment.
Learning is revealed for many aspects of the environment, including repeated spatial layout
(Chun & Jiang, 1998), motion trajectories (Chun & Jiang, 1999; Makovski, Vázquez, & Jiang,
2008), target locations (Miller, 1988; Umemoto, Scolari, Vogel, & Awh, 2010), visual or
movement sequences (Nissen & Bullemer, 1987; Swallow & Zacks, 2008), and object-to-object
associations (Fiser & Aslin, 2002; Turk-Browne, Junge, & Scholl, 2005).
For at least some types of visual statistical learning, making an overt motor response is
not necessary. For example, consistent association between objects can be learned when
observers are simply asked to look at a series of shapes (Fiser & Aslin, 2002). In other types of
learning, however, motor response appears to be an integral component, as shown in the Serial
Reaction Time task (SRT, Nissen & Bullemer, 1987). In this task, participants press one of
several keys to report the corresponding position of a stimulus on the screen. Unbeknown to
them, the positions of the stimulus over several trials sometimes form a repeated sequence (e.g.,
positions 12432431…12432431…). Participants usually respond faster to repeated sequences
than unrepeated one, even in situations where they are unaware of the repetition (Nissen &
Bullemer, 1987). Although participants can learn the motor sequence of finger movements
independent of the perceptual sequence of stimulus on the screen (Willingham, 1999), or the
perceptual sequence on the screen independent of the motor sequence (Remillard, 2003), co-
varying the motor and perceptual sequences may facilitate learning of complex sequences
(Dennis, Howard & Howard, 2006). Ziessler and Nattkemper (2001) suggest that response-to-
stimulus association governs learning in the SRT task. Specifically, in line with the notion of
response-effect learning (e.g., Hommel, Müsseler, Aschersleben & Prinz, 2001), participants
learn to predict the upcoming stimulus based on their current response.
Unlike the SRT task, spatial context learning in visual search does not involve predictive
association between a repeated display and a motor response, or between a motor response and
the next display. In this task, participants are asked to press a key to report the orientation of a T-
target embedded among L-distractors. Unbeknown to them, some search displays are repeated in
the experiment, presenting consistent associations between the spatial layout of the search
display and the target’s location (Chun & Jiang, 1998). However, the target’s orientation, and
hence the associated key press, is randomized, preventing participants from associating a
repeated display with a specific response. Nonetheless, participants are often faster searching
from repeated displays than from new ones, revealing “contextual cueing” (Brady & Chun, 2007;
Chun & Jiang, 1998; Kunar, Flusberg, Horowitz & Wolfe, 2007).
Although learning in contextual cueing cannot be attributed to the acquisition of
consistent stimulus-response association, there is indirect evidence that this type of learning is
not fully abstracted from the task and responses that participants made. First, when the same
spatial displays are used for either a change-detection or a visual search task, learning does not
fully transfer between the two tasks (Jiang & Song, 2005). Second, whereas young children (6-
13 years old) fail to show contextual cueing when making a keyboard response to the target’s
orientation (Vaidya, Huger, Howard, & Howard, 2007), they do show robust learning when they
simply touch the target’s location on a touch screen (Dixon, Zelazo, & De Rosa, 2010). Although
these two studies differ in several aspects (e.g., whether the search stimuli were fish or letters), it
is possible that some types of motor response promote greater learning than other types.
Specifically, touching a target on the screen involves a task-relevant, viewer-centered spatial
component that is absent in a keypress task. Moreover, touching a screen may facilitate learning

Spatial context learning Makovski & Jiang 4
because vision is superior near the hands (Abrams, Davoli, Du, Knapp & Paull, 2008). Therefore
visual learning may be enhanced when the hands are positioned near the screen than near the
keyboard. Third, the representation of spatial context is viewpoint specific, as contextual cueing
acquired from a virtual 3-D search display does not transfer after a 30º change in viewpoint
(Chua & Chun, 2003). The viewpoint-dependent characteristic suggests that what is learned in
contextual cueing may depend on the viewer’s perspective and goals toward the target. Finally,
in adults, whereas successful detection of a target leads to learning of the search display, learning
is absent when search is interrupted before the target is detected and a response is made (Shen &
Jiang, 2006).
The studies reviewed above suggest that statistical regularity alone is insufficient to fully
account for what is learned in contextual cueing. It is possible that making an action toward the
target is an integral part of the learning. Furthermore, making a detection response, as opposed to
no response, constitutes a change in the participant’s current activity, and this change may trigger
a re-checking or updating process that enhances the learning and memory of concurrently
presented visual information (Swallow & Jiang, 2010, 2011; Swallow, Zacks, & Abrams, 2009).
The main purpose of this study is to directly evaluate the role of motor actions in spatial
context learning. We test whether learning is specific to the kind of motor responses made to the
targets (keyboard vs. touch-screen response), and whether withholding a response to targets
hinders learning.
Experiment 1 Experiment 1 investigated the specificity of contextual cueing to different response
modes toward the search target. The ideomotor principle (cf. Stock & Stock, 2004) states that
movements are associated with their contingent sensory effects. Consistent with this principle,
Hommel and colleagues proposed that an action is automatically associated with all active event
codes to form an associative structure (action-effect binding; e.g., Elsner & Hommel, 2001;
Hommel, Alonso & Fuentes, 2006; Hommel et al., 2001). If action codes are integrated with
perceptual representation in spatial context learning, then contextual cueing acquired in one
response mode may not readily transfer to tasks involving a different response mode.
Alternatively, contextual cueing may be largely abstracted from the action made to the targets. If
this is the case, then it should transfer between different response modes.
To address this issue, in Experiment 1 we first tested whether spatial context learning was
affected by response modes. During training, all participants completed a touch–screen version
and a keyboard version of the standard contextual cueing task in separate sessions. We examined
whether contextual cueing was greater in the touch task than in the keypress task. After the
training session, we tested whether learning acquired from touch transferred to keypress and vice
versa.
Method
Participants: All participants were students from the University of Minnesota. They were
18 to 35 years old and had normal color vision and normal or corrected-to-normal visual acuity.
Twelve participants (mean age 19.4 years; 5 males) completed Experiment 1.

Spatial context learning Makovski & Jiang 5
Equipment: Participants were tested individually in a normally lit room and sat
unrestricted at about 55 cm from a 15” ELO touch screen monitor (resolution: 1024x768 pixels;
refresh rate: 75Hz). The experiment was programmed with psychophysics toolbox (Brainard,
1997; Pelli, 1997) implemented in MATLAB (www.mathworks.com).
Stimuli: The search items were white T and Ls (1.75° X 1.75°) presented against a black
background. Participants searched for a T rotated 90° to the right or to the left. The orientation
of the T was randomly selected provided that there were equal numbers of left and right Ts in
each condition of each block. Eleven L-shaped stimuli served as distractors. They were rotated in
one of the four cardinal orientations (the offset at the junction of the two L segments was
0.175°). All items were positioned in an imaginary 8 by 6 matrix (28° X 21°) and the position of
each item was slightly off the center of a cell to reduce co-linearity between items.
Touch task: In the touch task, participants initiated each trial by touching a small white
fixation point (0.42° X 0.42°) at the bottom of the screen. Then the search display appeared and
remained until participants touched the target’s position (Figure 1 Left). Responses falling within
an imaginary square (1.05 º X 1.05 º) surrounding the center of the target were considered
correct. Each incorrect response was followed by a red minus sign for 2000 ms.
Press task: In the keypress task, each trial started with a small white fixation point (0.42°
X 0.42°) appearing at the bottom of the screen for 500 ms, followed by the search array (Figure 1
Left). To make the keypress task similar to the touch task in terms of task requirement (detecting
the T), participants were asked to press the spacebar as soon as they detected the target. The time
from the search display onset to the spacebar response was taken as the search RT. To make
sure that participants had accurately located the target, we erased the display upon the spacebar
response and asked participants to report whether the T was rotated to the left (by pressing the
‘N’ key) or to the right (by pressing the ‘M’ key). The second response was unspeeded and
provided us with an accuracy measure. Each incorrect response was followed by a red minus
sign for 2000 ms.
Training:
press
(touch)
L
TL
L
L
L
L
L
L
L
L
L
L
L
T
L
L
L
L
L L
L
L
L
L
L
new
Block N
Old
L
T
L
L
L
L
L
L
L
L
L
L
L
new
Block N+1
Old
L
T
L
L
L
L
L
L
L
L
L
L
L
new
Block M
Old
L
T
L
L
L
L
L
L
L
L
L
L
L
..
.
..
.
..
.
L
T
L
L
L
L
L
LL
L
LL
L
Testing:
touch
(press)
Figure 1. Left: A schematic illustration of trial sequences used in the press and touch tasks of
Experiment 1. Right: A schematic illustration of old and new conditions. Items are not drawn to
scale.
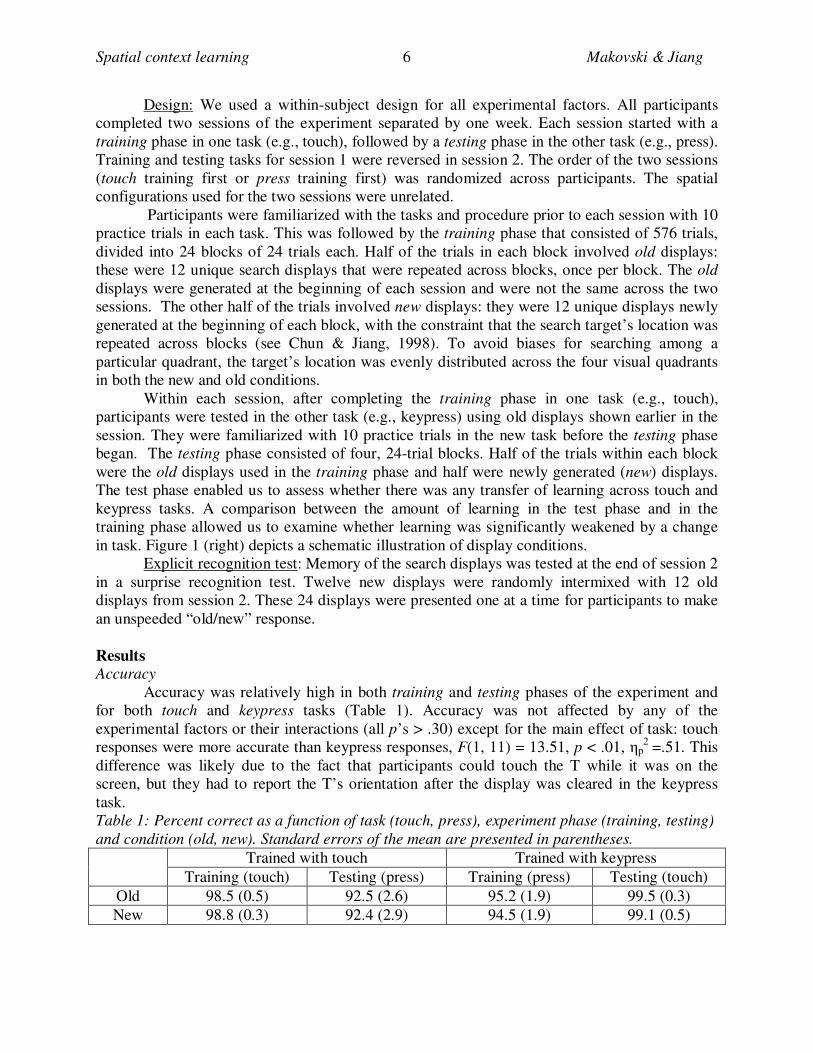
Spatial context learning Makovski & Jiang 6
Design: We used a within-subject design for all experimental factors. All participants
completed two sessions of the experiment separated by one week. Each session started with a
training phase in one task (e.g., touch), followed by a testing phase in the other task (e.g., press).
Training and testing tasks for session 1 were reversed in session 2. The order of the two sessions
(touch training first or press training first) was randomized across participants. The spatial
configurations used for the two sessions were unrelated.
Participants were familiarized with the tasks and procedure prior to each session with 10
practice trials in each task. This was followed by the training phase that consisted of 576 trials,
divided into 24 blocks of 24 trials each. Half of the trials in each block involved old displays:
these were 12 unique search displays that were repeated across blocks, once per block. The old
displays were generated at the beginning of each session and were not the same across the two
sessions. The other half of the trials involved new displays: they were 12 unique displays newly
generated at the beginning of each block, with the constraint that the search target’s location was
repeated across blocks (see Chun & Jiang, 1998). To avoid biases for searching among a
particular quadrant, the target’s location was evenly distributed across the four visual quadrants
in both the new and old conditions.
Within each session, after completing the training phase in one task (e.g., touch),
participants were tested in the other task (e.g., keypress) using old displays shown earlier in the
session. They were familiarized with 10 practice trials in the new task before the testing phase
began. The testing phase consisted of four, 24-trial blocks. Half of the trials within each block
were the old displays used in the training phase and half were newly generated (new) displays.
The test phase enabled us to assess whether there was any transfer of learning across touch and
keypress tasks. A comparison between the amount of learning in the test phase and in the
training phase allowed us to examine whether learning was significantly weakened by a change
in task. Figure 1 (right) depicts a schematic illustration of display conditions.
Explicit recognition test: Memory of the search displays was tested at the end of session 2
in a surprise recognition test. Twelve new displays were randomly intermixed with 12 old
displays from session 2. These 24 displays were presented one at a time for participants to make
an unspeeded “old/new” response.
Results Accuracy
Accuracy was relatively high in both training and testing phases of the experiment and
for both touch and keypress tasks (Table 1). Accuracy was not affected by any of the
experimental factors or their interactions (all p’s > .30) except for the main effect of task: touch
responses were more accurate than keypress responses, F(1, 11) = 13.51, p < .01, ηp2
=.51. This
difference was likely due to the fact that participants could touch the T while it was on the
screen, but they had to report the T’s orientation after the display was cleared in the keypress
task.
Table 1: Percent correct as a function of task (touch, press), experiment phase (training, testing)
and condition (old, new). Standard errors of the mean are presented in parentheses.
Trained with touch Trained with keypress
Training (touch) Testing (press) Training (press) Testing (touch)
Old 98.5 (0.5) 92.5 (2.6) 95.2 (1.9) 99.5 (0.3)
New 98.8 (0.3) 92.4 (2.9) 94.5 (1.9) 99.1 (0.5)
Spatial context learning Makovski & Jiang 7
RT
In the RT analysis, we excluded incorrect trials as well as trials exceeding three standard
deviations of each participant’s mean of each condition. This RT outlier cutoff removed 1.5% of
the correct trials.
1. Training phase
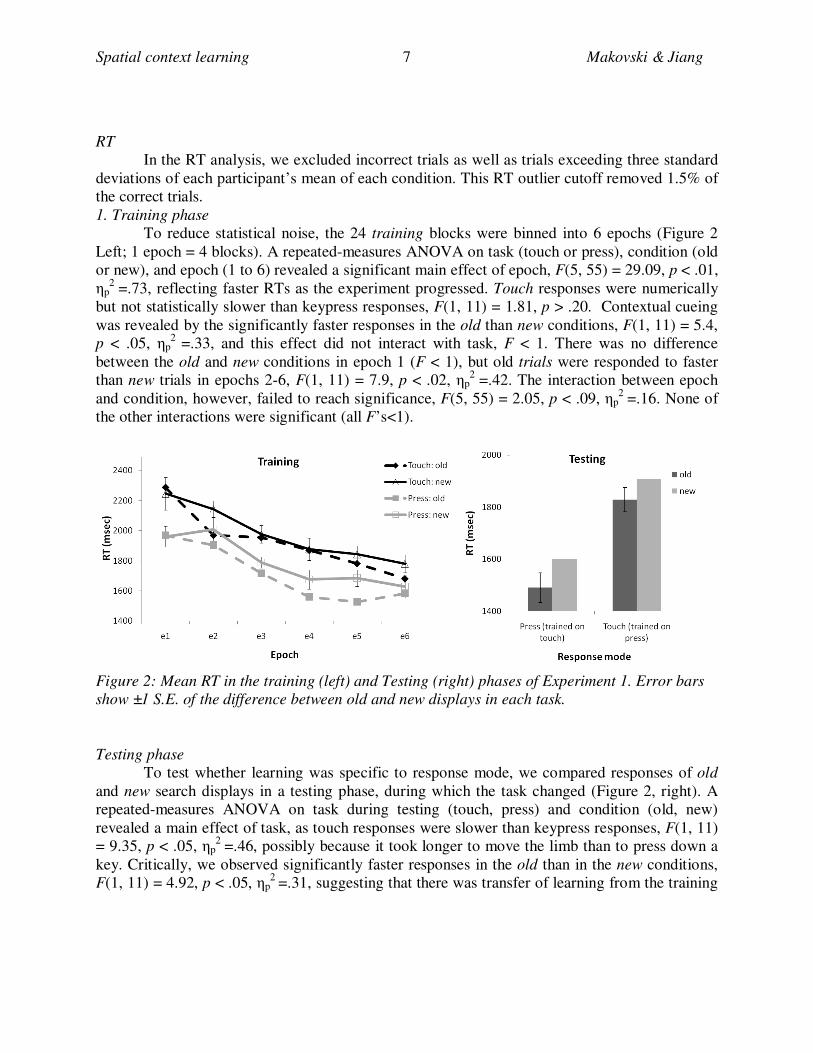
To reduce statistical noise, the 24 training blocks were binned into 6 epochs (Figure 2
Left; 1 epoch = 4 blocks). A repeated-measures ANOVA on task (touch or press), condition (old
or new), and epoch (1 to 6) revealed a significant main effect of epoch, F(5, 55) = 29.09, p < .01,
ηp2
=.73, reflecting faster RTs as the experiment progressed. Touch responses were numerically
but not statistically slower than keypress responses, F(1, 11) = 1.81, p > .20. Contextual cueing
was revealed by the significantly faster responses in the old than new conditions, F(1, 11) = 5.4,
p < .05, ηp2
=.33, and this effect did not interact with task, F < 1. There was no difference
between the old and new conditions in epoch 1 (F < 1), but old trials were responded to faster
than new trials in epochs 2-6, F(1, 11) = 7.9, p < .02, ηp2
=.42. The interaction between epoch
and condition, however, failed to reach significance, F(5, 55) = 2.05, p < .09, ηp2
=.16. None of
the other interactions were significant (all F’s<1).
Figure 2: Mean RT in the training (left) and Testing (right) phases of Experiment 1. Error bars
show ±1 S.E. of the difference between old and new displays in each task.
Testing phase
To test whether learning was specific to response mode, we compared responses of old
and new search displays in a testing phase, during which the task changed (Figure 2, right). A
repeated-measures ANOVA on task during testing (touch, press) and condition (old, new)
revealed a main effect of task, as touch responses were slower than keypress responses, F(1, 11)
= 9.35, p < .05, ηp2
=.46, possibly because it took longer to move the limb than to press down a
key. Critically, we observed significantly faster responses in the old than in the new conditions,
F(1, 11) = 4.92, p < .05, ηp2
=.31, suggesting that there was transfer of learning from the training

Spatial context learning Makovski & Jiang 8
to the testing phase. This transfer was observed from touch to press and vice versa, as the
interaction between task and condition was not significant, F < 1 [footnote1].
Was contextual cueing during the testing phase comparable to that shown in the training
phase? To answer this question, we compared the testing phase with the second half of the
training phase of that session. We calculated contextual cueing (new-old RT) and examined the
effects of phase (training vs. testing) and task (touch vs. press). An ANOVA revealed no
significant effects of phase, task, or their interaction, all F’s < 1. This suggests that contextual
cueing in the testing phase was comparable to that in the training phase, regardless of whether
subjects were trained in the touch task or the keypress task.
Explicit recognition
Participants were equally likely to identify a display as “old” when it was an old display
(M= 55.6%, S.E. = 4.1) as when it was a new display (M= 56.3%, S.E. = 4.6), F < 1, suggesting
that learning was largely implicit (Chun & Jiang, 2003; Reber, 1989).
Discussion
Experiment 1 addressed the possibility that response codes are incorporated in contextual
cueing. The results from the training phase revealed that learning was unaffected by the type of
responses made to the target: Search was faster in the old condition than in the new condition
regardless of whether the task was to touch the screen or to press a key. This finding rebuts the
idea that a touch-screen task that inherently involves a task-relevant, viewer-centered spatial
component, promotes learning more than a distal keyboard task. Furthermore, learning readily
transferred between response types, providing no evidence for the idea that response codes may
be incorporated in contextual cueing.
Previous studies on young children have found a discrepancy between touch screen
responses and keyboard responses in contextual cueing. A study that used touch screen response
revealed a significant contextual cueing effect in 5-9 year olds (Dixon et al., 2009), whereas one
that used keyboard response did not find significant learning in 6-13 year olds (Vaidya et al.,
2007). Although response type may have contributed to the discrepancy, other factors may also
be important. For example, children might have found the search items in Dixon et al.’s study
(fish) more interesting than in Vaidya et al.’s study (letters). In addition, new displays were
randomly intermixed with old displays during training in Vaidya et al.’s study, whereas only old
displays were shown during training in Dixon et al.’s study. These differences could make it
more difficult for children to acquire contextual cueing in Vaidya et al.’s study. Experiment 1 of
the current study used a within-subject design and similar stimuli and task requirements between
the two response types. This design revealed that contextual cueing was largely independent of
the format of responses to the target.
Experiment 2 Experiment 1 showed that spatial context learning is not specific to particular types of
response: learning transferred between touch and keypress responses toward the target. In both
1 Given that RT was faster in the press task than in the touch task there was a concern that any interaction between
response mode and learning was masked by this overall latency difference. To address this concern, we calculated a
normalized index of contextual cueing as (RT(new)-RT(old))/mean (RT(new)+RT(old)).The normalized learning
index also failed to reveal an effect of response mode on contextual cueing in either the training phase or the testing
phase (F’s<1).

Spatial context learning Makovski & Jiang 9
tasks, however, participants made a speeded response upon target detection. Thus, it remains
unclear as whether learning is contingent on making a response to the target. Previous
neuroscience research has shown that responding to targets changes brain activity. For example,
when monkeys pressed a lever upon detecting a vertical bar target, neurons in Locus Coeruleus
(LC) transiently increased their activity (Aston-Jones, Rajkowski, Kubiak, & Alexinsky, 1994).
In humans, target detection leads to increased activity in parietal and dorsolateral prefrontal
regions (Beck, Rees, Frith, & Lavie, 2001) and early visual areas (Ress & Heeger, 2003).
Behavior studies have shown that secondary materials presented concurrently with a target
response are better remembered and learned than those presented with distractors (Makovski,
Swallow, & Jiang, 2011; Seitz & Watanabe, 2003; Swallow & Jiang, 2010, 2011). Although
these brain responses and behavioral gains may be induced by target detection independent of the
responses made to the targets, it is also possible that they are partly driven by the response.
Indeed, the LC response was time locked to the animal’s response rather than to stimulus onset
(Clayton, Rajkowski, Cohen, & Aston-Jones, 2004). In addition, shapes presented concurrently
or immediately after a “no-go” response were judged less pleasant than shapes presented with or
after a “go” response (Buttaccio & Hahn, 2010). If producing a motor response to targets
modifies the encoding and memory of a visual display, then contextual cueing may depend on
making a response, even though the specific mode of response (touch or press) does not matter.
The other possibility is that contextual cueing is largely abstracted from motor actions: learning
is independent of whether participants have responded to the search target. Experiment 2
examines the role of response by comparing the magnitude of contextual cueing between
displays that received a response and displays that did not receive a response. Experiment 3 tests
the same question under conditions where eye movements are discouraged.
In Experiment 2, we asked participants to search for a T among Ls and to press the
spacebar if the T was titled to the left (“response” trials), and withhold response if the T was
tilted to the right (“no-response” trials). This compound search task (Duncan, 1985) required
participants to detect and attend to the T on both types of trials, but only respond to the T on the
response trials. If detecting targets is sufficient for contextual learning, then contextual cueing
should be comparable between the response and no-response conditions. In contrast, overt
response to the target may facilitate learning by triggering a re-checking or updating process
(analogous to that induced by segmenting events, Swallow et al., 2009). In addition, the need to
withhold a response may result in inhibition of learning (Buttaccio & Hahn, 2010), reducing the
learning of no-response displays, and possibly leading to negative transfer when participants
need to respond to these displays again.
Method
Participants: Nineteen new participants (mean age 21.1 years; 6 males) completed
Experiment 2.
Equipment and stimuli: The equipment and stimuli were identical to the ones used in
Experiment 1 except that a 17” CRT monitor replaced the touch screen. Additionally, in the
training phase, the T-item was rotated by 15°, 30° or 45° to the right or to the left, while the L-

Spatial context learning Makovski & Jiang 10
shaped distractors were randomly rotated (0° to 345° in steps of 15°) [footnote2]. In the testing
phase, the T was always vertical and the L-shaped distractors were randomly rotated in one of
the four cardinal orientations. There was no offset between the two segments of the L-shaped
distractors.
Training phase, compound search task: The training phase consisted of a compound
search task in which participants were asked to find the T and identify its orientation. The task
was to press the spacebar only when the T was rotated to the right (for half of the participants; or
left, for the other half). Each trial started with a small white fixation point (0.42° X 0.42°) at the
center of the screen for 500 ms, followed by the search array. To ensure that participants
attended to the search display for the same amount of time on the “response” and “no-response”
trials, the search array was presented for a fixed amount of time - 500 ms.
The search array was followed by a blank interval of 1000 ms (Figure 3, top).
Participants were instructed to find the T and to press the spacebar on “response” trials.
Responses made within 1500 ms from the onset of the search display were recorded. After this
time window, accuracy feedback (a green plus or a red minus) was displayed for 400 ms.
Testing phase, simple search task: The purpose of the testing phase was to assess whether
learning had occurred for “response” and “no response” trials. This was done by measuring
search RTs on the two types of old displays learned under either response or no-response
conditions, and comparing them with RT to the new displays. In the testing phase of the
experiment, each trial started with a small white fixation point (0.42° X 0.42°) for 500 ms. Then
the search display appeared. Participants searched for the T, which was present on every trial,
and pressed the spacebar upon detection. The time from the onset of the search display to the
spacebar response was used for RT analysis. After the response, all items turned into random
digits (1-6) and participants entered the digit that occupied the target’s location (Figure 3,
bottom). A green plus followed correct responses (400 ms) and a red minus followed incorrect
responses (2000 ms).
2 We used three possible angles in each orientation to minimize the possibility that observers would use a single
memory template for search, such as 45º-left tilted T. In debriefing, all participants confirmed that their strategy was
to first find the T and only then to determine its orientation.

Spatial context learning Makovski & Jiang 11
500ms
500ms
A. Training: Press only if the T is tilted to the left (right)
500ms
Until response
L
L
L
L L
L
L
T
L
L
L
L
Until response
B. Testing: Find the T
L
L
L
L L
L
L
T
L
L
L
L
1000ms
Figure 3. Trial’s sequence in the training (top) and testing (bottom) phases of Experiment 2.
Design: Participants were familiarized with the compound-search task in 40 practice
trials. Then, in the training phase, they completed 20 blocks of 32 trials of the compound-search
task. The 32 trials of each block were unique displays that were presented once per block, in a
random order. For each participant 16 displays were associated with a response (old-response)
and 16 displays were associated with no response (old-no-response), and this was repeated
across blocks. We did not include new displays because learning could not be assessed during
training for the old-no-response trials. After completing the training phase, participants did a
short practice block of 5 simple search trials before the testing phase began.
The testing phase consisted of four, 48-trial blocks of the simple search task. The search
displays were the 16 old-response and 16 old-no-response displays from the training phase,
randomly intermixed with 16 new displays. We asked subjects to respond to all types of displays
to obtain an RT measure, but the displays differed in the way they were learned previously. All
displays were presented again for 3 additional blocks in the testing phase to increase statistical
power. Finally, to control for the repetition of target locations, the same 16 target locations were
used in all 3 conditions (old-no-response, old –response, new).
Explicit recognition test: Participants’ explicit memory was tested at the end of the
experiment in a surprise recognition test. There were 64 trials. Participants were asked to decide
whether they have seen each display in the main experiment. The 64 displays consisted of the 16

Spatial context learning Makovski & Jiang 12
displays in each of the three conditions shown in the testing session (old-no-response, old –
response, new) randomly intermixed with 16 additional novel displays.
Results
Training phase
Data from three participants were excluded because their false alarm rate on no-response
trials in the training phase was higher than 35%, whereas the average false alarm rate of the
remaining sixteen participants was 10.7% (S.E. = 1.1). Participants correctly executed a response
on 83.3% (S.E. = 1.6) of the response trials, with a mean RT of 737 ms (S.E. = 13.5). Figure 4A
shows mean RT for detecting the target on response trials, and overall accuracy as a function of
training epoch (1 epoch = 4 blocks).
Testing phase: Accuracy
Accuracy in the testing phase was not affected by display type: 97.8% for the old-no-
response condition, 97.5% for the old-response condition, and 96.5% for the new condition, F(2,
30) = 1.66, p > .2. In the RT analysis, we excluded incorrect trials as well as trials exceeding
three standard deviations of each participant’s mean of each condition. The latter cutoff
eliminated 1.2% of the correct trials.
Testing phase: RT
Figure 4B shows RT in the testing phase of the experiment. A repeated-measures
ANOVA found a significant effect of condition, F(2, 30) = 4.1, p < .05, ηp2
=.22. Planned
contrasts showed that whereas the old-no-response and old-response conditions were not
significantly different (p > .72), they were both significantly faster than the new condition, t(15)
= 2.30, p < .05 for new vs. old-response; t(15) = 2.60, p < .05 for new vs. old-no-response. This
finding suggests that the omission of a target detection response during training was not
detrimental to spatial context learning.
0.5
0.6
0.7
0.8
0.9
1
1 2 3 4 5
Pro
po
rtio
n c
orr
ect
Epoch
600
660
720
780
840
RT
"h
its"
(m
s)
700
740
780
820
old-no-response old-response new
RT
(m
s)
Display type
A: Training B: Testing

Spatial context learning Makovski & Jiang 13
Figure 4: Left: Mean RT for hit responses (top) and overall proportion correct (bottom) in the
training phase of Experiment 2. Right: Mean RT in the testing phase of Experiment 2 . Error
bars show ±1 S.E.
Explicit recognition
In the recognition task, participants committed high false alarm rates for the new (59%)
and novel (54.3%) conditions, which were similar to the hit rates for the old-no-response
(53.1%) and the old-response conditions (57%), F < 1. These findings confirm that learning was
largely implicit for old displays that received a response and for those that received no response.
Discussion Experiment 2 showed that contextual cueing did not depend on making an overt motor
response to the search targets. Search displays that did not receive a motor response were learned
to the same extent as search displays that received a response. We found no evidence that
refraining from responding to the target reduced learning or produced inhibition. This finding
provides further evidence that spatial context learning is abstracted from responses. Not only is it
invariant to two different response modes to the target (touch or press, Experiment 1), but it is
also comparable for displays involving a detection response and ones where a response was
omitted. The advantages afforded by target detection observed in previous behavioral and
neuroscience studies (e.g., Aston-Jones et al., 1994; Swallow & Jiang, 2010, 2011) are likely
triggered by detecting the target, rather than making an overt motor response to it.
Experiment 3
The results have clearly shown that neither the need nor the nature of making a manual
response has an effect on spatial context learning. Before we can conclude that overt motor
action is not critical for such learning, we need to consider the role of oculomotor responses.
Previous research has shown that spatial context learning not only results in faster manual
response at detecting the target, but also faster eye movement towards the target (Peterson &
Kramer, 2001). Even though contextual cueing was observed when the search display was too
brief for eye movements (Chun & Jiang, 1998), this finding was observed when subjects made a
manual detection response to the target. Experiment 2 had revealed contextual cueing in the
absence of a manual detection response, however, subjects may have made saccadic eye
movements toward the target [footnote 3]3. To address whether contextual cueing depends on
any type of motor response, Experiment 3 repeated Experiment 2’s design under conditions
where eye movements were prevented or discouraged. In Experiment 3a participants were
discouraged from making any eye movements, and compliance with this requirement was
checked with the use of an eye tracker. In Experiment 3b the search display was briefly
presented for 150 ms, a duration long enough for shifting covert attention but shorter than a
typical saccade latency (Nakayama& Mackeben, 1989). If overt motor response is a critical
component of spatial context learning, then in the absence of eye movements or manual
responses, contextual cueing should be eliminated.
3 We thank Dr. Dominic Dwyer and an anonymous reviewer for raising this possibility.

Spatial context learning Makovski & Jiang 14
Experiment 3a
Method
Participants: Performing a search task for a long time without moving their eyes turned
out to be difficult for naïve subjects. Only eight (out of 14) participants (mean age 23.8 years; 6
males) were able to complete Experiment 3a.
Equipment, stimuli, procedure and design: The main novelty of this experiment was the
use of an ISCAN ETL-300LR eye-tracker to ensure fixation. A chinrest was used to fixate head
position at a viewing distance of 75 cm (thereby the perceived size of the stimuli was reduced by
~17%). Participants were told to fixate their gaze at the white fixation point (0.35° X 0.35°) that
remained on the screen throughout a trial. A trial would not start until participants had fixated
within a 1.04° X 1.04° imaginary box surrounding the center, for at least 60% of the preceding
500 ms sliding time window. The same criterion – fixating within the 1.04º fixation box for at
least 60% of a sliding 500 ms time window – was used to indicate whether fixation had been
broken during a trial, and was based on the notion that subjects would not be able to execute a
saccade towards the target without being detected. Violating this stringent criterion would
trigger a warning message (“you moved your eyes in the last trial!”) 500 ms after the accuracy
feedback. Compliance with the eye fixation requirement was checked during both training and
testing phases and a 15-30 minutes practice for maintaining fixation was given prior to the start
of the experiment. We did not administer the explicit recognition test. In all other respects the
experiment was identical to Experiment 2.
Results
Training phase
Except for one subject who broke fixation on 65% of the trials in the training phase, the
averaged fixation breaks was 28.9% (S.E. =4.8). Fixation breaks were more frequent on no-
response trials (38.4%) than on response trials (28.4%) probably because these trials lasted
longer, providing participants more opportunities to break fixations.
The average false alarm rate was 11.3% (S.E. = 2.5) and participants correctly executed a
response on 79.5% (S.E. = 2.0) of the response trials, with a mean RT of 792 ms (S.E. = 21.5)
Testing phase: Accuracy
Accuracy in the testing phase was not affected by display type: 94.3% for the old-no-
response condition, 92.8% for the old-response condition, and 93.6% for the new condition, F<1.
In the RT analysis, we excluded incorrect trials as well as trials exceeding three standard
deviations of each participant’s mean of each condition (2.5% of the correct trials).
Testing phase: RT
Figure 5a shows RT in the testing phase of the experiment. A repeated-measures
ANOVA revealed a significant effect of condition, F(2, 14) = 5.4, p < .02, ηp2
=.44. Planned
contrasts replicated the previous findings: Whereas the old-no-response and old-response
conditions were not significantly different (p > .79), they were both significantly faster than the
new condition, p’s<.02. This pattern of results held when we excluded trials where fixation was
broken during testing (42.8%).
It is important to note that a fixation break (according to the stringent criterion we used)
does not necessarily mean that subjects moved their eyes towards the target. Instead, it could
have resulted from measurement noise or small gaze fluctuations. To confirm that fixation
breaks were not associated with eye movements and learning we measured contextual cueing for
individual displays. This analysis showed that the amount of fixation breaks during training did
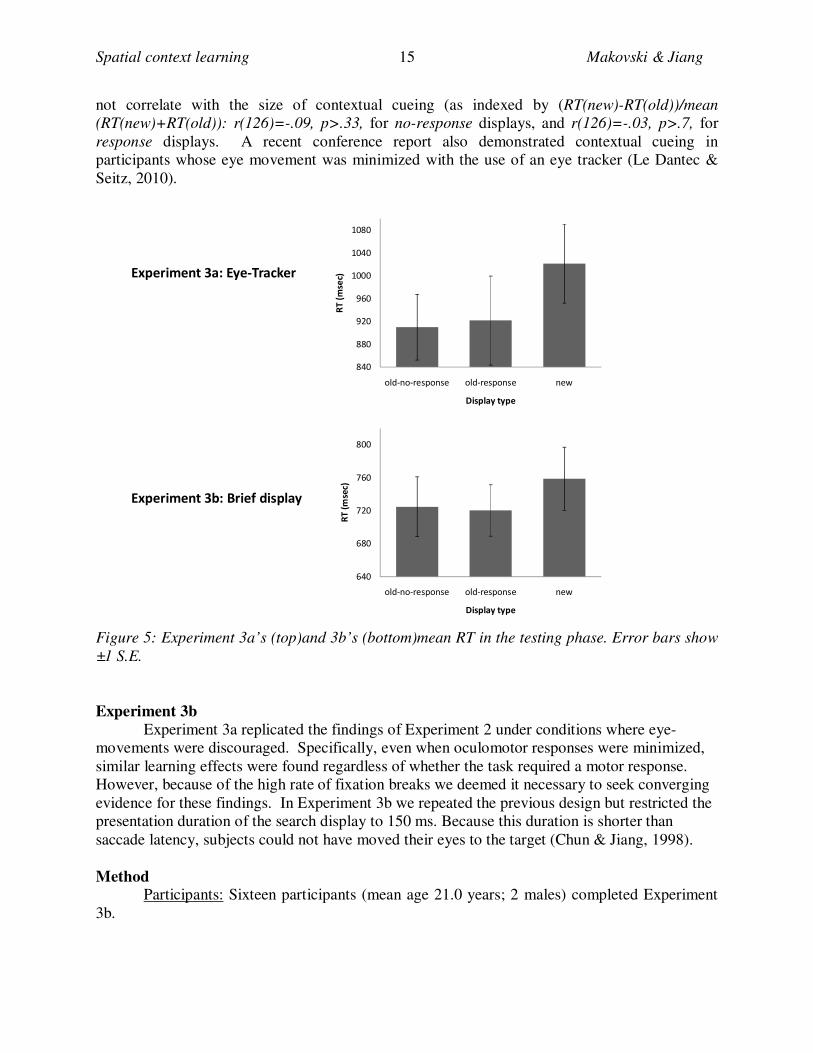
Spatial context learning Makovski & Jiang 15
not correlate with the size of contextual cueing (as indexed by (RT(new)-RT(old))/mean
(RT(new)+RT(old)): r(126)=-.09, p>.33, for no-response displays, and r(126)=-.03, p>.7, for
response displays. A recent conference report also demonstrated contextual cueing in
participants whose eye movement was minimized with the use of an eye tracker (Le Dantec &
Seitz, 2010).
640
680
720
760
800
old-no-response old-response new
RT
(m
sec)
Display type
840
880
920
960
1000
1040
1080
old-no-response old-response new
RT
(m
sec)
Display type
Experiment 3b: Brief display
Experiment 3a: Eye-Tracker
Figure 5: Experiment 3a’s (top)and 3b’s (bottom)mean RT in the testing phase. Error bars show
±1 S.E.
Experiment 3b
Experiment 3a replicated the findings of Experiment 2 under conditions where eye-
movements were discouraged. Specifically, even when oculomotor responses were minimized,
similar learning effects were found regardless of whether the task required a motor response.
However, because of the high rate of fixation breaks we deemed it necessary to seek converging
evidence for these findings. In Experiment 3b we repeated the previous design but restricted the
presentation duration of the search display to 150 ms. Because this duration is shorter than
saccade latency, subjects could not have moved their eyes to the target (Chun & Jiang, 1998).
Method Participants: Sixteen participants (mean age 21.0 years; 2 males) completed Experiment
3b.

Spatial context learning Makovski & Jiang 16
Equipment, stimuli, procedure and design: The main change to Experiment 3b was to
reduce the presentation duration of the training phase from 500 ms to 150 ms. A pilot study
showed that the target-detection task used in Experiment 2 was too difficult when the display
was presented briefly. We therefore simplified the search task by lowering set size from 12 to 8.
We also increased the difference between the target T and distractor Ls (the items were now
elongated to 1.75ºx1.28º) and simplified the T and Ls (the T-item was rotated by 15° to the right
or to the left, while the L-shaped distractors were randomly rotated in one of the four cardinal
orientations). Finally we asked participants to fixate their gaze at the white fixation point (0.42°
X 0.42°) that remained on the screen throughout a trial. We did not use an eye tracker, neither
did we administer the explicit recognition test. In all other respects the experiment was identical
to Experiment 2.
Results Training phase
The average false alarm on no-response trials was 8.7% (S.E. = 1.1). Accuracy on
response trials was 89.1% (S.E. = 2.1) and mean RT was 624 ms (S.E. = 18.5).
Testing phase: Accuracy
Accuracy in the testing phase was not affected by display type: 95.1% for the old-no-
response condition, 95.3% for the old-response condition, and 95.4% for the new condition, F <
1. In the RT analysis, we excluded incorrect trials as well as trials exceeding three standard
deviations of each participant’s mean of each condition (1.7% of the correct trials).
Testing phase: RT
Figure 5b shows RT in the testing phase of the experiment. Planned contrasts showed that
whereas the old-no-response and old-response conditions were not significantly different (p >
.82), they were both significantly faster than the new condition, t(15) = 2.18, p < .05 for new vs.
old-response; t(15) = 2.94, p < .01 for new vs. old-no-response. Direct comparison between these
data and Experiment 2’s findings revealed no effects of presentation duration, all F’s<1. These
findings confirm that spatial context learning does not require a motor response, as learning was
observed in the absence of manual response or eye-movements to the target.
Discussion Two control experiments were conducted to address the possibility that common eye
movements underlie learning in both the response and no-response conditions. The results of
these experiments argue against this idea. In both experiments subjects were discouraged from
moving their eyes either by an eye tracker or by the use of briefly presented displays. However,
in neither experiment was learning enhanced when participants made an overt manual detection
response to the target. While these findings do not rule out the possibility that covert
programming for saccadic eye movement, or covert detection responses are important for spatial
context learning, they do strengthen the idea that learning is abstracted from overt motor
responses.
General Discussion
According to a unified concept of perception, cognition and action, motor responses are
more than the mere outcome of a serial process going from perception to action (e.g., Song &

Spatial context learning Makovski & Jiang 17
Nakayama, 2009). Furthermore, the notion that action plays an important role in both perception
and memory has gained ample support (Elsner & Hommel, 2001; Hommel, et al., 2001; Hommel
et al., 2006; Forster & Stark, 1996; MacLeod et al., 2010; Milner & Goodale, 2006). Therefore,
the goal of the present study was to investigate the role of overt motor response in implicit visual
learning. Specifically, we asked whether learning is affected by different types of motor response
to a search target, and whether making an overt response to the target facilitates learning. Our
results showed that learning was comparable for displays that received a touch response and a
keypress response. In addition, spatial context learned through one type of response was
effectively used even when the response type had changed. Finally, learning took place even
when participants made no manual or oculomotor response to the target. These data provide
converging evidence to suggest that action plays a limited role in spatial context learning.
Remillard (2003) has differentiated among three types of learning in the SRT task:
perceptual-based learning for target locations, response-based learning for keypress locations,
and effector-based learning for finger movements. The results of Experiment 1 suggest that the
task-specificity of contextual cueing is neither due to motor-specificity (effector-based learning)
nor due to response-specificity. Rather, contextual cueing is a form of a perceptual-based
learning as learning transferred across the touch and press conditions even though both the motor
response and the spatial representation of the response had changed.
If contextual cueing is perception-based, how do we account for the learning specificity
to different tasks observed in the past? One reason is that when tasks had changed in previous
studies, perceptual encoding of the visual input had also changed. Consider the finding that
contextual cueing does not fully transfer between change detection and visual search tasks (Jiang
& Song, 2005). In visual search, the target’s location is strongly associated with its local context
– that is, items that are near the target (Brady & Chun, 2007; Jiang & Wagner, 2004; Olson &
Chun, 2002). In change detection, the target is associated with the global layout of the items
(Jiang, Olson, & Chun, 2000; Jiang & Song, 2005). Although the same spatial layout is presented
to participants, it is represented differently depending on the task.
That learning does not require a response (Experiments 2 and 3) raises the question of
why contextual cueing was not found on trials where search was interrupted before the target
was successfully located and responded to (Shen & Jiang, 2006). In an interrupted search, the
target is not found, so one cannot associate a search layout with the target’s location. Although
participants could still associate a search layout with where targets were not found (Greyer, Shi
& Müller, 2010), this information is likely too limited to facilitate search. The lack of learning in
interrupted search, therefore, may be due to the absence of detecting the target, rather than the
absence of making a response.
Why was learning not affected by action? One possible explanation is that the association
between spatial context and the target’s location requires a form of representation that is
abstracted from the viewer’s motor response. That is, unlike the action-effect binding where
action and perceptual codes are learned to form an associative structure (e.g., Elsner & Hommel,
2001; Hommel et al., 2001; Hommel et al., 2006), in contextual cueing, the spatial locations of
search target and other items are represented in relation to each other. This kind of relational
coding may have taken place before an action code (or a “no-action” code, Kühn & Brass, 2010)
is generated. Alternatively, it is possible that our measurements were not sensitive enough to
detect finer motor representations that might play a role in contextual cueing. Particularly, some
interactions between action and perception are found when the perceptual stimulus and the action
required shared common properties (e.g., the stimulus-response compatibility effect, Kornblum,

Spatial context learning Makovski & Jiang 18
Hasbroucq & Osman, 1990). Thus, it is possible that testing compatibility effects in contextual
cueing might reveal that some motor response codes are incorporated into learning. Presently this
possibility does not have strong support. Although a keypress response is arbitrary and not
highly related to the search task, a touch response and a saccadic eye movement have a viewer-
centered spatial component. However, learning acquired with a touch response was not
weakened when tested with a keypress response, and contextual cueing was observed in the
absence of an eye movement. These findings suggest that even a spatially directed motor
response is not a critical component of spatial context learning.
Nonetheless, we made an attempt to examine the possibility that motor response codes
might be incorporated in contextual cueing when a spatial compatibility component was
introduced between perception and action. In this follow-up experiment, we compared learning
of repeated displays under a condition where the motor response was spatially compatible with
the target display (press with the right hand for targets presented on the right and with the left
hand for targets presented on left) with a condition where the motor response was spatially
incompatible with the target display (press with the left hand for targets presented on the right
and with the right hand for targets presented on left). The results of this experiment showed that
although both the effects of compatibility and learning were highly significant, F’s(1, 19) > 14,
p’s < .01, ηp2
>.43, they did not interact, F<1. That is, contextual cueing was comparable for the
spatially compatible and spatially incompatible conditions. These results provide further
evidence for the perceptual nature of spatial context learning. Future research testing other types
of compatibility effects, particularly those with a stronger motor component, is important for
determining whether motor response codes are sometimes incorporated into learning.
To conclude, while it has been shown that vision-for-action differs from vision-for-
perception and that action codes are integrated into perceptual representations, the present results
show that spatial context learning is relatively independent of simple actions made to the search
target. Such learning transfers across response modes and occurs in the absence of an overt
response to the target.

Spatial context learning Makovski & Jiang 19
References Abrams, R.A., Davoli C.C., Du, F., Knapp, W.K., & Paull D. (2008). Altered vision near the
hands. Cognition, 107, 1035–104.
Allport, A. (1987). Selection for action: some behavioral and neurophysiological considerations
of attention and action. In: Heuer H., Sanders A. F. (eds.), Perspectives on perception and
action. Erlbaum, Hillsdale, pp. 395–419.
Aston-Jones, G., Rajkowski, J., Kubiak, P., & Alexinsky, T. (1994). Locus coeruleus neurons in
monkey are selectively activated by attended cues in a vigilance task. Journal of
Neuroscience, 14, 4467-4480.
Barsalou, L.W. (2008). Grounded cognition, Annual Review of Psychology, 59, 617–645.
Beck, D.M., Rees, G., Frith, C.D., & Lavie, N. (2001). Neural correlates of change detection and
change blindness. Nature Neuroscience, 4, 645-650.
Brady, T. F., & Chun, M. M. (2007). Spatial constraints on learning in visual search: Modeling
contextual cuing. Journal of Experimental Psychology: Human Perception and
Performance, 33, 798-815.
Brainard, D.H. (1997). The psychophysics toolbox. Spatial Vision, 10, 433-436.
Buttaccio, R., & Hahn, S. (2010). The effect of behavioral response on affective evaluation. Acta
Psychologica, 135, 343-348.
Chun, M. M., & Jiang, Y. H. (1998). Contextual-cueing: Implicit learning and memory of visual
context guides spatial attention. Cognitive Psychology, 36, 28-71.
Chua, K-P., & Chun, M. M. (2003). Implicit scene learning is view point dependent. Perception
and Psychophysics, 65, 72–80.
Chun, M.M., & Jiang, Y. (1999). Top-down attentional guidance based on implicit learning of
visual covariation. Psychological Science, 10,360-365.
Chun, M. M., & Jiang, Y. (2003). Implicit, long-term spatial contextual memory. Journal of
Experimental Psychology: Learning, Memory and Cognition, 29, 224-234.
Clayton, E.C., Rajkowski, J., Cohen, J.D., & Aston-Jones, G. (2004). Phasic activation of
monkey locus coeruleus neurons by simple decisions in a forced-choice task. Journal of
Neuroscience, 24, 9914-9920.
Dennis, N.A., Howard, J.H., Jr., & Howard, D.V. (2006). Implicit sequence learning without
motor sequencing in young and old adults. Experimental Brain Research, 175, 153-164.
Dixon, M.L., Zelazo, P.D., & De Rosa, E. (2010). Evidence for intact memory-guided attention
in school-aged children. Developmental Science, 13, 161-169.
Duncan, J. (1985). Visual search and visual attention. In M. I. Posner & O. S. M. Marin (Eds.),
Attention & performance XI (pp. 85-106). Hillsdale, NJ: Erlbaum.
Elsner, B., & Hommel, B. (2001). Effect anticipation and action control. Journal of Experimental
Psychology; Human Perception and Performance, 27, 229-240.
Fiser, J. Z., & Aslin, R. N. (2002). Statistical learning of higher-order temporal structure from
visual shape sequences. Journal of Experimental Psychology: Learning, Memory and
Cognition, 28, 458–467.
Forster, J., & Stark, F. (1996). Influence of overt head movements on memory for valenced
words: A case of conceptual-motor compatibility. Journal of Personality and Social
Psychology, 71, 421-430.
Goodale, M. A., & Milner, A. D. (1992). Separate visual pathways for perception and action.
Trends in Neurosciences, 15, 20–25.

Spatial context learning Makovski & Jiang 20
Geyer, T., Shi, Z., & Müller, H. J. (2010). Contextual cueing in multiconjunction visual search is
dependent on color- and configuration-based intertrial contingencies. Journal of
Experimental Psychology: Human Perception and Performance, 36, 515-532.
Hommel, B., Alonso, D., & Fuentes, L.J. (2006). Acquisition and generalization of action
effects. Visual Cognition, 10, 965-986.
Hommel, B., Müsseler, J., Aschersleben, G., & Prinz, W. (2001). The theory of event coding
(TEC): A framework for perception and action planning. Behavioral and Brain Sciences,
24, 849–937.
Jiang, Y., Olson, I. R., & Chun, M. M. (2000). Organization of visual-short term memory.
Journal of Experimental Psychology: Learning, Memory, & Cognition, 26, 683-702.
Jiang, Y., & Wagner, L.C. (2004). What is learned in spatial contextual cueing: Configuration or
individual locations? Perception & Psychophysics, 66, 454-463.
Jiang, Y., & Song, J.H. (2005). Spatial context learning in visual search and change detection.
Perception & Psychophysics, 67, 1128-1139.
Kornblum, S., Hasbroucq, T., & Osman, A. (1990) Dimensional overlap: Cognitive basis for
stimulus-response compatibility—a model and taxonomy. Psychological Review, 97,253
270.
Kühn, S., & Brass, M. (2010). The cognitive representation of intending not to act: Evidence
for specific non-action-effect binding. Cognition, 117, 9-16.
Kunar, M.A., Flusberg, S., Horowitz, T..S, & Wolfe, J.M. (2007). Does contextual cueing guide
the deployment of attention? Journal of Experimental Psychology: Human Perception
and Performance, 33, 816-828.
Le Dantec, C.C., & Seitz, A.R. (2010). Perceptual learning and contextual learning of a visual
search. Poster presented at the Society for Neuroscience conference.
MacLeod, C M., Gopie, N, Hourihan, K. L., Neary, K R., & Ozubko, J.D. (2010). The
production effect: Delineation of a phenomenon. Journal of Experimental Psychology:
Learning, Memory, and Cognition, 36, 671-685.
Makovski, T., Swallowk, K.M., & Jiang, Y.V. (2011). Attending to unrelated targets boosts
short-term memory for color arrays. Neuropsychologia.
Makovski, T., Vazquez, G.A., & Jiang, Y.V. (2008). Visual learning in multiple-object tracking.
PLoS ONE, 3(5): e2228.
Miller, J. (1988). Components of the location probability effect in visual search tasks. Journal of
Experimental Psychology: Human Perception and Performance, 14, 453-471.
Milner, A. D., & Goodale, M. A. (2006). The Visual Brain in Action (2nd
ed.). Oxford University
Press. Oxford.
Nakayama, K., & Mackeben, M. (1989). Sustained and transient components of focal visual
attention. Vision Research, 29(11), 1631–1647.
Nissen, M. J., & Bullemer, P. (1987). Attentional requirements of learning: Evidence from
performance measures. Cognitive Psychology, 19, 1–32.
Olson, I. R., & Chun, M. M. (2002). Perceptual constraints on implicit learning of spatial
context. Visual Cognition, 9, 273-302.
Pelli, D.G. (1997). The VideoToolbox software for visual psychophysics: Transforming number
into movies. Spatial Vision, 10, 437-442.
Peterson, M. S., & Kramer, A. F. (2001). Attentional guidance of the eyes by contextual
information and abrupt onsets. Perception & Psychophysics, 63, 1239-1249.

Spatial context learning Makovski & Jiang 21
Reber, A. S. (1989). Implicit learning and tacit knowledge. Journal of Experimental Psychology:
General, 118, 219–235.
Remillard, G. (2003). Pure perceptual-based sequence learning. Journal of Experimental
Psychology: Learning, Memory, and Cognition, 29, 581-597.
Ress, D., & Heeger, D.J. (2003). Neuronal correlates of perception in early visual cortex,
Nature Neuroscience 6, 414-420.
Rizzolatti, G., Riggio, L., Dascola, I. & Umiltá, C. (1987). Reorienting attention across the
horizontal and vertical meridians: evidence in favor of a premotor theory of attention.
Neuropsychologia 25, 31-40.
Seitz, A. R., & Watanabe, T. (2003). Is subliminal learning really passive? Nature, 422, 36.
Shen, Y.J., & Jiang, Y.V. (2006). Interrupted visual searches reveal volatile search memory.
Journal of Experimental Psychology: Human Perception &Performance, 32,1208-1220.
Song, J.H., & Nakayama, K. (2009). Hidden cognitive states revealed in choice reaching tasks.
Trends in Cognitive Sciences, 13, 360-366.
Stock, A. & Stock, C. (2004) A short history of ideo-motor action. Psychological Research, 68,
176-188.
Swallow, K.M., & Jiang, Y.V. (2010). Attentional boost effect: Transient increases in attention
to one task enhance performance in a second task. Cognition, 115, 115-132.
Swallow, K.M., & Jiang, Y.V. (2011). The role of timing in the attentional boost effect.
Attention, Perception, & Psychophysics. Swallow, K. M., & Zacks, J. M. (2008). Sequences learned without awareness can orient
attention during the perception of human activity. Psychonomic Bulletin and Review, 15,
116-122.
Swallow, K. M., Zacks, J. M., & Abrams, R. A. (2009). Event boundaries in perception affect
memory encoding and updating. Journal of Experimental Psychology: General, 138,
236-257.
Turk-Browne, N.B., Junge, J.A., & Scholl, B.J. (2005). The automaticity of visual statistical
learning. Journal of Experimental Psychology: General, 134, 552-564.
Umemoto, A., Scolari, M., Vogel, E.K.,& Awh, E. (2010). Statistical learning induces discrete
shifts in the allocation of working memory resources. Journal of Experimental
Psychology: Human Perception and Performance, 36, 1419-1429.
Vaidya, C.J., Huger, M., Howard, D.V., & Howard, J.H., Jr (2007). Developmental differences
in implicit learning of spatial context. Neuropsychology, 21, 497–506.
Willingham, D.B. (1999) Implicit motor sequence learning is not purely perceptual. Memory and
Cognition, 27, 561–572.
Ziessler, M. & Nattkemper, D. (2001). Learning of event sequences is based on response-effect
learning: Further evidence from serial reaction task. Journal of Experimental Psychology:
Learning, Memory, and Cognition, 27, 595-613