speaker: hung-yi lee spoken content retrieval beyond cascading speech recognition and text retrieval
TRANSCRIPT

Speaker: Hung-yi Lee
Spoken Content RetrievalBeyond Cascading Speech
Recognition and Text Retrieval

Text Retrieval
Voice Search
Obama

Spoken Content Retrieval
Lectures Broadcast Program
Multimedia Content
Spoken Content
Obama

Basic goal: Identify the time spans that the query term occurs in audio database This is called “Spoken Term Detection”
Spoken Content Retrieval – Goal
time 1:01time 2:05
…
……
“Obama”
user

Basic goal: Identify the time spans that the query term occurs in audio database This is called “Spoken Term Detection”
Advanced goal: Semantic retrieval of spoken content
Spoken Content Retrieval – Goal
user
“US President”
I know that the user is looking for “Obama”.
Retrieval system

People think ……
Spoken Content Retrieval
Speech Recognition +
Text Retrieval=
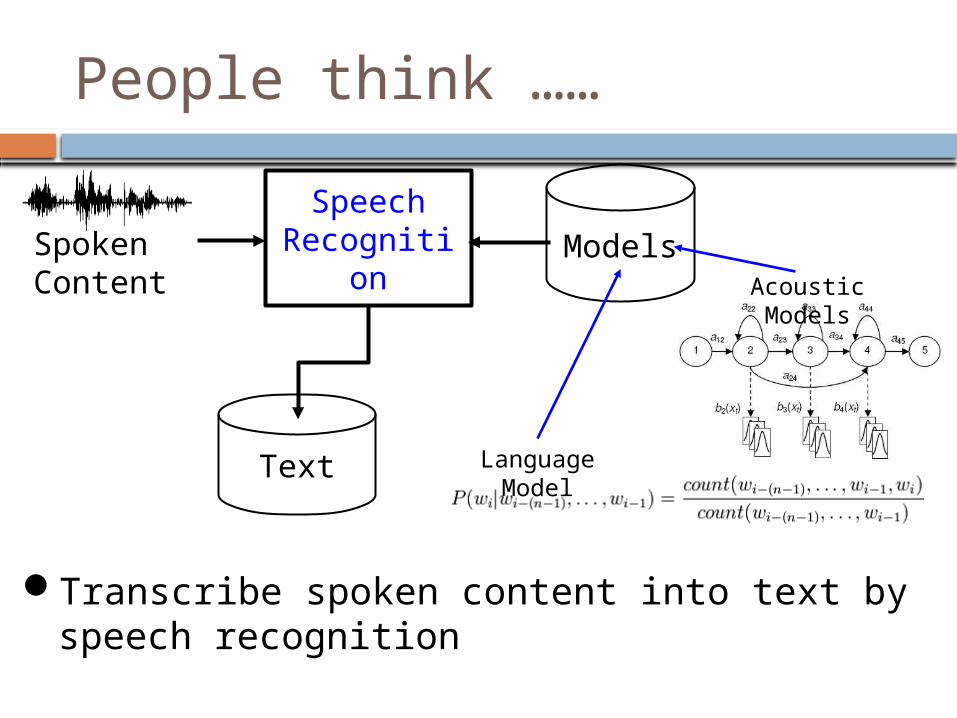
People think ……
SpeechRecognition Models
Text
Acoustic Models
Language Model
Transcribe spoken content into text by speech recognition
Spoken Content

People think ……
Transcribe spoken content into text by speech recognition
SpeechRecognition Models
Text
Retrieval ResultText
Retrieval Query user
Use text retrieval approach to search the transcriptions
Spoken Content
Black Box

People think ……
SpeechRecognition Models
Text
Retrieval ResultText
Retrieval user
Spoken Content
For spoken queries, transcribe them into text by speech recognition.
Black Box
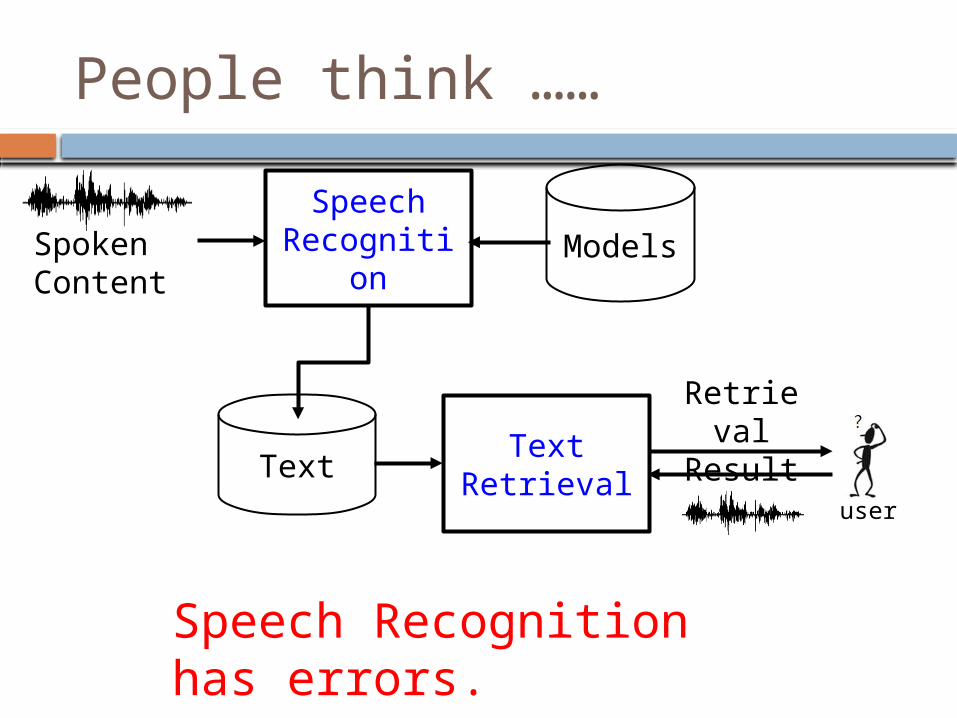
People think ……
SpeechRecognition Models
Text
Retrieval ResultText
Retrieval user
Spoken Content
Speech Recognition has errors.

Lattices
SpeechRecognition Models
Text
Retrieval ResultText
Retrieval Query learner
Spoken Content
LatticesKeep the possible recognition outputEach path has a weight (confidence to be
correct)
M. Larson and G. J. F. Jones, “Spoken content retrieval: A survey of techniques and technologies,” Foundations and Trends in Information Retrieval , vol. 5, no. 4-5, 2012.

Searching on Lattices
Consider the basic goal: Spoken Term Detection
“Obama”user

Searching on Lattices
Consider the basic goal: Spoken Term Detection Find the arcs hypothesized to be the query term
Obama“Obama”
user
Obama
x1
x2

Consider the basic goal: Spoken Term Detection Posterior probabilities computed from lattices are
usually used as confidence scores
Searching on Lattices
Obama
x1
R(x1)=0.9
Obama
x2
R(x2)=0.3

Consider the basic goal: Spoken Term Detection The results are ranked according to the scores
Searching on Lattices
Obama
x1
R(x1)=0.9
Obama
x2
R(x2)=0.3
x1 0.9x2 0.3
…

Consider the basic goal: Spoken Term Detection The results are ranked according to the scores
Searching on Lattices
Obama
x1
R(x1)=0.9
Obama
x2
R(x2)=0.3
x1 0.9x2 0.3
… user

Do lattices solve the problem? Need high quality recognition models to
accurately estimate the confidence scores In real application, such high quality
recognition models are not available Spoken content retrieval is still difficult even
with lattices.
Is the problem solved?

Hope for spoken content retrieval Accurate spoken content retrieval, even
under poor speech recognition Don’t completely rely on accurate speech
recognition Is the cascading of speech recognition and text
retrieval the only solution of spoken content retrieval?
Is the problem solved?

My point in this talk
Spoken Content Retrieval
Speech Recognition +
Text Retrieval=

Beyond Cascading Speech Recognition and Text Retrieval

New Directions
1. Incorporating Information Lost in Standard Speech Recognition
2. Improving Recognition Models for Retrieval Purposes
3. Special Semantic Retrieval Techniques designed for Spoken Content Retrieval
4. No Speech Recognition!
5. Speech is hard to browse! Interactive retrieval Visualization

New Direction 1:Incorporating Information Lost in
Standard Speech Recognition

Information beyond Speech Recognition Output
SpeechRecognition Models
Text
Retrieval ResultText
Retrieval Query user
Spoken Content
Black Box
Incorporating information lost in standard speech recognition to help text retrieval

Conventional Speech Recognition
Is it truly “Obama”?
Obama Recognition Models
Acoustic Models
Language Model
Lots of inaccurate assumption

Exemplar-based speech recognition
Is it truly “Obama”?“Obama”
“Obama”
“Obama”
similarity
The queries are usually special terminologies.
Use Pseudo-relevance Feedback (PRF)
It is not realistic to find examples for all queries.
[Kris Demuynck, et al., ICASSP 2011][Georg Heigold, et al., ICASSP 2012]
Exemplar-based spoken term detection• Judge whether an audio segment is the query
term by the audio examples of the query

RetrievalSystem
Pseudo Relevance Feedback (PRF)
Query Q
Lattices
First-pass Retrieval Resultx1
x2 x3

RetrievalSystem
Pseudo Relevance Feedback (PRF)
Query Q
Confidence scores from lattices
Lattices
R(x1)
First-pass Retrieval Resultx1
x2 x3
R(x2) R(x3)
Not shown to the user

RetrievalSystem
Pseudo Relevance Feedback (PRF)
Query Q
Lattices
R(x1)
First-pass Retrieval Resultx1
x2 x3
R(x2) R(x3)
Assume the results with high confidence scores as correct
Examples of Q
Considered as examples of Q

RetrievalSystem
Pseudo Relevance Feedback (PRF)
Query Q
Lattices
R(x1)
First-pass Retrieval Resultx1
x2 x3
R(x2) R(x3)
similar dissimilar
Examples of Q
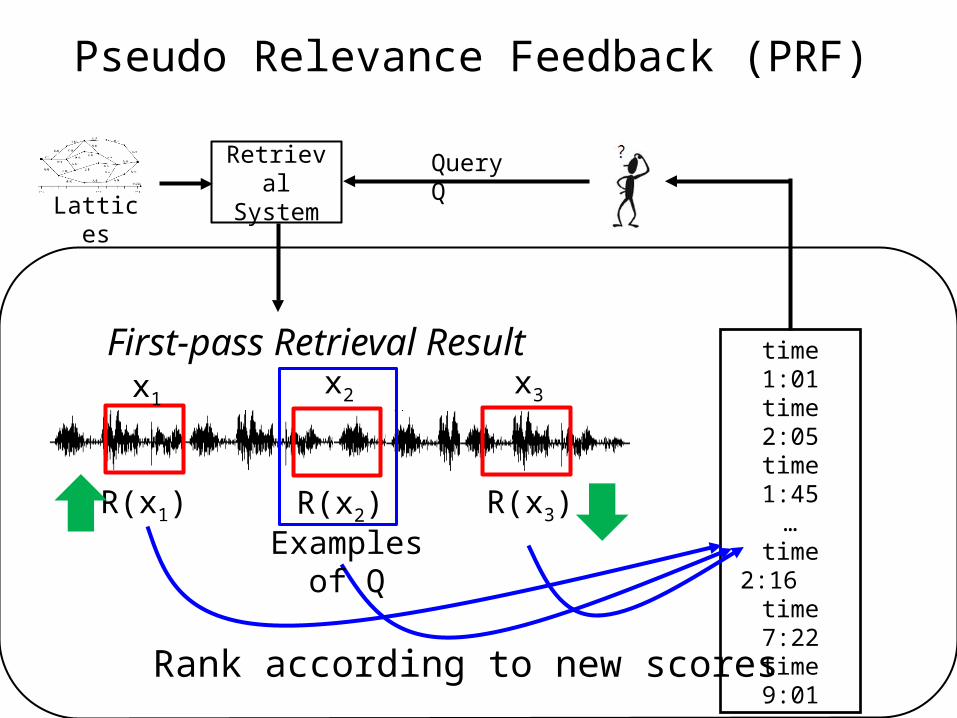
RetrievalSystem
Pseudo Relevance Feedback (PRF)
Query Q
Lattices
R(x1)
First-pass Retrieval Resultx1
x2 x3
R(x2) R(x3)
time 1:01time 2:05time 1:45
…time 2:16 time 7:22time 9:01
Rank according to new scores
Examples of Q

Similarity between Retrieved Results
Dynamic Time Warping (DTW)

(A) (B)
Digital Speech Processing (DSP) of NTU based on lattices
Pseudo Relevance Feedback (PRF)- Experiments
Evaluation Measure: MAP (Mean Average Precision)

(A) (B)
Pseudo Relevance Feedback (PRF)- Experiments
(B): speaker independent (50% recognition accuracy)
(A): speaker dependent (84% recognition accuracy)
(A) and (B) use different speech recognition systems

(A) (B)
PRF (red bars) improved the first-pass retrieval results with lattices (blue bars)
Pseudo Relevance Feedback (PRF)- Experiments

Graph-based Approach
PRF Each result considers the similarity to the audio examples Make some assumption to find the examples
Graph-based approach Not assume some results are correct Consider the similarity between all results

Graph Construction
The first-pass results is considered as a graph. Each retrieval result is a node
First-pass Retrieval Result from lattices
x1
x2
x3
x2
x3
x1
x4
x5

Graph Construction
The first-pass results is considered as a graph. Nodes are connected if their retrieval results are similar.
DTW similarities are considered as edge weights
x2
x3
x1
x4
x5Dynamic Time Warping
(DTW) Similarity
similar
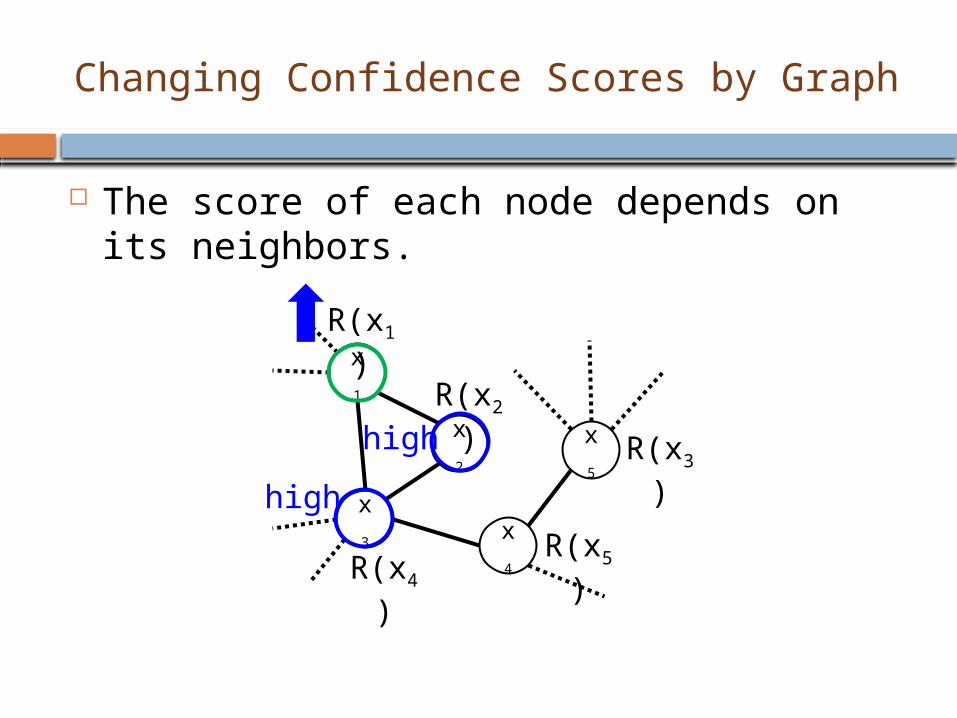
Changing Confidence Scores by Graph
The score of each node depends on its neighbors.
x2
x3
x1
x4
x5
R(x1)
R(x2)
R(x3)
R(x5)R(x4)
high
high

Changing Confidence Scores by Graph
The score of each node depends on its neighbors.
x2
x3
x1
x4
x5
R(x1)
R(x2)
R(x3)
R(x5)R(x4)
low
low
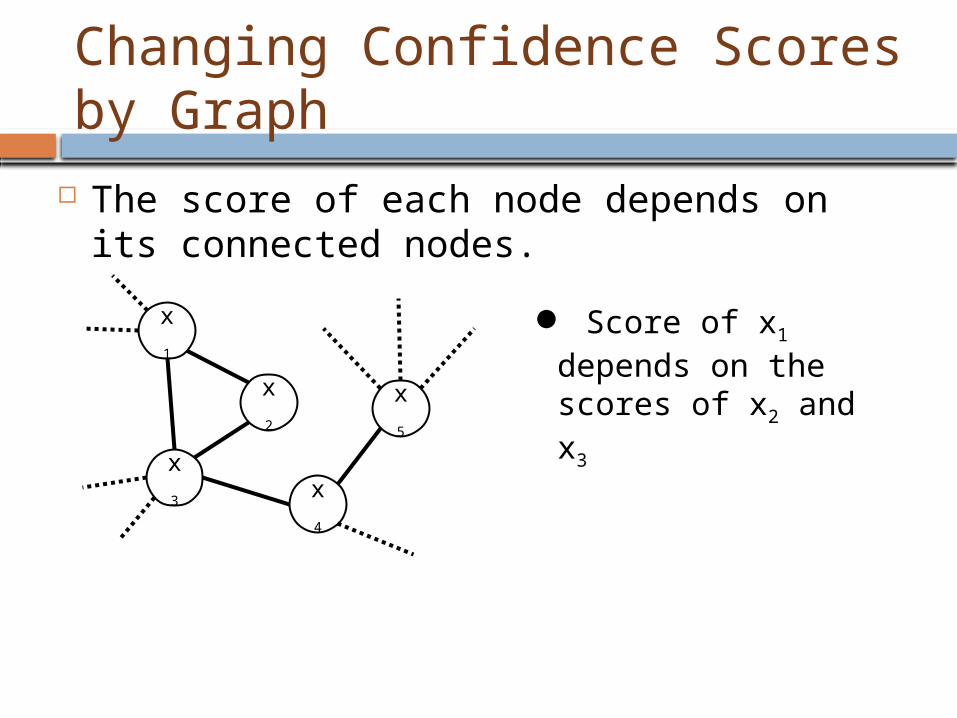
The score of each node depends on its connected nodes.
x2
x3
x1
x4
x5
Changing Confidence Scores by Graph
Score of x1 depends on the scores of x2 and x3

The score of each node depends on its connected nodes.
x2
x3
x1
x4
x5
Changing Confidence Scores by Graph
Score of x1 depends on the scores of x2 and x3
Score of x2 depends on the scores of x1 and x3

The score of each node depends on its connected nodes.
x2
x3
x1
x4
x5
……
Changing Confidence Scores by Graph
Score of x2 depends on the scores of x1 and x3
random walk algorithm.
None of the results can decide their scores individually
Score of x1 depends on the scores of x2 and x3

Digital Speech Processing (DSP) of NTU based on lattices
(A) (B)
Graph-based Approach - Experiments
(B): speaker independent (low recognition accuracy) (A): speaker dependent (high recognition accuracy)

(A) (B)
Graph-based re-ranking (green bars) outperformed PRF (red bars)
Graph-based Approach - Experiments

Graph-based Approach – Experiments from Other groups Johns Hopkins work shop 2012
13% relative improvement on OOV queries [Aren Jansen, ICASSP 2013][Atta Norouzian, Richard Rose, ICASSP 2013]
AMI Meeting Corpus 14% relative improvement [Atta Norouzian, Richard Rose,
Interspeech 2013]

Graph-based Approach – Experiments on Babel Program Join Babel program at MIT
Evaluation program of spoken term detection
More than 30 research groups divided into 4 teams
Spoken content to be retrieved are in special languages

Assamese Bengali Lao0.25
0.27
0.29
0.31
0.33
0.35
First Pass (on lattices)Graph
AT
WV
Graph-based Approach – Experiments on Babel Program

New Direction 2:Improving Recognition Models
for Retrieval Purposes

Motivation
Intuition: Higher recognition accuracy, better retrieval performance This is not always true!
In Taiwan, the need of …Recognition
System ARecognition
System B
In Taiwan, a need of … In Thailand, the need of …
Same recognition accuracy

Motivation
Intuition: Higher recognition accuracy, better retrieval performance This is not always true!
In Taiwan, the need of …Recognition
System ARecognition
System B
In Taiwan, a need of … In Thailand, the need of …
Not too much influence
Hurt retrieval
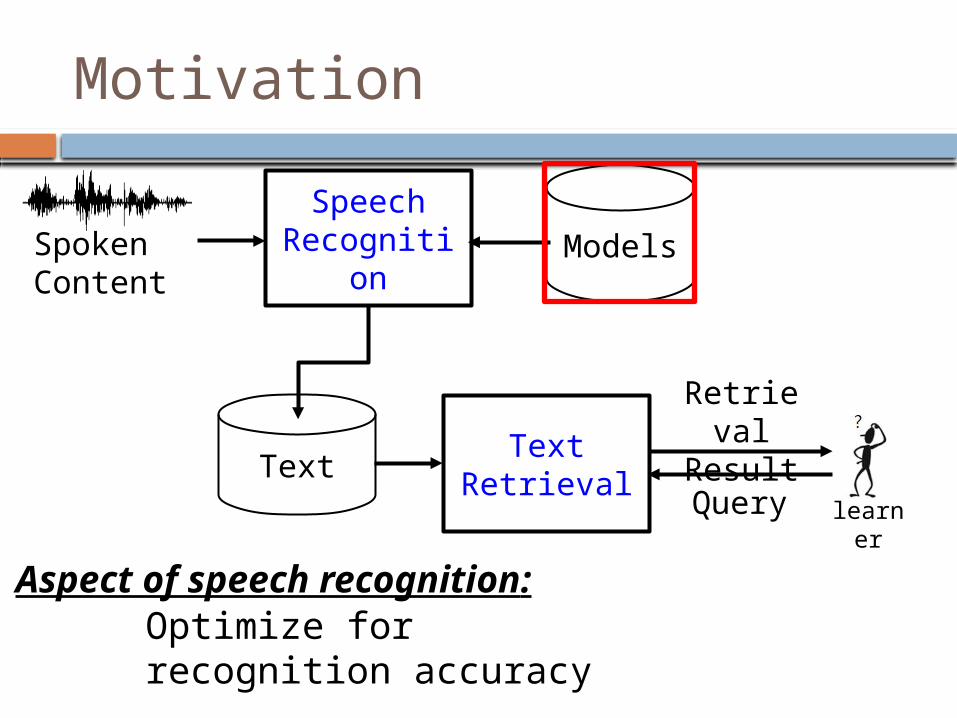
Motivation
SpeechRecognition Models
Text
Retrieval ResultText
Retrieval Query learner
Spoken Content
Optimize for recognition accuracyAspect of speech recognition:

Motivation
SpeechRecognition Models
Text
Retrieval ResultText
Retrieval Query learner
Spoken Content
Optimize for recognition accuracyRetrieval performance
Aspect of spoken content retrieval:

Related Research
Optimizing recognition models for downstream text-based processing [He, Deng, , PIEEE 2013]
In spoken term detection [Chao Weng, et al., Interspeech 12]
In acoustic model training, maximizing the recognition accuracies of the queries

Collect feedback data on-line Use the information to optimize search engines
Feedback can be implicit
Feedback Data
time 1:10 time 2:01 time 3:04 time 5:31 T
time 1:10 T time 2:01 F time 3:04 time 5:31
time 1:10 F time 2:01 time 3:04 time 5:31
Query Q1 Query Q2 Query Qn
……

Re-estimate Recognition Models
SpeechRecognition Models
TextRetrieval
Query learner
Spoken Content
Lattices
Retrieval Result
re-estimate
optimize
time 1:10 time 2:01 time 3:04 time 5:31 T
time 1:10 T time 2:01 F time 3:04 time 5:31
time 1:10 F time 2:01 time 3:04 time 5:31
Query Q1 Query Q2 Query Qn
……

Re-estimate Recognition Models
Each retrieval result x has a confidence score R(x)
R(x) determined by recognition model θ R(x) should be R(x;θ)
Re-estimate recognition
model θ
Update the scores R(x; θ)
The retrieval results can be
re-ranked.Considering some retrieval criterion here

xx
xRxRF ;;
Objective Function – Basic Form
Basic Form:
: confidence score of the correct result ;xR
: confidence score of the incorrect result ;xR
: correct resultx
: incorrect resultx
Fmaxargˆ

xx
xRxRF ;;
Objective Function – Basic Form
Increase the confidence scores of the correct results
Basic Form:
Fmaxargˆ
Decrease the confidence scores of the incorrect results

xx
xRxRF ;;
Objective Function – Basic Form
Basic Form:
Fmaxargˆ
The above formulation can be improved by:
1.Considering ranking property of retrieval performance measure
2.Considering unlabeled results

Digital Speech Processing (DSP) of NTU based on lattices 80 queries, each has 5 clicks
Feedback Data - Experiments
(A), (B), (C) are three original recognition models with different recognition accuracies

New Direction 3:Semantic Retrieval For Spoken Content

Semantic Retrieval
User expects semantic retrieval of spoken content. User asks “US President”, system also finds “Obama”
Widely studies on text retrieval Take query expansion as example
user
“US President”
Search both “US President” or “Obama”
“Obama” and “US President” are related
Retrieval system

Query Expansion in Text Retrieval
How can system know “Obama” is related to “US President”? Widely studied in text retrieval
Related terms frequently co-occur with the query terms in the same document.

Directly applying the text-based techniques on the audio transcriptions or lattices
Query Expansion for Spoken Content
“US President” “Obama”
Speech Recognition
How we know “Obama” really occurs in spoken content?

Query Expansion – Enhanced by Graph-based Approach
Use graph-based approach to better know if a term truly occurs in spoken content
Obama Obama Obama Obama
Better know if two terms co-occur in the spoken documents

Experiments on TV News
Query Expansion – Enhanced by Graph-based Approach

“US President” “Obama”
Query Expansion – Never Appear?
If “Obama” is not in the lexicon
We can never know “Obama” co-occur with “US President” in query expansion.
“Obama” will never appear in lattices.

Query Expansion with Speech Signals
US President US President US President

Query Expansion with Speech Signals
The speech signal patterns co-occur with “US President”.
Use these signal patterns to expand query
Corresponding to words related to “US President”.
US President US President US President
Obama Obama Obama
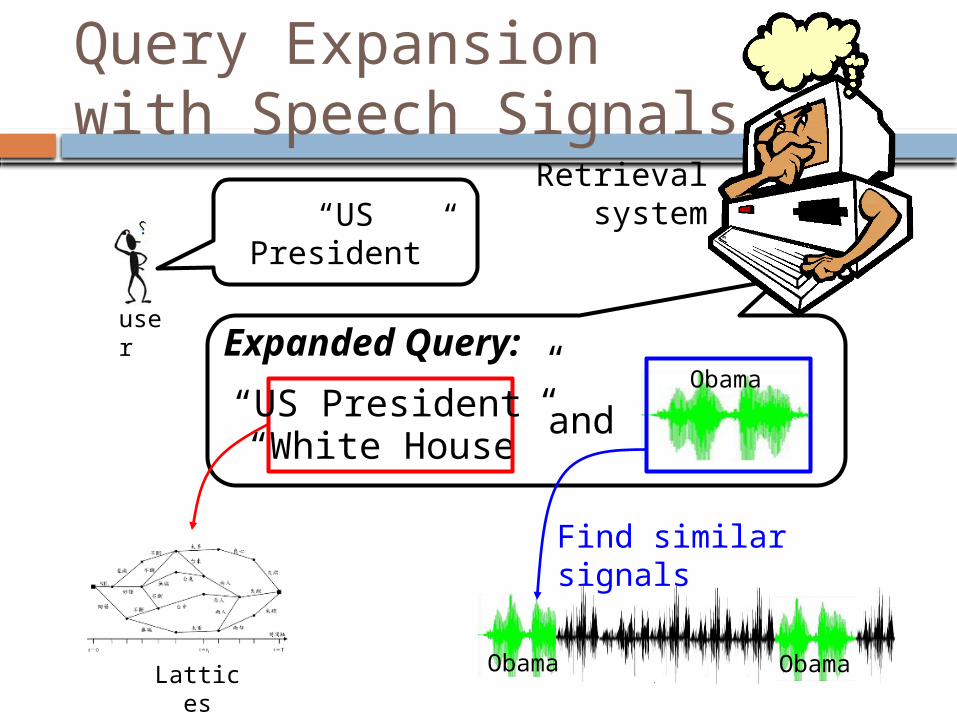
Query Expansion with Speech Signals
user
“US President”
Retrieval system
Expanded Query:
Lattices
Find similar signals
Obama
Obama Obama
“White House”“US President” and

Query Expansion – Acoustic Patterns Experiments on TV News

New Direction 4:No Speech Recognition!

Spoken Content Retrieval without Speech Recognition Why spoken content retrieval without speech
recognition? Some languages have little training data for
training speech recognition systems. Some languages even do not have text

Spoken Content Retrieval without Speech Recognition Spoken Term Detection
Spoken Content
user
“US President”
spoken query
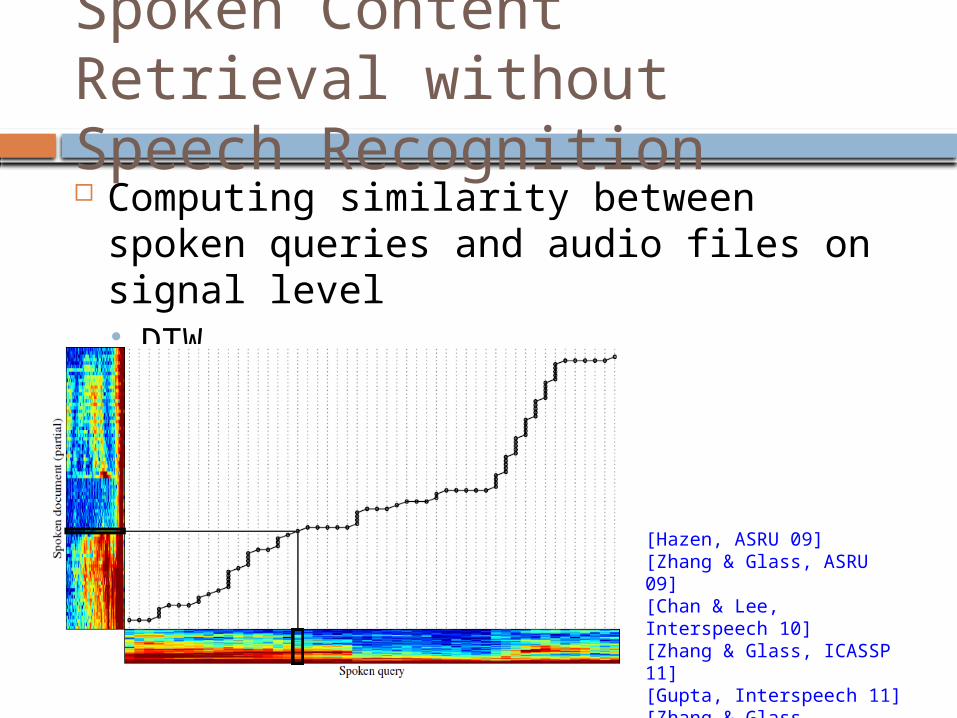
Spoken Content Retrieval without Speech Recognition Computing similarity between spoken queries and
audio files on signal level DTW
[Hazen, ASRU 09][Zhang & Glass, ASRU 09][Chan & Lee, Interspeech 10][Zhang & Glass, ICASSP 11][Gupta, Interspeech 11][Zhang & Glass, Interspeech 11]

Spoken Content Retrieval without Speech Recognition Computing similarity between spoken queries and
audio files on signal level Model-based matching
[Zhang & Glass, ASRU 09][Huijbregts, ICASSP 11][Chan & Lee, Interspeech 11]

Spoken Content Retrieval without Speech Recognition Computing similarity between spoken queries and
audio files on signal level
Can not handle semantic retrieval
For spoken term detection, DTW-based approach can obtain 28.3% MAP
For semantic retrieval, the same DTW-based approach can only obtain 8.8% MAP
Impossible to find the relevant audio file not include the query term

Spoken Content Retrieval without Speech Recognition
Spoken Queries
database
Expanded by acoustic patterns
DTW-based approach: 8.8% Query expansion:9.7%
Query expansion without speech recognition

New Direction 5:Audio is hard to browse!

Audio is hard to browse
When the system returns the retrieval results, user doesn’t know what he/she get at the first glance
Retrieval Result

Audio is hard to browse
Interactive spoken content retrieval Visualizing retrieved results
Visualizing multiple on-line courses

New Direction 5:Audio is hard to browse! (1)
Interactive Spoken Content Retrieval

Introduction
Conventional Retrieval Process
user
US President
Here are what you are looking for:
Doc3Doc1Doc2
…Can be noisy

Interactive retrieval
Introduction
user
US President
Not clear enough ……
More precisely, please.

Interactive retrieval
Is it related to “Election”?
Introduction
user
US President
Still not clear enough ……
More precisely, please.
Obama

Here are what you are looking for.
Interactive retrieval
Is it related to “Election”?
Introduction
user
US President
I see!
More precisely, please.
Obama
Yes.

Interact with Users - MDP
Given the information entered by the users at present, which action should be taken?
Model the interactive retrieval process as Markov Decision Process (MDP)
“Give me an example.”
“Is it relevant to XXX?”
“Can you give me another query?”
“Show the results.”

Interact with Users - MDP
In MDP The system is in certain states. Which action should be taken depends on the state the
system is in. In MDP for Interactive retrieval
State: the degree of clarity of the user’s information need
Ambiguous Clearstate space

S1
SpokenAchieve
SearchEngine
Query
US President.
Doc3Doc1Doc2
…
Ambiguous Clearstate space
State Estimator
[Cronen-Townsen, SIGIR 02]
[Zhou, SIGIR 07]
State Estimator: Estimate the degree of clarity from the retrieval results

S1
A1
A2
A3
A4
A set of candidate actions System: “More precise, please.” System: “Is it relevant to XXX?” …..
Ambiguous Clearstate space
There is an action “show results” When the system decides to show the results, the
retrieval session is ended

S1
A1
A2
A3
A4
Choose the actions by intrinsic policy π(S) The policy is a function Input: state S, output: action A
π(S)=“More precise, please”
π(S)=Show Results
Ambiguous Clearstate space

S1
SpokenAchieve
SearchEngine
Doc3Doc1Doc2
…
A1
A1: More precise, please.Obama
C1
User response The system gets a cost C1 due to user labor.
Ambiguous Clearstate space
π(S1) = A1
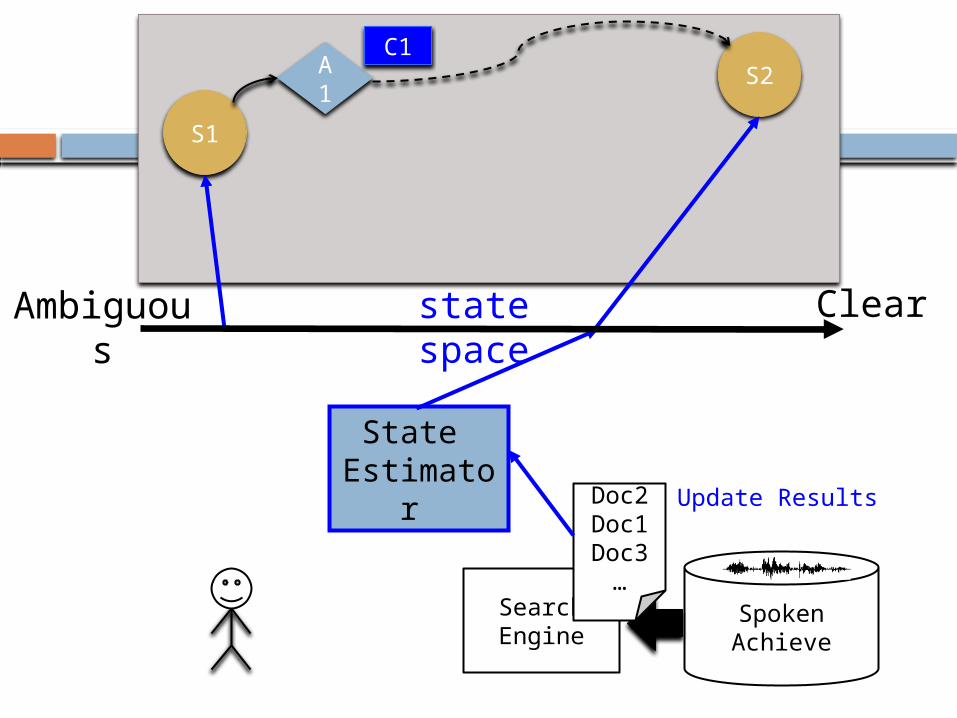
S1
SpokenAchieve
SearchEngine
Doc2Doc1Doc3
…
A1
Update Results
State Estimator
S2C1
Ambiguous Clearstate space

Interact with Users - MDP
Good interaction: The quality of final retrieval results shown to the
users are as good as possible The user labors (C1, C2) are as small as possible
S1
S3
S2A1
C1
C2
A2
End
Show

Interact with Users - MDP
Learn polity π maximizing:
Retrieval Quality - User labor The polity π can be learned from historical
interaction by reinforcement learning [Chandramohan, Interspeech 10]
S1
S3
S2A1
C1
C2
A2
End
Show

Interact with Users - Experiments
Broadcast news, semantic retrieval
0.52 0.54 0.56 0.58 0.6 0.62 0.64
Hand-craftedMDP
0 10 20 30 40 50 60 70 80 90 100
Hand-craftedMDP
Retrieval Quality Retrieval Quality - User labor

New Direction 5:Audio is hard to browse! (2)Visualizing On-line Courses

Introduction
Visualizing the retrieval results on an intuitive interface helps users know what is retrieved
Take retrieving on-line lectures as example Searching spoken lectures is a very good
application for spoken content retrieval The speech of the instructors conveys most
knowledge in the lectures
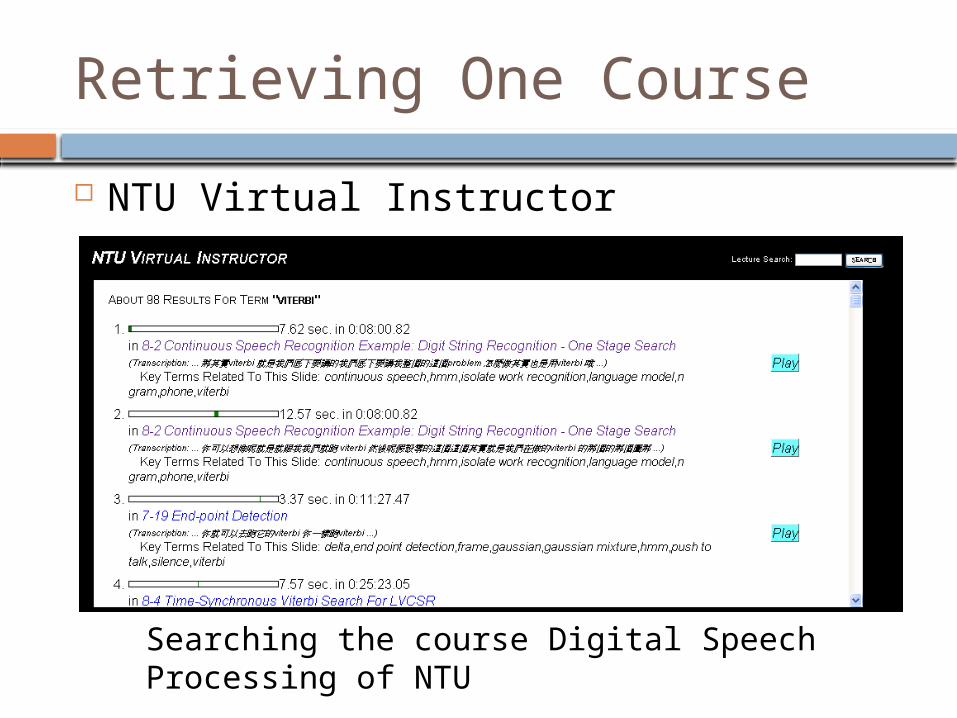
Retrieving One Course
NTU Virtual Instructor
Searching the course Digital Speech Processing of NTU

Massive Open On-line Courses (MOOCs) Enormous on-line courses
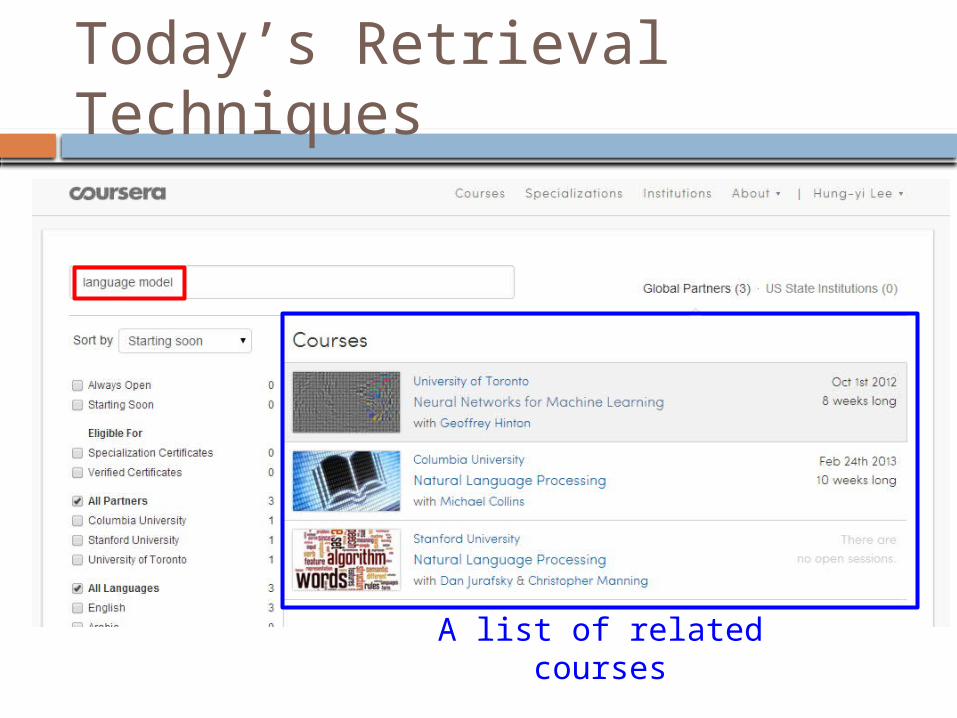
Today’s Retrieval Techniques
A list of related courses

Today’s Retrieval Techniques
a1
a2
a3
a4
b1
b2
b3
c1
c2
c3
(Each node represents a lecture.)

Today’s Retrieval Techniques
a1
a2
a3
a4
b1
b2
b3
c1
c2
c3
learner
Go through all the paths.
Focus on one path.
XX
Which lectures should I watch?

Organizing Multiple Courses
MIT: Cangjie Organizing the learning paths from multiple courses
into a map
a1
a2
a3
a4
b1
b2
b3
b4
a2+a3+b2
a4
b3
b4
a1+b1

User study: Comparing three system interfaces
Pilot User Study
Single Multiple Link
Show related lectures from only one course
Show related lectures from all courses
Show related lectures from all courses and link them

Pilot User Study
12 users: 6 from National Taiwan University (NTU) and 6 from MIT
Each user completes some tasks by the three interfaces Looking for desired information Writing short essays

v.s.
Multiple Single
Multiple v.s. Single
Learn Better?

v.s.
Multiple Single
Link v.s. Single
v.s.
Link Single
Learn Better?

Organizing Multiple Courses
Identify the lectures teaching the same content
a1
a2
a3
a4
b1
b2
b3
b4
Teaching same thing
Teaching same thing
Teaching same thing
Perplexity
Interpolation (part 1)
Interpolation (part 2)
Perplexity
Interpolation

Organizing Multiple Courses
The lectures for the same content are shown in the same node
a2
a3
a4
b2
b3
b4
Teaching same thing
Teaching same thing
a1+b1
InterpolationInterpolation (part 1)
Interpolation (part 2)
Perplexity

Interpolation
Organizing Multiple Courses
The lectures for the same content are shown in the same node
a4
b3
b4
a1+b1
Perplexity
a2+a3+b2

Automatically Linking the Lectures Problem
a1
a2
a3
a4
b1
b2
b3
b4
Teaching same thing or not?
Course A
Course B

Automatically Linking the Lectures Method 1: Pair by Pair
Compute the similarity of each pair of lectures Lexical and topical similarity of the audio transcriptions Lexical similarity and syntactic parsing tree similarity of
the titles of the lectures Weighted sum the similarity measures
a1
a2
a3
b1
b2
b3
Course A
Course B
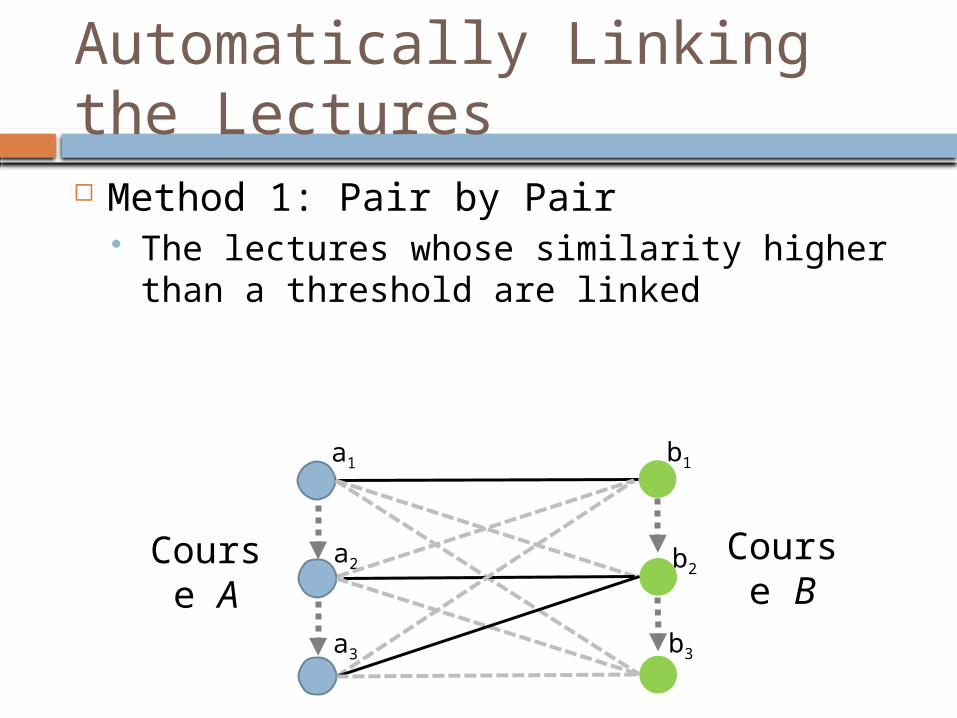
Automatically Linking the Lectures Method 1: Pair by Pair
The lectures whose similarity higher than a threshold are linked
a1
a2
a3
b1
b2
b3
Course A
Course B

Automatically Linking the Lectures Method 2: Globally consider the whole paths
Define L as a possible linking between the lectures of the two courses
a1
a2
a3
b1
b2
b3
L={ (a1,b3), (a2,b1), (a3,b2) }

Automatically Linking the Lectures Method 2: Globally consider the whole paths
Define a function F(L) which evaluates how good a linking L is
If L’ maximizes F(L), then L’ will be the output of the system
F(L1) F(L2) F(L3)
……
Enumerate all possible linking between two courses.
L1 L2 L3

Automatically Linking the Lectures Method 2: Globally consider the whole paths
Define a function F(L) which evaluates how good a linking L is
The teachers usually describe the concepts in the same order Ex: Usually describe “n-gram” before “language model smoothing”
a1
a2
a3
b1
b2
b3
Having lots of crossing
Less likely to be correct

Automatically Linking the Lectures Method 2: Globally consider the whole paths
Define a function F(L) which evaluates how good a linking L is
The teachers usually describe the concepts in the same order Ex: Usually describe “n-gram” before “language model smoothing”
a1
a2
a3
b1
b2
b3
Having little crossing
More likely to be correct
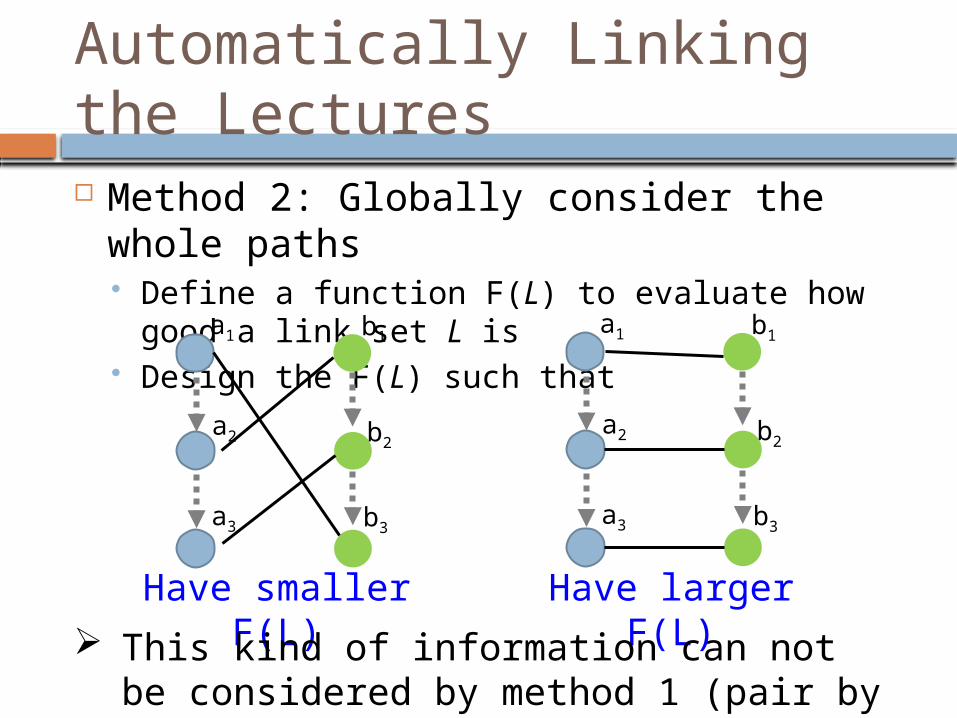
Automatically Linking the Lectures Method 2: Globally consider the whole paths
Define a function F(L) to evaluate how good a link set L is Design the F(L) such that
a1
a2
a3
b1
b2
b3
a1
a2
a3
b1
b2
b3
Have smaller F(L) Have larger F(L)
This kind of information can not be considered by method 1 (pair by pair).

Automatically Linking the Lectures Method 2: Globally consider the whole paths
𝐹 (𝐿 )= ∑(𝑎𝑖 ,𝑏 𝑗 )∈𝐿
𝑆𝑖𝑚 (𝑎𝑖 ,𝑏 𝑗 )+𝜆1|𝐿|+𝜆2𝐶 (𝐿 )
The summation of the similarity of all elements in the linking L

Automatically Linking the Lectures Method 2: Globally consider the whole paths
𝐹 (𝐿 )= ∑(𝑎𝑖 ,𝑏 𝑗 )∈𝐿
𝑆𝑖𝑚 (𝑎𝑖 ,𝑏 𝑗 )+𝜆1|𝐿|+𝜆2𝐶 (𝐿 )
Number of elements in the linking L

Automatically Linking the Lectures Method 2: Globally consider the whole paths
𝐹 (𝐿 )= ∑(𝑎𝑖 ,𝑏 𝑗 )∈𝐿
𝑆𝑖𝑚 (𝑎𝑖 ,𝑏 𝑗 )+𝜆1|𝐿|+𝜆2𝐶 (𝐿 )
Number of crossing between the elements of L
a1
a2
a3
b1
b2
b3
a1
a2
a3
b1
b2
b3
C(L)=2 C(L)=0

Automatically Linking the Lectures Experimental Results
Precision Recall F-measurePair by Pair 42.9 52.7 47.2
Global 51.7 54.6 53.1

Demo
System:
http://people.csail.mit.edu/tlkagk/Cangjie-v4/ Video: https://www.youtube.com/watch?
v=NblCTC3Ogq8

Concluding Remarks

Conclusion Remarks
New research directions for spoken content retrieval Incorporating Information Lost in Standard Speech
Recognition Improving Recognition Models for Retrieval
Purposes Semantic Retrieval for Spoken Content No Speech Recognition! Speech is hard to browse!

Take-Home Message
Spoken Content Retrieval
Speech Recognition +
Text Retrieval=

Thank You for Your Attention